spss实验报告
- 格式:doc
- 大小:1.44 MB
- 文档页数:37

spss分析实验报告SPSS分析实验报告引言在社会科学研究领域,SPSS(Statistical Package for the Social Sciences)作为一种数据分析工具,被广泛应用于统计分析和数据挖掘。
本实验报告旨在通过SPSS软件对某项研究进行数据分析,探索其背后的数据模式和相关关系。
一、研究背景与目的本次研究旨在探究大学生的学习成绩与睡眠时间之间的关系。
学习成绩和睡眠时间是大学生日常生活中两个重要的方面,通过分析两者之间的关联,可以为学生提供科学的学习指导,提高学习效果。
二、研究设计与数据收集本研究采用问卷调查的方式,通过随机抽样的方法选取了500名大学生作为研究对象。
问卷内容包括学生的学习成绩和每日平均睡眠时间。
收集到的数据以Excel表格的形式整理并导入SPSS软件进行分析。
三、数据预处理在进行数据分析之前,需要对数据进行预处理。
首先,检查数据是否存在缺失值或异常值。
通过SPSS软件的数据清洗功能,将缺失值进行填补或删除,确保数据的完整性和准确性。
其次,对数据进行标准化处理,以消除不同变量之间的量纲差异。
四、描述性统计分析描述性统计分析是对数据的基本特征进行总结和描述。
通过SPSS软件的统计功能,可以计算出学生的学习成绩和睡眠时间的平均值、标准差、最大值、最小值等统计指标。
同时,可以绘制直方图、箱线图等图表来展示数据的分布情况。
五、相关性分析相关性分析是研究不同变量之间相关关系的一种方法。
本研究中,我们使用Pearson相关系数来衡量学习成绩和睡眠时间之间的线性相关性。
通过SPSS软件的相关性分析功能,可以得到相关系数的数值和显著性水平。
如果相关系数接近于1或-1,并且显著性水平小于0.05,则说明学习成绩和睡眠时间之间存在显著的相关关系。
六、回归分析回归分析是研究自变量对因变量影响程度的一种方法。
在本研究中,我们使用线性回归模型来探究睡眠时间对学习成绩的影响。
通过SPSS软件的回归分析功能,可以得到回归方程的系数、显著性水平和模型的拟合优度。

spss实验报告,心得体会篇一:SPSS实验报告SPSS应用——实验报告班级:统计0801班学号:1304080116 姓名: 宋磊指导老师:胡朝明2010.9.8一、实验目的:1、熟悉SPSS操作系统,掌握数据管理界面的简单的操作;2、熟悉SPSS结果窗口的常用操作方法,掌握输出结果在文字处理软件中的使用方法。
掌握常用统计图(线图、条图、饼图、散点、直方图等)的绘制方法;3、熟悉描述性统计图的绘制方法;4、熟悉描述性统计图的一般编辑方法。
掌握相关分析的操作,对显著性水平的基本简单判断。
二、实验要求:1、数据的录入,保存,读取,转化,增加,删除;数据集的合并,拆分,排序。
2、了解描述性统计的作用,并1掌握其SPSS的实现(频数,均值,标准差,中位数,众数,极差)。
3、应用SPSS生成表格和图形,并对表格和图形进行简单的编辑和分析。
4、应用SPSS做一些探索性分析(如方差分析,相关分析)。
三、实验内容:1、使用SPSS进行数据的录入,并保存: 职工基本情况数据:操作步骤如下:打开SPSS软件,然后在数据编辑窗口(Data View)中录入数据,此时变量名默认为var00001,var00002,…,var00007,然后在Variable View窗口中将变量名称更改即可。
具体结果如下图所示:输入后的数据为:将上述的数据进行保存:单击保存即可。
2、读取上述保存文件:选择菜单File--Open—Data;选择数据文件的类型,并输入文件名进行读取,出现如下窗口:选定职工基本情况.sav文件单击打开即可读取数据。
3、对上述数据新增一个变量工龄,其操作步骤为将当前数据单元确定在某变量上,选择菜单Data—Insert Variable,SPSS自动在当前数据单元所在列的前一列插入一2个空列,该列的变量名默认为var00016,数据类型为标准数值型,变量值均是系统缺失值,然后将数据填入修改。
结果如下图所示:篇二:SPSS相关分析实验报告本科教学实验报告(实验)课程名称:数据分析技术系列实验实验报告学生姓名:一、实验室名称:二、实验项目名称:相关分析三、实验原理相关关系是不完全确定的随机关系。
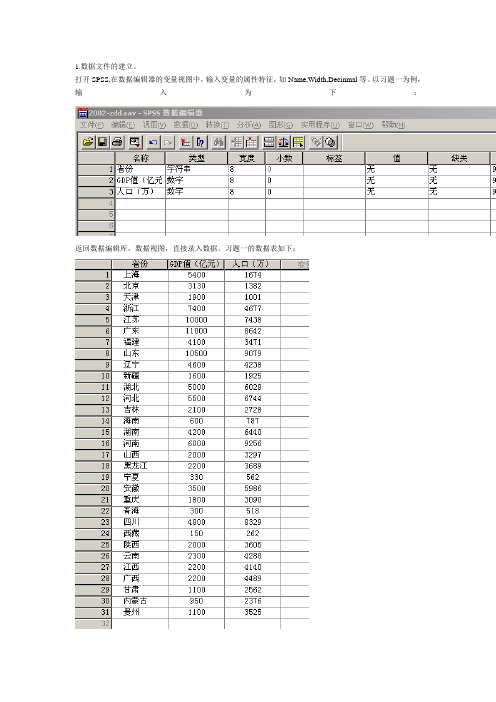
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。

SPSS实验实验课程专业统计软件应用上课时间学年学期周(年月日—日)学生姓名学号所在学院指导教师第五章第一题通过样本分析,结果如下图One-Sample StatisticsN Mean Std. Deviation Std. Error Mean 成绩27 77.9312.111 2.331One-Sample TestTest Value = 70t df Sig. (2-tailed)Mean Difference 95% Confidence Interval of theDifferenceLower Upper成绩 3.400 26.0027.926 3.13 12.72从图看出,sig=0.002,小于0.05,因此本班平均成绩与全国平均成绩70分有显著性差异。
第五章第二题通过独立样本分析,结果如下图Group Statistics成绩N Mean Std. Deviation Std. Error Mean成绩1=男10 84.0011.528 3.6450=女10 62.9018.454 5.836Independent Samples TestLevene's Test forEquality of Variances t-test for Equality of MeansF Sig. t dfSig.(2-tailed)MeanDifferenceStd. ErrorDifference95% Confidence Interval of theDifferenceLower Upper成绩Equalvariancesassumed1.607.221 3.06718.007 21.100 6.881 6.64435.556Independent Samples TestLevene's Test forEquality of Variances t-test for Equality of MeansF Sig. t dfSig.(2-tailed)MeanDifferenceStd. ErrorDifference95% Confidence Interval of theDifferenceLower Upper成绩Equalvariancesassumed1.607.221 3.06718.007 21.100 6.881 6.64435.556Equalvariancesnotassumed3.06715.096.008 21.100 6.881 6.44235.758在显著性水平为0.05的情况下,t统计量的概率p为0.007,故拒绝零假设,既两样本的均值不相等,既男女生成绩有显著性差异。

SPSS聚类分析实验报告一、实验目的本实验旨在通过SPSS软件对样本数据进行聚类分析,找出样本数据中的相似性,并将样本划分为不同的群体。
二、实验步骤1.数据准备:在SPSS软件中导入样本数据,并对数据进行处理,包括数据清洗、异常值处理等。
2.聚类分析设置:在SPSS软件中选择聚类分析方法,并设置分析参数,如距离度量方法、聚类方法、群体数量等。
3.聚类分析结果:根据分析结果,对样本数据进行聚类,并生成聚类结果。
4.结果解释:分析聚类结果,确定每个群体的特征,观察不同群体之间的差异性。
三、实验数据本实验使用了一个包含1000个样本的数据集,每个样本包含了5个变量,分别为年龄、性别、收入、教育水平和消费偏好。
下表展示了部分样本数据:样本编号,年龄,性别,收入,教育水平,消费偏好---------,------,------,------,---------,---------1,30,男,5000,大专,电子产品2,25,女,3000,本科,服装鞋包3,35,男,7000,硕士,食品饮料...,...,...,...,...,...四、实验结果1. 聚类分析设置:在SPSS软件中,我们选择了K-means聚类方法,并设置群体数量为3,距离度量方法为欧氏距离。
2.聚类结果:经过聚类分析后,我们将样本分为了3个群体,分别为群体1、群体2和群体3、每个群体的特征如下:-群体1:年龄偏年轻,女性居多,收入较低,教育水平集中在本科,消费偏好为服装鞋包。
-群体2:年龄跨度较大,男女比例均衡,收入中等,教育水平较高,消费偏好为电子产品。
-群体3:年龄偏高,男性居多,收入较高,教育水平较高,消费偏好为食品饮料。
3.结果解释:根据聚类结果,我们可以看到不同群体之间的差异性较大,每个群体都有明显的特征。
这些结果可以帮助企业更好地了解不同群体的消费习惯,为市场营销活动提供参考。
五、实验结论通过本次实验,我们成功地对样本数据进行了聚类分析,并得出了3个不同的群体。

实验报告——(方差分析)一、实验目的熟练使用SPSS软件进行方差分析。
学会通过方差分析分析不同水平的控制变量是否对结果产生显著影响。
二、实验内容1、某职业病防治院对31名石棉矿工中的石棉肺患者、可疑患者及非患者进行了用力肺活量(L)测定,问三组石棉矿工的用力肺活量有无差别?(自建数据集)石棉肺患者可疑患者非患者1.82.3 2.91.42.13.21.52.1 2.72.1 2.1 2.81.92.6 2.71.72.53.01.82.33.41.92.43.01.82.43.41.8 3.32.03.5SPSS计算结果:在建立数据集时定义group1为石棉肺患者,group2为可疑患者,group3为非患者。
零假设:各水平下总体方差没有显著差异。
相伴概率为0.075,大于0.05,可以认为各个组的方差是相等的,可以进行方差检验。
从上表可以看出3个组之间的相伴概率都小于显著性水平0.05,拒绝零假设,说明3个组之间都存在显著差别。
2、某汽车经销商在不同城市进行调查汽车的销售量数据分析工作,每个城市分别处于不同的区域:东部、西部和中部,而且汽车经销商在不同城市投放不同类型的广告,调查数据放置于附件中数据文件“汽车销量调查.sav”。
(1)试分析不同区域与不同广告类型是否对汽车的销量产生显著性的影响?(2)如果考虑到不同城市人均收入具有差异度时,再思考不同区域和不同广告类型对汽车销量产生的影响差异是否改变,这说明什么问题?SPSS计算结果:(1)此为多因素方差分析相伴概率为0.054大于0.05,可以认为各个组总体方差相等可以进行方差检验。
不同地区贡献的离差平方和为7149.781,均方为3574.891;不同广告贡献的离差平方和为7625.708,均方为3812.854。
说明不同广告和不同地区对汽车销量都有显著性影响。
广告对于销量的影响略大于地区对销量的影响。
从地区这个变量比较:第一组和第三组的相伴概率为0.000,低于显著性水平,一、三组均值差异显著;第二组和第三组的相伴概率为0.028,低于显著性水平,二、三组均值差异显著。
主成分分析、因子分析实验报告--SPSS主成分分析、因子分析实验报告SPSS一、实验目的主成分分析(Principal Component Analysis,PCA)和因子分析(Factor Analysis,FA)是多元统计分析中常用的两种方法,旨在简化数据结构、提取主要信息和解释变量之间的关系。
本次实验的目的是通过使用 SPSS 软件对给定的数据集进行主成分分析和因子分析,深入理解这两种方法的原理和应用,并比较它们的结果和差异。
二、实验原理(一)主成分分析主成分分析是一种通过线性变换将多个相关变量转换为一组较少的不相关综合变量(即主成分)的方法。
这些主成分是原始变量的线性组合,且按照方差递减的顺序排列。
主成分分析的主要目标是在保留尽可能多的数据信息的前提下,减少变量的数量,从而简化数据分析和解释。
(二)因子分析因子分析则是一种探索潜在结构的方法,它假设观测变量是由少数几个不可观测的公共因子和特殊因子线性组合而成。
公共因子解释了变量之间的相关性,而特殊因子则代表了每个变量特有的部分。
因子分析的目的是找出这些公共因子,并估计它们对观测变量的影响程度。
三、实验数据本次实验使用了一份包含多个变量的数据集,这些变量涵盖了不同的领域和特征。
数据集中的变量包括具体变量 1、具体变量 2、具体变量 3等,共X个观测样本。
四、实验步骤(一)主成分分析1、打开 SPSS 软件,导入数据集。
2、选择“分析”>“降维”>“主成分分析”。
3、将需要分析的变量选入“变量”框。
4、在“抽取”选项中,选择主成分的提取方法,如基于特征值大于1 或指定提取的主成分个数。
5、点击“确定”,运行主成分分析。
(二)因子分析1、同样在 SPSS 中,选择“分析”>“降维”>“因子分析”。
2、选入变量。
3、在“描述”选项中,选择相关统计量,如 KMO 检验和巴特利特球形检验。
4、在“抽取”选项中,选择因子提取方法,如主成分法或主轴因子法。
实验报告四.spss一元线性相关回归分析预测
本实验使用spss 17.0软件,针对50个被试者,使用一元线性相关回归分析预测变
量X和Y的关系。
一、实验目的
通过一元线性相关回归分析,预测50个被试者的被试变量X(会计实操次数)和被试变量Y(综合评价分)之间的关系,来检验变量X是否能够预测变量Y的值。
二、实验流程
(2)数据收集:通过收集50个被试者的实际实操次数与综合评价分,建立反映这两
者之间关系的一元线性回归方程。
(3)数据分析:通过SPSS软件的一元线性相关回归分析预测变量X和Y的关系,使
用R方值进行检验研究结果的显著性。
以分析变量X对于变量Y的影响程度。
三、实验结果及分析
1.回归分析结果如下所示:变量X的系数b = 0.6755,t = 7.561,p = 0.000,说
明变量X和被试变量Y之间存在着显著的相关关系;R方值为0.941,说明变量X可以较
好地预测变量Y。
2.可以得出一元线性回归方程为:Y=0.67×X+5.293,其中,b为系数,X是自变量,Y是因变量。
四、结论
(1)50个被试者实际实操次数与综合评价分之间存在着显著的相关性;
(2)变量X可以较好地预测变量Y,R方值较高;。
SPSS上机实验报告一、实验内容1.数据合并:(1)纵向拼接(添加个案):合并数据a.sav和b.sav(2)横向合并(添加变量):合并数据a.sav和c.sav2.对数据CCSS_Sample.sav作下列操作:(1)频率分析:对S0城市,S4学历分别做分析;(2)交叉列表:月份对城市做交叉分析;观察值;计算(行、列)百分百;(3)对多选题C0贷款情况进行分析:多响应频率分析;3.对数据Employee data.sav,分析员工的性别、受教育程度、少数名族、职位类别的分布情况,并尝试分析这些属性之间的关系以及这些属性和工资之间的关系.二、实验步骤1.合并数据(1)纵向拼接:打开spss软件,在菜单中打开a.sav文件,选择菜单:[数据]→[合并文件]→[添加个案],在弹出的窗口中将选择外部spss数据文件并在浏览中选择b.sav,点击继续,在弹出的窗口中将“非成对变量”中的所有变量添加到“新的活动数据集中的变量”,勾选“将个案表现为变量”,点击确定。
结果如图:(2)横向合并:打开a.sav,选择菜单:[数据]→[合并文件]→[添加变量],在弹出的窗口中选择外部数据文c.sav,在弹出的窗口中勾选“按照排序文件中的关键变量匹配个案”,将“已排除变量”中的id添加到“关键变量”中,点击确定。
结果如图:2.(1)频率分析:在spss中打开CCSS_Sample.sav,选择菜单:[分析]→[描述统计]→[频率],在弹出的窗口中双击左边框中的S0城市,S4学历加入到右边变量框中,如图:点击确定。
结果如图:分析:在北京,上海,广州工作的人数基本相同;大专毕业的人最多,其次是高中/中学毕业生和本科毕业生,硕士及以上学历的人非常少,仅占5%。
(2)交叉列表:打开CCSS_Sample.sav数据,选择菜单:[分析]→[描述统计]→[交叉表],在弹出的窗口中从左边框中将月份添加到行中,将城市添加到列中,如图:单击[单元格],勾选百分比中的行和列,如图:单击[继续],再单击[确定]。
实验报告课程名称:统计分析软件(SPSS)学生实验报告一、实验目的及要求二、实验描述及实验过程(一)、利用SPSS绘制统计图1、打开“职工数据.sav”,调用Graphs 菜单的Bar功能,绘制直条图。
直条图用直条的长短来表示非连续性资料的数量大小。
弹出Bar Chart定义选项。
2、在定义选项框的下方有一数据类型栏,大多数情形下,统计图都是以组为单位的形式来体现数据的。
在定义选项框的上方有3种直条图可选:Simple为单一直条图、Clustered 为复式直条图、Stacked为堆积式直条图,本实验选单一直条图。
3、点击Define钮,弹出Define Clustered Bar: Summaries for groups of cases对话框,在左侧的变量列表中选基本工资点击按钮使之进入Bars Represent栏的Other summary function选项的Variable框,选性别/文化程度/职称点击按钮使之进入Category Axis框。
1.点击analyze中的Descriptive Statistics选择frequencies,弹出一个frequencies对话框,选中基本工资和年龄拖入Variable(s)列2.点击statistics选择相应的统计量(例如:Mean,.median,mode等)3.点击continue ,点击OK。
(三)、用SPSS做回归分析(一元线性回归)1.点击Graphs 选择Scatter/dot2.选择simple scatter 点击Define3.将基本工资这个变量输入Y-Axis ,将年龄输入X-Axise4.点击OK ,结果如图5.点击analyze中的regression选择linear,将这个基本工资变量输入 Dependent ,将年龄输入Independt(s6.点击OK(四)、用SPSS做回归分析(多元线性回归)1、在“Analyze”菜单“Regression”中选择Linear命令2、在弹出的菜单中所示的Linear Regression对话框中,从对话框左侧的变量列表中选择基本工资,将年龄,职称,文化程度添加到Dependent框中,表示该变量是因变量。
(此文档为word格式,下载后您可任意编辑修改!) 《统计实习》SPSS实验报告姓名:成功学号:班级:会计二班实验报告二实验项目:描述性统计分析实验目的:1、掌握数据集中趋势和离中趋势的分析方法;2、熟练掌握各个分析过程的基本步骤以及彼此之间的联系和区别。
实验内容及步骤一、数据输入案例:对6名男生和6名女生的肺活量的统计,数据如下:1.打开SPSS软件,进行数据输入:通过打开数据的方式对XLS的数据进行输入其变量视图为:二、探索分析进行探索分析得出如下输出结果:由上表可以看出,6例均为有效值,没有记录缺失值得情况。
由上表可以看出,男女之间肺活量的差异,男生明显优于女生,范围更广,偏度大。
男 Stem-and-Leaf PlotFrequency Stem & Leaf 2.00 1 . 342.00 1 . 892.00 2 . 02Stem width: 1000Each leaf: 1 case(s)女女 Stem-and-Leaf PlotFrequency Stem & Leaf2.00 1 . 233.00 1 . 5681.00 2 . 0Stem width: 1000Each leaf: 1 case(s)三、频率分析进行频率分析得出如下输出结果:由上图可知,分析变量名:肺活量。
可见样本量N为6例,缺失值0例, 1500以下的33%,男生33%女生50%,2000以上女生16.7%,男生33%。
四、描述分析进行描述分析得出如下输出结果:由上图可知,分析变量名:工资,可见样本量N为6例,极小值为男1342女1213,极大值为男2200女2077,说明12人中肺活量最少的为女生是1213,最多的为男生有2200,均值为1810.501621.33,.标准差为327.735325.408,离散程度不算大。
五、交叉分析实验报告三实验项目:均值比较实验目的:.学习利用SPSS进行单样本、两独立样本以及成对样本的均值检验。
实验内容及步骤(一)描述统计案例:某医疗机构为研究某种减肥药的疗效,对15位肥胖者进行为期半年的观察测试,测试指标为使用该药之前和之后的体重。
编号 1 2 3 4 5 服药前198 237 233 179 219 服药后192 225 226 172 214 编号 6 7 8 9 10 服药前169 222 167 199 233 服药后161 210 161 193 226 编号11 12 13 14 15 服药前179 158 157 216 257 服药后173 154 143 206 249输入SPSS建立数据。
由上图可知,结果输出均值、样本量和标准差。
因为选择了分组变量,所以三项指标均给出分组及合计值,可见以这种方式列出统计量可以非常直观的进行各组间的比较。
由上表可知,在显著性水平为0.05时,服药前后的概率p值为小于0.05,拒绝零假设,说明服药前后的体重有显著性变化(二)单样本T检验进行单样本T检验分析得出如下输出结果:由上表可以知,单个样本统计量分析表,的基本情况描述,有样本量、均值、标准差和标准误,单样本t检验表,第一行注明了用于比较的已知总体均值为14,从左到右依次为t值(t)、自由度(df)、P值(Sig.2-tailed)、两均值的差值(Mean Difference)、差值的95%可信区间。
由上表可知:t=34.215,P=0.000<0.05。
因此可以认为肺气肿的总体均值不等于0.(三)双样本T检验案例:研究某安慰剂对肥胖病人治疗作用,用20名患者分组配对,测得体重如下表,要求测定该安慰剂对人的体重作用是否比药物好。
进行双样本T检验得出如下输出结果:T检验成对样本统计量均值N 标准差均值的标准误对 1 安慰剂组121.80 10 11.419 3.611药物组111.80 10 10.185 3.221 由上图可知,对变量各自的统计描述,此处只有1对,故只有对1。
成对样本相关系数N 相关系数Sig.对 1 安慰剂组& 药物10 .802 .005组此处进行配对变量间的相关性分析成对样本检验成对差分t df Sig.(双侧)均值标准差均值的标准误差分95%置信区间下限上限对1安慰剂组-药物组10.006.896 2.181 5.067 14.9334.586 9 .001 配对t检验表,给出最终的检验结果,由上表可见P=0.001,故可认为安慰剂组和药物组对肥胖病人的体重有差别影响实验报告四实验项目:相关分析实验目的:1.学习利用SPSS进行相关分析、偏相关分析、距离分析、线性回归分析和曲线回归。
实验内容及步骤(一)两变量的相关分析案例:某医疗机构为研究某种减肥药的疗效,对15位肥胖者进行为期半年的观察测试,测试指标为使用该药之前和之后的体重。
编号 1 2 3 4 5 服药前198 237 233 179 219 服药后192 225 226 172 214 编号 6 7 8 9 10 服药前169 222 167 199 233 服药后161 210 161 193 226 编号11 12 13 14 15服药前179 158 157 216 257 服药后173 154 143 206 249 进行相关双变量分析得出如下输出结果:相关性相关系数系数表。
变量间两两的相关系数是用方阵的形式给出的。
每一行和每一列的两个变量对应的格子中就是这两个变量相关分析结果结果,共分为三列,分别是相关系数、P值和样本数。
由于这里只分析了两个变量,因此给出的是2*2的方阵。
由上表可见,服药前和服药后自身的相关系数均为1(of course),而治疗前和治疗后的相关系数为0.911,P<0.01(二)偏相关分析偏相关已知有某河流的一年月平均流量观测数据和该河流所在地区当年的月平均雨量和月平均温度观测数据,如表所示。
试分析温度与河水流量之间的相关关系。
观测数据表月份月平均流量月平均雨量月平均气温1 0.50 0.10 -8.802 0.30 0.10 -11.003 0.40 0.40 -2.404 1.40 0.40 6.905 3.30 2.70 10.606 4.70 2.40 13.907 5.90 2.50 15.408 4.70 3.00 13.509 0.90 1.30 10.0010 0.60 1.80 2.7011 0.50 0.60 -4.8012 0.30 0.20 -6.00由上表可见控制月平均雨量之后,“月平均流量”与“月平均气温”的相关系数为0.365,P=0.27,P>0.05,因此“月平均流量”与“月平均气温”不存在显著相关性。
(三)距离分析案例:植物在不同的温度下的生长状况不同,下列是三个温度下的植物生长编号10度20度30度1 12.36 12.4 12.182 12.14 12.2 12.223 12.31 12.28 12.354 12.32 12.25 12.215 12.12 12.22 12.16 12.28 12.34 12.257 12.24 12.31 12.28 12.41 12.3 12.46 近似值(四)线性回归分析已知有某河流的一年月平均流量观测数据和该河流所在地区当年的月平均雨量和月平均温度观测数据,如表所示。
试分析关系。
观测数据表月份月平均流量月平均雨量月平均气温1 0.50 0.10 -8.802 0.30 0.10 -11.003 0.40 0.40 -2.404 1.40 0.40 6.905 3.30 2.70 10.606 4.70 2.40 13.907 5.90 2.50 15.408 4.70 3.00 13.509 0.90 1.30 10.0010 0.60 1.80 2.7011 0.50 0.60 -4.8012 0.30 0.20 -6.00进行线性回归分析得出如下输出结果:回归输入移去的变量b模型输入的变量移去的变量方法1 月平均流量a . 输入a. 已输入所有请求的变量。
b. 因变量: 月平均雨量由表可知,是第一个问题的分析结果。
这里的表格是拟合过程中变量进入退出模型的情况记录,由于只引入了一个自变量,所以只出现了一个模型1(在多元回归中就会依次出现多个回归模型),该模型中身高为进入的变量,没有移出的变量,这里的表格是拟合过程中变量进入退出模型的情况记录,由于只引入了一个自变量,所以只出现了一个模型(在多元回归中就会依次出现多个回归模型),该模型中身高为进入的变量,没有移出的变量。
模型汇总模型R R 方调整R 方标准估计的误差1 .855a .732 .705 .6117a. 预测变量: (常量), 月平均流量。
拟合模型的情况简报,显示在模型中相关系数R为0.855,而决定系数R2为0. 732,校正的决定系数为0.705,说明模型的拟合度较高。
Anovab模型平方和df 均方 F Sig.1 回归10.208 1 10.208 27.283 .000a残差 3.741 10 .374总计13.949 11a. 预测变量: (常量), 月平均流量。
b. 因变量: 月平均雨量这是所用模型的检验结果,可以看到这就是一个标准的方差分析表!从上表可见所用的回归模型F值为27.283,P值为.00a,因此用的这个回归模型是有统计学意义的,可以继续看下面系数分别检验的结果。
由于这里所用的回归模型只有一个自变量,因此模型的检验就等价与系数的检验,在多元回归中这两者是不同的。
系数a模型非标准化系数标准系数t Sig.B 标准误差试用版1 (常量) .387 .247 1.564 .149月平均流量.462 .088 .855 5.223 .000a. 因变量: 月平均雨量包括常数项在内的所有系数的检验结果。
用的是t检验,同时还会给出标化未标化系数。
可见常数项和身高都是有统计学意义的残差统计量a极小值极大值均值标准偏差N 预测值.526 3.113 1.292 .9633 12残差-.6337 1.1358 .0000 .5832 12标准预测值-.795 1.890 .000 1.000 12 标准残差-1.036 1.857 .000 .953 12a. 因变量: 月平均雨量图表(五)曲线回归分析某地1963年调查得儿童年龄(岁)与体重的资料试拟合对数曲线。
年龄(岁)体重1 2 3 4 5 6 7 68 65 67 50 707677进行曲线回归分析得出如下输出结果:实验报告五实验项目:聚类分析和判别分析实验目的:1.学习利用SPSS进行聚类分析和判别分析。
实验内容及步骤(一)系统聚类法为确定老年妇女进行体育锻炼还是增加营养会减缓骨骼损伤,一名研究者用光子吸收法测量了骨骼中无机物含量,对三根骨头主侧和非主侧记录了测量值,结果见教材表。