编译原理实验二语法分析器LL(1)实现教学内容
- 格式:doc
- 大小:200.50 KB
- 文档页数:17

课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include<iostream>#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length())NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;i<w.length();i++)if(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;i<w.length();i++)if(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;i<w.length();i++)if(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j<SUM;j++){if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro())<NODE.length()){for(i=0;i<SUM;i++)if(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i<ni.getrlen();i++){s=NODE.find(ni.getrg()[i]);if(s<NODE.length()&&s>-1) //是非终结符if(i<ni.getrlen()-1) //不在最右for(j=0;j<SUM;j++)if(n[j].getlf().find(ni.getrg()[i])==0){if(NODE.find(ni.getrg()[i+1])<NODE.length()){for(k=0;k<SUM;k++)if(n[k].getlf().find(ni.getrg()[i+1])==0){n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")<n[k].getfirst().length())n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro())<ENODE.length()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i<ni.getrlen();i++){for(j=0;j<SUM;j++)if(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length())return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;cout<<"{";for(i=0;i<p.length()-1;i++){cout<<p[i]<<",";}cout<<p[i]<<"}";}//连续输出符号void outfu(int a,string c){int i;for(i=0;i<a;i++)cout<<c;}//输出预测分析表void outgraph(edge *n,string (*yc)[50]){int i,j,k;bool flag;for(i=0;i<ENODE.length();i++){if(ENODE[i]!='@'){outfu(10," ");cout<<ENODE[i];}}outfu(10," ");cout<<"#"<<endl;int x;for(i=0;i<NODE.length();i++){outfu(4," ");cout<<NODE[i];outfu(5," ");for(k=0;k<ENODE.length();k++){flag=1;for(j=0;j<SUM;j++){if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]);if(x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout<<endl;}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b) {char ch,a;int x,i,j,k;b++;cout<<endl<<" "<<b;if(b>9)outfu(8," ");elseoutfu(9," ");cout<<fenxi;outfu(26-chuan.length()-fenxi.length()," "); cout<<chuan;outfu(10," ");a=chuan[0];ch=fenxi[fenxi.length()-1];x=ENODE.find(ch);if(x<ENODE.length()&&x>-1){if(ch==a){fenxi.erase(fenxi.length()-1,1);chuan.erase(0,1);cout<<"'"<<a<<"'匹配";if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}else{if(ch=='#'){if(ch==a){cout<<"分析成功"<<endl;return 1;}elsereturn 0;}elseif(ch=='@'){fenxi.erase(fenxi.length()-1,1);if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x<ENODE.length()&&x>-1)j=ENODE.length()-1;elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout<<NODE[i]<<"->"<<yc[i][j];fenxi.erase(fenxi.length()-1,1);for(k=yc[i][j].length()-1;k>-1;k--)if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cout<<"请输入上下文无关文法的总规则数:"<<endl;cin>>SUM;cout<<"请输入具体规则(格式:左部右部,@为空):"<<endl;n=new edge[SUM];for(i=0;i<SUM;i++)for(j=0;j<n[i].getrlen();j++){str=n[i].getrg();if(NODE.find(str[j])>NODE.length()&&ENODE.find(str[j])>ENODE.length()) ENODE+=str[j];}//计算first集合for(i=0;i<SUM;i++){first(n[i],n,i);}//outfu(10,"~*~");cout<<endl;for(i=0;i<SUM;i++)if(n[i].getfirst().find("@")<n[i].getfirst().length()){if(NODE.find(n[i].getro())<NODE.length()){for(k=1;k<n[i].getrlen();k++){if(NODE.find(n[i].getrg()[k])<NODE.length()){for(j=0;j<SUM;j++){if(n[i].getrg()[k]==n[j].getlf()[0]){n[i].newfirst(n[j].getfirst());break;}}if(n[j].getfirst().find("@")>n[j].getfirst().length()){n[i].delfirst();break;}}}}}//计算follow集合for(k=0;k<SUM;k++){for(i=0;i<SUM;i++){if(n[i].getlf()==n[0].getlf())n[i].newfollow("#");follow(n[i],n,i);}for(i=0;i<SUM;i++){for(j=0;j<SUM;j++)if(n[j].getrg().find(n[i].getlf())==n[j].getrlen()-1)n[i].newfollow(n[j].getfollow());}}//计算select集合for(i=0;i<SUM;i++){select(n[i],n);}for(i=0;i<NODE.length();i++){str.erase();for(j=0;j<SUM;j++)if(n[j].getlf()[0]==NODE[i]){if(!str.length())str=n[j].getselect();else{for(k=0;k<n[j].getselect().length();k++)if(str.find(n[j].getselect()[k])<str.length()){flag=1;break;}}}}//输出cout<<endl<<"非终结符";outfu(SUM," ");cout<<"First";outfu(SUM," ");cout<<"Follow"<<endl;outfu(5+SUM,"-*-");cout<<endl;for(i=0;i<NODE.length();i++){for(j=0;j<SUM;j++)if(NODE[i]==n[j].getlf()[0]){outfu(3," ");cout<<NODE[i];outfu(SUM+4," ");out(n[j].getfirst());outfu(SUM+4-2*n[j].getfirst().length()," ");out(n[j].getfollow());cout<<endl;break;}}outfu(5+SUM,"-*-");cout<<endl<<"判定结论: ";if(flag){cout<<"该文法不是LL(1)文法!"<<endl;return;}else{cout<<"该文法是LL(1)文法!"<<endl;}//输出预测分析表cout<<endl<<"预测分析表如下:"<<endl;yc=new string[NODE.length()][50];outgraph(n,yc);string chuan,fenxi,fchuan;cout<<endl<<"请输入符号串:";cin>>chuan;fchuan=chuan;fenxi="#";fenxi+=NODE[0];i=0;cout<<endl<<"预测分析过程如下:"<<endl;cout<<"步骤";outfu(7," ");cout<<"分析栈";outfu(10," ");cout<<"剩余输入串";outfu(8," ");cout<<"推导所用产生式或匹配";if(pipei(chuan,fenxi,yc,i))cout<<endl<<"输入串"<<fchuan<<"是该文法的句子!"<<endl;elsecout<<endl<<"输入串"<<fchuan<<"不是该文法的句子!"<<endl;}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。

编译原理程序设计实验报告——表达式语法分析器的设计班级:计算机1306班姓名:张涛学号:20133967实验目标:用LL(1)分析法设计实现表达式语法分析器实验内容:⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。
然后利用LL(1)分析法实现语法分析。
⑵数据结构:int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};⑶分析表及流程图逆序压栈int IsLetter(char ch) //判断ch是否为字母int IsDigit(char ch) //判断ch是否为数字int Iskey(char *string) //判断是否为关键字int Isbound(char ch) //判断是否为界符int Isboundnum(char ch) //给出界符所在token值int init(STack *s) //栈初始化int pop(STack *s,char *ch) //弹栈操作int push(STack *s,char ch) //压栈操作void LL1(); //分析函数源程序代码:(加入注释)#include<stdio.h>#include<string.h>#include<ctype.h>#include<windows.h>#include <stdlib.h>int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};typedef struct Stack STack;int init(STack *s) //栈初始化{(*s).base=(char*)malloc(100*sizeof(char));if(!(*s).base)exit(0);(*s).top=(*s).base;(*s).stacksize=100;printf("初始化栈\n");return 0;}int pop(STack *s,char *ch) //弹栈操作{if((*s).top==(*s).base){printf("弹栈失败\n");return 0;(*s).top--;*ch=*((*s).top);printf("%c",*ch);return 1;}int push(STack *s,char ch) //压栈操作{if((*s).top-(*s).base>=(*s).stacksize){(*s).base=(char*)realloc((*s).base,((*s).stacksize+10)*sizeof(char));if(!(*s).base)exit(0);(*s).top=(*s).base+(*s).stacksize;(*s).stacksize+=10;}*(*s).top=ch;*(*s).top++;return 1;}void LL1();int IsLetter(char ch) //判断ch是否为字母{int i;for(i=0;i<=45;i++)if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))return 1;return 0;}int IsDigit(char ch) //判断ch是否为数字{int i;for(i=0;i<=10;i++)if (ch>='0'&&ch<='9')return 1;return 0;}int Isbound(char ch) //判断是否为界符{int i;for(i=0;i<2;i++)if(ch==bound[i]){return i+1;}}return 0;}int Isoperate(char ch) //判断是否为运算符{int i;for(i=0;i<4;i++){if(ch==operate[i]){return i+3;}}return 0;}int main(){FILE *fp;int q=0,m=0;char sour[200]=" ";printf("请将源文件置于以下位置并按以下方式命名:F:\\2.txt\n");if((fp=fopen("F:\\2.txt","r"))==NULL) {printf("文件未找到!\n");}else{while(!feof(fp)){if(isspace(ch=fgetc(fp)));else{sour[q]=ch;q++;}}}int p=0;printf("输入句子为:\n");for(p;p<=q;p++)printf("%c",sour[p]);}printf("\n");int state=0,nowlen=0;BOOLEAN OK=TRUE,ERR=FALSE;int i,flagpoint=0;for(i=0;i<q;i++){if(sour[i]=='#')tokenlist[m].code=='#';switch(state){case 0:ch=sour[i];if(Isbound(ch)){if(ERR){printf("无法识别\n");ERR=FALSE;OK=TRUE;}else if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}state=4;}else if(IsDigit(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;state=3;OK=FALSE;break;}else{nowword[nowlen]=ch;nowlen++;}}else if(IsLetter(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;OK=FALSE;}else{nowword[nowlen]=ch;nowlen++;}}else if(Isoperate(ch)){if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}printf("<%d,%c>运算符\n",Isoperate(ch),ch);tokentemp.code=Isoperate(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;}break;case 3:if(IsLetter(ch)){printf("错误\n");nowword[nowlen]=ch;nowlen++;ERR=FALSE;state=0;break;}if(IsDigit(ch=sour[i])){nowword[nowlen]=ch;nowlen++;}else if(sour[i]=='.'&&flagpoint==0){flagpoint=1;nowword[nowlen]=ch;nowlen++;}else{printf("<20,%s>数字\n",nowword);i--;state=0;OK=TRUE;tokentemp.code=20;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;}break;case 4:i--;printf("<%d,%c>界符\n",Isbound(ch),ch);tokentemp.code=Isbound(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;state=0;OK=TRUE;break;}}printf("tokenlist值为%d\n",m);int t=0;tokenlist[m+1].code='r';m++;for(t;t<m;t++){printf("tokenlist%d值为%d\n",t,tokenlist[t].code);}LL1();printf("tokenlist值为%d\n",m);if(op+1==m)printf("OK!!!");elseprintf("WRONG!!!");return 0;}void LL1(){STack s;init(&s);push(&s,'#');push(&s,'E');char ch;int flag=1;do{pop(&s,&ch);printf("输出栈顶为%c\n",ch);printf("输出栈顶为%d\n",ch);printf("当前p值为%d\n",op);if((ch=='(')||(ch==')')||(ch=='+')||(ch=='-')||(ch=='*')||(ch=='/')||(ch==10)||(ch==20)){if(tokenlist[op].code==1||tokenlist[op].code==20||tokenlist[op].code==10||tokenlist[op].code==2||tokenlist[op] .code==3||tokenlist[op].code==4||tokenlist[op].code==5||tokenlist[op].code==6)op++;else{printf("WRONG!!!");exit(0);}}else if(ch=='#'){if(tokenlist[op].code==0)flag=0;else{printf("WRONG!!!@@@@@@@@@");exit(0);}}else if(ch=='E'){printf("进入E\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'R');printf("将R压入栈\n");push(&s,'T');}}else if(ch=='R'){printf("进入R\n");if(tokenlist[op].code==3||tokenlist[op].code==4){push(&s,'R');push(&s,'T');printf("将T压入栈\n");push(&s,'+');}if(tokenlist[op].code==2||tokenlist[op].code==0){}}else if(ch=='T'){printf("进入T\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'Y');push(&s,'F');}}else if(ch=='Y'){printf("进入Y\n");if(tokenlist[op].code==5||tokenlist[op].code==6){push(&s,'Y');push(&s,'F');push(&s,'*');}elseif(tokenlist[op].code==3||tokenlist[op].code==2||tokenlist[op].code==0||tokenlist[op].code==4) {}}else if(ch=='F'){printf("进入F\n");if(tokenlist[op].code==10||tokenlist[op].code==20){push(&s,10);}if(tokenlist[op].code==1){push(&s,')');push(&s,'E');push(&s,'(');}}else{printf("WRONG!!!!");exit(0);}}while(flag);}程序运行结果:(截屏)输入:((Aa+Bb)*(88.2/3))#注:如需运行请将文件放置F盘,并命名为:2.txt输出:思考问题回答:LL(1)分析法的主要问题就是要正确的将文法化为LL (1)文法。

编译原理实验报告LL(1)分析法课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length()) NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;iif(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;iif(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;iif(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j{if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro()){for(i=0;iif(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i{s=NODE.find(ni.getrg()[i]);if(s-1) //是非终结符if(ifor(j=0;jif(n[j].getlf().find(ni.getrg()[i])==0) {if(NODE.find(ni.getrg()[i+1]){for(k=0;kif(n[k].getlf().find(ni.getrg()[i+1])==0) {n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i{for(j=0;jif(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length()) return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;coutfor(i=0;i{cout}cout}//连续输出符号void outfu(int a,string c){int i;for(i=0;icout}//输出预测分析表void outgraph(edge *n,string (*yc)[50]) {int i,j,k;bool flag;for(i=0;i{if(ENODE[i]!='@'){outfu(10," ");cout}}outfu(10," ");coutint x;for(i=0;i{outfu(4," ");coutoutfu(5," ");for(k=0;k{flag=1;for(j=0;j{if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]); if(x-1){cout"yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x-1) {cout"yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b){char ch,a;int x,i,j,k; b++; cout9) outfu(8," "); else outfu(9," "); cout-1) { if(ch==a) { fenxi.erase(fenxi.length()-1,1); chuan.erase(0,1); coutfenxi.erase(fenxi.length()-1,1); if(pipei(chuan,fenxi,yc,b)) return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x-1) j=ENODE.length()-1; elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout"-1;k--) if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b)) return 1; elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cin>>SUM; coutNODE.length()&&ENODE.find(str[j])>ENODE.length())ENODE+=str[j]; } //计算first集合 for(i=0;in[j].getfirst().length()){ n[i].delfirst(); break; } } } } }for(k=0;koutfu(SUM," "); cout>chuan; fchuan=chuan; fenxi="#"; fenxi+=NODE[0]; i=0; coutoutfu(7," ");coutoutfu(10," ");coutoutfu(8," ");coutif(pipei(chuan,fenxi,yc,i))coutelsecout}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。

编译原理实验报告一、实验目的编译原理是计算机科学中的重要学科,它涉及到将高级编程语言转换为计算机能够理解和执行的机器语言。
本次实验的目的是通过实际操作和编程实践,深入理解编译原理中的词法分析、语法分析、语义分析以及中间代码生成等关键环节,提高我们对编译过程的认识和编程能力。
二、实验环境本次实验使用的编程语言为C++,开发环境为Visual Studio 2019。
此外,还使用了一些相关的编译工具和调试工具,如 GDB 等。
三、实验内容(一)词法分析器的实现词法分析是编译过程的第一步,其任务是将输入的源程序分解为一个个单词符号。
在本次实验中,我们使用有限自动机的理论来设计和实现词法分析器。
首先,定义了各种单词符号的类别,如标识符、关键字、常量、运算符等。
然后,根据这些类别设计了相应的状态转换图,并将其转换为代码实现。
在实现过程中,使用了正则表达式来匹配输入字符串中的单词符号。
对于标识符和常量等需要进一步处理的单词符号,使用了相应的规则进行解析和转换。
(二)语法分析器的实现语法分析是编译过程的核心环节之一,其任务是根据给定的语法规则,分析输入的单词符号序列是否符合语法结构。
在本次实验中,我们使用了递归下降的语法分析方法。
首先,根据实验要求定义了语法规则,并将其转换为相应的递归函数。
在递归函数中,通过对输入单词符号的判断和处理,逐步分析语法结构。
为了处理语法错误,在分析过程中添加了错误检测和处理机制。
当遇到不符合语法规则的输入时,能够输出相应的错误信息,并尝试进行恢复。
(三)语义分析及中间代码生成语义分析的目的是对语法分析得到的语法树进行语义检查和语义处理,生成中间代码。
在本次实验中,我们使用了三地址码作为中间代码的表示形式。
在语义分析过程中,对变量的定义和使用、表达式的计算、控制流语句等进行了语义检查和处理。
对于符合语义规则的语法结构,生成相应的三地址码指令。
四、实验步骤(一)词法分析器的实现步骤1、定义单词符号的类别和对应的正则表达式。

实验2 LL(1)分析法一、实验目的通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。
使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练学生掌握开发应用程序的基本方法。
有利于提高学生的专业素质,为培养适应社会多方面需要的能力。
二、实验要求1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
2、如果遇到错误的表达式,应输出错误提示信息。
3、对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG|—TG(3)G->ε(4)T->FS(5)S->*FS|/FS(6)S->ε(7)F->(E)(8)F->i三、实验内容根据某一文法编制调试LL ( 1 )分析程序,以便对任意输入的符号串进行分析。
构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。
分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号以及LL(1)分析表,对输入符号串自上而下的分析过程。
四、实验步骤1、根据流程图编写出各个模块的源程序代码上机调试。
2、编制好源程序后,设计若干用例对系统进行全面的上机测试,并通过所设计的LL(1)分析程序;直至能够得到完全满意的结果。
3、书写实验报告;实验报告正文的内容:写出LL(1)分析法的思想及写出符合LL(1)分析法的文法。
程序结构描述:函数调用格式、参数含义、返回值描述、函数功能;函数之间的调用关系图。
详细的算法描述(程序执行流程图)。
给出软件的测试方法和测试结果。
实验总结(设计的特点、不足、收获与体会)。
五、实验截图六、核心代码#include<iostream>#include<stdio.h>#include<stdlib.h>#include<string.h>#define MAX 20using namespace std;char A[MAX];char B[MAX];char v1[MAX] = { 'i','+','-','*','/','(',')','#'}; char v2[MAX] = {'E','G','T','S','F'};int j = 0, b = 0, top = 0;int l; //l是字符串长度class type{public:char origin;char array[7];int length;};type e, t, g,g0, g1, s, s0,s1, f, f1;type C[10][10];void print(){int a;for ( a = 0; a <= top + 1; a++)cout<<A[a];cout << "\t\t";}void print1(){int j;for (j = 0; j<b; j++)cout << " ";for (j = b; j <= l; j++)cout << B[j];cout << "\t\t\t";}int main(){int m, n, k = 0;int flag = 0,finish = 0;char ch, x;type cha;e.origin = 'E';strcpy(e.array, "TG");e.length = 2;t.origin = 'T';strcpy(t.array, "FS");t.length = 2;g.origin = 'G';strcpy(g.array, "+TG");g.length = 3;g0.origin = 'G';strcpy(g0.array, "-TG");g0.length = 3;g1.origin = 'G';g1.array[0] = '^';g1.length = 1;s.origin = 'S';strcpy(s.array, "*FS");s.length = 3;s0.origin = 'S';strcpy(s0.array, "/FS");s0.length = 3;s1.origin = 'S';s1.array[0] = '^';s1.length = 1;f.origin = 'F';strcpy(f.array, "(E)");f.length = 3;f1.origin = 'F';f1.array[0] = 'i';f1.length = 1;for (m = 0; m <= 4;m++)for (n = 0; n <= 7; n++)C[m][n].origin = 'N';/*C[0][0] = e; C[0][3] = e; C[1][2] = g0;C[1][1] = g; C[1][4] = g1; C[1][5] = g1;C[2][0] = t; C[2][3] = t;C[3][1] = s1; C[3][2] = s;C[3][4] = C[3][5] = s1;C[4][0] = f1; C[4][3] = f;*/C[0][0] = e; C[0][5] = e;C[1][1] = g; C[1][2] = g0;C[1][6] = g1; C[1][7] = g1;C[2][0] = t; C[2][5] = t;C[3][1] = s1; C[3][2] = s1;C[3][3] = s;C[3][4] = s0; C[3][6] = s1; C[3][7] = s1;C[4][0] = f1; C[4][5] = f;cout << "input,please~:";do{cin >> ch;if ((ch!='i') &&(ch!='+') &&(ch!='-') &&(ch!='*') &&(ch!='/') &&(ch!='(') &&(ch!=')') &&(ch!='#')){cout << "Error!\n";exit(1);}B[j] = ch;j++;} while (ch != '#');l = j; //l是字符串长度/* for(j=0;j<l;j++)cout<<B[j]<<endl;*/ch = B[0]; //当前分析字符A[top] = '#';A[++top] = 'E';/*'#','E'进栈*/cout << "步骤\t\t分析栈\t\t剩余字符\t\t所用字符\n"; do{x = A[top--];cout << k++;cout << "\t\t";for (j = 0; j<=7 ; j++)if (x == v1[j]){flag = 1;break;}if (flag==1){if (x == '#'){finish = 1;cout << "acc!\n";getchar();getchar();exit(1);}if (x == ch){print();print1();cout <<ch << "匹配\n";ch = B[++b];flag = 0;}else{cout<<"x:"<<x<<endl;cout<<"ch:"<<ch<<endl;print();print1();cout <<ch<< "出错\n" ;exit(1);}}else //非终结符{for (j = 0; j <= 4; j++)if (x == v2[j]){m = j;//行号break;}for (j = 0; j <= 7; j++)if (ch == v1[j]){n = j; //列号break;}cha = C[m][n];if (cha.origin != 'N'){print();print1();cout << cha.origin << "->";for (j = 0; j<cha.length; j++)cout << cha.array[j];cout << "\n";for (j = (cha.length - 1); j >= 0; j--)A[++top] = cha.array[j];if (A[top] == '^')/*为空则不进栈*/top--;}else{print();print1();cout<<"x:"<<x<<endl;cout<<"ch:"<<ch<<endl;cout<<"sign1"<<endl;cout << "Error!" << x;exit(1);}}} while (finish == 0);}。

编译原理程序设计实验报告——表达式语法分析器的设计班级:计算机1306班:涛学号:20133967 实验目标:用LL(1)分析法设计实现表达式语法分析器实验容:⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。
然后利用LL(1)分析法实现语法分析。
⑵数据结构:int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};⑶分析表及流程图逆序压栈int IsLetter(char ch) //判断ch是否为字母int IsDigit(char ch) //判断ch是否为数字int Iskey(char *string) //判断是否为关键字int Isbound(char ch) //判断是否为界符int Isboundnum(char ch) //给出界符所在token值int init(STack *s) //栈初始化int pop(STack *s,char *ch) //弹栈操作int push(STack *s,char ch) //压栈操作void LL1(); //分析函数源程序代码:(加入注释)#include<stdio.h>#include<string.h>#include<ctype.h>#include<windows.h>#include <stdlib.h>int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};typedef struct Stack STack;int init(STack *s) //栈初始化{(*s).base=(char*)malloc(100*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base;(*s).stacksize=100;printf("初始化栈\n");return 0;}int pop(STack *s,char *ch) //弹栈操作{if((*s).top==(*s).base){printf("弹栈失败\n");return 0;(*s).top--;*ch=*((*s).top);printf("%c",*ch);return 1;}int push(STack *s,char ch) //压栈操作{if((*s).top-(*s).base>=(*s).stacksize){(*s).base=(char*)realloc((*s).base,((*s).stacksize+10)*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base+(*s).stacksize;(*s).stacksize+=10;}*(*s).top=ch;*(*s).top++;return 1;}void LL1();int IsLetter(char ch) //判断ch是否为字母{int i;for(i=0;i<=45;i++)if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))return 1;return 0;}int IsDigit(char ch) //判断ch是否为数字{int i;for(i=0;i<=10;i++)if (ch>='0'&&ch<='9')return 1;return 0;}int Isbound(char ch) //判断是否为界符{int i;for(i=0;i<2;i++)if(ch==bound[i]){return i+1;}}return 0;}int Isoperate(char ch) //判断是否为运算符{int i;for(i=0;i<4;i++){if(ch==operate[i]){return i+3;}}return 0;}int main(){FILE *fp;int q=0,m=0;char sour[200]=" ";printf("请将源文件置于以下位置并按以下方式命名:F:\\2.txt\n");if((fp=fopen("F:\\2.txt","r"))==NULL){printf("文件未找到!\n");}else{while(!feof(fp)){if(isspace(ch=fgetc(fp)));else{sour[q]=ch;q++;}}}int p=0;printf("输入句子为:\n");for(p;p<=q;p++)printf("%c",sour[p]);}printf("\n");int state=0,nowlen=0;BOOLEAN OK=TRUE,ERR=FALSE;int i,flagpoint=0;for(i=0;i<q;i++){if(sour[i]=='#')tokenlist[m].code=='#';switch(state){case 0:ch=sour[i];if(Isbound(ch)){if(ERR){printf("无法识别\n");ERR=FALSE;OK=TRUE;}else if(!OK){printf("<10,%s>标识符\n",nowword); tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}state=4;}else if(IsDigit(ch)){if(OK){memset(nowword,0,strlen(nowword)); nowlen=0;nowword[nowlen]=ch;nowlen++;state=3;OK=FALSE;break;}else{nowword[nowlen]=ch;nowlen++;}}else if(IsLetter(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;OK=FALSE;}else{nowword[nowlen]=ch;nowlen++;}}else if(Isoperate(ch)){if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}printf("<%d,%c>运算符\n",Isoperate(ch),ch); tokentemp.code=Isoperate(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;}break;case 3:if(IsLetter(ch)){printf("错误\n");nowword[nowlen]=ch;nowlen++;ERR=FALSE;state=0;break;}if(IsDigit(ch=sour[i])){nowword[nowlen]=ch;nowlen++;}else if(sour[i]=='.'&&flagpoint==0){flagpoint=1;nowword[nowlen]=ch;nowlen++;}else{printf("<20,%s>数字\n",nowword);i--;state=0;OK=TRUE;tokentemp.code=20;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;}break;case 4:i--;printf("<%d,%c>界符\n",Isbound(ch),ch); tokentemp.code=Isbound(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;state=0;OK=TRUE;break;}}printf("tokenlist值为%d\n",m);int t=0;tokenlist[m+1].code='r';m++;for(t;t<m;t++){printf("tokenlist%d值为%d\n",t,tokenlist[t].code);}LL1();printf("tokenlist值为%d\n",m);if(op+1==m)printf("OK!!!");elseprintf("WRONG!!!");return 0;}void LL1(){STack s;init(&s);push(&s,'#');push(&s,'E');char ch;int flag=1;do{pop(&s,&ch);printf("输出栈顶为%c\n",ch);printf("输出栈顶为%d\n",ch);printf("当前p值为%d\n",op);if((ch=='(')||(ch==')')||(ch=='+')||(ch=='-')||(ch=='*')||(ch=='/')||(ch==10)||(ch==20)) {if(tokenlist[op].code==1||tokenlist[op].code==20||tokenlist[op].code==10||tokenlist[op].cod e==2||tokenlist[op].code==3||tokenlist[op].code==4||tokenlist[op].code==5||tokenlist[op].co de==6)op++;else{printf("WRONG!!!");exit(0);}}else if(ch=='#'){if(tokenlist[op].code==0)flag=0;else{printf("WRONG!!!");exit(0);}}else if(ch=='E'){printf("进入E\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'R');printf("将R压入栈\n");push(&s,'T');}}else if(ch=='R'){printf("进入R\n");if(tokenlist[op].code==3||tokenlist[op].code==4){push(&s,'R');push(&s,'T');printf("将T压入栈\n");push(&s,'+');}if(tokenlist[op].code==2||tokenlist[op].code==0){}}else if(ch=='T'){printf("进入T\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'Y');push(&s,'F');}}else if(ch=='Y'){printf("进入Y\n");if(tokenlist[op].code==5||tokenlist[op].code==6){push(&s,'Y');push(&s,'F');push(&s,'*');}elseif(tokenlist[op].code==3||tokenlist[op].code==2||tokenlist[op].code==0||tokenlist[op].code= =4){}}else if(ch=='F'){printf("进入F\n");if(tokenlist[op].code==10||tokenlist[op].code==20){push(&s,10);}if(tokenlist[op].code==1){push(&s,')');push(&s,'E');push(&s,'(');}}else{printf("WRONG!!!!");exit(0);}}while(flag);}程序运行结果:(截屏)输入:((Aa+Bb)*(88.2/3))#注:如需运行请将文件放置F盘,并命名为:2.txt输出:思考问题回答:LL(1)分析法的主要问题就是要正确的将文法化为LL (1)文法。

【实验2】LL(1)⽂法分析器实验2 LL(1)⽂法分析实验题⽬:编写LL(1)⽂法分析器实验⽬的:加深对⽂法分析基本理论的理解,锻炼实现LL(1)⽂法分析器程序的实践能⼒。
要求:实现基本LL(1)⽂法的功能。
输⼊⽂法,能够求出FIRST集、FOLLOW集、预测分析表,同时,输⼊⼀串字符,输出分析过程。
⼀.需求分析1.问题的提出:语法分析是编译过程的核⼼部分,其任务是在词法分析识别单词符号串的基础上,分析并判断程序的的语法结构是否符合语法规则。
语⾔的语法结构是⽤上下⽂⽆关⽂法描述的。
因此语法分析器的⼯作的本质上就是按⽂法的产⽣式,识别输⼊符号串是否为⼀个句⼦。
对于⼀个⽂法,当给出⼀串符号时,如何知道它是不是该⽂法的⼀个句⼦,这是本设计所要解决的⼀个问题。
2.问题解决:其实要知道⼀串符号是不是该⽂法的⼀个句⼦,只要判断是否能从⽂法的开始符号出发,推导出这个输⼊串。
语法分析可以分为两类,⼀类是⾃上⽽下的分析法,⼀类是⾃下⽽上的分析法。
⾃上⽽下的主旨是,对任何输⼊串,试图⽤⼀切可能的办法,从⽂法开始符号出发,⾃上⽽下的为输⼊串建⽴⼀棵语法树。
或者说,为输⼊串寻找⼀个最左推导,这种分析过程的本质是⼀种试探过程,是反复使⽤不同产⽣式谋求匹配输⼊串的过程。
3.解决步骤:在⾃上⽽下的分析法中,主要是研究LL(1)分析法。
它的解决步骤是,⾸先接收到⽤户输⼊的⼀个⽂法,对⽂法进⾏检测和处理,消除左递归,得到LL(1)⽂法,这个⽂法应该满⾜:⽆⼆义性,⽆左递归,⽆左公因⼦。
当⽂法满⾜条件后,再分别构造⽂法每个⾮终结符的FIRST和FOLLOW集合,然后根据FIRST 和FOLLOW集合构造LL(1)分析表,最后利⽤分析表,根据LL(1)语法分析构造⼀个分析器。
LL(1)的语法分析程序包含三个部分:总控程序,预测分析表函数,先进先出的语法分析栈。
⼆.概要设计1.设计原理:所谓LL(1)分析法,就是指从左到右扫描输⼊串(源程序),同时采⽤最左推导,且对每次直接推导只需向前看⼀个输⼊符号,便可确定当前所应当选择的规则。

目录引言 (1)第一章概述 (4)1.1设计内容 (4)1.2设计要求 (4)第二章设计的基本原理 (4)2.1预测分析表的构成原理 (4)2.2预测分析程序的生成 (5)第三章程序设计 (5)3.1总体方案设计 (6)3.2各模块设计 (6)第四章程序测试 (7)附录程序清单 (8)课 程 设 计L L (1)文法分析器2010 年 12 月设计题目学 号 专业班级 学生姓名指导教师合肥工业大学课程设计任务书第一章概述1.1 设计内容:1:预测分析表自动构造程序的实现2:预测分析程序的实现1.2 设计要求1:设计内容及要求:对于任意输入的一个LL(1)文法,构造其预测分析表。
要求:首先实现集合FIRST(X)构造算法和集合FOLLOW(A)构造算法,再实现教材P.79给出的预测分析表构造算法。
程序显示输出预测分析表或输出到指定文件中。
2:设计内容及要求:对文法 G: E→E+T|T 按教材P.76表4.1构造出G的预测分析程序,T→T*F|F 程序显示输出如P.78那样的匹配过程。
F→(E)|i第二章设计的基本原理2.1预测分析表的构成原理对于任意给定的LL(1) 文法G,为了构造它的预测分析表M,我们就必须构造与文法G有关的集合First和fellow.首先我们对每一个X∈V T U Vn ,构造FIRST(X),办法是,连续使用下面的规则,直至每个集合FIRST不再增大为止.(1)若X∈V T,,则FIRST(X)={X}.(2)若X∈Vn ,且有产生式X->a……,则把a加入到FIRST(X)中,若X->ε,也是一条产生式,则把ε也加到FIRST(X)中.(3)若X->Y……是一个产生式且Y∈Vn,则把FIRST(Y)中所有非ε-元素都加到FIRST(X)中,若X->Y1Y2……Y K ,是一个连续的产生式, Y1Y2……Y i-1 都是非终结符,而且,对于任何j,1≤j≤i-1,FIRST(Y j) 都含有ε(即Y1Y2……Y i-1=>ε),则把FIRST(Y i) 中的所有非ε-元素都加到FIRST(X)中,特别是,若所有的FIRST(Y j)均含有ε,j=1,2,……,k,则把ε加到FIRST(X)中.对于文法G中每个非终结符A构造FOLLOW(A)的办法是,连续使用下面的规则,直到每个FOLLOW不在增大为止.(1)对于文法的开始符号S,置#于FOLLOW(S)中;(2)若A->aBb是一个产生式,则把FIRST(b)\{ ε}加至FOLLOW(B)中;(3)若A->aB是一个产生式,或A->aBb是一个产生式而b=>ε(即ε∈FIRST( b))则把FOLLOW(A)加至FOLLOW(B)中构造分析表M的算法是:(1)对文法G的每个产生式A->a执行第二步和第三步;(2)对每个终结符a∈FIRST(a), 把A->a加至M[A,a]中;(3)若ε∈FIRST(a),则把任何b∈FOLLOW(A)把A->a加至M[A,b]中;(4)把所有无定义的M[A,a]标上出错标志.2.2 预测分析程序的生成预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号行事的,对于任何(X,a),总控程序每次都执行下述三种可能的动作之一;(1)若X=a=”#”,则宣布分析成功,停止分析过程.(2)若X=a≠”#”,则把X从STACK栈顶逐出,让a指向下一个输入符号.(3)若X是一个非终结符,则查看分析表M,若M[A,a]中存放着关于X的一个产生式,那么,首先把X逐出STACK栈顶,然后,把产生式的右部符号串按反序一一推进STACK栈(若右部符号为ε,则意味着不推什么东西进栈).在把产生式的右部符号推进栈的同时应做这个产生式相应得语义动作,若M[A,a]中存放着”出错标志”,则调用出错诊察程序ERROR.第三章程序设计3.1 总体方案设计在看到这个题目后,首先想到的就是要分模块进行设计.(1)第一模块:把文本文件中的LL(1)文法读入到程序中grammer类中的数组成员g中.(2)第二模块:通过对已输入到数组g中的文法,进行扫描,把相应的非终结符和终结符输入到非终结符数组VN中和终结符数组VT中.(3)第三模块:生成所有的非终结符的FIRST集合(4)第四模块:生成所有的非终结符的FOLLOW集合(5)第五模块:生成文法的预测分析表(6)第六模块:生成文法的预测分析程序通过这六模块的设计,最后可连接成一个预测分析程序.3.2 各模块程序设计首先要建立两个类,分别是grammer类和SeqStack类Grammer类中有保存从文本文件读入的LL(1)文法,用一个二维字符数组g保存, 保存非终结符的字符数组VN,保存终结符的字符数组VT,文法开始符号字符变量begin ,元素对应first集合中的有空字符的非终结符数组emptychar,预测分析表为二维整形数组form.SeqStack类主要的作用为在预测分析时作为符号栈.(1)第一模块的设计:对于这个模块的设计,就是用输入流对文本文件中的文法进行读入当读到字符’|’或’/n’时意味着一个产生式已结束,那么相应数组中相应的下标变量+1;数组g[i][0]所存放着这个产生式对应的字符的数量.g[i][1]为这个产生式左边的非终结符.(2)第二模块的设计:在已把文法读入到数组g中后,那么相应的g[i][0]为每个产生式的非终结符,若此非终结符不在数组VN中,那么把此字符加入到VN中对终结符的读入,则是从每个g[i][2]开始扫描,若此字符不在非终结符数组VN中,也不在VT 中,那么就把此字符加入到VT中.(3)第三模块的设计:生成FIRST集合这个算法基本上按照书上的原理,如对每个产生式进行扫描,当扫描到非终结符时,把此字符加入到相应非终结符的FIRST集合中,若遇到非终结符时,需把此非终结符的FIRST集合中除了空字符外全加入到对应的非终结符的first集合中,这就涉及到算法的一个递归算法,我是利用在函数的参数表中设置俩个参数,一个是FIRST数组,另外一个是非终结符,在用到递归时,我是利用把FIRST数组设为本产生式第一个非终结符的FIRST数组,而非终结符参数则设置为在扫描产生式右部过程中所遇到的非终结符.然后通过循环对这个文法中的所有非终结符进行函数的调用,这样来求到所有非终结符的FIRST集合.(4)第四模块的设计:生成FOLLOW集合这个算法,关键就是求某非终结符A的FOLLOW集合,那么就是扫描到A后面的字符,若为终结符,则把此终结符加入到A的FOLLOW集合,那么若为非终结符,则把此非终结符的FIRST集合加入到A的FOLLOW集合中,若A为某个产生式最后一个字符,则把这个产生式的第一个字符的FOLLOW集合加入到A的FOLLOW集合中,在这个算法的过程中叶涉及到运用递归,此递归的方法同样与上述求FIRST集合中运用的递归方法类似(5)第五模块的设计:求预测分析表的过程同样是对每个产生式进行扫描,对每个产生式的FIRST集合中的元素,都把相应的产生式的编号写入到对应的预测分析表中对应的位置(6)第六模块的设计:生成预测分析程序,就是把’#’和文法开始符号进入到栈中,然后把相应的分析语句中当前的输入符号对应,在每一步过程中按照书上讲到的原理,在预测分析表中找到相应的产生式.第四章程序测试附录程序清单class SeqStack;//声明栈类class grammer//定义grammer类,此类的作用把文本文件中的文法保存,并且产生这个文法的非终结符集合,终结符集合,first集合,fellow集合,预测分析表等{public:grammer();~grammer();void openfile(char *);void prepareform();void buildform();void buildProcess(SeqStack& ss);private:char begin;char *vt;char **g;char *vn;char **first;//这时所有非终结符的first集合char **fellow;//这是所有非终结符的fellow集合char *emptychar;//这个集合中的元素为对应first集合中的有空字符的非终结符int **form;//这是对应文法的预测分析表int count;void buildVn();void buildVt();void buildemptychar();void buildfirst();void buildfellow();void fellowzh(char *,char);void firstzh(char *,char);int search(char *,char);void printform();void outputblank(int);};const int stackIncreament=20;class SeqStack//定义SeqStack类,这个类的主要作用是在对语句的预测分析过程中作符号栈{public:friend grammer;SeqStack(int sz=50);~SeqStack();void Push(char x);bool Pop(char& x);bool getTop(char& x);bool IsEmpty();bool IsFull();int getSize();void MakeEmpty();void showPlay();private:char *elements;int top;int maxSize;void overflowProcess();};#include<fstream>#include<iostream>#include<stdio.h>#include<stdlib.h>#include<assert.h>#include<windows.h>#include "编译.h"using namespace std;grammer::grammer(){count=0;}grammer::~grammer(){int i;for(i=0;i<count;i++)delete g[i];delete g;delete vt;delete vn;}void grammer::openfile(char *file)//这个函数的主要功能在于对文本文件中的文法进行读入,并保存在对应的数组中,一并产生对应文法的终结符集合和非终结符集合{char ch;int i,j;ifstream infile(file,ios::in);//定义文件流if(!infile){cout<<"open error!"<<endl;exit(1);}while((ch=infile.get())!=EOF){if(ch=='-'){if((ch=infile.get())=='>'){count++;}else{infile.seekg(-1,ios::cur);}}else if(ch=='|'){count++;}else{}}g=new char *[count];for(i=0;i<count;i++){g[i]=new char [15];g[i][0]=0;}infile.clear();//能重新激活文件流infile.seekg(0,ios::beg);//定位i=0;j=1;while((ch=infile.get())!=EOF){if(ch=='-'){if(infile.get()!='>'){g[i][j]=ch;g[i][0]++;j++;if(ch==EOF)break;elseinfile.seekg(-1,ios::cur);}}else if(ch=='|'){i++;g[i][1]=g[i-1][1];g[i][0]=1;j=2;}else if(ch=='\n'){infile.seekg(-3,ios::cur);ch=infile.get();if(ch!='\n'){i++;j=1;}infile.seekg(2,ios::cur);}else{g[i][j]=ch;g[i][0]++;j++;}}cout<<count<<endl;for(i=0;i<count;i++){for(j=1;j<=g[i][0];j++){cout<<g[i][j]<<" ";}cout<<endl;}buildVn();//建立非终结符集合buildVt();//建立终结符集合}void grammer::buildVn()int i=1,j=0;vn=new char[count+1];vn[i]=g[j++][1];for(;j<count;j++)if(g[j][1]!=g[j-1][1]){i++;vn[i]=g[j][1];}vn[0]=i;begin=vn[1];cout<<"本文法开始符为:"<<begin<<endl;cout<<"本文法非终结符为:"<<" ";for(i=1;i<=vn[0];i++)cout<<vn[i]<<" ";cout<<endl;}void grammer::buildVt(){int i=1,j=0,t;char ch;vt=new char[100];vt[0]=0;for(;j<count;j++){t=2;for(;t<=g[j][0];t++){ch=g[j][t];if(!search(vt,ch)&&!search(vn,ch)){vt[i++]=g[j][t];vt[0]++;}}}cout<<"本文法终结符为:"<<" ";for(i=1;i<=vt[0];i++)cout<<vt[i]<<" ";cout<<endl;}int grammer::search(char *a,char ch)//搜索函数,用于在指定数组中对指定字符进行搜寻,若存在输出对应的序号,若不在则输出0for(int i=1;i<=a[0];i++){if(ch==a[i])return i;}return 0;}void grammer::buildemptychar()//建立对应first集合中含有空字符的的非终结符集合{int i=0,j=2,t=1;bool flag=true,flag1;emptychar=new char[vn[0]+1];emptychar[0]=0;for(;i<count;i++){if(g[i][2]=='@'&&!search(emptychar,g[i][1])){emptychar[t++]=g[i][1];emptychar[0]++;}}while(flag){flag=false;for(i=0;i<count;i++){for(j=2;j<=g[i][0];j++){if(search(emptychar,g[i][j])){flag1=true;}else{flag1=false;break;}}if(flag1==true&&!search(emptychar,g[i][1])){emptychar[t++]=g[i][1];emptychar[0]++;flag=true;}}cout<<"First集中含有空字符的有: ";for(i=1;i<=emptychar[0];i++){cout<<emptychar[i]<<" ";}cout<<endl;}void grammer::buildfirst(){int i;first=new char* [vn[0]];for(i=0;i<vn[0];i++){first[i]=new char[vt[0]+1];}for(i=0;i<vn[0];i++)first[i][0]=0;for(i=1;i<=vn[0];i++){firstzh(first[i-1],vn[i]);}}void grammer::buildfellow(){int i,j;fellow=new char* [vn[0]];for(i=0;i<vn[0];i++){fellow[i]=new char[vt[0]+1];}for(i=0;i<vn[0];i++)fellow[i][0]=0;for(i=1;i<=vn[0];i++){fellowzh(fellow[i-1],vn[i]);}for(i=0;i<vn[0];i++){cout<<vn[i+1]<<"的fellow集合为: ";for(j=1;j<=fellow[i][0];j++){cout<<fellow[i][j]<<" ";cout<<endl;}}void grammer::firstzh(char *a,char ch)//对指定非终结符建立对应的first集合{int i,j,t=1;for(i=0;i<count;i++){for(j=2;j<=g[i][0];j++){if(g[i][1]==ch){if(!search(vn,g[i][j])&&g[i][j]!='@')//找到对应产生式中的终结符时{if(!search(a,g[i][j])){a[t++]=g[i][j];a[0]++;}break;}else if(g[i][j]!='@')//找到对应的产生式中的非终结符时{firstzh(a,g[i][j]);//用递归的方法算出此非终结符的first集合if(!search(emptychar,g[i][j]))//当此非终结符的first集合中无空字符时,对此产生式扫描完毕break;}else{}}elsebreak;}}}void grammer::fellowzh(char *a,char ch)//对指定非终结符建立fellow集合{int i,j,k,m,n,t=a[0];if(ch==begin)//把#字符放入开始符的fellow集合{if(!search(a,'#'))a[++t]='#';a[0]++;}}for(i=0;i<count;i++){for(j=2;j<=g[i][0];j++){if(g[i][j]==ch){for(m=j;m<=g[i][0];m++){if(m==g[i][0]){if(g[i][1]!=ch)fellowzh(a,g[i][1]);//发现要求的非终结符在此产生式的末尾时elsebreak;}else{if(!search(vn,g[i][m+1]))//当此非终结符后面的字符为终结字符时,放入对应的fellow集合{if(!search(a,g[i][m+1])){a[++t]=g[i][m+1];a[0]++;}break;}else{k=search(vn,g[i][m+1]);//把此非终结符后面的非终结符的first集合中的元素放入对应的fellow集合for(n=1;n<=first[k-1][0];n++){if(!search(a,first[k-1][n])){a[++t]=first[k-1][n];a[0]++;}}if(!search(emptychar,g[i][m+1]))break;}}}}}}void grammer::prepareform(){int i,j;buildemptychar();buildfirst();buildfellow();for(i=0;i<vn[0];i++){if(search(emptychar,vn[i+1])){j=first[i][0];first[i][++j]='@';first[i][0]++;}}for(i=0;i<vn[0];i++){cout<<vn[i+1]<<"的first集合为: ";for(j=1;j<=first[i][0];j++){cout<<first[i][j]<<" ";}cout<<endl;}}void grammer::buildform(){int i,j,k,t,m,n;bool flag;form=new int*[vn[0]];for(i=0;i<vn[0];i++)form[i]=new int[vt[0]];for(i=0;i<vn[0];i++){for(j=0;j<vt[0];j++){form[i][j]=-1;}for(i=0;i<count;i++){t=search(vn,g[i][1]);flag=true;for(j=2;j<=g[i][0];j++){k=search(vt,g[i][j]);//若发现这个产生式的first集合中的对应的终结符时if(k){if(g[i][j]!='@'){if(form[t-1][k-1]!=-1){cout<<"本终结符错误!"<<endl;exit(1);}form[t-1][k-1]=i;flag=false;break;}else//若发现对应产生式中的first集合中含有空字符时{for(m=1;m<=fellow[t-1][0];m++){if(fellow[t-1][m]!='#')//可把对应的非终结符的fellow集合中的元素对应的表项中填入该产生式的标号{n=search(vt,fellow[t-1][m]);if(form[t-1][n-1]!=-1){cout<<"有终结符@本fellow集合中非#错误!"<<endl;exit(1);}form[t-1][n-1]=i;}else{if(form[t-1][k-1]!=-1){cout<<"有终结符@本fellow集合中#错误!"<<endl;exit(1);}form[t-1][k-1]=i;}flag=false;break;}}else//找到该产生式中的非终结符时{k=search(vn,g[i][j]);for(m=1;m<=first[k-1][0];m++){if(first[k-1][m]!='@'){n=search(vt,first[k-1][m]);if(form[t-1][n-1]!=-1){cout<<"本first集合中非@!"<<endl;exit(1);}form[t-1][n-1]=i;}else{}}if(!search(first[k-1],'@'))//若在此终结符对应的first集合中无空字符时{flag=false;break;}}}if(flag==true)//说明该产生式对应的first集合中含有空字符{for(m=1;m<=fellow[t-1][0];m++){if(fellow[t-1][m]!='#'){n=search(vt,fellow[t-1][m]);if(form[t-1][n-1]!=-1){cout<<"本fellow集合中非#错误!"<<endl;exit(1);}form[t-1][n-1]=i;}{n=search(vt,'@');if(form[t-1][n-1]!=-1){cout<<"本fellow集合中#错误!"<<endl;exit(1);}form[t-1][n-1]=i;}}}}printform();}void grammer::outputblank(int i){int j;for(j=0;j<i;j++)cout<<" ";}void grammer::printform(){int i,j,k,t,m;cout<<"-----------------------------预测分析表如下所示------------------------------"<<endl;outputblank(6);for(i=1;i<=vt[0];i++){if(vt[i]=='@'){cout<<"#";outputblank(10);}else{cout<<vt[i];outputblank(10);}}cout<<endl;for(i=0;i<vn[0];i++){cout<<" "<<vn[i+1];outputblank(4);{k=form[i][j];if(k==-1){Sleep(500);cout<<"error";outputblank(6);}else{Sleep(1000);t=9-g[k][0];cout<<g[k][1]<<"->";for(m=2;m<=g[k][0];m++){cout<<g[k][m];}outputblank(t);}}cout<<endl;}}void grammer::buildProcess(SeqStack& ss) {char *dia,ch;int i,j,inlen,m,n,index=0,proc=0;bool flag=true,flag1=false;dia=new char[20];cout<<"请输入待分析的字符串"<<endl;cin>>dia;for(i=0,inlen=0;i<20;i++){if(dia[i]!='\0')inlen++;elsebreak;}cout<<"步骤";outputblank(8);cout<<"符号栈";outputblank(15);cout<<"输入串";outputblank(15);cout<<"所用产生式"<<endl;dia[inlen++]='#';ss.Push('#');ss.Push(begin);while(flag){Sleep(1500);cout<<proc;if(proc>=10)outputblank(11);elseoutputblank(12);++proc;ss.showPlay();outputblank(21-ss.getSize());for(j=index;j<inlen;j++)cout<<dia[j];outputblank(21-inlen+index);if(flag1==true){cout<<g[form[m-1][n-1]][1]<<"->";for(j=2;j<=g[form[m-1][n-1]][0];j++)cout<<g[form[m-1][n-1]][j];cout<<endl;}elsecout<<endl;ss.getTop(ch);m=search(vn,ch);if(dia[index]!='#')n=search(vt,dia[index]);elsen=search(vt,'@');if(search(vt,ch))//当栈顶是终结符{if(ch==dia[index])//且此终结符与输入串此时检测的终结符符号相同{index++;ss.Pop(ch);flag1=false;}else{cout<<"该字符串不能由该文法推出"<<endl;exit(1);}}else if(ch=='#'){if(ch==dia[index]){cout<<endl;cout<<"---------------------------------分析完成------------------------------"<<endl;flag=false;}else{cout<<"该字符串不能由该文法推出"<<endl;exit(1);}}else if(form[m-1][n-1]!=-1)//当栈顶的非终结符与输入串对应的终结符在预测分析表中相应的项存在时{if(g[form[m-1][n-1]][2]!='@'){ss.Pop(ch);for(i=g[form[m-1][n-1]][0];i>=2;i--){ss.Push(g[form[m-1][n-1]][i]);}}elsess.Pop(ch);flag1=true;}else{cout<<"该字符串不能由该文法推出"<<endl;exit(1);}}}void SeqStack::overflowProcess(){char *newArray=new char[maxSize+stackIncreament];if(newArray==NULL){cerr<<"存储分配失败!"<<endl;exit(1);}for(int i=0;i<=top;i++)newArray[i]=elements[i];maxSize=maxSize+stackIncreament;delete []elements;elements=newArray;}void SeqStack::Push(char x){if(IsFull()==true)overflowProcess();elements[++top]=x;}bool SeqStack::Pop(char &x){if(IsEmpty()==true)return false;x= elements[top--];return true;}bool SeqStack::getTop(char &x){if(IsEmpty()==true)return false;x=elements[top];return true;}void SeqStack::showPlay(){for(int i=0;i<=top;i++)cout<<elements[i];}SeqStack::SeqStack(int sz):top(-1),maxSize(sz) {elements=new char[maxSize];assert(elements!=NULL);}SeqStack::~SeqStack(){delete []elements;}bool SeqStack::IsEmpty(){return(top==-1)?true:false;}bool SeqStack::IsFull(){return (top==maxSize-1)?true:false;}int SeqStack::getSize(){return top+1;}void SeqStack::MakeEmpty(){top=-1;}#include<iostream>#include"编译.h"using namespace std;void main(){//char ch;grammer ga;SeqStack ss;char filename[20];cout<<"欢迎来到本LL(1)文法预测分析表自动生成程序"<<endl;cout<<endl;cout<<endl;cout<<"请输入文法所在的文件名"<<endl;cin>>filename;ga.openfile(filename);ga.prepareform();ga.buildform();ga.buildProcess(ss);}。
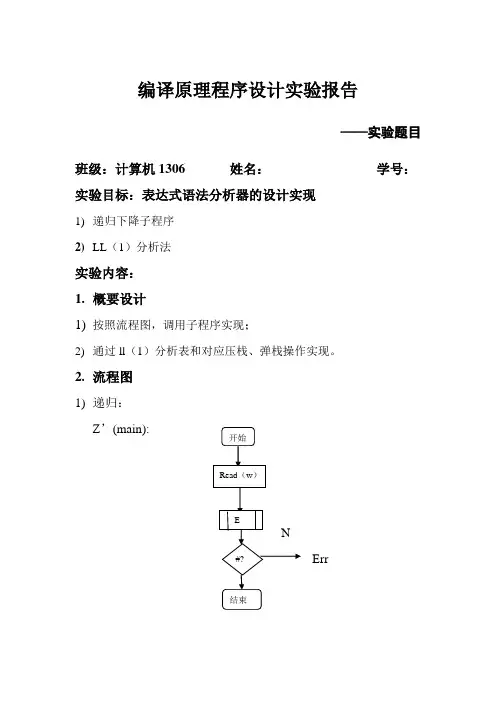
编译原理程序设计实验报告——实验题目班级:计算机1306姓名:学号:实验目标:表达式语法分析器的设计实现1) 递归下降子程序 2) LL (1)分析法实验内容: 1. 概要设计1) 按照流程图,调用子程序实现;2) 通过ll (1)分析表和对应压栈、弹栈操作实现。
2. 流程图1) 递归: Z ’(main):N Err开始Read (w ) E #? 结束E: E1:Y NY NT: T1:YNYNF :N N err Y YY N err入口 TE1 入口+? -? 出口Read(w) T出口入口 FT1 出口入口*?/?出口Read (w )T入口I ? (? Read (w )E )? Read (w )出口2) LL (1):BeginPUSH(#),PUSH(E)POP(x)x ∈VTx ∈VNx=wendW=#nyNEXT(w)yn err查LL (1)分析表空?nPUSH (i )errny逆序压栈开始构建LL(1)分析表调用函数token ()切分单词 调用*Analyse(char *token)进行分析 结束3.关键函数1)递归下降子程序void E(); //E->TX;int E1(); //X->+TX | evoid T(); //T->FYint T1(); //Y->*FY | eint F(); //F->(E) | i2)LL(1)分析法char *Find(char vn,char vt)//是否查到表char *Analyse(char *token)//分析过程int Token()//将token中数字表示成i,标识符表示成n源程序代码:(加入注释)1)递归下降子程序:#include<stdio.h>#include<iostream>#include <string.h>#include <stdlib.h>using namespace std;/********全局变量**********/char str[30];int index=0;void E();//E->TX;int E1();//X->+TX | evoid T();//T->FYint T1();//Y->*FY | eint F();//F->(E) | iFILE *fp;char cur;/*************主函数************/int main(){int len;int m;if((fp=fopen("source.txt","r"))==NULL){cout<<"can not open the source file!"<<endl;exit(1);}cur=fgetc(fp);while(cur!='#'){E();}cout<<endl;cout<<"success"<<endl;return 0;}/*************************************/void E(){T();E1();}/*************************************/int E1(){if(cur=='+'){cur=fgetc(fp);T();cout<<'+'<<" ";E1();}else if(cur=='-'){cur=fgetc(fp);T();cout<<'-'<<" ";E1();}return 0;}/************************************/void T(){F();T1();}/***********************************/int T1(){if(cur=='*'){cur=fgetc(fp);F();cout<<'*'<<" ";T1();}else if(cur=='/'){cur=fgetc(fp);F();cout<<'/'<<" ";T1();}return 0;}int F(){if((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'){for(int i=0;i<20;i++){str[i]='\0';index=0;}str[index++]=cur;cur=fgetc(fp);while((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'||(cur<='9'&&cur>='0')){str[index++]=cur;cur=fgetc(fp);}cout<<str;cout<<" ";return NULL;}else if (cur<='9'&&cur>='0'){for(int i=0;i<20;i++){str[i]='\0';index=0;}while(cur<='9'&&cur>='0'){str[index++]=cur;cur=fgetc(fp);}if(cur=='.'){str[index++]=cur;cur=fgetc(fp);while(cur<='9'&&cur>='0'){str[index++]=cur;cur=fgetc(fp);}cout<<str;cout<<" ";return NULL;}else if((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'){printf("error6\n");exit(1);}else{cout<<str;cout<<" ";return NULL;}}else if (cur=='('){cur=fgetc(fp);E();if(cur==')'){cur=fgetc(fp);return 0;}else{printf("error3\n");exit (1);}}else{printf("error4\n");exit(1);}return 0;}程序运行结果:(截屏)输入:Source.txt文本((Aa+Bb)*(88.2/3))#输出:2)LL(1)#include <iostream>#include <cstdio>#include <cstdlib>#include <cstring>#include <stack>using namespace std;struct Node1{char vn;char vt;char s[12];}MAP[22];//存储分析预测表每个位置对应的终结符,非终结符,产生式int k;char token[30];int token_index=0;charG[12][12]={"E->TR","R->+TR","R->-TR","R->e","T->FW","W->*FW","W->/FW", "W->e","F->(E)","F->i","F->n"};//存储文法中的产生式,用R代表E',W代表T',e代表空//char VN[6]={'E','R','T','W','F'};//存储非终结符//char VT[9]={'i','n','+','-','*','/','(',')','#'};//存储终结符char Select[12][12]={"(,i,n","+","-","),#","(,i,n","*","/","+,-,),#","(","i","n"};//存储文法中每个产生式对应的select集合charRight[12][8]={"->TR","->+TR","->-TR","->e","->FW","->*FW","->/FW","->e","->( E)","->i","->n"};stack<char> stak,stak1,stak2;char *Find(char vn,char vt){int i;for(i=0;i<k;i++){if(MAP[i].vn==vn&& MAP[i].vt==vt)return MAP[i].s;}return "error";}char *Analyse(char *token){char p,action[10],output[10];int i=1,j,k=0,l_act,m;while(!stak.empty())//判断栈中是否为空,若不空就将栈顶元素与分析表匹配进行相应操作stak.pop();stak.push('#');//栈底标志stak.push('E');//起始符号先入栈printf(" 步骤栈顶元素输入串推导所用产生式或匹配\n");p=stak.top();while(p!='#')//查预测分析表将栈顶元素进行匹配,若栈顶元素与输入串匹配成功则向前匹配,否则生成式反序入栈{printf("%7d ",i++);p=stak.top();//从栈中弹出一个栈顶符号,由p记录并输出stak.pop();printf("%6c ",p);for(j=0,m=0;j<token_index;j++)//将未被匹配的剩余输入串输出output[m++]=token[j];output[m]='\0';printf("%10s",output);if(p==token[k]){ if(p=='#')//若最后一个结束符号匹配说明输入表达式被接受,否则继续匹配{printf(" 接受\n");return "SUCCESS";}printf(" “%c”匹配\n",p);k++;}else{ //将未被匹配的第一个字符与find函数的结果进行比较,在预测分析表中查找相应生成式strcpy(action,Find(p,token[k]));if(strcmp(action,"error")==0){printf(" 没有可用的产生式\n");return "ERROR";}printf(" %c%s\n",p,action);int l_act=strlen(action);if(action[l_act-1]=='e')continue;for(j=l_act-1;j>1;j--)stak.push(action[j]);}}return "ERROR";}int Token(){FILE *fp;char cur;int i,j;fp=fopen("source.txt","r");cur=fgetc(fp);while(cur!=EOF)//把用字母数字表示的输入串转换为token序列的表示方法{if((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'){cur=fgetc(fp);while((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'||(cur<='9'&&cur>='0')){cur=fgetc(fp);} token[token_index++]='i';continue;}else if (cur<='9'&&cur>='0'){while(cur<='9'&&cur>='0')cur=fgetc(fp);if(cur=='.'){cur=fgetc(fp);while(cur<='9'&&cur>='0')cur=fgetc(fp);}token[token_index++]='n';continue;}else{token[token_index++]=cur;cur=fgetc(fp);continue;} }token[token_index]='#';cout<<"把文件中字符串用i表示,数字用n表示,转化后:";for(int index=0;index<=token_index;index++)cout<<token[index];cout<<endl<<endl;return 0;}int main (){int i,j,l,m;for(i=0,k=0;i<11;i++)//通过select集合生成预测分析表{l=strlen(Select[i]);for(j=0;j<l;j+=2){MAP[k].vn=G[i][0];MAP[k].vt=Select[i][j];strcpy(MAP[k].s,Right[i]);k++;}}Token();cout<<"分析过程如下:"<<endl;cout<<Analyse(token)<<endl;return 0;}程序运行结果:(截屏)输入:Source.txt文本((Aa+Bb)*(88.2/3))输出:目录第一章项目总论 ········································错误!未定义书签。


《编译原理》实验教学大纲一、实验目的和任务编译原理是计算机科学与技术专业的一门重要课程,它主要研究的是将高级语言程序翻译成机器语言程序的方法和技术。
通过本实验课程的学习,旨在使学生掌握编译原理的基本原理和方法,培养学生对编译器结构与构造技术的专门知识和技能,为学生今后进行编译器设计与实现打下基础。
二、实验设备和工具1.计算机和相关硬件设备2. 编程语言的开发环境,如C/C++或Java三、实验内容1.实验一:词法分析器设计与实现a)实验目的:学习词法分析器的原理和设计方法,掌握正则表达式、DFA和NFA的转换方法。
b)实验任务:i.设计并实现一个词法分析器的原型,能够正确地识别出给定的程序中的词法单元。
ii. 使用给定的正则表达式设计并实现识别给定程序中的关键字、标识符、常量等的词法分析器。
2.实验二:语法分析器设计与实现a)实验目的:学习语法分析器的原理和设计方法,掌握上下文无关文法和LR分析表的构造方法。
b)实验任务:i.学习并理解上下文无关文法和LR分析表的构造方法。
ii. 设计并实现一个简单的递归下降语法分析器。
3.实验三:语义分析器设计与实现a)实验目的:学习语义分析器的原理和设计方法,掌握语义动作的定义和处理方法。
b)实验任务:i.学习并理解语义分析器的原理和设计方法。
ii. 设计并实现一个简单的语义分析器,能够对给定的程序进行语义分析和语义动作的处理。
4.实验四:中间代码生成器设计与实现a)实验目的:学习中间代码生成器的原理和设计方法,掌握中间代码的生成和优化方法。
b)实验任务:i.学习并理解中间代码生成器的原理和设计方法。
ii. 设计并实现一个简单的中间代码生成器,能够将给定的程序翻译成中间代码。
5.实验五:目标代码生成器设计与实现a)实验目的:学习目标代码生成器的原理和设计方法,掌握目标代码的生成和优化方法。
b)实验任务:i.学习并理解目标代码生成器的原理和设计方法。
ii. 设计并实现一个简单的目标代码生成器,能够将中间代码翻译成目标代码。
青岛科技大学LL(1)分析编译原理实验报告学生班级__________________________学生学号__________________________学生姓名________________________________年 ___月 ___日一、实验目的LL(1)分析法的基本思想是:自项向下分析时从左向右扫描输入串,分析过程中将采用最左推导,并且只需向右看一个符号就可决定如何推导。
通过对给定的文法构造预测分析表和实现某个符号串的分析,掌握LL(1)分析法的基本思想和实现过程。
二、实验要求设计一个给定的LL(1)分析表,输入一个句子,能根据LL(1)分析表输出与句子相应的语法数。
能对语法数生成过程进行模拟。
三、实验内容(1)给定表达式文法为:G(E’): E’→#E# E→E+T | T T→T*F |F F→(E)|i(2)分析的句子为:(i+i)*i四、模块流程五、程序代码#include<iostream>#include<stdio.h>#include <string>#include <stack>using namespace std;char Vt[]={'i','+','*','(',')','#'}; /*终结符*/char Vn[]={'E','e','T','t','F'}; /*非终结符*/ int LENVt=sizeof(Vt);void showstack(stack <char> st) //从栈底开始显示栈中的内容{int i,j;char ch[100];j=st.size();for(i=0;i<j;i++){ch[i]=st.top();st.pop();}for(i=j-1;i>=0;i--){cout<<ch[i];st.push(ch[i]);}}int find(char c,char array[],int n) //查找函数,返回布尔值{int i;int flag=0;for(i=0;i<n;i++){if(c==array[i])flag=1;}return flag;}int location(char c,char array[]) //定位函数,指出字符所在位置,即将字母转换为数组下标值{int i;for(i=0;c!=array[i];i++);return i;}void error(){cout<<" 出错!"<<endl;}void analyse(char Vn[],char Vt[],string M[5][6],string str){int i,j,p,q,h,flag=1;char a,X;stack <char> st; //定义堆栈st.push('#');st.push(Vn[0]); //#与识别符号入栈j=0; //j指向输入串的指针h=1;a=str[j];cout<<"步骤"<<"分析栈"<<"剩余输入串"<<" 所用产生式"<<endl;while(flag==1){cout<<h<<" "; //显示步骤h++;showstack(st); //显示分析栈中内容cout<<" ";for(i=j;i<str.size();i++) cout<<str[i]; //显示剩余字符串X=st.top(); //取栈顶符号放入X if(find(X,Vt,LENVt)==1) //X是终结符if(X==a) //分析栈的栈顶元素和剩余输入串的第一个元素相比较if (X!='#'){cout<<" "<<X<<"匹配"<<endl;st.pop();a=str[++j]; //读入输入串的下一字符}else{ cout<<" "<<"acc!"<<endl<<endl; flag=0;}else{error();break;}else{p=location(X,Vn); //实现下标的转换(非终结符转换为行下标)q=location(a,Vt); //实现下标的转换(终结符转换为列下标)string S1("NULL"),S2("null");if(M[p][q]==S1 || M[p][q]==S2) //查找二维数组中的产生式{error();break;} //对应项为空,则出错else{string str0=M[p][q];cout<<" "<<X<<"-->"<<str0<<endl; //显示对应的产生式st.pop();if(str0!="$") //$代表"空"字符for(i=str0.size()-1;i>=0;i--) st.push(str0[i]);//产生式右端逆序进栈}}}}main(){string M[5][6]={"Te" ,"NULL","NULL","Te", "NULL","NULL","NULL","+Te" ,"NULL","NULL","$", "$","Ft", "NULL","NULL","Ft", "NULL","NULL","NULL","$", "*Ft", "NULL","$", "$","i", "NULL","NULL","(E)", "NULL","NULL"}; //预测分析表j string str;int errflag,i;cout<<"文法:E->E+T|T T->T*F|F F->(E)|i"<<endl;cout<<"请输入分析串(以#结束):"<<endl;do{ errflag=0;cin>>str;for(i=0;i<str.size();i++)if(!find(str[i],Vt,LENVt)){ cout<<"输入串中包含有非终结符"<<str[i]<<"(输入错误)!"<<endl;errflag=1;}} while(errflag==1); //判断输入串的合法性analyse(Vn, Vt, M,str);return 0;}六、实验结果七、实验总结。
《LL(1)分析器的构造》实验报告一、实验名称LL(1)分析器的构造二、实验目的设计、编制、调试一个LL(1)语法分析器,利用语法分析器对符号串的识别,加深对语法分析原理的理解。
三、实验内容和要求设计并实现一个LL(1)语法分析器,实现对算术文法:G[E]:E->E+T|TT->T*F|FF->(E)|i所定义的符号串进行识别,例如符号串i+i*i为文法所定义的句子,符号串ii+++*i+不是文法所定义的句子。
实验要求:1、检测左递归,如果有则进行消除;2、求解FIRST集和FOLLOW集;3、构建LL(1)分析表;4、构建LL分析程序,对于用户输入的句子,能够利用所构造的分析程序进行分析,并显示出分析过程。
四、主要仪器设备硬件:微型计算机。
软件:Code blocks(也可以是其它集成开发环境)。
五、实验过程描述1、程序主要框架程序中编写了以下函数,各个函数实现的作用如下:void input_grammer(string *G);//输入文法Gvoid preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k);//将文法G预处理得到产生式集合P,非终结符、终结符集合U、u,int eliminate_1(string *G,string *P,string U,string *GG);//消除文法G中所有直接左递归得到文法GGint* ifempty(string* P,string U,int k,int n);//判断各非终结符是否能推导为空string* FIRST_X(string* P,string U,string u,int* empty,int k,int n);求所有非终结符的FIRST集string FIRST(string U,string u,string* first,string s);//求符号串s=X1X2...Xn的FIRST集string** create_table(string *P,string U,string u,int n,int t,int k,string* first);//构造分析表void analyse(string **table,string U,string u,int t,string s);//分析符号串s2、编写的源程序#include<cstdio>#include<cstring>#include<iostream>using namespace std;void input_grammer(string *G)//输入文法G,n个非终结符{int i=0;//计数char ch='y';while(ch=='y'){cin>>G[i++];cout<<"继续输入?(y/n)\n";cin>>ch;}}void preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k)//将文法G预处理产生式集合P,非终结符、终结符集合U、u,{int i,j,r,temp;//计数char C;//记录规则中()后的符号int flag;//检测到()n=t=k=0;for( i=0;i<50;i++) P[i]=" ";//字符串如果不初始化,在使用P[i][j]=a时将不能改变,可以用P[i].append(1,a)U=u=" ";//字符串如果不初始化,无法使用U[i]=a赋值,可以用U.append(1,a)for(n=0;!G[n].empty();n++){ U[n]=G[n][0];}//非终结符集合,n为非终结符个数for(i=0;i<n;i++){for(j=4;j<G[i].length();j++){if(U.find(G[i][j])==string::npos&&u.find(G[i][j])==string::npos) if(G[i][j]!='|'&&G[i][j]!='^')//if(G[i][j]!='('&&G[i][j]!=')'&&G[i][j]!='|'&&G[i][j]!='^')u[t++]=G[i][j];}}//终结符集合,t为终结符个数for(i=0;i<n;i++){flag=0;r=4;for(j=4;j<G[i].length();j++){P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';/* if(G[i][j]=='('){ j++;flag=1;for(temp=j;G[i][temp]!=')';temp++);C=G[i][temp+1];//C记录()后跟的字符,将C添加到()中所有字符串后面}if(G[i][j]==')') {j++;flag=0;}*/if(G[i][j]=='|'){//if(flag==1) P[k][r++]=C;k++;j++;P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';r=4;P[k][r++]=G[i][j];}else{P[k][r++]=G[i][j];}}k++;}//获得产生式集合P,k为产生式个数}int eliminate_1(string *G,string *P,string U,string *GG)//消除文法G1中所有直接左递归得到文法G2,要能够消除含有多个左递归的情况){string arfa,beta;//所有形如A::=Aα|β中的α、β连接起来形成的字符串arfa、betaint i,j,temp,m=0;//计数int flag=0;//flag=1表示文法有左递归int flagg=0;//flagg=1表示某条规则有左递归char C='A';//由于消除左递归新增的非终结符,从A开始增加,只要不在原来问法的非终结符中即可加入for(i=0;i<20&&U[i]!=' ';i++){ flagg=0;arfa=beta="";for(j=0;j<100&&P[j][0]!=' ';j++){if(P[j][0]==U[i]){if(P[j][4]==U[i])//产生式j有左递归{flagg=1;for(temp=5;P[j][temp]!=' ';temp++) arfa.append(1,P[j][temp]);if(P[j+1][4]==U[i]) arfa.append("|");//不止一个产生式含有左递归}else{for(temp=4;P[j][temp]!=' ';temp++) beta.append(1,P[j][temp]);if(P[j+1][0]==U[i]&&P[j+1][4]!=U[i]) beta.append("|");}}}if(flagg==0)//对于不含左递归的文法规则不重写{GG[m]=G[i]; m++;}else{flag=1;//文法存在左递归GG[m].append(1,U[i]);GG[m].append("::=");if(beta.find('|')!=string::npos) GG[m].append("("+beta+")");else GG[m].append(beta);while(U.find(C)!=string::npos){C++;}GG[m].append(1,C);m++;GG[m].append(1,C);GG[m].append("::=");if(arfa.find('|')!=string::npos) GG[m].append("("+arfa+")");else GG[m].append(arfa);GG[m].append(1,C);GG[m].append("|^");m++;C++;}//A::=Aα|β改写成A::=βA‘,A’=αA'|β,}return flag;}int* ifempty(string* P,string U,int k,int n){int* empty=new int [n];//指示非终结符能否推导到空串int i,j,r;for(r=0;r<n;r++) empty[r]=0;//默认所有非终结符都不能推导到空int flag=1;//1表示empty数组有修改int step=100;//假设一条规则最大推导步数为100步while(step--){for(i=0;i<k;i++){r=U.find(P[i][0]);if(P[i][4]=='^') empty[r]=1;//直接推导到空else{for(j=4;P[i][j]!=' ';j++){if(U.find(P[i][j])!=string::npos){if(empty[U.find(P[i][j])]==0) break;}else break;}if(P[i][j]==' ') empty[r]=1;//多步推导到空else flag=0;}}}return empty;}string* FIRST_X(string* P,string U,string u,int* empty,int k,int n) {int i,j,r,s,tmp;string* first=new string[n];char a;int step=100;//最大推导步数while(step--){// cout<<"step"<<100-step<<endl;for(i=0;i<k;i++){//cout<<P[i]<<endl;r=U.find(P[i][0]);if(P[i][4]=='^'&&first[r].find('^')==string::npos) first[r].append(1,'^');//规则右部首符号为空else{for(j=4;P[i][j]!=' ';j++){a=P[i][j];if(u.find(a)!=string::npos&&first[r].find(a)==string::npos)//规则右部首符号是终结符{first[r].append(1,a);break;//添加并结束}if(U.find(P[i][j])!=string::npos)//规则右部首符号是非终结符,形如X::=Y1Y2...Yk{s=U.find(P[i][j]);//cout<<P[i][j]<<":\n";for(tmp=0;first[s][tmp]!='\0';tmp++){a=first[s][tmp];if(a!='^'&&first[r].find(a)==string::npos)//将FIRST[Y1]中的非空符加入first[r].append(1,a);}}if(!empty[s]) break;//若Y1不能推导到空,结束}if(P[i][j]==' ')if(first[r].find('^')==string::npos)first[r].append(1,'^');//若Y1、Y2...Yk都能推导到空,则加入空符号}}}return first;}string FIRST(string U,string u,string* first,string s)//求符号串s=X1X2...Xn的FIRST集{int i,j,r;char a;string fir;for(i=0;i<s.length();i++){if(s[i]=='^') fir.append(1,'^');if(u.find(s[i])!=string::npos&&fir.find(s[i])==string::npos){ fir.append(1,s[i]);break;}//X1是终结符,添加并结束循环if(U.find(s[i])!=string::npos)//X1是非终结符{r=U.find(s[i]);for(j=0;first[r][j]!='\0';j++){a=first[r][j];if(a!='^'&&fir.find(a)==string::npos)//将FIRST(X1)中的非空符号加入fir.append(1,a);}if(first[r].find('^')==string::npos) break;//若X1不可推导到空,循环停止}if(i==s.length())//若X1-Xk都可推导到空if(fir.find(s[i])==string::npos) //fir中还未加入空符号fir.append(1,'^');}return fir;}string** create_table(string *P,string U,string u,int n,int t,int k,string* first)//构造分析表,P为文法G的产生式构成的集合{int i,j,p,q;string arfa;//记录规则右部string fir,follow;string FOLLOW[5]={")#",")#","+)#","+)#","+*)#"};string **table=new string*[n];for(i=0;i<n;i++) table[i]=new string[t+1];for(i=0;i<n;i++)for(j=0;j<t+1;j++)table[i][j]=" ";//table存储分析表的元素,“ ”表示error for(i=0;i<k;i++){arfa=P[i];arfa.erase(0,4);//删除前4个字符,如:E::=E+T,则arfa="E+T"fir=FIRST(U,u,first,arfa);for(j=0;j<t;j++){p=U.find(P[i][0]);if(fir.find(u[j])!=string::npos){q=j;table[p][q]=P[i];}//对first()中的每一终结符置相应的规则}if(fir.find('^')!=string::npos){follow=FOLLOW[p];//对规则左部求follow()for(j=0;j<t;j++){if((q=follow.find(u[j]))!=string::npos){q=j;table[p][q]=P[i];}//对follow()中的每一终结符置相应的规则}table[p][t]=P[i];//对#所在元素置相应规则}}return table;}void analyse(string **table,string U,string u,int t,string s)//分析符号串s {string stack;//分析栈string ss=s;//记录原符号串char x;//栈顶符号char a;//下一个要输入的字符int flag=0;//匹配成功标志int i=0,j=0,step=1;//符号栈计数、输入串计数、步骤数int p,q,r;string temp;for(i=0;!s[i];i++){if(u.find(s[i])==string::npos)//出现非法的符号cout<<s<<"不是该文法的句子\n";return;}s.append(1,'#');stack.append(1,'#');//’#’进入分析栈stack.append(1,U[0]);i++;//文法开始符进入分析栈a=s[0];//cout<<stack<<endl;cout<<"步骤分析栈余留输入串所用产生式\n";while(!flag){// cout<<"步骤分析栈余留输入串所用产生式\n"cout<<step<<" "<<stack<<" "<<s<<" ";x=stack[i];stack.erase(i,1);i--;//取栈顶符号x,并从栈顶退出//cout<<x<<endl;if(u.find(x)!=string::npos)//x是终结符的情况{if(x==a){s.erase(0,1);a=s[0];//栈顶符号与当前输入符号匹配,则输入下一个符号cout<<" \n";//未使用产生式,输出空}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(x=='#'){if(a=='#') {flag=1;cout<<"成功\n";}//栈顶和余留输入串都为#,匹配成功else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(U.find(x)!=string::npos)//x是非终结符的情况{p=U.find(x);q=u.find(a);if(a=='#') q=t;temp=table[p][q];cout<<temp<<endl;//输出使用的产生式if(temp[0]!=' ')//分析表中对应项不为error{r=9;while(temp[r]==' ') r--;while(r>3){if(temp[r]!='^'){stack.append(1,temp[r]);//将X::=x1x2...的规则右部各符号压栈i++;}r--;}}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}step++;}if(flag) cout<<endl<<ss<<"是该文法的句子\n"; }int main(){int i,j;string *G=new string[50];//文法Gstring *P=new string[50];//产生式集合Pstring U,u;//文法G非终结符集合U,终结符集合uint n,t,k;//非终结符、终结符个数,产生式数string *GG=new string[50];//消除左递归后的文法GGstring *PP=new string[50];//文法GG的产生式集合PPstring UU,uu;//文法GG非终结符集合U,终结符集合uint nn,tt,kk;//消除左递归后的非终结符、终结符个数,产生式数string** table;//分析表cout<<" 欢迎使用LL(1)语法分析器!\n\n\n";cout<<"请输入文法(同一左部的规则在同一行输入,例如:E::=E+T|T;用^表示空串)\n"; input_grammer(G);preprocess(G,P,U,u,n,t,k);cout<<"\n该文法有"<<n<<"个非终结符:\n";for(i=0;i<n;i++) cout<<U[i];cout<<endl;cout<<"该文法有"<<t<<"个终结符:\n";for(i=0;i<t;i++) cout<<u[i];cout<<"\n\n 左递归检测与消除\n\n";if(eliminate_1(G,P,U,GG)){preprocess(GG,PP,UU,uu,nn,tt,kk);cout<<"该文法存在左递归!\n\n消除左递归后的文法:\n\n";for(i=0;i<nn;i++) cout<<GG[i]<<endl;cout<<endl;cout<<"新文法有"<<nn<<"个非终结符:\n";for(i=0;i<nn;i++) cout<<UU[i];cout<<endl;cout<<"新文法有"<<tt<<"个终结符:\n";for(i=0;i<tt;i++) cout<<uu[i];cout<<endl;//cout<<"新文法有"<<kk<<"个产生式:\n";//for(i=0;i<kk;i++) cout<<PP[i]<<endl;}else{cout<<"该文法不存在左递归\n";GG=G;PP=P;UU=U;uu=u;nn=n;tt=t;kk=k;}cout<<" 求解FIRST集\n\n";int *empty=ifempty(PP,UU,kk,nn);string* first=FIRST_X(PP,UU,uu,empty,kk,nn);for(i=0;i<nn;i++)cout<<"FIRST("<<UU[i]<<"): "<<first[i]<<endl;cout<<" 求解FOLLOW集\n\n";for(i=0;i<nn;i++)cout<<"FOLLOW("<<UU[i]<<"): "<<FOLLOW[i]<<endl; cout<<"\n\n 构造文法分析表\n\n";table=create_table(PP,UU,uu,nn,tt,kk,first);cout<<" ";for(i=0;i<tt;i++) cout<<" "<<uu[i]<<" ";cout<<"# "<<endl;for( i=0;i<nn;i++){cout<<UU[i]<<" ";for(j=0;j<t+1;j++)cout<<table[i][j];cout<<endl;}cout<<"\n\n 分析符号串\n\n";string s;cout<<"请输入要分析的符号串\n";cin>>s;analyse(table,UU,uu,tt,s);return 0;}3、程序演示结果(1)输入文法(2)消除左递归(3)求解FIRST和FOLLOW集(4)构造分析表(5)分析符号串匹配成功的情况:匹配失败的情况五、思考和体会1、编写的LL(1)语法分析器应该具有智能性,可以由用户输入任意文法,不需要指定终结符个数和非终结符个数。
编译原理实验⼆:LL(1)语法分析器⼀、实验要求 1. 提取左公因⼦或消除左递归(实现了消除左递归) 2. 递归求First集和Follow集 其它的只要按照课本上的步骤顺序写下来就好(但是代码量超多...),下⾯我贴出实验的⼀些关键代码和算法思想。
⼆、基于预测分析表法的语法分析 2.1 代码结构 2.1.1 Grammar类 功能:主要⽤来处理输⼊的⽂法,包括将⽂法中的终结符和⾮终结符分别存储,检测直接左递归和左公因⼦,消除直接左递归,获得所有⾮终结符的First集,Follow集以及产⽣式的Select集。
#ifndef GRAMMAR_H#define GRAMMAR_H#include <string>#include <cstring>#include <iostream>#include <vector>#include <set>#include <iomanip>#include <algorithm>using namespace std;const int maxn = 110;//产⽣式结构体struct EXP{char left; //左部string right; //右部};class Grammar{public:Grammar(); //构造函数bool isNotTer(char x); //判断是否是终结符int getTer(char x); //获取终结符下标int getNonTer(char x); //获取⾮终结符下标void getFirst(char x); //获取某个⾮终结符的First集void getFollow(char x); //获取某个⾮终结符的Follow集void getSelect(char x); //获取产⽣式的Select集void input(); //输⼊⽂法void scanExp(); //扫描输⼊的产⽣式,检测是否有左递归和左公因⼦void remove(); //消除左递归void solve(); //处理⽂法,获得所有First集,Follow集以及Select集void display(); //打印First集,Follow集,Select集void debug(); //⽤于debug的函数~Grammar(); //析构函数protected:int cnt; //产⽣式数⽬EXP exp[maxn]; //产⽣式集合set<char> First[maxn]; //First集set<char> Follow[maxn]; //Follow集set<char> Select[maxn]; //select集vector<char> ter_copy; //去掉$的终结符vector<char> ter; //终结符vector<char> not_ter; //⾮终结符};#endif 2.1.2 AnalyzTable类 功能:得到预测分析表,判断输⼊的⽂法是否是LL(1)⽂法,⽤预测分析表法判断输⼊的符号串是否符合刚才输⼊的⽂法,并打印出分析过程。
编译原理课程实验报告实验2:语法分析
三、系统设计得分
要求:分为系统概要设计和系统详细设计。
(1)系统概要设计:给出必要的系统宏观层面设计图,如系统框架图、数据流图、功能模块结构图等以及相应的文字说明。
1)系统的数据流图:
说明
说明:本语法分析器是基于上一个实验词法分析器的基础上,通过在界面写或者是导入源程序,词法分析器将源程序识别的词法单元传递给语法分析器,语法分析器验证这个词法单元组成的串是否可以由源语言的文法生成,能够输出语法分析的结果,文法的first集、follow 集和预测分析表,当然也可以以易于理解的方式报告语法错误。
2)系统框架图
本系统框架主要是三部分,一部分是词法分析,负责识别源程序的词法单元识别,并将其存
因为预测分析表实在是过于庞大,因此本处分段截取预测分析表,下面的表是接在上面表的右侧。
(3)针对一测试程序输出其句法分析结果;
测试程序:
语法分析结果:
语法分析树:
(4)输出针对此测试程序对应的语法错误报告;
带错误的测试程序:
语法错误报告:
(5)对实验结果进行分析。
总结:
本语法分析器具有强大的语法分析功能
●允许变量的连续声明,比如int a,b,c;
●允许声明的同时赋值,比如string c = “你好”;
●允许对数组的声明和引用,同时进行赋值,比如char[4] a = {‘a’,’b’,’c’,’d’};a[0] = ‘m’;
●支持多种类型的声明和赋值,比如int,short,long,flaot,double,char,string,boolean
的声明和赋值;
●允许声明和使用一个过程函数,比如:。
编译原理实验报告—LL(1)分析法程序班级:小组人员:实验2.2 LL(1)分析法一、实验目的:1.根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
2.本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
二、实验平台Windows + VC++6.0程序:“3-LL1.cpp”三、实验内容1.对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E→TG(2)G→+TG|-TG(3)G→ε(4)T→FS(5)S→*FS|/FS(6)S→ε(7)F→(E)(8)F→i程序功能:输入:一个以# 结束的符号串(包括+ - * /()i # ):例如:i+i*i-i/i#输出: 经完善程序目前能对所有输入串进行正确的分析.算法思想:栈用于存放文法符号,分析开始时,栈底先放一个‘#’,然后,放进文法开始符号。
同时,假定输入串之后也总有一个‘#’,标志输入串结束。
现设置一个文法分析表(见表1),矩阵M[A,a]中存放着一条关于A的产生式,指出当A面临符号a时所采用的侯选。
对任何(X,a)其中X为栈顶符号,程序每次都执行下述动作之一:✧如果X=a=‘#’,则输出分析成功,停止分析过程;✧如果X=a且不等于‘#’,则把X从栈顶逐出,让a指向下一个输入符号;✧如果X是一个非终结符,则查看分析表M.若M[A,a]中存放着关于X的一个产生式,那么首先把X从栈顶逐出,然后,把产生式的右部符号串按反序一一推进栈内,若右部符号为ε,则就什么都不进栈。
把产生式推进栈内的同时应做这个产生式相应的语义动作,例如字符i匹配成功,字符出错,相应的产生式等。
输出如下:输出每一步骤分析栈和剩余串的变化情况, 及每一步所用的产生式都明确显示出来。
运行步骤:首先在相同的路径下建一文本文档例如11.txt,将表达式写入文档内如i+i*i-i/i#;运行程序,显示界面如下,输入相应的文件名字,(输入输出文件名是自行定义)打开pp.txt文件,文法分析结果如下:错误提示:1>.输入i++i*i#,结果如下存在的问题:现在只能是遇到错误就停止,而没能实现同步符号ll(1)分析。
曲阜师范大学实验报告No. 2010416573 计算机系2010年级网络工程二班组日期2012-10-9姓名王琳课程编译原理成绩教师签章陈矗实验名称: LL(1)语法分析器实验报告【实验目的】1. 了解LL(1)语法分析是如何根据语法规则逐一分析词法分析所得到的单词,检查语法错误,即掌握语法分析过程。
2. 掌握LL(1)语法分析器的设计与调试。
【实验内容】文法:E ->TE’ ,E’-> +TE‘ | ,T-> FT’ ,T’->* FT’ | ,F-> (E ) |i针对上述文法,编写一个LL(1)语法分析程序:1. 输入:诸如i i *i 的字符串,以#结束。
2. 处理:基于分析表进行LL(1)语法分析,判断其是否符合文法。
3. 输出:串是否合法。
【实验要求】1. 在编程前,根据上述文法建立对应的、正确的预测分析表。
2. 设计恰当的数据结构存储预测分析表。
3. 在C、C++、Java 中选择一种擅长的编程语言编写程序,要求所编写的程序结构清晰、正确。
【实验环境】1.此算法是一个java 程序,要求在eclipse软件中运行2.硬件windows 系统环境中【实验分析】读入文法,判断正误,如无误,判断是否是LL(1)文法,若是构造分析表【实验程序】package llyufa;public class Accept2 {public static StringBuffer stack=new StringBuffer("#E");public static StringBuffer stack2=new StringBuffer("i+i*i+i#");public static void main(String arts[]){//stack2.deleteCharAt(0);System.out.print(accept(stack,stack2));}public static boolean accept(StringBuffer stack,StringBuffer stack2){//判断识别与否boolean result=true;o uter:while (true) {System.out.format("%-9s",stack+"");System.out.format("%9s",stack2+"\n");char c1 = stack.charAt(stack.length() - 1);char c2 = stack2.charAt(0);if(c1=='#'&&c2=='#')return true;switch (c1) {case'E':if(!E(c2)) {result=false;break outer;}break;case'P': //P代表E’if(!P(c2)) {result=false;break outer;}break;case'T':if(!T(c2)) {result=false;break outer;}break;case'Q': //Q代表T’if(!Q(c2)) {result=false;break outer;}break;case'F':if(!F(c2)) {result=false;break outer;}break;default: {//终结符的时候if(c2==c1){stack.deleteCharAt(stack.length()-1);stack2.deleteCharAt(0);//System.out.println();}else{return false;}}}if(result=false)break outer;}r eturn result;}public static boolean E(char c) {//语法分析子程序 Eb oolean result=true;i f(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("PT");}e lse if(c=='('){stack.deleteCharAt(stack.length()-1);stack.append("PT");}e lse{System.err.println("E 推导时错误!不能匹配!");result=false;}r eturn result;}public static boolean P(char c){//语法分析子程序 Pb oolean result=true;i f(c=='+') {stack.deleteCharAt(stack.length()-1);stack.append("PT+");}e lse if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse{System.err.println("P 推导时错误!不能匹配!");result=false;}r eturn result;}public static boolean T(char c) {//语法分析子程序 Tb oolean result=true;i f(c=='i') {stack.deleteCharAt(stack.length()-1);}e lse if(c=='(') {stack.deleteCharAt(stack.length()-1);stack.append("QF");}e lse{result=false;System.err.println("T 推导时错误!不能匹配!");}r eturn result;}public static boolean Q(char c){//语法分析子程序 Qb oolean result=true;i f(c=='+') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse if(c=='*') {stack.deleteCharAt(stack.length()-1);stack.append("QF*");}e lse if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse{result=false;System.err.println("Q 推导时错误!不能匹配!");}r eturn result;}public static boolean F(char c) {//语法分析子程序 Fb oolean result=true;i f(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("i");}e lse if(c=='(') {stack.deleteCharAt(stack.length()-1);}e lse{result=false;System.err.println("F 推导时错误!不能匹配!");}r eturn result;}/* public static StringBuffer changeOrder(String s){//左右交换顺序S tringBuffer sb=new StringBuffer();f or(int i=0;i<s.length();i++){sb.append(s.charAt(s.length()-1-i));}r eturn sb;}*/}【执行结果】【小结】通过这次的实验,更深入的了解了编译原理,熟悉了语法分析器的制作和使用,了解了更多关于语言的知识,极大地提高了动手能力。
编译原理实验二语法分析器L L(1)实现编译原理程序设计实验报告——表达式语法分析器的设计班级:计算机1306班姓名:张涛学号:20133967 实验目标:用LL(1)分析法设计实现表达式语法分析器实验内容:⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。
然后利用LL(1)分析法实现语法分析。
⑵数据结构:int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};⑶分析表及流程图逆序压栈int IsLetter(char ch) //判断ch是否为字母int IsDigit(char ch) //判断ch是否为数字int Iskey(char *string) //判断是否为关键字int Isbound(char ch) //判断是否为界符int Isboundnum(char ch) //给出界符所在token值int init(STack *s) //栈初始化int pop(STack *s,char *ch) //弹栈操作int push(STack *s,char ch) //压栈操作void LL1(); //分析函数源程序代码:(加入注释)#include<stdio.h>#include<string.h>#include<ctype.h>#include<windows.h>#include <stdlib.h>int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};typedef struct Stack STack;int init(STack *s) //栈初始化{(*s).base=(char*)malloc(100*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base;(*s).stacksize=100;printf("初始化栈\n");return 0;}int pop(STack *s,char *ch) //弹栈操作{if((*s).top==(*s).base){printf("弹栈失败\n");return 0;(*s).top--;*ch=*((*s).top);printf("%c",*ch);return 1;}int push(STack *s,char ch) //压栈操作{if((*s).top-(*s).base>=(*s).stacksize){(*s).base=(char*)realloc((*s).base,((*s).stacksize+10)*sizeof(char));if(!(*s).base)exit(0);(*s).top=(*s).base+(*s).stacksize;(*s).stacksize+=10;}*(*s).top=ch;*(*s).top++;return 1;}void LL1();int IsLetter(char ch) //判断ch是否为字母{int i;for(i=0;i<=45;i++)if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))return 1;return 0;}int IsDigit(char ch) //判断ch是否为数字{int i;for(i=0;i<=10;i++)if (ch>='0'&&ch<='9')return 1;return 0;}int Isbound(char ch) //判断是否为界符{int i;for(i=0;i<2;i++)if(ch==bound[i]){return i+1;}}return 0;}int Isoperate(char ch) //判断是否为运算符{int i;for(i=0;i<4;i++){if(ch==operate[i]){return i+3;}}return 0;}int main(){FILE *fp;int q=0,m=0;char sour[200]=" ";printf("请将源文件置于以下位置并按以下方式命名:F:\\2.txt\n");if((fp=fopen("F:\\2.txt","r"))==NULL){printf("文件未找到!\n");}else{while(!feof(fp)){if(isspace(ch=fgetc(fp)));else{sour[q]=ch;q++;}}}int p=0;printf("输入句子为:\n");for(p;p<=q;p++)printf("%c",sour[p]);}printf("\n");int state=0,nowlen=0;BOOLEAN OK=TRUE,ERR=FALSE;int i,flagpoint=0;for(i=0;i<q;i++){if(sour[i]=='#')tokenlist[m].code=='#';switch(state){case 0:ch=sour[i];if(Isbound(ch)){if(ERR){printf("无法识别\n");ERR=FALSE;OK=TRUE;}else if(!OK){printf("<10,%s>标识符\n",nowword); tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}state=4;}else if(IsDigit(ch)){if(OK){memset(nowword,0,strlen(nowword)); nowlen=0;nowword[nowlen]=ch;nowlen++;state=3;OK=FALSE;break;}else{nowword[nowlen]=ch;nowlen++;}}else if(IsLetter(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;OK=FALSE;}else{nowword[nowlen]=ch;nowlen++;}}else if(Isoperate(ch)){if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}printf("<%d,%c>运算符\n",Isoperate(ch),ch); tokentemp.code=Isoperate(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;}break;case 3:if(IsLetter(ch)){printf("错误\n");nowword[nowlen]=ch;nowlen++;ERR=FALSE;state=0;break;}if(IsDigit(ch=sour[i])){nowword[nowlen]=ch;nowlen++;}else if(sour[i]=='.'&&flagpoint==0){flagpoint=1;nowword[nowlen]=ch;nowlen++;}else{printf("<20,%s>数字\n",nowword);i--;state=0;OK=TRUE;tokentemp.code=20;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;}break;case 4:i--;printf("<%d,%c>界符\n",Isbound(ch),ch); tokentemp.code=Isbound(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;state=0;OK=TRUE;break;}}printf("tokenlist值为%d\n",m);int t=0;tokenlist[m+1].code='r';m++;for(t;t<m;t++){printf("tokenlist%d值为%d\n",t,tokenlist[t].code);}LL1();printf("tokenlist值为%d\n",m);if(op+1==m)printf("OK!!!");elseprintf("WRONG!!!");return 0;}void LL1(){STack s;init(&s);push(&s,'#');push(&s,'E');char ch;int flag=1;do{pop(&s,&ch);printf("输出栈顶为%c\n",ch);printf("输出栈顶为%d\n",ch);printf("当前p值为%d\n",op);if((ch=='(')||(ch==')')||(ch=='+')||(ch=='-')||(ch=='*')||(ch=='/')||(ch==10)||(ch==20)){if(tokenlist[op].code==1||tokenlist[op].code==20||tokenlist[op].code==10||tokenlist[op].code==2||tokenlist[op] .code==3||tokenlist[op].code==4||tokenlist[op].code==5||tokenlist[op].code==6)op++;else{printf("WRONG!!!");exit(0);}}else if(ch=='#'){if(tokenlist[op].code==0)flag=0;else{printf("WRONG!!!@@@@@@@@@");exit(0);}}else if(ch=='E'){printf("进入E\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'R');printf("将R压入栈\n");push(&s,'T');}}else if(ch=='R'){printf("进入R\n");if(tokenlist[op].code==3||tokenlist[op].code==4){push(&s,'R');push(&s,'T');printf("将T压入栈\n");push(&s,'+');}if(tokenlist[op].code==2||tokenlist[op].code==0){}}else if(ch=='T'){printf("进入T\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'Y');push(&s,'F');}}else if(ch=='Y'){printf("进入Y\n");if(tokenlist[op].code==5||tokenlist[op].code==6){push(&s,'Y');push(&s,'F');push(&s,'*');}else if(tokenlist[op].code==3||tokenlist[op].code==2||tokenlist[op].code==0||tokenlist[op].code==4) {}}else if(ch=='F'){printf("进入F\n");if(tokenlist[op].code==10||tokenlist[op].code==20){push(&s,10);}if(tokenlist[op].code==1){push(&s,')');push(&s,'E');push(&s,'(');}}else{printf("WRONG!!!!");exit(0);}}while(flag);}程序运行结果:(截屏)输入:((Aa+Bb)*(88.2/3))#注:如需运行请将文件放置F盘,并命名为:2.txt输出:思考问题回答:LL(1)分析法的主要问题就是要正确的将文法化为LL (1)文法。