
标准差与标准误的区别
标准差(Standard Deviation -S或SD)是用来反映变异程度,当两组观察值在单位相同、均数相近的情况下,标准差越大, 说明观察值间的变异程度越大。即观察值围绕均数的分布较离散,均数的代表性较差。反之,标准差越小,表明观察值间的变异较小, 观察值围绕均数的分布较密集,均数的代表性较好。
1 抽样误差的意义
样本与总体以及抽样误差的概念,由于存在人与人之间的个体差异,即使从同一总体用同样方法随机抽取例数相同的一些样本,各样本算得的某种指标,如平均数(或百分率),通常也参差不齐存在一定的差异。样本指标与相应的总体指标之间有或多或少的相差,这一点是不难理解的。如我们从某学院抽了80名男同学,测量其身高,计算出均数为168.10cm,若再从我们学院抽80名男同学,其平均身高未必仍等于168.10cm,也不一定恰好等于我们学校男同学身高的总体均数,这种差异,即由于抽样而带来的样本与总体间的误差,统计上叫抽样波动或抽样误差。
抽样误差和系统误差不一样,关于系统误差,当人们一旦发现它之后,是可能找到产生原因而采取一定措施加以纠正的,而抽样误差则无法避免。因为客观上既然存在个体差异,那么刚巧这一样本中多抽到几例数值大些的,所求样本均数就会稍大,另一样本多抽到几例数值小些,该样本均数就会稍小,这是不言而喻的。
抽样误差既然是样本统计数指标与总体参数指标之间的误差,那么抽样误差小就表示从样本算得的平均数或百分率与总体的较接近,该样本代表总体说明其特征的可靠性亦大。但是,通常总体均数或总体方差我们并不知道,所以抽样误差的数量大小,不能直观地加以说明,只能通过抽样实验来了解抽样误差的规律性。
2 标准误(Standard error —SE)及其计算
为了表示个体差异的大小,或者说表示某一变量变异程度的大小,可计算其标准差(Standard error —SE)等变异指标来说明,现在我们要表示抽样误差的大小,如要问,从同一总体抽取类似的许多样本,各样本均数(或各率)之间的变异程度如何?也可用变异指标来说明。这种指标是:
2.1 均数的标准误为了表示均数的抽样误差大小如何,用的一种指标称为均数的标准误。我们以样本均数为变量,求出它们的标准差即可表示其变异程度,所以将样本均数的“标准差”定名为均数的标准误,简称标准误,以区别于通常所说的标准差。标准差表示个体值的分布情形,而标准误则说明样本均数的参差情况,两者不能混淆。下面用抽样试验进一步说明之。
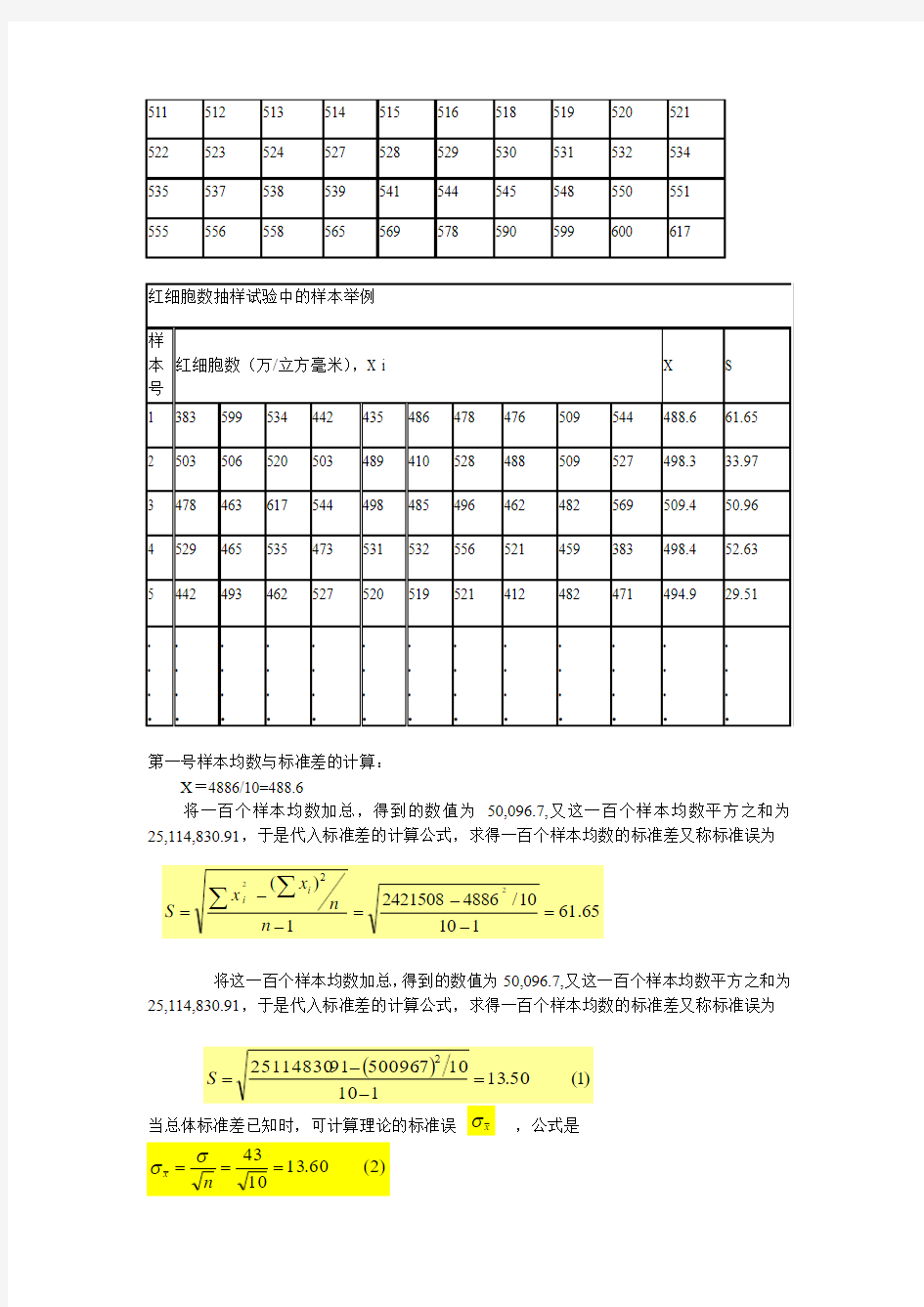
红细胞数抽样实验用的正态总体
第一号样本均数与标准差的计算:
X=4886/10=488.6
将一百个样本均数加总,得到的数值为50,096.7,又这一百个样本均数平方之和为25,114,830.91,于是代入标准差的计算公式,求得一百个样本均数的标准差又称标准误为
将这一百个样本均数加总,得到的数值为50,096.7,又这一百个样本均数平方之和为25,114,830.91,于是代入标准差的计算公式,求得一百个样本均数的标准差又称标准误为
由此,可见由一百个样本均数求得的标准误13.50与理论的标准误13.60比较接近。
在实际工作中,总体标准差往往并不知道,也不象抽样实验那样从同一总体随机抽取n
S作为总体标准差σ
的估计值。这样,公式中的σ就要用S
改为
再若将第将成为10.74
并不相等,可见的较好估计值。
以上介绍了求标准误的三种方法,其实我们平常用的只是式(3),而通过前两种方法的对比则可使我们明瞭标准误的含义。标准误是描述样本均数变异情况的一个指标,它的大小与总体标准差σ(一般只能用S估计)成正比,而与样本含量n的平方根成反比,因此若标准差小或样本含量大时,求出的标准误就小(标准误小表示样本均数与总体均数较接近),X代表μ较可靠,所以假若手头资料中观察值的变异程度较大(S大)时,为了保证样本代表总体比较可靠,就得适当增大样本含量(n)根据中心极限定理样本含量(n)大于30。
计算“标准差”和“变化系数” “标准差”(以d代表)是各种可能值与“期望值”离差的平方根其计算公式是: 以上述方案A的有关数据代入这个公式进行计算,得 £">a? A = £3 000 -2 0O0)a x 0.25 + (2 000 - 2 000>z x 0,50 + <1 000 —2 000)a x 0.25 -500 tMX) & - ysoo 000 = 707 3 “标准差”主要是由各种可能值与“期望值”之间的差距所决定。它们之间的差距越大,说明有关数值分布的离散程度越大,这是意味着有关方案包含的风险越大;它们之间的差距越小,说明各种可能值的分布越紧凑(越靠近于期望值),实际发生数将会更接近于期望值, 这就意味着有关方案包含的风险越小。所以,一般地说,一个方案标准差的大小,可以看作 其所含风险大小的具体标志。 但“标准差”的数值同时又受各种可能值的数值大小的影响。为了克服“标准差”的这 一缺陷,可同时计算与它相联系的另一个指标,称为“变化系数”(以q代表),其计算公式是以“标准差”除以“期望值”所得商: 以上关于“标准差”和“变化系数”的计算,为便于说明计算原理,只涉及到一个期间。一 个投资方案的现金流动实际上会涉及到许多期间。在这种情况下,整个方案的“标准差”(以 D代表)应以其各个期间的“期望值”和“标准差”为基础作进一步的综合,其算式是: 同时还应把各个期间的“期望值”统一换算为现值,称为“预期的现值”(以EPV代表),其算式是: 而整个方案的“变化系数”(以Q代表),则按下式计算:
Q = — w EPV 例:设上述方案 A 各年的净现金流入量如表所示 表 S 1年 第2年 第3年 园 ? * 倾錢人JS U ) ?审 (7C ) It 率 3 000 0.25 0.20 2 500 D.30 2W0 0.50 3呱 0.60 2 000 0.40 1000 0.25 2 000 0.2D 15D0 0.3D 可据以确定该方案各年净现金流入量的“期望值” 。 £1=3 000x0*25+2 000X0,50 + 1 000X0.25 =:2 000 (无) = 4 000X0.20+ 3 0X0.60 + 2 000X0.20=3 000 (元)r E 3 = 2 500 X 0.30 + 2 000 X 0.40+ 1 500 X 0.30 = 2 000 (元) 以各年净现金流入量的“期望值”为基础,计算各年的“标准差” 。 由=/{3 OW-Z O6o )j x0?25 + <2 00[)-2 000)? XQ .$I (1 000 - 2 (MO)1 25 = 707.1 亦=灯 W0)2xb.2+ (3 00ft-3 000)2x0.6+ (2 000-3 000)^0.2 -632.5 右=/ (2 500 - 2 000)s xfl~3 (2 000 - 2 x 0.4 + (i 500 J 000)a x Q.3 = 387,3 设要求达到的最低收益率为 6 %,则整个方案的“标准差”可计算如下: 707 J 2 ( 623.5^^7^^-931 4 [十 6% )2 (1 + 6% )4 (1 + 6% 户 而其各年净现金流入量的“预期的现值”是: 在确定了 D 和EPV 以后,可据以其出其整个方案的“变化系数”是: EP_咼T 册厂朋?丸236 (元) 3 000
计算方法 怎么计算它的大小呢?由标准差的概念可知,标准差反映离散程度的大小,那么多次抽取样本,把这些样本的均值集中起来作为一个新样本,计算它们的标准差,就可以反映它们的离散程度,离散程度大,说明这些均值偏离总体均值“5”越远,也就是抽样误差越大,这就是标准误—standard error。这里的error就是“误差”的英文,所以标准误其实应叫做“标准误差”,我们可以理解为由“标准差”计算得出的“误差”。
到这里可能有的人会说,我实际中怎么可能这么多次抽样呢,书上的公式也不是这样算的啊。没错,实际中我们一般只会抽样一次,而教科书上给出的公式就是通过一次样本的数据来计算标准误,即用样本标准差除以样本量的平方根。至于为什么公式是这样,这个公式准不准,已有统计学家的前辈们研究过了,我们只要去用就行了。如果想了解其原理,可以去更做深一步的研究。 举例 标准误在统计学中的应用十分广泛,以最简单的t检验为例,虽然t检验是应用最广泛的统计学方法之一,但很少有人思考过t值的意义。以单样本t检验为例,我们发现t值公式的分母就是标准误,代表抽样误差,而分子是两均数的差值,也就是实际差异。 所以t值就是实际差异与抽样误差的比值,如果实际差异大,t值就大,抽样误差大,t值就小。当t值大于某个临界值(可查表得出)时,我们更相信两组数据真的有差异,而不是抽样误差,结果就比较可靠,比如我们论文中常用的P<0.05,反之亦然。 需要注意的一点是,虽然我们用t检验来举例,教科书也把标准误放在t检验的章节,但不代表标准误是均数独有的,也可以是率或其他统计量,因此说标准误是“均数的标准差”是片面的,更合理的说法是“统计量的标准差”。 so,关于“标准差”和“标准误”的区别,你get了吗? 扫码关注我们
sd Std Dev,Standard Deviation 标准偏差(Std Dev,Standard Deviation) 一种量度数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。标准偏差的大小可通过标准偏差与平均值的倍率关系来衡量。标准偏差公式:S = Sqr(∑(xn-x拨)^2 /(n-1)) 公式中∑代表总和,x拨代表x的算术平均值,^2代表二次方,Sqr代表平方根。例子:有一组数字分别是200、50、100、200,求它们的标准偏差。 Java代码 1.x拨 = (200+50+100+200)/4 = 550/4 = 137.5 2.S^2 = [(200-137.5)^2+(50-137.5)^2+(100-137.5)^2+(200-137.5)^2]/ (4-1) =[62.5^2+(-87.5)^2+(-37.5)^2+62.5^2]/3 =[3906.25+7656.25+ 1406.25+3906.25]/3 = 16875/3 = 5625 3.标准偏差 S = Sqr(5625) = 75 cv 变异系数(coefficient of variation),亦称离散系数(coefficient of dispersion)或相对偏差(rsd),是标准偏差与平均值之比,用百分数表示,计算公式为: cv = sd/mean ×100% 200、50、100、200的cv=55% 在我用于本科毕业论文答辩的ppt里的某页赫然写着这么一行:“标准误:标准差除以样本量的平方根”。这是我对“数据处理”部分特地作出的一条说明。前些天打开看到的时候,我不禁有些囧。当年我们的《生物统计学》是一门选修课,授课的是生科院生物信息学方向的一个牛人,长得像藏人,不过一听口音就知道 他家和我家肯定离不太远。 不论生物还是药学,这门课历来就是门选修课。而且学的内容很浅,考试是开卷。我学得不咋地,学完的时候感觉,统计学说来就一句话:“有没有显著性差异”。你说这话啥意思,我也不太懂,能套公式把结果算出来就成。要说起来,有关统计学的基本知识,早在大一上分析化学的时候就专门讲过,很多实验报告也都要算平均数和标准差。 等到做完毕设写论文要处理数据的时候,我突然就发现了一个问题,为什么我看的那么多paper里面,在算样本平均数的时候,有的附的是标准差,有的 附的是标准误呢?而且国外的paper都是用的标准误。我又不懂,但是搜到有篇专门讲两者区别的文章说要用标准误,我也就用了。两者啥区别呢?标准差除 以样本量的平方根就等于标准误。可这数学关系反映了什么实质?我还是不懂。只是记得上生物统计学的课的时候,老师特别强调说国内生命科学和医学方面 的大部分paper都存在统计学错误。我就生怕我这么“正确地”使用标准误反而显得“错误”了,于是有了ppt上多此一举的那句话。 其实统计学是很多学科都需要用到的,而且重要性不言而喻。可就我所了解的,如我们这些生、化、医、药专业出身的学生有多少真的理解了统计学呢? 大部分都是停留在机械用软件、套公式、填结果的层面吧。当然了,这里存在一个学科差异的问题,也不是谁刻意地不想去理解统计学。比方说,去年国家就 三聚氰胺出台了一个最低检测限的标准的时候,很多没有科学素养的记者就开始疯狂质疑了。其实对“检测限”这个概念我们就很理解,我想心理学专业的学生倒不见得认同,而“检测限”的本质同属统计学中的“概率”和“误差”的范畴。不过总的说来,我们的统计学训练比起心理学实在差得太多。 终于进入正题了,因为统计学是心理学的基本功,所以我正儿八经地看起了考纲版的那本国内最经典的《现代心理与教育统计学》,等把第八章假设检验看完之后,我暂停了。我的基本感受是,一路看下来,条理是清晰的,逻辑是明白的,我也是理解的。如果说单纯应试的话,看到这样没问题。可这门课程当然 不止是应试之用的,那么,我在想,我看了这么多,它讲的这些东西到底是在干嘛呢?对,我的意思很明白。这本书是在讲鱼不是在讲渔。我纵使把计算标准 误的公式及其意义理解得化成灰也认识,可它到底是干嘛的呢? 我暂停是为了找些paper来自己体会统计学的用处,这时发现了手头正读着的《行为科学统计》,如获至宝地读完第一章我就恨不得骂脏话了,差距怎么能
标准差σ的4种计算公式
标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中的Pooled standard deviation(合并标准差) 做数据分析,经常会碰到提到标准差σ这个概念,关于标准差σ的计算方式,目前,本人知道有4种标准差σ的计算方法,如下: 一,简易标准差σ的计算方式 上面是计算整体的标准差,如果是计算样本的标准差,这里的N, 应该为N-1. 一般情况下,都是计算样本的标准差。关于这个
关于上面公式中用到的A2、A3、D2、D3、D4等常数请参考https://www.doczj.com/doc/fa5938774.html,/thread-476-1-1.html帖子下面的表格 三,XBAR-s管制图分析( X-sControl Chart)中的Sbar/C4算法 XBAR-S 管制图分析( X-S Control Chart):由平均数管制图与标准差管制图组成。
●与X-R管制图相同,惟s管制图检出力较R 管制图大,但计算麻烦。 ●一般样本大小n小于等于8可以使用R管制图,n大于8则使用S管制图。 ●有电脑软件辅助时,使用S管制图当然较好。 关于上面公式中用到的A2、A3、D2、D3、D4等常数请参考https://www.doczj.com/doc/fa5938774.html,/thread-476-1-1.html帖子下面的表格 四,Minitab中所使用的Pooled standard
deviation(合并标准差) Minitab中所使用的Pooled standard deviation,这个标准差的计算和一般的不一样,这个是Minitab默认的,相关的计算公式可以参考《Minitab: Pooled standard deviation》https://www.doczj.com/doc/fa5938774.html,/thread-288-1-1.html Minitab: Pooled standard deviation(合并标准差), Rbar, Sbar Pooled standard deviation(合并标准差) is a way to find a better estimate of the true standard deviation given several different samples taken in different circumstances where the mean may vary between samples but the true standard deviation (precision) is assumed to remain the same. It is calculated by where sp is the pooled standard deviation,
大家在写文章用统计分析时,用标准差还是标准误,这个我研究好久了,还准备发表一篇文章;希望大家讨论。 2.1 标准差的正确使用 一、标准差的主要作用是估计正常值的范围 实际应用中,估计观察值正常值范围应该用标准差(s),表示为“Mean ±SD”。此写法综合表达一组观察值的集中和离散特征的变异情况,说明样本平均数对观察值的代表性。s 的大或小说明数据取值的分散或集中。s与样本均数合用, 主要是在大样本调查研究中, 对正态或近似正态分布的总体正常值范围进行估计。如果不是为了正常值范围估计, 一般不用。当数据与正态分布相差很大,或者虽为正态分布, 但样本容量太小(小于30 或100),也不宜用估计正常值范围。 二、标准差还可用来计算变异系数(CV) 当两组观察值单位不同, 或两均数相差较大时, 不能直接用标准差比较其变异程度的大小, 须用变异系数系数来做比较。: 2.2 标准误的正确使用 一、标准误用来衡量抽样误差的大小和了解用样本平均数来推论总体平均数的可靠程度。 在抽样调查中,往往通过样本平均数来推论总体平均数,样本标准误适用于正态或近似正态分布的数据, 是主要描述小样本试验中,样本容量相同的同质的多个样本平均均数间的变异程度的统计量。即如果多次重复同一个试验, 它们之间的变异程度用。显然它越小,样本平均数变异越小,越稳定,用样本平均数估计总体均数越可靠。因此,为说明它的稳定性、可靠性或通过几个对几组数据进行比较(这是科研论文中最常见的),应当用描述数据。实际应用中应该写成“平均数±标准误”或而英文表示为“Mean ±SE”的形式。 二、标准误还可以进行总体平均数的区间估计与点估计(置信区间)。 根据正态分布原理,与合用还可以给出正态总体平均数的可信区间估计即推论总体平均数的可靠区间,例如常用(其中t0.05 (n-1) 为样本容量是n的t界值)表示总体均值的95%可信区间, 意指总体平均数有95%的把握在所给范围内。 三、标准误还可用来进行平均数间的显著性检验,从而判断平均数间的差别是否是由抽样误差引起的。 例如:某当地小麦良种的千粒重=34克,现在从外地引入一新品种,通过多小区的田间试验得到千粒重的平均数=35.2克,问新引进品种千粒重与当地良种有无显著差异? 新引进品种千粒重与当地良种有无显著差异实质是判断与的差别是否是有田间试验是抽样误差引起,所以要进行显著性检验,这里用t测验进行检验, 而,由于,故,所以认为新引进品种千粒重与当地良种千粒重的不同是由于田间试验是抽样误差引起,因此他们之间无显著差异。所以在进行平均数间的显著性检验是必须用到。 总之,标准差和标准误最常用的统计量,二者都是衡量样本变量(观察值) 随机性的指标,只是从不同角度来反映误差,二者在统计推断和误差分析中都有重要的应用。如果没有标准差,人们就无法看出一组观察值间变异程度有多大,这些数字到底有无代表性,如果没有标准误又很难看出我们的样本平均数是否可以代表总体平均数。所以二者都非常重要。
标准差 标准差(Standard Deviation),也称均方差(mean square error),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用σ表示。标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的,标准差未必相同。 标准差(Standard Deviation),在概率统计中最常使用作为统计分布程度(statistical dispersion)上的测量。标准差定义为方差的算术平方根,反映组内个体间的离散程度。测量到分布程度的结果,原则上具有两种性质: 为非负数值,与测量资料具有相同单位。一个总量的标准差或一个随机变量的标准差,及一个子集合样品数的标准差之间,有所差别。 标准计算公式 假设有一组数值X1,X2,X3,......Xn(皆为实数),其平均值为μ,公式如图1. 图1 标准差也被称为标准偏差,或者实验标准差,公式如图2。 图2 简单来说,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。 例如,两组数的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是7,但第二个集合具有较小的标准差。 标准差可以当作不确定性的一种测量。例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差和标准误的选择 (SD) 和 (SEM) Which error bar should you choose? It is easy to be confused about the difference between the standard deviation (SD) and standard error of the mean (SEM). The SD quantifies scatter - how much the values vary from one another. The SEM quantifies how accurately you know the true mean of the population. The SEM gets smaller as your samples get larger. This makes sense, because the mean of a large sample is likely to be closer to the true population mean than is the mean of a small sample. The SD does not change predictably as you acquire more data. The SD quantifies the scatter of the data, and increasing the size of the sample does not increase the scatter. The SD might go up or it might go down. You can't predict. On average, the SD will stay the same as sample size gets larger. If the scatter is caused by biological variability, your probably will want to show the variation. In this case, graph the SD rather than the SEM. You could also instruct Prism to graph the range, with error bars extending from the smallest to largest value. Also consider graphing every value, rather than using error bars. If you are using an in vitro system with no biological variability, the scatter can only result from experimental imprecision. In this case, you may not want to show the scatter, but instead show how well you have assessed the mean. Graph the mean and SEM or the mean with 95% confidence intervals. Ideally, the choice of which error bar to show depends on the source of the variability and the point of the experiment. In fact, many scientists always show the mean and SEM, to make the error bars as small as possible.
标准差和标准误:两个容易混淆的概念 标准误其实就是标准差的一种,不过二者的含义有所区别: 标准差计算的是一组数据偏离其均值的波动幅度,不管这组数是总体数据还是样本数据。你看standard deviation,说的就是“偏离”,只是在翻译为中文时,失去了其英文涵义。 而标准误(/ σ),衡量的是我们在用样本统计量去推断相应的总体参数(常见如均值、方差等)的时候,一种估计的精度。样本统计量本身就是随机变量,每一次抽样,都可以根据抽出的样本情况计算出一个不同的样本统计量值。理论上来讲,从既定的总体中按照既定的样本规模n,穷尽所有可能抽出的样本(不妨假设为NN),根据这些样本可以计算出NN个样本统计量值,把这些统计量值分组绘成直方图(X轴为分组的统计量数值,Y轴为落在某一分组区间内的频率),则这个直方图就反应了样本统计量的分布情况(即抽样分布)。既然是分布,当然就有均值和方差。如果所有可能的样本统计量值的平均值就是总体均值,这就是无偏估计。如果所有可能的样本统计量值的方差在所有用于估计总体参数的统计量里最小,这就是有效估计。因此,抽样分布的标准差(也就是标准误)越小,则用样本统计量去估计总体参数时,精度就越高。所以,你明白为什么叫标准误(standard error)了。一般意义上讲,standard error反映的是用样本统计量去估计总体参数的时候,可能发生的平均“差错”。 不妨这么理解吧,如果总体平均值是160,抽样误差是5,就是说用抽得的样本平均数去推断总体平均数时,平均差错可能在5左右;如果抽样误差是3,精度当然就比5要高啦。不同的总体、不同的样本规模,这个精度当然是不同的。如果总体的变异本身很小(也就是总体标准差小),样本规模越大,这种情况下精度当然就高啦。另外,根据大数定律,当样本规模大到一定程度的时候,不管总体是什么分布,样本平均数都会近似服从正态分布,这就为计算抽样误差(标准误)提供了理论依据。
2-3 變異的計算及解析 由基礎課程裡我們可以知道:表示變異的方法有很多,其最常使用的是“標準差”;關於標準差的計算又分兩個觀念:(真)標準差σ與估計標準差σ?。 為了解釋這兩個觀念的差異,我們先看下例數據: 下例數據有經過分組,每組抽測5個數據(即S/S 或n = 5的意思)。分組的原因不外乎量產、或長期研究等, 需要分批量測而形成母體與樣本的關係。
(1)(真)標準差σ: 若將所有Raw Data 視為一個母體、混合不分組,則 =STDEV( )所計算出來的標準差即為所求,即工程師最熟 悉的算法。
-------------------------------------------------------------- 使用時機:a.) 想了解母體真正的變異的時候;b.) 想敏銳地抓出上圖/組間變異的異常的時候。 --------------------------------- 目的:了解整個母體的總變異。 優點:可以充分反映整個母體的異常(含上圖/組間變異、及下圖/組內變異的異常…尤其是組間變異的異 常)。 缺點:數據量要夠大(避免誤差過大)、且上圖不能有異常(避免組間變異顯著),否則計算出來的 不具代 表性。 (2) 估計標準差σ?: 大部分的工程師沒聽說過估計標準差。Raw Data 若經過分組(分組與抽樣皆要隨機),我們可以利用樣本的變異、去估算整個母體的變異;但是要特別注意組間變 σ)已經被假設成常態分配;以白話來說:想像管制異(X 圖-上圖的每個組平均X是一顆綠豆,當這些綠豆被一把撒到管制圖-上圖的時候,這些綠豆皆自動定位到常態分配該有的位置上,因此整個上圖的假設都是常態分配,若真有異常、也早已被視而不見。 故以估計標準差σ?來看問題,祇能解析下圖/組內變異的
调用函数 STDEV 估算样本的标准偏差。标准偏差反映相对于平均值(mean) 的离散程度。 语法 STDEV(number1,number2,...) Number1,number2,... 为对应于总体样本的1 到30 个参数。也可以不使用这种用逗号分隔参数的形式,而用单个数组或对数组的引用。 说明 函数STDEV 假设其参数是总体中的样本。如果数据代表全部样本总体,则应该使用函数STDEVP 来计算标准偏差。 此处标准偏差的计算使用“无偏差”或“n-1”方法。 函数STDEV 的计算公式如下: 其中x 为样本平均值AVERAGE(number1,number2,…),n 为样本大小。 忽略逻辑值(TRUE 或FALSE)和文本。如果不能忽略逻辑值和文本,请使用STDEVA 工作表函数。 示例 假设有10 件工具在制造过程中是由同一台机器制造出来的,并取样为随机样本进行抗断强度检验。 如果您将示例复制到空白工作表中,可能会更易于理解该示例。 操作方法 创建空白工作簿或工作表。 请在“帮助”主题中选取示例。不要选取行或列标题。 从帮助中选取示例。 按Ctrl+C。 在工作表中,选中单元格A1,再按Ctrl+V。
若要在查看结果和查看返回结果的公式之间切换,请按Ctrl+`(重音符),或在“工具”菜单上,指向“公式审核”,再单击“公式审核模式”。 A 1 强度 2 1345 3 1301 4 1368 5 1322 6 1310 7 1370 8 1318 9 1350 10 1303 11 1299 公式说明(结果) =STDEV(A2:A11) 假定仅生产了10 件工具,其抗断强度的标准偏差 (27.46391572) 方差分析 EXCEL的数据处理除了提供了很多的函数外,但这个工具必须加载相应的宏后才能使用,操作步骤为:点击菜单“工具-加载宏”,会出现一个对话框,从中选择“分析工具库”,点击确定后,在工具菜单栏内出现了这个分析工具。 如果你的电脑中没有出现分析工具库,则需要使用OFFICE的安装光盘,运行安装程序。在自定义中点开EXCEL,找到分析工具库,选择“在本机运行”,安装添加即可。 在数据分析工具库中提供了3种基本类型的方差分析:单因素方差分析、双因素无重复试验和可重复试验的方差分析,本节将分别介绍这三种方差分析的应用: 单因素方差分析 在进行单因素方差分析之前,须先将试验所得的数据按一定的格式输入到工作表中,其中每种水平的试验数据可以放在一行或一列内,具体的格式如表,表中每个水平的试验数据结果放在同一行内。 数据输入完成以后,操作“工具-数据分析”,选择数据分析工具对话框内的“单因素方差分析”,出现一个对话框,对话框的内容如下: 1.输入区域:选择分析数据所在区域,可以选择水平标志,针对表中数据进行分析时选取(绿色)和***区域。 2.分组方式:提供列与行的选择,当同一水平的数据位于同一行时选择行,位于同一列时选择列,本例选择行。 3.如果在选取数据时包含了水平标志,则选择标志位于第一行,本例选取。4.α:显著性水平,一般输入0.05,即95%的置信度。
标准差与标准误的区别 在日常的统计分析中,标准差和标准误是一对十分重要的统计量,两者有区别也有联系。但是很多人却没有弄清其中的差异,经常性地进行一些错误的使用。对于标准差与标准误的区别,很多书上这样表达:标准差表示数据的离散程度,标准误表示抽样误差的大小。这样的解释可能对于许多人来说等于没有解释。 其实这两者的区别可以采用数据分布表达方式描述如下:如果样本服从均值为μ,标准差为δ的正态分布,即X~N(μ, δ2),那么样本均值服从均值为0,标准差为δ2/n的正态分布,即~ N(μ,δ2/n)。这里δ为标准差,δ/n1/2为标准误。明白了吧,用统计学的方法解释起来就是这么简单。 可是,实际使用中总体参数往往未知,多数情况下用样本统计量来表示。那么,关于这两者的区别可以这样表述:标准差是样本数据方差的平方根,它衡量的是样本数据的离散程度;标准误是样本均值的标准差,衡量的是样本均值的离散程度。而在实际的抽样中,习惯用样本均值来推断总体均值,那么样本均值的离散程度(标准误)越大,抽样误差就越大。所以用 标准误来衡量抽样误差的大小。 在此举一个例子。比如,某学校共有500名学生,现在要通过抽取样本量为30的一个样本,来推断学生的数学成绩。这时可以依据抽取的样本信息,计算出样本的均值与标准差。如果我们抽取的不是一个样本,而是10个样本,每个样本30人,那么每个样本都可以计算出均值,这样就会有10个均值。也就是形成了一个10个数字的数列,然后计算这10个数字的标准差,此时的标准差就是标准误。但是,在实际抽样中我们不可能抽取10个样本。所以,标准误就由样本标准差除以样本量来表示。当然,这样的结论也不是随心所欲,而是经过了统计学家的严密证明的。 在实际的应用中,标准差主要有两点作用,一是用来对样本进行标准化处理,即样本观察值减去样本均值,然后除以标准差,这样就变成了标准正态分布;而是通过标准差来确定异常值,常用的方法就是样本均值加减n倍的标准差。标准误的作用主要是用来做区间估计,常用的估计区间是均值加减n倍的标准误。
标准差(Standard Deviation) 和标准误差(Standard Error)本文摘自 Streiner DL.Maintaining standards: differences between the standard deviation and standarderror, and when to use each. Can J Psychiatry 1996; 41: 498–502. 标准差(Standard Deviation) 标准差,缩写为S.D., SD, 或者 s (就是为了把人给弄晕?),是描述数据点在均值(mean)周围聚集程度的指标。 如果把单个数据点称为“X i,” 因此“X1” 是第一个值,“X2” 是第二个值,以此类推。均值称为“M”。初看上去Σ(X i-M)就可以作为描述数据点散布情况的指标,也就是把每个X i与M的偏差求和。换句话讲,是(单个数据点—数据点的平均)的总和。 看上去挺有逻辑性的,但是它有两个缺点。 第一个困难是:上述定义的结果永远是0。根据定义,高出均值的和永远等于低于均值的和,因此它们相互抵消。可以取差值的绝对值来解决(也就是说,忽略负值的符号),但是由于各种神秘兮兮的原因,统计学家不喜欢绝对值。另外一个剔除负号的方法是取平方,因为任何数的平方肯定是正的。所以,我们就有Σ(X i-M)2。 另外一个问题是当我们增加数据点后此等式的结果会随之增大。比如我们手头有25个值的样本,根据前面公式计算出SD是10。如果再加25个一模一样的样本,直觉上50个大样本的数据点分布情况应该不变。但是我们的公式会产生更大的SD值。好在我们可以通过除以数据点数量N来弥补这个漏洞。所以等式就变成Σ(X i-M)2/N. 根据墨菲定律,我们解决了两个问题,就会随之产生两个新问题。 第一个问题(或者我们应该称为第三个问题,这样能与前面的相衔接)是用平方表达偏差。假设我们测量自闭症儿童的IQ。也许会发现IQ均值是75, 散布程度是100 个IQ点平方。这IQ点平方又是什么东西?不过这容易处理:用结果的平方根替代,这样结果就与原来的测量单位一致。所以上面的例子中的散布程度就是10个IQ点,变得更加容易理解。 最后一个问题是目前的公式是一个有偏估计,也就是说,结果总是高于或者低于真实的值。解释稍微有点复杂,先要绕个弯。在多数情况下,我们做研究的时候,更感兴趣样本来自的总体(population)。比如,我们探查有年轻男性精神分裂症患者的家庭中的外现情绪(expressed emotion,EE)水平时,我们的兴趣点是所有满足此条件的家庭(总体),而不单单是哪些受研究的家庭。我们的工作便是从样本中估计出总体的均值(mean)和SD。因为研究使用的只是样本,所以
标准差 次数分布中的数据不仅有集中趋势,而且还有离中趋势。所谓离中趋势指的是数据具有偏离中心位置的趋势,它反映了一组数据本身的离散程度和差异性程度。标准差能综合反映一组数据的离散程度或个别差异程度。 例如,甲、乙两班学生各50人,其语文平均成绩都是80分,但甲班最高成绩98分,最低42分,而乙班最高成绩86分,最低60分。初步看出,两班语文成绩是不一样的,甲班学生的语文成绩个别差异程度大、水平参差不齐;而乙班学生的语文成绩差异程度小,语文水平整齐度大些。怎样用标准差这个特征量数来刻画一组数据的差异程度呢?下面介绍标准差的概念及计算。 一、标准差概念与计算 1.标准差定义与计算公式 一组数据的标准差,指的是这组数据的离差平方和除以数据个数所得商的算术平方根。若用S 代表标准差,则标准差的计算公式为: 标准差的平方,称为方差,用S2表示方差。 计算标准差时,首先要计算数据的平均数,接着要计算各数据与平均数之间的离差 平方,即()2,最后由公式(2-5)计算标准差S。 例如,4名儿童的身高分别是110厘米,100厘米,120厘米和150厘米,若求4名儿童身高数据的标准差时,其基本步骤如下: ①求平均数:(厘米) ②求离差平方和: )2=(110―120)2+(100―120)2+(120―120)2+(150―120)2 =100+400+0+900=1400(平方厘米) ③求标准差S:S= (厘米)
这样,我们大体可认为,这4名儿童身高差异程度,从平均角度来看,约相差18.71厘米。 2.标准差的计算中心方法 计算标准差的方法有三种,一是按公式逐步分析计算,如上述所示;二是以列表计算的方式;三是利用计算器或计算机进行计算。下面再举一例说明采用列表方式计算标准差S。 [例7] 已知8 位同学在某图形辨认测验中的成绩数据(见表2-2),计算这组数据的标准差。 [分析解答] 采用列表计算方式,应用公式(2-5)确定数据的标准差,详见表2-2。 表2-2 计算标准差S的示例 - () (1) = (2) () = 标准差在实际中有广泛的用途,同时对深化研究数据也具有重要的作用。如不同班级考试成绩的平均数和标准差,不同年度或不同学科测验分数的平均数和标准差,以及其他体能测试或心理测验数据的平均数和标准差,就是一些具体的应用。后续各章内容的学习,将经常用到平均数、标准差和方差这些概念。 由于标准差计算公式结构适合于代数处理,因此,许多具有统计功能的计算器,都有计算方差和标准差的相应功能。学习者只要花少量时间学习与掌握有关计算器的使用,即可以轻松自如地处理大量数据,求取平均数和标准差。 在利用公式(2-5)手工求标准差时,如表2-2所示,由于平均数有小数,这使计算离差平方的数据更加复杂,小数点的位数加倍增加,同时四舍五入的计算误差以及出错的可能性都有所增加。为克服这个弊病,我们可从公式(2-5)出发,通过代数演算,推导出另一个与公式(2-5)等价的新公式,即公式(2-6)。这一新公式对计算标准差来讲,不用通过计 算平均数以及离差平方和,用原始数据直接计算标准差,因而在许多情况下,具有更简便、准确的特点。其计算公式:
1、计量资料的标准差和标准误有何区别与联系 标准差和标准误都是变异指标,但它们之间有区别,也有联系。区别: ①概念不 同;标准差是描述观察值(个体值)之间的变异程度;标准误是描述样本均数的抽 样误差;②用途不同;标准差与均数结合估计参考值范围,计算变异系数,计算 标准误等。标准误用于估计参数的可信区间,进行假设检验等。③它们与样本含 量的关系不同: 当样本含量n 足够大时,标准差趋向稳定;而标准误随n的增大 而减小,甚至趋于0 。联系: 标准差,标准误均为变异指标,当样本含量不变时, 标准误与标准差成正比。 2、二项分布、Poission分布的应用条件 二项分布的应用条件:医学领域有许多二分类记数资料都符合二项分布(传染病和遗传 病除外),但应用时仍应注意考察是否满足以下应用条件:(1) 每次实验只有两类对立 的结果;(2) n次事件相互独立;(3) 每次实验某类结果的发生的概率是一个常数。 Poisson分布的应用条件:医学领域中有很多稀有疾病(如肿瘤,交通事故等)资料都符合Poisson分布,但应用中仍应注意要满足以下条件:(1) 两类结果要相互对立;(2) n次试验相互独立;(3) n应很大, P应很小。 3、极差、四分位数间距、标准差、变异系数的适用范围有何异同? 答:这四个指标的相同点在于均用于描述计量资料的离散程度。其不同点为: 极差可用于各种分布的资料,一般常用于描述单峰对称分布小样本资料的变异程度,或用于初步了解资料的变异程度。若样本含量相差较大,不宜用极差来比较资料的离散程度。 四分位数间距适用于描述偏态分布资料、两端无确切值或分布不明确资料的离散程度。 标准差常用于描述对称分布,特别是正态分布或近似正态分布资料的离散程度。 变异系数适用于比较计量单位不同或均数相差悬殊的几组资料的离散程度。 4.中位数、均数、几何均数的适用条件有何异同。 (1)均数适用于描述对称分布,特别是正态分布的数值变量资料的平均水平;(2)几何均数适用于描述原始数据呈偏态分布,但经过对数变换后呈正态分布或近似正态分布的数值变量资料的平均水平;(3)中位数适用于描述呈明显偏态分布(正偏态或负偏态),或分布情况不明,或分布的末端有不确切数值的数值变量资料的平均水平。 5.第一类错误与第二类错误的区别与联系。
Excel计算方差和标准差 样本中各数据与的差的平方和的平均数叫做样本方差;样本方差的叫做样本标准差。样本方差和样本标准差都是衡量一个样本波动大小的量,样本方差或样本标准差越大,样本数据的波动就越大。 方差(Variance)和标准差(Standard Deviation)。方差和标准差是测算离散趋势最重要、最常用的。方差是各变量值与其均值离差平方的平均数,它是测算数值型数据离散程度的最重要的方法。标准差为方差的算术平方根,用S表示。标准差与方差不同的是,标准差和变量的计算单位相同,比方差清楚,因此很多时候我们分析的时候更多的使用的是标准差。平均值=AVERAGE () 方差=VAR ( ) 标准差=STDEV ( ) 一、标准差 函数STDEV:估算样本的标准偏差。标准偏差反映相对于平均值(mean) 的离散程度。 语法STDEV(number1,number2,...) Number1,number2,... 为对应于总体样本的1 到30 个参数。也可以不使用这种用逗号分隔参数的形式,而用单个数组或对数组的引用。 说明函数STDEV 假设其参数是总体中的样本。如果数据代表全部样本总体,则应该使用函数STDEVP 来计算标准偏差。此处标准偏差的计算使用“无偏差”或“n-1”方法。 函数STDEV 的计算公式如下: 其中x 为样本平均值AVERAGE(number1,number2,…),n 为样本大小。 忽略逻辑值(TRUE 或FALSE)和文本。如果不能忽略逻辑值和文本,请使用STDEVA 工作表函数。 示例假设有10件工具在制造过程中是由同一台机器制造出来的,并取样为随机样本进行抗断强度检验。如果您将示例复制到空白工作表中,可能会更易于理解该示例。 操作方法创建空白工作簿或工作表。请在“帮助”主题中选取示例。不要选取行或列标题。从帮助中选取示例。 按Ctrl+C。 在工作表中,选中单元格A1,再按Ctrl+V。 若要在查看结果和查看返回结果的公式之间切换,请按Ctrl+`(重音符),或在“工具”菜单上,指向“公式审核”,再单击“公式审核模式”。 A
标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中 标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中的Pooled standard deviation(合并标准差) 做数据分析,经常会碰到提到标准差σ这个概念,关于标准差σ的计算方式,目前,本人知道有4种标准差σ的计算方法,如下: 一,简易标准差σ的计算方式 上面是计算整体的标准差,如果是计算样本的标准差,这里的N, 应该为N-1. 一般情况下,都是计算样本的标准差。关于这个标准的详细运算公式和案例分析,可以参考附件,里面有比较详细的解释。 标准差的简易计算公式和案例分析.rar(28.19 KB, 下载次数: 1262) 二,XBAR-R管制图分析( X-R Control Chart)图中的Rbar/d2 算法 XBAR-R管制图分析( X-R Control Chart):由平均数管制图与全距管制图组成。 ●品质数据可以合理分组时,可以使用X管制图分析或管制制程平均;使用R管制图分析制程变异。 ●工业界最常使用的计量值管制图。
关于上面公式中用到的A2、A3、D2、D3、D4等常数请参考https://www.doczj.com/doc/fa5938774.html,/thread-476-1-1.html帖子下面的表格 三,XBAR-s管制图分析( X-sControl Chart)中的Sbar/C4算法 XBAR-S 管制图分析( X-S Control Chart):由平均数管制图与标准差管制图组成。 ●与X-R管制图相同,惟s管制图检出力较R管制图大,但计算麻烦。 ●一般样本大小n小于等于8可以使用R管制图,n大于8则使用S管制图。 ●有电脑软件辅助时,使用S管制图当然较好。
标准差与标准误关系与区别在日常的统计分析中,标准差和标准误是一对十分重要的统计量,两者有区别也有联系。但是很多人却没有弄清其中的差异,经常性地进行一些错误的使用。对于标准差与标准误的区别,很多书上这样表达:标准差表示数据的离散程度,标准误表示抽样误差的大小。这样的解释可能对于许多人来说等于没有解释。 其实这两者的区别可以采用数据分布表达方式描述如下:如果样本服从均值为μ,标准差为δ的正态分布,即X~N(μ, δ2),那么样本均值服从均值为0,标准差为δ2/n的正态分布,即~ N(μ,δ2/n)。这里δ为标准差,δ/n1/2为标准误。明白了吧,用统计学的方法解释起来就是这么简单。 可是,实际使用中总体参数往往未知,多数情况下用样本统计量来表示。那么,关于这两者的区别可以这样表述:标准差是样本数据方差的平方根,它衡量的是样本数据的离散程度;标准误是样本均值的标准差,衡量的是样本均值的离散程度。而在实际的抽样中,习惯用样本均值来推断总体均值,那么样本均值的离散程度(标准误)越大,抽样误差就越大。所以用标准误来衡量抽样误差的大小。 在此举一个例子。比如,某学校共有500名学生,现在要通过抽取样本量为30的一个样本,来推断学生的数学成绩。这时可以依据抽取的样本信息,计算出样本的均值与标准差。如果我们抽取的不是一个样本,而是10个样本,每个样本30人,那么每个样本都可以计算出均值,这样就会有10个均值。也就是形成了一个10个数字的数列,然后计算这10个数字的标准差,此时的标准差就是标准误。但是,在实际抽样中我们不可能抽取10个样本。所以,标准误就由样本标准差除以样本量来表示。当然,这样的结论也不是随心所欲,而是经过了统计学家的严密证明的。 在实际的应用中,标准差主要有两点作用,一是用来对样本进行标准化处理,即样本观察值减去样本均值,然后除以标准差,这样就变成了标准正态分布;而是通过标准差来确定异常值,常用的方法就是样本均值加减n倍的标准差。标准误的作用主要是用来做区间估计,常用的估计区间是均值加减n倍的标准误。