
纠错编码方式简介
2.1 奇偶监督码
奇偶校验码也称奇偶监督码,它是一种最简单的线性分组检错编码方式。其方法是首先把信源编码后的信息数据流分成等长码组,在每一信息码组之后加入一位(1比特)监督码元作为奇偶检验位,使得总码长n(包括信息位k和监督位1)中的码重为偶数(称为偶校验码)或为奇数(称为奇校验码)。如果在传输过程中任何一个码组发生一位(或奇数位)错误,则收到的码组必然不再符合奇偶校验的规律,因此可以发现误码。奇校验和偶校验两者具有完全相同的工作原理和检错能力,原则上采用任一种都是可以的。
由于每两个1的模2相加为0,故利用模2加法可以判断一个码组中码重是奇数或是偶数。模2 加法等同于“异或”运算。现以偶监督为例。
对于偶校验,应满足
故监督位码元a 0可由下式求出:
(2-2)
不难理解,这种奇偶校验编码只能检出单个或奇数个误码,而无法检知偶数个误码,对于连
续多位的突发性误码也不能检知,故检错能力有限,另外,该编码后码组的最小码距为 =2,故没有纠错码能力。
奇偶监督码常用于反馈纠错法。
2.2 行列监督码
行列监督码是二维的奇偶监督码,又称为矩阵码,这种码可以克服奇偶监督码不能发现偶数个差错的缺点,并且是一种用以纠正突发差错的简单纠正编码。
其基本原理与简单的奇偶监督码相似,不同的是每个码元要受到纵和横的两次监督。具体编码方法如下:将若干个所要传送的码组编成一个矩阵,矩阵中每一行为一码组,每行的最后加上一个监督码元,进行奇偶监督,矩阵中的每一列则由不同码组相同位置的码元组成,在每列最后也加上一个监督码元,进行奇偶监督。如果用×表示信息位,用 表示监督位,由矩阵码的结构可如图6-5所示,这样,它的一致监督关系按行及列组成。每一行每一列都是一个奇偶监督码,当某一行(或某一列)出现偶数个差错时,该行(或该列)虽不能发现,但只要差错所在的列(或行),没有同时出现偶数个差错,则这种差错仍然可以被发现。矩阵码不能发现的差错只有这样一类:差错数正好为4倍数,而且差错位置正好构成矩形的四个角,如图6- 5中所示有
的差错情况。因此,矩阵码发现错码的能力是十分强的,它的编码效率当然比奇偶监督码要
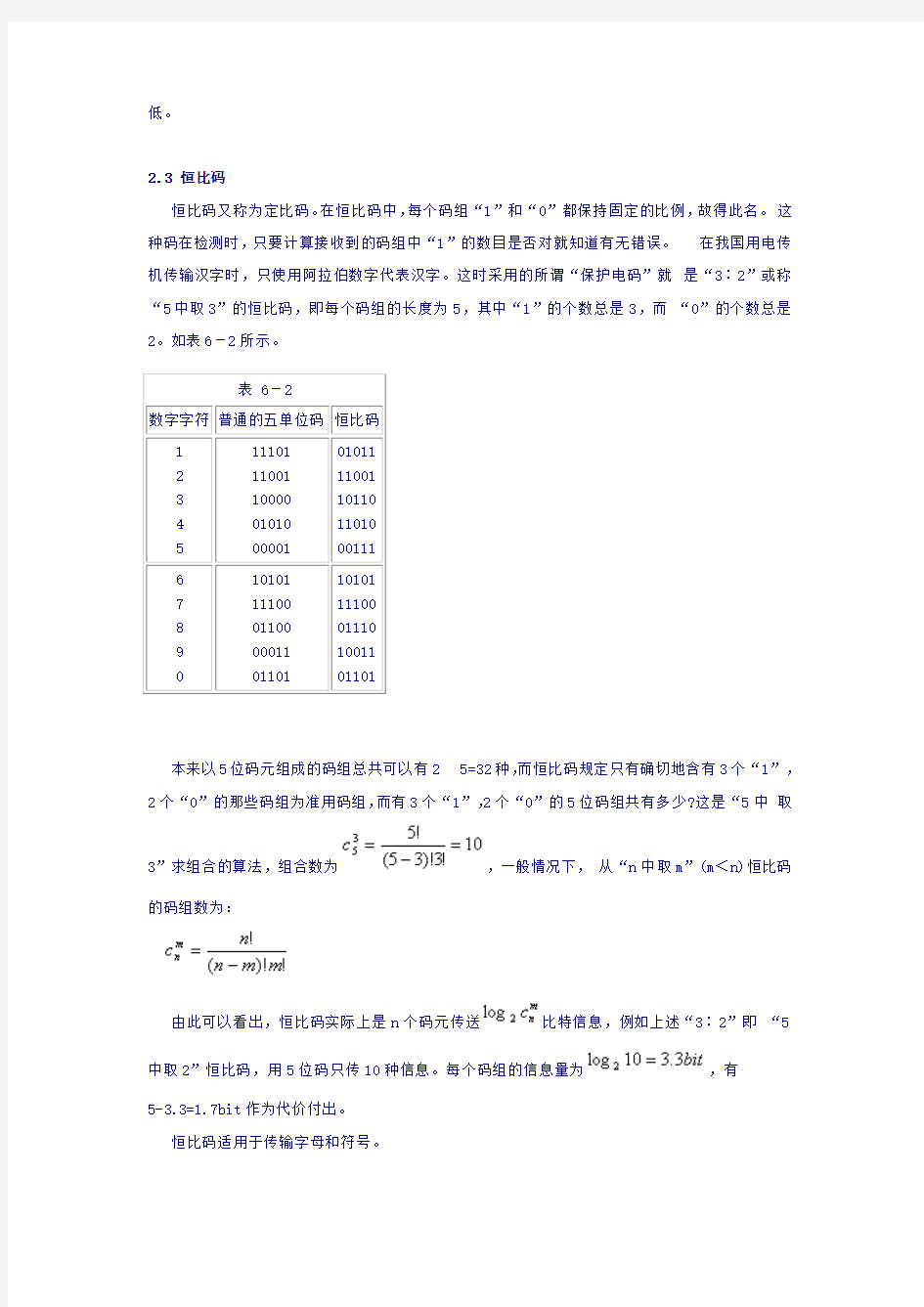
低。 2.3 恒比码
恒比码又称为定比码。在恒比码中,每个码组“1”和“0”都保持固定的比例,故得此名。 这种码在检测时,只要计算接收到的码组中“1”的数目是否对就知道有无错误。 在我国用电传机传输汉字时,只使用阿拉伯数字代表汉字。这时采用的所谓“保护电码”就 是“3∶2”或称“5中取3”的恒比码,即每个码组的长度为5,其中“1”的个数总是3,而 “0”的个数总是2。如表6-2所示。
本来以5位码元组成的码组总共可以有2 5=32种,而恒比码规定只有确切地含有3个“1”, 2个“0”的那些码组为准用码组,而有3个“1”,2个“0”的5位码组共有多少?这是“5中 取
3”求组合的算法,组合数为,一般情况下, 从“n 中取m”(m<n)恒比码
的码组数为:
由此可以看出,恒比码实际上是n 个码元传送
比特信息,例如上述“3∶2”即 “5
中取2”恒比码,用5位码只传10种信息。每个码组的信息量为,有
5-3.3=1.7bit 作为代价付出。 恒比码适用于传输字母和符号。
2.4 汉明码
汉明码属于线性分组编码方式,大多数分组码属于线性编码,其基本原理是,使信息码元与监督码元通过线性方程式联系起来。线性码建立在代数学群论的基础上,各许用码组的集合构成代数学中的群,故又称为群码。
(1)校验子和监督关系式
我们先回顾一下按式(2-2)条件构成的偶数监督码。由于我们使用了一位监督码C0,它就能
和信息码一起构成一个代数式,在接收端解码时,我们实际上是在计算
,
若S=0,就认为无错码。若S=1,就认为有错码。上式就是一致监督关系式。S称为“校验子”。由于校验子S的取值只有这样两种,它就只能代表有错和无错两种信息,而不能指出错码的位置。我们不难推想,如监督位增加一位,变成两位,则能增加一个类似于式(2-3)的监督关系式。两个校验子的可能值有4种组合00,01,10,11。故能表示4种不同的信息,其中一种表示无错,其余三种就有可能用来指示一位错码的3种不同位置。同理,r个监督关系式能指示
一位错码的
()个可能位置。
一般说来,若码长为n,信息码为k,则监督码数r=n-k。若希望用r个监督码构造出r个监督关系式来指示一位错码的n种可能位置,则要求:
下面通过一个例子来说明如何具体构造这些监督关系式。
设分组码(n、k)中k=4,为了能纠正一位错码,按式(2-4)可知,要求监督码数r≥3,现取r =3,
则n=k+r=4+3=7,这是一种(7、4)分组码。
我们用表示这7个码元,,
表示三个监督关系式中的校验子,则的值与错码位置的对应关系可以规定如表6-3,(当然也可以规定成另一种对应关系,这不影响讨论一般性 )。
按表6-3
的规定,仅当有一个错码位置在时,校验子S1为1 ,否则S1为0,
这就意味着四个码元构成偶数监督关系:
同理,
构成偶数监督关系:
以及
构成偶数监督关系:
(2)监督码的确定
在发送端编码时,信息码的值决定于输入信号,是随机的。而监督 码
则应根据信息码的取值按监督关系式决定。即监督码的取值应使上三式 中的值为
0,表示编成的码组中无错码:
由上式移项解出监督码:(在模2加法中,移项后没有负号)
已知信息码后,直接按上式可算出监督码,计算结果得出16个码组列于表6-4中。
(3)解码过程
接收端收到每个码组后,按下述顺序解码。先按式(2-4)~(2-6)计算出再按表6-3判断错误情况。例如,若接收码组为0000011,按式(2-4)~(2-6)计算得:
, 由于,查表6-3可知有一错码为a 3。 (4)汉明码的效率 汉明码的编码效率 η=1-r/n 当n很大时,效率是很高的。
2.5 循环码(CRC)
(1)循环码是一种重要的线性码,它有三个主要数学特征:
①循环码具有循环性,即循环码中任一码组循环一位(将最右端的码移至左端)以后,仍为该码中的一个码组。
②循环码组中任两个码组之和(模2)必定为该码组集合中的一个码组。
③循环码每个码组中,各码元之间还存在一个循环依赖关系,b代表码元,则有
(2)用多项式码作为检验码的编解码过程
用多项式码作为检验码时,发送器和接收器必须具有相同的生成多项式(Generator Polynom ial)G(x),其最高、最低项系数必须为1。CRC编码过程是将要发送的二进制序列看作是多项式的系数,除以生成多项式,然后把余数挂在原多项式之后。CRC译码过程是接收方用同一生成多项式除以接收到的CRC编码,若余数为零,则传输无错。
编码译码方法:
①令r为生成多项式G(x)的阶,将r个“0”附加在信息(数据)元的低端,使其长度变为k+r
位,相应于多项式;
②,得余数;
③与余数对应位异或,得编码信息T(x)。
例数据信息
/G(X)
④接收器收到发来的编码信息后,用同一个生成多项式G(x)除以编码信息,若余数为零,则表示接收到正确的编码信息,否则有错。
⑤把收到的正确编码信息T(x)去掉尾部r位,即得数据信息M(x)。
(3)多项式码检错能力及生成多项式G(x)的选择原则
设接收到的信息不是发送的编码信息T(x),而是T(x)+E(x)。
例有差错的编码信息为
1001001011 T(x)-E(x)=T(x)+E(x)
其中,1101011011 为T(x)
010******* 为E(x)
若接收到的有差错的编码信息为T(x)+E(x),用G(x)除以T(x)+E(x),则得余数为E(x)/G(x) 的余数,因为T(x)/G(x)余数为零,所以
[T(x)+E(x)]/G(x) E(x)/G(x)
这时应该有余数,若无余数则检不出错。
有r位校验位的多项式码将能检测所有≤r位的突发错,故只要k-1<r,就能检测出所有突发错,这是一个很有用的结论。
生成多项式G(x)的国际标准有:
CRC-12
CRC-16
CRC-
CCITT
CRC-16和CRC-CCITT两种生成多项式生成的CRC码可以捕捉一位错、二位错、具有奇数个错的全部错误,可以捕捉突发错长度小于16的全部错误、长度为17的突发错的99 99 8%、长度为18以上的突发错的99 997%。CRC-16和CRC-CCITT可以用硬件实现。
(4)CRC编码硬件电路的实现
设数据1010
多项式
生成多项式系数1011
多项式
系数1010000
多项式
余式系数011
多项式k(X)=X+1 CRC编码
信息组从高位端输入的CRC编码电路,如图6-6所示,其工作原理是:首先门1关闭,门2开通,依次输入的信息元1010一面经或门H直接输出,同时送往除法电路进行除法运算。4次移位后除法电路完成了运算,得余式系数为“011”,即为监督元。第5个移位脉冲开始门1 开通,门2关闭,断开了反馈,移位3次把移位寄存器中的3位余项作为监督元附在信息元后面,发出的码字就是1010011,最后门1关闭,门2开通,对下一信息组再行编码。有关工作过程见表6-5
表6-5 图6-6所示电路的工作过程
2.6 RS码(Reed-Solomon-里德-索罗门码)
RS码是一种重要的线性分组编码方式。它对突发性错误有较强的纠错能力,被DVB标准采用。
(1)在RS编码过程中,各符号不是直接出现,而是每个符号要乘以某个基本元素的幂次方后再模2加,如图6-7所示。
(2)在循环码中欲检查是否有错是用码字除一个多项式,而在RS码中,欲检出一系列误码则需要用码字除一定数量的一次多项式。如果要纠正七个错误,那么码字必须被2t个不同的一次多项式整除,例如被x+a n的一次多项式整除,这里的n取值直到2t的所有整数值,a是基本元素,例如a为010,输入5个符号,每个符号3比特,与相应的元素相乘后直接模2加输出,因为有两种系数,所以得到二个校检子,两个校验式为:
(3)下面举一个简单例子说明纠错过程在无差错时,S 0=0,S 1=0,有如下关系: 码字
A 101
式中
B 100
C 010 D
100 E 111 P 100 Q
100
=
000
当接收到的符号有错时通过计算也可以得到与符号有关的错误图形,这时有错的 码加撇,是
错误图形,真正的
D=D′+=101+001=100。但错误的位置将由S 1决定 ,这要利用
的关系。
A 101
B 100
C 010
D 101
E 111 P 100 Q 100 =
001
校验子的增加导致纠错能力的加强,通过的运算可以确定差错 的位子,并予以纠正。
尽管
都是同一个错误的不同图形,但因
次方的各接收符号模2加得 到
的,而的k
恰好是乘的那一个符号。
(4)RS码的生成多项式
从上面的例子可以看出,为了纠正一个符号错,要2个符号的检测码,一个用来确定位置,一个用来纠错。一般来说纠t个错误需要2t个检验符,这时要计算2t个等式,确定t个位置和纠t个错。能纠t个符号的RS码生成多项式为
按照DVB的CATV标准
RS码生成多项式为:
RS码为: RS(204,188,8)
即分组码符号长度为204个,188个信息符号,可纠错8个。
2.7 连环码(卷积码)
连环码是一种非分组码,通常它更适用于前向纠错法,因为其性能对于许多实际情况常优于分组码,而且设备简单。这种连环码在它的信码元中也有插入的监督码元但并不实行分组监督,每一个监督码元都要对前后的信息单元起监督作用,整个编解码过程也是一环扣一环,连锁地进行下去。这种码提出至今还不到三十年,但是近十余年的发展表明,连环码的纠错能力不亚于甚至优于分组码。这一小节只介绍一种最简单的连环码,以便了解连环码的基本概念。 图6-8是连环码的一种最简单的编码器。它由两个移位寄存器,一个模2加法器及一个电子开关组成。工作过程是:移位寄存器按信息码的速度工作,输入一位信息码,电子开关倒换一
次,即前半拍接通a端,后半拍接通b
端。因此,若输入信息为,则
输出连环码为…,其中“b”为监督码元。按图6-8 结构可得:
}模2
可见,这个连环码的结构是:“信息码元某、监督码元、信息码元、监督码元…。”一个信息码与一个监督码组成一组,但每组中的监督码除了与本组信息码有关外,还跟上一组的信息码有关,或者用另一种说法,每个信息码除有本组监督码外,还有下一组的监督码与它有关系。因此,这种编码就像一根链条,一环扣一环,连环码即由此得名。 在解码过程中,首先将接收到的信息码与监督码分离。由接收到的信息码再生监督码,这个过程与编码器相同,再将此再生监督码与接收到的监督码比较,判断有无差错。分布在相邻的三组码内可纠正一位差错。
2.8 交织法
交织法的原理见图6-9。在发送端,编码序列在送入信道传输之前先通过一个“交织寄存
器矩阵。”将输入序列逐行(即按的次序)存入寄存器矩
阵,存满以后,按列的次序(即)取出,再送入传输信道。接收端收到后先将序列存到一个与发端相同的交织寄存器矩阵,但按列的次序存入,存满以后,按行的次序取出然后送进解码器。由于收发端存取的程序正好相反,因此,送进解码器的序列与编码器输出的序列次序完全相同,解码器丝毫感觉不出交织矩阵的存在与否。
假设交织矩阵每行的寄存器数目N正好等于分组码的码长,传输过程中产生的成群差错长度,亦正好等于交织矩阵每列寄存器的数目M。图6-10表明,由于交织措施,送入解码器的差错被分解开了,每组只分配到一个。因此,如果所采用的分组码能纠正一差错;那么长度为M的成群差错就可全部纠正,可见,交织法结合纠正离散差错的简单编码就可完成纠正群差错的任务。
汉明码的编码检错原理 针对4位数据的汉明码编码示意图 汉明码是一个在原有数据中插入若干校验码来进行错误检查和纠正的编码技术。以典型的4位数据编码为例,汉明码将加入3个校验码,从而使实际传输的数据位达到7个(位),它们的位置如果把上图中的位置横过来就是: 数据位1234567 代码P1P2D8P3D4D2D1 说明第1个 汉明码 第2个 汉明码 第1个 数据码 第3个 汉明码 第2个 数据码 第3个 数据码 第4个 数据码 注:Dx中的x是2的整数幂(下面的幂都是指整数幂)结果,多少幂取决于码位,D1是0次幂,D8是3次幂,想想二进制编码就知道了 现以数据码1101为例讲讲汉明码的编码原理,此时D8=1、D4=1、D2=0、D1=1,在P1编码时,先将D8、D4、D1的二进制码相加,结果为奇数3,汉明码对奇数结果编码为1,偶数结果为0,因此P1值为1,D8+D2+D1=2,为偶数,那么P2值为0,D4+D2+D1=2,为偶数,P3值为0。这样,参照上文的位置表,汉明码处理的结果就是1010101。在这个4位数据码的例子中,我们可以发现每个汉明码都是以三个数据码为基准进行编码的。下面就是它们的对应表: 汉明码编码用的数据码 P1D8、D4、D1 P2D8、D2、D1 P3D4、D2、D1 从编码形式上,我们可以发现汉明码是一个校验很严谨的编码方式。在这个例子中,通过对4个数据位的3个位的3次组合检测来达到具体码位的校验与修正目的(不过只允许一个位出错,两个出错就无法检查出来了,这从下面的纠错例子中就能体现出来)。在校验时则把每个汉明码与各自对应的数据位值相加,如果结果为偶数(纠错代码为0)就是正确,如果为奇数(纠错代码为1)则说明当前汉明码所对应的三个数据位中有错误,此时再通过其他两个汉明码各自的运算来确定具体是哪个位出了问题。 还是刚才的1101的例子,正确的编码应该是1010101,如果第三个数据位在传输途中因干扰而变成了1,就成了1010111。检测时,P1+D8+D4+D1的结果是偶数4,第一位纠错代码为0,正确。P1+D8+D2+D1的结果是奇数3,第二位纠错代码为1,有错误。P3+D4+D2+D1的结果是奇数3,第三但纠错代码代码为1,有错误。那么具体是哪个位有错误呢?三个纠错代码从高到低排列为二进制编码110,换算成十进制就是6,也就是
《信息理论与编码》习题参考答案 1. 信息是什么信息与消息有什么区别和联系 答:信息是对事物存在和运动过程中的不确定性的描述。信息就是各种消息符号所包含的具有特定意义的抽象内容,而消息是信息这一抽象内容通过语言、文字、图像和数据等的具体表现形式。 2. 语法信息、语义信息和语用信息的定义是什么三者的关系是什么 答:语法信息是最基本最抽象的类型,它只是表现事物的现象而不考虑信息的内涵。语义信息是对客观现象的具体描述,不对现象本身做出优劣判断。语用信息是信息的最高层次。它以语法、语义信息为基础,不仅要考虑状态和状态之间关系以及它们的含义,还要进一步考察这种关系及含义对于信息使用者的效用和价值。三者之间是内涵与外延的关系。 第2章 1. 一个布袋内放100个球,其中80个球是红色的,20个球是白色的,若随机摸取一个球,猜测其颜色,求平均摸取一次所能获得的自信息量 答:依据题意,这一随机事件的概率空间为 120.80.2X x x P ????=???????? 其中: 1 x 表示摸出的球为红球事件, 2 x 表示摸出的球是白球事件。 a)如果摸出的是红球,则获得的信息量是 ()()11log log0.8 I x p x =-=-(比特) b)如果摸出的是白球,则获得的信息量是 ()()22log log0.2 I x p x =-=-(比特) c) 如果每次摸出一个球后又放回袋中,再进行下一次摸取。则如此摸取n 次,红球出现的次数为 () 1np x 次,白球出现的次数为 () 2np x 次。随机摸取n 次后总共所获得信息量为 ()()()() 1122np x I x np x I x + d)则平均随机摸取一次所获得的信息量为 ()()()()()()()()()112211221 log log 0.72 H X np x I x np x I x n p x p x p x p x =+????=-+????=比特/次
1. 在无失真的信源中,信源输出由H (X )来度量;在有失真的信源中,信源输出由R (D )来度量。 2. 要使通信系统做到传输信息有效、可靠和XX ,必须首先信源编码, 然后_____加密____编码,再______信道_____编码,最后送入信道。 3. 带限AWGN 波形信道在平均功率受限条件下信道容量的基本公式,也就是有名的香农公式是log(1)C W SNR =+;当归一化信道容量C/W 趋近于零时,也即信道完全丧失了通信能力,此时E b /N 0为-1.6dB ,我们将它称作香农限,是一切编码方式所能达到的理论极限。 4. XX 系统的密钥量越小,密钥熵H (K )就越 小 ,其密文中含有的关于明文的信息量I (M ;C )就越 大 。 5. 设输入符号表为X ={0,1},输出符号表为Y ={0,1}。输入信号的概率分布为p =(1/2,1/2),失真函数为d (0,0) = d (1,1) = 0,d (0,1) =2,d (1,0) = 1,则D min =0,R (D min )=1bit/symbol ,相应的编码器转移概率矩阵[p(y/x )]=1001?? ???? ;D max =0.5,R (D max )=0,相应的编码器转移概率矩阵[p(y/x )]=1010?? ???? 。 二、判断题 1. 可以用克劳夫特不等式作为唯一可译码存在的判据。(√) 2. 线性码一定包含全零码。 (√ ) 3. 算术编码是一种无失真的分组信源编码,其基本思想是将一定精度数值作为序列的 编码,是以另外一种形式实现的最佳统计匹配编码。(×) 4. 某一信源,不管它是否输出符号,只要这些符号具有某些概率特性,就有信息量。 (×) 5. 离散平稳有记忆信源符号序列的平均符号熵随着序列长度L 的增大而增大。 (×) 6. 限平均功率最大熵定理指出对于相关矩阵一定的随机矢量X ,当它是正态分布时具 有最大熵。 (√ ) 7. 循环码的码集中的任何一个码字的循环移位仍是码字。 (√ ) 8. 信道容量是信道中能够传输的最小信息量。(×) 9. 香农信源编码方法在进行编码时不需要预先计算每个码字的长度。 (×) 10. 在已知收码R 的条件下找出可能性最大的发码i C 作为译码估计值,这种译码方 法叫做最佳译码。(√ ) 三、计算题 某系统(7,4)码 )()(01201230123456c c c m m m m c c c c c c c ==c 其三位校验 位与信息位的关系为:
最小码距和检错纠错能力关系 一、码距? 码距就是两个码字C1与C2之间不同的比特数。如:1100与1010的码距为2;1111与0000的码距为4。 一个编码系统的码距就是整个编码系统中任意(所有)两个码字的最小距离。若一个编码系统有四种编码分别为:0000,0011,1100,1111,此编码系统中0000与1111的码距为4;0000与0011的码距为2,是此编码系统的最小码距。因此该编码系统的码距为2。 二、码距和检错纠错有何关联? 首先大家要了解以下两个概念: 1.在一个码组内为了检测e个误码,要求最小码距应该满足:d>=e+1 2.在一个码组内为了纠正t个误码,要求最小码距应该满足:d>=2t+1 现在举个例子来说明这个问题: 假如我们现在要对A,B两个字母进行编码。我们可以选用不同长度的编码,以产生不同码距的编码,分析它们的检错纠错能力。 ||-- 若用1位长度的二进制编码。若A=1,B=0。这样A,B之间的最小码距为1。 合法码:{0,1};非法码:{0,1}; 根据上面的规则可知此编码的检错纠错能力均为0,即无检错纠错能力。其实道理很简单,这种编码无论由1错为0,或由0错为1,接收端都无法判断是否有错,因为1,0都是合法的编码。 ||-- 若用2位长度的二进制编码,可选用11,00作为合法编码,也可以选用01,10作为合法编码。若以A=11,B=00为例,A、B之间的最小码距为2。 合法码:{11,00};非法码:{01,10}; 根据上面的规则可知此编码的检错位数为1位,无法纠错。因为无论A(11)或B(00),如果发生一位错码,必将变成01或10,这都禁用码组(非法码),故接收端可以判断为误码,却不能纠正其错误。因为无法判断误码(01或10)是A(00)错误还是B(11)错误造成,即无法判断原信息是A或B,或说A与B形成误码(01
2、3 一副充分洗乱的牌(含52张),试问: (1)任一特定排列所给出的不确定性就是多少? (2)随机抽取13张牌,13张牌的点数互不相同时的不确定性就是多少? 解:(1)52张扑克牌可以按不同的顺序排列,所有可能的不同排列数就就是全排列种数,为 526752528.06610P =!≈? 因为扑克牌充分洗乱,任一特定排列出现的概率相等,设事件A 为任一特定排列,则其发生概 率为 ()681 1.241052P A -=≈?! 可得,该排列发生所给出的信息量为 ()()22log log 52225.58I A P A =-=!≈ bit 67.91≈ dit (2)设事件B 为从中抽取13张牌,所给出的点数互不相同。 扑克牌52张中抽取13张,不考虑排列顺序,共有13 52C 种可能的组合。13张牌点数互不 相同意味着点数包括A,2,…,K,而每一种点数有4种不同的花色意味着每个点数可以取4中花色。所以13张牌中所有的点数都不相同的组合数为13 4。因为每种组合都就是等概率发生的,所以 ()131341352441339 1.05681052P B C -?!! ==≈?! 则发生事件B 所得到的信息量为 ()()13 21352 4log log 13.208I B P B C =-=-≈ bit 3.976≈ dit 2、5 设在一只布袋中装有100只对人手的感觉完全相同的木球,每只上涂有1种颜色。100只球的颜色有下列三种情况: (1) 红色球与白色球各50只; (2) 红色球99只,白色球1只; (3) 红,黄,蓝,白色各25只。 求从布袋中随意取出一只球时,猜测其颜色所需要的信息量。 解:猜测木球颜色所需要的信息量等于木球颜色的不确定性。令 R ——“取到的就是红球”,W ——“取到的就是白球”, Y ——“取到的就是黄球”,B ——“取到的就是蓝球”。 (1)若布袋中有红色球与白色球各50只,即 ()()501 1002P R P W == = 则 ()()221 log log 212 I R I W ==-== bit (2)若布袋中红色球99只,白色球1只,即
高纲1498 江苏省高等教育自学考试大纲 07025 数据通信与网络 南京信息工程大学编江苏省高等教育自学考试委员会办公室
Ⅰ课程性质与课程目标 一、课程性质和特点 本课程是物联网工程专业的专业必修课。课程系统地讲授了计算机网络的体系结构概念,对各个网络功能层的基本概念、工作原理和通信规程,数据通信技术、广域网和局域网技术、以及网络应用技术和发展都作了详细介绍。配合该课程的实验教学,将帮助学生掌握和了解数据通信和计算机网络的基本原理、工作过程和实现方法,加深学生对数据通信技术、计算机网络技术理论的认识和理解,培养网络应用技能。 本课程的目的,是使学生建立计算机网络体系机构的概念,掌握数据通信的基本概念和计算机网络的工作原理,了解计算机网络技术的应用和发展,辅以精心设计跟踪实际应用的实验教学内容,对提升学生动手操作实践能力,为后续的计算机网络专业课程的学习,建立良好的基础。 二、课程目标 1. 要求学生能够全面、深入理解和熟练掌握通信基础内容和计算机网络部分的内容,并能够用其分析、初步设计和解答与网络应用相关的问题,能够举一反三。 2.计算机网络的概念较多,因此要强调基本概念,而不是过多地讲具体的计算网络中所使用的专用设备。 3.计算机网络的发展非常迅速,新的技术不断出现,因此应尽可能地掌握较新的内容。另外本课程工程性较强,学生应注重理论联系实际和重视实验环节。 三、与相关课程的联系与区别 本课程先修课程应涉及计算机文化基础、计算机程序设计、管理信息系统、数据库原理与应用等。后继课程有网络操作系统、路由与交换技术、计算机网络安全、网络编程等。 本课程与其他课程的区别为:本课程立足于理论,与实际环节紧密结合,需要更多关注各种网络应用及新技术。 四、课程的重点和难点 课程的重点之一是网络通信的有关技术,包括数据通信技术、数据编码技术、数据交换技术、流量控制技术、差错控制技术;重点之二是五层网络体系结构,包括物理层、数据链路层、网络层、传输层、应用层,重点之三是局域网技术。 课程的次重点是数据通信与计算机网络领域的基本概念和工作原理,对网络的组
移动通信的发展日新月异,从1978年第一代模拟蜂窝通信系统诞生至今,不过20多年的时间,就已经过三代的演变,成为拥有10亿多用户的全球电信业最活跃、最具发展潜力的业务。尤其是进几年来,随着第三代移动通信系统(3G)的渐行渐近,以及各国政府、运营商和制造商等各方面为之而投入的大量人力物力,移动通信又一次地在电信业乃至全社会掀起了滚滚热潮。虽然目前由于全球电信业的低迷以及3G系统自身存在的一些问题尚未完全解决等因素,3G业务的全面推行并不象计划中的顺利,但新一代移动通信网的到来必是大势所趋。因此,人们对新的移动通信技术的研究的热情始终未减。 移动通信的强大魅力之所在就是它能为人们提供了固话所不及的灵活、机动、高效的通信方式,非常适合信息社会发展的需要。但同时,这也使移动通信系统的研究、开发和实现比有线通信系统更复杂、更困难。实际上,移动无线信道是通信中最恶劣、最难预测的通信信道之一。由于无线电波传输不仅会随着传播距离的增加而造成能量损耗,并且会因为多径效应、多普勒频移和阴影效应等的影响而使信号快速衰落,码间干扰和信号失真严重,从而极大地影响了通信质量。 为了解决这些问题,人们不断地研究和寻找多种先进的通信技术以提高移动通信的性能。特别是数字移动通信系统出现后,促进了各种数字信号处理技术如多址技术、调制技术、纠错编码、分集技术、智能天线、软件无线电等的发展。本文将主要关注在几代移动通信系统中所使用的不同的纠错编码技术,以展示纠错编码在现代数字通信中的重要作用。 二、纠错编码基础知识 1948年,香农(Shannon)在他那篇著名的论文《通信的数学理论》中提出并证明了:对于一个信道容量为C的有扰信道,消息源产生信息的速率为R,只要R≤C,则总可以找到一种信道编码和译码方式使编码错误概率P随着码长n的增加,按指数下降到任意小的值,表示为,这里E( R )称为误差指数;若R>C,则不存在编译码方式来实现无误传输。这一结论为信道编码指出了方向,但它仅是一个存在性定理,并未给出怎样
计算机网络检错码与纠错码 在通信系统中广泛应用的差错控制技术是差错控制编码技术。而差错控制编码包括检错码和纠错码两种,其中检错码是为传输的数据信号增加冗余码,以便发现数据信号中的错码,但不能纠正错码;纠错码是为传输的数据信号增加冗余码,以便发现数据信号中的错码,并自动纠正这些错码。下面介绍几种检错码和纠错码的校验方法。 1.奇偶校验码 奇偶校验码是一种最简单的无纠错能力的检错码,其编码规则是先将数据代码分组,例如,将ASCⅡ码中的一个字符或若干个字符分为一组。在各组数据后面附加一位校验位,使该数据连校验位在内的码元中1的个数恒为偶数则为偶校验,恒为奇数则为奇校验。奇偶校验无纠错能力,它只能检测出码元中的任意奇数个错误,若有偶数个错误必定漏检。由于奇偶校验码容易实现,所以当信道干扰较弱,并且数据码长较短时,使用奇偶校验码效果很好,在计算机网络的数据传输中经常使用该检错码。 根据数据代码的分组方法,奇偶校验码可以分为水平奇偶校验、垂直奇偶校验和垂直水平奇偶校验。 ●水平奇偶校验 如表3-1所示,在水平奇偶校验中,把数据先以适当的长度划分成小组,并把码元按表中所示的顺序一列一列地排列起来,然后对水平方向的码元进行奇偶校验,得到一列校验位,附加在其他各列之后,最后按行的顺序进行传输。水平奇偶校验能查出水平方向上奇数个错误和不大于数据代码长度的突发错误,无纠错能力,但产生校验码及校验逻辑相对复杂。 表3-1 水平奇偶校验 ●垂直奇偶校验 如表3-2所示,在垂直奇偶校验中,把数据先以适当的长度划分成小组,并把码元按表中所示的顺序一列一列地排列起来,然后对垂直方向的码元进行奇偶校验,得到一行校验位,附加在其他各行之后,然后按列的顺序进行传输。垂直奇偶校验能够查出列上的奇数个错误,只能查处50%的突发错误,无纠错能力,但产生校验码及校验逻辑相对简单。 表3-2 垂直奇偶校验
1、有一个二元对称信道,其信道矩阵如下图所示。设该信道以1500个二元符号/秒的速度传输输入符号。现有一消息序列共有14000个二元符号,并设在这消息中P(0)=P(1)=1/2。问从信息传输的角度来考虑,10秒钟内能否将这消息序列无失真地传送完? 解答:消息是一个二元序列,且为等概率分布,即P(0)=P(1)=1/2,故信源的熵为H(X)=1(bit/symbol)。则该消息序列含有的信息量=14000(bit/symbol)。 下面计算该二元对称信道能传输的最大的信息传输速率: 信道传递矩阵为: 信道容量(最大信息传输率)为: C=1-H(P)=1-H(0.98)≈0.8586bit/symbol 得最大信息传输速率为: Rt ≈1500符号/秒× 0.8586比特/符号 ≈1287.9比特/秒 ≈1.288×103比特/秒 此信道10秒钟内能无失真传输得最大信息量=10× Rt ≈ 1.288×104比特 可见,此信道10秒内能无失真传输得最大信息量小于这消息序列所含有的信息量,故从信息传输的角度来考虑,不可能在10秒钟内将这消息无失真的传送完。 2、若已知信道输入分布为等概率分布,且有如下两个信道,其转移概率矩阵分别为: 试求这两个信道的信道容量,并问这两个信道是否有噪声? 3 、已知随即变量X 和Y 的联合分布如下所示: 01 100.980.020.020.98P ?? =?? ??11112222 1111222212111122221111222200000000000000000000000000000000P P ????????????==????????????11 222 2111 2222 2 log 4(00)1/()log 42/log 8(000000)2/(),H bit symbol H X bit symbol C C H bit symbol H X C =-===>=-==1解答:(1)由信道1的信道矩阵可知为对称信道故C 有熵损失,有噪声。(2)为对称信道,输入为等概率分布时达到信道容量无噪声
数据通信技术基础知识 2.1 数据通信技术 2.1.1 模拟数据通信和数字数据通信 1.几个术语的解释 1)数据-定义为有意义的实体。数据可分为模拟数据和数字数据。模拟数据是在某区间内连续变化的值;数字数据是离散的值。 2)信号-是数据的电子或电磁编码。信号可分为模拟信号和数字信号。模拟信号是随时间连续变化的电流、电压或电磁波;数字信号则是一系列离散的电脉冲。可选择适当的参量来表示要传输的数据。 3)信息-是数据的内容和解释。 4)信源-通信过程中产生和发送信息的设备或计算机。 5)信宿-通信过程中接收和处理信息的设备或计算机。 6)信道-信源和信宿之间的通信线路。 2.模拟信号和数字信号的表示 模拟信号和数字信号可通过参量(幅度)来表示: 图2.1 模拟信号、数字信号的表示 3.模拟数据和数字数据的表示 模拟数据和数字数据都可以用模拟信号或数字信号来表示,因而无论信源产生的是模拟数据还是数字数据,在传输过程中都可以用适合于信道传输的某种信号形式来传输。 1)模拟数据可以用模拟信号来表示。模拟数据是时间的函数,并占有一定的频率范围,即频带。这种数据可以直接用占有相同频带的电信号,即对应的模拟信号来表示。模拟电话通信是它的一个应用模型。 2)数字数据可以用模拟信号来表示。如Modem可以把数字数据调制成模拟信号;也可以把模拟信号解调成数字数据。用Modem拨号上网是它的一个应用模型。 3)模拟数据也可以用数字信号来表示。对于声音数据来说,完成模拟数据和数字信号转换功能的设施是编码解码器CODEC。它将直接表示声音数据的模拟信号,编码转换成二进制流近似表示的数字信号;而在线路另一端的CODEC,则将二进制流码恢复成原来的模拟数据。数字电话通信是它的一个应用模型。 4)数字数据可以用数字信号来表示。数字数据可直接用二进制数字脉冲信号来表示,但为了改善其传播特性,一般先要对二进制数据进行编码。数字数据专线网DDN网络通信是它的一个应用模型。 4.数据通信的长距离传输及信号衰减的克服 1)模拟信号和数字信号都可以在合适的传输媒体上进行传输(如图2.2);
一、常用检错码 (1) 寄偶校验码 寄偶校验码是一种最简单的校验码,其编码规则:先将所要要传送的数据码元分组,并在每组的数据后面附加一位冗余位即校验位,使该组包括冗余位在内的数据码元中“1”的个数保持为奇数(奇校验)或偶数(偶校验)。在接收端按照同样的规则检查,如发现不符,说明有错误发生;只有“1”的个数仍然符合原定的规律时,认为传输正确。实际数据传输中所采用的寄偶校验码分为垂直奇偶校验、水平奇偶校验和水平垂直奇偶校验三种。 垂直奇偶校验是一字符为单位的校验方法。例如,传输数据信息为“1010001”,采用偶校验时,附加位为“1”,则发送信息变为“10100011”;采用奇校验时,附加位为“0”,发送信息变为“10100010”; (2) 循环冗余校验码(CRC) 循环冗余校验码CRC(Cyclic Redundancy Code)采用一种多项式的编码方法。把要发送的数据位串看成是系数只能为“1”或为“0”的多项式。一个k位的数据块可以看成Xk-1到X0的k项多项式的系数序列。例如,“110001”有6位,表示多项式是“X5 + X4+ 1”。多项式的运算是模2运算。 采用CRC码时,发方和收方必须事先约定一个生成多项式G(X),并且G(X)的最高位和最低必须是1。要计算m位数据块的M(X)的校验和,生成多项式必须比该多项式短。其基本思想是:将校验和附加在该数据块的末尾,使这个带校验和的多项式能被G(X)除尽。当接收方收到带校验和的数据块时,用G(X)去除它,如果有余数,则传输有错误。 二、纠错码 纠错码与检错码相比其功能更强,它不但能检错还能纠错。海明码就是一种能够纠正一位错误的检错码。海明码是海明(H.W.Hamming)于1950年提出的一种码制。在发送数据之前将数据按照海明码制形成海明码,然后发送海明码,到达对方后根据接收到的海明码进行解释分析、判错、纠错。 (1) 海明码的形成 ①海明码的组合规则 海明码是由数据与校验位组合而成的。其组合规则为:将数据与校验码(寄偶校验)自左至右进行编码,其中编号为2的幂的位均为校验位,其余为数据位。 ②校验位值的确定 将每一数据位的编号展开成2的幂的和(每一项不可重复),则每一项所对应的位均为该数据位的校验位。据此,按照寄偶校验规则确定各校验位的值。 例:要传送的数据为“11001100” 则相应的海明码为:AB1C100D1100 其中A、B、C、D是加入的校验位。 将每一数据位的编号展开成2的幂的和: 3=2+1 9=8+1
第五章 纠错编码习题解答 1、已知一纠错码的三个码组为(001010)、(101101)、(010001)。若用于检错,能检出几位错码?若用于纠错,能纠正几位错码?若纠检错结合,则能纠正几位错码同时检出几位错码? [解]该码的最小码距为d 0=4,所以有: 若用于检错,由d 0≥e +1,可得e =3,即能检出3位错码; 若用于纠错,由d 0≥2t +1,可得t =1,即能检出1位错码; 若纠检错结合,由d 0≥e +t +1 (e >t ),可得t =1,e =2,即能纠正1位错码同时能检出2位错码。 2、设某(n ,k )线性分组码的生成矩阵为: 001011100101010110G ?? ??=?????? ①试确定该(n ,k )码中的n 和k ; ②试求该码的典型监督矩阵H ; ③试写出该码的监督方程; ④试列出该码的所有码字; ⑤试列出该码的错误图样表; ⑥试确定该码的最小码距。 [解] ①由于生成矩阵G 是k 行n 列,所以k =3,n =6。 ②通过初等行变换,将生成矩阵G 变换成典型生成矩阵
[] 100101010110001011k G I Q ?? ??==?????? 由于101110110011011101T Q P Q ???? ????=???? ????????, ==,可知典型监督矩阵为 []110100011010101001r H PI ?? ??=?? ????= ③监督方程为5424315 300 00 a a a a a a a a a ⊕⊕=??⊕⊕=??⊕⊕=? ④所有码字见下表 ⑤错误图样表即错误图样与校正子关系表,见下表
一、填空题(每空1分,共35分) 1、1948年,美国数学家 发表了题为“通信的数学理论”的长篇论文,从而创立了信息论。信息论的基础理论是 ,它属于狭义信息论。 2、信号是 的载体,消息是 的载体。 3、某信源有五种符号}{,,,,a b c d e ,先验概率分别为5.0=a P ,25.0=b P ,125.0=c P ,0625.0==e d P P , 则符号“a ”的自信息量为 bit ,此信源的熵为 bit/符号。 4、某离散无记忆信源X ,其概率空间和重量空间分别为1 234 0.50.250.1250.125X x x x x P ????=??? ?????和1234 0.5122X x x x x w ???? =??????? ? ,则其信源熵和加权熵分别为 和 。 5、信源的剩余度主要来自两个方面,一是 ,二是 。 6、平均互信息量与信息熵、联合熵的关系是 。 7、信道的输出仅与信道当前输入有关,而与过去输入无关的信道称为 信道。 8、马尔可夫信源需要满足两个条件:一、 ; 二、 。 9、若某信道矩阵为????? ????? ??01000 1 000001 100,则该信道的信道容量C=__________。 10、根据是否允许失真,信源编码可分为 和 。 12、在现代通信系统中,信源编码主要用于解决信息传输中的 性,信道编码主要用 于解决信息传输中的 性,保密密编码主要用于解决信息传输中的安全性。 13、差错控制的基本方式大致可以分为 、 和混合纠错。 14、某线性分组码的最小汉明距dmin=4,则该码最多能检测出 个随机错,最多能纠正 个随机错。 15、码字101111101、011111101、100111001之间的最小汉明距离为 。 16、对于密码系统安全性的评价,通常分为 和 两种标准。 17、单密钥体制是 指 。 18、现代数据加密体制主要分为 和 两种体制。 19、评价密码体制安全性有不同的途径,包括无条件安全性、 和 。 20、时间戳根据产生方式的不同分为两类:即 和 。 二、选择题(每小题1分,共10分) 1、下列不属于消息的是( )。 A. 文字 B. 信号 C. 图像 D. 语言 2、设有一个无记忆信源发出符号A 和B ,已知43 41)(,)(==B p A p ,发出二重符号序列消息的信源,无记忆信源熵)(2 X H 为( )。 A. 0.81bit/二重符号 B. 1.62bit/二重符号 C. 0.93 bit/二重符号 D . 1.86 bit/二重符号 信息论与编码
汉明码计算及其纠错原理详解 当计算机存储或移动数据时,可能会产生数据位错误,这时可以利用汉明码来检测并纠错,简单的说,汉明码是一个错误校验码码集,由Bell 实验室的R.W.Hamming 发明,因此定名为汉明码。 汉明码(Hamming Code),是在电信领域的一种线性调试码,以发明者理查德·卫斯里·汉明的名字命名。汉明码在传输的消息流中插入验证码,以侦测并更正单一比特错误。由于汉明编码简单,它们被广泛应用于内存(RAM )。其SECDED (single error correction,double error detection)版本另外加入一检测比特,可以侦测两个或以下同时发生的比特错误,并能够更正单一比特的错误。因此,当发送端与接收端的比特样式的汉明距离(Hamming distance)小于或等于1时(仅有1 bit发生错误),可实现可靠的通信。相对的,简单的奇偶检验码除了不能纠正错误之外,也只能侦测出奇数个的错误。 在数学方面,汉明码是一种二元线性码。对于每一个整数,存在一个编码,带有个奇偶校验位个数据位。该奇偶检验矩阵的汉明码是通过列出所有米栏的长度是两两独立。 汉明码的定义和汉明码不等式:设:m=数据位数,k=校验位数为,n=总编码位数=m+k,有Hamming不等式: a)总数据长度为N,如果每一位数据是否错误都要记录,就需要N位来存储。 b)每个校验位都可以表示:对或错;校验位共K位,共可表示2k种状态 c)总编码长度为N,所以包含某一位错和全对共N+1种状态。 d)所以2k≧N+1 e)数据表见下 无法实现2位或2位以上的纠错,Hamming码只能实现一位纠错。 以典型的4位数据编码为例,演示汉明码的工作 D8=1、D4=1、D2=0、D1=1, P1 =1,P2=0、P3=0。 汉明码处理的结果就是1010101 假设:D8出错,P3’P2’P1’=011=十进制的3,即表示编码后第三位出错,对照存储
第一章 1.通信系统的基本模型: 2.信息论研究内容:信源熵,信道容量,信息率失真函数,信源编码,信道编码,密码体制的安全性测度等等 第二章 1.自信息量:一个随机事件发生某一结果所带的信息量。 2.平均互信息量:两个离散随机事件集合X 和Y ,若其任意两件的互信息量为 I (Xi;Yj ),则其联合概率加权的统计平均值,称为两集合的平均互信息量,用I (X;Y )表示 3.熵功率:与一个连续信源具有相同熵的高斯信源的平均功率定义为熵功率。如果熵功率等于信源平均功率,表示信源没有剩余;熵功率和信源的平均功率相差越大,说明信源的剩余越大。所以信源平均功率和熵功率之差称为连续信源的剩余度。信源熵的相对率(信源效率):实际熵与最大熵的比值 信源冗余度: 0H H ∞=ηη ζ-=1
意义:针对最大熵而言,无用信息在其中所占的比例。 3.极限熵: 平均符号熵的N 取极限值,即原始信源不断发符号,符号间的统计关系延伸到无穷。 4. 5.离散信源和连续信源的最大熵定理。 离散无记忆信源,等概率分布时熵最大。 连续信源,峰值功率受限时,均匀分布的熵最大。 平均功率受限时,高斯分布的熵最大。 均值受限时,指数分布的熵最大 6.限平均功率的连续信源的最大熵功率: 称为平均符号熵。 定义:即无记忆有记忆N X H H X H N X H X NH X H X H X H N N N N N N )() ()()()()()(=≤∴≤≤
若一个连续信源输出信号的平均功率被限定为p ,则其输出信号幅度的概率密度分布是高斯分布时,信源有最大的熵,其值为 1log 22 ep π.对于N 维连续平稳信源来说,若其输出的N 维随机序列的协方差矩阵C 被限定,则N 维随机矢量为正态分布时信源 的熵最大,也就是N 维高斯信源的熵最大,其值为1log ||log 222N C e π+ 7.离散信源的无失真定长编码定理: 离散信源无失真编码的基本原理 原理图 说明: (1) 信源发出的消息:是多符号离散信源消息,长度为L,可以用L 次扩展信 源表示为: X L =(X 1X 2……X L ) 其中,每一位X i 都取自同一个原始信源符号集合(n 种符号): X={x 1,x 2,…x n } 则最多可以对应n L 条消息。 (2)信源编码后,编成的码序列长度为k,可以用k 次扩展信宿符号表示为: Y k =(Y 1Y 2……Y k ) 称为码字/码组 其中,每一位Y i 都取自同一个原始信宿符号集合: Y={y 1,y 2,…y m } 又叫信道基本符号集合(称为码元,且是m 进制的) 则最多可编成m k 个码序列,对应m k 条消息 定长编码:信源消息编成的码字长度k 是固定的。对应的编码定理称为定长信源编码定理。 变长编码:信源消息编成的码字长度k 是可变的。 8.离散信源的最佳变长编码定理 最佳变长编码定理:若信源有n 条消息,第i 条消息出现的概率为p i ,且 p 1>=p 2>=…>=p n ,且第i 条消息对应的码长为k i ,并有k 1<=k 2<=…<=k n
第二节 纠错编码原理 一、纠错编码的原理 一般来讲,信源发出的消息均可用二进制信号来表示。例如,要传送的消息为A 和B ,则我们可以用1表示A ,0表示B 。在信道传输后产生了误码,0错为1,或1错为0,但接收端却无法判断这种错误,因此这种码没有任何抗干扰能力。如果在0或1的后面加上一位监督位(也称校验位),如以00表示A ,11表示B 。长度为2的二进制序列共有种组合,即00、01、10、11。00和11是从这四种组合中选出来的,称其为许用码组,01、10为禁用码。当干扰只使其中一位发生错误,例如00变成了01或10,接收端的译码器就认为是错码,但这时接收端不能判断是哪一位发生了错误,因为信息码11也可能变为01或10,因而不能自动纠错。如果在传输中两位码发生了错误,例如由00变成了11,译码器会将它判为B ,造成差错,所以这种1位信息位,一位监督位的编码方式,只能发现一位错误码。 224=按照这种思路,使码的长度再增加,用000表示A ,111表示B ,这样势必会增强码的抗干扰能力。长度为3的二进制序列,共有8中组合:000、001、010、011、100、101、110、111。这8种组合中有三种编码方案:第一种是把8种组合都作为码字,可以表示8种不同的信息,显然,这种编码在传输中若发生一位或多位错误时,都使一个许用码组变成另一个许用码组,因而接收端无法发现错误,这种编码方案没有抗干扰能力;第二种方案是只选四种组合作为信息码字来传送信息,例如:000、011、101、110,其他4种组合作为禁用码,虽然只能传送4种不同的信息,但接收端有可能发现码组中的一位错误。例如,若000中错了一位,变为100,或001或010,而这3种码为禁用码组。接收端收到禁用码组时,就认为发现了错码,但不能确定错码的位置,若想能纠正错误就还要增加码的长度。第三种方案中规定许用码组为000和111两个,这时能检测两位以下的错误,或能纠正一位错码。例如,在收到禁用码组100时,若当作仅有一位错码,则可判断出该错码发生在“1”的位置,从而纠正为000,即这种编码可以纠正一位差错。但若假定错码数不超出两位,则存在两种可能性,000错一位及111错两位都可能变为100,因而只能检错而不能纠错。 从上面的例子可以得到关于“分组码”的一般概念。如果不要求检错或纠错,为了传输两种不同的信息,只用1位码就够了,我们把代表所传信息的这位码称为信息位。若使用了2位码或3位码,多增加的码位数称为监督位。我们把每组信息码附加若干监督码的编码称为分组码。在分组码中,监督码元仅监督本码组中的信息码元。 图8-2分组码的结构 分组码一般用符号(表示, 其中k 是每组码中信息码元的数目,n 是码组的总位数,又称为码组的长度(码长),为每码组中的监督码元数目,或称为监督位数目。通常将分组码规定为如图8-2所示的结构,图中前面位为信息位,后面附 )n n a a ??,n k n k r ?=k 12(,,...,)r a
纠错输出编码(ECOC )综述和基本原理 目录 <机器学习导论> (1) 《Solving Multiclass Learning Problems via Error-Correcting Output Codes 》 (2) A Subspace to ECOC (3) 中文参考文献 (5) <机器学习导论> 在纠错输出编码中,主要的分类任务通过由基学习器实现的一组子任务来定义。其思想是:将一个类从其他类区分开来的原始任务可能是一个困难的问题。作为替代,我们定义一组简单的分类问题,每个专注于原始任务的一个方面,并通过组合这些简单的分类器来得到最终的分类器。 这时,基分类器是输出为-1/+1的二元分类器,并且有一个K*L 的编码矩阵W ,其K 行是关于L 个基学习器dj 类的二元编码。例如,(2, )[ 1 1 1 1]M =-++-表示若一个样本属于第2类(C 2),则该样本应在h 1和h 4上取负值,在h 2和h 3上取正值;(, 3)[ 1 1 1]T M =-++可理解为第三个基分类器h 3的任务是将属于C 1类的样本与属于C 2和C 3类的样本区分开。同时(, 3)M 也决定了如何构造基分类器h 3的训练样本集T 3:所有标记为C 2类及C 3类的样本形成正样本3χ+,而标记为C 1类的实例构成负样本3χ-,对h 3的训练应使得3T ?∈i x ,当3χ+∈i x 时,3()1h =+i x ;当3χ-∈i x 时,3()1h =-i x 。 这样,编码矩阵使得我们可以用二分类问题定义多分类问题,并且这是一种适用于任意可以实现二分基学习器的学习算法的方法,例如,线性或多层感知器,决策树或初始定义的两类问题的SVM 。 典型的每类一个判别式的情况对应于对角矩阵,其中L=K ,例如,对于K=4,我们有 W=【】 这里的问题是:如果某一个基学习器存在错误,就会有误分类,因为类的码
第二章 信息量和熵 2.2 八元编码系统,码长为3,第一个符号用于同步,每秒1000个码字,求它的 信息速率。 解:同步信息均相同,不含信息,因此 每个码字的信息量为 2?8log =2?3=6 bit 因此,信息速率为 6?1000=6000 bit/s 2.3 掷一对无偏骰子,告诉你得到的总的点数为:(a) 7; (b) 12。问各得到多少信 息量。 解:(1) 可能的组合为 {1,6},{2,5},{3,4},{4,3},{5,2},{6,1} )(a p =366=6 1 得到的信息量 =) (1 log a p =6log =2.585 bit (2) 可能的唯一,为 {6,6} )(b p =361 得到的信息量=) (1 log b p =36log =5.17 bit 2.4 经过充分洗牌后的一副扑克(52张),问: (a) 任何一种特定的排列所给出的信息量是多少? (b) 若从中抽取13张牌,所给出的点数都不相同时得到多少信息量? 解:(a) )(a p =! 521 信息量=) (1 log a p =!52log =225.58 bit (b) ???????花色任选 种点数任意排列 13413!13 )(b p =13 52134!13A ?=1352 13 4C 信息量=1313 52 4log log -C =13.208 bit
2.9 随机掷3颗骰子,X 表示第一颗骰子的结果,Y 表示第一和第二颗骰子的 点数之和,Z 表示3颗骰子的点数之和,试求)|(Y Z H 、)|(Y X H 、 ),|(Y X Z H 、)|,(Y Z X H 、)|(X Z H 。 解:令第一第二第三颗骰子的结果分别为321,,x x x ,1x ,2x ,3x 相互独立, 则1x X =,21x x Y +=,321x x x Z ++= )|(Y Z H =)(3x H =log 6=2.585 bit )|(X Z H =)(32x x H +=)(Y H =2?( 361log 36+362log 18+363log 12+364log 9+365log 536)+36 6 log 6 =3.2744 bit )|(Y X H =)(X H -);(Y X I =)(X H -[)(Y H -)|(X Y H ] 而)|(X Y H =)(X H ,所以)|(Y X H = 2)(X H -)(Y H =1.8955 bit 或)|(Y X H =)(XY H -)(Y H =)(X H +)|(X Y H -)(Y H 而)|(X Y H =)(X H ,所以)|(Y X H =2)(X H -)(Y H =1.8955 bit ),|(Y X Z H =)|(Y Z H =)(X H =2.585 bit )|,(Y Z X H =)|(Y X H +)|(XY Z H =1.8955+2.585=4.4805 bit 2.10 设一个系统传送10个数字,0,1,…,9。奇数在传送过程中以0.5的概 率错成另外一个奇数,其余正确接收,求收到一个数字平均得到的信息量。 解: 8,6,4,2,0=i √ );(Y X I =)(Y H -)|(X Y H 因为输入等概,由信道条件可知,
数据通信技术基础习题 答案:一、CCADA ABCBA 二、AC\ABCD\ABCD\AC\ABCD\ABC\AC\ABCD\ABC\ABC 三、1、数据通信 2、信息 3、数据 4 、信号 5、数字模拟数字模拟 6、发送设备传输设备接收设备 7、比特率 8、波特率 9、带宽 10、信道容量 11、误码率 12、吞吐量 13、串行传输 14、并行传输 15、同步 16 异步 17、单工 18、半双工 19、全双工 20、电路报文分组 21、电路建立数据传输拆除电路 22、报文交换存储-转发 23、分组交换 24、数据报方式虚电路方式 25、多路复用 26、频分多路复用时分多路复用 一、单项选择题 1.单工通信是指()。 A.通信双方可同时进行收、发信息的工作方式 B.通信双方都能收、发信息,但不能同时进行收、发信息的工作方式C.信息只能单方向发送的工作方式 D.通信双方不能同时进行收、发信息的工作方式 2.数据通信的信道包括()。 A.模拟信道B.数字信道 C.模拟信道和数字信道 D.同步信道和异步信道
3.双工通信是指()。 A.通信双方可同时进行收、发信息的工作方式 B.通信双方都能收、发信息,但不能同时进行收、发信息的工作方式C.信息只能单方向发送的工作方式 D.通信双方不能同时进行收、发信息的工作方式 4.半双工通信是指()。 A.通信双方可同时进行收、发信息的工作方式 B.通信双方都能收、发信息,但不能同时进行收、发信息的工作方式C.信息只能单方向发送的工作方式 D.通信双方不能同时进行收、发信息的工作方式 5.完整的通信系统是由()构成。 A.信源、变换器、信道、反变换器、信宿 B.信源、变换器、信道、信宿 C.信源、变换器、反变换器、信宿 D.变换器、信道、反变换器、信宿 6.移动通信系统一般由()构成。 A.移动台、基地站、移动业务交换中心、与公用电话网相连接的中继线 B.移动台、基地站、移动业务交换中心 C.移动台、移动业务交换中心、与公用电话网相连接的中继线D.移动台、移动业务交换中心、与公用电话网相连接的中继线7.无线寻呼是()。 A.一种传送简单语言信息的单向呼叫系统 B.一种传送非简单语言信息的单向呼叫系统 C.一种传送简单语言信息的双向呼叫系统