家得宝质量验厂清单
- 格式:doc
- 大小:76.50 KB
- 文档页数:3

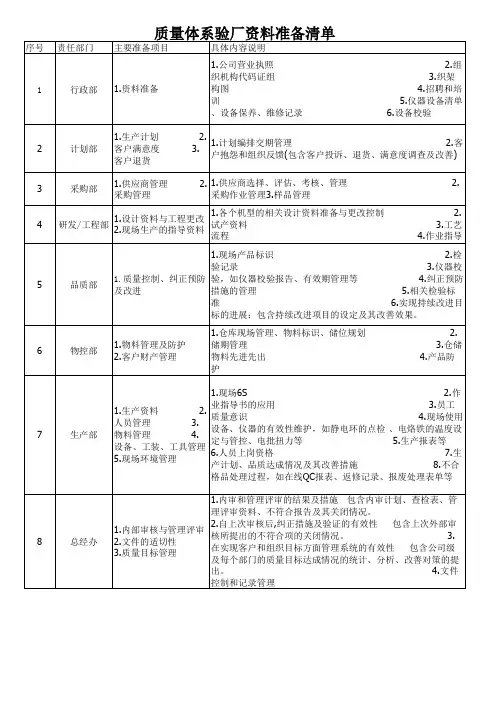
一、档案1 收集全厂现有员工有效身份证复印件(正反两面均需复印)和一寸照片2张,确认是否有虚假、借用他人或过期身份证。
2 确定验厂人员名单,将参加验厂人员的相关信息整理填入咨询师提供的花名册中。
9月份之前进厂但现在已经离职的人员全部做离职记录,9月之后进厂现在已经离职的人员不要列进花名册中。
3 所有离职人员在花名册上的“离职日期”一栏填入离职日期,并填写离职申请单。
4 确认花名册,检查并完善花名册中的所有信息。
5 根据最终确认的花名册确认每位员工的《人事档案表》、《劳动合同》及《厂牌》是否符合验厂要求,如不符合要求,则重新制作《人事档案表》、《劳动合同》及《厂牌》。
]6 打印《人事档案表》并给员工签名,签名必须是员工本人签字且签写的姓名应与身份证复印件上的名字保持一致,一定不能代签、不能用铅笔签字,应使用黑色的水笔签名;《人事档案表》只需员工在“员工签名”一栏签字以及“是否愿意加班”一栏填写“是”或“愿意”。
7 打印《劳动合同》并给员工签名,签名必须是员工本人签字且签写的姓名应与身份证复印件上的名字保持一致,一定不能代签、不能用铅笔、圆珠笔签字,应使用黑色的水笔签名;《劳动合同》只需员工在最后一页的“乙方签名”一栏签字,除此以外其他内容可不必填写;在“甲方签名”一栏盖法人章及公司公章。
8 提供正确的卡号以便完成系统考勤。
9 根据近期人员的请假情况(8-10名)填写请假条并给员工签名。
二、工时1 完成2010年9月至12月的工作时间计划表,并按照实际情况排班。
2 待花名册最终确认OK后,完成所有验厂人员9月份开始到验厂当日的考勤数据(其中周日固定休息),确保7天中有一天休息。
3 完成所有验厂人员8-10月份的工资,检查OK后打印成册。
4 按照打印出的工资表制作银行转账单。
5 按照银行转账单修改转账凭证。
6 将离职人员的工资表单独打印,补签名并填写日期(离职当日)。
7 制作验厂人员验厂前一个月发工资的验厂工资条并在验厂前将其发给员工查阅。

质量验厂文件清单公司标准化编码 [QQX96QT-XQQB89Q8-NQQJ6Q8-MQM9N]
“质量”验厂文件清单
文件要求:
1.公司营业执照,税务登记证,体系认证证书(ISO9001,IS014001,HACCP, BRC
等)
2.工厂平面图,组织机构图。
3.最新的员工花名册
4.质量手册,程序文件,作业指导书。
5.产品生产工艺流程图
6.质量方针目标分解及测评记录
7.受控文件清单,文件收发记录
8.人员职责权限规定
9.员工个人卫生标准。
10.员工培训计划,培训记录
11.产品追溯性管理程序/记录
12.产品召回程序,产品召回记录
13.客户投诉处理程序/记录
14.内审处理程序/记录
15.管理评审处理程序/记录
16.产品风险性评估程序/记录
17.合格供应商目录,供应商评估标准/供应商评估记录
18.原料测试报告,材质报告,有害物质测试报告
19.IQC,IPQC,FQC 检验标准,检验记录
20.生产计划单,生产报表,出货记录
21.不合格品处理程序/记录
22.纠正预防措施程序/记录
23.机器设备清单,设备保养计划,保养记录。
24.计量仪器清单,校准计划,校准记录。
25.虫害控制程序/记录
26.利器控制程序/记录
27.产品金属探测程序/记录
28.玻璃控制程序,玻璃制品完整性检查记录。
29.内部测试程序,内部测试记录。
30.外部测试报告
31.化学品清单,化学品管理程序。
32.法律法规获取及更新程序,法规清单
33.样品管理制度,确认样清单。

1. Machinery maintenance records/设备保养记录2.Fabric/yarn inspection records/布料或纱线检验记录3.Trim/accessories inspection records/辅料检验记录4.Fabric/shrinkage/elongation test records/布料缩水及延伸率测试记录5.Garment shrinkage/elongation test records/服装缩水及延伸测试记录6.Dye lot control records/色缸控制记录7.Fusing control records/热熔控制记录8.Packing measurement material/包装要求资料9.Pre-production meeting/产前会议记录10.Pilot run meeting and reports/试产会议及试产报告11.Production schedule and daily output records/生产计划及生产日报表Required document list for Technical & Quality audit质量体系审核文件清单Part I Softline Part I Softline((第一部分第一部分::纺织类纺织类))12.Fabric relaxation records/松布记录13.Cutting inspection records(cut&sewn)/裁剪记录(针对裁与缝的产品)14.Knitted panel inspection records/织片检验记录15.Embroidery/printing inspection records/绣花及印刷检验记录16.Inline inspection records/中查记录17.Final inspection records/尾查记录18.Pre-wash inspection records/洗水前检验记录19.Post-wash inspection records/洗水后检验记录20.Trimming inspection records/线头修剪记录21.Pressing inspection records/熨烫检验记录22.Final QA inspection records/尾部QA检验报告23.Broken needle policy and records/断针控制程序及记录24.Calibration records for metal/needle detector/金属控测仪或验针机校准记录25.Sharp tool control policy and records/利器控制程序及记录1. Machinery maintenance records/设备保养记录Part II Hardline Part II Hardline((第二部分第二部分::杂货类杂货类))2. Inspection standard for incoming quality control and incoming inspection records/ 来料检验标准及来料检验记录3. Inspection standard for sub-contracted parts/products and inspection records/ 外发产品检验记录4. Updated sample and product specification available at each production/现场提供最新样板及产品规格要求5. Updated packing information/最新的包装资料6. Production plan schedule, Production progress records/生产计划排期,生产进度记录7. Daily output records/生产日报表8. Inline inspection records with accetable/rejected standard/过程检验记录及可接受或不可接受之标准9. Inspection standard for each process/每道生产工序之检验标准10. Finished products inspection records/成品检验记录11. Final QA inspection records/成品包装后QA检验记录13. Internal testing procedure/内部测试程序15. Broken needle policy and broken needle records/断针控制程序及控制记录16. Metal/needle dectector in good working condition/金属控测器或验针机处于良好工作状态17. Sharp tools contorl policy and records/利器控制程序及记录<END <END 结束>结束>12. Internal testing records including: Frequency of testing, testing method and sample size /内部测试记录(含:测试频率,测试方法及抽样数量)备注:审核员在现场可能查看与公司运作有关的其它相关文件与记录。


FCCA Quality System Audit OutlineFCCA质量体系审核纲要(Hardline 杂货)(Quality System part质量体系部分)Factory Quality System工厂质量体系责任人1。
0 Factory Facilities and Environment工厂设施和环境1.0。
1 There is sufficient lighting on: Production, revising, finishing, inspection, packing and loading areas?在生产,修理,加工,检验,包装及装载的区域是否有足够的照明?1.0.2 The facility maintains clean and organized production, finishing and packing areas.工厂是否保持清洁,在生产,加工和包装区域是否有秩序?1.0。
3 Facility has separate inspection area with inspection table and proper ventilation。
工厂是否有单独的检验区与检验台并且通风良好?1.0。
4 Facility has documented pests/mildew and moisture control program, which includes frequent inspections. (In—house or 3rd party)工厂是否有害虫/霉菌和湿度的控制程序文件?是否有经常巡查(公司内部或第三方检查)?1。
0.5 No broken windows or leaking roofs that may result to product contamination was observed during audit.在审核其间有没有发现窗户破损及房顶漏水可能导致产品污染。

PB工厂技术评审
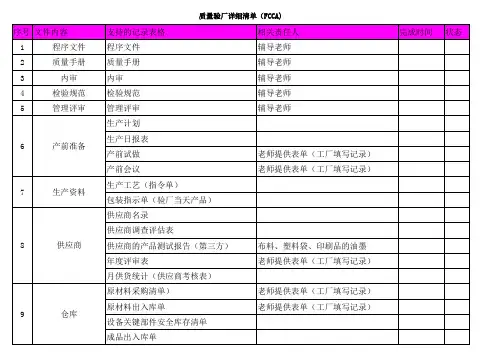
评审需提供的资料(记录部分须提供三个月, 如工厂允许, *画线部分要复印):
1 质量手册及年度评审记录
2 所有程序文件:
(如生产机器/设备管理, 货仓物料管理, 采购控制, 供应商评估, 物料进出控制, 客供物料控制, 设计控制, 来料/制程/成品品质控制, 不合格品控制, 质量记录控制, 利器/针控制, 检测仪器控制)
3 *工厂组织架构图
4 厂房/车间/设备分布图
5 基础设施(灯/电梯/电源/电脑/供水/窗户/墙)保养计划及保养记录
6 * 生产机器/设备清单, 保养指引及保养记录
7 生产用工模/夹具/机架清单及收发记录
8 物料采购单及供应商来料质量/数量/交货期历史记录
9 货仓物料收发货记录, 出入帐本, 物料定期盘点记录及客供物料沟通记录
10 生产总计划, 各工序生产计划, 生产日报, 生产周报及生产周会记录
11 出货装货柜指引及出货单据(包装清单, 提单, 发票等)
12 产品设计会议, 设计输入, 设计输出, 设计评审, 设计确认及设计更改记录
13 *产品生产流程图, 作业指导书, 试产后(产前)评审记录及生产绩效分析记录
14 *来料/过程/最终检验指引及报告,来料/过程紧急放行及成品仓定期巡查记录
15 不良品记录或检验报告, 品质部停产记录及不良品处理记录
16 纠正及预防措施记录
17 *利器/针收发记录, 断利器/针记录, 金属探测机检测及测货记录(如要求)
18 * 检验/测量/测试仪器清单, 计量证书/内较记录及实验室环境记录
19 *安全标准(美国, 欧洲, 日本, 加拿大等) (如要求)
20 *产品产前测试报告及成品批验测试报告
21 * ISO证书及外培训/内培训记录。

![Homedepot验厂_[全文]](https://uimg.taocdn.com/3c34daa164ce0508763231126edb6f1aff007135.webp)
Homedepot验厂Homedepot家得宝公司(英语:The Home Depot;NYSE:HD)成立于1978年,是全球最大的家具建材零售商,美国第二大的零售商。
家得宝销售各类建筑材料、家居用品和草坪花园产品,而且提供各类相关服务。
家得宝标准店平均室内占地接近9,758平方米,另外还有2,138平方米的户外花园产品区域。
除了家得宝标准店之外,我们还有主要为家庭装修和改建项目提供产品和服务的EXPO Design Center,面对专业客户服务的Home Depot Supply和The Home Depot Landscape Supply1></a>.Homedepot验厂在做工资单的时候,要注意配套的考勤表格的填写。
工作时间要符合法律法规。
包括最低工资标准,工作时间,加班时间等。
加班工资的计算要按照平时加班150%,假日按200%,节日按照300%的标准最好!Homedepot验厂之零容忍政策SER Compliance Zero Tolerance CategoriesThe Home Depot requires full cooperation from all suppliers and relevantfactories in order to improve SER compliance among its supplier base. In the event that a factory assessment yields results in which the factory is unable to meet Zero Tolerance Categories, The Home Depot will take one/all of the following steps:For all Existing Suppliers: Failure to meet any of the SER Zero Tolerance Categories will result in the factory receiving a failing rating. A failing grading outcome will require that the factory to undertake and complete a Corrective Action Plan (transparency and performance improvement commitments must be made by factory management) Failure to complete a Corrective Action Plan will result in the Supplier relationship being terminated and no new purchase orders issued by the Home Depot.Potential Factory (On-boarding): Failure to meet any of the SER Zero Tolerance Categories will result in disqualification from on-boarding selection process.Transparency Suppliers are required to provide transparency into their operations, policies, processes, and relevant records to The Home Depot or its designated third party.Age Requirements Suppliers will not employ any person(s) under the age of 14.Forced Labor THD will not accept or tolerate the use of any forced or involuntary labor, either directly or indirectly by our suppliers, contractors or subcontractors.Fraud THD will not tolerate Suppliers providing fraudulent documentation, or statements with a willful intent to deceive.Non-Payment of Wages All workers, including trainees, must be paid at least the cash equivalent of the minimum legal wage.Disciplinary Practices Suppliers must not use or permit corporal punishment or any other form of physical or psychological coercion including verbal abuse and sexual harassment.Collaboration Performance Improvement THD expects our suppliers to strive continuously for improvement of their respective operation that has an impact on THD business.The Home Depot人权验厂清单1. Business Registration certificates2. Factory regulations, including the policies on working hour system, overtime compensation and other legal benefits3. Labor contract (individual)4. Employment registration records5. Written policy and training records on anti-harassment/ discrimination/ abuse6. Written policy and training records on freedom of movement/ employment7.Written policy and training records on forced labor prevention8.Records of company handbook distribution/notification9.Approval on comprehensive calculation of working hour system (if applicable) or overtime waiver10. Payment receipt of social insurance schemes11. Official testimonials on coverage of social insurance schemes12. Fire drill records13. Fire prevention certification14. MSDS for hazardous substances / chemicals15. Work permits for special and dangerous operations16. Hygiene certificate for the canteen in factory17. Health examination records of canteen workers18. Health examination records of juvenile workers (aged 16-18)19. First aid certificates20. Leave application21. Payroll records of previous 12 months22. Attendance records of previous 12 months23. Production recordsHome Depot验厂质量审核文件清单1)附ITS质量体系文件及相关记录清单2)质量手册(程序文件,作业指导)3)合格供应商清单4)采购订单5)向关键供应商采购的订单6)来料记录7)各车间领料记录8)原料盘点记录9)成品入库/出库记录10)来料检验记录11)如有发生退货,工厂的纠正的措施程序,12)生产工单13)仪器清单及校正记录14)模具的保养记录15)对工人的培训计划及记录(重点是QC)16)制程中的检验方法及记录17)成品的检验方法及记录18)不良品的处理记录19)组织结构图及各工序的职责20)管理评审记录21)客户投诉程序及相关记录22)机器的安全操作指引Homedepot行为守则道德标准家得宝(Home Depot)及其附属机构、分部、子公司致力于以负责任的方式经营。

Home Depot验厂资料清单一.社会责任部分(Offered by ITS):1.过去12个月的工卡或考勤记录2.过去12个月的工资表3.人事花名册及员工个人档案4.劳动合同5.社会保险收据\花名册\及合格证明文件;6.工商营业执照;7.消防检查报告或合格证明文件8.消防演习记录\紧急疏散计划\工伤记录等9.环保证明文件10.厂规或员工手册11.政府有关当地最低工资规定文件12.设备安全许可证(如电梯使用许可证,厨房卫生许可证等)13.特种工人上岗证(如电梯工,电工,厨工卫生许可证等)14.当地劳动局关于延长加班之批文15.未成年工体检及劳动局登记记录(如适用)16.工厂平面图17.工人面谈文卷18.其他文件二.品质系统以及反恐部分(Offered by SGS)1.工厂简介\工厂平面图\工厂组织架构图\岗位职责说明\生产工序流程图2.反恐预警计划TV系统\自动报警系统布置图4.4人员\货物出入厂区管理制度5.可疑人\之识别与处理6.保安巡视记录7.货物装柜过程控制与管理8.可疑与恐怖事件的汇报与处理办法9.员工背景调查办法\调查记录10.员工反恐培训记录11.员工离职管理制度12.信息安全控制程序\记录13.ISO证书及最近一次外审报告14.质量手册\程序文件\质量计划15.文件更改收发记录16.员工培训计划\员工培训记录17.客户投诉处理记录18.内部审核计划\记录19.纠正与预防措施记录20.仪器设备清单\内外校正记录报告21.CE\EMC\相关的产品测试化验报告\其他相应有效的安全证书22.产品设计计划书23.产品设计要求评审报告24.产品设计评审\验证报告25.设计更改控制程序\记录26.样品测试报告\产品试产报告27.供应商评审程序及记录28.供应商清单\合格供应商清单29.采购单\采购合同30.物料\产品台帐31.物料收发记录32.盘点制度\记录33.来料中免检产品的质量保证书34.来料验货标准及规格书35.来料检查\测试报告36.不良品退货\让步接受记录37.作业指导书38.生产控制记录39.IPQC检验测试标准\记录40.不良品处理记录41.设备维护制度\记录42.FQC\OQC检验测试标准\记录43.不良品处理记录44.产品出\入库记录。
质量验厂文件资料清单质量验厂文件资料清单1. 营业执照 ;2. 质量体系认证证书 ;3. 组织架构图 ;4. 质量手册 ;5. 程序文件;6. 质量体系内审计划;7. 质量体系内审记录:1)内审员资格证书;2)首末次会议 ;3)检查表 ;4)不符合项报告;5)内审报告8. 质量体系管理评审计划9. 质量体系管理评审记录:1)管理评审会议记录;2)管理评审报告;3)决议事项的跟进记录10. 主要生产设备清单;11. 设备保养计划 ;12. 设备保养记录;13. 仪器清单 ;14. 仪器校准计划 ;15. 仪器校准记录:1)外校报告 ;2)内校人员资格证书3)内校规程;4)内校报告16. 年度培训计划17. 培训记录 :1)签到表;2)测试卷18. 品管人员岗前资质认定资料(培训及测试记录;19. 新产品设计开发资料 :1)产品规格书;2) BOM表 (BOM);3)安规认证证书;4)样品检测报告5)试产记录 ;6)试产评估报告 ;7)作业指导书 ;8)检验标准 ;9) FMEA分析资料 ;10)产品质量控制计划(QC工程图.20. 订单评审记录;21. 新供应商资格评定报告22. 现有供应商质量、交期、价格及服务定期评分表 ;23. 原材料采购订单 ;24. 原材料规格承认书25. 进料检验作业指导书 ;26. 进料检验标准 ;27. 进料检验样板清单及定期评估记录;28. 进料检验记录 ;29. 不合格来料处理记录(含供应商纠正预防措施报告;30. 原材料保存周期规定 ;31. 原材料过期重检记录 ;32. 控制图表及超限处理记录 ;33. CPK应用指引 ;34. CPK测量记录及制程能力不足时的改进记录 ;35. 生产作业指导书36. 制程检验作业指导书;37. 制程检验标准 ;38. 制程检验记录 :1)首件检验记录 ;2)巡检记录 ;3)抽检记录39. 制程不合格品的处理记录(含纠正预防措施报告)40. 制程检验不良统计报表(周报/月报,柏拉图41. 停线管理规定及记录 ;42. 成品检验作业指导书;43. 成品检验标准 ;44. 成品检验记录 ;45. 不合格成品处理记录:1)返工、返修记录 ;2)重检记录3)纠正预防措施报告46. 成品入库单 ;47. 产品可靠性及环境测试计划及记录;48. 数据分析程序;49. 质量目标统计资料50. 客户沟通资料 ;51. 客户投诉处理程序 ;52. 客户投诉处理记录。
BSCI验厂清单现场检查1、消防设备、灭火器及其安装地方2、紧急出口、逃生路线以及它们的标记/标示牌3、有关安全卫生的问题:设备,人员以及培训等等。
4、机器、电力设备以及发电机5、蒸汽发生器和蒸汽排放管6、室温、通风以及照明情况7、总体的清洁和卫生8、卫生设施(厕所、洗手间以及饮水设施)9、必要的福利和便利设施,例如:病房,急救包,饮食区,咖啡/茶水区,儿童养育院等等。
10、宿舍/住房情况(如提供给员工).11文件清单1、公司性质、公司名称、公司成立年份的正式文件的副本。
2、有效的营业执照以及进行操作,运行机器的所有必要的正式批准。
3、客户记录单核生产部门记录单4、有关员工结构的公司数字列表5、公司的财政数字6、管理体系和社会/行为守则审核的有效认证列表,代表其它组织,这些体系和审核在公司中已经进行,审核报告副本列表。
7、高级管理人员在公司中职责的文件证据,实施BSCI行为守则符合性以及检查的操作标准的文件证据。
8、计算遵守最低社会要求所必需的财力、人力情况。
9、书面形式的费用计算。
10、书面形式的计划生产能力。
11、对员工进行BSCI行为守则培训的文件证据。
12、记录对可能会出现的危险来源的检查结果,以及所采取的纠正行动(安全评估)13、所有员工的个人资料档案。
14、分包商列表,包括生产部门名称和地址。
15、对分包商遵守BSCI行为守则作出承诺的书面声明 16、分包商工厂中社会绩效持续改进的证明17、书面形式的公司社会方针18、书面形式的工作规则19、证明水是饮用水的文件20、工作时间记录系统21、关于员工所有津贴的文件证据,附带备注说明这些津贴是国家强制性的还是自愿性的22、行业中规定的工作时间以及此信息来源的文件证据 23、公司规定正常工作时间、轮班、多班工作、休息以及假期的文件证据 24、法定/行业最低工资水平以及此信息来源的文件证据25、员工工资条以及工资支付证明26、证明社会保险金交税的支付文件27、工资单以及工资计算情况,包括计件工人输出记录,包括工资和扣除的所有方面。
Depot:Cloud storage with minimal trustP.Mahajan,S.Setty,S.Lee,A.Seehra,A.Clement,L.Alvisi,M.Dahlin,and M.WalfishUTCS TR-10-21The University of Texas at Austinfuss@Abstract:We describe the design,implementation,and evaluation of Depot,a cloud storage system that mini-mizes trust assumptions.Depot assumes less than any prior system about the correct operation of participat-ing hosts—Depot tolerates Byzantine failures,including malicious or buggy behavior,by any number of clients or servers—yet provides safety and availability guaran-tees(on consistency,staleness,durability,and recovery) that are useful.The key to safeguarding safety without sacrificing availability(and vice versa)in this environ-ment is to join forks:participants(clients and servers) that observe inconsistent behaviors by other participants can join their forked view into a single view that is con-sistent with what each individually observed.Our exper-imental evaluation suggests that the costs of protecting the system are modest.Depot adds a few hundred bytes of metadata to each update and each stored object,and requires hashing and signing each update.1IntroductionThis paper describes the design,implementation,and evaluation of Depot,a cloud storage system in the spirit of S3[3]and Azure[5].However,given that to customers a storage service provider(SSP)is a potentially complex black box controlled by another party,it seems prudent to rely on end-to-end checks of well-defined properties rather than to make strong assumptions about the SSP’s design,implementation,operation,and status.Depot is therefore designed to tolerate Byzantine failures,includ-ing malicious or buggy behaviors by the SSP.More pre-cisely,Depot minimizes trust assumptions among nodes with respect to both safety and availability:•Depot eliminates trust for safety.A client needs to trust only itself to ensure correct operation.Depot guarantees that any subset of correct clients sharing data observe sensible,well-defined semantics.This holds regardless of how many nodes fail and no matter whether they are clients or servers,whether these are failures of omission or commission,and whether these failures are accidental or malicious.•Depot minimizes trust for availability.We wish we could say“trust only yourself”for availability.De-pot does eliminate trust for updates:a client can al-ways update any object for which it is authorized,and any subset of connected,correct clients can alwaysshare updates.However,for reads,there is a funda-mental limit to what any storage system can guaran-tee:if no correct,reachable node has an object,that object may be unavailable.We cope with this funda-mental limit by allowing reads to be served by any node(even other clients)while preserving the sys-tem’s guarantees,and by configuring the replication policy to use several servers(which protects against failures of clients and subsets of servers)and at least one client(which protects against temporary[11]and permanent[6,23]cloud failures).Safety vs.availability vs.trust.Though prior efforts have reduced trust assumptions in storage systems,they have not minimized trust with respect to safety,availabil-ity,or both.For example,quorum and replicated state machine approaches[9,24,28,29,32,41,53,54,85,95, 99,100]tolerate failures by a fraction of servers.How-ever,they sacrifice safety when faults exceed a threshold and availability when too few servers are reachable.Sys-tems like SUNDR[61]and FAUST[20],and other fork-based systems[19,22,62,64,74]that remain safe with-out trusting a server minimize trust for safety.However, they compromise availability in two ways.First,if the server is unreachable,clients must block.Second,a fault server can make correct clients’views diverge perma-nently,preventing them from ever observing each other’s new updates.Indeed,it is challenging to guarantee safety and pro-tect availability while minimizing trust assumptions: without some assumptions about correct operation,pro-viding even a weak guarantee like eventual consistency seems difficult.For example,a faulty storage node re-ceiving an update from a correct client might quietly fail to propagate that update,thereby hiding it from the rest of the system.Perhaps surprisingly,wefind that even-tual consistency is possible in this environment.In fact, Depot provides far stronger semantics.A client in the Depot storage system is guaranteed to see eventual consistency,bounded staleness,and a slight weakening of causal consistency that we call Fork-Join-Causal consistency(FJC).Roughly speaking,FJC means that all nodes eventually see the same updates,that all correct nodes’updates are eventually visible,and that a correct node’s updates and their dependencies are always observed in a causal order.Approach.Depot is designed around three key ideas.1.Local verification:Depot clients and servers maintainsufficient local state to validate updates for safety[61].2.Join forks:Faulty nodes can fork the system’s viewof history by introducing incompatible updates[61].Thus,a crucial requirement for availability is that nodes be able to join forks:nodes that observe incon-sistent behaviors by other nodes must join their forked histories into a single view that is consistent with what each individually observed.Such joining is challeng-ing;as mentioned above,prior systems permanently strand forked nodes on different branches of history.3.Unify protection of safety and availability.The key toDepot’s simplicity is in the realization that the forks caused by faulty nodes can be joined by leveraging the same mechanisms used to handle concurrency in sys-tems that remain globally available during partitions or disconnections.Depot introduces mechanisms to de-tect when a faulty node forks its history and to treat the faulty node’s writes on each fork as concurrent writes by two virtual nodes.Thus,rather than inventing ex-otic new abstractions for dealing with forks by faulty nodes,Depot employs familiar techniques from the lit-erature on disconnected operation[17,35,42,51,80, 92]to protect both safety and availability.Although in principle reducing trust assumptions is always desirable[58,59,81],in practice,cost matters. We therefore evaluate the costs of providing untrusted storage in our implementation of Depot.We also evalu-ate a modified Depot client that uses Amazon S3’s as an untrusted storage platform.Wefind costs to be modest. Depot adds a few hundred bytes to each request and a few milliseconds of processing to small requests and a few tens of milliseconds(due to larger overheads to per-form secure hashes)on largefiles.2Why untrusted storage?When we say that“servers are untrusted”,we do not sug-gest that they should be implemented or selected less carefully than they are today.Data owners should still try to hire a SSP that follows best practices.Rather,re-moving trust is about exercising more caution:it means tolerating a larger number of failures by making fewer and weaker assumptions.Thus,under Depot,it is good for nodes to operate correctly,but we do not assume that they do.Instead,participants can verify other nodes and ensure continued operation with clean semantics if some nodes fail to act as hoped.It is often desirable to minimize trust and employ end-to-end correctness checks in any system[58,59,81],but we take particular pains to minimize trust assumptions in our cloud storage service for three reasons.First,from a client’s point of view,the SSP is a po-tentially complex black box controlled by another party, so it seems prudent not to assume the correctness of the SSP’s internals.While most storage service providers may follow best practices,some may not,and it may be hard to tell the difference(until it is too late).For exam-ple,one customer discovered after repeated disk failures that his large ISP reused old disk drives in new servers until they failed[36].Though this is only an anecdote, it is rooted in the reality of providers’opacity.Further-more,any storage service,well-managed or otherwise,is subject to non-negligible risks:coping with known hard-ware failure modes in localfile systems is difficult[78]; in cloud storage,this difficulty can only grow.Second,replication across servers and locations is not a panacea.As V ogels notes,“[The]absolutely unrealis-tic assumption[of uncorrelated failures]will come back to haunt you in real life,where failures frequently are correlated,as they are often triggered by external or en-vironmental events”[96].In the context of cloud ser-vices,one must consider software bugs and vulnerabil-ities[15],correlated manufacturing defects[77],mis-configuration and operator error[73],malicious insid-ers[94],bankruptcy[6],undiagnosed problems[23],and acts of God[30]and man[70].Moreover,even when failures are uncorrelated,the risk that some objects are unlucky and struck by simultaneous failures rises rapidly as systems grow[72].Third,from an SSP’s point of view,lack of trust may be a significant barrier to the adoption of cloud services, so client-verifiable end-to-end guarantees may help con-vince customers to accept the approach.We also minimize trust towards clients.Clients are vulnerable to several of the same types of failures dis-cussed above.Having pushed the envelope on protecting the system against server misbehavior,we do not want a single faulty client to disrupt the operation of the system. 3Architecture and scopeFigure1depicts Depot’s high-level architecture.A set of clients stores key-value pairs on a set of servers.In our target scenario,the servers are operated by a storage ser-vice provider(SSP)that is distinct from the data owner that operates the clients.Keys and values are arbitrary strings,with overhead engineered to be low when values are at least a few KB.For scalability,we slice the system into groups of servers,where each group is responsible for one or more volumes.Each volume corresponds to a range of one cus-tomer’s keys,and a server independently runs the proto-col for each volume assigned to it.Many strategies for partitioning keys among nodes are possible[13,34,48, 50,72,90],and we leave the assignment of keys to vol-umes to layers above Depot.F IG.1—Architecture of Depot.The arrows between servers indicate replication and exchange.The servers for each volume may be geographically distributed,a client can access any server,and servers replicate updates using any arbitrary topology(chain, mesh,star,etc.)As in Dynamo[34],to maximize avail-ability Depot does not require overlapping read and write quorum,and—as the dotted lines suggest—Depot can even continue to function during periods of complete server unavailability by having clients communicate di-rectly with one another.We use the term node to mean either a client or a server.Clients and servers run the same basic Depot pro-tocol,though they are configured differently.3.1Issues addressedOne of our aims in this work is to push the envelope in the trade-offs between trust assumptions and system guaran-tees.Specifically,for a set of standard properties that one might desire in a storage system,we have asked,what is the minimum assumption that we need to provide use-ful guarantees,and what are those guarantees?Below we list the issues we examine.The next two sections then describe the core Depot protocol(§4)and explain how Depot builds on it to provide these properties(§5).•Consistency(§5.1)and bounded staleness(§5.3):We want to limit the extent to which the storage system can reorder,delay,or omit updates in a way that is visible to a client’s reads.The goal is to provide suf-ficiently strong and precise guarantees that users and programmers can understand and predict how the sys-tem will behave.•Availability and durability(§5.2):Durability means that we want to ensure that a client eventually succeedsin reading an object.Availability means that we want to maximize the fraction of time that a client succeeds in reading or updating an object.•Integrity and authorization(§5.4):Only clients autho-rized to update an object should be able to create valid updates that affect reads on that object.•Recovery(§5.5):Data owners care about end-to-end reliability.Data integrity,consistency,and durability are not enough when the layers above Depot—faulty client nodes,applications,or users—can issue autho-rized writes that replace good data with bad.Depot does not try to distinguish good updates from bad ones,nor does it innovate on the abstractions used to defend data from higher-layer failures.We do however explore how Depot can support standard techniques such as recovery to earlier versions of data.•Evicting faulty nodes(§5.6):If a faulty node provably deviates from the protocol,we wish to evict it from the system so that it will not continue to cause confusion. However,it is vital that we never evict correct nodes.Note that we explicitly do not attempt to solve the confidentiality/privacy problem within Depot.Instead, like commercial storage systems[3,5],Depot enforces integrity and authorization(via client signatures)but leaves it to higher layers to use appropriate techniques for the privacy requirements of each application(e.g.al-low global access,encrypt values,encrypt both keys and values,introduce artificial requests to thwart traffic anal-ysis,etc.).We do not claim that the above list of issues is com-prehensive.For example,it may be useful to audit storage service providers with black box tests to verify that they are storing data as promised[52,86,87],but we do not examine that issue.Still,we believe that the properties are sufficient to make the resulting system useful.3.2System and threat modelBefore continuing,we briefly describe our technical as-sumptions.First,nodes are subject to standard crypto-graphic hardness assumptions,and each node has a pub-lic key known to all nodes.Second,any number of nodes can fail in arbitrary(Byzantine[57])ways:they can crash,corrupt data,lose data,process some updates but not others,process messages incorrectly,collude,etc.Third,we assume an unbounded number of syn-chronous intervals of sufficient length to allow a pair of timely,connected,and correct nodes to exchange afinite number of messages.This assumption implies that a faulty node cannot forever prevent correct nodes from communicating.However,we make no assump-tions about when these synchronous intervals happen.Fourth,above we used the term correct node some-what loosely.This term refers to a node that neither devi-ates from the protocol nor becomes permanently unavail-able;a node that crashes and recovers is equivalent to a node that never crashes but that is sometimes slow.Two final technical points related to durability and liveness of garbage collection.First,a node that obeys the protocol for a time but later deviates is never counted as correct; second,we assume that unrecoverable clients are eventu-ally replaced:an administrator needs only the old client’s keys and configuration to bring up a new machine[24]. 4Core protocolIn Depot,clients’reads and updates to shared objects should always appear in an order that reflects the logic of higher layers.For example,an update that removes one’s parents from a friend list and an update that posts spring break photos should appear in that order,not the other way around[31].However,Depot has two challenges:first,it wants maximum availability,which fundamen-tally conflicts with the strictest orderings[38].Second,it wants to continue to provide its ordering guarantees de-spite arbitrary misbehavior from any subset of nodes.In this section,we describe how the protocol at Depot’s core achieves a sensible and robust order of updates while op-timizing for availability.Of course,ordering updates and reads is not the only thing that Depot must do.However,it is the essential building block for Depot’s other properties.In§5we de-fine precisely the consistency guarantee that Depot en-forces and discuss how Depot provides the other proper-ties listed in§3.Note that clients and servers run the same basic pro-tocol.This symmetry not only simplifies the design but also providesflexibility.For example,if servers are un-reachable,clients can share data directly.For simplicity, the discussion in this section does not distinguish be-tween clients and servers.4.1Basic protocol for update propagation This subsection describes the basic protocol to propagate updates,ignoring the problems raised by faulty nodes. The protocol is essentially a standard log exchange pro-tocol[16,76],but we describe it here for background and to define terms.Subsections4.2and4.3describe how Depot defends against faulty nodes.The core message in Depot is an update that changes the value associated with a key.It has the following form: dVV,{key,H(value),logicalClock@nodeID,H(history)}σnodeID Updates are associated with logical times.A node as-signs each update an accept stamp of the form logical-Clock@nodeID[76].A node increments its logical clock on each local write.Also,when a node N receives an up-date u from another node,N advances its logical clock to exceed u’s so that an update’s accept stamp exceeds the accept stamp of any update on which it depends[56].Each node maintains two main local data structures: a log of updates it has seen and a checkpoint reflecting the current state of the system to support random ac-cess reads and writes.Note that Depot separates data from metadata[16],so the log and checkpoint contain collision-resistant hashes of values.If a node knows the hash of a value,it can fetch the full value from another node and store the full value in its checkpoint.To garbage collect its log,a node creates a second checkpoint corre-sponding to a past logical time and removes all log en-tries with accept stamp prior to that time[76].Information about updates propagates through the system when nodes exchange tails of their logs.Each node N maintains a version vector VV with an entry for each node M in the system:N.vv[M]is the highest logi-cal clock N has observed for any update by M[75].To transmit updates from node M to node N,M sends to N the updates from its log that N has not seen.Each node sorts the writes in its log by accept stamp, sortingfirst by logicalClock and breaking ties with nodeID.Thus,each new write issued by a node ap-pears at the end of its own log and(assuming no faulty nodes)the log reflects a causally consistent ordering of all writes.Also,the checkpoint state for any object o is the most recent write to o in the log,so(assuming no faulty nodes)reads from the checkpoint are causally con-sistent.Conflict resolution.Two updates are logically concur-rent if neither appears in the other’s history.Logically concurrent updates that modify different objects can be readily applied by the local state of the node that re-ceives them.However,if two concurrent updates modify the same object,these updates conflict.Many approaches to resolving conflicting updates have been proposed[51,80,92],and Depot does not claim to extend the state of the art on this front.Our pro-totype implements a simple mechanism that supports a range of application-level conflict resolution policies:a read of key k in Depot returns the set of logically most recent updates to k.This set includes any update to k that has not been superseded by a logically later update of k. Applications may then resolve conflicts byfiltering(e.g., reads return the update by the highest-numbered node, reads return an application-specific merge of all updates, or reads return all updates)or by replacing(e.g.,the ap-plication reads the multiple concurrent values,performs some computation on them,and then writes a new value that is guaranteed to appear logically after and thereby supersede the conflicting writes.)4.2Defending against faulty nodesThere are threefields in an update that defend the proto-col against faulty nodes.Thefirst is a history hash that encodes the history on which the update depends usinga collision-resistant hash that covers the most recent up-date by each node in the system known to the writer when it issued the update.By recursion,this hash covers all up-dates included by the writer’s current version vector.Sec-ond,each update is sent with a dependency version vec-tor,dVV,that indicates the version vector that the history hash covers.Note that while dVV logically represents a full version vector,when node N creates an update,dVV actually contains only the entries that have changed since the last write by N[83].Third,a node signs its updates with its private key.These signatures ensure that,to be viewed as valid and to be applied to the local state at any correct node,an update on a given object must be signed by a node authorized to update the object.To defend against faulty nodes,a correct node N uses the update’s history hash and dVV to enforce the follow-ing invariant:an update u is accepted only if it is prop-erly signed and N has already accepted all the updates on which u depends.Attempts by a faulty node to fabri-cate u and pass it as coming from a correct node;reorder or omit updates on which u depends;or include in u in-compatible dVV and history hashes,will all result in N rejecting u.To compromise consistency,a faulty node has one re-maining option:make the system violate causal consis-tency by forking,that is,showing different histories to different communication partners[61].The rest of this section describes how Depot tolerates such attacks. Detecting forked histories.A correct node produces a sequence of updates with monotonically increasing his-tories captured by each update’s dVV and history hash. In contrast,a faulty node M can fork its updates,creat-ing two updates u1@M and u 1@M such that neither write’s history includes the other’s.M can then send u1@M and the updates on which it depends to one node,N1,and u 1@M and its preceding updates to another node,N2.If updates did not include their history hashes,such forking updates might confuse other nodes.To continue the running example,N1could issue some new updates that depend on updates from one of M’s forked updates (e.g.,u1@M)and then send these new updates to N2. N2might receive N1’s new updates,but not the updates by M on which they depend—because N2already re-ceived u 1@M,its version vector appears to already in-clude the prior updates.However,if now N2applies just N1’s writes to its log and checkpoint,multiple consis-tency violations may occur.First,the system may never achieve eventual consistency because N2may never see write u1@M.Further,the system may violate causality be-cause N2has updates from N1but not some earlier up-dates(e.g.,u1@M)on which they depend.The additional information with each update prevents such confusion.In the example,if N1tries to send its new updates to N2,N2will be unable to match the new updates’history hashes to the updates N2actually ob-served,and N2will break its connection;the reverse hap-pens if N2tries to send updates to N1.As a result,N1and N2will be unable to exchange any updates after the fork point introduced by M after u0@M.Discussion.If we stopped here,the protocol would en-force fork causal consistency,which we define precisely in a technical report[63].It means that each node sees a causally consistent subset of the system’s updates even though the system as a whole is no longer causally rmally,history has branched,but each node peers backward from its branch to the beginning of time, seeing causal events the entire way.Though these forks are regrettable,they are impossi-ble to prevent if nodes are allowed to misbehave arbitrar-ily.More precisely,as proved in[63],fork causal con-sistency is the strongest consistency guarantee that one can provide in a system in which(a)nodes can misbe-have;(b)causal consistency is provided in the absence of misbehavior;and(c)a node can exchange updates with another without needing to involve a third party.Unfortunately,enforcing this strong consistency would compromise availability:fork causal consistency requires that once two nodes have been forked,they can never observe one another’s updates after the fork point[61].In many environments,this lack of availabil-ity is unacceptable.In those cases,it would be far prefer-able to weaken consistency slightly to ensure an avail-ability property:correct nodes can always share updates. We now describe how Depot upholds this property. 4.3Joining forksTo protect availability,nodes must be able to join forked branches of the system’s history by receiving non-causally-consistent updates by a faulty node and updates by other nodes that depend on them.At a high level,Depot converts concurrent updates by a single faulty node into concurrent updates by a pair of virtual nodes.Depot then applies well-studied techniques for weakly consistent systems in benign settings[51,92]. We nowfill in the details that underly this approach. Tracking forked histories.A node identifies a fork when it receives two updates issued by the same writer (e.g.,u1@M and u 1@M)such that(i)neither update in-cludes the other in its history and(ii)each update’s his-tory hash links it to a history that includes the same pre-vious update by that writer(e.g.,u0@M).If a node N2receives from node N1an update that is incompatible with the updates it has received,and if neither node has yet identified the fork point,N1and N2perform a binary search on the updates included in the nodes’version vectors to identify the latest versionvector,VV common,encompassing a common history.N1 then sends its log of updates beginning from VV common. At some point,N2receives the update(e.g.,u1@M)that is incompatible with two updates(e.g.,u0@M and u 1@M) that N2has already received.After a node identifies the three updates responsible for a fork,it expands its version vector to include three entries for the node that issued the forking updates.The first is the pre-fork entry,whose index is the index(e.g., node ID)before the fork and whose contents will not ad-vance past the logical clock of the last update before the fork(e.g.,u0@M).The other two are the two post-fork en-tries,whose indices consist of the index before the fork augmented with the history hash of the respectivefirst update after the fork.These entries initially hold the log-ical clock of thefirst updates after the fork(e.g.,of u1@M and u 1@M),and these values advance as the node receives new updates after the fork point.A faulty node can be responsible for multiple forks[76],so we must ask whether multiple forks stymie the construction immediately above.The answer is no: this construction(augmenting the prior index with the hash of the update after the latest fork)is an opera-tion that composes.More specifically,after i dependent forks,a virtual node’s index in the version vector iswell-defined:it is nodeID+H(u fork1)+H(u fork2)+...+H(u forki).Log exchange revisited.This expanded version vector makes it easy to identify which updates to send to a peer. In the standard protocol,when a node wants to receive updates from another node,it sends its current version vector to the sender so that the sender knows which up-dates are needed.After a node detects a fork and splits one version vector entry into three,it includes all three entries when asking for updates.If the sender is already aware of the fork,it is already maintaining the same three entries summarizing its state,and as in the standard pro-tocol,the difference between the version vector entries identifies which updates from each fork must be sent. If the sender has received updates from one branch but not the other,it can identify which branch it is on us-ing the history hash and then use the logical time from that branch to identify which updates to send.Finally, if the sender has received updates that belong to neither branch,a new fork point is created as above.4.4Client access protocolSo far,we have described the update propagation proto-col,which is the core of Depot,but we have not described how GET s and PUT s are handled by clients.In this sec-tion,we describe the protocol clients use to interact with servers.Unlike the update propagation protocol,which is identical for both clients and servers,clients and servers take different actions in the client access protocol.The client access protocol can be divided into a PUT-protocol and a GET-protocol.A PUT in Depot involves the following steps.The is-suing client generates an appropriate update(as defined in§4.1)and value for the PUT request and stores this value and update in its local store.It then sends the value and update to a server for storage(which is usually a nearby server).On receiving this value and update from a client,the server verifies the update and that the value hash present in the update matches the hash of the re-ceived value.If so,the server stores the value and update on its persistent store and sends an acknowledgment to the client.In the background,the server propagates this update and value to the other servers through periodic gossip messages.A client retrieves these new updates during a GET or during background gossiping.A GET in Depot has two paths:fast and slow.The fast path is optimized for the scenario when the background gossips have propagated most updates to the client per-forming the GET.Therefore,in the fast path,we assume that the client has already received and verified all the updates and is missing only the value(s)for the accessed key.The client sends the requested key to a server which responds by sending back the most recent value(s)for the requested key from its local store.The client verifies that the hash(es)of the value(s)received for the requested key matches the value hash(es)present in the most recent update(s)it knows to that key.If successful,these steps constitute the fast path of Depot.The slow path is taken when a client with a stale up-date to a key tries to access that key.In this case,the hash(es)of value(s)sent by the server don’t match the value hash(es)of the most recent update(s)to the ac-cessed key.On detecting this mismatch,the client ini-tiates a value and update transfer by sending its version vector—to initiate the log-exchange as described in§4.1, and the key that it is interested in accessing—to request the value(s)for this key.The server sends back the new update(s)and the most recent value(s)for the requested key.The client verifies the received updates as described in§4.2and the value(s)as in the case of fast path.Depot includes an additional optimization to prevent the server from transferring the value(s)in the fast path when the client has a stale update.When a client issues a GET for a key,it includes a2-byte compact,but in-secure,hash of the most recent value hash(es)for the re-quested key.The server uses this compact hash to ensure, with high probability,that both the client have the same value(s)for the accessed key.If so,the server proceeds as described in the fast path description earlier.If not,the server sends back a message requesting the client to take the slow path,thereby avoiding the transfer of value(s).To avoid the slow path,Depot clients periodically re-trieve new updates from their preferred servers and,af-。
家得宝质量验厂清单
1. 营业执照 ;
2. 质量体系认证证书 ;
3. 组织架构图 ;
4. 质量手册 ;
5. 程序文件;
6. 质量体系内审计划;
7. 质量体系内审记录:
1)内审员资格证书;
2)首末次会议 ;
3)检查表 ;
4)不符合项报告;
5)内审报告
8. 质量体系管理评审计划
9. 质量体系管理评审记录:
1)管理评审会议记录;
2)管理评审报告;
3)决议事项的跟进记录
10. 主要生产设备清单;
11. 设备保养计划 ;
12. 设备保养记录;
13. 仪器清单 ;
14. 仪器校准计划 ;
15. 仪器校准记录:
1)外校报告 ;
2)内校人员资格证书
3)内校规程;
4)内校报告
16. 年度培训计划
17. 培训记录 :
1)签到表;
2)测试卷
18. 品管人员岗前资质认定资料(培训及测试记录;
19. 新产品设计开发资料 :
1)产品规格书;
2) BOM表 (BOM);
3)安规认证证书;
4)样品检测报告
5)试产记录 ;
6)试产评估报告 ;
7)作业指导书 ;
8)检验标准 ;
9) FMEA分析资料 ;
10)产品质量控制计划(QC工程图.
20. 订单评审记录;
21. 新供应商资格评定报告
22. 现有供应商质量、交期、价格及服务定期评分表 ;
23. 原材料采购订单 ;
24. 原材料规格承认书
25. 进料检验作业指导书 ;
26. 进料检验标准 ;
27. 进料检验样板清单及定期评估记录;
28. 进料检验记录 ;
29. 不合格来料处理记录(含供应商纠正预防措施报告;
30. 原材料保存周期规定 ;
31. 原材料过期重检记录 ;
32. 控制图表及超限处理记录 ;
33. CPK应用指引 ;
34. CPK测量记录及制程能力不足时的改进记录 ;
35. 生产作业指导书
36. 制程检验作业指导书;
37. 制程检验标准 ;
38. 制程检验记录 :
1)首件检验记录 ;
2)巡检记录 ;
3)抽检记录
39. 制程不合格品的处理记录(含纠正预防措施报告)
40. 制程检验不良统计报表(周报/月报,柏拉图
41. 停线管理规定及记录 ;
42. 成品检验作业指导书;
43. 成品检验标准 ;
44. 成品检验记录 ;
45. 不合格成品处理记录:
1)返工、返修记录 ;
2)重检记录
3)纠正预防措施报告
46. 成品入库单 ;
47. 产品可靠性及环境测试计划及记录;
48. 数据分析程序;
49. 质量目标统计资料
50. 客户沟通资料 ;
51. 客户投诉处理程序 ;
52. 客户投诉处理记录。