西安电子科技大学编译原理04-4
- 格式:ppt
- 大小:1.55 MB
- 文档页数:46

《计算机编译原理》试卷A2参考答案一、单项选择题(每小题1分,共25分)1、构造编译程序应掌握___D___。
A、源程序B、目标语言C、编译方法D、以上三项都是2、变量应当___C___。
A、持有左值B、持有右值C、既持有左值又持有右值D、既不持有左值也不持有右值3、编译程序绝大多数时间花在___D___上。
A、出错处理B、词法分析C、目标代码生成D、管理表格4、___D___不可能是目标代码。
A、汇编指令代码B、可重定位指令代码C、绝对指令代码D、中间代码5、使用___A___可以定义一个程序的意义。
A、语义规则B、词法规则C、产生规则D、词法规则6、词法分析器的输入是___B___。
A、单词符号串B、源程序C、语法单位D、目标程序7、中间代码生成时所遵循的是___C___。
A、语法规则B、词法规则C、语义规则D、等价变换规则8、编译程序是对___D___。
A、汇编程序的翻译B、高级语言程序的解释执行C、机器语言的执行D、高级语言的翻译9、文法G:S→xSx|y所识别的语言是___C___。
A、xyxB、(xyx)*C、x n yx n(n≥0)D、x*yx*10、文法G描述的语言L(G)是指___A___。
A、L(G)={α|S+ ⇒α ,α∈V T*}B、L(G)={α|S*⇒α,α∈V T*}C、L(G)={α|S*⇒α,α∈(V T∪V N*)}D、L(G)={α|S+ ⇒α,α∈(V T∪V N*)}11、有限状态自动机能识别___C___。
A、上下文无关文法B、上下文有关文法C、正规文法D、短语文法12、设G为算符优先文法,G的任意终结符对a、b有以下关系成立___C___。
A、若f(a)>g(b),则a>bB、若f(a)<g(b),则a<bC、A~B都不一定成立D、A~B一定成立13、如果文法G是无二义的,则它的任何句子α___A___。
A、最左推导和最右推导对应的语法树必定相同B、最左推导和最右推导对应的语法树可能不同C、最左推导和最右推导必定相同D、可能存在两个不同的最左推导,但它们对应的语法树相同14、由文法的开始符经0步或多步推导产生的文法符号序列是___C___。





#include<>#include<>#include<>#define MAX_COUNT 1024#define ILLEGAL_CHAR_ERR 1#define UNKNOWN_OPERATOR_ERR 2/*从标准输入读入第一个非空白字符(换行符除外)*/char getnbc(){char ch;ch = getchar();while (1){if (ch == '\r' || ch == '\t' || ch == ' '){ch = getchar();}else{break;}}return ch;}/*判断character是否为字母*/bool letter(char character){if ((character >= 'a'&&character <= 'z') || (character >= 'A'&&character <= 'Z')) return true;elsereturn false;}/*判断character是否为数字*/bool digit(char character){if (character >= '0'&&character <= '9')return true;elsereturn false;}/*回退字符*/void retract(char& character){ungetc(character, stdin);character = NULL;}/*返回保留字的对应种别*/int reserve(char* token){if (strcmp(token, "begin") == 0)return 1;else if (strcmp(token, "end") == 0)return 2;else if (strcmp(token, "integer") == 0)return 3;else if (strcmp(token, "if") == 0)return 4;else if (strcmp(token, "then") == 0)return 5;else if (strcmp(token, "else") == 0)return 6;else if (strcmp(token, "function") == 0) return 7;else if (strcmp(token, "read") == 0)return 8;else if (strcmp(token, "write") == 0)return 9;elsereturn 0;}/*返回标识符的对应种别*/int symbol(){return 10;}/*返回常数的对应种别*/int constant(){return 11;}/*按照格式输出单词符号和种别*/void output(const char* token, int kindNum){printf("%16s %2d\n", token, kindNum);}/*根据行号和错误码输出错误*/bool error(int lineNum, int errNum){char* errInfo;switch (errNum){case ILLEGAL_CHAR_ERR:errInfo = "出现字母表以外的非法字符";break;case UNKNOWN_OPERATOR_ERR:errInfo = "出现未知运算符";break;default:errInfo = "未知错误";}if (fprintf(stderr, "***LINE:%d %s\n", lineNum, errInfo) >= 0) return true;elsereturn false;}/*词法分析函数,每调用一次识别一个符号*/bool LexAnalyze(){static int lineNum = 1;char character;char token[17] = "";character = getnbc();switch (character){case'\n':output("EOLN", 24);lineNum++;break;case EOF:output("EOF", 25);return false;;if (fullName != NULL)strncpy(out, fullName + 1, strlen(fullName) - 1 - strlen(extension));elsestrncpy(out, in, strlen(in) - strlen(extension));}/*初始化函数,接收输入文件地址,并打开输入、输出、错误文件、将标准输入重定向到输入文件,将标准输出重定向到输出文件,标准错误重定向到错误文件*/bool init(int argc, char* argv[]){if (argc != 2){return false;}else{char* inFilename = argv[1];yd");rr");if (freopen(inFilename, "r", stdin) != NULL&&freopen(outFilename, "w", stdout) !=NULL&&freopen(errFilename, "w", stderr) != NULL)return true;elsereturn false;}}void main(int argc,char* argv[])//argv[1]是输入文件地址{if (init(argc,argv)){while (LexAnalyze()){}}fclose(stdin);fclose(stdout);fclose(stderr);return;}。



编译原理上机报告《DBMS的设计与实现》学号:姓名:手机:邮箱:完成时间:2013 年6月21日目录1.项目概况 (3)1.1基本目标 (3)1.2完成情况 (3)2.项目实现方案 (4)2.1逻辑结构与物理结构 (4)2.2语法结构与数据结构 (7)2.3执行流程 (19)2.4功能测试 (39)3.总结与未来工作 (48)3.1未完成功能 (48)3.2未来实现方案 (48)1.项目概况1.1 基本目标设计并实现一个DBMS原型系统,可以接受基本的SQL语句,对其进行词法分析、语法分析,然后解释执行SQL语句,完成对数据库文件的相应操作,实现DBMS的基本功能。
1.2 完成情况1.CREATE DATABASE 创建数据库2.SHOW DATABASES 显示数据库名3.DROP DATABASE 删除数据库E DATABASE 选择数据库5.CREATE TABLE 创建表6.SHOW TABLES 显示表名7.DROP TABLE 删除表8.INSERT 插入元组9.SELECT 查询元组10.DELETE 删除元组11.UPDATE 更新元组12.EXIT 退出系统2.项目实现方案2.1 逻辑结构与物理结构1.逻辑结构(1)系统数据库1)元数据的逻辑结构在我设计的系统数据库中,虽然建有元数据的文件,但是文件中没有任何数据,所以元数据的逻辑结构不存在。
2)基本数据的逻辑结构表1 系统数据库的基本数据的逻辑结构(2)用户数据库1)元数据的逻辑结构由于在我的设计中,为数据库中每个表创建一个基本数据文件,所以不需要ppt中的“起始页”,添加了一个“表中列的数目”的列,如下表所示:说明:表中col_type列,取值为整数,1表示字符串,2表示整型2)基本数据的逻辑结构与ppt中的参考方案不同的是,对于数据库中的每一个表,我并不是把每个表的基本数据均存放在一个与数据库同名的基本数据文件中,而是为每个表创建一个与表同名的基本数据文件。
Xidian University Li Huan编译原理题目解诗云:太初有道,道曰全真。
全真七子,星聚软院1。
重阳归天2,分道七篇。
各执一篇,授业终南。
当是时也,正乃王道长献青真人讲道西电,秘授编译原理心法一篇,以飨众生。
无量寿佛!今晚 Li Huan1此处作者指的是目前西电软件学院七位有德道长:总掌教大护法武道长、首席副掌教顾道长、刘道长讳西洋、沈道长讳沛意、王道长讳献青、高道长讳海昌、陈道婆讳静玉。
此乃huan说,另有其他版本。
不再赘述。
2此处指软件学院开山祖师陈真人讳平。
归天意本离世,此处特指升仙为四大护校法尊之一。
1、填空题(30 分)1.1 以阶段划分的编译器中,语法分析阶段以记号流为输入,语义分析阶段以语法树为输入。
1.2 有正规式 P=a|b 和 Q=cd 则 L(QP)={cda,cdb} ,L((P|Q)Q)={acd,bcd,cdcd} 。
1.3 有两个因素使得有限自动机是不确定的,一个是具有ε 状态转移,另一个是对同一字符,可能有多于一个的下一状态转移。
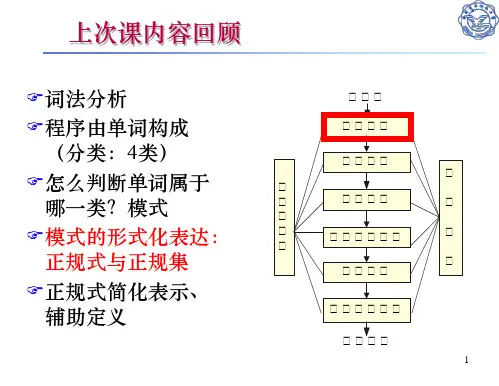
1.4 词法分析器有四个作用,请给出其中的任意两个:识别记号并交给语法分析器/滤掉源程序中的无用成分/处理与具体平台有关的输入/调用符号表管理器或出错管理器。
1.5 一个定义正确的上下文无关文法,非终结符集合和终结符集合的交集为空,所有出现在产生式左部的文法符号均是非终结符,仅出现在产生式右部的文法符号均是终结符。
1.6 编译源程序的过程中,发现函数定义末尾缺少花括号,该情况是语法错误;发现除数为 0,该情况是语义错误。
1.7 推导 S=>?H=>?FTP =>?FTc=>?Fbc=>?abc 是最右/规范推导。
1.8 产生式 F→A*F|A 提取左因子的结果为 F->AF' F'->*F|ε 。
1.9 对于算术表达式 “a*b+c”,当采用预测分析方法时,接受格局中的“当前剩余输入”应该为空,初始格局中的“当前剩余输入”应该是 a*b+c 。
电子科技大学22春“计算机科学与技术”《计算机编译原理》期末考试高频考点版(带答案)一.综合考核(共50题)1.词法分析器的输出是()。
A.单词符号B.源程序C.语法单位D.目标程序参考答案:A2.从功能上说,程序语言的语句大体可分为执行性语句和说明性语句两大类。
()A.正确B.错误参考答案:A3.描述文法符号语义的属性有()。
A.综合属性B.继承属性C.L-属性D.R-属性参考答案:AB4.语法分析程序主要功能是进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
()A.正确B.错误参考答案:B5.素短语是指至少含有一个终结符的短语,且除它自身之外不再含任何其他素短语。
()A.正确B.错误参考答案:A6.高级语言编译程序常用的语法分析方法中,递归下降分析法属于().分析方法。
A.自左至右B.自顶向下C.自底向上D.自右向左参考答案:B7.所谓自下而上分析法就是从输入串开始,逐步进行“归约”,直至归约到文法的()。
A.开始符号B.终结符C.非终结符D.空字ε参考答案:A8.已知文法G[S]:S→AB|PQx,A→xy,B→bc,P→dP|ε,Q→aQ|ε,该文法是LL(1)文法。
()A.正确B.错误参考答案:B9.语法分析最常用的方法有()分析法。
A.自上而下B.自下而上C.从左向右参考答案:AB10.编译程序中语法分析器的输入是()。
A.单词B.表达式C.直接短语D.句柄参考答案:A11.常用的中间代码形式有()。
A.状态机B.四元式C.转换表D.语法树参考答案:B12.所谓语法制导翻译方法是为每个产生式配上一个翻译子程序,并在语法分析的同时执行这些子程序。
()A.正确B.错误参考答案:A13.后缀式是一种把运算量写在前面,把算符写在后面的表示表达式的方法。
()A.正确B.错误参考答案:AA.正确B.错误参考答案:A15.运行阶段的存储组织与管理是为了()。
①提高编译程序的运行速度②节省编译程序的存储空间③提高目标程序的运行速度④为运行阶段的存储分配做准备A.①③B.②③C.③④D.①④参考答案:C16.按所涉及的程序范围可分为哪几级优化?()A.局部优化B.循环优化C.全局优化D.回溯优化参考答案:ABC17.数组的内情向量中肯定不含有数组的()的信息。