3D Photography Dataset-Action Figure (Warrior) (3D摄影数据集图(战士))_图像处理_科研数据集
- 格式:pdf
- 大小:61.89 KB
- 文档页数:3
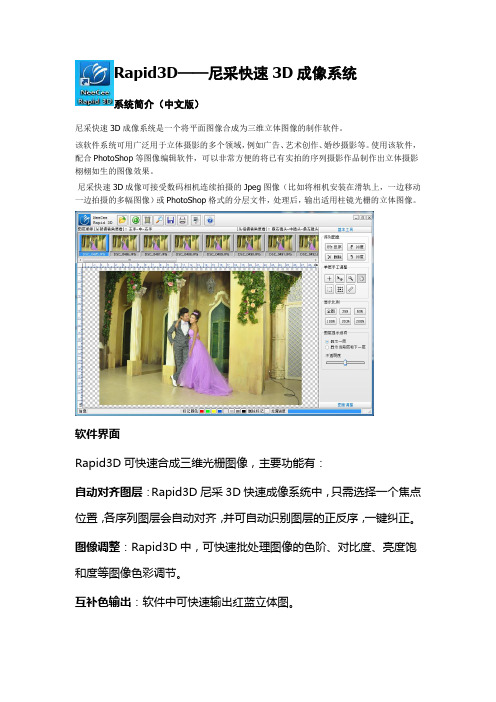
Rapid3D——尼采快速3D成像系统
系统简介(中文版)
尼采快速3D成像系统是一个将平面图像合成为三维立体图像的制作软件。
该软件系统可用广泛用于立体摄影的多个领域,例如广告、艺术创作、婚纱摄影等。
使用该软件,配合PhotoShop等图像编辑软件,可以非常方便的将已有实拍的序列摄影作品制作出立体摄影栩栩如生的图像效果。
尼采快速3D成像可接受数码相机连续拍摄的Jpeg图像(比如将相机安装在滑轨上,一边移动一边拍摄的多幅图像)或PhotoShop格式的分层文件,处理后,输出适用柱镜光栅的立体图像。
软件界面
Rapid3D可快速合成三维光栅图像,主要功能有:
自动对齐图层:Rapid3D尼采3D快速成像系统中,只需选择一个焦点位置,各序列图层会自动对齐,并可自动识别图层的正反序,一键纠正。
图像调整:Rapid3D中,可快速批处理图像的色阶、对比度、亮度饱和度等图像色彩调节。
互补色输出:软件中可快速输出红蓝立体图。
GIF动画输出:Rapid3D尼采3D快速成像系统中,可快速输出GIF 动画演示图像。
位移测量:不同的光栅材料和打印精度,允许的立体空间是不一样的。
只有选择了合适的位移量,才能制作出既立体感强又清晰的3D画面。
在软件中可准确测量出3D图像的前后景位移量,以便输出完美的3D 图像,避免不必要的浪费。
添加LOGO和文字:软件中可方便地添加LOGO标志及文字图形,并可自动变换位置和大小,可设定立体位移量。
光栅测试:在Rapid3D中,提供了光栅测试条打印功能,方便用户对光栅和打印机的测量。

3D人体姿态数据集TNT15目前,已知的 3D 人体姿态的公开数据集有 Human3.6M、HumanEva、MPII、COCO等,这些数据集由 RBG 图像和人体关节点的空间坐标组成。
根据拍摄人数的不同,数据集可分为单人数据集和多人数据集;根据图像是否连续,数据集可分为单帧图像数据集和连续帧视频数据集。
单人连续帧视频数据集的制作,基本上均依靠动捕设备来捕捉真实人体关节点的空间坐标,同时也有数据集消耗大量人力进行手工标注,以下对几种公开数据集进行简要介绍。
(1)Human3.6M 数据集:简称 H36M 数据集,是目前 3D 人体姿态估计领域中数据集样本数量最多、使用最为广泛的数据集。
H36M 数据集共包含约 360 万张图像,共 11 个演员进行数据集录制,其中只有 S1、S5、S6、S7、S8、S9、S11 这 7 个人带有 3D 人体姿态标签。
H36M 数据集中,分别从 4 个角度对演员进行拍摄录制,视频录制帧数为 50Hz,每位演员表演 17 种日常动作,例如:抽烟、照相、打招呼等。
在3D 人体姿态估计领域的研究中,学者们通常会将S1、S5、S6、S7、S8 这 5 个人的动作样本作为训练集,并将 S9、S11 两人的动作样本作为测试集对算法性能进行评测。
在使用 H36M 数据集时需要注意的是,部分视频的帧数与标注的 3D 人体关节点标签帧数不一致,需要对视频末尾帧数进行剪切后与 3D 人体关节点标签一一对应。
(2)HumanEva 数据集:该数据集由动作捕捉设备制作而成,数据集共录制 4 个演员的 6 种日常动作,例如行走、慢跑、拳击、打招呼等,该数据集共包含 20610 张标注图像,学者们通常会将 S1、S2、S3 这 3 个人的动作作为训练集,共 10041 张图像,剩下的样本则作为测试集,共包含 10569 张图像。

如何使用RepNet进行3D人体姿态估计作者:编辑部编译来源:《机器人产业》2019年第02期人体姿态估计是当前计算机视觉领域的热门研究问题。
最近,汉诺威莱布尼兹大学的教授提出了RepNet,一种用于3D人体姿态估计的对抗重投影网络的弱监督训练方法。
这种方法具有良好的性能表现,可以很好地进行单幅图像中的3D人体姿态估计。
本文研究了单幅图像中的3D人体姿态估计问题。
长期以来,人类骨骼都是通过满足重投影误差(reprojection error)进行参数化和适合性观察的,但是现在研究人员直接使用神经网络从观察结果中推断出3D姿态。
然而,这些方法大多忽略了必须满足重投影约束的事实,并且对过度拟合非常敏感。
我们通过忽略2D到3D的对应关系来解决过度拟合问题。
这有效地避免了对训练数据的简单记忆并且使得我们能够进行弱监督训练。
我们所提出的重投影网络(RepNet)的一部分使用对抗训练方法来学习从2D姿态分布到3D姿态分布的映射,而该网络的另一部分对摄相机中的结果进行估计。
这使得我们能够定义一个网络层,该网络层将已估计的3D姿态重投影到2D网络层,从而产生一个重投影损失函数。
实验表明,RepNet可以很好地泛化到未知数据中,并且当应用于未知数据时,其性能表现要优于当前最先进的方法。
此外,这种实施在标准台式PC上就可以实时运行。
介绍基于单眼图像(monocular images)的人体姿态估计是计算机视觉领域中的热门研究领域,在电影、医学、监控或人机交互等领域中有着广泛的应用。
当前的一些研究方法能够从高质量的单眼图像中推断出3D人体姿态。
但是这些方法大多数使用的是一种通过严格分配,从输入到输出数据进行直接训练的神经网络。
这导致对于相似的数据而言性能表现良好,但通常不能够很好地泛化到未知的运动和摄相机位置中。
本文提出使用一种通过弱监督对抗性学习方法进行训练的神经网络来解决该问题。
我们训练一个广泛用于生成对抗网络(GAN)的鉴别器网络来学习3D人体姿态分布,从而缓和了训练数据中每个图像都具有一个特定3D姿态的假设。

深度学习的多视角三维重建技术综述目录一、内容概览 (2)1.1 背景与意义 (2)1.2 国内外研究现状 (3)1.3 研究内容与方法 (5)二、基于单目图像的三维重建技术 (6)2.1 基于特征匹配的三维重建 (7)2.1.1 SIFT与SURF算法 (8)2.1.2 PCA与LDA算法 (10)2.2 基于多视图立体视觉的三维重建 (11)2.3 基于深度学习的三维重建 (12)2.3.1 立体卷积网络 (14)2.3.2 多视图几何网络 (15)三、基于双目图像的三维重建技术 (17)3.1 双目立体视觉原理 (19)3.2 基于特征匹配的双目三维重建 (20)3.3 基于深度学习的双目三维重建 (21)3.3.1 双目卷积网络 (22)3.3.2 GANbased双目三维重建 (23)四、基于多视角图像的三维重建技术 (25)4.1 多视角几何关系 (26)4.2 基于特征匹配的多视角三维重建 (27)4.2.1 ORB特征在多视角场景中的应用 (28)4.2.2 ALOHA算法在多视角场景中的应用 (29)4.3 基于深度学习的多视角三维重建 (30)4.3.1 三维卷积网络(3DCNN)在多视角场景中的应用 (32)4.3.2 注意力机制在多视角场景中的应用 (33)五、三维重建技术在深度学习中的应用 (35)5.1 三维形状描述与识别 (36)5.2 三维物体检测与跟踪 (37)5.3 三维场景理解与渲染 (39)六、结论与展望 (40)6.1 研究成果总结 (41)6.2 现有方法的局限性 (42)6.3 未来发展方向与挑战 (44)一、内容概览多视角数据采集与处理:分析多视角三维重建的关键技术,如相机标定、图像配准、点云配准等,以及如何利用深度学习方法提高数据采集和处理的效率。
深度学习模型与算法:详细介绍深度学习在多视角三维重建中的应用,包括卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN)等,以及这些模型在多视角三维重建任务中的优势和局限性。

激光雕刻机操作规程清华大学基础工业训练中心目录激光雕刻机操作规程 (1)1.点云生成 (2)1.1 3dvision (3)1.2 3DCrystal (15)2.模型雕刻(3DCraft) (28)2.1基本概念 (28)2.2雕刻功能 (30)3.雕刻机调试 (35)3.1 光路校正 (35)3.2标定 (37)4.维护 (40)4.1光学系统维护 (40)4.2 机械电气系统维护 (41)1.点云生成1.1 3dvision这款软件主要适用于图片及文字点云生成,三维点云添加文字及模型的平移旋转及缩放。
特别注意的是缩放只适用于于未生成点云文件之前的图片及文字,对于点云文件一般不进行缩放,否则会因为点间距过小引起水晶炸裂。
准备工作:首次使用本软件,在模型生成前,用户应该导入设定的点云参数,模型参数和水晶尺寸信息。
A.输入雕刻数据用的水晶尺寸根据您要把模型雕刻在什么样大小的水晶里,来调整水晶框的尺寸。
点击工具栏的【点云】/【参数设置】。
这时会弹出“点云参数设置”的对话框,根据实际的情况来调整水晶尺寸。
对于已经存在的水晶品名,可以随时进行修改并点击“更新”按钮进行确认。
在需要经常更改水晶尺寸时,在“水晶”的下拉菜单中选中“自定义”,再点击“新增”,此时可以对新增的水晶名进行重命名,然后随时可以更改水晶尺寸并点击“更新”就可以了。
B.输入模型的参数输入点云生成参数,邻近点的XYZ 向距离,点间距的选择取决于激光机的特性;输入层数和层间距(如果不使用“点云自动生成功能”,也可以在后面进行点云编辑时再设定)。
注意:其它参数作为默认值,无需更改。
推荐参数:XY 平面点间距:0.1 毫米,Z 向点间距:0.1 毫米;(取决于激光机的特性,使用先临科技提供的激光机时,建议这样设置,以取得较好的图像效果)层数和层间距:三维人像模型:层数:3~4 层,0.35 毫米;平面照片模型:层数:3~6 层,0.3~0.5 毫米;(对于三维人像和平面照片, 选择较多的层数,可以得到更为明亮的图像效果)三维配饰:层数:1 文字:层数:3 层,0.35 毫米(根据雕刻机的不同,需要适度调整)注意:每次设定之后,以上这些参数将在以后的3D-Vision 软件使用中作为默认参数。

3D Photography Dataset(华盛顿大学3D相机标定数据库)数据摘要:The following are multiview stereo data sets captured in our lab: a set of images, camera parameters and extracted apparent contours of a single rigid object. Each data set consists of 24 images. Image resolutions range from 1400x1300 pixels^2 to 2000x1800 pixels^2 depending on the data set. For calibration, we have used "Camera Calibration Toolbox for Matlab" by Jean-Yves Bouguet to estimate both the intrinsic and the extrinsic camera parameters. All the images have been corrected to remove radial and tangential distortions. For contour extraction, first, Photoshop has been used to segment the foreground from eachimage(pixel-level). Second, segmentation results have been used to initialize the apparent contour(s) of an object. Last, a b-spline snake has been applied to extract apparent contours in a sub-pixel level.Images are provided in the JPEG format. Camera parameters are provided in the same format as that of "Camera Calibration Toolbox for Matlab". Apparent contours are provided in our own format, but we hope are fairly easy to interpret. Please see the other sections at the bottom of this website for more details. Unfortunately, we do not have ground truth for all the data sets, but we believe that we can develop some photometricways to evaluate the reconstruction results. This page is still under construction, and we keep on updating the contents as well as adding more data sets as we capture. Note: we also provide some visual hull data sets, too.中文关键词:多视角,立体,轮廓,相机,标定,英文关键词:multiview,stereo,contours,Camera,Calibration,数据格式:IMAGE数据用途:multiview stereo data sets captured camera parameters and extracted apparent contours of a single rigid object.数据详细介绍:3D Photography DatasetThe following are multiview stereo data sets captured in our lab: a set of images, camera parameters and extracted apparent contours of a single rigid object. Each data set consists of 24 images. Image resolutions range from 1400x1300 pixels^2 to 2000x1800 pixels^2 depending on the data set.For calibration, we have used "Camera Calibration Toolbox for Matlab" by Jean-Yves Bouguet to estimate both the intrinsic and the extrinsic camera parameters. All the images have been corrected to remove radial and tangential distortions. For contour extraction, first, Photoshop has been used to segment the foreground from each image(pixel-level). Second, segmentation results have been used to initialize the apparent contour(s) of an object. Last, a b-spline snake has been applied to extract apparent contours in a sub-pixel level.Images are provided in the JPEG format. Camera parameters are provided in the same format as that of "Camera Calibration Toolbox for Matlab". Apparent contours are provided in our own format, but we hope are fairly easy to interpret. Please see the other sections at the bottom of this website for more details. Unfortunately, we do not have ground truth for all the data sets, but we believe that we can develop some photometric ways to evaluate the reconstruction results. This page is still under construction, and we keep on updating the contents as well as adding more data sets as we capture. Note: we also provide some visual hull data sets, too.E xperimental SetupsWe captured the above data sets in our lab by using 3 fixed cameras (Canon EOS 1D Mark II) and a motorized turn table (please see a picture below). We have followed the following 3 steps to acquire data.1. Put 3 cameras in different heights (or 1 at the top and 2 almost at the same height).2. Put an object on the motorized turn table, and take pictures while rotating the table. The table rotates approximately 45 degrees every time. We rotate it 8 times and each camera takes 8 images. Then at total, we obtain 8 x 3 = 24 images.3. Replace an object with a calibration board (checker board pattern), and take pictures of the board while rotating the table 8 times in exactly the same way. Note that although we have tried to make the incoming light diffuse and uniform as much as possible, lighting conditions with respect to an object are different in each image.File FormatsAs is described in the last section, each data set has been acquired by 3 cameras, and each camera has taken 8 pictures. Image files from 00.jpg through 07.jpg have been taken by the first camera, and hence, these 8 pictures share the same intrinsic camera parameters. Similarly, image files from 08.jpg through 15.jpg have been taken by the second camera, and Image files from 16.jpg through 23.jpg have been taken by the third camera. There is a camera parameter file for each camera: camera0.m (resp. camera1.m and camera2.m) for the first (resp. the second and the third) camera. Each filestores the intrinsic camera parameters of the corresponding camera and extrinsic camera parameters of the associated 8 images. For example, camera0.m contains intrinsic camera parameters for the first camera and extrinsic camera parameters of images 00.jpg through 07.jpg. The format of the camera parameter file is the same as that of "Camera Calibration Toolbox for Matlab". Please see their webpage for more detailed information. For convienience, we have computed the projection matrix from camera parameters and added the matrix to the file. Also note that marginal backgrounds have been clipped away to reduce the sizes of input images while keeping an object fully visible in each image. The principal point has been modified accordingly.An apparent contour is represented as a chain of points in our data sets (a piece-wise linear structures) and provided in a simple format. Each file starts with a single line header and an integer representing the number of apparent contours in the corresponding image, which are followed by the data sections of apparent contours. Note that a single image can have multiple apparent contours. A data section of an apparent contour starts with an integer representing the number of points in the component, followed by their actually 2D image coordinates. Points are listed in a counter clock-wise order for apparent contours containing foreground image region inside. Similarly, points are listed in a clock-wise order for apparent contours containing background image region inside (holes). Since all the objects in our data set are single connected components, each image has a single apparent contour of the first kind, which is given as the first apparent contour in all the files, but can have multiple holes. In some images, especially those of very complicated objects, there exists too many holes in a single image, and we could not extract all of them. However, we believe that this is not a critical issue, because a good visual hull can be still constructed, and our reconstruction algorithm did not have problems in using such visual hulls. If you build a visual hull and are not satisfied with the outcome, you can extract the silhouettes by yourself. The other thing you may want to try is to build a visual hull by using the apparent contours we provided, then project the visual hull back onto each image, and extract boundaries of its projection. Missing holes can be detected from the boundaries, furthermore, you may be able to extract more accurate silhouettes starting from the boundaries. In those cases, we really appreciate it if you can provide us more accurate data files.Calibration AccuracyWe have performed the following 3 tests to check the accuracy of the camera parameters.- Firstly, we need to make sure that the behavior of the turn table is repetitive, because pictures of an object and pictures of the calibration grids have not been taken at the same times. Note that we don't care if the rotation angle isexactly 45 degrees or not, but we want the rotation angle to be the same every time. We confirmed that the rotation is repetitive as follows.- Put a paper with some textures on the turn table, and take a picture from a fixed camera.- Rotate the table (approximately) -45 degrees.- Rotate the table (approximately) 45 degrees.- Take a picture.- Rotate the table (approximately) -45 x 2 = 90 degrees.- Rotate the table (approximately) 45 x 2 = 90 degrees.- Take a picture.- and etc.Those images look identical.- Secondly, we take pairs of (radially and tangentially undistorted) images, and draw a bunch of epipolar lines in them. We can check an accuracy of camera parameters by using frontier points, or salient image features where the epipolar lines go through. We put pairs of images with epipolar lines here for one of our objects. Please compare 2 images, which file names are ??_??_0.jpg and ??_??__1.jpg. We believe that epipolar lines go through the same image features or are off by a pixel or two at most.- Lastly, we can use the reconstruction of our algorithm for the check, that is, look at the alpha-blended surface textures backprojected from different images. Backprojected textures are consistent with each other only when the camera parameters and the geometry of an object are correct. We observed that backprojected textures are consistent even for surface structures that are a few pixels long. The following 2 pairs of images are examples of such alpha-blended textures. For each pair, left picture shows the consistent alpha-blended textures, while the right one is inconsistent.数据预览:点此下载完整数据集。
阿姆斯特丹大学的3D人体姿势恢复数据集(UvA 3D human pose recovery dataset)数据介绍:The data set involves 12 sequences of varying length (2360multi-view frames in total) for benchmarking 3D human pose estimation systems.The data set was recorded outdoors and contains cluttered dynamic backgrounds and lighting changes. The sequences contain diverse actions such as walking,关键词:基准,人类,姿势,三维,动作, benchmarking,human,pose,3D,actions,数据格式:TEXT数据详细介绍:UvA 3D human pose recovery datasetCompanion data set to CVPR 2009 paperM. Hofmann and D. M. Gavrila, “Multi-view 3D Human Pose Estimation combining Single-frame Recovery, Temporal Integration and Model Adaptation”, CVPR 2009.Description:∙The data set involves 12 sequences of varying length (2360 multi-view frames in total) for benchmarking 3D human pose estimation systems.∙The data set was recorded outdoors and contains cluttered dynamic backgrounds and lighting changes. The sequences contain diverseactions such as walking, standing, gesticulation and interaction withother persons.∙Images were recorded with three overlapping hardware-synchronized color CCD cameras at 20 fps and VGA resolution. We supply imageswhere lens distortion has already been removed.∙3D marker data for 17 body locations is made available for all sequences, derived from human labeling (one subject per sequence). License TermsThis data set is made available to the scientific community solely fornon-commercial research purposes such as academic research, teaching, scientific publications, or personal experimentation. Re-distribution is not permitted without the express permission of the authors.The data set comes "AS IS", without express or implied warranty. Although every effort has been made to ensure accuracy, the University of Amsterdam does not accept any responsibility for errors or omissions.The use of the data set is to be acknowledged by citing: M. Hofmann and D. M. Gavrila, “Multi-view 3D Human Pose Estimation combining Single-frame Recovery, Temporal Integration and Model Adaptation”, CVPR 2009.数据预览:点此下载完整数据集。
结构光相移法数据集
结构光相移法(Structured Light Phase Shifting)是一种用于三维重建和测量的技术。
这种方法通过投射已知模式的光到物体上,然后观察光在被物体表面形状调制后的变化,来测量物体的形状。
其中,结构光相移法是一种常用的实现方式。
结构光相移法的数据集是用于训练、验证或测试结构光相移法的算法或模型的数据集合。
这些数据集通常包括不同角度、不同光照条件下的物体表面图像,以及相应的深度信息或三维坐标。
一些公开的结构光相移法数据集包括:
1. ShapeNet: ShapeNet 是一个大型三维模型数据集,可用于三维重建和
形状识别等任务。
该数据集包括各种类型的物体,如汽车、椅子、床等,并为每个物体提供了多个视角的图像和三维坐标。
2. ScanNet: ScanNet 是一个用于三维重建和语义分割的大型数据集。
该数据集包括室内场景的多个视角的图像和三维坐标,可用于训练深度学习模型。
3. 3D Shape in-the-Wild (3D ShapeWit): 3D ShapeWit 是一个大型数据集,包括各种物体的图像和三维坐标,可用于训练深度学习模型进行三维重建和识别等任务。
4. ModelNet: ModelNet 是一个用于三维重建和识别的数据集,包括各种类型的物体,如家具、电器等。
该数据集为每个物体提供了多个视角的图像和三维坐标。
这些数据集通常用于训练深度学习模型、验证算法的有效性或进行相关研究工作。
对于使用这些数据集的开发者来说,需要遵守相应的授权协议和使用条款,确保合规性和道德准则得到遵守。
3D Photography Dataset-Action Figure (Warrior) (3D摄影数据集图(战士))
英文关键词:
multiview stereo data,images,camera parameters,contours,
中文关键词:
多视图的立体数据、图像、摄像机参数、轮廓,
数据格式:
IMAGE
数据介绍:
The following are multiview stereo data sets captured in our lab: a set of images, camera parameters and extracted apparent contours of a single rigid object. Each data set consists of 24 images. Image resolutions range from 1400x1300 pixels^2 to 2000x1800 pixels^2 depending on the data set. For calibration, we have used "Camera Calibration Toolbox for Matlab" by Jean-Yves Bouguet to estimate both the intrinsic and the extrinsic camera parameters. All the images have been corrected to remove radial and tangential distortions. For contour extraction, first, Photoshop has been used to segment the foreground from each
image(pixel-level). Second, segmentation results have been used to initialize the apparent contour(s) of an object. Last, a b-spline snake has been applied to extract apparent contours in a sub-pixel level.
Images are provided in the JPEG format. Camera parameters are provided in the same format as that of "Camera Calibration Toolbox for Matlab". Apparent contours are provided in our own format, but we hope are fairly easy to interpret. Please see the other sections at the bottom of this website for more details. Unfortunately, we do not have ground truth for all the data sets, but we believe that we can develop some photometric ways to evaluate the reconstruction results. This page is still under construction, and we keep on updating the contents as well as adding more data sets as we capture.
Action Figure (Warrior)
24 images
Approx 1500x1500 pixels^2
[以下内容来由机器自动翻译]
以下是我们的实验室中捕获的多视图立体数据集:一组图像、摄像机参数和提取明显轮廓的刚性的单个对象。
每个数据集包含24 图像。
图像分辨率在1400 x 1300 像素^2 到2000 x 1800 像素^2 取
决于数据集。
校准,我们估计,内在与外在的相机参数用"相机校准工具箱的Matlab"由让-伊夫·Bouguet。
若要删除径向和切向扭曲已更正所有图像。
轮廓提取,第一,Photoshop 已用分段前台从每个image(pixel-level)。
第二,分割结果已被用来初始化的对象的明显contour(s)。
最后,一b 样条蛇已经用于提取亚像素级别中明显的轮廓。
图像中的JPEG 格式提供。
摄像机参数提供了相同的格式,"相机校准Matlab 工具箱的了"。
只要在我们自己的格式,但我们希望都非常容易解释的明显的轮廓。
请其他节底部的本网站的更多详细信息,参阅。
不幸的是,我们并没有真正的事实,对于所有数据集,但我们相信我们可以培养出一些光度方法评估重建成果。
此页正在建设,和我们保持在更新内容,以及添加更多的数据集,正如我们所捕获。
行动图(战士)24 图像约1500 ×1500 像素^2
[自动翻译由Microsoft Translator完成]
点此下载完整数据集。