ch7第七章参数估计
- 格式:ppt
- 大小:523.00 KB
- 文档页数:45









统计学STATISTICS(第二版)不像其他科学,统计从来不打算使自己完美无缺,统计意味着你永远不需要确定无疑。
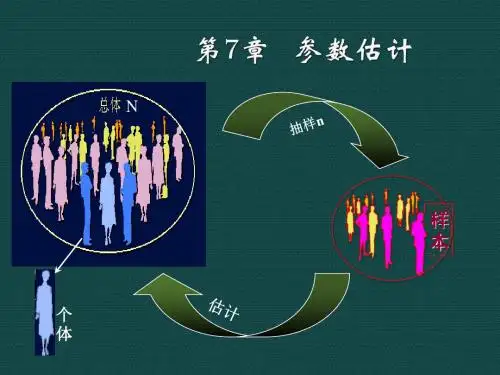
Gudmund R.Iversen7 - 17 - 2 统计学STATISTICS(第二版) 第 7 章 参数估计 作者:中国人民大学统计学院贾俊平7 - 3 统计学STATISTICS (第二版) 统计应用 一次失败的民意调查在1936年的美国总统选举前,一份名为Literary Digest 杂志进行了一次民意调查。
调查的焦点是谁将成为下一届总统—是挑战者,堪萨斯州州长Alf Landon ,还是现任总统 Franklin Delano Roosevelt为了解选民意向,民意调查专家们根据电话簿和车辆登记簿上的名单给一大批人发了简单的调查表(电话和汽车在1936年并不像现在那样普及,但是这些名单却比较容易得到)。
尽管发出的调查表大约有一千万张,但收回的比例并不高。
在收回的调查表中, Alf Landon 非常受欢迎。
于是该杂志预测 Landon 将赢得选举。
但事实上是Franklin Roosevelt 赢得了这次选举调查失败的主要原因是抽样框出现了问题。
在经济大萧条时期由于电话和汽车并不普及,只是富裕阶层才会拥有,调查有电话和汽车的人们,并不能够反映全体选民的观点7 - 4统计学STATISTICS(第二版) 第 7 章 参数估计7.1 参数估计的一般问题7.2 一个总体参数的区间估计7.3 两个总体参数的区间估计7.4 样本容量的确定7 - 5 统计学STATISTICS(第二版) 学习目标1.估计量与估计值的概念 2.点估计与区间估计的区别 3.评价估计量优良性的标准 4.一个总体参数的区间估计方法 5.两个总体参数的区间估计方法 6.样本容量的确定方法7 - 6 统计学STATISTICS (第二版) 参数估计在统计方法中的地位 参数估计假设检验统计方法描述统计 推断统计7 - 7统计学STATISTICS(第二版)统计推断的过程样本总体样本统计量如:样本均值、比例、方差7 - 8统计学STATISTICS(第二版) 7.1 参数估计的一般问题7.1.1 估计量与估计值7.1.2 点估计与区间估计7.1.3 评价估计量的标准统计学STATISTICS(第二版)估计量与估计值7 - 97 - 10 统计学STATISTICS(第二版) 1.估计量:用于估计总体参数的随机变量⏹如样本均值,样本比例、样本方差等 ⏹例如: 样本均值就是总体均值μ 的一个估计量2.参数用θ 表示,估计量用 表示3.估计值:估计参数时计算出来的统计量的具体值⏹如果样本均值 ⎺x =80,则80就是μ的估计值 估计量与估计值 (estimator & estimated value)θˆ统计学STATISTICS(第二版)点估计与区间估计7 - 117 - 12 统计学STATISTICS(第二版)参数估计的方法矩估计法最小二乘法最大似然法顺序统计量法估 计 方 法点 估 计区间估计7 - 13统计学STATISTICS(第二版) 点估计 (point estimate)1.用样本的估计量的某个取值直接作为总体参数的估计值▪例如:用样本均值直接作为总体均值的估计;用两个样本均值之差直接作为总体均值之差的估计2.无法给出估计值接近总体参数程度的信息 ⏹虽然在重复抽样条件下,点估计的均值可望等于总体真值,但由于样本是随机的,抽出一个具体的样本得到的估计值很可能不同于总体真值⏹一个点估计量的可靠性是由它的抽样标准误差来衡量的,这表明一个具体的点估计值无法给出估计的可靠性的度量7 - 14 统计学STATISTICS(第二版) 区间估计 (interval estimate)1.在点估计的基础上,给出总体参数估计的一个区间范围,该区间由样本统计量加减估计误差而得到 2.根据样本统计量的抽样分布能够对样本统计量与总体参数的接近程度给出一个概率度量比如,某班级平均分数在75~85之间,置信水平是95%样本统计量(点估计)置信区间 置信下限 置信上限7 - 15 统计学STATISTICS(第二版) 区间估计的图示μ x95% 的样本μ -1.96 σx μ +1.96σx99% 的样本μ - 2.58σx μ +2.58σx 90%的样本μ -1.65 σx μ +1.65σx x σxz x σμα2±=7 - 16统计学STATISTICS(第二版) 1.将构造置信区间的步骤重复很多次,置信区间包含总体参数真值的次数所占的比例称为置信水平2.表示为 (1 - α)⏹α 为是总体参数未在区间内的比例3.常用的置信水平值有 99%, 95%, 90%⏹相应的 α 为0.01,0.05,0.10置信水平 (confidence level)7 - 17STATISTICS(第二版) 1.由样本统计量所构造的总体参数的估计区间称为置信区间2.统计学家在某种程度上确信这个区间会包含真正的总体参数,所以给它取名为置信区间3.用一个具体的样本所构造的区间是一个特定的区间,我们无法知道这个样本所产生的区间是否包含总体参数的真值⏹我们只能是希望这个区间是大量包含总体参数真值的区间中的一个,但它也可能是少数几个不包含参数真值的区间中的一个 ⏹总体参数以一定的概率落在这一区间的表述是错误的 (confidence interval)7 - 18STATISTICS(第二版)(95%的置信区间)重复构造出μ的20个置信区间μ点估计值7 - 19统计学STATISTICS(第二版) 置信区间与置信水平均值的抽样分布(1 - α) 区间包含了μ α 的区间未包含μμμ=x 1 – α α /2α /2 xσx7 - 20 统计学STATISTICS(第二版)影响区间宽度的因素1. 总体数据的离散程度,用 σ 来测度2.样本容量,3. 置信水平 (1 - α),影响 z 的大小 n x σσ=统计学STATISTICS(第二版)评价估计量的标准7 - 217 - 22统计学STATISTICS (第二版)无偏性(unbiasedness)无偏性:估计量抽样分布的数学期望等于被 估计的总体参数P ( )BA 无偏有偏θθˆθˆ7 - 23统计学STATISTICS (第二版)有效性(efficiency)有效性:对同一总体参数的两个无偏点估计 量,有更小标准差的估计量更有效AB的抽样分布 的抽样分布 1ˆθ2ˆθP () θθˆθˆ7 - 24统计学STATISTICS (第二版)一致性(consistency)一致性:随着样本容量的增大,估计量的 值越来越接近被估计的总体参数AB较小的样本容量较大的样本容量P ( )θθˆθˆ7 - 25统计学STATISTICS (第二版)7.2 一个总体参数的区间估计7.2.1 总体均值的区间估计 7.2.2 总体比例的区间估计 7.2.3 总体方差的区间估计7 - 26统计学STATISTICS (第二版)一个总体参数的区间估计总体参数符号表示样本统计量均值 比例方差2σx p2sπμ7 - 27统计学STATISTICS (第二版)总体均值的区间估计(结果的四舍五入法则)1.当用原始数据构建置信区间时,置信区间的计算结果应保留的小数点位数要比原始数据中使用的小数点多一位如,原始数据有一位小数,置信区间的结果应保留两位小数2.当不知道原始数据,只使用汇总统计量(n ,x ,s )时,置信区间的计算结果保留的小数点位数应与样本均值使用的小数点位数相同统计学STATISTICS(第二版)总体均值的区间估计(正态总体、 2已知,或非正态总体、大样本)7 - 287 - 29统计学STATISTICS (第二版)总体均值的区间估计(大样本)1. 假定条件⏹总体服从正态分布,且方差(σ2) 已知⏹如果不是正态分布,可由正态分布来近似 (n ≥ 30)2.使用正态分布统计量 z3.总体均值 μ 在1-α 置信水平下的置信区间为)1,0(~N nx z σμ-=)(22未知或σσααnsz x n z x ±±7 - 30统计学STATISTICS (第二版)总体均值的区间估计(例题分析)【 例 】一家食品生产企业以生产袋装食品为主,为对产量质量进行监测,企业质检部门经常要进行抽检,以分析每袋重量是否符合要求。

第七章 参数估计1. 样本均值74.002X =样本方差822611() 6.8571081i i S X X -==-=⨯-∑ 样本二阶中心矩 822611()6108ii S X X -==-=⨯∑ 均值与方差的矩估计值分别为: 2674.002610μσ-= =⨯ 2.(1)矩估计(1)()1cccE X x c xdx c x dx θθθθθθθθ+∞+∞-+-===-⎰⎰ 令1c X θθ=-,得θ的估计量为 X X c θ=-,θ的估计值为 1111ni i ni i x n x c n θ===-∑∑ (2)极大似然估计(1)(1)(1)11()()()n n n L c x c x c x x θθθθθθθθθθ-+-+-+==1ln ()ln()(1)ln ni i L n c x θθθθ==-+∑令1ln ln ln 0ni i L n n c x θθ=∂=+-=∂∑得θ的估计值为 1ln ln nii nx n cθ==-∑,θ的估计量为 1ln ln nii nXn cθ==-∑3.(1) 矩估计121433X ++== 22()122(1)3(1)32E X θθθθθ=⨯+⨯-+⨯-=-令()E X X = 得θ的估计值为 56θ= 极大似然估计2256112233()()()()2(1)22L P X x P X x P X x θθθθθθθ=====⨯-⨯=-令ln 5101L θθθ∂=-=∂-,得θ的估计值为 56θ=(2)矩估计量11ni i X X n λ===∑极大似然估计1111211()()()...()...!!!...!inx x x nn n n n e e L P X x P X x P X x ex x x x λλλλλλλ---∑======令ln ()0i x L n λθλ∂=-+=∂∑,得λ的似然估计值为 i x nλ=∑, 从而λ的似然估计量为11ni i X X n λ===∑。
第七章 参数估计参数估计是数理统计研究的主要问题之一. 假设总体X ~N (μ,σ2),μ,σ2是未知参数,X 1,X 2,…,X n 是来自X 的样本,样本值是x 1,x 2,…,x n ,我们要由样本值来确定μ和σ2的估计值,这就是参数估计问题,参数估计分为点估计(Point estimation )和区间估计(Interval estimation).第一节 点估计所谓点估计是指把总体的未知参数估计为某个确定的值或在某个确定的点上,故点估计又称为定值估计.定义7.1 设总体X 的分布函数为F (x ,θ),θ是未知参数,X 1,X 2,…,X n 是X 的一样本,样本值为x 1,x 2,…,x n ,构造一个统计量(X 1,X 2,…,X n ),用它的观察值 (x 1,x 2,…,x n )作为θ的估计值,这种问题称为点估计问题.习惯上称随机变量(X 1,X 2,…,X n )为θ的估计量,称(x 1,x 2,…,x n )为的估计值.构造估计量(X 1,X 2,…,X n )的方法很多,下面仅介绍矩法和极大似然估计法. 1.矩法矩法(Moment method of estimation )是一种古老的估计方法.它是由英国统计学家皮尔逊(K .Pearson )于1894年首创的.它虽然古老,但目前仍常用.矩法估计的一般原则是:用样本矩作为总体矩的估计,若不够良好,再作适当调整. 矩法的一般作法:设总体X ~F (X ;θ1,θ2,…,θl )其中θ1,θ2,…,θl 均未知. (1) 如果总体X 的k 阶矩μk =E (X k ) (1≤k ≤l)均存在,则μk =μk (θ1,θ2,…,θl ),(1≤k ≤l ).(2) 令⎪⎪⎩⎪⎪⎨⎧.),,,(,),,,(,),,,(2122121211l l l l l A A A θθθμθθθμθθθμ其中A k (1≤k ≤l )为样本k 阶矩.求出方程组的解,ˆ,,ˆ,ˆ21l θθθ 我们称),,,(ˆˆ21n k k X X X θθ=为参数θk (1≤k ≤l )的矩估计量, ),,,(ˆˆ21nk k x x x θθ=为参数θk 的矩估计值. 例7.1 设总体X 的密度函数为:f (x )=⎩⎨⎧-><<+.,0),1(,10,)1(其他αααx x其中α未知,样本为(X 1,X 2,…,X n ),求参数α的矩法估计.解 A 1=X .由μ1=A 1及μ1=E (X )=21)1()(1++=+=⎰⎰+∞∞-ααααx x x x x xf d d , 有21++=ααX ,得121ˆ--=X Xα.例7.2 设X ~N (μ,σ2),μ,σ2未知,试用矩法对μ,σ2进行估计. 解⎪⎪⎩⎪⎪⎨⎧======∑∑==.1)(,1)(12222111ni i ni i X n A X E X n A X E μμ 又 E (X )=μ, E (X 2)=D (X )+(EX )2=σ2+μ2,那么 .1ˆˆ,ˆ2222S nn A X -=-==μσμ. 例7.3 在某班期末数学考试成绩中随机抽取9人的成绩.结果如下:试求该班数学成绩的平均分数、标准差的矩估计值.解 设X 为该班数学成绩,μ=E (X ),σ2=D (X ))558994(919191+++==∑= i i x x =75;2/19122)(819898⎥⎦⎤⎢⎣⎡-⋅=∑=i i x x s =12.14.⎪⎪⎩⎪⎪⎨⎧======∑∑==.91)(,91)(9122229111i i i i X A X E X A X E μμ 由于E (X 2)=D (X )+(EX )2=σ2+μ2,那么,2222228ˆˆˆ,().9X A A x S μσμ==-=-= 所以,该班数学成绩的平均分数的矩估计值x =μˆ=75分,标准差的矩估计值298ˆs =σ=12.14. 作矩法估计时无需知道总体的概率分布,只要知道总体矩即可.但矩法估计量有时不惟一,如总体X 服从参数为λ的泊松分布时,X 和B 2都是参数λ的矩法估计.2.极(最)大似然估计法极大似然估计法(Maximum likelihood estimation)只能在已知总体分布的前提下进行,为了对它的思想有所了解,我们先看一个例子.例7.4 假定一个盒子里装有许多大小相同的黑球和白球,并且假定它们的数目之比为3∶1,但不知是白球多还是黑球多,现在有放回地从盒中抽了3个球,试根据所抽3个球中黑球的数目确定是白球多还是黑球多.解 设所抽3个球中黑球数为X ,摸到黑球的概率为p ,则X 服从二项分布P {X =k }=k 3C p k(1-p )3-k , k =0,1,2,3.问题是p =1/4还是p =3/4?现根据样本中黑球数,对未知参数p 进行估计.抽样后,共有4种可能结果,其概率如表7-1所示.假如某次抽样中,只出现一个黑球,即X =1,p =1/4时,P {X =1}=27/64;p =3/4时,P {X =1}=9/64,这时我们就会选择p =1/4,即黑球数比白球数为1∶3.因为在一次试验中,事件“1个黑球”发生了.我们认为它应有较大的概率27/64(27/64>9/64),而27/64对应着参数p =1/4,同样可以考虑X =0,2,3的情形,最后可得p =⎪⎩⎪⎨⎧==.3,2,43,1,0,41时当时当x x(1) 似然函数在极大似然估计法中,最关键的问题是如何求得似然函数(定义下文给出),有了似然函数,问题就简单了,下面分两种情形来介绍似然函数. (a ) 离散型总体设总体X 为离散型,P {X =x }=p (x ,θ),其中θ为待估计的未知参数,假定x 1,x 2,…,x n 为样本X 1,X 2,…,X n 的一组观测值.P {X 1=x 1,X 2=x 2,…,X n =x n }=P {X 1=x 1}P {X 2=x 2}…P {X n =x n }=p (x 1,θ)p (x 2,θ)…p (x n ,θ)=∏=ni ix p 1),(θ.将∏=ni ix p 1),(θ看作是参数θ的函数,记为L (θ),即 L (θ)=∏=ni ix p 1),(θ. (7.1)(b ) 连续型总体设总体X 为连续型,已知其分布密度函数为f (x ,θ),θ为待估计的未知参数,则样本(X 1,X 2,…,X n )的联合密度为:f (x 1,θ)f (x 2,θ)…f (x n ,θ)=∏=ni ix f 1),(θ.将它也看作是关于参数θ的函数,记为L (θ),即L (θ)=∏=ni ix f 1),(θ. (7.2)由此可见:不管是离散型总体,还是连续型总体,只要知道它的概率分布或密度函数,我们总可以得到一个关于参数θ的函数L (θ),称L (θ)为似然函数.(2) 极大似然估计极大似然估计法的主要思想是:如果随机抽样得到的样本观测值为x 1,x 2,…,x n ,则我们应当这样来选取未知参数θ的值,使得出现该样本值的可能性最大,即使得似然函数L (θ)取最大值,从而求参数θ的极大似然估计的问题,就转化为求似然函数L (θ)的极值点的问题,一般来说,这个问题可以通过求解下面的方程来解决0)(=θθd d L . (7.3)然而,L (θ)是n 个函数的连乘积,求导数比较复杂,由于ln L (θ)是L (θ)的单调增函数,所以L (θ)与ln L (θ)在θ的同一点处取得极大值.于是求解(7.3)可转化为求解0)(=θθd dln L .(7.4)称ln L (θ)为对数似然函数,方程(7.4)为对数似然方程,求解此方程就可得到参数θ的估计值.如果总体X 的分布中含有k 个未知参数:θ1,θ2,…,θk ,则极大似然估计法也适用.此时,所得的似然函数是关于θ1,θ2,…,θk 的多元函数L (θ1,θ2,…,θk ),解下列方程组,就可得到θ1,θ2,…,θk 的估计值,⎪⎪⎪⎩⎪⎪⎪⎨⎧=∂∂=∂∂=∂∂.0),,,(ln ,0),,,(ln ,0),,,(ln 21221121k k k k L L L θθθθθθθθθθθθ(7.5) 例7.5 在泊松总体中抽取样本,其样本值为:x 1,x 2,…,x n ,试对泊松分布的未知参数λ作极大似然估计.解 因泊松总体是离散型的,其概率分布为:P {X =x }=λλ-e !x x,故似然函数为:L (λ)=∏∏==∑--⋅⋅==ni ni i x nixx x ni ii11!1!1λλλλee. ln L (λ)=11ln ln (!)nniii i n x x λλ==-+-∑∏,∑=+-=ni i x n 11)ln(λλλd d . 令λλd d ln =0,得: ∑=+-ni i x n 11λ=0.所以x x n ni i L ==∑=11ˆλ,λ的极大似然估计量为X L=λˆ(为了和λ的矩法估计区别起见,我们将λ的极大似然估计记为Lλˆ). 例7.6 设一批产品含有次品,今从中随机抽出100件,发现其中有8件次品,试求次品率θ的极大似然估计值.解 用极大似然法时必须明确总体的分布,现在题目没有说明这一点,故应先来确定总体的分布.设 X i =,100,,2,1,0,1 =⎩⎨⎧i ,i ,i 次取正品第次取次品第则X i 服从两点分布:12100p (x i ,θ)=P {X i =x i }=θ xi (1-θ)1-xi ,x i =0,1,故似然函数为:L (θ)=∑-∑=-==-=-∏1001100110010011)1()1(i ii i iix x i x x θθθθ由题知:∑=1001i ix =8,所以 L (θ)=θ8(1-θ)92. 两边取对数得:ln L (θ)=8ln θ+92ln (1-θ).对数似然方程为:θθθθ--=1928)(ln d d L =0.解之得θ=8/100=0.08.所以Lθˆ=0.08. 例7.7 设x 1,x 2,…,x n 为来自正态总体N (μ,σ2)的观测值,试求总体未知参数μ,σ2的极大似然估计.解 因正态总体为连续型,其密度函数为f (x )=222)(21σμσ--x e π,所以似然函数为:L (μ,σ2)=⎭⎬⎫⎩⎨⎧--⎪⎭⎫ ⎝⎛=⎭⎬⎫⎩⎨⎧--∑∏==n i i nni i x x 122122)(21exp 212)(exp 21μσσσμσππ ln L (μ,σ2)=∑=----n i i x n n 1222)(21ln 22ln 2μσσπ. 故似然方程组为:⎪⎪⎩⎪⎪⎨⎧=-+-=∂∂=-=∂∂∑∑==.0)(212),(ln ,0)(1),(ln 124222122ni i ni i x n L x L μσσσσμμσμσμ 解以上方程组得:⎪⎪⎩⎪⎪⎨⎧=-=-===∑∑∑===.ˆ)(1)(1,12121221B x x n x n x x n ni i n i i ni i μσμ 所以 ⎩⎨⎧==.ˆ,ˆ22B X L σμ例7.8 设总体X 服从[0,θ]上的均匀分布,X 1,X 2,…,X n 是来自X 的样本,求θ的矩法估计和极大似然估计.解 因为E (X )=θ/2,令X =E (X ),得.2ˆX =矩θ 又 f (x )=⎪⎩⎪⎨⎧≤≤.,0,0,1其他θθx所以L (θ)=n θ1,0≤x i ≤θ. 要L (θ)最大,θ必须尽可能小,又θ≥x i ,i =1,2,…,n ,所以{}ini L X ≤≤=1max ˆθ.第二节 估计量的评价标准设总体X 服从[0,θ]上的均匀分布,由上节例7可知ˆ2X θ=矩,{}1ˆmax L ii nX θ≤≤ 都是θ的估计,这两个估计哪一个好?下面我们首先讨论衡量估计量好坏的标准问题.1.无偏性定义7.2 若估计量(X 1,X 2,…,X n )的数学期望等于未知参数θ,即:ˆ()E θθ=, (7.6) 则称ˆθ为θ的无偏估计量(Non -deviation estimator ).估计量ˆθ的值不一定就是θ的真值,因为它是一个随机变量,若ˆθ是θ的无偏估计,则尽管ˆθ的值随样本值的不同而变化,但平均来说它会等于θ的真值.例7.9 设X 1,X 2,…,X n 为总体X 的一个样本,E (X )=μ,则样本平均数11nii X X n ==∑是μ的无偏估计量.证 因为E (X )=μ,所以E (X i )=μ,i =1,2,…,n ,于是1111()()n ni i i i E X E X E X n n ==⎛⎫== ⎪⎝⎭∑∑=μ.所以X 是μ的无偏估计量.例7.10 设有总体X ,E (X )=μ,D (X )=σ2,(X 1,X 2,…,X n )为从该总体中抽得的一个样本,样本方差S 2及二阶样本中心矩B 2=11()ni i X X n =-∑是否为总体方差σ2的无偏估计?解 因为E (S 2)=σ2,所以S 2是σ2的一个无偏估计,这也是我们称S 2为样本方差的理由.由于B 2=21n S n -, 那么 E (B 2)=2211()n n E S n nσ--=, 所以B 2不是σ2的一个无偏估计.还需指出:一般说来无偏估计量的函数并不是未知参数相应函数的无偏估计量.例如,当X ~N (μ,σ2)时,X 是μ的无偏估计量,但2X 不是μ2的无偏估计量,事实上:22222()()().E X D X E X nσμμ⎡⎤=+=+≠⎣⎦2.有效性对于未知参数θ,如果有两个无偏估计量1ˆθ与2ˆθ,即E (1ˆθ)=E (2ˆθ)=θ,那么在1ˆθ,2ˆθ中谁更好呢?此时我们自然希望对θ的平均偏差E (ˆθ-θ)2越小越好,即一个好的估计量应该有尽可能小的方差,这就是有效性.定义7.3 设1ˆθ和2ˆθ都是未知参数θ的无偏估计,若对任意的参数θ,有 D (1ˆθ)≤D (2ˆθ), (7.7)则称1ˆθ比2ˆθ有效. 如果1ˆθ比2ˆθ有效,则虽然1ˆθ还不是θ的真值,但1ˆθ在θ附近取值的密集程度较2ˆθ高,即用1ˆθ估计θ精度要高些. 例如,对正态总体N (μ,σ2),11ni i X X n ==∑,X i 和X 都是E (X )=μ的无偏估计量,但D (X )=2nσ≤D (X i )=σ2,故X 较个别观测值X i 有效.实际当中也是如此,比如要估计某个班学生的平均成绩,可用两种方法进行估计,一种是在该班任意抽一个同学,就以该同学的成绩作为全班的平均成绩;另一种方法是在该班抽取n 位同学,以这n 个同学的平均成绩作为全班的平均成绩,显然第二种方法比第一种方法好.3.一致性无偏性、有效性都是在样本容量n 一定的条件下进行讨论的,然而(X 1,X 2,…,X n )不仅与样本值有关,而且与样本容量n 有关,不妨记为n ,很自然,我们希望n 越大时,n 对θ的估计应该越精确.定义7.4 如果n 依概率收敛于θ,即∀ε>0,有{}ˆlim 1,nn P θθε→∞-<=,(7.8) 则称ˆnθ是θ的一致估计量(Uniform estimator ). 由辛钦大数定律可以证明:样本平均数X 是总体均值μ的一致估计量,样本的方差S 2及二阶样本中心矩B 2都是总体方差σ2的一致估计量.第三节 区间估计1.区间估计的概念上节我们介绍了参数的点估计,假设总体X ~N (μ,σ2),对于样本(X 1,X 2,…,X n ),ˆX μ=是参数μ的矩法估计和极大似然估计,并且满足无偏性和一致性.但实际上X =μ的可能性有多大呢?由于X 是一连续型随机变量,P {X =μ}=0,即ˆμ=μ的可能性为0,为此,我们希望给出μ的一个大致范围,使得μ有较高的概率在这个范围内,这就是区间估计问题.定义7.5 设1ˆθ(X 1,X 2,…,X n )及2ˆθ (X 1,X 2,…,X n )是两个统计量,如果对于给定的概率1-α(0<α<1),有:P {1ˆθ<θ<2ˆθ}=1-α, (7.9) 则称随机区间(1ˆθ,2ˆθ)为参数θ的置信区间(Confidence interval ),1ˆθ称为置信下限,2ˆθ称为置信上限,1-α叫置信概率或置信度(Confidence level).定义中的随机区间(1ˆθ,2ˆθ)的大小依赖于随机抽取的样本观测值,它可能包含θ,也可能不包含θ,(7.9)式的意义是指(1ˆθ,2ˆθ)以1-α的概率包含θ.例如,若取α=0.05,那么置信概率为1-α=0.95,这时,置信区间(1ˆθ,2ˆθ)的意义是指:在100次重复抽样中所得到的100个置信区间中,大约有95个区间包含参数真值θ,有5个区间不包含真值θ,亦即随机区间(1ˆθ,2ˆθ)包含参数θ真值的频率近似为0.95. 例7.11 设X ~N (μ,σ2),μ未知,σ2已知,样本X 1,X 2,…,X n 来自总体X ,求μ的置信区间,置信概率为1-α.解 因为X 1,X 2,…,X n 为来自X 的样本,而X ~N (μ,σ2),所以uX ~N (0,1),对于给定的α,查附录中表2可得上分位点2z α,使得2P z α⎫<⎬⎭=1-α,即22P X z X z ααμ⎧-<<+⎨⎩=1-α. 所以μ的置信概率为1-α的置信区间为X z X z αα⎛-+ ⎝. (7.10) 由(7.10)式可知置信区间的长度为22z α,若n 越大,置信区间就越短;若置信概率1-α越大,α就越小,2z α就越大,从而置信区间就越长.2.正态总体参数的区间估计由于在大多数情况下,我们所遇到的总体是服从正态分布的(有的是近似正态分布),故我们现在来重点讨论正态总体参数的区间估计问题.在下面的讨论中,总假定X ~N (μ,σ2),X 1,X 2,…,X n 为其样本. (1) 对μ的估计 分两种情况进行讨论. (a ) σ2已知此时就是例7.11的情形,结论是:μ的置信区间为22X z X z αα⎛-+ ⎝, 置信概率为1-α.(b ) σ2未知当σ2未知时,不能使用(7.10)式作为置信区间,因为(7.10)式中区间的端点与σ有关,考虑到S 2=211()1n ii X X n =--∑是σ2X σ换成S 得 TX ~t (n -1).对于给定的α,查附录中t 分布表4可得上分位点t σ/2(n -1),使得2(1)P t n α⎫<-⎬⎭=1-α,即22(1)(1)P X t n X t n ααμ⎧⎫-<<-⎨⎬⎩⎭=1-α.所以μ的置信概率为1-α的置信区间为22(1),(1)X t n X t n αα⎛⎫-- ⎪⎝⎭. (7.11)=,S 0,所以μ的置信区间也可写成22(1),(1)X t n X t n αα⎛⎫-+- ⎪⎝⎭.(7.12) 例7.12 某车间生产滚珠,已知其直径X ~N (μ,σ2),现从某一天生产的产品中随机地抽出6个,测得直径如下(单位:毫米)14.6 15.1 14.9 14.8 15.2 15.1试求滚珠直径X 的均值μ的置信概率为95%的置信区间.解 111(14.615.114.914.815.215.1)6n i i x x n ===+++++∑=14.95,s 0, t α/2(n -1)=t 0.025(5)=2.571,所以2(t n α-=2.571=0.24, 置信区间为(14.95-0.24,14.95+0.24),即(14.71,15.19),置信概率为95%.σ2的置信区间我们只考虑μ未知的情形.此时由于S 2=211()1n i i X X n =--∑是σ2的无偏估计,我们考虑22(1)n S σ-,由于222(1)~(1)n S n χσ--,所以,对于给定的α,2122222(1)(1)(1)n S P n n ααχχσ-⎧⎫--<<-⎨⎬⎩⎭=1-α. 即222221(1)(1)(1)(1)n S n S P n n αασχχ-⎧⎫--⎪⎪<<⎨⎬--⎪⎪⎩⎭=1-α.所以σ2的置信区间为2222221(1)(1),(1)(1)n S n S n n ααχχ-⎛⎫-- ⎪ ⎪--⎝⎭(7.13) 或222200221,(1)(1)nS nS n n ααχχ-⎛⎫ ⎪ ⎪--⎝⎭, 其中S 02=211()ni i X X n =-∑. 例7.13 某种钢丝的折断力服从正态分布,今从一批钢丝中任取10根,试验其折断力,得数据如下:572 570 578 568 596 576 584 572 580 566试求方差的置信概率为0.9的置信区间.解 因为111(572570566)10n i i x x n ===+++∑=576.2,s 02=2211n i i x x n =-∑=71.56, α=0.10,n -1=9,查附表得:2220.05(1)(9)n αχχ-==16.919,220.951(1)(9)n αχχ--==3.325,22021071.56(1)16.919ns n αχ⨯=-=42.30,220211071.56(1) 3.325ns n αχ-⨯=-=215.22.所以,σ2的置信概率为0.9的置信区间为(42.30,215.22).以上仅介绍了正态总体的均值和方差两个参数的区间估计方法.在有些问题中并不知道总体X 服从什么分布,要对E (X )=μ作区间估计,在这种情况下只要X 的方差σ2已知,并且样本容量n 很大,X 准正态分布N (0,1),因而μ的置信概率为1-α的近似置信区间为X z X z αα⎛-+ ⎝.小 结参数估计问题分为点估计和区间估计.设θ是总体X 的待估计参数.用统计量ˆθ=ˆθ(X 1,X 2,…,X n )来估计θ称ˆθ是θ的估计量,点估计只给出未知参数θ的单一估计.本章介绍了两种点估计的方法:矩估计法和极大似然估计法.矩法的做法:设总体X ~F (X ;θ1,θ2,…,θl )其中θk (1≤k ≤l )为未知参数. (1) 求总体X 的k (1≤k ≤l )阶矩E (x k ); (2) 求方程组112112(,,,)(),(,,,)().l l l l l E X A E X A μθθθμθθθ==⎧⎪⎨⎪==⎩的一组解1ˆθ,2ˆθ,…, ˆl θ,那么ˆk θ=ˆk θ (X 1,X 2,…,X n )(1≤k ≤l)为k 的矩估计量. ˆkθ(x 1,x 2,…,x n )为θk 的矩估计值. 极大似然估计法的思想是若已观察到样本值为(x 1,x 2,…,x n ),而取到这一样本值的概率为P =P (θ1,θ2,…,θl ),我们就取θk (1≤k ≤l )的估计值使概率P 达到最大,其一般做法如下: (1) 写出似然函数L =L (θ1,θ2,…,θl ) 当总体X 是离散型随机变量时,L =121(;,,,)nil i P x θθθ=∏,当总体X 是连续型随机变量时L =121(;,,,)nil i f x θθθ=∏,(2) 对L 取对数ln L =121ln (;,,,)nil i f x θθθ=∑,(3) 求出方程组ln kLθ∂∂=0, k =1,2,…,l . 的一组解ˆk θ=ˆk θ (x 1,…,x n ) (1≤k ≤l )即k 为未知参数θ的极大似然估计值,ˆkθ=(X 1,X 2,…,X n )为θk 的极大似然估计量.在统计问题中往往先使用极大似然估计法,在此法使用不方便时,再用矩估计法进行未知参数的点估计.对于一个未知参数可以提出不同的估计量,那么就需要给出评定估计量好坏的标准.本章介绍了三个标准:无偏性、有效性、一致性.重点是无偏性.点估计不能反映估计的精度,我们就引人区间估计.设θ是总体X 的未知参数,1ˆθ,2ˆθ均是样本X 1,X 2,…,X n 的统计量,若对给定值α(0<α<1)满足P (1ˆθ<θ<2ˆθ)=1-α,称1-α为置信度或置信概率,(1ˆθ,2ˆθ)为θ的置信度为1-α的置信区间.参数的区间估计中一个典型、重要的问题是正态总体X (X ~N (μ,σ2))中μ或σ2的区间估计,其置信区间如表7-3所示.表7-3 正态总体的均值、方差的置信度为(1-α)的置信区间区间估计给出了估计的精度与可靠度(1-α),其精度与可靠度是相互制约的即精度越高(置信区间长度越小),可靠度越低;反之亦然.在实际中,应先固定可靠度,再估计精度. 重要术语及主题矩估计量 极大似然估计量估计量的评选标准:无偏性、有效性、一致性, 参数θ的置信度为(1-α)的置信区间, 单个正态总体均值、方差的置信区间.习 题 七1.设总体X 服从二项分布b (n ,p ),n 已知,X 1,X 2,…,X n 为来自X 的样本,求参数p 的矩法估计.2.设总体X 的密度函数f (x ,θ)=22(),0,0,.x x θθθ⎧-<<⎪⎨⎪⎩其他X 1,X 2,…,X n 为其样本,试求参数θ的矩法估计.3.设总体X 的密度函数为f (x ,θ),X 1,X 2,…,X n 为其样本,求θ的极大似然估计.(1) f (x ,θ)=,0,0,0.e x x x θθ-⎧≥⎨<⎩(2) f (x ,θ)=1,01,0,.x x θθ-⎧<<⎨⎩其他5.随机变量X 服从[0,θ]上的均匀分布,今得X 的样本观测值:0.9,0.8,0.2,0.8,0.4,0.4,0.7,0.6,求θ的矩法估计和极大似然估计,它们是否为θ的无偏估计.6.设X 1,X 2,…,X n 是取自总体X 的样本,E (X )=μ,D (X )=σ2,2ˆσ=k 1211()n i ii XX -+=-∑,问k 为何值时2ˆσ为σ2的无偏估计. 7.设X 1,X 2是从正态总体N (μ,σ2)中抽取的样本112212312211311ˆˆˆ;;;334422X X X X X X μμμ=+=+=+ 试证123ˆˆˆ,,μμμ都是μ的无偏估计量,并求出每一估计量的方差. 8.某车间生产的螺钉,其直径X ~N (μ,σ2),由过去的经验知道σ2=0.06,今随机抽取6枚,测得其长度(单位mm )如下:14.7 15.0 14.8 14.9 15.1 15.2 试求μ的置信概率为0.95的置信区间.9.总体X ~N (μ,σ2),σ2已知,问需抽取容量n 多大的样本,才能使μ的置信概率为1-α,且置信区间的长度不大于L ? 10.设某种砖头的抗压强度X ~N (μ,σ2),今随机抽取20块砖头,测得数据如下(kg ·cm -2):64 69 49 92 55 97 41 84 88 99 84 66 100 98 72 74 87 84 48 81 (1) 求μ的置信概率为0.95的置信区间. (2) 求σ2的置信概率为0.95的置信区间. 11.设总体X ~f (x )=(1),01;10,.x x θθθ⎧+<<>-⎨⎩其中其他 X 1,X 2,…,X n 是X 的一个样本,求θ的矩估计量及极大似然估计量. (1997年研考)12.设总体X ~f (x )= 36(),0;0,.xx x θθθ⎧-<<⎪⎨⎪⎩其他X 1,X 2,…,X n 为总体X 的一个样本(1) 求θ的矩估计量;(2) 求ˆ()D θ. (1999研考) 13.设某种电子元件的使用寿命X 的概率密度函数为f (x ,θ)= 2()2,0;0,.e x x x θθ--⎧>⎨≤⎩其中θ(θ>0)为未知参数,又设x 1,x 2,…,x n 是总体X 的一组样本观察值,求θ的极大似然估计值. (2000研考)估计值和极大似然估计值. (2002研考)15.设总体X 的分布函数为F (x ,β)=1,,0,.x xx ββααα⎧->⎪⎨⎪<⎩其中未知参数β>1,α>0,设X 1,X 2,…,X n 为来自总体X 的样本(1) 当α=1时,求β的矩估计量;(2) 当α=1时,求β的极大似然估计量;(3) 当β=2时,求α的极大似然估计量. (2004研考) 16.从正态总体X ~N (3.4,62)中抽取容量为n 的样本,如果其样本均值位于区间(1.4,5.4)内的概率不小于0.95,问n 至少应取多大?2/2()d zt z t ϕ-=⎰(1998研考)17. 设总体X 的概率密度为f (x ,θ)=,01,1,12,0,.x x θθ<<⎧⎪-≤<⎨⎪⎩其他 其中θ是未知参数(0<θ<1),X 1,X 2,…,X n 为来自总体X 的简单随机样本,记N 的样本值x 1,x 2,…,x n 中小于1的个数.求: (1) θ的矩估计;(2) θ的最大似然估计. (2006研考)。
第七章 参数估计参数估计是这样一类问题, 即随机变量(总体)X 的分布类型(或说分布函数)已知, 但分布形式中含有未知参数, 如何通过X 的样本值来估计未知参数的值或它的取值范围以及该范围包含未知参数真值的可靠程度的问题.参数估计分为参数的点估计和参数的区间估计. 一、点估计1. 点估计的提法如下: 设已知总体X 的分布函数(;)F x θ(其中θ是未知参数)及X 的一个样本12,,,n X X X 和一组样本值12,,,n x x x , 建立统计量()12ˆ,,,n X X X θ, 用它的观察值()12ˆ,,,n x x x θ作为θ的近似值, 这称为参数的点估计. 观察值()12ˆ,,,n x x x θ称为θ的点估计值, 统计量()12ˆ,,,n X X X θ称为θ的点估计量.注意, 由于估计量是随机变量, 因此对于不同的样本值, 估计值一般是不同的.2. 估计方法 (1) 矩估计法矩估计法的思想: 第六章中曾指出11,1,2,n Pk k i k i A X k n μ==−−→=∑, 1212(,,,)(,,,)Pk k g A A A g μμμ−−→.因此, 我们可以以样本矩作为总体矩的估计得到一个方程组, 解该方程组便会得到未知参数的一个估计量——矩估计量.矩估计法的具体做法: 设12,,,n X X X 是来自总体X 的一个样本, 12,,,n x x x 是它的一组样本值.假设()()1,2,,iE Xi k =存在, 且都是总体X 分布中未知参数12,,,k θθθ的函数, 即()()12,,,, 1,2,,i i k E X A i k θθθ==,则令()()()1121221211211,,,,1,,,,1,,,.===⎧=⎪⎪⎪=⎪⎨⎪⎪⎪=⎪⎩∑∑∑nk i i n k i i n kk k i i A X n A X n A X n θθθθθθθθθ 解此方程组, 得12ˆˆˆk θθθ⎧=⎪=⎪⎨⎪⎪=⎩()()()11221212ˆ,,,,ˆ,,,,ˆ,,,.n n k nX X X X X X X X X θθθ 称1ˆθ=()112ˆ,,,n X X X θ, 2ˆθ=()212ˆ,,,,,n X X X θ ˆkθ=()12ˆ,,,k n X X X θ分别为12,,,kθθθ的矩估计量, 称()112ˆ,,,,n x x x θ()212ˆ,,,,,n x x x θ()12ˆ,,,k n x x x θ分别为12,,,k θθθ的矩估计值.例1 P178 例2 例2 P179 例3该例表明, 对任意总体X , 总体均值与总体方差的矩估计总为()2211ˆ,ni i X X X n μσ===-∑, 即它们不因不同的总体分布而有差异.(2) 最大似然估计法最大似然估计法的思想是: 设在总体变量X 的分布形式已知(含未知参数12,,,k θθθ)的情形下, 已观察到X 的样本12,,,n X X X 的一组样本值12,,,n x x x . 由于取到这组样本值的概率p (在总体变量是离散型的情况下), 或()12,,,n X X X 落在()12,,,n x x x 的邻域内的概率p (在总体变量是连续型的情况下)与参数12,,,k θθθ有关, 依据“实际推断原理”, 选取的12,,,k θθθ值(称为最大似然估计值)应该使p 达到最大.最大似然估计法的思想引出最大似然函数()1212,,,;,,,n n k L L x x x θθθ={}{}121121;,,,, ;,,,, ni k i n i k i X X P X x f x θθθθθθ==⎧=⎪⎪=⎨⎪⎪⎩∏∏当是离散型变量当是连续型变量. 最大似然估计法的具体做法: 设12,,,n X X X 是来自总体X 的一个样本, 12,,,n x x x 是它的一组样本值. 则①依总体变量X 的分布构造出最大似然函数()1212,,,;,,,n n k L x x x θθθ;②求解方程组0,1,2,,iLi k θ∂==∂或ln 0,1,2,,iLi k θ∂==∂.方程组的解()112ˆ,,,,n x x x θ()212ˆ,,,,,nx x x θ ()12ˆ,,,k nx x x θ称为12,,,k θθθ的最大似然估计值, 而相应的估计量1ˆθ=()112ˆ,,,nX X X θ,2ˆθ=()212ˆ,,,,,nX X X θ ˆkθ=()12ˆ,,,k n X X X θ称为12,,,k θθθ的最大似然估计量.最大似然估计具有性质: 设参数θ的函数(),u u θθ=∈Θ具有单值反函数(),u u U θθ=∈, 又设ˆθ是参数θ的最大似然估计, 则ˆˆ()uu θ=是()u θ的最大似然估计. 事实上, 因为ˆθ是θ的最大似然估计, 所以有 1212ˆ(,,,;)max (,,,;)n n L x x x L x x x θθθ∈Θ=,其中12,,,n x x x 是X 的一组样本值. 考虑到ˆˆ()uu θ=, 且有ˆˆ()u θθ=, 于是上式可写成 1212ˆ(,,,;())max (,,,;())n n u UL x x x uL x x x u θθ∈=.这就证明了ˆˆ()uu θ=是()u θ的最大似然估计. 例3 P182 例4 例4 P183 例5 例5 P183 例6例6 P185 基于截尾样本的最大似然估计在统计问题中往往先使用最大似然估计法, 在最大似然估计法使用起来不方便时再用矩估计法. 习题P207-209 1 2(1) 3(1) 4 73. 估计量的基本评估标准(1) 无偏性 设ˆθ=()12ˆ,,,n X X X θ为未知参数θ的估计量, 若ˆ()E θθ=, 则称ˆθ为θ的无偏估计量.注: ○1()ˆE θθ-称为以ˆθ作为θ的估计误差. 无偏估计的实际意义是要求估计为零误差. ○2样本均值X 和样本方差2S 是总体期望和总体方差的无偏估计量;()212ˆ1nii SXnμ==-∑也是总体方差的无偏估计量, 其中μ是总体变量的期望.○3()2211ˆ11,i nnii i SX XX nnX ====-∑∑是总体期望和总体方差的矩估计量, 也是泊松分布、指数分布、正态分布总体的期望与方差的最大似然估计量. 前者11==∑i ni X nX 是无偏估计量, 后者()221ˆ1==-∑nii SXX n不是无偏估计量.例7 P189 例1该例表明, 对任意总体X , 样本k 阶原点矩总是总体k 阶原点矩的无偏估计. 例8 P189 例2(2) 有效性(最小方差性) 设1ˆθ=()112ˆ,,,n X X X θ, 2ˆθ=()212ˆ,,,n X X X θ都是未知参数θ的无偏估计量, 若1ˆ()D θ2ˆ()D θ<, 则称1ˆθ较2ˆθ有效. 如果对于固定的n , 若某个ˆθ使ˆ()D θ达到最小, 则称ˆθ为θ的有效估计量.有效性表明, 在样本容量相同的情况下, 方差小的无偏估计量是相对好的估计量.(3) 相和性(一致性) 设ˆθ=()12ˆ,,,n X X X θ是未知参数θ的估计量, 若ˆθ依概率收敛于θ, 即对于任意正数ε, {}ˆlim 1n P θθε→∞-<=), 则称ˆθ为θ的相和估计量(或一致估计量). 注: ○1相和性表明, 若估计量不具有相和性, 那么不论样本容量n 有多么大, ˆθ都不能将θ估计得足够准确. 因此, 不具有相和性的估计量是不可取的.○2样本均值和样本方差是总体期望和总体方差的相和估计量; ()121nii Xnμ=-∑也是()D X 的相和估计量. 用矩估计法得到的许多估计量都具有这种性质. 最大似然估计量在一定条件下也具有相和性.○3样本k 阶原点矩11n kk i i A X n ==∑及其函数12(,,,)k g A A A 是总体k 阶原点矩k μ和12(,,,)k g μμμ的相和估计量.总的来说, 具有相和性且方差小的无偏估计量才是好的估计量. 习题P209-210 9 10 11(1)二、区间估计1. 区间估计的提法如下: 作为对未知参数的估计, 显然结果取得宽泛一些更合理. 另外, 对结果范围包含未知参数真值的可信程度应予以说明. 找到这个范围并判断未知参数真值落在这个范围的可信度的过程,称为参数的区间估计. 这个范围通常以区间的形式表示, 称为置信区间.2. 基本概念置信区间 设θ是总体X 分布中的未知参数, θ∈Θ(Θ是θ的可能取值范围). 对于给定的正数α(01α<<), 若由样本12,,,n X X X 的确定的两个统计量()12,,,n X X X θθ=和()12,,,n X X X θθθθ=<(), 对任意θ∈Θ满足 {}1P θθθα<<=-, (7.1)则随机区间(),θθ称为θ的置信水平为1α-的双侧置信区间, θ和θ分别称为θ的置信水平为1α-的双侧置信区间的置信下限和置信上限, 1α-称为置信水平.若()12,,,n X X X θθ=, 对任意θ∈Θ满足{}1P θθα<=-,则随机区间(),θ-∞称为θ的置信水平为1α-的单侧置信区间, θ称为θ的置信水平为1α-的单侧置信区间的单侧置信上限.若()12,,,n X X X θθ=, 对任意θ∈Θ满足{}1P θθα>=-,则随机区间(),θ+∞称为θ的置信水平为1α-的单侧置信区间, θ称为θ的置信水平为1α-的单侧置信区间的单侧置信下限.(7.1)式的含义如下: 若反复抽样多次(设各次抽样的样本容量相等,都是n ), 则每组样本值都会确定一个区间(,)θθ, 每个这样的区间要么包含θ的真值, 要么不包含θ的真值(参见右图). 按伯努里大数定理, 在这样多的区间中, 包含θ的真值的约占100(1)%α-, 不包含θ的真值的约占100%α. 例如, 若0.01α=, 反复抽样1000次, 则得到的1000个区间中不包含θ的真值的约仅为10个.3. 区间估计的方法求未知参数θ的置信区间的做法如下: 设12,,,n X X X 是来自总体X 的一个样本, 12,,,n x x x 是它的一组样本值. 则①寻求一个样本12,,,n X X X 的函数12(,,,;)n W W X X X θ=,它包含参数θ, 但不包含其它未知参数, 并且W 的分布已知且不依赖于任何未知参数(当然也不依赖于待估参数θ);②对于给定的置信水平1α-, 定出两个常数,a b , 使12{(,,,;)}1n P a W X X X b θα<<≥-;③若能从12(,,,;)n a W X X X b θ<<得到等价的不等式θθθ<<, 其中12(,,,)n X X X θθ=,12(,,,)n X X X θθ=都是统计量, 那么(,)θθ就是θ的一个置信水平为1α-的置信区间.函数12(,,,;)n W W X X X θ=的构造通常可以从θ的点估计着手考虑.显然θ的置信水平为1α-的置信区间不唯一. 置信区间小表示估计的精度高. 例9 P192 例4. 正态总体均值与方差的区间估计 (一)几个常用统计量及其分布 设12,,,n X X X 是来自正态总体()2,N μσ容量为n 的的样本, 样本均值11ni i X X n ==∑, 样本方差()22111ni i S X Xn ==--∑, 则有①21,XN n μσ⎛⎫ ⎪⎝⎭,()0,1X N ;②且()()22211n S n χσ--; ()1X t n -.(二) 单个正态总体()2,Nμσ的情形设给定置信水平为1α-, 并设12,,,n X X X 是来自总体()2,N μσ的一个样本, 2,X S 分别是样本均值和样本方差.1o . 均值μ的置信区间①若2σ已知,由于统计量()0,1U N =, 所以μ的置信水平是1α-的一个置信区间为2x z α⎛⎫ ⎪⎝⎭. 它是由{}21P U z αα<=-确定的; μ的置信水平是1α-的(单侧)置信区间为,x z α⎛⎫+∞ ⎪⎝⎭或,x z α⎛⎫-∞ ⎪⎝⎭. ②若2σ未知,由于统计量()1X T t n =-, 所以μ的置信水平是1α-的一个(双侧)置信区间为()()21x n α-. 它是由(){}211P T t n αα<-=-确定的; μ的置信水平是1α-的(单侧)置信区间为()()1,x n α-+∞或()(),1x n α-∞+-. 实际问题中, 总体方差未知的情况居多. 例10 P196 例1 例11 P2032o . 方差2σ的置信区间①若μ未知, 由于统计量()()222211n S n χχσ-=-, 所以2σ的置信水平是1α-的一个(双侧)置信区间为()()()()122222211,11n s n s n n ααχχ-⎛⎫-- ⎪ ⎪--⎝⎭. 它是由()(){}222122111n n P ααχχχα--<<-=-确定的; 2σ的置信水平是1α-的(单侧)置信区间为()()12210,1n s n αχ--⎛⎫ ⎪-⎝⎭或()()221,1n s n αχ-⎛⎫+∞ ⎪-⎝⎭. 这时实际中常见的情形. 例12 P197 例2 例13 P204 例 例14 P203(三) 两个正态总体()()221122,,,NN μσμσ的情形设给定置信水平为1α-, 并设121212,,,;,,,n n X X X Y Y Y 是分别来自总体()2111,X N μσ和()2222,X N μσ的两个样本, 它们相互独立. 又设,X Y 分别为总体一、二的样本均值, 2212,S S 分别为总体一、二的样本方差.1o . 均值差12μμ-的置信区间①若21σ与22σ已知, 由于统计量()120,1X X U N ---=, 所以12μμ-的置信水平是1α-的一个(双侧)置信区间为122x x α⎛⎫- ⎪⎝⎭. 它是由{}21U z P αα<=-确定的. 12μμ-的置信水平是1α-的(单侧)置信区间为12,x x α⎛⎫-+∞ ⎪⎝⎭或12,x x α⎛⎫-∞-+ ⎪⎝⎭.②若2212σσ=未知, 由于统计量()12122X X T t n n μμ---=+-, 其中()()22112212112Wn S n S S n n -+-=+-, 则12μμ-的置信水平是1α-的一个(双侧)置信区间为()()121222n n x x s α⎛⎫±+-- ⎪ ⎪⎝⎭. 它是由(){}12221P T t n n αα<+-=-确定的. 12μμ-的置信水平是1α-的(单侧)置信区间为()()12122,n n x x s ⎛⎫-+-+∞- ⎪⎪⎝⎭或()()1212,2n n x x s ⎛⎫-∞++-- ⎪ ⎪⎝⎭.例15 P198 例3 例16 P199 例42o. 方差比2122σσ的区间估计由于统计量()2211122222/1,1/S F F n n S σσ=--, 则2122σσ的置信水平是1α-的一个(双侧)置信区间为()()22112212122212211, 1,11,1F F n n n n s s s s αα-⎛⎫ ⎪ ⎪----⎝⎭. 它是由 ()(){}121212211,11,1P F F F n n n n ααα-<<=-----确定的. 2122σσ的置信水平是1α-的(单侧)置信区间为()2121221, 1,1F n n s s α⎛⎫+∞ ⎪--⎝⎭或()212112210,1,1F n n s s α-⎛⎫ ⎪--⎝⎭.例17 P200 例5(四)0-1分布参数的区间估计 自修 习题P210-211 14 16 17 21。