
第1期(总第125期)机械管理开发
2012年2月No.1(S UM No.125)
M EC HANIC AL
M ANAGEM ENT AND
DEVELOPM ENT
Feb.2012
0引言
从第一台计算机发明以来,以计算机为中心的信息处理技术得到迅速发展,然而,计算机在处理一些人工智能的问题时遇到很大困难。一个人很容易辨认出他人的脸庞,而计算机却很难做到。这是因为传统的信息处理,都有精确的模型做指导,而人工智能却没有,很难为计算机编写明确的指令或程序。大脑是由生物神经元构成的巨型网络,本质上不同于计算机,是一种大规模的秉性处理系统,它有学习、联想、记忆、综合等能力,并有巧妙的信息处理方法。神经元不仅是组成大脑的基本单元,而且是大脑进行信息处理的基本单元。
人工神经网络(Artificial Neural Netw ork-ANN )是对人脑最简单的一种抽象和模拟,是模仿人的大脑神经系统信息处理功能的一个智能化系统,也是人们进一步解开人脑思维奥秘的有力工具。智能是指对环境的适应和自我调整能力,人工神经网络是有智能的。预测作为决策的前提和基础,对最终决策方案的选择具有至关重要的作用。1神经网络的观念介绍1.1
神经网络的模型与内涵
神经网络的学习可分为有导师学习和无导师学习。有导师学习是指基于知识系统,在实际的学习过程中,需要通过给定的输入输出数据,所进行的一种学习方式。无导师学习是指通过系统自身的学习,来达到期望的学习结果,所进行的一种学习。该学习不需要老师为系统提供各种精确的输入输出信息和有关知识,而只需提供系统所期望达到的目标和结果。
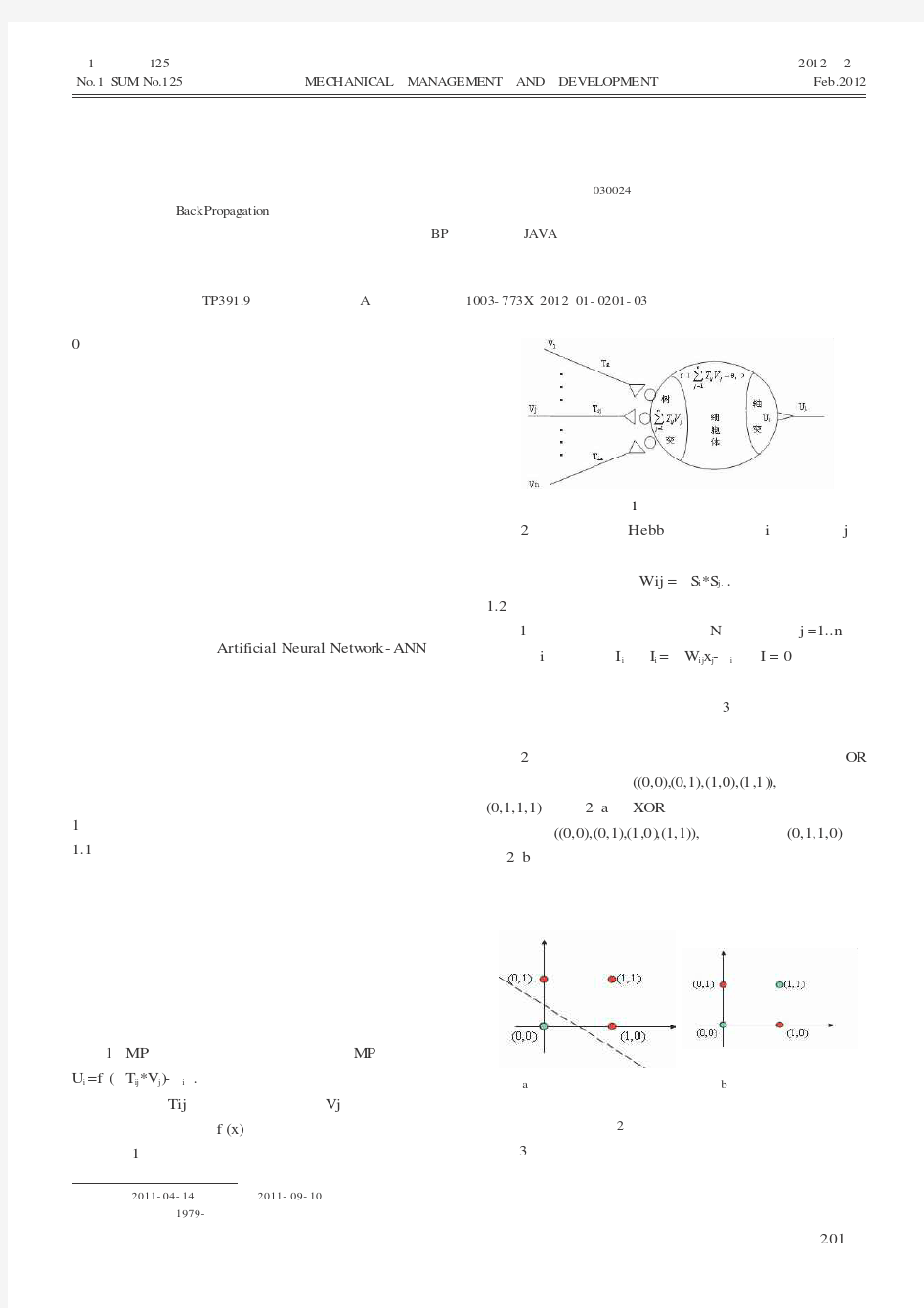
1)MP 模型。每个神经元的状态由M P 方程决定,U i =f ((ΣT ij *V j )-θi ).其意义是每个神经元的状态是由一定强度(权值Tij )的外界刺激(输入Vj )累加后经过细胞体加工(激励函数f (x))产生一个输出。神经元的模型,见图1
。
图1神经元的模型
2)联想学习。Hebb 定理:神经元i 和神经元j 之间,同时处于兴奋状态,则他们间的连接应该加强,即
△Wij =αS i *S j..
1.2
神经网络的几何意义与样本
1)神经网络的几何意义。N 个神经元(j =1..n )对神经元i 的总输入I i 为:I i =ΣW ij x j -θi 令I =0,得到一个几何上的超平面。从几何角度看,一个神经元代表一个超平面。超平面将解空间分为3部分:平面本身、平面上部、平面下部,神经元起到分类的作用。
2)线性样本和非线性样本。现举两例说明:OR (逻辑加法):输入为((0,0),(0,1),(1,0),(1,1)),期望输出为(0,1,1,1),见图2(a )。XOR (异或运算):
输入为((0,0),(0,1),(1,0),(1,1)),期望输出为(0,1,1,0),见图2(b )。非线性样本在最早的感知机模型中遇到了障碍,因为感知机的两层网络结构不能对非线性样本
进行超平面的划分。
(a )样本能够均匀的分布
(b )不存在一个超平面
在超平面的两侧
能将样本区分开
图2超平面的划分举例
3)非线性样本转化为线性样本。一个超平面不
收稿日期:;修回日期:作者简介:白
鹏(),男,山西太原人,在读工程硕士,研究方向:计算机软件开发。
神经网络算法的软件应用研究
白
鹏
(太原理工大学计算机科学与技术学院,山西
太原
030024)
摘
要:B ackPropagation 神经网络是重要的人工神经网络,有强大的非线性映射、自学习、泛化容错能力,并能充分
考虑主观因素,具有启发式搜索的特点。主要介绍BP 网络算法用JAVA 语言的实现方式及其在预测股票价格方面的应用。
关键词:神经网络;人工神经网络;预测中图分类号:TP391.9
文献标识码:A
文章编号:1003-773X (2012)01-0201-03
2011-04-142011-09-101979-201
最简单的人工神经网络实现 人工神经网络算法是模拟人的神经网络的一种算法. 该算法像人一样,具有一定的学习能力。人工神经网络可以学会它所能表达的任何东西. 该算法在模拟人类抽象思维方面较传统的算法具有优势,如图像识别(人脸识别,车牌识别),声音识别方面已经有成熟的运用。 举个简单的例子可以说明人工神经网络和传统算法的差别所在(等会也要实现): 假设要解决这个问题: 写一个程序,判断0, 1, 2, 3 ... 9 这10个数的奇偶性 1. 如果是传统算法,则是模拟人的逻辑思维,对这个问题进行形式化和逻辑化: if (input 模 2 == 零) { input 是偶数 } else { input 是奇数 } 2. 如果是ANN算法,则要提供一组正确的数据对处理这个问题的神经网络ANN进行训练: 未进行训练的神经网络,就像刚出生的婴儿一样,什么都不懂。这个时候, 你要教他0 是偶数,1是奇数...., 教完之后问ANN懂了没有,懂了则停止训练(网络已经形成),不懂则继续训练. while (1) { 训练;
if (测试通过) { 跳出循环; } } 训练完之后,这个ANN以后便能够正确处理奇偶性判断的问题了. 处理上面这个问题,只需要模拟一个神经元即可,再复杂的问题,可能需要多个神经元,再再复杂,需要多层多神经元的配合来实现(以后再研究) 下面是实现: [cpp]view plaincopyprint? 1. /***************************************** 2. * 感知器判断数字奇偶性 3. * 4. * 关键点,阈值应该怎么定? 5. ****************************************/ 6. #include
1.1 BP 神经网络原理简介 BP 神经网络是一种多层前馈神经网络,由输入、输出、隐藏层组成。该网络的主要特点是信号前向传递,误差反向传播。在前向传递中,输入信号从输入层经隐藏层逐层处理,直至输出层。每一层的神经元状态只影响下一层神经元状态。如果输出层得不到期望输出则转入反向传播,根据预测误差调整网络权值和阈值,从而使BP 神经网络预测输出不断逼近期望输出。结构图如下: 隐藏层传输函数选择Sigmoid 函数(也可以选择值域在(-1,1)的双曲正切函数,函数‘tansig ’),其数学表达式如下: x e 11)x ( f α-+=,其中α为常数 输出层传输函数选择线性函数:x )x (f = 1.隐藏层节点的选择 隐藏层神经元个数对BP 神经网络预测精度有显著的影响,如果隐藏层节点数目太少,则网络从样本中获取信息的能力不足,网络容易陷入局部极小值,有时可能训练不出来;如果隐藏层节点数目太多,则学习样本的非规律性信息会出现“过度吻合”的现象,从而导致学习时间延长,误差也不一定最佳,为此我们参照以下经验公式: 12+=I H ]10,1[ ,∈++=a a O I H I H 2log = 其中H 为隐含层节点数,I 为输入层节点数,O 为输出层节点数,a 为常数。 输入层和输出层节点的确定: 2.输入层节点和输出层节点的选择 输入层是外界信号与BP 神经网络衔接的纽带。其节点数取决于数据源的维数和输入特征向量的维数。选择特征向量时,要考虑是否能完全描述事物的本质特征,如果特征向量不能有效地表达这些特征,网络经训练后的输出可能与实际有较大的差异。因此在网络训练前,应全面收集被仿真系统的样本特性数据,并在数据处理时进行必要的相关性分析,剔除那些边沿和不可靠的数据,最终确定出数据源特征向量的维度。对于输出层节点的数目,往往需要根据实际应用情况灵活地制定。当BP 神经网络用于模式识别时,模式的自身特性就决定了输出的结果数。当网络作为一个分类器时,输出层节点数等于所需信息类别数。(可有可无) 训练好的BP 神经网络还只能输出归一化后的浓度数据,为了得到真实的数据
B P神经网络算法步骤 SANY GROUP system office room 【SANYUA16H-
传统的BP 算法简述 BP 算法是一种有监督式的学习算法,其主要思想是:输入学习样本,使用反向传播算法对网络的权值和偏差进行反复的调整训练,使输出的向量与期望向量尽可能地接近,当网络输出层的误差平方和小于指定的误差时训练完成,保存网络的权值和偏差。具体步骤如下: (1)初始化,随机给定各连接权[w],[v]及阀值θi ,rt 。 (2)由给定的输入输出模式对计算隐层、输出层各单元输出 (3)计算新的连接权及阀值,计算公式如下: (4)选取下一个输入模式对返回第2步反复训练直到网络设输出误差达到要求结束训练。 第一步,网络初始化 给各连接权值分别赋一个区间(-1,1)内的随机数,设定误差函数e ,给定计 算精度值 和最大学习次数M 。 第二步,随机选取第k 个输入样本及对应期望输出 ()12()(),(),,()q k d k d k d k =o d ()12()(),(),,()n k x k x k x k =x 第三步,计算隐含层各神经元的输入和输出 第四步,利用网络期望输出和实际输出,计算误差函数对输出层的各神经元的偏导数()o k a δ 第五步,利用隐含层到输出层的连接权值、输出层的()o k δ和隐含层的输出计算误差函数对隐含层各神经元的偏导数()h k δ 第六步,利用输出层各神经元的()o k δ和隐含层各神经元的输出来修正连接权值()ho w k 第七步,利用隐含层各神经元的()h k δ和输入层各神经元的输入修正连接权。 第八步,计算全局误差211 1(()())2q m o o k o E d k y k m ===-∑∑ ε
b p神经网络及m a t l a b实现
图1. 人工神经元模型 图中x1~xn是从其他神经元传来的输入信号,wij表示表示从神经元j到神经元i的连接权值,θ表示一个阈值 ( threshold ),或称为偏置( bias )。则神经元i的输出与输入的关系表示为: 图中 yi表示神经元i的输出,函数f称为激活函数 ( Activation Function )或转移函数 ( Transfer Function ) ,net称为净激活(net activation)。若将阈值看成是神经元i的一个输入x0的权重wi0,则上面的式子可以简化为: 若用X表示输入向量,用W表示权重向量,即: X = [ x0 , x1 , x2 , ....... , xn ]
则神经元的输出可以表示为向量相乘的形式: 若神经元的净激活net为正,称该神经元处于激活状态或兴奋状态(fire),若净激活net为负,则称神经元处于抑制状态。 图1中的这种“阈值加权和”的神经元模型称为M-P模型 ( McCulloch-Pitts Model ),也称为神经网络的一个处理单元( PE, Processing Element )。 2. 常用激活函数 激活函数的选择是构建神经网络过程中的重要环节,下面简要介绍常用的激活函数。 (1) 线性函数 ( Liner Function ) (2) 斜面函数 ( Ramp Function ) (3) 阈值函数 ( Threshold Function ) 以上3个激活函数都属于线性函数,下面介绍两个常用的非线性激活函数。 (4) S形函数 ( Sigmoid Function ) 该函数的导函数:
5.4 BP神经网络的基本原理 BP(Back Propagation)网络是1986年由Rinehart和 McClelland为首的科学家小组提出,是一种按误差逆传播算 法训练的多层前馈网络,是目前应用最广泛的神经网络模型 之一。BP网络能学习和存贮大量的输入-输出模式映射关系, 而无需事前揭示描述这种映射关系的数学方程。它的学习规 则是使用最速下降法,通过反向传播来不断调整网络的权值 和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结 构包括输入层(input)、隐层(hide layer)和输出层(output layer)(如图5.2所示)。 5.4.1 BP神经元 图5.3给出了第j个基本BP神经元(节点),它只模仿了生物神经元所具有的三个最基本 也是最重要的功能:加权、求和与转移。其中x 1、x 2 …x i …x n 分别代表来自神经元1、2…i…n 的输入;w j1、w j2 …w ji …w jn 则分别表示神经元1、2…i…n与第j个神经元的连接强度,即权 值;b j 为阈值;f(·)为传递函数;y j 为第j个神经元的输出。 第j个神经元的净输入值为: (5.12) 其中: 若视,,即令及包括及,则
于是节点j的净输入可表示为: (5.13)净输入通过传递函数(Transfer Function)f (·)后,便得到第j个神经元的输出 : (5.14) 式中f(·)是单调上升函数,而且必须是有界函数,因为细胞传递的信号不可能无限增加,必有一最大值。 5.4.2 BP网络 BP算法由数据流的前向计算(正向传播)和误差信号的反向传播两个过程构成。正向传播时,传播方向为输入层→隐层→输出层,每层神经元的状态只影响下一层神经元。若在输出层得不到期望的输出,则转向误差信号的反向传播流程。通过这两个过程的交替进行,在权向量空间执行误差函数梯度下降策略,动态迭代搜索一组权向量,使网络误差函数达到最小值,从而完成信息提取和记忆过程。 5.4.2.1 正向传播 设 BP网络的输入层有n个节点,隐层有q个节点,输出层有m个节点,输入层与隐层之间的权值为,隐层与输出层之间的权值为,如图5.4所示。隐层的传递函数为f (·), 1 (·),则隐层节点的输出为(将阈值写入求和项中): 输出层的传递函数为f 2
https://www.doczj.com/doc/be4871183.html,/s/blog_5bbd6ec00100b5nk.html 人工神经网络算法(2008-11-20 17:24:22) 标签:杂谈 人工神经网络算法的作用机理还是比较难理解,现在以一个例子来说明其原理。这个例子是关于人的识别技术的,在门禁系统,逃犯识别,各种验证码破译,银行预留印鉴签名比对,机器人设计等领域都有比较好的应用前景,当然也可以用来做客户数据的挖掘工作,比如建立一个能筛选满足某种要求的客户群的模型。 机器识别人和我们人类识别人的机理大体相似,看到一个人也就是识别对象以后,我们首先提取其关键的外部特征比如身高,体形,面部特征,声音等等。根据这些信息大脑迅速在内部寻找相关的记忆区间,有这个人的信息的话,这个人就是熟人,否则就是陌生人。 人工神经网络就是这种机理。假设上图中X(1)代表我们为电脑输入的人的面部特征,X(2)代表人的身高特征X(3)代表人的体形特征X(4)代表人的声音特征W(1)W(2)W(3)W(4)分别代表四种特征的链接权重,这个权重非常重要,也是人工神经网络起作用的核心变量。 现在我们随便找一个人阿猫站在电脑面前,电脑根据预设变量提取这个人的信息,阿猫面部怎么样,身高多少,体形胖瘦,声音有什么特征,链接权重初始值是随机的,假设每一个W均是0.25,这时候电脑按这个公式自动计 算,Y=X(1)*W(1)+X(2)*W(2)+X(3)*W(3)+X(4)*W(4)得出一个结果Y,这个Y要和一个门槛值(设为Q)进行比较,如果Y>Q,那么电脑就判定这个人是阿猫,否则判定不是阿猫.由于第一次计算电脑没有经验,所以结果是随机的.一般我们设定是正确的,因为我们输入的就是阿猫的身体数据啊. 现在还是阿猫站在电脑面前,不过阿猫怕被电脑认出来,所以换了一件衣服,这个行为会影响阿猫的体形,也就是X(3)变了,那么最后计算的Y值也就变了,它和Q比较的结果随即发生变化,这时候电脑的判断失误,它的结论是这个人不是阿猫.但是我们告诉它这个人就是阿猫,电脑就会追溯自己的判断过程,到底是哪一步出错了,结果发现原来阿猫体形X(3)这个 体征的变化导致了其判断失误,很显然,体形X(3)欺骗了它,这个属性在人的识别中不是那 么重要,电脑自动修改其权重W(3),第一次我对你是0.25的相信,现在我降低信任值,我0.10的相信你.修改了这个权重就意味着电脑通过学习认为体形在判断一个人是否是自己认识的人的时候并不是那么重要.这就是机器学习的一个循环.我们可以要求阿猫再穿一双高跟皮鞋改变一下身高这个属性,让电脑再一次进行学习,通过变换所有可能变换的外部特征,轮换让电脑学习记忆,它就会记住阿猫这个人比较关键的特征,也就是没有经过修改的特征.也就是电脑通过学习会总结出识别阿猫甚至任何一个人所依赖的关键特征.经过阿猫的训练电脑,电脑已经非常聪明了,这时你在让阿猫换身衣服或者换双鞋站在电脑前面,电脑都可以迅速的判断这个人就是阿猫.因为电脑已经不主要依据这些特征识别人了,通过改变衣服,身高骗不了它.当然,有时候如果电脑赖以判断的阿猫关键特征发生变化,它也会判断失误.我们就
毕业论文(设 计) 题目基于神经网络的中国人口预测 算法研究
所在院(系)数学与计算机科学学院 专业班级信息与计算科学1102班 指导教师赵晖 完成地点陕西理工学院 2015年5 月25日
基于神经网络的中国人口预测算法研究 作者:宋波 (陕理工学院数学与计算机科学学院信息与计算科学专业1102班,陕西汉中 723000) 指导教师:赵晖 [摘要]我国现正处于全面建成小康社会时期,人口发展面临着巨大的挑战,经济社会发展与资源环境的矛盾日益尖锐。我国是个人口大国、资源小国,这对矛盾将长期制约我国经济社会的发展。准确地预测未来人口的发展趋势,制定合理的人口规划和人口布局方案具有重大的理论意义和实用意义。本文介绍了人口预测的概念及发展规律等。 首先,本文考虑到人口预测具有大量冗余、流动范围和数量扩大的特性,又为提高人口预测的效果,因此,使用归一化对人口数据进行了处理,该方法不需要离散化原数据,这样就保证了人口预测的准确性和原始数据的信息完整性。其次,本文提出了一种基于神经网络预测的优化算法,该算法避免了人们在预测中参数选择的主观性而带来的精度的风险,增强了人口预测的准确性。同时,为说明该算法的有效性,又设计了几种人们通常所用的人口模型和灰色预测模型算法,并用相同的数据进行实验,得到了良好的效果,即本文算法的人口预测最为准确,其预测性能明显优于其他算法,而这主要是参数的选择对于增强预测性方面的影响,最终导致人口预测精确度。同时,在算法的稳定性和扩展性方面,该算法也明显优于其他算法。 考虑出生率、死亡率、人口增长率等因素的影响,重建神经网络模型预测人口数量。 [关键词] 神经网络人口模型灰色预测模型软件
人工神经网络是一种模仿人脑结构及其功能的信息处理系统,能提高人们对信息处理的智能化水平。它是一门新兴的边缘和交叉学科,它在理论、模型、算法等方面比起以前有了较大的发展,但至今无根本性的突破,还有很多空白点需要努力探索和研究。 1 人工神经网络研究背景 神经网络的研究包括神经网络基本理论、网络学习算法、网络模型以及网络应用等方面。其中比较热门的一个课题就是神经网络学习算法的研究。 近年来己研究出许多与神经网络模型相对应的神经网络学习算法,这些算法大致可以分为三类:有监督学习、无监督学习和增强学习。在理论上和实际应用中都比较成熟的算法有以下三种: (1) 误差反向传播算法(Back Propagation,简称BP 算法); (2) 模拟退火算法; (3) 竞争学习算法。 目前为止,在训练多层前向神经网络的算法中,BP 算法是最有影响的算法之一。但这种算法存在不少缺点,诸如收敛速度比较慢,或者只求得了局部极小点等等。因此,近年来,国外许多专家对网络算法进行深入研究,提出了许多改进的方法。 主要有: (1) 增加动量法:在网络权值的调整公式中增加一动量项,该动量项对某一时刻的调整起阻尼作用。它可以在误差曲面出现骤然起伏时,减小振荡的趋势,提高网络训练速度; (2) 自适应调节学习率:在训练中自适应地改变学习率,使其该大时增大,该小时减小。使用动态学习率,从而加快算法的收敛速度; (3) 引入陡度因子:为了提高BP 算法的收敛速度,在权值调整进入误差曲面的平坦区时,引入陡度因子,设法压缩神经元的净输入,使权值调整脱离平坦区。 此外,很多国内的学者也做了不少有关网络算法改进方面的研究,并把改进的算法运用到实际中,取得了一定的成果: (1) 王晓敏等提出了一种基于改进的差分进化算法,利用差分进化算法的全局寻优能力,能够快速地得到BP 神经网络的权值,提高算法的速度; (2) 董国君等提出了一种基于随机退火机制的竞争层神经网络学习算法,该算法将竞争层神经网络的串行迭代模式改为随机优化模式,通过采用退火技术避免网络收敛到能量函数的局部极小点,从而得到全局最优值; (3) 赵青提出一种分层遗传算法与BP 算法相结合的前馈神经网络学习算法。将分层遗传算法引入到前馈神经网络权值和阈值的早期训练中,再用BP 算法对前期训练所得性能较优的网络权值、阈值进行二次训练得到最终结果,该混合学习算法能够较快地收敛到全局最优解;
对如下的BP 神经网络,学习系数1=η,各点的阈值0=θ。作用函数为: ? ? ?<≥=111 )(x x x x f 。 输入样本0,121==x x ,输出节点z 的期望输出为1,对于第k 次学习得到的权值分别为1)(,1)(,1)(,2)(,2)(,0)(2122211211======k T k T k w k w k w k w ,求第k 次和1+k 次学习得到的输出节点值)(k z 和)1(+k z (写出计算公式和计算过程)。 y 2 )(11=k w 1)(22=k 11=x 02=x 计算如下: 1. 第k 次训练的正向过程如下: 1 )0()0210()()(12 1 11==?+?==-=∑=f f net f x w f y j j j θ) ()(i j i j ij i net f x w f y =-=∑θ
2 )2()0112()()(22 1 22==?+?==∑==f f net f x w f y j j j 3 )3()2111()()(2 1 ==?+?==∑==f f net f y T f z l i i i 2)31(2 1 2=-=E 2. 第k 次训练的反向过程如下: 212)3()31()(')(''-=?-=?-=-=f net f z z l l δ li l l i i T net f ∑=δδ)('' 1)2(01)2()0(')(''111=?-?=?-?==f T net f l δδ 2 1)2(11)2()2(')(''222-=?-?=?-?==f T net f l δδ 1 1)2(11)()()1(11111-=?-?+=+=?+=+y k T T k T k T l ηδ ) ()(l i l i li l net f y T f O =-=∑θ
浅谈神经网络 先从回归(Regression)问题说起。我在本吧已经看到不少人提到如果想实现强AI,就必须让机器学会观察并总结规律的言论。具体地说,要让机器观察什么是圆的,什么是方的,区分各种颜色和形状,然后根据这些特征对某种事物进行分类或预测。其实这就是回归问题。 如何解决回归问题?我们用眼睛看到某样东西,可以一下子看出它的一些基本特征。可是计算机呢?它看到的只是一堆数字而已,因此要让机器从事物的特征中找到规律,其实是一个如何在数字中找规律的问题。 例:假如有一串数字,已知前六个是1、3、5、7,9,11,请问第七个是几? 你一眼能看出来,是13。对,这串数字之间有明显的数学规律,都是奇数,而且是按顺序排列的。 那么这个呢?前六个是0.14、0.57、1.29、2.29、3.57、5.14,请问第七个是几? 这个就不那么容易看出来了吧!我们把这几个数字在坐标轴上标识一下,可以看到如下图形: 用曲线连接这几个点,延着曲线的走势,可以推算出第七个数字——7。 由此可见,回归问题其实是个曲线拟合(Curve Fitting)问题。那么究竟该如何拟合?机器不
可能像你一样,凭感觉随手画一下就拟合了,它必须要通过某种算法才行。 假设有一堆按一定规律分布的样本点,下面我以拟合直线为例,说说这种算法的原理。 其实很简单,先随意画一条直线,然后不断旋转它。每转一下,就分别计算一下每个样本点和直线上对应点的距离(误差),求出所有点的误差之和。这样不断旋转,当误差之和达到最小时,停止旋转。说得再复杂点,在旋转的过程中,还要不断平移这条直线,这样不断调整,直到误差最小时为止。这种方法就是著名的梯度下降法(Gradient Descent)。为什么是梯度下降呢?在旋转的过程中,当误差越来越小时,旋转或移动的量也跟着逐渐变小,当误差小于某个很小的数,例如0.0001时,我们就可以收工(收敛, Converge)了。啰嗦一句,如果随便转,转过头了再往回转,那就不是梯度下降法。 我们知道,直线的公式是y=kx+b,k代表斜率,b代表偏移值(y轴上的截距)。也就是说,k 可以控制直线的旋转角度,b可以控制直线的移动。强调一下,梯度下降法的实质是不断的修改k、b这两个参数值,使最终的误差达到最小。 求误差时使用累加(直线点-样本点)^2,这样比直接求差距累加(直线点-样本点) 的效果要好。这种利用最小化误差的平方和来解决回归问题的方法叫最小二乘法(Least Square Method)。 问题到此使似乎就已经解决了,可是我们需要一种适应于各种曲线拟合的方法,所以还需要继续深入研究。 我们根据拟合直线不断旋转的角度(斜率)和拟合的误差画一条函数曲线,如图:
深度学习 卷积神经网络算法简介 李宗贤 北京信息科技大学智能科学与技术系 卷积神经网络是近年来广泛应用在模式识别、图像处理领域的一种高效识别算法,具有简单结构、训练参数少和适应性强的特点。它的权值共享网络结构使之更类似与生物神经网络,降低了网络的复杂度,减少了权值的数量。以二维图像直接作为网络的输入,避免了传统是被算法中复杂的特征提取和数据重建过程。卷积神经网络是为识别二维形状特殊设计的一个多层感知器,这种网络结构对于平移、比例缩放、倾斜和其他形式的变形有着高度的不变形。 ?卷积神经网络的结构 卷积神经网络是一种多层的感知器,每层由二维平面组成,而每个平面由多个独立的神经元组成,网络中包含一些简单元和复杂元,分别记为C元和S元。C元聚合在一起构成卷积层,S元聚合在一起构成下采样层。输入图像通过和滤波器和可加偏置进行卷积,在C层产生N个特征图(N值可人为设定),然后特征映射图经过求和、加权值和偏置,再通过一个激活函数(通常选用Sigmoid函数)得到S层的特征映射图。根据人为设定C层和S层的数量,以上工作依次循环进行。最终,对最尾部的下采样和输出层进行全连接,得到最后的输出。
卷积的过程:用一个可训练的滤波器fx去卷积一个输入的图像(在C1层是输入图像,之后的卷积层输入则是前一层的卷积特征图),通过一个激活函数(一般使用的是Sigmoid函数),然后加一个偏置bx,得到卷积层Cx。具体运算如下式,式中Mj是输入特征图的值: X j l=f?(∑X i l?1?k ij l+b j l i∈Mj) 子采样的过程包括:每邻域的m个像素(m是人为设定)求和变为一个像素,然后通过标量Wx+1加权,再增加偏置bx+1,然后通过激活函数Sigmoid产生特征映射图。从一个平面到下一个平面的映射可以看作是作卷积运算,S层可看作是模糊滤波器,起到了二次特征提取的作用。隐层与隐层之间的空间分辨率递减,而每层所含的平面数递增,这样可用于检测更多的特征信息。对于子采样层来说,有N 个输入特征图,就有N个输出特征图,只是每个特征图的的尺寸得到了相应的改变,具体运算如下式,式中down()表示下采样函数。 X j l=f?(βj l down (X j l?1) +b j l)X j l) ?卷积神经网络的训练过程 卷积神经网络在本质上是一种输入到输出的映射,它能够学习大量的输入和输出之间的映射关系,而不需要任何输入和输出之间的精确数学表达式。用已知的模式对卷积网络加以训练,网络就具有了输
文章编号 2 2 2 一种快速神经网络路径规划算法α 禹建丽? ∏ √ 孙增圻成久洋之 洛阳工学院应用数学系日本冈山理科大学工学部电子工学科 2 清华大学计算机系国家智能技术与系统重点实验室日本冈山理科大学工学部信息工学科 2 摘要本文研究已知障碍物形状和位置环境下的全局路径规划问题给出了一个路径规划算法其能量函数 利用神经网络结构定义根据路径点位于障碍物内外的不同位置选取不同的动态运动方程并针对障碍物的形状设 定各条边的模拟退火初始温度仿真研究表明本文提出的算法计算简单收敛速度快能够避免某些局部极值情 况规划的无碰路径达到了最短无碰路径 关键词全局路径规划能量函数神经网络模拟退火 中图分类号 ×°文献标识码 ΦΑΣΤΑΛΓΟΡΙΤΗΜΦΟΡΠΑΤΗΠΛΑΝΝΙΝΓ ΒΑΣΕΔΟΝΝΕΥΡΑΛΝΕΤ? ΟΡΚ ≠ 2 ? ? ≥ 2 ≥ ∏ ΔεπαρτμεντοφΜατηεματιχσ ΛυοψανγΙνστιτυτεοφΤεχηνολογψ Λυοψανγ
ΔεπαρτμεντοφΕλεχτρονιχΕνγινεερινγ ΦαχυλτψοφΕνγινεερινγ ΟκαψαμαΥνι?ερσιτψοφΣχιενχε 2 Ριδαι2χηο 2 ?απαν ΔεπαρτμεντοφΧομπυτερΣχιενχε Τεχηνολογψ ΣτατεΚεψΛαβοφΙντελλιγεντΤεχηνολογψ Σψστεμσ ΤσινγηυαΥνι?ερσιτψ Βει?ινγ ΔεπαρτμεντοφΙνφορματιον ΧομπυτερΕνγινεερινγ ΦαχυλτψοφΕνγινεερινγ ΟκαψαμαΥνι?ερσιτψοφΣχιενχε 2 Ριδαι2χηο 2 ?απαν Αβστραχτ ∏ √ √ √ × ∏ ∏ ∏ ∏ ∏ ∏ 2 ∏ √ × ∏ ∏ ∏ ∏ √ ∏ Κεψωορδσ ∏ ∏ ∏ 1引言Ιντροδυχτιον 机器人路径规划问题可以分为两种一种是基于环境先验完全信息的全局路径规划≈ 另一种是基于传感器信息的局部路径规划≈ ?后者环境是未知或者部分未知的全局路径规划已提出的典型方法有可视图法 ! 图搜索法≈ ! 人工势场法等可视图法的优点是可以求得最短路径但缺乏灵活性并且存在组合爆炸问题图搜索法比较灵活机器人的起始点和目标点的改变不会造成连通图的重新构造但不是任何时候都可以获得最短路径可视图法和图搜索法适用于多边形障碍物的避障路径规划问题但不适用解决圆形障碍物的避障路径规划问题人工势场法的基本思想是通过寻找路径点的能量函数的极小值点而使路径避开障碍物但存在局部极小值问题且不适于寻求最短路径≈ 文献≈ 给出的神经网络路径规划算法我们称为原算法引入网络结构和模拟退火等方法计算简单能避免某些局部极值情况且具有并行性及易于从二维空间推广到三维空间等优点对人工势场法给予了较大的改进但在此算法中由于路径点的总能量函数是由碰撞罚函数和距离函数两部分的和构成的而路径点 第卷第期年月机器人ΡΟΒΟΤ? α收稿日期
神经网络算法详解 第0节、引例 本文以Fisher的Iris数据集作为神经网络程序的测试数据集。Iris数据集可以在https://www.doczj.com/doc/be4871183.html,/wiki/Iris_flower_data_set 找到。这里简要介绍一下Iris数据集: 有一批Iris花,已知这批Iris花可分为3个品种,现需要对其进行分类。不同品种的Iris花的花萼长度、花萼宽度、花瓣长度、花瓣宽度会有差异。我们现有一批已知品种的Iris花的花萼长度、花萼宽度、花瓣长度、花瓣宽度的数据。 一种解决方法是用已有的数据训练一个神经网络用作分类器。 如果你只想用C#或Matlab快速实现神经网络来解决你手头上的问题,或者已经了解神经网络基本原理,请直接跳到第二节——神经网络实现。 第一节、神经网络基本原理 1. 人工神经元( Artificial Neuron )模型 人工神经元是神经网络的基本元素,其原理可以用下图表示: 图1. 人工神经元模型 图中x1~xn是从其他神经元传来的输入信号,wij表示表示从神经元j到神经元i的连接权值,θ表示一个阈值( threshold ),或称为偏置( bias )。则神经元i的输出与输入的关系表示为:
图中yi表示神经元i的输出,函数f称为激活函数 ( Activation Function )或转移函数( Transfer Function ) ,net称为净激活(net activation)。若将阈值看成是神经元i的一个输入x0的权重wi0,则上面的式子可以简化为: 若用X表示输入向量,用W表示权重向量,即: X = [ x0 , x1 , x2 , ....... , xn ] 则神经元的输出可以表示为向量相乘的形式: 若神经元的净激活net为正,称该神经元处于激活状态或兴奋状态(fire),若净激活net 为负,则称神经元处于抑制状态。 图1中的这种“阈值加权和”的神经元模型称为M-P模型 ( McCulloch-Pitts Model ),也称为神经网络的一个处理单元( PE, Processing Element )。 2. 常用激活函数 激活函数的选择是构建神经网络过程中的重要环节,下面简要介绍常用的激活函数。 (1) 线性函数 ( Liner Function ) (2) 斜面函数 ( Ramp Function ) (3) 阈值函数 ( Threshold Function )
第1期(总第125期)机械管理开发 2012年2月No.1(S UM No.125) M EC HANIC AL M ANAGEM ENT AND DEVELOPM ENT Feb.2012 0引言 从第一台计算机发明以来,以计算机为中心的信息处理技术得到迅速发展,然而,计算机在处理一些人工智能的问题时遇到很大困难。一个人很容易辨认出他人的脸庞,而计算机却很难做到。这是因为传统的信息处理,都有精确的模型做指导,而人工智能却没有,很难为计算机编写明确的指令或程序。大脑是由生物神经元构成的巨型网络,本质上不同于计算机,是一种大规模的秉性处理系统,它有学习、联想、记忆、综合等能力,并有巧妙的信息处理方法。神经元不仅是组成大脑的基本单元,而且是大脑进行信息处理的基本单元。 人工神经网络(Artificial Neural Netw ork-ANN )是对人脑最简单的一种抽象和模拟,是模仿人的大脑神经系统信息处理功能的一个智能化系统,也是人们进一步解开人脑思维奥秘的有力工具。智能是指对环境的适应和自我调整能力,人工神经网络是有智能的。预测作为决策的前提和基础,对最终决策方案的选择具有至关重要的作用。1神经网络的观念介绍1.1 神经网络的模型与内涵 神经网络的学习可分为有导师学习和无导师学习。有导师学习是指基于知识系统,在实际的学习过程中,需要通过给定的输入输出数据,所进行的一种学习方式。无导师学习是指通过系统自身的学习,来达到期望的学习结果,所进行的一种学习。该学习不需要老师为系统提供各种精确的输入输出信息和有关知识,而只需提供系统所期望达到的目标和结果。 1)MP 模型。每个神经元的状态由M P 方程决定,U i =f ((ΣT ij *V j )-θi ).其意义是每个神经元的状态是由一定强度(权值Tij )的外界刺激(输入Vj )累加后经过细胞体加工(激励函数f (x))产生一个输出。神经元的模型,见图1 。 图1神经元的模型 2)联想学习。Hebb 定理:神经元i 和神经元j 之间,同时处于兴奋状态,则他们间的连接应该加强,即 △Wij =αS i *S j.. 1.2 神经网络的几何意义与样本 1)神经网络的几何意义。N 个神经元(j =1..n )对神经元i 的总输入I i 为:I i =ΣW ij x j -θi 令I =0,得到一个几何上的超平面。从几何角度看,一个神经元代表一个超平面。超平面将解空间分为3部分:平面本身、平面上部、平面下部,神经元起到分类的作用。 2)线性样本和非线性样本。现举两例说明:OR (逻辑加法):输入为((0,0),(0,1),(1,0),(1,1)),期望输出为(0,1,1,1),见图2(a )。XOR (异或运算): 输入为((0,0),(0,1),(1,0),(1,1)),期望输出为(0,1,1,0),见图2(b )。非线性样本在最早的感知机模型中遇到了障碍,因为感知机的两层网络结构不能对非线性样本 进行超平面的划分。 (a )样本能够均匀的分布 (b )不存在一个超平面 在超平面的两侧 能将样本区分开 图2超平面的划分举例 3)非线性样本转化为线性样本。一个超平面不 收稿日期:;修回日期:作者简介:白 鹏(),男,山西太原人,在读工程硕士,研究方向:计算机软件开发。 神经网络算法的软件应用研究 白 鹏 (太原理工大学计算机科学与技术学院,山西 太原 030024) 摘 要:B ackPropagation 神经网络是重要的人工神经网络,有强大的非线性映射、自学习、泛化容错能力,并能充分 考虑主观因素,具有启发式搜索的特点。主要介绍BP 网络算法用JAVA 语言的实现方式及其在预测股票价格方面的应用。 关键词:神经网络;人工神经网络;预测中图分类号:TP391.9 文献标识码:A 文章编号:1003-773X (2012)01-0201-03 2011-04-142011-09-101979-201
科技信息 2011年第 3期 SCIENCE &TECHNOLOGY INFORMATION 人工神经网络是模仿生理神经网络的结构和功能而设计的一种信息处理系统。大量的人工神经元以一定的规则连接成神经网络 , 神经元之间的连接及各连接权值的分布用来表示特定的信息。神经网络分布式存储信息 , 具有很高的容错性。每个神经元都可以独立的运算和处理接收到的信息并输出结果 , 网络具有并行运算能力 , 实时性非常强。神经网络对信息的处理具有自组织、自学习的特点 , 便于联想、综合和推广。神经网络以其优越的性能应用在人工智能、计算机科学、模式识别、控制工程、信号处理、联想记忆等极其广泛的领域。 1986年 D.Rumelhart 和 J.McCelland [1]等发展了多层网络的 BP 算法 , 使BP 网络成为目前应用最广的神经网络。 1BP 网络原理及学习方法 BP(BackPropagation 网络是一种按照误差反向传播算法训练的多层前馈神经网络。基于 BP 算法的二层网络结构如图 1所示 , 包括输入层、一个隐层和输出层 , 三者都是由神经元组成的。输入层各神经元负责接收并传递外部信息 ; 中间层负责信息处理和变换 ; 输出层向 外界输出信息处理结果。神经网络工作时 , 信息从输入层经隐层流向输出层 (信息正向传播 , 若现行输出与期望相同 , 则训练结束 ; 否则 , 误差反向进入网络 (误差反向传播。将输出与期望的误差信号按照原连接通路反向计算 , 修改各层权值和阈值 , 逐次向输入层传播。信息正向传播与误差反向传播反复交替 , 网络得到了记忆训练 , 当网络的全局误差小于给定的误差值后学习终止 , 即可得到收敛的网络和相应稳定的权值。网络学习过程实际就是建立输入模式到输出模式的一个映射 , 也就是建立一个输入与输出关系的数学模型 :
BP 神经网络算法 三层 BP 神经网络如图: 目标输出向量 传递函数 g 输出层,输出向量 权值为 w jk 传递函数 f 隐含层,隐含层 输出向量 输 入 层 , 输 入 向量 设网络的输入模式为 x (x 1 , x 2 ,...x n )T ,隐含层有 h 个单元,隐含层的输出为 y ( y 1 , y 2 ,...y h )T ,输出 层有 m 个单元,他们的输出为 z (z 1 , z 2 ,...z m )T ,目标输出为 t (t 1 ,t 2 ,..., t m )T 设隐含层到输出层的传 递函数为 f ,输出层的传递函数为 g n n 于是: y j f ( w ij x i ) f ( w ij x i ) :隐含层第 j 个神经元的输出;其中 w 0 j , x 0 1 i 1 i 0 h z k g( w jk y j ) :输出层第 k 个神经元的输出 j 此时网络输出与目标输出的误差为 1 m (t k z k ) 2 ,显然,它是 w ij 和 w jk 的函数。 2 k 1 下面的步骤就是想办法调整权值,使 减小。 由高等数学的知识知道:负梯度方向是函数值减小最快的方向 因此,可以设定一个步长 ,每次沿负梯度方向调整 个单位,即每次权值的调整为: w pq w pq , 在神经网络中称为学习速率 可以证明:按这个方法调整,误差会逐渐减小。
BP 神经网络(反向传播)的调整顺序为:1)先调整隐含层到输出层的权值 h 设 v k为输出层第k个神经元的输入v k w jk y j j 0 ------- 复合函数偏导公式 1 g'(u k ) e v k 1 (1 1 ) z k (1 z k ) 若取 g ( x) f (x) 1 e x,则(1e v k) 2 1e v k 1e v k 于是隐含层到输出层的权值调整迭代公式为:2)从输入层到隐含层的权值调整迭代公式为: n 其中 u j为隐含层第j个神经元的输入: u j w ij x i i 0 注意:隐含层第j 个神经元与输出层的各个神经元都有连接,即涉及所有的权值w ij,因此 y j m (t k z k )2 z k u k m y j k 0 z k u k y j (t k z k ) f '(u k )w jk k 0 于是: 因此从输入层到隐含层的权值调整迭代为公式为: 例: 下表给出了某地区公路运力的历史统计数据,请建立相应的预测模型,并对给出的 2010 和 2011 年的数据,预测相应的公路客运量和货运量。 人数 ( 单位:机动车数公路面积 ( 单公路客运量公路货运量 时间( 单位:万位:万平方公( 单位:万( 单位:万万人 ) 辆 ) 里) 人 ) 吨 ) 1990 20.55 0.6 0.09 5126 1237 1991 22.44 0.75 0.11 6217 1379 1992 25.37 0.85 0.11 7730 1385 1993 27.13 0.9 0.14 9145 1399 1994 29.45 1.05 0.2 10460 1663 1995 30.1 1.35 0.23 11387 1714 1996 30.96 1.45 0.23 12353 1834 1997 34.06 1.6 0.32 15750 4322 1998 36.42 1.7 0.32 18304 8132 1999 38.09 1.85 0.34 19836 8936 2000 39.13 2.15 0.36 21024 11099 2001 39.99 2.2 0.36 19490 11203 2002 41.93 2.25 0.38 20433 10524 2003 44.59 2.35 0.49 22598 11115 2004 47.3 2.5 0.56 25107 13320 2005 52.89 2.6 0.59 33442 16762 2006 55.73 2.7 0.59 36836 18673
一前言 让我们来看一个经典的神经网络。这是一个包含三个层次的神经网络。红色的是输入层,绿色的是输出层,紫色的是中间层(也叫隐藏层)。输入层有3个输入单元,隐藏层有4个单元,输出层有2个单元。后文中,我们统一使用这种颜色来表达神经网络的结构。 图1神经网络结构图 设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定; 神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别; 结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。 除了从左到右的形式表达的结构图,还有一种常见的表达形式是从下到上来
表示一个神经网络。这时候,输入层在图的最下方。输出层则在图的最上方,如下图: 图2从下到上的神经网络结构图 二神经元 2.结构 神经元模型是一个包含输入,输出与计算功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。 下图是一个典型的神经元模型:包含有3个输入,1个输出,以及2个计算功能。 注意中间的箭头线。这些线称为“连接”。每个上有一个“权值”。
图3神经元模型 连接是神经元中最重要的东西。每一个连接上都有一个权重。 一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。 我们使用a来表示输入,用w来表示权值。一个表示连接的有向箭头可以这样理解: 在初端,传递的信号大小仍然是a,端中间有加权参数w,经过这个加权后的信号会变成a*w,因此在连接的末端,信号的大小就变成了a*w。 在其他绘图模型里,有向箭头可能表示的是值的不变传递。而在神经元模型里,每个有向箭头表示的是值的加权传递。 图4连接(connection) 如果我们将神经元图中的所有变量用符号表示,并且写出输出的计算公式的话,就是下图。
算法起源 在思维学中,人类的大脑的思维分为:逻辑思维、直观思维、和灵感思维三种基本方式。 而神经网络就是利用其算法特点来模拟人脑思维的第二种方式,它是一个非线性动力学系统,其特点就是信息分布式存储和并行协同处理,虽然单个神经元的结构及其简单,功能有限,但是如果大量的神经元构成的网络系统所能实现的行为确实及其丰富多彩的。其实简单点讲就是利用该算法来模拟人类大脑来进行推理和验证的。 我们先简要的分析下人类大脑的工作过程,我小心翼翼的在网上找到了一张勉强看起来舒服的大脑图片 嗯,看着有那么点意思了,起码看起来舒服点,那还是在19世纪末,有一位叫做:Waldege 的大牛创建了神经元学活,他说人类复杂的神经系统是由数目繁多的神经元组成,说大脑皮层包括100亿个以上的神经元,每立方毫米源数万个,汗..我想的是典型的大数据。他们 相互联系形成神经网络,通过感官器官和神经来接受来自身体外的各种信息(在神经网络算法中我们称:训练)传递中枢神经,然后经过对信息的分析和综合,再通过运动神经发出控制信息(比如我在博客园敲文字),依次来实现机体与外部环境的联系。 神经元这玩意跟其它细胞一样,包括:细胞核、细胞质和细胞核,但是它还有比较特殊的,比如有许多突起,就跟上面的那个图片一样,分为:细胞体、轴突和树突三分部。细胞体内有细胞核,突起的作用是传递信息。树突的作用是作为引入输入信息的突起,而轴突是作为输出端的突起,但它只有一个。 也就是说一个神经元它有N个输入(树突),然后经过信息加工(细胞核),然后只有一 个输出(轴突)。而神经元之间四通过树突和另一个神经元的轴突相联系,同时进行着信息传递和加工。我去...好复杂....