2012年数学建模之遗传算法(改进与应用)
- 格式:ppt
- 大小:1.25 MB
- 文档页数:63

遗传算法的改进与应用遗传算法是一种模拟自然进化过程并求解最优解的计算方法。
它主要受到遗传学中的基因进化和自然选择的启发,模拟生物群体中个体之间的竞争、选择和繁殖过程,从而使种群逐步趋向最优解。
遗传算法的基本工作原理是以一定的适应度函数作为评价标准,在一个种群中不断地评估每个个体的适应度并进行复制、交叉、变异等操作,产生下一代群体。
通过不断地迭代求解,最终找到适应度函数达到最大值或最小值的优化解。
这种算法被广泛应用于函数优化、组合优化、动态优化、多目标优化等众多领域。
然而,遗传算法有其局限性和不足之处。
其中,算法本身的收敛速度较慢是被广泛诟病的问题之一。
在实际应用中,为了提升算法的收敛速度和精度,人们对遗传算法进行了各种修改和改进。
例如,基于分布式的遗传算法(DGA)将一个单点交叉操作改进为多点交叉,有效地提升了算法的搜索能力。
与此类似地,基于强化学习的遗传算法(RLGA)使用强化学习提高了算法的局部搜索能力,以更快地找到全局最优解。
此外,遗传算法还可以与其他算法结合使用,形成混合优化算法。
例如,粒子群算法(PSO)和遗传算法的结合使用,既保留了遗传算法的全局搜索特性,又充分发挥了PSO算法的速度快、精度高的特点。
除此之外,遗传算法可以应用于很多领域。
在工程领域,遗传算法常被应用于优化设计问题、机器人路径规划和信号处理等问题。
在经济领域,遗传算法可用于个人理财规划、股票投资策略的优化等问题。
在人工智能领域,遗传算法被用于构建深度学习模型、自然语言处理、图像识别等等。
总的来说,虽然遗传算法存在局限性,但它已经被证明是一种非常优秀、有效的优化算法。
随着新的技术和方法的不断出现,遗传算法的效率和精度将继续提高。
未来,这种算法将被广泛应用于更多的领域,并发挥出更强大的威力。

遗传算法及其应用实例遗传算法搜索最优解的方法是模仿生物的进化过程,即通过选择与染色体之间的交叉和变异来完成的。
遗传算法主要使用选择算子、交叉算子与变异算子来模拟生物进化,从而产生一代又一代的种群X (t )。
1.遗传算法的简单原理遗传算法(Genetic Algorithm, GA)是一种基于自然群体遗传演化机制的高效探索算法,它摒弃了传统的搜索方式,模拟自然界生物进化过程,采用人工进化的方式对目标空间进行随机化搜索。
它将问题域中的可能解看作是群体的一个个体或染色体,并将每一个体编码成符号串形式,模拟达尔文的遗传选择和自然淘汰的生物进化过程,对群体反复进行基于遗传学的操作(遗传,交叉和变异),根据预定的目标适应度函数对每个个体进行评价,依据适者生存,优胜劣汰的进化规则,不断得到更优的群体,同时以全局并行搜索方式来搜索优化群体中的最优个体,求得满足要求的最优解。
遗传算法主要是用来寻优,它具有很多优点:它能有效地避免局部最优现象,有及其顽强的鲁棒性,并且在寻优过程中,基本不需要任何搜索空间的知识和其他辅助信息等等。
利用遗传算法,可以解决很多标准优化算法解决不了的优化问题,其中包括目标函数不连续、不可微、高度非线性或随机的优化问题。
(1)选择算子:是模拟自然选择的操作,反映“优胜劣汰”原理。
它根据每一个个体的适应度,按照一定规则或方法,从t代种群X (t )中选择出一些优良的个体(或作为母体,或让其遗传到下一代种群X (t 1))。
(2)交叉算子:是模拟有性繁殖的基因重组操作,它将从种群X (t )所选择的每一对母体,以一定的交叉概率交换它们之间的部分基因。
(3)变异算子:是模拟基因突变的遗传操作,它对种群X (t )中的每一个个体,以一定的变异概率改变某一个或某一些基因座上的基因值为其他的等位基因。
交叉算子与变异算子的作用都在于重组染色体基因,以生成新的个体。
遗传算法的运算过程如下:步 1(初始化)确定种群规模 N ,交叉概率 P c ,变异概率 P m 和终止进化准则;随机生成 N 个个体作为初始种群 X (0);置 t ← 0。

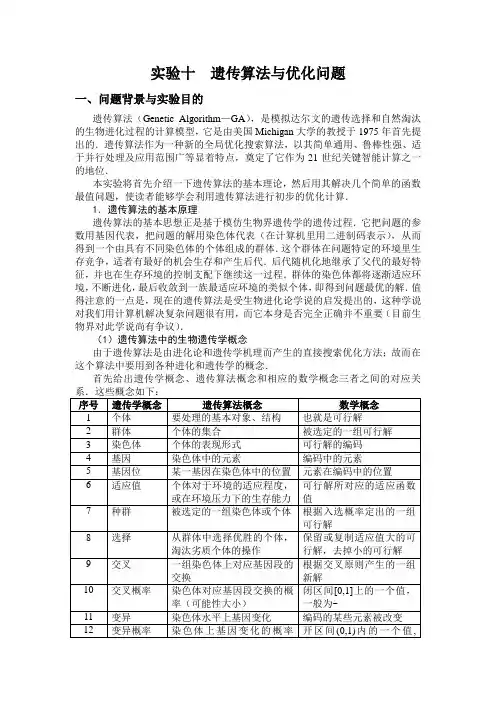
实验十遗传算法与优化问题一、问题背景与实验目的遗传算法(Genetic Algorithm—GA),是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,它是由美国Michigan大学的教授于1975年首先提出的.遗传算法作为一种新的全局优化搜索算法,以其简单通用、鲁棒性强、适于并行处理及应用范围广等显着特点,奠定了它作为21世纪关键智能计算之一的地位.本实验将首先介绍一下遗传算法的基本理论,然后用其解决几个简单的函数最值问题,使读者能够学会利用遗传算法进行初步的优化计算.1.遗传算法的基本原理遗传算法的基本思想正是基于模仿生物界遗传学的遗传过程.它把问题的参数用基因代表,把问题的解用染色体代表(在计算机里用二进制码表示),从而得到一个由具有不同染色体的个体组成的群体.这个群体在问题特定的环境里生存竞争,适者有最好的机会生存和产生后代.后代随机化地继承了父代的最好特征,并也在生存环境的控制支配下继续这一过程.群体的染色体都将逐渐适应环境,不断进化,最后收敛到一族最适应环境的类似个体,即得到问题最优的解.值得注意的一点是,现在的遗传算法是受生物进化论学说的启发提出的,这种学说对我们用计算机解决复杂问题很有用,而它本身是否完全正确并不重要(目前生物界对此学说尚有争议).(1)遗传算法中的生物遗传学概念由于遗传算法是由进化论和遗传学机理而产生的直接搜索优化方法;故而在这个算法中要用到各种进化和遗传学的概念.首先给出遗传学概念、遗传算法概念和相应的数学概念三者之间的对应关遗传算法计算优化的操作过程就如同生物学上生物遗传进化的过程,主要有三个基本操作(或称为算子):选择(Selection)、交叉(Crossover)、变异(Mutation).遗传算法基本步骤主要是:先把问题的解表示成“染色体”,在算法中也就是以二进制编码的串,在执行遗传算法之前,给出一群“染色体”,也就是假设的可行解.然后,把这些假设的可行解置于问题的“环境”中,并按适者生存的原则,从中选择出较适应环境的“染色体”进行复制,再通过交叉、变异过程产生更适应环境的新一代“染色体”群.经过这样的一代一代地进化,最后就会收敛到最适应环境的一个“染色体”上,它就是问题的最优解.下面给出遗传算法的具体步骤,流程图参见图1:第一步:选择编码策略,把参数集合(可行解集合)转换染色体结构空间;第二步:定义适应函数,便于计算适应值;第三步:确定遗传策略,包括选择群体大小,选择、交叉、变异方法以及确定交叉概率、变异概率等遗传参数;第四步:随机产生初始化群体;第五步:计算群体中的个体或染色体解码后的适应值;第六步:按照遗传策略,运用选择、交叉和变异算子作用于群体,形成下一代群体;第七步:判断群体性能是否满足某一指标、或者是否已完成预定的迭代次数,不满足则返回第五步、或者修改遗传策略再返回第六步.图1 一个遗传算法的具体步骤遗传算法有很多种具体的不同实现过程,以上介绍的是标准遗传算法的主要步骤,此算法会一直运行直到找到满足条件的最优解为止.2.遗传算法的实际应用例1:设2()20.5f x x x =-++,求 max (), [1,2]f x x ∈-.注:这是一个非常简单的二次函数求极值的问题,相信大家都会做.在此我们要研究的不是问题本身,而是借此来说明如何通过遗传算法分析和解决问题.在此将细化地给出遗传算法的整个过程.(1)编码和产生初始群体首先第一步要确定编码的策略,也就是说如何把1-到2这个区间内的数用计算机语言表示出来.编码就是表现型到基因型的映射,编码时要注意以下三个原则:完备性:问题空间中所有点(潜在解)都能成为GA 编码空间中的点(染色体位串)的表现型;健全性:GA 编码空间中的染色体位串必须对应问题空间中的某一潜在解; 非冗余性:染色体和潜在解必须一一对应.这里我们通过采用二进制的形式来解决编码问题,将某个变量值代表的个体表示为一个{0,1}二进制串.当然,串长取决于求解的精度.如果要设定求解精度到六位小数,由于区间长度为2(1)3--=,则必须将闭区间 [1,2]-分为6310⨯等分.因为216222097152231024194304=<⨯<= 所以编码的二进制串至少需要22位.将一个二进制串(b 21b 20b 19…b 1b 0)转化为区间[1,2]-内对应的实数值很简单,只需采取以下两步(Matlab 程序参见附录4):1)将一个二进制串(b 21b 20b 19…b 1b 0)代表的二进制数化为10进制数: 2)'x 对应的区间[1,2]-内的实数:例如,一个二进制串a=<1>表示实数.'x =(1)2=2288967二进制串<0000000000000000000000>,<1>,则分别表示区间的两个端点值-1和2.利用这种方法我们就完成了遗传算法的第一步——编码,这种二进制编码的方法完全符合上述的编码的三个原则.首先我们来随机的产生一个个体数为4个的初始群体如下:pop(1)={<0>, %% a1<001000010>, %% a2<000000000>, %% a3<0>} %% a4(Matlab 程序参见附录2)化成十进制的数分别为:pop(1)={ , , , }接下来我们就要解决每个染色体个体的适应值问题了.(2)定义适应函数和适应值由于给定的目标函数2()20.5f x x x =-++在[1,2]-内的值有正有负,所以必须通过建立适应函数与目标函数的映射关系,保证映射后的适应值非负,而且目标函数的优化方向应对应于适应值增大的方向,也为以后计算各个体的入选概率打下基础.对于本题中的最大化问题,定义适应函数()g x ,采用下述方法:式中min F 既可以是特定的输入值,也可以是当前所有代或最近K 代中()f x 的最小值,这里为了便于计算,将采用了一个特定的输入值.若取min 1F =-,则当()1f x =时适应函数()2g x =;当() 1.1f x =-时适应函数()0g x =.由上述所随机产生的初始群体,我们可以先计算出目标函数值分别如下(Matlab 程序参见附录3):f [pop(1)]={ , , , }然后通过适应函数计算出适应值分别如下(Matlab 程序参见附录5、附录6): 取min 1F =-,g[pop(1)]= { , , 0 , }(3)确定选择标准这里我们用到了适应值的比例来作为选择的标准,得到的每个个体的适应值比例叫作入选概率.其计算公式如下:对于给定的规模为n 的群体pop={123,,,,n a a a a L },个体i a 的适应值为()i g a ,则其入选概率为由上述给出的群体,我们可以计算出各个个体的入选概率.首先可得 41() 6.478330ii g a ==∑, 然后分别用四个个体的适应值去除以41()i i g a =∑,得:P (a 1)= / = %% a 1P (a 2)= / = %% a 2P (a 3)= 0 / = 0 %% a 3P (a 4)= / = %% a 4(Matlab 程序参见附录7)(4)产生种群计算完了入选概率后,就将入选概率大的个体选入种群,淘汰概率小的个体,并用入选概率最大的个体补入种群,得到与原群体大小同样的种群(Matlab 程序参见附录8、附录11).要说明的是:附录11的算法与这里不完全相同.为保证收敛性,附录11的算法作了修正,采用了最佳个体保存方法(elitist model ),具体内容将在后面给出介绍.由初始群体的入选概率我们淘汰掉a 3,再加入a 2补足成与群体同样大小的种群得到newpop(1)如下:newpop(1)={<0>, %% a 1<001000010>, %% a 2<001000010>, %% a 2<0>} %% a 4(5)交叉交叉也就是将一组染色体上对应基因段的交换得到新的染色体,然后得到新的染色体组,组成新的群体(Matlab程序参见附录9).我们把之前得到的newpop(1)的四个个体两两组成一对,重复的不配对,进行交叉.(可以在任一位进行交叉)<0 >,<001000010>交叉得:<0 >,<0><0 01000010>,<0>交叉得:<0 >,<001000010>通过交叉得到了四个新个体,得到新的群体jchpop (1)如下:jchpop(1)={<001000010>,<0>,<0>,<001000010>}这里采用的是单点交叉的方法,当然还有多点交叉的方法,不过有些烦琐,这里就不着重介绍了.(6)变异变异也就是通过一个小概率改变染色体位串上的某个基因(Matlab程序参见附录10).现把刚得到的jchpop(1)中第3个个体中的第9位改变,就产生了变异,得到了新的群体pop(2)如下:pop(2)= {<001000010>,<0>,<0>,<001000010> }然后重复上述的选择、交叉、变异直到满足终止条件为止.(7)终止条件遗传算法的终止条件有两类常见条件:(1)采用设定最大(遗传)代数的方法,一般可设定为50代,此时就可能得出最优解.此种方法简单易行,但可能不是很精确(Matlab程序参见附录1);(2)根据个体的差异来判断,通过计算种群中基因多样性测度,即所有基因位相似程度来进行控制.3.遗传算法的收敛性前面我们已经就遗传算法中的编码、适应度函数、选择、交叉和变异等主要操作的基本内容及设计进行了详细的介绍.作为一种搜索算法,遗传算法通过对这些操作的适当设计和运行,可以实现兼顾全局搜索和局部搜索的所谓均衡搜索,具体实现见下图2所示.图2 均衡搜索的具体实现图示应该指出的是,遗传算法虽然可以实现均衡的搜索,并且在许多复杂问题的求解中往往能得到满意的结果,但是该算法的全局优化收敛性的理论分析尚待解决.目前普遍认为,标准遗传算法并不保证全局最优收敛.但是,在一定的约束条件下,遗传算法可以实现这一点.下面我们不加证明地罗列几个定理或定义,供读者参考(在这些定理的证明中,要用到许多概率论知识,特别是有关马尔可夫链的理论,读者可参阅有关文献).定理 1 如果变异概率为)1,0(∈m P ,交叉概率为]1,0[∈c P ,同时采用比例选择法(按个体适应度占群体适应度的比例进行复制),则标准遗传算法的变换矩阵P 是基本的.定理2 标准遗传算法(参数如定理1)不能收敛至全局最优解.由定理2可以知道,具有变异概率)1,0(∈m P ,交叉概率为]1,0[∈c P 以及按比例选择的标准遗传算法是不能收敛至全局最最优解.我们在前面求解例1时所用的方法就是满足定理1的条件的方法.这无疑是一个令人沮丧的结论.然而,庆幸的是,只要对标准遗传算法作一些改进,就能够保证其收敛性.具体如下:我们对标准遗传算法作一定改进,即不按比例进行选择,而是保留当前所得的最优解(称作超个体).该超个体不参与遗传.最佳个体保存方法(elitist model )的思想是把群体中适应度最高的个体不进行配对交叉而直接复制到下一代中.此种选择操作又称复制(copy ).De Jong 对此方法作了如下定义:定义 设到时刻t (第t 代)时,群体中a *(t )为最佳个体.又设A (t +1)为新一代群体,若A (t +1)中不存在a *(t ),则把a *(t )作为A (t +1)中的第n +1个个体(其中,n 为群体大小)(Matlab 程序参见附录11).采用此选择方法的优点是,进化过程中某一代的最优解可不被交叉和变异操作所破坏.但是,这也隐含了一种危机,即局部最优个体的遗传基因会急速增加而使进化有可能限于局部解.也就是说,该方法的全局搜索能力差,它更适合单峰性质的搜索空间搜索,而不是多峰性质的空间搜索.所以此方法一般都与其他选择方法结合使用.定理3 具有定理1所示参数,且在选择后保留当前最优值的遗传算法最终能收敛到全局最优解.当然,在选择算子作用后保留当前最优解是一项比较复杂的工作,因为该解在选择算子作用后可能丢失.但是定理3至少表明了这种改进的遗传算法能够收敛至全局最优解.有意思的是,实际上只要在选择前保留当前最优解,就可以保证收敛,定理4描述了这种情况.定理4 具有定理1参数的,且在选择前保留当前最优解的遗传算法可收敛于全局最优解.例2:设2()3f x x x =-+,求 max (), [0,2]f x x ∈,编码长度为5,采用上述定理4所述的“在选择前保留当前最优解的遗传算法”进行.此略,留作练习.二、相关函数(命令)及简介本实验的程序中用到如下一些基本的Matlab 函数:ones, zeros, sum, size, length, subs, double 等,以及 for, while 等基本程序结构语句,读者可参考前面专门关于Matlab 的介绍,也可参考其他数学实验章节中的“相关函数(命令)及简介”内容,此略.三、实验内容上述例1的求解过程为:群体中包含六个染色体,每个染色体用22位0—1码,变异概率为,变量区间为[1,2]-,取Fmin=2-,遗传代数为50代,则运用第一种终止条件(指定遗传代数)的Matlab程序为:[Count,Result,BestMember]=Genetic1(22,6,'-x*x+2*x+',-1,2,-2,,50)执行结果为:Count =50Result =BestMember =图2 例1的计算结果(注:上图为遗传进化过程中每一代的个体最大适应度;而下图为目前为止的个体最大适应度——单调递增)我们通过Matlab软件实现了遗传算法,得到了这题在第一种终止条件下的最优解:当x取时,Max () 1.4990f x=.当然这个解和实际情况还有一点出入(应该是x取1时,Max () 1.5000f x=),但对于一个计算机算法来说已经很不错了.我们也可以编制Matlab程序求在第二种终止条件下的最优解.此略,留作练习.实践表明,此时的遗传算法只要经过10代左右就可完成收敛,得到另一个“最优解”,与前面的最优解相差无几.四、自己动手1.用Matlab编制另一个主程序,求例1的在第二种终止条件下的最优解.提示:一个可能的函数调用形式以及相应的结果为:[Count,Result,BestMember]=Genetic2(22,6,'-x*x+2*x+',-1,2,-2,,Count =13Result =BestMember =可以看到:两组解都已经很接近实际结果,对于两种方法所产生的最优解差异很小.可见这两种终止算法都是可行的,而且可以知道对于例1的问题,遗传算法只要经过10代左右就可以完成收敛,达到一个最优解.2.按照例2的具体要求,用遗传算法求上述例2的最优解.3.附录9子程序中的第3行到第7行为注解语句.若去掉前面的%号,则程序的算法思想有什么变化?4.附录9子程序 中的第8行至第13行的程序表明,当Dim(1)>=3时,将交换数组Population 的最后两行,即交换最后面的两个个体.其目的是什么?5.仿照附录10子程序,修改附录9子程序 ,使得交叉过程也有一个概率值(一般取~);同时适当修改主程序或主程序,以便代入交叉概率.6.设2()41f x x x =--+,求 max (), [2,2]f x x ∈-,要设定求解精度到15位小数.五、附录附录1:主程序function[Count,Result,BestMember]=Genetic1(MumberLength,MemberNumber,FunctionFitn ess,MinX,MaxX,Fmin,MutationProbability,Gen)Population=PopulationInitialize(MumberLength,MemberNumber);global Count;global CurrentBest;Count=1;PopulationCode=Population;PopulationFitness=Fitness(PopulationCode,FunctionFitness,MinX,MaxX,Mumbe rLength);PopulationFitnessF=FitnessF(PopulationFitness,Fmin);PopulationProbability=Probability(PopulationFitnessF);[Population,CurrentBest,EachGenMaxFitness]=Elitist(PopulationCode,Populatio nFitness,MumberLength);EachMaxFitness(Count)=EachGenMaxFitness;MaxFitness(Count)=CurrentBest(length(CurrentBest));while Count<GenNewPopulation=Select(Population,PopulationProbability,MemberNumber); Population=NewPopulation;NewPopulation=Crossing(Population,FunctionFitness,MinX,MaxX,MumberLength);Population=NewPopulation;NewPopulation=Mutation(Population,MutationProbability);Population=NewPopulation;PopulationFitness=Fitness(Population,FunctionFitness,MinX,MaxX,MumberLength);PopulationFitnessF=FitnessF(PopulationFitness,Fmin);PopulationProbability=Probability(PopulationFitnessF);Count=Count+1;[NewPopulation,CurrentBest,EachGenMaxFitness]=Elitist(Population,PopulationFitn ess,MumberLength);EachMaxFitness(Count)=EachGenMaxFitness;;MaxFitness(Count)=CurrentBest(length(CurrentBest));Population=NewPopulation;endDim=size(Population);Result=ones(2,Dim(1));for i=1:Dim(1)Result(1,i)=Translate(Population(i,:),MinX,MaxX,MumberLength);endResult(2,:)=PopulationFitness;BestMember(1,1)=Translate(CurrentBest(1:MumberLength),MinX,MaxX,Mumb erLength);BestMember(2,1)=CurrentBest(MumberLength+1);close allsubplot(211)plot(EachMaxFitness)subplot(212)plot(MaxFitness)【程序说明】主程序包含了8个输入参数:(1) MumberLength : 表示一个染色体位串的二进制长度.(例1中取22)(2) MemberNumber : 表示群体中染色体的个数.(例1中取6个)(3) FunctionFitness : 表示目标函数,是个字符串,因此用表达式时,用单引号括出.(例1中是2()20.5f x x x =-++)(4) MinX : 变量区间的下限.(例1中是[1,2]-中的)(5) MaxX : 变量区间的上限.(例1中是[1,2]-中的 2)(6) Fmin : 定义适应函数过程中给出的一个目标函数的可能的最小值,由操作者自己给出.(例1中取Fmin=2-)(7) MutationProbability : 表示变异的概率,一般都很小.(例1中取)(8) Gen : 表示遗传的代数,也就是终止程序时的代数.(例1中取50) 另外,主程序包含了3个输出值: Count 表示遗传的代数;Result 表示计算的结果,也就是最优解;BestMember 表示最优个体及其适应值.附录2:子程序function Population=PopulationInitialize(MumberLength,MemberNumber) Temporary=rand(MemberNumber,MumberLength);Population=(Temporary>=*ones(size(Temporary)));【程序说明】子程序 用于产生一个初始群体.这个初始群体含有MemberNumber 个染色体,每个染色体有MumberLength 个基因(二进制码).附录3:子程序function PopulationFitness=Fitness(PopulationCode,FunctionFitness,MinX,MaxX,MumberLength)Dim=size(PopulationCode);PopulationFitness=zeros(1,Dim(1));for i=1:Dim(1)PopulationFitness(i)=Transfer(PopulationCode(i,:),FunctionFitness,MinX,MaxX,MumberLength);end【程序说明】子程序用于计算群体中每一个染色体的目标函数值.子程序中含有5个输入参数:PopulationCode表示用0—1代码表示的群体,FunctionFitness 表示目标函数,它是一个字符串,因此写入调用程序时,应该用单引号括出,MumberLength表示染色体位串的二进制长度.MinX和MaxX 分别指变量区间的上下限.附录4:子程序function PopulationData=Translate(PopulationCode,MinX,MaxX,MumberLength) PopulationData=0;Dim=size(PopulationCode);for i=1:Dim(2)PopulationData=PopulationData+PopulationCode(i)*(2^(MumberLength-i));endPopulationData=MinX+PopulationData*(MaxX-MinX)/(2^Dim(2)-1);【程序说明】子程序把编成码的群体翻译成变量的数值.含有4个输入参数,PopulationCode, MinX, MaxX, MumberLength.附录5:子程序function PopulationFitness=Transfer(PopulationCode,FunctionFitness,MinX,MaxX,MumberLength) PopulationFitness=0;PopulationData=Translate(PopulationCode,MinX,MaxX,MumberLength);PopulationFitness=double(subs(FunctionFitness,'x',sym(PopulationData)));【程序说明】子程序Transfer 把群体中的染色体的目标函数值用数值表示出来,它是Fitness的重要子程序.其有5个输入参数分别为PopulationCode, FunctionFitness, MinX, MaxX,MumberLength.附录6:子程序function PopulationFitnessF=FitnessF(PopulationFitness,Fmin)Dim=size(PopulationFitness);PopulationFitnessF=zeros(1,Dim(2));for i=1:Dim(2)if PopulationFitness(i)>FminPopulationFitnessF(i)=PopulationFitness(i)-Fmin;endif PopulationFitness(i)<=FminPopulationFitnessF(i)=0;endend【程序说明】子程序是用于计算每个染色体的适应函数值的.其输入参数如下:PopulationFitness 为群体中染色体的目标函数值,Fmin为定义适应函数过程中给出的一个目标函数的可能的最小值.附录7:子程序function PopulationProbability=Probability(PopulationFitness)SumPopulationFitness=sum(PopulationFitness);PopulationProbability=PopulationFitness/SumPopulationFitness;【程序说明】子程序用于计算群体中每个染色体的入选概率,输入参数为群体中染色体的适应函数值PopulationFitness.附录8:子程序function NewPopulation=Select(Population,PopulationProbability,MemberNumber)CProbability(1)=PopulationProbability(1);for i=2:MemberNumberCProbability(i)=CProbability(i-1)+PopulationProbability(i);endfor i=1:MemberNumberr=rand(1);Index=1;while r>CProbability(Index)Index=Index+1;endNewPopulation(i,:)=Population(Index,:);end【程序说明】子程序根据入选概率(计算累计概率)在群体中按比例选择部分染色体组成种群,该子程序的3个输入参数分别为:群体Population,入选概率PopulationProbability,群体中染色体的个数MemberNumber.附录9:子程序function NewPopulation=Crossing(Population,FunctionFitness,MinX,MaxX,MumberLength)%%PopulationFitness=%% Fitness(Population,FunctionFitness,MinX,MaxX,MumberLength);%%PopulationProbability=Probability(PopulationFitness);%%[SortResult,SortSite]=sort(PopulationProbability);%%Population=Population(SortSite,:);Dim=size(Population);if Dim(1)>=3Temp=Population(Dim(1),:);Population(Dim(1),:)=Population(Dim(1)-1,:);Population(Dim(1)-1,:)=Temp;endfor i=1:2:Dim(1)-1SiteArray=randperm(Dim(2));Site=SiteArray(1);Temp=Population(i,1:Site);Population(i,1:Site)=Population(i+1,1:Site);Population(i+1,1:Site)=Temp;endNewPopulation=Population;【程序说明】子程序用于群体中的交叉并产生新群体.其输入参数为:Population, FunctionFitness,MinX,MaxX,MumberLength.附录10:子程序function NewPopulation=Mutation(Population,MutationProbability)Dim=size(Population);for i=1:Dim(1)Probability=rand(1);Site=randperm(Dim(2));if Probability<MutationProbabilityif Population(i,Site(1))==1Population(i,Site(1))=0;endif Population(i,Site(1))==0Population(i,Site(1))=1;endendendNewPopulation=Population;【程序说明】子程序用于群体中少量个体变量并产生新的群体.输入参数为:群体Population和变异概率MutationProbability.附录11:子程序function [NewPopulationIncludeMax,CurrentBest,EachGenMaxFitness]=Elitist(Population,PopulationFitness,MumberLength)global Count CurrentBest;[MinFitness,MinSite]=min(PopulationFitness);[MaxFitness,MaxSite]=max(PopulationFitness);EachGenMaxFitness=MaxFitness;if Count==1CurrentBest(1:MumberLength)=Population(MaxSite,:);CurrentBest(MumberLength+1)=PopulationFitness(MaxSite);elseif CurrentBest(MumberLength+1)<PopulationFitness(MaxSite);CurrentBest(1:MumberLength)=Population(MaxSite,:);CurrentBest(MumberLength+1)=PopulationFitness(MaxSite);endPopulation(MinSite,:)=CurrentBest(1:MumberLength);endNewPopulationIncludeMax=Population;【程序说明】子程序用到最佳个体保存方法(“优胜劣汰”思想).输入参数为:群体Population, 目标函数值PopulationFitness和染色体个数MumberLength.“遗传算法”专题一、遗传算法的主要特征:我们的目的是获得“最好解”,可以把这种任务看成是一个优化过程。


遗传算法应用实例及matlab程序遗传算法是一种模拟自然进化过程的优化算法,在多个领域都有广泛的应用。
下面将以一个经典的实例,车间调度问题,来说明遗传算法在实际问题中的应用,并给出一个基于MATLAB的实现。
车间调度问题是一个经典的组合优化问题,它是指在给定一系列任务和一台机器的情况下,如何安排任务的执行顺序,以便最小化任务的完成时间或最大化任务的完成效率。
这个问题通常是NP困难问题,因此传统的优化算法往往难以找到全局最优解。
遗传算法能够解决车间调度问题,其基本思想是通过模拟生物进化的过程,不断演化和改进任务的调度顺序,以找到最优解。
具体步骤如下:1. 初始种群的生成:生成一批初始调度方案,每个方案都表示为一个染色体,一般采用随机生成的方式。
2. 个体适应度的计算:根据染色体中任务的执行顺序,计算每个调度方案的适应度值,一般使用任务完成时间作为适应度度量。
3. 选择操作:根据个体的适应度,采用选择策略选择一部分优秀个体作为父代。
4. 交叉操作:对选中的个体进行交叉操作,生成新的子代个体。
5. 变异操作:对子代个体进行变异操作,引入随机性,增加搜索空间的广度。
6. 替换操作:用新的个体替换原来的个体,形成新一代的种群。
7. 迭代过程:重复执行选择、交叉、变异和替换操作,直到达到预定的终止条件。
下面给出基于MATLAB的实现示例:matlabfunction [best_solution, best_fitness] =genetic_algorithm(num_generations, population_size) % 初始化种群population = generate_population(population_size);for generation = 1:num_generations% 计算适应度fitness = calculate_fitness(population);% 选择操作selected_population = selection(population, fitness);% 交叉操作crossed_population = crossover(selected_population);% 变异操作mutated_population = mutation(crossed_population);% 替换操作population = replace(population, selected_population, mutated_population);end% 找到最优解[~, index] = max(fitness);best_solution = population(index,:);best_fitness = fitness(index);endfunction population = generate_population(population_size) % 根据问题的具体要求,生成初始种群population = randi([1, num_tasks], [population_size, num_tasks]); endfunction fitness = calculate_fitness(population)% 根据任务执行顺序,计算每个调度方案的适应度% 这里以任务完成时间作为适应度度量fitness = zeros(size(population, 1), 1);for i = 1:size(population, 1)solution = population(i,:);% 计算任务完成时间completion_time = calculate_completion_time(solution);% 适应度为任务完成时间的倒数fitness(i) = 1 / completion_time;endendfunction selected_population = selection(population, fitness) % 根据适应度值选择父代个体% 这里采用轮盘赌选择策略selected_population = zeros(size(population));for i = 1:size(population, 1)% 计算选择概率prob = fitness / sum(fitness);% 轮盘赌选择selected_population(i,:) = population(find(rand <= cumsum(prob), 1),:);endendfunction crossed_population = crossover(selected_population) % 对选中的个体进行交叉操作% 这里采用单点交叉crossed_population = zeros(size(selected_population));for i = 1:size(selected_population, 1) / 2parent1 = selected_population(2*i-1,:);parent2 = selected_population(2*i,:);% 随机选择交叉点crossover_point = randi([1, size(parent1,2)]);% 交叉操作crossed_population(2*i-1,:) = [parent1(1:crossover_point), parent2(crossover_point+1:end)];crossed_population(2*i,:) = [parent2(1:crossover_point), parent1(crossover_point+1:end)];endendfunction mutated_population = mutation(crossed_population) % 对子代个体进行变异操作% 这里采用单点变异mutated_population = crossed_population;for i = 1:size(mutated_population, 1)individual = mutated_population(i,:);% 随机选择变异点mutation_point = randi([1, size(individual,2)]);% 变异操作mutated_population(i,mutation_point) = randi([1, num_tasks]);endendfunction new_population = replace(population, selected_population, mutated_population)% 根据选择、交叉和变异得到的个体替换原来的个体new_population = mutated_population;for i = 1:size(population, 1)if ismember(population(i,:), selected_population, 'rows')% 保留选择得到的个体continue;else% 随机选择一个父代个体进行替换index = randi([1, size(selected_population,1)]);new_population(i,:) = selected_population(index,:);endendend该示例代码实现了车间调度问题的遗传算法求解过程,具体实现了种群的初始化、适应度计算、选择、交叉、变异和替换等操作。



遗传算法优化设计方法及其应用一、简介遗传算法(Genetic Algorithm, GA)是一种基于模拟生物进化的随机化优化算法,具有全局寻优、鲁棒性强等优点,被广泛应用于优化设计中。
二、遗传算法的基本原理遗传算法是通过模拟生物进化来进行全局寻优的一种优化算法。
(一)种群初始化: 随机生成一组初始个体。
(二)适应度函数: 将每个个体映射到一个适应度值。
(三)选择操作: 根据适应度值,以一定的概率选取优良个体。
(四)交叉操作: 对选出的个体进行交叉操作,生成新个体。
(五)变异操作: 对新生成的个体进行变异操作,使其产生更强的种群。
(六)终止条件: 满足特定的终止条件,如达到一定的迭代次数、收敛到一定的精度等。
三、遗传算法的优点(一)全局寻优: 遗传算法具有全局寻优能力,并能避免局部最优解的困扰。
(二)鲁棒性强: 遗传算法具有鲁棒性强的特点,能够很好地处理非线性、不连续、多模态等问题。
(三)可并行化: 遗传算法具有可并行化的特点,适合于高性能计算。
(四)灵活性高: 遗传算法的参数设置灵活性高,可以对具体问题进行调整。
四、遗传算法在优化设计中的应用(一)机械设计:在机械设计中,需要进行优化设计以实现轻量化、高强度等目标。
遗传算法可以对参数进行全局寻优,实现机械设计的优化。
(二)控制系统设计:在控制系统设计中,需要优化控制器的参数,以实现系统的稳定性和响应速度等目标。
遗传算法可以对控制器参数进行全局寻优,实现控制系统设计的优化。
(三)通讯网络设计:在通讯网络设计中,需要优化网络拓扑结构、传输速率等参数,以实现网络的高效性。
遗传算法可以对网络参数进行全局寻优,实现通讯网络的优化。
(四)其他领域:遗传算法在医药设计、金融优化、能源优化等领域也有广泛应用。
五、总结遗传算法是一种基于生物进化的随机化优化算法,具有全局寻优、鲁棒性强等优点,被广泛应用于各个领域的优化设计中。
在实际应用中,遗传算法需要根据具体问题进行参数调整,以发挥最大的优化效果。

数学建模⽅法-遗传算法(理论篇)⼀、引⾔ 哈喽⼤家好,今天要给⼤家讲的是“遗传算法”。
跟粒⼦群算法、蚁群算法⼀样,遗传算法也是属于启发式算法,它基于达尔⽂的进化论,模拟进化论中的“⾃然选择,物竞天择、适者⽣存”,通过N代的遗传、变异、交叉、复制,进化出问题的最优解。
⼆、浅谈⽣物学2.1 达尔⽂教你进化论 学过初中⽣物的应该都知道达尔⽂的进化论。
总结起来其实就是“物竞天择、适者⽣存”。
这是什么意思呢?通俗讲,就是在弱⾁强⾷的时代,唯有强者才能⽣存下来。
记住这句话,这是遗传算法的核⼼。
2.2 遗传学所告诉我们的 好,达尔⽂告诉我们要⽣存下去就要适应环境,但是如何它没告诉我们存活下来的⽣物是如何不被淘汰的。
遗传学告诉了我们答案。
我们知道,细胞是所有⽣物的基⽯。
对于每个细胞,都有⼀套相同的染⾊体,⽽染⾊体,则是由DNA所聚合⽽成,其中DNA⼜是由基因组成的。
每个基因都编码了⼀个独特的性状,⽐如头发或眼⽪的颜⾊。
如下图: 我们假设在某个地区O,⽣活着两类⽣物,其中携带基因a的⽣物种群P能够适应当前的⾃然环境,携带基因b的⽣物种群Q不能够适应当前的⾃然环境。
因此,随着岁⽉的流逝,那些不能适应当前⾃然环境的⽣物⼀个个死去,⽽能够适应当前⾃然环境的⽣物不断的繁衍。
很多年很多年过去后,这个地区O留下来的都是携带基因a的⽣物种群P。
好了,⽣物学知识暂且讲到这⾥,⾜够我们接下来解释我们的遗传算法了。
三、遗传算法3.1 遗传算法的定义 我们把种群P当成问题的最优解,把除P外的种群当成普通解。
那么进化就是普通解不断被淘汰⽽最后留下的只有最优解的过程。
这就是遗传算法的思想。
我们先给出遗传算法的流程如下,具体在后⾯解释: 1. 种群初始化 2. 计算每个种群的适应度值 3. 选择(Selection) 4. 交叉(Crossover) 5. 变异(Mutation) 6. 重复2-5步直⾄达到进化次数 现在,我们来逐步理解⼀下整个流程。

遗传算法优化问题求解中的应用和改进策略思考遗传算法是一种受到生物进化理论启发的优化算法,它通过模拟自然选择、交叉和变异等生物的进化过程,在解决复杂问题的同时,不断进化寻找更优解。
遗传算法在问题求解和优化领域有着广泛应用,并且在解决一些难以求解的问题上表现出色。
为了进一步提高遗传算法的效果,可以尝试一些改进策略。
首先,多样性保持是提高遗传算法效果的关键之一。
在算法的迭代过程中,为了保持种群的多样性,可以采取一些措施,如避免早熟收敛、引入多目标函数、动态调整交叉和变异概率等。
这样可以避免算法过早陷入局部最优解,增加全局搜索的能力,提高求解的效果。
其次,选择适当的适应度函数也是改进遗传算法的重要策略之一。
适应度函数是衡量解的优劣程度的指标,选择合适的适应度函数可以更好地引导遗传算法的搜索过程。
在耦合约束的问题中,可以设计考虑约束信息的适应度函数,将约束信息纳入计算,使得算法更加准确地搜索可行解空间。
另外,改进遗传算法的交叉和变异操作也有助于提高算法的性能。
在交叉操作中,可以采用一些新的交叉方式,如基于局部搜索或者专家经验的交叉方式,以增加算法的搜索能力。
在变异操作中,可以引入自适应的变异概率,根据个体适应度的变化动态调整变异的强度,以引入更多的多样性或者加快算法进化的速度。
此外,引入种群的精英保留机制也是提高遗传算法性能的有效策略之一。
将适应度最好的个体保留下来,确保其在下一代种群中存在,防止优秀解的丢失,可以加速算法的收敛速度。
此外,还可以通过并行计算、多目标遗传算法、变邻域搜索等技术来改进遗传算法的性能。
并行计算可以利用多核或分布式计算资源,加快算法的执行速度。
多目标遗传算法则可以应对多目标优化问题,通过维护一个种群中的多个最优解,实现对多个目标的优化。
变邻域搜索则可以通过迭代地搜索附近的解空间,实现对优化解的进一步优化。
总的来说,遗传算法是一种强大而灵活的优化算法,它可以用于解决各种问题。
为了提高算法的效果,我们可以从多样性保持、适应度函数的选择、交叉和变异操作的改进、精英保留机制的引入以及利用并行计算、多目标遗传算法和变邻域搜索等方面入手进行改进。
遗传算法遗传算法技术遗传算法的改进应用1. 遗传算法
遗传算法是一种启发式算法,它根据自然选择和遗传学的原理,模拟生物进化过程,以此来寻找最优解或最优解集的算法。
在遗传算法中,将问题抽象成个体的基因类型,构造初始个体集,通过遗传算子(交叉、变异、选择等)进行个体的演化,最终得到适应度高的解或解集。
2. 遗传算法技术
遗传算法技术包括初始个体生成、适应度函数设计、遗传算子设计等。
初始个体生成需要选择一定的随机策略,保证生成的个体具有一定的多样性和可行性。
适应度函数设计需要准确反映出问题的优化目标,同时需要避免出现局部最优解陷阱。
遗传算子设计需要根据问题的特点来确定交叉、变异和选择的策略,保证搜索的效率和质量。
3. 遗传算法的改进
遗传算法的改进主要包括进化策略、多目标优化、协方差矩阵适应度进化等。
进化策略中,通过设置不同的演化控制策略,可以改进寻优效率和质量。
多目标优化中,考虑多个目标同时优化的问题,可以采用多种策略来解决。
协方差矩阵适应度进化中,结合梯度下降算法的思想,通过适应度函数的形式来调节种群的参
数,可以快速有效地找到最优解。
4. 应用
遗传算法可以应用于多种领域,如优化问题、机器学习、控制系统、计算机视觉、图像处理等。
在优化问题中,可以解决线性规划、非线性规划、整数规划等多种类型的优化问题。
在机器学习中,可以用于特征选择、分类、回归等任务。
在控制系统中,可以用于控制器设计、参数优化等问题。
在计算机视觉和图像处理中,可以用于图像分割、图像匹配等任务。
遗传算法在优化问题求解中的应用遗传算法是一种模拟自然进化过程的优化算法,它可以有效的解决在许多实际问题中出现的优化问题,例如图像处理、机器学习等领域。
因此,本文将介绍遗传算法在优化问题求解中的应用,以及它的原理和优点。
一、遗传算法的原理遗传算法是一种基于进化论和遗传学原理的优化算法。
其基本原理是通过模拟自然界中的遗传、变异、选择等过程,不断进化出更优的解。
具体来说,遗传算法一般包含以下几个步骤:1. 初始化种群:首先,随机生成初始的种群,每个个体都是一个解,即染色体。
2. 交叉和变异:将种群中的染色体进行交叉和变异操作,产生新的染色体。
交叉操作是指将两个染色体的部分基因进行交换,以产生新的组合。
变异操作则是对染色体中的某些基因进行随机改变,以保持种群的多样性和探索空间。
3. 选择:根据适应度函数,从新生代种群中选择一定数量的染色体作为下一代的种群。
适应度函数一般用来评估染色体的适应程度,越优秀的染色体被选择的概率越大,从而使种群逐渐趋近于最优解。
4. 终止:当达到预设的终止条件时,停止算法并输出最优解。
终止条件一般可以是最大迭代次数、达到一定的适应度阈值或者连续若干代收敛等。
二、遗传算法在优化问题求解中的应用遗传算法已经被广泛应用于实际问题求解中,例如最优化问题、图像处理、机器学习、神经网络等领域。
以下是几个遗传算法应用的例子:1. 最优化问题在最优化问题中,目标函数一般很难求解或者没有解析解。
遗传算法可以通过不断的进化来搜索参数空间,找到最优化的解。
例如,在机器学习中,遗传算法可以用来优化神经网络的超参数,以提高其分类和预测的准确率。
2. 图像处理在图像处理领域中,遗传算法可以被用来寻找最优的图像特征,以用于分类、识别等应用中。
例如,在人脸识别中,遗传算法可以优化人脸特征的集合,从而提高识别的准确率。
3. 机器学习在机器学习中,遗传算法可以被用来训练神经网络、优化损失函数等。
例如,在深度学习中,遗传算法可以用来寻找最优的网络拓扑结构或者优化权重和偏差,从而提高模型的准确率和泛化能力。
数学建模遗传算法与优化问题Document number:NOCG-YUNOO-BUYTT-UU986-1986UT实验十遗传算法与优化问题一、问题背景与实验目的遗传算法(Genetic Algorithm—GA),是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,它是由美国Michigan大学的教授于1975年首先提出的.遗传算法作为一种新的全局优化搜索算法,以其简单通用、鲁棒性强、适于并行处理及应用范围广等显着特点,奠定了它作为21世纪关键智能计算之一的地位.本实验将首先介绍一下遗传算法的基本理论,然后用其解决几个简单的函数最值问题,使读者能够学会利用遗传算法进行初步的优化计算.1.遗传算法的基本原理遗传算法的基本思想正是基于模仿生物界遗传学的遗传过程.它把问题的参数用基因代表,把问题的解用染色体代表(在计算机里用二进制码表示),从而得到一个由具有不同染色体的个体组成的群体.这个群体在问题特定的环境里生存竞争,适者有最好的机会生存和产生后代.后代随机化地继承了父代的最好特征,并也在生存环境的控制支配下继续这一过程.群体的染色体都将逐渐适应环境,不断进化,最后收敛到一族最适应环境的类似个体,即得到问题最优的解.值得注意的一点是,现在的遗传算法是受生物进化论学说的启发提出的,这种学说对我们用计算机解决复杂问题很有用,而它本身是否完全正确并不重要(目前生物界对此学说尚有争议).(1)遗传算法中的生物遗传学概念由于遗传算法是由进化论和遗传学机理而产生的直接搜索优化方法;故而在这个算法中要用到各种进化和遗传学的概念.首先给出遗传学概念、遗传算法概念和相应的数学概念三者之间的对应关系.这些概念如下:遗传算法计算优化的操作过程就如同生物学上生物遗传进化的过程,主要有三个基本操作(或称为算子):选择(Selection)、交叉(Crossover)、变异(Mutation).遗传算法基本步骤主要是:先把问题的解表示成“染色体”,在算法中也就是以二进制编码的串,在执行遗传算法之前,给出一群“染色体”,也就是假设的可行解.然后,把这些假设的可行解置于问题的“环境”中,并按适者生存的原则,从中选择出较适应环境的“染色体”进行复制,再通过交叉、变异过程产生更适应环境的新一代“染色体”群.经过这样的一代一代地进化,最后就会收敛到最适应环境的一个“染色体”上,它就是问题的最优解.下面给出遗传算法的具体步骤,流程图参见图1:第一步:选择编码策略,把参数集合(可行解集合)转换染色体结构空间;第二步:定义适应函数,便于计算适应值;第三步:确定遗传策略,包括选择群体大小,选择、交叉、变异方法以及确定交叉概率、变异概率等遗传参数;第四步:随机产生初始化群体;第五步:计算群体中的个体或染色体解码后的适应值;第六步:按照遗传策略,运用选择、交叉和变异算子作用于群体,形成下一代群体;第七步:判断群体性能是否满足某一指标、或者是否已完成预定的迭代次数,不满足则返回第五步、或者修改遗传策略再返回第六步.图1 一个遗传算法的具体步骤遗传算法有很多种具体的不同实现过程,以上介绍的是标准遗传算法的主要步骤,此算法会一直运行直到找到满足条件的最优解为止.2.遗传算法的实际应用例1:设2()20.5f x x x =-++,求 max (), [1,2]f x x ∈-.注:这是一个非常简单的二次函数求极值的问题,相信大家都会做.在此我们要研究的不是问题本身,而是借此来说明如何通过遗传算法分析和解决问题.在此将细化地给出遗传算法的整个过程. (1)编码和产生初始群体首先第一步要确定编码的策略,也就是说如何把1-到2这个区间内的数用计算机语言表示出来.编码就是表现型到基因型的映射,编码时要注意以下三个原则: 完备性:问题空间中所有点(潜在解)都能成为GA 编码空间中的点(染色体位串)的表现型;健全性:GA 编码空间中的染色体位串必须对应问题空间中的某一潜在解; 非冗余性:染色体和潜在解必须一一对应.这里我们通过采用二进制的形式来解决编码问题,将某个变量值代表的个体表示为一个{0,1}二进制串.当然,串长取决于求解的精度.如果要设定求解精度到六位小数,由于区间长度为2(1)3--=,则必须将闭区间 [1,2]-分为6310⨯等分.因为216222097152231024194304=<⨯<= 所以编码的二进制串至少需要22位.将一个二进制串(b 21b 20b 19…b 1b 0)转化为区间[1,2]-内对应的实数值很简单,只需采取以下两步(Matlab 程序参见附录4):1)将一个二进制串(b 21b 20b 19…b 1b 0)代表的二进制数化为10进制数: 2)'x 对应的区间[1,2]-内的实数: 'x 2=2288967利用这种方法我们就完成了遗传算法的第一步——编码,这种二进制编码的方法完全符合上述的编码的三个原则.首先我们来随机的产生一个个体数为4个的初始群体如下: pop(1)={ <>, %% a1 <>, %% a2 <>, %% a3<>} %% a4(Matlab 程序参见附录2) 化成十进制的数分别为: pop(1)={ , , , }接下来我们就要解决每个染色体个体的适应值问题了. (2)定义适应函数和适应值由于给定的目标函数2()20.5f x x x =-++在[1,2]-内的值有正有负,所以必须通过建立适应函数与目标函数的映射关系,保证映射后的适应值非负,而且目标函数的优化方向应对应于适应值增大的方向,也为以后计算各个体的入选概率打下基础.对于本题中的最大化问题,定义适应函数()g x ,采用下述方法:式中min F 既可以是特定的输入值,也可以是当前所有代或最近K 代中()f x 的最小值,这里为了便于计算,将采用了一个特定的输入值.若取min 1F =-,则当()1f x =时适应函数()2g x =;当() 1.1f x =-时适应函数()0g x =.由上述所随机产生的初始群体,我们可以先计算出目标函数值分别如下(Matlab 程序参见附录3):f [pop(1)]={ , , , }然后通过适应函数计算出适应值分别如下(Matlab 程序参见附录5、附录6):取min 1F =-, g[pop(1)]= { , , 0 , } (3)确定选择标准这里我们用到了适应值的比例来作为选择的标准,得到的每个个体的适应值比例叫作入选概率.其计算公式如下:对于给定的规模为n 的群体pop={123,,,,n a a a a },个体i a 的适应值为()i g a ,则其入选概率为由上述给出的群体,我们可以计算出各个个体的入选概率. 首先可得 41() 6.478330i i g a ==∑,然后分别用四个个体的适应值去除以41()i i g a =∑,得:P (a 1)= / = %% a 1 P (a 2)= / = %% a 2P (a 3)= 0 / = 0 %% a 3P (a 4)= / = %% a 4(Matlab 程序参见附录7) (4)产生种群计算完了入选概率后,就将入选概率大的个体选入种群,淘汰概率小的个体,并用入选概率最大的个体补入种群,得到与原群体大小同样的种群(Matlab 程序参见附录8、附录11).要说明的是:附录11的算法与这里不完全相同.为保证收敛性,附录11的算法作了修正,采用了最佳个体保存方法(elitist model ),具体内容将在后面给出介绍.由初始群体的入选概率我们淘汰掉a 3,再加入a 2补足成与群体同样大小的种群得到newpop(1)如下:newpop(1)={ <>, %% a 1 <>, %% a 2<>, %% a2<>} %% a4(5)交叉交叉也就是将一组染色体上对应基因段的交换得到新的染色体,然后得到新的染色体组,组成新的群体(Matlab程序参见附录9).我们把之前得到的newpop(1)的四个个体两两组成一对,重复的不配对,进行交叉.(可以在任一位进行交叉)< >, <>交叉得:< >, <>< 01000010>, <1000011>交叉得:< >, <>通过交叉得到了四个新个体,得到新的群体jchpop (1)如下:jchpop(1)={<>,<>,<>,<01101010>}这里采用的是单点交叉的方法,当然还有多点交叉的方法,不过有些烦琐,这里就不着重介绍了.(6)变异变异也就是通过一个小概率改变染色体位串上的某个基因(Matlab程序参见附录10).现把刚得到的jchpop(1)中第3个个体中的第9位改变,就产生了变异,得到了新的群体pop(2)如下:pop(2)= { <>, <>, <1>, <0110> }然后重复上述的选择、交叉、变异直到满足终止条件为止. (7)终止条件遗传算法的终止条件有两类常见条件:(1)采用设定最大(遗传)代数的方法,一般可设定为50代,此时就可能得出最优解.此种方法简单易行,但可能不是很精确(Matlab 程序参见附录1);(2)根据个体的差异来判断,通过计算种群中基因多样性测度,即所有基因位相似程度来进行控制.3.遗传算法的收敛性前面我们已经就遗传算法中的编码、适应度函数、选择、交叉和变异等主要操作的基本内容及设计进行了详细的介绍.作为一种搜索算法,遗传算法通过对这些操作的适当设计和运行,可以实现兼顾全局搜索和局部搜索的所谓均衡搜索,具体实现见下图2所示.图2 均衡搜索的具体实现图示应该指出的是,遗传算法虽然可以实现均衡的搜索,并且在许多复杂问题的求解中往往能得到满意的结果,但是该算法的全局优化收敛性的理论分析尚待解决.目前普遍认为,标准遗传算法并不保证全局最优收敛.但是,在一定的约束条件下,遗传算法可以实现这一点.下面我们不加证明地罗列几个定理或定义,供读者参考(在这些定理的证明中,要用到许多概率论知识,特别是有关马尔可夫链的理论,读者可参阅有关文献).定理1 如果变异概率为)1,0(∈m P ,交叉概率为]1,0[∈c P ,同时采用比例选择法(按个体适应度占群体适应度的比例进行复制),则标准遗传算法的变换矩阵P 是基本的.定理2 标准遗传算法(参数如定理1)不能收敛至全局最优解.由定理2可以知道,具有变异概率)1,0(∈m P ,交叉概率为]1,0[∈c P 以及按比例选择的标准遗传算法是不能收敛至全局最最优解.我们在前面求解例1时所用的方法就是满足定理1的条件的方法.这无疑是一个令人沮丧的结论.然而,庆幸的是,只要对标准遗传算法作一些改进,就能够保证其收敛性.具体如下:我们对标准遗传算法作一定改进,即不按比例进行选择,而是保留当前所得的最优解(称作超个体).该超个体不参与遗传.最佳个体保存方法(elitist model )的思想是把群体中适应度最高的个体不进行配对交叉而直接复制到下一代中.此种选择操作又称复制(copy ).De Jong 对此方法作了如下定义:定义 设到时刻t (第t 代)时,群体中a *(t )为最佳个体.又设A (t +1)为新一代群体,若A (t +1)中不存在a *(t ),则把a *(t )作为A (t +1)中的第n +1个个体(其中,n 为群体大小)(Matlab 程序参见附录11).采用此选择方法的优点是,进化过程中某一代的最优解可不被交叉和变异操作所破坏.但是,这也隐含了一种危机,即局部最优个体的遗传基因会急速增加而使进化有可能限于局部解.也就是说,该方法的全局搜索能力差,它更适合单峰性质的搜索空间搜索,而不是多峰性质的空间搜索.所以此方法一般都与其他选择方法结合使用.定理3 具有定理1所示参数,且在选择后保留当前最优值的遗传算法最终能收敛到全局最优解.当然,在选择算子作用后保留当前最优解是一项比较复杂的工作,因为该解在选择算子作用后可能丢失.但是定理3至少表明了这种改进的遗传算法能够收敛至全局最优解.有意思的是,实际上只要在选择前保留当前最优解,就可以保证收敛,定理4描述了这种情况.定理4 具有定理1参数的,且在选择前保留当前最优解的遗传算法可收敛于全局最优解.例2:设2()3f x x x =-+,求 max (), [0,2]f x x ∈,编码长度为5,采用上述定理4所述的“在选择前保留当前最优解的遗传算法”进行.此略,留作练习.二、相关函数(命令)及简介本实验的程序中用到如下一些基本的Matlab 函数:ones, zeros, sum, size, length, subs, double 等,以及 for, while 等基本程序结构语句,读者可参考前面专门关于Matlab 的介绍,也可参考其他数学实验章节中的“相关函数(命令)及简介”内容,此略.三、实验内容上述例1的求解过程为:群体中包含六个染色体,每个染色体用22位0—1码,变异概率为,变量区间为[1,2]-,取Fmin=2-,遗传代数为50代,则运用第一种终止条件(指定遗传代数)的Matlab程序为:[Count,Result,BestMember]=Genetic1(22,6,'-x*x+2*x+',-1,2,-2,,50)执行结果为:Count =50Result =BestMember =图2 例1的计算结果(注:上图为遗传进化过程中每一代的个体最大适应度;而下图为目前为止的个体最大适应度——单调递增)我们通过Matlab软件实现了遗传算法,得到了这题在第一种终止条件下的最优解:当x取时,Max () 1.4990f x=.当然这个解和实际情况还有一点出入(应该是x取1时,f x=),但对于一个计算机算法来说已经很不错了.Max () 1.5000我们也可以编制Matlab程序求在第二种终止条件下的最优解.此略,留作练习.实践表明,此时的遗传算法只要经过10代左右就可完成收敛,得到另一个“最优解”,与前面的最优解相差无几.四、自己动手1.用Matlab编制另一个主程序,求例1的在第二种终止条件下的最优解.提示:一个可能的函数调用形式以及相应的结果为:[Count,Result,BestMember]=Genetic2(22,6,'-x*x+2*x+',-1,2,-2,,Count =13Result =BestMember =可以看到:两组解都已经很接近实际结果,对于两种方法所产生的最优解差异很小.可见这两种终止算法都是可行的,而且可以知道对于例1的问题,遗传算法只要经过10代左右就可以完成收敛,达到一个最优解.2.按照例2的具体要求,用遗传算法求上述例2的最优解.3.附录9子程序中的第3行到第7行为注解语句.若去掉前面的%号,则程序的算法思想有什么变化4.附录9子程序中的第8行至第13行的程序表明,当Dim(1)>=3时,将交换数组Population的最后两行,即交换最后面的两个个体.其目的是什么5.仿照附录10子程序,修改附录9子程序,使得交叉过程也有一个概率值(一般取~);同时适当修改主程序或主程序,以便代入交叉概率.6.设2f x x∈-,要设定求解精度到15位小=--+,求max(),[2,2]f x x x()41数.五、附录附录1:主程序function[Count,Result,BestMember]=Genetic1(MumberLength,MemberNumber,FunctionFitn ess,MinX,MaxX,Fmin,MutationProbability,Gen)Population=PopulationInitialize(MumberLength,MemberNumber);global Count;global CurrentBest;Count=1;PopulationCode=Population;PopulationFitness=Fitness(PopulationCode,FunctionFitness,MinX,MaxX,Mumbe rLength);PopulationFitnessF=FitnessF(PopulationFitness,Fmin);PopulationProbability=Probability(PopulationFitnessF);[Population,CurrentBest,EachGenMaxFitness]=Elitist(PopulationCode,Populatio nFitness,MumberLength);EachMaxFitness(Count)=EachGenMaxFitness;MaxFitness(Count)=CurrentBest(length(CurrentBest));while Count<GenNewPopulation=Select(Population,PopulationProbability,MemberNumber);Population=NewPopulation;NewPopulation=Crossing(Population,FunctionFitness,MinX,MaxX,MumberLength);Population=NewPopulation;NewPopulation=Mutation(Population,MutationProbability);Population=NewPopulation;PopulationFitness=Fitness(Population,FunctionFitness,MinX,MaxX,MumberLength);PopulationFitnessF=FitnessF(PopulationFitness,Fmin);PopulationProbability=Probability(PopulationFitnessF);Count=Count+1;[NewPopulation,CurrentBest,EachGenMaxFitness]=Elitist(Population,PopulationFitn ess,MumberLength);EachMaxFitness(Count)=EachGenMaxFitness;;MaxFitness(Count)=CurrentBest(length(CurrentBest));Population=NewPopulation;endDim=size(Population);Result=ones(2,Dim(1));for i=1:Dim(1)Result(1,i)=Translate(Population(i,:),MinX,MaxX,MumberLength);endResult(2,:)=PopulationFitness;BestMember(1,1)=Translate(CurrentBest(1:MumberLength),MinX,MaxX,Mumb erLength);BestMember(2,1)=CurrentBest(MumberLength+1);close allsubplot(211)plot(EachMaxFitness)subplot(212)plot(MaxFitness)【程序说明】主程序包含了8个输入参数:(1) MumberLength:表示一个染色体位串的二进制长度.(例1中取22)(2) MemberNumber:表示群体中染色体的个数.(例1中取6个)(3) FunctionFitness : 表示目标函数,是个字符串,因此用表达式时,用单引号括出.(例1中是2()20.5f x x x =-++)(4) MinX : 变量区间的下限.(例1中是[1,2]-中的) (5) MaxX : 变量区间的上限.(例1中是[1,2]-中的 2)(6) Fmin : 定义适应函数过程中给出的一个目标函数的可能的最小值,由操作者自己给出.(例1中取Fmin=2-)(7) MutationProbability : 表示变异的概率,一般都很小.(例1中取) (8) Gen : 表示遗传的代数,也就是终止程序时的代数.(例1中取50) 另外,主程序包含了3个输出值: Count 表示遗传的代数;Result 表示计算的结果,也就是最优解;BestMember 表示最优个体及其适应值. 附录2:子程序function Population=PopulationInitialize(MumberLength,MemberNumber) Temporary=rand(MemberNumber,MumberLength); Population=(Temporary>=*ones(size(Temporary)));【程序说明】子程序 用于产生一个初始群体.这个初始群体含有MemberNumber 个染色体,每个染色体有MumberLength 个基因(二进制码). 附录3:子程序function PopulationFitness=Fitness(PopulationCode,FunctionFitness,MinX,MaxX,MumberLength)Dim=size(PopulationCode);PopulationFitness=zeros(1,Dim(1)); for i=1:Dim(1)PopulationFitness(i)=Transfer(PopulationCode(i,:),FunctionFitness,MinX,MaxX,MumberLength);end 【程序说明】子程序用于计算群体中每一个染色体的目标函数值.子程序中含有5个输入参数:PopulationCode 表示用0—1代码表示的群体,FunctionFitness 表示目标函数,它是一个字符串,因此写入调用程序时,应该用单引号括出,MumberLength表示染色体位串的二进制长度.MinX和MaxX 分别指变量区间的上下限.附录4:子程序function PopulationData=Translate(PopulationCode,MinX,MaxX,MumberLength) PopulationData=0;Dim=size(PopulationCode);for i=1:Dim(2)PopulationData=PopulationData+PopulationCode(i)*(2^(MumberLength-i));endPopulationData=MinX+PopulationData*(MaxX-MinX)/(2^Dim(2)-1);【程序说明】子程序把编成码的群体翻译成变量的数值.含有4个输入参数,PopulationCode, MinX, MaxX, MumberLength.附录5:子程序function PopulationFitness=Transfer(PopulationCode,FunctionFitness,MinX,MaxX,MumberLength) PopulationFitness=0;PopulationData=Translate(PopulationCode,MinX,MaxX,MumberLength);PopulationFitness=double(subs(FunctionFitness,'x',sym(PopulationData))); 【程序说明】子程序 Transfer 把群体中的染色体的目标函数值用数值表示出来,它是Fitness的重要子程序.其有5个输入参数分别为PopulationCode, FunctionFitness, MinX, MaxX,MumberLength.附录6:子程序function PopulationFitnessF=FitnessF(PopulationFitness,Fmin)Dim=size(PopulationFitness);PopulationFitnessF=zeros(1,Dim(2));for i=1:Dim(2)if PopulationFitness(i)>FminPopulationFitnessF(i)=PopulationFitness(i)-Fmin;endif PopulationFitness(i)<=FminPopulationFitnessF(i)=0;endend【程序说明】子程序是用于计算每个染色体的适应函数值的.其输入参数如下:PopulationFitness 为群体中染色体的目标函数值,Fmin为定义适应函数过程中给出的一个目标函数的可能的最小值.附录7:子程序function PopulationProbability=Probability(PopulationFitness)SumPopulationFitness=sum(PopulationFitness);PopulationProbability=PopulationFitness/SumPopulationFitness;【程序说明】子程序用于计算群体中每个染色体的入选概率,输入参数为群体中染色体的适应函数值PopulationFitness.附录8:子程序function NewPopulation=Select(Population,PopulationProbability,MemberNumber)CProbability(1)=PopulationProbability(1);for i=2:MemberNumberCProbability(i)=CProbability(i-1)+PopulationProbability(i);endfor i=1:MemberNumberr=rand(1);Index=1;while r>CProbability(Index)Index=Index+1;endNewPopulation(i,:)=Population(Index,:);end【程序说明】子程序根据入选概率(计算累计概率)在群体中按比例选择部分染色体组成种群,该子程序的3个输入参数分别为:群体Population,入选概率PopulationProbability,群体中染色体的个数MemberNumber.附录9:子程序function NewPopulation=Crossing(Population,FunctionFitness,MinX,MaxX,MumberLength)%%PopulationFitness=%% Fitness(Population,FunctionFitness,MinX,MaxX,MumberLength);%%PopulationProbability=Probability(PopulationFitness);%%[SortResult,SortSite]=sort(PopulationProbability);%%Population=Population(SortSite,:);Dim=size(Population);if Dim(1)>=3Temp=Population(Dim(1),:);Population(Dim(1),:)=Population(Dim(1)-1,:);Population(Dim(1)-1,:)=Temp;endfor i=1:2:Dim(1)-1SiteArray=randperm(Dim(2));Site=SiteArray(1);Temp=Population(i,1:Site);Population(i,1:Site)=Population(i+1,1:Site);Population(i+1,1:Site)=Temp;endNewPopulation=Population;【程序说明】子程序用于群体中的交叉并产生新群体.其输入参数为:Population, FunctionFitness,MinX,MaxX,MumberLength.附录10:子程序function NewPopulation=Mutation(Population,MutationProbability)Dim=size(Population);for i=1:Dim(1)Probability=rand(1);Site=randperm(Dim(2));if Probability<MutationProbabilityif Population(i,Site(1))==1Population(i,Site(1))=0;endif Population(i,Site(1))==0Population(i,Site(1))=1;endendendNewPopulation=Population;【程序说明】子程序用于群体中少量个体变量并产生新的群体.输入参数为:群体Population和变异概率MutationProbability.附录11:子程序function [NewPopulationIncludeMax,CurrentBest,EachGenMaxFitness]= Elitist(Population,PopulationFitness,MumberLength)global Count CurrentBest;[MinFitness,MinSite]=min(PopulationFitness);[MaxFitness,MaxSite]=max(PopulationFitness); EachGenMaxFitness=MaxFitness; if Count==1CurrentBest(1:MumberLength)=Population(MaxSite,:);CurrentBest(MumberLength+1)=PopulationFitness(MaxSite); elseif CurrentBest(MumberLength+1)<PopulationFitness(MaxSite); CurrentBest(1:MumberLength)=Population(MaxSite,:);CurrentBest(MumberLength+1)=PopulationFitness(MaxSite); endPopulation(MinSite,:)=CurrentBest(1:MumberLength); endNewPopulationIncludeMax=Population;【程序说明】子程序用到最佳个体保存方法(“优胜劣汰”思想).输入参数为:群体Population, 目标函数值PopulationFitness 和染色体个数MumberLength .“遗传算法”专题一、遗传算法的主要特征:我们的目的是获得“最好解”,可以把这种任务看成是一个优化过程。