SPSS数据文件的建立和管理实验报告
- 格式:doc
- 大小:3.34 MB
- 文档页数:4
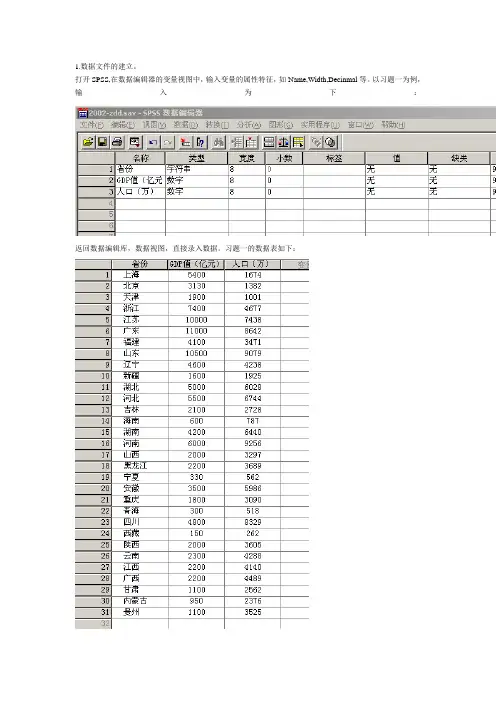
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。

实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构和定义方法;2.掌握spss数据的录入与编辑:数据的录入、数据的定位、插入和删除一个个案、插入和删除一个变量、数据的移动、复制和删除;3.掌握spss数据的保存,保存为excel文件格式和spss文件格式;4.掌握读取excel文件格式和txt文件格式的数据;5.掌握spss数据文件的纵向与横向的合并。
二.实验基本方法1. spss数据的结构和定义方法操作步骤:参阅教材第24页。
2. spss数据的录入与编辑操作步骤:(1)数据的录入:参阅教材第29页。
(2)数据的定位:参阅教材第30页。
(3)插入和删除一个个案:参阅教材第31页。
(4)插入和删除一个变量:参阅教材第31页。
(5)数据的移动、复制和删除:参阅教材第32页。
3. spss数据的保存操作步骤:参阅教材第33页。
4. 读取excel文件格式和txt文件格式的数据操作步骤:参阅教材第35页。
5. spss数据文件的纵向与横向的合并操作步骤:(1)纵向合并数据文件:参阅教材第40页。
(2)横向合并数据文件:参阅教材第42页。
三.实验内容(一)验证性实验(1)教材第25页“关于居民储户调查问卷的spss变量的设计”(2)教材第38页“职工基本情况数据的纵向合并和横向合并”(二)实践性实验(1)针对“零散数据”文件夹中的若干excel数据和txt数据,将其转换为spss的数据文件,要求转换为spss数据后,根据变量的类型正确定义数据结构。
(2)针对“经管学院考试成绩”文件夹中的数据,首先,通过spss软件将“成绩1”和“成绩2”的excel文档打开,并保存为相同文件名的spss数据文件。
要求:spss读取excel的变量名,数据结构定义准确。
其次,利用横向合并的功能,将“成绩1”和“成绩2”进行合并,并存为“三次考试成绩汇总表.sav”的文件。
最后,将“三次考试成绩汇总表.sav”的文件保存一份txt本文数据和excel文件数据。
数据管理一、实验目的与要求1.掌握计算新变量、变量取值重编码的基本操作.2。
掌握记录排序、拆分、筛选、加权以及数据汇总的操作。
3.了解数据字典的定义和使用、数据文件的重新排列、转置、合并的操作。
二、实验内容提要1.自行练习完成课本中涉及的对CCSS案例数据的数据管理操作2.针对SPSS自带数据Employee data.sav进行以下练习。
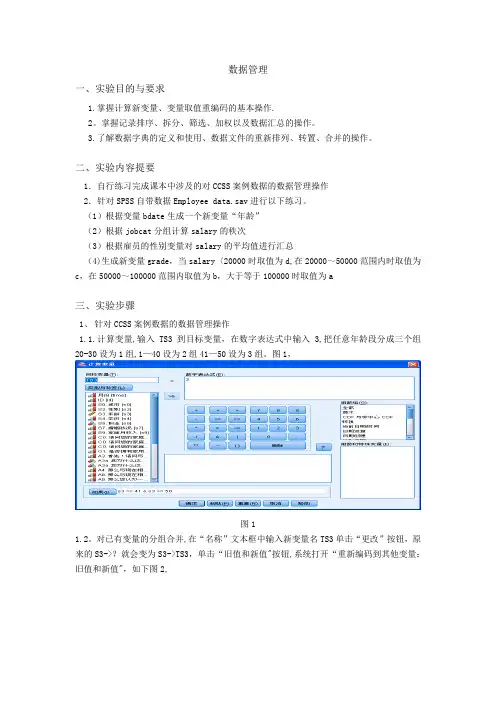
(1)根据变量bdate生成一个新变量“年龄”(2)根据jobcat分组计算salary的秩次(3)根据雇员的性别变量对salary的平均值进行汇总(4)生成新变量grade,当salary〈20000时取值为d,在20000~50000范围内时取值为c,在50000~100000范围内取值为b,大于等于100000时取值为a三、实验步骤1、针对CCSS案例数据的数据管理操作1.1.计算变量,输入TS3到目标变量,在数字表达式中输入3,把任意年龄段分成三个组20-30设为1组,1—40设为2组41—50设为3组。
图1,图11.2。
对已有变量的分组合并,在“名称”文本框中输入新变量名TS3单击“更改”按钮,原来的S3->?就会变为S3->TS3,单击“旧值和新值"按钮,系统打开“重新编码到其他变量:旧值和新值",如下图2,图2图31。
3.可视离散化,选择“转换”—〉“可视离散化”,打开的对话框要求用户选择希望进行离散化的变量,单击继续,如下图4,图4单击“生成分割点”,设定分割点数量为10,宽度为5,第一个分割点位置为18,单击“应用”,如下图,图5结果显示如下,图62.针对SPSS自带数据Employee data。
sav进行以下练习。
2。
1。
根据变量bdate生成一个新变量“年龄",选择“转换”-〉”计算变量”,如下图,图7结果显示如下,图8 2.2.根据jobcat分组计算salary的秩次,图9 结果显示如下,图102。

spss数据分析实验报告《SPSS》实验报告册20 12 - 20 13 学年第 1 学期班级:学号:姓名:授课教师: 实验教师: 实验学时: 实验组号:《SPSS》上机实验指导书目录 1. 实验一 SPSS的数据管理 2. 实验二描述性统计分析 3. 实验三均值检验 4. 实验四相关分析 5. 实验五因子分析 6. 实验六聚类分析 7. 实验七回归分析 8. 实验八判别分析《SPSS》上机实验指导书实验一 SPSS的数据管理一、实验目的1( 熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2(掌握SPSS的数据管理功能。
二、实验内容及步骤:1、实验内容:定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
表1 大学教师基本情况调查表问题备选答案1姓名2 性别3年龄 4(1)专科(2)本科(3)硕士(4)博士(5)4学历博士后5 工作年月6 (1)助教(2)讲师(3)副教授(4)教授 6职称7 (1)0~120(2)120~240 (3)240~320 7本年度教学工作量(课时) (4)320~480 (5) 480以上8 本年度公开发表论文数9 本年度您的科研经费总额(万元)10.您认为学校对科研人员每年的科研成(1)合理 (2)不合理 (3)无所谓果要求是否合理11 您最常用的全文期刊数据库的名称(多(1)cnki (2)万方 (3)SpringerLink (4)选,限选2个) EBSCO12 您对学校科研管理部门的工作是否满(1)非常满意 (2)满意 (3)一般 (4)不意满意实验步骤:1.打开spss 13.0 for windows ,选择type in date .2先选择左下角的Varible View,将数据的属性输入,如“姓名”的类型为“字符串”,性别的类型为“数值型”。

SPSS统计分析第章数据文件建立和管理引言SPSS(Statistical Product and Service Solutions)是一个被广泛使用的统计分析软件,它的分析功能十分强大,因此在社会科学、教育研究、医学研究等领域得到了广泛的应用。
而SPSS的数据文件建立和管理是使用SPSS时必须掌握的基本操作,它能够让我们更加高效地管理数据,减少误操作,提高分析效率。
本文将介绍SPSS的数据文件建立和管理。
SPSS数据文件建立SPSS数据文件包含两个主要部分:数据字典和数据录入。
数据字典是说明数据文件包含哪些变量,每个变量的名称、类型、取值范围等信息。
数据录入是将实际数据输入到数据文件中。
在建立SPSS数据文件时,需要先建立数据字典,然后再进行数据录入。
数据字典的建立数据字典是SPSS数据文件的重要组成部分,它包含了数据文件中的变量定义和取值范围。
在SPSS中建立数据字典的过程如下:1.打开SPSS软件并新建数据文件:打开SPSS软件,点击“文件”菜单,选择“新建数据文件”选项,弹出新建数据文件对话框。
选择“默认”选项设置数据文件名称和存储位置,并点击“确定”按钮,即可新建一个空的SPSS数据文件。
2.添加变量定义:在新建数据文件中,点击“变量视图”选项卡,然后在空白区域右键单击,选择“插入变量”选项,弹出“建立变量”对话框。
在该对话框中输入变量名称、类型(数值型、文字型、日期型等)、长度、标签等信息,然后点击“添加”按钮。
3.设置变量取值范围:在“建立变量”对话框中,设置变量的取值范围,例如最小值、最大值、有效值等。
点击“确定”按钮,变量将被添加到数据字典中。
4.重复以上步骤,创建所有需要的变量。
数据录入数据录入是向SPSS数据文件中输入实际数据的过程,通常可以使用多种方式进行,如手动输入、导入外部数据等。
手动输入是最常见的方式,它需要打开数据文件并逐行录入数据,并注意每个字段的格式要与数据字典一致。

实验一:SPSS数据文件的建立和管理操作以及数据预处理操作1.有两份关于职工基本情况的SPSS数据文件“职工数据.sav”和“追加职工.sav”,两份数据文件中的数据项不尽相同,且同一数据项的变量名也不完全一致。
请将这两份文件合并到一起。
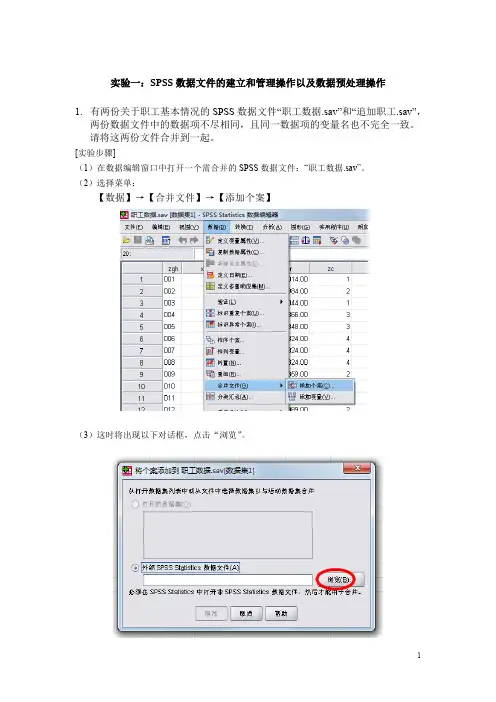
[实验步骤](1)在数据编辑窗口中打开一个需合并的SPSS数据文件:“职工数据.sav”。
(2)选择菜单:【数据】→【合并文件】→【添加个案】(3)这时将出现以下对话框,点击“浏览”。
(4)打开需进行纵向合并处理的SPSS数据文件“追加职工.sav”。
按“继续”后,显示纵向合并数据文件窗口。
(如下图)(5)对话框右边【新的活动数据集中的变量】框中显示的变量名是两个数据文件中的同名变量,对话框左边【非成对变量】框中显示的变量名是两个文件中的不同名变量。
其中,变量名后面的【*】表示该变量是当前数据编辑窗口中(“职工数据.sav”)的变量,【+】表示该变量是(2)“追加职工.sav”中指定的磁盘文件中的变量。
SPSS默认这些变量的含义不同,且不放入合并后的新文件中。
如果不接受这种默认,可选择其中的两个变量名并按【对】按钮指定配对,表示虽然它们的名称不同但数据含义是相同的,可进入合并后的数据文件中。
本题中,显然职称zc(*)和职称zc1(+)两个变量名需要按【对】按钮指定配对。
方法是:按住“Ctrl键”,同时鼠标点zc(*)和zc1(+),然后按【对】按钮,这时【新的活动数据集中的变量】框中出现“zc&zc1”变量名。
(6)把【非成对变量】框中显示的其他变量名全部标记,按右向箭头。
(7)按【确定】,完成操作。
2.根据“住房状况调查.sav”数据,通过数据排序功能分析本市户口和外地户口家庭的住房面积情况。
(按升序排列)[实验步骤](1)在数据编辑窗口中打开SPSS数据文件:“住房状况调查.sav”。
(2)选择菜单:【数据】→【排序个案】(3)指定主排序变量“户口状况”到【排序依据】框中,并选择【排序顺序】框中的选项指出该变量按升序还是降序排序。
【最新整理,下载后即可编辑】数据管理一、实验目的与要求1.掌握计算新变量、变量取值重编码的基本操作。
2.掌握记录排序、拆分、筛选、加权以及数据汇总的操作。
3.了解数据字典的定义和使用、数据文件的重新排列、转置、合并的操作。
二、实验内容提要1.自行练习完成课本中涉及的对CCSS案例数据的数据管理操作2.针对SPSS自带数据Employee data.sav进行以下练习。
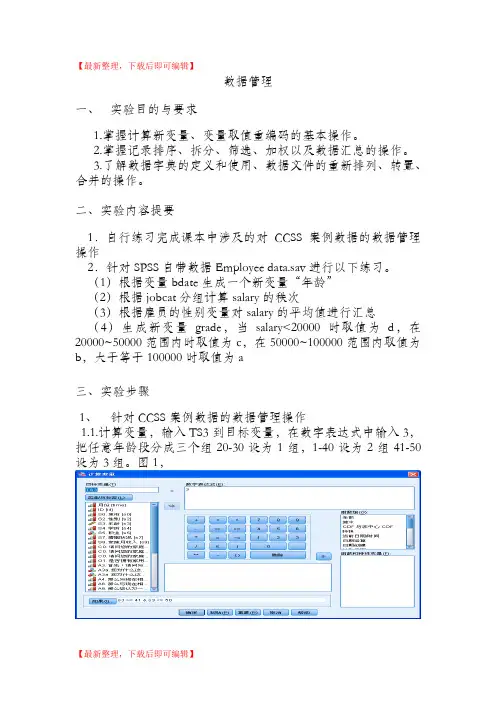
(1)根据变量bdate生成一个新变量“年龄”(2)根据jobcat分组计算salary的秩次(3)根据雇员的性别变量对salary的平均值进行汇总(4)生成新变量grade,当salary<20000时取值为d,在20000~50000范围内时取值为c,在50000~100000范围内取值为b,大于等于100000时取值为a三、实验步骤1、针对CCSS案例数据的数据管理操作1.1.计算变量,输入TS3到目标变量,在数字表达式中输入3,把任意年龄段分成三个组20-30设为1组,1-40设为2组41-50设为3组。
图1,图11.2.对已有变量的分组合并,在“名称”文本框中输入新变量名TS3单击“更改”按钮,原来的S3->?就会变为S3->TS3,单击“旧值和新值”按钮,系统打开“重新编码到其他变量:旧值和新值”,如下图2,图2图31.3.可视离散化,选择“转换”->“可视离散化”,打开的对话框要求用户选择希望进行离散化的变量,单击继续,如下图4,图4单击“生成分割点”,设定分割点数量为10,宽度为5,第一个分割点位置为18,单击“应用”,如下图,图5结果显示如下,图62.针对SPSS自带数据Employee data.sav进行以下练习。
2.1.根据变量bdate生成一个新变量“年龄”,选择“转换”->”计算变量”,如下图,图7结果显示如下,图82.2.根据jobcat分组计算salary的秩次,图9结果显示如下,图102.3.根据雇员的性别变量对salary的平均值进行汇总图11结果显示如下,图122.4.生成新变量grade,当salary<20000时取值为d,在20000~50000范围内时取值为c,在50000~100000范围内取值为b,大于等于100000时取值为a图13结果显示如下,图14 四、实验结果与结论。

一、实验目的1. 掌握SPSS数据文件的基本建立和管理方法。
2. 熟练运用SPSS进行数据排序、分组、筛选等操作。
3. 了解SPSS数据文件的基本维护和备份方法。
二、实验环境1. 软件环境:SPSS 25.02. 硬件环境:个人电脑三、实验内容及步骤1. 数据文件建立(1)启动SPSS,选择“文件”菜单中的“新建”选项,选择“数据”,进入数据编辑窗口。
(2)在数据编辑窗口中,根据实验需求,定义变量名、变量类型、变量宽度等属性。
(3)在变量视图中,设置每个变量的属性,如数值类型、小数位数、标签等。
(4)在数据视图中,输入实验数据。
2. 数据文件管理(1)数据排序:选择“数据”菜单中的“排序”,根据需要选择排序方式(升序或降序)和排序依据。
(2)数据分组:选择“数据”菜单中的“分组”,设置分组依据和分组变量。
(3)数据筛选:选择“数据”菜单中的“选择”,根据需要设置筛选条件。
(4)数据计算:选择“转换”菜单中的“计算变量”,创建新变量,输入计算公式。
3. 数据文件维护与备份(1)数据备份:选择“文件”菜单中的“保存”或“另存为”,将数据文件保存到指定位置。
(2)数据恢复:选择“文件”菜单中的“打开”,选择需要恢复的数据文件。
四、实验结果与分析1. 成功建立了SPSS数据文件,并完成了数据录入。
2. 通过数据排序、分组、筛选等操作,对数据进行初步整理。
3. 通过计算变量,实现了对数据的进一步分析。
4. 成功备份和恢复了数据文件,确保了数据安全。
五、实验总结本次实验使我对SPSS数据文件管理有了更深入的了解。
通过实验,我掌握了以下技能:1. 建立SPSS数据文件的基本方法。
2. 数据排序、分组、筛选等操作的运用。
3. 数据计算和变量创建的方法。
4. 数据文件维护和备份的方法。
在今后的学习和工作中,我将不断巩固和拓展这些技能,提高数据分析能力。

实验1 数据文件管理一、实验目的与要求通过本实验项目,使学生理解并掌握SPSS软件包有关数据文件创建和整理的基本操作,学习如何将收集到的数据输入计算机,建成一个正确的SPSS数据文件,并掌握如何对原始数据文件进行整理,包括数据查询,数据修改、删除,数据的排序等等。
二、实验原理SPSS数据文件是一种结构性数据文件,由数据的结构和数据的内容两部分构成,也可以说由变量和观测两部分构成。
一个典型的SPSS数据文件如表2.1 所示。
表2.1 SPSS数据文件结构SPSS变量的属性SPSS中的变量共有10个属性,分别是变量名(Name)、变量类型(Type)、长度(Width)、小数点位置(Decimals)、变量名标签(Label)、变量名值标签(Value)、缺失值(Missing)、数据列的显示宽度(Columns)、对其方式(Align)和度量尺度(Measure)。
定义一个变量至少要定义它的两个属性,即变量名和变量类型,其他属性可以暂时采用系统默认值,待以后分析过程中如果有需要再对其进行设置。
在spss数据编辑窗口中单击“变量视窗”标签,进入变量视窗界面(如图2.1所示)即可对变量的各个属性进行设置。
图2.1 变量视窗三、实验练习的内容1.创建一个数据文件数据文件的创建分成三个步骤:(1)选择菜单【文件】→【新建】→【数据】新建一个数据文件,进入数据编辑窗口。
窗口顶部标题为“PASW Statistics数据编辑器”。
(2)单击左下角【变量视窗】标签进入变量视图界面,根据实验的设计定义每个变量类型。
(3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具体的变量值录入数据库单元格内。
2.读取外部数据当前版本的SPSS可以很容易地读取Excel数据,步骤如下:(1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图2.2所示。
图2.2 Open File对话框(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图2.3所示。
广东金融学院实验报告课程名称:市场调查与预测
四、实验结果(包括程序或图表(截图)、结论陈述、数据记录及分析等,可附页)
1.①变量视图截图(zc和zcl合并为zc)
②数据视图的截图(“职工数据.sav”的变量中多了income)
2. 数据视图的截图(户口状况和现住面积都是按升序排的,且先排户口状况再排现住
面积)
3.数据视图的截图(户口状况=2,即属于外地户口的都被划掉了,从而筛选出本市户口,
此外后面的filter_$为1是被选中的数据)
4. 数据视图的截图(由图看出本市户口人均面积的均值为48.93,外地户口人均面积的
均值为34.03,两者在人均面积上有较大的差异,但本市户口和外地户口计划面积的均值都为90.00,所以两者在计划面积上没有较大的差异)
五、实验总结(包括心得体会、问题回答及实验改进意见,可附页)
1.通过实验,我熟练掌握了SPSS数据文件的合并,排序筛选个案和分类汇总的具体操
作。
2.实验的过程必须要自己亲自练习才有效果,所以即使有步骤,也不要怕麻烦,多练几
次。
3.SPSS是一个数据统计的强大工具,我们必须好好学习。
六、教师评语
1.□优秀(90~100分):完成所有规定实验内容,实验步骤正确,结果正确;
2.□良好(80~89分):完成绝大部分规定实验内容,实验步骤正确,结果正确;
3.□中等(70~79分):完成绝大部分规定实验内容,实验步骤基本正确,结果基本正确;
4.□及格(60~69分):基本完成规定实验内容,实验步骤基本正确,完成结果基本正确;
5.□不及格(< 60分):未能完成规定实验内容或实验步骤不正确或结果不正确。
教师签名:
2013年12 月8 日。
一、实验目的和要求1、熟练掌握SPSS软件进入和退出等操作,了解SPSS的基本窗口和菜单安排。
2、明确SPSS数据的基本组织方式和数据行列的含义。
3、掌握从哪些方面描述SPSS数据文件的结构特征。
4、熟练掌握建立SPSS数据文件以及管理SPSS数据的基本操作。
二、实验步骤及过程三、实验结果分析四、实验体会一、实验目的和要求1、熟练掌握SPSS数据筛选的基本方法和具体操作。
2、熟练掌握SPSS数据排序、计数的具体操作。
3、掌握SPSS分类汇总的含义并熟练掌握具体操作。
4、掌握各种数据分组的特点和适用场合,并熟练掌握SPSS组距分组的具体操作。
二、实验步骤进入SPSS环境,并导入数据。
点击“转换——>计算变量”进入计算变量对话框进行变量计算,并通过数据——>排序个案、数据——>分类汇总、数据——>加权个案等对数据进行预处理。
三、实验内容及过程四、实验结果分析一、实验目的和要求1、熟练掌握SPSS频数分析的基本方法和具体操作。
2、明确基本描述统计量的含义,并熟练掌握其计算的具体操作。
3、掌握交叉列联表的基本方法,了解卡方检验的基本思想,能够数量掌握其具体操作。
4、掌握对多选项问题的不同拆分方法和应用场合,并熟练掌握SPSS进行多选项数分析。
二、实验步骤进入SPSS环境,并导入数据。
点击“分析——>描述统计——>频率”进入对变量的频数计算;点击“分析——>描述统计——>描述”,对变量进行描述统计分析;“分析——>描述统计——>列联表”,对数据变量进行交叉列联表分析;“分析——>描述统计——>比率”,对数据变量进行比率分析。
三、实验内容及过程。
《统计软件》实验报告实验序号:01 实验项目名称:SPSS数据文件的建立和编辑学号姓名专业、班实验地点指导教师时间一、实验目的及要求熟悉SPSS的工作环境;掌握系统的三种运行方式,并能根据自己的需要选择所熟悉的方式使用软件;了解SPSS的基本窗口类型,熟悉数据窗口的两个界面,自己动手建立一个数据文件,并对数据文件作主要的编辑操作。
本实验目的是:了解数据文件的结构,建立正确的SPSS数据文件,掌握如何对原始数据文件进一步整理和变换的主要方法,为后面的统计分析过程作好准备。
二、实验设备(环境)及要求Windows XP,SPSS三、实验内容与步骤1、数据文件的建立:(1)选择File-New-Data命令,打开一个新的Data Editor;(2)单击窗口左下角的Variable View标签,切换到全屏定义界面;(3)从第一行的名称列开始,按行依次输入定义变量各个特性值,如图(4)切换到数据视图,输入数据;(5)选择数据→排序个案,选择月收入,降序,如图。
即按月收入由高到低排序。
(6)选择数据→选择个案→如果条件满足→如果,进行编辑,如图(7)以评估为“优”工资上涨20%为例。
选择转换→计算变量→目标变量输入月收入→表达式输入月收入*1.2→选择如果→如果个案条件包括→输入“年终业务考核成绩=4”,如图(8)重复(7)操作,得到最后结果。
2.以第1、6、10题正确答案为a为例。
选择转换→对个案内的值计数→目标变量s1→选择q1、q6、q10→选择定义值→输入a,点击“添加”,“继续”,“确认”,统计每个样品在第1、6、10题上选择A的个数,重复这样的操作,建立第二个新变量s2,统计每个样品在q4、q5、q7、q8取值为B的个数,同样的步骤,建立s3、s4。
如图所示。
然后选择转换,计算变量,编辑函数,计算sum=(s1+s2+s3+s4)*10, 选择数据→排序个案→降序排列,如图。
3. 建立统计一班、统计二班文件,并且分别按照统计学成绩、预测与决策成绩降序排列,如图。