CDH-HDP-MAPR-DKH-星环组件比较
- 格式:docx
- 大小:25.94 KB
- 文档页数:7

从CDH和HDP到CDP看大数据平台架构的演进近年来,随着大数据技术的快速发展,大数据平台架构也经历了多次演进。
本文将从CDH和HDP这两个代表性的大数据平台产品,再到CDP这种全新的架构,来探讨大数据平台架构的发展脉络。
一、CDH和HDP的出现CDH(Cloudera's Distribution Including Apache Hadoop)和HDP (Hortonworks Data Platform)是业内最早出现的两种大数据平台产品。
它们的出现可以追溯到大数据技术初期,主要基于Apache Hadoop生态系统。
首先,CDH和HDP基于分布式文件系统HDFS(Hadoop Distributed File System),可以高效地存储和管理海量数据。
同时,它们还具备了处理大数据的计算框架MapReduce,使得用户可以方便地进行数据分析和处理。
其次,CDH和HDP还包含了其他一些核心组件,如HBase、Hive和Pig等。
这些组件能够满足用户在实际应用中的不同需求,从而构建出完整的大数据处理和分析平台。
然而,随着大数据技术的不断发展和用户需求的不断增加,CDH和HDP在某些方面已经显现出一些不足之处,这也推动了大数据平台架构的演进。
二、大数据平台的演进:从CDH和HDP到CDPCDP(Cloudera Data Platform)是近年来新兴的大数据平台架构,它对传统的CDH和HDP进行了全面升级和优化。
首先,CDP将传统的HDFS分布式文件系统升级为CDS(Cloudera Data Storage)。
相比于HDFS,CDS具有更高的可靠性和扩展性,能够更好地应对大规模数据存储和管理的需求。
其次,CDP引入了SDX(Shared Data Experience)的概念。
SDX能够提供统一的数据安全和管理,确保数据在不同的组件和应用之间的一致性和可靠性。
这一点在多租户环境下特别重要,可以减少管理工作的复杂性。

Hadoop 生态系统介绍Hadoop生态系统是一个开源的大数据处理平台,它由Apache基金会支持和维护,可以在大规模的数据集上实现分布式存储和处理。
Hadoop生态系统是由多个组件和工具构成的,包括Hadoop 核心,Hive、HBase、Pig、Spark等。
接下来,我们将对每个组件及其作用进行介绍。
一、Hadoop核心Hadoop核心是整个Hadoop生态系统的核心组件,它主要由两部分组成,一个是Hadoop分布式文件系统(HDFS),另一个是MapReduce编程模型。
HDFS是一个高可扩展性的分布式文件系统,可以将海量数据存储在数千台计算机上,实现数据的分散储存和高效访问。
MapReduce编程模型是基于Hadoop的针对大数据处理的一种模型,它能够对海量数据进行分布式处理,使大规模数据分析变得容易和快速。
二、HiveHive是一个开源的数据仓库系统,它使用Hadoop作为其计算和存储平台,提供了类似于SQL的查询语法,可以通过HiveQL 来查询和分析大规模的结构化数据。
Hive支持多种数据源,如文本、序列化文件等,同时也可以将结果导出到HDFS或本地文件系统。
三、HBaseHBase是一个开源的基于Hadoop的列式分布式数据库系统,它可以处理海量的非结构化数据,同时也具有高可用性和高性能的特性。
HBase的特点是可以支持快速的数据存储和检索,同时也支持分布式计算模型,提供了易于使用的API。
四、PigPig是一个基于Hadoop的大数据分析平台,提供了一种简单易用的数据分析语言(Pig Latin语言),通过Pig可以进行数据的清洗、管理和处理。
Pig将数据处理分为两个阶段:第一阶段使用Pig Latin语言将数据转换成中间数据,第二阶段使用集合行处理中间数据。
五、SparkSpark是一个快速、通用的大数据处理引擎,可以处理大规模的数据,支持SQL查询、流式数据处理、机器学习等多种数据处理方式。

⼤数据平台:HDP,CDH
HDP:
(1) 介绍:
HDP全称叫做Hortonworks Data Platform。
Hortonworks数据平台是⼀款基于Apache Hadoop的是开源数据平台,提供⼤数据云存储,⼤数据处理和分析等服务。
该平台是专门⽤来应对多来源和多格式的数据,并使其处理起来能变成简单、更有成本效益。
HDP还提供了⼀个开放,稳定和⾼度可扩展的平台,使得更容易地集成Apache Hadoop的数据流业务与现有的数据架构。
该平台包括各种的Apache Hadoop项⽬以及Hadoop分布式⽂件系统(HDFS)、MapReduce、Pig、Hive、HBase、Zookeeper和其他各种组件,使Hadoop的平台更易于管理,更加具有开放性以及可扩展性。
(2)平台架构:
CDH:
(1)介绍:
Cloudera版本(Cloudera Distribution Hadoop,简称“CDH”),还有其他的版本,⽬前中国公司我发现⽤的CDH版本较多。
(2)平台架构:
HDP与CDH对⽐:
tips:
1. CDH⽀持的存储组件更丰富
2. HDP⽀持的数据分析组件更丰富
3. HDP对多维分析及可视化有了⽀持,引⼊Druid和Superset
4. HDP的HBase数据使⽤Phoenix的jdbc查询;CDH的HBase数据使⽤映射Hive到Impala的jdbc查询,但分析数据可以存储Impala内部
表,提⾼查询响应
5. 多维分析Druid纳⼊集群,会⽅便管理;但可视化⼯具Superset可以单独安装使⽤
6. CDH没有时序数据库,HDP将Druid作为时序数据库使⽤。

hadoop的生态体系及各组件的用途
Hadoop是一个生态体系,包括许多组件,以下是其核心组件和用途:
1. Hadoop Distributed File System (HDFS):这是Hadoop的分布式文件系统,用于存储大规模数据集。
它设计为高可靠性和高吞吐量,并能在低成本的通用硬件上运行。
通过流式数据访问,它提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
2. MapReduce:这是Hadoop的分布式计算框架,用于并行处理和分析大规模数据集。
MapReduce模型将数据处理任务分解为Map和Reduce两个阶段,从而在大量计算机组成的分布式并行环境中有效地处理数据。
3. YARN:这是Hadoop的资源管理和作业调度系统。
它负责管理集群资源、调度任务和监控应用程序。
4. Hive:这是一个基于Hadoop的数据仓库工具,提供SQL-like查询语言和数据仓库功能。
5. Kafka:这是一个高吞吐量的分布式消息队列系统,用于实时数据流的收集和传输。
6. Pig:这是一个用于大规模数据集的数据分析平台,提供类似SQL的查询语言和数据转换功能。
7. Ambari:这是一个Hadoop集群管理和监控工具,提供可视化界面和集群配置管理。
此外,HBase是一个分布式列存数据库,可以与Hadoop配合使用。
HBase 中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。

cloudera data platform使用(原创版)目录1.Cloudera Data Platform 简介2.Cloudera Data Platform 的主要组件3.Cloudera Data Platform 的应用场景4.Cloudera Data Platform 的优势与不足5.总结正文【1.Cloudera Data Platform 简介】Cloudera Data Platform(CDP)是 Cloudera 公司推出的一款大数据平台,它集成了数据存储、数据处理、数据分析和机器学习等多种功能,帮助企业实现数据的采集、存储、处理、分析和应用。
CDP 的目标是让企业能够更加高效地管理和利用海量数据,从而实现数据驱动的业务决策。
【2.Cloudera Data Platform 的主要组件】CDP 由以下几个主要组件构成:1.Cloudera Manager:Cloudera Manager 是 CDP 的管理界面,通过它,用户可以对整个平台进行监控、管理和配置。
2.Cloudera Data Platform (CDH):CDH 是 CDP 的核心组件,它集成了 Hadoop、Spark、Hive、Pig、Flink 等大数据处理技术,提供了丰富的数据处理和分析功能。
3.Cloudera Data Warehouse (CDW):CDW 是 CDP 的数据仓库组件,它提供了高效的数据存储和查询功能,支持 SQL 查询和机器学习模型的训练。
4.Cloudera Analytics Platform (CAP):CAP 是 CDP 的数据分析和机器学习组件,它提供了可视化的数据分析工具和丰富的机器学习算法,支持实时和离线的数据分析。
5.Cloudera Collaborative Data Platform (CCP):CCP 是 CDP 的数据共享和协作组件,它提供了安全的数据共享和协作功能,支持多种数据格式和协议。
Hadoop⽣态圈各个组件简介Hadoop是⼀个能够对⼤量数据进⾏分布式处理的软件框架。
具有可靠、⾼效、可伸缩的特点。
Hadoop的核⼼是HDFS和MapReduce,HDFS还包括YARN。
1.HDFS(hadoop分布式⽂件系统)是hadoop体系中数据存储管理的他是⼀个基础。
它是⼀个⾼度容错的的系统,能检测和应对硬件故障。
client:切分⽂件,访问HDFS,与之交互,获取⽂件位置信息,与DataNode交互,读取和写⼊数据。
namenode:master节点,在hadoop1.x中只有⼀个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。
DataNode:slave节点,存储实际的数据,汇报存储信息给namenode.secondary namenode:辅助namenode,分担其⼯作量:定期合并fsimage和fsedits,推送给namenode;紧急情况下和辅助恢复namenode,但其并⾮namenode的热备。
2.mapreduce(分布式计算框架)mapreduce是⼀种计算模型,⽤于处理⼤数据量的计算。
其中map对应数据集上的独⽴元素进⾏指定的操作,⽣成键-值对形式中间,reduce则对中间结果中相同的键的所有的值进⾏规约,以得到最终结果。
jobtracker:master节点,只有⼀个管理所有作业,任务/作业的监控,错误处理等,将任务分解成⼀系列任务,并分派给tasktracker. tacktracker:slave节点,运⾏map task和reducetask;并与jobtracker交互,汇报任务状态。
map task:解析每条数据记录,传递给⽤户编写的map()执⾏,将输出结果写⼊到本地磁盘(如果为map-only作业,则直接写⼊HDFS)。
reduce task:从map的执⾏结果中,远程读取输⼊数据,对数据进⾏排序,将数据分组传递给⽤户编写的reduce函数执⾏。
大数据处理中的常用工具和技术随着互联网的快速发展,大数据处理已经成为了一个热门的话题。
在日常生活中,我们不断产生的数据量无处不在,如何有效地处理和分析这些海量数据成为了一个重要的挑战。
在大数据处理中,有许多常用的工具和技术可以帮助我们更好地处理和分析数据。
接下来,我将介绍一些常见的工具和技术。
1. Hadoop: Hadoop是一个开源的分布式计算平台,可以用于存储和处理大规模的数据。
它基于MapReduce算法,分为HDFS(Hadoop分布式文件系统)和MapReduce两个主要组件。
Hadoop提供了高性能、高可靠性的数据处理和存储能力,被广泛应用于大数据分析中。
2. Spark: Spark是另一个流行的大数据处理框架,它提供了内存计算的能力,相比于Hadoop更快速和高效。
Spark支持多种编程语言,如Java、Scala和Python,提供了丰富的API,方便用户处理和分析大数据。
3. SQL: SQL是结构化查询语言,用于管理和操作关系型数据库。
对于大数据处理来说,SQL仍然是一种很重要的工具。
许多大数据处理框架都支持使用SQL来查询和分析数据,比如Hive和Impala。
此外,还有一些专门用于大数据处理的SQL引擎,如Apache Drill和Presto。
4. NoSQL数据库: NoSQL数据库是一种非关系型数据库,在大数据处理中得到了广泛应用。
NoSQL数据库可以存储和处理非结构化或半结构化的数据,比如文档、键值对和图数据。
常见的NoSQL数据库包括MongoDB、Cassandra和Redis。
5.数据仓库:数据仓库是一个用于存储和管理大量结构化数据的数据库系统。
数据仓库可以提供快速的数据查询和分析,它通过将数据存储在专门的硬件设备上,并使用特定的存储和索引技术,提高数据的读写性能。
常见的数据仓库包括Teradata、Snowflake和Amazon Redshift。
6.数据可视化工具:数据可视化工具用于将大数据转换为可视化图表和仪表盘,以便更直观地展示和分析数据。
Hadoop三大核心组件及应用场景分析Hadoop是一个开源的分布式计算平台,拥有良好的可扩展性和容错性,已成为大数据处理领域的领导者。
Hadoop的三大核心组件包括Hadoop分布式文件系统(HDFS)、MapReduce和YARN,本文将分别介绍它们的特点和应用场景。
一、HDFSHDFS是Hadoop分布式文件系统,是Hadoop的存储层。
它的设计灵感来源于Google的GFS(Google File System)。
HDFS将文件分割成块(Block)并存储在集群的不同节点上,块的大小通常为128MB。
这样,大文件可以并发地读取和写入,加快了数据处理的速度。
同时,HDFS具有高可靠性,它能够自动将数据复制到不同节点上,从而避免节点故障时数据的丢失。
HDFS常用于处理海量数据,例如日志分析、数据挖掘等。
在日志分析中,HDFS可以存储大量的日志数据,MapReduce处理日志数据并生成相应的统计结果。
在数据挖掘中,HDFS可以存储大量的原始数据,MapReduce处理数据并生成分析报告。
二、MapReduceMapReduce是Hadoop的计算框架,是Hadoop的处理层。
它的设计灵感来源于Google的MapReduce。
MapReduce将计算分解成两个过程:Map(映射)和Reduce(归约)。
Map过程将数据分割成小块并交给不同的节点处理,Reduce过程将不同节点处理的结果汇总起来生成最终的结果。
MapReduce适用于大规模的数据处理、批量处理和离线处理等场景。
例如,某电商公司需要对每个用户的操作行为进行分析,并生成商品推荐列表。
这种场景下,可以将用户的操作行为数据存储在HDFS中,通过MapReduce对数据进行分析和聚合,得到每个用户的偏好和行为模式,最终为用户生成相应的商品推荐列表。
三、YARNYARN(Yet Another Resource Negotiator)是Hadoop的资源管理框架,能够为分布式计算集群提供高效的资源管理和调度功能。
Hadoop生态圈的技术架构解析Hadoop是一个开源的分布式计算框架,它可以处理大规模数据集并且具有可靠性和可扩展性。
Hadoop生态圈是一个由众多基于Hadoop技术的开源项目组成的体系结构。
这些项目包括Hadoop 组件以及其他与Hadoop相关的组件,例如Apache Spark、Apache Storm、Apache Flink等。
这些组件提供了不同的功能和服务,使得Hadoop生态圈可以满足各种不同的需求。
Hadoop生态圈的技术架构可以分为以下几层:1.基础设施层基础设施层是Hadoop生态圈的底层技术架构。
这一层包括操作系统、集群管理器、分布式文件系统等。
在这一层中,Hadoop 的核心技术——分布式文件系统HDFS(Hadoop Distributed File System)占据了重要位置。
HDFS是一种高度可靠、可扩展的分布式文件系统,它可以存储大规模数据集,通过将数据划分成多个块并存储在不同的机器上,实现数据的分布式存储和处理。
此外,Hadoop生态圈还使用了一些其他的分布式存储系统,例如Apache Cassandra、Apache HBase等。
这些系统提供了高可用性、可扩展性和高性能的数据存储和访问服务。
2.数据管理层数据管理层是Hadoop生态圈的中间层技术架构。
这一层提供了数据管理和数据处理的服务。
在这一层中,MapReduce框架是Hadoop生态圈最为重要的组件之一。
MapReduce框架是一种用于大规模数据处理的程序模型和软件框架,它可以将数据分解成多个小任务进行计算,并在分布式环境下执行。
MapReduce框架提供了自动管理任务调度、数据分片、容错等功能,可以处理大规模的数据集。
除了MapReduce框架,Hadoop生态圈中还有其他一些数据管理和数据处理技术,例如Apache Pig、Apache Hive、Apache Sqoop等。
这些组件提供了从数据提取、清洗和转换到数据分析和报告等各个方面的服务。
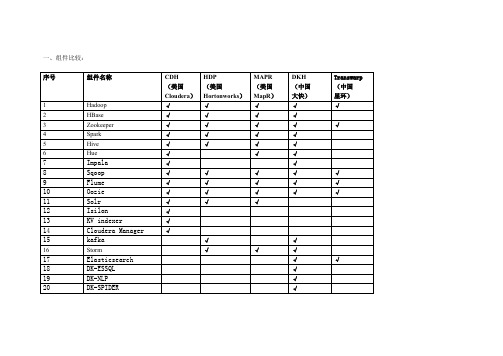
一、组件比较:
二、组件简介:
1、Hadoop
简介:集群基础组件,分为存储(HDFS)和计算(Mapreduce)两大部分。
apache社区开源。
技术来源于2、Hbase
简介:键-值非关系型数据库,apache
3、Zookeeper
4、Spark
简介:内存计算框架,伯克利首先提出,现已开源。
5、Hive
简介:基于HDFS的SQL工具,facebook开发,后开源。
6、Hue
简介:图形化集群工具,cloudera开发,后开源。
7、Impala
简介:基于HDFS的SQL工具,cloudera开发,后开源。
8、Sqoop
简介:用于关系型数据库与NOSQL数据库之间的数据导入导出。
Cloudera开发,已开源。
9、Flume
简介:用于数据流的导入, Cloudera开发,已开源。
10、Oozie
简介:工作流系统,用于提交、监控集群作业。
Cloudera开发,已开源。
11、Solr
简介:基于Lucene的全文搜索服务器。
已开源。
12、Isilon
简介:基于OneFs操作系统的存储产品,美国赛龙公司开发,后属于EMC,一种集群存储方案。
13、K-V store indexer
简介:为HBase到solr的索引中间件,为NGDATA公司开发,已开源。
14、Cloudera Manager
简介:CDH集群安装管理工具。
Cloudera开发。
15、kafka
简介:消息队列组件。
已经开源。
16、Storm
简介:流数据处理组件。
17、Elasticsearch
简介:基于Lucene的全文搜索服务器。
已开源。
18、ESSQL
简介:基于Elasticsearch的SQL工具,大快开发。
19、DK-NLP
简介:自然语言处理组件。
大快开发,已开源。
20、DK-SPIDER
简介:分布式爬虫组件。
大快开发。
21、DKM
简介:集群安装管理工具。
大快开发。
22、DK-DMYSQL
简介:分布式MYSQL组件,大快改写。
23、Apache Falcon
简介:Falcon 是一个面向Hadoop的、新的数据处理和管理平台,设计用于数据移动、数据管道协调、生命周期管理和数据发现。
24、Apache Knox
简介:Apache knox是一个访问hadoop集群的restapi网关,它为所有rest访问提供了一个简单的访问接口点。
25、Apache Phoenix
简介:Phoenix 是HBase的SQL驱动。
26、Apache Pig
简介:Pig定义了数据流语言Pig Latin,它是MapReduce编程抽象。
27、Apache Ranger
简介:ranger是一个hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的hadoop生态圈的所有数据权限。
28、Apache Slider
简介:Slider 是一个 YARN 应用,用于发布已有的分布式应用到 YARN 上,并对这些应用进行监控以及根据需要调整规模。
29、Tez
简介:Tez支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分形成一个大的DAG 作业。
30、Apache Drill
简介:Apache Drill是一个低延迟的分布式海量数据(涵盖结构化、半结构化以及嵌套数据)交互式查询引擎,使用ANSI SQL兼容语法。
31、MapR-DB
简介:MapR开发
32、MapR Streams
简介:MapR开发
33、Mahout
简介:机器学习算法库,现已停止更新。
34、HttpFS
简介:Cloudera开发的基于http协议的HDFS操作组件。
35、Sentry
简介:Apache Sentry 是Cloudera公司发布的一个Hadoop开源组件,截止目前还是Apache的孵化项目,它提供了细粒度级、基于角色的授权以及多租户的管理模式。
36、Sahara
简介:Sahara旨在为用户提供简单部署Hadoop集群的能力,提供在OpenStack上快速配置和部署Hadoop集群的能力。
37、Myriad 0.1.0
简介:Myriad是一个Mesos框架用来动态扩展YARN集群,并支持运行Hadoop应用,如Spark和非Hadoop应用,如Node.js、Memcached、RoR等。
38、Transwarp Inceptor
简介:由Apache Spark改写,Transwarp Inceptor交互式分析引擎提供高速SQL分析和R语言数据挖掘能力,可帮助企业建立高速可扩展的数据仓库和/ 或数据集市,结合多种报表工具提供交互式数据分析、即时报表和可视化能力。
星环开发。
39、Transwarp Hyperbase
简介:Transwarp Hyperbase实时数据库是建立在Apache HBase基础之上,融合了多种索引技术、分布式事务处理、全文实时搜索、图形数据库在内的实时NoSQL数据库。
星环开发。
40、Transwarp Stream
简介:Transwarp Stream实时流处理引擎提供了强大的流计算表达能力,支持复杂的应用逻辑,生产系统的消息通过实时消息队列进入计算集群,在集群内以流水线方式被依次处理,完成数据转换、特征提取、策略检查、分析告警等复杂服务计算,最终输出到Hyperbase 等存储集群,实时生成告警页面、实时展示页面等。
星环开发。
41、Apache Ambari
简介:Ambari 创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个web工具。