二分图理论
- 格式:pdf
- 大小:563.84 KB
- 文档页数:7

分形几何理论在图像处理中的应用随着计算机技术的不断发展,图像处理已经成为了一个日益重要的领域。
分形几何理论作为一种新兴的数学理论,在图像处理中得到了广泛的应用。
本文将介绍分形几何理论在图像处理中的应用,并探讨其在该领域中所发挥的作用。
一、分形几何理论的基本概念和原理分形几何理论是由法国数学家Mandelbrot提出的,它对不规则、复杂的自然物体和现象进行了研究。
分形是指具有自相似性的图形或物体,即整体的一部分与整体的形状相似。
分形几何理论提供了一种描述和分析复杂系统的数学工具。
二、分形几何在图像压缩中的应用图像压缩是图像处理中的一个重要环节,它可以将原始图像的数据进行压缩存储,从而减少存储空间和传输带宽的占用。
分形几何理论可以通过对图像的分解和重构,实现对图像的压缩。
其基本思想是将图像分解为一系列的分形图元,并利用放缩变换对其进行重构,从而实现对图像的压缩和恢复。
三、分形几何在图像增强中的应用图像增强是将原始图像进行处理,以改善图像质量和显示效果的过程。
分形几何理论可以通过对图像的细节进行分解和合成,实现对图像的增强。
其基本思想是通过分形细节的提取和重构,对图像进行增强,使其更加清晰、细腻。
四、分形几何在图像分类与识别中的应用图像分类与识别是图像处理中的一个重要任务,它可以将图像按照其内容进行分类和识别。
分形几何理论可以通过对图像的分形维数和分形特征的提取,实现对图像的分类和识别。
其基本思想是通过分形维数的计算和分形特征的提取,对图像进行特征描述和匹配,从而实现对图像的分类和识别。
五、分形几何在图像生成中的应用图像生成是利用计算机生成新的图像,以满足特定需求的过程。
分形几何理论可以通过对图像的分解和合成,实现对图像的生成。
其基本思想是通过分形的自相似性和可变性,对图像的形状和颜色进行生成,从而实现对图像的创造和设计。
六、分形几何在图像编辑中的应用图像编辑是对原始图像进行修改和处理的过程,以改变图像的外观和内容。

分形几何学摘要:分形几何学作为当今活跃在科学领域和风靡世界的新理论与新学科,它也是一种方法论。
分形作为一门新兴的交叉学科满足了艺术多元化的需求。
分形图案将几何美学与视觉形态融为一体。
分形几何学利用其的自相似性,可以构造出千变万化而又具有任意高分辨率结构的艺术图案,被民众广泛关注。
分形几何学作为科学与艺术交融的载体,已成为当今世界科学文化发展的一大热点。
关键词:分形几何;科学与艺术;自相似中图分类号:g642.0 文献标志码:a 文章编号:1674-9324(2013)25-0133-02一、引言艺术是一种感悟,一如海德格尔所说的“朝向未来”,就艺术而言,无论视觉还是听觉,总包含着新的可能[1]。
法国著名文学家福楼拜早在19世纪中叶预言:“越往前走,艺术越要科学化,同时科学越要艺术化。
两者在山麓分手,回头又在山顶会合”,其实质已表明随着社会的发展和进步,科学与艺术逐步分化然后达到融合,分形艺术则是其最好的载体。
二、分形几何学分形(fractal)理论,是由美籍数学家、哈佛大学教授曼德勃罗特(mandelbrot)1975年提出的,它是20世纪70年代同混沌理论一起发展起来的非线性科学的重要组成部分。
自然界中不规则现象普遍存在,可以充分利用分形理论描述和解释自然界中不光滑、不规则的物体表面及形态,因此分形几何就是描述大自然的几何学。
它不同于传统的欧氏几何中以一维、二维、三维、四维对应的线、面、体和时空来描述物体的形状,分形理论用“分维”(fractal dimension)来描述大自然。
几何学中无法用语言表述的局部或整体概念由于分形的诞生从而得到了解决。
mandelbrot集合是向传统几何学的挑战。
mandelbrot集合其图形边界处具有无限复杂结构,其边界可以无限放大,假如计算机精度不受限制。
无论怎样放大其局部,它总是显示出曲折而且不光滑曲线,即连续不可微。
在生活中,微积分中抽象的光滑曲线实际上是不存在的。

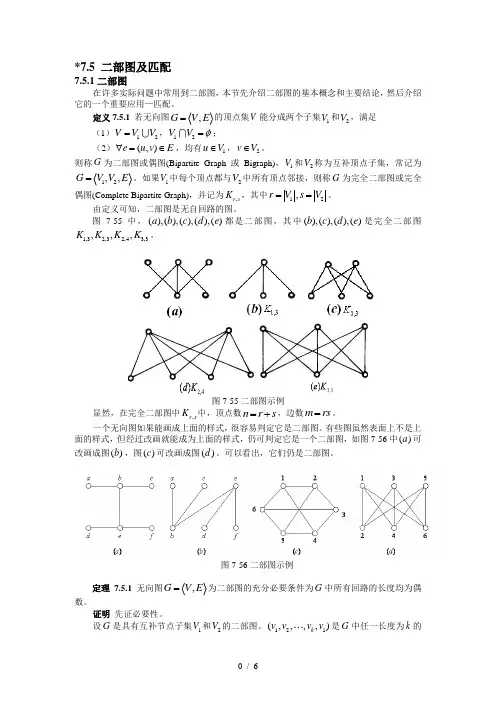
*7.5 二部图及匹配7.5.1二部图在许多实际问题中常用到二部图,本节先介绍二部图的基本概念和主要结论,然后介绍它的一个重要应用—匹配。
定义7.5.1 若无向图,G V E =的顶点集V 能分成两个子集1V 和2V ,满足(1)12V V V =,12V V φ=;(2)(,)e u v E ∀=∈,均有1u V ∈,2v V ∈。
则称G 为二部图或偶图(Bipartite Graph 或Bigraph),1V 和2V 称为互补顶点子集,常记为12,,G V V E =。
如果1V 中每个顶点都与2V 中所有顶点邻接,则称G 为完全二部图或完全偶图(Complete Bipartite Graph),并记为,r s K ,其中12,r V s V ==。
由定义可知,二部图是无自回路的图。
图7-55中,(),(),(),(),()a b c d e 都是二部图,其中(),(),(),()b c d e 是完全二部图1,32,32,43,3,,,K K K K 。
图7-55二部图示例显然,在完全二部图中,r s K 中,顶点数n r s =+,边数m rs =。
一个无向图如果能画成上面的样式,很容易判定它是二部图。
有些图虽然表面上不是上面的样式,但经过改画就能成为上面的样式,仍可判定它是一个二部图,如图7-56中()a 可改画成图()b ,图()c 可改画成图()d 。
可以看出,它们仍是二部图。
图7-56二部图示例定理7.5.1 无向图,G E =为二部图的充分必要条件为G 中所有回路的长度均为偶数。
证明 先证必要性。
设G 是具有互补节点子集1V 和2V 的二部图。
121(,,,,)k v v v v 是G 中任一长度为k 的回路,不妨设11v V ∈,则211m v V +∈,22m v V ∈,所以k 必为偶数,不然,不存在边1(,)k v v 。
再证充分性。
设G 是连通图,否则对G 的每个连通分支进行证明。



基于二部图(Bipartite Network)的推荐算法不必考虑用户和项目的内容信息,它是一种结合物质扩散(Massive Diffusion)理论的推荐算法。
周涛[1]等人研究了一些物理学的知识,比如热传导理论以及物质扩散理论等,并将它们应用在推荐算法中,提出了这种基于二部图的推荐算法。
二部图是一种特殊的网络,它包含有两类不同类型节点,并且仅允许不同类型的节点之间可以有连线。
自然界许多问题可以利用二部图进行解决,比如性别关系、边着色问题等。
在二部图的应用中,同一类型节点之间的合作相互关系成为了研究领域的热点。
比如,可以利用由演员节点和演出剧目节点组成的二部图来研究演员之间在演出中的合作关系。
在一个具体的推荐系统中,可以把用户看作是一类节点,把项目看作是另一类节点。
通过由用户节点和项目节点组成的二部图,我们可以利用相邻的用户为目标用户推荐可能感兴趣的项目。
物质扩散类似于在复杂网络中的随机游走的概念。
它假设在一个系统中有着固定数量的“物质”在传递,并且在传递的过程中这些“物质”的总量始终保持守恒。
最后系统稳定状态的结果与节点的度数成正比。
在推荐系统中,我们认为目标用户所选择过的项目能够提供一定的推荐能力信息。
在操作过程中,首先为每个项目赋予初始资源1。
根据物质扩散的理论,物质的传递过程分两步走。
第一步,每个项目将自己的资源通过二部图的边均匀地分配给选择过该项目的每个用户,这样资源就从项目节点传递到了用户节点。
第二步,每个用户再将自己分配到的资源通过二部图的边平均分配给他选择过的项目,这样资源又传回到了项目节点。
虽然资源的总量在传递过程中是守恒的,但通过两次传递,每个项目所具有资源的分配状态发生了改变。
系统最后可以根据项目所拥有的资源的分布状态来计算它们之间的相似度,并确定最近邻集。
(引入具体的公式,并将改进的论文附上)文献[2]将物质扩散理论运用到了Item-based协同过滤推荐算法。
算法将选选项目的资源初始值都设为1,用稳定状态时两个项目的资源传递总量来表示它们之间的相似程度,最后利用这个相似度来计算目标用户的预测评分,并把评分较高的项目推荐给他。

江恩二分之一理论计算公式江恩二分之一理论
理论跌幅=明显高点-明显低点-明显低点(涨幅反之)------用股票的收盘价线来计算准确率更高
公式是:
最高收盘价-最低收盘价-最低收盘价=调整目标位。
(就是常说的颈线位理论)(图1)
算跌幅抄大底
计算方法是:(复权计算)(高点-低点-低点)的绝对值=理论最低点
⑴ 测算反弹的理论高度
方法是用最高点减去最低点再除以2,然后再加上最低点,即为最后的反弹理论高度。
其计算公式可表述为:X(理论涨幅)= D(最低点或最低价)+[H(最高点或最高价)—D(最低点或最低
价)]÷2。
⑵ 下跌低点的预测
其计算方法是用前期明显高点减前期明显反弹低点二次,负数为多少,就是它的理论跌幅的最低点或最低
价。
用公式表示为:X买入价=H前期高点-前期低点-前期低点
头碰脚跌,脚顶头涨。
(指上涨时碰到前期底点要回调,下跌时到了前期高点要涨)
江恩的二分之一理论:前期高点-(2 次)前期低点。
(就是常说的颈线位理论).。


图像语义分析学习(⼀):图像语义分割的概念与原理以及常⽤的⽅法1图像语义分割的概念1.1图像语义分割的概念与原理图像语义分割可以说是图像理解的基⽯性技术,在⾃动驾驶系统(具体为街景识别与理解)、⽆⼈机应⽤(着陆点判断)以及穿戴式设备应⽤中举⾜轻重。
我们都知道,图像是由许多像素(Pixel)组成,⽽「语义分割」顾名思义就是将像素按照图像中表达语义含义的不同进⾏分组(Grouping)/分割(Segmentation)。
图像语义分割的意思就是机器⾃动分割并识别出图像中的内容,⽐如给出⼀个⼈骑摩托车的照⽚,机器判断后应当能够⽣成右侧图,红⾊标注为⼈,绿⾊是车(⿊⾊表⽰back ground)。
2⽬前常⽤的算法2.1前 DL 时代的语义分割从最简单的像素级别“阈值法”(Thresholding methods)、基于像素聚类的分割⽅法(Clustering-based segmentation methods)到“图划分”的分割⽅法(Graph partitioning segmentation methods),在深度学习(Deep learning, DL)“⼀统江湖”之前,图像语义分割⽅⾯的⼯作可谓“百花齐放”。
在此,我们仅以“Normalized cut” [1]和“Grab cut” [2]这两个基于图划分的经典分割⽅法为例,介绍⼀下前DL时代语义分割⽅⾯的研究。
2.1.1Normalized Cut图像分割在Deeplearning技术快速发展之前,就已经有了很多做图像分割的技术,其中⽐较著名的是⼀种叫做“Normalized cut”的图划分⽅法,简称“N-cut ”。
Normalized cut (N-cut)⽅法是基于图划分(Graph partitioning)的语义分割⽅法中最著名的⽅法之⼀,于 2000 年 Jianbo Shi 和 Jitendra Malik 发表于相关领域顶级期刊 TPAMI。
![二分图中存在哈密顿[k,k+1]因子的条件](https://uimg.taocdn.com/1658b15aad02de80d4d84019.webp)
轮廓分割原理一、引言轮廓分割是图像处理和计算机视觉中的一项基本任务,它涉及到从数字图像中提取出感兴趣对象的边界。
这一过程对于后续的图像分析和理解至关重要,因为它可以帮助我们识别、定位和量化图像中的对象。
轮廓分割的原理和方法在许多领域都有广泛的应用,包括医学成像、遥感图像分析、工业检测、安全监控等。
二、轮廓分割的基本概念轮廓分割是指将图像分割成多个区域或对象,并识别出这些区域的边界。
在这个过程中,通常需要识别出图像中的不同特征,如颜色、纹理、亮度等,并将它们用于构建对象的轮廓。
轮廓分割的目标是尽可能地将图像中的每个独立对象与其周围环境区分开来,以便进行进一步的分析。
三、图像处理中的轮廓分割在图像处理中,轮廓分割通常涉及以下几个步骤:1. 预处理:包括去噪、增强对比度等,以改善图像质量。
2. 特征提取:识别图像中的关键特征,如边缘、角点等。
3. 分割算法应用:根据提取的特征应用不同的分割算法。
4. 后处理:对分割结果进行优化,如去除小的噪声区域、平滑边界等。
四、轮廓分割的算法与技术4.1 边缘检测边缘检测是一种基于图像亮度变化来检测对象边界的技术。
常用的边缘检测算子包括Sobel、Canny和Laplacian等。
这些算子通过计算图像中像素点的梯度强度和方向来识别边缘。
4.2 阈值分割阈值分割是一种简单有效的分割方法,它通过设定一个或多个灰度阈值将图像分为不同的区域。
当像素值高于(或低于)阈值时,该像素被归为对象区域;否则,被归为背景区域。
4.3 区域生长区域生长是一种基于区域相似性的分割方法。
它从一个或多个种子点开始,逐步将相邻的像素点合并到种子点所在的区域,直到满足一定的停止条件。
4.4 分水岭算法分水岭算法是一种基于拓扑理论的分割方法。
它将图像视为地形图,像素值代表高度,通过模拟水流的融合过程来确定区域的边界。
五、轮廓分割在不同领域的应用- 医学成像:用于病变组织的检测和分割,辅助医生进行诊断。
配第——克拉克定理配第——克拉克定理,是一种在计算机科学领域应用广泛的算法定理,可以用来判断无向图是否为二分图。
下面我们将分步骤来介绍这一定理的具体内容。
第一步,了解二分图首先,我们需要了解什么是二分图。
简单来说,二分图是指图中的所有顶点可以被分为两个不相交的子集,每个子集中的顶点之间没有边相连。
在实际应用中,二分图常常被用来表示一些具有互斥关系的问题,比如集合覆盖问题、染色问题等等。
第二步,理解配第算法接下来,我们需要理解配第算法。
配第算法,也称为匈牙利算法,是一种用来解决二分图匹配问题的算法。
在一个二分图中,我们需要找到一个子图,使其所有顶点都能够匹配到另一个子图的顶点。
为了实现这一目的,配第算法采用了一种贪心的思想。
具体来说,该算法从图中任选一个顶点(比如A),然后搜索与之相邻的点,如果找到了一个没有被匹配过的顶点(比如B),就将A和B匹配起来,并标记B 为已匹配。
接着,再找到图中与B相邻但未匹配的点,并将二者匹配起来。
如此循环查找直到无法再匹配为止。
第三步,介绍克拉克定理克拉克定理,也称为配第——克拉克定理,是判断一个无向图是否为二分图的定理。
克拉克定理的核心思想是:如果一个无向图中的每个点的度数都不超过二分图中最大的独立集大小(即子图中每个顶点都没有与自己相邻的点),那么它就是一个二分图。
这个定理的证明跟配第算法有关,通过一系列的推理可以证明,如果一个无向图不是二分图,那么存在一个奇环,且这个奇环大小不小于三。
接着,通过把奇环上的点分为两个集合,即黑白两个集合,就可以得到一个二分图。
第四步,实现配第——克拉克定理最后,我们需要介绍如何实现配第——克拉克定理。
实际上,这个定理的实现非常简单,只需要遍历图中的每个顶点,检查它的度数是否都不超过最大独立集的大小即可。
如果发现某个顶点的度数大于最大独立集的大小,那么这个图就不是一个二分图。
以上就是关于配第——克拉克定理的介绍,这个定理在计算机科学领域应用广泛,有着重要的理论和实际价值。
证明白色路径定理白色路径定理的证明可以通过归纳法来进行。
首先,我们来看一下什么是二分图。
二分图是一种特殊的图,其顶点集可以被分成两个互不相交的子集,使得每条边的两个端点在不同的子集中。
在一个二分图中,如果存在一条奇数长的路径,那么这个图一定存在偶数长的环,而实际上二分图是不可能存在奇数长的环的。
证明白色路径定理的基本思路是利用反证法。
假设存在一条从顶点u到顶点v的最短路径上经过了奇数条边。
我们将这条路径上经过的边全部重新染成红色,不在路径上的边则染成蓝色。
因为最短路径上经过了奇数条边,所以路径的起点和终点的连线是蓝色的。
接下来我们来证明这个情况下一定存在一个奇数长的环。
因为路径的起点和终点的连线是蓝色的,所以我们可以沿着蓝色的边从顶点u到达顶点v。
在顶点v处,我们发现了一条蓝色的边,这条边连接了顶点v和顶点w。
接着我们再沿着蓝色的边从顶点v到顶点w。
在顶点w处,我们又发现了一条蓝色的边,这条边连接了顶点w和顶点x。
我们一直重复这个过程,直到我们再次到达顶点u为止。
这样我们就得到了一条经过奇数个蓝色边的环。
由于我们假设了最短路径上经过了奇数条边,而我们通过反证得到了一条经过了奇数条蓝色边的环,这就产生了矛盾。
因此,我们的假设是错误的,最短路径一定不会经过奇数条边,也就证明了白色路径定理。
上面这一段是白色路径定理证明过程的基本思路,下面我们来进一步展开证明。
首先,我们需要介绍一些图论中使用到的概念和理论。
首先是二分图的概念。
二分图是一个图,其节点可以被分成两个互不相交的子集,使得每条边的两个端点在不同的子集中。
二分图在实际中有着广泛的应用,比如匹配问题、任务分配等。
二分图的性质非常重要,它为后续证明白色路径定理提供了重要的理论基础。
其次是路径的概念。
路径是指图中顶点的一个序列,这些顶点之间依次相连,且每两个相邻的顶点之间有一条边。
路径是图论中的基本概念之一,它在解决实际问题中的路径规划以及网络通信等方面有着重要的应用。
图7-55二部图示例显然,在完全二部图中中,顶点数,边数。
,r s K n r s =+m rs =一个无向图如果能画成上面的样式,很容易判定它是二部图。
有些图虽然表面上不是上面的样式,但经过改画就能成为上面的样式,仍可判定它是一个二部图,如图7-56可改画成图。
可以看出,它们仍是二部图。
)()d 图7-56二部图示例
()a()c()b 利用定理7.5.1可以很快地判断出图7-57中的、是二部图,而则不是二部图。
图7-57
即可。
给出匹配的基本概念和术语。
图7-59匹配问题示意图
设无向图,中有边集,且在中任意两条边都没有公,G V E =G M ⊆E M 共的端点,称边集为图的一个匹配(Matching)。
中一条边的两个端点,叫做在M G M 中不存在匹配,使得,则称为最大匹配(Maximum G 1M 1M M >M
4),(2,5),(3,6)}
图7-60
图7-61的一个匹配。
用(*)标记)a 3152{(,),(,)}M x y x y =V 的新标记过的节点,用()标记不通过中的边与邻接且未标记过的1x 1x M 1x ;类似地,用()标记。
2x 2y 的新标记过的节点, 用()标记通过中的边与1y 1y M 1y ;类似地,用()标记。
2y 5x 的新标记过的节点,因为不存在不通过中的边与邻接的3x M 3x 的节点;用()标记或,假定用()标记5x 3y 4y 5x y
图7-62这个问题即为:二部图是否存在―完全匹配。
当取12,,G V V E =1V ,根据霍尔定理,二部图没有―完全匹配,所以要使每()N A A <1V 个人都能分配到一项工作是不可能的。
基本原理
该算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转化为求完备匹配的问题的。
设顶点Xi的顶标为A[ i ],顶点Yj的顶标为B[ j ],顶点Xi与Yj之间的边权为
w[i,j]。
在算法执行过程中的任一时刻,对于任一条边(i,j),A[ i ]+B[j]>=w[i,j]始终成立。
KM算法的正确性基于以下定理:
若由二分图中所有满足A[ i ]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。
这个定理是显然的。
因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和。
所以相等子图的完备匹配一定是二分图的最大权匹配。
初始时为了使A[ i ]+B[j]>=w[i,j]恒成立,令A[ i ]为所有与顶点Xi关联的边的最大权,B[j]=0。
如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直
到相等子图具有完备匹配为止。
我们求当前相等子图的完备匹配失败了,是因为对于某个X顶点,我们找不到一条从它
出发的交错路。
这时我们获得了一棵交错树,它的叶子结点全部是X顶点。
现在我们把交错
树中X顶点的顶标全都减小某个值d,Y顶点的顶标全都增加同一个值d,那么我们会发现:
1)两端都在交错树中的边(i,j),A[ i ]+B[j]的值没有变化。
也就是说,它原来属于相等子图,现在仍属于相等子图。
2)两端都不在交错树中的边(i,j),A[ i ]和B[j]都没有变化。
也就是说,它原来属于(或不属于)相等子图,现在仍属于(或不属于)相等子图。
3)X端不在交错树中,Y端在交错树中的边(i,j),它的A[ i ]+B[j]的值有所增大。
它原来不属于相等子图,现在仍不属于相等子图。
4)X端在交错树中,Y端不在交错树中的边(i,j),它的A[ i ]+B[j]的值有所减小。
也就说,它原来不属于相等子图,现在可能进入了相等子图,因而使相等子图得到了扩大。
现在的问题就是求d值了。
为了使A[ i ]+B[j]>=w[i,j]始终成立,且至少有一条边进入相等子图,d应该等于:
Min{A[ i ]+B[j]-w[i,j] | Xi在交错树中,Yi不在交错树中}。
改进
以上就是KM算法的基本思路。
但是朴素的实现方法,时间复杂度为O(n4)——需要找
O(n)次增广路,每次增广最多需要修改O(n)次顶标,每次修改顶标时由于要枚举边来求d值,复杂度为O(n2)。
实际上KM算法的复杂度是可以做到O(n3)的。
我们给每个Y顶点一个“松弛量”函数slack,每次开始找增广路时初始化为无穷大。
在寻找增广路的过程中,检查边(i,j)时,如果它不在相等子图中,则让slack[j]变成原值与A[ i ]+B[j]-w[i,j]的较小值。
这样,在修改顶标时,取所有不在交错树中的Y顶点的slack值中的最小值作为d值即可。
但还要注意一点:修改顶标后,要把所有的不在交错树中的Y顶点的slack值都减去d。
Kuhn-Munkras算法流程:
(1)初始化可行顶标的值
(2)用匈牙利算法寻找完备匹配
(3)若未找到完备匹配则修改可行顶标的值
(4)重复(2)(3)直到找到相等子图的完备匹配为止。