常见随机方案模型
- 格式:docx
- 大小:11.14 KB
- 文档页数:2

几种常见的概率模型及应用Common Probability Models and Their Applications.Probability models are mathematical representations of random phenomena that allow us to make predictions and inferences about future events. They are widely used in various fields, including statistics, machine learning, finance, and biology. Here are some of the most commonly used probability models and their applications:1. Binomial Model.The binomial model describes the probability of success in a sequence of independent trials, each of which has a constant probability of success. It is commonly used in situations where we are interested in the number of successes in a fixed number of trials, such as:Counting the number of defective items in a batch of production.Predicting the number of customers visiting a store in a particular day.Estimating the probability of winning a lottery.2. Poisson Model.The Poisson model describes the probability of observing a random number of events occurring over a fixed period of time or distance. It is often used in situations where the occurrence of events is rare and independent of each other, such as:Modeling the number of phone calls received by a call center in an hour.Estimating the number of accidents on a particular highway per week.Predicting the number of mutations in a DNA sequence.3. Normal Distribution.The normal distribution, also known as the Gaussian distribution, is a continuous probability distribution that describes the distribution of continuous variables that are normally distributed, such as:Heights of individuals.Weights of products.Test scores of students.It is widely used in statistical inference, hypothesis testing, and estimation of population parameters.4. Exponential Distribution.The exponential distribution is a continuousprobability distribution that describes the waiting time between events that occur randomly and independently at a constant rate. It is commonly used in situations where thetime between events is of interest, such as:Modeling the time between arrivals of customers in a queue.Estimating the time to failure of a machine.Predicting the lifespan of a light bulb.5. Markov Models.Markov models are a class of stochastic processes that describe the evolution of a system over time. They are defined by the current state of the system and the probability of transitioning to each possible next state. Markov models are widely used in various applications, such as:Modeling speech and language recognition.Simulating financial markets.Predicting customer behavior.中文回答:常见的概率模型及其应用。


数学知识总结解决实际问题的常用数学模型数学作为一门科学,不仅仅是学科的基础,还是解决实际问题的重要工具。
在工程、物理、经济、生物等领域中,数学模型被广泛运用于解决各种实际问题。
本文将总结一些常用的数学模型,并说明它们在应用中的具体作用。
1. 线性回归模型线性回归模型是一种常见的统计学模型,它用于描述两个变量之间的线性关系。
在实际问题中,我们常常需要通过已知的数据来预测或估计未知的变量。
线性回归模型通过建立一个线性方程,根据已知的数据点进行拟合,并用于预测未知数据点的取值。
这种模型广泛应用于经济预测、市场分析等领域。
2. 概率统计模型概率统计模型是研究随机现象规律性的数学工具。
在实际问题中,我们常常需要确定某个事件发生的可能性。
概率统计模型通过统计分析已有的数据,从而得到事件发生的概率。
根据已有的统计数据,我们可以计算出事件发生的可能性,并做出相应的决策。
例如,在风险评估中,我们可以通过概率统计模型来评估某个投资产品的风险。
3. 最优化模型最优化模型是研究如何找到使某个目标函数取得最优值的数学模型。
在实际问题中,我们常常需要在一定的约束条件下,找到一组满足特定条件的最优解。
最优化模型可以通过建立数学模型,并应用最优化算法来求解。
在工程设计、物流规划等领域中,最优化模型被广泛应用。
4. 图论模型图论模型是研究图的性质和关系的数学工具。
在实际问题中,我们常常需要分析和描述事物之间的关系。
图论模型可以通过构建图来描述和分析事物之间的关系,并帮助我们解决实际问题。
在社交网络分析、交通规划等领域中,图论模型发挥着重要的作用。
5. 随机过程模型随机过程模型是研究随机现象随时间变化规律的数学工具。
在实际问题中,我们常常需要研究某个随机变量随时间的变化趋势,或者某个随机事件在一段时间内的累积概率。
随机过程模型可以通过建立数学模型,对随机现象进行建模和分析。
在金融风险管理、天气预测等领域中,随机过程模型被广泛应用。

四类基本模型1优化模型1.1数学规划模型线性规划、整数线性规划、非线性规划、多目标规划、动态规划。
1.2微分方程组模型阻滞增长模型、SARS传播模型。
1.3图论与网络优化问题最短路径问题、网络最大流问题、最小费用最大流问题、最小生成树问题(MST)、旅行商问题(TSP)、图的着色问题。
1.4概率模型决策模型、随机存储模型、随机人口模型、报童问题、Markov链模型。
1.5组合优化经典问题多维背包问题(MKP)背包问题:n个物品,对物品i,体积为W i,背包容量为W。
如何将尽可能多的物品装入背包。
多维背包问题:n个物品,对物品i,价值为P i,体积为W i,背包容量为W。
如何选取物品装入背包,是背包中物品的总价值最大。
多维背包问题在实际中的应用有:资源分配、货物装载和存储分配等问题。
该问题属于NP难问题。
二维指派问题(QAP)工作指派问题:n个工作可以由n个工人分别完成。
工人i完成工作j的时间为d j。
如何安排使总工作时间最小。
二维指派问题(常以机器布局问题为例):n台机器要布置在n个地方,机器i 与k之间的物流量为f ik,位置j与l之间的距离为d jl,如何布置使费用最小。
二维指派问题在实际中的应用有:校园建筑物的布局、医院科室的安排、成组技术中加工中心的组成问题等。
旅行商问题(TSP)旅行商问题:有n个城市,城市i与j之间的距离为d ij,找一条经过n个城市的巡回(每个城市经过且只经过一次,最后回到出发点),使得总路程最小。
车辆路径问题(VRP)车辆路径问题(也称车辆计划):已知n个客户的位置坐标和货物需求,在可供使用车辆数量及运载能力条件的约束下,每辆车都从起点出发,完成若干客户点的运送任务后再回到起点,要求以最少的车辆数、最小的车辆总行程完成货物的派送任务。
TSP问题是VRP问题的特例。
车间作业调度问题(JSP)车间调度问题:存在j个工作和m台机器,每个工作由一系列操作组成,操作的执行次序遵循严格的串行顺序,在特定的时间每个操作需要一台特定的机器完成,每台机器在同一时刻不能同时完成不同的工作,同一时刻同一工作的各个操作不能并发执行。


概率计算常见模型概率计算是一项非常重要的数学工具,广泛应用于各个领域,包括统计学、金融、自然语言处理、机器学习等。
概率计算模型是用来描述和计算不确定性的工具,可以帮助我们理解和解决各种问题。
本文将介绍几种常见的概率计算模型,包括贝叶斯网络、隐马尔可夫模型、条件随机场和朴素贝叶斯分类器。
一、贝叶斯网络贝叶斯网络是一种用图表示概率模型的工具。
它由一组随机变量和他们之间的依赖关系组成的有向无环图来表示,节点表示随机变量,边表示变量之间的依赖关系。
贝叶斯网络可以用来表示和计算概率分布,以及进行推断和预测。
通过贝叶斯网络,我们可以计算给定一些证据的情况下,某个节点的概率分布。
这使得我们可以通过观察一些已知信息来预测未知的变量。
二、隐马尔可夫模型隐马尔可夫模型是一种描述随机序列的统计模型。
它由一个随机序列和一个相对应的观察序列组成。
在隐马尔可夫模型中,随机序列是不可见的,而观察序列是可见的。
隐马尔可夫模型可以用来描述和计算两个序列之间的概率。
通过观察已有的观察序列,我们可以推断出随机序列的概率分布。
这使得我们可以通过观察一些已知的序列来预测未知的序列。
三、条件随机场条件随机场是一种判别模型,用于对给定输入随机变量的条件下,建立输出随机变量的条件概率分布模型。
条件随机场常用于序列标注、语音识别、自然语言处理等领域。
条件随机场可以通过定义特征函数和定义求和项的方式,来建立输入和输出之间的条件概率关系。
通过采用最大似然估计或其他方式,可以对模型进行参数估计,从而完成对未知序列的预测。
四、朴素贝叶斯分类器朴素贝叶斯分类器是一种简单而常用的分类模型,它基于贝叶斯定理和特征条件独立性假设。
朴素贝叶斯分类器常用于文本分类、垃圾邮件过滤、情感分析等任务。
朴素贝叶斯分类器可以通过训练集中已有的特征和相应的标签,来计算特征和标签之间的条件概率分布。
通过计算给定特征下每个标签的概率,可以确定最有可能的标签,从而完成对未知样本的分类。



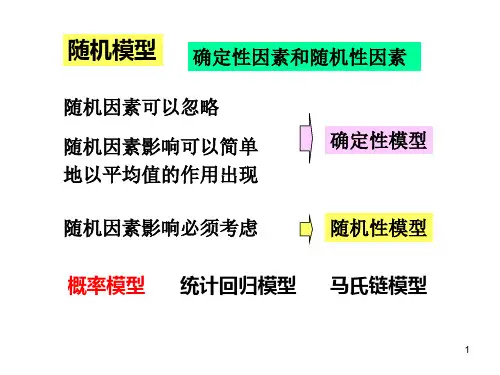

常用随机分配方法在许多领域的研究和实践中,随机分配方法都发挥着重要作用。
它能够有效地消除偏差,确保结果的可靠性和公正性。
接下来,让我们一起了解一些常用的随机分配方法。
首先要提到的是简单随机分配。
这是一种最基本也最直观的方法。
想象一下,我们有一个装有所有参与者名字或编号的“大箱子”,然后通过随机抽取的方式,将他们分配到不同的组中。
比如说,要研究某种药物的效果,把患者随机地分到用药组和对照组。
实现简单随机分配可以使用随机数生成器,比如常见的计算机程序或在线工具,它们能够快速生成随机数,然后根据这些随机数来决定参与者的分组。
这种方法的优点是操作简单,容易理解。
但也存在一定的局限性,如果样本量较小,可能会导致分组不均衡,影响实验结果的准确性。
分层随机分配是对简单随机分配的一种改进。
在进行分层随机分配之前,我们先根据一些重要的特征,比如年龄、性别、病情严重程度等,将参与者分层。
然后在每一层内进行随机分配。
这样做的好处是能够保证各层之间的特征分布相对均衡,从而提高实验的精度。
举个例子,如果我们研究的是青少年和成年人对某种教育方法的反应,就可以先把参与者按年龄分为两层,再在每一层内随机分组。
区组随机分配也是一种常用的方法。
在这种方法中,我们将参与者按照一定的顺序分成若干个区组,每个区组内的人数是固定的。
然后在每个区组内进行随机分配。
这样可以保证在一段时间或一定范围内,分组的均衡性。
比如说,在临床试验中,每天新入组的患者可以组成一个区组,然后在这个区组内随机分配治疗方案。
动态随机分配则更加灵活。
在实验过程中,根据不断更新的信息和条件来实时调整分组的概率。
这种方法适用于情况较为复杂、需要不断适应变化的研究。
但由于其复杂性,在实际应用中需要更高级的技术和计算资源支持。
还有一种叫做最小化随机分配的方法。
它的目标是在分组过程中,使各个组之间的重要协变量尽可能地平衡。
通过不断计算和比较不同分组方案下协变量的不平衡程度,选择不平衡程度最小的分组方案。
常见随机方案随机方案是在实验设计或决策过程中常用的一种方法。
通过随机抽取或生成随机数,可以使实验或决策结果具有一定的随机性和代表性。
下面,介绍几种常见的随机方案。
1. 简单随机抽样简单随机抽样是最常用的一种随机抽样方案。
其思想是从总体中随机选择若干个样本,使得每个样本具有相同的被选中的概率。
简单随机抽样常用于民调、调查研究等领域,可以有效保证样本的代表性。
2. 系统抽样系统抽样也是一种常见的随机抽样方案。
它的思想是在总体中选择一个随机开始的位置,然后按照固定的间隔选择样本。
例如在一条街道上进行调查,可以从某个起始点开始,每隔一定数量的房屋选择一个样本。
系统抽样相对于简单随机抽样可以提高调查的效率,并且仍具有一定的随机性。
3. 分层抽样分层抽样是一种将总体划分为若干层次,然后从每个层次中进行随机抽样的方法。
分层抽样可以有效保证样本的多样性和代表性。
例如,在一项教育调查中,可以按照不同年级划分层次,然后从每个年级中进行随机抽样。
这样可以确保每个年级的样本数量均衡,并且能够覆盖到各个层次的特征。
4. 簇抽样簇抽样又称作群体抽样,它是将总体划分为若干个相互独立的群体,然后从每个群体中抽取所有样本的方法。
簇抽样常用于地理学调查、社会学调查等领域。
例如在一项城市调查中,可以将城市划分为多个区域,然后从每个区域中随机选择一个样本点进行调查。
5. 整群抽样整群抽样是将总体划分为若干个群体,然后从每个群体中随机选择一个或多个群体作为样本的方法。
与簇抽样不同的是,整群抽样不需要对每个群体进行全面抽样,而是选择部分群体作为样本。
这种抽样方式在一些大规模调查中常用,例如在国家或地区层面的统计调查中,可以将各个省份或城市作为群体进行抽样。
总结起来,以上介绍了几种常见的随机方案,包括简单随机抽样、系统抽样、分层抽样、簇抽样和整群抽样。
每种随机方案都有其适用的场景和应用领域。
在实际应用中,可以根据具体需求选择合适的随机方案,确保实验或决策结果的可靠性和代表性。
第三章 随机数学模型§3.1 多元回归与最优逐步回归一、数学模型设可控或不可控的自变量x x x p 12,,, ;目标函数y y y m 12,,, ,已测得的n 组数据为: },,,,,,,{2121m p y y y x x x αααααα(1.1)其中y j m n j αα,,,,,,,,==1212 是系统的测试数据,相当于如下模型:设多目标系统为:为简化问题,不妨设该系统为单目标系统,且由函数关系y f x x x p =(,,,)12 ,可以设:y x x p p =+++βββ011(1.2)可得如下线性模型⎪⎪⎩⎪⎪⎨⎧+++++=+++++=+++++=n np p n n n p p p p x x x y x x x y x x x y εββββεββββεββββ 22110222222211021112211101 (1.3)εεε12,,, n 为测量误差,相互独立,εσi N ~(,)0。
令Y y y y X x x x x x x x x x n p p n n np p n =⎛⎝ ⎫⎭⎪⎪⎪⎪=⎛⎝⎫⎭⎪⎪⎪⎪=⎛⎝ ⎫⎭⎪⎪⎪⎪=⎛⎝ ⎫⎭⎪⎪⎪⎪121112121222120112111 ββββεεεε可得Y X =+βε(1.4)(1.4) 称为线性回归方程的数学模型。
y 1y 2y mx 1x 2x p利用最小二乘估计或极大似然估计,令 ∑=----=ni ip p i ix x yQ 12110][βββ 使Q Q =min ,由方程组⎪⎩⎪⎨⎧==p i Qi ,,2,1,00 ∂β∂(1.5)可得系数βββ01,,, p 的估计。
令 A X X p T =+设()1方阵可逆,由模型Y X =β 可得: X Y X X A T T ==ββ即有 β=-A X Y T 1 (1.6)可以证明(1.6)与(1.5)是同解方程组的解,它是最优线性无偏估量,满足很多良好的性质,另文补讲。
超市服务方案的随机模型(doc 13页)超市服务方案的随机模型数学系01数本2001141120 刘晨凡指导老师:周天明摘要:为了提高超市服务效率,我们根据超市顾客到达及服务问题的基本规律,建立了超市服务系统的随机模型,并由此得出最佳服务方案,并对所建立的模型进行仿真模拟,验证了所得模型的合理性。
本方案可以用于超市服务方案的确定。
关键词:随机摸拟;随机数字;随机变量;仿真摸拟;Poisson分布;指数分布;随机模型0、引言超级市场门口排列着若干收款台,顾客携带着采购的商品在收款台前排队等候验货付款。
若在顾客少时,就能只接付款离开;若在购物高峰期,顾客就得排队等待。
作为顾客,我们所关心的是何时能付款后离开,作为超市记()10a f =≥,则11n f a n ⎛⎫= ⎪⎝⎭,因此对于任意正整数m 及n 成立1mmn m f f a n n ⎡⎤⎛⎫⎛⎫== ⎪ ⎪⎢⎥⎝⎭⎝⎭⎣⎦(4)这样,我们已证得(4)对一切有理数成立,再用利用无理数的性质及函数的连续性可以证明对无理数也成立,从而证明了引理。
引理2:用ξ表示 [0,]t 内到达的顾客数,则ξ服从参数为t λ的Poisson 分布,即()()()!nt n t P t P n e n λλξ-===。
证明:对0t ∆>,考虑[]0,t t +∆中来到n 个顾客的概率是()n P t t +∆,由独立性增量性及全概率公式得()()()()()()()0110n n n n P t t P t P t P t P t P t P t -+∆=∆+∆+⋅⋅⋅+∆ (5)特别地()()()000P t t P t P t +∆=∆,()0P t 表示在长度为t 的时间间隔中没有来顾客的概率,因此它关于t 单调下降,由引理知()0tP t a =。
其中0a ≥,若0a =,则()00P t ≡,这说明不管怎么短的时间间隔内都要来顾客,这种情形不在我们考虑之列。
概率计算中的常用概率模型与分布在概率计算中,常用的概率模型和分布是非常重要的工具,能够帮助我们研究和解决各种问题。
本文将介绍几种常见的概率模型和分布,并论述它们在实际应用中的作用和特点。
一、二项分布二项分布是最基础的离散概率分布之一,适用于一系列独立重复实验中成功次数的概率问题。
其概率质量函数为:P(X=k)=C(n,k) * p^k * (1-p)^(n-k),其中n为实验次数,k为成功次数,p为每次实验成功的概率。
二项分布在统计学和实验设计中被广泛运用,如市场调研中对不同观众群体的喜好偏好进行调查和分析。
二、泊松分布泊松分布是一种描述单位时间或单位空间内事件发生次数的离散概率分布。
其概率质量函数为:P(X=k)=(e^(-λ) * λ^k) / k!,其中λ为单位时间或单位空间内事件的平均发生率。
泊松分布常被用于模拟和预测罕见事件的发生概率,例如自然灾害、交通事故等。
三、正态分布正态分布又称为高斯分布,是连续型概率分布中最为重要和常用的分布之一。
其概率密度函数为:f(x)=(1 / (σ * √(2π))) * e^(-(x-μ)^2 /(2*σ^2)),其中μ为均值,σ为标准差。
正态分布在自然和社会科学中应用广泛,如模拟金融市场变动、研究人类身高体重等。
四、指数分布指数分布是连续型概率分布中描述时间间隔的常用分布。
其概率密度函数为:f(x)=λ * e^(-λx),其中λ为事件的平均发生率。
指数分布在可靠性工程、排队论以及金融学等领域有广泛的应用,如分析设备的寿命、计算服务的响应时间等。
五、贝塔分布贝塔分布是常用的连续型概率分布,用于描述一个随机事件成功的概率。
其概率密度函数为:f(x)= (x^(α-1) * (1-x)^(β-1)) / (B(α, β)),其中α和β为正参数,B(α, β)为贝塔函数。
贝塔分布在产品质量控制、医学统计和生物学研究中有着重要的应用,如药物疗效的评估、疾病发病率的研究等。
常见随机方案模型
引言
随机方案模型是统计学中常用的工具,用于描述和分析随机变量之间的关系。
在实际问题中,往往需要从大量的随机事件中进行抽样并进行分析。
常见的随机方案模型包括正态分布、泊松分布、指数分布等。
本文将分别介绍这些常见的随机方案模型,并讨论它们的特点和应用场景。
正态分布
正态分布是最常见的一种连续型随机方案模型。
它的概率密度函数在数学上是
一个钟形曲线,以均值μ为中心对称。
正态分布的一个重要性质是68-95-99.7规律,即约有68%的观测值落在均值附近的一个标准差范围内,约有95%的观测值
落在两个标准差范围内,约有99.7%的观测值落在三个标准差范围内。
正态分布在很多领域中都有广泛的应用。
例如,在自然和社会科学领域中,许
多变量都服从正态分布,例如身高、体重、考试成绩等。
在概率统计学和假设检验中,正态分布也是很重要的一类分布。
此外,正态分布还是许多其他分布的极限分布,因此在一些实际问题中可以使用正态分布来进行近似计算。
泊松分布
泊松分布是一种描述离散型随机事件发生次数的模型。
它的概率质量函数具有
单峰性,随着参数λ的增大而右移。
泊松分布的参数λ表示单位时间或单位空间
内事件发生的平均次数。
泊松分布的期望和方差均为λ。
泊松分布常用于描述单位时间内发生的稀疏事件,如交通事故、电话呼叫次数、自然灾害的频率等。
在实际应用中,泊松分布可以用于估计罕见事件的概率,例如在某个时间段内发生的车祸次数等。
此外,在排队理论、信号处理和生物统计学中也经常使用泊松分布来建模。
指数分布
指数分布是一种连续型随机方案模型,用于描述等待时间或持续时间的模型。
它的概率密度函数具有单峰性,呈指数递减的形状。
指数分布的一个重要性质是无记忆性,即过去的等待时间不会影响未来的等待时间。
在实际问题中,指数分布常用于描述服务时间、故障修复时间、客户到达时间等。
例如,在排队论中,服务时间经常假设服从指数分布。
在可靠性工程中,指数分布可以用于描述设备的寿命分布。
其他常见的随机方案模型
除了上述介绍的正态分布、泊松分布和指数分布之外,还有许多其他常见的随机方案模型。
•均匀分布:均匀分布是最简单的分布之一,它的概率密度函数在给定的区间上均匀分布。
•二项分布:二项分布描述了在一系列独立重复的伯努利试验中成功的次数的概率分布。
•几何分布:几何分布描述了第一次成功发生之前重复独立的伯努利试验的次数的概率分布。
•超几何分布:超几何分布描述了从有限总体中抽取固定大小的样本中成功的次数的概率分布。
•负二项分布:负二项分布描述了在一系列独立重复的伯努利试验中成功的次数达到指定数量之前的失败次数的概率分布。
结论
随机方案模型是统计学中常用的工具,用于描述和分析随机变量之间的关系。
本文介绍了几种常见的随机方案模型,包括正态分布、泊松分布、指数分布等,并讨论了它们的特点和应用场景。
了解这些常见的随机方案模型对于理解和解决实际问题具有重要意义,希望读者能够从中受益。