化探数据处理方法
- 格式:doc
- 大小:104.50 KB
- 文档页数:9

化探数据处理的一般性方法一、分析质量:1.看技术报告中质量评述部分,看各项指标是否合格。
主要有:检出限、报出率、异常检查率、异检合格率、内检率、内检合格率、国家一级或二级标准物质的准确度和精密度等。
看是否符合标准(设计)。
这些数据由化验室提供。
这些一般不会超差的,否则化验室不能给出化验报告。
2.RE计算RE=abs(C1-C2)/(C1+C2)×200要求:小于3倍检出限时,RE≤85%,大于3倍检出限时,RE≤66%为合格。
总合格率一般要求大于70%。
需要说明的是:这种方法适用于简单对比,就是一个点取2个样时使用。
如果用三重套合分析,就不能用这种方法了。
所以写设计时,一定要用简单对比方法。
还有,这些年的化探中的RE还没有超标的,如果真的超标了,我也不知道怎样处理。
二、数据处理:1.剔除一级及二级标准样;2.剔除重复样;3.剔除0值及化验室输入错误的值,或小于检出限的值。
主要是指≤0.3这样数据的≤号;4.做原始数据图;5.计算异常下限,做单元素异常图,圈定单元素异常。
单点异常,只有外带的不圈,有中、内带的圈出。
外带用黄色,中带用浅红色,内带用深红色。
单元素异常编号为Au-1,Ag-1等。
需要指出的是,圈定异常时应该形成数据异常图,但交报告时,必须分开,就是形成一张数据图,再形成一张异常图;需要说明的是,如果面积较大(这个没有标准),总体说是水系面积超过一个5万图幅,就要分子区计算下限。
分子区的原则是不同年代、不同地质体都要划分成子区。
如果各个子区的异常下限接近,就采用总的,否则分别确定子区的异常下限,然后分别圈定子区的异常。
6.填单元素异常评序表。
异常点数、面积、平均值、极大值、标准离差、衬度、规模、浓度分带等。
评序有5参数和多参数两个评序,5参数不参与的参数有标准离差、浓度分带及异常点数。
需要说明的是,排序时,单项值高的给1,以下类推2、3等,一样的值给一样的排序。
不产生空的值。
浓度分带有内带的给1,中带的给2,外带的给3;7.做组合异常图,先把所有的元素做成1张组合异常图,只要外带,圈定组合异常。





最新最详细化探数据处理与编图流程⼀、指导思想成矿地质背景地球化学研究就是从地球化学特征出发,借助已建⽴的地球化学信息提取技术,充分利⽤地球化学调查所获得的海量数据信息,提取有关反应成矿地质背景条件的地球化学信息,并编制相应地球化学图及相应的推断解释图件,为资源潜⼒评价有关成矿地质背景的研究提供地球化学⽀撑。
⼆、⼯作内容(⼀)基础图件成矿地质背景条件的地球化学信息提取⾸先是要编制有关基础地球化学图件。
主要有:1. 单元素(化合物)地球化学图2. 地球化学组合异常图3. 地球化学综合异常图(⼆)解释推断图件地球化学解释推断图件,内容包括:1. 地球化学推断解译地质图2. 地球化学找矿预测图三、⼯作⽅法(⼀)数据校正处理1|数据检查的必要性,因为实验室的分析报告还是⼿⼯输⼊的,还是存在录⼊错误的,我们重点检查的是“>”,数据中间的空格等录⼊错误问题;另外还有畸变检查,数据的特⼤值,⽐如超过10倍变差,⼀般对这样的分析值实验室会很重视的,你也可以提出让他们再确认⼀下,做到⼼中有数。
另⼀类错误可能会是我们录⼊样号或者坐标时出现的错误,如:“56b” 写成“56 b”,程序是以空格分开数据的,数据如果写成这样就会产⽣错误结果,有时在完成处理后才可能发现,这样⼀来我们前⾯的⼯作就作废了。
所以数据检查是⾮常必要的。
2|异常下限值的确定采⽤逐渐剔除法:①计算全区各元素原始数据的均值(X)和标准偏差(S);②按X1+3S1的条件剔除⼀批⾼值后获得⼀个新数据集,再计算此数据集的均值(X2)和标准偏差(S2);③重复第⼆步,直⾄⽆特⾼值点存在,求出最终数据集的均值(X)和标准偏差(S),则X做为背景平均值,S为标准离差,T(异常下限值)= X (背景平均值)+2S(标准离差)求出理论异常下限值,再结合地球化学等量线、地质背景及圈定效果确定出实⽤异常下限值。
3|重复样样品合格率统计野外重采样品以密码样形式插⼊样品中进⾏了分析,结果(C2)与第⼀次分析结果(C1)进⾏了⽐对。

所有数据均输入计算机、以MAPGIS 制图系统为平台,以原始数据筛选替换特高值后,转计算成对数值后,用 X +2S 求出异常下限,分别以X -2S 、X -0.5S 、X +0.5S 、X +2S 分出色区,绘制各元素地球化学图,以上做图过程均在计算机上用MAPGIS 软件完成。
对化验室的样品分析结果取对数分组作直方图,证明所有元素均符合对数正态分布。
元素异常参数的确定:首先对原始数据进行假设正态检验,再作X -
+3S 特高值逐步剔除,然后进行各参数统计。
Au 元素含量为W×10-9,其它元素含量为W×10-6。
(1)背景平均值:f
fxc X ∑∑= (2)对数标准离差:1)(22-∑-∑=
n n fxc fxL S (3)对数异常下限:T0=X -L+2S
(4)变异系数:%1001%2230285.2⨯-=⋅S e Cv
e -自然对数,2.30285为常用对数与自然对数模数的倒数
S -对数标准离差,1为常数
(5)衬度:To
Xa K =(Xa 为异常平均值) (6)异常规模:P=k×km 2(km 2为异常面积)
各类系数计算和所利用的公式均符合规范要求。
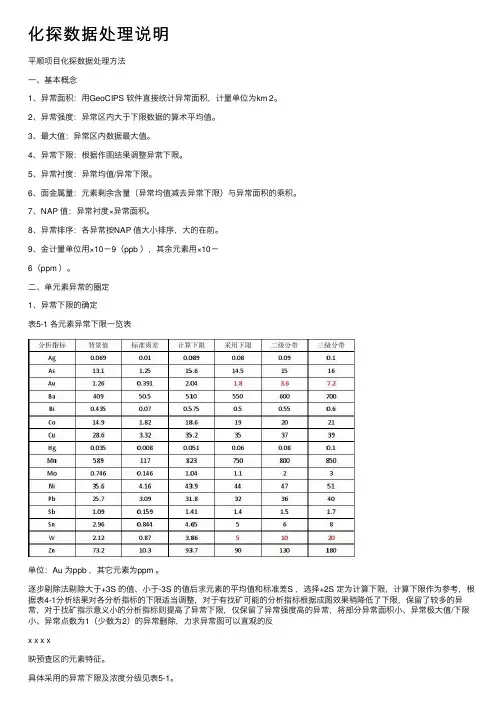
化探数据处理说明平顺项⽬化探数据处理⽅法⼀、基本概念1、异常⾯积:⽤GeoCIPS 软件直接统计异常⾯积,计量单位为km 2。
2、异常强度:异常区内⼤于下限数据的算术平均值。
3、最⼤值:异常区内数据最⼤值。
4、异常下限:根据作图结果调整异常下限。
5、异常衬度:异常均值/异常下限。
6、⾯⾦属量:元素剩余含量(异常均值减去异常下限)与异常⾯积的乘积。
7、NAP 值:异常衬度×异常⾯积。
8、异常排序:各异常按NAP 值⼤⼩排序,⼤的在前。
9、⾦计量单位⽤×10-9(ppb ),其余元素⽤×10-6(ppm )。
⼆、单元素异常的圈定1、异常下限的确定表5-1 各元素异常下限⼀览表单位:Au 为ppb ,其它元素为ppm 。
逐步剔除法剔除⼤于+3S 的值、⼩于-3S 的值后求元素的平均值和标准差S ,选择+2S 定为计算下限,计算下限作为参考,根据表4-1分析结果对各分析指标的下限适当调整,对于有找矿可能的分析指标根据成图效果稍降低了下限,保留了较多的异常,对于找矿指⽰意义⼩的分析指标则提⾼了异常下限,仅保留了异常强度⾼的异常,将部分异常⾯积⼩、异常极⼤值/下限⼩、异常点数为1(少数为2)的异常删除,⼒求异常图可以直观的反x x x x映预查区的元素特征。
具体采⽤的异常下限及浓度分级见表5-1。
2、浓度分级预查区各分析指标尽量采⽤1、2、4分带。
由于预查区各分析指标整体含量低,仅Au、W采⽤了1、2、4分带,部分变异系数⼩和采⽤下限较⼤的分析指标,灵活调整了浓度分带。
三、综合异常的圈定与类别划分1、综合异常的圈定根据预查区内单元素异常分布及组合特征,以主要成矿元素的异常为主,把在空间上分布基本⼀致,相互重合的多个单元素异常圈定为⼀个综合异常。
共圈定以Ag、As、Au、Bi、Cu、Hg、Mo、Pb、Sb、Sn、W、Zn为主要异常元素的综合异常7个。
按所处地质环境、找矿意义和已有资料现阶段的认识⽔平,将各综合异常按下列标准进⾏分类,其中⼄2类异常1个,⼄3类异常4个,丁类异常2个。
化探数据处理方法
1、采样点坐标生成
如果为GPS测定,直接把坐标转成文本文档。
在投影变换中用户文件投影转换把坐标数据投成点文件。
(具体操作可问孔德成,注意:该步骤只有在带虚拟狗的MAPGIS61或67下运行)
如果为手工图件,则先把采样点做成点文件(注意:点的顺序要与化验结果一致),参照以下步骤操作:
(1)、在投影变换中打开点文件,在工具中选择编辑属性结构,按下图编辑后,点OK。
(2)在工具中选择点位置转换为属性,弹出下图,依次点击转换、保存、确定。
确定。
通过以上过程,在桌面上生成坐标文本。
2、异常下限的确定:从化验结果中统计下图中的各个值。
(用的是EXCEL中的公式,不明之处可问吴邦友),下图中异常下限之下的各值仅为判别推断用,可以不要。
3、异常图制作:先把点坐标及各元素化验结果复制成文本文档。
在DTM分析中选择GRD模型——离散数据网格化,打开文本文档,
参照下图设置:
确定后自动生成Tmpgrid.Grd文件。
选择GRD模型——平面等值线图绘制,打开Tmpgrid.Grd文件,根据异常下限设置等值层值及其它项,参照下图:
确定后生成等值线图。

内蒙古扎赉特旗东芒合矿和哈拉街吐矿化探数据处理及图件编制方法1 化探数据质量评价的数据处理(分矿区)⑴统计重采样和重分析抽查样所占样品总数的比例比例 = (重采样和重分析抽查样数/工作样总数)100%⑵作出SSPS数据文件将重采样和重分析样分别作成SSPS数据文件。
文件中列出项目为:①重采抽查样重采样号元素含量相应的工作样号元素含量②重分析抽查样重分析样号元素含量相应的工作样号元素含量⑶计算各元素相对误差重采样和重分析抽查样相对误差均按RE(%) = |C1-C2|/0.5×(C1+C2)×100%计算。
C1为重采样或重分析抽查样的分析含量C2为重采样或重分析抽查样的相应的工作样的分析含量| |为绝对值RE(%)≤30%为合格,>30为超差(不合格);(Au:RE(%)≤50%为合格,>50为超差)⑷计算各元素的合格率η= (抽查样品中合格的样品数/抽查样品的总数)100%合格率(η)应>80%,即这批样品的分析结果是可信的。
⑸列表表示检查或分析质量结果表××化探重采样抽查各元素的合格率(%)Cu Pb Zn Cr Ni Co Sn V Ag Ti2 矿区地球化学特征研究的数据处理(以哈拉街吐为例)⑴作出SSPS数据文件作出下列SSPS数据文件:①文件1:整个矿区数据文件;②文件2:矿区地层数据文件;③文件3:矿区岩浆岩数据文件;④文件4 :下二叠统大石寨组(P1d)数据文件;⑤文件5 :下白垩统大磨拐河含煤组(K1d)数据文件;⑥文件6 :华力西晚期侵入岩数据文件;⑦文件7 :燕山期早期侵入岩数据文件;⑧文件8 :燕山期晚期侵入岩数据文件;⑨文件9:已知矿附近一定范围数据文件每一数据文件的内容项目包括:序号野外号 X坐标 Y坐标各元素的含量⑵整个矿区和各地质单元(各地层、各岩浆岩)样品各元素含量特征统计统计的参数包括:①元素含量平均值;②最大值;③最小值;④标准离差;⑤变化系数(标准离差/含量平均值);⑥浓度克拉克值(元素含量平均值/该元素的克拉克值)整个矿区和各地质单元统计结果含量平均值、最小值、最大值用表表示。
化探数据处理⽅法与步骤
⼀、化探数据计算
1、⾸先从⽹上下载Surfer软件
2、将Excel数据转换为CSV(逗号分隔)格式
3、⽤surfer软件将数据打开
4、选中单元素数据,⽤统计功能计算出数据平均值及标准偏差(弹出选项⽤默认即可)
5、采⽤统计出的平均值与标准偏差计算背景值与异常下限:
①⾸先剔除异常⾼值与异常低值,使数据服从正态分布
⽅法:剔除⼤于或者⼩于“平均值±3*标准偏差”的数据,⽤迭代法反复剔除
如:Cu,第⼀次统计结果平均值为27.51,标准偏差36.57
剔除⼤于137.22的数据以后;再次统计得出平均值26.09;标准偏差9.536;同理,再次对数据进⾏剔除,直到不再出现⼤于或者⼩于“平均值±3*标准偏差”的数,最终得出:Cu 平均值24.81;标准偏差6.392。
②此时的平均值即为背景值(取整为25),可⽤“平均值+ 2*标准偏差”作为异常下限。
⼆、作图
作图采⽤原始数据(未剔除异常⾼值与异常低值数据)
⽤Mapgis空间分析,DTM分析
1、⾸先对离散数据⽹格化
X/Y对应经纬度公⾥⽹值,Z对应单元素异常值
⽹络参数设置对应盟铺马幅左下和右上坐标,如图设置其它设置如图,确定保存即可
2、平⾯等值线绘制
①菜单栏中选择平⾯等值线绘制,如图
②选择刚才保存的CU.GRD⽂件(⽹格化⽂件)
等值线值从最⼩值形始设置,⼀般设5-6阶,要单独把背景值,异常下限值标⽰出来,如Cu:背景值25,异常下限37,其它设置如图所⽰,不同元素⽤不同颜⾊表⽰,保存即可。
.
采⽤误差校正,使异常图与5万图幅套合即可,作图例等修饰。
内蒙古扎赉特旗东芒合矿和哈拉街吐矿化探数据处理及图件编制方法1 化探数据质量评价的数据处理(分矿区)⑴统计重采样和重分析抽查样所占样品总数的比例比例 = (重采样和重分析抽查样数/工作样总数)100%⑵作出SSPS数据文件将重采样和重分析样分别作成SSPS数据文件。
文件中列出项目为:①重采抽查样重采样号元素含量相应的工作样号元素含量②重分析抽查样重分析样号元素含量相应的工作样号元素含量⑶计算各元素相对误差重采样和重分析抽查样相对误差均按RE(%) = |C1-C2|/0.5×(C1+C2)×100%计算。
C1为重采样或重分析抽查样的分析含量C2为重采样或重分析抽查样的相应的工作样的分析含量| |为绝对值RE(%)≤30%为合格,>30为超差(不合格);(Au:RE(%)≤50%为合格,>50为超差)⑷计算各元素的合格率η= (抽查样品中合格的样品数/抽查样品的总数)100%合格率(η)应>80%,即这批样品的分析结果是可信的。
⑸列表表示检查或分析质量结果表××化探重采样抽查各元素的合格率(%)Cu Pb Zn Cr Ni Co Sn V Ag Ti2 矿区地球化学特征研究的数据处理(以哈拉街吐为例)⑴作出SSPS数据文件作出下列SSPS数据文件:①文件1:整个矿区数据文件;②文件2:矿区地层数据文件;③文件3:矿区岩浆岩数据文件;④文件4 :下二叠统大石寨组(P1d)数据文件;⑤文件5 :下白垩统大磨拐河含煤组(K1d)数据文件;⑥文件6 :华力西晚期侵入岩数据文件;⑦文件7 :燕山期早期侵入岩数据文件;⑧文件8 :燕山期晚期侵入岩数据文件;⑨文件9:已知矿附近一定范围数据文件每一数据文件的内容项目包括:序号野外号 X坐标 Y坐标各元素的含量⑵整个矿区和各地质单元(各地层、各岩浆岩)样品各元素含量特征统计统计的参数包括:①元素含量平均值;②最大值;③最小值;④标准离差;⑤变化系数(标准离差/含量平均值);⑥浓度克拉克值(元素含量平均值/该元素的克拉克值)整个矿区和各地质单元统计结果含量平均值、最小值、最大值用表表示。
⑶整个矿区和各地质单元样品各元素的概率分布特征统计①标准离差②峰度③偏度④概率分布曲线特征⑷矿区各地层样品各元素的局域丰度和蚀变-矿化叠加系数特征统计根据地球化学过程的基本定律(A.B.Vstelius,1960),一个矿区地层中元素的“丰度”应该是沉积岩沉积成岩时的初始平均含量,而不应包括后期岩浆、蚀变、矿化作用等地质作用造成的元素含量的增赢或亏损。
而矿区内局部地区地层中元素的“局域丰度”,至少应排除最后蚀变-成矿作用叠加的那一部分元素的含量。
若本区各地层中元素概率分布及其偏度和峰度特征表明元素呈偏对数正态分布。
这说明地层中多数元素都受到了后期不同程度的蚀变-成矿作用的叠加。
据此,剔除了不服从正态分布的超差样品(即含量大于或等于元素的平均值加上2倍标准离差(c+2δ)的那些样品)后,再求出的元素含量平均数即为本区各地层中元素的“局域丰度”(x)。
该局域丰度可被认为是本区各地层在区域沉积作用(包括海底喷气喷流、热水沉积作用等)的元素平均含量。
而该区各地层元素的平均值(c)则是在局域丰度的基础上叠加了岩浆、蚀变-矿化作用后的平均含量。
用克拉克值除以局域丰度(x/克值)所得的浓集系数称为初始浓集系数(k 0),反映了沉积作用对元素的初步聚集程度;用局域丰度除以平均值(c/x) 所得的浓集系数称为局域蚀变-矿化叠加系数(k),反映了本区地层形成后遭受的矿化强度。
因此k 0和k可作为评价地层含矿性的参数。
统计结果可用下表表示:表××哈拉街吐矿区下二叠统中微量元素的平均值(c)、局域丰度(x)、初始浓集系数(k 0)和蚀变-矿化叠加系数(k)-9-6表××哈拉街吐矿区下白垩统中微量元素的平均值(c)、局域丰度(x)、初始浓集系数(k 0)和蚀变-矿化叠加系数(k)-9-6⑸整个矿区和各地质单元样品各元素的相关关系特征统计作出整个矿区和各地质单元样品各元素的相关矩阵⑹整个矿区和各地质单元样品各元素的聚类特征统计作出整个矿区和各地质单元样品各元素的R型聚类图3 矿区单元素地球化学异常的数据处理和成图⑴背景值和异常下限值的确定地质地球化学观察法和统计法相结合确定。
①在全区数据表上观察,一般含量的中间值确定为背景值(C0);②高于背景值3~5倍的数据确定为异常下限值(C a);③统计某一元素≥异常下限值的样品的个数占总样品数的百分数,一般主要成矿元素异常下限值的样品所占的百分数为30%左右。
④根据元素的概率分布曲线特征,若分布曲线为对称对数正态分布,取正态分布曲线的中值作为背景值,取背景值+2×标准离差(C0+2δ)作为异常下限;若分布曲线为不对称对数正态分布,则将全区数据去掉大于标准离差的数据后,再作概率分布曲线,直至出现对称对数正态分布,这时再正态分布曲线的中值作为背景值,取背景值+2×标准离差作为异常下限。
⑤根据地质地球化学观察法和统计法相结合正确确定背景值和异常下限值。
⑵编制全区单元素含量等值线图等值线间隔按实际情况适宜确定⑶编制全区单元素异常图将等值线的间隔设为异常下限值(1 C a)、2倍异常下限值(2 C a)、4倍异常下限值(4 C a),每间隔间充填适当的颜色,即为异常图。
⑷单元素异常图的整饰每张图可放置2~3个单元素异常图。
4 矿区综合地球化学异常的数据处理和成图⑴共生元素累加和异常图的编制①共生累加元素的选择综合矿区元素相关分析、聚类分析、因子分析等获得的信息及元素地球化学习性,选择有较密切共生关系元素的含量相加,作为综合指标圈定异常图,此时的背景值、异常下限值要重新求取。
②编图方法以求得的几个元素含量的和成图,方法同单元素成图,可作出综合等值线图或综合异常图。
⑵对抗元素(累加)商异常图的编制①对抗(累加)商元素的选择综合矿区元素相关分析、聚类分析、因子分析等获得的信息及元素地球化学习性,选择有明显对抗关系的元素,求其商,作为综合指标圈定异常图,此时的背景值、异常下限值要重新求取。
②编图方法以求得的元素含量的商成图,方法同单元素成图,可作出综合等值线图或综合异常图。
⑶单元素趋势剩余值异常图的编制①趋势剩余值数字化处理过程趋势剩余值数字化及成图方法简述如下:经趋势分析处理的采样点上元素含量Z将被分解成3个基本分量:趋势分量Z i、异常分量A I和随机分量L i,即Z = Z i+T i或Z = Z i+A I+L i趋势分量Z i由区域构造、地层、岩浆岩等因素引起,反映了区域因素引起的元素的含量变化,这种变化往往代表来自多重母体不同背景的起伏变化,实际上反映了元素含量的背景部分。
异常分量A i由局域范围的矿化作用、特殊的岩性或地球化学异常引起。
在趋势分析中,用其剩余值(残差值)T i表示局部因素引起的元素含量变化。
剩余值T i 和趋势值不同,它的变化是不连续的,代表了元素的异常部分。
有时为了进一步突出异常,又将剩余值T i分解为异常分量A I和随机分量L i。
随机分量L i有可能由采样、样品加工、分析等偶然误差因素造成。
本次处理的数据主要在矿田范围内及其周边,目的是要突出地球化学异常,故采用趋势分析的剩余值成图。
趋势分析通常是在二维空间进行的。
每一采样点上元素的含量Z和地理坐标之间存在着函数关系,即Z = f(x,y)趋势分析的任务就是导出函数f(x,y)的一个多项式去拟合或逼近元素含量的观察值。
函数f(x,y)的一次、二次、三次等多项式(趋势面方程)为:Z i = a0+a1x i+a2y i+a3x i y iZ i = a0+a1x i+a2y i+a3x i y i+a4x i2+a5y i2Z i = a0+a1x i+a2y i+a3x i y i+a4x i2y+a5xy i2+a6x i3+a7y i3式中,Z i是各采样点或元素含量Z的预测值,或者说用Z i去拟合实际的元素的含量Z,Z i 就是所谓趋势分量。
a0、a1、a2、a3、a4、a5……等待定系数须用最小二乘法原理求取,最小二乘法可使多项式中的误差波动达到极小,也就是使趋势值Z i更好地逼近元素的含量Z。
求取各采样点元素含量的趋势值Z i后,即可用每点的实际元素含量Z减去该点的趋势值Z i求得每点的剩余值T i。
即T i = Z - Z i剩余值为负值的,计为零。
根据每点所求得的剩余值T i即可绘出剩余值等值线图。
趋势面方程阶数的选择在数学理论上是应以求出的趋势值Z i最为逼近观察值Z,即拟合度最大为宜。
拟合度以趋势面上的变差占总变差的百分比来表示。
但在实际成图过程中,拟合度的选择要充分考虑化探工作的目的和工作区地质构造及矿化分布等情况,拟合度过高,剩余异常就少了。
一般区域化探拟合度选择为20%。
由于本次工作的目的是突出矿区的剩余异常,拟合度的选择为15%左右。
②编图方法以求得的每个元素含量的趋势剩余值T i成图,方法同单元素成图,作出综合等值线图即可。
⑷单元素值因子得分异常图的编制①因子得分数字化处理过程因子得分数字化及成图方法简述如下:化探样品的多元素分析数据(变量)之间存在一定的相关关系,因此有可能用较少的综合指标反映各变量中的各类信息,而各综合指标之间彼此不相关,就是说其所代表的信息不重叠,这种数理统计方法称为因子分析。
代表各类信息的综合指标称为因子或主成分。
具体的程序是:①通过对原始数据变量(元素含量)的相关分析结果,进行初始因子的提取并获取碎石图信息和因子负荷矩阵;②在此基础上选择一定的方法进行因子旋转并获取旋转后的因子负荷矩阵和因子转换矩阵;③建立起因子得分系数矩阵和回归因子分数的协方差矩阵(以考察旋转后的因子是否仍然正交);④根据因子得分系数导出每个因子得分的计算方程式;⑤将每一采样点的各个原始变量(元素含量)代入因子得分的计算式,求出每一采样点各因子得分值;⑥根据每一采样点各因子得分值编制因子得分等值线图。
如某矿区次生晕数据因子分析根据原始数据相关分析结果,初始因子采用主成分分析法提取公因子,初始分析结果和因子碎石图(图1)表明:第1初始因子和第2初始因子之间、第6初始因子和第7初始因子之间特征值差值较大,第3、第4、第5、第6初始因子相互之间特征值差值较小,因此可以初步得出提取3个综合因子将能得出概括出各元素数据所反映的大部分的信息的认识。
因子旋转使用Varimax法(方差最大旋转法),经3次迭代收敛,得出的旋转后的因子负荷系数矩阵(表1)表明:经旋转后3个综合因子负荷系数对各原始变量(元素)的绝对值有较大的差别。
第1因子(F1)对Pb、Zn有绝对值较大的负荷因子,第2因子(F2)对As、F有绝对值较大的负荷因子,第3因子(F3)对Sn有绝对值较大的负荷因子。