sklearn SVM算法库小结
- 格式:docx
- 大小:34.10 KB
- 文档页数:10

sklearn机器学习算法--线性模型线性模型⽤于回归的线性模型线性回归(普通最⼩⼆乘法)岭回归lasso⽤于分类的线性模型⽤于多分类的线性模型1、线性回归LinearRegression,模型简单,不同调节参数#2、导⼊线性回归模型from sklearn.linear_model import LinearRegression#3、实例化线性回归模型对象lr = LinearRegression()#4、对训练集进⾏训练lr.fit(X_train,y_train)#“斜率”参数(w,也叫作权重或系数)被保存在coef_ 属性中,⽽偏移或截距(b)被保存在intercept_ 属性中:print('lr.coef_:{}'.format(lr.coef_))print('lr.intercept_:{}'.format(lr.intercept_))View Code2、岭回归Ridge,调节参数alpha,默认使⽤L2正则化,alpha越⼤模型得到的系数就更接近于0,减少alpha可以让系数受到的约束减⼩。
#导⼊岭回归模型from sklearn.linear_model import Ridge#实例化岭回归模型对象并对训练集进⾏训练ridge = Ridge().fit(X_train,y_train)#查看模型在训练集和测试集上的精确度print('training score:{}'.format(ridge.score(X_train,y_train)))print('testing score:{}'.format(ridge.score(X_test,y_test)))#在实例化Ridge模型中存在参数alpha,alpha越⼤模型得到的系数就更接近于0,减少alpha可以让系数受到的约束减⼩。
#⽐较alpha=0.1,1,10和LinearRegression系数⼤⼩ridge10 = Ridge(alpha=10).fit(X_train, y_train)ridge01 = Ridge(alpha=0.1).fit(X_train, y_train)View Code3、Lasso除了Ridge,还有⼀种正则化的线性回归是Lasso。

SVM算法说明和优化算法介绍SVM(Support Vector Machine,支持向量机)是一种常用的机器学习算法,用于分类和回归分析。
SVM的基本思想是通过在特征空间中构造一个最优超平面,将不同类别的样本分开。
本文将为您介绍SVM的基本原理、分类和回归问题的实现方法以及一些常见的优化算法。
SVM的基本原理是寻找一个能够最大化类别间间隔(margin)的超平面,从而达到更好的分类效果。
在特征空间中,样本点可以用向量表示,所以SVM也可以看作是在特征空间中寻找一个能够最优分割两类样本的超平面。
为了找到这个最优超平面,SVM使用了支持向量(Support Vector),即离超平面最近的样本点。
支持向量到超平面的距离被称为间隔,而最优超平面使得间隔最大化。
对于线性可分的情况,SVM的目标是最小化一个损失函数,同时满足约束条件。
损失函数由间隔和误分类样本数量组成,约束条件则包括对超平面的限制条件。
通过求解优化问题,可以得到最优超平面的参数值。
对于非线性可分的情况,SVM使用核函数进行转换,将低维特征空间中的样本映射到高维特征空间中,从而使得样本在高维空间中线性可分。
SVM在分类问题中的应用广泛,但也可以用于回归问题。
在回归问题中,SVM的目标是找到一个超平面,使得点到该平面的距离尽可能小,并且小于一个给定的阈值。
SVM回归的思想是通过引入一些松弛变量,允许样本点在一定程度上偏离超平面来处理异常数据,从而得到更好的回归结果。
在实际应用中,SVM的性能和效果受到许多因素的影响,如数据集的分布、样本的数量和特征的选择等。
为了进一步优化SVM的性能,许多改进算法被提出。
下面我们介绍几种常见的SVM优化算法。
1.序列最小优化算法(SMO):SMO是一种简单、高效的SVM优化算法。
它通过将大优化问题分解为多个小优化子问题,并使用启发式方法进行求解。
每次选择两个变量进行更新,并通过迭代优化这些变量来寻找最优解。
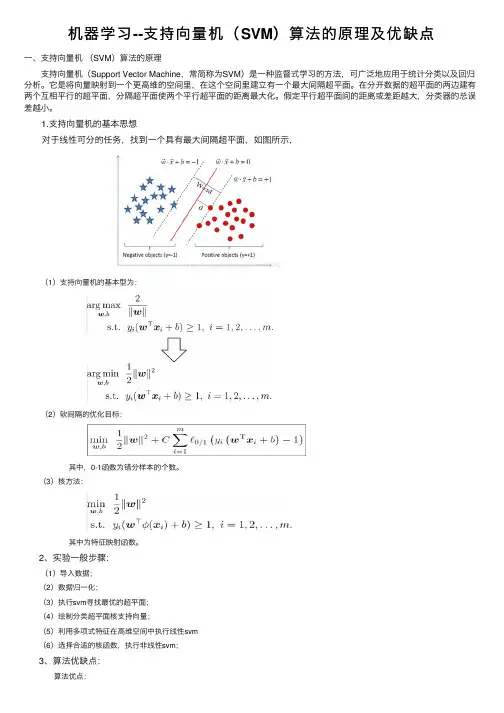
机器学习--⽀持向量机(SVM)算法的原理及优缺点⼀、⽀持向量机(SVM)算法的原理 ⽀持向量机(Support Vector Machine,常简称为SVM)是⼀种监督式学习的⽅法,可⼴泛地应⽤于统计分类以及回归分析。
它是将向量映射到⼀个更⾼维的空间⾥,在这个空间⾥建⽴有⼀个最⼤间隔超平⾯。
在分开数据的超平⾯的两边建有两个互相平⾏的超平⾯,分隔超平⾯使两个平⾏超平⾯的距离最⼤化。
假定平⾏超平⾯间的距离或差距越⼤,分类器的总误差越⼩。
1.⽀持向量机的基本思想 对于线性可分的任务,找到⼀个具有最⼤间隔超平⾯,如图所⽰, (1)⽀持向量机的基本型为: (2)软间隔的优化⽬标: 其中,0-1函数为错分样本的个数。
(3)核⽅法: 其中为特征映射函数。
2、实验⼀般步骤: (1)导⼊数据; (2)数据归⼀化; (3)执⾏svm寻找最优的超平⾯; (4)绘制分类超平⾯核⽀持向量; (5)利⽤多项式特征在⾼维空间中执⾏线性svm (6)选择合适的核函数,执⾏⾮线性svm; 3、算法优缺点: 算法优点: (1)使⽤核函数可以向⾼维空间进⾏映射 (2)使⽤核函数可以解决⾮线性的分类 (3)分类思想很简单,就是将样本与决策⾯的间隔最⼤化 (4)分类效果较好 算法缺点: (1)SVM算法对⼤规模训练样本难以实施 (2)⽤SVM解决多分类问题存在困难 (3)对缺失数据敏感,对参数和核函数的选择敏感 ⼆、数学推导过程 对于线性可分的⽀持向量机求解问题实际上可转化为⼀个带约束条件的最优化求解问题: 推理过程: 结果: 对于线性不可分的⽀持向量机求解问题实际上可转化为⼀个带约束条件的soft-margin最优化求解问题:三、代码实现1、线性svmimport numpy as npfrom sklearn.datasets import load_irisimport matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScalerfrom sklearn.svm import LinearSVCfrom matplotlib.colors import ListedColormapimport warningsdef plot_decision_boundary(model,axis):x0,x1=np.meshgrid(np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1))x_new=np.c_[x0.ravel(),x1.ravel()]y_predict=model.predict(x_new)zz=y_predict.reshape(x0.shape)custom_cmap=ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_cmap)w = model.coef_[0]b = model.intercept_[0]plot_x = np.linspace(axis[0],axis[1],200)up_y = -w[0]/w[1]*plot_x - b/w[1] + 1/w[1]down_y = -w[0]/w[1]*plot_x - b/w[1] - 1/w[1]up_index = (up_y>=axis[2]) & (up_y<=axis[3])down_index = (down_y>=axis[2]) & (down_y<=axis[3])plt.plot(plot_x[up_index],up_y[up_index],c='black')plt.plot(plot_x[down_index],down_y[down_index],c='black')warnings.filterwarnings("ignore")data = load_iris()x = data.datay = data.targetx = x[y<2,:2]y = y[y<2]scaler = StandardScaler()scaler.fit(x)x = scaler.transform(x)svc = LinearSVC(C=1e9)svc.fit(x,y)plot_decision_boundary(svc,axis=[-3,3,-3,3])plt.scatter(x[y==0,0],x[y==0,1],c='r')plt.scatter(x[y==1,0],x[y==1,1],c='b')plt.show()输出结果:2、⾮线性-多项式特征import numpy as npfrom sklearn import datasetsimport matplotlib.pyplot as pltfrom sklearn.preprocessing import PolynomialFeatures,StandardScaler from sklearn.svm import LinearSVCfrom sklearn.pipeline import Pipelinefrom matplotlib.colors import ListedColormapimport warningsdef plot_decision_boundary(model,axis):x0,x1=np.meshgrid(np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1) )x_new=np.c_[x0.ravel(),x1.ravel()]y_predict=model.predict(x_new)zz=y_predict.reshape(x0.shape)custom_cmap=ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_cmap)def PolynomialSVC(degree,C=1.0):return Pipeline([('poly',PolynomialFeatures(degree=degree)),('std_scaler',StandardScaler()),('linearSVC',LinearSVC(C=1e9))])warnings.filterwarnings("ignore")poly_svc = PolynomialSVC(degree=3)X,y = datasets.make_moons(noise=0.15,random_state=666)poly_svc.fit(X,y)plot_decision_boundary(poly_svc,axis=[-1.5,2.5,-1.0,1.5])plt.scatter(X[y==0,0],X[y==0,1],c='red')plt.scatter(X[y==1,0],X[y==1,1],c='blue')plt.show()输出结果:3、⾮线性-核⽅法from sklearn.preprocessing import StandardScalerfrom sklearn.svm import SVCfrom sklearn.pipeline import Pipelinefrom sklearn import datasetsfrom matplotlib.colors import ListedColormapimport numpy as npimport matplotlib.pyplot as pltimport warningsdef plot_decision_boundary(model,axis):x0,x1=np.meshgrid(np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1) )x_new=np.c_[x0.ravel(),x1.ravel()]y_predict=model.predict(x_new)zz=y_predict.reshape(x0.shape)custom_cmap=ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_cmap)def RBFKernelSVC(gamma=1.0):return Pipeline([('std_scaler',StandardScaler()),('svc',SVC(kernel='rbf',gamma=gamma))])warnings.filterwarnings("ignore")X,y = datasets.make_moons(noise=0.15,random_state=666)svc = RBFKernelSVC(gamma=100)svc.fit(X,y)plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])plt.scatter(X[y==0,0],X[y==0,1],c='red')plt.scatter(X[y==1,0],X[y==1,1],c='blue')plt.show()输出结果:。

scikit-learn决策树算法类库使⽤⼩结 之前对决策树的算法原理做了总结,包括和。
今天就从实践的⾓度来介绍决策树算法,主要是讲解使⽤scikit-learn来跑决策树算法,结果的可视化以及⼀些参数调参的关键点。
1. scikit-learn决策树算法类库介绍 scikit-learn决策树算法类库内部实现是使⽤了调优过的CART树算法,既可以做分类,⼜可以做回归。
分类决策树的类对应的是DecisionTreeClassifier,⽽回归决策树的类对应的是DecisionTreeRegressor。
两者的参数定义⼏乎完全相同,但是意义不全相同。
下⾯就对DecisionTreeClassifier和DecisionTreeRegressor的重要参数做⼀个总结,重点⽐较两者参数使⽤的不同点和调参的注意点。
2. DecisionTreeClassifier和DecisionTreeClassifier 重要参数调参注意点 为了便于⽐较,这⾥我们⽤表格的形式对DecisionTreeClassifier和DecisionTreeRegressor重要参数要点做⼀个⽐较。
参数DecisionTreeClassifier DecisionTreeRegressor特征选择标准criterion 可以使⽤"gini"或者"entropy",前者代表基尼系数,后者代表信息增益。
⼀般说使⽤默认的基尼系数"gini"就可以了,即CART算法。
除⾮你更喜欢类似ID3, C4.5的最优特征选择⽅法。
可以使⽤"mse"或者"mae",前者是均⽅差,后者是和均值之差的绝对值之和。
推荐使⽤默认的"mse"。
⼀般来说"mse"⽐"mae"更加精确。
除⾮你想⽐较⼆个参数的效果的不同之处。

svm算法过程SVM算法过程一、引言SVM(Support Vector Machine,支持向量机)是一种常用的机器学习算法,广泛应用于分类和回归问题。
其核心思想是通过找到一个最优的超平面,将不同类别的样本分开。
本文将介绍SVM算法的具体过程。
二、数据预处理在使用SVM算法之前,需要对数据进行预处理。
首先,需要将数据集划分为训练集和测试集。
然后,对数据进行标准化处理,使其具有相同的尺度和分布。
最后,根据需要选择合适的特征提取方法,以提高模型的准确性和泛化能力。
三、构建模型1. 定义问题在使用SVM算法之前,需要明确问题的定义。
例如,如果是一个二分类问题,需要明确两个类别,并将其转化为标签0和1。
2. 选择核函数核函数在SVM算法中起到了关键作用,它可以将数据从原始空间映射到高维空间,从而使数据在高维空间中线性可分。
常用的核函数包括线性核函数、多项式核函数和高斯核函数等。
3. 定义目标函数SVM算法的目标是找到一个最优的超平面,使得训练样本与超平面的间隔最大化。
为了实现这一目标,需要定义一个目标函数,通常为最小化正则化的损失函数。
4. 优化求解为了求解目标函数,可以使用优化算法进行求解。
常用的优化算法包括最小二乘法、梯度下降法和牛顿法等。
通过迭代优化求解,可以找到最优的超平面参数。
四、模型评估在构建好模型之后,需要对其进行评估,以判断其性能和泛化能力。
常用的评估指标包括准确率、精确率、召回率和F1值等。
通过对测试集进行预测,并与真实标签进行比较,可以得到模型的评估结果。
五、参数调优在实际应用中,常常需要对模型的参数进行调优,以达到更好的性能。
常用的参数调优方法包括网格搜索和交叉验证等。
通过尝试不同的参数组合,并使用交叉验证方法进行评估,可以选择最优的参数组合。
六、模型应用在模型评估和参数调优之后,可以将模型应用于实际问题。
例如,可以使用训练好的模型对新的样本进行分类,或者进行预测分析等。
七、总结SVM算法是一种常用的机器学习算法,具有良好的分类和回归性能。

svm算法python代码SVM算法介绍支持向量机(Support Vector Machine,简称SVM)是一种二分类模型,它的基本思想是在特征空间中寻找最优超平面,使得不同类别的样本点与该超平面的距离最大化。
SVM算法在分类问题中具有很好的性能和泛化能力,在实际应用中被广泛使用。
SVM算法Python代码实现在Python中,可以使用scikit-learn库来实现SVM算法。
以下是一个简单的示例代码:```pythonfrom sklearn import datasetsfrom sklearn.model_selection import train_test_splitfrom sklearn.svm import SVCfrom sklearn.metrics import accuracy_score# 加载数据集iris = datasets.load_iris()X = iris.data[:, :2] # 只使用前两个特征y = iris.target# 分割数据集为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)# 创建SVM模型并拟合训练集数据model = SVC(kernel='linear', C=1.0)model.fit(X_train, y_train)# 使用测试集数据进行预测,并计算准确率y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print('Accuracy:', accuracy)```代码解析1. 导入所需库:datasets用于加载数据集,train_test_split用于分割数据集,SVC用于创建SVM模型,accuracy_score用于计算准确率。

机器学习技术中的SVM算法介绍SVM算法介绍机器学习技术中的支持向量机(SVM)算法是一种非常强大和广泛应用的监督学习方法。
它不仅被用于分类问题,还可以用于回归和异常检测等多个领域。
本文将介绍SVM算法的原理、应用场景以及优缺点。
一、SVM算法原理SVM算法的核心目标是找到一个最优的超平面,能够将不同类别的样本完全分开,并最大化两个类别间的间隔。
这个超平面将数据集投影到高维空间中,从而使得不同类别的样本能够更好地分离。
在SVM算法中,我们首先将样本映射到高维特征空间中,然后通过找到一个最佳的超平面来实现分类。
这个超平面可以由一个决策函数表示:f(x) = sign(w·x - b),其中w是一个权重向量,x是输入样本,b是偏移量。
决策函数返回的结果为+1或-1,代表了样本x所属的类别。
SVM算法的关键是确定超平面的位置。
为了实现这一点,我们需要找到一组支持向量,它们是离超平面最近的样本点。
通过最小化支持向量到超平面的距离,我们可以确定超平面的位置。
这样的超平面被称为最大间隔超平面(Maximum Margin Hyperplane)。
二、SVM算法应用场景由于其良好的分类性能和灵活性,SVM算法被广泛应用于各种领域。
以下是一些常见的SVM算法应用场景:1. 文本分类:SVM算法在自然语言处理中被广泛应用,可以用于将文本分类为不同的类别,如垃圾邮件过滤、情感分析等。
2. 图像识别:SVM算法可以用于图像分类和目标识别任务。
通过将图像转换为特征向量,可以利用SVM算法将不同类别的图像进行分类。
3. 生物信息学:SVM算法在生物信息学领域中有很多应用,比如蛋白质结构预测、基因表达分析等。
SVM算法可以识别出与特定疾病相关的基因或蛋白质。
4. 金融领域:SVM算法可以用于信用评级、欺诈检测和股票市场分析等金融领域的问题。
它可以帮助识别信用风险、预测股票价格和发现异常交易等。
5. 医学领域:SVM算法在医学图像处理和医学诊断中也有广泛应用。

svm 实验报告SVM实验报告引言支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,广泛应用于模式识别、图像分类、文本分类等领域。
本篇实验报告将介绍SVM的原理、实验设计和结果分析。
一、SVM原理SVM是一种监督学习算法,其基本思想是通过寻找一个最优的超平面来将不同类别的样本分开。
在二维空间中,这个超平面就是一条直线,而在多维空间中,这个超平面则是一个超平面。
SVM的目标是使得两个不同类别的样本点离超平面的距离最大化,从而提高分类的准确性。
二、实验设计本次实验使用了一个开源的数据集,该数据集包含了一些花朵的特征数据,共分为三个类别。
首先,我们将数据集划分为训练集和测试集,其中70%的数据用于训练,30%的数据用于测试。
然后,我们使用Python编程语言中的scikit-learn库来实现SVM算法,并将训练集输入模型进行训练。
最后,使用测试集对模型进行评估,并计算分类的准确率。
三、实验结果分析经过训练和测试,我们得到了如下结果:SVM在测试集上的准确率为90%。
这意味着模型能够正确分类90%的花朵样本。
通过观察分类结果,我们发现SVM对于不同类别的花朵具有较好的区分能力,分类边界清晰。
然而,也存在一些分类错误的情况,可能是由于样本之间的重叠或噪声数据的干扰所导致。
四、结果讨论在本次实验中,我们成功地应用了SVM算法进行花朵分类,并取得了较好的分类准确率。
然而,我们也发现了一些问题。
首先,SVM对于噪声数据和重叠样本的处理能力相对较弱,这可能导致一些错误分类的情况。
其次,SVM的计算复杂度较高,在处理大规模数据时可能会面临一些挑战。
因此,在实际应用中需要对数据进行预处理,如特征选择和降维等,以提高算法的效率和准确性。
五、结论本次实验通过实现SVM算法对花朵数据集进行分类,取得了较好的结果。
SVM 作为一种常用的机器学习算法,在模式识别和分类问题中具有广泛的应用前景。

svm实验报告SVM 实验报告一、实验目的本次实验的主要目的是深入了解支持向量机(Support Vector Machine,SVM)算法的原理和应用,并通过实际实验来验证其性能和效果。
二、实验原理SVM 是一种基于统计学习理论的监督学习算法,其基本思想是在特征空间中寻找一个最优的超平面,将不同类别的样本尽可能地分开。
这个最优超平面是通过最大化两类样本之间的间隔来确定的。
对于线性可分的情况,SVM 通过求解一个凸二次规划问题来找到最优超平面。
对于线性不可分的情况,通过引入核函数将样本映射到高维特征空间,使其在高维空间中变得线性可分。
三、实验数据本次实验使用了两个数据集,分别是鸢尾花数据集(Iris Dataset)和手写数字数据集(MNIST Dataset)。
鸢尾花数据集包含了 150 个样本,每个样本具有四个特征,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度,共分为三个类别:Setosa、Versicolor 和 Virginica。
手写数字数据集包含了 60000 个训练样本和 10000 个测试样本,每个样本是一个 28×28 的灰度图像,代表了 0 到 9 中的一个数字。
四、实验环境本次实验使用的编程语言是 Python,主要使用了 scikitlearn 库来实现 SVM 算法。
实验环境为 Jupyter Notebook。
五、实验步骤1、数据预处理对于鸢尾花数据集,直接使用其原始特征。
对于手写数字数据集,将 28×28 的图像展平为 784 维的向量,并进行标准化处理。
2、划分训练集和测试集对于鸢尾花数据集,随机将其分为80%的训练集和20%的测试集。
对于手写数字数据集,使用其自带的训练集和测试集划分。
3、选择核函数分别尝试了线性核函数(Linear Kernel)、多项式核函数(Polynomial Kernel)和高斯核函数(RBF Kernel)。
4、训练 SVM 模型使用训练集对 SVM 模型进行训练,调整相关参数,如正则化参数C 和核函数的参数。

时间序列分类中的SVM算法随着时间序列数据的不断涌现和应用范围的不断扩大,时间序列分类算法也越来越受到重视。
而SVM算法作为一种受欢迎的分类算法,也被广泛应用于时间序列分类问题。
SVM算法的基本原理SVM算法在处理分类问题时,会将数据集映射到高维空间中,通过寻找一个最优的超平面来对数据进行分类。
具体来说,在特征空间中,SVM算法会尽可能地找到一个能够将两个不同类别的数据分开的超平面。
而对于非线性分类问题,SVM通过核函数的转换,将数据集映射到高维空间中,从而实现分类。
SVM算法在时间序列分类中的应用在时间序列分类中,SVM算法也能够发挥出其优异的分类能力。
对于一个时间序列,可以将其表示成一个向量形式。
然后,SVM算法通过核函数的转换,将时间序列映射到高维空间中进行分类。
下面以UCR时间序列分类数据集为例,介绍SVM算法在时间序列分类中的应用。
读取数据首先,需要将时间序列数据集读取进来。
UCR时间序列分类数据集是一个经典的时间序列数据集,包含了许多不同的数据集,每个数据集都对应一个不同的分类问题。
加载数据集的方法可以使用相关的Python库,如下所示:``` pythonfrom sklearn.datasets import load_X_train, y_train, X_test, y_test = load_('GunPoint')```其中,'GunPoint'是UCR数据集中的一个数据集名称,X_train 和y_train表示训练集数据和标签,X_test和y_test表示测试集数据和标签。
特征提取在进行分类之前,需要对时间序列进行特征提取。
常见的时间序列特征提取方法包括峰值、均值、标准差、自相关、互相关等方法。
以峰值特征为例,可以使用np.argmax()函数获取时间序列中的峰值位置。
代码如下所示:``` pythonimport numpy as npdef max_feature(X):return np.argmax(X)X_train_ = np.apply_along_axis(max_feature, axis=1, arr=X_train) X_test_ = np.apply_along_axis(max_feature, axis=1, arr=X_test) ```这里使用了np.apply_along_axis()函数,可以对每个时间序列应用max_feature()函数,最终得到峰值特征。

python svm参数Python SVM参数支持向量机(Support Vector Machine, SVM)是一种常用的监督学习算法,用于分类和回归问题。
在Python中,我们可以使用scikit-learn库来实现SVM模型。
在使用SVM模型时,选择合适的参数是非常重要的,本文将详细介绍Python SVM模型中常用的参数。
1. 核函数(kernel)核函数是SVM模型中的一个重要参数,它用于将输入空间映射到高维特征空间。
常用的核函数有线性核函数、多项式核函数、高斯核函数等。
在scikit-learn库中,可以通过kernel参数来选择不同的核函数,默认为径向基函数(Radial Basis Function, RBF)。
选择合适的核函数可以提高模型的性能。
2. 惩罚参数(C参数)惩罚参数C是SVM模型中的另一个重要参数,它控制了错误分类样本的惩罚程度。
C越大,错误分类的惩罚越大,模型越倾向于选择较小的间隔来最小化错误分类样本的数量;C越小,错误分类的惩罚越小,模型越倾向于选择较大的间隔来最小化间隔内的错误分类样本数量。
在scikit-learn库中,可以通过C参数来设置惩罚参数的值,默认为1.0。
3. gamma参数对于使用RBF核函数的SVM模型,gamma参数用于控制高斯核的宽度,即决定了样本对模型的影响范围。
gamma越大,模型对于离样本较近的点的影响越大,决策边界将更加准确,但可能过拟合;gamma越小,模型对于离样本较远的点的影响越大,决策边界可能过于简单。
在scikit-learn库中,可以通过gamma参数来设置gamma的值,默认为"scale",表示根据特征数量自动选择合适的gamma。
4. 类别权重(class_weight)类别权重参数用于解决不均衡数据集的问题。
在某些情况下,数据集中的不同类别样本数量差异较大,这会导致模型对于数量较多的类别更加关注,忽视数量较少的类别。
从核函数到SVM原理--sklearn-SVM实现SVM核函数及sklearn实现SVM在SVM中,其中最重要的也是最核⼼的就是核函数的选取和参数选择,当然这个需要⼤量的经验来⽀撑。
今天我们就是抛砖引⽟形象的讲解⼀下什么是核函数,及在SVM中在哪⽤到。
我们知道,SVM相对感知机⽽⾔,它可以解决线性不可分的问题,那么它是怎么解决的呢?它的解决思想很简单,就是对原始数据的维度变换,⼀般是扩维变换,使得原样本空间中的样本点线性不可分,但是在变维之后的空间中样本点是线性可分的,然后再变换后的⾼维空间中进⾏分类。
了解SVM原理,并且有凸优化理论知识的话,都应该知道SVM其实主要是在⽤对偶理论求解⼀个⼆次凸优化问题,其中对偶问题如下:求的最终结果:其中表⽰任选的⼀个⽀持向量当然这是线性可分的情况,那么如果问题本⾝是线性不可分的情况呢,那就是先扩维后再计算,计算形式是⼀样的:其中表⽰原来的样本扩维后的坐标。
从中可以看出,不管是不扩维的求解还是扩维的求解,在求解对偶问题的过程中都会⽤到各样本点的内积的结果,那么这时候问题来了,在很多情况下,扩维可能会吧原数据扩到很⾼维(甚⾄⽆穷维),这时候直接求内积是⾮常困难的,我们为了避免做这样的事就提出了核函数的概念。
核函数:任意两个样本点在扩维后的空间的内积,如果等于这两个样本点在原来空间经过⼀个函数后的输出,那么这个函数就叫核函数。
当然这是我⾃⼰的理解定义,意思就是这么个意思。
也就是说:这个函数f就是核函数。
我们接下来举⼀个例⼦:为简单起见,假设所有样本点都是⼆维点,其值分别为(x,y),,可以验证任意两个扩维后的样本点在3维空间的内积等于原样本点在2维空间的函数输出: 有了这个核函数,以后的⾼维内积都可以转化为低维的函数运算了,这⾥也就是只需要计算低维的内积,然后再平⽅。
明显问题得到解决且复杂度降低极⼤。
总⽽⾔之,核函数它本质上隐含了从低维到⾼维的映射,从⽽避免直接计算⾼维的内积。
sklearn库用法-回复sklearn(Scikit-learn)是一个用于机器学习的Python库。
它由NumPy、SciPy和matplotlib等库构建而成,提供了各种用于分类、回归、聚类和降维等数据挖掘任务的工具。
本文将以sklearn库的用法为中心,为读者详细介绍其基本功能和使用方法。
第一部分:概述(200字)在当今大数据时代,机器学习成为了逐渐流行的领域。
为了解决机器学习算法的复杂性,开发者创建了sklearn这个强大的Python库。
sklearn 提供了一系列高效、高质量的机器学习算法,包括分类、回归、聚类、降维等。
它还提供了用于数据预处理、特征选择和模型评估的工具,极大地简化了机器学习任务的实现过程。
第二部分:基本功能(400字)sklearn提供了丰富的功能模块,如数据预处理、模型选择、特征工程等。
其中,数据预处理是机器学习任务中重要的一环。
sklearn提供了多种常用的预处理方法,包括数据缩放、标准化、正则化等。
例如,使用sklearn 可以很方便地将数据集进行标准化处理,使得不同尺度的特征具有统一的分布范围,有利于模型的拟合。
模型选择是机器学习中的重要步骤之一。
sklearn提供了多种模型选择算法,如交叉验证、网格搜索等。
交叉验证是一种评估模型性能的有效方法,它可以将数据集划分为训练集和验证集,并重复多次计算模型评价指标,最后取平均值。
网格搜索则通过尝试不同的参数组合来求解机器学习模型的最佳参数,从而提高模型的泛化能力。
特征工程是机器学习中非常重要的一步,它包括特征选择、特征变换等操作。
sklearn库提供了多种常用的特征工程方法,如主成分分析(PCA)、因子分析等。
特征选择可以去除冗余和无关的特征,提高模型的效率和准确性;特征变换则可以将原始特征转化为新的特征空间,提炼出更有用的信息。
第三部分:使用方法(600字)使用sklearn进行机器学习任务的基本步骤如下:1.准备数据:首先需要准备好用于训练的数据集。
1 IntroductionSVMs (Support Vector Machines) are a useful technique for data classification. Although SVM is considered easier to use than Neural Networks, users not familiar with it often get unsatisfactory results at first. Here we outline a \cookbook" approach which usually gives reasonable results. Note that this guide is not for SVM researchers nor do we guarantee you will achieve the highest accuracy. Also, we do not intend to solve challenging or difficult problems. Our purpose is to give SVM novices a recipe for rapidly obtaining acceptable results.Although users do not need to understand the underlying theory behind SVM, we briefly introduce the basics necessary for explaining our procedure. A classification task usually involves separating data into training and testing sets. Each instance in the training set contains one ‘target value’ (i.e. the class labels) and several ‘attributes’ (i.e. the features or observed variables). The goal of SVM is to produce a model (based on the training data) which predicts the target values of the test data given only the test data attributes.Given a training set of instance-label pairs (xi; yi); i = 1; : : : ; l where xi ∈R n and y ∈ {-1,1}l; the support vector machines (SVM) (Boser et al., 1992; Cortes and Vapnik, 1995) require the solution of the following optimization problem: 1分类的很有用的技术。
svm算法原理以及python实现支持向量机(Support Vector Machine,简称SVM)是一种经典的机器学习算法,主要用于分类和回归问题。
SVM的基本思想是找到一个最优的超平面,使得离该超平面最近的样本点到该超平面的距离最大化。
在本文中,我们将介绍SVM 算法的原理,并使用Python进行实现。
一、SVM算法原理1. 数据预处理在使用SVM算法之前,我们需要对数据进行预处理。
常见的预处理步骤包括数据清洗、特征选择和特征缩放等。
数据清洗指的是处理缺失值、异常值和重复值等。
特征选择是从原始数据中选择最相关的特征,以减少计算复杂度和提高预测性能。
特征缩放是对特征进行归一化,使得它们具有相似的量纲。
2. 线性可分情况SVM算法首先考虑线性可分的情况,即存在一个超平面可以完全将两类样本分开。
我们希望找到一个超平面,使得正负样本离该超平面的距离最大化。
假设我们的训练数据为{(x1, y1), (x2, y2), ..., (xn, yn)},其中xi是样本的特征向量,yi是样本的标签。
标签yi只能取+1或-1,表示样本的类别。
超平面的方程可以表示为:w·x + b = 0,其中w是法向量,b是截距。
对于一个样本(xi, yi),离超平面的距离可以表示为:yi(w·xi + b)。
通过最大化边界距离,我们可以得到下面的优化问题:max(2/||w||) subject to yi(w·xi + b) ≥ 1这是一个凸二次规划问题,可以使用拉格朗日乘子法进行求解。
通过求解得到的最优解,我们可以得到超平面的法向量w和截距b。
3. 线性不可分情况在实际问题中,数据往往是线性不可分的。
为了解决这个问题,我们可以使用核函数来将数据从原始空间映射到高维特征空间,使得数据在新的空间中变得线性可分。
常用的核函数有线性核、多项式核和高斯径向基核等。
通过引入核函数,我们可以得到新的超平面方程:f(x) = w·φ(x) + b其中φ(x)表示将原始数据映射到高维特征空间的函数。
SVM算法1. 简介支持向量机(Support Vector Machine,SVM)是一种非常强大的机器学习算法,常用于分类和回归问题。
它的主要思想是找到一个最优的超平面来分隔数据集的不同类别。
SVM算法在实践中表现出色,并且具有较强的泛化能力。
2. SVM的原理SVM的核心思想是将输入空间映射到高维特征空间,并在特征空间中找到最优的超平面。
该超平面能够将不同类别的样本尽可能地分开。
超平面的位置和方向由支持向量确定,支持向量是离超平面最近的样本点。
因此,SVM具有较强的鲁棒性和泛化能力。
SVM算法的数学形式可以描述为最小化以下优化问题:$$ \\min_{w,b}\\frac {1}{2}||w||^2+C\\sum_{i=1}^{n}max(0,1-y_i(wx_i+b)) $$其中,w是超平面的法向量,w是超平面的截距,w是惩罚系数,w w是样本特征向量,w w是样本标签。
以上优化问题可以通过拉格朗日乘子法求解,最终得到超平面的参数。
3. SVM的优点SVM算法具有以下优点:•适用于高维空间:SVM算法将输入空间映射到高维特征空间,使得数据在高维空间中线性可分的可能性更大。
•鲁棒性强:SVM算法通过支持向量确定超平面的位置和方向,支持向量是离超平面最近的样本点,因此SVM对于噪声数据相对不敏感。
•泛化能力好:SVM算法通过最大化样本间隔,使得分类效果更加准确,并且具有较强的泛化能力。
•可解释性强:SVM算法得到的超平面可以提供直观的解释,对于实际应用非常有帮助。
4. SVM的应用SVM算法在机器学习和数据挖掘领域被广泛应用,主要包括以下几个方面:4.1 分类问题SVM算法可以用于分类问题,通过将不同类别的样本划分到不同的超平面上实现分类。
由于SVM算法具有较强的泛化能力,因此在处理复杂问题时往往优于其他分类算法。
4.2 回归问题SVM算法也可以用于回归问题。
对于回归问题,SVM的目标是找到一个超平面,使得样本点尽可能地靠近这个超平面。
一个简单的案例带你了解支持向量机算法支持向量机(Support Vector Machine,简称SVM)是一种常用的监督学习算法,可以用于分类和回归问题。
它的基本思想是将样本映射到高维空间中,使得样本在该空间中能够被一个超平面进行有效地分类或回归。
本文以一个简单的分类问题为例,介绍如何使用Python中的sklearn库实现支持向量机算法。
首先,我们需要导入相关的库和数据集。
这里我们使用sklearn自带的一个经典数据集Iris,该数据集包含了3个分类的鸢尾花的样本。
我们将使用SVM对这些样本进行分类。
```pythonfrom sklearn import datasetsfrom sklearn.model_selection import train_test_splitfrom sklearn.svm import SVCfrom sklearn.metrics import accuracy_score# 导入Iris数据集iris = datasets.load_irisX = iris.datay = iris.target#将数据集划分为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.2, random_state=42)```接下来,我们使用sklearn中的SVC类来创建一个支持向量机分类器,并进行训练。
```python#创建支持向量机分类器svm = SVC#训练分类器svm.fit(X_train, y_train)```训练完成后,我们可以使用测试集来评估模型的准确率。
```python#对测试集进行预测y_pred = svm.predict(X_test)#计算准确率accuracy = accuracy_score(y_test, y_pred)print("准确率:", accuracy)```运行上述代码,即可得到支持向量机分类器在该问题上的准确率。
scikit-learn 支持向量机算法库使用小结 之前通过一个系列对支持向量机(以下简称SVM)算法的原理做了一个总结,本文从实践的角度对scikit-learn SVM算法库的使用做一个小结。scikit-learn SVM算法库封装了libsvm 和 liblinear 的实现,仅仅重写了算法了接口部分。
1. scikit-learn SVM算法库使用概述 scikit-learn中SVM的算法库分为两类,一类是分类的算法库,包括SVC, NuSVC,和LinearSVC 3个类。另一类是回归算法库,包括SVR, NuSVR,和LinearSVR 3个类。相关的类都包裹在sklearn.svm模块之中。
对于SVC, NuSVC,和LinearSVC 3个分类的类,SVC和 NuSVC差不多,区别仅仅在于对损失的度量方式不同,而LinearSVC从名字就可以看出,他是线性分类,也就是不支持各种低维到高维的核函数,仅仅支持线性核函数,对线性不可分的数据不能使用。
同样的,对于SVR, NuSVR,和LinearSVR 3个回归的类, SVR和NuSVR差不多,区别也仅仅在于对损失的度量方式不同。LinearSVR是线性回归,只能使用线性核函数。
我们使用这些类的时候,如果有经验知道数据是线性可以拟合的,那么使用LinearSVC去分类或者LinearSVR去回归,它们不需要我们去慢慢的调参去选择各种核函数以及对应参数,速度也快。如果我们对数据分布没有什么经验,一般使用SVC去分类或者SVR去回归,这就需要我们选择核函数以及对核函数调参了。
什么特殊场景需要使用NuSVC分类和 NuSVR 回归呢?如果我们对训练集训练的错误率或者说支持向量的百分比有要求的时候,可以选择NuSVC分类和 NuSVR 。它们有一个参数来控制这个百分比。
这些类的详细使用方法我们在下面再详细讲述。 2. 回顾SVM分类算法和回归算法 我们先简要回顾下SVM分类算法和回归算法,因为这里面有些参数对应于算法库的参数,如果不先复习下,下面对参数的讲述可能会有些难以理解。
对于SVM分类算法,其原始形式是: min12||w||22+C∑i=1mξimin12||w||22+C∑i=1mξi s.t.yi(w∙ϕ(xi)+b)≥1−ξi(i=1,2,...m)s.t.yi(w∙ϕ(xi)+b)≥1−ξi(i=1,2,...m) ξi≥0(i=1,2,...m)ξi≥0(i=1,2,...m) 其中m为样本个数,我们的样本为(x1,y1),(x2,y2),...,(xm,ym)(x1,y1),(x2,y2),...,(xm,ym) 。w,bw,b 是我们的分离超平面的w∙ϕ(xi)+b=0w∙ϕ(xi)+b=0 系数, ξiξi 为第i个样本的松弛系数, C为惩罚系数。ϕ(xi)ϕ(xi) 为低维到高维的映射函数。
通过拉格朗日函数以及对偶化后的形式为: minα12∑i=1,j=1mαiαjyiyjK(xi,xj)−∑i=1mαimin⏟α12∑i=1,j=1mαiαjyiyjK(xi,xj)−∑i=1mαi s.t.∑i=1mαiyi=0s.t.∑i=1mαiyi=0 0≤αi≤C0≤αi≤C 其中和原始形式不同的αα 为拉格朗日系数向量。K(xi,xj)K(xi,xj) 为我们要使用的核函数。
对于SVM回归算法,其原始形式是: min12||w||22+C∑i=1m(ξ∨i+ξ∧i)min12||w||22+C∑i=1m(ξi∨+ξi∧) s.t.−ϵ−ξ∨i≤yi−w∙ϕ(xi)−b≤ϵ+ξ∧is.t.−ϵ−ξi∨≤yi−w∙ϕ(xi)−b≤ϵ+ξi∧ ξ∨i≥0,ξ∧i≥0(i=1,2,...,m)ξi∨≥0,ξi∧≥0(i=1,2,...,m) 其中m为样本个数,我们的样本为(x1,y1),(x2,y2),...,(xm,ym)(x1,y1),(x2,y2),...,(xm,ym) 。w,bw,b 是我们的回归超平面的w∙xi+b=0w∙xi+b=0 系数, ξ∨i,ξ∧iξi∨,ξi∧为第i个样本的松弛系数, C为惩罚系数,ϵϵ 为损失边界,到超平面距离小于ϵϵ 的训练集的点没有损失。ϕ(xi)ϕ(xi) 为低维到高维的映射函数。
通过拉格朗日函数以及对偶化后的形式为: minα∨,α∧12∑i=1,j=1m(α∧i−α∨i)(α∧j−α∨j)K(xi,xj)−∑i=1m(ϵ−yi)α∧i+(ϵ+yi)α∨imin⏟α∨,α∧12∑i=1,j=1m(αi∧−αi∨)(αj∧−αj∨)K(xi,xj)−∑i=1m(ϵ−yi)αi∧+(ϵ+yi)αi∨
s.t.∑i=1m(α∧i−α∨i)=0s.t.∑i=1m(αi∧−αi∨)=0 00其中和原始形式不同的α∨,α∧α∨,α∧为拉格朗日系数向量。K(xi,xj)K(xi,xj) 为我们要使用的核函数。
3. SVM核函数概述 在scikit-learn中,内置的核函数一共有4种,当然如果你认为线性核函数不算核函数的话,那就只有三种。
1)线性核函数(Linear Kernel)表达式为:K(x,z)=x∙zK(x,z)=x∙z ,就是普通的内积,LinearSVC 和 LinearSVR 只能使用它。
2) 多项式核函数(Polynomial Kernel)是线性不可分SVM常用的核函数之一,表达式为:K(x,z)=(γx∙z+r)dK(x,z)=(γx∙z+r)d ,其中,γ,r,dγ,r,d 都需要自己调参定义,比较麻烦。
3)高斯核函数(Gaussian Kernel),在SVM中也称为径向基核函数(Radial Basis Function,RBF),它是libsvm默认的核函数,当然也是scikit-learn默认的核函数。表达式为:K(x,z)=exp(−γ||x−z||2)K(x,z)=exp(−γ||x−z||2) , 其中,γγ 大于0,需要自己调参定义。
4)Sigmoid核函数(Sigmoid Kernel)也是线性不可分SVM常用的核函数之一,表达式为:K(x,z)=tanh(γx∙z+r)K(x,z)=tanh(γx∙z+r) ,其中,γ,rγ,r 都需要自己调参定义。
一般情况下,对非线性数据使用默认的高斯核函数会有比较好的效果,如果你不是SVM调参高手的话,建议使用高斯核来做数据分析。
4. SVM分类算法库参数小结 这里我们对SVM分类算法库的重要参数做一个详细的解释,重点讲述调参的一些注意点。 参数 LinearSVC SVC NuSVC
惩罚系数C 即为我们第二节中SVM分类模型原型形式和对偶形式中的惩罚系数C,默认为1,一般需要通过交叉验证来选择一个合适的C。一般来说,如果噪音点较多时,C需要小一些。 NuSVC没有这个参数, 它通过另一个参数nu来控制训练集训练的错误率,等价于选择了一个C,让训练集训练后满足一个确定的错误率 nu LinearSVC 和SVC没有这个参数,LinearSVC 和SVC使用惩罚系数C来控制惩罚力度。 nu代表训练集训练的错误率的上限,或者说支持向量的百分比下限,取值范围为(0,1],默认是0.5.它和惩罚系数C类似,都可以控制惩罚的力度。
核函数 kernel LinearSVC没有这个参数,LinearSVC限制了只能使用线性核函数 核函数有四种内置选择,第三节已经讲到:‘linear’即线性核函数, ‘poly’即多项式核函数, ‘rbf’即高斯核函数, ‘sigmoid’即sigmoid核函数。如果选择了这些核函数,对应的核函数参数在后面有单独的参数需要调。默认是高斯核'rbf'。 还有一种选择为"precomputed",即我们预先计算出所有的训练集和测试集的样本对应的Gram矩阵,这样K(x,z)K(x,z) 直接在对应的Gram矩阵中找对应的位置的值。
当然我们也可以自定义核函数,由于我没有用过自定义核函数,这里就不多讲了。
正则化参数penalty 仅仅对线性拟合有意义,可以选择‘l1’即L1正则化或者 ‘l2’即L2正则化。默认是L2正则化,如果我们需要产生稀疏话的系数的时候,可以选L1正则化,这和线性回归里面的Lasso回归类似。 SVC和NuSVC没有这个参数 是否用对偶形式优化dual 这是一个布尔变量,控
制是否使用对偶形式来SVC和NuSVC没有这个参数 优化算法,默认是True,即采用上面第二节的分类算法对偶形式来优化算法。如果我们的样本量比特征数多,此时采用对偶形式计算量较大,推荐dual设置为False,即采用原始形式优化
核函数参数degree LinearSVC没有这个参数,LinearSVC限制了只能使用线性核函数 如果我们在kernel参数使用了多项式核函数 'poly',那么我们就需要对这个参数进行调参。这个参数对应K(x,z)=(γx∙z+r)dK(x,z)=(γx∙z+r)d 中的dd 。默认是3。一般需要通过交叉验证选择一组合适的γ,r,dγ,r,d
核函数参数gamma LinearSVC没有这个参数,LinearSVC限制了只能使用线性核函数 如果我们在kernel参数使用了多项式核函数 'poly',高斯核函数‘rbf’, 或者sigmoid核函数,那么我们就需要对这个参数进行调参。 多项式核函数中这个参数对应K(x,z)=(γx∙z+r)dK(x,z)=(γx∙z+r)d 中的γγ 。一般需要通过交叉验证选择一组合适的γ,r,dγ,r,d 高斯核函数中这个参数对应K(x,z)=exp(−γ||x−z||2)K(x,z)=exp(−γ||x−z||2) 中的γγ 。一般需要通过交叉验证选择合适的γγ
sigmoid核函数中这个参数对应K(x,z)=tanh(γx∙z+r)K(x,z)=tanh(γx∙z+r) 中的γγ 。一般需要通过交叉验证选择一组合适的γ,rγ,r
γγ 默认为'auto',即1特征维度1特征维度