生物统计学第五版李春喜课后习题
- 格式:docx
- 大小:14.40 KB
- 文档页数:7
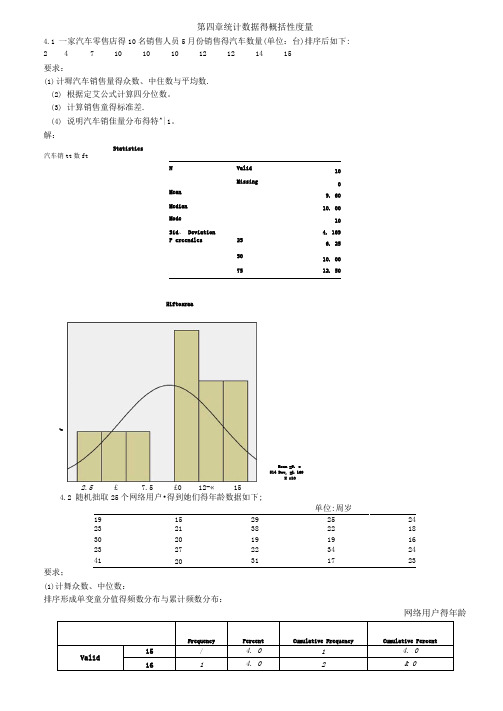
第四章统计数据得概括性度量4.1 一家汽车零售店得10名销售人员5月份销售得汽车数量(单位:台)排序后如下: 24710101012121415要求:(1) 计墀汽车销售量得众数、中住数与平均数. (2) 根据定艾公式计算四分位数。
(3) 计算销售童得标准差. (4) 说明汽车销隹量分布得特^|1。
解:Statistics汽车销tt 数ftNValid 10Missing0 Mean9. 60Median10. 00Mode10Sid 、 Deviation4. 169P crcendles25 6. 255010. 007512. 50单位:周岁19 15 29 25 24 23 21 38 22 18 30 20 19 19 16 23 27 22 34 24 4120311723要求;(1)计舞众数、中位数:排序形成单变童分值得频数分布与累计频数分布:网络用户得年龄Kean =9. e 514 Dev, =L 169X =102.5 £ 7.5 £0 12-« 154.2 随机拙取25个网络用户•得到她们得年龄数据如下;HiftosraaS从频数瞧出,众数Mo有两个:19、23;从累计频数瞧,中位数Me=23.(2)根据定爻公式计算四分位数。
01位置=25/4=6、25,因此01=19.03位置=3X25/4=8、75,因此03=27,或者,由于25与27都只有一个, 因此Q3也可等于25+0、75X2=26、5。
(3)计舞平均数与标准差;Mean=24、00; Std、Dev i at i ori=6、652(4)计舞偏态系数与峰态系数:Skewnessh、080:Kurtosis=0> 773(5)对网民年龄得分布特征进行综合分析:分布•均值=24、标准差=6、652、呈右偏分布•如需瞧清楚分布形态,需要进行分组.为分组情况下得直方图;KK用户的年K为分组情况下得槪率密度曲线:分组: k 确定组数;K = l +里凹= l + li凹=11.398ig(2)2s 确定纽•瞪:组距=( 3s 分组频数表网络用户得年龄(Binned)Frequency Percent Cumulative Frequency Cumulative PercentValid<=15 / 4、0 / 4、016-20 8 32、0 9 36、0 21-259 36. 0 IS 72、026-30 3 12. 0 21 84、031-35 2 8、0 23 92、0 36-40 1 4、0 24 96、041 + 1 4、0 25100. 0Total25100、0Mean23、 3000 Sld> Deviation 7. 0237?V^iance 49. 333 Skewness }、163 KunosisI. 302分组后得直方图;L>-lg2 + 0.30103 取 k"最大值-最小值)m 组数=(41-15)^6=4. 3,取5M *1U U A » U » n 丛 3 :s ■«用户»年》3233010.00 II» :&»» 30.05 非.00 10 00&中値4.3某银行为缩短顾客到银行办理业务等待得吋间。

2.2试计算下列两个玉米品种10个果穗长度(cm)的标准差和变异系数,并解释所得结果。
24号:19,21,20,20,18,19,22,21,21,19;金皇后:16,21,24,15,26,18,20,19,22,19。
【答案】1=20,s1=1.247,CV1=6.235%;2=20,s2=3.400,CV2=17.0%。
2.3某海水养殖场进行贻贝单养和贻贝与海带混养的对比试验,收获时各随机抽取50绳测其毛重(kg),结果分别如下:单养50绳重量数据:45,45,33,53,36,45,42,43,29,25,47,50,43,49,36,30,39,44,35,38,46,51,42,38,51,45,41,51,50,47,44,43,46,55,42,27,42,35,46,53,32,41,4,50,51,46,41,34,44,46;若侵犯了您的版权利益,敬请来信通知我们!℡课后答案网=4.7398,s=0.866,CV=18.27%2.2试计算下列两个玉米品种10个果穗长度(cm)的标准差和变异系数,并解释所得结果。
24号:19,21,20,20,18,19,22,21,21,19;金皇后:16,21,24,15,26,18,20,19,22,19。
【答案】1=20,s1=1.247,CV1=6.235%;2=20,s2=3.400,CV2=17.0%。
2.3某海水养殖场进行贻贝单养和贻贝与海带混养的对比试验,收获时各随机抽取50绳测其毛重(kg),结果分别如下:单养50绳重量数据:45,45,33,53,36,45,42,43,29,25,47,50,43,49,36,30,39,44,35,38,46,51,42,38,51,45,41,51,50,47,44,43,46,55,42,27,42,35,46,53,32,41,4,50,51,46,41,34,44,46;若侵犯了您的版权利益,敬请来信通知我们!℡课后答案网1=42.7,R=30,s1=7.078,CV1=16.58%;2=52.1,R=30,s2=6.335,CV2=12.16%。
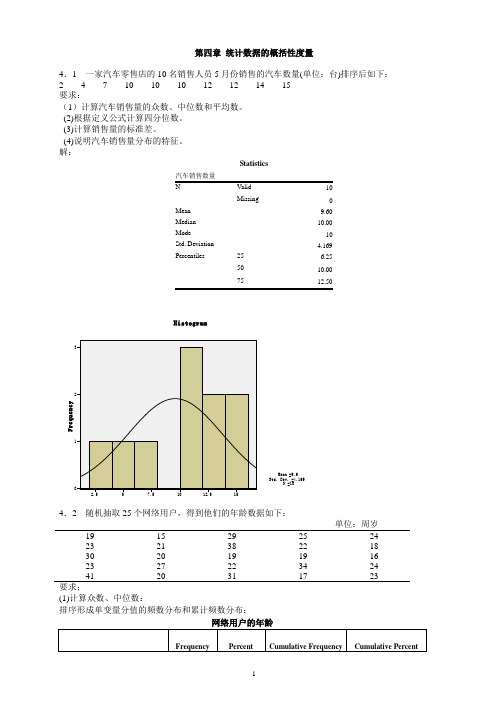
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数:()l g 25l g ()1.3981115.64l g (2)l g 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取5 3、分组频数表网络用户的年龄 (Binned)分组后的直方图:客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。



《生物统计学》第三版课后作业答案(李春喜、姜丽娜、邵云、王文林编著)第一章概论(P7)习题1.1 什么是生物统计学?生物统计学的主要内容和作用是什么?答:(1)生物统计学(biostatistics)是用数理统计的原理和方法来分析和解释生物界各种现象和实验调查资料,是研究生命过程中以样本来推断总体的一门学科。
(2)生物统计学主要包括实验设计和统计推断两大部分的内容。
其基本作用表现在以下四个方面:①提供整理和描述数据资料的科学方法;②确定某些性状和特性的数量特征;③判断实验结果的可靠性;④提供由样本推断总体的方法;⑤提供实验设计的一些重要原则。
习题1.2 解释以下概念:总体、个体、样本、样本容量、变量、参数、统计数、效应、互作、随机误差、系统误差、准确性、精确性。
答:(1)总体(populatian)是具有相同性质的个体所组成的集合,是研究对象的全体。
(2)个体(individual)是组成总体的基本单元。
(3)样本(sample)是从总体中抽出的若干个个体所构成的集合。
(4)样本容量(sample size)是指样本个体的数目。
(5)变量(variable)是相同性质的事物间表现差异性的某种特征。
(6)参数(parameter)是描述总体特征的数量。
(7)统计数(statistic)是由样本计算所得的数值,是描述样本特征的数量。
(8)效应(effection)试验因素相对独立的作用称为该因素的主效应,简称效应。
(9)互作(interaction)是指两个或两个以上处理因素间的相互作用产生的效应。
(10)实验误差(experimental error)是指实验中不可控因素所引起的观测值偏离真值的差异,可以分为随机误差和系统误差。
(11)随机误差(random)也称抽样误差或偶然误差,它是有实验中许多无法控制的偶然因素所造成的实验结果与真实结果之间产生的差异,是不可避免的。
随机误差可以通过增加抽样或试验次数降低随机误差,但不能完全消。

第四章 统计数据的概括性度量4.1 一家汽车零售店的 10 名销售人员 5 月份销售的汽车数量 (单位:台 )排序后如下: 2 4 7 10 10 10 12 12 14 15 要求:(1) 计算汽车销售量的众数、中位数和平均数。
(2) 根据定义公式计算四分位数。
(3) 计算销售量的标准差。
(4) 说明汽车销售量分布的特征。
解:汽车销售数量StatisticsNValid 10Missing0 Mean9.60Median10.00 Mode10Std. Deviation4.169Percentiles25 6.25 5010.007512.504.2 随机抽取 25 个网络用户,得到他们的年龄数据如下:单位:周岁19 15 29 25 24 23 21 38 22 18 30 20 19 19 162327 22 34 24 41 20 31 17 23要求;(1) 计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布: 网龄2.5 57.5 10 汽车销售数量12.515Mean =9.6 Std. Dev. =4.169N =10Histogram3 2ycneuqer(2) 根据定义公式计算四分位数。
Q1位置=25/4=6.25 ,因此Q1=19 ,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3 也可等于25+0.75× 2=26.5。
(3) 计算平均数和标准差;Mean=24.00 ;Std. Deviation=6.652(4) 计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5) 对网民年龄的分布特征进行综合分析:分布,均值=24 、标准差=6.652 、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线:分组:1、确定组数:l gn( ) l g 25 1. 398 K 1 1 1 5. 6,4取k=6lg(2) lg 2 0. 301032、确定组距:组距=( 最大值- 最小值)÷ 组数=(41-15)÷ 6=4.3,取53、分组频数表网络用户的年龄(Binned)分组后的直方图:4. 3 某银行为缩短顾客到银行办理业务等待的时间。

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
![统计学第五版课后练答案解析[4_6章]](https://img.taocdn.com/s1/m/40af1b0cdd36a32d7375813b.png)

《生物统计学》第三版课后作业答案(李春喜、姜丽娜、邵云、王文林编著)第一章概论(P7)习题1、1 什么就是生物统计学?生物统计学的主要内容与作用就是什么?答:(1)生物统计学(biostatistics)就是用数理统计的原理与方法来分析与解释生物界各种现象与实验调查资料,就是研究生命过程中以样本来推断总体的一门学科。
(2)生物统计学主要包括实验设计与统计推断两大部分的内容。
其基本作用表现在以下四个方面:①提供整理与描述数据资料的科学方法;②确定某些性状与特性的数量特征;③判断实验结果的可靠性;④提供由样本推断总体的方法;⑤提供实验设计的一些重要原则。
习题1、2 解释以下概念:总体、个体、样本、样本容量、变量、参数、统计数、效应、互作、随机误差、系统误差、准确性、精确性。
答:(1)总体(populatian)就是具有相同性质的个体所组成的集合,就是研究对象的全体。
(2)个体(individual)就是组成总体的基本单元。
(3)样本(sample)就是从总体中抽出的若干个个体所构成的集合。
(4)样本容量(sample size)就是指样本个体的数目。
(5)变量(variable)就是相同性质的事物间表现差异性的某种特征。
(6)参数(parameter)就是描述总体特征的数量。
(7)统计数(statistic)就是由样本计算所得的数值,就是描述样本特征的数量。
(8)效应(effection)试验因素相对独立的作用称为该因素的主效应,简称效应。
(9)互作(interaction)就是指两个或两个以上处理因素间的相互作用产生的效应。
(10)实验误差(experimental error)就是指实验中不可控因素所引起的观测值偏离真值的差异,可以分为随机误差与系统误差。
(11)随机误差(random)也称抽样误差或偶然误差,它就是有实验中许多无法控制的偶然因素所造成的实验结果与真实结果之间产生的差异,就是不可避免的。

01习题 1、什么是生物试验?它有哪些要求? 2、什么事食盐试验的精确度和准确度?它们各有何特点? 3、什么是实验误差?它与试验错误有何不同?生物试验误差的来源有哪些?如何控制它们以减少误差? 4、实验设计的三大基本原则是什么?常见的试验设计有哪些?它们分别适合什么情况? 5、解释名词:总体;样本;观察值;变数;随机抽样;分层抽样;整群抽样;典型抽样;机械抽样。 6、什么是间断性变数资料和连续性变数资料? 7、从某小麦品种群体中随机抽取10株,统计其单株有效分蘖数,分别是3,4,4,5,5,5,6,6,7,8。请计算其中数、众数、平均数、几何平均数、极差、离均差平方和、方差、标准差、变异系数。 8、某玉米品种的100个穗子的长度(cm)资料如题表1.1所示。试整理之形成频数分布表和频数分布图。 题表1.1 15 17 19 16 15 20 18 19 17 17 17 18 17 16 18 20 19 17 16 18 16 17 19 18 18 17 17 17 18 18 18 15 16 18 18 18 17 20 19 18 19 15 17 17 17 16 17 18 18 17 17 19 19 17 19 17 18 16 18 17 19 16 16 17 17 17 16 17 16 18 18 19 18 18 19 19 20 15 16 19 17 18 20 19 17 18 17 17 16 15 15 16 18 17 18 16 17 19 19 17
9、试以第8题中的数据,计算其中数、众数、平均数、几何平均数、极差、离均差平方和、方差、标准差、变异系数等统计参数。
02习题 1、设A,B,C表示三个随机事件,试将下列事件用A,B,C表示出来:(1)仅A发生;(2)A,B,C都发生;(3)A,B,C都不发生;(4)A,B,C不都发生;(5)A不发生,而且B,C中至少有一个事件发生;(6)A,B,C中至少有一个事件发生;(7)A,B,C中只有一个事件发生;(8)A,B,C中至少有两个事件发生;(9)A,B,C中最多有一个事件发生。 2、请将下列概率从大到小进行排序:P(A),P(A+B),P(A)+P(B),P(AB)。 3、一批产品有20,其中一等品6件、二等品10件,三等品4件,从其中任意取3件产品(不返回),求都取得一等品的概率、都取得二等品的概率、都取得三等品的概率。 4、设人类某疾病的发生率为0.1%。在进行全国城市人口抽查中,需选择一定的群体大小为样方,以便使每一个样方至少出现一个患该种疾病的个体的概率在95%以上。请问样方至少应为多大? 5、在200m2麦田内平均每平方米内有1株杂草,若从中随机抽取1 m2区域,试求该区域内杂草株数的概率分布。 6、一个养鸡场,拟将一批小鸡出售,每30只小鸡装在一个笼子中,每笼中有6只小鸡重量不合格(低于标准)。购买者从一个笼中随机抽出2只称重,若两只都合格则接受这批小鸡,否则拒绝。求:(1)检查第1只就不合格的概率;(2)抽检第1只合格、第2只不合格的概率;(3)接受这批小鸡的概率? 7、在某植物抗病性的遗传学研究中抗病性对感病性符合单显性基因选择模式,因此理论上纯系双亲的杂交F2代抗病植株与感病植株的分离比例为3:1。在某杂交后代F2群体中有60个植株。请问:(1)F2群体植株抗病性的概率分布;(2)F2群体抗病植株的概率分布;(3)若要使F2代群体中分理出至少一个感病个体的概率在95%以上,则在F2代的群体应至少为多大? 8、有10只绵羊迁移到一个废弃的核试验基地小荒岛上放牧。由于残余核辐射的影响,绵羊将完全不育,而且从理论上推断其年死亡率为20%。试求:(1)第一年该绵羊群体存活个体数的概率分布;(2)绵羊存存活年数的概率分布。 9、一农场主租用河滩地3年。若无洪水,每年年终可获纯利20 000元。若出现洪水,则将亏损15 000元(含租地、种子、肥料、人工 费等)。根据常年的经验,出现洪灾的概率为0.3。求:(1)农场主获利年数的概率分布;(2)农场主平均获利多少?(3)若保险公司同意农场主每年交投保金2 000元,以补偿可能发生的洪灾损失(15 000元),请问农场主是否需要买保险?(4)你认为保险公司的投保额太多还是太少? 10、若随机变量X服从N(5,16)分布,求P(X<3),P(X<5),P(3<X<5),P(X>5)。 11、随机变量X服从N(0,1),求下列各式中x0的数值:(1)P(X<x0)=0.01;(2)P(X>x0)=0.01;(3)P(X<x0)= 0.025;(4)P(X>x0)=0.025;(5)P(X<x0)=0.05;(6)P(X>x0)=0.05。 12、从一正态分布N(0,9)中随机抽样得一容量为10的样本,其平均数和方差分别是 =0.56,S2=16。(1)求随机变量 <-1、 >-1、在区间[-1,1]上的概率各是多少?(2)求该样本x2值及随机样本x2小于该x2值的概率。 13、人口普查发现我国城市人口每年夏天痢疾发病率为2.5%。现在某夏天调查某城市,从中随机抽取1 00人,检查其患痢疾的人数。求其中患痢疾的人数在2人以下。2~3人以及在3人以上的概率各为多少? 14、根据常年各地区的检测,两个小麦品种(A和B)的蛋白质含量(服从正态分布)分别为:μ1=12.5%,σ12=1.56;μ2=14.8%,σ22=2.5,。现对来自5个不同地区的这两个品种种子进行蛋白质含量的检测。问这两个品种样本蛋白质含量之差小于1%,小于4%,在1%~4%的概率

生物统计附实验设计第五版答案1、下列植物器官中,属于营养器官的是()[单选题] *A.叶(正确答案)B.花C.果实D.种子2、下列动物中,幼体和成体的呼吸方式完全不同的是()[单选题]A.爬行动物B.两栖动物(正确答案)D.哺乳动物C.鱼3、65.豹猫是一种哺乳动物,近年来相继在北京松山和野鸭湖地区被监测发现。
豹猫的下列行为中属于学习行为的是[单选题] *A.习惯昼伏夜出,活动比较隐蔽B.经过多次试探后不再害怕监测设备(正确答案)C.幼崽一出生就会吮吸乳汁D.通常在每年的春夏两季进行繁殖4、16.控制物质进出人体肝脏细胞的结构是[单选题] *A.细跑核B.细胞壁C.细胞质D.细胞膜(正确答案)5、下列有关合理膳食的叙述中,错误的是()[单选题] * A.主副食合理搭配B.粗细粮合理搭配C.荤多素少合理搭配(正确答案)D.三餐合理搭配6、下列对桃树和松树区别的叙述中,错误的是()[单选题] *A.是否有果实B.是否有种子(正确答案)C.是否有花D.种子是否裸露7、溶菌酶能破坏酵母菌和乳酸菌的细胞壁[判断题] *对错(正确答案)8、人的胚胎发育开始于()[单选题] *A.卵细胞的产生B.子宫内C.精子的产生D.受精卵的形成(正确答案)9、线性动物中,属于研究遗传、发育、衰老等过程的重要实验动物的是()[单选题]A.蛔虫B.蛲虫C.钩虫D.秀丽隐杆线虫(正确答案)10、发面过程常需要添加酵母菌。
下列关于酵母菌的叙述错误的是( ) [单选题] *A.是由一个细胞构成的生物体B.气体交换要通过细胞膜进行C.可通过出芽生殖产生新个体D.可在叶绿体中合成有机物(正确答案)11、19.砂生槐是西藏高原生态恢复的理想树种,具有较高的生态效益。
为初步筛选适合西藏某地区栽培的品种,研究人员测定了4个砂生槐品种幼苗的CO2吸收速率,结果如图。
下列相关叙述错误的是[单选题] *A.4种幼苗应在相同光照强度下进行检测B.丁品种砂生槐适合选为该地区极培品种(正确答案)C.CO2吸收速率可以反映光合作用速率D.砂生槐进行光合作用的场所是叶绿体12、人长时间剧烈运动时,骨骼肌细胞中每摩尔葡萄糖生成ATP的量与安静时相等[判断题] *对错(正确答案)13、将葡萄糖分解成丙酮酸的酶是附着在内质网上的核糖体合成的[判断题] *对错(正确答案)14、用手触摸蚯蚓体壁,感觉到体表有黏液。

统计学(第五版)贾俊平-课后思考题和练习题答案(完整版)统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果, 数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
生物统计学第五版李春喜课后习题
第一章绪论
1.1 生物统计学的定义和目的
生物统计学是研究生物学领域中数据的收集、整理、分析
和解释的一门学科。
其目的是通过数据分析来揭示生物学的规律和特征。
1.2 生物统计学的应用领域
生物统计学广泛应用于生物医学研究、流行病学调查、遗
传学研究、环境科学研究等领域。
通过统计学方法可以更好地理解和解释生物现象,为科学研究提供有力的支持。
1.3 生物统计学的基本概念
在生物统计学中,我们需要了解一些基本概念,如样本、
总体、参数、变量等。
样本是从总体中取出的一部分个体或观测。
总体是我们想要研究的整体。
参数是描述总体特征的数字。
而变量是指我们想要观察或测量的特征。
第二章数据的收集
2.1 数据的来源
数据可以从多个渠道收集,包括实验研究、调查问卷、观测记录等。
在收集数据时,我们需要设计合适的实验方案或调查问卷,以确保数据的准确性和可靠性。
2.2 数据的处理和整理
收集到的数据需要进行处理和整理,以便后续的分析。
处理数据通常包括数据清洗、去除异常值、变量的转换等步骤。
整理数据则是将数据进行分类和整合,便于后续的统计分析。
2.3 数据的质量控制
在数据收集过程中,我们需要关注数据的质量控制。
这包括确保数据的准确性、可靠性和一致性。
通过合理的设计实验和严格的数据管理,可以最大程度地减少数据质量问题。
3.1 数据的图形展示
描述统计学通过图形展示数据的分布和特征。
常用的图形
包括直方图、箱线图、散点图等。
这些图形可以帮助我们更直观地了解数据。
3.2 数据的概括统计
概括统计是对数据进行数值描述的方法,包括均值、中位数、标准差等。
这些统计量可以提供关于数据的集中趋势和离散程度的信息。
3.3 数据的相关性分析
通过相关性分析,我们可以了解不同变量之间的相关程度。
相关性分析通常用相关系数来度量,常见的有皮尔逊相关系数和斯皮尔曼相关系数。
4.1 参数估计
参数估计是根据样本数据来估计总体参数的方法。
常用的参数估计方法包括点估计和区间估计。
4.2 假设检验
假设检验是用来判断总体参数是否满足某个假设的方法。
假设检验通常包括建立原假设和备择假设、选择显著性水平、计算检验统计量等步骤。
4.3 方差分析
方差分析是用来比较多个总体均值差异的方法。
通过方差分析可以判断不同因素对总体均值的影响程度。
第五章非参数统计学
5.1 非参数方法概述
非参数统计学是一种不依赖总体分布假设的统计方法。
与参数统计学相比,非参数方法更加灵活,适用于各种不同类型的数据。
5.2 秩次检验
秩次检验是一种常用的非参数检验方法,特别适用于小样
本数据或不符合正态分布假设的数据。
通过将观测值转化为秩次,可以对样本数据进行比较和推断。
5.3 非参数方差分析
非参数方差分析是一种用于比较多个总体均值差异的方法,适用于不满足方差齐性假设的情况。
第六章生存分析
6.1 生存分析的概念
生存分析是研究个体从某个特定时间点出发到达某个事件
的时间的方法。
生存分析广泛应用于医学研究、流行病学调查等领域。
6.2 生存函数和生存率
生存函数是反映个体在一定时间段内存活的概率分布函数。
生存率是指生存函数的导数,表示个体在某个特定时间点存活的概率。
6.3 生存分析方法
生存分析的常用方法包括Kaplan-Meier方法、Cox比例风
险回归模型等。
这些方法可以用于分析和预测个体的生存情况。
第七章多元统计分析
7.1 多元统计分析方法
多元统计分析是研究多个变量之间关系的方法。
常用的多
元统计分析方法包括多元回归分析、主成分分析、因子分析等。
7.2 多元回归分析
多元回归分析是用于研究多个自变量对因变量的影响的方法。
通过建立回归模型,可以预测因变量并评估自变量对因变量的贡献程度。
7.3 主成分分析
主成分分析是一种数据降维的方法,通过将多个相关变量
转化为少数几个无关的主成分,可以简化数据分析和解释。
以上是《生物统计学第五版李春喜》的课后习题的一些概述。
生物统计学作为一门重要的学科,对于生物研究有着重要
的意义。
通过学习生物统计学,我们可以更加准确地分析和解释生物学领域的数据,并为科学研究提供有力的支持。
希望通过这本教材的学习,能够帮助读者更好地掌握生物统计学的基本原理和方法。