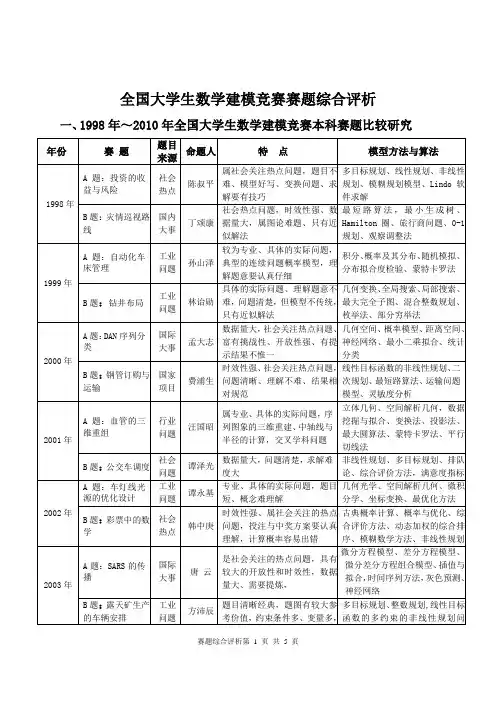
清华大学数学建模竞赛题目
- 格式:doc
- 大小:41.00 KB
- 文档页数:4

2001年全国大学生数学建模竞赛题目●答卷用A4纸,论文题目和摘要写在第一页上,不能有其他任何标志。
●从今年起,将提高摘要在整篇论文评阅中所占的权重。
●全部题目(包括数据)可以从以下网址下载:A题血管的三维重建断面可用于了解生物组织、器官等的形态。
例如,将样本染色后切成厚约1 m的切片,在显微镜下观察该横断面的组织形态结构。
如果用切片机连续不断地将样本切成数十、成百的平行切片,可依次逐片观察。
根据拍照并采样得到的平行切片数字图象,运用计算机可重建组织、器官等准确的三维形态。
假设某些血管可视为一类特殊的管道,该管道的表面是由球心沿着某一曲线(称为中轴线)的球滚动包络而成。
例如圆柱就是这样一种管道,其中轴线为直线,由半径固定的球滚动包络形成。
现有某管道的相继100张平行切片图象,记录了管道与切片的交。
图象文件名依次为0.bmp、1.bmp、…、 99.bmp,格式均为BMP,宽、高均为512个象素(pixel)。
为简化起见,假设:管道中轴线与每张切片有且只有一个交点;球半径固定;切片间距以及图象象素的尺寸均为1。
取坐标系的Z轴垂直于切片,第1张切片为平面Z=0,第100张切片为平面Z=99。
Z=z切片图象中象素的坐标依它们在文件中出现的前后次序为(-256,-256,z),(-256,-255,z),…(-256,255,z),(-255,-256,z),(-255,-255,z),…(-255,255,z),……( 255,-256,z),( 255,-255,z),…(255,255,z)。
试计算管道的中轴线与半径,给出具体的算法,并绘制中轴线在XY、YZ、ZX平面的投影图。
第2页是100张平行切片图象中的6张,全部图象请从网上()下载。
关于BMP图象格式可参考:1. 《Visual C++数字图象处理》第12页2.3.1节。
何斌等编著,人民邮电出版社,2001年4月。
2. /home/mxr/gfx/2d/BMP.txtB题公交车调度公共交通是城市交通的重要组成部分,作好公交车的调度对于完善城市交通环境、改进市民出行状况、提高公交公司的经济和社会效益,都具有重要意义。


2023年全国数学建模竞赛赛题【题目】城市交通流量预测与优化【背景】随着城市化的发展和人口的快速增长,城市交通问题日益突出。
交通流量预测和优化是解决城市交通问题的关键。
本题旨在通过数学建模方法,预测城市某一时段的交通流量,并通过优化策略,提出改善城市交通的方案。
【问题描述】某城市的交通局希望预测下一小时内城市的交通流量,并针对预测结果提出相应的优化策略。
已知该城市的交通网络包含多个路口和道路,且每个路口在不同时段的车辆通过数是不同的。
为了简化问题,假设该城市的交通网络可以表示为一个有向图,路口作为节点,道路作为边。
已知该城市的地理信息和历史交通数据。
任务1:交通流量预测1.根据历史交通数据,建立数学模型来预测下一小时内各个路口的交通流量。
2.给出模型的假设和相关参数,并对模型进行验证。
任务2:交通优化方案1.在预测结果的基础上,分析该城市交通网络的瓶颈路段和拥堵路口。
2.提出优化策略,包括但不限于:增加车道、调整信号灯时长、改善道路状况等。
3.设计一个优化评价指标,并利用该指标评估不同策略的效果。
任务3:方案实施1.选择一个最具代表性的拥堵路口,根据优化策略进行改进。
2.编制改进方案,并对该方案进行成本估算和效果预测。
3.分析改进方案的可行性,并对实施可能遇到的问题进行讨论。
【要求】1.在完成任务1时,要求构建合理的数学模型和算法,考虑到历史数据的可靠性和预测的准确性。
2.在完成任务2时,要求合理设计交通优化策略,并给出可行的方案。
3.在完成任务3时,要求综合考虑方案的成本和效果,并分析其可行性。
4.要求使用逻辑清晰、表达准确的文档,包括模型的建立过程、参数设定、实验结果等。
5.要求对模型进行验证和灵敏度分析,并对结果进行可视化展示和讨论。
【考核标准】1.模型的构建和算法的设计是否合理。
2.预测结果的准确性和优化方案的有效性。
3.对优化方案的成本和效果进行综合评价和分析。
4.文档的逻辑性和可读性。


题1.对非负实数x 令π(x )为不超过x 的素数个数,如π(1)=0,π(2)=1,再令f (x )为第 x 4 +1个素数,求 1000 π(x )+14f (x ) d x 的值.题2.若定义在R 上的光滑函数h (x )在x =0处的泰勒展开为c k x k +c k +1x k +1+···,其中c k =0,则定义ord (h )=k ,若h (x )在x =0处泰勒展开系数均为0,则定义ord (h )=∞,令S = f (x ) f (x )为定义在R 上的光滑函数,满足f ′(0)=1,设m =min {ord (f (g (x ))−g (f (x )))|f (x )∈S,g (x )∈S }1.求m ;2.对于f (x ),g (x )∈S ,设f (i )(0)=a i ,g (i )(0)=b i ,i =2,3,...,求f (g (x ))−g (f (x ))在x =0处泰勒展开式中x m 的系数关于a i ,b i 的表达式.题3.给定正整数n ,设A,B 为n 阶复方阵,满足AB +A =BA +B ,求证(A −B )n =0.题4.对x =(x 1,x 2,x 3)∈Z 3,定义|x |=x 21+x 22+x 23.求所有的实数α,使lim λ→∞x ∈Z 3,0<|x |<λ|x |α存在且有限.题5.给定正整数m ⩾2,n ⩾2以及实数a,b ,设有m +n 阶实方阵A =J K12023年清华大学领军计划专业测试数学一试试题其中J为m阶方阵,K为n阶方阵:J=a00 (00)1a0 (00)01a (00)...............000···a0000···1am×m,K=b00 (00)1b0 (00)01b (00)...............000···b0000···1bn×n.求线性空间{X∈M m+n(R)|AX=XA}的维数.题6.给定整数n⩾2及实数a1,a2,...,a n,令n阶实矩阵A=000···0a1 100···0a2 010···0a3............... 000···0a n−1 000···1a n.对线性空间V=x∈M n(R)X T=X,定义线性变换V→V,F(X)=AXA T,求tr(F)和det(F).题7.给定整数n⩾2.记S n为n阶置换群.考虑线性空间V={(x1,x2,...,x n)∈R n|x1+x2+···+x n=0},对于τ∈S n,定义线性变换ρτ:V→V,(x1,x2,...,x n)→(xτ(1),xτ(2),...,xτ(n)).记χ(τ)=tr(ρτ).1.对τ∈S n,求χ(τ)所有可能取值.2.求τ∈S n(χ(τ))2的值.题8.设p∈[1,+∞),对x∈R n,x=(x1,x2,...,x n),定义∥x∥=ni=1|x i|p1p.问:是否存在常数C,使得对于∀x,y∈R n满足∥x∥p=∥y∥p,以及∀θ∈[0,1],满足∥x−y∥p⩽C∥θx−(1−θ)y∥p若存在,求出C的最小值,若不存在,说明理由.2。

承诺书我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们参赛选择的题号是(从A/B/C/D中选择一项填写):我们的参赛报名号为(如果赛区设置报名号的话):所属学校(请填写完整的全名):参赛队员(打印并签名) :1.2.3.指导教师或指导教师组负责人(打印并签名):日期:年月日赛区评阅编号(由赛区组委会评阅前进行编号):编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):一个给足球队排名次的方法戚立峰毛威马斌(北京大学数学系,100871)指导教师樊启洪摘要本文利用层次分析法建立了一个为足球排名次的数学模型.它首先用来排名次的数据是否充分做出判断,在能够排名次时对数据的可依赖程度做出估计,然后给出名次.文中证明了这个名次正是比赛成绩所体现的各队实力的顺序.文中将看到此模型充分考虑了排名结果对各场比赛的重要性的反馈影响,基本上消除了由于比赛对手的强弱不同造成的不公平现象.文中还证明了模型的稳定性,这保证了各队在发挥水平上的小的波动不会对排名顺序造成大的变动.本模型比较完满地解决了足球队排名次问题,而且经过简单修改,它可以适用于任何一种对抗型比赛的排名.§1 问题的提出及分析本题的表1给出的是我国12支足球队在1988-1989年全国甲级联赛中的成绩,要求通过建立数学模型,对各队进行排名次.按照通常的理解,排名的目的是根据比赛成绩排出反映各队真实实力状况的一个顺序.为达到这一点,一个好的排名算法应满足下面一些基本要求:(1)保序性;(2)稳定性;(3)能够处理不同场比赛的权重;(4)能够判断成绩表的可约性;(5)能够准确地进行补残;(6)容忍不一致现象;(7)对数据可依赖程度给出较为精确的描述.可以想象,各队的真实实力水平在成绩表中反映出来(见§3假定Ⅱ),所以根据排名目的,我们要求排名顺序与成绩表反映的各队实力水平的顺序是一致的,这就是要求(1).也就是说,如果a比b表现出色,a的名次就应排在b前面.但a比b出色不能只是由a对b这一场比赛所决定,必须参考a,b相对于其他队的成绩,像a平c,c胜d,d平b这组比赛对a,b的相对表现是有影响的.为使一个算法满足保序性,就必须充分考虑到将a,b连结起来的所有场比赛.下面的例子表明积分法布满足保序性.例1 a平c,c胜d,d平b,a平b.在上述比赛中a表现应比b出色,但按积分法计算a,b都积2分.其原因就在于积分法没有把a平c,c胜d,d平b这组比赛中所体现的a,b实力对比情况考虑进去;要求(2)就是说成绩表小的变动不会对排名结果造成巨大影响.这是由于球队发挥水平存在正常波动而必须提供的,如果这种正常的小波动引起名次的巨大变化,那么排名就不令人信服;要求(3)使得不同场比赛在排名中的地位不同,这是因为在实际比赛中,往往会有的队不幸遇到较强的队而输掉.为了避免由于对手的强弱不同造成的不公平,要求(3)是必须的.但现在的排名制度大都满足不了要求(3),以至于许多时候“运气”对名次起了重要作用;要求(4)—(7)是为了适应实际比赛中可能会出现在一些复杂情况而提出的.首先是可能某两个队之间没有打比赛,我们称之为数据(成绩)残缺.对于两队成绩残缺,只能通过它们同其他队的比赛成绩来判断它们的实力比较.如果残缺元素过多,就有可能导致参赛队分成两组,组与组之间没有比赛,称这种情况为成绩表可约,这时显然是不应该排名次的.这样就有要求(4),(5);其次是前后比赛成绩矛盾,比如说a胜b,b胜c,c平a,称这种情况为数据不一致.如果不一致的情况过于严重,说明比赛偶然因素太大,数据的可依赖程度太低,应该考虑放弃比赛成绩.所以排名算法还应满足(6),(7).本文使用的层次分析法的特征根方法已满足了上述要求,下面将在§2中给出具体算法.§3中给出算发满足上述要求的解释和论证.§2 模型设计及其算法一、基本假设和名词约定假设Ⅰ参赛各队存在客观的真实实力(见名词约定1).这是任何一种排名算法的基础.假设Ⅱ 在每场比赛中体现出来的强队对弱队的表面实力对比是以它们的真实实力对比为中心的互相对立的正态分布.(见名词约定2)这条假设保证了我们可以以比赛成绩为依据对球队的真实实力进行排名,另外它在很大程度上反映了球队水平发挥的不稳定性.名词约定1 .称w =(12,,,n w w w …)为真实实力向量,如果i w 的大小表现了i T 的实力强弱.当i w 的大小表现了i T 在比赛中出色程度时,称w 为排名向量.由假设Ⅱ,两者应是近似相同的,以后就把它们当成同一个.2 .称i T 对j T 这场比赛中体现出来的i T 对j T 的相对强弱程度为i T 对j T 的表面实力对比,一般记作ij a ,当i T 对j T 成绩残缺是约定ij a =0.显然地有1()0,(),() 1.ij ji ii iji a ii a iii a a ≥== (2.1) 矩阵A=()ij n n a ⨯就称为比赛成绩的判断矩阵,它是可以通过各种方法(见§5)从比赛成绩中求出来的.由假设Ⅱ,若i T 对j T 成绩不残缺且1i j w w ≥时有2~(,)ij i j ij a N w w σ(2.2) 这里w 是真实实力向量.3 .称方阵n n A ⨯为正互反对称的,若(1)ij a >0,(2)1ji ija a =,1,i j n ≤≤.显然一个无残缺的比赛成绩的判断矩阵是正互反对称的.4 .称矩阵n n A ⨯是可约的,若A 能用行列同时调换化1240AA A ⎛⎫⎪⎝⎭,这里1A ,4A 都是方阵,在[1]的227页证明了一个判断矩阵可约当且仅当成绩表可约.5 .称判断矩阵A 是一致的,若对任意1,,i k j n ≤≤满足ij jk ik a a a ⋅=.显然地,A 一致则存在w ,使得()in n jw A w ⨯= (2.3) 6 .称矩阵A 的最大正特征根max λ为主特征根;对应于max λ的右特征向量w 称为主特征向量,若11ni i w ==∑且i w >0.由非负矩阵的Perron-Frobenius 定理,一个判断矩阵A 的max λ存在唯一且可以让对应于max λ的特征向量()1w 的每个分量都大于零,令()()111nii w w w ==∑即得主特征向量.二、模型设计与算法我们的模型的主要部分是一个算法,模型的输入是一张成绩表,输出是关于是否可约的判断、数据可依赖程度值和排名次的结果.算法(一)根据比赛成绩表构造判断矩阵A . i 从1到n,j 从1到n 的循环.1)若i T 与j T 互胜场次相等,则1净胜球=0时令1ij ji a a ==;跳出作下一步循环; 2i T 净胜球多时以i T 净胜j T 一场作后续处理. 2)若i T 净胜j T k 场且k>0,则2,14;19,4.ij k k b k ≤≤⎧=⎨>⎩ 2ij i m T =胜j T 平均每场净胜球数;1,2;0,02;1,0.ij ij ij ij m d m m ⎧>⎪=≤≤⎨⎪-<⎩3,1/ij ij ij ji ij a b d a a =+=.3)若i T 与j T 无比赛成绩,则0ij ji a a ==.(二)检测A 的可约性,如果可约则输出可约信息后退出. (三)构造辅助矩阵~A i 从1到n,j 从1到n 循环~,01,A 000.ij ij ij i i ij a i j a a m i j m i a ≠≠⎧⎪=+=⎨⎪=⎩且;,其中为的第行的个数;,(四)计算~A的主特征根max λ和住特征向量w .1)允许误差ε,任取初始正向量()()()()()000012,,,Tnxx x x =…,令k=0,计算(){}001max i i nm x ≤≤=;()()()()()0000101,,Tny y y x m ==…. 2)迭代计算()()1k k xy +=~A;{}111max k k i i nm x ++≤≤=; ()()1111k k k y x m +++=; 1k k =+; 直到1||k k m m ε+-<.3)()max 1;k k n k ii y m w yλ===∑.(五)按w 各分量由大到小的顺序对参赛各队排名次. (六)计算220011//i j i j ijijij ij w w w w i j i j a a i ja a h w w w w >=≠≠>⎛⎫⎛⎫=-+- ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭∑∑;1(1)22n ii m n n Y =-=-∑;其中i m 为A 的第i 行0的个数.根据2h 查2x 表得到可依赖程度2(2)a P x h =>.关于算法的几点说明算法的第(一)步可以有多种不同的方法,这在§5还将讨论.第(二)步实际上是把A 看作有向图的邻接矩阵表示求图是否连通.算法是标准的,可参阅任何一本有关于算法的书,这里省略.它在可约时作的退出处理保证了以后各步处理的是一个不可约阵.第(三)步使用的是幂法,其整个算法收敛性和正确性的证明可参阅[1]的103页.第(四)步是一个排序,可参阅任何一本有关算法的书.第(五)步我们举了一个例子,若算出2h=47.56,r=48,则在2x 表的自由度为48一行找到47.56,它所在的列的a 值为65%左右.§3 算法的理论分析一、排名的合理性和保序性要求关于为什么无残缺的判断矩阵A 的主特征向量就是排名向量是层次分析法中特征根发的基础,可以在[1]的211页找到详细证明,这里只作简单说明.先假定比赛无残缺,此时算法中~A =A .先看一下A 为一致矩阵时,有(2.3)式存w 使得A (/)i j n n w w ⨯=,显然向量w 就是排名向量.而我们有 1(/),1,2,,ni j j i i w w w n w i n =⋅=⋅=∑…;即A w nw = (3.1) 在[1]的109页证明了下述定理:定理 n 阶互反矩阵是一致的,当且仅当max n λ=.再由(3.1)可见w 还是A 的主特征向量,这样,对于一个一致矩阵A,求排名向量就是求A 的主特征向量.对于一个不一致的判断矩阵A (注意:无残缺),令1,||A ||ij i j na ≤≤=∑(3.2)1/||A ||,1ni ij i w a i n ==≤≤∑; (3.3)由于i w 是A 的第i 列元素(即i T 与其他队的表面实力对比)的和被||A||除,可以猜测它给出了i T 的排序权重.但正如问题分析中所提到的,i T 与j T 的实力对比必须考虑到将i T 与j T 连结起来的所有场比赛,反应到判断矩阵A 上就是所有1121k ii i i i j a a a -…都要考虑进去.令()k ij a 是A k 的第i 行j 列元素,不难看出()112k-1121111k n n nk ij ii i i i j i i i a a a a -====∑∑∑…… (3.4)而()k ij a 就是考虑了所有经过k 场比赛将i T ,j T 连结起来的路径后反映的i T ,j T 的相对强弱,称其为i T 对j T 的k 步优势.当1k i j -=时11k i j a -=,所以(3.4)式成为111211121()1111k k k k k n n n nk ijii i j ii i j i i i i i iaa a a a -----====≠=+∑∑∑∑…………;注意到等式右端一项正是(1)k ij a -,所以k 步优势就隐含了k-1步以及k-2, (1)同(3.3)式,令()()1/||A ||,1,,nk k k ij j wa i n ===∑…; 再令()()()1(,,)k k k Tnw w w =…,可以想象,当k 足够大时,()k w 就给出了A 所反映的排名向量.在[1]的104页正证明了等式A lim A k T k k ew e e→∞=,其中(1,1,,1)T e =…;w 是A 的主特征向量.即 ()lim k k w w →∞=;所以在充分考虑了足够步优势后得到的排名向量()w ∞就是A 的主特征向量w .上面的讨论表明在比赛无残缺时,我们的排名是合理的和保序的,下面来看看残缺的情况.二、残缺的处理对于一个残缺的判断矩阵A,可以通过下述方法转化成一中讨论的情形,0,,0,ij ij ij ijij ij a a c d a d ≠⎧=⎨=⎩其中为正数,如果这样得到得矩阵C=()ij n n c ⨯的主特征向量为w ,那么当/ij i j d w w =时,我们认为补残是准确的.如果令,0;/,0;ij ij ij ij ij a a c w w a ≠⎧=⎨=⎩_,0,;0,0,;1,,i ij ij ij ij ii a a i j a a i j m i j m ≠≠⎧⎪==≠⎨⎪+=⎩是A 的第行0的个数;C ()ij n n c ⨯=;~~A ()ij n n a ⨯=;则有下面命题成立:命题 Cw w λ=等价于~A w w λ=. 证 1,1,,.nij i i j c w w i n λ===∑…110,0(/),1,,.ij ij nnij j i j j i i j j a i ja a w w w w w w i n λ==≠≠=⇔+⋅+==∑∑…1(1),1,,.nij j i i i j i j a w m w w i n λ=≠⇔++==∑…~1,1,,.nij i i j a w w i n λ=⇔==∑…由上述命题还可知,C 的最大特征根也是~A 的主特征根,C 的主特征向量也是A 的主特征向量.这样,我们只需解~max A w w λ=即可,这正是算法(三)、(四)步作的工作.从上面讨论可知,本模型对于残缺的处理是非常准确的,满足了要求(1),(5).另外算法第(二)步对成绩表的可约性作出了判断,这也满足了因为残缺而提出的要求(4).下面继续讨论其余四个要求三、对手的强弱对自己名次的影响排名向量满足~max A w w λ=,即~1max1,1,2,,.ni ijjj w a w i n λ===∑…如果i T 对k T 成绩不残缺,则~0ik ik a a =>,固定ik a ,令k w 变大,则~ik k a w 就会变大,从而引起i w 变大.这实际上是排名结果对每场比赛权重的反馈影响.这样的话,若i T 对k T 战线固定,i T 排名靠前,k T 也会因此受益.这就满足了要求(3).四、模型稳定性的分析不加证明地引用下面定理([1]103页).定理 则A 为n n ⨯复矩阵,1λ是A 的单特征根,B 是n n ⨯矩阵,则一定可以从A+e B (其中|ε|足够小)的特征根中找到一个特征根~λ满足~1()O λλε=+. 由名词的约定6中解释~A 的最大特征根是单的,由上述定理可知,只要判断矩阵的变动微小,主特征根的变动是微小的,进一步容易证明线性方程组~max (A )0E w λ-=的满足111n i w ==∑的解的变动是微小的,即主特征向量的变动是微小的,排名是稳定的,满足了要求(2).五、关于可依赖程度的分析很明显本模型是容忍不一致现象的,即满足要求(6).当A 是一个残缺的不一致矩阵时,由它得到的排名向量设为w ,由名词约定(1)我们认为这既是真实实力向量,令1,,1,,./ijij i j a i j n w w δ=-=…(3.5) 则由(2.2)式可知/1i j w w ≥时,2/~N(0,).//ij i jij ij i j i j a w w w w w w σδ-= (3.6)为计算方便,我们进一步假定/1i j w w ≥时,22/iji jw w σσ=为常数, (3.7)令 22/1/100,i j i j ij ij ij ij w w w w a a i j h δδ>>≠≠>=+∑∑. (3.8)则h 可看作A 的前后矛盾程度,再由(3.6),(3.7)可知22/~r h x σ, (3.9)其中 1(1)22n i i m n n r --=-∑, (3.10) i m 为第i 行零的个数.那么对某个固定0A ,可以通过(3.10)求出0r ,通过(3.8)求出0h ,设随机变量022/~r h x σ,则查2x 表可得到022()h ha P σσ=>(3.11) 称a 为0A 的可依赖程度.则一个判断矩阵0A 的可依赖程度为a 就表示,如果与0A 相同的几个队在同样的比赛程序(队编号相同,残缺元素相同)下踢大量赛季的比赛(假定各队水平不长进),判断矩阵为0A 的这次的前后矛盾程度0h 比大约a ⨯100%的赛季的比赛前后矛盾程度h 要小.2σ的值可以用统计的方法估出,在本模型中我们只是简单地取2σ=12.a 临界值的确定可以很灵活地由比赛组织者决定,也可以通过大量好的和坏的比赛成绩比较给出一个值.这样,我们的模型就满足了要求(7).§4 模型运行结果的分析我们在计算机上实现了上述模型,并对表1中的数据进行了排名,结果是令人满意的,运算时间小于1秒,得到的结果是:排名顺序(由强到弱):731921081265114,,,,,,,,,,,.T T T T T T T T T T T T数据可依赖程度为65%;7T 踢了9场比赛,全部获胜,4T 踢了9场比赛全部输掉,所以7T 第一而4T 最末是显然的.下面考虑一对水平接近的队3T 和1T .在3T ,1T 与其它队的比赛中,只有945,,T T T 的比赛中,1T 成绩比3T 稍好,而在与其余6个队的比赛中,3T 成绩都优于1T ,而且在3T 与1T 比赛时3T 在净胜球方面占了上风,因此将3T 排在1T 前面是合适的.数据可依赖程度为65%说明表1中所给数据还是不错的,当然优于算法中取2σ=12是先验的,这个指标暂时还不是准确的.模型有缺点及改进方向通过与现行的一些排名方法比较,上述模型的优势是很明显的;1)它存在反馈机制,并且具有稳定性,保证了排名的公平和令人信服;2)能较准确地处理残缺,不一致等性质差的数据,对比赛程序没有严格的要求;3)灵活机动,这包括了它提供了对比赛成绩表进行取舍的参考指标,以及它适合任意N 个队任何对抗型比赛的排名;4)满足保序性.模型主要的一个缺点就是算法复杂,必须用到计算机,而且对指导教练制定战略造成了困难,这是无法改进的,但这同时也使球队的战术水平在比赛中的地位上升,有利于刺激竞争.另外我们还基于另一种思路建立了一个便于手算的模型,优于算法简单,效果没有本模型好,本文中省略.在从成绩表构造判断矩阵时用到的方法也不是最好的,它只是为了简单和较合乎常识,这一步在整个模型里引入的误差最大.稍微复杂一点的方法是根据成绩通过查表或专家咨询获得实力对比的值.另外一个不足之处是在某些残缺元素过多的情况下排名的稳定性和可靠性较低,而可依赖程度这个指标并没有考虑这些情况.如比较下面两个判断矩阵,它们的差别就不大.11102110000112011⎛⎫ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭与11021100001110112⎛⎫ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭. 但排名结果分别为4321,,,T T T T 和2134,,,T T T T 结构变化很大.这种情况可以也只能对比赛程序作一些要求,以避免这种几乎可约的情形,本模型并没有作这种工作.还有就是像§4所说的,可依赖程度的计算中取2σ=12是没有多少道理的,这可以通过用统计的方法估出2σ来解决.不基于本模型的不足,模型的改进余地也是很大的.它只使用了层次分析法中单一准则一个层次的排序方法,可以考虑使用多个准则和递阶层次,比如将净胜局数,净胜球数,射门次数,犯规次数作为四个准则,两个层次.甚至能将观众反应等许多细小因素考虑在内,使排名更加反应球队实力.参考文献[1]王莲芬,许树柏,层次分析法引论,中国人民大学出版社,北京,1990。

2023华数杯数学建模c题用dbscan算法1.引言2023年华数杯数学建模竞赛是一场集合数学、计算机科学和实际问题解决能力于一体的综合性比赛。
其中,C题要求参赛者使用dbscan算法来解决一个实际的问题。
本文将就2023华数杯数学建模C题使用dbscan算法的相关问题展开讨论。
2. 算法介绍2.1 dbscan算法的基本原理dbscan算法全称Density-based spatial clustering of applications with noise,是一种基于密度的聚类算法。
该算法将数据点分为核心对象、边界对象和噪声点三种类型,通过计算数据点周围的密度来进行聚类。
核心对象是在给定半径Eps内含有超过MinPts个点的数据点,边界对象是在给定半径Eps内包含少量点的数据点,而噪声点则是既不是核心对象也不是边界对象的点。
2.2 dbscan算法的优势与传统的K-means聚类算法相比,dbscan算法不需要预先指定聚类的数量,且对异常点相对较为鲁棒,对于具有复杂形状和大小差异的聚类集合有很好的效果。
3. 2023华数杯数学建模C题对dbscan算法的要求3.1 问题描述本次比赛的C题是关于城市交通拥堵的问题,要求选手基于给定的交通数据集,使用dbscan算法对城市中的交通拥堵情况进行分析。
要求选手利用该算法确定拥堵区域,并对不同拥堵区域的特征进行描述和分析。
3.2 数据集说明给定的交通数据集包含城市中各交叉路口的车辆流量、车速、拥堵指数等信息,数据量庞大,包含了城市各个不同区域的交通情况。
3.3 算法运用选手需使用dbscan算法对数据集进行聚类分析,确定不同的拥堵区域,并结合实际情况对每个拥堵区域的特征进行描述和分析,最终给出相应的建议和解决方案。
4. 算法实现4.1 数据预处理选手需要对原始数据进行清洗和预处理,包括去除异常值、缺失值的处理,对数据进行标准化等工作,以保证数据的质量和准确性。

清华竞赛试题及答案1. 题目:请解释什么是二进制数,并给出一个十进制数转换为二进制数的例子。
答案:二进制数是一种基数为2的数制,它仅使用0和1两个数字来表示数值。
例如,十进制数5转换为二进制数的过程如下:5除以2得到商2余1,2除以2得到商1余0,1除以2得到商0余1,因此十进制数5转换为二进制数为101。
2. 题目:在物理学中,牛顿第二定律描述了什么?答案:牛顿第二定律描述了力和加速度之间的关系,其公式为F=ma,其中F表示作用在物体上的力,m表示物体的质量,a表示物体的加速度。
3. 题目:请列举三个常见的数据结构,并简要说明它们的特点。
答案:常见的数据结构有数组、链表和栈。
数组是一种线性数据结构,可以存储固定大小的相同类型元素;链表是一种线性数据结构,由节点组成,每个节点包含数据和指向下一个节点的指针;栈是一种后进先出(LIFO)的数据结构,只允许在一端进行插入和删除操作。
4. 题目:在化学中,什么是摩尔?答案:摩尔是物质的量的单位,表示的是一定数量的粒子(如原子、分子、离子等)的集合体。
1摩尔的粒子数等于阿伏伽德罗常数,约为6.022 x 10^23个粒子。
5. 题目:请解释什么是算法的时间复杂度,并给出一个例子。
答案:算法的时间复杂度是指算法执行时间随输入数据量增加而增加的速率。
例如,对于一个简单的线性搜索算法,其时间复杂度为O(n),意味着随着输入数据量的增加,算法的执行时间将线性增加。
6. 题目:在计算机科学中,什么是递归函数?答案:递归函数是一种自我调用的函数,它在其定义中调用自己。
递归函数通常用于解决可以分解为更小、相似问题的问题,例如计算阶乘。
7. 题目:请解释什么是相对论,并列举两个相对论的基本假设。
答案:相对论是物理学中的一种理论,由阿尔伯特·爱因斯坦提出,它描述了在不同参照系中物理现象的相对性。
相对论有两个基本假设:一是物理定律在所有惯性参照系中都是相同的;二是光在真空中的速度在任何惯性参照系中都是常数。

1全国大学生数学建模竞赛竞赛题目汇编(1992-2000)[注]相关优秀论文已经汇编成册正式出版:全国大学生数学建模竞赛组委会编,《全国大学生数学建模竞赛优秀论文汇编(1992-2000)》,北京:中国物价出版社,2002 年3 月出版。
1992 年赛题A 题施肥效果分析某地区作物生长所需的营养素主要是氮(N)、钾(K)、磷(P)。
某作物研究所在该地区对土豆与生菜做了一定数量的实验,实验数据如下列表格所示,其中ha 表示公顷,t 表示吨,kg表示公斤。
当一个营养素的施肥量变化时,总将另二个营养素的施肥量保持在第七个水平上,如对土豆产量关于N 的施肥量做实验时,P 与K 的施肥量分别取为196kg/ha 与372kg/ha。
试分析施肥量与产量之间关系,并对所得结果从应用价值与如何改进等方面作出估价。
土豆:N P K施肥量(kg/ha)产量(t/ha)施肥量(kg/ha)产量(t/ha)施肥量(kg/ha)产量(t/ha)346710113520225933640447115.1821.3625.7232.2939.45 43.15 43.46 40.83 30.75 024 49 73 98 147 196 245 294 342 33.46 32.4736.0637.96 41.0440.0941.2642.17 40.36 42.73 047 93 140 186 279 372 465 558 651 18.98 27.35 34.86 38.52 38.4437.7338.43 43.8746.22生菜:N P K 施肥量(kg/ha)产量(t/ha)施肥量(kg/ha)产量(t/ha)施肥量(kg/ha)产量(t/ha)28568411216822428033639211.0212.7014.5616.2717.7522.5921.6319.3416.1214.1149981471962943914895876.399.4812.4614.3817.1021.9422.6421.3422.0724.53479314018627937246555865115.7516.7616.8916.2417.5619.2017.9715.8420.1119.40(北京理工大学叶其孝提供)B 题实验数据分解组成生命蛋白质的若干种氨基酸可以形成不同的组合。

数学建模竞赛题目
A 题倾斜纸杯的盛水问题
一次性纸杯是生活中常见的容器之一,现有一个一次性纸杯如图,可量得纸杯的高度为95mm ,杯底面直径为50mm ,杯口直径为75mm ,现假定纸杯材料厚度忽略不计
1、若给纸杯注水,则纸杯内可盛水最大体积是多少升?
2、此时将纸杯倾斜如下图所示,设倾斜角度为4πθ=
,求此时杯中最多可盛水多少升?
水平线
3、若忽略水杯的杯口与杯底直径之差,即将水杯看成圆柱体,杯的高度为95mm ,杯底面直径为50mm ,忽略水杯材料厚度,将水杯倾斜,设倾斜角度4π
θ=,
试给出在水不溢出的情况下水面最高点与最低点的高度h 与杯中水的体积v 的函数关系式。
B 题雪堆融化问题
假定一个底面半径为r ,高度为h 的圆锥形雪堆,其融化时体积的变化率正比于雪堆的锥面面积,比例常数为k>0(k 与环境的相对湿度、阳光、空气温度等因素有关),且在融化时假定底面半径保持不变,已知一个小时内融化了其体积的四分之一。
1、给出高度和时间的函数关系式;
2、设圆锥雪堆的底面半径r 为0.5m,高度h 为1m 时,还需多长时间雪堆可全部融化。
C 题校园内垃圾箱的布局问题
观察现在校园内的垃圾箱的布局
1、详细绘制校园内路径图(简化,并测量或者估计距离),如果想使得任何人手提垃圾袋的距离不超过50米,应该在那些地方放置垃圾箱。
如何布局才能使得垃圾箱数目最少?
2、如果在每条主干道之间布置的垃圾箱不能超过两个(两头各安置一个),那么又应该如何布局垃圾箱,使得行人手提垃圾袋的距离最小?。
为杯数学建模d 题一、单选题1.已知函数()11f x x x =-,在下列区间中,包含()f x 零点的区间是( )A .14 ,12⎛⎫ ⎪⎝⎭B .12 ,1⎛⎫ ⎪⎝⎭C .(1,2)D .(2,3)9.已知集合{}3,1,0,2,3,4A =--,{|0R B x x =≤或3}x >,则A B =( )A.∅B.{}3,1,0,4--C.{}2,3D.{}0,2,32.下列函数中,既是偶函数又在区间(0),-∞上单调递增的是( )A .2(1)f x x =B .()21f x x =+C .()2f x x =D .()2x f x -=3.命题:00x ∃≤,20010x x -->的否定是( ) A .0x ∀>,210x x --≤ B .00x ∃>,20010x x --> C .00x ∃≤,20010x x --≤ D .0x ∀≤,210x x --≤4.要得到函数2sin x y e =的图像,只需将函数cos2x y e =的图像( )A .向右平移4π个单位B .向右平移2π个单位C .向左平移4π个单位D .向左平移2π个单位5.“1<x <2”是“x <2”成立的A.充分不必要条件B.必要不充分条件C.充分必要条件D.既不充分也不必要条件6.设32x y +=,则函数327x y z =+的最小值是( )A.12B.6C.27D.307.设集合{}{}234345M N ==,,,,,, 那么M N ⋃=( )A.{} 2345,,,B.{}234,,C.{}345,,D.{}34,8.已知函数()f x 的定义域为[0,2],则(2)()1f x g x x =-的定义域为( ) A.[)(]0,11,2 B.[)(]0,11,4 C.[0,1) D.(1,4]9.2020年,一场突如其来的“肺炎”使得全国学生无法在春季正常开学,不得不在家“停课不停学”.为了解高三学生居家学习时长,从某校的调查问卷中,随机抽取n 个学生的调查问卷进行分析,得到学生可接受的学习时长频率分布直方图(如下图所示),已知学习时长在[9,11)的学生人数为25,则n 的值为( )A .40B .50C .80D .10010.某学校党支部评选了5份优秀学习报告心得体会(其中教师2份,学生3份),现从中随机抽选2份参展,则参展的优秀学习报告心得体会中,学生、教师各一份的概率是( )A .120B .35C .310D .91011.在△ABC 中,角A ,B ,C 的对边分别为a ,b ,c ,若a =3,b =5,c =2acosA ,则cosA =( )A .13 B .24 C .3 D .6二、填空题12.定义在(1,1)-上的函数()f x 满足()()()1f x g x g x =--+,对任意的1212,(1,1),x x x x ∈-≠,恒有()()()12120f x f x x x -->⎡⎤⎣⎦,则关于x 的不等式(21)()2f x f x ++>的解集为( )。
2023年全国数学建模竞赛赛试题一、选择题(每题3分,共30分)下列运算正确的是( )A. 3a + 2b = 5abB. a6÷a2=a3C. (a+b)2=a2+b2D. a3⋅a2=a5下列函数中,是正比例函数的是( )A. y=2xB. y=2x+1C. y=x1D. y=x2下列调查方式中,最适合采用全面调查(普查)的是( )A. 对重庆市中学生每天学习所用时间的调查B. 对端午节期间市场上粽子质量情况的调查C. 对某校七年级(1)班学生视力情况的调查D. 对“神舟十二号”飞船零部件安全性能的检查下列几何体中,主视图是三角形的是_______。
下列说法正确的是_______。
A. 有理数就是有限小数和无限小数的统称B. 一个数的绝对值等于它本身,则这个数是正数C. 数轴上的点仅能表示整数D. 两个数互为相反数,则它们的和为零下列计算正确的是_______。
下列事件中,是必然事件的是_______。
下列各组线段中,能组成三角形的是_______。
若分式x−1x2−1 的值为零,则 x 的值为_______。
在平面直角坐标系中,点P(−2,3)关于 y 轴对称的点的坐标是_______。
二、填空题(每题3分,共18分)若∣x−3∣=5,则 x= _______。
多项式2x2y−3xy+5是_______ 次_______ 项式。
计算:(−a2)3= _______。
若关于 x 的方程 2x+m=3 的解是正数,则 m 的取值范围是_______。
已知一个圆锥的底面半径为 3cm,母线长为 5cm,则这个圆锥的侧面积为_______ cm2。
在平面直角坐标系中,点 A(2,0),点 B(0,4),以原点 O 为位似中心,相似比为 21,把线段 AB 缩小,则点 A 的对应点A′的坐标为_______。
三、解答题(共72分)(8分)解下列方程:(1)3(x−2)+x=4(x−1);(2)32x−1−610x+1=1。
清华大学考试题及答案数学清华大学数学考试题及答案一、选择题(每题3分,共30分)1. 下列哪个选项是最小的正整数?A. 0B. 1C. 2D. -1答案:B2. 函数f(x) = x^2在x=2处的导数是:A. 2B. 4C. 6D. 8答案:A3. 不等式x^2 + 3x + 2 > 0的解集是:A. (-∞, -2)B. (-2, -1)C. (-1, ∞)D. (1, 2)答案:C4. 圆的方程为(x-3)^2 + (y-4)^2 = 25,该圆的半径是:A. 5B. 10D. 20答案:A5. 极限lim (x->0) [sin(x)/x]的值是:A. 0B. 1C. ∞D. 不存在答案:B6. 方程组x + y = 52x - y = 1的解是:A. (1, 4)B. (2, 3)C. (3, 2)D. (4, 1)答案:C7. 集合A = {1, 2, 3},B = {2, 3, 4},则A∪B是:A. {1, 2, 3}B. {1, 2, 3, 4}C. {2, 3}D. {1, 4}答案:B8. 已知数列1, 4, 7, 10, ...的第n项是3n-2,那么该数列的第5项是:A. 10C. 16D. 19答案:B9. 如果一个平面图形的周长是固定的,要使其面积最大,该图形应该是:A. 正方形B. 长方形C. 圆形D. 三角形答案:C10. 微分方程dy/dx = x/y的通解是:A. y^2 = x^2 + CB. y^2 = 2x + CC. x^2 = y^2 + CD. x^2 = 2y^2 + C答案:A二、填空题(每题4分,共20分)11. 圆心在原点,半径为5的圆的方程是________。
答案:(x-0)^2 + (y-0)^2 = 5^212. 函数f(x) = 2x^3 - 6x^2 + 3x的拐点个数是________。
答案:213. 已知向量a = (3, 4),b = (-2, 1),则向量a与b的夹角余弦值为________。
2011年清华大学“华罗庚杯”数学建模竞赛论文格式规范●论文(答卷)用白色A4纸,上下左右各留出2.5厘米的页边距。
●论文第一页为承诺书,具体内容和格式见本规范第二页。
●论文题目和摘要写在论文第二页上,从第三页开始是论文正文。
●论文从第二页开始编写页码,页码必须位于每页页脚中部,用阿拉伯数字从
“1”开始连续编号。
●论文不能有页眉,论文中不能有任何可能显示答题人身份的标志。
●论文题目用3号黑体字、一级标题用4号黑体字,并居中。
论文中其他汉字
一律采用小4号黑色宋体字,行距用单倍行距。
●提请大家注意:摘要在整篇论文评阅中占有重要权重,请认真书写摘要(注
意篇幅不能超过一页)。
●引用别人的成果或其他公开的资料(包括网上查到的资料) 必须按照规定的
参考文献的表述方式在正文引用处和参考文献中均明确列出。
正文引用处用方括号标示参考文献的编号,如[1][3]等;引用书籍还必须指出页码。
参考文献按正文中的引用次序列出,其中书籍的表述方式为:
[编号] 作者,书名,出版地:出版社,出版年。
参考文献中期刊杂志论文的表述方式为:
[编号] 作者,论文名,杂志名,卷期号:起止页码,出版年。
参考文献中网上资源的表述方式为:
[编号] 作者,资源标题,网址,访问时间(年月日)。
2011年清华大学“华罗庚杯”数学建模竞赛
承诺书
我们仔细阅读了清华大学数学建模竞赛的竞赛规则.
我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们参赛的题目是:商务电梯运载效率的分析与建模
参赛队员(打印并签名) :1.
2.
3.
日期: 2011 年 5 月 16 日
2011年清华大学“华罗庚杯”数学建模竞赛
(A题、B题中任选一题)
A题:电梯的运载效率的分析与建模
在高层商务楼里,电梯承担着将人和货物运送到各个楼层的任务。
目前的高层商务楼等大多数高层建筑中,通常都使用传统的单井道单轿箱电梯,单轿箱电梯的特点是,如果电梯轿厢上方楼层的人希望上行,电梯就会一直上行,直到满足了所有“上行请求”后,才会响应“下行请求”,而一旦开始下行,电梯就不再接纳任何希望上行的乘客,直到轿箱下面的楼层不再有下行请求。
使用这样的电梯,经常会出现冗长的等待时间和拥挤的现象,若要提高运载效率,只能通过增加电梯井道数来实现。
双轿厢电梯系统在同一电梯井道内同时拥有两个独立运作的电梯轿厢,两个电梯轿厢具备各自独立的牵引系统、配重和安全系统等,可以不同的方向独立运行分别驶往不同的楼层。
双轿厢电梯和传统的单轿箱电梯最大不同的是,乘客在进入轿厢前就通过特殊的按钮面板选择了要停靠的楼层,这样系统可以迅速地整合分析接收到的流量数据,并调度合适的轿箱来应接乘客,使之能更快地到达目的地。
现有一座商务楼,设计地上层数为28层,地下停车楼2层,每层的建筑面积为1500平方米,楼内有7个电梯井道,其中一个电梯井道用于安装消防电梯,其余的均设计为客梯使用。
电梯按照商务楼建筑面积15至20平方米每人的标准来设计。
第1层的楼层高为4.8米,其余层均为3.2米,设计电梯的平均运行速度1.6米/秒。
问题一:试建立一个合适的单轿箱客梯系统的运行方案,使尽可能地提高电梯系统的运行效率。
问题二:若所有的客梯设计为双轿箱的电梯,请评价该电梯系统与问题一的单轿箱电梯系统的运行方案的优劣性,并分别在运行的高峰期与非高峰期,对双轿箱的电梯系统与单轿箱的电梯系统的运行效率等进行对比分析,并估计双轿箱电梯系统的运行效率能大致能提高多少?
B题:网站搜索引擎中广告收入问题
网络广告收入是目前各大门户网站的最重要的收入来源之一,门户网站利用搜索引擎提供在线广告业务是增加网站收入的重要手段之一。
当网络用户用某网站的搜索引擎查询某一关键词时,在搜索引擎提供的搜索结果的网页中,经常会在该网页的某个地方出现与该关键词相关的产品的广告或服务的链接。
提供这些广告或服务的厂商一般会按其链接的点击次数来支付相应的广告费用。
考虑到关键词的查询以及用户是否点击查询结果网页中的广告或服务的链接具有随机性,不同厂商支付给网站的每次其链接的点击费用是可以不同的,并且由于不同厂商的财力不同,也为避免某些恶意点击,每个厂商在一个固定的广告时段内的总广告支出费用均有自己的上限。
你们的任务是如何针对某个关键词的查询,来设置相应的广告或服务的链接的数量等,使得网站的平均收入达到最大?并根据你们的模型的结果,对网站提供有益的意见。