SPSS数据文件的建立和管理实验报告
- 格式:doc
- 大小:3.34 MB
- 文档页数:4
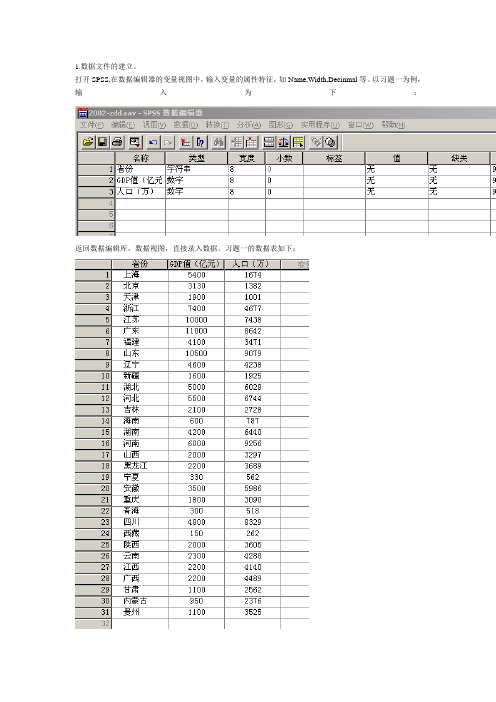
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。

SPSS统计分析软件实验报告石河子大学经济与管理学院经济与贸易系国际经济与贸易专业2009级1班雍荣2009165106实验一SPSS基本操作一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容及步骤(一)数据的输入和保存1. SPSS界面当打开SPSS后,展现在我们面前的界面如下:请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
该界面和EXCEL极为相似,很多操作也与EXCEL类似,同学们可以自己试试。
2.定义变量选择菜单Data==>Define Variable。
系统弹出定义变量对话框如下:对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
假如有两组数据如下:GROUP 1: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 GROUP 2: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87先来建立分组变量GROUP。
请将变量名改为GROUP,然后单击OK按钮。
现在SPSS的数据管理窗口如下所示:第一列的名称已经改为了“group”,这就是我们所定义的新变量“group”。
现在我们来建立变量X。
单击第一行第二列的单元格,然后选择菜单Data==>Define Variable,同样,将变量名改为X,然后确认。


实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构和定义方法;2.掌握spss数据的录入与编辑:数据的录入、数据的定位、插入和删除一个个案、插入和删除一个变量、数据的移动、复制和删除;3.掌握spss数据的保存,保存为excel文件格式和spss文件格式;4.掌握读取excel文件格式和txt文件格式的数据;5.掌握spss数据文件的纵向与横向的合并。
二.实验基本方法1. spss数据的结构和定义方法操作步骤:参阅教材第24页。
2. spss数据的录入与编辑操作步骤:(1)数据的录入:参阅教材第29页。
(2)数据的定位:参阅教材第30页。
(3)插入和删除一个个案:参阅教材第31页。
(4)插入和删除一个变量:参阅教材第31页。
(5)数据的移动、复制和删除:参阅教材第32页。
3. spss数据的保存操作步骤:参阅教材第33页。
4. 读取excel文件格式和txt文件格式的数据操作步骤:参阅教材第35页。
5. spss数据文件的纵向与横向的合并操作步骤:(1)纵向合并数据文件:参阅教材第40页。
(2)横向合并数据文件:参阅教材第42页。
三.实验内容(一)验证性实验(1)教材第25页“关于居民储户调查问卷的spss变量的设计”(2)教材第38页“职工基本情况数据的纵向合并和横向合并”(二)实践性实验(1)针对“零散数据”文件夹中的若干excel数据和txt数据,将其转换为spss的数据文件,要求转换为spss数据后,根据变量的类型正确定义数据结构。
(2)针对“经管学院考试成绩”文件夹中的数据,首先,通过spss软件将“成绩1”和“成绩2”的excel文档打开,并保存为相同文件名的spss数据文件。
要求:spss读取excel的变量名,数据结构定义准确。
其次,利用横向合并的功能,将“成绩1”和“成绩2”进行合并,并存为“三次考试成绩汇总表.sav”的文件。
最后,将“三次考试成绩汇总表.sav”的文件保存一份txt本文数据和excel文件数据。

SPSS统计分析第章数据文件建立和管理引言SPSS(Statistical Product and Service Solutions)是一个被广泛使用的统计分析软件,它的分析功能十分强大,因此在社会科学、教育研究、医学研究等领域得到了广泛的应用。
而SPSS的数据文件建立和管理是使用SPSS时必须掌握的基本操作,它能够让我们更加高效地管理数据,减少误操作,提高分析效率。
本文将介绍SPSS的数据文件建立和管理。
SPSS数据文件建立SPSS数据文件包含两个主要部分:数据字典和数据录入。
数据字典是说明数据文件包含哪些变量,每个变量的名称、类型、取值范围等信息。
数据录入是将实际数据输入到数据文件中。
在建立SPSS数据文件时,需要先建立数据字典,然后再进行数据录入。
数据字典的建立数据字典是SPSS数据文件的重要组成部分,它包含了数据文件中的变量定义和取值范围。
在SPSS中建立数据字典的过程如下:1.打开SPSS软件并新建数据文件:打开SPSS软件,点击“文件”菜单,选择“新建数据文件”选项,弹出新建数据文件对话框。
选择“默认”选项设置数据文件名称和存储位置,并点击“确定”按钮,即可新建一个空的SPSS数据文件。
2.添加变量定义:在新建数据文件中,点击“变量视图”选项卡,然后在空白区域右键单击,选择“插入变量”选项,弹出“建立变量”对话框。
在该对话框中输入变量名称、类型(数值型、文字型、日期型等)、长度、标签等信息,然后点击“添加”按钮。
3.设置变量取值范围:在“建立变量”对话框中,设置变量的取值范围,例如最小值、最大值、有效值等。
点击“确定”按钮,变量将被添加到数据字典中。
4.重复以上步骤,创建所有需要的变量。
数据录入数据录入是向SPSS数据文件中输入实际数据的过程,通常可以使用多种方式进行,如手动输入、导入外部数据等。
手动输入是最常见的方式,它需要打开数据文件并逐行录入数据,并注意每个字段的格式要与数据字典一致。

实验一:SPSS数据文件的建立和管理操作以及数据预处理操作1.有两份关于职工基本情况的SPSS数据文件“职工数据.sav”和“追加职工.sav”,两份数据文件中的数据项不尽相同,且同一数据项的变量名也不完全一致。
请将这两份文件合并到一起。
[实验步骤](1)在数据编辑窗口中打开一个需合并的SPSS数据文件:“职工数据.sav”。
(2)选择菜单:【数据】→【合并文件】→【添加个案】(3)这时将出现以下对话框,点击“浏览”。
(4)打开需进行纵向合并处理的SPSS数据文件“追加职工.sav”。
按“继续”后,显示纵向合并数据文件窗口。
(如下图)(5)对话框右边【新的活动数据集中的变量】框中显示的变量名是两个数据文件中的同名变量,对话框左边【非成对变量】框中显示的变量名是两个文件中的不同名变量。
其中,变量名后面的【*】表示该变量是当前数据编辑窗口中(“职工数据.sav”)的变量,【+】表示该变量是(2)“追加职工.sav”中指定的磁盘文件中的变量。
SPSS默认这些变量的含义不同,且不放入合并后的新文件中。
如果不接受这种默认,可选择其中的两个变量名并按【对】按钮指定配对,表示虽然它们的名称不同但数据含义是相同的,可进入合并后的数据文件中。
本题中,显然职称zc(*)和职称zc1(+)两个变量名需要按【对】按钮指定配对。
方法是:按住“Ctrl键”,同时鼠标点zc(*)和zc1(+),然后按【对】按钮,这时【新的活动数据集中的变量】框中出现“zc&zc1”变量名。
(6)把【非成对变量】框中显示的其他变量名全部标记,按右向箭头。
(7)按【确定】,完成操作。
2.根据“住房状况调查.sav”数据,通过数据排序功能分析本市户口和外地户口家庭的住房面积情况。
(按升序排列)[实验步骤](1)在数据编辑窗口中打开SPSS数据文件:“住房状况调查.sav”。
(2)选择菜单:【数据】→【排序个案】(3)指定主排序变量“户口状况”到【排序依据】框中,并选择【排序顺序】框中的选项指出该变量按升序还是降序排序。
【最新整理,下载后即可编辑】数据管理一、实验目的与要求1.掌握计算新变量、变量取值重编码的基本操作。
2.掌握记录排序、拆分、筛选、加权以及数据汇总的操作。
3.了解数据字典的定义和使用、数据文件的重新排列、转置、合并的操作。
二、实验内容提要1.自行练习完成课本中涉及的对CCSS案例数据的数据管理操作2.针对SPSS自带数据Employee data.sav进行以下练习。
(1)根据变量bdate生成一个新变量“年龄”(2)根据jobcat分组计算salary的秩次(3)根据雇员的性别变量对salary的平均值进行汇总(4)生成新变量grade,当salary<20000时取值为d,在20000~50000范围内时取值为c,在50000~100000范围内取值为b,大于等于100000时取值为a三、实验步骤1、针对CCSS案例数据的数据管理操作1.1.计算变量,输入TS3到目标变量,在数字表达式中输入3,把任意年龄段分成三个组20-30设为1组,1-40设为2组41-50设为3组。
图1,图11.2.对已有变量的分组合并,在“名称”文本框中输入新变量名TS3单击“更改”按钮,原来的S3->?就会变为S3->TS3,单击“旧值和新值”按钮,系统打开“重新编码到其他变量:旧值和新值”,如下图2,图2图31.3.可视离散化,选择“转换”->“可视离散化”,打开的对话框要求用户选择希望进行离散化的变量,单击继续,如下图4,图4单击“生成分割点”,设定分割点数量为10,宽度为5,第一个分割点位置为18,单击“应用”,如下图,图5结果显示如下,图62.针对SPSS自带数据Employee data.sav进行以下练习。
2.1.根据变量bdate生成一个新变量“年龄”,选择“转换”->”计算变量”,如下图,图7结果显示如下,图82.2.根据jobcat分组计算salary的秩次,图9结果显示如下,图102.3.根据雇员的性别变量对salary的平均值进行汇总图11结果显示如下,图122.4.生成新变量grade,当salary<20000时取值为d,在20000~50000范围内时取值为c,在50000~100000范围内取值为b,大于等于100000时取值为a图13结果显示如下,图14 四、实验结果与结论。
1班级: 209208704学号: 28姓名:***重庆理工大学商贸信息学院2011年9月实验1 认识SPSS一、实验目的通过本次实验,了解SPSS的基本特征、结构、运行模式、主要窗口等,对SPSS 有一个浅层次的综合认识。
二、实验内容1.打开SPSS、文件、保存文件的基本方法2.认识各种窗口类型,本次实验涉及file、analyze、graphs。
3.练习系统参数设置4.完成一次SPSS的应用三、实验步骤1.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS2.认识SPSS数据编辑窗、结果输出窗、帮助窗口、图表编辑窗、语句编辑窗3.完成实验任务4.关闭SPSS,关机四、实验任务1、按要求完成表“各地区工业企业主要经济效益指标”的以下数据分析操作:广东25.36 8.88 56.41 2.03 4.99 64161 97.28广西30.48 9.64 56.08 1.50 6.73 6337l 96.34海南25.28 6.44 55.14 1.28 3.10 59593 91.59重庆31.38 10.08 45.14 1.52 5.63 10649l 96.64四川31.84 8.61 56.74 l.50 6.66 86379 97.13贵州30.57 2.17 61.90 0.80 -2.36 35622 98.56云南32.10 9.97 48.35 1.30 11.69 86255 96.88陕西33.62 12.93 55.83 l.29 13.59 138768 96.99甘肃28.57 5.13 63.65 1.11 2.02 67697 99.86青海20.96 11.66 50.51 1.88 18.28 94167 95.92宁夏33.47 3.62 61.15 1.08 -3.OO 61714 91.12新疆29.55 6.1l 59.39 0.95 7.08 70000 94.25 说明:指标中,“流动资产周转次数”量纲为“次/年”;“全员劳动生产率”量纲为“元/人”;其它指标的量纲均为“%”。
广东金融学院实验报告课程名称:市场调查与预测
四、实验结果(包括程序或图表(截图)、结论陈述、数据记录及分析等,可附页)
1.①变量视图截图(zc和zcl合并为zc)
②数据视图的截图(“职工数据.sav”的变量中多了income)
2. 数据视图的截图(户口状况和现住面积都是按升序排的,且先排户口状况再排现住
面积)
3.数据视图的截图(户口状况=2,即属于外地户口的都被划掉了,从而筛选出本市户口,
此外后面的filter_$为1是被选中的数据)
4. 数据视图的截图(由图看出本市户口人均面积的均值为48.93,外地户口人均面积的
均值为34.03,两者在人均面积上有较大的差异,但本市户口和外地户口计划面积的均值都为90.00,所以两者在计划面积上没有较大的差异)
五、实验总结(包括心得体会、问题回答及实验改进意见,可附页)
1.通过实验,我熟练掌握了SPSS数据文件的合并,排序筛选个案和分类汇总的具体操
作。
2.实验的过程必须要自己亲自练习才有效果,所以即使有步骤,也不要怕麻烦,多练几
次。
3.SPSS是一个数据统计的强大工具,我们必须好好学习。
六、教师评语
1.□优秀(90~100分):完成所有规定实验内容,实验步骤正确,结果正确;
2.□良好(80~89分):完成绝大部分规定实验内容,实验步骤正确,结果正确;
3.□中等(70~79分):完成绝大部分规定实验内容,实验步骤基本正确,结果基本正确;
4.□及格(60~69分):基本完成规定实验内容,实验步骤基本正确,完成结果基本正确;
5.□不及格(< 60分):未能完成规定实验内容或实验步骤不正确或结果不正确。
教师签名:
2013年12 月8 日。