无序分类资料统计分析
- 格式:pdf
- 大小:392.65 KB
- 文档页数:33

无序多分类logistic回归模型随着大数据时代的到来,机器学习在各个领域的应用越来越广泛。
其中,分类问题作为机器学习的一个重要分支,一直备受关注。
而在分类问题中,多分类问题是最为复杂的一种。
本文将介绍一种无序多分类logistic回归模型,并对其进行分析和实现。
一、模型介绍logistic回归是一种基于概率的非线性分类方法,适用于二分类问题。
对于多分类问题,常用的解决方法有softmax回归、支持向量机等。
然而,这些方法在处理无序多分类问题时,可能会遇到一些困难。
因此,无序多分类logistic回归模型应运而生。
该模型通过引入多个logistic回归分类器,对每个类别的样本进行分类,最终得到一个投票结果,实现多分类问题的解决。
二、模型分析1. 优势:无序多分类logistic回归模型能够有效地解决无序多分类问题,具有简单、易实现、准确率高等优点。
同时,该模型还可以结合其他机器学习算法,如随机森林、梯度提升树等,进一步提高模型的性能。
2. 缺点:虽然无序多分类logistic回归模型具有一定的优势,但也存在一些缺点。
首先,该模型需要大量的训练数据和计算资源,不适合处理大规模数据。
其次,模型对特征的选择和设计较为敏感,需要针对具体问题进行调整和优化。
3. 适用场景:无序多分类logistic回归模型适用于处理无序多分类问题,如情感分析、垃圾邮件过滤、疾病预测等。
同时,该模型也可以与其他机器学习算法结合使用,提高模型的性能和泛化能力。
三、模型实现1. 参数设置:在实现无序多分类logistic回归模型时,需要设置一些参数,如迭代次数、学习率等。
这些参数的选取需要结合具体问题和数据集进行实验和调整。
2. 特征选择:选择合适的特征对于提高模型性能至关重要。
需要根据具体问题,对特征进行选择和设计,以减小特征选择对模型性能的影响。
3. 训练过程:训练无序多分类logistic回归模型时,需要将数据集划分为训练集和测试集。


统计学中categorical
在统计学中,categorical(分类型)变量指的是不连续的变量,通常是基于一组可能的值进行分类。
它们通常是基于文本或符号表示,而不是数字。
例如,性别、种族、地区、教育程度、职业等都是分类型变量的例子。
分类型变量可分为有序和无序变量。
有序变量是指具有顺序或层次结构的变量,例如教育程度(小学、初中、高中、大学)和官阶(上校、中校、下校)。
而无序变量是指没有明显层次结构的变量,例如
性别和地域。
在统计分析中,分类型变量通常使用频数表或透视表进行描述和分析。
频数表显示各个分类的数量,而透视表则将数据按照分类变量的交叉情况进行分组并计算总和、平均值等统计量。
常用的分类型变量分析方法包括卡方检验、t检验、方差分析等。
在使用这些方法时,需要将分类型变量转换为数值型变量,以便进行计算和比较。
总之,分类型变量在统计学中具有重要的作用,它们提供了有关人口统计学、社会科学和医学研究等领域的重要信息。
因此,熟练掌握分类型变量的描述和分析方法对于从事统计学研究和数据分析的
人士来说至关重要。
- 1 -。

无序多分类logistic回归结果解读-回复多分类logistic 回归是一种机器学习算法,可用于将样本分为多个类别。
本文将详细介绍该算法的原理、实现步骤以及针对结果的解读。
一、算法原理在介绍多分类logistic 回归之前,我们先回顾一下二分类logistic 回归的原理。
对于二分类问题,在logistic 回归中,我们使用sigmoid 函数将输入转化为概率值,公式如下:h_{\theta}(x)=\frac{1}{1+e^{-\theta^{T} x}}其中h_{\theta}(x) 表示预测为正例的概率,\theta 是模型的参数,x 是输入特征。
对于多分类问题,我们引入了softmax 函数,它可以将多个分类的预测概率归一化,使其总和为1。
公式如下:P(y=i \mid x)=\frac{e^{\theta^T_i x}}{\sum_{j=1}^{K} e^{\theta^T_j x}}其中P(y=i \mid x) 表示样本x 属于第i 个类别的概率,\theta_i 表示对应类别的参数,K 表示总共有K 个类别。
二、算法实现步骤下面我们来介绍多分类logistic 回归的实现步骤。
1. 数据预处理:如其他机器学习算法一样,首先需要对数据进行预处理,包括特征选择、特征缩放、数据标准化等。
2. 参数初始化:对于多分类问题,我们需要为每个类别初始化一组参数\theta。
3. 计算梯度:使用训练集数据来计算损失函数对参数\theta 的梯度。
具体而言,我们可以使用梯度下降法或其他优化算法来最小化损失函数。
4. 更新参数:根据梯度下降法的更新规则,更新参数\theta。
重复该步骤直到满足停止条件。
5. 预测:使用训练好的模型参数对新样本进行预测。
三、结果解读在得到多分类logistic 回归的结果后,我们需要进行结果解读,以评估模型的性能和有效性。
下面介绍几个常用的评估指标:1. 混淆矩阵:混淆矩阵可以帮助我们了解模型在每个类别上的预测情况。


基本统计⽅法的选择与应⽤⼀、确定资料的类型:分类资料、定量资料; 选择适当的统计⽅法,资料不同,设计不同,采⽤的分析⽅法不同;1、计量资料的⽐较(⽐较集中趋势是否不同):(1)两组:t检验、Wilcoxon秩和检验 … t分布(近似正态分布):⽤于根据⼩样本来估计呈且⽅差未知的总体的均值。
定义:假设X服从标准正态分布N(0,1),Y服从卡⽅分布,那么的分布称为⾃由度为n的t分布,记为。
分布密度函数,其中,Gam(x)为伽马函数。
如:医保患者与⾃费患者住院天数是否不同?资料与设计:两组独⽴的计量资料⽐较统计⽅法:两独⽴样本 t 检验(independent samples t-test)分析结果:t=2.17,P=0.033参数统计⽅法(t检验、ANOVA)有应⽤前提条件:A:资料满⾜正态性;B:⽐较的各组资料之间⽅差相等(满⾜⽅差齐性)。
(2)三组(及以上):⽅差分析、Kruskal-Wallis检验 …如:医⽣、护⼠、医护⼈员的期望收⼊指数是否有差别?资料与设计:三组独⽴的计量资料⽐较统计⽅法:完全随机设计的⽅差分析(one-way ANOVA)分析结果:F=20.89,P<0.0001结论:有差别。
两变量之间关系的分析:相关分析、回归分析、秩相关 …如研究门急诊量与收⼊的关系、床位数与护⼠⼈数的关系变化趋势分析:Cochran-Armitage趋势检验、卡⽅检验 …如分析两周患病率随年龄变化的趋势综合评价:层次分析法、TOPSIS法、秩和⽐法 …如评价三甲医院医疗质量、综合绩效⽰例:研究医院床位数与护⼠⼈数之间是否有相关性。
研究⽬的:床位数(X)与护⼠⼈数(Y)之间是否有关?关系如何(线性、⾮线性)?关系⼤⼩?(由样本推断总体)资料与设计:来⾃于同⼀医院的两个指标统计⽅法:相关分析(correlaion analysis)衡量两指标之间是否有线性关系,及关系的强度和⽅向。
回归分析(regression analysis)定量进⾏X到Y的量化估计或预测。

无序多分类logistic回归公式首先,让我们回顾一下二元logistic回归。
在二元logistic回归中,我们希望将数据分为两个不同的类别,通常是正类和负类。
我们使用一个sigmoid函数来建模分类的概率。
二元logistic回归的公式如下:P(y=1,x) = 1 / (1 + exp(-wx))其中,P(y=1,x)表示给定输入特征x时属于正类的概率,wx表示模型的权重向量与输入特征的乘积,exp(表示自然指数函数。
对于无序多分类logistic回归,我们需要考虑将数据分为多个类别。
一种常见的方法是使用一对多(one-vs-rest)策略。
也就是说,我们为每个类别训练一个二元logistic回归模型,然后将具有最高概率的类别作为预测结果。
以下是无序多分类logistic回归的公式:P(y=i,x) = exp(wi * x) / (1 + sum(exp(wj * x) for j inrange(k-1)))其中,P(y=i,x)表示给定输入特征x时属于类别i的概率,wi表示第i个类别的权重向量与输入特征的乘积,k表示类别的总数。
在公式中,我们使用了指数函数来保证分类概率的非负性,并且用分母中的求和项来对所有类别的概率进行标准化。
这样可以确保所有类别的概率之和为1在训练无序多分类logistic回归模型时,我们需要最小化一个损失函数,通常使用最大似然估计。
具体来说,我们需要最大化每个样本被正确分类的概率的乘积。
L = -sum(log(P(yi,xi)))为了最小化损失函数,我们可以使用梯度下降等优化算法来更新权重向量。
具体地,我们需要计算损失函数对权重向量的偏导数,然后根据梯度的方向和学习率来更新权重。
最后,我们可以使用训练得到的权重向量来进行预测。
即对于给定的输入特征,我们计算每个类别的概率,并选择具有最高概率的类别作为预测结果。
总结起来,无序多分类logistic回归是一种基于logistic函数的分类算法,通过使用一对多策略将数据分为多个类别。


表1-1 ××病感染按性别、年龄整理表(问题表) 性别 年龄(岁) 合计 男 女 0~ 5~ 10~ 15~ 调查人数感染人数表1-2 ××病感染按性别、年龄整理表(正确表) 年龄组 男 女 调查人数 感染人数 调查人数 感染人数0~ 5~ 10~ 15~ 合计 第一节 中医药统计学的意义和内容中医药统计学(Statistics for Traditional Chinese Medicine )是将数理统计的原理和方法应用于生物医药特别是中医中药科研,收集、整理和分析资料,推断和表达不确定现象客观数量规律的一门应用学科。
中医药统计学的主要内容包括统计学基本理论和统计分析方法,统计分析方法包括统计设计(statistical design )、统计描述(statistical description )和统计推断(statistical inference ),表达因素间的关系、生存分析、多元分析等。
例如,表1-1,由于将性别与年龄这两个有联系的项目分割开来,计算不出不同性别、年龄的感染率,丧失了有价值的信息,为了克服上述缺点,应采用表1-2的整理表。
又如,第六章例6-1表6-2两种疗法的疗效资料,治愈率按治愈数/治疗数计算,从病情重、中、轻三种情形来看,都是甲疗法治愈率低于乙疗法。
但是,合计起来却是乙疗法治愈率低于甲疗法。
不作统计处理,就不能得到正确的疗效结论。
再如,第九章例9- 表9- 资料,怎样判断降压宁的疗效,需要一定的理论和方法,才能从表9- 的观测数据推理到任何高血压患者服用降压宁后的疗效。
因此,国家中医药管理局规定,未经统计处理的数据是无效数据。
中医药科研的基本步骤包括立题,设计,实施试验,收集整理分析试验所得信息和资料,均需用到中医药统计学的思维和方法。
我国的《药品注册管理办法》规定,新药临床试验必须自始至终有统计学人员参与;生物医药实验室研究、临床研究和医药公共事业管理都要寻求统计学家的帮助。



分类数据常用统计方法在科研数据的统计分析中,经常会遇到分类数据。
分类数据包括计数资料和等级资料,两者都是将观察指标分类(组),然后统计每一类(组)数目所得到的数据,区别是如果观察指标的分类是无序的则为计数资料,也叫定性资料或无序分类变量;如果观察指标的分类是有序的,则为等级资料,也叫有序分类数据。
如调查某人群的血型分布,按照A 、B 、AB 与O 四型分组,计数所得该人群的各血型组的人数就是计数资料(因为A 、B 、AB 与O 血型之间是平等的,并没有度或量的差异);观察用某药治疗某病患者的疗效,以患者为观察单位,结果可分为治愈、显效、好转、无效四级,然后对该病的患者,分别计数治愈、显效、无效、好转的人数则为等级数据(因为无效的疗效最差、次之为好转、治愈的疗效最好,它们之间有度或者量的区别)。
分类数据进行统计分析时要列成表格,根据表格中分组变量和指标变量的性质、样本含量(n )和理论频数(T )的大小以及分析的目的,所用的统计方法是不一样的。
下面通过一些有代表性的例子来介绍分类数据常用的统计分析方法。
一、2×2表2×2表也叫四格表。
在实验研究中,将研究对象分为2组进行实验,实验只有2种可能的结果,如阳性与阴性,故叫2×2表;因为基本数据只有4个,所以也叫四格表。
根据不同的实验安排,四格表又分为完全随机设计四格表和配对设计四格表。
表1 某抗生素的人群耐药性情况用药史 不敏感 敏感 合计 耐药率(%) 曾服该药 180(174.10) 215(220.90) 395 45.57 未服该药 73(78.90) 106(100.10)179 40.78 合计25332157444.08表 1 为完全随机设计四格表。
其目的是要比较曾服该抗生素的人群和未曾服过该抗生素的人群,对该抗生素的耐药率有无差异。


福建中医药大学医学统计学第二章资料收集与整理主要内容资料类型资料收集与整理第一节第二节第一节资料类型•统计学中需要处理的数据统称为资料(data)。
•资料由变量及其变量值组成。
•变量(variable)表示随机现象的某种特征或属性,即研究的项目或指标。
•变量值(value of variable)又称观察值(observed value),是指变量的测定结果。
一、变量类型●变量类型的划分方法有多种●不同的划分方法产生不同的变量类型一、变量类型按取值结果分连续型变量(continuous variable)离散型变量(discrete variable)该变量的可取值为某个区间的任何数值。
数字的特点:可取小数该变量的可取值为有限个或可列无穷个。
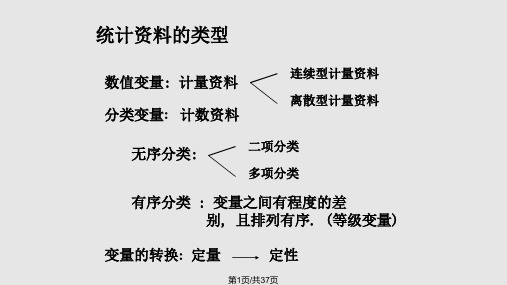
数字的特点:正整数一、变量类型----连续型变量正常人血清铜含量(pg/L)20.216.519.923.420.021.315.516.818.917.016.119.218.116.818.414.721.917.413.018.317.422.815.617.119.918.519.523.023.217.4 19.122.421.019.516.517.817.212.415.021.1 17.718.414.915.914.916.014.221.014.218.5身高、体重、血常规、肝功能、肾功能等,各种生理生化检测指标一、变量类型----离散型变量某年甲、乙两县人口资料(人)细胞数、人口数、治疗有效例数等一、变量类型按在统计分析中所起的作用分标识变量分析变量自变量因变量协变量如编号、住院号,用于对数据进行管理一、变量类型按观察指标的性质分类定量变量分类变量无序变量,名义变量数值变量,尺度变量需用一定的仪器或尺度测量的变量有序变量,名义变量二、资料类型对应于变量按观察指标性质的分类。
计量资料(定量资料)计数资料等级资料由定量变量及其观测值组成由无序变量及其观测值组成由有序变量及其观测值组成分类资料二、资料类型资料类型特点变量类型实例计量资料(定量资料) 每个个体都能观察到一个观察指标的数值,有度量衡单位连续型或离散型,数值变量身高(cm),体重(kg),细胞数(个),人口数(人)分类资料(定性资料)无序分类资料(计数资料) 每个个体观察结果的属性或分类间无大小顺序之分。

1有序分类资料的秩和检验医学统计学2009年2•医学上会用-、±、++、+++来表示临床体检或实验室检查的测量结果,用治愈、好转、有效、无效来表示某种药物的临床效果。
像这样一些“取值”中自然存在着次序的分类变量,称为有序分类变量或等级变量。
•对有序分类资料,若用R ×C 表资料的检验,将损失关于等级的信息,不合适的。
因为R ×C 表的检验只能推断构成比之间的差别。
•此时,可以采用秩和检验推断不同处理组之间的等级强度差别。
31、两独立样本有序资料一、分组变量为多分类有序资料,指标变量为二分类无序资料研究目的是比较分组变量不同水平下某指标变量的发生率,如:利用有序的检验指标判断患者是否患病,其实质是对该检验指标不同水平下患者患病率的比较;以及对不同年龄阶段某指标的阳性率的比较,都属于多个样本率比较的问题。
对于这样的资料,可以将分组变量视为无序的,采用前一章中介绍的检验进行多个样本率的比较。
2χ4二、分组变量为两分类无序资料,指标变量为多分类有序资料研究目的是比较分组变量两个不同水平下某指标变量的平均水平是否有差异,如:两种药物疗效(治愈、好转、有效、无效)之间的比较。
两种疗法疗效的取值均为有序分类资料。
对于这样的资料前面介绍的χ2检验已不再适用,因为它无法考虑分组变量(药物)不同水平下疗效取值的等级关系。
此时可以采用第七章中介绍的Wilcoxon 秩和检验。
5例39名吸烟工人和40名不吸烟工人的碳氧血红蛋白HbCO(%)含量见下表。
问吸烟工人的HbCO(%)含量是否高于不吸烟工人的HbCO(%)含量?秩 和含 量吸烟 工人 不吸烟 工人 合计 秩范围平均秩吸烟工人 不吸烟工人(1) (2) (3) (4) (5) (6) (7)=(2)(6) (8)=(3)(6)很低1 2 3 1~3 2 2 4 低8 23 31 4~3419 152 437 中 16 11 27 35~6148 768 528 偏高 10 4 14 62~75 68.5 685 274 4 0 4 76~79 77.5 310 0 高合 计 39(1n ) 40(2n ) 79──1917(1T ) 1243(2T )60H :吸烟工人和不吸烟工人的HbCO 含量总体分布位置相同1H :吸烟工人的HbCO 含量高于不吸烟工人的HbCO 含量0.05α=①先确定各等级的合计人数、秩范围和平均秩,见表的(4)栏、(5)栏和(6)栏,再计算两样本各等级的秩和,见(7)栏和(8)栏;②本例T =1917(n 1<n 2);12311133.计算检验统计量H 。