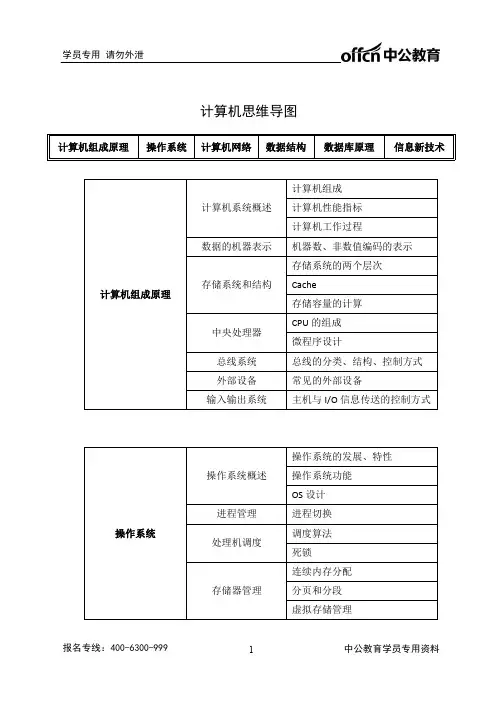
【思维导图】关系数据库设计理论-
- 格式:xmin
- 大小:702.06 KB
- 文档页数:1






数据库设计基础知识关系数据库设计范式和冗余处理数据库设计基础知识:关系数据库设计范式和冗余处理数据库是现代信息系统中的重要组成部分,它用于存储和管理大量的数据,保证数据的可靠性和高效性。
在数据库设计中,关系数据库设计范式和冗余处理是两个重要的方面。
本文将对这两个主题展开讨论。
一、关系数据库设计范式关系数据库设计范式是指在关系数据库中对数据进行合理分解和组织的规范。
它的目的是消除数据冗余、提高数据存储和查询效率、确保数据的一致性和完整性。
常见的关系数据库设计范式有三范式(3NF)和BC范式(BCNF)。
1. 第一范式(1NF):要求数据表中的每个字段都是原子性的,即不可再分解的属性。
例如,一个学生表中的姓名字段应该是原子性的,而不是将姓名拆分成姓和名两部分。
2. 第二范式(2NF):在满足1NF的基础上,要求表中的非主键字段完全依赖于主键。
也就是说,如果一个表的主键是学生ID,那么其他字段(如姓名、年龄、学校)必须完全依赖于学生ID,而不能部分依赖。
3. 第三范式(3NF):在满足2NF的基础上,要求表中的非主键字段之间不存在传递依赖关系。
简单说,就是要消除非主键字段之间的冗余。
4. BC范式(BCNF):在满足3NF的基础上,要求表中的每个函数依赖关系都是自主的。
也就是说,对于表中的每个函数依赖关系A→B,要求A是该表的一个超键。
通过合理地应用关系数据库设计范式,可以提高数据库的规范性和性能,从而更好地满足用户的需求。
二、冗余处理冗余是指在数据库中存储了重复的数据,它不仅浪费存储空间,还可能导致数据的不一致性和更新操作的异常。
因此,在数据库设计中,需要采取措施来处理冗余。
1. 分析和设计阶段:在数据库的分析和设计阶段,通过仔细分析数据的特点和关系,合理地设计表结构,尽量避免冗余数据的存储。
2. 规范化:通过应用关系数据库设计范式,可以有效地消除数据冗余。
通过分解和组织数据,确保每个数据只在数据库中存储一次,并通过外键建立表之间的关联关系,减少数据的冗余。