使用GMM方法分析动态面板数据.
- 格式:doc
- 大小:236.50 KB
- 文档页数:5


动态面板数据模型:对微观数据的方法和实践指南摘要本文回顾了动态面板数据模型的计量方法,并给出例子,说明这些程序的使用。
其中一个重点是个人或企业大量的时间段为数量少,典型的数据应用与微观经济观察小组。
重点是与自回归动态及未严格外生解释变数,因此对广义矩估计方法,即在这方面被广泛采用单方程模型。
有两个例子使用企业级别小组进行了详细讨论:一个简单的投资率自回归模型和基本生产功能。
介绍面板数据是目前广泛使用的动态计量经济模型来估算。
它过去在这方面的横截面数据的优点是显而易见的:我们不能估计一个时间点从观察动态模型,这是罕见的单一断面进行调查调查,以提供有关动态关系较早时期的足够信息。
在总的时间序列数据,其优点包括以下可能性:可能是潜在的微观动力学通过聚集偏见,遮蔽的范围1,该小组以调查数据之间提供个人,家庭或企业的不同类型的调整力度异质性。
虽然这些优势是共同的重复交叉部分或队列的数据,从观测伪于分组面板数据可以构造,二真正的面板数据 - 与同一个人重复观测 - 通常的变异allowmore的微观数据将用于建造参数估计,以及允许相对简单的经济计量技术的使用。
动态模型是在经济应用范围广泛,包括欧拉方程家庭消费,为企业的要素需求调整成本模型,以及经济增长的实证模型的兴趣。
即使在因变量的滞后系数不是直接利害关系的,允许在底层的动态过程,可用于恢复,其他参数一致的估计是至关重要的。
一个例子发生在生产函数估计当生产率冲击是序列相关和相对要素投入应对这些冲击,这是下文第3节中讨论进一步。
本文的重点将是对单方程估计,从一个截面单位数目众多面板自回归,分布滞后模型,每个观察了一段时间少数。
这种情况是对个人或公司的微观面板数据,并估算方法不需要时间维变大,以获得一致的参数估计值调用的典型。
对初始条件的属性假设在这种背景下也发挥了重要作用,因为最初的结论性意见以后每次观测的影响不能安全地被忽略的时间维度是短暂的。
我们还着眼于可用于任何严格外生解释变量或文书的情况下,而且容易扩展与预定或内源性的解释变量模型的方法。

动态面板数据估计方法
动态面板数据估计方法主要有以下几种:
1. 差分GMM(DIF-GMM)和系统GMM(SYS-GMM)估计方法:这两
种方法主要适用于短动态面板数据。
差分GMM估计方法被使用的较多,在学术界被广泛用来处理动态面板数据模型中的严重内生性问题。
为了克服这一问题,Blundell和Bond提出了系统广义矩估计即系统GMM估计方法。
系统GMM估计方法是基于差分GMM之上形成的,结合了差分方程和水
平方程,此外,还增加了一组滞后的差分变量作为水平方程相应的工具变量,更具有系统性。
2. 传统的固定效应(FE)、Pesaran和Smith的平均组估计量MG(估计
动态异质面板的长期关系)、Pesaran、Shin和Smith的混合平均组估计PMG(估计动态异质面板中的长期关系)。
此外,还有一些其他的方法如固定效应或随机效应估计、固定效应估计和工具变量估计的组合等。
以上内容仅供参考,建议查阅专业书籍或者咨询专业人士获取更准确的信息。



收稿日期:2010-10-25作者简介:陈芳(1983-),女,湖南新化人,华南理工大学经济与贸易学院管理科学与工程专业博士研究生;研究方向:区域经济的空间经济计量。
中国县域经济差距的收敛性研究———基于动态面板数据的GMM 方法陈芳,龙志和(华南理工大学经济与贸易学院,广东广州510006)Dynamic Panel GMM Analysis of Economic Growth Convergence in ChinaChen Fang,Long Zhihe(School of Economics and Commerce,South China University of Technology,Guangzhou 510006,China )Abstract:In this paper,we use the unbalanced panel data including 1994counties of China from 2000to 2007.We construct a dynamic panel model based on the regional economic structure and growth characteristics of China.Then we analyze the conditional beta-convergence across the counties of China with a GMM dynamic panel estimation method.Empirical results turn out the existence of conditional beta -convergence trend among counties of China.Moreover,we also prove that it is helpful to control the regional disparity if the regional differences of population growth,industrial structure,fiscal expenditure and investment gradually reduced.Key words:economic growth,conditional beta-convergence,county economy,dynamic panel data,GMM摘要:基于我国2000—2007年1994个县(及县级市)的非平衡面板数据,采用动态面板分析方法,对我国县域经济发展差距的条件β收敛性进行验证。

数字普惠金融如何影响实体经济的发展基于系统GMM模型和中介效应检验的分析一、本文概述本文旨在深入探索数字普惠金融如何影响实体经济的发展,利用系统GMM模型和中介效应检验的分析方法,对这一问题进行全面而细致的研究。
随着科技的快速发展,数字普惠金融作为一种新型的金融模式,已经逐渐成为推动实体经济发展的重要力量。
然而,其影响机制和作用路径尚未得到充分的理解和阐述。
因此,本文旨在揭示数字普惠金融与实体经济之间的内在联系,为政策制定者和实践者提供有价值的参考。
本文首先将对数字普惠金融和实体经济的概念进行界定,明确研究范围和对象。
接着,通过文献综述的方式,梳理国内外关于数字普惠金融与实体经济关系的研究现状,找出研究的空白点和不足之处。
在此基础上,本文构建了一个理论框架,提出了研究假设,即数字普惠金融的发展会促进实体经济的增长,并且这种影响是通过一系列中介变量实现的。
为了验证这一假设,本文采用了系统GMM模型和中介效应检验的方法。
系统GMM模型可以充分考虑数据的动态性和内生性问题,使得估计结果更加准确可靠。
而中介效应检验则可以揭示数字普惠金融影响实体经济的具体路径和机制。
通过这两种方法的结合使用,本文希望能够全面揭示数字普惠金融与实体经济之间的内在联系。
本文将对研究结果进行详细的解释和讨论,提出相应的政策建议和实践启示。
也会对研究的局限性和未来研究方向进行说明,以期为后续研究提供参考和借鉴。
二、文献综述随着数字技术的飞速发展,数字普惠金融作为新兴的金融业态,正在逐步渗透到全球经济的每一个角落,并对实体经济产生深远影响。
近年来,国内外学者围绕数字普惠金融与实体经济发展的关系进行了大量研究,旨在揭示这一影响机制的内在逻辑。
在理论框架方面,学者们普遍认为,数字普惠金融通过降低金融服务门槛、提高金融可得性,为实体经济提供了更加便捷、高效的融资渠道。
这一观点得到了许多实证研究的支持。
例如,一些研究发现,数字普惠金融的发展能够有效缓解小微企业融资难、融资贵的问题,从而促进实体经济的发展。

动态面板模型系统GMM 差分GMM Hansen过度识别检验AR检验SPSSAU动态面板模型分析如果在面板模型中,解释变量包括被解释变量的滞后值,此时则称之为“动态面板模型”,其目的是处理内生性问题。
动态面板模型发展分为3个阶段,第1阶段是由Arellano and Bond(1991)提出的差分GMM(difference GMM),第2阶段由Arellano and Bover(1995)提出水平GMM,第3阶段是Blundell and Bond(1998)将差分GMM和水平GMM结合一起进行GMM估计即系统GMM(System GMM)。
SPSSAU默认当前提供差分GMM和系统GMM两种类型,多数情况下使用系统GMM法。
需要注意的是,动态面板模型通常只针对‘大N小T’这样的面板数据,如果T 过大这会导致滞后项很多,待估计参数值可能过多无法拟合等。
动态面板模型时,通常会涉及到几种变量,分别说明如下:显著,就用到第几期。
例如,被解释变量的2期滞后项作为解释变量,1期和2期滞后项都显著,但加上3期滞后项后第2期不显著,第1期仍然显著,则一般只使用滞后的1和2期作为解释变量,不能用3期。
并且必须用1和2期,不能只用1期或2期。
因为结果表明1期和2期都显著,如果只用1期或2期,则会人为造成遗漏变量。
系统GMM在选择被解释变量和解释变量的几期滞后项作为IV时,有较大选择空间。
只要能满足系统GMM的两个检验就行。
系统GMM的两个检验是Hansen过度识别检验和扰动项无自相关AR检验,Hansen过度识别检验研究是否工具变量均为外生变量,如果其对应的p值大于0.05则意味着工具变量均外生,与此同时还需要通过AR检验,AR检验扰动项是否无自相关性,一般来说AR(2)对应的p值>0.05则接受原假设意味着模型通过自相关检验。
动态面板模型构建时,工具变量参数的设置尤其复杂,但无论如何均需要通过Hansen过度识别检验和AR检验,才意味着模型可用,因而建议实际研究中让SPSSAU自动进行参数配置,即设置参数时让系统自动识别寻找最佳模型,当SPSSAU无法自动找出最优模型时,此时结合自身数据及专业实际情况进行逐一参数设置和调整。

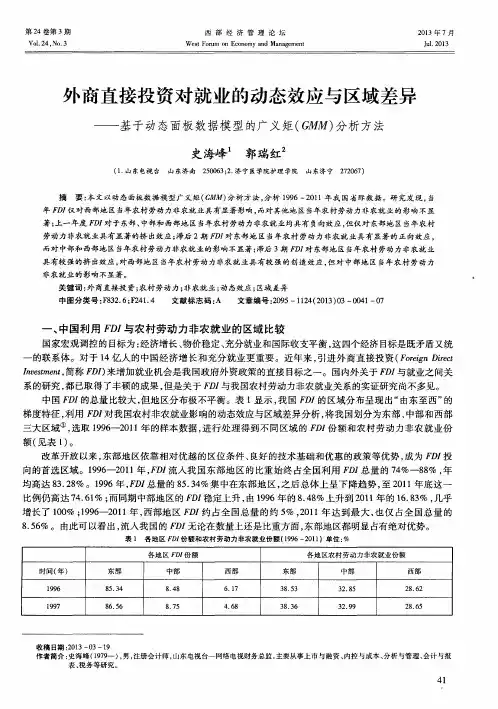
中国人口年龄结构变动对能源消费的影响研究——基于省际动态面板数据的GMM分析张玉周【摘要】人的生产者和消费者的双重身份以及人口结构的动态变化使得人口因素对能源消费的影响极其复杂,不同年龄结构的人口对能源消费会产生不同影响.文章通过将反映人口年龄结构变动的少儿抚养比、老年抚养比和总抚养比3个指标引入扩展的STIRPAT模型,基于我国30个省市区1996-2013年的面板数据,利用GMM法对我国人口年龄结构变动对能源消费的影晌进行了实证分析,结果表明:少儿抚养比、总抚养比、前期能源消费、经济增长、居民消费等因素对我国能源消费均具有显著影响,老年抚养比对能源消费的影响暂时不显著,但随着人口老龄化的加剧其影晌会逐步显现;少儿抚养比和总抚养比与能源消费反方向变动;前期能源消费对当期能源消费存在显著正影响;经济增长和居民消费与能源消费同方向变动;在所有影响能源消费的因素中,前期能源消费的作用最大,少儿抚养比和总抚养比变动对能源消费的影响已超过经济增长,正逐步成为影响能源消费的主要因素.基于此,文章提出应将人口年龄结构因素纳入相关政策视野,适时调整完善人口政策,根据人口年龄结构变动特征不断优化能源消费结构,加快促进经济增长方式转变,大力发展节能技术,逐步提高能源利用率等相关政策建议,以促进我国人口、资源、环境和经济社会的可持续发展.【期刊名称】《中国人口·资源与环境》【年(卷),期】2015(025)011【总页数】6页(P69-74)【关键词】人口年龄结构;能源消费;面板数据;GMM【作者】张玉周【作者单位】河南财经政法大学统计学院,河南郑州450002【正文语种】中文【中图分类】F063.2能源是经济社会发展的重要基础和经济增长的主要动力。
改革开放以来,伴随着我国经济的快速增长,能源消费也在不断增加。
我国能源消费总量由1978年的5.7 亿tce,增加到2013年的37.5亿tce,年均增长6.5%。
动态面板的gmm估计原理动态面板数据模型被广泛应用于经济学和社会科学领域,其中GMM估计(Generalized Method of Moments estimation)是其中一种常用的估计方法。
GMM估计方法适用于含有内生性问题或测量误差的多期数据模型,它利用样本矩条件等式将矩条件矩阵与参数矩阵进行匹配,从而得到一致且有效的估计量。
在动态面板数据模型中,时间维度上的内生性、个体异质性以及序列相关性都需要被处理,GMM估计能够通过引入工具变量和控制变量来解决这些问题。
在介绍GMM估计原理之前,我们先定义动态面板数据模型。
动态面板数据模型可以表示为:Y_{it} = \alpha + \rho Y_{it-1} + X_{it}'\beta + \varepsilon_{it}其中,Y_{it}是因变量,X_{it}是自变量,\alpha是截距项,\rho是滞后项系数,\varepsilon_{it}是误差项。
在这个模型中,有自变量的当前值和滞后值作为解释变量,因此模型包含了一部分动态关系。
GMM估计的目标是寻找一组参数估计值\hat{\theta},使得模型的矩条件期望等式满足:E[\mathbf{g}(\mathbf{Y}, \mathbf{X}, \mathbf{Z}, \hat{\theta})] =\mathbf{0}其中,\mathbf{g}是一个满足一定条件的函数,\mathbf{Y}和\mathbf{X}是观测到的数据矩阵,\mathbf{Z}是工具变量矩阵。
通过构造一组条件矩阵,我们可以得到一组GMM估计方程:\frac{1}{n}\sum_{i=1}^{n}\mathbf{g}(\mathbf{Y}_i, \mathbf{X}_i,\mathbf{Z}_i, \hat{\theta}) = \mathbf{0}GMM估计的关键在于如何选择合适的工具变量和控制变量,并构造满足条件的矩阵。
城乡居民消费结构的动态面板GMM分析作者:张玉春来源:《市场周刊》2019年第09期摘要:本文从人口年龄结构的角度研究我国城镇和农村居民消费结构的差异。
对我国2005~2016年城镇和农村的省级面板数据进行动态面板GMM估计。
结果表明,城乡少儿抚养比的增加会导致教育文化娱乐消费支出的增加;城乡老年抚养比的增加是影响医疗保健支出增加的最重要因素;农村居民消费结构在逐步升级,城镇居民消费结构更加稳定;收入水平低、负担重是限制农村居民消费结构升级的重要因素。
关键词:人口年龄结构;消费结构;面板GMM;消费升级中图分类号:F014.5 文献标识码:A 文章编号:1008-4428(2019)09-0178-03一、引言2005年以来,我国居民消费支出快速增长,但农村居民的消费水平与城镇居民相比仍有较大的差距。
人类的消费模式从低级到高级可以分为生存型、发展型和享受型三种,目前我国农村居民正处于从生存型消费过渡到发展型消费的进程中:2016年利用ELES模型计算的农村居民食品类的边际消费倾向为19.7%,而城镇居民为12.6%:且农村居民交通通信和医疗保健边际消费倾向也显著高于城镇居民。
由于农村居民占全国总人口的44%,所以优化消费结构、促进居民尤其是农村居民的消费是国家实施扩大内需战略、拉动经济增长的重点任务之一。
随着人口老龄化进程的加剧,人口年龄结构因素对消费的影响越来越受到学者的重视。
国内学者对人口年龄结构影响居民消费的研究大多是从加总的宏观角度(王金营,2006;李文星,2008)或者是单独研究人口年龄结构对城镇居民消费或农村居民消费的影响(王宇鹏,2011;李春琦,2009);较少文献研究人口年龄结构对消费结构的影响(马琳,2016;王雪琪,2016)。
由于不同学者选择的解释变量、数据及模型的形式不同,最终得到的分析结果也不完全一致,但几乎没有比较研究城镇居民和农村居民消费结构的。
本文使用分城镇和农村的省级面板数据,对比分析了城镇和农村人口年龄结构变动造成的七类居民消费支出结构的变动。
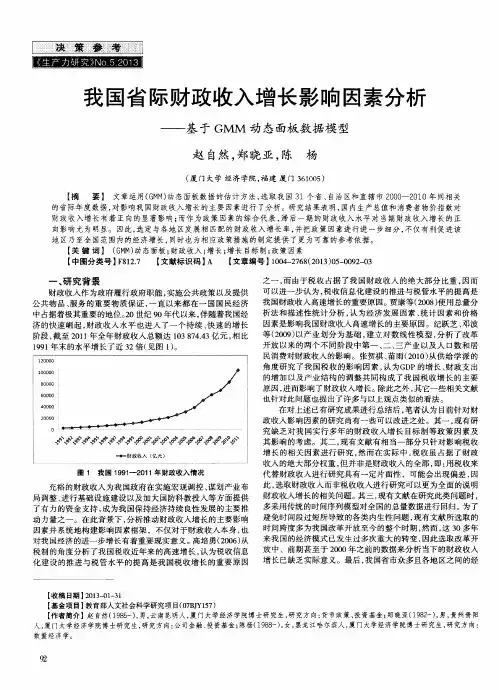
中国人口老龄化对经济增长的影响研究——基于动态面板模型的系统GMM分析摘要随着人口老龄化的加剧和劳动力人口绝对数量的下降,中国第一次人口红利逐渐消失,经济增长须实现从依靠劳动力数量转移到依靠劳动力质量上来。
因此,厘清人口老龄化与经济增长的关系有助于应对人口老龄化可能对经济增长的冲击,保障经济可持续增长和转变经济增长模式,推动全面建成小康社会。
本文基于对国内外文献的系统回顾和梳理,剖析人口老龄化的现状、特征及成因,理清中国人口老龄化对经济增长的影响机理,构建动态面板模型,结合1997-2017年的统计数据,选择系统GMM方法对模型进行估计,发现在其他经济增长驱动因素不变的情况下,人口老龄化对中国经济增长具有一定的负面冲击,通过稳健性检验依然支持此结论,需采取多种措施应对中国老龄化陷阱。
为了避免这一困境,应从以下方面出发:充分发掘第二次人口红利,完善养老保障制度,释放老年人口的相对优势,延伸老年就业市场;适度延缓退休年龄,缓解社会养老负担;同时,健全现阶段的教育培训体系,提高中西部的人力资本存量和改善农村地区的劳动力素质,为地区经济发展提供必要的人才储备。
最后,制定相应的人口迁移政策,减缓地区人口老龄化发展速度,促进区域经济协调发展。
关键字:人口老龄化;经济增长;动态面板模型;系统GMMSTUDY ON THE IMPACT OF CHINA’S POPULATION AGING ON ECONOMIC GROWTH——SYSTEM GMM ANALYSIS BASED ONDYNAMIC PANEL MODELABSTRACTWith the aggravation of the aging of population and the decline of the absolute number of labor force, China's first demographic dividend will gradually disappear, and economic growth must be shifted from relying on the number of labor force to relying on the quality of labor. Therefore, clarifying the relationship between population aging and economic growth can help to cope with the impact of population aging on economic growth, ensure sustainable economic growth, transform economic growth models, and promote the establishment of a well-off society in an all-round way.Based on the systematic review and combing of domestic and foreign literatures, this paper analyzes the current situation, characteristics, and causes of population aging, and clarifies the mechanism of China's population aging on economic growth, builds a dynamic panel model, and combines statistical data from 1997 to 2017. The system GMM method is selected to estimate the model. It is found that under the condition that other economic growth drivers are unchanged, population aging has a certain negative impact on China's economic growth. This conclusion is still supported by the robustness test. It is necessary to take various measures to deal with China's aging trap.In order to avoid this dilemma, we should proceed from the following aspects: fully exploit the second demographic dividend, improve the old-age security system, release the relative advantages of the elderly population, and extend theelderly employment market; moderately delay the retirement age, and ease the burden of social pension; At the same time, improve the current education and training system, improve the stock of human capital in the central and western regions and improve the quality of labor in rural areas, and provide the necessary talent reserves for regional economic development. Finally, the corresponding population migration policies should be formulated to slow down the speed of regional population aging development, and promote the coordinated development of regional economy.KEYWORDS:Population ageing; Economic growth; Dynamic panel model; System GMM目录摘要 (I)ABSTRACT (II)一、引言 (1)1.1研究背景及意义 (1)1.1.1研究背景 (1)1.1.2研究意义 (2)1.2文献综述 (3)1.2.1国外文献综述 (3)1.2.2国内文献综述 (4)1.2.3文献评述 (8)1.3研究思路、内容及方法 (8)1.3.1研究思路与内容 (8)1.3.2研究方法 (10)1.4创新点 (11)二、中国人口老龄化的现状、特征及成因 (12)2.1人口老龄化现状 (12)2.2人口老龄化特征及成因 (14)2.2.1人口老龄化规模大,发展迅速 (14)2.2.2人口老龄化发展不平衡 (15)2.2.3“未富先老”现象 (19)2.2.4人口老龄化成因 (19)三、中国人口老龄化对经济增长影响的理论分析 (21)3.1理论基础 (21)3.1.1人口转变理论 (21)3.1.2古典理论中的经济增长思想 (22)3.1.3新古典经济增长理论 (23)3.1.4内生经济增长理论 (23)3.2模型设计 (24)四、中国人口老龄化对经济增长影响的实证分析 (27)4.1数据来源及模型构建 (27)4.2变量的选取 (28)4.3解释变量与被解释变量间的关联趋势 (29)4.4单位根检验 (31)4.5协整检验 (32)4.6模型估计及解释 (33)4.6.1静态面板模型估计 (33)4.6.2动态面板模型估计 (34)4.7人口老龄化对经济增长影响的区域差异估计 (37)4.8人口老龄化对经济增长影响的稳健性检验 (39)4.9小结 (42)五、结论与建议 (43)5.1结论 (43)5.2相关建议 (43)5.2.1充分利用老年人口机会窗口优势 (43)5.2.2增加社会人力资本存量 (44)5.2.3制定相应的人口迁移政策 (45)参考文献 (46)致谢 (52)一、引言1.1研究背景及意义1.1.1研究背景近40年来,随着人口自然增长率和死亡率下降,中国人口增速逐渐放缓,人口老龄化程度在不断加深。
动态gmm估计方法啥是动态 GMM 估计方法呀?嘿,这可真是个挺高深的玩意儿呢!咱就打个比方吧,它就像是一个神奇的魔法工具,能帮我们在一堆数据的迷雾中找到那条正确的路。
你想啊,数据就像那漫天的星星,一闪一闪的,看着挺热闹,但咱得从这里面找出规律来呀。
动态 GMM 估计方法就是那个能让这些星星有序排列起来的魔法。
它可不是随随便便就能玩转的哦!这需要我们有足够的耐心和细心去研究它。
就好像学骑自行车,一开始可能会摇摇晃晃,但慢慢掌握了技巧,就能骑得稳稳当当啦。
动态 GMM 估计方法在很多领域都大显身手呢!比如说经济学里,它能帮我们分析各种经济现象背后的规律,让那些复杂的数据变得不再那么让人头疼。
它是怎么做到的呢?这就像是一个高明的侦探,通过仔细观察每一个线索,一点点拼凑出整个事件的真相。
它会从大量的数据中提取出关键的信息,然后构建出一个合理的模型。
哎呀,这可真不容易啊!要知道,数据可不是那么好摆弄的,它们有时候就像调皮的小孩子,得好好哄着才行。
但一旦掌握了动态 GMM 估计方法,就好像有了一把万能钥匙,能打开很多知识的大门。
你可能会问了,那这方法难不难学呀?嗯,怎么说呢,肯定不是一蹴而就的啦。
就像爬山,得一步一步地往上爬,中间可能会遇到陡峭的地方,会累得气喘吁吁,但只要坚持,总能爬到山顶,看到那美丽的风景。
学动态GMM 估计方法也是这样呀,一开始可能会觉得云里雾里的,但别着急,慢慢来。
多看看相关的资料,多做些实践,总会慢慢找到感觉的。
而且呀,现在有很多资源可以利用呢!网上有各种各样的教程和例子,还有很多专家分享他们的经验。
咱可不能浪费了这些好东西呀!总之呢,动态 GMM 估计方法虽然有点复杂,但它真的很有用呀!它就像一个隐藏在数据世界里的宝藏,等着我们去发掘呢。
你准备好了吗?让我们一起踏上探索这个神奇方法的旅程吧,说不定会有很多意想不到的收获呢!别再犹豫啦,赶紧行动起来吧!。
GMM 方法与动态面板数据——一个简介2015年8月在阅读文献中经常看到有使用GMM 方法分析动态面板数据,但没有深入研究。
最近开始自己用此方法时,感觉很困惑,因为使用此方法的文献中,对方法的原理大多语焉不详。
对该方法的适用性,为什么用此方法,以及方法优缺点介绍聊聊几句。
因此,通过读文献很难对该方法有全面的把握。
由于时常有学生过来问我怎么用GMM 方法处理动态面板数据,不能总是含糊地回答,同时自己也在写这方面的文章,因此找来几本参考书,搜集了大量的文献,详细阅读之后,撰写本文。
文中主要内容摘要并整理自Roodman (2009),这是STATA 命令xtabond2命令的作者所写的介绍性文章,应该有权威性,如果该文不准确,那么所有使用此命令做的研究将全部失效。
同时参考了Cameron and Trivedi (2009)和(Angrist and Pischke ,2009)等书籍。
本文仅为作者对该方法的理解,如有不妥、疑问或建议请联系:hyang_zhang@ 。
(一) 为什么要用GMM 方法本文所谓动态面板数据(Dynamic Panel data, DPD)分析,指的是分析中采用如下的回归方程:,,1i t i t it i it Y Y X u αβε-=+++ (1)1,...,i N =,1,...,t T =其中,,1i t Y -是因变量的滞后项,i u 是个体i 的固定效应。
因变量的滞后项和固定效应同时存在,是动态面板数据分析特殊性的关键。
如果固定效应不存在,那么回归方程变为:,,1i t i t it it Y Y X αβε-=++ (2)这时,用OLS 或者随机效应模型回归分析即可。
如果因变量的滞后项,1i t Y α-不存在,那么回归方程变为:,i t it i it Y X u βε=++ (3)对于该模型,用固定效应模型分析即可。
如果因变量的滞后项和固定效应都存在,那么对于(1)式这样的回归方程,如果采用差分方法去掉固定效应,会得到如下的结果,,1i t i t it it Y Y X αβε-∆=∆+∆+∆ (4)其中,,,-1=-i t i t i t Y Y Y ∆,,-1,-1,-2=-i t i t i t Y Y Y ∆,,,,-1=-i t i t i t X X X ∆,,,,-1=-i t i t i t εεε∆。
收稿日期:2010-10-25作者简介:陈芳(1983-),女,湖南新化人,华南理工大学经济与贸易学院管理科学与工程专业博士研究生;研究方向:区域经济的空间经济计量。
中国县域经济差距的收敛性研究———基于动态面板数据的GMM 方法陈芳,龙志和(华南理工大学经济与贸易学院,广东广州510006)Dynamic Panel GMM Analysis of Economic Growth Convergence in ChinaChen Fang,Long Zhihe(School of Economics and Commerce,South China University of Technology,Guangzhou 510006,China )Abstract:In this paper,we use the unbalanced panel data including 1994counties of China from 2000to 2007.We construct a dynamic panel model based on the regional economic structure and growth characteristics of China.Then we analyze the conditional beta-convergence across the counties of China with a GMM dynamic panel estimation method.Empirical results turn out the existence of conditional beta -convergence trend among counties of China.Moreover,we also prove that it is helpful to control the regional disparity if the regional differences of population growth,industrial structure,fiscal expenditure and investment gradually reduced.Key words:economic growth,conditional beta-convergence,county economy,dynamic panel data,GMM摘要:基于我国2000—2007年1994个县(及县级市)的非平衡面板数据,采用动态面板分析方法,对我国县域经济发展差距的条件β收敛性进行验证。
对外经济贸易大学金融学院张海洋 S EN ( Z ' ε ( z ' z 1 1 ˆ ˆ E'Z( Z'Z
1 Z'E N
2 j k 然而,该统计量有时候是不一致的,如果在命令中要求报告稳健的Sargan统计量,软件ˆ ;再根会做两阶段GMM估计(先找任意合理的H,令 A=( Z'HZ ,估计出第一步参数β 1 1 ˆ ˆ ,令 A=( Z'ˆ ˆ Z ,估计出第二部参数β ˆ ,计算出残差项的方差-协方差矩阵ˆ )据β 1 2 ,β β 1 1 1 根据第二步的参数结果,默默报告出Hansen统计量。
整体上说,Hansen统计量好像更靠谱一点,所以报告的时候,更多关注Hansen统计量。
(三)动态面板数据现在回到我们的动态面板数据,对数据和模型有如下假定: 1 2
3
4 动态。
模型中包含了因变量的滞后项;有个体的固定效应;可以有一些自变量是内生的;除了固定效应之外的误差项 it 可以异方差,可以序列相关;
5 不同个体之间的误差项 it 和 jt 不会相关。
6
7 可以有前定的(Predetermined)但不是完全外生的变量。
“大N,小T” ,即个体数量要足够多,但时间不用太长。
如果时间足够长的话,动态面板误差不会太大,用固定效应即可。
从上述要求可以看出,GMM方法特别适合宏观的面板数据分析,因为宏观变量中,很难找出绝对外生的变量,变量之间多少会互相影响。
而GMM方法可以“有一些自变量是内生的” ,这可能也是GMM
方法在文献中这么常用的原因。
此前已经说过,不能用传统的OLS方法或者固定效应模型进行动态面板数据的分析,那样会得到有偏的估计量。
先要对数据进行一定的变换,然后根据不同的矩条件设定开展矩估计。
其中数据变换有两种方法,矩条件的设定也有两种方法。
6
对外经济贸易大学金融学院张海洋 1、数据的变换方法:一阶差分还是垂直离差为了消除动态面板数据中的固定效应,通常用的有两种方法:一阶差分 (first difference和垂直离差(orthogonal deviations。
一阶差分之前已经介绍过了,这种方法是difference GMM 中默认的方法。
缺点是如果数据中有缺失值,那么最终的估计会缺失很多样本,原始数据缺一行往往会导致差分后的数据缺两行。
一种替代的方案是用垂直离差(xtabond2 命令中用 orthogonal 选项实现),每个变量减去该变量未来所有观测值的平均值,即: wi ,t 1 cit ( wi ,t 1 Tit w s t is 式子中, cit Tit / (Tit 1 为调整权重变量, Tit 是从t 期开始以后观测值的数量。
对于非平衡面板,和数据有缺失的面板,这种方法避免了因缺失数据带来的样本损失,因为调整的时候只是把未来的平均值减去,样本数不会因缺失未来个别观测值而受损。
然而,对于平衡面板数据,一阶差分和垂直离差估计出来的结果会完全一样。
2、 Different GMM 还是 System GMM 令数据变换之后的回归方程变为 Yi ,t * Yi ,t 1 * X it * it (5)这种变换可以是一阶差分,也可以是垂直离差。
Different GMM的逻辑是,如果是垂直离差变换,用 Yi ,t 2 作为 Yi ,t 1 * 的工具变量;如果是一阶差分变换,用Yi ,t 2 作为 Yi ,t 1 * 的工具变量,此时 Yi ,t 1*=Yi ,t 1 。
X it * 对应的工具变量也类似,如果是垂直离差,就用滞后一阶的,如果是差分就用滞后一阶的差分作为工具变量。
在实现的时候,为了提高估计的有效性,通常还会加入更高阶的滞后项(滞后差分)作为工具变量。
这些变量的加入利用了更多的信息,然而也会带来麻烦,让工具变量的数量随T平方成比例增加。
为了控制工具变量的数量,一个选择就是采用collapse选项把这些工具变量变成一列。
如果因变量的变化过程接近随机游走,那么Difference GMM的估计量会有较大偏差。
7
对外经济贸易大学金融学院张海洋 System GMM的方法和Different GMM完全不同,它不需要对自变量和因变量进行数据变换。
它假定工具变量的差分,即wit =wit wi ,t 1 ,应该外生于固定效应: E ( wit ui =0 。
如果 w 是内生的,wi ,t -1 就可以作为工具变量,更高阶的差分也可以做工具变量。
如果 w 是前定的但不是完全外生的,wi ,t 可以作为工具变量,更高阶的差分也可以做工具变量。
当然,更高阶差分加入后,还是会增加工具变量数量,需要在具体计算时想办法控制。
(四)使用 GMM 方法的注意事项可以尝试先做(2)式的OLS,再做(3)式的固定效应。
当然这两个估计都是有偏误的,然而这两个估计的系数应该是真实系数的上限和下限,可以给最后的 GMM 估计限定参考范围。
“大 N,小T” ,如果 N 太小了,则估计出来的标准差可能不太靠谱。
实际上如果用省际面板去做的话,不满足“大N”这个条件,但中文文献中充斥着这样的研究。
如果样本的 N 较小,但还可以接受(比如 N=70),然而又想用此方法,那么加上 small 选项。
解释变量中,放入时间虚拟变量。
比如,数据有 10 年,则放入 9 个虚拟变量。
加入后,可以让“误差项 it 和 jt 不会相关”这个条件更容易满足。
如果数据中间有间隙,尽量利用垂直离差(对于每个变量,包括自变量和因变量,wit 减去它未来值的平均值,就是加上 orthogonal 选项,见Roodman(2009)),这会减少样本量的损失。
因为数据中间缺一行,一阶差分( wit wi ,t 1 )后就会缺两行数据。
但对平衡面板数据,两种数据变换方法结果一样。
通常,每个自变量都要出现两次(除了系统外的工具变量)。
先作为自变量出现在在 xtabond2 命令中逗号的左边,再以某种形式作为工具变量出现在逗号右边。
如果变量 w 是完全外生的,那么放到 ivstyle(w(表示直接作为工具变量);如果 w 是前定的,但不是完全外生的,则放到 gmmstyle(w (表示从滞后一期开始都作为工具变量) ; 如果 w 是内生的,则放到 gmmstyle(L.w(表示从滞后两期开始都作为工具变量)。
报告工具变量的数量。
如果按照上一条的做法,工具变量的数量会很多。
这样会导致 overidentification test 不准确,【一个标志就是 Hansen 统计量的 p 值变为 1,Hansen test 的 p 值在(0.1,0.25)之外都要小心,太小表明拒绝工具变量有效的假设,太大表明选的工具变量太多, hansen 检验变弱了】。
通常,需要限制工具变量数量,可以用 collapse 选项,也可以用
laglimits(选项。
习惯做法是,选择不同数量的工具变量以显示估计系数的稳健性。
工具变量数量的上限就是模型中个体的数量(也就是 N),超出此上限,xtabond2 命令会报警。
使用 system GMM 的时候要注意,能使用该模型的前提是,工具变量的变化 wit wi ,t 1 8
对外经济贸易大学金融学院张海洋要和固定效应垂直。
因此数据应该在稳态附近,否则这些变量的变化就会和固定效应关系比较大,从而不满足 system GMM 适用的条件。
由于 GMM 方法有很多设定选项,在报告结果时,报告你的选项。
System GMM 还是 Difference GMM;是用垂直离差还是一阶差分;选用什么工具变量,滞后几期;选择什么样的 robust 标准差,等等。
参考文献 [1] Angrist, J. D. and J. Pischke , Mostly Harmless Econometrics. Princeton, New Jersey: Princeton University Press, 2009. [2] Roodman, D. , "How to Do Xtabond2: An Introduction to Difference and System GMM in Stata", The Stata Journal, 2009, 1( 9, 86-136. 9。