
第六章 联立方程计量经济学模型案例
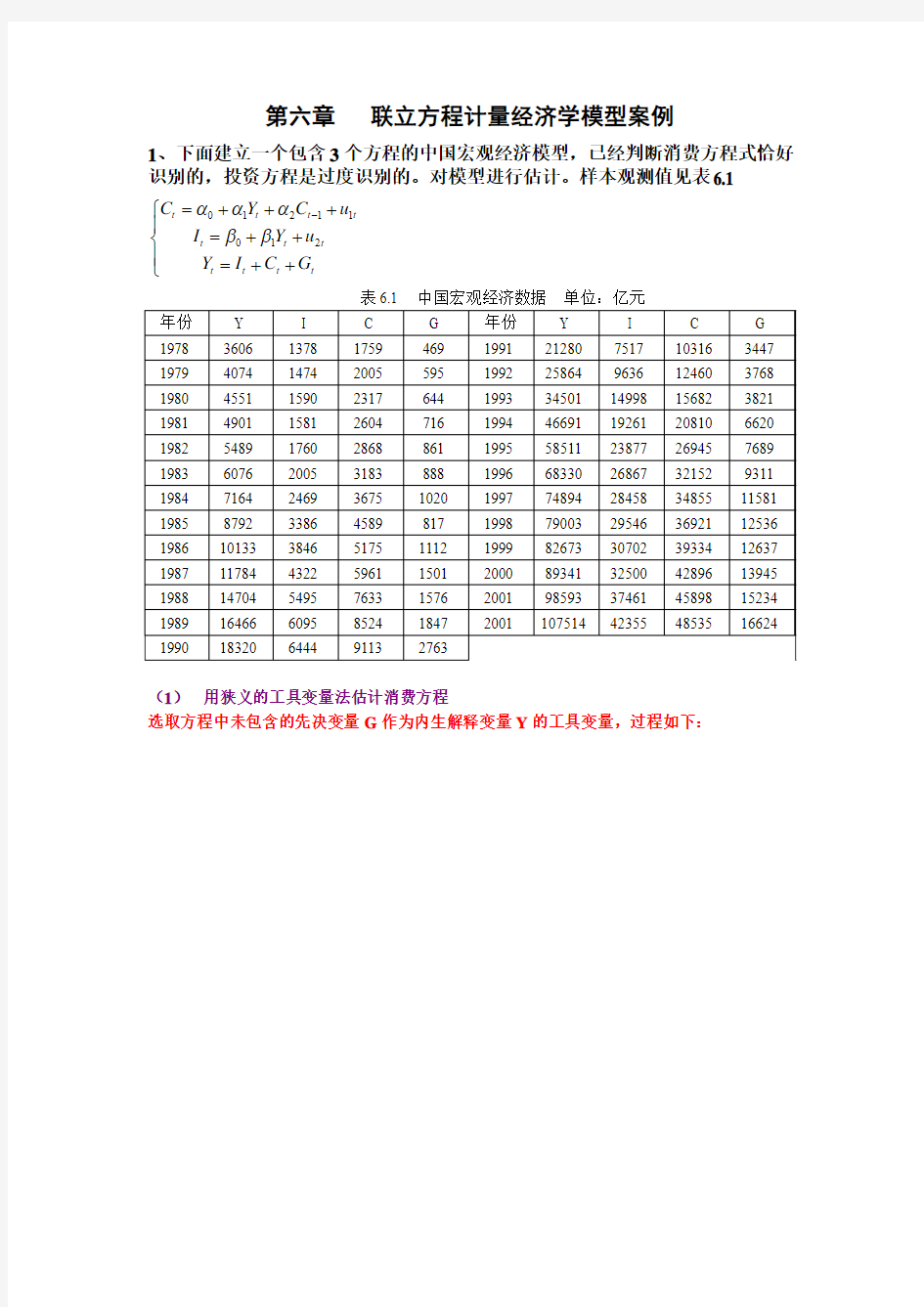
1、下面建立一个包含3个方程的中国宏观经济模型,已经判断消费方程式恰好识别的,投资方程是过度识别的。对模型进行估计。样本观测值见表6.1
01211012t t t t t t t t t t t C Y C u I Y u Y I C G αααββ-=+++??
=++??=++?
表6.1 中国宏观经济数据 单位:亿元
(1) 用狭义的工具变量法估计消费方程
选取方程中未包含的先决变量G 作为内生解释变量Y 的工具变量,过程如下:
结果如下:
所以,得到结构参数的工具变量法估计量为:
012???582.27610.2748560.432124αα
α===,, (2) 用间接最小二乘法估计消费方程
消费方程中包含的内生变量的简化式方程为:
1011112120211222t t t t
t
t t t C C G Y C G πππεπππε--=+++??
=+++? 参数关系体系为:
11121210012012122000
παπαπααππαπ--=??
--=??-=?
用普通最小二乘法估计,结果如下:
所以参数估计量为:
101112???1135.937,0.619782, 1.239898π
ππ=== 202122???2014.368,0.682750, 4.511084π
ππ=== 所以,得到间接最小二乘估计值为:
12122??0.274856?π
α
π
==
211121????0.432124α
παπ=-= 010120????582.2758α
παπ=-= (3)用两阶段最小二乘法估计消费方程
第一阶段使用普通最小二乘法估计内生解释变量的简化方程,得到
1?2014.3680.68275 4.511084t t t
Y C G -=++ 用Y 的预测值替换消费方程中的Y ,直接用OLS 估计消费方程,过程如下:
也可以用工具变量法估计消费方程,过程如下:
结果如下:
综上所述,可知道,对于恰好识别方程,三种方法得到的结论是一样的。
(4)用两阶段最小二乘法估计投资方程,过程同上。
(5)投资方程是过度识别的方程,也可以用GMM估计,选择的工具变量为先决变量C01、G。
估计结果如下:
与2SLS 结果比较,结构参数估计量变化不大。残差平方和由81641777变为15209108,显著减少。为什么?利用了更多的信息。
2.以表6.2所示的中国的实际数据为资料,估计下面的联立模型。
01121t t t t t Y M C I u ββγγ=++++ 0132t t t t M Y P u ααγ=+++
表6.2
建立联立模型,并命名为MY
在SYSTEM窗口里面定义联立方程组和使用的工具变量。
选择两阶段最小二乘法进行估计。
得到如下输出结果:
所以得到联立方程计量经济学模型的估计表达式为:
1306.30.151 2.0640.686t t t t Y M C I =--++
43243.34 2.938511.413t t t M Y P =+-
3、以Klein (克莱因)联立方程模型为例介绍两阶段最小二乘估计。
首先建立工作文件,数据如表7。
0123(1)()CC PP PP WP WG αααα=++-++ (消费方程) 0123(1)II PP PP KK ββββ=++-+ (投资方程) 0123(1)WP XX XX AA γγγγ=++-+ (私人工资方程)
XX CC II GG =++ (均衡需求恒等式) PP XX TT WP =-- (私人利润恒等式)
(1)KK KK II =-+ (私人存量恒等式)
使用的工具变量是:WG GG TT AA PP(-1) KK XX(-1) C
过程如下:
选择System,并起名为KleinModel
在窗口空白处输入方程指令,只要求写行为方程(前3个方程),不需定义方程(后3个方程),最后一行命令列出的是所用工具变量。
对联立方程进行估计:点击system窗口上的estimate键
选择2TSLS即两阶段最小二乘估计
得到如下Klein联立方程的估计结果:
上述输出结果与线性单方程分析相同。
1.对联立方程组进行预测
联立方程的预测是以上述估计结果为基础进行的。主要分为3步:第1步:建立模型
出现如下对话框:
第2步:输入定义方程
由于在设定联立方程时没有输入定义方程,因此在求解模型时应该加入,否则,模型只识别System中设定的内生变量。
加入定义方程的方法如下:
输入需要加入的定义方程:
联立方程模型 一、概念: 联立方程模型系统将变量分为内生变量和外生变量两大类。 由系统决定的,同时也对模型系统产生影响,它会受到随机项的影 响。一般都是经济变量。每一个内生变量的值都要利用模型中的全 部方程才能决定。 外生变量:是不由系统决定的变量,是系统外变量,取值由系统外决定。一般是确定性变量,或者是具有临界概率分布的随机变量,其参数不是 模型系统研究的元素。外生变量影响系统,但本身不受系统的影响。 外生变量一般是经济变量、条件变量、政策变量、虚变量。 先决变量:外生变量和滞后内生变量 注:联立方程模型中有多少个内生变量就必定有多少个方程 :根据经济理论和行为规律建立的描述经济变量之间直接结构关系 的计量经济学方程系统称为结构式模型。 结构方程的正规形式:将一个内生变量表示为其他内生变量、先 决变量和随机干扰项的函数形式 完备的结构式模型:g个内生变量、k个先决变量、g个结构方程 行为方程:描述变量之间经验关系的方程,含有未知的参数和随 机扰动项。例如:凯恩斯收入决定模型中的消费函数 制度方程:由法律、制度、政策等制度性规定的经济变量之间的 函数关系,如税收方程。 恒等式:定义方程式和平衡方程。 简化式模型:用所有先决变量作为每个内生变量的解释变量所形成的模型。 参数关系体系:描述简化式参数与结构式参数之间的关系。
二、识别 方程之间的关系有严格的要求,一个方程模型想要能估计,必须可识别。 ∴进行模型的估计之前需要判断模型是否可以识别(即是否能被估计)。 1、识别的基本定义:是否具有确定的统计形式。 注:识别的定义是针对结构方程而言的。 模型中每个需要估计其参数的随机方程都存在识别问题。 如果一个模型中的所有随机方程都是可以识别的,则认为该联立方程模型 系统是可以识别的。反之不识别。 恒等方程由于不存在参数估计问题,所以也不存在识别问题。但是,在判 断随机方程的识别性问题时,应该将恒等方程考虑在内。 恰好识别:某一个随机方程只有一组参数估计量 过度识别:某一个随机方程具有多组参数估计量 方程的线性组合是否得到的新方程具有与消费方程相同的统计形式,决定了方程也是否是可以识别的。 2、如何修改模型使不可识别的方程变成可以识别 (1)或者在其它方程中增加变量; (2)或者在该不可识别方程中减少变量。 (3)必须保持经济意义的合理性。 3、识 别条件 结构式: B ΓN Y X +=
第二章 案例分析 研究目的:分析各地区城镇居民计算机拥有量与城镇居民收入水平的关系,对更多规律的研究具有指导意义. 一. 模型设定 2011年年底城镇居民家庭平均每百户计算机拥有量Y 与城镇居民平均每人全年家庭总收入X 的关系 图2.1 各地区城镇居民每百户计算机拥有量与人均总收入的散点图 由图可知,各地区城镇居民每百户计算机拥有量随着人均总收入水平的提高而增加,近似于线性关系,为分析其数量性变动规律,可建立如下简单线性回归模型: Y t =β1+β2X t +u t 50 60 708090100 110120130140 X Y
二.估计参数 假定所建模型及其随机扰动项u i满足各项古典假设,用普通最小二乘法(OLSE)估计模型参数.其结果如下: 表2.1 回归结果 Dependent Variable: Y Method: Least Squares Date: 11/13/17 Time: 12:50 Sample: 1 31 Included observations: 31 Variable Coefficient Std. Error t-Statistic Prob. C 11.95802 5.622841 2.126686 0.0421 X 0.002873 0.000240 11.98264 0.0000 R-squared 0.831966 Mean dependent var 77.08161 Adjusted R-squared 0.826171 S.D. dependent var 19.25503 S.E. of regression 8.027957 Akaike info criterion 7.066078 Sum squared resid 1868.995 Schwarz criterion 7.158593 Log likelihood -107.5242 Hannan-Quinn criter. 7.096236 F-statistic 143.5836 Durbin-Watson stat 1.656123 Prob(F-statistic) 0.000000 由表2.1可得, β1=11.9580,β2=0.0029 故简单线性回归模型可写为: ^ Y X t t=11.9580+0.0029 其中:SE(β1)=5.6228, SE(β2)=0.0002 R-squared=0.8320,F=143.5836,n=31
第三章、经典单方程计量经济学模型:多元线性回归模型 一、内容提要 本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的情形相同。主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方面的应用等方面。只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。 本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。与一元回归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性这一假设;在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是否对被解释变量有显著线性影响关系的联合性F检验,并讨论了F检验与拟合优度检验的内在联系。 本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如何转化为线性回归模型的常见类型与方法。这里需要注意各回归参数的具体经济含义。 本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约束检验。参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与邹氏预测检验两种类型的检验。检验都是以F检验为主要检验工具,以受约束模型与无约束模型是否有显著差异为检验基点。参数的非线性约束检验主要包括最大似然比检验、沃尔德检验与拉格朗日乘数检验。它们仍以估计无约束模型与受约束模型为基础,但以最大似然 χ分布为检验统计原理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的2 量的分布特征。非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。 二、典型例题分析 例1.某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为36 .0 . + = - 10+ 094 medu fedu .0 sibs edu210 131 .0 R2=0.214 式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。问
计量经济学案例分析1 一、研究的目的要求 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2002年全国城市居民家庭平均每人每年消费支出为元, 最低的黑龙江省仅为人均元,最高的上海市达人均10464元,上海是黑龙江的倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我们研究的对象是各地区居民消费的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。所以模型的被解释变量Y选定为“城市居民每人每年的平均消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2002年截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 从2002年《中国统计年鉴》中得到表的数据: 表 2002年中国各地区城市居民人均年消费支出和可支配收入
第六章 案例分析 一、研究目的 2003年中国农村人口占59.47%,而消费总量却只占41.4%,农村居民的收入和消费是一个值得研究的问题。消费模型是研究居民消费行为的常用工具。通过中国农村居民消费模型的分析可判断农村居民的边际消费倾向,这是宏观经济分析的重要参数。同时,农村居民消费模型也能用于农村居民消费水平的预测。 二、模型设定 正如第二章所讲述的,影响居民消费的因素很多,但由于受各种条件的限制,通常只引入居民收入一个变量做解释变量,即消费模型设定为 t t t u X Y ++=21ββ (6.43) 式中,Y t 为农村居民人均消费支出,X t 为农村人均居民纯收入,u t 为随机误差项。表6.3是从《中国统计年鉴》收集的中国农村居民1985-2003年的收入与消费数据。 表6.3 1985-2003年农村居民人均收入和消费 单位: 元
2000 2001 2002 2003 2253.40 2366.40 2475.60 2622.24 1670.00 1741.00 1834.00 1943.30 314.0 316.5 315.2 320.2 717.64 747.68 785.41 818.86 531.85 550.08 581.85 606.81 为了消除价格变动因素对农村居民收入和消费支出的影响,不宜直接采用现价人均纯收入和现价人均消费支出的数据,而需要用经消费价格指数进行调整后的1985年可比价格计的人均纯收入和人均消费支出的数据作回归分析。 根据表6.3中调整后的1985年可比价格计的人均纯收入和人均消费支出的数据,使用普通最小二乘法估计消费模型得 t t X Y 0.59987528.106?+= (6.44) Se = (12.2238) (0.0214) t = (8.7332) (28.3067) R 2 = 0.9788,F = 786.0548,d f = 17,DW = 0.7706 该回归方程可决系数较高,回归系数均显著。对样本量为19、一个解释变量的模型、5%显著水平,查DW 统计表可知,d L =1.18,d U = 1.40,模型中DW #学术探讨# 现代计量经济学模型体系解析* 李子奈刘亚清 内容提要:本文对现代计量经济学模型体系进行了系统的解析,指出了现代计量经济学的各个分支是以问题为导向,在经典计量经济学模型理论的基础上,发展成为相对独立的模型理论体系,包括基于研究对象和数据特征而发展的微观计量经济学、基于充分利用数据信息而发展的面板数据计量经济学、基于计量经济学模型的数学基础而发展的现代时间序列计量经济学、基于非设定的模型结构而发展的非参数计量经济学,并对每个分支进行了扼要的描述。最后在/交叉与综合0的方向上提出了现代计量经济学模型理论的研究前沿领域。 关键词:经典计量经济学时间序列计量经济学微观计量经济学 一、引言 计量经济学自20世纪20年代末30年代初诞生以来,已经形成了十分丰富的内容体系。一般认为,可以以20世纪70年代为界将计量经济学分为经典计量经济学(Classical Econometrics)和现代计量经济学(Mo dern Eco no metr ics),而现代计量经济学又可以分为四个分支:时间序列计量经济学(Tim e Ser ies Econo metrics)、微观计量经济学(M-i cro-econometrics)、非参数计量经济学(Nonpara-m etric Econometrics)以及面板数据计量经济学(Panel Data Eco nom etrics)。这些分支作为独立的课程已经被列入经济学研究生的课程表,独立的教科书也已陆续出版,应用研究已十分广泛,标志着它们作为计量经济学的分支学科已经成熟。 据此提出三个问题:一是经典计量经济学的地位问题。既然现代计量经济学模型体系已经成熟,而且它们都是在经典模型理论的基础上发展的,那么经典模型还有应用价值吗?是不是凡是采用经典模型的研究都是低水平和落后的?二是现代计量经济学的各个分支的发展导向问题。即它们是如何发展起来的?三是现代计量经济学进一步创新和发展的基点在哪里?回答这些问题,对于正确理解计量经济学的学科体系,对于计量经济学的课程设计和教学内容安排,对于正确评价计量经济学理论和应用研究的水平,对于进一步推动中国的计量经济学理论研究,都是十分有益的。 现代计量经济学的各个分支是以问题为导向,以经典计量经济学模型理论为基础而发展起来的。所谓/问题0,包括研究对象和表征研究对象状态和变化的数据。研究对象不同,表征研究对象状态和变化的数据具有不同的特征,用以进行经验实证研究的计量经济学模型既然不同,已有的模型理论方法不适用了,就需要发展新的模型理论方法。按照这个思路,就可以用图1简单地描述经典计量经济学模型与现代计量经济学模型各个分支之间的关系。 本文试图从方法论的角度对现代计量经济学模型的发展,特别是现代计量经济学模型与经典计量经济学模型之间的关系进行较为系统的讨论,以期对未来我国计量经济学的发展研究提供借鉴和启示。本文的内容安排如下:首先分析经典计量经济学模型的基础地位,明确它在现代的应用价值,同时对发生于20世纪70年代的/卢卡斯批判0的实质进行讨论;然后依次讨论时间序列计量经济学、微观计量经济学、非参数计量经济学以及面板数据计量经济学的发展,回答它们是以什么问题为导向,以什么为目的而发展的;最后以/现代计量经济学模型体系的分解与综合0为题,讨论现代计量经济学的前沿研究领域以及从对我国计量经济学理论的创新和发展 ) 22 ) *本文受国家社会科学基金重点项目(08AJY001,计量经济学模型方法论基础研究)的资助。 第六章 经典联立方程计量经济学模型:理论与方法 一、内容提要 联立方程计量经济学模型是相对于单一方程模型提出来的,旨在在讨论多个经济变量相互影响的错综复杂的运行规律,或者说讨论多个内生变量被联立决定的问题。 本章学习内容的一个重点是关于联立方程计量经济学模型区别于单方程模型的若干基本概念,包括内生变量、外生变量、前定变量的概念;结构式模型、简化式模型的概念;随机方程、恒等方程的概念;行为方程、技术方程、制度方程、统计方程、定义方程、平衡方程等相关概念。 本章学习的另一个重点是联立模型的识别问题。需掌握模型识别的基本概念、模型识别的类型(不可识别、恰好识别、过渡识别)、模型的结构式识别条件、模型的简化式识别条件以及实际应用中的经验识别方法。 本章学习的第三个重点是联立模型的估计问题。首先明确联立模型估计时会遇到的三个方面的问题。一是随机解释变量问题,即模型中的某些解释变量也能是与随机扰动项相关的随机解释变量;二是损失变量信息的问题,即以单方程方法估计模型时会损失其他方程变量所提供的信息;三是损失方程之间的相关性信息问题,即以单方程方法估计模型时会损失不同方程随机扰动项间的相关性方面的一些信息。其次,需要掌握联立模型两大类估计方法中的主要估计方法,如单方程估计方法中的狭义工具变量法(IV )、间接最小二乘法(ILS )、二阶段最小二乘法(2SLS ),系统估计方法中的三阶段最小二乘法(3SLS )等。 本章学习中不容忽视的还有联立方程计量经济学模型估计方法的比较,以及联立方程模型的检验问题。前者需要考察大样本估计量特性与小样本估计量的特性;后者包括拟合效果检验、预测性检验、方程间误差传递检验等方面的内容。 二、典型例题分析 1、如果我们将“供给”1Y 与“需求”2Y 写成如下的联立方程的形式: 第八章案例分析 改革开放以来,随着经济的发展中国城乡居民的收入快速增长,同时城乡居民的储蓄存 款也迅速增长。经济学界的一种观点认为,20世纪90年代以后由于经济体制、住房、医疗、养老等社会保障体制的变化,使居民的储蓄行为发生了明显改变。为了考察改革开放以来中 国居民的储蓄存款与收入的关系是否已发生变化,以城乡居民人民币储蓄存款年底余额代表 居民储蓄(Y),以国民总收入GNI代表城乡居民收入,分析居民收入对储蓄存款影响的数量关系。 表8.1为1978-2003年中国的国民总收入和城乡居民人民币储蓄存款年底余额及增加额的数据。 单位:亿元 2004 鉴数值,与用年底余额计算的数值有差异。 为了研究1978—2003年期间城乡居民储蓄存款随收入的变化规律是否有变化,考证城 乡居民储蓄存款、国民总收入随时间的变化情况,如下图所示: 图8.5 从图8.5中,尚无法得到居民的储蓄行为发生明显改变的详尽信息。若取居民储蓄的增量 (YY ),并作时序图(见图 8.6) 从居民储蓄增量图可以看出,城乡居民的储蓄行为表现出了明显的阶段特征: 2000年有两个明显的转折点。再从城乡居民储蓄存款增量与国民总收入之间关系的散布图 看(见图8.7),也呈现出了相同的阶段性特征。 为了分析居民储蓄行为在 1996年前后和2000年前后三个阶段的数量关系,引入虚拟变 量D 和D2°D 和D 2的选择,是以1996>2000年两个转折点作为依据,1996年的GNI 为66850.50 亿元,2000年的GNI 为国为民8254.00亿元,并设定了如下以加法和乘法两种方式同时引入 虚拟变量的的模型: YY = 1+ 2GNI t 3 GNI t 66850.50 D 1t + 4 GNh 88254.00 D 2t i D 1 t 1996年以后 D 1 t 2000年以后 其中: D 1t _ t 1996年及以前 2t 0 t 2000年及以前 对上式进行回归后,有: Dependent Variable: YY Method: Least Squares Date: 06/16/05 Time: 23:27 120000 8.7 1996年和 100000- 40000 2WM GNi o eOB2&ISEea9a9l2949698[Ma2 20CUC ir-“- 1CC0C 图 8.6 *OOCO mnoot , RtKXD Tconr GF* 第六章 联立方程计量经济学模型案例 1、下面建立一个包含3个方程的中国宏观经济模型,已经判断消费方程式恰好识别的,投资方程是过度识别的。对模型进行估计。样本观测值见表6.1 01211012t t t t t t t t t t t C Y C u I Y u Y I C G αααββ-=+++?? =++??=++? 表6.1 中国宏观经济数据 单位:亿元 (1) 用狭义的工具变量法估计消费方程 选取方程中未包含的先决变量G 作为内生解释变量Y 的工具变量,过程如下: 结果如下: 所以,得到结构参数的工具变量法估计量为: 012???582.27610.2748560.432124α αα===,, (2) 用间接最小二乘法估计消费方程 消费方程中包含的内生变量的简化式方程为: 1011112120211222t t t t t t t t C C G Y C G πππεπππε--=+++?? =+++? 参数关系体系为: 11121210012012122000 παπαπααππαπ--=?? --=??-=? 用普通最小二乘法估计,结果如下: 所以参数估计量为: 101112???1135.937,0.619782, 1.239898π ππ=== 202122???2014.368,0.682750, 4.511084π ππ=== 所以,得到间接最小二乘估计值为: 12122??0.274856?π α π == 211121????0.432124α παπ=-= 010120????582.2758α παπ=-= (3)用两阶段最小二乘法估计消费方程 第一阶段使用普通最小二乘法估计内生解释变量的简化方程,得到 1?2014.3680.68275 4.511084t t t Y C G -=++ 用Y 的预测值替换消费方程中的Y ,直接用OLS 估计消费方程,过程如下: 第二章案例分析 一、研究的目的要求 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我们研究的对象是各地区居民消费的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2002年截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 从2002年《中国统计年鉴》中得到表2.5的数据: 表2.52002年中国各地区城市居民人均年消费支出和可支配收入 ∑ x = 1264471.423 ∑ y = 516634.011 ∑ X = 52432495.137 ∑ ? ? ? ? 案例分析 1— 一元回归模型实例分析 依据 1996-2005 年《中国统计年鉴》提供的资料,经过整理,获得以下农村居民人均 消费支出和人均纯收入的数据如表 2-5: 表 2-5 农村居民 1995-2004 人均消费支出和人均纯收入数据资料 单位:元 年度 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 人均纯 收入 1577.7 1926.1 2090.1 2161.1 2210.3 2253.4 2366.4 2475.6 2622.2 2936.4 人均消 费支出 1310.4 1572.1 1617.2 1590.3 1577.4 1670.1 1741.1 1834.3 1943.3 2184.7 一、建立模型 以农村居民人均纯收入为解释变量 X ,农村居民人均消费支出为被解释变量 Y ,分析 Y 随 X 的变化而变化的因果关系。考察样本数据的分布并结合有关经济理论,建立一元线 性回归模型如下: Y i =β0+β1X i +μi 根据表 2-5 编制计算各参数的基础数据计算表。 求得: X = 2262.035 Y = 1704.082 2 i 2 i ∑ x i y i = 788859.986 2 i 根据以上基础数据求得: β1 = ∑ x i y 2 i i = 788859.986 126447.423 = 0.623865 β 0 = Y - β1 X = 1704.082 - 0.623865 ? 2262.035 = 292.8775 样本回归函数为: Y i = 292.8775 + 0.623865X i 上式表明,中国农村居民家庭人均可支配收入若是增加 100 元,居民们将会拿出其中 的 62.39 元用于消费。 计量经济学案例分析 一、问题提出 国内生产总值(GDP)指一个国家或地区所有常住单位在一定时期内(通常为1 年)生产活动的最终成果,即所有常住机构单位或产业部门一定时期内生产的可供最终使用的产品和劳务的价值,包括全部生产活动的成果,是一个颇为全面的经济指标。对国内生产总值的分析研究具有极其重要的作用和意义,可以充分地体现出一个国家的综合实力和竞争力。因此,运用计量经济学的研究方法具体分析国内生产总值和其他经济指标的相关关系。对预测国民经济发展态势,制定国家宏观经济政策,保持国民经济平稳地发展具有重要的意义。 二、模型变量的选择 模型中的被解释变量为国内生产总值Y。影响国内生产总值的因素比较多,根据其影响因素的大小和资料的可比以及预测模型的要求等方面原因, 文章选择以下指标作为模型的解释变量:固定资产投资总量(X1 ) 、财政支出总量(X2 )、城乡居民储蓄存款年末余额(X3 )、进出口总额(X4 )、上一期国内生产总值(X5)、职工工资总额(X6)。其中,固定资产投资的增长是国内生产总值增长的重要保障,影响效果显著;财政支出是扩大内需的保证,有利于国内生产总值的增长;城乡居民储蓄能够促进国内生产总值的增长,是扩大投资的重要因素,但是过多的储蓄也会减缓经济的发展;进出口总额反映了一个国家或地区的经济实力;上期国内生产总值是下期国内生产总值增长的基础;职工工资总额是国内生产总值规模的表现。 三、数据的选择 文中模型样本观测数据资料来源于20XX 年《中国统计年鉴》,且为当年价格。固定资产投资总量1995-20XX 年的数据取自20XX 年统计年鉴,1991-1994 年的为搜集自其他年份统计年鉴。详细数据见表1。 表1 1 ?什么是计量经济学?它与经济学、统计学和数学的关系怎样?答:1、计量经济学是一门运用经济理论和统计技术来分析经济数据的科学和艺术,它以经济理论为指导,以客观事实为依据,运用数学、统计学的方法和计算机技术,研究带有随机影响的经济变量之间的数量关系和规律。2、经济理论、数学和统计学知识是在计量经济学这一领域进行研究的必要前提,这三者中的每一个对于真正理解现代经济生活中的数量关系是必要的,但不充分,只有结合在一起才行。 2计量经济学三个要素是什么? 经济理论、经济数据和统计方法。 3. 计量经济学模型的检验包括哪几个方面?其具体含义是什么? 答:(1)经济意义检验,即根据拟定的符号、大小、关系,对参数估计结果的可靠性进行判断(2)统计检验,由数理统计理论决定。包括:拟合优度检验、总体显着性检验。(3)计量经济学检验,由计量经济学理论决定。包括:异方差性检验、序列相关性检验、多重共线性检验。(4)模型预测检验,由模型应用要求决定。包括:稳定性检验:扩大样本重新估计;预测性能检验:对样本外一点进行实际预测。 4. 计量经济学方法与一般经济数学方法有什么区别? 答:计量经济学揭示经济活动中各因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各因素之间的理论关系,用确定性的数学方程加以描述。 5. 计量经济学模型研究的经济关系有那两个基本特征? 答:一是随机关系,二是因果关系J - . ' /■ 6. 计量经济学研究的对象和核心内容是什么? 答:计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律。计量经济学的核心内容包括两个方面:一是方法论,即计量经济学方法或者理论计量经济学。二是应用,即应用计量经济学。 无论是理论计量经济学还是应用计量经济学,都包括理论、方法和数据三种要素。 7. 计量经济学中应用的数据类型怎样?举例解释其中三种数据类型的结构。 答:计量经济模型:WAGE二f(EDU,EXP,GEND,山 1)时间序列数据是按时间周期收集的数据,如年度或季度的国民生产总值。 2)横截面数据是在同一时间点手机的不同个体的数据。如世界各国某年国民生产总值。 3)混合数据是兼有时间序列和横截面成分的数据,女口 1985 —2010世界各国GDP数据。 8. 建立与应用计量经济学模型的主要步骤有哪些? (1)理论模型的设计(2)样本数据的收集(3)模型参数的估计(4)模型的检验 9. 用OLS建立多元线性回归模型,有哪些基本假设? 1、回归模型是线性的,模型设定无误且含有误差项 2、误差项总体均值为零 3、所有解释变量与误差 项都不相关4、误差项互不相关(不存在序列相关性)5、误差项具有同方差6、任何一个解释变量都不是其他解释变量的完全线性函数7、误差项服从正态分布。 10. 随机误差项包含哪些因素影响? 在解释变量中被忽略的因素的影响(影响不显着的因素、未知的影响因素、无法获得数据的因素);变量观测值的观测误差的影响;模型关系的设定误差的影响;其它随机因素的影响。 11. 为什么要计算调整后的可决系数? 在应用过程中发现,如果在模型中增加一个解释变量,?往往增大。这是因为残差平方和往往随着解 释变量的增加而减少,至少不会增加。这就给人一个错觉:要使得模型拟合得好,只要增加解释变量即可。但是,现实情况往往是,由增加解释变量个数引起的的增大与拟合好坏无关,需调整。 =0.89表示被解释变量Y的变异性的89%能用估计的回归方程解释。 12. 叙述多重共线性的概念、后果和补救措施。 概念:如果两个或多于两个解释变量之间出现了相关性,则称模型存在多重共线性。 后果:1、估计量仍然是无偏的2、参数估计量的方差和标准差增大3、置信区间变宽4、t统计量会变 小5、估计量对模型设定的变化及其敏感6、对方程的整体拟合程度几乎没有影响7、回归系数符号 第七章 案例分析 【案例7.1】 为了研究1955—1974年期间美国制造业库存量Y 和销售额X 的关系,我们在例7.3中采用了经验加权法估计分布滞后模型。尽管经验加权法具有一些优点,但是设置权数的主观随意性较大,要求分析者对实际问题的特征有比较透彻的了解。下面用阿尔蒙法估计如下有限分布滞后模型: t t t t t t u X X X X Y +++++=---3322110ββββα 将系数i β(i =0,1,2,3)用二次多项式近似,即 00αβ= 2101αααβ++= 210242αααβ++= 210393αααβ++= 则原模型可变为 t t t t t u Z Z Z Y ++++=221100αααα 其中 3 212321132109432---------++=++=+++=t t t t t t t t t t t t t X X X Z X X X Z X X X X Z 在Eviews 工作文件中输入X 和Y 的数据,在工作文件窗口中点击“Genr ”工具栏,出现对话框,输入生成变量Z 0t 的公式,点击“OK ”;类似,可生成Z 1t 、Z 2t 变量的数据。进入Equation Specification 对话栏,键入回归方程形式 Y C Z0 Z1 Z2 点击“OK ”,显示回归结果(见表7.2)。 表7.2 表中Z0、 Z1、Z2对应的系数分别为210ααα、、的估计值210? ??ααα、、。将它们代入 分布滞后系数的阿尔蒙多项式中,可计算出 3210????ββββ、、、的估计值为: -0.522)432155.0(9902049.03661248.0?9?3??0.736725)432155.0(4902049.02661248.0?4?2?? 1.131142)432155.0(902049.0661248.0????661248.0??2101 2101 2101 00 =-?+?+=++==-?+?+=++==-++=++===αααβαααβαααβαβ 从而,分布滞后模型的最终估计式为: 32155495.076178.015686.1630281.0419601.6----+++-=t t t t t X X X X Y 在实际应用中,Eviews 提供了多项式分布滞后指令“PDL ”用于估计分布滞后模型。下面结合本例给出操作过程: 在Eviews 中输入X 和Y 的数据,进入Equation Specification 对话栏,键入方程形式 Y C PDL(X, 3, 2) 其中,“PDL 指令”表示进行多项式分布滞后(Polynomial Distributed Lags )模型的估计,括号中的3表示X 的分布滞后长度,2表示多项式的阶数。在Estimation Settings 栏中选择Least Squares(最小二乘法),点击OK ,屏幕将显示回归分析结果(见表7.3)。 表 7.3 需要指出的是,用“PDL ”估计分布滞后模型时,Eviews 所采用的滞后系数多项式变换不是形如(7.4)式的阿尔蒙多项式,而是阿尔蒙多项式的派生形式。因此,输出结果中PDL01、PDL02、PDL03对应的估计系数不是阿尔蒙多项式 研究城镇居民可支配收入与人均消费性支出的关系 班级:08投资姓名:陈婷婷学号:802025105 一、研究的目的 本案例分析根据1980年~2009 年城镇居民人均可支配收入和人均消费性支出的基本数据,应用一元线性回归分析的方法研究了城镇居民人均可支配收入和人均消费性支出之间数量关系的基本规律,并在预测2010年人均消费性支出的发展趋势。从理论上说,居民人均消费性支出应随着人均可支配收入的增长而提高。随着消费更新换代的节奏加快,消费日益多样化,从追求物质消费向追求精神消费和服务消费转变。因此,政府在制定当前的宏观经济政策时,考虑通过增加居民收入来鼓励消费,以保持经济的稳定增长。 二、模型设定 表1 1980—2009年城镇人均可支配收入和人均消费性支出 为分析1980—2009年城镇人均可支配收入(X)和人均消费性支出(Y)的关系,作下图所示的散点图。 图1 城镇人均可支配收入和人均消费性支出的散点图 从散点图可以看出城镇人均可支配收入(X)和人均消费性支出(Y)大体呈现为线性关系,为分析中国城镇人均消费性支出随城镇人均可支配收入变动的数量规律性,可以建立如下简单线性回归模型: Y=β+βX+u i12i 三、估计参数 Eviews的回归结果如下表所示: 表2 回归结果 ① 参数估计和检验的结果写为: ^ 184.59590.780645i i Y X =+ (41.10880)(0.004281) t =(4.490423) (182.3403) 2R =0.999159 2R (修正值)=0.999129 F =33247.99 n=30 ② 回归系数的区间估计[α=5% 2 t α(n-2)=2.048 ] ^^ 22222 2 2 ????[()()]1P t SE t SE ααβββββα-≤≤+=- =P (0.780645—2.048*0.004281 2β≤≤0.780645+2.048*0.004281) =P (0.7719 2β≤≤0.7894) =95% 剩余项(Residual )、实际值(Actual )、拟合值(Fitted )的图形如下: 图2 剩余项、实际项、拟合值的图形 四、模型检验 1、 经济意义检验 所估计的参数β1= 184.5959,β2=0.780645,说明城镇人均可支配收入每增加一元,可导致人均消费性支出提高0.780645元。 第五章经典单方程计量经济学模型:专门问题 一、内容提要 本章主要讨论了经典单方程回归模型的几个专门题。 第一个专题是虚拟解释变量问题。虚拟变量将经济现象中的一些定性因素引入到可以进行定量分析的回归模型,拓展了回归模型的功能。本专题的重点是如何引入不同类型的虚拟变量来解决相关的定性因素影响的分析问题,主要介绍了引入虚拟变量的加法方式、乘法方式以及二者的组合方式。在引入虚拟变量时有两点需要注意,一是明确虚拟变量的对比基准,二是避免出现“虚拟变量陷阱”。 第二个专题是滞后变量问题。滞后变量包括滞后解释变量与滞后被解释变量,根据模型中所包含滞后变量的类别又可将模型划分为自回归分布滞后模型与分布滞后模型、自回归模型等三类。本专题重点阐述了产生滞后效应的原因、分布滞后模型估计时遇到的主要困难、分布滞后模型的修正估计方法以及自回归模型的估计方法。如对分布滞后模型可采用经验加权法、Almon多项式法、Koyck方法来减少滞项的数目以使估计变得更为可行。而对自回归模型,则根据作为解释变量的滞后被解释变量与模型随机扰动项的相关性的不同,采用工具变量法或OLS法进行估计。由于滞后变量的引入,回归模型可将静态分析动态化,因此,可通过模型参数来分析解释变量对被解释变量影响的短期乘数和长期乘数。 第三个专题是模型设定偏误问题。主要讨论当放宽“模型的设定是正确的”这一基本假定后所产生的问题及如何解决这些问题。模型设定偏误的类型包括解释变量选取偏误与模型函数形式选取取偏误两种类型,前者又可分为漏选相关变量与多选无关变量两种情况。在漏选相关变量的情况下,OLS估计量在小样本下有偏,在大样本下非一致;当多选了无关变量时,OLS估计量是无偏且一致的,但却是无效的;而当函数形式选取有问题时,OLS估计量的偏误是全方位的,不仅有偏、非一致、无效率,而且参数的经济含义也发生了改变。在模型设定的检验方面,检验是否含有无关变量,可用传统的t检验与F检验进行;检验是否遗漏了相关变量或函数模型选取有错误,则通常用一般性设定偏误检验(RESET检验)进行。本专题最后介绍了一个关于选取线性模型还是双对数线性模型的一个实用方法。 第四个专题是关于建模一般方法论的问题。重点讨论了传统建模理论的缺陷以及为避免这种缺陷而由Hendry提出的“从一般到简单”的建模理论。传统建模方法对变量选取的 第七章联立方程模型和两阶段最小二乘法 建立一个OBJECT。确定内外生变量: cc=c(1)+c(2)*PP+c(3)*PP(-1)+c(4)*(WP+WG) ii=c(5)+c(6)*PP+c(7)*PP(-1)+c(8)*KK WP=c(9)+c(10)*XX+c(11)*XX(-1)+c(12)*AA INST WG GG TT AA PP(-1) KK XX(-1) C 回归结果: System: KLEINMODEL Estimation Method: Two-Stage Least Squares Date: 07/13/11 Time: 15:29 Sample: 1921 1941 Included observations: 21 Total system (balanced) observations 63 Coefficient Std. Error t-Statistic Prob. C(1) 16.55476 1.467979 11.27725 0.0000 C(2) 0.017302 0.131205 0.131872 0.8956 C(3) 0.216234 0.119222 1.813714 0.0756 C(4) 0.810183 0.044735 18.11069 0.0000 C(5) 20.27821 8.383249 2.418896 0.0192 C(6) 0.150222 0.192534 0.780237 0.4389 C(7) 0.615944 0.180926 3.404398 0.0013 C(8) -0.157788 0.040152 -3.929751 0.0003 C(9) 1.500297 1.275686 1.176070 0.2450 C(10) 0.438859 0.039603 计量经济学实例分析 The Standardization Office was revised on the afternoon of December 13, 2020 计量经济学实例分析 -------居民消费水平与GDP之间关系 摘要 改革开放以来,我国居民收入与消费水平不断提高,居民消费需求成为我国经济增长的关键动力,特别是21世纪初以来,居民消费需求对过敏寂静的发展起到了越来越大的作用。及时把握居民消费需求的变化,并制定相关政策推动内需,对于提高我国经济增长速度和质量都有了重要的意义。 凯恩斯认为,短期影响个人消费的主观因素是确定的,消费者的消费主要取决于收入的多少,而其他因素对消费的影响相对较小。因此,本文只对我国居民消费水平和GDP的变化情况之间建立了粗略的模型。 本文利用了1990-2009年之间20年内居民消费水平和GDP数据,旨在说明其中的相互关系,并建立模型以供参考。 关键词 消费收入 GDP 一,理论陈述 1,凯恩斯的绝对收入假说 凯恩斯在《货币通论》中提出了绝对收入假说,即人们的消费支出是起当期的可支配收入决定的。当人们的可支配收入增加时,其中用于消费的数额也会增加,但消费增量在收入增量中的比重是下降的,因此随着收入的增加,人们的消费在收入中的比重是下降的,而储蓄在收入中所占的比重则是上升的。 凯尔斯构建的绝对收入消费函数中,当人们的可支配收入增加时,其中用于消费的数额也会增加,但是消费增量在收入增量中的比重是下降的,因此随着收入的增加,人们的消费在收入中的比重是下降的,而储蓄在收入中的比重则是上升的。 二,实证分析 消费水平是指,一个国家在一定时期内人们在消费过程中对物质文化生活需要的满足程度。 本文以分析居民消费水平为目的,考虑到了GDP 对消费水平的影响,根据学到的计量经济学知识,采用了1990-2009年间的完整数据,构建了以居民收入水平为被解释变量,GDP 为解释变量的一元回归线性模型。 1,参数估计 设模型表达式为:i i i Y U +βX α=+ 其中:Yi :居民消费水平(元) Xi :GDP (亿元) Ui :随机干扰项 表一:居民消费水平与GDP 数据表现代计量经济学模型体系解析
计量经济学:联立方程部分习题以及解析
计量经济学-案例分析-第八章
第六章联立方程计量经济学模型案例
计量经济学-案例分析-第二章
计量经济学案例分析一元回归模型实例分析报告
推荐-计量经济学案例分析 精品
计量经济学简答题(经典)
计量经济学案例分析第七章
计量经济学案例分析
第五章--经典单方程计量经济学模型:专门问题.doc
第七章_联立方程模型和两阶段最小二乘法
计量经济学实例分析
相关主题
文本预览