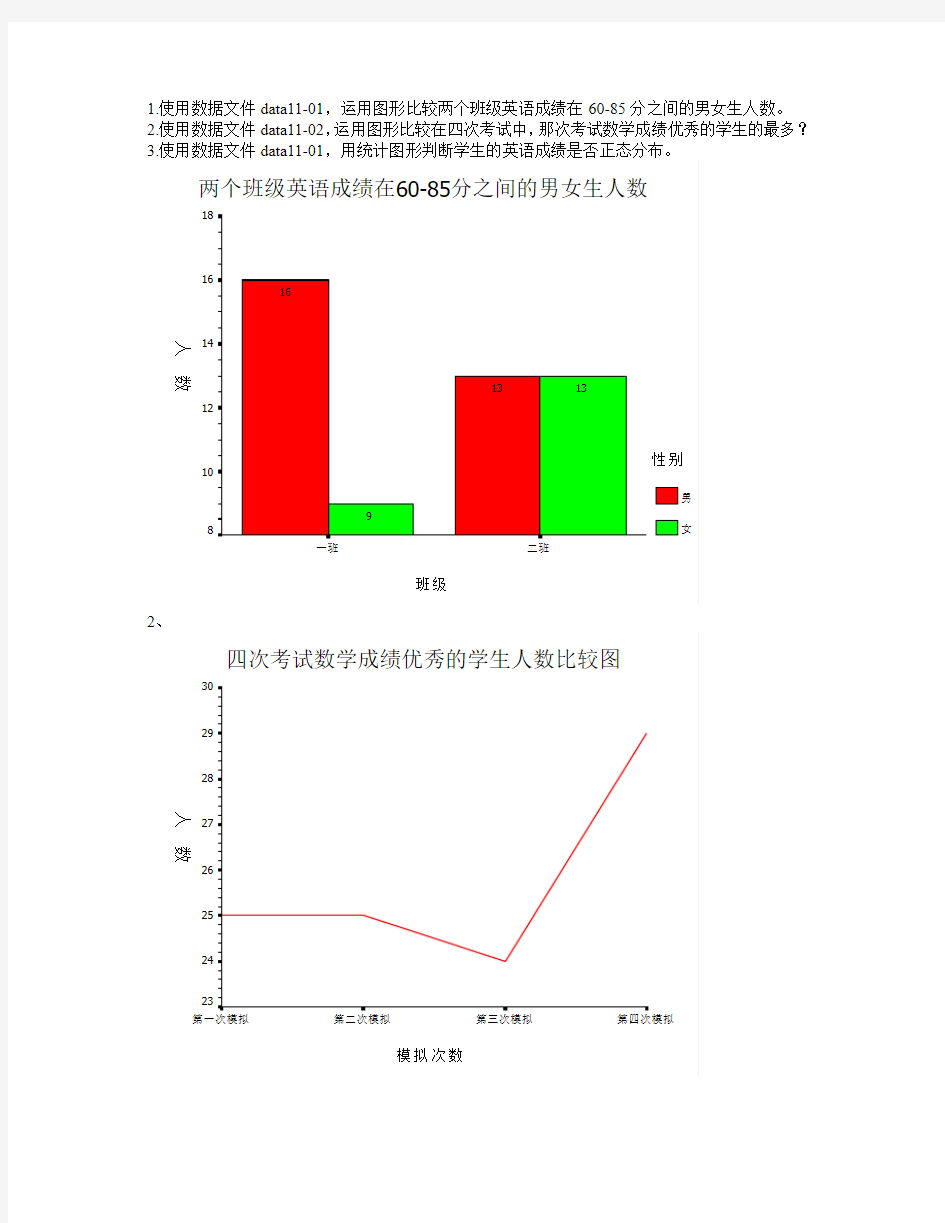
1.使用数据文件data11-01,运用图形比较两个班级英语成绩在60-85分之间的男女生人数。
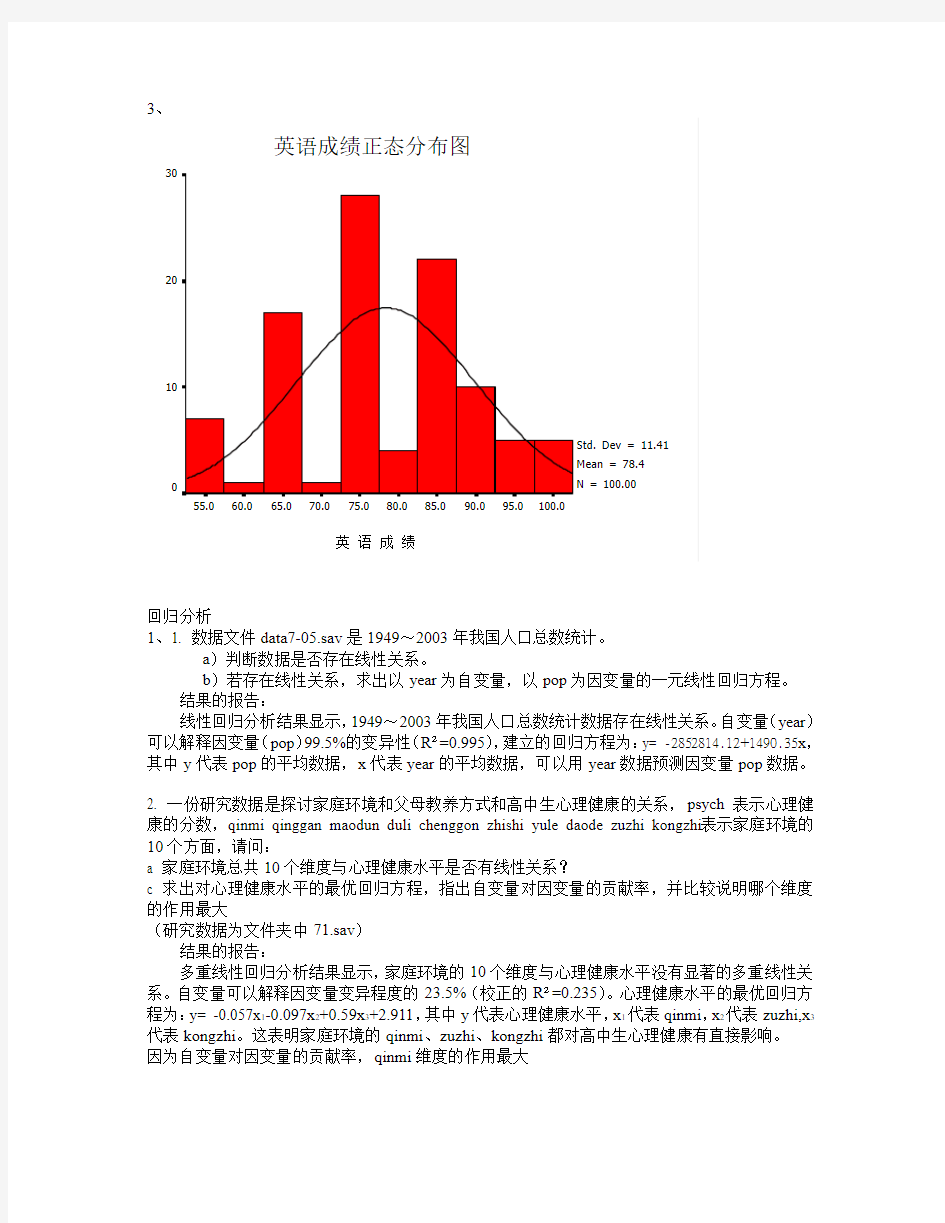
2.使用数据文件data11-02,运用图形比较在四次考试中,那次考试数学成绩优秀的学生的最多?
回归分析
1、1. 数据文件data7-05.sav是1949~2003年我国人口总数统计。
a)判断数据是否存在线性关系。
b)若存在线性关系,求出以year为自变量,以pop为因变量的一元线性回归方程。
结果的报告:
线性回归分析结果显示,1949~2003年我国人口总数统计数据存在线性关系。自变量(year)可以解释因变量(pop)99.5%的变异性(R2=0.995),建立的回归方程为:y= -2852814.12+1490.35x,其中y代表pop的平均数据,x代表year的平均数据,可以用year数据预测因变量pop数据。
2. 一份研究数据是探讨家庭环境和父母教养方式和高中生心理健康的关系,psych表示心理健康的分数,qinmi qinggan maodun duli chenggon zhishi yule daode zuzhi kongzhi表示家庭环境的10个方面,请问:
a 家庭环境总共10个维度与心理健康水平是否有线性关系?
c 求出对心理健康水平的最优回归方程,指出自变量对因变量的贡献率,并比较说明哪个维度的作用最大
(研究数据为文件夹中71.sav)
结果的报告:
多重线性回归分析结果显示,家庭环境的10个维度与心理健康水平没有显著的多重线性关系。自变量可以解释因变量变异程度的23.5%(校正的R2=0.235)。心理健康水平的最优回归方程为:y= -0.057x1-0.097x2+0.59x3+2.911,其中y代表心理健康水平,x1代表qinmi,x2代表zuzhi,x3代表kongzhi。这表明家庭环境的qinmi、zuzhi、kongzhi都对高中生心理健康有直接影响。
因为自变量对因变量的贡献率,qinmi维度的作用最大
假设检验
1.学校举行教学评价活动,要求学生对教师进行7点评价(1-7分)。下面是某班学生对一位教师的两次评价结果:
评价活动之前:3 2 5 1 3 2 1 3 3 1 3 1 5 2 3 1 5 1 4 3 3 1 1 4 3 5 4 5
评价活动之中:6 7 4 5 2 3 3 7 2 3 3 2 4 6 6 4 3 2 6 2 7 2 3 6 5 3 3 6
请问这两次结果有无差异?(自己动手录入数据,以data1命名保存后分析)
结果的报告:
(1)为考察学生对教师教学两次评价结果是否有差异,对两次评价结果进行了Wilcoxon Signed-Rank检验。结果显示,评价活动之中对教师的评价要高于评价活动之前的评分,Z=-2.97,p<0.01。
(2)为考察学生对教师教学两次评价结果是否有差异,对两次评价结果进行了Sign检验。结果显示,评价活动之中对教师的评价要高于评价活动之前的评分,Z=-1.93,p<0.05。
2.某高校往年关于文科、理科和艺术学科招生人数的比例为5:3:2,今年的招生人数见数据文件data2。试分析今年的招生比例与往年相比是否显著不同?
结果的报告:
为考察某高校今年的文科、理科和艺术学科招生比例与往年相比是否显著不同,对今年的招生人数进行卡方检验。结果显示,今年的招生比例与往年相比有显著不同, 卡方=19.26,df=2,p<0.01.
3.抛硬币50次,其中正面与反面向上的次数见数据文件data3,试分析这枚硬币是否均匀?
结果的报告:
.抛硬币结果的二项分布检验结果显示,其结果显著,p<0.05。这表明这枚硬币是均匀的。
4.分别在周一至周五对一组儿童进行体温测量,测量结果见数据文件data4,试分析五次测量结果是否差异显著?
结果的报告:
(1)为考察一组儿童分别在周一至周五的体温测量结果是否差异显著,对五次测量结果进行了Friedman检验。结果显示,五次测量结果没有差异显著,卡方=4.93,df=4,p>0.05
(2)为考察一组儿童分别在周一至周五的体温测量结果是否差异显著,对五次测量结果进行了Kendall W检验。结果显示,五次测量结果没有差异显著,卡方=4.93,df=4,p>0.05
5.医生测试甲乙两种安眠药的疗效,独立观察20名患者,10人服甲药,10人服乙药,结果如下:
服甲药者睡眠延长时数:1.9 0.8 1.1 0.1 0.1 4.4 5.5 1.6 4.6 3.4
服乙药者睡眠延长时数:0.7 -1.6 -0.2 -1.2 -0.1 3.4 3.7 0.8 0.0 2.0
问这两种安眠药的疗效是否有显著差异?(自己动手录入数据,以data5命名保存后分析)
结果的报告:
(1)为考察甲乙两种安眠药的疗效,对两种安眠药的睡眠延长时数进行了Mann-Whitney检验。结果显示,两种安眠药(甲、乙)的疗效有显著差异,Z= -1.97,p<0.05
(2)为考察甲乙两种安眠药的疗效,对两种安眠药的睡眠延长时数进行了Moses检验。结果显示,两种安眠药(甲、乙)的疗效没有显著差异,p>0.05
(3)为考察甲乙两种安眠药的疗效,对两种安眠药的睡眠延长时数进行了双样本Kolmogorov-Smirnov检验。结果显示,两种安眠药(甲、乙)的疗效没有显著差异,Z=1.12,p>0.05
(4)为考察甲乙两种安眠药的疗效,对两种安眠药的睡眠延长时数进行了Wald-Wolfowitz 检验。结果显示,两种安眠药(甲、乙)的疗效没有显著差异,Z= -1.15,p>0.05
相关分析
第一题:皮尔逊相关、斯皮尔曼相关和肯德尔相关各自适用的数据条件是什么? 皮尔逊相关:1、数据为两列连续变量。2、数据呈正态分布。3、数据为直线性。 斯皮尔曼相关:1、当数据不是等距等比时,而是具有等级顺序。2、数据是等距或等比的,但总体分布不是正态的。3、数据是秩而不是实际数值。 肯德尔等级相关:1、tau-b 是测量两个有秩变量间的密切程度。2、w 系数是多列等级变量。
第二题:data6-04:是10名学生两次考试的成绩,请讨论此数据用哪种相关分析 方法更恰当,为什么?
皮尔逊相关,因为10名考生的两次考试的成绩是两列连续变量,符合皮尔逊积差相关的适用条件,不足是样本量小。 第三题:data6-05:是29名被试者的身高、体重、肺活量的数据,试分析肺活量 与哪个因素的相关更高?说明为什么计算偏相关? 表
1肺活量与身高、体重的相关系数矩阵表
结果的报告:
偏相关分析的结果表明,肺活量与身高没有显著的正相关,r=0.10,p>0.05;肺活量与体重有显著的正相关,r=0.57,p<0.01。 1.学校举行教学评价活动,要求学生对教师进行7点评价(1-7分)。下面是某班学生对一位教师的两次评价结果: 评价活动之前:3 2 5 1 3 2 1 3 3 1 3 1 5 2 3 1 5 1 4 3 3 1 1 4 3 5 4 5
评价活动之中:6 7 4 5 2 3 3 7 2 3 3 2 4 6 6 4 3 2 6 2 7 2 3 6 5 3 3 6
请问这两次结果有无差异?(自己动手录入数据,以data1命名保存后分析)
结果的报告:
(1)为考察学生对教师教学两次评价结果是否有差异,对两次评价结果进行了Wilcoxon
Signed-Rank 检验。结果显示,评价活动之中对教师的评价要高于评价活动之前的评分,Z=-2.97,p<0.01。 (2)为考察学生对教师教学两次评价结果是否有差异,对两次评价结果进行了Sign 检验。结果显示,评价活动之中对教师的评价要高于评价活动之前的评分,Z=-1.93,p<0.05。 2.某高校往年关于文科、理科和艺术学科招生人数的比例为5:3:2,今年的招生人数见数据文件data2。试分析今年的招生比例与往年相比是否显著不同?
结果的报告:
为考察某高校今年的文科、理科和艺术学科招生比例与往年相比是否显著不同,对今年的招生人数进行卡方检验。结果显示,今年的招生比例与往年相比有显著不同, 卡方=19.26,df=2,p<0.01.
data3,试分析这枚硬币是否均匀? p<0.05。这表明这枚硬币是均匀的。 data4,试分析五次测量结=4.93,df=4,p>0.05 (2)为考察一组儿童分别在周一至周五的体温测量结果是否差异显著,对五次测量结果进行了Kendall W 检验。结果显示,五次测量结果没有差异显著,卡方=4.93,df=4,p>0.05 5.医生测试甲乙两种安眠药的疗效,独立观察20名患者,10人服甲药,10人服乙药,结果如下:
服甲药者睡眠延长时数:1.9 0.8 1.1 0.1 0.1 4.4 5.5 1.6 4.6 3.4 服乙药者睡眠延长时数:0.7 -1.6 -0.2 -1.2 -0.1 3.4 3.7 0.8 0.0 2.0
问这两种安眠药的疗效是否有显著差异?(自己动手录入数据,以data5命名保存后分析)
第四题(选做)data6-06:四川绵阳地区3年中山柏的数据,分析月生长量与月平均气温、 月降雨量、月平均日照时数、月平均湿度这4个气候因素哪个因素有关。 (注意:这4个气候因素彼此均有影响,分析时对生长量与4个气候因素分别求偏 相关,在求生长量与一个气候因素的相关时控制其它因素的影响,然后比较相关 系数,按4个相关系数的大小排队。)
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
教育统计学课后作业 一、P118 1 题目:10位大一学生平均每周所花的学习时间与他们的期末考试成绩见表6-17.试问: (1)学习时间与考试成绩之间是否相关? (2)比较两组数据谁的差异程度大一些? (3)比较学生2与学生9的期末考试测验成绩。 表6-17 学习时间与期末考试成绩 1 2 3 4 5 6 7 8 9 10 学习时间考试成绩40 58 43 73 18 56 10 47 25 58 33 54 27 45 17 32 30 68 47 69 解题步骤: (1)第一步:定义变量:“xuexishijian”、“xuexichengji”后,输入数据.如下图: 1
第二步:单击选择“分析(Analyze)”中的“相关(Correlate)”中的“双变量(Bivariate Correlations)”, 将上图中的“xuexishijian”和“xuexichengji”添加到右边变量框中,如下图: 第三步:点击“确定“后,输出结果如下图: 第四步:分析结果
3 由上图可知:学习时间与学习成绩之间的pearson 相关系数为0.714,p (双侧)为0.20。自由度 df=10-2=8时,查“皮尔逊积差相关系数显著临界值表”知:r 0.05= 0.623 ; r 0.01=0.765。 因为0.765 > 0.714 >0.623,所以在0.05水平上学习时间和学习成绩是相关显著的。 (2)SPSS 软件分析结果如下图: 由上图可知:学习时间标准差和平均值为:S 1=12.037 ?X 1= 29.00 ;学习时间标准差和平均值为:S 2=12.437?X 2=56.00 根据差异系数公式可知: 学习时间差异系数为:%100?=X S CV S =12.037/29.00×100%=41.51% 学习成绩差异系数为:%100?= X S CV S =12.437/56.00×100%=22.27% 有上述结果可知学习时间差异程度大于学习成绩差异程度。 (4) 把学生2和学生9的期末考试成绩转化成标准分数: Z 2=(X -?X) /S= (73—56)/12.437=1.367 Z 9=(X-?X)/S=(68—56)/12.437=0.965 由上计算可知:学生2期末考试测验成绩优于学生9的期末考试测验成绩。 二、P119 2 题目:某班数学的平均成绩为90,标准差10;化学的平均分为85,标准差为8;物理的平均分为79,标准差为15.某生这三科成绩分别为95,80,80.试问 (1) 该生在哪一学科上突出一些? (2) 该班三科成绩的差异度如何?有无学习分化现象? (3) 该生的学期分数是多少? (4) 三科的总平均和总标准差是多少? 解题步骤:
课程名称:《SPSS分析方法与应用》 课程号: 2007422 一、单项选择题(共112小题) 1、试题编号:1000110,答案:RetEncryption(D)。 SPSS的安装类型有() A. 典型安装 B.压缩安装 C.用户自定义安装 D.以上都是 2、试题编号:1000310,答案:RetEncryption(D)。 数据编辑窗口的主要功能有() A.定义SPSS数据的结构 B.录入编辑和管理待分析的数据 C.结果输出 和B 3、试题编号:1000410,答案:RetEncryption(A)。 ()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。 4、试题编号:1000510,答案:RetEncryption(D)。 ()是SPSS为用户提供的基本运行方式。 A.完全窗口菜单方式 B.程序运行方式 C.混合运行方式 D.以上都是 5、试题编号:1000810,答案:RetEncryption(D)。 ()是SPSS中有可用的基本数据类型 A.数值型 B.字符型 C.日期型 D.以上都是 6、试题编号:1000910,答案:RetEncryption(D)。 spss数据文件的扩展名是( ) A..htm B..xls C..dat D..sav 7、试题编号:1001010,答案:RetEncryption(B)。 数据编辑窗口中的一行称为一个() A.变量 B.个案 C.属性 D.元组 8、试题编号:1001110,答案:RetEncryption(C)。
变量的起名规则一般:变量名的字符个数不多于() A. 6 B. 7 C. 8 D. 9 9、试题编号:1001210,答案:RetEncryption(A)。 统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 B.定距型数据 C.定序型数据 D.定类型数据 10、试题编号:1001310,答案:RetEncryption(A)。 在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 B.降序排序 C.不排序 D.可升可降 11、试题编号:1001810,答案:RetEncryption(A)。 SPSS算术表达式中,字符型()应该用引号引起来。 A 常量 B变量 C算术运算符 D函数 12、试题编号:1001910,答案:RetEncryption(A)。 复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 B AND C OR D都不是 13、试题编号:1002010,答案:RetEncryption(A)。 数据选取的方法中,()是按符合条件的数据进行选取。 A 按指定条件选取 B 随即选取 C选取某一区域内样本 D过滤变量选取 14、试题编号:1002110,答案:RetEncryption(B)。 通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的。 A 数据转置 B 加权处理 C 数据才分 D以上都是 15、试题编号:1002210,答案:RetEncryption(A)。 SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 B 加权处理 C 数据才分 D以上不都是 16、试题编号:1002310,答案:RetEncryption(B)。 SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。 A、哈佛大学 B、斯坦福大学 C、波士顿大学 D、剑桥大学 17、试题编号:1002710,答案:RetEncryption(D)。 SPSS中进行参数检验应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 18、试题编号:1002810,答案:RetEncryption(A)。 SPSS中进行输出结果的保存应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 19、试题编号:1002910,答案:RetEncryption(C)。 SPSS中进行数据的排序应选择()主窗口菜单。 A、视图 B、编辑 C、数据 D、分析
《统计分析软件》试(题)卷 班级XXX 班姓名XXX 学号XXX ____________ 1. 2. 考试时间为100分钟; 3. 每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav ;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav ”与“学生成绩二.sav ”合并,并保存为“成绩.sav. ” (2)对所建立的数据文件“成绩.sav ”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X > 85),良(75 < X < 84),中(X < 74),并对优良中的人数进行统计
分析: (2) 描述统计量
性别:rj sxcj 11391.0090.0061.00242.0D 1.00 r 214女91.0090.0061 Q0242,00 1.D0 31女95.0079.0065.00239.03200匸4Q女95.0079.0065 00239.00 2.D0 53立92.00B4.0062.00230.00200 S 4 女92.0084.0062 00238.00 2.00 79女眨00S2.0062.00236.00200 310女92.0002.0062 0023G.OO 2 DO 95男39.00S5.0D69 00233.03 1.00 10E男39.0085.0059 00233.00 1.00 1111立9U.OO SO.OO60.00230.0J200「1212女90.0080.0060 00230.00 2.00 1319立眨0075.0062.00229.03200 20女92.0076.00G2 00229.00 2 DO 1 1516男SB.00B2.0053.00220.03200 15男38.0077.0068 00223.00200 1 1717女91.0071.00 61 00223.00 3.00 女91.0071.0061 00223.03 3.00 1016 1 19 1女89.0067.0059 00215.00 3.00 202女39.0067.0069 00215.0J 3. DO 注:成绩优良表示栏位sxcj 优为1良为2中为3 由表统计得,成绩为优的同学有4人,占总人数的20%良的同学有12人,占总人数的60%中的同学有4人,占总人数的40% 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进 行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调 查.exe ”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查.Sav ”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
当代大学生对全球气候变化 认知程度的研究 摘要:随着我国经济建设的飞速发展,人们向大自然排放的有害物质与日俱增,环境问题日益严重。环境污染问题不仅影响我国人民的生存环境和生存质量,也危害人民的身体健康,在环境污染中城市环境污染已经成为制约社会发展的重要问题。本研究采样方式为匿名方式随机投放网络问卷以及纸质问卷,采用SPSS statistics软件分析采样数据,得到频率表以及考虑性别的交叉表。本文考虑性别、城乡等差异,分别从基本的环保知识到主动投身环保事业等各方面加以分析,研究当代大学生对环境污染问题认知程度的差异。 关键字:性别;气候变化;差异;SPSS 一、研究背景 我国改革开放30多年的经济发展迅速,主要是以粗放式发展为主要模式。由此而带来的就是高增长、高能耗、高排放的三高企业,我国是发展中国家,在经济发展的过程中,政府对环境破坏的监管不力,睁一眼闭一眼,所以我国改革开放30年快速发展以牺牲能源、破坏环境为代价的,尤其我国的经济发展又极不平衡,主要是以城市主力军,这样城市的环境恶化就很严重。同样,农村人口环境保护意识淡薄,农村环境恶化也不可小觑,我国高速发展的近几十年来,环境的恶化程度逐年增加,应该引起政府环保部门的重视。 环境污染对人们的生活影响越来越严重,我们现在出门看到的最打眼的一景就是戴口罩的人越来越多,人们越来越感受到空气污染对
自己身心健康的威胁,据统计,世界儿童死亡80%是由于空气污染导致的,这个数字让人触目惊心。 环境污染很大因素是由于企业恣意排放污染物,但在日常生活中,民众的环保意识与环保行为对生活污染——尤其是随处可见的污染——有较大的影响。性别、年龄等不同,对气候变化认知程度也会存在差异。本文考虑到男女性别的差异、城乡区别,分别从基本的环保知识到主动投身环保事业等各方面加以分析,研究不同性别对环境污染问题认知程度的差异。 二、研究方法及样本描述 (一)研究方法 本研究采样方式为匿名方式随机投放网络问卷以及纸质问卷调查的方法,与2014年5月在西安交通大学进行问卷调查。调查面向西安交大本科生以及研究生,最终获得有效问卷431份。 (二)样本特征描述 431位被访者中,女性209位,占48.5%;男性222位,占51.5%。如图1所示,样本主要来自大一、大二以及大三群体,总共381位,占88.4%;大四毕业生以及研究生占11.6%。被访者所读专业性质也有较大差别,文科生178位,占41.3%;工科生人数122位,占28.3%;理科生108位,占比25.1%,如表1所示。
CHAPTER 15 西北研究院蔡嘉驰131246 15.4 (i) What we choose is part of u t. Then gMIN t and u t are correlated, which causes OLS to be biased and inconsistent. (ii) I think it is uncorrelate because gGDP t controls for the overall performance of the U.S. economy. (iii) The change of U.S. minimum may someway change the state minimum and vice versa. If the state minimum is always the U.S. minimum, then gMIN t is exogenous in this equation and we would just use OLS. 15.7 (i) Because students that would do better anyway are also more likely to attend a choice school. (ii) Since u1 does not contain income, random assignment of grants within income class means that grant designation is not correlated with unobservables such as student ability, motivation, and family support. (iii) The reduced form is choice= π0 + π1faminc + π2grant + v2, and we need π2≠ 0. (iv) The reduced form for score is just a linear function of the exogenous variables: score= α0 + α1faminc + α2grant + v1. This equation allows us to directly estimate the effect of increasing the grant amount on the test score, holding family income fixed.So it is useful. C15.1 (i) The regression of log(wage) on sibs gives
t检验:一般是用于检验两组观测值的均值之间差异是否显著的统计分析方法。 单样本t检验:用于检验样本均值与总体均值或某个已知值之间的差异的显著性。如果总体均值已知,那么样本均值与总体均值之间的差异显著性检验就属于单样本的t检验。 独立样本t检验:独立样本指的是样本之间彼此独立,没有任何关联。两个独立样本的t检验用于检验两个不相关样本在相同变量上的观测值均值之间差异的显著性。要求①正态性,各个样本均来自于正态分布的总体;②方差齐性,各个样本所在的总体的方差相等;③独立性,两组数据之间是相互独立的,不能够相互影响。 配对样本t检验:配对样本(或相关样本)指两个样本的数据之间彼此有关联。配对样本t 检验用于检验两个相关样本的均值或一个样本,两次测量结果的均值之间差异的显著性。 方差分析:是一种通过分析样本数据的各项变异来源,以检验三个或三个以上样本平均 数是否具有显著性差异的一种统计方法。 单因素方差分析:用于检验一个因素变量的不同水平是否给一个(或几个相互独立的)因变量造成了显著的差异或变化。 多重比较:进行了全方差分析之后,当自变量有3个或3个以上水平时,还有要对每两个组之间均值的差异进行比较,这称作事后组间均值的“多重比较”。 多因素方差分析:是检验两个或两个以上因素变量(自变量)的不同水平是否给一个(或几个相互独立的)因变量造成了显著的差异或变化的分析方法。 主效应和“交互作用”效应:主效应考察的是在忽略其他因素的情况下一个自变量对观察变量的影响,即这一个因素变量的不同水平分组下的观测值的均值之间的差异是否显著。当一个自变量的单独效应随另一个自变量的水平的不同而不同时,则这两个自变量对因变量的影响存在交互作用。 协变量方差分析:是在进行方差分析时将那些除了要考察的自变量之外的、很难控制的、且对因变量产生显著影响的无关变量作为“协变量”,在分析自变量对因变量的影响时,消除协变量对因变量的影响,从而使分析的结果更准确。。 多元方差分析:有两个或两个以上的因变量的方差分析(可以是单因素的,也可以是多因素的)称为多元方差分析。 重复测量的方差分析:用于某个测量指标对每个被试在不同的时间内进行多次(3次或3次以上)重复测量的情况。 组间因素:是被试分组的因素,组间因素有几个水平就把被试划分成几个组。 组内因素:又称重复测量因素,就是测试的不同水平或不同次数,是在每个被试内的因素。组内因素的不同水平决定了重复测量的次数。 方差成分分析:是对混合效应模型的分析,如对单变量重复测量和随机区组设计的分析,用于分析混合效应模型中各随机效应对因变量变异贡献的大小。通过对方差的成分进行分析,可以确定如何减小方差。 相关分析:是分析两个变量观测值变化的一致性程度或密切程度的统计方法。 简单相关分析:用于只对两个变量的数据做相关分析,其中包括两个连续变量之间的相关和两个等级变量之间的秩相关。 偏相关分析:是控制第三变量(或其他多个变量)的影响后,两变量间相关程度的统计方法。皮尔逊相关:是对两列变量为连续等间隔(等距、等比)数据,而且数据呈正态分布的相关
SPSS在教育研究中的应用某大学学生对本校的满意度调查 学院:教育学院 专业:课程与教学论 学号:201411000156 姓名:李平 2014年12月13日
目录 一、研究问题的提出 (3) 二、研究内容与方法 (3) (一) 研究内容 (3) (二) 研究方法 (3) 三、调查对象及人数 (4) 四、问卷分析 (5) (一)回收情况 (5) (二)信度分析 (5) 五、数据统计与分析 (6) (一)数据输入 (6) (二)数据分析 (7) 1.描述统计 (7) (1)多选题描述统计 (7) (2)单选题描述统计 (9) 2.推断统计 (12) (1)独立样本T检验 (12) (2)单一样本T检验 (15) (3)单因素方差分析 (17) (4) X2检验 (21) 3.相关分析 (22) (1)变量间相关分析 (22) (2)维度间相关分析 (23) 六、结论 (27) 七、附录 (28)
一、研究问题的提出 学生的学校生活和成长密切相关。我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。 二、研究内容与方法 (一)研究内容 了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。 (二)研究方法 1.问卷编制 本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。 表2-1 某大学学生对本校的满意度测评指标体系 一 级指标 二级指标(潜在变量)三级指标(观测变量) 对自己师资水平对教师教学方法、对教师工作态 度、对教师人品修养、对师资配备 学校的意学校环境对学习环境、对就餐环境、对居住 环境、对校园绿化环境 满度指数日常管理对专业课时安排、对收费标准、对 奖、助学金制度、对学校治安
吉林财经大学 《SPSS统计软件分析》作业(2010——2011学年第一学期) 学院信息学院 专业班级电子商务0806班 学生姓名王瑞霞 学号1403080616
1、对未分组资料频数分析 从中国统计局中获得从11月21日至30日国内50个城市主要食品平均价格变动情况,以该数据为例为例,进行频数分析。 首先输入数据: 选择Analyze中Descriptive Statistics——Frequencies,打开Frequencies对话框;将需处理的变量键入变量框中
单击Statistics…按钮统计量子对话框12指标,选中所需要计算的指标: 单击Charts …按钮,选择需绘制的统计图: 单击OK按钮开始运行,运行结果为:
从上图中可以看出数据中缺失值为0,花生油的平均价格104.84是最高的,而巴氏牛奶的平均价格1.81最低,全部食品平均价格的平均数为16.5327,标准差为22.4668,各种食品的平均价格差距较大。
条形图、饼形图以及直方图是用不同的图形表示方法来说明数据的指标,其实质是一样的,从图中可以看出平均价格在0—22元之间的食品是最多的,20—40元之间的食品数次之,接下来是40—60元之间的食品,不存在平均价格在60—100之间的食品。 2、以食品平均价格为依据对数据进行分组并对分组后的数据进行频数分析: Transform —Recode—Into same V ariables ,将要分组的变量放入Numeric 栏中,单击Old and new V alues分组:
分组结果如下图所示: 回到数据编辑窗,定义变量的V alue labels : 再对食品平均价格进行频数分析,分析结果如下截图所示
●一。变量的赋值 1.乘方(**),例如二的三次方:2**3 2.不同规则的赋值:转换→计算变量(如果),每一个规则的赋值都要重新进行此步骤(但注意每一遍的变量名都不变,并且他都会问你要不要替换成新的变量,你选是就行了) 3.不同规则的赋值:(1)转换→重新编码为不同变量:输入变量,输出变量,要点击“变化量”才可保存输出变量→新值和旧值:值(直接选取取值)、范围(最大到最小的范围,包含端点值),点击“添加”成功保存新值和旧值→所有不同取值规则都完成后点击继续、确定,则在变量视图多出一个新变量(2)若不想包含端点值,可以采取小数的方式变换,eg. 899.9(小数位比该变量属性的小数位多一位就行了) (3)这种要先把BMI按照男女分开,然后再分组的,可以在对话框中点击“如果”选项进行设置,并且要分别对男女进行上述操作(一共做两遍)。 二。离散化 1可视离散化:转换→可视分箱,分割点:所以想生成几组,就定义几个分割点;填写第一个分割点的时候就必须填写最小值;一定要选中上端点排除。 三。排序 1.转换→自动重新编码:不分组,从头到尾排序 2.转换→个案排秩(1)多层次数据:基于A变量对B变量进行排序。(例如,基于职称对收入进行排序,就是不同职称各自组内排工资的高低)(2)设置秩1;绑定值 四。时间序列:转换→变动值 五。查找与计数:转换→对个案内的值计数(查找“基本工资800-900女职工”,生成新变量,满足这个条件的标为1,不符合这个标准的标为0,男职工标为缺失。范围:包含上限下限) ●六。数据→个案排序:把变量顺序完全按照你想要的标准排序,所有的变量顺序都会改变 七。拆分文件:要分男女进行数据统计:数据→拆分文件→比较组/按组输出,分组依据。不分男女进行数据统计:数据→拆分文件→分析所有个案 八。选择个案(例如只选择三年级的变量进行分析):数据→选择个案→如果条件满足:如果;随机个案样本;基于时间或个案范围;使用过滤变量(例如要把身高为缺失值和值为0的剔除)→输出:过滤(不符合条件的数据会画上“/”,原始数据并未删除);将选定个案复制到新数据集(形成一个新的SPSS数据文件,原始数据并未删除);删除未选定的个案(删除原始数据,不建议使用)→之后在分析的时候就只会分析三年级的变量。不想只分析三年及,记得重新做这一步。 九。加权个案:数据→加权个案(例。100分的有5人)。不想加权了,记得重新做这一步。 十。分类汇总(1)例如算不同年级的人的身高的均值、方差…(只能计算函数)(2)数据→汇总,分界变量(分类标准变量),变量摘要(计算变量),函数:选择计算变量函数,变量名称与标签:定义新生成变量的名称与标签 ●十一。长宽数据的转换 1.长数据变宽数据:索引变量消失变成score的尾缀 (1)数据→重组(重构)→个案重组为变量,标识变量,索引变量,电脑会自动帮你选出是xx xx要重构(不同疗程值不同的变量)。选完上述这些之后就一直点下一步&完成&立即重构&确定即可 (2)注意:当有多个变量需要重构时要自己决定“新变量组的顺序”。(A1A2B1B2;A1B1A2B2) 2.宽数据变长数据:score的尾缀消失变成索引变量 (1)数据→重组(重构)→变量重组为个案,个案组标识:使用选定变量,固定变量(手动选择,电脑不会自动帮你选出了),要转置的变量即值不固定的要重构的变量(手动选择,电脑不会自动帮你选出了)。选完上述这些之后就一直点击下一步&完成&立即重构数据&确定就行了 (2)当有多个变量需要重构时,这块的操作要特别注意:○1首先在“变量组数目”中选择“多个”○2然后在“选择变量”里要对于不同的“目标变量”分别定义“要转置的变量”(在本题中,即对于kidid目标变量定义一遍要转置的变量;对于age目标变量在定义一遍要转置的变量。其中,这两个要转置的变量必须是完全不同的)。但只需要定义一次“个案组标识”&“固定变量”(固定变量是相对于kidid & age都固定的那些变量;而不是说在对kidid进行转置的时候,age就是固定变量了;因此,固定变量只用定义一次且固定变量可以为空)。并且,你要特别注意,“个案组标识”里选择的变量& n个“要转置的变量”里选择的变量&“固定变量”里选择的变量都必须是完全不相同的。
SPSS课后作业 第一章 1-1、spss的运行方式有几种?分别是什么? 答:SPSS的运行方式有三种,分别是批处理方式、完全窗口菜单运行方式、程序运行方式。1-2、SPSS中“DataView”所对应的表格与一般的电子处理软件有什么区别? 答:与一般电子表格处理软件相比,SPSS的“Data View”窗口还有以下一些特性:(1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征;(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括一个观测中的单个变量值;(4)数据文件是一张长方形的二维表。 第二章 2-1、在SPSS中可以使用那些方法输入数据? 答:SPSS中输入数据一般有以下三种方式:(1)通过手工录入数据;(2)可以将其他电子表格软件中的数据整列(行)的复制,然后粘贴到SPSS中;(3)通过读入其他格式文件数据的方式输入数据。 2-2、对于缺失值,如何利用SPSS进行科学替代? 答:选择“Transform”菜单的Replace Missing Values命令,弹出Replace Missing Values 对话框。先在变量名列中选择1个或多个存在缺失值的变量,使之添加到“New Variable(s)”框中,这时系统自动产生用于替代缺失值的新变量。最后选择合适的替代方式即可。 2-3、在计算数据的加权平均数时,如何对变量进行加权? 答:选择“Data”菜单中的Weight Cases命令,出现如图2-22所示的Weight Cases对话框。其中, Do not weight cases项表示不做加权,这可用于取消加权;Weight cases by 项表示选择1个变量做加权。 2-4、如何对变量进行自动赋值? 答:变量的自动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在一个新的变量中。具体操作的过程如下:选择“Transform”菜单中的Automatic Recode命令,在出现的对话框中,从左边的变量列表中选择需要自动赋值的变量,将它添加到Variable -> New Name框中,然后在下面New Name右边的文本框中输入新的变量名称,单击New Name 按钮,将新的变量名添加到上面的框中。从Recode Starting from框中有两个选项中选择一个,然后单击OK按钮,即可完成自动赋值运算。 3-1、一组数据的分布特征可以从哪几个方面进行测度? 答:一组数据的分布特征可以从平均数、中位数、众数、方差、百分位、频数、峰度、偏度等方面描述。 3-2、简述众数、中位数和均值的特点及应用场合。 答:均值是总体各单位某一数量标志的平均数。平均数可应用于任何场合,比如在简单时序预测中可用一定观察期内预测目标的时间序列的均值作为下一期的预测值。中位数是指将数据按大小顺序排列起来,形成一个数列,居于数列中间位置的那个数据。中位数的作用与算术平均数相近,也是作为所研究数据的代表值。在一个等差数列或一个正态分布数列中,中位数就等于算术平均数。在数列中出现了极端变量值的情况下,用中位数作为代表值要比用算术平均数更好,因为中位数不受极端变量值的影响。众数是指一组数据中出现次数最多的那个数据。它主要用于定类(品质标志)数据的集中趋势,当然也适用于作为定序(品质标志)数据以及定距和定比(数量标志)数据集中趋势的测度值。 3-3、
SPSS操作实验 (作业1) 作为华夏儿女都曾为有着五千年的文化历史而骄傲过,作为时代青年都曾为中国所饱受的欺压而愤慨过,因为我们多是炎黄子孙。然而,当代大学生对华夏文明究竟知道多少呢 某研究机构对大学电气、管理、电信、外语、人文几个学院的同学进行了调查,各个学院发放问卷数参照各个学院的人数比例,总共发放问卷250余份,回收有效问卷228份。调查问卷设置了调查大学生对传统文化了解程度的题目,如“佛教的来源是什么”、“儒家的思想核心是什么”、“《清明上河图》的作者是谁”等。调查问卷给出了每位调查者对传统文化了解程度的总得分,同时也列出了被调查者的性别、专业、年级等数据信息。请利用这些资料,分析以下问题。 问题一:分析大学生对中国传统文化的了解程度得分,并按了解程度对得分进行合理的分类。 问题二:研究获得文化来源对大学生了解传统文化的程度是否存在影响。 要求: 直接导出查看器文件为.doc后打印(导出后不得修改) 对分析结果进行说明,另附(手写、打印均可)。 于作业布置后,1周内上交 本次作业计入期末成绩
答案 问题一 操作过程 1.打开数据文件作业。同时单击数据浏览窗口的【变量视图】按钮,检查各个 变量的数据结构定义是否合理,是否需要修改调整。 2.选择菜单栏中的【分析】→【描述统计】→【频率】命令,弹出【频率】对 话框。在此对话框左侧的候选变量列表框中选择“X9”变量,将其添加至【变量】列表框中,表示它是进行频数分析的变量。 3.单击【统计量】按钮,在弹出的对话框的【割点相等组】文本框中键入数字 “5”,输出第20%、40%、60%和80%百分位数,即将数据按照题目要求分为等间隔的五类。接着,勾选【标准差】、【均值】等选项,表示输出了解程度得分的描述性统计量。再单击【继续】按钮,返回【频率】对话框。
《统计分析软件》试(题)卷 班级xxx班姓名xxx 学号xxx 题号一二三四五六总成绩成绩 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
S P S S调查报告期末作业 Document serial number【LGGKGB-LGG98YT-LGGT8CB-LGUT-
---------------------------------------------装--------------------------------- --------- 订 ---------------------------------------- -线----------------------------------- -- - --
上表表明,5中不同年级形式下共有80个样本,大一的均值最高,大二的均值次之,接着,大四的均值排第三,而大三的均值是最低的。由于在录入数据当中,选择调查问卷中选项A“是”,身边有请人带过课的同学,则录为1:;选择调查问卷中选项B“否”,身边没有请人带过课的同学,则录为2。所以,均值的结果表明,数值越大,则身边出现代课同学越少,数值越小,则表明身边出现的代课同学越多。因此,大三中的代课同学是最多的,大四次之,大二次之,大一最少。 上表表明,不同年级下代课情况的方差齐性检验值为,概率为,。如果显着性水平为,由于概率值大于显着性水平,不应拒绝零假设,认为不同年级下代课情况的总体方差无显着差异,满足方差分析的前提要求。 上表分别显示了两两不同年级下代课情况均值检验的结果。通过两两比较,最终可以得出,大一的均值>大二的均值>大三的均值,大四的均值大小情况不能确定,基本上得出的结论与实际情况相符。 五、建议 在以上对数据的分析过程当中,我们提到了逃课现象严重,收费代课行为愈发普遍的原因,这里稍微再做一下总结。原因如下: a.一些专业课程,教学内容循规蹈矩,考试题目照本宣科,无法引起学生兴趣; b.学校管理有较大漏洞,上课学生中“替身”大量潜伏而不知; c.学生自身自制力不够,容易受到外界的影响,不能静心学习; d.社会就业压力大,导致学生青睐于早点实习; 针对以上这些导致收费代课产生的原因,我想提出几点建议: (一)学校在专业设置、教师的互动性教学、知识的创新性和灵活体现、教学管理体系建设等诸多方面,都应反思,并采取一定的措施。高校则应该实行自主办学措施,在课程设置、专业方向设置上应当有自我特色。与其大张旗鼓地对“收费代课”现象进行大力批判,还不如放开手来,从根本上指导学生如何学会自主学习,如何利用有限的学习时间。倘若不加以反思,做出课程设置、教师互动性教学的改进,而是纯粹地一味加强考勤管理,必然会扼杀一部分学生的学习积极性,“人在心不在”的上课状态恐怕也难以培养出符合时代需求的大学生。 (二)学生应该分清楚学习和工作的不同意义,学习是一种能力的提高过程。大学生应当学会对自己的现在以及未来负责。大学四年,是相当宝贵的青春年华。我们年轻,我们活动,但是这些都不应该成为我们虚度时间,不学习的理由。调查结果中显示,大三的收费代课现象是最为严重的,这样的结果确实应该引起学生的重视了。我们都知道,大三是专业学习的主要一年,很多的专业课都在大三进行安排。可是大三的同学的不认真学习专业课,选择请人代课,这不是明显浪费了学习专业课的机会吗所以,这里,我想提醒本部的同学们,要合理地定位自己的身份与任务,不要在该学习的阶段去实习或娱乐。另外,也要明确自己上大学的初衷,不要因为大学生活的闲适,而慢慢丢失了自己的理想。 (三)政府要给大学生提供公平的就业环境,打击不规范的就业行为,消除掉大学生的就业焦虑。为大学生就业,提供更加全面完整的服务系统,让大学生在大学期间安心学
江苏理工学院2017—2018学年第1学期 《spss软件应用》上机操作题库 1.随机抽取100人,按男女不同性别分类,将学生成绩分为中等以上及中等以下两类,结果 如下表。问男女生在学业成绩上有无显著差异? 中等以上中等以下 男 女 性别* 学业成绩交叉制表 计数 学业成绩 中等以上中等以下 合计 性别男23 17 40 女38 22 60 合计61 39 100 根据皮尔逊卡方检验,p=0.558〉0.05 所以男生女生在学业成绩上无显著性差异。 2.为了研究两种教学方法的效果。选择了6对智商、年龄、阅读能力、家庭条件都相同的儿童进行了实验。结果(测试分数)如下。问:能否认为新教学方法优于原教学方法(采用非参数检验)? 序号新教学方法原教学方法 1 83 78
2 3 4 5 6 69 87 93 78 59 65 88 91 72 59 答:由威尔逊非参数检验分析可知p=0.08〉0.05,所以不能认为新教学方法显著优于原教学方法。 3.下面的表格记录了某公司采用新、旧两种培训前后的工作能力评分增加情况,分析目的是比较这两种培训方法的效果有无差异。考虑到加盟公司时间可能也是影响因素,将加盟时间按月进行了记录。 方法加盟时间分数方法加盟时间分数 旧方法 1.5 9 新方法 2 12 旧方法 2.5 10.5 新方法 4.5 14 旧方法 5.5 13 新方法7 16 旧方法 1 8 新方法0.5 9 旧方法 4 11 新方法 4.5 12 旧方法 5 9.5 新方法 4.5 10 旧方法 3.5 10 新方法 2 10 旧方法 4 12 新方法 5 14 旧方法 4.5 12.5 新方法 6 16 (1)分不同的培训方法计算加盟时间、评分增加量的平均数。 (2)分析两种培训方式的效果是否有差异? 答:(1) 描述统计量 N 极小值极大值均值标准差 培训方法 = 1 (FILTER) 9 1 1 1.00 .000 加盟时间9 .50 7.00 4.0000 2.09165 分数增加量9 9.00 16.00 12.5556 2.60342 有效的 N (列表状态)9 所以新方法的加盟时间平均数为4 分数增加量的平均数为12.5556
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。