第7章__SAX解析XML
- 格式:ppt
- 大小:338.00 KB
- 文档页数:17

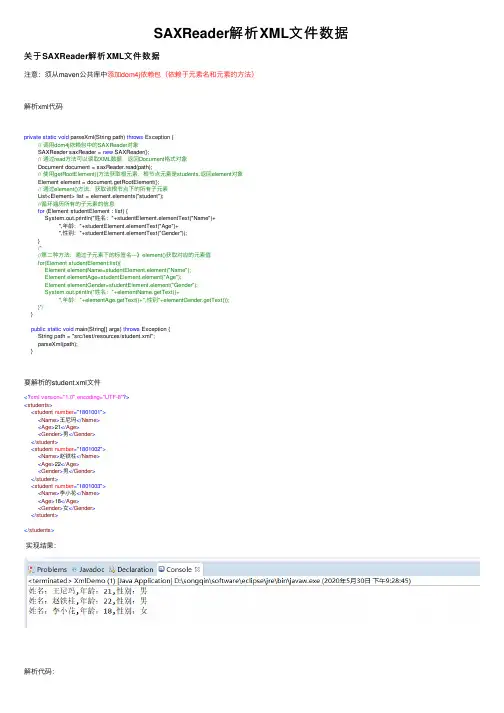
SAXReader解析XML⽂件数据关于SAXReader解析XML⽂件数据注意:须从maven公共库中添加dom4j依赖包(依赖于元素名和元素的⽅法)解析xml代码private static void parseXml(String path) throws Exception {// 调⽤dom4j依赖包中的SAXReader对象SAXReader saxReader = new SAXReader();// 通过read⽅法可以读取XML数据,返回Document格式对象Document document = saxReader.read(path);// 使⽤getRootElement()⽅法获取根元素,根节点元素是students,返回element对象Element element = document.getRootElement();// 通过element()⽅法,获取该根节点下的所有⼦元素List<Element> list = element.elements("student");//循环遍历所有的⼦元素的信息for (Element studentElement : list) {System.out.println("姓名:"+studentElement.elementText("Name")+",年龄:"+studentElement.elementText("Age")+",性别:"+studentElement.elementText("Gender"));}/*//第⼆种⽅法:通过⼦元素下的标签名---》element()获取对应的元素值for(Element studentElement:list){Element elementName=studentElement.element("Name");Element elementAge=studentElement.element("Age");Element elementGender=studentElement.element("Gender");System.out.println("姓名:"+elementName.getText()+",年龄:"+elementAge.getText()+",性别"+elementGender.getText());}*/}public static void main(String[] args) throws Exception {String path = "src/test/resources/student.xml";parseXml(path);}要解析的student.xml⽂件<?xml version="1.0" encoding="UTF-8"?><students><student number="1801001"><Name>王尼玛</Name><Age>21</Age><Gender>男</Gender></student><student number="1801002"><Name>赵铁柱</Name><Age>22</Age><Gender>男</Gender></student><student number="1801003"><Name>李⼩花</Name><Age>18</Age><Gender>⼥</Gender></student></students>实现结果:解析代码:1、读取xml⽂件创建SAXReader对象并调⽤其read()⽅法来读取xml数据,并返回Document格式的对象。

解析Xml⽂件的三种⽅式1、Sax解析(simple api for xml) 使⽤流式处理的⽅式,它并不记录所读内容的相关信息。
它是⼀种以事件为驱动的XML API,解析速度快,占⽤内存少。
使⽤回调函数来实现。
1class MyDefaultHander extends DefaultHandler{2private List<Student> list;3private Student student;45 @Override6public void startDocument() throws SAXException {7super.startDocument();8 list=new ArrayList<>();9 }1011 @Override12public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {13super.startElement(uri, localName, qName, attributes);14if(qName.equals("student")){15 student=new Student();1617 }18 preTag=qName;19 }2021 @Override22public void endElement(String uri, String localName, String qName) throws SAXException {23if(qName.equals("student")){24 list.add(student);25 }26 preTag=null;27 }2829 @Override30public void characters(char[] ch, int start, int length) throws SAXException {31if(preTag!=null){32if(preTag.equals("id")){33 student.setId(Integer.parseInt(new String(ch,start,length)));34 }else if(preTag.equals("name")){35 student.setName(new String(ch,start,length));36 }else if(preTag.equals("age")){37 student.setAge(Integer.parseInt(new String(ch,start,length)));38 }39 }40 }41public List<Student> getStudents(){42return list;43 }44 }45public List<Student> sax_parser(){46 List<Student> list=null;47try {48 SAXParser parser= SAXParserFactory.newInstance().newSAXParser();49 InputStream is= getAssets().open("student.xml");50 MyDefaultHander hander=new MyDefaultHander();51 parser.parse(is,hander);52 list= hander.getStudents();53 } catch (ParserConfigurationException e) {54 e.printStackTrace();55 } catch (SAXException e) {56 e.printStackTrace();57 } catch (IOException e) {58 e.printStackTrace();59 }60return list;61 }2、Dom解析 DOM(Document Object Model) 是⼀种⽤于XML⽂档的对象模型,可⽤于直接访问XML⽂档的各个部分。

xml 格式解析XML格式解析是一种常见的数据解析方法,它可以将XML格式的数据转换为可供程序使用的数据结构。
XML即可扩展标记语言(eXtensible Markup Language),它被广泛应用于数据交换和存储。
下面将介绍XML格式解析的原理和常用的解析方法。
XML格式解析的原理是通过读取XML文件并识别其中的标签、属性和文本内容,将其转换为内存中的数据结构,以便程序进行进一步处理。
XML文件由起始标签、结束标签、属性和文本内容组成。
解析器会根据这些组成部分对XML文档进行解析。
常用的XML格式解析方法有两种:DOM解析和SAX解析。
DOM(文档对象模型)解析是一种将整个XML文档加载到内存中,并构建一个XML树结构的解析方法。
它可以方便地对XML文档进行增删改查操作。
DOM解析器会先将整个XML文档加载到内存中,然后构建一个树状结构,通过遍历树状结构来访问和操作XML文档的节点。
SAX(简单 API for XML)解析是一种基于事件驱动的解析方法。
它边读取XML文档边解析,并在读取到XML文档的不同部分时触发相应的事件。
相比DOM解析,SAX解析更加高效,特别适用于大型XML文件的解析。
SAX解析器会逐行读取XML文档,当遇到起始标签、结束标签或文本内容时触发相应的事件,并通过事件处理程序来处理这些事件。
选择使用DOM解析还是SAX解析取决于具体的需求。
如果需要对XML文档进行多次操作或查询,DOM解析更方便。
但是,如果处理大型XML文件或只需一次性读取XML数据,SAX解析更高效。
总之,XML格式解析是处理XML数据的重要技术。
通过DOM解析和SAX 解析,我们可以将XML格式的数据转换为程序可以处理的数据结构,实现数据的读取、分析和操作。

xml格式讲解XML(eXtensible Markup Language)是一种用于描述和传输数据的标记语言。
它能够通过自定义标签来定义数据的结构和内容。
本文将对XML格式进行详细讲解。
一、XML的基本语法XML采用了类似于HTML的标签语法,但与HTML不同的是,XML标签必须自行定义,且对大小写敏感。
以下是XML的基本语法要点:1. 标签:XML使用尖括号(< >)来定义标签,标签通常成对出现,分为开始标签和结束标签。
例如:<book>...</book>2. 元素(Element):元素由开始标签、结束标签和标签内容组成。
例如:<name>John</name>3. 属性(Attribute):属性为元素提供更多的信息,通常出现在开始标签中。
例如:<book category="novel">...</book>4. 注释:注释用于添加对XML代码的说明,以"<!--"开头,以"-->"结尾。
例如:<!-- This is a comment -->二、XML的文档结构一个合法的XML文档必须包含一个根元素,并且所有的元素都必须严格嵌套。
以下是一个简单的XML文档示例:<?xml version="1.0" encoding="UTF-8"?><library><book><title>《Pride and Prejudice》</title><author>Jane Austen</author></book><book><title>《1984》</title><author>George Orwell</author></book></library>在上述示例中,根元素是"library",它包含了两个子元素"book",并且每个"book"元素分别包含了"title"和"author"元素。

xml文件解析方法XML文件解析方法引言:XML(可扩展标记语言)是一种用于存储和传输数据的标记语言,它具有良好的可读性和灵活性,被广泛应用于数据交换和配置文件等领域。
在处理XML文件时,解析是必不可少的环节。
本文将介绍几种常用的XML文件解析方法,包括DOM、SAX和StAX。
一、DOM解析方法DOM(文档对象模型)是一种将整个XML文件以树形结构加载到内存中的解析方法。
DOM解析器将XML文件解析为一个树状结构,通过遍历节点来获取和操作XML文件中的数据。
DOM解析方法的优点是易于理解和使用,可以随机访问XML文件中的任意节点,但缺点是占用内存较大,不适用于大型XML文件的解析。
1. 创建DOM解析器对象:使用标准的Java API,可以通过DocumentBuilderFactory类来创建DOM解析器对象。
2. 加载XML文件:通过DOM解析器对象的parse()方法加载XML文件,将其转化为一个树形结构。
3. 遍历节点:使用DOM解析器对象提供的方法,如getElementsByTagName()、getChildNodes()等,可以遍历XML文件中的各个节点,获取节点的名称、属性和文本内容等信息。
4. 获取节点数据:通过节点对象提供的方法,如getNodeName()、getTextContent()等,可以获取节点的名称和文本内容。
二、SAX解析方法SAX(简单API for XML)是一种基于事件驱动的XML解析方法。
在SAX解析过程中,解析器顺序读取XML文件,当遇到节点开始、节点结束或节点文本等事件时,会触发相应的回调方法。
相比于DOM 解析方法,SAX解析方法具有内存占用小、解析速度快的优点,但缺点是无法随机访问XML文件中的节点。
1. 创建SAX解析器对象:使用标准的Java API,可以通过SAXParserFactory类来创建SAX解析器对象。
2. 实现事件处理器:自定义一个事件处理器,实现SAX解析器提供的DefaultHandler类,并重写相应的回调方法,如startElement()、endElement()和characters()等。

查看文章4种常见的xml解析方法2009-11-03 14:40==========================================xml文件<?xml version="1.0" encoding="GB2312"?><RESULT><VALUE><NO>A1234</NO><ADDR>四川省XX县XX镇XX路X段XX号</ADDR></VALUE><VALUE><NO>B1234</NO><ADDR>四川省XX市XX乡XX村XX组</ADDR></VALUE></RESULT>需要什么包自己到网上找下吧?==========================================1)DOM(JAXP Crimson解析器)DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准。
DOM是以层次结构组织的节点或信息片断的集合。
这个层次结构允许开发人员在树中寻找特定信息。
分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。
由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。
DOM 以及广义的基于树的处理具有几个优点。
首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。
它还可以在任何时候在树中上下导航,而不是像SAX那样是一次性的处理。
DOM使用起来也要简单得多。
import java.io.*;import java.util.*;import org.w3c.dom.*;import javax.xml.parsers.*;public class MyXMLReader{public static void main(String arge[]){long lasting =System.currentTimeMillis();try{File f=new File("data_10k.xml");DocumentBuilderFactoryfactory=DocumentBuilderFactory.newInstance();DocumentBuilder builder=factory.newDocumentBuilder();Document doc = builder.parse(f);NodeList nl = doc.getElementsByTagName("VALUE");for (int i=0;i<nl.getLength();i++){System.out.print("车牌号码:" +doc.getElementsByTagName("NO").item(i).getFirstChild().getNodeValue() );System.out.println("车主地址:" +doc.getElementsByTagName("ADDR").item(i).getFirstChild().getNodeValue ());}}catch(Exception e){e.printStackTrace();}==========================================2)SAXSAX处理的优点非常类似于流媒体的优点。

XML的四种解析器原理及性能比较XML(可扩展标记语言)是一种非常常见的数据交换格式,用于在应用程序之间传递和存储数据。
在处理XML数据时,需要使用解析器来读取和解析XML文档。
下面将介绍XML的四种解析器的原理和性能比较。
1. DOM解析器(Document Object Model Parser):DOM解析器将整个XML文档加载到内存中,并将其表示为一个树形结构,每个节点都对应XML文档中的一个元素或属性。
解析器可以通过遍历这个树形结构来访问和操作XML数据。
由于将整个文档加载到内存中,DOM解析器所需的内存较大,适合处理比较小的XML文档。
虽然性能较差,但它提供了灵活的访问和操作XML数据的方法。
2. SAX解析器(Simple API for XML Parser):3. StAX解析器(Streaming API for XML Parser):StAX解析器是一种混合了DOM和SAX解析器的解析器,它允许开发人员以推拉模型访问XML数据。
开发人员可以使用迭代器的形式遍历XML文档,并根据需要拉取或推送事件。
StAX解析器的内存需求较低,同时也具备灵活的操作XML数据的能力。
4. JAXB解析器(Java Architecture for XML Binding):JAXB解析器是一种用于将XML数据绑定到Java对象的解析器。
它可以将XML文档中的元素和属性映射到具体的Java类和对象上,并提供了将Java对象序列化为XML的能力。
相比于前三种解析器,JAXB解析器需要定义Java类和XML的映射关系,稍微复杂一些。
但它提供了方便的对象操作方式,可以更加简洁地处理XML数据。
对于解析性能的比较,DOM解析器的性能最差,因为它需要将整个XML文档加载到内存中。
对于大型XML文档,DOM解析器可能会导致内存不足的问题。
SAX解析器和StAX解析器的性能较好,因为它们是基于事件驱动的解析器,可以逐行读取XML文档,无需将整个文档加载到内存中。

三种解析XML文件的方法在Android平台上可以使用Simple API for XML(SAX) 、 Document Object Model(DOM)和Android附带的pull解析器解析XML文件。
下面是本例子要解析的XML文件:文件名称:china.xml例子定义了一个javabean用于存放上面解析出来的xml内容,这个javabean为Person,代码:使用SAX读取XML文件SAX是一个解析速度快并且占用内存少的xml解析器,非常适合用于Android等移动设备。
SAX解析XML文件采用的是事件驱动,也就是说,它并不需要解析完整个文档,在按内容顺序解析文档的过程中,SAX会判断当前读到的字符是否合法XML语法中的某部分,如果符合就会触发事件。
所谓事件,其实就是一些回调(callback)方法,这些方法(事件)定义在ContentHandler接口。
下面是一些ContentHandler接口常用的方法:startDocument()当遇到文档的开头的时候,调用这个方法,可以在其中做一些预处理的工作。
endDocument()和上面的方法相对应,当文档结束的时候,调用这个方法,可以在其中做一些善后的工作。
startElement(String namespaceURI, String localName, String qName, Attributes atts) 当读到一个开始标签的时候,会触发这个方法。
namespaceURI就是命名空间,localName 是不带命名空间前缀的标签名,qName是带命名空间前缀的标签名。
通过atts可以得到所有的属性名和相应的值。
要注意的是SAX中一个重要的特点就是它的流式处理,当遇到一个标签的时候,它并不会纪录下以前所碰到的标签,也就是说,在startElement()方法中,所有你所知道的信息,就是标签的名字和属性,至于标签的嵌套结构,上层标签的名字,是否有子元属等等其它与结构相关的信息,都是不得而知的,都需要你的程序来完成。

SAX解析XMLsax解析特点:1、逐⾏读取2、事件处理-- ⽅法3、解析器调⽤相应的事件 4、只能读取⽂件DefaultHandler 可以触发5个事件*startDocument() 开始⽂档*startElement() 开始元素*characters() ⽂本*endElement() 结束元素*endDocument() 结束⽂档在startElement/*** 如果xml⽂件使⽤了schema约束 <xs:element>* * uri:schema -- targetNameSpace* * localName--element* * qName---xs:element* 如果不使⽤* * uri:null* * localName:null* * qName : element** Attributes:当前元素的所有的属性的集合*/1//获得解析⼯⼚实例2 SAXParserFactory factory=SAXParserFactory.newInstance();3//获得解析器4 SAXParser parser=factory.newSAXParser();5//解析xml6 DefaultHandler dh=new MyDefaultHandler();78 parser.parse("books.xml", dh);Demo1public void SaxDemo() throws Exception2 {3 SAXParser parser= SAXParserFactory.newInstance().newSAXParser();4 parser.parse(Demo.class.getClassLoader().getResourceAsStream("users.xml"), new DefaultHandler(){ 5private boolean nameOrAge=false;6 @Override7public void startElement(String uri, String localName,8 String qName, Attributes attributes) throws SAXException {9if(qName.equals("user"))10 {11 System.err.println(attributes.getValue("id"));12 }13else if(qName.equals("name") || qName.equals("age")){14 nameOrAge=true;15 }16 }1718 @Override19public void endElement(String uri, String localName, String qName)20throws SAXException {21if(qName.equals("name")|| qName.equals("age"))22 {23 nameOrAge=false;24 }25 }2627 @Override28public void characters(char[] ch, int start, int length) 29throws SAXException {30if(nameOrAge)31 {32 String value=new String(ch,start,length);33 System.err.println(value);34 }35 }3637 });38 }。

解析xml格式字符串标签数据的方法
XML格式字符串是一种常见的数据格式,它由标签和标签中的数据组成。
解析XML格式字符串中的标签数据可以帮助我们更方便地获取和处理数据。
以下是解析XML格式字符串标签数据的方法:
1. 使用DOM解析器:DOM解析器是一种常用的解析XML格式字符串的方法。
它可以将整个XML文档加载到内存中,然后通过对DOM树进行操作来获取标签数据。
具体步骤是:使用DOM解析器加载XML文件,然后通过对DOM树进行遍历,找到所需的标签并获取其中的数据。
2. 使用SAX解析器:SAX解析器是一种基于事件驱动的解析XML格式字符串的方法。
它可以在解析XML文件的过程中触发一系列事件,程序员可以根据这些事件来获取标签数据。
具体步骤是:使用SAX解析器解析XML文件,然后在遇到标签时触发startElement事件,在标签结束时触发endElement事件,程序员可以在这些事件中获取标签数据。
3. 使用XPath:XPath是一种用于在XML文档中定位节点的语言,它可以帮助我们更方便地获取标签数据。
具体步骤是:使用XPath解析器加载XML文件,然后使用XPath表达式在XML文档中定位所需的标签,最后获取标签中的数据。
以上是解析XML格式字符串标签数据的一些常用方法,程序员可以根据自己的需求选择适合的方法来获取和处理数据。
解析xml格式字符串标签数据的方法XML格式字符串是一种常用的数据格式,它可以表示复杂的数据结构。
在处理XML格式字符串时,我们需要解析其中的标签数据,才能获取其中的内容。
下面是几种解析XML格式字符串标签数据的方法: 1. DOM解析:DOM是Document Object Model的缩写,它将XML 数据组织成一个树形结构,可以通过操作节点对象来访问和修改数据。
使用DOM解析XML格式字符串需要加载完整的XML文档到内存中,因此适合处理较小的XML数据,但对于大型XML数据,DOM解析可能会导致性能问题。
2. SAX解析:SAX是Simple API for XML的缩写,它是一种基于事件驱动的解析方式,可以在读取XML数据时逐个处理数据。
SAX解析对内存的要求非常低,适合处理大型XML数据,但由于它是基于事件驱动的,因此需要编写复杂的回调函数来处理数据。
3. XPath解析:XPath是一种查询语言,可以通过路径表达式来访问XML数据中的元素、属性等。
使用XPath解析XML格式字符串时,可以通过XPath表达式来获取特定的元素或属性的值,非常方便。
不过,XPath解析需要加载完整的XML文档到内存中,对于大型XML数据仍然存在性能问题。
4. XML解析器:除了DOM、SAX和XPath解析之外,还有一些XML 解析器可以用来解析XML格式字符串。
例如,Python中的ElementTree 模块提供了一种简单的解析方式,可以快速地访问和修改XML数据。
总之,在解析XML格式字符串时,需要根据实际的需求选择合适的解析方式。
如果对内存要求比较高,可以使用SAX解析;如果需要快速访问和修改XML数据,可以考虑使用XPath解析或XML解析器。
xml的四种解析方法及源代码(SAX、DOM、JDOM、DOM4J)第一种:SAX解析SAX处理机制:SAX是一种基于事件驱动的API。
利用SAX解析XML文档,牵涉到两个部分:解析器和事件处理器。
解析器负责读取XML文档,并向事件处理器发生事件,如元素开始和元素结束事件;而事件处理器则负责对事件做出响应,对传递的XML数据进行处理。
测试用的xml文件:db.xmlXml代码<?xml version="1.0"encoding="UTF-8"?><!--<!DOCTYPE dbconfig SYSTEM "db.dtd">--><dbconfig><db type="oracle"><driver>oracle.jdbc.driver.OracleDriver</driver><url>jdbc:oracle:thin:@localhost:1521:oracle</url><user>scott</user><password>tiger</password></db></dbconfig><?xml version="1.0" encoding="UTF-8"?><!--<!DOCTYPE dbconfig SYSTEM "db.dtd">--><dbconfig><db type="oracle"><driver>oracle.jdbc.driver.OracleDriver</driver><url>jdbc:oracle:thin:@localhost:1521:oracle</url><user>scott</user><password>tiger</password></db></dbconfig>DTD文件db.dtdXml代码<!ELEMENT dbconfig (db+)><!ELEMENT db (driver,url,user,password)><!ELEMENT driver (#PCDATA)><!ELEMENT url (#PCDATA)><!ELEMENT user (#PCDATA)><!ELEMENT password (#PCDATA)><!ATTLIST db type CDATA #REQUIRED><!ELEMENT dbconfig (db+)><!ELEMENT db (driver,url,user,password)><!ELEMENT driver (#PCDATA)><!ELEMENT url (#PCDATA)><!ELEMENT user (#PCDATA)><!ELEMENT password (#PCDATA)><!ATTLIST db type CDATA #REQUIRED>SAX解析实例一org.xml.sax.DefalutHandler类: 可以扩展该类,给出自己的解析实现SAXPrinter.javaJava代码import java.io.File;import javax.xml.parsers.SAXParser;import javax.xml.parsers.SAXParserFactory;import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.helpers.DefaultHandler;public class SAXPrinter extends DefaultHandler{/** *//*** 文档开始事件*/public void startDocument() throws SAXException{System.out.println("<?xml version=\"1.0\" encoding=\"utf-8 \"?>");}/** *//*** 接收处理指令事件*/public void processingInstruction(String target, String data) throws SAXException{System.out.println("<?"+target+" "+data+"?>");}/** *//*** 元素开始事件* 参数说明:* uri - 名称空间 URI,如果元素没有任何名称空间 URI,或者没有正在执行名称空间处理,则为空字符串。
JAXP(Java API for XML Processing)为打包器提供了两种不同的处理XML数据的机制,第一种是XML的简单API(Simple API for XML,即SAX),第二种是文档对象模型(Document Object Model,即DOM)。
SAX解析核心思路:在SAX模型中,XML文档作为一系列的事件提供给应用程序,每个事件表示XML文档的一种转换。
SAX解析优缺点:SAX解析的利用事件进行处理可以处理很大的文档,并且不必立即将整个文档读入内存。
然而使用XML文档的片段可能会变得复杂,因为开发人员必须跟踪给定片段的所有事件。
SAX是个广泛使用的标准,但不受任何行业团体控制。
现在SAX得到开源项目的支持。
SAX事件模型:SAX事件包括:文档事件(通知程序一个XML文档的开始和结束)、元素事件(通知程序每个元素的开始和结束)、字符事件(通知程序在元素之间找到的任何字符数据,包括文本、实体和CDATA段),还有不常见的事件:命名空间、实体和实体声明、可忽略的空白、处理指令。
SAX事件处理器:1.ContentHandlerContentHanler是任何SAX解析器的核心接口。
它定义了在SAX API中最常用的10个回调函数。
2.DefaultHandler具体实现了ContentHandler接口,允许集中于常用的事件。
可以使用自己的子类扩展(extends)DefaultHandler类。
基本的SAX回调函数:1.文档回调public void startDocument() throws SAXException;SAX通过调用该函数来开始每次解析。
public void endDocument() throws SAXException;SAX通过调用该函数来表示解析的结束。
2.元素回调public void startElement(String uri, String localName, String qName, Attributes atts) throwsSAXException;qName是元素的名称;元素的属性可以依据名称简单地进行引用。
sax解析的基础原理SAX解析的基础原理SAX(Simple API for XML)是一种基于事件驱动的XML解析技术,它适用于处理大型XML文件,可以边读取XML数据边处理,不需要将整个XML文件加载到内存中。
本文将介绍SAX解析的基础原理。
一、SAX解析原理概述SAX解析器将XML文件视为一系列的事件流,当解析器读取到XML 文件的某个部分时,会触发相应的事件,并通知注册的事件处理器进行处理。
这种解析方式相比于DOM(Document Object Model)解析方式更加高效,因为它避免了将整个XML文件加载到内存中的开销。
二、SAX解析器的工作流程SAX解析器的工作流程可以分为以下几个步骤:1. 创建SAX解析器对象:首先需要创建一个SAX解析器对象,该对象用于解析XML文件。
2. 注册事件处理器:在解析XML文件之前,需要注册事件处理器,用于处理解析器触发的不同事件。
3. 解析XML文件:开始解析XML文件之前,需要将XML文件作为输入传递给SAX解析器。
解析器会逐行读取XML文件,并根据文件内容触发相应的事件。
4. 处理事件:当解析器触发某个事件时,会调用注册的事件处理器的相应方法进行处理。
例如,当解析器读取到一个元素的开始标签时,会调用事件处理器的startElement()方法。
5. 返回结果:解析器在解析完整个XML文件后,会返回解析结果给调用者。
解析结果可以是解析器解析到的数据、错误信息等。
三、SAX解析事件及其处理器SAX解析器在解析XML文件时,会触发以下几个事件:1. 文档开始事件(startDocument):当解析器开始解析XML文档时触发。
2. 元素开始事件(startElement):当解析器读取到一个元素的开始标签时触发。
3. 元素内容事件(characters):当解析器读取到元素的内容时触发。
4. 元素结束事件(endElement):当解析器读取到一个元素的结束标签时触发。
解析XML文件的五种技术1.1SAX技术SAX处理的优点非常类似于流媒体的优点。
分析能够立即开始,而不是等待所有的数据被处理。
而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。
这对于大型文档来说是个巨大的优点。
事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。
一般来说,SAX还比它的替代者DOM快许多。
选择DOM还是选择SAX?对于需要自己编写代码来处理XML文档的开发人员来说,选择DOM 还是SAX解析模型是一个非常重要的设计决策。
DOM采用建立树形结构的方式访问XML文档,而SAX采用的事件模型。
DOM解析器把XML文档转化为一个包含其内容的树,并可以对树进行遍历。
用DOM解析模型的优点是编程容易,开发人员只需要调用建树的指令,然后利用navigation APIs访问所需的树节点来完成任务。
可以很容易的添加和修改树中的元素。
然而由于使用DOM解析器的时候需要处理整个XML文档,所以对性能和内存的要求比较高,尤其是遇到很大的XML文件的时候。
由于它的遍历能力,DOM解析器常用于XML文档需要频繁的改变的服务中。
SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。
SAX对内存的要求通常会比较低,因为它让开发人员自己来决定所要处理的tag.特别是当开发人员只需要处理文档中所包含的部分数据时,SAX这种扩展能力得到了更好的体现。
但用SAX解析器的时候编码工作会比较困难,而且很难同时访问同一个文档中的多处不同数据。
1.1.1 SAX语法简介SAX是一个解析速度快并且占用内存少的xml解析器,非常适合用于Android等移动设备。
SAX 解析XML文件采用的是事件驱动,也就是说,它并不需要解析完整个文档,在按内容顺序解析文档的过程中,SAX会判断当前读到的字符是否合法XML语法中的某部分,如果符合就会触发事件。