ibatis调用存储过程
- 格式:docx
- 大小:12.35 KB
- 文档页数:3

Kettle调用DB存储过程1. 介绍在数据仓库和ETL(Extract, Transform, Load)过程中,使用Kettle这个开源的数据集成工具非常方便。
Kettle(也叫Pentaho Data Integration)提供了丰富的功能,可以处理数据抽取、转换、加载等各个环节。
在ETL过程中,常常需要调用数据库的存储过程来完成一些特定的计算、转换或者是数据处理任务。
本文将讨论如何使用Kettle调用数据库中的存储过程。
2. Kettle概述Kettle是一款功能强大的数据集成工具,它可以从各种数据源中抽取数据,并进行转换、过滤、排序、合并等操作,最后将数据加载到目标数据库中。
Kettle可以通过图形化的方式创建ETL作业,也可以通过编写Kettle的脚本来实现复杂的数据处理任务。
3. 存储过程简介存储过程是一组预定义的SQL语句集合,它们可以在数据库中被调用和执行。
存储过程通常用于完成一些复杂的、需要多步操作的任务,比如数据计算、数据清洗等。
在Kettle中,我们可以使用存储过程来实现一些特定的数据处理逻辑。
4. 在Kettle中调用存储过程的方法4.1 设置数据库连接在Kettle中调用存储过程之前,首先需要设置数据库的连接信息。
在Kettle的工作界面中,选择”数据库连接”选项,然后配置数据库的相关信息,包括数据库类型、主机名、端口号、用户名和密码等。
4.2 创建一个作业在Kettle中,一个作业(Job)是一个由一系列步骤(Step)组成的工作流。
为了调用存储过程,我们需要创建一个新的作业。
4.3 添加步骤在作业中添加一个”SQL脚本”步骤。
在该步骤中,我们可以编写SQL语句调用存储过程。
输入以下SQL语句:CALL存储过程名(参数列表);4.4 设置输入参数如果存储过程接受输入参数,我们需要在”SQL脚本”步骤中设置输入参数。
在”输入参数”选项中,点击”新增”按钮,然后依次设置参数的名称、类型和值。

ibatis iterate用法摘要:1.iBatis 简介2.iBatis Iterate 用法概述3.iBatis Iterate 的具体用法4.示例代码5.总结正文:1.iBatis 简介iBatis 是一个流行的Java 持久层框架,它支持定制化SQL、存储过程以及高级映射。
iBatis 避免了几乎所有的JDBC 代码和手动设置参数以及获取结果集。
iBatis 可以使用简单的XML 或注解进行配置和原生映射,将接口和Java 的POJO(Plain Old Java Objects,普通的Java 对象)映射成数据库中的记录。
2.iBatis Iterate 用法概述在iBatis 中,Iterate 是一个非常有用的标签,用于处理结果集的迭代。
使用Iterate 标签,可以方便地对结果集进行遍历和处理。
iBatis 的Iterate 用法主要分为两种:一种是在SQL 语句中使用,另一种是在Java 代码中使用。
3.iBatis Iterate 的具体用法(1) 在SQL 语句中使用在SQL 语句中使用Iterate,可以通过"foreach" 关键字实现。
以下是一个示例:```sql<select id="findAll" resultMap="userResultMap">SELECT * FROM userWHERE deleted = #{deleted}ORDER BY #{orderBy}</select><iterate open="(" close=")" conjunction="),("><select id="findUserByName" resultMap="userResultMap"> SELECT * FROM user WHERE name = #{name}</select></iterate>```(2) 在Java 代码中使用在Java 代码中使用Iterate,可以通过以下步骤实现:1) 创建一个ResultMap 对象,用于映射结果集到Java 对象。

在易语⾔中调⽤MSSQLSERVER数据库存储过程(Transact-SQL)⽅法总结作者:liigo⽇期:2010/8/25 Microsoft SQL SERVER 数据库存储过程,根据其输⼊输出数据,笼统的可以分为以下⼏种情况或其组合:⽆输⼊,有⼀个或多个输⼊参数,⽆输出,直接返回(return)⼀个值,通过output参数返回⼀个或多个值,返回⼀个记录集(recordset)。
⽆论哪⼀种情况,⽆论输⼊输出参数多复杂的存储过程,都可以在易语⾔中正确调⽤,准确的传⼊参数,并获取正确的输出数据。
下⾯我(liigo)分多种情况介绍在易语⾔中调⽤MS SQL SERVER数据库存储过程的详细⽅法,使⽤数据库操作⽀持库(eDatabase.fne)。
此前多有⼈说易语⾔⽆法调⽤数据库存储过程,或咨询调⽤存储过程的⽅法,因成此⽂。
⼀、调⽤“⽆输⼊输出数据”的存储过程 这是最简单的情况,执⾏⼀个简单的SQL语句就OK了,下⾯直接给出代码:数据库连接1.执⾏SQL (“exec dbproc”) 其中,“数据库连接1”是数据库操作⽀持库中“数据库连接”控件的实例,"exec" 表⽰调⽤存储过程,"dbproc"为被调⽤的存储过程的名称。
即使存储过程有返回值,在不想接收返回值的情况下,也可按这种⽅法调⽤。
⼆、调⽤“有⼀个或多个输⼊参数”的存储过程 ⼀个输⼊参数的情况(其中5为参数值,跟在存储过程名称之后,以空格分隔):数据库连接1.执⾏SQL (“exec dbproc_p1 5”) 两个输⼊参数的情况(其中3和6为参数值,之间以逗号分隔):数据库连接1.执⾏SQL (“exec dbproc_p2 3,6”)三、调⽤“返回记录集(recordset)”的存储过程 存储过程最后⼀条SQL语句为Select语句,通常将返回⼀个记录集(recordset)给调⽤者。
在易语⾔中,可通过数据库操作⽀持库中的“记录集”控件接收该记录集,具体代码如下图:易语⾔调⽤MSSQL存储过程 核⼼代码就是中间淡黄底⾊加亮的那⼀⾏(记录集1.打开),这⾏代码执⾏成功后,记录集1内容就是存储过程返回的recordset内容,通过⼀个简单的循环语句可以遍历所有记录。

mysql存储过程execute的用法在MySQL中,存储过程是一组为了完成特定功能的SQL 语句集。
你可以使用EXECUTE语句来执行存储过程。
以下是如何使用EXECUTE语句执行存储过程的简单示例:1. 创建存储过程首先,让我们创建一个简单的存储过程:sql复制代码:DELIMITER //CREATE PROCEDURE SimpleProcedure()BEGINSELECT 'Hello, World!';END //DELIMITER ;2. 执行存储过程要执行上面的存储过程,你可以使用以下EXECUTE语句:sql复制代码:CALL SimpleProcedure();或者,你也可以使用EXECUTE语句:sql复制代码:EXECUTE SimpleProcedure();3. 使用EXECUTE传递参数如果你想在存储过程中使用参数,你可以这样做:sql复制代码:DELIMITER //CREATE PROCEDURE ParameterizedProcedure(IN param1 INT)BEGINSELECT CONCAT('Parameter value: ', param1);END //DELIMITER ;然后,你可以这样调用它并传递一个参数:sql复制代码:CALL ParameterizedProcedure(123);或者,使用EXECUTE语句:sql复制代码:EXECUTE ParameterizedProcedure(123);4. 注意事项•在使用EXECUTE之前,确保你已经定义了存储过程。
否则,你会收到一个错误。
•如果你使用的是MySQL的某个版本,并且该版本不支持EXECUTE语句,那么你可能需要使用CALL语句来代替。

kettle调用db存储过程
Kettle是一款开源的ETL工具,可以用于数据抽取、转换和加载。
在Kettle中调用数据库存储过程可以方便地实现数据处理和分析。
以下是Kettle调用数据库存储过程的步骤:
1. 创建数据库连接:在Kettle中创建一个数据库连接,连接到要执行存储过程的数据库。
2. 创建转换:在Kettle中创建一个转换,用于调用存储过程并处理返回结果。
3. 添加“调用存储过程”步骤:在转换中添加一个“调用存储过程”步骤。
在该步骤中,需要设置以下参数:
- 数据库连接:选择第一步创建的数据库连接。
- 存储过程名:输入要执行的存储过程的名称。
- 参数列表:输入要传递给存储过程的参数列表。
可以使用变量或常量来设置参数值。
4. 添加“结果集输入”步骤:在转换中添加一个“结果集输入”步骤。
该步骤将返回从存储过程中检索到的数据,并将其传递给下一个步骤
进行处理。
5. 添加其他步骤:根据需要,在转换中添加其他步骤来处理返回数据。
例如,可以使用“选择字段”、“排序”或“插入/更新表格”等步骤来进一步处理数据。
6. 运行转换:保存并运行该转换,即可调用存储过程并处理返回结果。
总之,Kettle调用数据库存储过程的步骤包括创建数据库连接、创建
转换、添加“调用存储过程”步骤、添加“结果集输入”步骤、添加
其他步骤以及运行转换。
通过这些步骤,可以方便地实现数据处理和
分析。

finereport js调用oracle存储过程如何在FineReport中使用JavaScript调用Oracle存储过程FineReport是一款强大的企业级报表设计与展示平台,它与Oracle数据库的集成十分紧密,可以方便地进行数据的查询和处理。
当我们需要在FineReport中使用JavaScript调用Oracle存储过程时,可以按照下面的步骤进行操作。
步骤一:安装FineReport与配置Oracle数据库连接首先,确保您已经安装了FineReport并且已经配置好了与Oracle数据库的连接。
在FineReport中,我们可以通过在数据源配置中设置数据库的连接信息来实现与Oracle数据库的连接。
步骤二:创建存储过程在Oracle数据库中创建存储过程,以供JavaScript调用。
存储过程是在数据库中预定义的一组SQL语句,可以按照需要进行参数传递和数据处理。
例如,我们创建一个简单的存储过程来查询员工表中的数据:CREATE OR REPLACE PROCEDURE get_emp_data ISBEGINSELECT * FROM employees;END;步骤三:在FineReport中创建报表使用FineReport设计工具,创建一个报表用于展示存储过程返回的数据。
在报表设计中,我们可以使用FineReport提供的各种组件来展示数据,例如表格、图表等。
步骤四:使用JavaScript调用存储过程在FineReport中,我们可以使用JavaScript来编写与报表交互的逻辑。
下面是一个示例代码,演示如何使用JavaScript调用Oracle存储过程并将结果展示在报表中:function callProcedure() {var conn = database.openConn(); 打开数据库连接var stmt = conn.prepareStatement("{call get_emp_data}"); 准备调用存储过程的SQL语句var rs = stmt.executeQuery(); 执行查询语句while(rs.next()) {处理查询结果var empName = rs.getString("emp_name");var empAge = rs.getInt("emp_age");var empSalary = rs.getDouble("emp_salary");将结果展示在报表中report.setCellData("employee_table", empName, empAge, empSalary);}rs.close(); 关闭结果集stmt.close(); 关闭语句conn.close(); 关闭连接}在上述代码中,使用database.openConn()方法打开数据库连接,然后使用prepareStatement方法准备调用存储过程的SQL语句。

java jdbc mysql 调用存储过程写法在Java中,使用JDBC调用MySQL存储过程的基本步骤如下:1. 加载MySQL的JDBC驱动。
```javaClass.forName("com.mysql.jdbc.Driver");```2. 建立数据库连接。
```javaConnection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydatabase", "username", "password");```3. 创建CallableStatement对象,并设置存储过程的名称和参数。
```javaCallableStatement cstmt = conn.prepareCall("{call my_stored_proc(?, ?)}");cstmt.setInt(1, 123); // 设置第一个参数为123cstmt.registerOutParameter(2, Types.INTEGER); // 注册第二个参数为输出参数```4. 执行存储过程。
```javacstmt.execute();```5. 获取存储过程的返回值。
```javaint result = cstmt.getInt(2); // 获取第二个参数的值,即存储过程的返回值```6. 关闭连接和语句对象。
```javacstmt.close();conn.close();```完整的示例代码如下:```javaimport java.sql.*;public class JdbcCallProcedureExample {public static void main(String[] args) {try {Class.forName("com.mysql.jdbc.Driver");Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydatabase","username", "password");CallableStatement cstmt = conn.prepareCall("{call my_stored_proc(?, ?)}");cstmt.setInt(1, 123); // 设置第一个参数为123cstmt.registerOutParameter(2, Types.INTEGER); // 注册第二个参数为输出参数cstmt.execute(); // 执行存储过程int result = cstmt.getInt(2); // 获取第二个参数的值,即存储过程的返回值System.out.println("Result: " + result); // 输出结果cstmt.close(); // 关闭语句对象conn.close(); // 关闭连接对象} catch (Exception e) {e.printStackTrace();}}}```。

odbc调用存储过程ODBC(Open Database Connectivity)是一种用于访问数据库的标准接口。
通过ODBC,我们可以使用统一的方式连接和操作不同类型的数据库,包括调用存储过程。
调用存储过程是一种常见的数据库操作,它可以将一系列的SQL语句封装在数据库中,以便在需要时进行重复使用。
下面是关于如何使用ODBC调用存储过程的详细步骤:1. 首先,我们需要确保已经安装了适当的ODBC驱动程序,以便与目标数据库建立连接。
这通常是在操作系统或数据库厂商的官方网站上下载和安装的。
2. 接下来,我们需要在代码中引入ODBC相关的库或模块,以便在程序中使用ODBC接口。
这通常是通过在代码中导入相应的库或模块来实现的。
3. 建立与数据库的连接。
通过使用ODBC连接字符串,我们可以指定要连接的数据库和相关的连接参数。
连接字符串的具体格式和参数可能因数据库类型而异。
4. 执行存储过程。
使用ODBC接口提供的函数或方法,我们可以执行存储过程。
首先,我们需要准备一个ODBC命令对象,然后将存储过程的名称和参数传递给该命令对象。
参数可以是输入参数、输出参数或输入/输出参数,具体取决于存储过程的定义。
5. 处理返回结果。
如果存储过程有返回结果集,我们可以使用ODBC接口提供的方法来获取和处理这些结果。
这通常涉及使用游标或迭代器来遍历结果集,并提取所需的数据。
需要注意的是,具体的代码实现可能因编程语言和ODBC库的不同而有所差异。
因此,在实际使用中,我们需要根据所选的编程语言和ODBC库的文档或示例进行相应的调整。
总结起来,使用ODBC调用存储过程涉及到安装适当的ODBC驱动程序、引入ODBC相关的库或模块、建立与数据库的连接、执行存储过程以及处理返回结果。
这样,我们就可以通过ODBC接口来方便地调用和管理存储过程。

mybatis中sqlrunner的用法MyBatis的SQLRunner是一个帮助执行SQL语句的工具类。
它提供了一系列静态方法,可以用于执行SQL语句、批量执行SQL语句、执行存储过程等。
使用SQLRunner的方法如下:1. 首先,导入SQLRunner类所在的包:javaimport org.apache.ibatis.jdbc.SQLRunner;2. 然后,使用静态方法执行SQL语句。
例如,执行一个查询语句并返回结果:javaString sql = "SELECT * FROM users WHERE id = ?";Object[] params = {1};List<Map<String, Object>> result = SQLRunner.executeQuery(sql, params);该方法接受两个参数:SQL语句和参数数组。
执行查询语句时,会返回一个包含查询结果的List<Map<String, Object>>对象。
3. 如果要执行更新语句(如插入、更新、删除等),可以使用executeUpdate 方法:javaString sql = "INSERT INTO users (name, age) VALUES (?, ?)";Object[] params = {"John", 25};int affectedRows = SQLRunner.executeUpdate(sql, params);该方法返回一个整数值,表示受影响的行数。
4. 如果要批量执行SQL语句,可以使用executeBatch方法:javaString sql = "INSERT INTO users (name, age) VALUES (?, ?)";List<Object[]> paramsList = new ArrayList<>();paramsList.add(new Object[]{"John", 25});paramsList.add(new Object[]{"Alice", 30});int[] affectedRows = SQLRunner.executeBatch(sql, paramsList);该方法接受两个参数:SQL语句和参数列表。
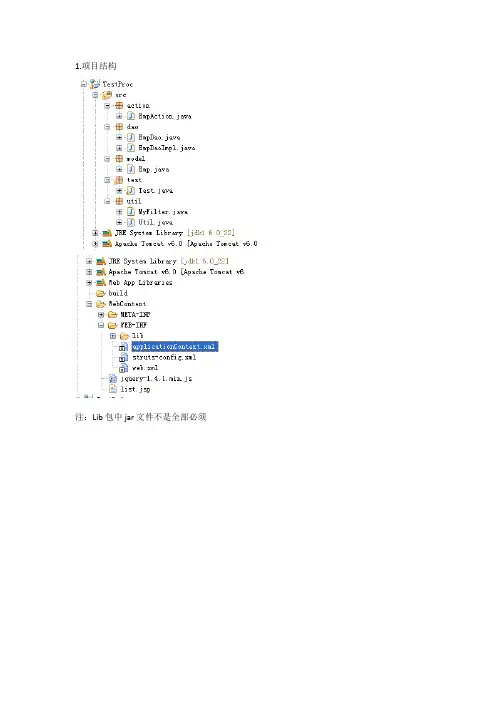
1.项目结构注:Lib包中jar文件不是全部必须2.action包2.1 action.EmpActionpackage action;import java.util.List;import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse;import model.Emp;import org.apache.struts.action.ActionForm; import org.apache.struts.action.ActionForward; import org.apache.struts.action.ActionMapping; import org.apache.struts.actions.DispatchAction;import dao.EmpDao;public class EmpAction extends DispatchAction{public EmpDao dao;public void setDao(EmpDao dao) {this.dao = dao;}public ActionForward list(ActionMapping mapping, ActionForm form,HttpServletRequest request, HttpServletResponse response)throws Exception {List<Emp> emps=dao.list();request.setAttribute("emps", emps);return mapping.findForward("list");}public ActionForward changeEmp(ActionMapping mapping, ActionForm form,HttpServletRequest request, HttpServletResponse response)throws Exception {System.out.println("调用了changeEmpAction");System.out.println(request.getParameter("empno"));int empno=Integer.parseInt(request.getParameter("empno"));String colName=request.getParameter("colName");String val=request.getParameter("val");System.out.println(val);dao.change(empno, colName, val);return mapping.findForward("listDo");}}3.dao包3.1 dao.EmpDaopackage dao;import java.util.List;import model.Emp;public interface EmpDao {public List<Emp> list();public void change(int empno,String colName,String val); }3.2 dao.EmpDaoImplpackage dao;import java.sql.CallableStatement;import java.sql.Connection;import java.sql.ResultSet;import java.util.ArrayList;import java.util.List;import model.Emp;import util.Util;public class EmpDaoImpl implements EmpDao{@Overridepublic List<Emp> list() {Util util = new Util();Connection conn;List<Emp> emps = new ArrayList<Emp>();try {conn = util.getConnection();CallableStatement stmt = conn.prepareCall("{call list(?)}");stmt.registerOutParameter(1, oracle.jdbc.OracleTypes.CURSOR);stmt.execute();ResultSet rs = (ResultSet) stmt.getObject(1);while(rs.next()){Emp emp=new Emp();emp.setEmpno(rs.getInt(1));emp.setEname(rs.getString(2));emp.setJob(rs.getString(3));emp.setMgr(rs.getInt(4));emp.setHiredate(rs.getDate(5));emp.setSal(rs.getInt(6));emp.setComm(rs.getInt(7));emp.setDeptno(rs.getInt(8));emps.add(emp);System.out.println("empno: "+rs.getInt(1)+"ename: "+rs.getString(2)+"job: "+rs.getString(3)+"mgr: "+rs.getInt(4)+"hiredate: "+rs.getDate(5)+"sal: "+rs.getInt(6)+"comm: "+rs.getInt(7)+"deptno: "+rs.getInt(8));}rs.close();util.closeConnection();} catch (Exception e) {e.printStackTrace();}return emps;}@Overridepublic void change(int empno, String colName, String val) {Util util = new Util();Connection conn;try {conn = util.getConnection();CallableStatement stmt = conn.prepareCall("{call change_emp(?,?,?)}");stmt.setInt(1, empno);stmt.setString(2, colName);stmt.setString(3, val);stmt.execute();util.closeConnection();} catch (Exception e) {e.printStackTrace();}System.out.println(empno);System.out.println("调用了changeDao");}public static void main(String[] args) {EmpDaoImpl dao=new EmpDaoImpl();dao.change(7876, "job", "MANAGER");}}4.model包4.1 model.Emppackage model;import java.sql.Date;public class Emp {private int empno;private String ename;private String job;private int mgr;private Date hiredate;private double sal;private double comm;private int deptno;public Emp() {super();// TODO Auto-generated constructor stub }public int getEmpno() {return empno;}public void setEmpno(int empno) { this.empno = empno;}public String getEname() {return ename;}public void setEname(String ename) { this.ename = ename;}public String getJob() {return job;}public void setJob(String job) {this.job = job;}public int getMgr() {return mgr;}public void setMgr(int mgr) {this.mgr = mgr;}public Date getHiredate() {return hiredate;}public void setHiredate(Date hiredate) { this.hiredate = hiredate;}public double getSal() {return sal;}public void setSal(double sal) {this.sal = sal;}public double getComm() {return comm;}public void setComm(double comm) { m = comm;}public int getDeptno() {return deptno;}public void setDeptno(int deptno) { this.deptno = deptno;}5. util 包5.1 util.MyFilterpackage util;import java.io.IOException;import javax.servlet.Filter;import javax.servlet.FilterChain;import javax.servlet.FilterConfig;import javax.servlet.ServletException;import javax.servlet.ServletRequest;import javax.servlet.ServletResponse;/*** Servlet Filter implementation class MyFilter*/public class MyFilter implements Filter {/*** Default constructor.*/public MyFilter() {// TODO Auto-generated constructor stub}/*** @see Filter#destroy()*/public void destroy() {// TODO Auto-generated method stub}/*** @see Filter#doFilter(ServletRequest, ServletResponse, FilterChain)*/public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {request.setCharacterEncoding("utf-8");response.setCharacterEncoding("utf-8");chain.doFilter(request, response);}* @see Filter#init(FilterConfig)*/public void init(FilterConfig fConfig) throws ServletException {// TODO Auto-generated method stub}}5.2 util.Utilpackage util;import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQLException;public class Util {private String url="jdbc:oracle:thin:@10.87.66.174:1521:oracle";private String username="scott";private String password="tiger";private Connection conn;public Connection getConnection()throws Exception{Class.forName("oracle.jdbc.driver.OracleDriver");conn=DriverManager.getConnection(url, username, password);return conn;}public void closeConnection(){if(conn!=null){try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}public static void main(String[] args) throws Exception {Util util=new Util();Connection conn=util.getConnection();System.out.println(conn);}}6.applicationContext.xml<?xml version="1.0" encoding="UTF-8"?><beans xmlns="/schema/beans"xmlns:xsi="/2001/XMLSchema-instance"xmlns:aop="/schema/aop"xmlns:tx="/schema/tx" xsi:schemaLocation="/schema/beans /schema/beans/spring-beans-2.5.xsd/schema/aop/schema/aop/spring-aop-2.5. xsd/schema/tx/schema/tx/spring-tx-2.5.xs d"><bean id="dao" class="dao.EmpDaoImpl"></bean><bean name="/emp" class="action.EmpAction"><property name="dao" ref="dao"></property> </bean></beans>7.struts-config.xml<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE struts-config PUBLIC"-//Apache Software Foundation//DTD Struts Configuration 1.2//EN""/struts/dtds/struts-config_1_2.dtd"><struts-config><action-mappings><action path="/emp" type="action.EmpAction" parameter="method"><forward name="list" path="/list.jsp" /><forward name="listDo" path="emp.do?method=list" /></action></action-mappings><!--Struts 将action交给DelegatingRequestProcessor控制完成这个设置后,Struts会将拦截到的用户请求转发到Springcontext下的bean,根据bean 的name属性来匹配。

I b a t i s2.3A P I使用文档拟制:魏铁胜审核:_______________批准:_______________联创科技(南京)有限公司二零零九年八月一.配置1.第一步配置sqlMap配置文件与sqlMap XML文件,配置文件的简单样例如下:SqlMapConfig.xml(sqlMap配置文件)<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE sqlMapConfigPUBLIC "-////DTD SQL Map Config 2.0//EN""/dtd/sql-map-config-2.dtd"><sqlMapConfig><transactionManager type="JDBC" commitRequired="false"><dataSource type="SIMPLE"><property name="JDBC.Driver" value="oracle.jdbc.driver.OracleDriver"/><property name="JDBC.ConnectionURL" value="jdbc:oracle:thin:@localhost:1521:ora1"/><property name="ername" value="scott"/><property name="JDBC.Password" value="tiger"/></dataSource></transactionManager><!- 这里写出所有的sqlMap XML文件-><sqlMap resource="cn/david/domain/ Person.xml"/></sqlMapConfig>Person.xml(sqlMapXML文件)<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE sqlMapPUBLIC "-////DTD SQL Map 2.0//EN""/dtd/sql-map-2.dtd"><sqlMap namespace="Person"><typeAlias alias="Person" type="cn.david.domain.Person"/><resultMap id="PersonResult" class="Person"><result property="id" column="P_ID"/><result property="name" column="P_NAME"/><result property="email" column="P_EMAIL"/><result property="birthday" column="P_BIRTHDAY"/></resultMap><insert id="insertBySequence" parameterClass="Person"><selectKey keyProperty="id" resultClass="int">select PERSON_SEQ.nextVal as id from dual</selectKey>insert into Person values(#id#,#name#,#email#,#birthday#)</insert>……</sqlMap>说明: typeAlias定义了别名,以后引用中就不用写上类的全限类名, resultMap将Domain Object类与表进行了对应的映射,以后的查询结果就可以引用这个resultMap.Person类是个简单的JavaBean只有id,name,email,birthday几个属性.这个文件中只列出了一种sql insert statement,其他的statement将在例子中给出.,这些文件配置好以后就可以创建SqlMapClient实例,调用它提供的增删改查的方法.2.构建SqlMapClient实例代码如下:Reader reader= Resources.getResourceAsReader("cn/david/test/SqlMapConfig.xml"); SqlMapClient sqlMap = SqlMapClientBuilder.buildSqlMapClient(reader);reader.close();二.用SqlMapClient执行SQL语句SqlMapClient类提供了执行所有mapped statement的API,下文配合相关代码介绍它所有API的使用.1.插入方法Object insert(String id, Object parameterObject) throws SQLException;根据在sqlMapXML文件中mapped statement名称作为第一个参数, 第二个参数是参数对象.向数据库插入数据,返回的Object为主键. 插入动作时用的是sqlMapXML文件中的sql insert statement,sqlMapXML文件中的insert片断如下: <insert id="insertBySequence" parameterClass="Person"><selectKey keyProperty="id" resultClass="int">select PERSON_SEQ.nextVal as id from dual</selectKey>insert into Person values(#id#,#name#,#email#,#birthday#)</insert>说明: Person表的主键生成方式是通过selectKey使用sequence. parameterClass="Person"这里引用了定义的别名,没有写类的全限类名.程序代码: (IbatisCommon类提供了构建SqlMapClient实例的方法getClient) SqlMapClient sqlMap = IbatisCommon.getClient();Person person = new Person();person.setName(“david”);person.setEmail(“xx@”);person.setBirthday(new Date());sqlMap.insert("insertBySequence", person);2.插入方法,只需mapped statement名称一个参数Object insert(String id) throws SQLException;这个方法同Object insert(String id, Object parameterObject)使用一样,只是不需要参数对象.3.更新方法int update(String id, Object parameterObject) throws SQLException;参数id为mapped statement名称, 第二个参数是参数对象.进行更新操作,返回的是受影响的行数. 更新动作时用的是sqlMapXML文件中的sql update statement,sqlMapXML文件中的update片断如下:<update id="updateById" parameterClass="Person">update Person set P_NAME=#name#,P_EMAIL=#email#,P_BIRTHDAY=#birthday#where P_ID=#id#</update>程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();Person person = person = new Person();person.setId(1);person.setName(“robin”);person.setEmail(“robin@”);person.setBirthday(new Date());sqlMap.update("updateById", person);4.更新方法,只需mapped statement名称一个参数int update(String id) throws SQLException;这个方法同update(String id, Object parameterObject)使用一样,只是不需要参数对象. sqlMapXML文件中的update片断如下:<statement id="dropTable">DROP TABLE PERSON</statement>程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();sqlMap.update("dropTable");5.删除方法int delete(String id, Object parameterObject) throws SQLException;删除操作,参数同上,返回受影响的行数. 删除动作时用的是sqlMapXML文件中的sql delete statement,sqlMapXML文件中的delete片断如下:<delete id="deleteByName" parameterClass="ng.String">delete from Person where P_NAME=#name#</delete>程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();sqlMap.delete("deleteByName",”david”);6.删除方法,只需mapped statement名称一个参数int delete(String id) throws SQLException;这个方法同delete(String id, Object parameterObject)使用一样,只是不需要参数对象. sqlMapXML文件中的delete片断如下:<delete id="deleteAll">delete from Person</delete>程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();sqlMap.delete("deleteAll ");7.查询方法,返回的是OjbectObject queryForObject(String id, Object parameterObject) throws SQLException;参数id为mapped statement名称, 第二个参数是参数对象,返回查询得到的新对象.查询动作时用的是sqlMapXML文件中的sql select statement,sqlMapXML文件中的select片断如下:<select id="selectPersonById" resultMap="PersonResult" parameterClass="int"> select * from Person a where a.P_ID=#id#</select>程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();Person person = (Person)sqlMap.queryForObject("selectPersonById", 2);8.查询方法,返回的是OjbectObject queryForObject(String id, Object parameterObject, Object resultObject) throws SQLException;这个方法和上一个方法的唯一区别是通过查询出的对象的值赋给了第三个参数.程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();Person person = new Person();sqlMap.queryForObject("selectPersonById", 2,person);最终查询到对象赋值给了参数person.9.查询方法,返回的是ListList queryForList(String id) throws SQLException;执行一个查询并返回所有的查询结果,返回的是List. 查询动作时用的是sqlMapXML文件中的sql select statement,sqlMapXML文件中的select片断如下: <select id="selectAll" resultMap="PersonResult">select * from Person</select>程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();List list = sqlMap.queryForList("selectAll");10.查询方法,返回的是ListList queryForList(String id, Object parameterObject) throws SQLException;这个方法是根据mapped statement名称和参数对象查询返回List,用法与上一个方法相同.11.查询方法,返回的是List,可以控制返回的结果集List queryForList(String id, Object parameterObject, int skip, int max) throws SQLException;List queryForList(String id, int skip, int max) throws SQLException;这两个方法的后两个参数允许指定跳过结果的数目和返回结果的最大数目.对于查询一个数量很大的结果集,并且不想返回所有的数据时很有用. sqlMapXML文件中的定义片断与其他的查询的一样,程序代码如下:SqlMapClient sqlMap = IbatisCommon.getClient();List list = sqlMap.queryForList("selectByName", name, 3, 5);执行一次查询,返回的结果跳过3行,最终返回的是5行.12.查询方法,可以对返回的每结果行进一步进行处理void queryWithRowHandler(String id, RowHandler rowHandler) throws SQLException;void queryWithRowHandler(String id, Object parameterObject, RowHandler rowHandler) throws SQLException;这两个方法的用途是对查询的结果,可以针对每结果行进一步进行处理, sqlMapXML文件中的定义片断与其他的查询的一样,程序代码有些不同,首先定义一个类实现了RowHandler接口:public class PersonXmlRowHandler implements RowHandler {private StringBuffer xmlDocument = new StringBuffer("<PersonList>");private String returnValue = null;public void handleRow(Object valueObject) {Person person = (Person) valueObject;xmlDocument.append("<name>");xmlDocument.append(person.getName());xmlDocument.append("</name>");}public String getPersonListXml() {if (null == returnValue) {xmlDocument.append("</PersonList >");returnValue = xmlDocument.toString();}return returnValue;}}SqlMapClient sqlMap = IbatisCommon.getClient();PersonXmlRowHandler rh = new PersonXmlRowHandler ();sqlMap.queryWithRowHandler("selectAll",rh);String xmlData = rh.getPersonListXml ();说明:用mapped statement名称为”selectAll”进行查询,最后对查询到的结果封装成自定义的XML字符串.13.查询方法,返回的结果可以进行分页显示PaginatedList queryForPaginatedList(String id, Object parameterObject, int pageSize) throws SQLException;PaginatedList queryForPaginatedList(String id, int pageSize) throws SQLException;这两个方法由于性能原因已不推荐使用.14.查询方法,返回的对象是MapMap queryForMap(String id, Object parameterObject, String keyProp) throws SQLException;将查询到的结果集放在一个Map对象中,这个Map对象用一个传入参数keyProperty作为key值,value值为查询返回的对象,sqlMapXML文件中的片断与其他的查询的一样,程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();Map map = sqlMap.queryForMap("selectPersonById",8, "name");Person p = (Person)map.get("wei7");说明:查询到的结果被保存到Map中,用Person类的name属性作为key,通过name 属性就可以获得查询到的每一个Person对象.15.查询方法,返回的对象是Map,可以指定Map的valueMap queryForMap(String id, Object parameterObject, String keyProp, String valueProp) throws SQLException;此方法与上一个方法区别是将Map的value值指定为结果类中具体的某一个属性,程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();Map map = sqlMap.queryForMap("selectPersonById",8, "name",”email”);String email = (String)map.get("wei7");说明:查询到的结果被保存到Map中,用Person类的name属性作为key,value是Person类的email属性.16.批处理的方法void startBatch() throws SQLException;int executeBatch() throws SQLException;这两个方法在我们要执行很多非查询(如:insert/update/delete)的语句时推荐使用,将它们作为一个批处理来执行,以减少网络通讯流量,并让JDBC Driver进行优化.SQL Map API使用批处理很简单,可以使用两个简单的方法划分批处理的边界,程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();Person person = null;sqlMapClient.startBatch();for (int i=0;i<100;i++) {person = new Person();person.setName(“david” + i);person.setEmail(“xx@”);person.setBirthday(new Date());sqlMap.insert("insertBySequence", person);}sqlMapClient.executeBatch();三.用SqlMapClient执行其他操作1.如何调用数据库中的存储过程或函数首先在数据库在建立一个简单的存储过程testStr只有两个参数,参数类型为in out, sqlMapXML文件中的片断如下:<parameterMap id="procMap" class="java.util.Map"><parameter property="userId" javaType="int" jdbcType="INTEGER" mode="INOUT" /><parameter property="rtnStr" javaType="string" jdbcType="V ARCHAR" mode="INOUT" /></parameterMap><procedure id="callProc" parameterMap="procMap">{call testStr(?,?)}</procedure>程序代码:String rtnStr = "";HashMap map = new HashMap();map.put("userId", 1);map.put("rtnStr", rtnStr);IbatisCommon.getClient().queryForObject("callProc", map);System.out.println(map.get("rtnStr"));2.将查询结果转换成XMLsqlMapXML文件中的片断如下:<select id="selectValueXml" resultClass="xml" xmlResultName="person" parameterClass="int">select * from person where p_id = #value#</select>说明: 注意xmlResultName="person"这是XML内容中根节点显示的值.程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();String xmlData = (String) sqlMap.queryForObject("selectValueXml",new Integer(1));3.动态SQL的用法sqlMapXML文件中的片断如下:<select id="selectByDynSQL" parameterClass="Person" resultMap="PersonResult"> select * from person<dynamic prepend="where "><isNull property="email" prepend="and">p_email IS NULL</isNull><isNotNull property="name" prepend="and">p_name like '%$name$%'</isNotNull><isGreaterEqual property="id" compareValue="10" prepend="and"> p_id >= #id#</isGreaterEqual></dynamic></select>程序代码:SqlMapClient sqlMap = IbatisCommon.getClient();Person p = new Person();p.setId(10);p.setName("wei");List list = sqlMap.queryForList("selectByDynSQL", p)。
oracle procedure 调用 procedure
要调用Oracle存储过程(procedure),可以按照以下步骤进行:
1. 确保具有适当的权限:调用存储过程可能需要一些特定的权限。
请确保你有足够的权限来调用所需的存储过程。
2. 连接到Oracle数据库:使用适当的连接信息,通过Oracle 的客户端工具(如SQL Developer、SQL*Plus或JDBC等)连接到Oracle数据库。
3. 查找存储过程:使用以下语法查找要调用的存储过程:
```
SELECT object_name, object_type
FROM all_objects
WHERE object_type = 'PROCEDURE'
AND object_name = 'your_procedure_name';
```
4. 调用存储过程:根据存储过程的参数要求和语法,使用以下语法调用存储过程:
```
EXECUTE your_procedure_name(parameter1, parameter2, ...); ```
或者
```
BEGIN
your_procedure_name(parameter1, parameter2, ...);
END;
```
5. 检查存储过程的返回结果:根据存储过程的设计,可以使用适当的方法检查和获取存储过程的返回结果。
请注意,以上步骤是一般的指导,具体的步骤可能会根据你的实际需求和环境有所不同。
建议参考Oracle的文档和资源,以获取更详细和准确的信息。
oracle存储过程中动态调用方法
在Oracle存储过程中,您可以使用动态SQL来调用方法。
以下是一个示例,说明如何在存储过程中动态调用一个PL/SQL块:
```sql
CREATE OR REPLACE PROCEDURE dynamic_call AS
v_sql VARCHAR;
BEGIN
-- 构建动态SQL
v_sql := 'BEGIN '
' -- 这里是您的方法'
'END;';
-- 执行动态SQL
EXECUTE IMMEDIATE v_sql;
END dynamic_call;
/
```
在上面的示例中,`v_sql`变量包含一个动态SQL块,该块包含要调用的方
法的代码。
您可以将方法的实际代码插入`BEGIN`和`END;`之间。
要调用此存储过程,可以使用以下语句:
```sql
BEGIN
dynamic_call;
END;
/
```
请注意,使用动态SQL需要谨慎,因为它们可能会引入SQL注入等安全风险。
确保在构建动态SQL时验证和清理输入数据,以避免潜在的安全问题。
TiDB 是一个分布式NewSQL 数据库,它与MySQL 兼容。
在TiDB 中,你可以使用SQL 语句来创建存储过程。
以下是如何在TiDB 中创建存储过程的示例:
1. 登录到TiDB
首先,你需要使用TiDB 的客户端工具或任何支持TiDB 的MySQL 客户端工具登录到TiDB。
mysql -h <tidb-host> -P <port> -u <username> -p
2. 创建存储过程
以下是一个简单的存储过程示例,该存储过程接受一个参数并返回其平方:DELIMITER //
CREATE PROCEDURE SquareValue(IN num INT, OUT square INT)
BEGIN
SET square = num * num;
END //
DELIMITER ;
你可以使用上面的SQL 语句来创建存储过程。
`DELIMITER` 命令用于更改命令分隔符,因为存储过程的定义中包含分号。
3. 调用存储过程
创建存储过程后,你可以调用它:
CALL SquareValue(5, @result);
SELECT @result; -- 这将返回25,因为5 的平方是25。
4. 删除存储过程
如果你想删除存储过程,可以使用以下SQL 语句:
DROP PROCEDURE SquareValue;
注意:在生产环境中操作之前,请确保备份任何重要数据,并充分测试所有操作,以确保它们按预期工作。
sqlserver 函数中调用存储过程
在SQLServer中,我们可以在一个函数中调用存储过程来完成一些特定的任务。
这种方法在某些情况下非常有用,例如当我们需要在函数中使用一些存储过程中的计算结果时。
要在 SQL Server 函数中调用存储过程,我们需要使用 EXECUTE 或 EXECUTE sp_executesql 语句。
下面是一个示例:
CREATE FUNCTION MyFunction (@Param1 INT, @Param2 INT)
RETURNS INT
AS
BEGIN
DECLARE @Result INT
EXECUTE MyStoredProcedure @Param1, @Param2, @Result OUTPUT
RETURN @Result
END
在上面的示例中,我们定义了一个名为 MyFunction 的函数,它接受两个整数参数并返回一个整数值。
在函数体中,我们声明了一个变量 @Result,它将在存储过程中被输出。
然后,我们使用 EXECUTE 语句来调用名为 MyStoredProcedure 的存储过程,并将 @Param1 和@Param2 传递给它。
最后,我们返回 @Result 变量的值。
需要注意的是,我们必须在存储过程中使用 OUTPUT 关键字来将需要返回的结果传递回函数。
另外,我们还需要确保存储过程和函数
在相同的数据库中。
总的来说,调用存储过程是 SQL Server 函数中非常有用的技术,它可以帮助我们完成一些特定的任务,并且可以提高代码的效率和可读性。
Hibernate调用存储过程传参获取返回值简介Hibernate是一个流行的Java持久化框架,它提供了一种将Java对象映射到关系型数据库的方式。
在某些情况下,我们可能需要调用存储过程来执行一些复杂的数据库操作。
本文将介绍如何使用Hibernate调用存储过程,并传递参数和获取返回值。
准备工作在开始之前,我们需要完成以下准备工作:1.安装Java JDK和Hibernate框架。
2.配置Hibernate的数据库连接信息,包括数据库驱动、URL、用户名和密码等。
3.创建数据库存储过程,并确保它已经在数据库中正确地定义和测试。
Hibernate映射文件在使用Hibernate调用存储过程之前,我们需要创建一个Hibernate映射文件来定义存储过程的调用。
下面是一个示例的映射文件:<hibernate-mapping><sql-query name="callStoredProcedure" callable="true">{ call my_stored_procedure(:param1, :param2) }</sql-query></hibernate-mapping>在上面的示例中,我们定义了一个名为”callStoredProcedure”的SQL查询,其中”callable”属性被设置为”true”,表示这是一个调用存储过程的查询。
存储过程的调用语法是{ call procedure_name(:param1, :param2) },其中”:param1”和”:param2”是存储过程的输入参数。
调用存储过程一旦我们有了Hibernate映射文件,我们就可以在Java代码中使用Hibernate来调用存储过程。
下面是一个示例代码:Session session = HibernateUtil.getSessionFactory().getCurrentSession(); Transaction tx = session.beginTransaction();Query query = session.getNamedQuery("callStoredProcedure");query.setParameter("param1", value1);query.setParameter("param2", value2);query.executeUpdate();mit();在上面的示例中,我们首先获取Hibernate的Session对象,并开启一个事务。
finereport 调用postgres 存储过程-回复如何使用FineReport调用PostgreSQL存储过程。
FineReport是一款企业级报表软件,可以帮助用户快速创建和展示报表。
而PostgreSQL是一种功能强大的开源关系型数据库。
在实际应用中,有时需要使用存储过程来执行一系列的数据库操作。
本文将详细介绍如何使用FineReport调用PostgreSQL存储过程,以帮助读者更好地利用这两个工具。
在开始之前,我们需要先进行一些准备工作。
首先,确保你已经安装了FineReport和PostgreSQL,并且两者能够正常运行。
其次,你需要在PostgreSQL中创建一个存储过程,作为我们的示例。
接下来,我们将一步一步地进行操作。
第一步:创建存储过程在PostgreSQL中,我们可以使用CREATE PROCEDURE语句来创建存储过程。
例如,我们创建一个名为get_employee的存储过程,用于获取员工表中的数据。
sqlCREATE OR REPLACE PROCEDURE get_employee() LANGUAGE plpgsqlASBEGINSELECT * FROM employee;END;;以上代码创建了一个简单的存储过程,它从employee表中选择所有的数据。
你可以根据自己的需求编写更复杂的存储过程。
第二步:在FineReport中创建数据集在FineReport中,数据集是用来获取数据库中数据的工具。
我们需要创建一个数据集来调用PostgreSQL中的存储过程。
请按照以下步骤进行操作:1. 打开FineReport,在左侧导航栏中找到“数据集”选项,并点击它。
2. 在数据集界面中,点击“新建”按钮来创建一个新的数据集。
3. 在数据集编辑界面中,选择“数据库查询”作为数据源,然后选择PostgreSQL作为数据库类型。
4. 在连接信息中填写PostgreSQL的相关信息,包括主机名、端口号、数据库名、用户名和密码。
iBatis调用存储过程
1. 什么是iBatis
iBatis是一种持久层框架,用于简化Java应用程序与关系型数据库之间的交互。
它提供了一种简单的方式来执行数据库操作,使开发人员能够更加专注于业务逻辑的实现,而无需过多关注底层数据库的细节。
2. 存储过程的概念
存储过程是一组预定义的SQL语句集合,被存储在数据库中并可以通过名称进行调用。
存储过程可以接受参数,并可以返回结果集或输出参数。
它提供了一种封装和重用SQL代码的方式,提高了数据库的性能和安全性。
3. iBatis调用存储过程的步骤
使用iBatis调用存储过程需要以下步骤:
3.1 配置数据源
首先,需要在iBatis的配置文件中配置数据库连接信息,包括数据库的URL、用
户名、密码等。
这样iBatis才能够连接到数据库。
3.2 定义存储过程的映射
在iBatis的映射文件中,需要定义存储过程的映射关系。
这包括存储过程的名称、参数列表、以及结果集的映射方式等。
3.3 调用存储过程
在Java代码中,可以使用iBatis提供的API来调用存储过程。
首先,需要获取一个iBatis的SqlMapClient对象,然后通过该对象来执行存储过程的调用。
// 获取SqlMapClient对象
SqlMapClient sqlMapClient = SqlMapClientBuilder.buildSqlMapClient(reader);
// 调用存储过程
sqlMapClient.queryForObject("proc_get_user", parameterObject);
3.4 处理存储过程的结果
在执行存储过程之后,可以通过返回的结果对象来获取存储过程的执行结果。
根据存储过程的定义,可能会返回一个结果集或者输出参数。
// 获取存储过程的执行结果
ResultObject result = (ResultObject) sqlMapClient.queryForObject("proc_get_use
r", parameterObject);
// 处理结果
...
4. 示例:调用存储过程获取用户信息
下面以一个示例来说明如何使用iBatis调用存储过程来获取用户信息。
4.1 配置数据源
首先,在iBatis的配置文件中配置数据库连接信息,如下所示:
<settings>
...
</settings>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mydatabase"/> <property name="username" value="root"/>
<property name="password" value="password"/>
</dataSource>
</environment>
</environments>
<mappers>
...
</mappers>
4.2 定义存储过程的映射
在iBatis的映射文件中,定义存储过程的映射关系,如下所示:
<mapper namespace="UserMapper">
<procedure id="getUser" parameterMap="userParamMap">
{ call proc_get_user(#{id, mode=IN}) }
</procedure>
</mapper>
4.3 调用存储过程
在Java代码中,通过iBatis的API来执行存储过程的调用,如下所示:
// 获取SqlMapClient对象
SqlMapClient sqlMapClient = SqlMapClientBuilder.buildSqlMapClient(reader);
// 定义参数对象
Map<String, Object> parameterObject = new HashMap<String, Object>(); parameterObject.put("id", 1);
// 调用存储过程
User user = (User) sqlMapClient.queryForObject("UserMapper.getUser", parameter Object);
4.4 处理存储过程的结果
在执行存储过程之后,可以根据存储过程的定义来处理返回的结果,如下所示:
// 获取存储过程的执行结果
User user = (User) sqlMapClient.queryForObject("UserMapper.getUser", parameter Object);
// 处理结果
if (user != null) {
System.out.println("User ID: " + user.getId());
System.out.println("User Name: " + user.getName());
System.out.println("User Email: " + user.getEmail());
} else {
System.out.println("User not found.");
}
5. 总结
通过使用iBatis调用存储过程,我们可以方便地执行数据库操作,尤其是复杂的业务逻辑。
只需要配置好数据源和存储过程的映射关系,然后调用存储过程即可。
同时,iBatis还提供了灵活的结果集映射方式,使我们能够方便地处理存储过程的执行结果。
以上就是关于iBatis调用存储过程的介绍和示例,希望对你有所帮助。
如果有任何疑问,请随时提问。