R语言编程基础-第二讲 数据类型
- 格式:pptx
- 大小:1.29 MB
- 文档页数:17

R语⾔-数据类型、结构以及对象类型1R语⾔-数据类型|数据结构|对象类型⽬录 1. 数据类型 2. 数据结构 3. 对象类型1. 数据类型 向量的类型:mode()返回的结果logical(逻辑型)numeric(数值型)complex(复数型)character(字符型) 其中integer 和 double 在mode() 时返回的都是 numericfactor 在 mode() 时返回的也是 numeric 其它类型listS4 检验对象的类型is.logical()is.numeric()is.integer()is.double()is.factor()plex()is.character() 强制转换as.logical()as.numeric()-- as.integer()-- as.double()-- as.factor()plex()as.character() R特殊值数据# 为确保所有数据都能被正确识别、计算或统计等,R定义了⼀些特殊值数据:NULL:空数据NA:表⽰⽆数据NaN:表⽰⾮数字inf:数字除以0得到的值# 判断⼀个object (x)是不是属于这些类型有相应的函数:is.null(x)is.na(x)is.nan(x)is.infinite(x) R中获取数据类型信息的⼀些有⽤函数 R语⾔的对象“类”很多,虽然我们不可能⼀⼀去详细学习,但接触到⼀类新数据时我们需要了解⼀些基本信息才能进⾏进⼀步的操作。
R 提供了⼀些⾮常有⽤的⽅法(函数)。
getClass( )函数我们前⾯已经见过了,它的参数是表⽰类的字符串。
class( )可获取⼀个数据对象所属的类,它的参数是对象名称。
str( )可获取数据对象的结构组成,这很有⽤。
mode( )和storage.mode( )可获取对象的存储模式。
2. 数据结构 R中的数据结构主要⾯向《线性代数》中的⼀些概念,如向量、矩阵等。

r语言常用运算R语言是一种非常强大的统计分析和数据挖掘工具,它提供了大量的函数和运算符来处理数据。
在本篇文章中,我们将介绍R语言中一些常用的运算,包括数据类型、向量、矩阵、数组、数据框以及它们的基本操作。
1. 数据类型R语言中有几种基本的数据类型,包括:- 向量(Vector):由多个元素组成的一维数组,可以包含不同类型的元素。
- 矩阵(Matrix):由行和列组成的数组,每行具有相同数量的元素。
- 数组(Array):多维数组,可以包含不同类型的元素。
- 数据框(Data Frame):数组,每行具有相同数量的列,每列具有相同的数据类型。
2. 向量向量是R语言中最基本的数据结构,它可以包含数字、字符和逻辑值等不同类型的元素。
向量的创建和基本操作包括:- 创建向量:可以使用c()函数创建向量,例如:c(1, 2, 3, 4)。
- 向量长度:length()函数可以获取向量的长度。
- 向量元素:可以使用$或[]操作符获取向量的元素,例如:vector$element或vector[i]。
- 向量赋值:可以使用=操作符给向量赋值,例如:vector = c(1, 2, 3, 4)。
- 向量拼接:可以使用c()函数拼接向量,例如:v1 = c(1, 2),v2 = c(3, 4),v1v2 = c(v1, v2)。
- 向量长度调整:可以使用rep()函数调整向量的长度,例如:new_vector =rep(original_vector, times = 3)。
3. 矩阵矩阵是R语言中非常重要的数据结构,它可以用于表示数据集。
矩阵的创建和基本操作包括:- 创建矩阵:可以使用matrix()函数创建矩阵,例如:matrix(c(1, 2, 3, 4, 5, 6), nrow = 2, ncol = 3)。
- 矩阵维度:dim()函数可以获取矩阵的维度。
- 矩阵元素:可以使用[]操作符获取矩阵的元素,例如:matrix[i, j]。

R语言数据类型和数据结构1. 引言在使用R语言进行数据分析和处理时,了解R语言的数据类型和数据结构是非常重要的。
不同的数据类型和数据结构在R语言中有着不同的表示方式和操作方法,对于不同的数据处理任务,选择合适的数据类型和数据结构可以提高程序的效率和可读性。
本文将详细介绍R语言中常用的数据类型和数据结构,并对每种类型和结构进行深入探讨和实例演示。
2. R语言的数据类型R语言中常用的数据类型包括向量(Vector)、矩阵(Matrix)、数组(Array)、列表(List)、数据框(Data Frame)和因子(Factor)等。
下面将分别介绍这些数据类型的特点和用法。
2.1 向量(Vector)向量是R语言中最基本的数据类型,它由相同类型的元素组成,可以是数值、字符、逻辑值等。
在R语言中,向量可以使用c()或vector()函数来创建,也可以通过索引和赋值的方式进行元素的访问和修改。
# 创建向量x <- c(1, 2, 3, 4, 5)y <- vector("numeric", 10)# 访问和修改向量元素x[2] # 输出第二个元素x[2] <- 10 # 修改第二个元素的值为102.2 矩阵(Matrix)矩阵是由同类型的元素组成的二维数据结构。
在R语言中,矩阵可以使用matrix()函数来创建,也可以通过索引和赋值的方式进行元素的访问和修改。
# 创建矩阵m <- matrix(c(1, 2, 3, 4, 5, 6), nrow = 2, ncol = 3)# 访问和修改矩阵元素m[1, 2] # 输出第一行第二列的元素m[1, 2] <- 10 # 修改第一行第二列的元素值为102.3 数组(Array)数组是由同类型的元素组成的多维数据结构。
在R语言中,数组可以使用array()函数来创建,也可以通过索引和赋值的方式进行元素的访问和修改。
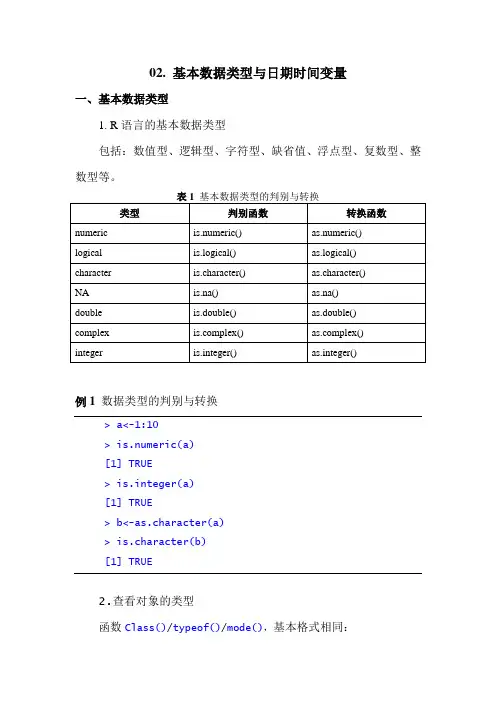
02. 基本数据类型与日期时间变量一、基本数据类型1. R语言的基本数据类型包括:数值型、逻辑型、字符型、缺省值、浮点型、复数型、整数型等。
例1 数据类型的判别与转换> a<-1:10>is.numeric(a)[1] TRUE>is.integer(a)[1] TRUE> b<-as.character(a)>is.character(b)[1] TRUE2.查看对象的类型函数Class()/typeof()/mode(),基本格式相同:class(x)其中x为要查看的对象。
注:在展现数据的细节上,mode()<class()<typeof()二、日期时间变量1. 日期值通常以字符串形式传入R中,然后转化为以数值形式存储的日期变量。
注意:R的内部日期是以1970年1月1日至今的天数来存储,内部时间则是以1970年1月1日至今的秒数来存储。
读取系统当前日期时间的函数(注意大小写):(1)S ys.Date()——返回系统当前的日期(2)S ys.time()——返回系统当前的日期和时间(3)d ate()——返回系统当前的日期和时间(字符串形式)2. 日期时间转化函数(1)字符串型日期变量转化为日期变量函数as.Date(),基本格式为:as.Date(x,format=" ",...)其中,x为字符串型日期值,format指定日期格式。
表2日期时间格式注意:as.Date()只能转化包含年月日星期的字符串,无法转化具体到时间的字符串。
例2将字符型日期转化为日期变量> day<-"07/28/2016" #创建字符串日期值>day[1] "07/28/2016"> date<-as.Date(day,"%m/%d/%Y") #转化为日期变量>date[1] "2016-07-28"(2)字符串日期时间变量转化为时间变量函数as.POSIXlt()与as.POSIXct(),前者为“字符串式”存储,后者为“整数(秒数)”存储,基本格式为:as.POSIXlt(x,tz=" ", format)as.POSIXct(x,tz=" ", format)其中,x为字符串型日期时间值,tz指定转化后的时区(" "为当前时区,“GMT”为格林尼治标准时也是协调世界时UTC的俗称,“CST”为中国标准时即北京时间);format指定日期时间格式。

R语言学习系列04-数据结构Ⅱ—数据框,因子,列表04. 数据结构Ⅱ—数据框,因子,列表四、数据框(数据表)R语言中做统计分析的样本数据,都是按数据框类型操作的。
数据框的每一列代表一个变量属性的所有取值,每一行代表一条样本数据。
1. 创建数据框通过函数data.frame()把多个向量组合起来创建,并设置列名称。
其基本格式为:data.frame(col1,col2,col3,...)其中,列向量col1, col2, col3, …可以为任意类型。
注:矩阵也可以通过函数data.frame()转化为数据库。
>data_iris<-data.frame(Sepal.Length=c(5.1,4.9,4.7,4.6), Sepal.Width=c(3.5,3.0,3.2,3.1), Petal.Length=c(1.4,1. 4,1.3,1.5), Petal.Width=rep(0.2,4))>data_irisSepal.LengthSepal.WidthPetal.LengthPetal.Width1 5.1 3.5 1.4 0.22 4.9 3.0 1.4 0.23 4.7 3.2 1.3 0.24 4.6 3.1 1.5 0.2> #矩阵转化为数据框>dmatrix<-matrix(1:8,c(4,2))>dmatrix[,1] [,2][1,] 1 5[2,] 2 6[3,] 3 7[4,] 4 8>data.frame(dmatrix)X1 X21 1 52 2 63 3 74 4 82. 数据框索引列标或列名称索引:data_iris[,1]——返回数据框data_iris的第1列data_iris$Sepal.Length或data_iris["Sepal.Length"]——同data_iris[,1]行索引:data_iris[1,]——返回数据框data_iris的第1行data_iris[1:3,]——返回数据框data_iris的第1至3行元素索引:data_iris[1,1]——返回数据框data_iris的第1列第1个数据data_iris$Sepal.Length[1]或data_iris["Sepal.Length"][1]——返回数据框data_iris的Sepal.Length列第1个数据用函数subset()按条件索引>subset(data_iris,Sepal.Length<5)Sepal.LengthSepal.WidthPetal.LengthPetal.Width2 4.9 3.0 1.4 0.23 4.7 3.2 1.3 0.24 4.6 3.1 1.5 0.2注:还可用sqldf包中的sqldf()函数,借助sql语句索引。

R语言基础数据类型...R语言主要有三种基本的数据类型,分别是数值型(Numeric)、整型(integer)以及字符型(character)。
一、数据类型1.数值型(Numeric)数值型(Numeric)分为双整型(double)和整型(integer)两种(1)双整型(double)双整型数据,可正可负,可大可小,可含小数可不含。
R中键入的任何一个数值都默认以double型存储。
可以使用typeof() 函数进行查看数据类型1.> typeof(1)#查看“1”的数据类型2.[1] "double" #输出结果为双整型(2)整型(integer)顾名思义,只能用来储存整数。
在计算机内存中,整型的定义方式要比双整型更加准确(除非该整数非常大或非常小)1.> typeof(1L)#在数字后面加大写字母L,申明该数字以整型方式储存。
2.[1] "integer"3.> as.integer(-3.14)#将双整形转换为整型4.[1] -35.> as.integer(-3.99)#只取整数部分,不会进行四舍五入6.[1] -32.字符型(character)字符型向量用以储存一小段文本,在R中字符要加双引号表示字符型向量中的单个元素被称为“字符串(string)”,注意:字符串不仅可以包含英文字母,也可以由数字或符号组成1.> typeof("Hello world") #字符型要加双引号表示2.[1] "character"字符串常用函数举例1.> a<-"Hello world"#赋值2.> nchar(a)#计算字符串长度3.[1] 114.#大小写转换5.> toupper(a)6.[1] "HELLO WORLD"7.> tolower(a)8.[1] "hello world"9.#字符转连接10.> paste("hello","world",sep="_")11.[1] "hello_world"3.逻辑型(logical)用以储存TRUE(真)和FALSE(假),在实际使用过程中,可以简写成T/F。

r语言数据类型和数据结构一、引言R语言是一种广泛应用于数据分析和统计建模的编程语言,它具有丰富的数据类型和数据结构。
本文将详细介绍R语言中常见的数据类型和数据结构。
二、基本数据类型1. 数值型(numeric):表示实数或整数,可以进行算术运算。
2. 字符型(character):表示文本字符串,用单引号或双引号括起来。
3. 逻辑型(logical):表示真或假,只有两个取值TRUE和FALSE。
4. 复数型(complex):由实部和虚部组成的复数。
三、向量向量是R语言中最基本的数据结构,它由相同的数据类型组成。
向量可以通过c()函数创建,例如:x <- c(1, 2, 3, 4) # 创建一个包含四个元素的数值型向量四、矩阵矩阵是二维数组,其中每个元素都具有相同的数据类型。
可以使用matrix()函数创建矩阵,例如:x <- matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2) # 创建一个包含四个元素的矩阵五、数组数组是多维矩阵,其中每个元素都具有相同的数据类型。
可以使用array()函数创建数组,例如:x <- array(c(1, 2, 3, 4), dim = c(2, 2)) # 创建一个包含四个元素的二维数组六、列表列表是一种复合数据类型,其中每个元素可以是不同的数据类型。
可以使用list()函数创建列表,例如:x <- list(name = "Tom", age = 20, gender = "male") # 创建一个包含三个元素的列表七、因子因子是一种用于表示分类变量的数据类型,它将离散变量编码为整数。
可以使用factor()函数创建因子,例如:x <- factor(c("A", "B", "A", "C")) # 创建一个包含四个元素的因子八、数据框数据框是一种二维表格形式的数据结构,其中每列可以有不同的数据类型。

r语言的基础语法及常用命令R语言是一种用于数据分析和统计建模的编程语言,它具有丰富的基础语法和常用命令。
本文将介绍R语言的基础语法和常用命令,帮助读者快速入门和理解R语言的使用。
1. 变量和数据类型在R语言中,可以通过使用赋值符号“<-”或“=”来创建变量,并且不需要事先声明变量的类型。
R语言支持多种数据类型,包括数值型、字符型、逻辑型、因子型等。
例如,可以使用以下代码创建一个数值型变量x,并赋值为10:```Rx <- 10```2. 数据结构R语言中常用的数据结构包括向量、矩阵、数组、数据框和列表。
向量是最基本的数据结构,可以存储多个相同类型的元素。
矩阵是二维的数据结构,可以存储多个相同类型的元素。
数组是多维的数据结构,可以存储多个相同类型的元素。
数据框是类似于Excel表格的数据结构,可以存储多个不同类型的变量。
列表是一种包含不同类型元素的数据结构。
3. 控制结构R语言中常用的控制结构包括条件语句(if-else语句)和循环语句(for循环、while循环)。
条件语句用于根据条件执行不同的代码块。
例如,以下代码展示了一个简单的if-else语句:```Rx <- 10if (x > 5) {print("x大于5")} else {print("x小于等于5")}```循环语句用于重复执行一段代码块。
例如,以下代码展示了一个简单的for循环:```Rfor (i in 1:5) {print(i)}```4. 函数R语言中的函数是一段具有特定功能的代码块,可以重复使用。
R语言提供了许多内置函数,还可以自定义函数。
例如,以下代码展示了一个自定义函数,用于计算两个数的和:```Rsum <- function(a, b) {return(a + b)}result <- sum(3, 5)print(result) # 输出8```5. 数据读写R语言中可以通过各种方式读取和写入数据。


r语言的数据结构R语言是一种非常流行的数据分析和统计编程语言,其拥有多种数据结构,用于不同类型的数据处理和分析。
下面就是R语言中常用的数据结构:1. 向量(Vector)向量是最基本的数据结构,它可以存储同一种类型的数据,可以是数值、字符、逻辑等等,只要它们类型相同。
要创建向量,请使用c()函数,如下例子所示:num <- c(1, 2, 3, 4, 5) # 数值类型向量char <- c("apple", "orange", "banana") # 字符类型向量log <- c(TRUE, FALSE, TRUE) # 逻辑类型向量2. 矩阵(Matrix)矩阵是由同一类型的数据组成的二维数组,它可以是数值、字符、逻辑等等,只要它们类型相同。
可以使用matrix()函数创建矩阵,如下例子所示:mat1 <- matrix(1:9, nrow = 3) # 数值类型矩阵mat2 <- matrix(c("a", "b", "c", "d", "e", "f"), nrow = 2) # 字符类型矩阵mat3 <- matrix(c(TRUE, FALSE, TRUE), nrow = 3) # 逻辑类型矩阵3. 数组(Array)数组是由同一类型的数据组成的多维数组,它可以是数值、字符、逻辑等等,只要它们类型相同。
可以使用array()函数创建数组,如下例子所示:arr1 <- array(1:24, dim = c(2, 3, 4)) # 三维数值类型数组arr2 <- array(c("a", "b", "c", "d", "e", "f"), dim = c(2, 3)) # 二维字符类型数组4. 列表(List)列表是不同类型数据的集合,可以是向量、矩阵、数组、数据框等等。

R语⾔数据类型R语⾔⽤来存储数据的对象包括: 向量, 因⼦, 数组, 矩阵, 数据框, 时间序列(ts)以及列表, 下⾯讲意义介绍.1. 向量(⼀维数据): 只能存放同⼀类型的数据语法: c(data1, data2, ...), 访问的时候下标从1开始(和Matlab相同); 向量⾥⾯只能存放相同类型的数据.> x <- c(1,5,8,9,1,2,5)> x[1] 1 5 8 9 1 2 5> y <- c(1,"zhao") # 这⾥⾯有integer和字符串, 整数⾃动转化成了字符> y[1][1] "1"访问:> x[-(1:2)] # 不显⽰第1,2个元素[1] 8 9 1 2 5> x[2:4] # 访问第2,3,4个元素[1] 5 8 92. 因⼦(factors): 提供了⼀个处理分类数据的更简洁的⽅式因⼦在整个计算过程中不再作为数值, ⽽是作为⼀个"符号"⽽已.factor(x=character(), levels, labels=levels, exclude=NA, ordered=is.ordered(x), nmax=NA)x: ⼀个数据向量, 它将被转换成为因⼦;levels: ⽤来指定因⼦可能出现的⽔平(默认也就是向量x⾥⾯互异的值, sort(unique(x)));它是⼀个字符向量(即每个元素是单个字符, 组成的⼀个向量), 下⾯的变量b就是⼀个字符向量(可以使⽤as.character()函数来⽣成).labels: ⽤来指定⽔平的名字;> a <- c(6,1,3,0)> b = as.character(a)> b[1] "6" "1" "3" "0"exclude: ⼀个值向量, 表⽰从向量x⾥⾯剔除的⽔平值.nmax: ⽔平数⽬的上界.> factor(1:3)[1] 1 2 3Levels: 1 2 3> factor(1:3, levels=1:6)[1] 1 2 3Levels: 1 2 3 4 5 6> factor(1:6, exclude = 2)[1] 1 <NA> 3 4 5 6Levels: 1 3 4 5 6⼀般因⼦(factor) VS 有序因⼦(ordered factor)因⼦⽤来存放变量或者有序变量, 这类变量不能⽤来计算, ⽽只能⽤来分类或者计数. ⼀般因⼦表⽰分类变量, 有序因⼦⽤来表⽰有序变量.创建⼀个因⼦:> colour <- c('G', 'G', 'R', 'Y', 'G', 'Y', 'Y', 'R', 'Y')> col <- factor(colour) #⽣成因⼦#labels⾥⾯的内容代替对应位置处的levels内容> col1 <- factor(colour, levels = c('G', 'R', 'Y'), labels = c('Green', 'Red', 'Yellow'))> levels(col)[1] "G" "R" "Y"> levels(col1)[1] "Green" "Red" "Yellow"> col2 <- factor(colour, levels = c('G', 'R', 'Y'), labels = c('1', '2', '3'))> levels(col2)[1] "1" "2" "3"> col_vec <- as.vector(col2)> class(col_vec)[1] "character"> col2[1] 1 1 2 3 1 3 3 2 3Levels: 1 2 3> col_num <- as.numeric(col2)> col_num[1] 1 1 2 3 1 3 3 2 3> col3 <- factor(colour, levels = c('G', 'R')) #levels⾥⾯没有'B',导致col3⾥⾯的'B'变成了<NA>> col3[1] G G R <NA> G <NA> <NA> R <NA>Levels: G R> colour[1] "G" "G" "R" "Y" "G" "Y" "Y" "R" "Y"创建⼀个有序因⼦:> score <- c('A', 'B', 'A', 'C', 'B')> score1 <- ordered(score, levels = c('C', 'B', 'A'));> score1[1] A B A C BLevels: C < B < A3. 矩阵(matrix, ⼆维数据): 只能存放同⼀类型语法: matrix(data, nrow = , ncol = , byrow = F) -- byrow = F表⽰按列来存放数据(默认), byrow=T表⽰按⾏存放数据;> xx = matrix(1:10, 2, 5)> xx[,1] [,2] [,3] [,4] [,5][1,] 1 3 5 7 9[2,] 2 4 6 8 104. 数组(⼤于等于三维的数据): 只能存放同⼀类型语法: array(data, dim) -- data: 必须是同⼀类型的数据; dim: 各维的维度组成的向量;(怎么感觉和matlab⾥⾯的reshape函数那么像) > a = array(1:10,c(2,5))> a[,1] [,2] [,3] [,4] [,5][1,] 1 3 5 7 9[2,] 2 4 6 8 105. 数据框(data frame)数据框是⼀种矩阵形式排列的数据(类似于excel表格), 但是和矩阵不同的是, 它的每⼀列可以是不同的数据类型(还是和excel很像).语法: data.frame(data1, data2,...) -- data1,...为每列的数据.> name <- c("Mr A", "Mr B", "Mr C")> group <- rep(1,3)> scort <- c(58,15,41)> df <- data.frame(name, group, scort)> dfname group scort1 Mr A 1 582 Mr B 1 153 Mr C 1 41数据访问:> df$name[1] Mr A Mr B Mr CLevels: Mr A Mr B Mr C> df[1]name1 Mr A2 Mr B3 Mr C6. 列表(list): 可以存放不同类型的数据语法: list(name1=component1, name2=component2, ...)> xx <- rep(1:2, 3:4)> yy <- c('Mr A', 'Mr B', 'Mr C', 'Mr D', 'Mr E', 'Mr D', 'Mr F')> zz <- 'discussion group'> name.list <- list(group = xx, name = yy, decription = zz)> name.list$group[1] 1 1 1 2 2 2 2$name[1] "Mr A" "Mr B" "Mr C" "Mr D" "Mr E" "Mr D" "Mr F"$decription[1] "discussion group"。
R语⾔--基本数据管理(变量、缺失值、⽇期值、数据类型转换、数据框)1 基本数据管理1.1⼀个⽰例(1)定义向量,造数据框manage<-c(1,2,3,4,5)date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")country<-c("US","US","UK","UK","UK")gender<-c("M","F","F","M","F")age<-c(32,45,24,34,88)q1<-c(5,3,3,3,2)q2<-c(4,5,5,3,2)q3<-c(5,2,5,4,1)q4<-c(5,5,5,NA,2)q5<-c(5,5,2,NA,1)lendership<-data.frame(manager,country,gender,age,q1,q2,q3,q4,q5)(2)创建新变量⽅法⼀:使⽤$q6<-q4+q5lendership$q6<-lendership$q4+lendership$q5⽅法⼆:transform()为数据表添加列lendership<-transform(lendership,q7=q4+q5,q8=q1+q2)(3)变量重编码⽅式⼀:使⽤$lendership$age[lendership$age==88]<-NAlendership$agecat[lendership$age>50]<-"Elder"lendership$agecat[lendership$age>40 & lendership$age<=50]<-"Middle Aged"lendership$agecat[lendership$age<40]<-"Young"⽅式⼆:使⽤withinlendership1<-within(lendership,{agecat<-NAagecat[age>50]<-"Elder"agecat[age>40 & age<=50]<-"Middle Aged"agecat[age<=40]<-"Young"})(4)变量重命名⽅式⼀:弹出数据编辑器⽅式⼆:使⽤names(),只能索引⼀列⼀列的改,不⽅便names(lendership)[1]<-"manager1"解释:names⾥⾯是表名,[1]代表修改第⼀列⽅式三:导⼊编辑包plyr,使⽤函数rename()library(plyr)lendership<-rename(lendership,c(manager1="ID",q1="qq1"))2 缺失值2.1 识别缺失值函数is.na()y<-c(1,2,NA)is.na(y)2.2 重编码某些值为缺失值lendership$age[lendership$age==88]<-NA2.3 缺失值参与计算会怎样y<-c(1,2,NA)z<-y[1]+y[2]+y[3]z<-sum(y,na.rm = T) #na.rm = T意思是有缺失值就移除2.4 移除含有缺失值的观测(⾏)newdata<-na.omit(lendership) #删除含有缺失值的⾏3 ⽇期值3.1 ⽇期值的读⼊ as.Datemydata<-as.Date(c("2008-06-11","2018-08-08"))3.2 ⽇期值的格式strdata<-c("01/05/1996","08/22/1998")mydata1<-as.Date(strdata,"%m/%d/%Y") #指定⽇期格式3.3 系统⽇期与当前⽇期系统⽇期:Sys.Date()当前⽇期:date()3.4 ⽇期值的输出格式format(today,format="%B %d %Y") #调整⽇期输出格式format,%B表⽰⽉份⽂字输出3.5 ⽇期值的间隔计算⽅式⼀:按天计算startdata<-as.Date("1996-11-22")enddata<-as.Date("2021-07-02")days<-enddata-startdata⽅式⼆:按周计算,使⽤函数difftim()difftime(enddata,startdata,units = "weeks")4 类型转换4.1 is.xxx()函数,⽤来判断类型4.2 as.xxx()函数,⽤来转换5 数据排序lendership2<-lendership[order(lendership$gender,lendership$age),]6 数据集操作数据输⼊:manage<-c(1,2,3,4,5)date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")country<-c("US","US","UK","UK","UK")gender<-c("M","F","F","M","F")age<-c(32,45,24,34,88)q1<-c(5,3,3,3,2)q2<-c(4,5,5,3,2)q3<-c(5,2,5,4,1)q4<-c(5,5,5,NA,2)q5<-c(5,5,2,NA,1)lendership<-data.frame(manager,country,gender,age,q1,q2,q3,q4,q5)leader_a<-data.frame(manage,country,gender,age)leader_b<-data.frame(manage,q1,q2,q3,q4,q5)leader_b<-leader_b[order(-leader_b$manage),]6.1 数据集(框)的合并 merge()lendership1<-merge(leader_a,leader_b,by="manage") #通过主键manage合并6.2 数据集(框)取⼦集(1)保留变量⽅式⼀:newdata<-lendership[,c(5:9)]⽅式⼆: myvar<-c("gender","country","q5")newdata1<-lendership[myvar](2)删除变量⽅式⼀:前⾯加负号 -newdata<-newdata[c(-2,-3)]⽅式⼆:赋值NULLnewdata$q3<-NULL(3)选⼊观测(保留⾏)newdata2<-lendership[1:3,] #选择1到3⾏newdata3<-lendership[lendership$gender=="M" & lendership$age>30,](4)subset函数newdata4<-subset(lendership,gender=="M" & age>25,select=c("manager","gender","age"))解释:gender=="M" & age>25这是选择保留的⾏,select是选择保留的列若出现了错误:选择了未定义的列修正:检查⾃⼰的列变量名字是否写错(5)使⽤SQL语句操作数据集(框)加载包:library(sqldf)语句:newdf<-sqldf("select * from mtcars where carb=1 order by mpg",s = T)。
R语⾔--变量与数据类型R语⾔的数据分类R语⾔的数据类型较多,但都是动态声明,即变量不会声明为某种数据类型。
变量分配为R对象向量列表矩阵数组数据帧因⼦下⾯是⼏种最简单对象的类型# Atomic vector of type character.print("abc");#character# Atomic vector of type double.print(12.5)#numeric# Atomic vector of type integer.print(63L)#integer# Atomic vector of type logical.print(TRUE)#logical# Atomic vector of type complex.print(2+3i)#complex# Atomic vector of type raw.print(charToRaw('hello'))#raw向量vector最简单的是向量类型,即使⽤c()的形式声明。
以下⽰例中,如果其中⼀个元素是字符,则⾮字符值被强制转换为字符类型# The logical and numeric values are converted to characters.s <- c('apple','red',5,TRUE)print(s)实际上,向量的多元素可以⽤冒号表⽰,⽐如v <- 6.6:12.6print(v)w <- 3.8:11.4即表⽰从6.6到12.6,逐次加⼀构成的向量;w表⽰从3.8逐次加⼀到10.8。
还可以⽤函数创建:# Create vector with elements from 5 to 9 incrementing by 0.4.print(seq(5, 9, by = 0.4))如果其中⼀个元素是字符,则⾮字符值被强制转换为字符类型。
R语⾔数据类型当编写任何编程语⾔程序,需要使⽤不同的变量来存储各种信息。
变量不过是⽤于保留存储器位置的存储值。
这意味着,当创建⼀个变量,它会保留在内存中的⼀些空间。
你可能喜欢存储诸如字符以外的数据类型,如:宽字符,整型,浮点型,双浮点型,布尔等信息。
基于变量的数据类型,操作系统分配内存,并决定什么可以存储在存储器。
在其他编程语⾔中,如C和Java R中的变量没有声明为某些数据类型。
变量分配R-对象和R对象的数据类型变为变量的数据类型。
有许多类型的R-对象。
常⽤的有:⽮量,列表,矩阵,数组,因⼦,数据帧这些对象的是最简单的⽮量对象并且这些原⼦⽮量有六种数据类型,也被称为六类向量。
另外R-对象是建⽴在原⼦向量。
数据类型⽰例验证逻辑TRUE , FALSE v <- TRUE print(class(v))它产⽣以下结果:[1] "logical"数字12.3, 5, 999v <- 23.5 print(class(v))它产⽣以下结果:[1] "numeric"整数2L, 34L, 0L v <- 2L print(class(v))它产⽣以下结果:[1] "integer"复数 3 + 2i v <- 2+5i print(class(v))它产⽣以下结果:[1] "complex"字符'a' , '"good", "TRUE", '23.4'v <- "TRUE" print(class(v))它产⽣以下结果:[1] "character"原始"Hello" 将被存储为 48 65 6c 6c 6f v <- charToRaw("Hello") print(class(v))它产⽣以下结果:[1] "raw"因此,在R语⾔中的⾮常基本的数据类型是R-对象,如上图所⽰占据着不同类别的元素向量。
整数型根据整数位长短,通常需要2字节或4字节
实数型用来存储包含小数位的数值型数据,根据实数取值范围的大小和小数位精度高度,通常需要4字节或8字节
字符型(Character)逻辑型(Logical)
向量(Vector)
矩阵(Matrix)数组(Array)数据框(Data
Frame)
列表(List)定义:是一个二维表格形式用于组织多个具有相同存储类型的变量。
矩阵的列通常为变量
定义:多张二维表的集合,一般用于组织统计中的面板数据
定义:也是一张二维表格,与矩阵有类似之处,但用于组织存储类型不尽相同的多个变量。
其中,数据框的列通常为变量,行为观测。
定义:多个向量,矩阵,数组,数据框,列表的集合即列表。
多用于相关统计分析结果的“打包”集合
数据对象划
分
存储角度
结构角度
数值型
(Numeric)包
含
不同组织结构
的R对象
定义:由于不同类型的数据在计算机中所需的存储字节不同
定义:储存数值型数据类型总称
定义:存储诸如姓名,籍贯等字符形式数据的类型
定义:判断是否已婚,或已经通过某个考试等,判断值只有大写的TRUE和
FALSE,只需要一字节储存
定义:由于数据分析实践中有不同的数据组织结构
定义:向量是R数据组织的基本单位,从统计角度来看,一个向量对应一个
变量,存储着多个具有相同存储类型的变量值,向量一般为列向量。