计量经济分析受教育程度与收入的研究
- 格式:doc
- 大小:131.50 KB
- 文档页数:6

转载请联系计量经济学相关问题1计量经济学是分析啥的?包含些什么内容?计量经济学的主要用途或目的主要有两个方面:1、理论检验。
2、预测应用。
研究对象:计量经济学的两大研究对象: 横截面数据(Cross-sectionalData)和时间序列数据(Time-series Data)。
前者旨在归纳不同经济行为者是否具有相似的行为关联性,以模型参数估计结果显现相关性;后者重点在分析同一经济行为者不同时间的资料,以展现研究对象的动态行为。
新兴计量经济学研究开始切入同时具有横截面及时间序列的资料,换言之,每个横截面都同时具有时间序列的观测值,这种资料称为追踪资料 (Panel data,或称面板资料分析)。
追踪资料研究多个不同经济体动态行为之差异,可以获得较单纯横截面或时间序列分析更丰富的实证结论。
涉及到的相关学科:计量经济学是结合经济理论与数理统计,并以实际经济数据作定量分析的一门学科。
计量经济学以古典回归分析方法为出发点。
依据数据形态分为:横截面数据回归分析、时间序列分析、面板数据分析等。
依据模型假设的强弱分为:参量计量经济学、非参量计量经济学、半参量计量经济学等。
常运用的软件:EViews、Gretl、MATLAB、Stata、R、SAS、SPSS等……2什么叫做伪回归若是所建立的回归模型在经济意义上没有因果关系,那么这个就是伪回归,例如路边小树年增长率和国民经济年增长率之间存在很大的相关系数,但是建立的模型却是伪回归。
如果你直接用数据回归,那肯定存在正相关,而其实这个是没有意义的回归。
3在什么情况下,应将变量取对数再进行回归?为 避免 伪回归,消除异方差,在不改变时间序列的性质及相关性的前提下,为获得平稳数据,通常会对时间序列取自然对数。
对数据进行平稳性检验是研究中不可或缺的步骤,因为时间序列分析法只适用于平稳的数据。
那么什么情况下会对数据取对数呢?第一,关于对数的问题,若是自己选取的变量数据,里面有部分小于0,或者负数,需要重新考量下,看是否数据或者其他问题,此时肯定是没法取对数;第二,针对CD 等生产函数等类型的数据分析,由于建模需要,一般需要取对数,此类情况一般会在柯布道格拉斯函数基础上,引入新的变量,包括但不局限于资本和劳动等变量;第三,平时在一些数据处理中,经常会把原始数据取对数后进一步处理。


我国人口出生率的影响因素分析计量回归分析我国人口出生率是指每千人口中新生儿的数量。
人口出生率是一个国家或地区人口年度增长率的重要因素之一,对于我国的人口结构、经济发展和社会进步具有重要的影响。
本文将采用计量回归分析方法来探讨我国人口出生率的影响因素。
首先,家庭经济状况是影响我国人口出生率的重要因素之一、家庭经济状况好的家庭更容易提供良好的生活条件和教育环境,从而促进生育意愿的增加。
因此,我们可以采用家庭收入或者家庭消费水平作为衡量家庭经济状况的变量。
另外,家庭经济状况也与女性就业率相关,女性就业率的增加可能会影响家庭经济状况和人口出生率。
其次,教育水平也是影响人口出生率的关键因素之一、教育水平的提高可以提高人们的生活质量和工作能力,从而影响生育意愿。
因此,我们可以采用受教育程度作为衡量教育水平的变量。
此外,女性受教育程度的提高可能会影响女性的就业意愿和生育意愿,因此,我们还可以考虑女性受教育程度作为影响因素。
再次,社会保障政策也对人口出生率产生着重要的影响。
社会保障政策的完善可以提高人们的生活保障水平,减少生育风险,从而影响生育意愿。
因此,我们可以采用社会保障开支作为衡量社会保障政策的变量。
最后,文化观念和价值观也是影响人口出生率的因素之一、传统文化观念中重男轻女、多子多福等观念可能会影响人们的生育意愿。
因此,我们可以考虑一些与文化观念和价值观相关的变量,比如核心家庭大小、重男轻女的思想传统等。
综上所述,人口出生率受多方面因素的影响,包括家庭经济状况、教育水平、社会保障政策以及文化观念和价值观等。
对这些因素进行计量回归分析可以更加深入地了解这些因素对人口出生率的具体影响,为我国人口政策的制定和调整提供科学依据。

计量经济学中的blue名词解释计量经济学是经济学的一个分支,它运用数理统计方法和经济理论,对经济现象进行测量和分析。
在计量经济学的研究中,经常会出现一些特定的术语,比如Blue名词。
在本文中,我们将对计量经济学中的Blue名词进行解释和讨论,并深入探究它们在研究中的作用和意义。
1. Blue名词之自变量(exogenous variable)自变量在计量经济学中指的是对某个经济现象产生影响的变量。
在回归分析中,我们将自变量视为独立的变量,不受其他变量的影响。
自变量可以是经济学中的任何因素,如工资水平、物价指数、失业率等。
通过对自变量的测量和分析,我们可以了解其对因变量的影响程度,并可以预测其随着自变量变化可能产生的结果。
2. Blue名词之因变量(endogenous variable)因变量是自变量引起的反应或结果。
在计量经济学中,因变量用来衡量某一经济现象的变化。
例如,在研究收入水平的影响因素时,收入水平即为因变量,而工资水平、教育程度等则作为自变量。
因变量是模型中需要加以解释和预测的变量。
3. Blue名词之蓝色回归(blue regression)蓝色回归是指一种经济学计量方法,它通过进行一系列转换和处理,来解决回归模型中存在的问题。
蓝色回归的主要目标是解决模型中存在的多重共线性问题,即自变量之间存在高度相关的情况。
蓝色回归方法利用了辅助变量,通过将原始模型进行改进,消除自变量之间的多重共线性,从而得到更加可靠和准确的估计结果。
4. Blue名词之蓝色函数(blue function)蓝色函数是指在计量经济学中对某个未知函数进行估计的过程。
通常情况下,我们无法直接获得一个经济关系的函数形式,因此需要通过估计技术来估计这个未知函数。
蓝色函数方法是一种非参数估计方法,它不依赖于对函数形式的假设,能够更加灵活地捕捉经济现象的变化规律。
5. Blue名词之蓝色变量(blue variable)蓝色变量是指在计量经济学中具有随机性的变量。

heckman两阶段法的应用HECKMAN两阶段法(Heckman two-step approach)是一种经济计量方法,常用于解决因果效应评估的问题。
该方法通常被应用于处理选择性取样问题,其中一个变量的取值仅在某些特定条件下才能观察到。
本文将详细介绍HECKMAN两阶段法的应用。
HECKMAN两阶段法是由经济学家James Heckman于1979年提出的。
它基于开始于正态分布的隐变量模型(random utility model)的原理,并结合一种选择性取样模型(sample selection model),从而解决了选择性取样问题。
在介绍HECKMAN两阶段法的具体应用之前,我们先来了解一下选择性取样问题的本质。
选择性取样问题存在于许多经济和社会科学研究中。
简言之,选择性取样问题是指研究者能够观察到的样本并不代表整个总体,因为某些样本只有在满足某些特定条件时才会被观察到。
假设我们希望研究教育对工资的影响,即教育的因果效应。
在真实情况下,我们可能只能观察到劳动力市场中已经工作的人们的工资和教育程度。
然而,如果我们仅仅依据这个样本进行分析,就可能忽略了那些没有就业的人们和没有接受教育的人们。
这样,我们就会面临一个选择性取样问题,即因为工资的观察条件是就业状态,而就业状态又受到教育程度的影响,所以只能观察到部分数据。
这时,我们就可以借助HECKMAN两阶段法来解决选择性取样问题。
HECKMAN两阶段法是基于两个步骤的操作原理而得名。
第一步是估计参与方程(participation equation),用于估计选择进入分析的效应变量的条件概率。
在上述例子中,参与方程是用于估计就业状态对教育程度的影响。
通过对参与方程进行估计,我们可以得到一个关于就业状态的回归模型,从而控制了观察到的教育程度和未观察到的教育程度之间的影响。
第二步是估计结果方程(outcome equation),用于估计参与方程中得到的概率条件下,效应变量与其他解释变量之间的关系。
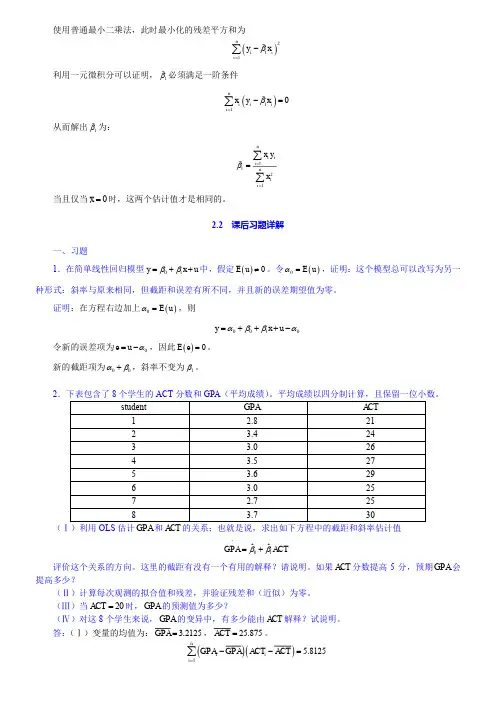
使用普通最小二乘法,此时最小化的残差平方和为()211niii y x β=-∑利用一元微积分可以证明,1β必须满足一阶条件()110niiii x y x β=-=∑从而解出1β为:1121ni ii nii x yxβ===∑∑当且仅当0x =时,这两个估计值才是相同的。
2.2 课后习题详解一、习题1.在简单线性回归模型01y x u ββ=++中,假定()0E u ≠。
令()0E u α=,证明:这个模型总可以改写为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
证明:在方程右边加上()0E u α=,则0010y x u αββα=+++-令新的误差项为0e u α=-,因此()0E e =。
新的截距项为00αβ+,斜率不变为1β。
2(Ⅰ)利用OLS 估计GPA 和ACT 的关系;也就是说,求出如下方程中的截距和斜率估计值01ˆˆGPA ACT ββ=+^评价这个关系的方向。
这里的截距有没有一个有用的解释?请说明。
如果ACT 分数提高5分,预期GPA 会提高多少?(Ⅱ)计算每次观测的拟合值和残差,并验证残差和(近似)为零。
(Ⅲ)当20ACT =时,GPA 的预测值为多少?(Ⅳ)对这8个学生来说,GPA 的变异中,有多少能由ACT 解释?试说明。
答:(Ⅰ)变量的均值为: 3.2125GPA =,25.875ACT =。
()()15.8125niii GPA GPA ACT ACT =--=∑根据公式2.19可得:1ˆ 5.8125/56.8750.1022β==。
根据公式2.17可知:0ˆ 3.21250.102225.8750.5681β=-⨯=。
因此0.56810.1022GPA ACT =+^。
此处截距没有一个很好的解释,因为对样本而言,ACT 并不接近0。
如果ACT 分数提高5分,预期GPA 会提高0.1022×5=0.511。
(Ⅱ)每次观测的拟合值和残差表如表2-3所示:根据表可知,残差和为-0.002,忽略固有的舍入误差,残差和近似为零。
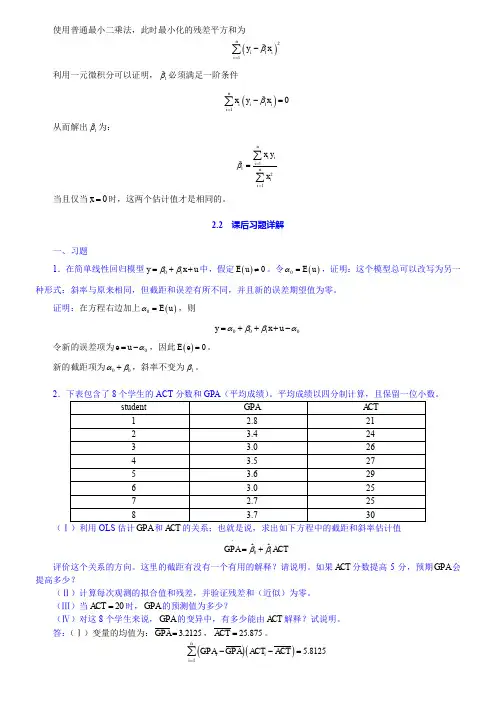


计量经济学课后思考题答案第五章异⽅差性思考题5.1 简述什么是异⽅差?为什么异⽅差的出现总是与模型中某个解释变量的变化有关?答:设模型为,如果其他假定均不变,但模),....,,(....n 21i X X Y i i 33i 221i =µ+β++β+β=型中随机误差项的⽅差为,则称具有异⽅差性。
由于异⽅差性),...,,()(n 21i Var 2i i =σ=µi µ指的是被解释变量观测值的分散程度是随解释变量的变化⽽变化的,所以异⽅差的出现总是与模型中某个解释变量的变化有关。
5.2 试归纳检验异⽅差⽅法的基本思想,并指出这些⽅法的异同。
答:各种异⽅差检验的共同思想是,基于不同的假定,分析随机误差项的⽅差与解释变量之间的相关性,以判断随机误差项的⽅差是否随解释变量变化⽽变化。
其中,⼽德菲尔德-跨特检验、怀特检验、ARCH 检验和Glejser 检验都要求⼤样本,其中⼽德菲尔德-跨特检验、怀特检验和Glejser 检验对时间序列和截⾯数据模型都可以检验,ARCH 检验只适⽤于时间序列数据模型中。
⼽德菲尔德-跨特检验和ARCH 检验只能判断是否存在异⽅差,怀特检验在判断基础上还可以判断出是哪⼀个变量引起的异⽅差。
Glejser 检验不仅能对异⽅差的存在进⾏判断,⽽且还能对异⽅差随某个解释变量变化的函数形式进⾏诊断。
5.3 什么是加权最⼩⼆乘法?它的基本思想是什么?答:以⼀元线性回归模型为例:12i i i Y X u ββ=++经检验存在异⽅差,公式可以表i µ⽰为22var()()i i i u f X σσ==。
选取权数,当越⼩时,权数越⼤。
当 i w 2i σi w 越⼤时,权数越⼩。
将权数与残差平⽅相乘以后再求和,得到加权的残差平⽅和:2i σi w ,求使加权残差平⽅和最⼩的参数估计值。
这种2i 21i 2i i X Y w e w )(**β-β-=∑∑**??21ββ和求解参数估计式的⽅法为加权最⼩⼆乘法。
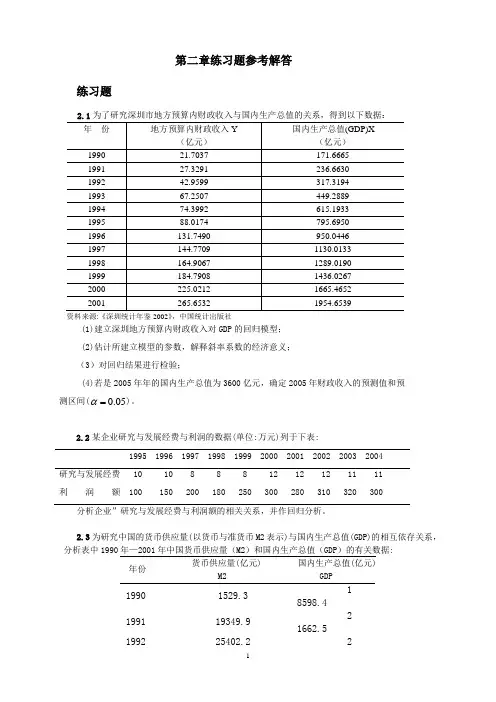
第二章练习题参考解答练习题资料来源:《深圳统计年鉴2002》,中国统计出版社(1)建立深圳地方预算内财政收入对GDP的回归模型;(2)估计所建立模型的参数,解释斜率系数的经济意义;(3)对回归结果进行检验;(4)若是2005年年的国内生产总值为3600亿元,确定2005年财政收入的预测值和预测区间(0.05α=)。
2.2某企业研究与发展经费与利润的数据(单位:万元)列于下表:1995 1996 1997 1998 1999 2000 2001 2002 2003 2004研究与发展经费 10 10 8 8 8 12 12 12 11 11利润额 100 150 200 180 250 300 280 310 320 300 分析企业”研究与发展经费与利润额的相关关系,并作回归分析。
2.3为研究中国的货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相互依存关系,分析表中1990年—2001年中国货币供应量(M2)和国内生产总值(GDP)的有关数据:年份货币供应量(亿元)M2国内生产总值(亿元)GDP1990 1529.31 8598.41991 19349.92 1662.51992 25402.2 26651.91993 34879.8 34560.51994 46923.5 46670.01995 60750.5 57494.91996 76094.9 66850.51997 90995.3 73142.71998 104498.5 76967.21999 119897.9 80579.42000 134610.3 88228.12001158301.994346.4资料来源:《中国统计年鉴2002》,第51页、第662页,中国统计出版社对货币供应量与国内生产总值作相关分析,并说明分析结果的经济意义。
2.4表中是16支公益股票某年的每股帐面价值和当年红利:根据上表资料:(1)建立每股帐面价值和当年红利的回归方程; (2)解释回归系数的经济意义;(3)若序号为6的公司的股票每股帐面价值增加1元,估计当年红利可能为多少?2.5美国各航空公司业绩的统计数据公布在《华尔街日报1999年年鉴》(The Wall Street Journal 1。

计量经济学的步骤1.概念计量经济学是以经济理论和经济数据为事实为依据,运用数学,统计学的方法,通过建立数学模型来研究经济数量关系和规律的一门经济学科。
2.计量经济学的性质(1)计量经济学所研究的主体是经济现象及其发展变化的规律,所以它是一门经济学科。
(2)计量经济学的目的是要把实际经验的内容纳入经济理论,确定表现各种经济关系的经济参数,从而验证经济理论,预测经济发展趋势,为制定经济政策提供依据。
为了解决达到上述目的的理论和方法论问题,计量经济学分成了两种类型:理论计量经济学和应用计量经济学。
3.计量经济学的研究步骤 (1)模型设定设定一个合理的模型,应该注意以下3个方面的问题:要有科学的理论依据;模型要选择适当的数学形式;方程中的变量要有可观测性。
(2)估计参数参数与变量不同,它是计量经济模型中表现经济变量相互依存程度的那些因素,通常参数在模型中式一些相对稳定的量。
如何通过变量的样本观测数据正确的估计总体模型的参数,这是计量经济学研究的核心内容;如何去确定满足计量经济要求的参数估计式,是理论计量经济学的主要内容之一。
(3)模型检验对计量经济模型的检验主要应从以下4个方面进行:经济意义的检验;统计推断检验;计量经济学检验;模型预测检验。
(4)模型应用计量经济模型主要可以用于经济结构分析,经济预测和政策评价等几个方面。
4.与其他经济学科的关系计量经济学是与经济学,经济统计学及数理统计学都有关系的交叉学科。
计量经济学是建立在经济理论的基础上,对经济学现象和关系进行分析的学科;数理统计学是计量经济学的方法论基础;经济统计提供的数据时计量经济学估计参数,验证理论的基本依据;三者独立存在,都不是计量经济学,三者的有力结合才构成了计量经济学。
线性回归模型经典假设a.零均值假定,在给定解释变量Xi的条件下,随机干扰项Ui的条件均值为0b.同方差假定,对于给定的每一个Xi,随机干扰项Ui的条件方差都等于一个参数c.无自相关假定,随机干扰项u的逐次只互不相关,或者说对于所有的i和j,Ui,Uj的协方差为0d.随机干扰项Ui与解释变量Xi不相关e.正态性假定,随机干扰项Ui服从正态分布。
第二章练习题参考解答练习题资料来源:《深圳统计年鉴2002》,中国统计出版社(1)建立深圳地方预算内财政收入对GDP的回归模型;(2)估计所建立模型的参数,解释斜率系数的经济意义;(3)对回归结果进行检验;(4)若是2005年年的国内生产总值为3600亿元,确定2005年财政收入的预测值和预测区间(0.05α=)。
2.2某企业研究与发展经费与利润的数据(单位:万元)列于下表:1995 1996 1997 1998 1999 2000 2001 2002 2003 2004研究与发展经费 10 10 8 8 8 12 12 12 11 11利润额 100 150 200 180 250 300 280 310 320 300 分析企业”研究与发展经费与利润额的相关关系,并作回归分析。
2.3为研究中国的货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相互依存关系,分析表中1990年—2001年中国货币供应量(M2)和国内生产总值(GDP)的有关数据:年份货币供应量(亿元)M2国内生产总值(亿元)GDP1990 1529.31 8598.41991 19349.92 1662.51992 25402.2 26651.91993 34879.8 34560.51994 46923.5 46670.01995 60750.5 57494.91996 76094.9 66850.51997 90995.3 73142.71998 104498.5 76967.21999 119897.9 80579.42000 134610.3 88228.12001158301.994346.4资料来源:《中国统计年鉴2002》,第51页、第662页,中国统计出版社对货币供应量与国内生产总值作相关分析,并说明分析结果的经济意义。
2.4表中是16支公益股票某年的每股帐面价值和当年红利:根据上表资料:(1)建立每股帐面价值和当年红利的回归方程; (2)解释回归系数的经济意义;(3)若序号为6的公司的股票每股帐面价值增加1元,估计当年红利可能为多少?2.5美国各航空公司业绩的统计数据公布在《华尔街日报1999年年鉴》(The Wall Street Journal 1。
计量经济学did模型计量经济学DID模型引言计量经济学是经济学中的一个重要分支,通过运用统计学和数学方法来解决经济问题。
DID模型(Difference-in-Differences)是计量经济学中一种常用的分析方法,用于评估政策或其他干预措施对某一特定群体或地区的影响。
本文将介绍DID模型的基本原理、应用领域以及一些相关的注意事项。
一、DID模型的基本原理DID模型是一种自然实验设计,通过比较两个群体或地区在政策干预前后的差异,来评估政策对实验组的影响。
其中,实验组是受到政策干预的群体或地区,对照组是没有受到政策干预的群体或地区。
通过比较实验组和对照组在政策干预前后的差异,可以得出政策对实验组的效应。
DID模型的基本原理可以通过以下公式表示:Y_it = α + β*T_i + γ*D_t + δ*(T_i*D_t) + ε_it其中,Y_it表示观测单位i在时间t的结果变量;T_i表示观测单位i 是否受到政策干预的虚拟变量(Treatment);D_t表示时间t是否为政策干预的虚拟变量(Difference);α、β、γ、δ分别表示常数项和各个系数;ε_it表示误差项。
二、DID模型的应用领域DID模型在计量经济学中有广泛的应用领域。
以下列举了一些常见的应用案例:1. 教育政策评估:DID模型可以用于评估教育政策对学生学业成绩的影响。
通过比较政策实施前后不同学校或学生群体的学业成绩差异,可以评估教育政策的效果。
2. 劳动力市场研究:DID模型可以用于研究最低工资政策对就业率的影响。
通过比较实施最低工资政策的地区和没有实施最低工资政策的地区的就业率变化,可以评估最低工资政策的效果。
3. 医疗政策评估:DID模型可以用于评估医疗政策对健康指标的影响。
通过比较实施医疗政策的地区和没有实施医疗政策的地区的健康指标变化,可以评估医疗政策的效果。
4. 环境政策研究:DID模型可以用于研究环境政策对环境污染的影响。
一、1、列举计量经济分析过程的几个要素:1、数据;2、计量模型。
3、解释变量;4、被解释变量;5、相关影响。
2、计量经济分析过程基本围绕着四类值。
例如要预测一个硬币被抛1000次出现正面的次数,第一步: 从理论上研究,出现正面的概率是1/2, 这个概率是真值;第二步:做实验,例如抛硬币100次,观察出现正面的次数,那么这个次数为观察值;第三步:估计概率,用观察的次数除以100作为概率的估计值;第四步:用估计的概率乘以1000作为硬币被抛1000次出现正面的预测值。
3、估计量一般都采用哪三种评选标准:1、无偏性;2、有效性;3、一致性.4、无偏估计量的概念:若估计量的数学期望存在且等于其对应真值,即$()E θθ=。
4估计量的有效性:设$1θ与$2θ均为θ的无偏估计量,若对于任意θ,有$1θ的方差小于等于$2θ的方差,则$1θ较$2θ有效。
5、列举计量经济分析的三种数据类型:1、横截面数据;2、时间序列数据;3、面板数据。
6、虚拟变量即一种二值变量,是对解释变量的一种定性描述。
二、:1、简述多元线性回归中('i i i y x βε=+)的高斯-马科夫假设(Gauss – Markov assumption )?若要求得到无偏估计量需满足其中的哪(些)项?112{}0,1,2,...,{,...,}{,...,}{}1,2,...,{,}0i N N i i j E i Nx x V i NCov εεεεσεε=====与相互独立, 若想得到无偏估计量,需满足{}0,1,2,...,i E i N ε==,和11{,...,}{,...,}N N x x εε与相互独立 某种元件的寿命X(以小时计)服从正态分布N(),均未知.现测得16只元件的寿命如下(已知 t 0.05(15) =1.7531) : 159 280 101 212 224 379 179 264222 362 168 250 149 260 485 170问是否有理由认为元件的平均寿命大于225(小时)?2:解 按题意需检验: =225, :取a =0.05.此检验问题的拒绝域为t=t a (n-1).现在n=16, t 0.05(15) =1.7531.又根据 ,s= 算得=241.5, s=98.7259,即有t==0.66851.7531.t没有落在拒绝域中,故接受,即认为元件的平均寿命不大于225小时.3、在平炉上进行一项试验以确定改变操作方法的建议是否会增加钢的得率,试验是在同一只平炉上进行的,每炼一炉钢时除操作方法外,其他条件都尽可能做到相同.先用标准方法炼一炉,然后用建议的方法炼一炉,以后交替进行,各炼成了10炉,其得率分别为(1) 标准方法78.1 72.4 76.2 74.3 77.4 78.476.0 75.5 76.7 77.3(2) 新方法79.1 81.0 77.3 79.1 80.0 79.179.1 77.3 80.2 82.1设这两个样本相互独立,且分别来自正态总体N()和N(),,均未知.问建议的新操作方法能否提高得率?(取a=0.05,已知t0.05(18)=1.7341)3:解需要检验假设: -0,: -0分别求出标准方法和新方法下的样本均值和样本方差如下:根据 ,s= =10, =76.23, =3.325, 根据 ,s= =10, =79.43, =2.225. 又,==2.775, t 0.05(18)=1.7341,故拒绝域为 t =-t 0.05(18)=-1.7341.现在由于样本观察值t = -4.295-1.7341,所以拒绝,即认为建议的新操作方法较原来的方法为优.4、时间序列过程t Y 为平稳过程需要满足哪些条件?若121.20.32t t t t Y Y Y ε--=-+,试问这个过程是一个平稳过程吗?解:平稳过程需满足三个条件:1、{}t E Y μ=,期望为有限常数与时间t 无关。
《教育经济学》辅导纲要第一章教育经济学概论主要内容:1、教育经济学的形成2、教育经济学的发展3、教育经济学的对象和方法重点掌握:1、马克思、恩格斯教育经济思想的主要内容有:①教育与经济的辨证关系。
马克思、恩格斯认为物质资料生产是人类社会存在和发展的基础,它决定着人类的政治生活和精神生活,也决定着教育及其发展。
②教育的社会经济功能。
马克思是把教育的社会经济功能放在社会再生产中加以考察的,指出教育会生产劳动能力,教育是劳动力再生产重要手段。
③劳动价值论与教育的社会经济效益。
马克思在揭示劳动二重性]的基础上所创立的科学的劳动价值论,为我们科学地计量教育对经济增长的贡献,计量教育的社会经济效益指明了方向。
教育之所以能促进经济增长,带来社会经济效益,其直接的原因就在于教育可以生产和提高劳动者的劳动能力,可以把简单劳动变为复杂劳动,从而可以创造更多的价值。
2、第二次世界大战以后教育经济学得以产生和发展的历史条件是:第一,二战后科学技术和社会生产力的高度发展,科学技术和教育的迅速发展,使得其在社会经济发展中的战略地位日益提高,并成为社会生产和经济发展的决定性因素。
由此就为教育经济学的产生提供了深厚的社会基础。
第二,现代西方增长经济学和发展经济学的理论发展,在其发展和深入研究的过程中,都遇到并提出了人力资本问题,都强调了教育对经济增长和经济发展的作用。
3、人力资本理论的主要内容是:全部的资本概念应该包括人力资本和物力资本,人力资本主要指凝聚在劳动者身上的知识、技能及其所表现出来的劳动能力,这是现代经济增长的主要因素,是具有经济价值的一种资本。
人力资本是社会进步的决定性因素,但人力资本的取得不是无代价的,需要耗费稀缺资源。
人力资本是投资的结果,掌握了知识和技能的人力资源是一切生产资源中最重要的资源。
人力资本投资是经济增长的主要源泉,是人类增进福利的一条重要途径。
人力资本投资是效益最佳的投资,人力资本投资的收益率高于物质资本投资的收益率。
《教育经济学》考前复习资料第一章绪论知识点1.教育经济学的概念【P68】【名词解释】教育经济学是研究教育与经济相互作用以及教育领域内经济现象和规律,并且要用数量的形式来表示的一门边缘学科。
知识点2.教育投资的含义【P68】【名词解释】教育投资,也称教育投入、教育资本、教育经济条件等,是一个国家或地区根据教育事业发展的需要,向教育领域内投入的人力、物力和财力的总和及其货币表现。
知识点3.教育效率的含义【P68】【判断、名词解释】教育效率又称教育经济效率、教育机构内部效能、教育资源利用效率等,是指教育投入与教育产出之比,即在一定的社会条件下,为取得同样的教育成果,教育资源占用和消耗的程度。
知识点4.教育收益的含义【P68】【判断、名词解释】又称教育社会经济效益、教育社会经济价值、教育经济收益等。
是指教育领域内劳动消耗同教育所得到的经济报酬在数量上的对比。
知识点5.教育经济学的研究范方法有哪些?(1)定性分析与定量分析相结合的方法;(2)实证分析与规范分析方法;(3)经济分析法;(4)教育研究法;(5)经济计量法和教育统计法;(6)比较研究法;(7)概算法。
知识点6.教育经济学在西方萌芽于20世纪20年代,产生于50年代,形成于60年代,发展于70年代。
【P73】【单选、判断】知识点7.标志着现代教育经济学学科萌芽起点的研究,是前苏联C·T·斯特鲁米林于1924年写的《国民教育的经济意义》学术论文。
【P74】【单选、判断】知识点8.西方“人力资本论理论“是教育经济学产生和形成的直接理论来源。
【P74】【单选、判断】知识点9.西欧北美各国最早讨论教育经济意义的论文,是美国哈佛大学教授J·R·沃尔什于1935年撰写的《人力的资本观》,他主要采用的是”现值折算法“。
【P75】【单选、判断】知识点10.20世纪70年代之后,教育经济学学科发展的特点有哪些?【P76】【简答】(1)研究的内容及范围有了很大的拓展;(2)出现了许多新的研究课题,重视研究教育对社会需求和职业岗位的适应问题;(3)在研究工作组织方面,国际性研究组织与机构不断增加,许多国家孩子高等学校设立专题性研究组织、学会及机构;(4)在具体计算方法研究方面,数量化、定量化以及数学模型设计等计量方法继续被重视并且有了计算方面的专著;(5)国际上许多国家大学里开设了“教育经济学”课程。
受教育程度与收入的研究
受教育是一个人的终身大事,也是一个人在社会上身份的证明,它可以体现一个人在社会上的身份,影响一个人的素质品位、修养,它还可以改变和决定我们的命运,甚至可以在很大程度上影响一个人、一个家庭的收入水平。
通过我们的调查发现,受教育程度与收入水平有密切的联系,它们所成的比例是正比,一般所受教育程度高的,他所得到的收入相对来说就越多,相反,一般所受教育程度越低,他所得到的收入水平相对来说也就越低。
受教育是一个人的终身大事,也是一个人在社会上身份的证明,它可以体现一个人在社会上的身份不同,影响一个人的素质品位、修养,它还可以改变和决定我们的命运,甚至可以在很大程度上影响一个人、一个家庭的收入水平。
一、收集数据
(在数据处理中用1代表小学及以下2代表初中3代表高中4代表专科5代表本科学历6代表硕士及以上)
对数据进行整理描述如下:
二、建立模型
建立如下一元回归模型:
β
β+
μ
y
+
=x
1
(其中x表示受教育程度,y表示收入水平,μ表示残差)
三、模型检验
(一)、T 检验
(二)、回归分析
可决系数2R=1,截距项与斜率项的T检验值均大于5%显著性水
T(4)=3.555。
可以看出可决系数平下自由度为N-2=4的临界值0.0061
2
R的值较大,表明中国居民收入水平与受教育程度有关,且相关性很强。
Test Statistics
受教育程度收入水平
Chi-Square .000a.000a
df 5 5
Asymp. Sig. 1.000 1.000
a. 6 cells (100.0%) have expected
frequencies less than 5. The minimum
expected cell frequency is 1.0.
对数据进行回归分析的计算结果,表明可建立如下中国居民收入水平与受教育程度的关系函数:
X +=1250Y
ˆ 通过T 型检验 T=7.856,自由度df=5,sig.=0.000并且sig.(双侧)=0.000。
由于sig.比α=0.05小得多可知我国居民受教育程度与居民收入有显著相关性。
四、结论与建议
根据对“受教育程度与收入水平的研究”调查的结果,我们每个人都要从中吸取教训。
我们是未来的主人,我们要认真的学习知识,以适应现代竞争激烈和交际广泛的社会生活,在心理、性格、思维、修养等内在素质铸造方面做好充分的准备,同时在语言表达能力、社交能力等方面也必须打下良好的基础,这样才能顺应未来社会的发展潮流。
同时还应该广开视野,广长见识,广泛了解博大的世界和社会,不断增加丰富的现代社会知识和世界信息,有这样的精神准备,才能迅速的成熟、长大,将来才可以自由地翱翔于世界的蓝天。
否则,我们将永远是妈妈怀抱中的乖宝宝,将永远是温室里面的豆芽菜,那样,我们将怎样走向社会、走向世界呢?所以作为未来主人的我们,从现在开始,我们要认真的学习知识,提高自己的受教程度与文化水平,为自己将来的美好前程打下良好的基础,铺好自己人生的道路,将来做个有出息的人,回报社会与父母,为社会做贡献。
因为知识是可以改变命运的。
通过调查,得出的结论是:受教育程度与收入水平有着密切的联系,它们所成的比例是正比。
一般所受教育程度越高,他所得的收入水平就越多,相反,一般所受教育程度越低,他所得到的收入水平
相对来说也就越低,但对于一些少数的特殊情况来讲,受教育程度与收入水平不会成决对的正比关系。
所以,为了我们将来能够有更好的发展前程,更为了我们将来能够过上好生活,建议我们每个人都要好好的学习知识,培养自己的文化素养,提高自己的受教育程度与收入水平,为自己的美好前程打下良好的基础,铺好自己人生的道路,将来做个有出息的人,回报社会与父母,为社会做贡献。