实验7线性回归
- 格式:doc
- 大小:286.45 KB
- 文档页数:13

你应该要掌握的7种回归分析⽅法你应该要掌握的7种回归分析⽅法标签:机器学习回归分析2015-08-24 11:29 4749⼈阅读评论(0) 收藏举报分类:机器学习(5)⽬录(?)[+]转载:原⽂链接:7 Types of Regression Techniques you should know!(译者/刘帝伟审校/刘翔宇、朱正贵责编/周建丁)什么是回归分析?回归分析是⼀种预测性的建模技术,它研究的是因变量(⽬标)和⾃变量(预测器)之间的关系。
这种技术通常⽤于预测分析,时间序列模型以及发现变量之间的因果关系。
例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究⽅法就是回归。
回归分析是建模和分析数据的重要⼯具。
在这⾥,我们使⽤曲线/线来拟合这些数据点,在这种⽅式下,从曲线或线到数据点的距离差异最⼩。
我会在接下来的部分详细解释这⼀点。
我们为什么使⽤回归分析?如上所述,回归分析估计了两个或多个变量之间的关系。
下⾯,让我们举⼀个简单的例⼦来理解它:⽐如说,在当前的经济条件下,你要估计⼀家公司的销售额增长情况。
现在,你有公司最新的数据,这些数据显⽰出销售额增长⼤约是经济增长的2.5倍。
那么使⽤回归分析,我们就可以根据当前和过去的信息来预测未来公司的销售情况。
使⽤回归分析的好处良多。
具体如下:1.它表明⾃变量和因变量之间的显著关系;2.它表明多个⾃变量对⼀个因变量的影响强度。
回归分析也允许我们去⽐较那些衡量不同尺度的变量之间的相互影响,如价格变动与促销活动数量之间联系。
这些有利于帮助市场研究⼈员,数据分析⼈员以及数据科学家排除并估计出⼀组最佳的变量,⽤来构建预测模型。
我们有多少种回归技术?有各种各样的回归技术⽤于预测。
这些技术主要有三个度量(⾃变量的个数,因变量的类型以及回归线的形状)。
我们将在下⾯的部分详细讨论它们。
对于那些有创意的⼈,如果你觉得有必要使⽤上⾯这些参数的⼀个组合,你甚⾄可以创造出⼀个没有被使⽤过的回归模型。




7种回归⽅法!请务必掌握!7 种回归⽅法!请务必掌握!线性回归和逻辑回归通常是⼈们学习预测模型的第⼀个算法。
由于这⼆者的知名度很⼤,许多分析⼈员以为它们就是回归的唯⼀形式了。
⽽了解更多的学者会知道它们是所有回归模型的主要两种形式。
事实是有很多种回归形式,每种回归都有其特定的适⽤场合。
在这篇⽂章中,我将以简单的形式介绍 7 中最常见的回归模型。
通过这篇⽂章,我希望能够帮助⼤家对回归有更⼴泛和全⾯的认识,⽽不是仅仅知道使⽤线性回归和逻辑回归来解决实际问题。
本⽂将主要介绍以下⼏个⽅⾯:1. 什么是回归分析?2. 为什么使⽤回归分析?3. 有哪些回归类型?线性回归(Linear Regression)逻辑回归(Logistic Regression)多项式回归(Polynomial Regression)逐步回归(Stepwise Regression)岭回归(Ridge Regression)套索回归(Lasso Regression)弹性回归(ElasticNet Regression)4. 如何选择合适的回归模型?1什么是回归分析?回归分析是⼀种预测建模技术的⽅法,研究因变量(⽬标)和⾃变量(预测器)之前的关系。
这⼀技术被⽤在预测、时间序列模型和寻找变量之间因果关系。
例如研究驾驶员鲁莽驾驶与交通事故发⽣频率之间的关系,就可以通过回归分析来解决。
回归分析是进⾏数据建模、分析的重要⼯具。
下⾯这张图反映的是使⽤⼀条曲线来拟合离散数据点。
其中,所有离散数据点与拟合曲线对应位置的差值之和是被最⼩化了的,更多细节我们会慢慢介绍。
2为什么使⽤回归分析?如上⾯所说,回归分析能估计两个或者多个变量之间的关系。
下⾯我们通过⼀个简单的例⼦来理解:⽐如说,你想根据当前的经济状况来估计⼀家公司的销售额增长。
你有最近的公司数据,数据表明销售增长⼤约是经济增长的 2.5 倍。
利⽤这种洞察⼒,我们就可以根据当前和过去的信息预测公司未来的销售情况。

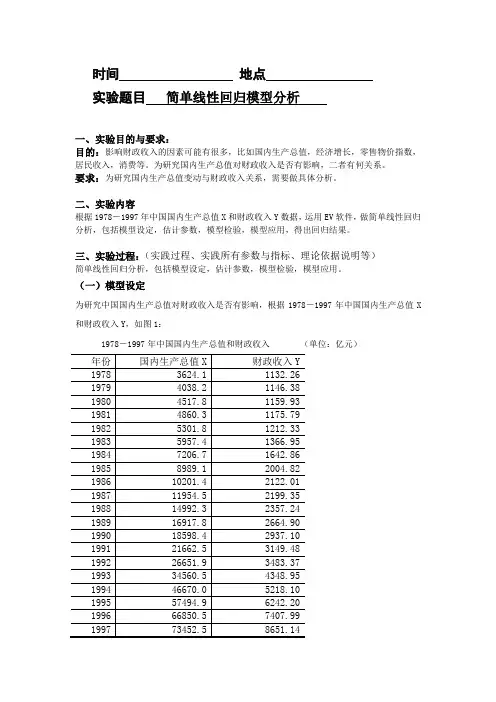
时间地点实验题目简单线性回归模型分析一、实验目的与要求:目的:影响财政收入的因素可能有很多,比如国内生产总值,经济增长,零售物价指数,居民收入,消费等。
为研究国内生产总值对财政收入是否有影响,二者有何关系。
要求:为研究国内生产总值变动与财政收入关系,需要做具体分析。
二、实验内容根据1978-1997年中国国内生产总值X和财政收入Y数据,运用EV软件,做简单线性回归分析,包括模型设定,估计参数,模型检验,模型应用,得出回归结果。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)简单线性回归分析,包括模型设定,估计参数,模型检验,模型应用。
(一)模型设定为研究中国国内生产总值对财政收入是否有影响,根据1978-1997年中国国内生产总值X 和财政收入Y,如图1:1978-1997年中国国内生产总值和财政收入(单位:亿元)根据以上数据,作财政收入Y 和国内生产总值X 的散点图,如图2:从散点图可以看出,财政收入Y 和国内生产总值X 大体呈现为线性关系,所以建立的计量经济模型为以下线性模型:01i i i Y X u ββ=++(二)估计参数1、双击“Eviews ”,进入主页。
输入数据:点击主菜单中的File/Open /EV Workfile —Excel —GDP.xls;2、在EV 主页界面点击“Quick ”菜单,点击“Estimate Equation ”,出现“Equation Specification ”对话框,选择OLS 估计,输入“y c x ”,点击“OK ”。
即出现回归结果图3:图3. 回归结果Dependent Variable: Y Method: Least Squares Date: 10/10/10 Time: 02:02 Sample: 1978 1997 Included observations: 20Variable Coefficient Std. Error t-Statistic Prob. C 857.8375 67.12578 12.77955 0.0000 X0.1000360.00217246.049100.0000R-squared 0.991583 Mean dependent var 3081.158 Adjusted R-squared 0.991115 S.D. dependent var 2212.591 S.E. of regression 208.5553 Akaike info criterion 13.61293 Sum squared resid 782915.7 Schwarz criterion 13.71250 Log likelihood -134.1293 F-statistic 2120.520 Durbin-Watson stat0.864032 Prob(F-statistic)0.000000参数估计结果为:i Y = 857.8375 + 0.100036i X(67.12578) (0.002172)t =(12.77955) (46.04910)2r =0.991583 F=2120.520 S.E.=208.5553 DW=0.8640323、在“Equation ”框中,点击“Resids ”,出现回归结果的图形(图4):剩余值(Residual )、实际值(Actual )、拟合值(Fitted ).(三)模型检验1、 经济意义检验回归模型为:Y = 857.8375 + 0.100036*X (其中Y 为财政收入,i X 为国内生产总值;)所估计的参数2ˆ =0.100036,说明国内生产总值每增加1亿元,财政收入平均增加0.100036亿元。

第七章回归分析本章介绍用于回归分析的常用SAS过程,包括一般回归分析过程REG、建立二次响应曲面回归模型过程RSREG、逐步回归分析过程STEPWISE、非线性回归分析过程NLIN等。
§7.1 一般回归分析过程 REG7.1.1 概述REG过程是一个通用回归过程,用最小二乘法估计线性回归模型。
此过程可以有多个模型(MODEL)语句,输入数据可以是原始样本数据,也可以是相关阵,可打印模型中的参数估计值、预测值、残差及置信区间等,并可作线性假设检验。
7.1.2 过程说明可用下列语句调用REG过程:PROC REG 选项;LABEL:MODEL 因变量表=回归变量表/选项;OUTPUT OUT=数据集关键字=名称表;BY 变量表;(1)PROC REG 选项;常用的选项有:DATA=数据集指定要分析的数据集,缺省时为最新建立的数据集。
ALL 要求各种输出项。
SIMPLE 为每个变量打印简单统计量。
NOPRINT 抑制正常的打印输出。
CORR 打印模型中所有变量的相关阵。
USSCP 为所用变量打印平方和及叉积阵。
(2)LABEL :MODEL 因变量=回归变量/选项;LABEL是模型标号,可省略。
如果使用多个模型,则可给予模型标号名称,便于区别。
常用的选项有:NOPRINT 抑制回归分析结果的打印输出。
NOINT 抑制模型中常数项的出现,缺省时模型中包括常数项。
I 打印X'X的逆矩阵。
XPX 打印X'X阵。
ALL 要求各项输出。
P 打印观测值号、实测值、预测值及残差。
R 要求残差分析。
包括预测值及残差的标准误,学生化残差及COOK'S统计量D。
CLM 打印每个观测值的因变量期望值的95%可信上下限,给出参数估计的变异范围,而不是预测区间。
CLI 要求为每一个观测值打印95%可信度的上下限。
DW 要求计算DURBIN-WASTON统计量,可检验误差是否有一阶自相关。
第七章 回归分析174 PARTIAL 要求打印每个回归变量的偏回归影响图。


线性回归教学设计一、教学目标1、知识与技能目标(1)体会最小二乘法和回归分析的思想;(2)能根据线性回归方程系数公式建立线性回归方程. 2、过程与方法目标(1)经历代数法寻求回归直线方程的过程;(2)体验用计算器或工作表软件得出回归直线方程的过程. 3、情感态度与价值观通过对数据的分析和处理,增强学生应用数学知识解决实际问题的意识,体会数学应用的广泛性.二、重点难点重点:了解最小二乘法思想,会根据给出的线性回归方程系数公式建立线性回归方程. 难点:体会最小二乘法和回归分析的思想.三、教学方法:问题探究式和启发式教学方法四、教学工具:科学计算器、Excle 工作表软件以及多媒体电脑展示设备五、教学过程:1.复习引入首先展示学生上节课得出的不同直线. 然后呈现问题组一问题1: 如何评价这些直线拟合的优劣程度以及标准的合理性? 问题2:试文字语言概括最优拟合直线的标准.说明:学生可能在对得出的不同直线评价其优劣性以及标准的合理性时会提出很多不同的标准,为了防止漫无目的,教师对直线优劣性的判断提出一些基本要求,如尽可能考虑到全部数据,体现整体性,尽可能便于数学计算等,并通过对标准的逐步修正,引导学生得出最优直线的标准:从整体上看,各点与此直线最贴近. 2.探求新知给出概念:我们把整体上最贴近已知数据点的直线叫做回归直线.设回归直线方程为bx a y +=ˆ,其中b 叫做回归系数.坐标点),(i i y x 表示第i 个样本点,坐标点)ˆ,(y x i 表示回归直线方程bx a y +=ˆ上的点,点),(i i y x 和点)ˆ,(y x i 的偏离差记作)ˆ(y y i -,问题组二问题1:如何从代数的角度刻画“从整体上看,各点与此直线最贴近”?问题2:∑=-ni iyy1)ˆ(能反映这些数据点与直线的贴近程度吗?,该怎么规避呢?问题3:比较∑=-ni iyy1|ˆ|和∑=-ni iyy12)ˆ(,在“使各点与此直线的总偏离差最小”的判断上可以等同吗?我们一般选择哪一个代数式作为我们研究的对象,为什么?说明:1、学生可能会把“从整体上看,各点与此直线最贴近”理解为:“各点与此直线的离差之和最小”,这样既是求代数式∑=-ni iyy1)ˆ(的最小值.这时我们给出问题2,学生可能会想到加绝对值,也可能会想到平方.此时给出问题3.因为学生在初二下学期的统计学中的“数据的波动分析”中学习了方差的概念,并在课后的阅读与思考:“数据波动的几种度量”中了解了差的绝对值的和∑=-ni iyy1|ˆ|与差的平方和∑=-ni iyy12)ˆ(.所以在这里学生不难理解其等同性,这时可以给学生说明:为了计算方便,我们通常选择差的平方和∑=-ni iyy12)ˆ(作为研究对象来求最小值.通过三个问题的设置,逐步引导学生利用最小二乘法来求回归直线方程.2、如果有学生在问题1中把“从整体上看,各点与此直线最贴近”理解为“各点与此直线的距离之和最小”,这样既是求距离和∑=ni id1的最小值.在这里可以给学生从形的角度来解释一下(PPT ),通过图形我们看到,距离和∑=ni id1与差的绝对值的和∑=-ni iyy1|ˆ|成比例关系,所以二者在判断“整体上各点与此直线最贴近”上是等同的,为了计算方便,我们通常选择差的平方和∑=-ni iyy12)ˆ(作为研究对象来求最小值.这时给学生指出:这种使“离差平方和为最小”的方法叫做最小二乘法.这样就把学生从定性的观察引导到了定量的分析,不仅完成了几何问题代数化的过程,而且在三个问题的引导下体会到了最小二乘法的思想. 问题组三问题1:怎样用最小二乘法求回归直线方程中的b a ,?问题2:回归直线方程中的b a ,的公式为: ⎪⎪⎩⎪⎪⎨⎧-=--=∑∑==x b y a x n x y x n y x b ni i ni i i ˆˆˆ1221如何更好的认识和应用公式求出回归直线方程?说明:1、教材没有给出公式的具体推导过程,在这里我们通过一个具体的例子来推导一下: 以教材74页例1为例,即:某小卖部为了了解热茶销售量与气温之间的关系,随机统计并制作了某6天卖出热茶的量x 的前3个值带入待定的直线方程bx a y +=ˆ,得到相应的3个ˆy 的值:b a b a b a 13,18,26+++,这3个值与表中相应的实际值应该越接近越好.所以,我们用类似于估计平均数时的思想,考虑离差的平方和2132156278811431169)1334()1824()2620()ˆ()ˆ()ˆ(22222233222211+--++=--+--+--=-+-+-=a b ab a b b a b a b a y y y y yy Q先把a 看作常数,那么Q 是关于b 的二次函数.易知,当1169571394ab -=时, Q 取得最小值.同理, 把b 看作常数,那么Q 是关于a 的二次函数.当b a 1926-=时, Q 取得最小值.因此,当558.6,023.1≈-≈a b 时,Q 取的最小值,此时回归直线方程为x y023.1558.6ˆ-=. 这是根据具体实例,利用二次函数求最值的方法来求得了Q 取最小值时b a ,的值,通过这个特例,让学生简单了解了用最小二乘法求得回归直线方程中b a ,的值的过程,既避免了直接给出公式的唐突,又不用花费大量的时间进行冗繁的推理,而对于一般情况下的推导可以鼓励学生在课后自己尝试推导.并告诉学生,在选修2-3的相关章节中,我们会给出另外一种推导方式.2、通过特例了解了如何用最小二乘法求得回归直线方程中b a ,的值后,我们直接给出一般情况下的系数公式, 由于公式比较复杂,因此在运用这个公式求b a ,时,必须要有条理,先求什么,再求什么.这里可以分析b 中分式的各个组成部分,让学生熟悉每一个数据,以便求解.3、引导学生再观察回归直线方程,发现回归直线一定通过样本点中心),(y x ,在不确定问题探讨中出现的确定性的性质,再次激发学生的探究欲望,而此问题的探究,使得学生在“回归直线是两个变量具有相关关系的代表”的理解上,上升到“回归直线过双变量样本点的中心”这一高度,深化对回归直线和回归思想的理解,完成学生认知结构的再次建构. 3.应用新知:例1 在某种产品表面进行腐蚀刻线实验,得到腐蚀深度Y 与腐蚀时间x 之间相应的一组观察值如下表:(1)画出表中数据的散点图;(2)试求Y 对x 的回归直线方程;(结果保留到小数点后3位数字) (3)试预测腐蚀时间为100s 时腐蚀深度是多少? 问题组四:问题1、回归系数b ˆ的意义是什么?问题2、预测腐蚀时间为100s 时的腐蚀深度准确吗?你怎么理解回归方程的预测功能? 说明:1、这是教材的一个例题,在求回归直线方程时,我们采用的方法是:把数据列成表格,代入公式分别计算b a ,的值,进而求出回归直线方程.通过本例,教师带领学生一起来应用公式,求出回归直线方程.不仅让学生在学以致用中加深对公式结构的理解和认识,而且通过第三问的预测,体现了回归直线方程的应用价值.2、通过问题1,让学生在具体实例中对回归系数b ˆ再认识,强化了学生对数据的实际意义的认识.问题2的设置,让学生在实例中正确认识回归方程的预测功能,体会到了回归直线的应用价值.3、在学生通过具体实例,掌握了根据给出的系数公式建立回归直线方程的方法后,鼓励学生尝试使用函数型计算器(参考教材例3)和Excle 工作表软件(详细过程参见附录)来处理数据求得回归方程.需要说明的是,课标的要求是:能根据给出的线性回归方程系数公式求出线性回归方程.所以必须要让学生掌握方法一.方法二和方法三并没有用到课本所给出的公式.但是方法二和三的介绍会给学生在处理实际问题时带了很大的方便,为下一节课作好铺垫.4.小结和作业:小结:了解最小二乘法思想,会根据给出的线性回归方程系数公式建立线性回归方程. 作业:课本第79页练习A第1题;习题2-3第1题.说明:通过小结和作业,进一步明确本节课的目标,突出了教学重点. 六、教学反思1、关于本单元的教学设计是2个课时还是4个课时的思考.在进行本单元的教学设计时,我们遇到了到底安排几个课时进行教学的问题,如果把统计理解为了解概念、会使用公式解题,那么2个课时就足够了.但是课标要求通过实际问题学习统计知识,强调让学生通过解决实际问题,较为系统地经历数据收集与处理的全过程,本节虽然知识内容不多,但引入新知识的过程中承载着新的数学方法,再加上这节内容是统计必修内容的最后一节,实际上需要综合运用前面的知识,为了让学生真正动起来,提升学生运用统计知识解决实际问题的能力,正确理解统计推断的结论,在实际的教学中我安排了4个课时进行教学.2、关于如何通过几何问题代数化的过程让学生体会最小二乘法的思想的思考.如何把“从整体上看,各点与此直线最贴近”用合适的代数式刻画并化简,化几何问题为代数问题,是顺利了解“最小二乘法思想”的前提;要了解“最小二乘法思想”,还必须要求对给出的系数公式的来源进行一定的说明.而如何化简复杂的代数式,学生缺乏处理的经验,在计算能力的要求上也很高.知识发展的要求与学生能力和经验的欠缺成为本节课遇到的最大矛盾.在教学中,我认为要防止两种倾向:一是直接套用公式求解回归方程而回避说理过程;二是过多纠缠于数学刻画过程,甚至在课堂内花大量时间对回归系数公式进行推导.这两种倾向,都脱离了课标的要求,前者忽略了“最小二乘法思想”,迷失了本节课的教学目标;后者人为拔高教材要求,偏离了本节课教学的重难点.基于此,我在教学中通过问题组的设置一步步引导学生完成几何问题代数化,并通过特例,利用二次函数求最值的方法来求得了Q 取最小值时b a ,的值,突破了本节课的难点. 3、关于合理使用计算器的意义的思考.使用计算器降低了计算的难度,就可以给学生安排更多的动手操作的机会,从而使学生的活动集中于解决问题之中,这样就会使学生淡化回归直线系数公式的记忆,更多的思考如何处理数据,以及对回归方程的推断作用进行更多的全面的思考,这也符合课标对学习统计学的要求.。

《数据挖掘与商务智能实验》实验报告实验题目:统计分析:逻辑回归:王俊学号:4指导教师:大斌实验时间:2016.11.092016年11月10日实验题纲:一、实验目的1)了解和熟悉SPSSModeler及其相关知识。
2)掌握SPSSModeler工具建立多项Logistic回归的方法。
3)学会运用SPSSModeler进行多项Logistic回归的容。
二、实验容本实验采用的数据源来自文件Brand.sav。
该数据集的变量分别是不同性别(x2,1为男,2为女)、三种职业(x1)顾客选购三种品牌(x3)的数据。
本实验主要探讨的例子说明多项Logistic回归的操作和意义。
三、实验步骤与结果步骤1构建多项式Logistic回归数据流1)通过“Statistic文件”节点读入文件名为Brand.sav的数据。
2)数据流中添加“类型”节点。
3)在“建模”模块下选择“Logistic”节点连接在数据流的恰当位置。
步骤2设置相关参数1)右击“类型”节点,将x3设置为目标,其他保持不变,如图所示。
2)右击“Logistic”节点,在模型下,将使用分区数据勾选为“无”,采用的过程选择“多项式”,“多项式过程”中“方法”采用“进入法”,其他保持不变,如图所示。
步骤3结果运行本例的计算结果如图所示。
结果包含两个回归方程。
以第三种职业作为职业的参照水平,以女性作为性别的参照水平,研究对象是选择第一品牌的概率与第三品牌概率之比的自然对数。
当性别相同时,第一种职业的比数自然对数比第三种职业(参照水平)平均减少了1.315,第一种职业是第三种职业的0.269倍。
第一种职业选择第一品牌的倾向不如第三种职业,且统计显著,第一种职业选择第一品牌的倾向性与第三种职业有显著差异。
当职业相同时,男性的比数自然对数比女性(参照水平)平均多0.747个单位,男性是女性的2.112倍。
男性较女性更倾向选择第一品牌,且统计表明,男性选择第一品牌的倾向性与女性有显著差异。
资料范本本资料为word版本,可以直接编辑和打印,感谢您的下载线性回归方程——非线性方程转化为线性方程地点:__________________时间:__________________说明:本资料适用于约定双方经过谈判,协商而共同承认,共同遵守的责任与义务,仅供参考,文档可直接下载或修改,不需要的部分可直接删除,使用时请详细阅读内容线性回归方程——非线性方程转化为线性方程例1.(2015·高考全国卷Ⅰ)某公司为确定下一年度投入某种产品的宣传费,需了解年宣传费x(单位:千元)对年销售量y(单位:t)和年利润z (单位:千元)的影响,对近8年的宣传费xi和年销售量yii=1,2,⋯,8数据作了初步处理,得到下面的散点图及一些统计量的值.表中wi=xi ,w =18 i=18wi.(I)根据散点图判断,y=a+bx与y=c+dx,哪一个适宜作为年销售量y关于年宣传费x的回归方程类型(给出判断即可,不必说明理由);(II)根据(I)的判断结果及表中数据,建立y关于x的回归方程;(III)已知这种产品的年利润z与x,y的关系为z=0.2y-x ,根据(II)的结果回答下列问题:(i)年宣传费x=49时,年销售量及年利润的预报值是多少?(ii)年宣传费x为何值时,年利润的预报值最大?附:对于一组数据(u1,v1),(u2,v2),…,(un,vn),其回归直线v=α+βu 的斜率和截距的最小二乘估计分别为:β=i=1n(ui-u)(vi-v)i=1n(ui-u)2,α=v-βu.【答案】(Ⅰ)y=c+dx适宜作为年销售量y关于年宣传费x的回归方程类型;(Ⅱ)y=100.6+68x;(Ⅲ)(i)答案见解析;(ii)46.24千元.【解析】(I)由散点图可以判断,y=c+dx适宜作为年销售量y关于年宣传费x的回归方程类型.(II)令w=x,先建立y关于w的线性回归方程,由于d=i=18(wi-w)(yi-y)i=18(wi-w)2=108.81.6=68,∴c=y-dw=563−68×6.8=100.6,∴y关于w的线性回归方程为y=100.6+68w,因此y关于x的回归方程为y=100.6+68x.(III)(ⅰ)由(II)知,当x=49时,年销售量y的预报值y=100.6+6849=576.6,年利润z的预报值为z=576.6×0.2-49=66.32.(ⅱ)根据(II)的结果知,年利润z的预报值z=0.2(100.6+68x)-x=-x+13.6x+20.12,所以当x=13.62=6.8,即x=46.24时,z取得最大值. 故年宣传费为46.24千元时,年利润的预报值最大.例2.某地级市共有200000中小学生,其中有7%学生在2017年享受了“国家精准扶贫”政策,在享受“国家精准扶贫”政策的学生中困难程度分为三个等次:一般困难、很困难、特别困难,且人数之比为5:3:2,为进一步帮助这些学生,当地市政府设立“专项教育基金”,对这三个等次的困难学生每年每人分别补助1000元、1500元、2000元。
实验编号: 07 四川师大SPSS实验报告 2017 年 4 月 24 日
计算机科学学院2015级5班实验名称:线性回归
姓名:唐雪梅学号: 2015110538 指导老师:__朱桂琼___ 实验成绩:_ __
实验七线性回归
一.实验目的及要求
1.了解SPSS 特点结构操作
2.利用SPSS进行简单数据统计
二.实验内容
(1)消费者品牌偏好分析:通过品牌使用时间和价格敏感度了解消费者的品牌偏好。
某彩妆系列产品公司进行了一项关于消费者品牌偏好态度的分析,调研人员收集了有关的调研数据,用11点标尺度量态度(1=非常不喜欢该品牌,11=非常喜欢该品牌)对于价格敏感度的度量也用11点标尺(1=对价格完全不敏
思考题:
(1)消费者对品牌的使用时间以及对其价格的敏感度对消费者的品牌偏好有何种影响?它们之间是一种什么样的关系?
(2)如果有影响,品牌偏好与使用时间之间的关系能否用一个模型表示出来?
(2)销售额和员工数量的关系:
随着公司的持续发展,常常有滑入无效率困境的危险,假定某公司的销售开始滑坡,但公司还是不停地招聘新人,公司有某个10年的关于销售额和员
(1)以销售额为自变量,员工数为因变量画出散点图,并建立一个回归模型,通过员工的数量来预测销售额。
(2)解释回归系数的实际意义。
(3)根据分析的结果回答:如果这个趋势继续下去,你对公司的管理层有何建议?你认为管理层应该关注什么?
(3)制度变迁是经济增长的源头,根据研究衡量制度变迁有两个变量:非国有化率和国家财政收入占GDP的比重。
自1998年以来中国的经济增长率一直未突破9%的状态,因此以9%为分界点,将经济增长定义为1(经济增长大于等于9%)或0(经济增长小于9%),
三、实验主要流程、基本操作或核心代码、算法片段(该部分如不够填写,请另加附页)实验一:多元线性回归分析
1.建立数据库
2.分析步骤:分析——回归——线性
3.结果
结论:在对编号为1的模型进行线性回归分析时所采用的方法是全部引入法:输入,此处无被剔出的变量
结论:R Square=0.966,接近于1,说明模型的拟合优度很高,方程拟合很好。
结论:sig=0<0.01,该模型具有显著性意义
系数a
模型
非标准化系数标准系数
t Sig.
B 标准误差试用版
1 (常量) .376 .629 .598 .565
使用时间.516 .060 .819 8.550 .000
价格敏感.235 .085 .266 2.772 .022
a. 因变量: 品牌偏好
拟合结果:y=0.516x1+0.235x2+0.376
Sig.取值大于0.05,没有理由拒绝原假设,即回归系数与零无显著性差异,模型中不存在共线性问题。
结论:特征根均不等于0,则不存在共线性问题,条件指数均小于30,本例中模型不存在共线性的问题。
(1)研究品牌偏好与使用时间之间的关系模型
B)原假设:回归系数与零无显著性差异
C)线性回归分析:
单击分析→回归→线性→打开线性回归主对话框;在弹出的线性回归对话框中,选择变量“品牌偏好(Y)”,添加到因变量框中;选择变量“使用时间(X1)”添加到自变量框中,单机统计量,选中估计、模型拟合度和DW 三个选项。
结果分析:R Square=0.936,接近于1,说明模型的拟合优度很高,方程拟合很好。
DW=2.783,说明残差是负自相关的,表明所假设的模型合理的。
拟合结果:y=0.59x+1.079
残差Mean=0,表明这些数据中无离群值,且数据的标准差也比较小,可以认为模型是合理的
实验二:回归分析
原假设:回归系数与零无显著性差异
1.建立数据库
2.散点图建立:图形——旧对话框——散点\点状——散点图
从图中看出销售额与员工数为非线性关系
(4)回归分析:
A)操作流程:
单击分析→回归→曲线估计→打开曲线估计主对话框;在弹出的曲线估计对话框中,选择变量“员工数”,添加到因变量框中;选择
变量“销售额”添加到自变量框中。
结论:从表中数据可以看出,三次方程的R Square=0.935最接近1,所以员工数和销售呈三次方的关系。
实验三:二维Logistic回归分析
(1)录入实验数据:
(2)二维Logistic回归分析:
1)原假设:回归系数与0无显著性差异
2)操作流程:选择菜单分析→回归→二维Logistic;然后选择Y变量使之添加到因变量框中,选择x1和x2变量,使它们分别进入协变量框中
3)结果分析:
其中常数项包括在模型中,初始-2LL为15.278,迭代结束于第三步,因为此时参数估计与其在上一步的变化已经小于0.001
分类结果表说明Step0的拟合效果。
可以看出对于y=1,有100%的准确性,对于y=0,有0%准确性,总共有66.7%的准确性
似然比卡方检验的观测值等于0.039,概率p值等于0.981。
显著性水平均大于0.05,所以可以拒绝原假设,即认为所有回归系数不同时为0,解释变量的全体与Logit P之间的线性关系显著,采用该模型合理。
模型拟合优度,给出了-2对数似然值较大,说明拟合优度并不理想,Cox和Shell 值以及Nagelkerke值较小,也说明拟合程度较低。
与前一步相比较,预测的准确率不变,模型的总体预测精度也不变。
Sig的值大于0.05,没有理由拒绝原假设,即认为该回归系数与0无显著性差异,它与Logit P的线性关系不是显著的,所以该模型是不可用的,应该重新建模。
四、实验结果的分析与评价(该部分如不够填写,请另加附页)
1.线性回归分析步骤
(1)确定回归方程中的解释变量(自变量)和被解释变量(因变量)。
(2)确定回归模型:通过观察散点图确定应通过哪种数学模型来概括回归线。
(3)建立回归方程:在一定的统计拟合准则下估计出模型中的各个参数,得到一个确定的回归方程
(4)对回归方程进行各种检验:检验回归方程是否真实地反映了事物总体间的统计关系以及回归方程能否用于预测等
(5)利用回归方程进行预测:根据回归方程对事物的未来发展趋势进行预测
2.一元线性回归操作
1.单击Analyze→Regression→Linear→打开Linear Regression主对话框
2.在弹出的LinearRegression对话框中,选择变量“气压”,添加到Dependent框中,表
示因变量;选择变量“沸点”,添加到Independent框中,表示自变量。
3.多元线性回归操作
Analyze→Regression→Linear命令,打开Linear Regression 对话框
选择解释变量Y进入Dependent框
将X1,X2和X5直接纳入模型
X3和X4通过逐步法。
而X6直接不予考虑
选择被解释变量X1,X2和X5进入Independent(s)框
在Method框中选择Enter(默认)表示所选变量强行进入回归方程
单击Next
选择被解释变量X3、X4进入Independent(s)框
在Method框中选择Stepwise对所选变量进行逐步筛选策略
在Linear Regression对话框中单击Statistics按钮
选中Estimates 和Model fit 复选框
选中Collinearity diagnostics复选框
单击OK按钮
4. 二维Logistic回归的SPSS操作
选择菜单Analyze →Regression→Binary Logistic
选择y变量使之添加到Dependent框中,选择x1变量、x2、x3,使它们分别进入Covariates 框中,表示其为自变量
单击Logistic Regression对话框中的Options按钮,选择所有选项,但保留各选项中的缺省值单击Continue按钮,返回上一个对话框,单击OK按钮
注:实验成绩等级分为(90-100分)优,(80-89分)良,(70-79分)中,(60-69分)及格,(59分)不及格。