正态分布图做法(输入数据自动生成)
- 格式:xls
- 大小:836.50 KB
- 文档页数:5

如何用EXCEL制作成绩分析的正态分布图摘要:教学评价在学校教育教学工作中的重要地位毋容置疑。
考试是对学生进行的一种教育测量,也是对教师教学质量、出题水平的评价。
特别是数理统计方法的应用,使得我们对学生的教育测量转化为教学评价得到了有效的帮助。
本文论述了如何用EXCEL制作考试成绩的正态分成图,并结合其它相关的衡量标准,比如,区分度,学生成绩柱状分布图,难度系数,优秀率等,融合于一个图表中进行分析。
这是一种有效的可操作的方法,能让每一位教师从图中获得一种易于接受的直观认识,并且方便找出教学中存在的问题,并为以后教学改进措施的制定提供有效的帮助。
关键词:教学评价,EXCEL,成绩分析,正态分布。
教育评价学是教育科学领域中的一个重要的应用性很强的分支学科。
在当今世界教育领域中,教育评价、教育基础理论和教育发展被认为是三大研究范围。
教育是人类有目的、有计划、有组织的活动,教育活动涉及教育方案、教育活动的实施、教育活动的参与者等等,要提高学校教育活动的有效性,就必须对这些内容进行适当的评价。
因此,教育评价对于学校教育的改革和发展,对于学校教育的管理和决策,都有着至关重要的作用,所以备受各国政府及其教育行政部门的重视。
在学校日常工作中,通过教育评价活动来强化管理,已受到人们的广泛重视。
不论是宏观的教育行政管理还是微观的学校工作管理,都把教育评价当作一种有效的管理手段。
就一所学校而言,管理水平的高低在一定程度上能反映出该校的评价工作开展得怎么样,而评价水平的高低又能体现出学校领导者的管理水平。
实施素质教育的关键是教师素质的高低。
为了提高教师素质,教育行政部门和学校都加大了对教师的管理力度,开展了对教师的教学评价工作。
通过有效地评价教师,不仅调动了教师工作的积极性,而且进一步促进了师资队伍的建设。
所以,要做一个有效的管理者,就要重视教育评价的作用。
教学评价是教育评价的重要组成部分。
它以考试作为一种基础性的手段,来收集有关学生对知识的掌握程度方面的信息;以测验作为测量的手段,获得客观的数据,进行进一步的分析、综合,并作出价值上的判断。

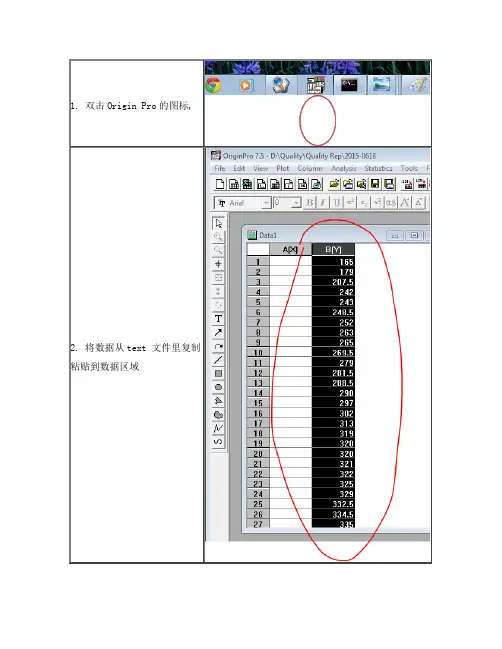
1. 双击Origin Pro的图标,
2. 将数据从text 文件里复制粘贴到数据区域
3. 按照如下路径,选择频率分
析.Frequency Count
4. 设置起点终点和步进,一般
步进50,单击ok
5. 选择生成的 X,Y列数据,点
击plot,按如下路径画图,
--------------------
6. 对得到的柱形图进行颜色调整,默认是红色。
7. 单击菜单栏的Analysis选项,按照图中路径,选择高级拟合(Advanced Fitting Tool)
8. 在Advanced Fitting Tool 菜单界面选择Action-Fit
9. 弹出的对话框,选择
Active Dateset。
10. 选择100Iter,单击Done。
11. 对模型的解释框内容进行删除,只保留Model,Equation,and R2的信息。
12. 右击边框,在属性Properties窗口中去掉边框。
13. 对坐标轴进行命名
14. 右击空白区域,弹出菜单中单击添加Text选项,添加本图表的制作日期。
15. 右击图标空白区域,探出菜单中选择Export Page 导出图片,图片DPI选择200,格式选择png or jpg
16. 最后,保存数据
继续阅读。

python⽣成正态分布数据,并绘图和解析1、⽣成正态分布数据并绘制概率分布图import pandas as pdimport numpy as npimport matplotlib.pyplot as plt# 根据均值、标准差,求指定范围的正态分布概率值def normfun(x, mu, sigma):pdf = np.exp(-((x - mu)**2)/(2*sigma**2)) / (sigma * np.sqrt(2*np.pi))return pdf# result = np.random.randint(-65, 80, size=100) # 最⼩值,最⼤值,数量result = np.random.normal(15, 44, 100) # 均值为0.5,⽅差为1print(result)x = np.arange(min(result), max(result), 0.1)# 设定 y 轴,载⼊刚才的正态分布函数print(result.mean(), result.std())y = normfun(x, result.mean(), result.std())plt.plot(x, y) # 这⾥画出理论的正态分布概率曲线# 这⾥画出实际的参数概率与取值关系plt.hist(result, bins=10, rwidth=0.8, density=True) # bins个柱状图,宽度是rwidth(0~1),=1没有缝隙plt.title('distribution')plt.xlabel('temperature')plt.ylabel('probability')# 输出plt.show() # 最后图⽚的概率和不为1是因为正态分布是从负⽆穷到正⽆穷,这⾥指截取了数据最⼩值到最⼤值的分布根据范围⽣成正态分布:result = np.random.randint(-65, 80, size=100) # 最⼩值,最⼤值,数量根据均值、⽅差⽣成正态分布:result = np.random.normal(15, 44, 100) # 均值为0.5,⽅差为12、判断⼀个序列是否符合正态分布import numpy as npfrom scipy import statspts = 1000np.random.seed(28041990)a = np.random.normal(0, 1, size=pts) # ⽣成1个正态分布,均值为0,标准差为1,100个点b = np.random.normal(2, 1, size=pts) # ⽣成1个正态分布,均值为2,标准差为1, 100个点x = np.concatenate((a, b)) # 把两个正态分布连接起来,所以理论上变成了⾮正态分布序列k2, p = stats.normaltest(x)alpha = 1e-3print("p = {:g}".format(p))# 原假设:x是⼀个正态分布if p < alpha: # null hypothesis: x comes from a normal distributionprint("The null hypothesis can be rejected") # 原假设可被拒绝,即不是正态分布else:print("The null hypothesis cannot be rejected") # 原假设不可被拒绝,即使正态分布3、求置信区间、异常值import numpy as npimport matplotlib.pyplot as pltfrom scipy import statsimport pandas as pd# 求列表数据的异常点def get_outer_data(data_list):df = pd.DataFrame(data_list, columns=['value'])df = df.iloc[:, 0]# 计算下四分位数和上四分位Q1 = df.quantile(q=0.25)Q3 = df.quantile(q=0.75)# 基于1.5倍的四分位差计算上下须对应的值low_whisker = Q1 - 1.5 * (Q3 - Q1)up_whisker = Q3 + 1.5 * (Q3 - Q1)# 寻找异常点kk = df[(df > up_whisker) | (df < low_whisker)]data1 = pd.DataFrame({'id': kk.index, '异常值': kk})return data1N = 100result = np.random.normal(0, 1, N)# result = np.random.randint(-65, 80, size=N) # 最⼩值,最⼤值,数量mean, std = result.mean(), result.std(ddof=1) # 求均值和标准差# 计算置信区间,这⾥的0.9是置信⽔平conf_intveral = stats.norm.interval(0.9, loc=mean, scale=std) # 90%概率print('置信区间:', conf_intveral)x = np.arange(0, len(result), 1)# 求异常值outer = get_outer_data(result)print(outer, type(outer))x1 = outer.iloc[:, 0]y1 = outer.iloc[:, 1]plt.scatter(x1, y1, marker='x', color='r') # 所有离散点plt.scatter(x, result, marker='.', color='g') # 异常点plt.plot([0, len(result)], [conf_intveral[0], conf_intveral[0]])plt.plot([0, len(result)], [conf_intveral[1], conf_intveral[1]])plt.show()4、采样点离散图和概率图import numpy as npimport matplotlib.pyplot as pltfrom scipy import statsimport pandas as pdimport timeprint(time.strftime('%Y-%m-%D %H:%M:%S'))# 根据均值、标准差,求指定范围的正态分布概率值def _normfun(x, mu, sigma):pdf = np.exp(-((x - mu)**2)/(2*sigma**2)) / (sigma * np.sqrt(2*np.pi))return pdf# 求列表数据的异常点def get_outer_data(data_list):df = pd.DataFrame(data_list, columns=['value'])df = df.iloc[:, 0]# 计算下四分位数和上四分位Q1 = df.quantile(q=0.25)Q3 = df.quantile(q=0.75)# 基于1.5倍的四分位差计算上下须对应的值low_whisker = Q1 - 1.5 * (Q3 - Q1)up_whisker = Q3 + 1.5 * (Q3 - Q1)# 寻找异常点kk = df[(df > up_whisker) | (df < low_whisker)]data1 = pd.DataFrame({'id': kk.index, '异常值': kk})return data1N = 100result = np.random.normal(0, 1, N)# result = np.random.randint(-65, 80, size=N) # 最⼩值,最⼤值,数量# result = [100]*100 # 取值全相同# result = np.array(result)mean, std = result.mean(), result.std(ddof=1) # 求均值和标准差# 计算置信区间,这⾥的0.9是置信⽔平if std == 0: # 如果所有值都相同即标准差为0则⽆法计算置信区间conf_intveral = [min(result)-1, max(result)+1]else:conf_intveral = stats.norm.interval(0.9, loc=mean, scale=std) # 90%概率# print('置信区间:', conf_intveral)# 求异常值outer = get_outer_data(result)# 绘制离散图fig = plt.figure()fig.add_subplot(2, 1, 1)plt.subplots_adjust(hspace=0.3)x = np.arange(0, len(result), 1)plt.scatter(x, result, marker='.', color='g') # 画所有离散点plt.scatter(outer.iloc[:, 0], outer.iloc[:, 1], marker='x', color='r') # 画异常离散点plt.plot([0, len(result)], [conf_intveral[0], conf_intveral[0]]) # 置信区间线条plt.plot([0, len(result)], [conf_intveral[1], conf_intveral[1]]) # 置信区间线条plt.text(0, conf_intveral[0], '{:.2f}'.format(conf_intveral[0])) # 置信区间数字显⽰plt.text(0, conf_intveral[1], '{:.2f}'.format(conf_intveral[1])) # 置信区间数字显⽰info = 'outer count:{}'.format(len(outer.iloc[:, 0]))plt.text(min(x), max(result)-((max(result)-min(result)) / 2), info) # 异常点数显⽰plt.xlabel('sample count')plt.ylabel('value')# 绘制概率图if std != 0: # 如果所有取值都相同fig.add_subplot(2, 1, 2)x = np.arange(min(result), max(result), 0.1)y = _normfun(x, result.mean(), result.std())plt.plot(x, y) # 这⾥画出理论的正态分布概率曲线plt.hist(result, bins=10, rwidth=0.8, density=True) # bins个柱状图,宽度是rwidth(0~1),=1没有缝隙info = 'mean:{:.2f}\nstd:{:.2f}\nmode num:{:.2f}'.format(mean, std, np.median(result))plt.text(min(x), max(y) / 2, info)plt.xlabel('value')plt.ylabel('Probability')else:fig.add_subplot(2, 1, 2)info = 'non-normal distribution!!\nmean:{:.2f}\nstd:{:.2f}\nmode num:{:.2f}'.format(mean, std, np.median(result))plt.text(0.5, 0.5, info)plt.xlabel('value')plt.ylabel('Probability')plt.savefig('./distribution.jpg')plt.show()print(time.strftime('%Y-%m-%D %H:%M:%S'))以上就是python ⽣成正态分布数据,并绘图和解析的详细内容,更多关于python 正态分布的资料请关注其它相关⽂章!。

正态分布函数的语法是NORMDIST(x,mean,standard_dev,cumulative)cumulative为一逻辑值,如果为0则是密度函数,如果为1则是累积分布函数。
如果画正态分布图,则为0。
例如均值10%,标准值为20%的正态分布,先在A1中敲入一个变量,假定-50,选中A列,点编辑-填充-序列,选择列,等差序列,步长值10,终止值70。
然后在B1中敲入NORMDIST (A1,10,20,0),返回值为0.000222,选中B1,当鼠标在右下角变成黑十字时,下拉至B13,选中A1B13区域,点击工具栏上的图表向导-散点图,选中第一排第二个图,点下一步,默认设置,下一步,标题自己写,网格线中的勾去掉,图例中的勾去掉,点下一步,完成。
图就初步完成了。
下面是微调把鼠标在图的坐标轴上点右键,选坐标轴格式,在刻度中填入你想要的最小值,最大值,主要刻度单位(x轴上的数值间隔),y轴交叉于(y 为0时,x多少)等等。
确定后,正态分布图就大功告成了。
PS:标准正态分布的语法为NORMSDIST(z),正态分布(一)NORMDIST函数的数学基础利用Excel计算正态分布,可以使用函数。
格式如下:变量,均值,标准差,累积,其中:变量:为分布要计算的值;均值:分布的均值;标准差:分布的标准差;累积:若1,则为分布函数;若0,则为概率密度函数。
当均值为0,标准差为1时,正态分布函数即为标准正态分布函数。
例3已知考试成绩服从正态分布,,,求考试成绩低于500分的概率。
解在Excel中单击任意单元格,输入公式:“ 500,600,100,1 ”,得到的结果为0.158655,即,表示成绩低于500分者占总人数的15.8655%。
例4假设参加某次考试的考生共有2000人,考试科目为5门,现已知考生总分的算术平均值为360,标准差为40分,试估计总分在400分以上的学生人数。
假设5门成绩总分近似服从正态分布。
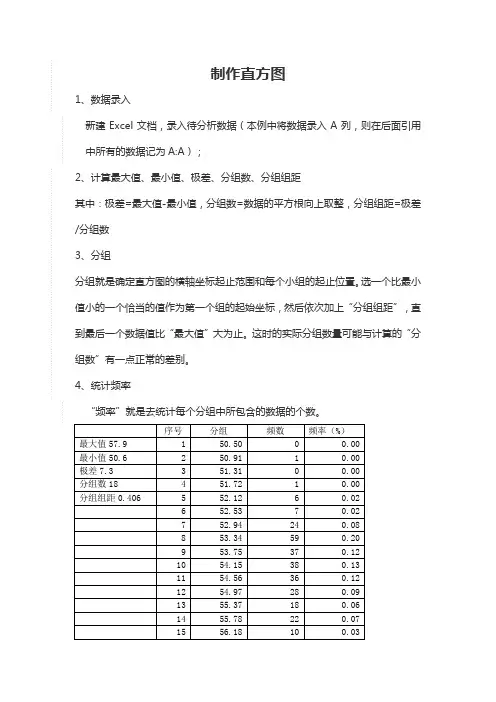
制作直方图
1、数据录入
新建Excel文档,录入待分析数据(本例中将数据录入A列,则在后面引用中所有的数据记为A:A);2
2、计算最大值、最小值、极差、分组数、分组组距
其中:极差=最大值-最小值,分组数=数据的平方根向上取整,分组组距=极差/分组数
3、分组
分组就是确定直方图的横轴坐标起止范围和每个小组的起止位置。
选一个比最小值小的一个恰当的值作为第一个组的起始坐标,然后依次加上“分组组距”,直到最后一个数据值比“最大值”大为止。
这时的实际分组数量可能与计算的“分组数”有一点正常的差别。
4、统计频率
5、制作直方图
选中统计好的直方图每个小组的分布个数的数据源(就是“频率”),用“柱形图”来完成直方图:选中频率列下所有数据(G1:G21),插入→柱形
选中正态分布柱形图→右键→更改系列图表类型,选中“拆线图”,确定。
选中正态分布曲线→右键→设置数据列格式→线型→勾选“平滑线”→关闭。

excel利用函数制作正态分布图的方法Excel中的正太分布图具体该如何利用函数制作呢?接下来是小编为大家带来的excel利用函数制作正态分布图的方法,供大家参考。
excel利用函数制作正态分布图的方法函数制作正太分布图步骤1:获取正态分布概念密度正态分布概率密度正态分布函数NORMDIST获取。
在这里是以分组边界值为X来计算:Mean=AVERAGE(A:A)(数据算术平均)Standard_dev=STDEV(A:A)(数据的标准方差)Cumulative=0(概率密度函数)excel利用函数制作正态分布图的方法图1 函数制作正太分布图步骤2:向下填充excel利用函数制作正态分布图的方法图2 函数制作正太分布图步骤3:在直方图中增加正态分布曲线图1、在直方图内右键选择数据添加2、系列名称:选中H1单元格3、系列值:选中H2:H214、确定、确定excel利用函数制作正态分布图的方法图3 EXCEL中如何控制每列数据的长度并避免重复录入1、用数据有效性定义数据长度。
用鼠标选定你要输入的数据范围,点数据-有效性-设置,有效性条件设成允许文本长度等于5(具体条件可根据你的需要改变)。
还可以定义一些提示信息、出错警告信息和是否打开中文输入法等,定义好后点确定。
2、用条件格式避免重复。
选定A列,点格式-条件格式,将条件设成公式=COUNTIF($A:$A,$A1)1,点格式-字体-颜色,选定红色后点两次确定。
这样设定好后你输入数据如果长度不对会有提示,如果数据重复字体将会变成红色。
在EXCEL中如何把B列与A列不同之处标识出来(一)、如果是要求A、B两列的同一行数据相比较:假定第一行为表头,单击A2单元格,点格式-条件格式,将条件设为:单元格数值不等于=B2点格式-字体-颜色,选中红色,点两次确定。
用格式刷将A2单元格的条件格式向下复制。
B列可参照此方法设置。
(二)、如果是A列与B列整体比较(即相同数据不在同一行):假定第一行为表头,单击A2单元格,点格式-条件格式,将条件设为:公式=COUNTIF($B:$B,$A2)=0点格式-字体-颜色,选中红色,点两次确定。

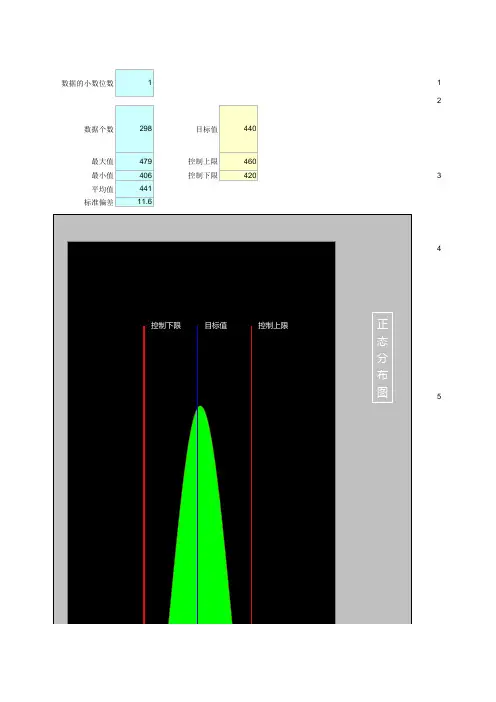

概率正态分布excel
在 Excel 中,可以使用概率密度函数表来计算正态分布。
具体步骤如下:
1. 选择要计算正态分布的变量,将其转换为数值型。
2. 在 Excel 中打开概率密度函数表,该表包含标准正态分布的概率密度函数值。
使用该表查找标准正态分布的密度函数值,并将其替换为变量值。
3. 计算正态分布的概率值。
使用公式
=NORM.S.DIST(x,mu,sigma) 计算标准正态分布中 x 值的概率值,其中 mu 为均值,sigma 为方差。
如果使用的是多维正态分布,则需要使用多个公式来计算不同维度的概率值。
4. 绘制正态分布的图形。
使用 Excel 的绘图功能绘制正态分布的图形,可以使用公式 =NORM.S.DIST(x,mu,sigma) 计算 x 值的概率值,并将其绘制在图形中。
下面是一个简单的示例,假设要计算成绩分布在标准正态分布中的概率值:
1. 将成绩变量转换为数值型。
2. 打开概率密度函数表,并查找标准正态分布的概率密度函数值。
在本例中,标准正态分布的均值为 0,方差为 1。
3. 使用公式 =NORM.S.DIST(x,0,1) 计算成绩 x 值在标准正态分布中的概率值。
4. 使用 Excel 的绘图功能绘制正态分布的图形。
可以绘制一维
正态分布,也可以绘制多维正态分布。
以下是绘制一维正态分布的示例:
```
=NORM.S.DIST(X,0,1)
```
将上述公式插入到一个单元格中,然后拖动该单元格以绘制正态分布图形。
excel 正态分布曲线
Excel正态分布曲线是指Excel中的一个函数,它可以根据给定的均值和标准差生成一个正态分布曲线,用于描述某一连续变量的分布情况。
在Excel中使用正态分布曲线函数需要用到“NORMDIST”函数,其中的参数包括变量值、均值、标准差和累积值等。
根据不同的参数,可以生成不同形态的正态分布曲线,如对称正态分布、偏态正态分布等。
正态分布曲线在统计学和科学研究中有广泛的应用,例如用于描述人群身高、体重、智力水平等连续变量的分布情况。
在Excel 中,通过生成正态分布曲线可以帮助我们更直观地理解和分析数据的分布情况,从而更准确地进行数据处理和决策。
- 1 -。
Excel表格中如何制作正态分布数据图和正态曲线模板Excel制作模板主要是方便直接使用,以后只要将新的样本数据替换,就可以随时做出正态分布图来,很简单。
以下是店铺为您带来的关于Excel表格中制作正态分布数据图和正态曲线模板,希望对您有所帮助。
Excel表格中制作正态分布数据图和正态曲线模板计算均值,标准差及相关数据1、假设有这样一组样本数据,存放于A列,首先我们计算出样本的中心值(均值)和标准差。
如下图,按图写公式计算。
为了方便对照着写公式,我在显示“计算结果”旁边一列列出了使用的公式。
公式直接引用A列计算,这样可以保证不管A列有多少数据,全部可以参与计算。
因为是做模板,所以这样就不会因为每次样本数据量变化而计算错误。
Excel在2007版本以后标准差函数有STDEV.S和STDEV.P。
STDEV.S是样本标准偏差,STDEV.P是基于样本的总体标准偏差。
如果你的Excel里没有STDEV.S函数,请使用STDEV函数。
2、正态分布直方图需要确定分组数,组距坐标上下限等。
如下图写公式计算。
分组数先使用25,上下限与中心值距离(多少个sigma)先使用4。
因为使用公式引用完成计算,所以这两个值是可以任意更改的。
这里暂时先这样放3、计算组坐标。
“组”中填充1-100的序列。
此处列了100个计算值。
原因后面再解释。
在G2,G3分别填入1,2。
选中G2,G3单元格,将鼠标放在右下角选中框的小黑方块上。
当鼠标变成黑色十字时,下拉。
直至数值增加至100。
如下两图4、如下图,H2输入公式=D9,H3单元格输入公式=H2+D$7。
为了使公式中一直引用D7单元格,此处公式中使用了行绝对引用。
5、选中H3单元格,将鼠标放在右下角选中框的小黑方块上。
当鼠标变成黑色十字时双击,填充H列余下单元格。
6、计算频数。
如图所示,在I2,I3分别填写公式计算频数。
同样,选中I3单元格,将鼠标放在右下角选中框的小黑方块上。
当鼠标变成黑色十字时双击,填充I列余下单元格。
利用Excel绘制正态分布曲线的实践正态分布是一种很重要的连续型随机变量的概率分布。
我们在生产中接触到的许多变量都是服从或近似服从正态分布的,如家畜的体长、体重、产奶量、产毛量、血红蛋白含量、血糖含量等。
许多统计分析方法都是以正态分布为基础的,因此在统计学中,正态分布无论在理论研究上还是实际应用中,均占有重要的地位。
但目前无论是网络还是其他参考资料,对正态分布曲线绘制的描述都不系统,对大多数人而言,绘制正态分布曲线依然是难点中的难点。
现以200头大白经产母猪所产仔猪一月龄窝重资料(见图1)为例,谈谈利用Excel绘制正态分布曲线的实践。
图1 200头大白经产母猪所产仔猪一月龄窝重资料1 直方图绘制直方图又称频率分布图,是一种显示数据分布情况的柱形图,可直观、快速地观察数据的分散程度和中心趋势。
直方图的频率计算和图形绘制有两种方式:一是计算数据频率并绘制直方图,二是使用数据分析工具生成直方图。
1.1 计算数据频率并绘制直方图第一步:利用Excel的COUNT、MAX、MIN、AVERAGE、STDEV函数,分别统计出数据个数、最大值、最小值、平均数、标准偏差。
第二部:统计出绘制直方图的基本参数。
在直方图基本参数中,最大值和最小值等于数据统计中的最大值和最小值,而“区间”,也就是“全距”,等于直方图的最大值与最小值的差;直方图的“柱数”,也就是“分组数”,一般等于数据个数的开方再加1(本例中是“SQRT(M2)+1”);组距一般是“区间”除以“直方图的柱数减1”(本例中是“H4/(H5-1)”)。
柱数和组距都取整数(见图2)。
第三步:计算制图数据。
其一是要计算分组数据。
在Excel 中,频数是按照“左开右闭”的方式对落在各区间的数据进行统计的,因此分组数据中要录入的是组上限值,要确保第一组分组数据中必须包含资料中的最小值,最后一个组必须包含资料中的最大值。
基于此,第一组的组上限值一般要大于、接近于资料中的最小值,且最好取整数。
用Excel2007制作直方图和正态分布曲线图••|•浏览:4284•|•更新:2014-04-15 02:39•|•标签:excel2007•••••••分步阅读在学习工作中总会有一些用到直方图、正态分布曲线图的地方,下面手把手教大家在Excel2007中制作直方图和正态分布曲线图工具/原料•Excel(2007)1. 1数据录入新建Excel文档,录入待分析数据(本例中将数据录入A列,则在后面引用中所有的数据记为A:A);2. 2计算“最大值”、“最小值”、“极差”、“分组数”、“分组组距”,公式如图:3. 3分组“分组”就是确定直方图的横轴坐标起止范围和每个小组的起止位置。
选一个比最小值小的一个恰当的值作为第一个组的起始坐标,然后依次加上“分组组距”,直到最后一个数据值比“最大值”大为止。
这时的实际分组数量可能与计算的“分组数”有一点正常的差别。
类似如下图。
4. 4统计频率“频率”就是去统计每个分组中所包含的数据的个数。
最简单的方法就是直接在所有的数据中直接去统计,但当数据量很大的时候,这种方法不但费时,而且容易出错。
一般来说有两种方法来统计每个小组的数据个数:1.采用“FREQUENCY”函数;2.采用“COUNT IF”让后再去相减。
这里介绍的是“FREQUENCY”函数方法:“Date_array”:是选取要统计的数据源,就是选择原始数据的范围;“Bins_array”:是选取直方图分组的数据源,就是选择分组数据的范围;5. 5生成“FREQUENCY”函数公式组,步骤如下:1. 先选中将要统计直方图每个子组中数据数量的区域6. 62. 再按“F2”健,进入到“编辑”状态7.73. 再同时按住“Ctrl”和“Shift”两个键,再按“回车Enter”键,最后三键同时松开,大功告成!8.8制作直方图选中统计好的直方图每个小组的分布个数的数据源(就是“频率”),用“柱形图”来完成直方图:选中频率列下所有数据(G1:G21),插入→柱形图→二维柱形图9.9修整柱形图选中柱形图中的“柱子”→右键→设置数据系列格式:1、系列选项,分类间距设置为0%;2、边框颜色:实线,白色(你喜欢的就好)3、关闭“设置数据系列格式”窗口10.10直方图大功造成!END制作正态分布图1.获取正态分布概念密度正态分布概率密度正态分布函数“NORMDIST”获取。
用Excel2007制作直方图和正态分布曲线图••|•浏览:4284•|•更新:2014-04-15 02:39•|•标签:excel2007•••••••分步阅读在学习工作中总会有一些用到直方图、正态分布曲线图的地方,下面手把手教大家在Excel2007中制作直方图和正态分布曲线图工具/原料•Excel(2007)1. 1数据录入新建Excel文档,录入待分析数据(本例中将数据录入A列,则在后面引用中所有的数据记为A:A);2. 2计算“最大值”、“最小值”、“极差”、“分组数”、“分组组距”,公式如图:3. 3分组“分组”就是确定直方图的横轴坐标起止范围和每个小组的起止位置。
选一个比最小值小的一个恰当的值作为第一个组的起始坐标,然后依次加上“分组组距”,直到最后一个数据值比“最大值”大为止。
这时的实际分组数量可能与计算的“分组数”有一点正常的差别。
类似如下图。
4. 4统计频率“频率”就是去统计每个分组中所包含的数据的个数。
最简单的方法就是直接在所有的数据中直接去统计,但当数据量很大的时候,这种方法不但费时,而且容易出错。
一般来说有两种方法来统计每个小组的数据个数:1.采用“FREQUENCY”函数;2.采用“COUNT IF”让后再去相减。
这里介绍的是“FREQUENCY”函数方法:“Date_array”:是选取要统计的数据源,就是选择原始数据的范围;“Bins_array”:是选取直方图分组的数据源,就是选择分组数据的范围;5. 5生成“FREQUENCY”函数公式组,步骤如下:1. 先选中将要统计直方图每个子组中数据数量的区域6. 62. 再按“F2”健,进入到“编辑”状态7.73. 再同时按住“Ctrl”和“Shift”两个键,再按“回车Enter”键,最后三键同时松开,大功告成!8.8制作直方图选中统计好的直方图每个小组的分布个数的数据源(就是“频率”),用“柱形图”来完成直方图:选中频率列下所有数据(G1:G21),插入→柱形图→二维柱形图9.9修整柱形图选中柱形图中的“柱子”→右键→设置数据系列格式:1、系列选项,分类间距设置为0%;2、边框颜色:实线,白色(你喜欢的就好)3、关闭“设置数据系列格式”窗口10.10直方图大功造成!END制作正态分布图1.获取正态分布概念密度正态分布概率密度正态分布函数“NORMDIST”获取。