实验2SPSS的交叉列联表和方差分析
- 格式:doc
- 大小:492.00 KB
- 文档页数:9

根据实验结果,进行多元方差分析SPSS操作步骤多元方差分析(MANOVA)是一种统计方法,用于比较两个以上组之间在多个连续因变量上的差异。
SPSS是一款功能强大的统计分析软件,可以用于进行多元方差分析。
下面是进行多元方差分析的SPSS操作步骤:1. 打开SPSS软件,并导入实验数据。
2. 在菜单栏选择“分析”(Analyze),然后选择“一元方差分析”(General Linear Model)。
3. 在弹出的对话框中,将多个连续因变量添加到“因变量”(Dependent Variables)框中。
点击“添加”按钮,然后选择需要分析的连续因变量。
4. 将一个或多个离散自变量添加到“因子”(Factors)框中。
点击“添加”按钮,然后选择需要分析的离散自变量。
5. 点击“选项”(Options)按钮,可以进行一些附加的设置。
例如,可以选择是否计算效应大小、调整误差项或进行共同协方差矩阵的检验等。
6. 点击“确定”按钮,开始进行多元方差分析。
7. 分析结果会显示在SPSS的输出窗口中。
可以查看因变量之间的差异是否显著,以及不同组之间是否存在显著差异。
8. 为了更好地理解结果,可以进一步进行后续分析。
例如,可以进行事后比较(Post hoc tests)来确定具体哪些组之间存在显著差异。
请注意,进行多元方差分析前,需要确保数据满足一些假设条件,如正态性、方差齐性和无多重共线性等。
另外,为了减少假阳性结果,应谨慎解释显著性水平。
以上是根据实验结果进行多元方差分析SPSS操作的步骤。
希望对您有所帮助!如有需要,请随时与我联系。




《SPSS数据分析教程》方差分析方差分析是一种常用的统计方法,用于比较三个或三个以上组之间的均值差异是否显著。
它用于探究不同组别的因素对所研究的因变量的影响是否具有统计显著性。
在SPSS数据分析教程中,方差分析是一个非常重要的分析方法。
本文将介绍方差分析的原理、SPSS中的操作步骤以及结果的解读。
方差分析的原理是基于三个或三个以上不同组别之间的方差之间的比较来判断均值之间的差异是否显著。
方差分析的核心思想是通过比较组内方差与组间方差的大小来判断均值的差异是否显著。
方差分析的原假设是所有组别的均值相等,而备择假设是至少存在一个组别的均值与其他组别的均值不相等。
在SPSS中进行方差分析的操作步骤如下:步骤1:打开SPSS软件,点击“变量视图”页面。
在第一栏输入不同组别的名称,例如“组别1”、“组别2”、“组别3”。
步骤2:在第二栏输入待分析的因变量名称,并设置其测量类型为“比例”。
步骤3:点击“数据视图”页面,输入各组别的数据。
确保每个组别的数据都在同一列中,并且分组的数据之间用“空格”或“逗号”隔开。
步骤4:点击菜单栏上的“分析,—比较手段,—单因素方差分析”。
步骤5:在方差分析的对话框中,将因变量移入因变量方框,将分组变量移入因子方框。
步骤6:点击“选项”按钮,出现选项对话框。
可以选择计算哪些统计量,如均值、标准差、总和平方和等。
步骤7:点击“确定”按钮,SPSS将得出方差分析的结果。
方差分析的结果包括了多个统计量,如SS(组间平方和)、SS(组内平方和)、MS(组内均方和)、MS(组间均方和)、F值和P值。
-SS(组间平方和)反映了组间差异的大小,SS(组内平方和)反映了组内差异的大小。
-MS(组间均方和)是SS(组间平方和)除以自由度(组间)得到的,反映了组间差异的平均大小。
-MS(组内均方和)是SS(组内平方和)除以自由度(组内)得到的,反映了组内差异的平均大小。
-F值是MS(组间均方和)除以MS(组内均方和)得到的,是判断组间差异是否显著的依据。
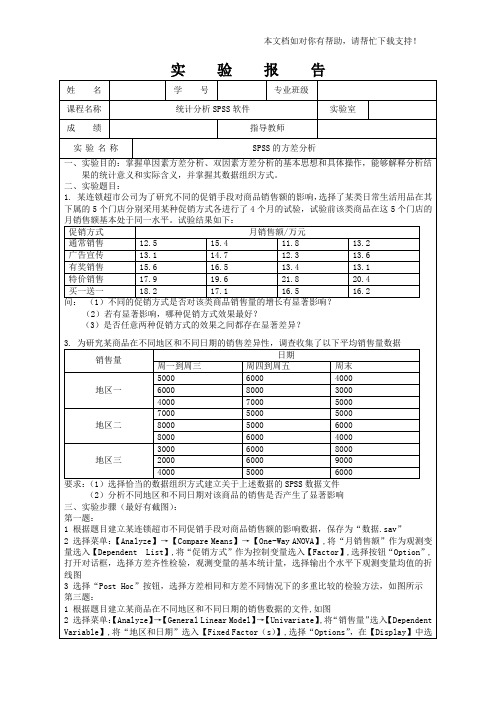


22.方差分析一、方差分析原理1.方差分析概述方差分析可用来研究多个分组的均值有无差异,其中分组是按影响因素的不同水平值组合进行划分的。
方差分析是对总变异进行分析。
看总变异是由哪些部分组成的,这些部分间的关系如何。
方差分析,是用来检验两个或两个以上均值间差别显著性(影响观察结果的因素:原因变量(列变量)的个数大于2,或分组变量(行变量)的个数大于1)。
一元时常用F检验(也称一元方差分析),多元时用多元方差分析(最常用Wilks' A检验)。
方差分析可用于:(1)完全随机设计(单因素)、随机区组设计(双因素)、析因设计、拉丁方设计和正交设计等资料;(2)可对两因素间交互作用差异进行显著性检验;(3)进行方差齐性检验。
要比较几组均值时,理论上抽得的几个样本,都假定来白正态总体,且有一个相同的方差,仅仅均值可以不相同。
还需假定每一个观察值都由若干部分累加而成,也即总的效果可分成若干部分,而每一部分都有一个特定的含义,称之谓效应的可加性。
所谓的方差是离均差平方和除以白由度,在方差分析中常简称为均方(Mean Square)。
2.基本思想基本思想是,将所有测量值上的总变异按照其变异的来源分解为多个部份,然后进行比较,评价由某种因素所引起的变异是否具有统计学意义。
根据效应的可加性,将总的离均差平方和分解成若干部分,每一部分都与某一种效应相对应,总白由度也被分成相应的各个部分,各部分的离均差平方除以各白的白由度得出各部分的均方,然后列出方差分析表算出F检验值,作出统计推断。
方差分析的关键是总离均差平方和的分解,分解越细致,各部分的含义就越明确,对各种效应的作用就越了解,统计推断就越准确。
效应项与试验设计或统计分析的目的有关,一般有:主效应(包括各种因素),交互影响项(因素间的多级交互影响),协变量(来白回归的变异项),等等。
当分析和确定了各个效应项S后,根据原始观察资料可计算出各个离均差平方和SS再根据相应的白由度df,由公式MS=SSdf,求出均方MS,最后由相应的均方,求出各个变异项的F值,F值实际上是两个均方之比值,通常情况下,分母的均方是误差项的均方。

利用SPSS进行方差分析以及正交试验设计方差分析是一种常见的统计方法,用于比较两个或多个组之间的差异。
正交试验设计是一种实验设计方法,能够同时考虑多个因素对结果的影响。
本文将利用SPSS进行方差分析和正交试验设计的步骤介绍,并讨论如何解读分析结果。
首先,我们将介绍方差分析的步骤。
方差分析的基本思想是比较组间和组内的变异程度。
假设我们有一个因变量和一个自变量,自变量有两个或多个水平。
下面是方差分析的步骤:1.导入数据:将数据导入SPSS软件,并确保每个变量都已正确标记。
2.选择统计分析:点击SPSS菜单栏上的"分析",然后选择"方差",再选择"单因素"。
3.设置因变量和自变量:在弹出的对话框中,将需要进行方差分析的因变量拖放到因素列表框中,然后将自变量也拖放到因素列表框中。
4.点击"设定"按钮:点击"设定"按钮,设置方差分析的参数,例如是否需要进行正态性检验、多重比较等。
然后点击"确定"。
5.查看结果:SPSS将输出方差分析的结果,包括各组之间的F值、p值等统计指标。
可以根据p值判断各组之间是否存在显著差异。
接下来,我们将介绍正交试验设计的步骤。
正交试验设计是一种多因素独立变量的实验设计方法,可以在较小的实验次数内获得较高的信息量。
下面是正交试验设计的步骤:1.设计矩阵:根据研究目的和独立变量的水平,构建正交试验的设计矩阵。
2.导入数据:将设计矩阵导入SPSS软件,并将每个变量的水平标注为自变量。
3.选择统计分析:点击SPSS菜单栏上的"分析",然后选择"一般线性模型",再选择"多元方差分析"。
4.设置因变量和自变量:在弹出的对话框中,将因变量拖放到因子列表框中,然后将自变量也拖放到因子列表框中。
5.点击"设定"按钮:点击"设定"按钮,设置正交试验设计的参数,例如交互作用是否显著、多重比较等。

SPSS⽅差分析实验⽬的:1、学会使⽤SPSS的简单操作。
2、掌握⽅差分析。
实验内容:1.单因素⽅差分析;2.双因素⽅差分析。
实验步骤: 1.单因素⽅差分析,⽅差分析是基于变异分解的思想进⾏的,在单因数⽅差分析中,整个样本的变异可以看成由两个部分构成:总变异=随机变异+处理因数导致的变异,其中随机变异是永远存在的,确定处理因数导致的变异是否存在就是所要达到的研究⽬标,即只要能证明它不等于0,就等同于证明了处理因数的确存在影响。
这样可采⽤⼀定的⽅法来⽐较组内变异和组间变异的⼤⼩,如果后者远远⼤于前者,则说明处理因数的影响的确存在,如果两者相差⽆⼏,则说明该影响不存在。
SPSS操作:【分析】→【⼀般线性模型-单变量】,将因变量选⼊【因变量】,将⾃变量选⼊【固定因⼦】。
如果需要均值图⽰,【绘图】,将因⼦选⼊【⽔平轴】,【图】→【添加】。
如果需要多重⽐较时,【事后多重⽐较】,将因⼦选⼊【两两⽐较检验】,【假定⽅差齐性】→【LSD】。
如果需要相关统计量时,【选项】→【显⽰】→【描述统计量】。
如果需要⽅差齐性检验时,【选项】→【输出】→【齐性检验】。
如果需要对模型的参数进⾏估计时,【选项】→【输出】→【参数估计值】。
如果需要预测值时,【保存】→【预测值】→【未标准化】。
1 UNIANOVA 销售额 BY 超市位置2 /METHOD=SSTYPE(3)3 /INTERCEPT=INCLUDE4 /CRITERIA=ALPHA(0.05)5 /DESIGN=超市位置.⽅差单变量分析11 UNIANOVA 销售额 BY 超市位置2 /METHOD=SSTYPE(3)3 /INTERCEPT=INCLUDE4 /PLOT=PROFILE(超市位置) TYPE=LINE ERRORBAR=NO MEANREFERENCE=NO YAXIS=AUTO5 /CRITERIA=ALPHA(0.05)6 /DESIGN=超市位置.单因数⽅差分析2轮廓图1 UNIANOVA 销售额 BY 超市位置2 /METHOD=SSTYPE(3)3 /INTERCEPT=INCLUDE4 /POSTHOC=超市位置(LSD)5 /CRITERIA=ALPHA(0.05)6 /DESIGN=超市位置.单因数⽅差分析31 UNIANOVA 销售额 BY 超市位置2 /METHOD=SSTYPE(3)3 /INTERCEPT=INCLUDE4 /PRINT DESCRIPTIVE5 /CRITERIA=ALPHA(.05)6 /DESIGN=超市位置.单因数⽅差分析41 UNIANOVA 销售额 BY 超市位置2 /METHOD=SSTYPE(3)3 /INTERCEPT=INCLUDE4 /PRINT HOMOGENEITY5 /CRITERIA=ALPHA(.05)6 /DESIGN=超市位置.单因数⽅差分析51 UNIANOVA 销售额 BY 超市位置2 /METHOD=SSTYPE(3)3 /INTERCEPT=INCLUDE4 /PRINT PARAMETER5 /CRITERIA=ALPHA(.05)6 /DESIGN=超市位置.单因数⽅差分析61 UNIANOVA 销售额 BY 超市位置2 /METHOD=SSTYPE(3)3 /INTERCEPT=INCLUDE4 /SAVE=PRED5 /CRITERIA=ALPHA(.05)6 /DESIGN=超市位置.单因数⽅差分析7 2.双因数⽅差分析:分析两个因数对实验结果的影响。


《基于SPSS的数据分析》实验报告实验项目1:交叉分组下的频数分析(一)实验目的交叉分组下的频数分析又称列联表分析,包括两大任务:一是根据收集到的样本数据编制交叉列联表,二是在交叉列联表的基础上,对两两变量间是否存在一定的相关性进行分析。
(二)实验资料利用“大学生职业生涯规划”数据,分析不同性别大学生在填报高考志愿时所考虑的因素是否存在差异,影响高考志愿填报的因素与性别是否有关。
具体数据见下表:(三)实验步骤1、选择菜单2、进行二维列联表分析3、统计量设置(四)实验结果及分析被调查的898名学生中,男生有369人,女生有529人,分别占总人数的41.1%和58.9%。
以兴趣爱好、市场就业、职业目标、能力优势、性格特点、其他为高考志愿填报决定因素的人数依次为270,287,76,138,68,59人。
其中,兴趣爱好、市场就业和能力优势的占比较高,分别为30.1%,32.0%和15.4%.其次,对不同性别进行分析。
在369名男生中,填报高考志愿时只考虑兴趣爱好和市场就业,百分比分别为73.2%和26.8%。
显然,大多男生是依据自己的兴趣爱好填报志愿的。
在529名女生中,填报高考志愿时考虑的主要因素是市场就业、能力优势、职业目标和性格特点等,而不考虑兴趣爱好。
可见,性别的差异性是比较明显的。
实验项目2:两独立样本t检验(一)实验目的两独立样本t检验的目的是利用来自两个总体的独立样本,推断两个总体的均值是否存在显著差异。
(二)实验资料利用大学生职业生涯规划数据,研究男生与女生的专业和职业认知得分的平均值是否存在显著差异具体数据如下(三)实验步骤1.选择菜单2.定义组(四)实验结果及分析由上表可以看出,男生与女生的认知得分的样本平均值有一定差距。
上表分析分为两个部分,第一步,两总体方差是否相等的F检验。
这里,该检验的F统计量的观测值为25.8,对应概率为0.00.如果显著性水平a为0.05,由于概率小于0.05,可以认为两总体的方差有显著差异。

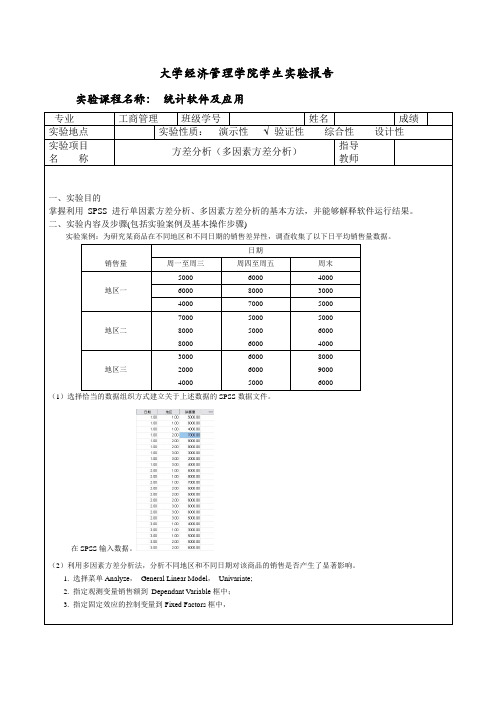
大学经济管理学院学生实验报告实验课程名称:统计软件及应用专业工商管理班级学号姓名成绩实验地点实验性质:演示性 验证性综合性设计性实验项目名称方差分析(多因素方差分析)指导教师一、实验目的掌握利用SPSS 进行单因素方差分析、多因素方差分析的基本方法,并能够解释软件运行结果。
二、实验内容及步骤(包括实验案例及基本操作步骤)实验案例:为研究某商品在不同地区和不同日期的销售差异性,调查收集了以下日平均销售量数据。
销售量日期周一至周三周四至周五周末地区一5000 6000 4000 6000 8000 3000 4000 7000 5000地区二700080008000500050006000500060004000地区三300020004000600060005000800090006000(1)选择恰当的数据组织方式建立关于上述数据的SPSS数据文件。
在SPSS输入数据。
(2)利用多因素方差分析法,分析不同地区和不同日期对该商品的销售是否产生了显著影响。
1. 选择菜单Analyze,General Linear Model,Univariate;2. 指定观测变量销售额到Dependant Variable框中;3. 指定固定效应的控制变量到Fixed Factors框中,4. OK,得到分析结果。
(3)地区和日期是否对该商品的销售产生了交互影响?若没有显著的交互影响,则试建立非饱和模型进行分析,并与饱和模型进行对比。
三、实验结论(包括SPSS输出结果及分析解释)SPSS输出的多因素方差分析的饱和模型分析:表的第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是方差;第五列是F检验统计量的观测值;第六列是检验统计量的概率P-值。
F日期,,F地区,F日期*地区概率P-值分别为0.254,0.313,0.000。
如果显著性水平α为0.05,由于F日期、,F地区大于显著性水平α,所以不应拒绝原假设,不同地区和不同日期对该商品没有显著性影响。

用SPSS进行列联表分析(Crosstabs)实例列联表分析(Crosstabs)列联表是指两个或多个分类变量各水平的频数分布表,又称频数交叉表。
SPSS的Crosstabs过程,为二维或高维列联表分析提供了22种检验和相关性度量方法。
其中卡方检验是分析列联表资料常用的假设检验方法。
例子:山东烟台地区病虫测报站预测一代玉米螟卵高峰期。
预报发生期y为3级(1级为6月20日前,2级为6月21-25日,3级为6月25日后);预报因子5月份平均气温x1(℃)分为3级(1级为16.5℃以下,2级为16.6-17.8℃,3级为17.8℃以上),6月上旬平均气温x2(℃)分为3级(1级为20℃以下,2级为20.1-21.5℃,3级为21.5℃以上),6月上旬降雨量x3(mm)分为3级(1级为15mm以下,2级为15.1-30mm,3级为30mm以上),6月中旬降雨量x4(mm)分为3级(1级为29mm以下,2级为29.1-36mm,3级为36mm以上)。
数据如下表。
注:摘自《农业病虫统计测报》131页。
1) 输入分析数据在数据编辑器窗口打开“data1-3.sav”数据文件。
数据文件中变量格式如下:2)调用分析过程在菜单选中“Analyze-Descriptive- Crosstabs”命令,弹出列联表分析对话框,如下图3)设置分析变量选择行变量:将“五月气温[x1],六月上气温[x2],六月上降雨[x3],六月中降雨[x4]”变量选入“Rows:”行变量框中。
选择列变量:将“玉米螟卵高峰发生期[y]”变量选入“Columns:”列变量框中。
4)输出条形图和频数分布表Display clustered bar charts: 选中显示复式条形图。
Suppress table: 选中则不输出多维频数分布表。
5)统计量输出点击“Statistics”按钮,弹出统计分析对话框(如下图)。
Chi-Square: 卡方检验。

科研实务交叉设计方差分析的SPSS操作一.问题与数据表1为A、B两种闪烁液测定血浆中3H-cGMP的交叉试验结果。
第1阶段1、3、4、7、9号用A测定,2、5、6、8、10号用B测定;第2阶段1、3、4、7、9号用B测定,2、5、6、8、10号用A测定,试对交叉试验结果进行分析。
二.分析问题在医学统计中,欲将A、B两种处理先后施加于同一批实验对象,随机地使半数实验对象先接受A后接受B,而另一半实验对象则正好相反,即先接受B后接受A。
由于两种处理在全部实验过程中交叉进行,这种设计称为交叉设计。
在交叉设计中,A、B两处理先后以同等的机会出现在两个实验阶段中,固又称为两阶段交叉设计。
在医学研究中交叉设计多用于止痛、镇静、降压等药物或治疗方法间疗效的比较。
三.SPSS操作1.操作步骤数据录入格式:将数据放入因变量,将实验阶段和闪烁液类型放入固定因子,受试者编号放入随机因子。
点击模型,出现如下对话框,选择定制,将实验阶段、闪烁液类型、受试者编号选入模型,构建项类型选择主效应。
点击选项,出现如下对话框,选择描述统计和参数估计值。
2.结果解读此操作主要分析主体间效应检验的结果,由结果可以看出:实验阶段的P值为0.014<0.05,具有统计学意义,认为不同的实验阶段对结果测定是有影响的;闪烁液类型间的P值为0.080>0.05,不具有统计学意义,即还不能认为两种闪烁液的测定结果有差别;受试者编号的显著性也具有统计学意义,可以认为各受试者的3H-cGMP值不同。
交叉实验最主要的是观察A、B处理间的差别,不同阶段和受试者间通常是已知的控制因素。
四.知识拓展该设计方法有很多优点,它不仅平衡了处理顺序的影响,还能把处理方法之间的差别、时间先后之间的差别以及实验对象之间的差别分开来分析。
但是该设计有一个较为严格的限制条件:前一个实验阶段的处理效应不能持续作用到下一个实验阶段,因此,有必要在两个阶段之间设一个洗脱阶段,以消除残留效应的影响。
图1以“性别”为行变量,“专业”为列变量的列联表
图2以“性别”为行变量,“专业”为列变量的复式条形图
图4以“性别”为行变量,“家庭住址”为列变量的列联
图1以“性别”为行变量,“家庭住址”为列变量的复式条形图图1以“性别”为行变量,“家庭住址”为列变量的卡方分布
图1以“是否签约”为行变量,“就业形势看法”为列变量的交叉列联表图2以“是否签约”为行变量,“就业形势看法”为列变量的卡方检验
图3 以“是否签约”为行变量,“就业形势看法”为列变量的复式条形图图4 以“是否签约”为行变量,“预期薪酬”为列变量的交叉列联表
图6 以“是否签约”为行变量,“预期薪酬”为列变量的复式条形图
图7 以“是否签约”为行变量,“理想就业单位”为列变量的交叉列联表
图10 以“是否签约”为行变量,“培养模式契合”为列变量的列联表
图12 以“是否签约”为行变量,“培养模式契合”为列变量的复式条形图
图14 以“是否签约”为行变量,“在校努力与最终就业”为列变量的卡方检验图15 以“是否签约”为行变量,“在校努力与最终就业”为列变量的复式条形图图16 以“是否签约”为行变量,“所学专业与就业应该怎样”为列变量的列联表
图18 以“是否签约”为行变量,“所学专业与就业应该怎样”为列变量的复式条形图
(3)使用方差分析的方法探索不同性别在性别、形象、英语水平、计算机水平、毕业高校、专业背景、资格证书、社会实践经历、在校成绩这些因素对就业的影响方面的看法是否显著不同。
操作步骤及显示结果:。