免费《统计学》课后答案
- 格式:doc
- 大小:653.00 KB
- 文档页数:20

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)整理by__kiss-ahuang第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

《统计学》课后题答案第一章导论一、选择题1.C2.A3.C4.C5.C6.B7.A8.D9.C 10.D 11.A 12.C 13.C 14.A 15.B 16.A 17.C 18.B 19.D 20.A 21.D 22. D23.B 24.C 25.A 26.A 27.A 28.B 29.A 30.D 31.C 32.A 33.B第二章数据的收集一、选择题1.A2.B3.A4.D5.B6.C7.D8.D9.D 10.C 11.C 12.A 13.D 14.D 15.C 16.A 17.D 18.C 19.B 20.B 21.A 22.B 23.C 24.A 25.B 26.B 27.A 28.B 29.C 30.C (A)二、判断题1.∨2.∨3.×4. ∨5. ×6. ×7. ∨8. ×9. ×10. ×第三章数据整理与显示一、选择题CABCD CBBAB BACBD DDBC第四章数据分布特征的测度一、选择题1.A2.C3.B4.C5.D6.D7.A8.B9.A 10.B 11.A 12.D 13.C 14.C 15.D 16.A 17.A 18.B 19.A 20.B 21.A 22.A 23.B 24.C 25.C 26.D 27.D 28.A 29.D 30.C 31.C 32.D二、判断题1. ×2. ∨3. ×4. ×5. ×6. ×7. ∨8. ×9. × 10. ∨ 11. ∨ 12. ×四、计算题1. 11399073.8954ki ii kii x fx f=====∑∑甲11.96σ===甲73.89100%100% 6.18%11.96x σν=⨯=⨯=甲73.8100%100%7.43%9.93x σν=⨯=⨯=乙甲的代表性强2. 10.2510.966ki ii kii x fx f====∑∑0.250.056σ==0.250.056100%100% 5.834%0.966xσν=⨯=⨯= 1114.534ki ii kii x fx f====∑∑10.1295σ==10.1295100%100% 2.857%4.534xσν=⨯=⨯=该教练的说法不成立。

判断统计着眼于事物的整体,不考虑个别事物的数量特征。
(×)一个人口总体的特征,可以用人口总数、年龄、性别、民族等概念来反应。
(×)凡是以绝对数形式出现均为数量指标,以相对数和平均数形式出现是质量指标。
(√)变异是统计的前提条件,没有变异就用不着统计了。
(√)男性是品质标志,(×)统计设计就是要从纵横两个方面对整个统计工作作出考虑和安排。
(√)从理论、认识顺序上讲,统计设计是完整的统计工作开始阶段。
(√)对统计工作各个环节的考虑和安排是指统计工作实际进行的各个阶段。
(×)一个统计指标体系之间若干指标必须是在口径时间空间方法等方面相互联系。
(√)统计指标体系按其说明问题不同可分为专项研究用、基层单位、经济与社会发展的(√)统计调查的任务是搜集总体的原始资料。
(×)统计调查方案的首要问题是确定调查任务与目的,其核心是调查表。
(√)在统计调查方案中,时间指调查资料所属的时间,期限指调查工作的期限。
(√)调查对象是调查项目的承担者。
(×)重点调查所选择的重点指这些单位的被研究的标志总量占总数的绝大部分。
(×)抽样调查是非全面调查中最有科学根据的方法,唯一它适用于完成任何调查任务。
(×)标志变动程度指标与平均数代表性成正比关系。
(×)反应总体各单位标志值的离散程度只能用相对数,不能用绝对数。
(×)标志变异指标中,平均差最好,(×)如果根据组距式分组资料计算全距,则计算公式为:全距=最高组下限-最低组下限(×)标准差是总体中各单位标志值与算术平均数的离差平方的算术平均数的平方根(√)标准差的实质和平均差基本相同,也是各个标志值对其算术平均数的平均距离。
(√)填空题统计设计是统计工作的第一阶段,是根据统计研究目的和研究对象的特点对统计工作的各个方面和各个环节所做的全面安排部署。
统计设计按研究对象包括的范围分为整体设计和专项设计。

1.1什么是统计学?统计学是一门研究随机现象,以推断为特征的方法论科学,“由部分推及全体”的思想贯穿于统计学的始终。
具体地说,它是研究如何搜集、整理、分析反映事物总体信息的数字资料,并以此为依据,对总体特征进行推断的原理和方法。
用统计来认识事物的步骤是:研究设计—>抽样调查—>统计推断—>结论。
这里,研究设计就是制定调查研究和实验研究的计划,抽样调查是搜集资料的过程,统计推断是分析资料的过程。
显然统计的主要功能是推断,而推断的方法是一种不完全归纳法,因为是用部分资料来推断总体。
增加定义:是关于收集、整理、分析和解释统计数据的科学,是一门认识方法论性质的科学,其目的是探索数据内在的数量规律性,以达到对客观事物的科学认识。
统计学是收集、分析、表述和解释数据的科学1.2解释描述统计和推断统计描述统计学(Descriptive Statistics)研究如何取得反映客观现象的数据,并通过图表形式对所收集的数据进行加工处理和显示,进而通过综合概括与分析得出反映客观现象的规律性数量特征。
内容包括统计数据的收集方法、数据的加工处理方法、数据的显示方法、数据分布特征的概括与分析方法等。
推断统计学(1nferential Statistics)则是研究如何根据样本数据去推断总体数量特征的方法,它是在对样本数据进行描述的基础上,对统计总体的未知数量特征做出以概率形式表述的推断。
描述统计学和推断统计学的划分,一方面反映了统计方法发展的前后两个阶段,同时也反映了应用统计方法探索客观事物数量规律性的不同过程。
统计研究过程的起点是统计数据,终点是探索出客观现象内在的数量规律性。
在这一过程中,如果搜集到的是总体数据(如普查数据),则经过描述统计之后就可以达到认识总体数量规律性的目的了;如果所获得的只是研究总体的一部分数据(样本数据),要找到总体的数量规律性,则必须应用概率论的理论并根据样本信息对总体进行科学的推断。
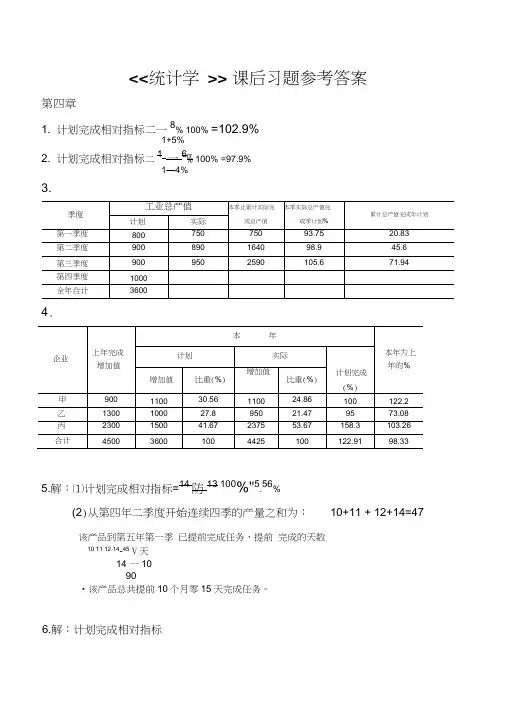
<<统计学 >> 课后习题参考答案第四章1. 计划完成相对指标二一8% 100% =102.9%1+5%2. 计划完成相对指标二1一6% 100% =97.9%1—4%3.4.5.解:⑴计划完成相对指标=14防13 100%"5.56%(2)从第四年二季度开始连续四季的产量之和为:10+11 + 12+14=47该产品到第五年第一季 已提前完成任务,提前 完成的天数90•该产品总共提前10个月零15天完成任务。
6.解:计划完成相对指标10 11 12 14-45V 天 14 一10156 230 540 279 325 470 535200 1040.1% 100% =126.75%(2) 156+230+540+279+325+470=2000 (万吨)所以正好提前半年完成计划7.第五章平均指标与标志变异指标1 . X 甲= :.26 27 28 29 30 31 32 3334=309—20 25 28 30 32 34 36 38 40 '1.44X乙二9AD甲二26-30卩27 -30 28-30 29 -30 30-30 |31 -30 32 - 30 亠|33 - 30 叫34 - 309-2.22AD乙二20—31.44” 25—31.44 十2〔8—31.44 屮30—31.44 +|32|— 31.44 + 34卜31.44 + 網 + 31.44 + 38—|31.44 + 4Q — 9= 5.06R 甲=34-26=8R 乙=40-20=20(26一30)2 (27 一30)2 (28一30)2 (29一30)2 (30 一 30)2 ⑶ 一 30)2 (32 一 30)2 (33一 30)2 (34一33)2--------------------------------------------------------------------- 9=2.58(T 乙一(20 -31.44)2 - (25 -31.44)2 (28 —31.44)2 (30 -31.44)2 (32 -31.44)2 (34-31.44)2 (36 -31.44)2 • (38-31.44)2 • (40_31.44)2----------------------------------------------------------------------------------------- 9=6.06 2 58 V 甲二 100%=8.6% 30V 乙二100% =19.3%31.44 所以甲组的平均产量代表性大一些2. 解:计算过程如下表:3. 解:计算过程如下表:X 甲80 77600X 乙=80= 970(元)X 甲=9550 119.480 (件)X 乙二 9660120.8=80(件)V 甲二旦06100%=7.58%119.4V 乙二!08! 100% =8.94%120.8所以甲厂工人的平均产量的代表性要高些4. 解:55 3 65 7 75 18 85 12 95 5=11 =7010=76.4718-7 18-1245 “10=70 上 10 = 76.94185.解:(1)上期的平均计划完成程度为100% =99.67%CT 甲=6568.7580二 9.06 (件)9355'80-10.81(件)3 7 18 12 5 18 -780 110% 700 108% 1000 100% 1500 95%80 700 1000 1500(2)下期的平均计划完成程度为:96 810 1200 1400------------------------------------------ =103.37%96 810 1200 1400110% 107% 101% 103%6解:P =300 _28100% =90.67%300X P二P = 90.67%二P「90.67% 1 -90.67% =0.2910.291V P100% =32.1%0.9067432.604 321.255 506.943 1042884.3兀/t 432.604 321.255 506.943、 4----------- +------------- +------------ ix 102800 2900 2950 丿苗吾第八章1.= 8722.a =600 670 2 .670 840 2 . 840 1020 1 . 1020 900 2 • 900 980 3 980 4030 ?2 2 2 2 2 23.解:全年月平均计划完成程 度为: 303 306 324 310 350 368 410 412 485 463 350 385 303 306 ------ + -------- 101% 102% 435 如00% = 105.85%324 310 350 368 410 412 485 463 350 385 + ------- + -------- + -------- + ------- + -------- + -------- + ------- + ------- + --------- + --------- 110% 105% 106% 98% 112% 105% 120% 97% 102% 113%576 4500 462亠 100% =79.63% 580 620 580 600 - 2 25.解:⑴甲工区上半年建筑安装 工人的月平均工资为:680 620 620 680 680 720 720 690 690 700 700 710 /汇600+ 汇620+ 江640+ 汇645 + ^625+ 汉610 2 2 2 680 620 680 720 690 7002 22乙工区上半年建筑安装工人的月平均工资为:650 670 670 680 “c 680 730 730 655 655 710 一 710 690640 600 620 655 615600 =623.7(元)2 650 + 670 + 680+730 + 655 + 710 +2 2 二 621.6(元)6■解:平均增长速度=4黔1皿7% 2000年该县粮食产量为:500 1 4.67% 10 = 788.7(万吨) 7解:计算过程如下表a y=竺=45.44 n 9则直线趋势方程为:y = a bt1994年的地方财政支出额为:45.44, 4.3 5 =66.94(万元)二次曲线方程为:y = 0.0108x2 + 4.1918x + 24.143过程略)指数曲线方程为:y = 26.996e0.0978x8.解:计算过程如下表原数列趋势图日期9•解:(1)同季平均法求季节比率的过程如下表第一季第二季第三季度第四季合计1987 13 18 311988 5 8 14 18 451989 6 10 16 22 541990 8 12 19 25 641991 15 17 32平均8.5 11.75 15.5 20.75 14.125 季节比率60.2% 83.2% 109.7% 146.9% 100.0%⑵趋势剔除法测定的季节变动如下表第一季第二季第三季度第四季合计19871988 44.94 71.11 123.08 153.191989 48.98 76.92 116.36 154.391990 53.78 76.8 112.59 136.051991平均49.23 74.94 117.34 147.88 389.40校正系数 1.0272214 1.027221366 1.027221366 1.02722137季节比率50.57 76.98 120.54 151.90 400.00第七章统计指数' q i Z。

第一章:数据与统计学思考与练习:思考题:1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。
2.试举出日常生活或工作中统计数据及其规律性的例子。
3.简要说明统计数据的来源答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。
间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。
4.获取直接统计数据的渠道主要有哪些?5.简要说明抽样误差和非抽样误差答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
6.一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
7.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。

第1章导论1、某森林公园的一项研究试图确定哪些因素有利于成年松树长到60英尺以上的高度.经估计,森林公园生长着25000颗成年松树,该研究需要从中随机抽取250颗成年松树并丈量它们的高度后进行分析。
该研究的总体是()A、250颗成年松树 B、公园中25000颗成年松树C、所有高于60英尺的成年松树D、森林公园中所有年龄的松树2、某森林公园的一项研究试图确定成年松树的高度。
该研究需要从中随机抽取250颗成年松树并丈量它们的高度后进行分析。
该研究所感兴趣的变量是()A、森林公园中松树的年龄B、森林公园中松树的数量C、森林公园中松树的高度D、森林公园中数目的种类3、推断统计的主要功能是()A、应用总体的信息描述样本B、描述样本中包含的信息C、描述总体中包含的信息D、应用样本信息描述总体4、对高中生的一项抽样调查表明,85%的高中生愿意接受大学教育.这一叙述是()的结果A、定性变量B、试验 C、描述统计 D、推断统计5、一名统计学专业的学生为了完成其统计学作业,在图书馆找到一本参考书中包含美国50个州的家庭收入中位数。
在该生的作业中,他应该将此数据报告来源于()A、试验B、实际观察 C、随机抽样D、已发表的资料6、某大公司的人力资源部主任需要研究公司雇员的饮食习惯。
他注意到,雇员的午饭要么从家里带来,要么在公司餐厅就餐,要么在外面的餐馆就餐。
该研究的目的是为了改善公司餐厅的现状。
这种数据的收集方式可以认为是()A、观察研究B、设计的试验C、随机抽样D、全面调查7、下列不属于描述统计问题的是()A、根据样本信息对总体进行的推断B、感兴趣的总体或样本C、图、表或其他数据汇总工具D、了解数据分布特征8、某大学的一位研究人员希望估计该大学一年级新生在教科书上的花费,为此,他观察了200名新生在教科书上的花费,发现他们每个学期平均在教科书上的花费是250元。
该研究人员感兴趣的总体是()A、该大学的所有学生B、所有的大学生C、该大学所有的一年级新生D、样本中的200名新生9、某大学的一位研究人员希望估计该大学一年级新生在教科书上的花费,为此,他观察了200名新生在教科书上的花费,发现他们每个学期平均在教科书上的花费是250元。

统计学课后题及答案解析王文华1 、什么是统计学?答:统计学是关于数据的科学,它所提供的是一套有关数据收集、处理、分析、解释并从数据中得出结论的方法,统计所研究的是来自各领域的数据。
数据收集即取得统计数据;数据处理是将数据用图表等形式展示出来;数据分析则是选择适当的统计方法研究数据,并从数据中提取有用信息进而得出结论。
2、解释描述统计和推断统计。
答:数据分析所用的方法可分为描述统计方法和推断统计方法。
(1)描述统计研究的是数据收集、处理、汇总、图表描述、概括与分析等统计方法。
(2)推断统计是研究如何利用样本数据来推断总体特征的统计方法。
比如,对产品的质量进行检验,往往是破坏性的,不可能对每个产品进行测量。
这就需要抽取部分个体即样本进行测量,然后根据获得的样本数据对所研究的总体特征进行推断,这就是推断统计要解决的问题。
3、统计数据可分为哪几种类型?不同类型的数据各有什么特点?答:统计数据是对现象进行测量的结果,可以从不同角度对统计数据进行分类:(1)按照所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和数值型数据。
①在分类数据中,各类别之间是平等的并列关系,无法区分优劣或大小,各类别之间的顺序是可以改变的;②顺序数据也表现为类别,但这些类别之间是有顺序的;③数值型数据具有分类数据和顺序数据的特点,并且还可以进行加、减、乘、除运算。
(2)按照统计数据的收集方法,可以将其分为观测数据和实验数据。
①观测数据是通过调查或观测而收集到的数据,这类数据是在没有对事物进行人为控制的条件下得到的,有关社会经济现象的统计数据几乎都是观测数据;②实验数据是在实验中通过控制实验对象收集到的数据,自然科学领域的大多数数据都是实验数据。
(3)按照被描述的现象与时间的关系,可以将统计数据分为截面数据和时间序列数据。
①截面数据是在相同或近似相同的时间点上收集的数据,这类数据通常是在不同的空间上获得的,用于描述现象在某一时刻的变化情况;②时间序列数据是在不同时间上收集到的数据,这类数据是按时间顺序收集到的,用于描述现象随时间变化的情况。


统计学课后习题答案第一章二、判断分析题1. √2. ×3. √4. ×5. ×6. ×7. ×8. ×9. ×10. √11. ×12. ×13. ×14. √15. √三、单选1.D2.A3.B4.D5.D6.D7.C8.B9.D 10.D 11.C 12.B 13.C14.C四、多选1.BCE2.AC3.ABD4.ABE5.BCDE6.ABD7.ABD8.CE第二章一、判断分析题1. ×2. √3. ×4. √5. √6. ×7. ×8. ×9. × 10. ×11. √12. ×13. ×14. ×15. √16. √二、单选1.A2.D3.B4.C5.B6.C7.D8.C9.A 10.C 11.A12.D 13.B 14.C 15.A 16.D 17.C 18.D三、多选1.CD2.ACE3.ADE4.ABCDE5.ABD6.BC7.ADE8.CDE9.ABC 10.BCE 11.AC 12.ABCD 13.ADE 14.ABD 15.CE 16.BE 17.BCD 18.ADE 19.CDE 20.CE 21.ADE 22.BD 23.ABCDE24.ACE 25.AB 26.BCDE 第三章一、判断分析题1. √2. ×3. √4. √5. √6. ×7. ×8. ×9. ×10. × 二、单选1.B2.D3.C4.B5.C6.A7.C8.D9.B 10.D 11.D 12.B 13.B 14.D 15.D 16.C 三、多选1.ADE2.BE3.BC4.BCE5.BE6.BD7.ABDE8.CE9.ABDE 10.ACD 11.AE 12.ABD 13.ACD 14.ABC 四、计算题 1.﹪﹪程度计划完成5.102100120123=⨯= 提前完成计划时间:因为自1999年3月起至2000年2月底连续12个月的时间内该厂自行车的实际产量已达到120万辆〔119+﹙10.1–9.6﹚+(10.1–9.6)=120〕,即已完成计划任务,提前完成计划10个月。
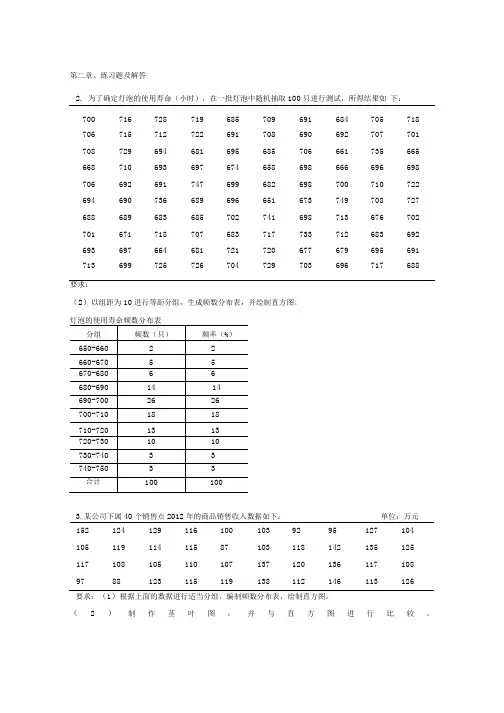
第二章、练习题及解答2.为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下:700 716 728 719 685 709 691 684 705 718 706 715 712 722 691 708 690 692 707 701 708 729 694 681 695 685 706 661 735 665 668 710 693 697 674 658 698 666 696 698 706 692 691 747 699 682 698 700 710 722 694 690 736 689 696 651 673 749 708 727 688 689 683 685 702 741 698 713 676 702 701 671 718 707 683 717 733 712 683 692 693 697 664 681 721 720 677 679 695 691 713 699 725 726 704 729 703 696 717 688要求:(2)以组距为10进行等距分组,生成频数分布表,并绘制直方图。
3.某公司下属40个销售点2012年的商品销售收入数据如下:单位:万元152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 10897 88 123 115 119 138 112 146 113 126要求:(1)根据上面的数据进行适当分组,编制频数分布表,绘制直方图。
(2)制作茎叶图,并与直方图进行比较。
1.已知下表资料:25 20 10 500 2.5 30 50 25 1500 7.5 35 80 40 2800 14 40 36 18 1440 7.2 4514 7 630 3. 15 合 计200100687034. 35_y xf 6870根据频数计算工人平均日产量:〒=金^ =北* = 34.35 (件)£f 200结论:对同一资料,采用频数和频率资料计算的变量值的平均数是一致的。
统计学习题参考答案 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】第一章导论(1)数值型变量。
(2)分类变量。
(3)离散型变量。
(4)顺序变量。
(5)分类变量。
(1)总体是该市所有职工家庭的集合;样本是抽中的2000个职工家庭的集合。
(2)参数是该市所有职工家庭的年人均收入;统计量是抽中的2000个职工家庭的年人均收入。
(1)总体是所有IT从业者的集合。
(2)数值型变量。
(3)分类变量。
(4)截面数据。
(1)总体是所有在网上购物的消费者的集合。
(2)分类变量。
(3)参数是所有在网上购物者的月平均花费。
(4)参数(5)推断统计方法。
第二章数据的搜集1.什么是二手资料使用二手资料需要注意些什么与研究内容有关的原始信息已经存在,是由别人调查和实验得来的,并会被我们利用的资料称为“二手资料”。
使用二手资料时需要注意:资料的原始搜集人、搜集资料的目的、搜集资料的途径、搜集资料的时间,要注意数据的定义、含义、计算口径和计算方法,避免错用、误用、滥用。
在引用二手资料时,要注明数据来源。
2.比较概率抽样和非概率抽样的特点,举例说明什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。
概率抽样是指抽样时按一定概率以随机原则抽取样本。
每个单位被抽中的概率已知或可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽中的概率,概率抽样的技术含量和成本都比较高。
如果调查的目的在于掌握和研究总体的数量特征,得到总体参数的置信区间,就使用概率抽样。
非概率抽样是指抽取样本时不是依据随机原则,而是根据研究目的对数据的要求,采用某种方式从总体中抽出部分单位对其实施调查。
非概率抽样操作简单、实效快、成本低,而且对于抽样中的专业技术要求不是很高。
它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备。
非概率抽样也适合市场调查中的概念测试。
3.调查中搜集数据的方法主要有自填式、面方式、电话式,除此之外,还有那些搜集数据的方法?实验式、观察式等。
第一章1.举出你所知道的统计应用的例子。
答:期末考试后统计班里同学的成绩,从而进行排名等;人口普查统计,从而得知男女人口比例,年龄分布等;统计一个生态系统里某种物种的密度;统计股票市场上某一天的各种数据;统计某个城市的人均收入水平,人民幸福指数,对某一电视节目的看法等。
2. 解释定性数据和定量数据的区别,分别给出一个定性数据和一个定量数据的例子。
答:定性数据和定量数据的区别:定性数据是由于我们考虑的是取值为类别的变量,对这些类别用数字来分别代表就得到定性数据;定量数据是我们所考虑的变量的取值为数值,它将在某个区间上连续取值,或在某个区间上取离散的值。
定性数据的例子:例如考察某幼儿园10个人的性别,定义1=男,2=女,则所得到定性数据为:1,1,2,2,2,1,2,1,1,1. ;定量数据的例子:考察某幼儿园10个人的身高,则此变量取值区间为(0,200)(单位:cm)3. 解释样本和总体的区别。
答:总体是根据一定目的和要求所确定的研究事物的全体。
为了了解总体的分布,我们从总体中随机地抽取一些个体,称这些个体的全体为样本。
样本和总体的区别在于总体是要考虑对象的全体,而样本是从总体中抽取出的一部分具有代表性的个体,从而通过对样本的研究得出关于总体的一些结论。
4. 解释离散型变量和连续型变量的区别,并各举一例。
离散型变量是指其数值只能用自然数或整数单位计算。
例如:某企业里职工的人数连续型变量是如果所考虑变量可以在某个区间内取任一实数,即变量的取值可以是连续的。
例如:生产零件的规格尺寸。
5.阐述四种主要的收集数据方法的区别。
答:观测,访问,问卷,实验区别:观测数据的研究者尽量不干涉研究对象的行为模式;访问在一定程度上对被访问者心理造成干扰,则收集到的数据会有误差;问卷常会产生未响应误差;实验时需要其控制它变量的影响。
6.举出一些观测数据和实验数据的例子。
·答:(1)观测数据:证券分析人员可能会记录某即将收购的公司在被收购的前一天的股市收盘价,并与宣布被收购的当天的收盘价比较。
思考题与练习题参考答案【友情提示】请各位同学完成思考题和练习题后再对照参考答案。
回答正确,值得肯定;回答错误,请找出原因更正,这样使用参考答案,能力会越来越高,智慧会越来越多。
学而不思则罔,如果直接抄答案,对学习无益,危害甚大。
想抄答案者,请三思而后行!第一章绪论思考题参考答案1.不能,英军所有战机=英军被击毁的战机+英军返航的战机+英军没有弹孔的战机,因为英军被击毁的战机有的掉入海里、敌军占领区,或因堕毁而无形等,不能找回;没有弹孔的战机也不可能自己拿来射击后进行弹孔位置的调查。
即便被击毁的战机找回或没有弹孔的战机自己拿来射击进行实验,也不能从多个弹孔中确认那个弹孔是危险的。
2.问题:飞机上什么区域应该加强钢板?瓦尔德解决问题的思想:在他的飞机模型上逐个不重不漏地标示返航军机受敌军创伤的弹孔位置,找出几乎布满弹孔的区域;发现:没有弹孔区域是军机的危险区域。
3.能,拯救和发展自己的参考路径为:①找出自己的优点,②明确自己大学阶段的最佳目标,③拟出一个发扬自己优点,实现自己大学阶段最佳目标的可行计划。
练习题参考答案一、填空题1.调查。
2.探索、调查、发现。
3.目的。
二、简答题1.瓦尔德;把剩下少数几个没有弹孔的区域加强钢板。
2.统计学解决实际问题的基本思路,即基本步骤是:①提出与统计有关的实际问题;② 建立有效的指标体系;③收集数据;④选用或创造有效的统计方法整理、显示所收集数据的特征;⑤根据所收集数据的特征、结合定性、定量的知识作出合理推断;⑥根据合理推断给出更好决策的建议。
不解决问题时,重复第②-⑥步。
3.在结合实质性学科的过程中,统计学是能发现客观世界规律,更好决策,改变世界和培养相应领域领袖的一门学科。
三、案例分析题1.总体:我班所有学生;单位:我班每个学生;样本:我班部分学生;品质标志:姓名;数量标志:每个学生课程的成绩;指标:全班学生课程的平均成绩;指标体系:上学期全班同学学习的科目;统计量:我班部分同学课程的平均成绩;定性数据:姓名;定量数据:课程成绩;离散型变量:学习课程数;连续性变量:学生的学习时间;确定性变量:全班学生课程的平均成绩;随机变量:我班部分同学课程的平均成绩,每个同学进入教室的时间;横截面数据:我班学生月门课程的出勤率;时间序列数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;面板数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;选用描述统计。
第一章总论2. 统计有几种涵义?各种涵义的关系如何?统计的三种涵义是指统计工作、统计资料及统计学。
统计工作是统计的实践活动,统计资料是统计工作的成果,统计学是统计实践活动的科学总结,反过来又指导统计实践。
8. 什么是统计总体、总体单位?总体和单位的关系如何?统计总体是指客观存在的,在同一性质基础上结合起来的许多个别事物的整体。
构成统计总体的每个基本单位或元素称为总体单位。
总体和单位的关系:(1)总体是由单位构成的;(2)总体和总体单位不是固定不变的,而是随着统计任务的不同,可以变换位置;(3)统计总体与总体单位是互为存在条件地联结在一起的,没有总体单位,总体也就不存在了。
10. 什么是标志?标志有几种?分别举例说明。
标志是说明总体单位特征的名称。
标志有品质标志与数量标志之分。
品质标志表示事物的质的特征,是不能用数值表示的,如人的性别、工人的工种等。
数量标志表示事物的量的特征,是可以用数值表示的,如人的年龄、企业的产值等。
第二章统计调查1. 调查对象、调查单位以及填报单位的关系是什么?试举例说明。
调查对象是需要调查的那些社会经济现象的总体。
调查单位是调查对象中所要调查的具体单位,是调查项目的直接承担者,它可能是全部总体单位,也可能是其中的一部分。
填报单位是负责向上报告调查内容的单位,又称报告单位。
调查对象和调查单位在同一次调查中是包含和被包含的关系。
确定调查对象是要划清所要研究的总体界限,确定调查单位是要明确调查标志有谁来承担。
填报单位和调查单位有联系也有区别,二者有时一致,有时不一致。
如工业企业设备普查,调查对象是工业企业设备,调查单位是每台设备,填报单位是每个工业企业。
2. 什么是统计调查?它有哪些分类?统计调查是按照预定的统计任务,运用科学的调查方法,有计划有组织地向客观实际搜集统计资料的过程。
按调查对象包括范围的不同,可以分为全面调查和非全面调查;按调查登记时间的连续性,分为经常性调查和一次性调查;按调查组织方式分为统计报表制度和专门调查;按搜集资料的方法可分为直接观察法、报告法、采访法。
第四章 抽样分布与参数估计3.某地区粮食播种面积5000亩,按不重复抽样方法随机抽取了100亩进行实测,调查结果,平均亩产450公斤,亩产量标准差为52公斤。
试以95%的置信度估计该地区粮食平均亩产量和总产量的置信区间。
解:已知X =450公斤,n =100(大样本),n/N=1/50,11≈-Nn,不考虑抽样方式的影响,用重复抽样计算。
s =52公斤,1-α=95%,α=5%。
这时查标准正态分布表,可得临界值:96.1025.02/==z z α该地区粮食平均亩产量的置信区间是:1005296.14502⨯±=±nsz x α=[439.808,460.192] (公斤) 总产量的置信区间是:[439.808⨯5000,460.192⨯5000] (公斤) =[2199040,2300960](公斤)4.已知某种电子管使用寿命服从正态分布。
从一批电子管中随机抽取16只,检测结果,样本平均寿命为1490小时,标准差为24.77小时。
试以95%的置信度估计这批电子管的平均寿命的置信区间。
解:(1)已知X =1490小时,n =16,s =24.77小时,1-α=95%,α=5%。
这时查t 分布表,可得 2.13145)1(2/=-n t α该批电子管的平均寿命的置信区间是:1677.2413145.214902⨯±=±nst x α=[ 1476.801,1503.199](小时)因此,这批电子管的平均寿命的置信区间在1476.801小时与1503.199小时之间。
6.采用简单随机重复抽样的方法,从2 000件产品中抽查200件,其中合格品190件。
要求:(1)计算合格品率及其抽样平均误差。
(2)以95.45%的置信度,对合格品率和合格品数量进行区间估计。
(3)如果极限误差为2.31%,则其置信度是多少? 解:(1)合格品率:P=190/200⨯100%=95% 抽样平均误差:np p p )1()(-=σ=0.015(2)%3%95%100015.02%95)(22/02275.02/±=⨯⨯±=±==p Z P Z Z σαα]19601840[]2000%982000%92[(%]98%92[,,的置信区为:件合格品数量,:合格品率的置信区间为=⨯⨯)(3)%64.87)(8764.01,54.1%31.2%100015.0%31.2)(2/2/2/==-==⨯⨯==∆z F Z Z p Z ασααα查表得7.从某企业工人中随机抽选部分进行调查,所得工资分布数列如下:试求:(1)以95.45%的置信度估计该企业工人平均工资的置信区间,以及该企业工人中工资不少于800元的工人所占比重的置信区间;(2)如果要求估计平均工资的允许误差范围不超过30元,估计工资不少于800元的工人所占比重的允许误差范围不超过10%,置信度仍为95.45%,试问至少应抽多少工人? 解(1)通过EXCEL 计算可得: X =816元,n =50人,s =113.77元。
统计学费宇石磊(主编)第2章练习题参考答案2.1解:(1)首先将顾客态度分别用代码1、2、3表示,然后在数据文件的Varible View窗口Values栏定义变量值标签:1代表“喜欢并愿意购买”;2代表“不喜欢”,3代表“喜欢并愿意购买”。
操作步骤:依次点击File→点击open→点击Data→打开数据文件ex2.1→点击Analyze→点击Descriptive Statistics→点击Frequencies→将“态度”选入Variable框→点击OK。
输出结果如表2.1所示:(2)根据表2.1频数分布表资料建立的数据文件为绘制条形图操作步骤:依次点击File→点击open→点击Data→打开数据文件,选中Summaries for groups of cases→单击Define→选中Other Summary function→将“人数”选入Variable(纵轴),将“态度分类”选入Category Axis (横轴)→点击OK。
输出结果如图2.1所示:图2.1 30名顾客满意程度分布条形图绘制饼图操作步骤:依次点击File→点击open→点击Data→打开数据文件ofindividual cases→点击Define→将“人数”选入Slices Represent栏,将“态度分类”选入Variable栏→点击OK。
输出结果如图2.2所示:2.2解:首先列计算表如表2.2所示:表2.2 120名学生英语成绩的均值、中位数、众数、偏态系数、峰度系数计算表(1)均值151872072.67120iii ii xf x f=====∑∑(分) 表2.2中,分布次数最多的组是“40~50”组,这就是众数所在组;2N=60,中位数大约在第60位,可确定中位数也在“40~50”组。
众数10124230701073.333018M L i ∆-=+⨯=+⨯=∆+∆-+-(分)(42)(42)中位数11204922701072.6242m e m N S M L i f ---=+⨯=+⨯=(分) (2)首先计算标准差:11.65s ==(分)31133()/38389.64/1200.202311.65kki ii i x x f f SK s ==-===∑∑由计算结果可看出,偏态系数为正值,但与零的差距不大,说明120名大学生英语成绩为轻微右偏分布,成绩较低的同学占有一定的比例,但偏斜程度不大。
41144()/5108282.61/120330.689111.65kki ii i x x f f K s ==-=-=-=-∑∑由计算结果可看出,峰度系数为负值,说明120名大学生英语成绩为平峰分布,成绩较低的同学占一定比例,但低成绩区域的集中程度并不很高。
2.3解(1)整理的组距数列如表表2.3.1 连续60天计算机销售量频数分布表(2) 下面使用SPSS16.0绘制图形:绘制直方图操作步骤:点击File→点击open→点击Data→读取数据文件ex2.3→点击Graphs→点击Histogram→将“销售量”选入Variable栏→点击OK。
若选中Display normal curve选项,则在生成的直方图上还显示正态曲线。
输出结果如图图2.3.1 连续60天计算机销售量直方图从图,连续60天中,销售量为40~50台的天数较多。
绘制简单箱线图操作步骤:点击File→点击open→点击Data→读取数据文件ex2.3→点击Graphs→点击Boxplot→选中simple,选中summaries of separate Variables→点击Define→将“销售量”选入Boxes Represent栏→点击Ok。
输出结果如图图2.3.2 连续60天计算机销售量箱线图从图,下横线之外有两个点,它们分别是第59和第60个观测值,原始数据中可查到,这两天的销售量分别为19台和18台,它们是离总体观测数据较远的离群点。
绘制茎叶图操作步骤:点击File→点击open→点击Data→读取数据文件ex2.3→点击Analyze→点击Descriptive Statistics-Explore→将“销售量”选入“Dependent List”栏→点击Ok。
输出结果如图销售量(台) Stem-and-Leaf PlotFrequency Stem & Leaf2.00 Extremes (=<19)1.00 2 . 25.00 2 . 568998.00 3 . 0022334415.00 3 . 778889919.00 4 . 00010.00 4 . 89Stem width: 10Each leaf: 1 case(s)图2.3.3 连续60天计算机销售量茎叶图(3)描述统计分析操作步骤:点击File→点击open→点击Data→读取数据文件ex2.3→点击Analyze→点击Descriptive Statistics→Descriptives→将“销售量”选入Variable栏→点击Options,选中Mean(均值)、Std.(标准差)、Minimum (最小值)、Maximum(最大值)、Kurtosis(峰态系数)、Skwness(偏态系数),选中Variable list(变量顺序排列显示输出结果)→点击Continue→点击Ok。
输出结果如表表2.3.2 连续60天计算机销售量的描述统计量Descriptive StatisticsN Minimum Maximum Mean Std. Skewness Kurtosis Statistic Statistic Statistic Statistic Statistic Statistic Std.Error Statistic Std.Error XSHL60 18 49 37.88 7.140 -.879 .309 .422 .608 销售量(台)Valid N60(listwise)表,连续60天中计算机销售量的最小值为18台,最大值为49台,平均销售量为37.88台,标准差为7.14台;偏态系数为-0.879,表明计算机销售量为左偏分布,在连续60天中,销售量较高的天数占一定比例,具有一定的偏斜度;峰态系数为0.608,表明计算机销售量为尖峰分布,销售量较高的天数具有一定的集中度。
第3章练习题参考答案3.1 解:操作步骤:Analyze→Descriptive Statistics→Explore,将x选入Dependent List,在Statistics中选中Descriptives结果分析:由表3-1可知,该超市每位顾客的平均花费金额的点估计180.0500,可信度为95%的区间估计为(156.8678,203.2322)(保留两位小数)。
3.2 解:(1)先估计每位顾客平时的平均花费金额和周末的平均花费金额的置信区间操作步骤:Analyze→Descriptive Statistics→Explore,将x选入Dependent List,将顾客总体选入Factor List,在Statistics中选中Descriptives;操作步骤:Analyze→Compare means→Independent—Samples T test,将x选入Test Variable(s),将顾客总体选入Grouping Variable(s),在Define Groups中分别定义总体一和总体二。
结果分析:表3-2-1是探索性分析的结果,可知每位顾客平时的平均花费金额的置信区间为(124.5854,195.0146),周末的平均花费金额的置信区间为(169.9718,230.6282)。
表3-2-2是独立样本t检验的结果,Levene's Test for Equality of Variances为方差检验的结果,F=1.312,其P值为0.255<0.05,拒绝方差相等的原假设,认为两总体的方差不等,因此两总体的差的置信区间为(-86.40631,5.40631)3.3 解:操作步骤:Analyze→Descriptive Statistics→Explore,将x选入Dependent List,在Statistics中选中Descriptives;输出结果:结果分析:表3-3是探索性分析的结果,由分析结果可知,该市成年男子体重置信度为95%的区间估计为(64.4538,71.9212)。
3.4 解:nX 近似的服从(0,1)N 分布,于是有/2/21X P z z ααα⎧⎫⎪⎪-<<≈-⎨⎬⎪⎪⎭⎩(3.4) 该市所有家庭中安装了宽带上网的家庭的百分比为p 是(0,1)分布的参数,200n =,192/2000.96x ==,10.95α-=,/2 1.96z α=,代入式(3.4)求得p 的置信水平为95%的置信区间为(0.92,0.98)第4章 练习题参考答案4.1 解:操作步骤:进行单样本T 检验,Analyze →Compare means →One —Samples T test ,将x 选入Test Variable(s),在Test Value 中输入0.618。
输出结果:结果分析:根据表4-1中单样本T 检验的结果,0.0110.05P =<,按显著性水平0.05α=无法拒绝0.618x =的原假设,认为该厂生产的工艺品框架宽与长的比值符合黄金比率。
4.2 解:H0:p>=50% H1:p<50% p=160/360=44.44% Z==-2.11这是一个单侧检验,-2z α=-1.645 拒绝原假设,这个专家的论断不成立。
4.3 解:0H :030000X X ≥=,即该厂家广告可信 1H :030000X X <=,即该厂家广告不可信 操作步骤:进行单样本T 检验,Analyze →Compare means →One —Samples T test ,将x 选入Test Variable(s),在Test Value 中输入0.618。
输出结果:结果分析:由表4-3-1可知,样本均值为30905.8333,表4-3-2是单样本双侧T 检验的结果,可知平均寿命95%的置信区间为(-293.9818,2105.6485),根据平均寿命大于0以及双侧检验和单侧检验的关系,95%的单侧置信区间应为(0,2105.6485),该置信区间与显著性水平0.05的本题的左边检验问题相对应,而X 0=30000并不在置信区间(0,2105.6485)内,因此拒绝H 0,认为该厂家的广告不可信。