一文看懂神经网络之Epoch、Batch Size和迭代
- 格式:doc
- 大小:15.00 KB
- 文档页数:2

关于深度学习中的batch_size5.4.1 关于深度学习中的batch_size举个例⼦:例如,假设您有1050个训练样本,并且您希望设置batch_size等于100.该算法从训练数据集中获取前100个样本(从第1到第100个)并训练⽹络。
接下来,它需要第⼆个100个样本(从第101到第200)并再次训练⽹络。
我们可以继续执⾏此过程,直到我们通过⽹络传播所有样本。
最后⼀组样本可能会出现问题。
在我们的例⼦中,我们使⽤了1050,它不能被100整除,没有余数。
最简单的解决⽅案是获取最终的50个样本并训练⽹络。
最终⽬的:通过⼀批⼜⼀批的样本去优化参数使⽤批量⼤⼩的优点<所有样本的数量:它需要更少的内存。
由于您使⽤较少的样本训练⽹络,因此整体训练过程需要较少的内存。
如果您⽆法将整个数据集放⼊机器的内存中,那么这⼀点尤为重要。
通常,⽹络通过⼩批量训练更快。
那是因为我们在每次传播后更新权重。
在我们的例⼦中,我们已经传播了11批(其中10个有100个样本,1个有50个样本),在每个批次之后我们更新了⽹络的参数。
如果我们在传播过程中使⽤了所有样本,我们只会对⽹络参数进⾏1次更新。
使⽤批量⼤⼩的缺点<所有样本的数量:批次越⼩,梯度的估计就越不准确。
在下图中,您可以看到⼩批量渐变(绿⾊)的⽅向与完整批次渐变(蓝⾊)的⽅向相⽐波动更⼤。
batch_size可以理解为批处理参数,它的极限值为训练集样本总数,当数据量⽐较少时,可以将batch_size值设置为全数据集(Full batch cearning)。
实际上,在深度学习中所涉及到的数据都是⽐较多的,⼀般都采⽤⼩批量数据处理原则。
⼩批量训练⽹络的优点:相对海量的的数据集和内存容量,⼩批量处理需要更少的内存就可以训练⽹络。
通常⼩批量训练⽹络速度更快,例如我们将⼀个⼤样本分成11⼩样本(每个样本100个数据),采⽤⼩批量训练⽹络时,每次传播后更新权重,就传播了11批,在每批次后我们均更新了⽹络的(权重)参数;如果在传播过程中使⽤了⼀个⼤样本,我们只会对训练⽹络的权重参数进⾏1次更新。

如何调整卷积神经网络的超参数卷积神经网络(Convolutional Neural Network,简称CNN)是一种深度学习模型,广泛应用于图像识别、目标检测、语音识别等领域。
超参数是指在训练CNN模型时需要手动设置的参数,如学习率、批大小、卷积核大小等。
合理地调整超参数可以提高模型的性能和泛化能力。
本文将探讨如何调整卷积神经网络的超参数,以提高模型的表现。
1. 学习率(Learning Rate)学习率是控制模型在每一次迭代中学习的步长。
过大的学习率可能导致模型无法收敛,而过小的学习率则会使模型收敛速度过慢。
因此,合理地设置学习率是非常重要的。
一种常用的方法是通过网格搜索或随机搜索来寻找最佳学习率。
另外,还可以使用自适应学习率算法,如Adam、RMSprop等,来动态地调整学习率,以提高模型的性能。
2. 批大小(Batch Size)批大小是指每次迭代中训练样本的数量。
较小的批大小可以提高模型的收敛速度,但也会增加训练时间。
较大的批大小可以减少训练时间,但可能导致模型陷入局部最优。
因此,选择合适的批大小非常重要。
一种常用的方法是尝试不同的批大小,并观察模型在验证集上的性能。
根据验证集的表现,选择最佳的批大小。
3. 卷积核大小(Kernel Size)卷积核大小是指卷积层中卷积核的尺寸。
较小的卷积核可以提取更细节的特征,但可能会丢失一些全局信息。
较大的卷积核可以捕捉更多的上下文信息,但也会增加模型的参数数量。
因此,选择合适的卷积核大小是非常重要的。
一种常用的方法是通过实验来确定最佳的卷积核大小。
可以尝试不同的卷积核大小,并观察模型在验证集上的性能。
根据验证集的表现,选择最佳的卷积核大小。
4. 池化操作(Pooling)池化操作是在卷积神经网络中常用的一种操作,用于减少特征图的尺寸和参数数量。
常见的池化操作有最大池化和平均池化。
最大池化可以保留图像中最显著的特征,而平均池化可以保留更多的全局信息。

【转】BatchSize设置过⼤时,对神经⽹络性能的影响情况之前的⼀⽚博⽂写了Batch Size的作⽤和应该如何设置⽐较合适,同时还有Batch Size⼤⼩,与学习率lrlr、训练次数epochepoch之间的关系。
⾥⾯提及Batch Size越⼤,梯度的⽅向越准确。
上述的说法是没错的,梯度⽅向准确,最后⽹络收敛情况好,但是收敛情况好并不意味⽹络的性能就好,⽹络收敛好意味着对训练数据作出了较好的拟合,但是并不意味着就会对测试数据作出很好的拟合。
这存在的⼀个“泛化”的问题。
ON LARGE-BATCH TRAINING FOR DEEP LEARNING:GENERALIZATION GAP AND SHARP MINIMA 论⽂发现了使⽤large-batch训练得到的⽹络具有较差的泛化能⼒。
使⽤large-batch的情况下容易收敛成“sharp minimizers”,使其的泛化能⼒差。
⽽相对使⽤“small-batch”训练的最终会收敛到“flat minimizers”,这是因为在“small-batch”中在梯度计算中固有噪声的存在,使得⽹络的最终收敛成“flat minimizers”论⽂中提及了使⽤“large-batch”造成泛化能⼒差的原因可能是⽹络直接收敛到初始值附近。
同时,论⽂尝试提出⼏种⽅法,如数据增强,“conservative training”和“robust optimization”,但好像也没什么效果。
另⼀种补救⽅法包括使⽤动态抽样,在这种情况下,随着迭代的进⾏,批⼤⼩逐渐增⼤。
感想:batch size从64下降到6,发现平均准确率提升0.4%左右。
我的ResNet最佳层数为6.。

神经⽹络CNN名词解释隐藏层不是输⼊或输出层的所有层都称为隐藏层.激活和池化都没有权重使层与操作区分开的原因在于层具有权重。
由于池操作和激活功能没有权重,因此我们将它们称为操作,并将其视为已添加到层操作集合中。
例如,我们说⽹络中的第⼆层是⼀个卷积层,其中包含权重的集合,并执⾏三个操作,即卷积操作,relu激活操作和最⼤池化操作。
传⼊Linear层之前展平张量在将输⼊传递到第⼀个隐藏的Linear层之前,我们必须reshape()或展平我们的张量。
每当我们将卷积层的输出作为Linear层的输⼊传递时,都是这种情况。
正向传播正向传播是将输⼊张量转换为输出张量的过程。
神经⽹络的核⼼是将输⼊张量映射到输出张量的功能,⽽正向传播只是将传递输⼊到⽹络并从⽹络接收输出的过程的特殊名称。
in_channels对于最初输⼊图⽚样本的通道数in_channels取决于图⽚的类型,如果是彩⾊的,即RGB类型,这时候通道数固定为3,如果是灰⾊的,通道数为1。
out_channels卷积完成之后,输出的通道数out_channels取决于过滤器的数量。
从这个⽅向理解,这⾥的out_channels设置的就是过滤器的数⽬。
对于第⼆层或者更多层的卷积,此时的 in_channels 就是上⼀层的 out_channels , out_channels 还是取决于过滤器数⽬。
为什么GPU在深度学习中能够如此⼴泛的使⽤?因为神经⽹络是易并⾏的(embarrassing parallel),即:很容易就能够将任务分解成⼀组独⽴的⼩任务;神经⽹络的很多计算都可以很容易地分解成更⼩的相互独⽴的计算,这使得GPU在深度学习任务中⾮常有⽤。
⼀个卷积核对⼀张图像进⾏卷积的每个运算是独⽴且相继发⽣的,故可将其分成⼀个个⼩任务,使⽤GPU加速运算; (图像分块后送⼊神经⽹络是否同理?)张量张量是神经⽹络中使⽤的主要数据结构,⽹络中的输⼊、输出和转换均使⽤张量表⽰.张量与张量之间的运算必须是相同数据类型在相同的设备上发⽣的.张量是包含⼀个同⼀类型的数据.索引数量计算机科学中的名称数学中的名称Tensor表⽰0数字标量0维张量1数组⽮量1维张量2⼆维数组矩阵2维张量n N维数组N维张量n维张量张量的阶是指张量中的维数。

神经⽹络术语神经⽹络术语Optimization MethodsBatch Gradient Descent: GDMini-Batch Gradient DescentStochastic Gradient Descent: SGDMomentum: 动⼒Convergence: 收敛Avoid OscillateMomentumRMSPropAdamExponentially Weighted Averageiteration与epochiteration迭代⼀次batchSize就是⼀次iterationepoch迭代⼀次整个训练集就是⼀次epoch⽰例假如训练集: 1000, batchSize=10, 迭代完1000个样本iteration=1000/10=100epoch=1Image Enhancementcolor prior: 颜⾊先验patch: 块coarse: 粗的depth map: 深度图(距离图)estimate: 估计Ambient illumination: 环境亮度semantic: 语义spatially: 空间adjacent: 相邻的feature extraction: 特征提取accommodate: 适应receptive: 接受intermediate: 中间extensive: ⼴泛的qualitatively: 定性的quantitatively: 定量的breakdown: 分解synthetic: 合成的ablation study: 对⽐实验occlude: 挡住state-of-the-art: 达到当前世界领先⽔平disparity: 差距consecutive: 连续criterion: 标准visual perception: 视觉感受undermine: 破坏degrade: 降低particle: 颗粒optical: 光纤的fidelity: 保真度various extents: 各种程度的影响concentrate: 堆积transmission map: 透射图maximum extent: 最⼤程度surface albedo: 表⾯反照率component: 分量color tone: ⾊调atmospheric veil: ⼤⽓幕factorial: 因⼦的disturbance: ⼲扰coarse: 粗糙的color distortion: 颜⾊扭曲haze thickness: 雾的厚度fusion principle: 融合原理quad-tree: 四叉树light attenuation: 光衰减depth perception: 深度感知amplification factor: 放⼤因⼦detail enhancement: 细节增强spatially varying: 空间变化adaptive: ⾃适应的deviation: 偏差evaluation deviation: 偏差retina: 视⽹膜subjective brightness perceived: 主观视觉感知anticipating: 预测intention: 意图power outlet: 插座wrist: 腕persistently: 持续地trigger: 触发PN(Policy Network)jointly: 连带地proactively: 主动地facilitate: ⽅便, 促进, 帮助accelerometer: 加速度计trajectory: 轨迹modalities: 模式sacrificing: 牺牲gist: 主旨fuse: 融合mechanism: 机制transductive: 传导的dominate: 控制sub-optimal: 次优化leverage: 优势in an incremental manner: 渐进的⽅式whilst: 同时adopt: 采⽤simultaneously: 同时probabilistic: 概率similation: 模拟key addressing: 键寻址value reading: 值读取posterior: 后验的error prone: 容易出错the model inference uncertainty: 模型推理不确定性univocal: 单义aspect ratios: 宽⾼⽐。

机器学习与人工智能领域中常用的英语词汇1.General Concepts (基础概念)•Artificial Intelligence (AI) - 人工智能1)Artificial Intelligence (AI) - 人工智能2)Machine Learning (ML) - 机器学习3)Deep Learning (DL) - 深度学习4)Neural Network - 神经网络5)Natural Language Processing (NLP) - 自然语言处理6)Computer Vision - 计算机视觉7)Robotics - 机器人技术8)Speech Recognition - 语音识别9)Expert Systems - 专家系统10)Knowledge Representation - 知识表示11)Pattern Recognition - 模式识别12)Cognitive Computing - 认知计算13)Autonomous Systems - 自主系统14)Human-Machine Interaction - 人机交互15)Intelligent Agents - 智能代理16)Machine Translation - 机器翻译17)Swarm Intelligence - 群体智能18)Genetic Algorithms - 遗传算法19)Fuzzy Logic - 模糊逻辑20)Reinforcement Learning - 强化学习•Machine Learning (ML) - 机器学习1)Machine Learning (ML) - 机器学习2)Artificial Neural Network - 人工神经网络3)Deep Learning - 深度学习4)Supervised Learning - 有监督学习5)Unsupervised Learning - 无监督学习6)Reinforcement Learning - 强化学习7)Semi-Supervised Learning - 半监督学习8)Training Data - 训练数据9)Test Data - 测试数据10)Validation Data - 验证数据11)Feature - 特征12)Label - 标签13)Model - 模型14)Algorithm - 算法15)Regression - 回归16)Classification - 分类17)Clustering - 聚类18)Dimensionality Reduction - 降维19)Overfitting - 过拟合20)Underfitting - 欠拟合•Deep Learning (DL) - 深度学习1)Deep Learning - 深度学习2)Neural Network - 神经网络3)Artificial Neural Network (ANN) - 人工神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Autoencoder - 自编码器9)Generative Adversarial Network (GAN) - 生成对抗网络10)Transfer Learning - 迁移学习11)Pre-trained Model - 预训练模型12)Fine-tuning - 微调13)Feature Extraction - 特征提取14)Activation Function - 激活函数15)Loss Function - 损失函数16)Gradient Descent - 梯度下降17)Backpropagation - 反向传播18)Epoch - 训练周期19)Batch Size - 批量大小20)Dropout - 丢弃法•Neural Network - 神经网络1)Neural Network - 神经网络2)Artificial Neural Network (ANN) - 人工神经网络3)Deep Neural Network (DNN) - 深度神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Feedforward Neural Network - 前馈神经网络9)Multi-layer Perceptron (MLP) - 多层感知器10)Radial Basis Function Network (RBFN) - 径向基函数网络11)Hopfield Network - 霍普菲尔德网络12)Boltzmann Machine - 玻尔兹曼机13)Autoencoder - 自编码器14)Spiking Neural Network (SNN) - 脉冲神经网络15)Self-organizing Map (SOM) - 自组织映射16)Restricted Boltzmann Machine (RBM) - 受限玻尔兹曼机17)Hebbian Learning - 海比安学习18)Competitive Learning - 竞争学习19)Neuroevolutionary - 神经进化20)Neuron - 神经元•Algorithm - 算法1)Algorithm - 算法2)Supervised Learning Algorithm - 有监督学习算法3)Unsupervised Learning Algorithm - 无监督学习算法4)Reinforcement Learning Algorithm - 强化学习算法5)Classification Algorithm - 分类算法6)Regression Algorithm - 回归算法7)Clustering Algorithm - 聚类算法8)Dimensionality Reduction Algorithm - 降维算法9)Decision Tree Algorithm - 决策树算法10)Random Forest Algorithm - 随机森林算法11)Support Vector Machine (SVM) Algorithm - 支持向量机算法12)K-Nearest Neighbors (KNN) Algorithm - K近邻算法13)Naive Bayes Algorithm - 朴素贝叶斯算法14)Gradient Descent Algorithm - 梯度下降算法15)Genetic Algorithm - 遗传算法16)Neural Network Algorithm - 神经网络算法17)Deep Learning Algorithm - 深度学习算法18)Ensemble Learning Algorithm - 集成学习算法19)Reinforcement Learning Algorithm - 强化学习算法20)Metaheuristic Algorithm - 元启发式算法•Model - 模型1)Model - 模型2)Machine Learning Model - 机器学习模型3)Artificial Intelligence Model - 人工智能模型4)Predictive Model - 预测模型5)Classification Model - 分类模型6)Regression Model - 回归模型7)Generative Model - 生成模型8)Discriminative Model - 判别模型9)Probabilistic Model - 概率模型10)Statistical Model - 统计模型11)Neural Network Model - 神经网络模型12)Deep Learning Model - 深度学习模型13)Ensemble Model - 集成模型14)Reinforcement Learning Model - 强化学习模型15)Support Vector Machine (SVM) Model - 支持向量机模型16)Decision Tree Model - 决策树模型17)Random Forest Model - 随机森林模型18)Naive Bayes Model - 朴素贝叶斯模型19)Autoencoder Model - 自编码器模型20)Convolutional Neural Network (CNN) Model - 卷积神经网络模型•Dataset - 数据集1)Dataset - 数据集2)Training Dataset - 训练数据集3)Test Dataset - 测试数据集4)Validation Dataset - 验证数据集5)Balanced Dataset - 平衡数据集6)Imbalanced Dataset - 不平衡数据集7)Synthetic Dataset - 合成数据集8)Benchmark Dataset - 基准数据集9)Open Dataset - 开放数据集10)Labeled Dataset - 标记数据集11)Unlabeled Dataset - 未标记数据集12)Semi-Supervised Dataset - 半监督数据集13)Multiclass Dataset - 多分类数据集14)Feature Set - 特征集15)Data Augmentation - 数据增强16)Data Preprocessing - 数据预处理17)Missing Data - 缺失数据18)Outlier Detection - 异常值检测19)Data Imputation - 数据插补20)Metadata - 元数据•Training - 训练1)Training - 训练2)Training Data - 训练数据3)Training Phase - 训练阶段4)Training Set - 训练集5)Training Examples - 训练样本6)Training Instance - 训练实例7)Training Algorithm - 训练算法8)Training Model - 训练模型9)Training Process - 训练过程10)Training Loss - 训练损失11)Training Epoch - 训练周期12)Training Batch - 训练批次13)Online Training - 在线训练14)Offline Training - 离线训练15)Continuous Training - 连续训练16)Transfer Learning - 迁移学习17)Fine-Tuning - 微调18)Curriculum Learning - 课程学习19)Self-Supervised Learning - 自监督学习20)Active Learning - 主动学习•Testing - 测试1)Testing - 测试2)Test Data - 测试数据3)Test Set - 测试集4)Test Examples - 测试样本5)Test Instance - 测试实例6)Test Phase - 测试阶段7)Test Accuracy - 测试准确率8)Test Loss - 测试损失9)Test Error - 测试错误10)Test Metrics - 测试指标11)Test Suite - 测试套件12)Test Case - 测试用例13)Test Coverage - 测试覆盖率14)Cross-Validation - 交叉验证15)Holdout Validation - 留出验证16)K-Fold Cross-Validation - K折交叉验证17)Stratified Cross-Validation - 分层交叉验证18)Test Driven Development (TDD) - 测试驱动开发19)A/B Testing - A/B 测试20)Model Evaluation - 模型评估•Validation - 验证1)Validation - 验证2)Validation Data - 验证数据3)Validation Set - 验证集4)Validation Examples - 验证样本5)Validation Instance - 验证实例6)Validation Phase - 验证阶段7)Validation Accuracy - 验证准确率8)Validation Loss - 验证损失9)Validation Error - 验证错误10)Validation Metrics - 验证指标11)Cross-Validation - 交叉验证12)Holdout Validation - 留出验证13)K-Fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation - 留一法交叉验证16)Validation Curve - 验证曲线17)Hyperparameter Validation - 超参数验证18)Model Validation - 模型验证19)Early Stopping - 提前停止20)Validation Strategy - 验证策略•Supervised Learning - 有监督学习1)Supervised Learning - 有监督学习2)Label - 标签3)Feature - 特征4)Target - 目标5)Training Labels - 训练标签6)Training Features - 训练特征7)Training Targets - 训练目标8)Training Examples - 训练样本9)Training Instance - 训练实例10)Regression - 回归11)Classification - 分类12)Predictor - 预测器13)Regression Model - 回归模型14)Classifier - 分类器15)Decision Tree - 决策树16)Support Vector Machine (SVM) - 支持向量机17)Neural Network - 神经网络18)Feature Engineering - 特征工程19)Model Evaluation - 模型评估20)Overfitting - 过拟合21)Underfitting - 欠拟合22)Bias-Variance Tradeoff - 偏差-方差权衡•Unsupervised Learning - 无监督学习1)Unsupervised Learning - 无监督学习2)Clustering - 聚类3)Dimensionality Reduction - 降维4)Anomaly Detection - 异常检测5)Association Rule Learning - 关联规则学习6)Feature Extraction - 特征提取7)Feature Selection - 特征选择8)K-Means - K均值9)Hierarchical Clustering - 层次聚类10)Density-Based Clustering - 基于密度的聚类11)Principal Component Analysis (PCA) - 主成分分析12)Independent Component Analysis (ICA) - 独立成分分析13)T-distributed Stochastic Neighbor Embedding (t-SNE) - t分布随机邻居嵌入14)Gaussian Mixture Model (GMM) - 高斯混合模型15)Self-Organizing Maps (SOM) - 自组织映射16)Autoencoder - 自动编码器17)Latent Variable - 潜变量18)Data Preprocessing - 数据预处理19)Outlier Detection - 异常值检测20)Clustering Algorithm - 聚类算法•Reinforcement Learning - 强化学习1)Reinforcement Learning - 强化学习2)Agent - 代理3)Environment - 环境4)State - 状态5)Action - 动作6)Reward - 奖励7)Policy - 策略8)Value Function - 值函数9)Q-Learning - Q学习10)Deep Q-Network (DQN) - 深度Q网络11)Policy Gradient - 策略梯度12)Actor-Critic - 演员-评论家13)Exploration - 探索14)Exploitation - 开发15)Temporal Difference (TD) - 时间差分16)Markov Decision Process (MDP) - 马尔可夫决策过程17)State-Action-Reward-State-Action (SARSA) - 状态-动作-奖励-状态-动作18)Policy Iteration - 策略迭代19)Value Iteration - 值迭代20)Monte Carlo Methods - 蒙特卡洛方法•Semi-Supervised Learning - 半监督学习1)Semi-Supervised Learning - 半监督学习2)Labeled Data - 有标签数据3)Unlabeled Data - 无标签数据4)Label Propagation - 标签传播5)Self-Training - 自训练6)Co-Training - 协同训练7)Transudative Learning - 传导学习8)Inductive Learning - 归纳学习9)Manifold Regularization - 流形正则化10)Graph-based Methods - 基于图的方法11)Cluster Assumption - 聚类假设12)Low-Density Separation - 低密度分离13)Semi-Supervised Support Vector Machines (S3VM) - 半监督支持向量机14)Expectation-Maximization (EM) - 期望最大化15)Co-EM - 协同期望最大化16)Entropy-Regularized EM - 熵正则化EM17)Mean Teacher - 平均教师18)Virtual Adversarial Training - 虚拟对抗训练19)Tri-training - 三重训练20)Mix Match - 混合匹配•Feature - 特征1)Feature - 特征2)Feature Engineering - 特征工程3)Feature Extraction - 特征提取4)Feature Selection - 特征选择5)Input Features - 输入特征6)Output Features - 输出特征7)Feature Vector - 特征向量8)Feature Space - 特征空间9)Feature Representation - 特征表示10)Feature Transformation - 特征转换11)Feature Importance - 特征重要性12)Feature Scaling - 特征缩放13)Feature Normalization - 特征归一化14)Feature Encoding - 特征编码15)Feature Fusion - 特征融合16)Feature Dimensionality Reduction - 特征维度减少17)Continuous Feature - 连续特征18)Categorical Feature - 分类特征19)Nominal Feature - 名义特征20)Ordinal Feature - 有序特征•Label - 标签1)Label - 标签2)Labeling - 标注3)Ground Truth - 地面真值4)Class Label - 类别标签5)Target Variable - 目标变量6)Labeling Scheme - 标注方案7)Multi-class Labeling - 多类别标注8)Binary Labeling - 二分类标注9)Label Noise - 标签噪声10)Labeling Error - 标注错误11)Label Propagation - 标签传播12)Unlabeled Data - 无标签数据13)Labeled Data - 有标签数据14)Semi-supervised Learning - 半监督学习15)Active Learning - 主动学习16)Weakly Supervised Learning - 弱监督学习17)Noisy Label Learning - 噪声标签学习18)Self-training - 自训练19)Crowdsourcing Labeling - 众包标注20)Label Smoothing - 标签平滑化•Prediction - 预测1)Prediction - 预测2)Forecasting - 预测3)Regression - 回归4)Classification - 分类5)Time Series Prediction - 时间序列预测6)Forecast Accuracy - 预测准确性7)Predictive Modeling - 预测建模8)Predictive Analytics - 预测分析9)Forecasting Method - 预测方法10)Predictive Performance - 预测性能11)Predictive Power - 预测能力12)Prediction Error - 预测误差13)Prediction Interval - 预测区间14)Prediction Model - 预测模型15)Predictive Uncertainty - 预测不确定性16)Forecast Horizon - 预测时间跨度17)Predictive Maintenance - 预测性维护18)Predictive Policing - 预测式警务19)Predictive Healthcare - 预测性医疗20)Predictive Maintenance - 预测性维护•Classification - 分类1)Classification - 分类2)Classifier - 分类器3)Class - 类别4)Classify - 对数据进行分类5)Class Label - 类别标签6)Binary Classification - 二元分类7)Multiclass Classification - 多类分类8)Class Probability - 类别概率9)Decision Boundary - 决策边界10)Decision Tree - 决策树11)Support Vector Machine (SVM) - 支持向量机12)K-Nearest Neighbors (KNN) - K最近邻算法13)Naive Bayes - 朴素贝叶斯14)Logistic Regression - 逻辑回归15)Random Forest - 随机森林16)Neural Network - 神经网络17)SoftMax Function - SoftMax函数18)One-vs-All (One-vs-Rest) - 一对多(一对剩余)19)Ensemble Learning - 集成学习20)Confusion Matrix - 混淆矩阵•Regression - 回归1)Regression Analysis - 回归分析2)Linear Regression - 线性回归3)Multiple Regression - 多元回归4)Polynomial Regression - 多项式回归5)Logistic Regression - 逻辑回归6)Ridge Regression - 岭回归7)Lasso Regression - Lasso回归8)Elastic Net Regression - 弹性网络回归9)Regression Coefficients - 回归系数10)Residuals - 残差11)Ordinary Least Squares (OLS) - 普通最小二乘法12)Ridge Regression Coefficient - 岭回归系数13)Lasso Regression Coefficient - Lasso回归系数14)Elastic Net Regression Coefficient - 弹性网络回归系数15)Regression Line - 回归线16)Prediction Error - 预测误差17)Regression Model - 回归模型18)Nonlinear Regression - 非线性回归19)Generalized Linear Models (GLM) - 广义线性模型20)Coefficient of Determination (R-squared) - 决定系数21)F-test - F检验22)Homoscedasticity - 同方差性23)Heteroscedasticity - 异方差性24)Autocorrelation - 自相关25)Multicollinearity - 多重共线性26)Outliers - 异常值27)Cross-validation - 交叉验证28)Feature Selection - 特征选择29)Feature Engineering - 特征工程30)Regularization - 正则化2.Neural Networks and Deep Learning (神经网络与深度学习)•Convolutional Neural Network (CNN) - 卷积神经网络1)Convolutional Neural Network (CNN) - 卷积神经网络2)Convolution Layer - 卷积层3)Feature Map - 特征图4)Convolution Operation - 卷积操作5)Stride - 步幅6)Padding - 填充7)Pooling Layer - 池化层8)Max Pooling - 最大池化9)Average Pooling - 平均池化10)Fully Connected Layer - 全连接层11)Activation Function - 激活函数12)Rectified Linear Unit (ReLU) - 线性修正单元13)Dropout - 随机失活14)Batch Normalization - 批量归一化15)Transfer Learning - 迁移学习16)Fine-Tuning - 微调17)Image Classification - 图像分类18)Object Detection - 物体检测19)Semantic Segmentation - 语义分割20)Instance Segmentation - 实例分割21)Generative Adversarial Network (GAN) - 生成对抗网络22)Image Generation - 图像生成23)Style Transfer - 风格迁移24)Convolutional Autoencoder - 卷积自编码器25)Recurrent Neural Network (RNN) - 循环神经网络•Recurrent Neural Network (RNN) - 循环神经网络1)Recurrent Neural Network (RNN) - 循环神经网络2)Long Short-Term Memory (LSTM) - 长短期记忆网络3)Gated Recurrent Unit (GRU) - 门控循环单元4)Sequence Modeling - 序列建模5)Time Series Prediction - 时间序列预测6)Natural Language Processing (NLP) - 自然语言处理7)Text Generation - 文本生成8)Sentiment Analysis - 情感分析9)Named Entity Recognition (NER) - 命名实体识别10)Part-of-Speech Tagging (POS Tagging) - 词性标注11)Sequence-to-Sequence (Seq2Seq) - 序列到序列12)Attention Mechanism - 注意力机制13)Encoder-Decoder Architecture - 编码器-解码器架构14)Bidirectional RNN - 双向循环神经网络15)Teacher Forcing - 强制教师法16)Backpropagation Through Time (BPTT) - 通过时间的反向传播17)Vanishing Gradient Problem - 梯度消失问题18)Exploding Gradient Problem - 梯度爆炸问题19)Language Modeling - 语言建模20)Speech Recognition - 语音识别•Long Short-Term Memory (LSTM) - 长短期记忆网络1)Long Short-Term Memory (LSTM) - 长短期记忆网络2)Cell State - 细胞状态3)Hidden State - 隐藏状态4)Forget Gate - 遗忘门5)Input Gate - 输入门6)Output Gate - 输出门7)Peephole Connections - 窥视孔连接8)Gated Recurrent Unit (GRU) - 门控循环单元9)Vanishing Gradient Problem - 梯度消失问题10)Exploding Gradient Problem - 梯度爆炸问题11)Sequence Modeling - 序列建模12)Time Series Prediction - 时间序列预测13)Natural Language Processing (NLP) - 自然语言处理14)Text Generation - 文本生成15)Sentiment Analysis - 情感分析16)Named Entity Recognition (NER) - 命名实体识别17)Part-of-Speech Tagging (POS Tagging) - 词性标注18)Attention Mechanism - 注意力机制19)Encoder-Decoder Architecture - 编码器-解码器架构20)Bidirectional LSTM - 双向长短期记忆网络•Attention Mechanism - 注意力机制1)Attention Mechanism - 注意力机制2)Self-Attention - 自注意力3)Multi-Head Attention - 多头注意力4)Transformer - 变换器5)Query - 查询6)Key - 键7)Value - 值8)Query-Value Attention - 查询-值注意力9)Dot-Product Attention - 点积注意力10)Scaled Dot-Product Attention - 缩放点积注意力11)Additive Attention - 加性注意力12)Context Vector - 上下文向量13)Attention Score - 注意力分数14)SoftMax Function - SoftMax函数15)Attention Weight - 注意力权重16)Global Attention - 全局注意力17)Local Attention - 局部注意力18)Positional Encoding - 位置编码19)Encoder-Decoder Attention - 编码器-解码器注意力20)Cross-Modal Attention - 跨模态注意力•Generative Adversarial Network (GAN) - 生成对抗网络1)Generative Adversarial Network (GAN) - 生成对抗网络2)Generator - 生成器3)Discriminator - 判别器4)Adversarial Training - 对抗训练5)Minimax Game - 极小极大博弈6)Nash Equilibrium - 纳什均衡7)Mode Collapse - 模式崩溃8)Training Stability - 训练稳定性9)Loss Function - 损失函数10)Discriminative Loss - 判别损失11)Generative Loss - 生成损失12)Wasserstein GAN (WGAN) - Wasserstein GAN(WGAN)13)Deep Convolutional GAN (DCGAN) - 深度卷积生成对抗网络(DCGAN)14)Conditional GAN (c GAN) - 条件生成对抗网络(c GAN)15)Style GAN - 风格生成对抗网络16)Cycle GAN - 循环生成对抗网络17)Progressive Growing GAN (PGGAN) - 渐进式增长生成对抗网络(PGGAN)18)Self-Attention GAN (SAGAN) - 自注意力生成对抗网络(SAGAN)19)Big GAN - 大规模生成对抗网络20)Adversarial Examples - 对抗样本•Encoder-Decoder - 编码器-解码器1)Encoder-Decoder Architecture - 编码器-解码器架构2)Encoder - 编码器3)Decoder - 解码器4)Sequence-to-Sequence Model (Seq2Seq) - 序列到序列模型5)State Vector - 状态向量6)Context Vector - 上下文向量7)Hidden State - 隐藏状态8)Attention Mechanism - 注意力机制9)Teacher Forcing - 强制教师法10)Beam Search - 束搜索11)Recurrent Neural Network (RNN) - 循环神经网络12)Long Short-Term Memory (LSTM) - 长短期记忆网络13)Gated Recurrent Unit (GRU) - 门控循环单元14)Bidirectional Encoder - 双向编码器15)Greedy Decoding - 贪婪解码16)Masking - 遮盖17)Dropout - 随机失活18)Embedding Layer - 嵌入层19)Cross-Entropy Loss - 交叉熵损失20)Tokenization - 令牌化•Transfer Learning - 迁移学习1)Transfer Learning - 迁移学习2)Source Domain - 源领域3)Target Domain - 目标领域4)Fine-Tuning - 微调5)Domain Adaptation - 领域自适应6)Pre-Trained Model - 预训练模型7)Feature Extraction - 特征提取8)Knowledge Transfer - 知识迁移9)Unsupervised Domain Adaptation - 无监督领域自适应10)Semi-Supervised Domain Adaptation - 半监督领域自适应11)Multi-Task Learning - 多任务学习12)Data Augmentation - 数据增强13)Task Transfer - 任务迁移14)Model Agnostic Meta-Learning (MAML) - 与模型无关的元学习(MAML)15)One-Shot Learning - 单样本学习16)Zero-Shot Learning - 零样本学习17)Few-Shot Learning - 少样本学习18)Knowledge Distillation - 知识蒸馏19)Representation Learning - 表征学习20)Adversarial Transfer Learning - 对抗迁移学习•Pre-trained Models - 预训练模型1)Pre-trained Model - 预训练模型2)Transfer Learning - 迁移学习3)Fine-Tuning - 微调4)Knowledge Transfer - 知识迁移5)Domain Adaptation - 领域自适应6)Feature Extraction - 特征提取7)Representation Learning - 表征学习8)Language Model - 语言模型9)Bidirectional Encoder Representations from Transformers (BERT) - 双向编码器结构转换器10)Generative Pre-trained Transformer (GPT) - 生成式预训练转换器11)Transformer-based Models - 基于转换器的模型12)Masked Language Model (MLM) - 掩蔽语言模型13)Cloze Task - 填空任务14)Tokenization - 令牌化15)Word Embeddings - 词嵌入16)Sentence Embeddings - 句子嵌入17)Contextual Embeddings - 上下文嵌入18)Self-Supervised Learning - 自监督学习19)Large-Scale Pre-trained Models - 大规模预训练模型•Loss Function - 损失函数1)Loss Function - 损失函数2)Mean Squared Error (MSE) - 均方误差3)Mean Absolute Error (MAE) - 平均绝对误差4)Cross-Entropy Loss - 交叉熵损失5)Binary Cross-Entropy Loss - 二元交叉熵损失6)Categorical Cross-Entropy Loss - 分类交叉熵损失7)Hinge Loss - 合页损失8)Huber Loss - Huber损失9)Wasserstein Distance - Wasserstein距离10)Triplet Loss - 三元组损失11)Contrastive Loss - 对比损失12)Dice Loss - Dice损失13)Focal Loss - 焦点损失14)GAN Loss - GAN损失15)Adversarial Loss - 对抗损失16)L1 Loss - L1损失17)L2 Loss - L2损失18)Huber Loss - Huber损失19)Quantile Loss - 分位数损失•Activation Function - 激活函数1)Activation Function - 激活函数2)Sigmoid Function - Sigmoid函数3)Hyperbolic Tangent Function (Tanh) - 双曲正切函数4)Rectified Linear Unit (Re LU) - 矩形线性单元5)Parametric Re LU (P Re LU) - 参数化Re LU6)Exponential Linear Unit (ELU) - 指数线性单元7)Swish Function - Swish函数8)Softplus Function - Soft plus函数9)Softmax Function - SoftMax函数10)Hard Tanh Function - 硬双曲正切函数11)Softsign Function - Softsign函数12)GELU (Gaussian Error Linear Unit) - GELU(高斯误差线性单元)13)Mish Function - Mish函数14)CELU (Continuous Exponential Linear Unit) - CELU(连续指数线性单元)15)Bent Identity Function - 弯曲恒等函数16)Gaussian Error Linear Units (GELUs) - 高斯误差线性单元17)Adaptive Piecewise Linear (APL) - 自适应分段线性函数18)Radial Basis Function (RBF) - 径向基函数•Backpropagation - 反向传播1)Backpropagation - 反向传播2)Gradient Descent - 梯度下降3)Partial Derivative - 偏导数4)Chain Rule - 链式法则5)Forward Pass - 前向传播6)Backward Pass - 反向传播7)Computational Graph - 计算图8)Neural Network - 神经网络9)Loss Function - 损失函数10)Gradient Calculation - 梯度计算11)Weight Update - 权重更新12)Activation Function - 激活函数13)Optimizer - 优化器14)Learning Rate - 学习率15)Mini-Batch Gradient Descent - 小批量梯度下降16)Stochastic Gradient Descent (SGD) - 随机梯度下降17)Batch Gradient Descent - 批量梯度下降18)Momentum - 动量19)Adam Optimizer - Adam优化器20)Learning Rate Decay - 学习率衰减•Gradient Descent - 梯度下降1)Gradient Descent - 梯度下降2)Stochastic Gradient Descent (SGD) - 随机梯度下降3)Mini-Batch Gradient Descent - 小批量梯度下降4)Batch Gradient Descent - 批量梯度下降5)Learning Rate - 学习率6)Momentum - 动量7)Adaptive Moment Estimation (Adam) - 自适应矩估计8)RMSprop - 均方根传播9)Learning Rate Schedule - 学习率调度10)Convergence - 收敛11)Divergence - 发散12)Adagrad - 自适应学习速率方法13)Adadelta - 自适应增量学习率方法14)Adamax - 自适应矩估计的扩展版本15)Nadam - Nesterov Accelerated Adaptive Moment Estimation16)Learning Rate Decay - 学习率衰减17)Step Size - 步长18)Conjugate Gradient Descent - 共轭梯度下降19)Line Search - 线搜索20)Newton's Method - 牛顿法•Learning Rate - 学习率1)Learning Rate - 学习率2)Adaptive Learning Rate - 自适应学习率3)Learning Rate Decay - 学习率衰减4)Initial Learning Rate - 初始学习率5)Step Size - 步长6)Momentum - 动量7)Exponential Decay - 指数衰减8)Annealing - 退火9)Cyclical Learning Rate - 循环学习率10)Learning Rate Schedule - 学习率调度11)Warm-up - 预热12)Learning Rate Policy - 学习率策略13)Learning Rate Annealing - 学习率退火14)Cosine Annealing - 余弦退火15)Gradient Clipping - 梯度裁剪16)Adapting Learning Rate - 适应学习率17)Learning Rate Multiplier - 学习率倍增器18)Learning Rate Reduction - 学习率降低19)Learning Rate Update - 学习率更新20)Scheduled Learning Rate - 定期学习率•Batch Size - 批量大小1)Batch Size - 批量大小2)Mini-Batch - 小批量3)Batch Gradient Descent - 批量梯度下降4)Stochastic Gradient Descent (SGD) - 随机梯度下降5)Mini-Batch Gradient Descent - 小批量梯度下降6)Online Learning - 在线学习7)Full-Batch - 全批量8)Data Batch - 数据批次9)Training Batch - 训练批次10)Batch Normalization - 批量归一化11)Batch-wise Optimization - 批量优化12)Batch Processing - 批量处理13)Batch Sampling - 批量采样14)Adaptive Batch Size - 自适应批量大小15)Batch Splitting - 批量分割16)Dynamic Batch Size - 动态批量大小17)Fixed Batch Size - 固定批量大小18)Batch-wise Inference - 批量推理19)Batch-wise Training - 批量训练20)Batch Shuffling - 批量洗牌•Epoch - 训练周期1)Training Epoch - 训练周期2)Epoch Size - 周期大小3)Early Stopping - 提前停止4)Validation Set - 验证集5)Training Set - 训练集6)Test Set - 测试集7)Overfitting - 过拟合8)Underfitting - 欠拟合9)Model Evaluation - 模型评估10)Model Selection - 模型选择11)Hyperparameter Tuning - 超参数调优12)Cross-Validation - 交叉验证13)K-fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation (LOOCV) - 留一法交叉验证16)Grid Search - 网格搜索17)Random Search - 随机搜索18)Model Complexity - 模型复杂度19)Learning Curve - 学习曲线20)Convergence - 收敛3.Machine Learning Techniques and Algorithms (机器学习技术与算法)•Decision Tree - 决策树1)Decision Tree - 决策树2)Node - 节点3)Root Node - 根节点4)Leaf Node - 叶节点5)Internal Node - 内部节点6)Splitting Criterion - 分裂准则7)Gini Impurity - 基尼不纯度8)Entropy - 熵9)Information Gain - 信息增益10)Gain Ratio - 增益率11)Pruning - 剪枝12)Recursive Partitioning - 递归分割13)CART (Classification and Regression Trees) - 分类回归树14)ID3 (Iterative Dichotomiser 3) - 迭代二叉树315)C4.5 (successor of ID3) - C4.5(ID3的后继者)16)C5.0 (successor of C4.5) - C5.0(C4.5的后继者)17)Split Point - 分裂点18)Decision Boundary - 决策边界19)Pruned Tree - 剪枝后的树20)Decision Tree Ensemble - 决策树集成•Random Forest - 随机森林1)Random Forest - 随机森林2)Ensemble Learning - 集成学习3)Bootstrap Sampling - 自助采样4)Bagging (Bootstrap Aggregating) - 装袋法5)Out-of-Bag (OOB) Error - 袋外误差6)Feature Subset - 特征子集7)Decision Tree - 决策树8)Base Estimator - 基础估计器9)Tree Depth - 树深度10)Randomization - 随机化11)Majority Voting - 多数投票12)Feature Importance - 特征重要性13)OOB Score - 袋外得分14)Forest Size - 森林大小15)Max Features - 最大特征数16)Min Samples Split - 最小分裂样本数17)Min Samples Leaf - 最小叶节点样本数18)Gini Impurity - 基尼不纯度19)Entropy - 熵20)Variable Importance - 变量重要性•Support Vector Machine (SVM) - 支持向量机1)Support Vector Machine (SVM) - 支持向量机2)Hyperplane - 超平面3)Kernel Trick - 核技巧4)Kernel Function - 核函数5)Margin - 间隔6)Support Vectors - 支持向量7)Decision Boundary - 决策边界8)Maximum Margin Classifier - 最大间隔分类器9)Soft Margin Classifier - 软间隔分类器10) C Parameter - C参数11)Radial Basis Function (RBF) Kernel - 径向基函数核12)Polynomial Kernel - 多项式核13)Linear Kernel - 线性核14)Quadratic Kernel - 二次核15)Gaussian Kernel - 高斯核16)Regularization - 正则化17)Dual Problem - 对偶问题18)Primal Problem - 原始问题19)Kernelized SVM - 核化支持向量机20)Multiclass SVM - 多类支持向量机•K-Nearest Neighbors (KNN) - K-最近邻1)K-Nearest Neighbors (KNN) - K-最近邻2)Nearest Neighbor - 最近邻3)Distance Metric - 距离度量4)Euclidean Distance - 欧氏距离5)Manhattan Distance - 曼哈顿距离6)Minkowski Distance - 闵可夫斯基距离7)Cosine Similarity - 余弦相似度8)K Value - K值9)Majority Voting - 多数投票10)Weighted KNN - 加权KNN11)Radius Neighbors - 半径邻居12)Ball Tree - 球树13)KD Tree - KD树14)Locality-Sensitive Hashing (LSH) - 局部敏感哈希15)Curse of Dimensionality - 维度灾难16)Class Label - 类标签17)Training Set - 训练集18)Test Set - 测试集19)Validation Set - 验证集20)Cross-Validation - 交叉验证•Naive Bayes - 朴素贝叶斯1)Naive Bayes - 朴素贝叶斯2)Bayes' Theorem - 贝叶斯定理3)Prior Probability - 先验概率4)Posterior Probability - 后验概率5)Likelihood - 似然6)Class Conditional Probability - 类条件概率7)Feature Independence Assumption - 特征独立假设8)Multinomial Naive Bayes - 多项式朴素贝叶斯9)Gaussian Naive Bayes - 高斯朴素贝叶斯10)Bernoulli Naive Bayes - 伯努利朴素贝叶斯11)Laplace Smoothing - 拉普拉斯平滑12)Add-One Smoothing - 加一平滑13)Maximum A Posteriori (MAP) - 最大后验概率14)Maximum Likelihood Estimation (MLE) - 最大似然估计15)Classification - 分类16)Feature Vectors - 特征向量17)Training Set - 训练集18)Test Set - 测试集19)Class Label - 类标签20)Confusion Matrix - 混淆矩阵•Clustering - 聚类1)Clustering - 聚类2)Centroid - 质心3)Cluster Analysis - 聚类分析4)Partitioning Clustering - 划分式聚类5)Hierarchical Clustering - 层次聚类6)Density-Based Clustering - 基于密度的聚类7)K-Means Clustering - K均值聚类8)K-Medoids Clustering - K中心点聚类9)DBSCAN (Density-Based Spatial Clustering of Applications with Noise) - 基于密度的空间聚类算法10)Agglomerative Clustering - 聚合式聚类11)Dendrogram - 系统树图12)Silhouette Score - 轮廓系数13)Elbow Method - 肘部法则14)Clustering Validation - 聚类验证15)Intra-cluster Distance - 类内距离16)Inter-cluster Distance - 类间距离17)Cluster Cohesion - 类内连贯性18)Cluster Separation - 类间分离度19)Cluster Assignment - 聚类分配20)Cluster Label - 聚类标签•K-Means - K-均值1)K-Means - K-均值2)Centroid - 质心3)Cluster - 聚类4)Cluster Center - 聚类中心5)Cluster Assignment - 聚类分配6)Cluster Analysis - 聚类分析7)K Value - K值8)Elbow Method - 肘部法则9)Inertia - 惯性10)Silhouette Score - 轮廓系数11)Convergence - 收敛12)Initialization - 初始化13)Euclidean Distance - 欧氏距离14)Manhattan Distance - 曼哈顿距离15)Distance Metric - 距离度量16)Cluster Radius - 聚类半径17)Within-Cluster Variation - 类内变异18)Cluster Quality - 聚类质量19)Clustering Algorithm - 聚类算法20)Clustering Validation - 聚类验证•Dimensionality Reduction - 降维1)Dimensionality Reduction - 降维2)Feature Extraction - 特征提取3)Feature Selection - 特征选择4)Principal Component Analysis (PCA) - 主成分分析5)Singular Value Decomposition (SVD) - 奇异值分解6)Linear Discriminant Analysis (LDA) - 线性判别分析7)t-Distributed Stochastic Neighbor Embedding (t-SNE) - t-分布随机邻域嵌入8)Autoencoder - 自编码器9)Manifold Learning - 流形学习10)Locally Linear Embedding (LLE) - 局部线性嵌入11)Isomap - 等度量映射12)Uniform Manifold Approximation and Projection (UMAP) - 均匀流形逼近与投影13)Kernel PCA - 核主成分分析14)Non-negative Matrix Factorization (NMF) - 非负矩阵分解15)Independent Component Analysis (ICA) - 独立成分分析16)Variational Autoencoder (VAE) - 变分自编码器17)Sparse Coding - 稀疏编码18)Random Projection - 随机投影19)Neighborhood Preserving Embedding (NPE) - 保持邻域结构的嵌入20)Curvilinear Component Analysis (CCA) - 曲线成分分析•Principal Component Analysis (PCA) - 主成分分析1)Principal Component Analysis (PCA) - 主成分分析2)Eigenvector - 特征向量3)Eigenvalue - 特征值4)Covariance Matrix - 协方差矩阵。

深度学习到底需要迭代10次还是100次?不能仅看验证效果深度学习是当今最火的研究方向之一。
它以其卓越的学习能力,实现了AI的关键功能。
一般来说,深度学习一次肯定是不够的,那到底学习多少次合适呢?翻了翻各位大牛的研究成果,有训练10个迭代的,有30个,甚至也有1万个以上的。
这就让小白迷茫了,到底训练多少次合适?训练的检验标准是什么?有一些大牛上来直接就说训练多少次,也不解释为什么,就说是凭经验,这种我们学不来。
还有一些专家给出了一些理由,我们来总结一下。
01 当loss值收敛时结束迭代深度学习的一个关键原理就是比较学习结果和样本标签之间的差距。
理论上差距越小,表明学习的效果越好。
这个差距就是loss值。
Loss值不可能变为0,只能无限逼近0。
所以通过脚趾都能想到,当loss值无法变小的时候,这称为收敛,就是学习结束之时。
比如像下图这样的:02 使用验证集来检验训练成果你以为就靠一个收敛就能解决一切问题吗?没那么简单。
深度学习常常会遇到一个问题——过拟合。
训练的时候学习效果很好,但是拿到其它地方测试发现效果就不行了。
就是说,并不一定是学习效果最好的时候才停止。
那如何来判断停止的时机呢?有学者提出了验证切分。
就是说,把训练集分为2部分,比如70%用来训练,30%用来测试。
就像下面的代码。
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=seed)然后在训练时加入验证的参数,就像这样:autoencoder.fit(train_data, train_data,epochs=50,batch_size=128,shuffle=True,validation_data=(noisy_imgs, data_test))然后就是观察验证曲线,什么时候验证的loss值最小,就选那一次的训练模型进行测试应用。

迭代次数-训练
迭代次数(Iteration)是指在训练过程中,使用一个批次(Batch)数据对模型进行一次参数更新的过程。
迭代次数决定了模型在训练过程中对参数的更新次数,从而影响模型的训练效果。
在训练神经网络时,迭代次数与另外两个概念密切相关:epoch和batc
h size。
1. epoch:表示使用训练集的全部数据对模型进行一次完整训练。
当一个epoch完成后,模型已经使用整个训练集训练了一次。
2. batch size:表示在训练过程中,每次使用的小批量数据样本数。
bat ch size通常设为2的n次幂,如64、128、256等。
较小的网络可以使用较大的batch size,较大的网络则使用较小的batch size。
在实际训练过程中,迭代次数与epoch的关系可以通过以下公式计算:iteration = epoch * batch size
例如,假设训练集有50000张图像,batch size为256,那么迭代次数为:
iteration = 50000 / 256 ≈200
这意味着在训练过程中,模型将进行200次迭代。
需要注意的是,迭代次数与训练效果之间的关系并非线性。
过多的迭代次数可能导致模型过拟合,而迭代次数过少则可能导致模型欠拟合。
因此,在实际应用中,需要根据实际情况调整迭代次数以达到最佳的训练效果。

pytorch中epoch,batch概念batch_size、epoch、iteration是深度学习中常见的⼏个超参数:(1)batch_size:每批数据量的⼤⼩。
DL通常⽤SGD的优化算法进⾏训练,也就是⼀次(1 个iteration)⼀起训练batchsize个样本,计算它们的平均损失函数值,来更新参数。
(2)iteration:1个iteration即迭代⼀次,也就是⽤batchsize个样本训练⼀次。
(3)epoch:1个epoch指⽤训练集中的全部样本训练⼀次,此时相当于batchsize 等于训练集的样本数。
最初训练DNN采⽤⼀次对全体训练集中的样本进⾏训练(即使⽤1个epoch),并计算⼀次损失函数值,来更新⼀次权值。
当时数据集较⼩,该⽅法尚可。
后来随着数据集迅速增⼤,导致这种⽅法⼀次开销⼤进⽽占⽤内存过⼤,速度过慢。
后来产⽣了⼀次只训练⼀个样本的⽅法(batchsize=1),称作在线学习。
该⽅法根据每⼀个样本的情况更新⼀次权值,开销⼩速度快,但收到单个样本的巨⼤随机性,全局来看优化性能较差,收敛速度很慢,产⽣局部震荡,有限迭代次数内很可能⽆法收敛。
⽬前常⽤随机梯度下降SGD来训练,相当于上述两个“极端”⽅法的折中:将训练集分成多个mini_batch(即常说的batch),⼀次迭代训练⼀个minibatch(即batchsize个样本),根据该batch数据的loss更新权值。
这相⽐于全数据集训练,相当于是在寻找最优时⼈为增加了⼀些随机噪声,来修正由局部数据得到的梯度,尽量避免因batchsize过⼤陷⼊局部最优。
这种⽅法存在两对⽭盾。
由于⼀次只分析的⼀⼩部分数据,因此整体优化效果与batchsize有关:batchsize越⼩,⼀个batch中的随机性越⼤,越不易收敛。
然⽽batchsize越⼩,速度越快,权值更新越频繁;且具有随机性,对于⾮凸损失函数来讲,更便于寻找全局最优。

机器学习中BatchSize、Iteration和Epoch的概念
Batch Size:批尺⼨。
机器学习中参数更新的⽅法有三种:
(1)Batch Gradient Descent,批梯度下降,遍历全部数据集计算⼀次损失函数,进⾏⼀次参数更新,这样得到的⽅向能够更加准确的指向极值的⽅向,但是计算开销⼤,速度慢;
(2)Stochastic Gradient Descent,随机梯度下降,对每⼀个样本计算⼀次损失函数,进⾏⼀次参数更新,优点是速度快,缺点是⽅向波动⼤,忽东忽西,不能准确的指向极值的⽅向,有时甚⾄两次更新相互抵消;
(3)Mini-batch Gradient Decent,⼩批梯度下降,前⾯两种⽅法的折中,把样本数据分为若⼲批,分批来计算损失函数和更新参数,这样⽅向⽐较稳定,计算开销也相对较⼩。
Batch Size就是每⼀批的样本数量。
Iteration:迭代,可以理解为w和b的⼀次更新,就是⼀次Iteration。
Epoch:样本中的所有样本数据被计算⼀次就叫做⼀个Epoch。
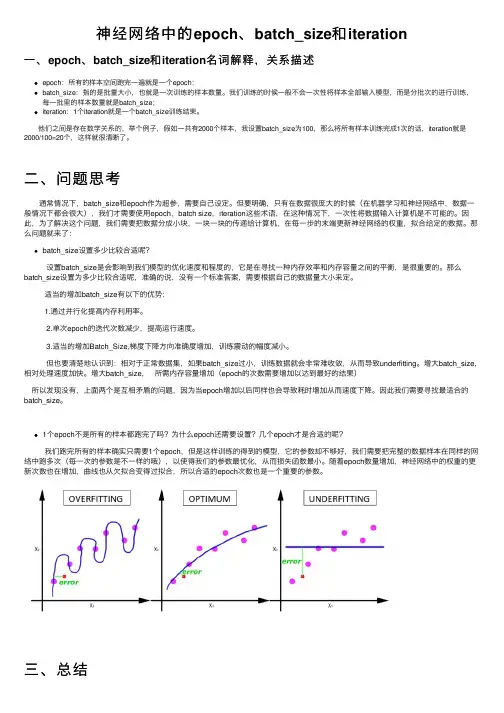
神经⽹络中的epoch、batch_size和iteration⼀、epoch、batch_size和iteration名词解释,关系描述epoch:所有的样本空间跑完⼀遍就是⼀个epoch;batch_size:指的是批量⼤⼩,也就是⼀次训练的样本数量。
我们训练的时候⼀般不会⼀次性将样本全部输⼊模型,⽽是分批次的进⾏训练,每⼀批⾥的样本数量就是batch_size;iteration:1个iteration就是⼀个batch_size训练结束。
他们之间是存在数学关系的,举个例⼦,假如⼀共有2000个样本,我设置batch_size为100,那么将所有样本训练完成1次的话,iteration就是2000/100=20个,这样就很清晰了。
⼆、问题思考 通常情况下,batch_size和epoch作为超参,需要⾃⼰设定。
但要明确,只有在数据很庞⼤的时候(在机器学习和神经⽹络中,数据⼀般情况下都会很⼤),我们才需要使⽤epoch,batch size,iteration这些术语,在这种情况下,⼀次性将数据输⼊计算机是不可能的。
因此,为了解决这个问题,我们需要把数据分成⼩块,⼀块⼀块的传递给计算机,在每⼀步的末端更新神经⽹络的权重,拟合给定的数据。
那么问题就来了:batch_size设置多少⽐较合适呢? 设置batch_size是会影响到我们模型的优化速度和程度的,它是在寻找⼀种内存效率和内存容量之间的平衡,是很重要的。
那么batch_size设置为多少⽐较合适呢,准确的说,没有⼀个标准答案,需要根据⾃⼰的数据量⼤⼩来定。
适当的增加batch_size有以下的优势:1.通过并⾏化提⾼内存利⽤率。
2.单次epoch的迭代次数减少,提⾼运⾏速度。
3.适当的增加Batch_Size,梯度下降⽅向准确度增加,训练震动的幅度减⼩。
但也要清楚地认识到:相对于正常数据集,如果batch_size过⼩,训练数据就会⾮常难收敛,从⽽导致underfitting。
深度学习中的batch的⼤⼩对学习效果的影响Batch_size参数的作⽤:决定了下降的⽅向极端⼀:batch_size为全数据集(Full Batch Learning):好处:1.由全数据集确定的⽅向能够更好地代表样本总体,从⽽更准确地朝向极值所在的⽅向。
2.由于不同权重的梯度值差别巨⼤,因此选择⼀个全局的学习率很困难。
Full Batch Learning可以使⽤Rprop只基于梯度符号并且针对性单独更新各权值。
坏处:1.随着数据集的海量增长和内存限制,⼀次性载⼊所有的数据进来变得越来越不可⾏。
2.以Rprop的⽅式迭代,会由于各个Batch之间的采样差异性,各次梯度修正值相互抵消,⽆法修正。
极端⼆:Batch_size=1:Batch_size=1,也就是每次只训练⼀个样本。
这就是在线学习(Online Learning)。
线性神经元在均⽅误差代价函数的错误⾯是⼀个抛物⾯,横截⾯是椭圆。
对于多层神经元,⾮线性⽹络,在局部依然近似是抛物⾯。
使⽤在线学习,每次修正⽅向以各⾃样本的梯度⽅向修正,难以达到收敛。
选择适中的Batch_size值:也就是批梯度下降法。
因为如果数据集⾜够充分,那么⽤⼀半,甚⾄少得多的数据训练算出来的梯度与⽤全部数据训练出来的梯度⼏乎是⼀样的。
在合理范围内,增⼤Batch_size的好处:1.提⾼了内存利⽤率以及⼤矩阵乘法的并⾏化效率。
2.减少了跑完⼀次epoch(全数据集)所需要的迭代次数,加快了对于相同数据量的处理速度。
盲⽬增⼤Batch_size的坏处:1.提⾼了内存利⽤率,但是内存容量可能不⾜。
2.跑完⼀次epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间⼤⼤增加,从⽽对参数的修正也就显得更加缓慢。
3.Batch_size增⼤到⼀定程度,其确定的下降⽅向已经基本不再变化。
调节Batch_size会如何影响训练效果?实验:使⽤不同的batch_size,在LeNet上训练Mnist数据集的效果。
epoch的用法Epoch是一个Python深度学习框架,它提供了一种快速创建、训练和部署神经网络的方式。
在本文中,我们将探讨Epoch的用法,包括安装、数据准备、模型构建、训练和评估。
一、安装首先,我们需要安装Epoch。
可以通过pip来安装:```pip install epoch```如果你使用的是Anaconda,则可以使用以下命令来安装:```conda install -c conda-forge epoch```二、数据准备在开始构建模型之前,我们需要准备数据。
Epoch支持多种数据格式,包括CSV、JSON和Numpy数组等。
这里我们以CSV文件为例。
1. 加载数据首先,我们需要加载CSV文件:```pythonimport epochdata = epoch.load_csv('data.csv')```2. 数据预处理接下来,我们需要对数据进行预处理。
这包括将类别变量转换为数字变量、缺失值处理等。
```python# 将类别变量转换为数字变量data = epoch.convert_categorical(data)# 处理缺失值data = epoch.impute_missing_values(data)```3. 数据分割最后,我们需要将数据分割成训练集和测试集:```pythontrain_data, test_data = epoch.split_data(data, test_size=0.2)```三、模型构建现在我们已经准备好了数据,接下来我们可以开始构建模型了。
Epoch支持多种类型的神经网络,包括全连接、卷积和循环神经网络等。
1. 创建模型首先,我们需要创建一个模型:```pythonmodel = epoch.models.Sequential()```2. 添加层接下来,我们需要向模型中添加层。
这里我们以全连接层为例:```pythonmodel.add(yers.Dense(64, activation='relu',input_shape=(10,)))model.add(yers.Dense(32, activation='relu')) model.add(yers.Dense(1, activation='sigmoid'))```3. 编译模型最后,我们需要编译模型。
深度学习常见问题解析深度学习常见问题解析计算机视觉与⾃动驾驶今天⼀、为什么深层神经⽹络难以训练?1、梯度消失。
梯度消失是指通过隐藏层从后向前看,梯度会变得越来越⼩,说明前⾯层的学习会显著慢于后⾯层的学习,所以学习会卡主,除⾮梯度变⼤。
梯度消失的原因:学习率的⼤⼩,⽹络参数的初始化,激活函数的边缘效应等。
在深层神经⽹络中,每⼀个神经元计算得到的梯度都会传递给前⼀层,较浅层的神经元接收到的梯度受到之前所有层梯度的影响。
如果计算得到的梯度值⾮常⼩,随着层数增多,求出的梯度更新信息将会以指数形式衰减,就会发⽣梯度消失。
2、梯度爆炸。
在深度⽹络或循环神经⽹络(Recurrent Neural Network, RNN)等⽹络结构中,梯度可在⽹络更新的过程中不断累积,变成⾮常⼤的梯度,导致⽹络权重值的⼤幅更新,使得⽹络不稳定;在极端情况下,权重值甚⾄会溢出,变为值,再也⽆法更新。
3、权重矩阵的退化导致模型的有效⾃由度减少。
参数空间中学习的退化速度减慢,导致减少了模型的有效维数,⽹络的可⽤⾃由度对学习中梯度范数的贡献不均衡,随着相乘矩阵的数量(即⽹络深度)的增加,矩阵的乘积变得越来越退化。
在有硬饱和边界的⾮线性⽹络中(例如 ReLU ⽹络),随着深度增加,退化过程会变得越来越快。
⼆、深度学习和机器学习有什么不同?传统的机器学习需要定义⼀些⼿⼯特征,从⽽有⽬的的去提取⽬标信息,⾮常依赖任务的特异性以及设计特征的专家经验。
⽽深度学习可以从⼤数据中先学习简单的特征,并从其逐渐学习到更为复杂抽象的深层特征,不依赖⼈⼯的特征⼯程。
三、为什么需要⾮线性激活函数1、激活函数可以把当前特征空间通过⼀定的线性映射转换到另⼀个空间,学习和模拟其他复杂类型的数据,例如图像、视频、⾳频、语⾳等。
2、假若⽹络中全部是线性部件,那么线性的组合还是线性,与单独⼀个线性分类器⽆异。
这样就做不到⽤⾮线性来逼近任意函数。
3、使⽤⾮线性激活函数,以便使⽹络更加强⼤,增加它的能⼒,使它可以学习复杂的事物,复杂的表单数据,以及表⽰输⼊输出之间⾮线性的复杂的任意函数映射。
学习深度学习需要掌握的基础知识
1.数学基础:矩阵运算、线性变换、奇异值分解等线性代数知识;导数、微分、积分等高等数学知识;概率分布、期望、方差、协方差、卡方分布等概率论和数理统计知识。
2.训练数据、特征、目标、模型、激活函数、损失函数、优化算法等机器学习基础知识;BP神经网络的基本原理。
3.卷积、池化、dropout、Batch Normalization、全连接、epoch、batch_size、iterration等卷积神经网络的概念和原理;LeNet、AlexNet、VGG、ResNet、LSTM、GAN、Attention机制、Transformer等经典模型和算法的基本原理。
4.Python的基础语法;深度学习框架的基本使用方法,例如用PyTorch 搭建一个CNN模型,对MNIST数据集进行训练和测试。
由于第十四周除了正常上课外,其余时间在整理机器学习的笔记,做中特社会调查报告,然后就是元旦放假,故第十四周没提交周报。
本周正常上课,继续完成老师都布置的课业任务,总结通信系统仿真结果,并且完成报告的撰写,分析社会调查结果,做好报告,查阅物理层安全方面的资料,翻译和整理论文。
其余时间是开始学习深度学习理论和编程实践,人工神经网络(ANN)和卷积神经网络,了解深度学习几个框架(Caffe 、Torch、TensorFlow、MxNet),最主要还是TensorFlow,学习和查找了一下深度学习优化算法,并且利用人工神经网络做手写数字识别。
心得体会:第一个感受是时间过得很快,已然是15周了,要加快各方面进程。
神经网络从线性分类器开始,线性分类器是产生一个超平面将两类物体分开。
一层神经网络叫做感知器,线性映射加激励输出,每个神经元对输入信号利用激励函数选择输出,就像大脑神经元的兴奋或抑制,增加神经元数量、隐层数量,就可以无限逼近位置函数分布的形态,过多会出现过拟合算法。
ANN的学习方法是BP后向传播算法,其主要思想是每一层的带来的预测误差是由前一层造成的,通过链式求导法则将误差对每一层的权重和偏置进行求导更新权重和偏置,以达到最优结果。
因为ANN每一层神经元是全连接的,对于图像这种数据就需要非常大数量的参数,所以就出现了卷积神经网路CNN,利用一些神经元以各种模版在图像上滑动做卷积形成几张特征图,每个神经元的滑动窗口值不一样代表其关注点不一样,单个神经元对整张图的窗口权重是一样的即权值共享(这就是减少参数和神经元数量的原因),这么做的依据是像素局部关联性。
CNN主要有数据数据输入层、卷积计算层、激励层、池化层(下采样层)、全连接层、Batch Normalization层(可能有)CNN学习方法也是BP算法迭代更新权重w和偏置b。
CNN优点是共享卷积核,对高维数据处理无压力,无需手动选取特征,训练好权重,即得特征,深层次的网络抽取,信息丰富,表达效果好,缺点是需要调参,需要大样本量,训练最好要GPU,物理含义不明确。
800个数据batch-size
BATCH_SIZE的含义BATCH_SIZE:即一次训练所抓取的数据样本数量;BATCH_SIZE的大小影响训练速度和模型优化。
同时按照以上代码可知,其大小同样影响每一epoch训练模型次数。
BATCH_SIZE 带来的好处最大的好处在于使得CPU或GPU满载运行,提高了训练的速度。
其次是使得梯度下降的方向更加准确。
因此为了弄懂BATCH_SIZE的优点,需要学习梯度下降的方法。
BATCH_SIZE大小的影响若BATCH_SIZE=m(训练集样本数量);相当于直接抓取整个数据集,训练时间长,但梯度准确。
但不适用于大样本训练,比如IMAGENET。
只适用于小样本训练,但小样本训练一般会导致过拟合[1]现象,因此不建议如此设置。
若BATCH_SIZE=1;梯度变化波动大,网络不容易收敛。
若BATCH_SIZE设置合适,梯度会变准确。
此时再增加BATCH_SIZE大小,梯度也不会变得更准确。
同时为了达到更高的训练网络精度,应该增大epoch,使训练时间变长。
一文看懂神经网络之Epoch、Batch Size和迭代
是不是还在纠结网上的各类技术代名词,是不是都觉得十分的相似,为了理解这些术语有什么不同,你需要了解一些关于机器学习的术语,比如梯度下降,以帮助你理解。
梯度下降这是一个在机器学习中用于寻找最佳结果(曲线的最小值)的迭代优化算法。
梯度的含义是斜率或者斜坡的倾斜度。
下降的含义是代价函数的下降。
算法是迭代的,意思是需要多次使用算法获取结果,以得到最优化结果。
梯度下降的迭代性质能使欠拟合的图示演化以获得对数据的最佳拟合。
梯度下降中有一个称为学习率的参量。
如上图左所示,刚开始学习率更大,因此下降步长更大。
随着点下降,学习率变得越来越小,从而下降步长也变小。
同时,代价函数也在减小,或者说代价在减小,有时候也称为损失函数或者损失,两者都是一样的。
(损失/代价的减小是一件好事)
只有在数据很庞大的时候(在机器学习中,几乎任何时候都是),我们才需要使用epochs,batch size,迭代这些术语,在这种情况下,一次性将数据输入计算机是不可能的。
因此,为了解决这个问题,我们需要把数据分成小块,一块一块的传递给计算机,在每一步的末端更新神经网络的权重,拟合给定的数据。
EPOCHS当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个epoch。
然而,当一个epoch 对于计算机而言太庞大的时候,就需要把它分成多个小块。
为什么要使用多于一个epoch?
我知道这刚开始听起来会很奇怪,在神经网络中传递完整的数据集一次是不够的,而且我们需要将完整的数据集在同样的神经网络中传递多次。
但是请记住,我们使用的是有限的。