
随机选择问题算法说明
问题描述
问题描述:寻找第k小元素的一个直接方法是对所有的元素排序并取出第k 小的元素,这个方法需要Ω(n log n)时间,因为任何基于比较的排序过程在最坏情况下必须至少要花这么多时间。一个具有n个元素的集合中,第k小元素能够在最优线性时间内找到,这个问题也称为选择问题。其基本思想如下:假设递归算法中,在每个递归调用的划分步骤后,我们丢弃元素的一个固定部分并且对剩余的元素递归,则问题的规模以几何级数递减,也就是在每个调用过程中,问题的规模以一个常因子被减小。
随机选择问题,首先随机产生一个数组A中的元素x,然后将数组划分成三个数组:A1,A2和A3,其中分别包含小于,等于和大于x的元素。接着求出第k小元素出现在三个数组中的哪一个,并根据测试的结果,算法或返回第k小的元素,或者在A1或A3上递归。
问题分析
对于算法select ,我们已经证明了算法的运行时间是Θ(n),具有一个很大的常系数使得算法变得不切实际,特别是对小的和中等的n值也如此。所以现在对选择给出一个既简单又快捷的随机Las Vegas选择算法,它的期望运行时间是一个带有小的常系数的Θ(n)。正如算法RANDOMIZEDSELECT一样,在最坏情况下它的运行时间是Θ(n2),而且最坏情况的界限也和算法求解的实例无关,它只是一个由随机数发生器选择的一个不凑巧的序列的结果,它发生的概率是非常小的。算法的运作在下述意义上像二分搜索算法一样,不断丢弃输入的一部分直到所求第k个最小元素已经得出。算法精确描述在RANDOMIZEDSELECT中给出。算法描述
算法RANDOMIZEDSELECT
输入:n个元素的数组A[1…n]和整数k,1<=k<=n。
输出:A中的第k小元素。
1.rselect(A,1,n,k)
过程rselect(A,low,high,k)
1.v = random(low,high)
2.x = A[v]
3.将A[low,high]分成三个数组
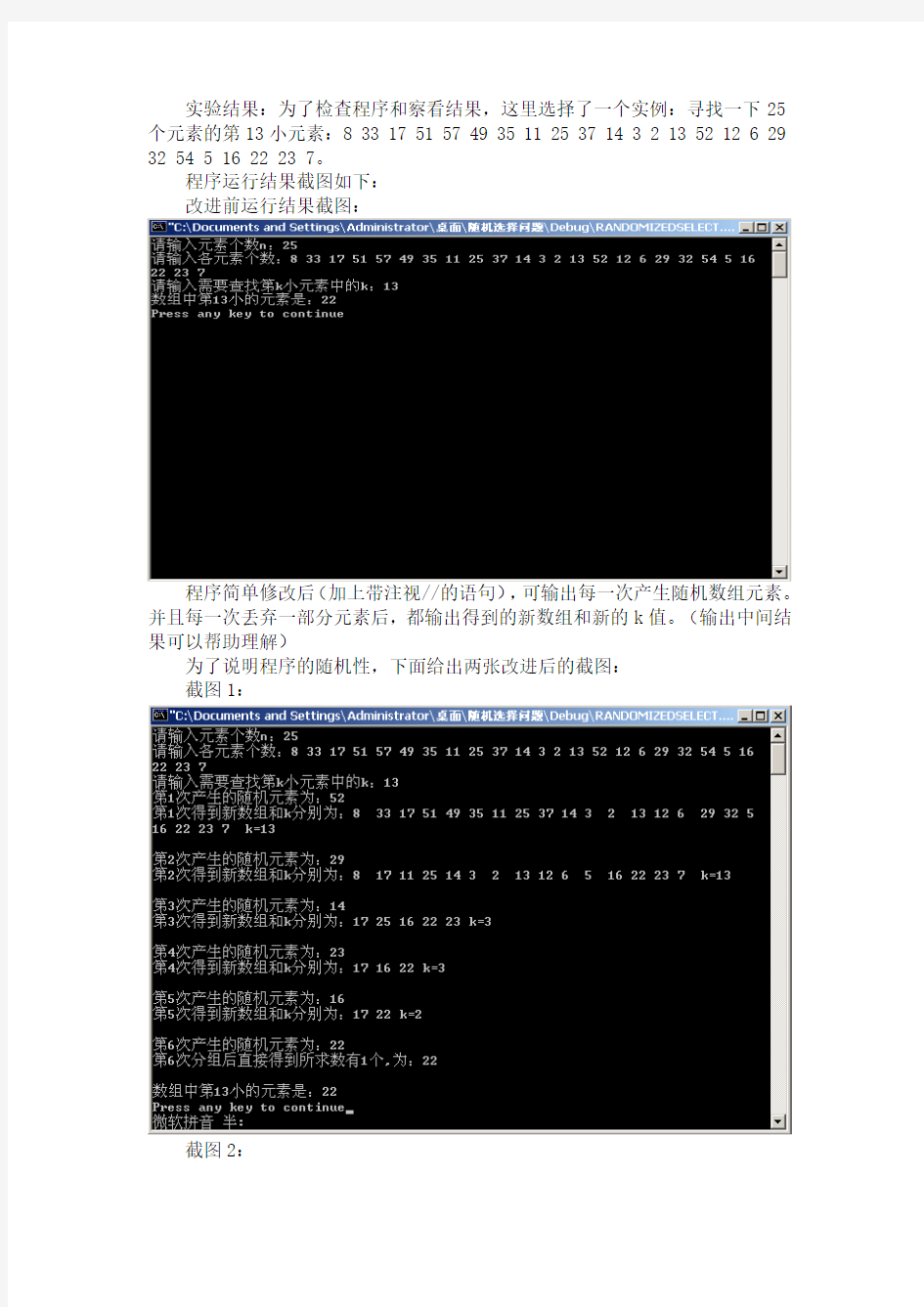
A1 = {a|a A2 = {a|a=x} A3 = {a|a>x} 4.case |A1|〉=k: return rselect(A1,1, |A1|,k) |A1|+|A2|>=k: return x |A1|+|A2| 5.end case 结果分析 实验结果:为了检查程序和察看结果,这里选择了一个实例:寻找一下25个元素的第13小元素:8 33 17 51 57 49 35 11 25 37 14 3 2 13 52 12 6 29 32 54 5 16 22 23 7。 程序运行结果截图如下: 改进前运行结果截图: 程序简单修改后(加上带注视//的语句),可输出每一次产生随机数组元素。并且每一次丢弃一部分元素后,都输出得到的新数组和新的k值。(输出中间结果可以帮助理解) 为了说明程序的随机性,下面给出两张改进后的截图: 截图1: 截图2: 基于小波分析方法的水文随机模拟 摘要:本文对小波分析进行了简要介绍,包括小波分析的发展历史、分析方法、应用领域以及发展现状,在此基础之上介绍了小波分析在水文随机模拟中的应用,最后,对小波分析方法在今后水文水资源领域中的应用进行了展望。总而言之,小波分析在水文预报、水文随机模拟、水文多时间尺度分析、水文时间序列变化特性分析等很多方面具有很大的研究价值和发展前景。 关键词:小波分析;不确定性;水文随机模拟 1引言 由于水文系统较为复杂,受制于气候和人为活动等多因素的影响,所以目前没有一个准确的数学物理方程能够描述并求解这一过程,而传统的随机模型结构简单、参数少,能描述水文序列的主要统计特性。但通过数理统计方法得到的参数描述水文过程过于粗糙,信息量少。小波分析是一种多分辨率分析方法,能充分展示水文序列的精细结构,挖掘更多的信息,可揭示水文系统的多时间尺度特性,较方便识别出水文时间序列中隐含的主要周期。通过小波消噪技术可把高频成分有效分离,从两方面分别研究其水文序列特性。鉴此,本文提出了基于小波分析的随机水文模型。 1.1小波分析的分析方法及发展历史 小波分析或小波转换是指用有限长或快速衰减的、称为母小波的振荡波形来表示信号。该波形被缩放和平移以匹配输入的信号。 小波变换的概念是由法国从事石油信号处理的工程师J.Morlet在1974年首先提出的,通过物理的直观和信号处理的实际需要经验的建立了反演公式,当时未能得到数学家的认可。随后,1986年著名数学家Y.Meyer偶然构造出一个真正的小波基,小波分析自此才开始蓬勃发展起来。小波变换与Fourier变换、窗口Fourier变换相比,这是一个时间和频率的局域变换,因而能有效的从信号中提取信息,通过伸缩和平移等运算功能对函数或信号进行多尺度细化分析,解决了Fourier变换不能解决的许多困难问题,因此,小波变化被誉为“数学显微镜”,它是调和分析发展史上里程碑式的进展。 1.2小波分析的应用领域及发展现状 事实上小波分析的应用领域十分广泛,包括数学领域的许多学科、信号分析、图像处理、理论物理、医学成像与诊断、地震勘探数据处理、大型机械的故障诊断等方面;例如,在数学方面,它已用于数值分析、构造快速数值方法、曲线曲面构造、微分方程求解、控制论等; 实验一 随机序列的产生及数字特征估计 一、实验目的 1、学习和掌握随机数的产生方法; 2、实现随机序列的数字特征估计。 二、实验原理 1. 随机数的产生 随机数指的是各种不同分布随机变量的抽样序列(样本值序列)。进行随机信号仿真分析时,需要模拟产生各种分布的随机数。 在计算机仿真时,通常利用数学方法产生随机数,这种随机数称为伪随机数。伪随机数是按照一定的计算公式产生的,这个公式称为随机数发生器。伪随机数本质上不是随机的,而且存在周期性,但是如果计算公式选择适当,所产生的数据看似随机的,与真正的随机数具有相近的统计特性,可以作为随机数使用。 (0,1)均匀分布随机数是最最基本、最简单的随机数。(0,1)均匀分布指的是在[0,1]区间上的均匀分布,即U(0,1)。实际应用中有许多现成的随机数发生器可以用于产生(0,1)均匀分布随机数,通常采用的方法为线性同余法,公式如下: N y x N ky Mod y y n n n n /))((110===-, (1.1) 序列{}n x 为产生的(0,1)均匀分布随机数。 下面给出了上式的3组常用参数: (1) 7101057k 10?≈==,周期,N ; (2) (IBM 随机数发生器)8163110532k 2?≈+==,周期,N ; (3) (ran0)95311027k 12?≈=-=,周期,N ; 由均匀分布随机数,可以利用反函数构造出任意分布的随机数。 定理1.1 若随机变量X 具有连续分布函数F X (x),而R 为(0,1)均匀分布随机变量,则有 )(1R F X x -= (1.2) 由这一定理可知,分布函数为F X (x)的随机数可以由(0,1)均匀分布随机数按上式进行变换得到。 2. MATLAB 中产生随机序列的函数 (1) (0,1)均匀分布的随机序列 函数:rand 用法:x = rand(m,n) 功能:产生m ×n 的均匀分布随机数矩阵。 (2) 正态分布的随机序列 函数:randn 用法:x = randn(m,n) 功能:产生m ×n 的标准正态分布随机数矩阵。 如果要产生服从2N(,)μσ分布的随机序列,则可以由标准正态随机序列产生。 (3) 其他分布的随机序列 MATLAB 上还提供了其他多种分布的随机数的产生函数,下表列出了部分函数。 MATLAB 中产生随机数的一些函数 表1.1 MATLAB 中产生随机数的一些函数 3、随机序列的数字特征估计 对于遍历过程,可以通过随机序列的一条样本函数来获得该过程的统计特性。这里我们假定随机序列X (n)为遍历过程,样本函数为x(n),其中n=0,1,2,…,N-1。那么,X (n)的均值、方差和自相关函数的估计为 临床试验中的随机分组方法 时间:2009-10-23 22:17:46 来源:admin 万霞1,刘建平2 (1.中国医学科学院基础医学研究所/中国协和医科大学基础医学院流行病学教研室,北京市东单三5号, 100005; 2.北京中医药大学循证医学中心) 【摘要】成功地实施随机分配依赖于两个相关的步骤:(1)产生随机分配序列用于试验组和对照组的分配; (2)随机分配方案在随机分组实施过程中的隐匿。随机分组方法有: 简单随机化、区组随机化分段(或分层)随机化、分层区组随机化及动态随机化等;随机分配方案隐匿的方法有按顺序编码、不透光、密封的信封, 中心随机系统, 编号或编码的瓶子或容器, 中心药房准备的药物等。科研工作者在临床研究中需要根据设计方法, 正确选择随机分组及随机分配方案隐匿的方法。 【关键词】随机分配; 随机分组; 随机方案; 隐匿 随机分配方法确保对比组之间基线均衡可比,被认为是减少两组患者选择偏倚的最佳方法[1]。因此,有学者认为正是由于随机分配方法,使得随机对照试验在提高医疗卫生服务中起着至关重要的作用[2]。在临床研究中,正确地实施真正的随机分配是临床试验的关键。成功地实施随机分配依赖于两个相关的步骤[3]:(1)产生随机分配序列并用于随机分配到试验组和 对照组; (2) 随机分配方案在随机分组中的隐匿(allocation concealment)。没有随机隐匿的随机临床试验也称为开放式的随机对照试验。 有试验研究表明[4],如果用不适当的分组和双盲方法, 即使是随机临床试验,其干预效果也 会被显着地高估(在一项研究中干预效果平均被夸大约50% )。遗憾的是90%以上的随机临床试验随机分组不恰当[5]。对卫生系统重大科研课题的终审标书进行的系统评价发现,部分治疗性研究存在假的随机分组[6]。有学者分层随机选择综合性国家级中医药学术期刊4种、省级和中医学院(大学)学报类中医药学术期刊各10种, 专业杂志(如针灸) 4种, 共计28种, 从1996 年12月开始回溯20年, 从中选取所有中医药疗效评价的文章逐一评阅。研究结果发现, 83%的文章未描述随机分组方法,操作是否恰当难以判断[7]。 第7章随机有限元法 §7.1 绪论 结构工程中存在诸多的不确定性因素,从结构材料性能参数到所承受的主要荷载,如车流、阵风或地震波,无不存在随机性。在有限单元法已成为分析复杂结构的强有力的工具和广泛使用的数值方法的今天,人们已不满足精度越来越高的确定性有限元计算,而设法用这一强有力的工具去研究工程实践中存在的大量不确定问题。随机有限元法(Stochastic FEM),也称概率有限元法(Probabilistic FEM)正是随机分析理论与有限元方法相结合的产物,是在传统的有限元方法的基础上发展起来的随机的数值分析方法。 最初是Monte-Carlo法与有限元法直接结合,形成独特的统计有限元方法。Astill和Shinozuka(1972)首先将Monte-Carlo法引入结构的随机有限元法分析。该法通过在计算机上产生的样本函数来模拟系统的随机输入量的概率特征,并对于每个给定的样本点,对系统进行确定性的有限元分析,从而得到系统的随机响应的概率特征。由于是直接建立在大量确定性有限元计算的基础上,计算量极大,不适用于大型结构,而且最初的直接Monte-Carlo 法还不是真正意义上的随机有限元法。但与随后的摄动随机有限元法(PSFEM)相比,当样本容量足够大时,Monte-Carlo有限元法的结果更可靠也更精确。 结构系统的随机分析一般可分为两大类:一类是统计方法,另一类是非统计方法。因此,随机有限元法同样也有统计逼近和非统计逼近两种类型。前者通过样本试验收集原始的数据资料,运用概率和统计理论进行分析和整理,然后作出科学推断。这里,样本试验和数据处理的工作量很大,随着计算机的普及和发展,数值模拟法,如蒙特卡罗(Monte Carlo)模拟,已成为最常用的统计逼近法。后者从本质上来说是利用分析工具找出结构系统的(确定的或随机的)输出随机信号与输入随机信号之间的关系,采用随机分析与求解系统控制方程相结合的方法得到输出信号的各阶随机统计量的数字特征(如各阶原点矩或中心矩)。 在20世纪70年代初,Cambou首先采用一次二阶矩方法研究线弹性问题。由于这种方法将随机变量的影响量进行Taylor级数展开,就称之为Taylor展开法随机有限元(TSFEM)。Shinozuka和Astill(1972)分别独立运用摄动技术研究了随机系统的特征值问题。随后,Handa(1975)等人在考虑随机变量波动性时采用一阶和二阶摄动技术,并将这种摄动法随机有限元成功地应用于框架结构分析。Vanmarcke等人(1983)提出随机场的局部平均理论,并将它引入随机有限元。局部平均理论是用随机场函数在每一个离散单元上的局部平均的随机变量来代表该单元的统计量的近似理论。Liu W. K.等人(1986、1988)的系列工作,提供了一种“主模态”技术,运用随机变量的特征正交化方法,将满秩的协方差矩阵变换为对角矩阵,减少计算工作量,对摄动随机有限元法的发展做出贡献,此外,提出了一个随机变分原理。 Yamazaki和Shinozuka(1987)创造性地将算子的Neumann级数展开式引入随机有限元的列式工作。从本质上讲,Neumann级数展开方法也是一类正则的小参数摄动方法,正定的随机刚度矩阵和微小的随机扰动量是两个基本要求,这两个基本要求保证了摄动解的正则性和收敛性,其优点在于摄动形式较简单并可以得到近似解的高阶统计量。Shinozuka等人(1987)将随机场函数的Monte-Carlo模拟与随机刚度矩阵的Neumann级数展开式结合,得到具有较好计算精度和效率的一类Neumann随机有限元列式(称NSFEM)。Benaroya等(1988)指出,将出现以随机变分原理为基础的随机有限元法来逐渐取代以摄动法为基础的随机有限元法。Spanos和Ghanem等人(1989,1991)结合随机场函数的Karhuen-Loeve展式和Galerkin (迦辽金)射影方法建立了相应的随机有限元列式,并撰写了随机有限元法领域的第一本专著《随机有限元谱方法》。 国内对随机有限元的研究起步较晚。吴世伟等人(1988)提出随机有限元的直接偏微 多指标综合评价中 指标正向化和无量纲化方法的选择 叶宗裕 摘要:本文用实例说明了多指标综合评价中,用“倒数逆变换法”进行指标正向化时会完全改变原指标的分布规律,影响综合评价结果的准确性;对三种常用无量纲化方法——极差变换法、标准化法和均值化法的选择使用问题,用实例进行了比较分析。 关键词:综合评价,正向化,无量纲化,标准化法,均值化法 在多指标综合评价中,有些是指标值越大评价越好的指标,称为正向指标(也称效益型指标或望大型指标);有些是指标值越小评价越好的指标,称为逆向指标(也称成本型指标或望小型指标),还有些是指标值越接近某个值越好的指标,称为适度指标。在综合评价时,首先必须将指标同趋势化,一般是将逆向指标和适度指标转化为正向指标,所以也称为指标的正向化。不同评价指标往往具有不同的量纲和量纲单位,直接将它们进行综合是不合适的,也没有实际意义。所以必须将指标值转化为无量纲的相对数。这种去掉指标量纲的过程,称为指标的无量纲化(也称同度量化),它是指标综合的前提。在多指标评价实践中,常将指标无量纲化以后的数值作为指标评价值,此时,无量纲化过程就是指标实际值转化为指标评价值(即效用函数值)的过程,无量纲化方法也就是指如何实现这种转化。从数学角度讲就是要确定指标评价值依赖于指标实际值的一种函数关系式,即效用函数f j。因此,指标的无量纲化是综合评价的一项重要内容,对综合评价结果有重要影响。 指标的正向化和无量纲化都有多种方法,应用时,应根据实际情况选择合适的方法,否则将会使综合评价的准确性受到影响。本章就如何选择正向化和无量纲化方法作些讨论。 (一)关于指标正向化方法 对于指标的正向化,在实际应用中许多学者常使用将指标取倒数的方法(苏为华教授称其为“倒数逆变换法”[1]),写成公式为: y ij=C/x ij(1)其中C为正常数,通常取C=1。很明显,用(1)式作为指标的正向化公式时,当原指标值x ij较大时,其值的变动引起变换后指标值的变动较慢;而当原指标 关于特征值与特征向量的求解方法与技巧 摘 要:矩阵的初等变换是高等代数中运用最广泛的运算工具,对矩阵的特征值与特征向量的求解研究具有一定意义。本文对矩阵特征值与特征向量相关问题进行了系统的归纳,得出了通过对矩阵进行行列互逆变换就可同时求出特征值及特征向量的结论。文章给出求解矩阵特征值与特征向量的两种简易方法: 列行互逆变换方法与列初等变换方法。 关键词: 特征值,特征向量; 互逆变换; 初等变换。 1 引言 物理、力学、工程技术的许多问题在数学上都归结为求矩阵的特征值与特征向量问题,直接由特征方程求特征值是比较困难的,而在现有的教材和参考资料上由特征方程求特征值总要解带参数的行列式,且只有先求出特征值才可由方程组求特征向量。一些文章给出了只需通过行变换即可同步求出特征值及特征向量的新方法,但仍未摆脱带参数行列式的计算问题。本文对此问题进行 了系统的归纳,给出了两种简易方法。 一般教科书介绍的求矩阵的特征值和特征向量的方法是先求矩阵A 的特征方程()0A f I A λλ=-=的全部特征根(互异) ,而求相应的特征向量的方法则是对每个i λ 求齐次线性方程组()0i I A X λ-=的基础解系,两者的计算是分离的,一个是计算行列式,另一个是解齐次线性方程组, 求解过程比较繁琐,计算量都较大。 本文介绍求矩阵的特征值与特征向量的两种简易方法, 只用一种运算 ——矩阵运算, 其中的列行互逆变换法是一种可同步求出特征值与特征向量的方法, 而且不需要考虑带参数的特征矩阵。而矩阵的列初等变换法, 在求出特征值的同时, 已经进行了大部分求相应特征向量的运算, 有时碰巧已完成了求特征向量的全部运算。两种方法计算量少, 且运算规范,不易出错。 2 方法之一: 列行互逆变换法 定义1 把矩阵的下列三种变换称为列行互逆变换: 1. 互换i 、j 两列()i j c c ?,同时互换j 、i 两行()j i r r ? ; 2. 第i 列乘以非零数()i k kc , 同时第i 行乘11i c k k ?? ?? ? ; 3. 第i 列k 倍加到第j 列()j i c kc +, 同时第j 行- k 倍加到第i 行 ()i j r kr -。 定理1 复数域C 上任一n 阶矩阵A 都与一个Jordan 标准形矩阵 1212,,....r k k kr J diag J J J λλλ? ? ???????? ??? ? ?? ?? ? ? ? ?? ? ?=相似, 其中 111110...0001...00..................000...1000...0ki ki J λλλλ?? ?? ?? ??=????????称为Jordan 块, 12r k k k n ++ +=并且 这个Jordan 标准形矩阵除去其中Jordan 块的排列次序外被矩阵A 唯一确定, J 称为A 的Jordan 标准形。 定理2 A 为任意n 阶方阵, 若T A J I P ?? ????????→ ? ????? 一系列列行互逆变换其中 摘要 摘要 本文着重讨论了随机数生成方法、随机数生成法比较以及检验生成的随机序列的随机性的方法。 在随机序列生成方面,本文讨论了平方取中法、斐波那契法、滞后斐波那契法、移位法、线性同余法、非线性同余法、取小数法等,并比较了各方法的优劣性。 在统计检验方面,介绍了统计检验的方法,并用其检验几种随机数生成器生成的随机数的随机性。 最后介绍了两种新的随机数生成法,并统计检验了生成随机序列的随机性。关键词:随机数,随机数生成法,统计检验 I ABSTRACT ABSTRACT This article focuses on methods of random number generator, random number generation method comparison and test the randomness of the generated random sequence method. In random sequence generation, the article discusses the square method, Fibonacci method, lagged Fibonacci method, the shift method, linear congruential method, linear congruence method, taking minority law, and Comparison of advantages and disadvantages of each method. In statistical test, the introduction of the statistical test method, and used to test some random number generator random random numbers generated. Finally, two new random number generation method, and statistical tests of randomness to generate a random sequence. Key Words: random number,random number generator,statistical test II 多指标综合评价方法及权重系数的选择 来源:中国论文下载中心 [ 09-02-01 10:17:00 ] 编辑:studa20 作者:王晖,陈丽,陈垦,薛漫清,梁庆 【摘要】由于计算机的发展及一些相关领域的不断深入研究,综合评价方法得到了不断的发展和改进。而指标权重系数的确定方法作为综合评价中的重中之重,近几年来也取得了一些新的进展。本文对多指标评价方法和权重系数的选择进行概括介绍。 【关键词】多指标综合评价;评价方法;权重系数;选择 基金项目:广东药学院引进人才科研启动基金资助项目( 2005ZYX12)、广州市科技计划项目( 2007J1-C0281)、广东省科技计划项目(2007A060305006) 综合评价是利用数学方法(包括数理统计方法)对一个复杂系统的多个指标信息进行加工和提炼,以求得其优劣等级的一种评价方法。本文就近年来国内外有关多指标综合评价及权重系数选择的方法进行综述,以期为药理学多指标的研究提供一些方法学的资料。 1 多指标综合评价方法 1.1 层次分析加权法(AHP法)[1] AHP法是将评价目标分为若干层次和若干指标,依照不同权重进行综合评价的方法。 根据分析系统中各因素之间的关系,确定层次结构,建立目标树图→ 建立两两比较的判断矩阵→ 确定相对权重→ 计算子目标权重→ 检验权重的一致性→ 计算各指标的组 合权重→计算综合指数和排序。 该法通过建立目标树,可计算出合理的组合权重,最终得出综合指数,使评价直观可靠。采用三标度(-1,0,1)矩阵的方法对常规的层次分析加权法进行改进,通过相应两两指标的比较,建立比较矩阵,计算最优传递矩阵,确定一致矩阵(即判断矩阵)。该方法自然满足一致性要求,不需要进行一致性检验,与其它标度相比具有良好的判断传递性和标度值的合理性;其所需判断信息简单、直观,作出的判断精确,有利于决策者在两两比较判断中提高准确性[2]。 1.2 相对差距和法[3] 设有m项被评价对象,有n个评价指标,则评价对象的指标数据库为 Kj=(K1j,K2j,……,Knj),j=1,2,……,m。设最优数据为K0=(K1、K2、……Kn)。最优单位K0中各数据的确定如下:高优指标,取所有m个单位中该项评价指标最大者;低优指标,取所有m个单位中该项评价指标最小者。各单位与最优单位的加权相对差距和 1.////////////////////////////////////////////////////////////////////// 2.// 求实对称矩阵特征值与特征向量的雅可比法 3.// 4.// 参数: 5.// 1. double dblEigenValue[] - 一维数组,长度为矩阵的阶数,返回时存放特征值 6.// 2. CMatrix& mtxEigenVector - 返回时存放特征向量矩阵,其中第i列为与 7.// 数组dblEigenValue中第j个特征值对应的特征向量 8.// 3. int nMaxIt - 迭代次数,默认值为60 9.// 4. double eps - 计算精度,默认值为0.000001 10.// 11.// 返回值:BOOL型,求解是否成功 12.////////////////////////////////////////////////////////////////////// 13.BOOL CMatrix::JacobiEigenv(double dblEigenValue[], CMatrix& mtxEigenVector, int nMaxIt /*= 60*/, double eps /*= 0.000001*/) 14.{ 15.int i,j,p,q,u,w,t,s,l; 16.double fm,cn,sn,omega,x,y,d; 17. 18.if (! mtxEigenVector.Init(m_nNumColumns, m_nNumColumns)) 19.return FALSE; 20. 21.l=1; 22.for (i=0; i<=m_nNumColumns-1; i++) 23.{ 24.mtxEigenVector.m_pData[i*m_nNumColumns+i]=1.0; 25.for (j=0; j<=m_nNumColumns-1; j++) 26.if (i!=j) 27.mtxEigenVector.m_pData[i*m_nNumColumns+j]=0.0;//单位矩阵 28.} 29. 30.while (TRUE) 31.{ 32.fm=0.0; 33.for (i=1; i<=m_nNumColumns-1; i++) 34.{ 35.for (j=0; j<=i-1; j++) 36.{ 37.d=fabs(m_pData[i*m_nNumColumns+j]); 38.if ((i!=j)&&(d>fm)) 39.{ 40.fm=d; 41.p=i; 42.q=j; }//取绝对值最大的非对角线元素,并记住位置 一维正态分布随机数序列的产生方法 一、文献综述 1.随机数的定义及产生方法 1).随机数的定义及性质 在连续型随机变量的分布中,最简单而且最基本的分布是单位均匀分布。由该分布抽取的简单子样称,随机数序列,其中每一个体称为随机数。 单位均匀分布也称为[0,1]上的均匀分布。 由于随机数在蒙特卡罗方法中占有极其重要的位置,我们用专门的符号ξ表示。由随机数序列的定义可知,ξ1,ξ2,…是相互独立且具有相同单位均匀分布的随机数序列。也就是说,独立性、均匀性是随机数必备的两个特点。 随机数具有非常重要的性质:对于任意自然数s,由s个随机数组成的 s维空间上的点(ξn+1,ξn+2,…ξn+s)在s维空间的单位立方体Gs上 均匀分布,即对任意的ai,如下等式成立: 其中P(·)表示事件·发生的概率。反之,如果随机变量序列ξ1, ξ2…对于任意自然数s,由s个元素所组成的s维空间上的点(ξn+1,…ξn+s)在Gs上均匀分布,则它们是随机数序列。 由于随机数在蒙特卡罗方法中所处的特殊地位,它们虽然也属于由具有已知分布的总体中产生简单子样的问题,但就产生方法而言,却有着本质上的差别。 2).随机数表 为了产生随机数,可以使用随机数表。随机数表是由0,1,…,9十个数字组成,每个数字以0.1的等概率出现,数字之间相互独立。这些数字序列叫作随机数字序列。如果要得到n位有效数字的随机数,只需将表中每n 个相邻的随机数字合并在一起,且在最高位的前边加上小数点即可。例如,某随机数表的第一行数字为7634258910…,要想得到三位有效数字的随机数依次为0.763,0.425,0.891。因为随机数表需在计算机中占有很大内存, 而且也难以满足蒙特卡罗方法对随机数需要量非常大的要求,因此,该方法不适于在计算机上使用。 3).物理方法 随机分析在金融套利中的应用 习宇 (华中师范大学物理科学与技术学院 2010210421(10班)) 摘要:依据证券市场的资产定价模型、指数模型、因素模型、套利模型,引进随机信号分析,提出随机分析在套利模型中的初步尝试性应用。 关键词:CAPM;APT;SIM;套利模式;随机分析;单边上扬套利;震荡套利。 0引言: 当今世界金融数学(Financial Mathematics),又称数理金融学、数学金融学、分析金融学,是利用数学工具研究金融,用随机分析,随机最优控制,倒向随机微分方程,非线性分析,分形几何等现代数学,进行数学建模、理论分析、数值计算等定量分析,,以求找到金融动内在规律并用以指导实践,是基于应用数学在金融中的运用。其所涉及的数学知识主要有率论、随机分析、控制论金融数学里面用的主要是随机控制、粘性解、数值算法、时间序列。继而推广到了经济学中发展产生的现如今计量经济学的基础。而今我们基于以上来探讨股票的价格的各种波动受到随机市场信息及各种相关的因素随时间的变化,来建立股票的套利模式。 首先探讨何谓套利?套利定价理论(APT)是一种资产定价模式,其重点是每项资产的回报率均可从该资产与众多的共同风险因素的关系推测得到由斯蒂芬·罗斯创于1976年提出这一理论,这一理论从众多独立的宏观经济因素变量的线性组合预测投资组合的回报。当资产被错误定价时,套利定价理论(APT)会指出正确的价格何在。它通常被视为资本资产定价模型(CAPM)的替代品,因为APT具有更灵活的假设要求。鉴于CAPM的公式需要市场的预期回报,APT则套用风险资产的预期收益率和各宏观经济因素的风险溢价。套利者使用APT模型,利用证券的错误定价从中取利。当证券出现错误定价,其价格将异于从理论模式预测出来的价格。 数学概率上的套利定义是:初始投入为X的资产组合,在将来的某个有限时刻T,该组合的价值为v(t),如果v(t)的概率p满足p(v(t)>=X)=1且p(v (t)>X)>0,则称这样的情况为套利。如果一个初始投资为X的资产组合,在将来能获得概率1的带来严格正的收益,那么这个市场就存在套利机会。在证券市场中,该定义就可以理解为,在买入证券时的价格为P,在将来某个时间卖出的时 一、国际贸易(International Trade) 国际贸易亦称“世界贸易”,泛指国际间的商品和劳务(或货物、知识和服务)的交换。它由各国(地区)的对外贸易构成,是世界各国对外贸易的总和。国际贸易在奴隶社会和封建社会就已发生,并随生产的发展而逐渐扩大。到资本主义社会,其规模空前扩大,具有世界性。 二、对外贸易(Foreign Trade) 对外贸易亦称“国外贸易”或“进出口贸易”,是指一个国家(地区)与另一个国家(地区)之间的商品和劳务的交换。这种贸易由进口和出口两个部分组成。对运进商品或劳务的国家(地区)来说,就是进口;对运出商品或劳务的国家(地区)来说,就是出口。这在奴隶社会和封建社会就开始产生和发展,到资本主义社会,发展更加迅速。其性质和作用由不同的社会制度所决定。 国贸与外贸的区别 国贸:国际贸易,外贸:对外贸易。国际贸易是从整个世界的范围来说,对外贸易是从某个国家的角度来说。但是在国内,说到这两个词,给人的感觉概念上差不多,因为我们都是从我们中国的角度来说的。楼上的朋友有一点说得不对,出口中国的产品到国外去只是国贸或外贸的一小部分内容,国贸或外贸不止包括产品的进出口(不仅是出口而已)(或叫有形贸易),还包括无形贸易,比如技术进出口、服务贸易等。1.国际贸易指标主要用来反映我国贸易的开放发展程度,一般是使用具有高度代表性的贸易依存度指标,即开放度(OPE)。本文还选取了制成品出口量占国际贸易出口总额的比重,同时作为国际贸易发展水平的指标,用EX 来代表。金融发展水平指标通常采用金融相关率,即金融资产与GDP的比率,反映金融中介的总体规模。由于我国的证券市场成立时间较晚,发展程度和开放程度都还处于初级阶段,因此本文就银行体系为基础,选取货币和准货币的数量作为金融资产代表,其与GDP的比率用FD 来代表,即金融深度(Financial Depth)。我们试图寻找FD 与OPE、EX 之间的关系,观察OPE 与FD,EX 与FD 的散点图后,用最小二乘估计法对上述变量分别进行回归。 (二)实证分析 1.变量相关性分析 为了清楚地观察各变量间的相关关系, 运用 Eviews5.0 对各变量进行相关性分析 (1)融资成本对国际贸易的影响 (2)货币的流动性对国际贸易的影响 (3)汇率对国际贸易的影响 (4)技术创新对贸易的影响 一) 指标选取 由于研究的目的在于揭示我国金融发展对国际贸易的影响, 选用的指标包括金融发展与国际贸易两个方面。Goldsmith ( 1969) 提出用金融相关率( Financial Interrelation Ratio, FIR) 即 一、计算 1.求齐次线性方程组 x x x x x x x x x x x x --+= ? ? --+= ? ?--+= ? 1234 1234 1234 42420 33320 75740 的一个基础解系 2.求齐次线性方程组 --+= ? ? --+= ? ?--+= ? 1234 1234 1234 44420 34320 78740 x x x x x x x x x x x x 的一个基础解系 3.求4元齐次线性方程组 1245 1245 1245 32420 3390 2570 x x x x x x x x x x x x +-+= ? ? --+= ? ?+--= ? 的一个基础解系 4.求4元齐次线性方程组 1245 1245 1245 42430 4330 42470 x x x x x x x x x x x x ---= ? ? +-+= ? ?+--= ? 的一个基础解系 5.解齐次线性方程组 12345 1345 12345 220 320 220 x x x x x x x x x x x x x x ++-+=? ? ++-=? ?--+++=? 6.解齐次线性方程组 12345 1345 12345 20 30 20 x x x x x x x x x x x x x x ++-+=? ? ++-=? ?--+-+=? 7.已知实对称矩阵 141 411 114 A ?? ? = ? ? ?? ,计算A的全部特征值,并求最大特征值相应 的一个特征向量。 8.已知实对称 453 543 332 A - ?? ? =- ? ? ?? ,计算A的全部特征值,并求最大特征值相应的 一个特征向量。 9.已知实对称 331 151 117 ?? ? = ? ? ?? A,计算A的特征值,并求最大特征值相应的全体特 征向量。 实验一随机序列的产生及数字特征估计 一、实验目的 1、学习和掌握随机数的产生方法。 2、实现随机序列的数字特征估计。 二、实验原理 1、随机数的产生 随机数指的是各种不同分布随机变量的抽样序列(样本值序列)。进行随机信号仿真分析时,需要模拟产生各种分布的随机数。在计算机仿真时,通常利用数学方法产生随机数,这种随机数称为伪随机数。伪随机数是按照一定的计算公式产生的,这个公式称为随机数发生器。伪随机数本质上不是随机的,而且存在周期性,但是如果计算公式选择适当,所产生的数据看似随机的,与真正的随机数具有相近的统计特性,可以作为随机数使用。(0,1)均匀分布随机数是最最基本、最简单的随机数。(0,1)均匀分布指的是在[0,1]区间上的均匀分布,即U(0,1)。实际应用中有许多现成的随机数发生器可以用于产生(0,1)均匀分布随机数,通常采用的方法为线性同余法,公式如下: y0=1,y n=ky n?1mod N(1.1) x n=y n N 序列x n为产生的(0,1)均匀分布随机数。 下面给出了(1.1)式的3 组常用参数: ①N = 1010,k = 7,周期≈5*10^7; ②(IBM随机数发生器)N = 2^31,k = 2^16 + 3,周期≈5*10^8; ③(ran0)N = 2^31 - 1,k = 7^5,周期≈2*10^9; 由均匀分布随机数,可以利用反函数构造出任意分布的随机数。 定理1.1 若随机变量X具有连续分布函数F X(X),而R为(0,1)均匀分布随机变量,则有 X=F X?1(R)(1.2) 由这一定理可知,分布函数为F X(X)的随机数可以由(0,1)均匀分布随机数按(1.2)式进行变换得到。 2、MATLAB 中产生随机序列的函数 (1)(0,1)均匀分布的随机序列 函数:rand 用法:x = rand(m,n) 功能:产生m×n的均匀分布随机数矩阵。 (2)正态分布的随机序列 函数:randn 用法:x = randn(m,n) 功能:产生m×n的标准正态分布随机数矩阵。 如果要产生服从N(μ,σ2)分布的随机序列,则可以由标准正态随机序列产生。(3)其他分布的随机序列 MATLAB 上还提供了其他多种分布的随机数的产生函数,表1.1 列出了部分函数。 实验一 随机序列的产生及数字特征估计 一、实验目的 1、学习和掌握随机数的产生方法; 2、实现随机序列的数字特征估计。 二、实验原理 1. 随机数的产生 随机数指的是各种不同分布随机变量的抽样序列(样本值序列)。进行随机信号仿真分析时,需要模拟产生各种分布的随机数。 在计算机仿真时,通常利用数学方法产生随机数,这种随机数称为伪随机数。伪随机数是按照一定的计算公式产生的,这个公式称为随机数发生器。伪随机数本质上不是随机的,而且存在周期性,但是如果计算公式选择适当,所产生的数据看似随机的,与真正的随机数具有相近的统计特性,可以作为随机数使用。 (0,1)均匀分布随机数是最最基本、最简单的随机数。(0,1)均匀分布指的是在[0,1]区间上的均匀分布,即U (0,1).实际应用中有许多现成的随机数发生器可以用于产生(0,1)均匀分布随机数,通常采用的方法为线性同余法,公式如下: N y x N ky Mod y y n n n n /))((110===-, (1.1) 序列{}n x 为产生的(0,1)均匀分布随机数。 下面给出了上式的3组常用参数: (1) 7101057k 10?≈==,周期,N ; (2) (I BM 随机数发生器)8163110532k 2?≈+==,周期,N ; (3) (ran0)95311027k 12?≈=-=,周期,N ; 由均匀分布随机数,可以利用反函数构造出任意分布的随机数。 定理1。1 若随机变量X具有连续分布函数FX (x),而R 为(0,1)均匀分布随机变量,则有 )(1R F X x -= (1.2) 由这一定理可知,分布函数为F X (x)的随机数可以由(0,1)均匀分布随机数按上式进行变换得到。 2。 MAT LAB 中产生随机序列的函数 (1) (0,1)均匀分布的随机序列 函数:rand 用法:x = r and(m,n ) 功能:产生m ×n 的均匀分布随机数矩阵。 (2) 正态分布的随机序列 函数:randn 用法:x = randn (m ,n) 功能:产生m ×n 的标准正态分布随机数矩阵. 如果要产生服从2N(,)μσ分布的随机序列,则可以由标准正态随机序列产生。 ?选择岗位评价指标的方法 ?A、B、C分类权重法 ?专家调查权重法 选择岗位评价指标的方法 选择岗位评价指标的方法多种多样,目前企业大多数都采用因素分析法。也就是从 企业的实际出发,对企业生产和岗位劳动状况进行全面分析,并遵循选择指标原则 的基础上,寻找出影响和决定岗位劳动状况和劳动量的所有因素,然后确定评价指 标。选择过程应该是由表及里、由粗到细、层层分析,即从总体到局部,从粗到细 的过程。 评价岗位劳动的24个指标全面体现了各行业生产岗位的劳动状况。但具体对每个行 业或企业而言,由于生产经营状况各不相同,劳动环境和条件各有差异,因此,在 开展岗位评价时,应结合本身的实际情况,从中选择合适的评价指标。 A、B、C分类权重法 该方法是根据“重要的少数和次要的多数”的基本原理确定各因素权数的简便方法, 也是在管理统计分析中常用的主次因素分析法。即将指标体系中的所有因素按其重 要程度和对岗位劳动量的影响程度,进行分类排队,然后分别用不同的权数对各类 因素进行不同权重。 具体步骤如下: 1、排队阶段。首先对各因素进行分析,然后根据企业岗位劳动的特点和各因素对 岗位劳动量的影响程度极其重要程度,将全部因素按其重要性依次排列。 2、分类阶段。将全部因素划分为三类,即: A类:主要因素,占全部因素10%左右; B类:次要因素,占全部因素的20%左右; C类:一般因素,占全部因素的70%左右; 3、权重设定阶段。根据因素分类结果,即可对A、B、C三类因素赋予3、2、1的 不同权数。 总之,对于各因素权数、指标权数的确定,应根据企业类型、生产的结构和特点慎 重确定。一般来说机器设备先进、技术水平要求较高的技术密集型的加工、机械制 造业,其劳动技能方面的指标权重应大些;而对于综合性的联合企业,可根据实际 情况或需要突出某一重点或部分,并进行全面考虑,保持基本平衡。 专家调查权重法 该方法主要依据“德尔菲法”的基本原理,选择企业各方面的专家,采取独立填表选取权数的形式,然后将他们各自选取的权数进行整理和统计分析,最后确定出各因素,各指标的权数。总的来讲,它是一个较科学合理的方法,它集合了各方面专家的智慧和意见,并运用数理统计的方法进行检验和修正。 随机数序列的产生方法 一维连续型随机数序列的产生方法 一.综述 由具有已知分布的总体中抽取简单子样,在蒙特卡罗方法中占有非常重要的地位。总体和子样的关系,属于一般和个别的关系,或者说属于共性和个性的关系。由具有已知分布的总体中产生简单子样,就是由简单子样中若干个性近似地反映总体的共性。 随机数是实现由已知分布抽样的基本量,在由已知分布的抽样过程中,将随机数作为已知量,用适当的数学方法可以由它产生具有任意已知分布的简单子样。 二.随机数的定义及性质 在连续型随机变量的分布中,最简单而且最基本的分布是单位均匀分布。由该分布抽取的简单子样称,随机数序列,其中每一个体称为随机数。单位均匀分布也称为[0,1]上的均匀分布,其分布密度函数为: 分布函数为: 其中P (·)表示事件·发生的概率。反之,如果随机变量序列ξ1, ξ2…对于任意自然数s ,由s 个元素所组成的s 维空间上的点(ξ n+1 ,…ξ n+s )在G s 上均匀分布,则它们是随机数序列。 由于随机数在蒙特卡罗方法中所处的特殊地位,它们虽然也属于由 1, 01()0, x f x ≤≤?=? ?其他 0,0(), 011,1 x F x x x x ? 具有已知分布的总体中产生简单子样的问题,但就产生方法而言,却有着本质上的差别 三.连续型随机数的模拟产生 最常用、最基础的随机数是在(0,1)区间内均匀分布的随机数(简记为RND)。一般采用某种数值计算方法产生随机数序列,在计算机上运算来得到.通常是利用递推公式: 给定k 个初始值ξ1,ξ2,…,ξk , 利用递推公式递推出一系列随机数ξ1,ξ2,…,ξn ,…. 利用在(0 , 1) 区间上均匀分布的随机数来模拟具有给定分布的连续型随机数. 1.反函数法 设连续型随机变量Y 的概率函数为 f (x ), 需产生给定分布的随机数. (1)算法:1)产生n 个RND 随机数r 1,r 2,…,r n ; 所得y i ,i =1,2, …,n 即所求。 (2)基本原理: 设随机变量Y 的分布函数F (y )是连续函数,而且随机变量X ~ U (0,1),令Z =F -1(X ),则Z 与Y 有相同分布. 证明:F Z (z )= P {F -1(X ) ≤ z }= P {X ≤F (z )}=G (F (z )) = F (z ) 因G (x )是随机变量X 的分布函数: 12(,,,) n n n n k f ξξξξ---= ; )()2i y i y dy y f r i 中解出从等式?∞ -= ?? ? ??≤<≤<=. 1,1;10, ;0, 0)(x x x x x G 特征值和特征向量的性质与求法 方磊 (陕理工理工学院(数学系)数学与应用数学专业071班级,陕西汉中 723000)” 指导老师:周亚兰 [摘要] :本文主要给出了矩阵特征值与特征向量的几个性质及特征值、特征向量的几种简单求法。 [关键词]:矩阵线性变换特征值特征向量 1 特征值与特征向量的定义及性质 定义1:(ⅰ)设A 是数域p 上的n 阶矩阵,则多项式|λE-A|称A 的特征多项式,则它在 c 上的根称为A 的特征值。 (ⅱ)若λ是A 的特征值,则齐次线性方程组(λE-A) X =0的非零解,称为A 的属于特征值λ的特征向量。 定义2:设α是数域P 上线性空间v 的一个线性变换,如果对于数域P 中的一数0λ存在一个非零向量ξ,使得a ξ=0λξ,那么0λ 成为α的一个特征值而ξ称为α的属于特征值0λ的一个特征向量。 性质1: 若λ为A 的特征值,且A 可逆,则0≠λ、则1-λ 为1-A 的特征知值。 证明: 设n λλλ 21为A 的特征值,则A =n λλλ 21ο≠ ∴λi≠0(i=1、2…n) 设A 的属于λ的特征向量为ξ 则ξλξi =?A 则λ1 -A ξ=ξ即有 1 -A ξ=1 -λ ξ ∴1 -λ 为1 -A 的特征值,由于A 最多只有n 个特征值 ∴1 -λ 为1 -A ξ的特征值 性质2:若λ为A 的特征值,则()f λ为()f A 的特征值 ()χf =n n a χ +1 0111 1x a x a x a n n +++-- 证明:设ξ为A 的属于λ的特征向量,则A ξ=λξ ∴ ()A f ξ=(n n A a +E a A a A a n n 011 1+++-- )ξ = n n A a ξ+ 1 1--n n A a ξ+… +E a 0 ξ =n n a λξ+1 1--n n a λ+…+E 0a ξ =()λf ξ 又ξ≠0 ∴ ()λf 是()A f 的特征值 性质3:n 阶矩阵A 的每一行元素之和为a ,则a 一定是A 的特征值水文随机分析
随机信号分析实验
临床试验中的随机分组方法
随机有限元法
多指标综合评价中指标正向化和无量纲化方法的选择
关于特征值与特征向量的求解方法与技巧
随机数生成方法、随机数生成法比较以及检验生成的随机序列的随机性的方法讲义
多指标综合评价方法及权重系数的选择
雅克比过关法求特征值和特征向量
一维正态分布随机数序列的产生方法
随机分析在套利分析中的应用
指标选取和分析方法
解方程、求表示法、求特征向量
实验一随机序列的产生及数字特征估计
随机信号分析实验
指标确定
一维连续型随机数序列的产生方法
特征值和特征向量的性质与求法
相关主题
文本预览