编译原理知识点
- 格式:doc
- 大小:219.50 KB
- 文档页数:7

编译原理知识点
1.1 翻译程序的三种方式
1.编译:将高级语言编写的源程序翻译成等价的机器语言或汇编语言。
2.解释:将高级语言编写的源程序翻译一句执行一句,不生成目标文件,直接执行源代码文件。
3.汇编:用汇编语言编写的源程序翻译成与之等价的机器语言。
1.2 编译程序的五个阶段
1.词法分析:对源程序的字符串进行扫描和分解,识别出每个单词符号。
2.语法分析:根据语言的语法规则,把单词符号分解成各类语法单位。
3.语义分析与中间代码生成:对各种语法范畴进行静态语义检查,若正确则进行中间代码翻译。
4.代码优化:遵循程序的等价变换规则。
5.目标代码生成:将中间代码变换成特定机器上的低级语言代码。
2.1.1 字母表
1.定义:字母表是有穷非空的符号集合。
2.表示:通常用字母表大写字母A,B,…Z和希腊字母Σ表示。
eg:A={0,1},Σ={a,b,c,d}
3.说明
1)字母表包含了语言中所允许出现的一切符号。
2)字母表中的符号也称字符。
2.1.2 符号串
1.定义:由字母表中的符号组成的有穷序列。
2.表示:通常由t,u,v,w,x,y,z等小写英文字母来表示。
3.说明
1)符号串由构成的符号的种类、数量、顺序共同决定。
2)不包含任何符号的符号串称为空符号串,简称空串,用ε表示。
4.对于给定的字母表Σ,符号串的递归定义如下:
1)ε是Σ上的一个符号串。
2)若x是Σ上的符号串,a是Σ的符号,则xa是Σ上的符号串。
并规定。

编译原理知识点范文编译原理是计算机科学中的一门重要课程,它研究的是将高级语言程序转化为机器语言程序的过程。
编译原理主要包括词法分析、语法分析、语义分析、中间代码生成和目标代码生成等几个核心知识点。
一、词法分析词法分析是编译器的第一个阶段,它将输入的字符序列转换为有意义的单词序列。
词法分析器通过扫描输入字符的方式,识别并生成词法单元(Token),例如关键字、标识符、常量、运算符等。
具体的词法分析技术有有限自动机、正则表达式、状态图等。
二、语法分析语法分析是编译器的第二个阶段,它根据词法分析器生成的词法单元序列,分析语言的结构,并构造语法分析树。
语法分析树由各种语法规则组成,其中每个节点代表一个语法规则。
常用的语法分析算法有递归下降法、LL(1)分析法、LR分析法等。
三、语义分析语义分析是编译器的第三个阶段,它对语法树进行静态语义检查,并生成中间代码。
语义分析是一个比较复杂的过程,主要涉及类型检查、作用域分析、常量折叠、类型推导、中间代码生成等。
语义分析是编译原理中最核心的知识点之一四、中间代码生成中间代码生成是编译器的第四个阶段,它将经过语义分析的语法树转化为中间表示形式,以便进一步进行优化和目标代码生成。
中间代码的形式有很多种,常见的有三地址码、四元式、抽象语法树等。
中间代码生成的过程主要包括表达式的转换、控制流语句的转换等。
五、目标代码生成目标代码生成是编译器的最后一个阶段,它将中间代码转换为机器代码。
目标代码生成是编译原理中最复杂、也是最底层的知识点之一、目标代码生成涉及到寄存器分配、指令选择、指令调度、代码填充、代码优化等技术。
常见的目标代码形式有汇编代码、机器代码等。
六、优化优化是编译过程中非常重要的一个环节,它的目标是对生成的中间代码或目标代码进行优化,以提高程序的效率和性能。
常见的编译优化技术包括常量传播、公共子表达式消除、循环优化、函数内联等。
编译器的优化水平对程序的运行效率有着直接的影响。

编译原理部分知识点①编译程序的工作过程一般划分为5个阶段:词法分析,语法分析,语义分析与中间代码生成,优化,目标代码生成【还有表格管理还有出错管理】②编译器常用的语法分析方法两种。
自顶向下,自下而上分析方法。
LR方法(自下而上),LL(1)属于什么方法(自上而下)、算符优先分析法(自下而上)③概念:句子(仅含终结符号的句型是一个句子)、最左素短语(语法树中最左边的素短语为最左素短语)、句柄、(一个句型的最左直接短语)二义:(如果一个文法存在某个句子对应两颗不同的语法树,则称这个文法是二义的)正规文法(左线性文法和右线性文法统称为正规文法)④程序语言的单词符号分为5种(关键字、标识符、常数、运算符、界符)⑤属性通常分为两类(综合属性)(继承属性)⑥LR分析器的实质是一个后进先出确定有限状态自动机。
⑦常用的参数传递方式(传地址),(传值),(传名)(传结果)⑧一个LL(1)文法一定是无二义的。
⑨解释程序、编译处理语言时的特点(源语言程序作为输入,但不产生目标程序,而是边解释边执行源程序本身。
①边解释边执行②有利于程序的调试③ 1次运算)⑩语法分析器作用(按文法的产生式,识别输入符号串是否为一个句子)⑪任何算符优先文法与优先函数的关系(任何算符优先文法可能有若干个优先函数,不一定存在优先函数)⑫确定有限自动机的化简是要实现目的(寻找一个状态数比M少的DFA M’,使得L(M)=L(M’))⑬间接三元式表示法的优点为(采用间接码表,节省三元式空间,便于优化处理)⑭词法分析器任务(从左到右逐个字符地对源程序进行扫描,产生一个个的单词符号,把作为字符串的源程序改造成为单词符号串的中间程序)2、设文法G(S)S→(T)|aT→T+S | S计算FIRSTVT和LASTVT;构造优先关系表。
(1) FIRSTVT(S)={a, ( }FIRSTVT(T)={+, a a, (}LASTVT(S)={a, ) }LASTVT(T)={+, a, )}(2)a + ( )a .> .>+ <. .> <. .>( <. <. <. =.) .> .> >.3、设文法G(S):S→( T ) | aS | aT→T, S | S消除左递归和提取公因子;构造相应的FIRST和FOLLOW集合;构造预测分析表。

编译:编译1、利用编译程序从源语言编写的源程序产生目标程序的过程。
2、用编译程序产生目标程序的动作。
编译就是把高级语言变成计算机可以识别的2进制语言,计算机只认识1和0,编译程序把人们熟悉的语言换成2进制的。
编译原理:编译原理是计算机专业的一门重要专业课,旨在介绍编译程序构造的一般原理和基本方法。
内容包括语言和文法、词法分析、语法分析、语法制导翻译、中间代码生成、存储管理、代码优化和目标代码生成。
编译原理是计算机专业设置的一门重要的专业课程。
编译原理课程是计算机相关专业学生的必修课程和高等学校培养计算机专业人才的基础及核心课程,同时也是计算机专业课程中最难及最挑战学习能力的课程之一。
编译原理课程内容主要是原理性质,高度抽象。
基本概念:编译原理即是对高级程序语言进行翻译的一门科学技术, 我们都知道计算机程序由程序语言编写而成, 在早期计算机程序语言发展较为缓慢, 因为计算机存储的数据和执行的程序都是由0、1代码组合而成的, 那么在早期程序员编写计算机程序时必须十分了解计算机的底层指令代码通过将这些微程序指令组合排列从而完成一个特定功能的程序, 这就对程序员的要求非常高了。
人们一直在研究如何如何高效的开发计算机程序, 使编程的门槛降低。
编译器:C语言编译器是一种现代化的设备, 其需要借助计算机编译程序, C语言编译器的设计是一项专业性比较强的工作, 设计人员需要考虑计算机程序繁琐的设计流程, 还要考虑计算机用户的需求。
计算机的种类在不断增加, 所以, 在对C语言编译器进行设计时, 一定要增加其适用性。
C语言具有较强的处理能力, 其属于结构化语言, 而且在计算机系统维护中应用比较多, C语言具有高效率的优点, 在其不同类型的计算机中应用比较多。
C语言编译器前端设计编译过程一般是在计算机系统中实现的, 是将源代码转化为计算机通用语言的过程。
编译器中包含入口点的地址、名称以及机器代码。
编译器是计算机程序中应用比较多的工具, 在对编译器进行前端设计时, 一定要充分考虑影响因素, 还要对词法、语法、语义进行分析。

编译原理要点整理//红色字体标注的是重点中的重点,大题的归宿第一章引论1.翻译器,编译器的定义2.编译器工作步骤和流程3.编译器前端后端的概念,理解为什么要有前端后端4.“遍”的概念第二章词法分析1.词法分析器的定义2.词法分析器所要完成的任务3.记号,模式,词法单元概念区分4.串的运算(和,连接,指数,闭包,正闭包)5.正规定义6.转换图(注意开始状态和结束状态以及需要将指针回退的状态)7.不确定的有限自动机(NFA)定义8.确定的有限自动机(DFA)定义9.从正规式到NFA(明确通过正规式如何构造连接运算,和运算,闭包运算的NFA)10.此方法产生的NFA的性质11.从NFA到DFA(子集构造法)12.DFA的化简(合并不可区别状态)13.从语言描述直接到DFA14.了解Lex学完本章:能语言描述改写成正规定义,能将正规定义转化为语言描述,给出一个正规式,能转换成相应的NFA,DFA并化简。
第三章语法分析1.上下文无关文法定义2.区分句子和句型3.最左推导&& 最右推导4.分析树5.文法二义性6.消除左递归&& 提左因子7.了解语言鸟瞰(0型文法:短语文法;1型文法:上下文有关文法;2型文法:上下文无关文法;3型文法:正规式)8.FIRST集合&& FOLLOW集合定义及计算方法9.LL(1)文法定义10.了解自上而下的递归下降的预测分析11.自上而下非递归的预测分析(详细明确预测分析器接受某一输入串时的具体过程,明确栈如何变化,输入输出如何变化)12.预测分析表的构造13.句柄的概念14.自下而上的分析方法:用栈实现移近-归约分析(详细明确预测分析器接受某一输入串时的具体过程,明确栈如何变化,输入输出如何变化)15.LR文法和LR分析算法16.构造SLR分析表(从文法构造识别活前缀的DFA(LR(0)项目集规范族),从DFA构造SLR分析表)17.构造规范的LR分析表(从文法构造识别活前缀的DFA(LR(1)项目集规范族),从DFA构造规范的LR分析表)18.构造LALR分析表(从文法构造识别活前缀的DFA(合并同心的LR(1)项目集),从DFA构造规范的LR分析表)(合并同心项目集可能会引起归约-归约冲突,不会引起新的移进-归约冲突)学完本章:能计算FIRST集合和FOLLOW集合;给定一个文法,能判断是否是LL(1)文法,并为其构造分析表;能构造LR(1)文法的三种预测分析表;明确移近归约分析中的每一个步骤,明确栈如何变化。

第一章1. 程序设计语言是人与计算机联系的工具,通过程序设计语言指挥计算机按照自己的意志进行运算和操作显示信息和输出运算结果。
2. 最早的计算机程序设计语言是机器语言(指令系统)。
机器语言中的指令都是用二进制代码直接表示的。
3. 机器语言和符号语言以及汇编语言都是低级程序设计语言。
4. 1954年FORTRAN I语言的问世标志计算机高级程序设计语言的诞生。
5. 计算机高级程序设计语言独立于机器,比较接近于自然语言,容易学习掌握,编写程序效率高,编写的程序易读易理解易移植。
6. 翻译程序:将高级语言编写的程序翻译成机器语言。
7. 编译程序的工作过程:编译程序这要功能是将源程序翻译成等价的目标程序,这个翻译过程分为词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
8. 编译程序的重要意义在于它使高级语言独立于机器语言,使程序员用高级语言编写程序时不必考虑那些直接与机器有关的琐碎的环节,这些细节由编译程序区处理。
9. 编译程序包括:词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序和目标代码生成程序以及表格处理程序和出错处理程序。
10.编译程序的组织方式:编译过程分为六个阶段,改划分是编译程序的逻辑组织方式。
编译过程分为前端和后端。
前端包括词法分析、语法分析、语义分析、中间代码生成、代码优化。
后端包括目标代码生成,依赖于计算机的硬件系统和机器指令系统。
这种组织方式便于编译程序的移植,如果移植到不同类型的机器上只需修改编译程序的后端即可。
11.翻译方式:编译方式和解释方式。
12.源程序:用高级语言编写的程序。
源程序是编译程序加工的对象。
13.编译方式:先将源程序翻译成汇编语言程序或机器语言程序(目标程序),然后再执行。
这个翻译程序为编译程序.14.编译方式中源程序的编译和目标程序的运行时分成两个阶段完成的。
编译所的目标程序计算机暂时不能执行,必须由连接装配程序将目标程序和编译程序及系统子程序连接成一个可执行程序,这个可执行程序可直接被计算机执行。

《编译原理》知识点总结目录第一章引论第二章高级语言及其语法描述第三章语法分析——自上而下分析第四章属性文法和语法制导翻译第五章语义分析和中间代码产生第六章优化第一章引论一.编译程序(compiler):把某一种高级语言程序等价地转换成另一种低级语言程序(如汇编语言或机器语言程序)的程序二.编译程序的工作的五个阶段:词法分析、语法分析、中间代码产生、优化、目标代码产生1.词法分析任务: 输入源程序,对构成源程序的字符串进行扫描和分解,识别出一个个单词符号。
依循的原则:构词规则描述工具:有限自动机FOR I := 1 TO 100 DO保留字标识符等符整常数保留字整常数保留字2.语法分析任务:在词法分析的基础上,根据语言的语法规则把单词符号串分解成各类语法单位。
依循的原则:语法规则述工具:上下文无关文法3.语义分析与中间代码产生任务:对各类不同语法范畴按语言的语义进行初步翻译。
(变量是否定义、类型是否正确等)依循的原则:语义规则中间代码:三元式,四元式,逆波兰记号,树形结构等。
是一种独立于具体硬件的记号系统。
例:将Z:=X + 0.618 * Y 翻译成四元式为(1) * 0.618 Y T1(2) + X T1 T2(3) := T2 _ Z4. 优化任务:对于前阶段产生的中间代码进行加工变换,以期在最后阶段产生更高效的目标代码。
依循的原则:程序的等价变换规则FOR K:=1 TO 100 DOBEGINM := I + 10 * K;N := J + 10 * K;END4.目标代码产生任务: 把中间代码变换成特定机器上的目标代码。
依赖于硬件系统结构和机器指令的含义目标代码三种形式:a)绝对指令代码: 可直接运行b)可重新定位指令代码: 需要连接装配c)汇编指令代码: 需要进行汇编第二章高级语言及其语法描述2.1.1语法词法规则:单词符号的形成规则。
a)单词符号是语言中具有独立意义的最基本结构。

编译原理知识点(总7页) -CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除1.解释程序:不生成目标代码编译程序:生成目标代码2.编译程序组成:8个分析< 前端 >:(词法分析程序、语法分析程序、语义分析程序、中间代码生成程序)综合< 后端 >:(代码优化程序、目标代码生成程序)贯穿始末:表格管理程序、出错处理程序3.文法四元组:终结符号集合Vt 、非终结符号集合Vn、产生式集合P、识别符号(开始符号)SV T∩V N=Φ文法 -> 语言(推导、规约)唯一;语言 -> 文法(凑规则)不唯一。
4.文法分类:0型文法(短语结构文法):左侧至少含有一个非终结符1型文法(上下文有关文法):左侧长度 <= 右侧长度 S->ε除外, S不能出现在右侧2型文法(上下文无关文法):左侧只能有一个非终结符 ( 语法分析 )3型文法(正规文法):A-> aB A->a 右线性; ( 词法分析 )A->Ba 或A->a 左线性(看非终结符位置)5.A*= A0 ∪A+ A0 ={ε} != { } =Φ空集A+ = AA* = A*A6.句型:符号串x是从识别符号S推导出来的,x称为一个句型句子:x仅由终结符号组成,仅含终结符号的句型是一个句子短语:子树的末端(叶子)从左至右连成的串(包括整棵语法树)简单子树:只含有单层分枝的子树直接短语( 简单短语 ):由简单子树的叶子组成句柄:最左边的直接短语(不一定含终结符)素短语:至少含有一个终结符的短语,并且除它自身之外不再含任何更小的素短语最左素短语:最左边的素短语短语:P(相对于T、E)、 P+T(相对于E)、i(相对于P、F)、P+T+i(相对于E)直接短语:P、i 句柄:P (最左边的直接短语)素短语:P+T 、i (至少含有一个终结符的短语)最左素短语:P+T7.二义性文法:有两个不同的最左推导或有两个不同的最右推导或能产生两棵语法树8.文法产生式正规式规则1 A xB B y A = xy规则2 A xA|y A = x*y 右线性A Ax|y A = yx* 左线性规则3 A x A y A = x|y9.DFA 初态唯一,转换函数为单值映射表示方式:转移矩阵、状态转换图状态转换图上若存在一条从初态到某一终态的道路,且这条路上所有弧的标记符连成的字符串为t,则称t被DFA接受。
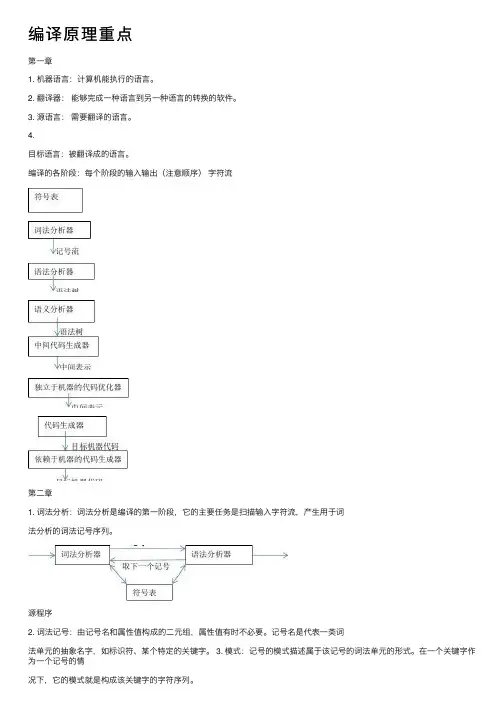
编译原理重点第⼀章1. 机器语⾔:计算机能执⾏的语⾔。
2. 翻译器:能够完成⼀种语⾔到另⼀种语⾔的转换的软件。
3. 源语⾔:需要翻译的语⾔。
4.⽬标语⾔:被翻译成的语⾔。
编译的各阶段:每个阶段的输⼊输出(注意顺序)字符流第⼆章1. 词法分析:词法分析是编译的第⼀阶段,它的主要任务是扫描输⼊字符流,产⽣⽤于词法分析的词法记号序列。
源程序2. 词法记号:由记号名和属性值构成的⼆元组,属性值有时不必要。
记号名是代表⼀类词法单元的抽象名字,如标识符、某个特定的关键字。
3. 模式:记号的模式描述属于该记号的词法单元的形式。
在⼀个关键字作为⼀个记号的情况下,它的模式就是构成该关键字的字符序列。
4.词法单元:单词,是源程序中匹配⼀个记号模式的字符序列,它有词法分析器标识为该记号的实例。
5.例2.1Position = initial + rate * 60 的记号⽤⼆元组序列表⽰:-------唯⼀的,所以可以省略属性值6.字母表:表⽰符号的有限集合。
7.串:字母表中符号的⼜穷序列。
8.串的长度:串s的长度是出现在s中的符号的个数,写为|s|;空串长度为0 记为ε。
9.语⾔:表⽰字母表上的⼀个串集,属于该语⾔的串称为该语⾔的句⼦或字。
10.P17:表2.2语⾔运算的定义,例2.2、例2.3、表2.3正规式的代数定理11.P23:不确定的有限⾃动机(NFA)、P24:确定的有限⾃动机(DFA)-------NFA—DFA转化、DFA 化简。
12.P36—37: 习题2.3、2.7、2.8、2.11、2.12.● 2.3叙述由下列正规式描述的语⾔0(0|1)*0—以0开头和结尾的,长度⾄少是2的01串。
((ε|0)1*)*—所有的01串。
(0|1)*0(0|1)(0|1)—倒数第3位是0的01串。
0*10*10*10*—含有3个1的01串。
(00|11)*((01|10)(00|11)*(01|10)(00|11)*)* —含有偶数个0和偶数个1的01串。
1、名词:解释器/解释程序interpreter ;编译器/编译程序compiler ;翻译器/翻译程序translator 。
三者的区别与联系。
虚拟机(如 JAVA 虚拟机JVM 、Tiny 语言虚拟机)是哪种程 序?(1)解释器(也称为解析程序) 则是只在执行程序时,才一条一条的解释成机器语言给计算 机来执行,所以运行速度是不如编译后的程序运行的快的•(2) 编译器(也称为编译程序)是把源程序的每一条语句都编译成机器语言,并保存成二进 制文件,这样运行时计算机可以直接以机器语言来运行此程序 ,速度很快;(3) 翻译器(也称为翻译程序)是一种系统程序,它将计算机编程语言编写的程序翻译成另 外一种计算机语言的一般来说等价的程序,主要包括编译程序和解释程序,汇编程序也被认 为是翻译程序。
程序的最初形式称为源程序或者源代码,翻译后的形式被称为目标程序或者 目标代码。
大多数翻译程序是将高级语言编写的程序翻译为机器语言形式的可执行程序。
但 是也有些翻译程序将源程序翻译成其他高级语言或者字节码等中间形式。
(4) 解释器翻译源程序时不生成独立的目标程序,而编译器则将源程序翻译成独立的目标程 序。
解释器是另外种形式的语言处理器,它相当于不生成上面的目标程序,直接将输入 放到”源 程序中,然后经过解释器,就得到了输出。
通常情况下,编译过程比解释过程更快,但解释 器能够有更好的错误诊断,因为解释器是逐句进行解释的。
编 .0译器和解释器可以结合起来 进行处理,Java 语言处理器就是其中的代表,其过程是源程序经过翻译器处理后得到中间程 序,也被称作字节码(bytecode ),然后和输入共同加入到虚拟机(virtual machine )的前 端,得到输出,其前一部分用到编译器,后一部分用到解释器,这样做的好处是一个机器解 释的代码可以应用在另外的机器上,甚至可以延伸到网络上。
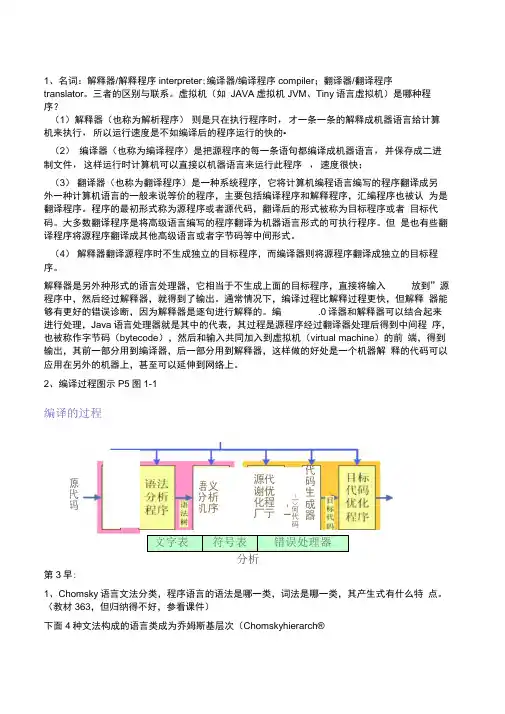
2、编译过程图示P5图1-1编译的过程文字表符号表 错误处理器 分析第3早: 1、Chomsky 语言文法分类,程序语言的语法是哪一类,词法是哪一类,其产生式有什么特 点。

编译原理知识点总结编译原理知识点总结编译原理是大学计算机专业的必修科目,也是计算机的基础知识,学好编译原理,有助于更好的进行编程的操作,下面是编译原理知识点总结,一起来看看吧!编译原理知识点总结一编译器简单讲,编译器就是将“高级语言”翻译为“机器语言(低级语言)”的程序。
一个现代编译器的主要工作流程:源代码(source code) → 预处理器(preprocessor) → 编译器(compiler) → 汇编程序 (assembler) → 目标代码(object code) → 链接器(Linker) → 可执行程序(executables)二工作原理编译是从源代码(通常为高阶语言)到能直接被计算机或虚拟机执行的目标代码(通常为低阶语言或机器语言)的翻译过程。
然而,也存在从低阶语言到高阶语言的编译器,这类编译器中用来从由高阶语言生成的低阶语言代码重新生成高阶语言代码的又被叫做反编译器。
也有从一种高阶语言生成另一种高阶语言的编译器,或者生成一种需要进一步处理的的中间代码的编译器(又叫级联)。
典型的编译器输出是由包含入口点的名字和地址,以及外部调用(到不在这个目标文件中的函数调用)的机器代码所组成的目标文件。
一组目标文件,不必是同一编译器产生,但使用的编译器必需采用同样的输出格式,可以链接在一起并生成可以由用户直接执行的可执行程序三编译器的发展史(1) 20世纪50年代IBM的John Backus带领一个研究小组对FORTRAN语言及其编译器进行开发。
但由于当时人们对编译理论了解不多,开发工作变得既复杂又艰苦。
与此同时,Noam Chomsky开始了他对自然语言结构的研究。
他的发现最终使得编译器的结构异常简单,甚至还带有了一些自动化。
Chomsky的`研究导致了根据语言文法的难易程度以及识别它们所需要的算法来对语言分类。
正如现在所称的Chomsky架构(Chomsky Hierarchy),它包括了文法的四个层次:0型文法、1型文法、2型文法和3型文法,且其中的每一个都是其前者的特殊情况。
第一章引言1.从面向机器的语言到面向人类的语言汇编指令:用符号表示的指令被称为汇编指令汇编语言:汇编指令的集合称为汇编语言2.语言之间的翻译转换(也被称为预处理):高级语言之间的翻译,如FORTRAN到ADA 的转换编译:高级语言可以直接翻译成机器语言,也可以翻译成汇编语言,这两个翻译过程称为编译汇编:从汇编语言到机器语言的翻译被称为汇编交叉汇编:将一个汇编语言程序汇编成为可在另一机器上运行的机器指令成为交叉汇编反汇编:把机器语言翻译成汇编语言反编译:把汇编语言翻译成高级语言3. 编译器与解释器(1)语言翻译的两种基本形态解释器与编译器的主要区别:运行目标程序时的控制权在解释器而不在目标程序.(2)各自特点•编译器:工作效率高,即时间快、空间省;交互性与动态性差,可移植性差.•解释器:工作效率低,,即时间慢、空间费;交互性与动态性好,可移植性好.共同点:均完成对源程序的翻译.差异:编译器采用先翻译后执行,解释器采用边翻译边执行.4. 编译器的工作原理与基本组成(0)通用程序设计语言的主要成份声明+操作=完整定义(1)以过程为基本结构的程序设计语言的组成•声明性语句:提供操作对象的性质,如数据类型、值、作用域等;•操作性语句:确定操作的计算次序,完成实际操作。
•过程定义= 过程头+过程体(2)以阶段划分编译器注:符号表管理器和出错处理贯穿编译器工作的各个阶段.(3)编译器各阶段工作1> 词法分析:词法分析的输入是源程序,输出是识别出的记号流.目的是识别单词. 至少分以下几类:关键字(保留字)、标识符、字面量、特殊符号2> 语法分析:输入是词法分析器返回的记号流,输出是语法树.目的是得到语言结构并以树的形式表示.对于声明性语句,进行符号表的查填,对于可执行语句,检查结构合理的表达式运算是否有意义.3> 语义分析:根据语义规则对语法树中的语法单元进行静态语义检查,如类型检查和转换等,目的在于保证语法正确的结构在语义分析上也是合法的.4> 中间代码生成(可选):生成一种既接近目标语言,又与具体机器无关的表示,便于代码优化与代码生成.(到目前为止,编译器与解释器可以一致)5> 中间代码优化(可选):局部优化、循环优化、全局优化等;优化实际上是一个等价变换,变换前后的指令序列完成同样的功能,但在占用的空间上和程序执行的时间上都更省、更有效6> 目标代码生成:不同形式的目标代码—汇编语言形式、可重定位二进制代码形式、内存形式(Load-and-Go)7> 符号表管理:合理组织符号,便于各阶段查找\填写等.8> 出错处理:动态错误:源程序中的逻辑错误,发生在程序运行的时候。
1、编译程序:能够把用各种高级语言书写的源程序翻译成某种等价的目标程序的翻译程序。
2、遍:指编译程序对源程序或中间代码程序从头到尾扫描一次。
3、静态分配:在编译时就能够安排好目标程序运行时的全部数据空间。
4、编译程序包括词法分析、语法分析、中间代码生成、优化,目标代码产生五个阶段,上述各阶段中还要进行表格处理和出错处理的工作。
5、编译程序可分为五个阶段:词法分析、语法分析、中间代码生成、优化、目标代码生成。
上述五个阶段之间每个阶段输出为作下一阶段的输入,第一阶段的输入是源程序,最后阶段的输出是目标代码。
6、程序语言是由语法和语义两方面定义的。
语法指可以形成和产生一个合式的程序的一组规则,语义是定义一个程序的意义的一组规则。
7、一个名字的属性包括类型和作用域。
8、目标代码一般有三种形式:能够立即执行的机器语言代码,待装配的机器语言模块和汇编语言代码。
9、2型文法又称为(上下文无关文法),3型文法又为(正规文法)。
10、虽然名字都是用标识符表示的,但名字和标识符有着本质的区别。
11、词法分析器的任务是从左至右逐个字符地对源程序进行扫描,产生一个个的单词符号,把作为字符串的源程序改造成单词符号串的中间程序。
12、执行词法分析的程序称为词法分析器或扫描器。
13、词法分析器所输出的单词符号常常表示成如下二元关系:(单词种别,单词自身值)。
14、词法分析器:是一种程序,它能将字符串形式的源程序改造成单词符号串形式的中间程序。
15、程序语言的单词符号包括:(标识符)、(运算符)、(常数)、(基本字)、界符等。
16、超前搜索:在词法分析过程中,有时为了确定词性,需要超前扫描若干个字符,这个动作为超前搜索。
17、状态转换图是一张有限方向图,其中结点代表状态,状态之间用箭弧连接,箭弧上的标记代表在射出结点状态下可能出现的输入字符或字符类,状态中有一个初态,至少有一个终态。
18、自上而下分析的主旨是,对任何输入串,试图用一切可能的办法,从文法开始符号(根结)出发,自上而下地为输入串建立一颗语法树。
编译原理的复习提纲1.编译原理=形式语言+编译技术2.汇编程序:把汇编语言程序翻译成等价的机器语言程序3.编译程序:把高级语言程序翻译成等价的低级语言程序4.解释执行方式:解释程序,逐个语句地模拟执行翻译执行方式:翻译程序,把程序设计语言程序翻译成等价的目标程序5.计算机程序的编译过程类似,一般分为五个阶段:词法分析、语法分析、语义分析及中间代码生成、代码优化、目标代码生成词法分析的任务:扫描源程序的字符串,识别出的最小的语法单位(标识符或无正负号数等)语法分析是:在词法分析的基础上的,语法分析不考虑语义。
语法分析读入词法分析程序识别出的符号,根据给定的语法规则,识别出各个语法结构。
语义分析的任务是检查程序语义的正确性,解释程序结构的含义,语义分析包括检查变量是否有定义,变量在使用前是否具有值,数值是否溢出等。
语法分析完成之后,编译程序通常就依据语言的语义规则,利用语法制导技术把源程序翻译成某种中间代码。
所谓中间代码是一种定义明确、便于处理、独立于计算机硬件的记号系统,可以认为是一种抽象机的程序代码优化的主要任务是对前一阶段产生的中间代码进行等价变换,以便产生速度快、空间小的目标代码编译的最后一个阶段是目标代码生成,其主要任务是把中间代码翻译成特定的机器指令或汇编程序编译程序结构包括五个基本功能模块和两个辅助模块6.编译划分成前端和后端。
编译前端的工作包括词法分析、语法分析、语义分析。
编译前端只依赖于源程序,独立于目标计算机。
前端进行分析编译后端的工作主要是目标代码的生成和优化后端进行综合。
独立于源程序,完全依赖于目标机器和中间代码。
把编译程序分为前端和后端的优点是:可以优化配置不同的编译程序组合,实现编译重用,保持语言与机器的独立性。
7.汇编器把汇编语言代码翻译成一个特定的机器指令序列第二章1.符号,字母表,符号串,符号串的长度计算P18,子符号串的含义,符号串的简单运算XY,Xn,2.符号串集合的概念,符号串集合的乘积运算,方幂运算,闭包与正闭包的概念P19,P20A0={ε}3.重写规则,简称规则。
第一、二章引论、高级语言及其描述1、用汇编语言或高级语言编写的程序,必须先送入计算机,经过转换成用机器语言表示的目标程序(这个过程叫做编译),才能由计算机执行。
执行转换过程的程序叫做编译程序。
汇编程序是指没有编译过的汇编语言源文件。
编译程序转换过的叫做目标程序,也就是机器语言。
2、编译程序是一种翻译程序3、通常一个编译程序中,不仅包含词法分析、语法分析、中间代码生成、代码优化、目标代码生成等五个部分,还应包括表格处理和出错处理,其中中间代码生成和代码优化不是每个编译程序都必须的。
4、产生式是用于定义语法成分的一种书写规则。
5、四种类型的文法的主要特点:6、解释程序和编译程序的区别在于是否生成目标程序。
7、中间代码有:逆波兰记号、树形表示、三元式、四元式等形式8、语法制导翻译即可用来产生中间代码,也可以用来产生目标指令,甚至可用来对输入串进行解释执行。
第三章词法分析3.1 确定的有限自动机DFA M是一个五元组M =(S,∑,δ ,S0 ,F )(1) S 是一个非空有限集,它的每个元素称为一个状态(2)∑是一个有穷字母表,它的每个元素称为一个输入符号,所以也称为输入符号字母表(3)δ是状态转换函数,是在S×å→S上的单值映射(4) s0 s0∈S,是唯一的一个初态(5) F F含于S,可空,是一个终态集,终态也称可接受状态或结束状态3.2 一个NFA M是五元式M=(S,S,δ,S0,F)(1)S 有穷非空状态集合(2)∑ 有穷的输入字母表集合(3)δ 从S´∑*到S的子集的映射(4)S0Í 是S的非空子集,称为初始状态集合(5)F Í 是S的子集(可空),称为终止状态集合3.3 DFA与NFA特点比较DFA特点:1. 初态唯一2. 输入字符不包括空符号串3. 有向边上只有一个字符4. 一个状态对某个字符最多只有一条出边NFA特点:1. 初态不唯一2. 输入字符包括空符号串3. 有向边上可以为字符串4. 一个状态对某个字符可能有多条输出边,即状态的后继不唯一3.4 词法分析是基于正则文法进行,即识别的单词是该文法的句子;语法分析基于上下文无关文法进行,即识别的是该类文法的句子。
可编辑修改精选全文完整版第一章编译概述1.1 翻译程序的三种方式1.编译:将高级语言编写的源程序翻译成等价的机器语言或汇编语言。
2.解释:将高级语言编写的源程序翻译一句执行一句,不生成目标文件,直接执行源代码文件。
3.汇编:用汇编语言编写的源程序翻译成与之等价的机器语言。
1.2 编译程序的五个阶段1.词法分析:对源程序的字符串进行扫描和分解,识别出每个单词符号。
2.语法分析:根据语言的语法规则,把单词符号分解成各类语法单位。
3.语义分析与中间代码生成:对各种语法范畴进行静态语义检查,若正确则进行中间代码翻译。
4.代码优化:遵循程序的等价变换规则。
5.目标代码生成:将中间代码变换成特定机器上的低级语言代码。
第二章文法和语言2.1 符号串和语言2.1.1 字母表1.定义:字母表是有穷非空的符号集合。
2.表示:通常用字母表大写字母A,B,…Z和希腊字母Σ表示。
eg:A={0,1},Σ={a,b,c,d}3.说明1)字母表包含了语言中所允许出现的一切符号。
2)字母表中的符号也称字符。
2.1.2 符号串1.定义:由字母表中的符号组成的有穷序列。
2.表示:通常由t,u,v,w,x,y,z等小写英文字母来表示。
3.说明1)符号串由构成的符号的种类、数量、顺序共同决定。
2)不包含任何符号的符号串称为空符号串,简称空串,用ε表示。
4.对于给定的字母表Σ,符号串的递归定义如下:1)ε是Σ上的一个符号串。
2)若x是Σ上的符号串,a是Σ的符号,则xa是Σ上的符号串。
并规定εa=a,aε=a3)y是Σ上的符号串,当且仅当y由1)和2)导出。
5.子符号串:一个非空符号串中若干连续符号组成的部分。
6.字符串的前缀和后缀若z=abd是字母表Σ={a,b,c,d}上的符号串,则ε,a,ab,abd都是z的前缀;ε,d,bd,abd都是z的后缀。
(正序逆序排序即可,前缀为正序排序的所有子串,后缀为逆序排序的所有子串)7.符号串之间的运算1)连接:符号串x,y的连接xy就是把符号串y写在x后面得到的字符串。
1.解释程序:不生成目标代码编译程序:生成目标代码2.编译程序组成:8个分析< 前端>:(词法分析程序、语法分析程序、语义分析程序、中间代码生成程序) 综合< 后端>:(代码优化程序、目标代码生成程序)贯穿始末:表格管理程序、出错处理程序3.文法四元组:终结符号集合Vt 、非终结符号集合Vn、产生式集合P、识别符号(开始符号)SV T∩V N=Φ文法-> 语言(推导、规约)唯一;语言-> 文法(凑规则)不唯一。
4.文法分类:0型文法(短语结构文法):左侧至少含有一个非终结符1型文法(上下文有关文法):左侧长度<= 右侧长度S->ε除外,S不能出现在右侧2型文法(上下文无关文法):左侧只能有一个非终结符( 语法分析)3型文法(正规文法):A-> aB A->a 右线性;( 词法分析)A->Ba 或A->a 左线性(看非终结符位置)5.A*=A0 ∪A+ A0 ={ε} !={ } =Φ空集A+ =AA* =A*A6.句型:符号串x是从识别符号S推导出来的,x称为一个句型句子:x仅由终结符号组成,仅含终结符号的句型是一个句子短语:子树的末端(叶子)从左至右连成的串(包括整棵语法树)简单子树:只含有单层分枝的子树直接短语( 简单短语):由简单子树的叶子组成句柄:最左边的直接短语(不一定含终结符)素短语:至少含有一个终结符的短语,并且除它自身之外不再含任何更小的素短语最左素短语:最左边的素短语短语:P(相对于T、E)、P+T(相对于E)、i(相对于P、F)、P+T+i(相对于E)直接短语:P、i 句柄:P (最左边的直接短语)素短语:P+T 、i (至少含有一个终结符的短语)最左素短语:P+T7.二义性文法:有两个不同的最左推导或有两个不同的最右推导或能产生两棵语法树8.文法产生式正规式规则1 A→xB B→y A = xy规则2 A→xA|y A = x*y 右线性A→Ax|y A = yx* 左线性规则3 A→x A→y A = x|y9.DFA 初态唯一,转换函数为单值映射表示方式:转移矩阵、状态转换图状态转换图上若存在一条从初态到某一终态的道路,且这条路上所有弧的标记符连成的字符串为t,则称t被DFA接受。
10.NFA初态可为多个,转换函数为多值映射确定化:与某一NFA等价的DFA不唯一1.状态集合I的ε-闭包2.move函数最小化:消除多余状态和合并等价状态多余状态:从自动机的开始状态出发,任何输入串也不能到达的那个状态;或者从这个状态没有通路到达终态。
11.左公因子显式左公因子提取若A→αβ1|αr,则将其改写为:i.A→α(β1|r)ii.或引入新非终结符A→αA’A’→β1|r隐式左公因子:产生式右部以非终结符开始用该非终结符的右部以终结符开始的产生式去替换它,再提取S→aSd|Ac A→aS|b把A的产生式代入S中:S→aSd|aSc|bcS→aS S’S’→d|c S→bc12.左递归1.简单左递归:消除左递归改写为右递归A→Aα|βA→βA’A’→αA’|ε2.间接左递归非终结符号排序(出现频率高的排后面)左部非终结符下标 > 右部时改写(替换右部)消除直接左递归13.自顶向下:LL(1)FIRST:A→X1X2X3…Xn若X1 ⇒εX2 ⇒εX3 !⇒ε后面不用管则FIRST(A)= First(X1)-{ε} U First(X2)-{ε} First(X3)若全能推出ε则先求所有FIRIST(X)-{ε}并集再并上{ε} FOLLOW:•(a)设S为开始符号,则#∈FOLLOW(S)•(b)若有产生式A→αBβ,β !⇒* ε,则FIRST(β) 加至FOLLOW(B)•(c)若β⇒*ε(即ε∈FIRST(β)),则FIRST(β)-{ε}和FOLLOW(A)加至FOLLOW(B) SELECT:A→α的可选集SELECTα !⇒ε,则SELECT(A→α)= FIRST(α)*α⇒ε,则SELECT(A→α)= FIRST(α)-{ε}∪FOLLOW(A)*一个上下文无关文法G是LL(1)文法的充要条件是:对于G的每个非终结符号A的任何两个不同产生式A→α,A→β满足:▪SELECT(A→α)∩SELECT(A→β)=∅▪α、β不同时推导出εLL(1)的含义:第一个L:从左到右扫描输入串第二个L:分析过程中用最左推导1:只需向右看1个输入符号(Look ahead)便可确定选用哪个产生式进行推导–LL(1)文法是无二义的。
–LL(1)文法不含左递归。
14.自底向上:算符优先、LR(0)、SLR(1)、LR(1)、LALR(1)15.规范归约:最右推导的逆过程(最左归约)•最右推导是规范推导右句型(最右推导可得的句型)是规范句型•规范句型的特点:句柄后(右边)不会出现非终结符•规范归约的中心问题是:如何寻找或确定一个句型的句柄。
•可归约串:•最左素短语(算符优先分析法)•句柄(LR分析法)算符优先分析法不是规范归约方法。
16.若文法G中不存在右部含有相邻非终结符的产生式,则G为算符文法算符优先分析的可归约串是句型的最左素短语。
起决定作用的是相邻两个终结符的优先关系a≡b 当且仅当G中存在产生式规则A→…ab…,或A→…aBb…a<⋅b 当且仅当G中存在产生式规则A→…aB…,且B⇒+b…或B⇒+Cb…a⋅>b 当且仅当G中存在产生式规则A→…Bb…,且B⇒+…a或B⇒+…aC 不允许有a<·b、a≡b、a·>b中的两种关系同时存在17.FIRSTVT计算如下:若有产生式A→a…或A→Ba…则a∈FIRSTVT(A) A左侧的终结符< FIRSTVT(A)若a∈FIRSTVT(B)且有产生式A→B…(B后面没有紧跟一个终结符)则a∈FIRSTVT(A)A->a.......,即以终结符开头,该终结符入FirstvtA->B.......,即以非终结符开头,该非终结符的Firstvt入A的FirstvtA->Ba.....,即先以非终结符开头,紧跟终结符,则终结符入FirstvtLASTVT计算如下:若有产生式A→…a或A→…aB则a∈LASTVT(A) A右侧的终结符< LASTVT (A)若a∈LASTVT(B)且有产生式A→…B则a∈LASTVT(A)A->.......a,即以终结符结尾,该终结符入LastvtA->.......B,即以非终结符结尾,该非终结符的Lastvt入A的LastvtA->.....aB,即先以非终结符结尾,前面是终结符,则终结符入Lastvt18.LR分析法的归约过程是规范推导的逆过程,所以LR分析过程是一种规范归约过程无回溯的“移进-归约”方法符号栈中的符号是规范句型的前缀,且不含句柄以后的任何符号(活前缀)ACTION 移进归约接受出错ACTION[i,a]=空白出错ACTION[i,a]=acc 符号栈中仅有#和文法开始符号S,输入串仅为#,分析结束。
19.一个句型的某个前缀的后缀是该句型的句柄,则这个前缀称为该句型的可归前缀。
一个规范句型的一个前缀,若不含句柄之后的任何符号,则称它为该句型的一个活前缀。
S -> a Ac. B e 项目中.之前a Ac为活前缀20.A→α⋅ aβ,a∈V T 移进项目A→α⋅ Bβ,B∈V N 待归约项目A→α⋅归约项目特别地:A→ε只有A→⋅S’→S, S’→S ⋅接受项目以上项目称作LR(0)项目。
21.LR(0) 项目集规范族(识别G的活前缀的DFA)如果不存在移进-归约冲突,归约-归约冲突,则称它是LR(0)文法。
拓展文法的目的:使文法只有一个以识别符号作为左部的产生式,从而使构造出来的分析器有唯一的接受状态。
22.对给定的文法,利用LR(0)方法判断符号串是否为该文法的句子:1.扩充文法为拓广文法;2.构造识别此文法的全部活前缀的DFA,即构造LR(0)项目集规范族;3.判断是否为LR(0)文法;4.是构造LR(0)分析表利用LR分析算法分析符号串。
5.否,做其他处理。
23.SLR(1)对所有非终结符都求出其FOLLOW集合发生冲突时,归约项目左部终结符FOLLOW集与移进项目.后的终结符交集为空时,才能按此规约项目的产生式进行归约。
–LR(0)分析对所有终结符均采用归约动作–SLR(1)分析参考FOLLOW集,以确定归约动作。
24.Follow集无法解决移进-归约冲突或归约-归约冲突,考虑后继符25.归约动作的选择:a)LR(0)分析考虑所有终结符b)SLR(1)分析参考FOLLOW 集,为了确定归约c)LR(1)分析仅考虑LR(1)项目中的后继符(归约展望集,向前搜索符)拓展文法的后继符为#,即[ S’->S , #] 为初态集的初始项目,S后first(ε,#) = {#}LR(1)项目集规范族中,每个状态中添加新的产生式时,需求产生式左部字母后面的First集作为新产生式的后继符;否则后继符照抄前一个状态的I : A->a.BβB->.e ,需求出First(β)作为B->.e的后继符26.任何二义文法决不是一个LR文法LL(k)文法都是LR(k)文法。
27.a=b*c+b*d 逆波兰式:abc*bd*+= (算符优先的一个应用)无括号; 运算对象顺序不变; 运算符号的位置反映运算顺序。
◆三元式运算结果用三元式编号表示b*c (*,b,c)◆四元式运算结果用临时变量表示b*c (*,b,c,t)a:=b*c+b*d的三元式表示a:=b*c+b*d的四元式表示注意最后一步写法四元式直观写法:t1:=b*c t2:=b*d t3:=t1+t2a:=t3中间代码优化处理时,四元式比三元式方便的多28.终结符只有综合属性,由词法程序提供;非终结符可有综合也可有继承属性,但文法开始符号无继承属性。
29.按优化所涉及的程序范围可分为三种级别:局部优化、循环优化、全局优化。
局部优化指在只有一个入口一个出口的基本块内进行的优化。
30.判定入口语句的规则:(a)代码序列的第1个语句。
(b)条件或无条件转移语句的转移目标语句。
If… goto Goto(c)紧跟在无条件转移语句或条件转移语句后面的语句。
例:B1 -> (1) read x(2) read yB2 -> (3) r:=x mod y(4) if r=0 goto (8)B3 -> (5) x:=y(6) y:=r(7) goto (3)B4 -> (8) write y(9) halt基本块i和基本块j满足如下条件之一,则从i引一条有向边到j 。