
发动机故障代码编写规则
1.规则
1.1故障代码形式:
1.2.1第1位:处理方式
出现故障后的处理情况。分为:整机更换、换零件、换总成件、换相关件、修复、补件、换油、故障检查、待处理、(底盘)相关处理。其代码及说明如下:
1.1.2第2位:故障类别
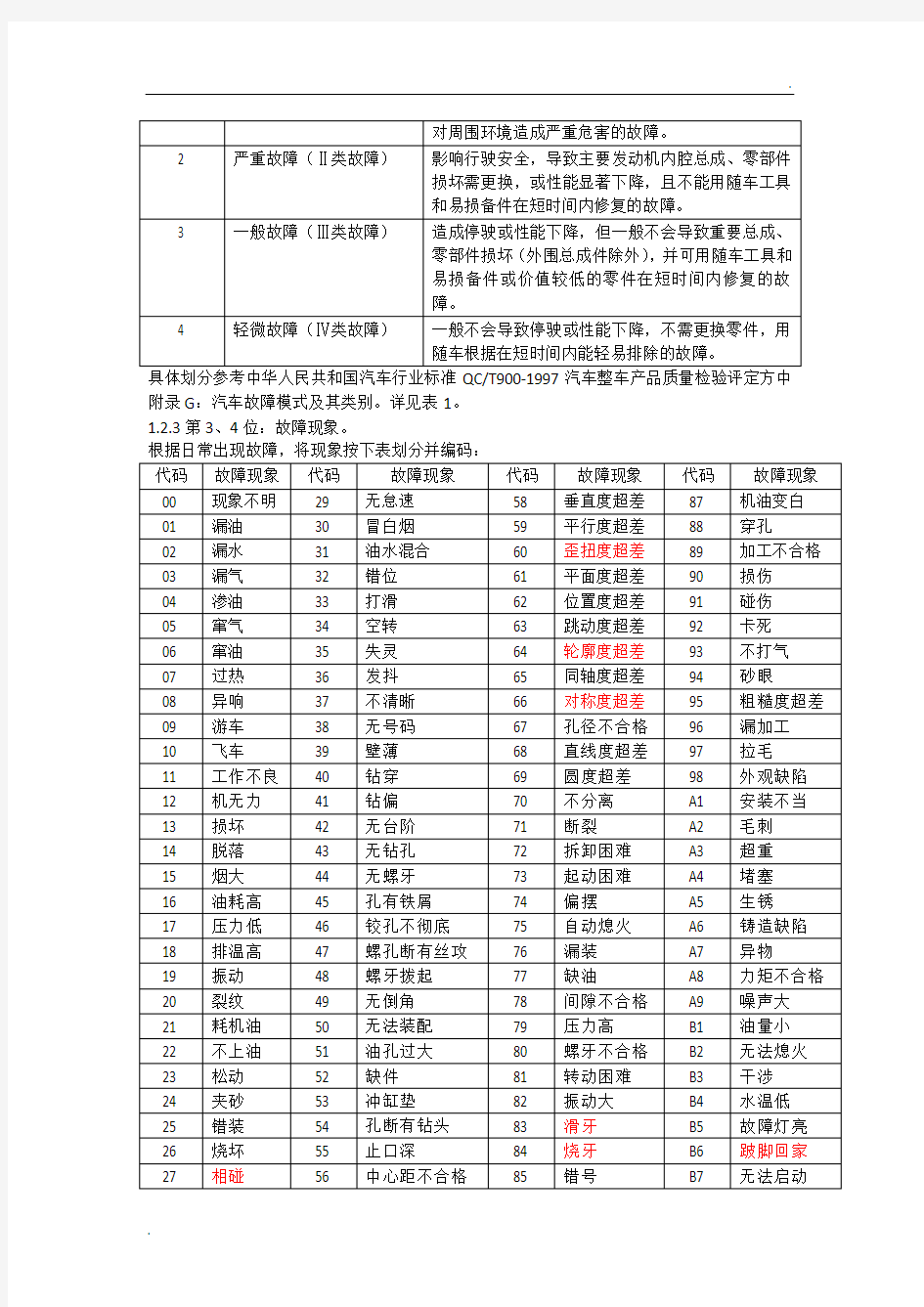
附录G:汽车故障模式及其类别。详见表1。1.2.3第3、4位:故障现象。
根据日常出现故障,将现象按下表划分并编码:
其中5、6位为总成或部件编码,第7、8位为零件在本总成或部件中的编码。现行的零件代码是按技术部门零件代码标准。
1.2.5第9位:零件故障发生的原因。
按影响产品质量的五个因素“人”、“机”、“料”、“法”、“环”及非产品质量因素(外部因素),
1.2.6第10、11位:故障模式。
根据日常出现的故障,将其模式按下表划分并编码:
代码编写实例
2.1故障代码的含义
2.1.1该故障引起的后果(对整机而言是致命的、严重的、还是一般的、轻微的)。2.1.2该故障发生的现象、状态。
2.1.3该故障发生在哪一个总成(部件)上的哪一个零件。
2.1.4该故障是由产品质量中哪个因素引起或非产品质量因素引起。
2.1.5该故障的表现形式。
2.2实例
2.2.1故障代码:
该代码含义为:连杆轴瓦剥落产生异响,属Ⅲ类故障(一般故障),处理方式为换件。
2.2.2故障代码:
该代码含义为:第一道活塞环断拉伤缸套产生窜气窜油,属Ⅱ类故障,是由活塞环质量差引起,处理方式为换相关件。
2.2.3某一故障表现为“异响”,发生故障里程为2000km,拆检发现是由于连杆螺栓松而断引起打烂机体。
分析如下:
a、由于机体、连杆总成、连杆轴瓦已损坏,故处理方式为“更换相关件”。
b、该故障后果损坏机体,且机体不能用焊补方修复。因此该故障类别为“Ⅰ类”——类别。
c、发生此故障给人的第一感觉就是“异常”——现象。
d、拆检发现为连杆螺栓松引起,连杆螺栓——故障件。
e、原因为“装配没拧紧”——“人”的因素造成。
f、故障件发生该故障时的表现形式为“松动”——模式。
所以该故障代码为“R1080611217”
数据挖掘作业The document was prepared on January 2, 2021
1、给出K D D的定义和处理过程。 KDD的定义是:从大量数据中提取出可信的、新颖的、有用的且可以被人理解的模式的高级处理过程。因此,KDD是一个高级的处理过程,它从数据集中识别出以模式形式表示的知识。这里的“模式”可以看成知识的雏形,经过验证、完善后形成知识:“高级的处理过程”是指一个多步骤的处理过程,多步骤之间相互影响反复调整,形成一种螺旋式上升的过程。 KDD的全过程有五个步骤:1、数据选择:确定发现任务的操作对象,即目标数据,它是根据用户的需要从原始数据库中抽取的一组数据;2、数据预处理:一般可能包括消除噪声、推到技术却只数据、消除重复记录、完成数据类型转换等;3、数据转换:其主要目的是消减数据维数或降维,即从初始特征中找出真正有用的特征以减少数据开采时要考虑的特征或变量个数;4、数据挖掘:这一阶段包括确定挖掘任务/目的、选择挖掘方法、实施数据挖掘;5、模式解释/评价:数据挖掘阶段发现出来的模式,经过用户或机器的评价,可能存在冗余或无关的模式,需要剔除;也有可能模式不满足用户的要求,需要退回到整个发现阶段之前,重新进行KDD过程。 2、阐述数据挖掘产生的背景和意义。 数据挖掘产生的背景:随着信息科技的进步以及电子化时代的到来,人们以更快捷、更容易、更廉价的方式获取和存储数据,使得数据及信息量以指数方式增长。据粗略估计,一个中等规模企业每天要产生100MB以上的商业数据。而电信、银行、大型零售业每天产生的数据量以TB来计算。人们搜集的数据越来越多,剧增的数据背后隐藏着许多重要的信息,人们希望对其进行更高层次的分析,以便更好的利用这些数据。先前的数据库系统可以高效的实现数据的录入、查询、统计等功能,但无法发现数据中存在的关系与规则,无法根据现有的数据来预测未来的发展趋势。缺乏挖掘数据背后隐藏的知识的手段。导致了“数据爆炸但知识贫乏”的现象。于是人们开始提出“要学会选择、提取、抛弃信息”,并且开始考虑:如何才能不被信息淹没如何从中及时发现有用的知识、提高信息利用率如何从浩瀚如烟海的资料中选择性的搜集他们认为有用的信息这给我们带来了另一些头头疼的问题:第一是信息过量,难以消
《数据挖掘》作业 第一章引言 一、填空题 (1)数据库中的知识挖掘(KDD)包括以下七个步骤:、、、、、和 (2)数据挖掘的性能问题主要包括:、和 (3)当前的数据挖掘研究中,最主要的三个研究方向是:、和 (4)在万维网(WWW)上应用的数据挖掘技术常被称为: (5)孤立点是指: 二、单选题 (1)数据挖掘应用和一些常见的数据统计分析系统的最主要区别在于: A、所涉及的算法的复杂性; B、所涉及的数据量; C、计算结果的表现形式; D、是否使用了人工智能技术 (2)孤立点挖掘适用于下列哪种场合? A、目标市场分析 B、购物篮分析 C、模式识别 D、信用卡欺诈检测(3)下列几种数据挖掘功能中,()被广泛的应用于股票价格走势分析 A. 关联分析 B.分类和预测 C.聚类分析 D. 演变分析 (4)下面的数据挖掘的任务中,()将决定所使用的数据挖掘功能 A、选择任务相关的数据 B、选择要挖掘的知识类型 C、模式的兴趣度度量 D、模式的可视化表示 (5)下列几种数据挖掘功能中,()被广泛的用于购物篮分析 A、关联分析 B、分类和预测 C、聚类分析 D、演变分析 (6)根据顾客的收入和职业情况,预测他们在计算机设备上的花费,所使用的相应数据挖掘功能是() A.关联分析 B.分类和预测 C. 演变分析 D. 概念描述(7)帮助市场分析人员从客户的基本信息库中发现不同的客户群,通常所使用的数据挖掘功能是() A.关联分析 B.分类和预测 C.聚类分析 D. 孤立点分析 E. 演变分析(8)假设现在的数据挖掘任务是解析数据库中关于客户的一般特征的描述,通常所使用的数据挖掘功能是() A.关联分析 B.分类和预测 C. 孤立点分析 D. 演变分析 E. 概念描述 三、简答题 (1)什么是数据挖掘? (2)一个典型的数据挖掘系统应该包括哪些组成部分? (3)请简述不同历史时代数据库技术的演化。 (4)请列举数据挖掘应用常见的数据源。(或者说,我们都在什么样的数据上进行数据挖掘)(5)什么是模式兴趣度的客观度量和主观度量? (6)在哪些情况下,我们认为所挖掘出来的模式是有趣的? (7)根据挖掘的知识类型,我们可以将数据挖掘系统分为哪些类别?
有问题到淘宝找“大数据部落”就可以了 可以看到数据中一共有这些变量: colnames(trans.list) [1] "住院号""流水号" [3] "病案号""姓名" [5] "付款方式""合同单位" [7] "是否特病""住院次" [9] "性别""出生年月日" [11] "年龄""新生儿月份" [13] "新生儿体重""新生儿入院体重" [15] "婚姻""职业" [17] "出生地""民族" [19] "国籍""身份证号" [21] "出生地.省""市" [23] "县""籍贯.省" [25] "市.1""现住址.省" [27] "市.2""县.1" [29] "X""邮编" [31] "户口地址.省""市.3" [33] "县.2""X.1" [35] "邮编.1""工作单位及地址" [37] "工作单位电话""工作单位邮编" [39] "入院日期""入院途径" [41] "入院科别""出院科别" [43] "出院日期""出院科别" [45] "住院天数""门.急.诊诊断" [47] "门.急.诊诊断ICD""入院诊断" [49] "入院诊断ICD.10""病理诊断" [51] "病理诊断ICD.10""其他诊断" [53] "其他诊断ICD.10""出院诊断" [55] "出院诊断ICD.10""入院病情" [57] "损伤.中毒""药物过敏" [59] "过敏药物名称""日期" [61] "手术.操作编码""手术.操作名称" [63] "手术级别""手术.操作日期" [65] "麻醉方式""切口种类" [67] "愈合等级""尸检" [69] "血型""Rh" [71] "出院诊断2""入院病情2" [73] "出院诊断3""入院病情3"
关联规则数据挖掘 学习报告
目录 引言 2 案例 2 关联规则 3 (一)关联规则定义 (二)相关概念 (三)关联规则分类 数据 6 (一)小型数据 (二)大型数据 应用软件7 (一)WEKA (二)IBM SPSS Modeler 数据挖掘12 总结27
一、引言 数据库与互联网技术在日益发展壮大,人们每天可以获得的信息量呈指数级增长。如何从这浩如瀚海的数据中找出我们需要的数据显得尤为重要。数据挖掘又为资料探勘、数据采矿。它是数据库知识发现中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。 数据挖掘大致分为以下几类:分类(Classification)、估计(Estimation)、预测(Prediction)、相关性分组或关联规则(Affinity grouping or association rules)、聚类(Clustering)、复杂数据类型挖掘(Text, Web ,图形图像,视频,音频等)。 二、案例 "尿布与啤酒"的故事。 在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售。但是这个奇怪的举措却使尿布和啤酒的销量双双增加了。这不是一个笑话,而是发生在美国沃尔玛连锁店超市的真实案例,并一直为商家所津津乐道。沃尔玛拥有世界上最大的数据仓库系统,为了能够准确了解顾客在其门店的购买习惯,沃尔玛对其顾客的购物行为进行购物篮分析,想知道顾客经常一起购买的商品有哪些。沃尔玛数据仓库里集中了其各门店的详细原始交易数据。在这些原始交易数据的基础上,沃尔玛利用数据挖掘方法对这些数据进行分析和挖掘。一个意外的发现是:"跟尿布一起购买最多的商品竟是啤酒!经过大量实际调查和分析,揭示了一个隐藏在"尿布与啤酒"背后的美国人的一种行为模式:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有30%~40%的人同时也为自己买一些啤酒。产生这一现象的原因是:美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。 按常规思维,尿布与啤酒风马牛不相及,若不是借助数据挖掘技术对大量交易数据进行挖掘分析,沃尔玛是不可能发现数据内在这一有价值的规律的。
1、给出K D D的定义和处理过程。 KDD的定义是:从大量数据中提取出可信的、新颖的、有用的且可以被人理解的模式的高级处理过程。因此,KDD是一个高级的处理过程,它从数据集中识别出以模式形式表示的知识。这里的“模式”可以看成知识的雏形,经过验证、完善后形成知识:“高级的处理过程”是指一个多步骤的处理过程,多步骤之间相互影响反复调整,形成一种螺旋式上升的过程。 KDD的全过程有五个步骤:1、数据选择:确定发现任务的操作对象,即目标数据,它是根据用户的需要从原始数据库中抽取的一组数据;2、数据预处理:一般可能包括消除噪声、推到技术却只数据、消除重复记录、完成数据类型转换等;3、数据转换:其主要目的是消减数据维数或降维,即从初始特征中找出真正有用的特征以减少数据开采时要考虑的特征或变量个数;4、数据挖掘:这一阶段包括确定挖掘任务/目的、选择挖掘方法、实施数据挖掘;5、模式解释/评价:数据挖掘阶段发现出来的模式,经过用户或机器的评价,可能存在冗余或无关的模式,需要剔除;也有可能模式不满足用户的要求,需要退回到整个发现阶段之前,重新进行KDD过程。 2、阐述数据挖掘产生的背景和意义。 ?数据挖掘产生的背景:随着信息科技的进步以及电子化时代的到来,人们以更快捷、更容易、更廉价的方式获取和存储数据,使得数据及信息量以指数方式增长。据粗略估计,一个中等规模企业每天要产生100MB以上的商业数据。而电信、银行、大型零售业每天产生的数据量以TB来计算。人们搜集的数据越来越多,剧增的数据背后隐藏着许多重要的信息,人们希望对其进行更高层次的分析,以便更好的利用这些数据。先前的数据库系统可以高效的实现数据的录入、查询、统计等功能,但无法发现数据中存在的关系与规则,无法根据现有的数据来预测未来的发展趋势。缺乏挖掘数据背后隐藏的知识的手段。导致了“数据爆炸但知识贫乏”的现象。于是人们开始提出“要学会选择、提取、抛弃信息”,并且开始考虑:如何才能不被信息淹没?如何从中及时发现有用的知识、提高信息利用率?如何从浩瀚如烟海的资料中选择性的搜集他们认为有用的信息?这给我们带来了另一些头头疼的问题:第一是信息过量,难以消化;第二是信息真假难以辨别;第三是信息安全难以保证;第四是信息形式不一致,难以统一处理?
关联规则挖掘的过程 关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组(Frequentitemsets),第二阶段再由这些高频项目组中产生关联规则(Association Rules)。 关联规则挖掘的第一阶段必须从原始资料集合中,找出所有高频项目组(Large Itemsets)。高频的意思是指某一项目组出现的频率相对于所有记录而言,必须达到某一水平。一项目组出现的频率称为支持度(Support),以一个包含A与B两个项目的2-itemset为例,我们可以经由公式(1)求得包含{A,B}项目组的支持度,若支持度大于等于所设定的最小支持度(Minimum Support)门槛值时,则{A,B}称为高频项目组。一个满足最小支持度的k-itemset,则称为高频k-项目组(Frequent k-itemset),一般表示为Large k或Frequent k。算法并从Large k的项目组中再产生Large k+1,直到无法再找到更长的高频项目组为止。 关联规则挖掘的第二阶段是要产生关联规则(Association Rules)。从高频项目组产生关联规则,是利用前一步骤的高频k-项目组来产生规则,在最小信赖度(Minimum Confidence)的条件门槛下,若一规则所求得的信赖度满足最小信赖度,称此规则为关联规则。例如:经由高频k-项目组{A,B}所产生的规则AB,其信赖度可经由公式(2)求得,若信赖度大于等于最小信赖度,则称AB为关联规则。 就沃尔马案例而言,使用关联规则挖掘技术,对交易资料库中的纪录进行资料挖掘,首先必须要设定最小支持度与最小信赖度两个门槛值,在此假设最小支持度min_support=5% 且最小信赖度min_confidence=70%。因此符合此该超市需求的关联规则将必须同时满足以上两个条件。若经过挖掘过程所找到的关联规则「尿布,啤酒」,满足下列条件,将可接受「尿布,啤酒」的关联规则。用公式可以描述Support(尿布,啤酒)>=5%且Confidence(尿布,啤酒)>=70%。其中,Support(尿布,啤酒)>=5%于此应用范例中的意义为:在所有的交易纪录资料中,至少有5%的交易呈现尿布与啤酒这两项商品被同时购买的交易行为。Confidence(尿布,啤酒)>=70%于此应用范例中的意义为:在所有包含尿布的交易纪录资料中,至少有70%的交易会同时购买啤酒。因此,今后若有某消费者出现购买尿布的行为,超市将可推荐该消费者同时购买啤酒。这个商品推荐的行为则是根据「尿布,啤酒」关联规则,因为就该超市过去的交易纪录而言,支持了“大部份购买尿布的交易,会同时购买啤酒”的消费行为。 关联规则挖掘通常比较适用与记录中的指标取离散值的情况。如果原始数据库中的指标值是取连续的数据,则在关联规则挖掘之前应该进行适当的数据离散化(实际上就是将某个区间的值对应于某个值),数据的离散化是数据挖掘前的重要环节,离散化的过程是否合理将直接影响关联规则的挖掘结果。
同学录设计论文 第一章前言 Internet是目前世界上最大的计算机互联网络,它遍布全球,将世界各地各种规模的网络连接成一个整体。作为Internet上一种先进的,易于被人们所接受的信息检索手段,World Wide Web(简称WWW)发展十分迅速,成为目前世界上最大的信息资源宝库。据估计,目前Internet上已有上百万个Web站点,其内容范围跨越了教育科研、文化事业、金融、商业、新闻出版、娱乐、体育等各个领域,其用户群十分庞大,因此,建设一个好的Web站点对于一个机构的发展十分重要。 近年来计算机技术的快速发展,特别是计算机网络的发展,越来越深刻的改变了人们生活的方方面面。使得人们能以更低廉的价格,开发出更方便、更实用的网络工具。各种在线服务系统,更是深刻的影响了人们的联系方式,使得人们可以在远隔千里之遥随时通讯。过去的种种陈旧的联系方式,已经不能满足现代生活的需要。同学录作为一种方便同学之间联系的实用系统便应运而生。工商同学录是为工商同学之间进行交流和联系提供的一个平台。通过提供完善的同学录服务和规范同学录的管理,可以达到增进同学之间、同学与母校之间的感情,方便校友联系的目的。 要实现这样的功能,离不开后台数据库的支持。用户验证信息,收集到的用户点击信息,主题层次信息,分析得出的关联规则表等大量的数据都由数据库管理系统管理。本文中数据库服务器端采用了Microsoft Access数据库作为ODBC(Open DataBase Connectivity )数据源,并以先进的ADO(ActiveX Data Objects)技术进行数据库存取等操作,使Web与数据库紧密联系起来。 整个个性化页面生成系统主要由使用Dreamweaver_MX开发的关联规则采掘系统和利用IIS+ASP技术实现的个性化Web页面生成器两部分组成。关联规则采掘系统对数据库中的历史记录进行分析,产生用户关联规则表;页面生成器则负责记录用户行为和根据关联规则表动态生成用户个性化Web页面。二者通过数据
您的本次作业分数为:100分 1.【第001章】孤立点挖掘适用于下列哪种场合? A 目标市场分析 B 购物篮分析 C 模式识别 D 信用卡欺诈检测 正确答案:D 2.【第01章】根据顾客的收入和职业情况,预测他们在计算机设备上的花费,所使用的相应数据挖掘功能是()。 A 关联分析 B 分类和预测 C 演变分析 D 概念描述 正确答案:B 3.【第01章】数据挖掘应用和一些常见的数据统计分析系统的最主要区别在于()。 A 所涉及的算法的复杂性 B 所涉及的数据量 C 计算结果的表现形式 D 是否使用了人工智能技术 正确答案:B 4.【第01章】下列几种数据挖掘功能中,()被广泛的应用于股票价格走势分析。 A 关联分析 B 分类和预测
C 聚类分析 D 演变分析 正确答案:D 5.【第01章】下列几种数据挖掘功能中,()被广泛的用于购物篮分析。 A 关联分析 B 分类和预测 C 聚类分析 D 演变分析 正确答案:A 6.【第01章】帮助市场分析人员从客户的基本信息库中发现不同的客户群,通常所使用的数据挖掘功能是()。 A 关联分析 B 分类和预测 C 聚类分析 D 孤立点分析 E 演变分析 正确答案:C 7.【第01章】下面的数据挖掘的任务中,()将决定所使用的数据挖掘功能。 A 选择任务相关的数据 B 选择要挖掘的知识类型 C 模式的兴趣度度量 D 模式的可视化表示 正确答案:B
8.【第01章】假设现在的数据挖掘任务是解析数据库中关于客户的一般特征的描述,通常所使用的数据挖掘功能是()。 A 关联分析 B 分类和预测 C 孤立点分析 D 演变分析 E 概念描述 正确答案:E 9.【第02章】下列哪种可视化方法可用于发现多维数据中属性之间的两两相关性? A 空间填充曲线 B 散点图矩阵 C 平行坐标 D 圆弓分割 正确答案:B 10.【第02章】计算一个单位的平均工资,使用哪个中心趋势度量将得到最合理的结果? A 算术平均值 B 截尾均值 C 中位数 D 众数 正确答案:B 11.【第02章】字段Size = {small, medium, large}属于那种属性类型? A 标称属性
INFO411/911 Laboratory exercises on Association Rule Mining Overview: Association rule mining can help uncover relationships between seemingly unrelated data in a transactional database. In data mining, association rules are useful in discovering consequences of commonly observed patterns within a set of transactions. What you need: 1.R software package (already installed on the lab computers) 2.The file "laboratory_week5.zip" on Moodle. Preparation: 1.Work in a group of size two to three (minimum size of a group is two. But no more than three students are to work together). Penalties apply if a group exeeds these limits. 2.Boot computer into Windows mode. 3.Download laboratory_week5.zip then save to an arbitrary folder, say "C:\Users\yourname\Desktop" 4.Uncompress laboratory_week 5.zip into this folder 5.Start "R" 6.Change the working directory by entering: setwd("C:/Users/yourname/Desktop") (Note that R expects forward slashes rather than backwars slashes as used by Windows.) Your task: Your are to submit a PDF document which contains your answers of the questions in this laboratory exercise. One document is to be submitted by each group. The header of the document must list the name and student number of all students in the group. Clearly indicate which question you have answered. The following link provides a documentation of the association rule module in R (called arules). The link can help you develop a better understanding of the usage and parameters of the association rule package in R: https://www.doczj.com/doc/a45533046.html,/web/packages/arules/arules.pdf Work through the following step and answer given questions: Step1: Familiarize yourself with the arules package in R. Start R and type: library(arules) to load the package. We shall start from the analysis of a small file sample1.csv that contains some transactional data. To load data into R enter: sample1.transactions <- read.transactions("sample1.csv", sep=",") To get information about the total number of transactions in a file sample1.csv enter: sample1.transactions To get a summary of data set sample1.csv enter: summary(sample1.transactions) The data set is described as sparse matrix that consists of 10 rows and five columns. The density of
数据挖掘考试题目——关联分析 一、10个选择 1.以下属于关联分析的是() A.CPU性能预测B.购物篮分析 C.自动判断鸢尾花类别D.股票趋势建模 2.维克托?迈尔-舍恩伯格在《大数据时代:生活、工作与思维的大变革》一书中,持续强调了一个观点:大数据时代的到来,使我们无法人为地去发现数据中的奥妙,与此同时,我们更应该注重数据中的相关关系,而不是因果关系。其中,数据之间的相关关系可以通过以下哪个算法直接挖掘() A.K-means B.Bayes Network C.C4.5 D.Apriori 3.置信度(confidence)是衡量兴趣度度量()的指标。 A.简洁性B.确定性 C.实用性D.新颖性 4.Apriori算法的加速过程依赖于以下哪个策略() A.抽样B.剪枝 C.缓冲D.并行 5.以下哪个会降低Apriori算法的挖掘效率() A.支持度阈值增大B.项数减少 C.事务数减少D.减小硬盘读写速率 6.Apriori算法使用到以下哪些东东() A.格结构、有向无环图B.二叉树、哈希树 C.格结构、哈希树D.多叉树、有向无环图 7.非频繁模式() A.其置信度小于阈值B.令人不感兴趣 C.包含负模式和负相关模式D.对异常数据项敏感 8.对频繁项集、频繁闭项集、极大频繁项集的关系描述正确的是()[注:分别以1、2、3代表之] A.3可以还原出无损的1 B.2可以还原出无损的1 C.3与2是完全等价的D.2与1是完全等价的 9.Hash tree在Apriori算法中所起的作用是() A.存储数据B.查找 C.加速查找D.剪枝 10.以下不属于数据挖掘软件的是() A.SPSS Modeler B.Weka C.Apache Spark D.Knime 二、10个填空 1.关联分析中表示关联关系的方法主要有:和。 2.关联规则的评价度量主要有:和。 3.关联规则挖掘的算法主要有:和。 4.购物篮分析中,数据是以的形式呈现。 5.一个项集满足最小支持度,我们称之为。 6.一个关联规则同时满足最小支持度和最小置信度,我们称之为。
第5章关联分析 5.1 列举关联规则在不同领域中应用的实例。 5.2 给出如下几种类型的关联规则的例子,并说明它们是否是有价值的。 (a)高支持度和高置信度的规则; (b)高支持度和低置信度的规则; (c)低支持度和低置信度的规则; (d)低支持度和高置信度的规则。 5.3 数据集如表5-14所示: (a) 把每一个事务作为一个购物篮,计算项集{e}, {b, d}和{b, d, e}的支持度。 (b) 利用(a)中结果计算关联规则{b, d}→{e} 和 {e}→{b, d}的置信度。置信度是一个对称的度量吗? (c) 把每一个用户购买的所有商品作为一个购物篮,计算项集{e}, {b, d}和{b, d, e}的支持度。 (d) 利用(b)中结果计算关联规则{b, d}→{e} 和 {e}→{b, d}的置信度。置信度是一个对称的度量吗? 5.4 关联规则是否满足传递性和对称性的性质?举例说明。 5.5 Apriori 算法使用先验性质剪枝,试讨论如下类似的性质 (a) 证明频繁项集的所有非空子集也是频繁的 (b) 证明项集s 的任何非空子集s ’的支持度不小于s 的支持度 (c) 给定频繁项集l 和它的子集s ,证明规则“s’→(l – s’)”的置信度不高于s →(l – s)的置信度,其中s’是s 的子集 (d) Apriori 算法的一个变形是采用划分方法将数据集D 中的事务分为n 个不相交的子数据集。证明D 中的任何一个频繁项集至少在D 的某一个子数据集中是频繁的。 5.6 考虑如下的频繁3-项集:{1, 2, 3},{1, 2, 4},{1, 2, 5}, {1, 3, 4},{1, 3, 5},{2, 3, 4},{2, 3, 5},{3, 4, 5}。 (a)根据Apriori 算法的候选项集生成方法,写出利用频繁3-项集生成的所有候选4-项集。 (b)写出经过剪枝后的所有候选4-项集 5.7 一个数据库有5个事务,如表5-15所示。设min_sup=60%,min_conf = 80%。
数据挖掘实验报告(二)关联规则挖掘 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1. 1.掌握关联规则挖掘的Apriori算法; 2.将Apriori算法用具体的编程语言实现。 二、实验设备 PC一台,dev-c++5.11 三、实验内容 根据下列的Apriori算法进行编程:
四、实验步骤 1.编制程序。 2.调试程序。可采用下面的数据库D作为原始数据调试程序,得到的候选1项集、2项集、3项集分别为C1、C2、C3,得到的频繁1项集、2项集、3项集分别为L1、L2、L3。
代码 #include 数据挖掘课后习题 数据挖掘作业1——6 第一章绪论 1)数据挖掘处理的对象有哪些?请从实际生活中举出至少三种。 1、关系数据库 2、数据仓库 3、事务数据库 4、高级数据库系统和数据库应用如空间数据库、时序数据库、文本数据库和多媒体数据库等,还可以是 Web 数据信息。 实际生活的例子: ①电信行业中利用数据挖掘技术进行客户行为分析,包含客户通话记录、通话时间、所开通的服务等,据此进行客户群体划分以及客户流失性分析。 ②天文领域中利用决策树等数据挖掘方法对上百万天体数据进行分类与分析,帮助天文学家发现其他未知星体。 ③市场业中应用数据挖掘技术进行市场定位、消费者分析、辅助制定市场营销策略等。 2)给出一个例子,说明数据挖掘对商务的成功是至关重要的。该商务需要什么 样的数据挖掘功能?它们能够由数据查询处理或简单的统计分析来实现吗? 以一个百货公司为例,它可以应用数据挖掘来帮助其进行目标市场营销。运用数据挖掘功能例如关联规则挖掘,百货公司可以根据销售记录挖掘出强关联规则,来诀定哪一类商品是消费者在购买某一类商品的同时,很有可能去购买的,从而促使百货公司进行目标市场营销。数据查询处理主要用于数据或信息检索,没有发现关联规则的方法。同样地,简单的统计分析没有能力处理像百货公司销售记录这样的大规模数据。 第二章数据仓库和OLAP技术 1)简述数据立方体的概念、多维数据模型上的OLAP操作。 ●数据立方体 数据立方体是二维表格的多维扩展,如同几何学中立方体是正方形的三维扩展一样,是一类多维矩阵,让用户从多个角度探索和 分析数据集,通常是一次同时考虑三个维度。数据立方体提供数据 的多维视图,并允许预计算和快速访问汇总数据。 ●多维数据模型上的OLAP操作 a)上卷(roll-up):汇总数据 通过一个维的概念分层向上攀升或者通过维规约 b)下卷(drill-down):上卷的逆操作 由不太详细的数据到更详细的数据,可以通过沿维的概念分层向下或引入新的维来实现 c)切片和切块(slice and dice) 投影和选择操作 d)转轴(pivot) 立方体的重定位,可视化,或将一个3维立方体转化为一个2维平面序列 2)OLAP多维分析如何辅助决策?举例说明。 OLAP是在多维数据结构上进行数据分析的,一般在多维数据上切片、切块成简单数据来进行分析,或是上卷、下卷来分析。OLAP要查询 大量的日常商业信息,以及大量的商业活动变化情况,如每周购买量的 变化值,经理通过查询变化值来做决策。 例如经理看到利润小于预计值是,就会去深入到各地区去查看产品利润情况,这样他会发现一些比较异常的数据。经过进一步的分析和追 踪查询可以发现问题并解决 3)举例说明OLAP的多维数据分析的切片操作。 切片就是在某两个维上取一定区间的维成员或全部维成员。 如用三维数组表示为(地区,时间,产品,销售额),如果在地区维度上选定一个维成员,就可以得到在该地区的一个切片(关于时间和产 品的切片)。 聚类分析和关联规则属于数据挖掘这个大概念中的两类挖掘问题, 聚类分析是无监督的发现数据间的聚簇效应。 关联规则是从统计上发现数据间的潜在联系。 细分就是 聚类分析与关联规则是数据挖掘中的核心技术; 从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。 从机器学习的角度讲,簇相当于隐藏模式。聚类是搜索簇的无监督学习过程。与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据对象有类别标记。聚类是观察式学习,而不是示例式的学习。 聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。 从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。聚类分析还可以作为其他算法(如分类和定性归纳算法)的预处理步骤。 关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组(FrequentItemsets),第二阶段再由这些高频项目组中产生关联规则(AssociationRules)。 关联规则挖掘的第一阶段必须从原始资料集合中,找出所有高频项目组(LargeItemsets)。高频的意思是指某一项目组出现的频率相对于所有记录而言,必须达到某一水平。 关联规则挖掘的第二阶段是要产生关联规则(AssociationRules)。从高频项目组产生关联规则,是利用前一步骤的高频k-项目组来产生规则,在最小信赖度(MinimumConfidence)的条件门槛下,若一规则所求得的信赖度满足最小信赖度,称此规则为关联规则。 浙江大学远程教育学院 《数据挖掘》课程作业 姓名:学号: 年级:学习中心:————————————————————————————— 第一章引言 一、填空题 (1)数据库中的知识挖掘(KDD)包括以下七个步骤:数据清理、数据集成、数据选择、数据交换、数据挖掘、模式评估和知识表示 (2)数据挖掘的性能问题主要包括:算法的效率、可扩展性和并行处理 (3)当前的数据挖掘研究中,最主要的三个研究方向是:统计学、数据库技术和机器学习 (4)孤立点是指:一些与数据的一般行为或模型不一致的孤立数据 二、简答题 (1)什么是数据挖掘? 答:数据挖掘指的是从大量的数据中挖掘出那些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识。 (2)一个典型的数据挖掘系统应该包括哪些组成部分? 答:一个典型的数据挖掘系统应该包括以下部分:1、数据库、数据仓库或其他信息库,2、数据库或数据仓库服务器,3、知识库,4、数据挖掘引擎,5、模式评估魔磕,6图形用户界面。 (3)Web挖掘包括哪些步骤? 答:数据清理:(这个可能要占用过程60%的工作量)、数据集成、将数据存入数据仓库、建立数据立方体、选择用来进行数据挖掘的数据、数据挖掘(选择适当的算法来找到感兴趣的模式)、展现挖掘结果、将模式或者知识应用或者存入知识库。 (4)请列举数据挖掘应用常见的数据源。 (或者说,我们都在什么样的数据上进行数据挖掘) 答:常见的数据源包括关系数据库、数据仓库、事务数据库和高级数据库系统和信息库。其中高级数据库系统和信息库包括:空间数据库、时间数据库和时间序列数据库、流数据、多媒体数据库、面向对象数据库和对象——关系数据库、异种数据库和遗产数据库、文本数据库和万维网等。 数据挖掘中关联规则挖掘的应用研究 吴海玲,王志坚,许峰 河海大学计算机及信息工程学院,江苏南京(210098) 摘 要:本文首先介绍关联规则的基本原理,并简单概括其挖掘任务,然后说明关联规则的经典挖掘算法Apriori 算法,通过一个实例分析进一步明确关联规则在CRM 中的应用,最后展望了关联规则挖掘的研究方向。 关键词:数据挖掘,关联规则,Apriori 算法,CRM 引言 关联规则是表示数据库中一组对象之间的某种关联关系的规则,关联规则挖掘的主要对象是交易(Transaction)数据库。这种数据库的一个主要应用是零售业,比如超级市场的销售管理。条形码技术的发展使得数据的收集变得更容易、更完整,从而可以存储大量的交易资料。关联规则就是辨别这些交易项目之间是否存在某种关系。例如:关联规则可以表示“购买了商品A 和B 的顾客中有80%的人又购买了商品C 和D”。这种关联规则提供的信息可以用作商品目录设计、商场货架的布置、生产安排、具有针对性的市场营销等。 [1] 1 关联规则的基本原理 设I={i 1,i 2,……,i m }是项的集合,设任务相关的数据D 是数据库事务的集合,其中每个事务T 是项的集合,使得T I 。每一个事务有一个标识符,称作T ID 。设X 是一个项集,事务T 包含X 当且仅当X T 。关联规则是形如X Y 的蕴涵式,其中X I ,Y ?I ,并且X ∩Y =?。规则X Y 在事务集D 中成立,具有支持度s ,其中s 是D 中事务包含X ∪Y (即X 和Y 二者)的百分比,它是概率P (X ∪Y )。规则X Y 在事务集中具有可信度c ,如果D 中包含X 的事务同时也包含Y 的百分比c 。这是条件概率P (X Y ∣)。即是 ??????support(X ?Y)= P (X Y ∪) confidence(X ?Y)= P (X Y ∣) 同时满足最小支持度(minsup)和最小可信度阈值(minconf )的规则称作强规则[1]。 项的集合称为项集(itemset )。包含k 个项的项集成为k -项集,例如集合{computer, software }是一个2—项集。项集的出现频率是包含项集的事务数,简称为项集的频率。项集满足最小支持度minsup ,如果项集的出现频率大于或者等于minsup 与D 中事务总数的乘积。如果项集满足最小支持度,则称它为频繁项集(frequent itemset) [2]。 2 关联规则的发现任务 关联规则挖掘的问题就是要找出这样的一些规则,它们的支持度或可信度分别大于指定的最小支持度minsup 和最小可信度minconf 。因此,该问题可以分解成如下两个子问题[3]: 1.产生所有支持度大于或等于指定最小支持度的项集,这些项目集称为频繁项目集(frequent itemsets ),而其他的项目集则成为非频繁项目集(non-frequent itemsets ) 2.由频繁项集产生强关联规则。根据定义,这些规则必须满足最小支持度和最小可信度。 关联规则挖掘的问题的主要特征是数据量巨大,因此算法的效率很关键。目前研究的重点在第一步,即发现频繁项目集,因此第二步相对来说是很容易的。 数据挖掘第一次作业 第一题: (a).由最大-最小规范化公式vi′=vi?minA maxA?minA new_maxA?new_minA+new_minA得 35规范化后的值为35?13 70?13 1?0+0=0.386 (b).先计算属性的均值A’和标准差σA A’=1 n (v1+v2+?+v n)=1 27 13+15+16+?+70=29.963 35经过Z分数规划后的结果为v?A′ σA =35?29.963 12.94 =0.38 (c).由于属性绝对值最大为70,我们用100来除每个值 35规范化后的结果为 0.35 (d).最大—最小规范方法保持原始数据值之间的联系;Z分数规范化当属性的最大值和最小值未知,或离群点左右了最小-最大规范化时,该方法有用;小数定标规范化过于简单。我比较喜欢最小-最大规范化,因为这种方法计算起来没有Z分数复杂,并且不会使原始数据改变很多,保留了它们之间的联系。 第二题: (a).?X∈transaction,共有4个事务,最小相对支持度为60%,因此最小支持度计数阀值为3,用Apriori算法找到最大的频繁项集 L3={Milk, Cheese, Bread},过程如下: L3的非空子集{Milk,Cheese},{Milk,Bread},{Cheese,Bread},{Milk},{Cheese},{Bread},结果关联规则如下: {Milk, Cheese}=>Bread, confidence=3/3=100% {Milk, Bread}=>Cheese, confidence=3/4=75% {Cheese, Bread}=>Milk, confidence=3/3=100% Milk=>{Cheese, Bread}, confidence=3/4=75% Cheese=>{Milk, Bread}, confidence=3/3=100% Bread=>{Milk, Cheese}, confidence=3/4=75% 由于min_conf=80%,所以只有第一个、第三个和第五个规则可以输出,是强规则。即,所有强规则如下: ?X∈transaction buys(X, Milk)^buys(X, Cheese)=>buys(X, Bread) ?X∈transaction buys(X, Bread)^buys(X, Cheese)=>buys(X, Milk) ?X∈transaction buys(X, Cheese)=>buys(X, Milk)^ buys(X, Bread) (b)?X∈customer,共有3个事务,最小相对支持度为60%,因此最小支持度计数阀值为2,用Apriori算法找到的最大频繁项集 L2={{Sunset-Milk, Dairyland-Cheese, Wonder-Bread}, {Dairyland-Milk, Wonder-Bread, Tasty-Pie} }共两个最大频繁项集 过程如下:电子科大数据挖掘作业1-6
聚类分析、数据挖掘、关联规则这几个概念的关系
数据挖掘离线作业
数据挖掘中关联规则挖掘的应用研究
数据挖掘作业
相关主题
文本预览