二分图
- 格式:ppt
- 大小:1.02 MB
- 文档页数:40

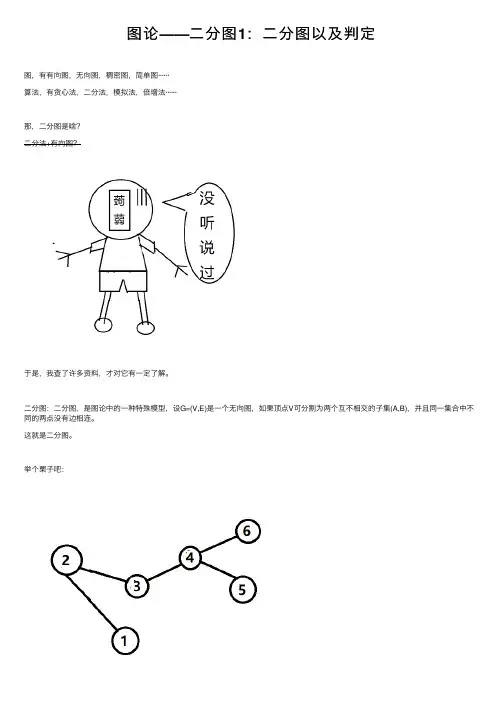
图论——⼆分图1:⼆分图以及判定图,有有向图,⽆向图,稠密图,简单图······算法,有贪⼼法,⼆分法,模拟法,倍增法······那,⼆分图是啥?⼆分法+有向图?于是,我查了许多资料,才对它有⼀定了解。
⼆分图:⼆分图,是图论中的⼀种特殊模型,设G=(V,E)是⼀个⽆向图,如果顶点V可分割为两个互不相交的⼦集(A,B),并且同⼀集合中不同的两点没有边相连。
这就是⼆分图。
举个栗⼦吧:这是不是⼆分图?反正我第⼀次看觉得不是其实,是的,他是⼆分图,尽管看上去是连着的。
若我们将图中的⼀些边转⼀下,变成:这就是⼀个明显的⼆分图。
集合A与B中的点互不相连。
因此,在⼿动判定⼆分图时学会转边!辣魔,⼆分图要⽤计算机判定怎么实现?数竞⼤佬:简单!!!!染⾊⼤法!!!有没有熟悉的感觉0表⽰还未访问,1表⽰在集合A中,2表⽰在集合B中。
col(color)储存颜⾊。
初始化为0.上代码:其实是模板可以记忆。
1 vector <int> v[N];2void dfs(int x,int y){3 col[x]=y;4for (int i=0; i<v[x].size(); i++) {5if (!col[v[x][i]]) dfs(v[x][i],3-y);6if (col[v[x][i]]==col[x]) FLAG=true; //产⽣了冲突7 }8 }9for (i=1; i<=n; i++) col[i]=0; //初始化10for (i=1; i<=n; i++) if (!col[i]) dfs(i,1); //dfs染⾊11if (FLAG) cout<<"NO"; else cout<<"YES";下⼀章我们将讲到⼆分图的匹配,我们明天见。

设G=(V,{R})是一个无向图。
如顶点集V可分割为两个互不相交的子集,并且图中每条边依附的两个顶点都分属两个不同的子集。
则称图G为二分图。
v给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
v选择这样的边数最大的子集称为图的最大匹配问题(maximal matching problem)v如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
最大匹配在实际中有广泛的用处,求最大匹配的一种显而易见的算法是:先找出全部匹配,然后保留匹配数最多的。
但是这个算法的复杂度为边数的指数级函数。
因此,需要寻求一种更加高效的算法。
匈牙利算法是求解最大匹配的有效算法,该算法用到了增广路的定义(也称增广轨或交错轨):若P是图G中一条连通两个未匹配顶点的路径,并且属M的边和不属M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M 的一条增广路径。
由增广路径的定义可以推出下述三个结论:v 1. P的路径长度必定为奇数,第一条边和最后一条边都不属于M。
v 2. P经过取反操作(即非M中的边变为M中的边,原来M中的边去掉)可以得到一个更大的匹配M’。
v 3. M为G的最大匹配当且仅当不存在相对于M的增广路径。
从而可以得到求解最大匹配的匈牙利算法:v(1)置M为空v(2)找出一条增广路径P,通过取反操作获得更大的匹配M’代替Mv(3)重复(2)操作直到找不出增广路径为止根据该算法,我选用dfs (深度优先搜索)实现。
程序清单如下:int match[i] //存储集合m中的节点i在集合n中的匹配节点,初值为-1。
int n,m,match[100]; //二分图的两个集合分别含有n和m个元素。
bool visit[100],map[100][100]; //map存储邻接矩阵。
bool dfs(int k){int t;for(int i = 0; i < m; i++)if(map[k][i] && !visit[i]){visit[i] = true;t = match[i];match[i] = k; //路径取反操作。

二分图的最优匹配(KM算法)KM算法用来解决最大权匹配问题:在一个二分图内,左顶点为X,右顶点为Y,现对于每组左右连接XiYj有权wij,求一种匹配使得所有wij的和最大。
基本原理该算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转化为求完备匹配的问题的。
设顶点Xi的顶标为A[ i ],顶点Yj的顶标为B[ j ],顶点Xi与Yj之间的边权为w[i,j]。
在算法执行过程中的任一时刻,对于任一条边(i,j),A[ i ]+B[j]>=w[i,j]始终成立。
KM算法的正确性基于以下定理:若由二分图中所有满足A[ i ]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。
首先解释下什么是完备匹配,所谓的完备匹配就是在二部图中,X点集中的所有点都有对应的匹配或者是Y点集中所有的点都有对应的匹配,则称该匹配为完备匹配。
这个定理是显然的。
因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和。
所以相等子图的完备匹配一定是二分图的最大权匹配。
初始时为了使A[ i ]+B[j]>=w[i,j]恒成立,令A[ i ]为所有与顶点Xi关联的边的最大权,B[j]=0。
如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。
我们求当前相等子图的完备匹配失败了,是因为对于某个X顶点,我们找不到一条从它出发的交错路。
这时我们获得了一棵交错树,它的叶子结点全部是X顶点。
现在我们把交错树中X顶点的顶标全都减小某个值d,Y顶点的顶标全都增加同一个值d,那么我们会发现:1)两端都在交错树中的边(i,j),A[ i ]+B[j]的值没有变化。
也就是说,它原来属于相等子图,现在仍属于相等子图。
2)两端都不在交错树中的边(i,j),A[ i ]和B[j]都没有变化。


⼆分图概念及性质 段段续续的看⼆分图已经有些时⽇了。
现在借着周末整理⼀下这么多天对⼆分图的掌握程度。
也好对⼆分图有个整体的认知。
另外,此⽂只针对与⼆分图的⼀些概念和性质,不涉及求最⼤匹配的算法。
好吧,切⼊正题: ⾸先我们抛开⼆分图严谨准确的定义,从⼀个感性的⾓度来认识⼀下什么是⼆分图。
所谓⼆分图,就是能够把图中的定点分成两个X,Y两部分;并且整个图的边只存在于X与Y之间。
就是说,X与Y的内部是不存在边的,否则的话就不是⼆分图了。
举个例⼦:如果把整个⼈类中的男⼈和⼥⼈看成顶点,⼈与⼈之间的恋爱关系(这⾥只讨论异性之间的正常恋爱,同性恋是不被承认的)为边来建⽴图模型的话。
那么这其实就是⼀个⼆分图,其中的男⼈为X部分,⼥⼈为Y部分。
好了,现在我们给出⼆分图严谨的科学定义: 假设图G=(V,E)是⼀个⽆向图,若顶点集 V 可以分解成两个互不相交的⼦集(A,B),并且图中的所有边(i,j)的端点 i,j 分别属于⼦集 A,B 中的元素,则称图 G 是⼀个⼆分图。
为了更好的叙述下⽂,先让我们清楚⼀个概念: 匹配:⽆公共点的边集合。
(形象点就是 X与Y之间的边的个数) 匹配数:边集中边的个数。
最⼤匹配:匹配数最⼤的匹配。
边独⽴集:指图中边集的⼀个⼦集,且该⼦集中的任意两条边之间没有公共点。
(对⽐匹配的概念我们发现,其实边独⽴集和匹配是⼀个概念) 最⼤边独⽴集:包含边数最多的边独⽴集。
(其实就是最⼤匹配,为了⽅便,以后统称最⼤匹配)图1如图1,如果<1,4>是⼀个合法匹配,那么<1,5>就不是⼀个合法的匹配,因为它们有公共点1 。
同样的如果<2,5>是⼀个合法的匹配,那么<2,6>和<3,5>就不是⼀个合法的匹配。
不难看出,其中最⼤匹配是边集:{1, 4, 5},最⼤匹配数为3 。
独⽴集: 是指图的顶点集的⼀个⼦集,且该⼦集中的任意两个顶点之间不存在边。

二分图的定义二分图的定义非常简单,有两组顶点,一组顶点记为L ,另一组记为R ,L 和R 没有公共的元素,并且所有的边都是连接L 和R 中的点的,对于L 和R 本身,它们内部的任何两个点都没有边相连,这样的无向图就叫二分图。
《组合数学》上这样讲解:二分图可描述为:一,顶点的集合;二,将该顶点集分成两部分的一个划分;三,连接一部分的一个顶点与另一部分的一个顶点的边的集合。
二分图是无向图,那么什么样的无向图是二分图呢?有以下定理:定理:无向图G 为二分图的充分必要条件是,G 至少有两个顶点, 且其所有回路的长度均为偶数。
证明:至少两个顶点,这个显然,把这个条件忽略掉,着重考虑回路长度为偶数这一条件。
先证充分性:由于图中可能有回路也可能无回路,无回路的情况应该最简单,自然考虑分类讨论。
于是,分类讨论后,充分性的证明转化成以下两个命题:a)所有无回路的无向图都是二分图;b)所有有回路且回路长度为偶数的无向图都是二分图。
对于a) ,因为无回路无向图总是能把它画成一棵树,所以,这个命题等价于:所有的树都是二分图。
到这里,命题a) 证明显然,因为有一种很简单的从树构造二分图的方法:令树的奇数层的结点为集合L ,令树的偶数层结点为集合R ,这样就从树得到了一个二分图。
再看命题b) ,可以把b) 转化为a) 。
对于图中的每一个回路,我们都从中拿掉一条边,这样可以消灭所有的回路,由a) 知消灭掉所有回路之后的图是二分图。
把此时得到的二分图画成一棵树,拿掉一条边后的回路此时就是树中的一条路径,并且路径的长度为奇数,这就意味着路径的头结点和尾结点所在层数的编号一个是奇数一个是偶数,用上面的从树构造二分图的方法知,头结点和尾结点分别在集合L 中和集合R 中,我们再把拿掉的这条边加上去,只不过是在L 和R 中的两个顶点间连接了一条边,图仍然是原来的二分图。
至此,充分性得证。
再证必要性。
假设二分图中的一条回路是(v0, v1, v2, …, vm, v0) ,由于是二分图,相邻顶点必不属于同一个集合,用L 标记属于集合L 的点,用R 标记属于集合R 的点,不妨假设v0 属于L ,则上面的回路可以标记为L, R, L, R, …, L, R ,由此可见,回路必有偶数个顶点,因此必有偶数条边。

最大二分图匹配(匈牙利算法)二分图指的是这样一种图:其所有的顶点分成两个集合M和N,其中M或N中任意两个在同一集合中的点都不相连。
二分图匹配是指求出一组边,其中的顶点分别在两个集合中,并且任意两条边都没有相同的顶点,这组边叫做二分图的匹配,而所能得到的最大的边的个数,叫做最大匹配。
计算二分图的算法有网络流算法和匈牙利算法(目前就知道这两种),其中匈牙利算法是比较巧妙的,具体过程如下(转自组合数学):令g=(x,*,y)是一个二分图,其中x={x1,x2...},y={y1,y2,....}.令m为g中的任意匹配。
1。
将x的所有不与m的边关联的顶点表上¥,并称所有的顶点为未扫描的。
转到2。
2。
如果在上一步没有新的标记加到x的顶点上,则停,否则,转33。
当存在x被标记但未被扫描的顶点时,选择一个被标记但未被扫描的x的顶点,比如xi,用(xi)标记y 的所有顶点,这些顶点被不属于m且尚未标记的边连到xi。
现在顶点xi 是被扫描的。
如果不存在被标记但未被扫描的顶点,转4。
4。
如果在步骤3没有新的标记被标记到y的顶点上,则停,否则转5。
5。
当存在y被标记但未被扫描的顶点时。
选择y的一个被标记但未被扫描的顶点,比如yj,用(yj)标记x的顶点,这些顶点被属于m且尚未标记的边连到yj。
现在,顶点yj是被扫描的。
如果不存在被标记但未被扫描的顶点则转道2。
由于每一个顶点最多被标记一次且由于每一个顶点最多被扫描一次,本匹配算法在有限步内终止。
代码实现:bfs过程:#include<stdio.h>#include<string.h>main(){bool map[100][300];inti,i1,i2,num,num1,que[300],cou,stu,match1[100],match2[300],pqu e,p1,now,prev[300],n;scanf("%d",&n);for(i=0;i<n;i++){scanf("%d%d",&cou,&stu);memset(map,0,sizeof(map));for(i1=0;i1<cou;i1++){scanf("%d",&num);for(i2=0;i2<num;i2++){scanf("%d",&num1);map[i1][num1-1]=true;}}num=0;memset(match1,int(-1),sizeof(match1)); memset(match2,int(-1),sizeof(match2)); for(i1=0;i1<cou;i1++){p1=0;pque=0;for(i2=0;i2<stu;i2++){if(map[i1][i2]){prev[i2]=-1;que[pque++]=i2;}elseprev[i2]=-2;}while(p1<pque){now=que[p1];if(match2[now]==-1)break;p1++;for(i2=0;i2<stu;i2++){if(prev[i2]==-2&&map[match2[now]][i2]){prev[i2]=now;que[pque++]=i2;}}}if(p1==pque)continue;while(prev[now]>=0){match1[match2[prev[now]]]=now; match2[now]=match2[prev[now]]; now=prev[now];}match2[now]=i1;match1[i1]=now;num++;}if(num==cou)printf("YES\n");elseprintf("NO\n");}}dfs实现过程:#include<stdio.h>#include<string.h>#define MAX 100bool map[MAX][MAX],searched[MAX]; int prev[MAX],m,n;bool dfs(int data){int i,temp;for(i=0;i<m;i++){if(map[data][i]&&!searched[i]){searched[i]=true;temp=prev[i];prev[i]=data;if(temp==-1||dfs(temp))return true;prev[i]=temp;}}return false;}main(){int num,i,k,temp1,temp2,job;while(scanf("%d",&n)!=EOF&&n!=0) {scanf("%d%d",&m,&k);memset(map,0,sizeof(map));memset(prev,int(-1),sizeof(prev)); memset(searched,0,sizeof(searched));for(i=0;i<k;i++){scanf("%d%d%d",&job,&temp1,&temp2); if(temp1!=0&&temp2!=0)map[temp1][temp2]=true;}num=0;for(i=0;i<n;i++){memset(searched,0,sizeof(searched)); dfs(i);}for(i=0;i<m;i++){if(prev[i]!=-1)num++;}printf("%d\n",num);}}。


算法———艺术二分图匹配剖析很多人说,算法是一种艺术。
但是对于初学者的我,对算法认识不是很深刻,但偶尔也能感受到他强大的魅力与活力。
这让我追求算法的脚步不能停止。
下面我通过分析匈牙利算法以及常用建图方式,与大家一起欣赏算法的美。
匈牙利算法匈牙利算法是用来解决最大二分图匹配问题的,所谓二分图即“一组点集可以分为两部分,且每部分内各点互不相连,两部分的点之间可以有边”。
所谓最大二分图匹配即”对于二分图的所有边,寻找一个子集,这个子集满足两个条件,1:任意两条边都不依赖于同一个点。
2:让这个子集里的边在满足条件一的情况下尽量多。
首先可以想到的是,我们可以通过搜索,找出所有的这样的满足上面条件的边集,然后从所有的边集中选出边数最多的那个集合,但是我们可以感觉到这个算法的时间复杂度是边数的指数级函数,因此我们有必要寻找更加高效的方法。
目前比较有效的方法有匈牙利算法和通过添加汇点和源点的网络流算法,对于点的个数都在200 到300 之间的数据,我们是采取匈牙利算法的,因为匈牙利算法实现起来要比网络流简单些。
下面具体说说匈牙利算法:介绍匈牙利之前,先说说“增广轨”。
定义:若P是图G中一条连通两个未匹配顶点的路径,并且属最大匹配边集M的边和不属M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广轨定义总是抽象的下面通过图来理解它。
图中的线段(2->3, 3->1, 1->4)便是上面所说的p路径,我们假定边(1,3)是以匹配的边,(2,3)(1,4)是未匹配的边,则边(4,1)边(1,3)和边(3,2)在路径p上交替的出现啦,那么p就是相对于M的一条增广轨,这样我们就可以用边1,4 和边2,3来替换边1,3 那么以匹配的边集数量就可以加1,。
匈牙利算法就是同过不断的寻找增广轨实现的。
很明显如果二分图的两部分点分别为n 和m,那么最大匹配的数目应该小于等于MIN(n,m); 因此我们可以枚举任第一部分(的二部分也可以)里的每一个点,我们从每个点出发寻找增广轨,最后吧第一部分的点找完以后,就找到了最大匹配的数目,当然我们也可以通过记录找出这些边。

【算法】⼆分图的判定⼆分图的判定 给定⼀个具有n个顶点的图。
要给图上每个顶点染⾊,并且要使相邻的顶点颜⾊不同。
判断是否能最多⽤两种颜⾊进⾏染⾊。
题⽬保证没有重边和⾃环。
概念:把相邻顶点染成不同颜⾊的问题叫做图的着⾊问题。
对图进⾏染⾊所需要的最⼩颜⾊数称为最⼩着⾊度。
最⼩着⾊度为2的图称作⼆分图。
分析:如果只⽤两种颜⾊,那么确定⼀个顶点的颜⾊之后,和它相邻的顶点的颜⾊也就确定了。
因此,选择任意⼀个顶点出发,依次确定相邻顶点的颜⾊,就可以判断是否可以被2种颜⾊染⾊了。
这个问题⽤深度优先搜索可以简单实现。
#include <bits\stdc++.h>using namespace std;#define MAX_V 1000//输⼊vector<int> G[MAX_V]; //图int V; //顶点数int color[MAX_V]; //顶点的颜⾊(1 or -1)//顶点v,颜⾊cbool dfs(int v,int c){color[v] = c;//把当前顶点相邻的顶点扫⼀遍for(int i = 0;i < G[v].size(); i++){//如果相邻顶点已经被染成同⾊了,说明不是⼆分图if(color[G[v][i]] == c) return false;//如果相邻顶点没有被染⾊,染成-c,看相邻顶点是否满⾜要求if(color[G[v][i]] == 0 && !dfs(G[v][i],-c)) return false;}//如果都没问题,说明当前顶点能访问到的顶点可以形成⼆分图return true;}void solve(){//可能是不连通图,所以每个顶点都要dfs⼀次for(int i = 0;i < V; i++){if(color[i] == 0){//第⼀个点颜⾊为 1if(!dfs(i,1)){cout << "No" << endl;return;}}}}int main(){//输⼊}。
二分图又称双分图、二部图,指顶点可以分成两个不相交的集使得在同一个集内的顶点不相邻(没有共同边)的图。
特性∙最小边覆盖集的基数等于最大独立集的基数∙最大独立集的基数与最大匹配的基数之和,等于顶点数目∙连通的二部图:o最小顶点覆盖集的基数等于最大匹配的基数图为二分图当且仅当……∙没有奇数圈∙点色数为2问题简介设G=(V,E)是一个无向图。
如顶点集V可分区为两个互不相交的子集V1,V2之并,并且图中每条边依附的两个顶点都分属于这两个不同的子集。
则称图G为二分图。
二分图也可记为G=(V1,V2,E)。
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
选择这样的子集中边数最大的子集称为图的最大匹配问题(maximal matching problem)如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备,完美匹配。
算法描述求最大匹配的一种显而易见的算法是:先找出全部匹配,然后保留匹配数最多的。
但是这个算法的时间复杂度为边数的指数级函数。
因此,需要寻求一种更加高效的算法。
下面介绍用增广路求最大匹配的方法(称作匈牙利算法,匈牙利数学家Edmonds于1965年提出)。
增广路的定义(也称增广轨或交错轨):若P是图G中一条连通两个未匹配顶点的路径,并且属于M的边和不属于M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广路径。
由增广路的定义可以推出下述三个结论:1-P的路径长度必定为奇数,第一条边和最后一条边都不属于M。
2-将M和P进行异或操作(去同存异)可以得到一个更大的匹配M’。
3-M为G的最大匹配当且仅当不存在M的增广路径。
算法轮廓:(1)置M为空(2)找出一条增广路径P,通过异或操作获得更大的匹配M’代替M(3)重复(2)操作直到找不出增广路径为止时间空间复杂度时间复杂度邻接矩阵:最坏为O(n^3) 邻接表:O(mn) 空间复杂度邻接矩阵:O(n^2) 邻接表:O(m+n)样例程序Program Hungary;CosntMax=100;VarData:Array[1..Max,1..Max] of Boolean;Result:Array[1..Max] of Longint;State:Array[1..Max] of Boolean;M,N1,N2,I,T1,T2,Ans:Longint;Function Dfs(P:Longint):Boolean;VarI:Longint;BeginFor I:=1 to N2 doIf Data[P,I] and Not(State[I]) Then BeginState[I]:=True;If (Result[I]=0) or Dfs(Result[I]) Then BeginResult[I]:=P;Exit(True);End;End;Exit(False);End;BeginReadln(N1,N2,M);Fillchar(Data,Sizeof(Data),False);For I:=1 to M do BeginReadln(T1,T2);Data[T1,T2]:=True;End;Fillchar(Result,Sizeof(Result),0);Ans:=0;For I:=1 to N1 do BeginFillchar(State,Sizeof(State),0);If Dfs(I) Then Inc(Ans);End;Writeln(Ans);End.。
二分图与匹配
满足如下条件的无向图G=<V,E>有非空集合X,Y:X∪Y=V,X∩Y=∅,且每个vᵢ ,vⱼ∈E,都有:vᵢ∈X∧vⱼ∈Y,或者vᵢ∈Y∧vⱼ∈X可以用G=<X,E,Y>表示二分图
完全二分图 : 如果X,Y中任意两个顶点之间都有边,则称为完全二分图
匹配 : 将E的子集M称作一个匹配
最大匹配 : 如果M中的任意两条边都没有公共端点边数最多的匹配称作最大匹配
完全匹配 : 如果X(Y)中的所有的顶点都出现在匹配M中,则称M是X(Y)-完全匹配 如果M既是X-完全匹配,又是Y-完全匹配,称M是完全匹配最大匹配匈牙利算法 : ①任意取一个匹配M (可以是空集或只有一条边) ②令S是非饱和点(尚未匹配的点)的集合 ③如果S=∅,则M已经是最大匹配 ④从S中取出一个非饱和点u₀作为起点,从此起点走交错路(交替属于M和非M的边构成的极大无重复点通路或回路)P ⑤如果P是一个增广路(P的终点也是非饱和点),则令M=M⊕P=(M-P)∪(P-M) ⑥如果P都不是增广路,则从S中去掉u₀,转到step3。
[二分图带权匹配与最佳匹配]什么是二分图的带权匹配?二分图的带权匹配就是求出一个匹配集合,使得集合中边的权值之和最大或最小。
而二分图的最佳匹配则一定为完备匹配,在此基础上,才要求匹配的边权值之和最大或最小。
二分图的带权匹配与最佳匹配不等价,也不互相包含。
我们可以使用KM算法实现求二分图的最佳匹配。
方法我不再赘述,可以参考tianyi的讲解。
KM算法可以实现为O(N^3)。
[KM算法的几种转化]KM算法是求最大权完备匹配,如果要求最小权完备匹配怎么办?方法很简单,只需将所有的边权值取其相反数,求最大权完备匹配,匹配的值再取相反数即可。
KM算法的运行要求是必须存在一个完备匹配,如果求一个最大权匹配(不一定完备)该如何办?依然很简单,把不存在的边权值赋为0。
KM算法求得的最大权匹配是边权值和最大,如果我想要边权之积最大,又怎样转化?还是不难办到,每条边权取自然对数,然后求最大和权匹配,求得的结果a再算出e^a就是最大积匹配。
至于精度问题则没有更好的办法了。
[求最小(大)权匹配的费用流建模方法]求最小(大)权匹配,可以用最小(大)费用最大流的方法。
和二分图最大匹配的构图方法类似,添加附加源S和附加汇T,从S向二分图X集合中每个顶点连接一条权值为0,容量为1的有向边,从Y集合中每个顶点向T也连接一条权值为0,容量为1的有向边。
然后把原有的边变成容量为1,权值不变的有向边。
求从S到T的最小(大)费用最大流,就能求得最小(大)权匹配。
上述建模求最大权匹配的方法求得的一定是最佳匹配(如果存在完备匹配),因为S到X集合每条边全部满流。
如下图所示,最小费用最大流为2。
要求最大权匹配(不一定完备匹配)。
如下图,只需再引入一个顶点A,从X集合的每个顶点向A连接一条容量为1,权值为0的边,然后再由A向T连接一条权值为0,容量不小于|X|的边,求最大费用最大流,这时是100。
最小权匹配也类似,不过新加的边权要为一个极大值,大于所有已有边权值。