数理统计5.2例子
- 格式:pdf
- 大小:36.41 KB
- 文档页数:4





数理统计复习题详解:(姚赛君、黄慧坚编制)方差分析5.1 某灯泡厂试验4种不同材料的灯丝对灯泡寿命的影响,结果如表所示(1)假定4种不同材料的灯丝对灯泡寿命分别服从正态分布,且方差相等,试在显著水平α=0.05下检验这4种灯泡的平均寿命是否有显著差异。
(2)分别给出4种不同的材料灯泡平均寿命的无偏估计值。
解:以α1、α2、α3、α4分别表示不同材料对应的效应,则需检验假设H 0:α1=α2=α3=α4=0 依题意得:r=4,n=19,n 1=6,n 2=5,n 3=4,n 4=4=-=∑∑==r i n j j i T ix x S 112)(96663.16=-=∑∑==r i n j i j i ix x Se 112)(71580S A =S T -S e =25083.16=--=)/()1/(r n Se r S F A 1.7521(统计量)由设定显著水平α=0.05,得F 1-α(r-1,n-r)=F 0.95(3,15)=3.28738(F 分布分位数) F< F 0.95(3,15),不拒绝原假设H 0,因此4种灯泡的平均寿命无显著差异。
(解法:xls ,方差分析) (2)过程未搞,答案:1 690,1668,1655,1590(P29)5.2 某林场对一种树的种子进行了4种不同的种植方法,每种方法试种6粒种子,一段时间后观测树高,获得数据如表所示。
假定树种在4种处理方法下的树高分别服从正态分布,且方差相等。
种植方法及相应树高 单位:cm(2)试求误差项的方差σ2的点估计值。
解:(1)以α1、α2、α3、α4分别表示不同方法种植的效应,则需检验假设H 0:α1=α2=α3=α4=0, 依题意得:r=4,n=28,n 1=7,n 2=7,n 3=7,n 4=7=-=∑∑==r i n j j i T i x x S 112)(902.37857 =-=∑∑==r i n j i j i ix x Se 112)(596.36571S A =S T -S e =306.01286=--=)/()1/(r n Se r S F A 4.10504(统计量)由设定显著水平α=0.05,得F 1-α(r-1,n-r)=F 0.95(3,15)=3.00879(F 分布分位数) F > F 0.95(3,15),拒绝原假设H 0,因此树苗的平均高度有显著差异。

数理统计习题答案习题5.1解答1. 设总体服从()λP 分布,试写出样本的联合分布律. n X X X ,,,12 解:()的分布律为:即X P X ~,λ ()!k e P X k k λλ-==, 0,1,2,,,n k =n X X X ,,,12 的联合分布律为:()n n P X x X x X x ===,,,1122 = ()()()n n P X x P X x P X x === 1122=nx x x x e x e x e nλλλλλλ---⋅2121=λλn n x x xe x x x n-+++!!!1212, n i n x i 0,1,2,,,1,2,, ==2. 设总体X 服从()0,1N 分布,试写出样本的联合分布密度. n X X X ,,,12 解:,即()~0,1X N X 分布密度为:()2221x p x e -=π,+∞<<-∞xn X X X ,,,12 的联合分布密度为:()∏==ni i n x x x p x p112*(),,...=22222221212121n x x x eee --⋅-πππ=()}212exp{122∑=--n i i x n π x i n i ,1,2,, =+∞<<∞-. 3. 设总体X 服从()2,μσN 分布,试写出样本的联合分布密度. n X X X ,,,12 解:()2~,μσX N ,即X 分布密度为:()p x =()}2exp{2122σμπσ--x ,∞<<∞-xn X X X ,,,12 的联合分布密度为:()∏==ni i n x xx p x p 112*,,...)(=)()}21exp{121222∑-⋅⋅-=-ni i n n x μσπσ, x i n i ,1,2,, =+∞<<∞-.4. 根据样本观测值的频率分布直方图可以对总体作什么估计与推断? 解:频率分布直方图反映了样本观测值落在各个区间长度相同的区间的频率大小,可以估计X 取值的位置与集中程度,由于每个小区间的面积就是频率,所以可以估计或推断X 的分布密度. 5. 略. 6. 略.习题5.2解答1. 观测5头基础母羊的体重(单位:kg)分别为53.2,51.3,54.5,47.8,50.9,试计算这个样本观测值的数字特征:(1)样本总和,(2)样本均值,(3)离均差平方和,(4)样本方差,(5)样本标准差,(6)样本修正方差,(7)样本修正标准差,(8)样本变异系数,(9)众数,(10)中位数,(11)极差,(12)75%分位数.解:设53.2,51.3,54.5,47.8,50.954321=====x x x x x()257.7151=∑=i ix,()51.54251==∑=i ix x(3) ss =()2512512xx xnx i ii i-=-∑∑===13307.84-5×51.542=25.982(4)=2s ()∑=-51251i i x x =51ss =5.1964, (5)s =2.28; (6) =s s *ss n 11-=6.4955(7)=2.5486; (8)*s cv =100⨯*xs =4.945;(9)每个数都是一个,故没有众数.(10)中位数为=51.3; (11)极差为54.5-47.8=6.7;(12)0.75分位数为53.2. 3x2. 观测100支金冠苹果枝条的生长量(单位:cm)得到频数表如下:组下限 19.5 24.5 29.5 34.5 39.5 44.5 49.5 54.5 59.5 组上限 24.5 29.5 34.5 39.5 44.5 49.5 54.5 59.5 64.5 组中值 22 27 32 37 42 47 52 57 62频数 8 11 13 18 18 15 10 4 3试计算这个样本观测值的数字特征:(1)样本总和,(2)样本均值,(3)离均差平方和,(4)样本方差,(5)样本标准差,(6)样本修正方差,(7)样本修正标准差,(8)样本变异系数,(9)众数,(10)中位数,(11)极差,(12)75%分位数.解:设组中值依次为,频数依次为,129,,,x x x 129,,,n n n +=++=912n n n n 100,()=∑=911i i in x 3950;()=+=∑=911912i i in xn n x 39.5;()()-=-==∑∑==29129123ss n x x n xnx i i ii i i 210039.5166300-⨯=10275;()==s ss 100142102.75; ()=s 510.137;()=-=*ss n s 1162103.788 ()=*s 710.188;()=⨯=*1008xs cv 25.79;()93742或众数是()50,210=n ;中位数为39.523742=+;()11极差为:62-22=40;()4783,0.7568,12612512分位数为+++=+++=∴n n n n n n .3.略.4. 设是一组实数,a 和是任意非零实数,n x x x ,,,12 b bx ay i i -=(i n 1,, =),x 、y 分别为、的均值, =i x i y 2xs ∑-iixn(x 2)1,=2ys 1n(y y i i-)∑2,试证明:① b x a y -=;② 222b s s x y =. 解①:∑∑==-==ni i ni i b x a ny ny 1111= ()∑=-ni i x a bn11= ⎪⎪⎭⎫ ⎝⎛-∑=n i i x na nb 11= b x a -;②=2y s 1n∑-ii y y 2()=∑=⎪⎪⎭⎫⎝⎛---ni i b x a b x a n121=∑=⎪⎪⎭⎫⎝⎛-ni i b x x n 121=221x s b .1.求分位数(1),(2)()820.05x ()1220.95x 。


习题五1试检验不同日期生产的钢锭的平均重量有无显著差异?(α=0.05) 解 根据问题,因素A 表示日期,试验指标为钢锭重量,水平为5.假设样本观测值(1,2,3,4)ij y j =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .检验的问题:01251:,:i H H μμμμ===L 不全相等 .计算结果:表5.1 单因素方差分析表注释: 当=0.001表示非常显著,标记为 ‘***’,类似地,= 0.01,0.05,分别标记为 ‘**’ ,‘*’ .查表0.95(4,15) 3.06F =,因为0.953.9496(4,15)F F =>,或p = 0.02199<0.05, 所以拒绝0H ,认为不同日期生产的钢锭的平均重量有显著差异.2 考察四种不同催化剂对某一化工产品的得率的影响,在四种不同催化剂下分别做试验 试检验在四种不同催化剂下平均得率有无显著差异?(α=0.05)解根据问题,设因素A 表示催化剂,试验指标为化工产品的得率,水平为4 .假设样本观测值(1,2,...,)ij i y j n =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .其中样本容量不等,i n 分别取值为6,5,3,4 .检验的问题:012341:,:i H H μμμμμ===不全相等 .计算结果:表5.2 单因素方差分析表查表0.95(3,14) 3.34F =,因为0.952.4264(3,14)F F =<,或p = 0.1089 > 0.05,所以接受0H ,认为在四种不同催化剂下平均得率无显著差异 .3 试验某种钢的冲击值(kg ×m/cm2),影响该指标的因素有两个,一是含铜量A ,另试检验含铜量和试验温度是否会对钢的冲击值产生显著差异?(α=0.05) 解 根据问题,这是一个双因素无重复试验的问题,不考虑交互作用.设因素,A B 分别表示为含铜量和温度,试验指标为钢的冲击力,水平为12.假设样本观测值(1,2,3,1,2,3,4)ij yi j ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ=1,2,3,4j = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零;(2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; 计算结果:表5.3 双因素无重复试验的方差分析表查表0.95(2,6) 5.143F =,0.95(3,6) 4.757F =,显然计算值,A B F F 分别大于查表值,或p = 0.0005,0.0009 均显著小于0.05,所以拒绝1020,H H ,认为含铜量和试验温度都会对钢的冲击值产生显著影响作用.设每个工人在每台机器上的日产量都服从正态分布且方差相同 .试检验:(α=0.05)1) 操作工之间的差异是否显著? 2) 机器之间的差异是否显著?3) 它们的交互作用是否显著?解 根据问题,这是一个双因素等重复(3次)试验的问题,要考虑交互作用.设因素,A B 分别表示为机器和操作,试验指标为日产量,水平为12. 假设样本观测值(1,2,3,1,2,3,4)ijk y i j ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ= 1,2,3,4j =,1,2,3k = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;记ij γ为对应于交互作用A B ⨯的主效应; 检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零; (2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; (3)30:ij H γ全部等于零,31:ij H γ不全等于零;计算结果:表5.4 双因素无重复试验的方差分析表查表0.95(3,24) 3.01F =,0.95(2,24) 3.4F =,0.95(6,24) 2.51F =,计算值 3.01,A F <3.4, 2.51B A B F F ⨯>>,或0.05A p >>,而,B A B p p ⨯均显著小于0.05,所以拒绝2030,H H ,接受10H ,认为操作工之间的差异显著,机器之间的差异不显著,它们之间的交互作用显著 . 5 某轴承厂为了提高轴承圈退火的质量,制定因素水平分级如下表所示因素 上升温度℃ 保温时间(h)出炉温度℃水平1 800 6 400 水平28208500试填好正交试验结果分析表并对试验结果进行直观分析和方差分析 .解 根据题意,这是一个3因素2水平的试验问题 .试验指标为硬度的合格率 .应选择正交表44(2)L 来安排试验,随机生成正交试验表如下:方差来源 自由度 平方和 均方 F 值 P 值 因素A 因素B 相互效应A ×B误差 总和3 2 6 24 352.750 27.167 73.5 41.333 144.750.917 13.583 12.250 1.7220.5323 7.8871 7.11290.6645 0.00233** 0.00192**由此可见第三号试验条件为:上升温度800℃、保温时间6h 、出炉温度500℃ . 直观分析需要计算K 值,计算结果如下:直观分析 由计算的K 值知,因素A 、B 、C 的极差分别为70,40,40,因此主次关系为A B C >=,B ,C 相当 .由于试验指标为硬度的合格率,应该是越大越好,所以各确定因素的水平分别是121,,A B C ,即最佳的水平组合是121A B C ,即最佳搭配为:上升温度800℃、保温时间8h 、出炉温度400℃.采用方差分析法,计算得下表:表5.7 方差分析表方差来源平方和 自由度 均方差 F 值 A 1225 1 1225 1 B 400 1 400 0.33 C 400 1 400 0.33 误差 1225 1 1225 总和32504如果显著性检验水平取0.1α=,则查表得0.9(1,1)39.9F =,显然计算的F 值1,0.33A B C F F F ===均小于查表值,所以认为三个因素对结果影响都显著 .6问应选用哪张正交表安排试验,并写出第8号试验的条件;如果9组试验结果为(单位:kg/100m 2):62.925,57.075,51.6,55.05,58.05,56.55,63.225,50.7,54.45,试对该正交试验结果进行直观分析和方差分析.解 该问题属于3因素3水平的试验问题,试验指标为水稻产量 .根据题意应选择正交表49(3)L 来安排试验,随机生成正交表如下:由表可知,第8号试验的条件:品种(A 3)珍珠矮11号,插值密度(B 2)3.75棵/100m 2,施肥量(C 1)0.75kg/100m 2纯氨; 直观分析需要计算K 值,计算结果如下:同上题进行直观分析,得出K 值的大小关系为:111312212223333132,,K K K K K K K K K >>>>>>由直观分析看出:本例较好的水平搭配是:113A B C 采用方差分析法,计算得下表:表5.10 方差分析表方差来源平方和自由度 均方差F 值A 1.759 2 0.879 0.0223B 65.861 2 32.931 0.8361C 6.660 2 3.330 0.0845 误差78.776 239.388 39.3880.9(2,2)9F =,所以认为三个因素对结果影响都不显著.7 在阿魏酸的合成工艺考察中,为了提高产量,选取了原料配比A ,吡啶量B 和反应时间C 三个因素,它们各取了7个水平如下:原料配比A :1.0,1.4,1.8,2.2,2.6,3.0,3.4 吡啶量B :10,13,16,19,22,25,28 反应时间C :0.5,1.0,1.5,2.0,2.5,3.0,3.5试选用合适的均匀设计表安排试验,并写出第7号试验的条件;如果7组试验的结果(收率)为:0.33,0.336,0.294,0.476,0.209,0.451,0.482,试对该均匀试验结果进行直观分析并通过回归分析发现可能更好的工艺条件.解 根据题意选择均匀设计表47(7)U 来安排试验,有3个因素,根据使用表,实验安排如:表5.11 试验安排表6 6 5 4 0.4517 7 7 7 0.482 所以第7号实验的条件为:原配料比3.4,吡啶量28ml,反应时间3.5h.通过直观分析,最好的实验条件是:原配料比3.4,吡啶量28ml,反应时间3.5h. 通过回归分析,最合适的实验条件是:原配料比2.6,吡啶量16ml,反应时间0.5h.习题六1 从某中学高二女生中随机选取8名,测得其升高、体重如下:1 2 3 4 5 6 78身高(cm)160 159 160 157 169 162 165 154体重(kg)49 46 53 41 49 50 48 43在绝对距离下,试用最短距离法和离差平方和法对其进行聚类分析.解由R软件,用最短距离(左)和差离平方和法(右)对题目进行聚类分析如下图6.1,表6.1和表6.2:最短距离法离差平方和法图6.1 聚类树形图表6.1 聚类附表(最短距离法)步骤聚类合并系数首次出现的阶段类别下一步组1 组2 组1 组21 1 6 5.000 0 0 22 1 2 10.000 1 0 43 4 8 13.000 0 0 74 1 7 13.000 2 0 55 1 3 13.000 4 0 66 1 5 17.000 5 0 7表6.2 聚类附表(离差平方和法)2 已知五个变量的距离矩阵为03674012340444401592343331).;2);3)036034022020401000⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭试用最短距离法和最长距离法对这些变量进行聚类,并画出聚类图和二分树.解 针对距离矩阵1),采用两种方法计算如下. ①最短距离法的聚类步骤如下:12345036740159036020w w w w w ⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭a )将()236,1w w f h =合并为一类,,{}11456,,,,H w w w h =距离矩阵如下0743023060⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}()457457),,,2b w w h w w f h ==合并为一类,{}2167,,,H w h h =距离矩阵如下:034030⎛⎫ ⎪⎪ ⎪⎝⎭{}()()1681689),,3,3c w h h w h f h f h ===合并为一类,最后,,聚类图和树状图如图6.2:图6.2 聚类图(左)与树状图(右)②最长距离法与最短距离法类似,步骤如下: a )()236,1w w f h =合并为一类,{}11456,,,,H w w w h =距离矩阵如下0746025090⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭ {}(){}4574572167),,,2,,,b w w h w w f h H w h h ===合并为一类,距离矩阵如下:067090⎛⎫⎪⎪ ⎪⎝⎭{}()()1681689),,69c w h h w h f h f h ===合并为一类,最后,,,聚类图和树状图如图6.3:图6.3 聚类图(左)与树状图(右)(2)针对距离矩阵2)012340234034040⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭①最短距离法的聚类步骤如下 a )()216,1w w f h =合并为一类,{}13456,,,,0342043040H w w w h =⎛⎫⎪⎪ ⎪ ⎪⎝⎭距离矩阵如下{}()367367),,,2b w h h w h f h ==合并为一类,{}24567,,,,H w w h h =聚类矩阵如下:043040⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,聚类图和树状图如图6.4:图6.4 聚类图(左)与树状图(右)②由于本题数据的特殊性,最长距离法与最短距离法结果相同(略). (3)044440333022010⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭最短距离法的聚类步骤如下a ) ()456,1w w f h =合并为一类,{}11236,,,,H w w w h =距离矩阵如下0444033020⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}(){}36736724567),,,2,,,,b w h h w h f h H w w h h ===合并为一类,距离矩阵如下:044030⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,,聚类图和树状图如图6.5:图6.5 聚类图(左)与树状图(右)由于本题数据的特殊性,最长距离法与最短距离法结果相同(略).3 在一项关于作物对土壤营养的反应的研究中,要测定土壤的总磷量和总氮量(占干物质重的百分比),今对10份土样测得数据如下:总氮量(%)0.120.63 1.19 2.30 1.29 0.73 0.52 0.33 0.61 0.470.66在绝对距离下,试用重心法对其进行聚类分析.解由R软件得到重心法聚类分析的结果如图6.6与表6.3:图6.6 聚类树形图表6.3 聚类过程记录表步骤聚类合并系数首次出现的阶段类别下一步组1 组2 组1 组21 1 8 .001 0 0 22 1 10 .002 1 0 43 6 9 .005 0 0 64 15 .010 2 0 75 2 4 .010 0 0 86 67 .027 3 0 77 1 6 .048 4 6 88 1 2 .459 7 5 99 1 3 2.572 8 0 04 1975年Dagnelie收集了11年的气象数据资料如下表变量年序x1x2x3x4其中:x 1—前一年11月12日的降水量;x 2—7月均温;x 3—7月降雨量;x 4—月日辐射,试对这四个气象因子进行主成分分析. 解 由R 软件分析得到如下表6.4,6.5:表6.4 各主成分的重要性:主成分1 主成分2 主成分3 主成分4 标准差 1.6103349 0.9890848 0.53407741 0.37854199 方差贡献率 0.6482947 0.2445722 0.07130967 0.03582351 累积贡献率0.64829470.89286680.964176491.00000000表6.5 因子荷载:主成分1 主成分2 主成分3 主成分4 X1 0.291 0.871 0.332 -0.214 X2 -0.506 0.425 -0.742 -0.111 X3 0.577 0.136 -0.418 0.688 X4-0.5710.2050.4040.685由于前两个主成分对应的累积贡献率已经达到89.287,因此选取主成分的数目为2.5 对某初中12岁的女生进行体检,测量其身高x 1、体重x 2、胸围x 3和坐高x 4,共测得58个样本,并算得1234(,,,)x x x x x ='的样本协方差为19.9410.5023.566.5919.7120.958.637.97 3.937.55S ⎛⎫ ⎪⎪= ⎪ ⎪ ⎪⎝⎭ 试进行样本主成分分析.解 首先计算样本的相关系数矩阵:10.484410.32240.887210.70330.59760.31251⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭设相关系数矩阵的特征值和特征向量分别为d 和v 阵,计算得到0.0546000 0 0.312600= 000.96470 000 2.6681d ⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭即四个特征值依次为:2.6681,0.9647,0.3126,0.0546,前两个主成分的累计贡献率为:90.8471%,因此提取主成分为2.四个特征根相应的特征向量为0.06000.70600.5333 0.4620 0.7317 0.17430.34040.5642=0.60570.19320.60400.48060.30690.65870.48460.4870v -⎛⎫ ⎪-⎪ ⎪--- ⎪-⎝⎭ 因此,两个主成分的表达式为:112340.060.73170.60570.3069z x x x x =+-- 212340.7060.17430.19320.6587z x x x x =-+-+6 比较因子分析和主成分分析模型的异同,阐明两者的关系. 解(1)提取公因子的方法主要有主成分法和公因子法.若采取主成分法,则主成分分析和因子分析基本等价,该法从解释变量的变异的角度出发,尽量使变量的方差能被主成分解释;而公因子法主要从解释变量的相关性角度,尽量使变量的相关程度能被公因子解释,当因子分析目的重在确定结构时则用到该法.(2)主成分分析和因子分析都是在多个原始变量中通过他们之间的内部相关性来获得新的变量,达到既减少分析指标个数,又能概括原始指标主要信息的目的.但他们各有其特点:主成分分析是将n 个原始变量提取m 个支配原始变量的公因子,和1个特殊因子,各因子之间可以相关或不相关.(3)统用降维的方法,但差异也很明显:主成分分析把方差划分为不同的正交成分,而因子分析则把方差化分为不同的起因因子;因子分析中的特征值的计算只能从相关系数矩阵出发,且必须把主成分划分为因子.(4)因子分析提取的公因子比主成分分析提取的主成分更具有可解释性.(5)两者分析的实质及重点不同.主成分的数学模型为Y AX =,因子分析的数学模型为X AF ε=+.因而可知主成分分析是实际上是线性变换,无假设检验,而因子分析是统计模型,某些因子模型是可以得到假设检验的;主成分分析主要综合原始数据的信息,而因子分析重在解释原始变量之间的关系.(6)SPSS 数据的实现:两者都通过“analyzedata reduction Factor ···”过程实现,但主成分分析主要使用“descriptires ”,“extraction ”,“stores ”对话框,而因子分析处使用这些外,还可使用“rotaction ”对话框进行因子旋转.7 试对第4题的变量作因子分析,并将结果和上面的结果进行比较. 解 用SPSS 分析,计算结果如下表6.6-6.8:表6.6 反应压缩比情况表 提取方法: 主成分法计算的相关系数矩阵的特征值和方差贡献率:表6.7 方差解释度提取方法: 主成分法表6.8 主成分矩阵8 为研究某一树种的叶片形态,选取50片叶测量其长度x 1(mm )和宽度x 2(mm ),按样本数据求得其平均值和协方差矩阵为:129048134,92,4845x x S ⎛⎫=== ⎪⎝⎭求出相关系数阵R ,并由R 出发作因子分析;解1)求相关系数矩阵:904810.7303,48900.73031S R ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭ 2)用R 软件求R 的特征根及其相应的特征向量,软件输出结果如下:$values[1] 2.99393809 0.07273809 $vectors[,1] [,2] [1,] 0.7071068 -0.7071068 [2,] 0.7071068 0.7071068122.9939,0.0727,λλ∴==12(),()0.7071,0.7071-0.7071,0.7071T Tηη==3) 求载荷矩阵A :1.22350.19071.22350.1907A -⎛⎫= ⎪⎝⎭4)22121.5333, 1.5333,h h == 0.98810.154*0.98810.154A -⎛⎫= ⎪⎝⎭12121,1,0.3043,0.3043u u v v ===-=,222222000011112,0,()0.9074,20i i iii i i i i i A u B v C u v D u v =========-===∑∑∑∑9 1981年,生物学家Grogan 和Wirth 对两种蠓虫Af 和Apf 根据其触角长度x 1和翼长x 2进行了分类,分类的数据资料如下:Af 1 2 3 4 5 6 7 8 x 1 1.24 1.36 1.38 1.38 1.38 1.40 1.48 1.54 x 2 1.27 1.74 1.64 1.82 1.90 1.70 1.82 1.82 Apf 1 2 3 4 5 6 x 1 1.14 1.18 1.20 1.26 1.28 1.30 x 2 1.78 1.96 1.86 2.00 2.00 1.96 (1)试建立Af 和Apf 的Fisher 判别模型;(2)对样本(1.24,1.80),(1.28,1.84),(1.40,2.04)进行判别分类. 解 (1)建立Fisher 判别模型991122121111(,)(1.42,1.75),(,)(1.23,1.93)99T TT T i i i i i i x x y y μμ======∑∑120.08480.1490.01980.0218,0.1490.39120.02180.039A A ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭12120.0080.0130.0130.0332A A n n ⎛⎫+== ⎪+-⎝⎭∑()120.19,0.18Tμμ-=-,()()121 1.325,1.842T μμ+= 1345.05135.42135.4283.33--⎛⎫= ⎪-⎝⎭∑, 带入Fisher 判别函数 ()12345.05135.42[(,)(1.325,1.84)]0.19,0.18135.4283.33Tx x -⎛⎫-- ⎪-⎝⎭1291.301741.336944.534x x =--(2)把三个样本(1.24,1.80),(1.28,1.84),(1.4,2.04)带入模型,得到结果:三个样本均属于Apf 类.10 在两个玉米品种之间进行判别:137玉米G 1和甜玉米G 2,选取的两个变量是:x 1—玉米果穗长;x 2—玉米果穗直径,两个类的样本容量为n 1=n 2=40,实际算得两个类的样本均值和样本协方差为:121218.5625.348.120 4.4589.661 3.720,,,5.98 4.12 4.458 4.350 3.720 3.410x x S S ⎛⎫⎛⎫⎛⎫⎛⎫==== ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎝⎭试建立G 1,G 2的Bayes 类线性判别函数.解 因为已知两类的样本均值和样本协方差为:12(18.56,5.98),(25.34,4.12)T T x x ==,128.120 4.4589.661 3.720,4.458 4.350 3.720 3.410S S ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭可计算得到修正的公共协方差矩阵和逆矩阵12120.2280.1450.1450.0992A A n n ⎛⎫+== ⎪+-⎝⎭∑,15.6393.738.25147.38--⎛⎫= ⎪-⎝⎭∑()()()121216.78,1.86,21.95,5.052TTμμμμ-=-+= 带入Fisher 判别函数()112121(())()2T W x x μμμμ-=-+-∑ ()()12 5.6393.73[(,)21.95,5.05] 6.78,1.868.25147.38Tx x -⎛⎫=-- ⎪-⎝⎭1274.396.951141.29x x =-+-。


第五章作业题解5.1 已知正常男性成人每毫升的血液中含白细胞平均数是7300, 标准差是700. 使用切比雪 夫不等式估计正常男性成人每毫升血液中含白细胞数在5200到9400之间的概率.解:设每毫升血液中含白细胞数为,依题意得,7300)(==X E μ,700)(==X Var σ由切比雪夫不等式,得)2100|7300(|)94005200(<-=<<X P X P982100700112222=-=-≥εσ.5.2 设随机变量X 服从参数为λ的泊松分布, 使用切比雪夫不等式证明1{02}P X λλλ-<<≥.解:因为)(~λP X ,所以λμ==)(X E 。
λσ==)(2X Var故由切比雪夫不等式,得)|(|)20(λλλ<-=<<X P X P λλλλεσ111222-=-=-≥不等式得证.5.3 设由机器包装的每包大米的重量是一个随机变量, 期望是10千克, 方差是0.1千克2. 求100袋这种大米的总重量在990至1010千克之间的概率.解:设第i 袋大米的重量为X i ,(i =1,2,…,100),则100袋大米的总重量为∑==1001i i X X 。
因为 10)(=i X E ,1.0)(=i X Var ,所以 100010100)(=⨯=X E ,101.0100)(=⨯=X Var由中心极限定理知,101000-X 近似服从)1,0(N故 )10|1000(|)1010990(<-=<<X P X P1)10(2)10|101000(|-Φ≈<-=X P998.01999.021)16.3(2=-⨯=-Φ=5.4 一加法器同时收到20个噪声电压,(1,2,,20)i V i = ,设它们是相互独立的随机变量,并且都服从区间[0,10]上的均匀分布。
记201kk V V==∑,求(105)P V >的近似值。
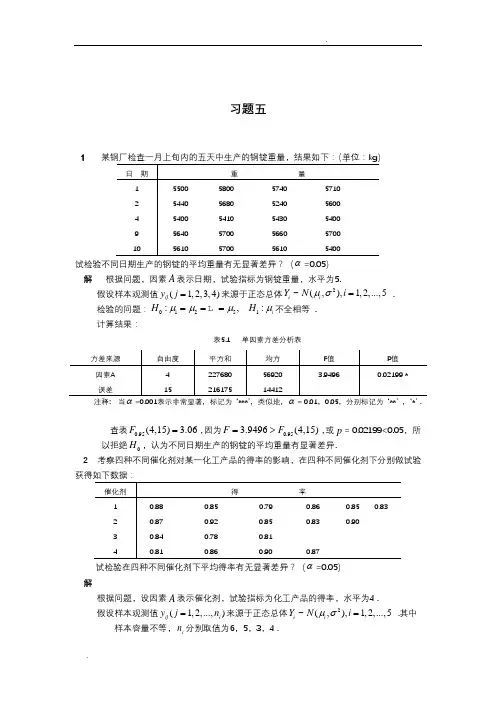
习题五1 某钢厂检查一月上旬内的五天中生产的钢锭重量,结果如下:(单位:k g)日期重旦量1 5500 5800 5740 57102 5440 5680 5240 56004 5400 5410 5430 54009 5640 5700 5660 570010 5610 5700 5610 5400试检验不同日期生产的钢锭的平均重量有无显著差异? ( =0.05)解根据问题,因素A表示日期,试验指标为钢锭重量,水平为 5.2假设样本观测值y j(j 123,4)来源于正态总体Y~N(i, ),i 1,2,...,5检验的问题:H。
:i 2 L 5, H i : i不全相等.计算结果:注释当=0.001表示非常显著,标记为*** '类似地,=0.01,0.05,分别标记为查表F0.95(4,15) 3.06,因为F 3.9496 F0.95(4,15),或p = 0.02199<0.05 ,所以拒绝H。
,认为不同日期生产的钢锭的平均重量有显著差异2 考察四种不同催化剂对某一化工产品的得率的影响,在四种不同催化剂下分别做试验解根据问题,设因素A表示催化剂,试验指标为化工产品的得率,水平为 4 .2假设样本观测值y j(j 1,2,..., nJ来源于正态总体Y~N(i, ), i 1,2,...,5 .其中样本容量不等,n分别取值为6,5,3,4 .日产量操作工查表 F O .95(3,14) 3.34,因为 F 2.4264 F °.95(3,14),或 p = 0.1089 > 0.05, 所以接受H 。
,认为在四种不同催化剂下平均得率无显著差异3试验某种钢的冲击值(kg Xm/cm2 ),影响该指标的因素有两个,一是含铜量 A ,另一个是温度试检验含铜量和试验温度是否会对钢的冲击值产生显著差异? ( =0.05 )解 根据问题,这是一个双因素无重复试验的问题,不考虑交互作用设因素A,B 分别表示为含铜量和温度,试验指标为钢的冲击力,水平为 12.2假设样本观测值y j (i 1,2,3, j 1,2,3,4)来源于正态总体 Y j ~N (j ,),i 1,2,3,j 1,2,3,4 .记i 为对应于A 的主效应;记 j 为对应于B j 的主效应;检验的问题:(1) H i 。