
一.编制基本最小二乘算法和加权最小二乘算法(包括一次完成算法和递推算法)程序,并进行测试。
辨识模型:() 1.5(1)0.7(2)(1)0.5(2)()z k z k z k u k u k v k --+-=-+-+,()v k 是服从标准正态分布的噪声,()u k 是幅度为1的7阶M 序列。
1.一次完成最小二乘算法:
编程思路:对此辨识模型来说2a b n n ==,0.99β= ,
(3)(4),(2)L z z Z Z L ?? ? ?= ? ?+??(1)(2)()(1)(2)z k z k h k u k u k --??
?-- ?= ?
- ?-??
,(3)(4)(2)T T
L T h h H h L ?? ? ?= ? ? ?+??,当L
Λ(加权矩阵)为单位阵时,即为最小二乘基本一次完成算法,否则为最小二乘加权一次完成算法。 程序运行结果:
最小二乘基本一次完成算法: compare1 =
-1.5000 -1.4967 0.7000 0.6956 1.0000 1.0386 0.5000 0.5076
最小二乘加权一次完成算法: compare2 =
-1.5000 -1.5084 0.7000 0.7039 1.0000 1.0546 0.5000 0.5238 2.最小二乘递推算法:
编程思路:1()(1)()[()(1)()1/()]()(1)()[()()(1)]()[()()](1)T T T K k P k h k h k P k h k k k k K k z k h k k P k I K k h k P k θθθ-?=--+Λ?
=-+--??=--?
,并且给定()P k ,
()k θ 的初值。()P k 为充分大的实数,()k θ为充分小的向量。()k Λ为1时,为
最小二乘递推算法(RLS ),否则为加权最小二乘递推算法(RWLS )。 程序运行结果:
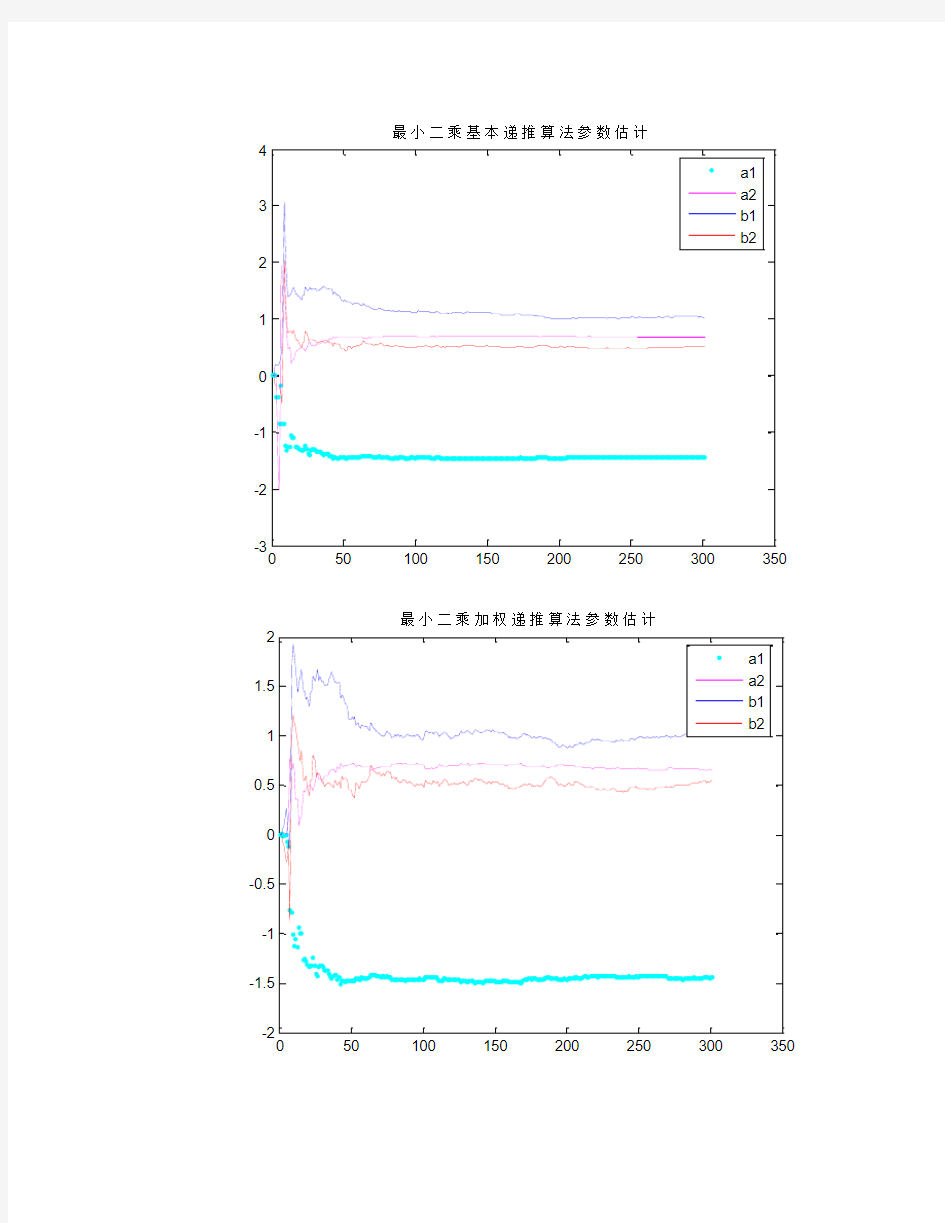
050100150200250300350
-3
-2
-1
1
2
3
4
最小二乘基本递推算法参数估计
a1a2b1b2
050100150200250300350
-2
-1.5-1-0.500.511.52最小二乘加权递推算法参数估计
a1a2b1b2
可以看出,最小二乘一次完成算法和最小二乘递推算法估计出的系统参数和给定的参数相近,因此利用这两种方法可以辨识系统。
二.实现最小二乘算法的适应算法和进行偏差补偿的最小二乘算法。
1.最小二乘适应算法 (1)遗忘因子法:
a )一次完成算法:
编程思路:给数据加上衰减因子(01)ββ<≤,
12*(1)(2),()L L L z z Z Z L ββ--?? ? ?= ? ? ???12*(1)(2)()L T L T L T h h H h L ββ--?? ? ?= ? ? ???,**1**()T T L L L L H H H Z θ-=。 程序运行结果:
最小二乘遗忘因子法一次完成算法: compare1 =
-1.5000 -1.4677 0.7000 0.6925 1.0000 1.0537 0.5000 0.6236 b )递推算法: 编程思路:
12
()(1)()[()(1)()]()(1)()[()()(1)],(01)()[()()](1)/T T T K k P k h k h k P k h k k k K k z k h k k P k I K k h k P k μθθθμβμμ-?=--+?=-+--=<≤??=--?
相比于最小二乘基本递推算法加了遗忘因子β。 程序运行结果:
050100150200250300
-3
-2
-1
1
2
3
4
最小二乘遗忘因子法递推算法参数估计
a1a2b1b2
最小二乘遗忘因子法递推算法:
ans =
-1.5065 0.7142 0.9547 0.4239
程序中0.99β=,本来想实现β从0.9每隔0.01一直到11种情况下的参数估计情况,但是循环一直写不对,就没再写。
(2)限定记忆法: 编程思路: 1(1,)(,)()[1()(,)()](1,)(,)(1,)[()()(,)](1,)[(1,)()](,)T T
T
K k k L P k k l h k h k P k k L h k k k L k k L K k k L z k h k k k L P k k L I K k k L h k P k k L θθθ-?++=+-+?++=+-++-+??++=-+++?
去老 1
(,)(,1)()[1()(,1)()](,)(,1)(,)[()()(,1)](,)[(,)()](,1)T T
T K k k L P k k L h k L h k L P k k L h k L k k L k k L K k k L z k L h k L k k L P k k L I K k k L h k L P k k L θθθ-?+=+-++++-+?+=+-+++-++-??
+=-+++-?
更新 给定初值,利用上式不断迭代,即可获得最终辨识结果。
程序运行结果:
050100150200250300350
-1.5
-1
-0.5
0.5
1
1.5
限定记忆递推算法
a1a2b1b2
限定记忆递推算法: ans =
-1.4589 0.6724 1.0278 0.5119 theta1 = -1.4579 0.6699 1.0314 0.5079
2.偏差补偿最小二乘算法(RCLS ):
编程思路:1
2
2()(1)()[()(1)()1]()(1)()[()()(1)]
()[()()](1)
[()()(1)]()(1)()(1)()1()
[1(1)()]
000()a b T T LS LS LS T T LS T w c LS n n c K k P k h k h k P k h k k k K k z k h k k P k I K k h k P k z k h k k J k J k h k P k h k J k k k D k I D k θθθθσθθθ-=--+=-+--=----=-+
-+=
+-??=??
????
2()()(1)
LS w c k k P k D k θσθ=+-
程序运行结果:
偏差补偿最小二乘算法:
ans =
-1.6010 0.8123 1.0368
0.3411
50
100
150
200
250
300-5-4-3-2-1012345偏差补偿最小二乘算法参数估计
a1a2b1b2
调试过程中遇到的问题:(1)矩阵尺寸对应问题,尤其是后面的算法:限定记忆法,偏差补偿最小二乘法,matlab中矩阵运算一定要尺寸对应上,所以事
先得计算好矩阵行值列值,而且得赋初值。
(2)编写偏差补偿最小二乘递推算法的时候从课件上抄公式漏掉了转置,结果调了半天也不知道怎么回事,后来再核对了一遍
公式才发现。
(3)循环问题,写循环遇到各种问题,解决了一些,还是比较难的。
由于每个程序都要()
v k,()
u k序列,我采用的方法是把产生的数的序列保存成.mat文件,直接调用就行。最小二乘参数估计的各种程序都在文件夹里。
摘要 软件测试是保证软件质量和可靠性重要手段,在这方面发挥着其它方法不可替代的作用。然而,软件测试是一个复杂的过程,需要耗费巨大的人力、物力和时间,约占整个软件开发成本的40%~50%。因此,提高软件测试工具的自动化程度对于确保软件开发质量、降低软件开发成本非常重要。而提高测试用例生成的自动化程度又是提高测试工具乃至整个测试过程自动化程度的关键所在,本文主要针对这一问题进行了研究和设计。 本文在分析软件测试和算法基本概念的基础上,提出软件测试用例的设计是软件测试的难点之一。论文提出了基于算法的测试用例生成的内含是应用算法来求解一组优化的测试用例,其框架包括了测试环境构造、算法及测试运行环境三部分,论文给出了基于算法的测试用例生成的模型。最后以三角形分类程序为例应用算法进行测试用例生成的模拟,结果显示,应用算法进行测试用例生成可行。 关键词:软件测试测试用例算法
ABSTRACT Software test is the important means that guarantee software quality and reliability,and in this respect,it plays the role that other method cannot replace. However software test is a complex process , it needs to consume huge manpower,material resources and time,which takes the 40%~50% of entire software development cost approximately . Therefore,raising the automation level of software test tool is very important for ensure software development quality and reduction software development cost . And then,the most important is raising the automation level of the test case generation for raising the automation level of test tool and even entire test process,so this paper study and design mainly according to this problem. Based on the analysis of basic concepts of software testing and genetic algorithm, this article proposes that software test case design is one of the difficulties of software testing. Paper presents the inherent in software test case designing based on genetic algorithm is using genetic algorithm to solve a set of optimization test cases, and the framework includes three parts which are test environment construction, genetic algorithm and the environment for test . Paper presents the model of software test case generation based on genetic algorithm. Finally, we take the triangle categorizer as an example, simulate software test case generation based on genetic algorithm. The results display that software test case generation basing on genetic algorithm is possible. KEY WORDS: software test , test case , genetic algorithm
《系统辨识与建模》(MATLAB编程) 信研0701 孙娅萍2007000694 编程第四次作业 仿真模型参数为:a=[-1.5 0.7];b=[1.0 0.5],由下式递推产生502组数据,并形成如下矩阵: z(k)=1.5z(k–1)-0.7z(k–2)+1.0u(k–1)+0.5u(k–2)+v(k) 试用一次完成最小二乘法辨识系统模型。 程序部分: %************************************************************% % ***** 二阶系统的最小二乘一次完成算法辨识程序*****% % 系统辨识的输入信号u是6阶的M序列,长度是500; L = 500; u = load('u.txt'); u2 = load('u2.txt'); u1 = load('u1.txt'); z = zeros(1,L+1); for k = 3 : (L+1) % 理想输出作为系统观测值 z(k) = 1.5 * z(k-1) - 0.7 * z(k-2) + u(k-1) + 0.5 * u(k-2); end % 绘制输入信号和输出观测值的图形 figure(1) i = 1 : 1 : L; subplot(2,1,1) plot(i,u) k = 1 : 1 : (L+1); subplot(2,1,2) plot(k,z) z = z' z1 = load('z1.txt'); z2 = load('z2.txt'); z3 = load('z3.txt'); Na = 2; Nb = 2; % 定义Na、Nb; for i = 1 : (Na+Nb) if ((i == 1)) H = -1 * z2; end if (i == 2) H = -1 * z1; end if (i == (Na+1)) H = u2; end
算法递归典型例题 实验一:递归策略运用练习 三、实验项目 1.运用递归策略设计算法实现下述题目的求解过程。 题目列表如下: (1)运动会开了N天,一共发出金牌M枚。第一天发金牌1枚加剩下的七分之一枚,第二天发金牌2枚加剩下的七分之一枚,第3天发金牌3枚加剩下的七分之一枚,以后每天都照此办理。到了第N天刚好还有金牌N枚,到此金牌全部发完。编程求N和M。 (2)国王分财产。某国王临终前给儿子们分财产。他把财产分为若干份,然后给第一个儿子一份,再加上剩余财产的1/10;给第二个儿子两份,再加上剩余财产的1/10;……;给第i 个儿子i份,再加上剩余财产的1/10。每个儿子都窃窃自喜。以为得到了父王的偏爱,孰不知国王是“一碗水端平”的。请用程序回答,老国王共有几个儿子?财产共分成了多少份? 源程序: (3)出售金鱼问题:第一次卖出全部金鱼的一半加二分之一条金鱼;第二次卖出乘余金鱼的三分之一加三分之一条金鱼;第三次卖出剩余金鱼的四分之一加四分之一条金鱼;第四次卖出剩余金鱼的五分之一加五分之一条金鱼;现在还剩下11条金鱼,在出售金鱼时不能把金鱼切开或者有任何破损的。问这鱼缸里原有多少条金鱼? (4)某路公共汽车,总共有八站,从一号站发轩时车上已有n位乘客,到了第二站先下一半乘客,再上来了六位乘客;到了第三站也先下一半乘客,再上来了五位乘客,以后每到一站都先下车上已有的一半乘客,再上来了乘客比前一站少一个……,到了终点站车上还有乘客六人,问发车时车上的乘客有多少? (5)猴子吃桃。有一群猴子摘来了一批桃子,猴王规定每天只准吃一半加一只(即第二天吃剩下的一半加一只,以此类推),第九天正好吃完,问猴子们摘来了多少桃子? (6)小华读书。第一天读了全书的一半加二页,第二天读了剩下的一半加二页,以后天天如此……,第六天读完了最后的三页,问全书有多少页? (7)日本著名数学游戏专家中村义作教授提出这样一个问题:父亲将2520个桔子分给六个儿子。分完后父亲说:“老大将分给你的桔子的1/8给老二;老二拿到后连同原先的桔子分1/7给老三;老三拿到后连同原先的桔子分1/6给老四;老四拿到后连同原先的桔子分1/5给老五;老五拿到后连同原先的桔子分1/4给老六;老六拿到后连同原先的桔子分1/3给老大”。结果大家手中的桔子正好一样多。问六兄弟原来手中各有多少桔子? 四、实验过程 (一)题目一:…… 1.题目分析 由已知可得,运动会最后一天剩余的金牌数gold等于运动会举行的天数由此可倒推每一 天的金牌剩余数,且每天的金牌数应为6的倍数。 2.算法构造 设运动会举行了N天, If(i==N)Gold[i]=N; Else gold[i]=gold[i+1]*7/6+i;
一、 递推最小二乘法 递推最小二乘法的一般步骤: 1. 根据输入输出序列列出最小二乘法估计的观测矩阵?: ] )(u ... )1( )( ... )1([)(T b q n k k u n k y k y k ------=? 没有给出输出序列的还要先算出输出序列。 本例中, 2)]-u(k 1),-u(k 2),-1),-y(k -[-y(k )(T =k ?。 2. 给辨识参数θ和协方差阵P 赋初值。一般取0θ=0或者极小的数,取σσ,20I P =特别大,本例中取σ=100。 3. 按照下式计算增益矩阵G : ) ()1()(1)()1()(k k P k k k P k G T ???-+-= 4. 按照下式计算要辨识的参数θ: )]1(?)()()[()1(?)(?--+-=k k k y k G k k T θ?θθ 5. 按照下式计算新的协方差阵P : )1()()()1()(---=k P k k G k P k P T ? 6. 计算辨识参数的相对变化量,看是否满足停机准则。如满足,则不再递推;如不满足, 则从第三步开始进行下一次地推,直至满足要求为止。 停机准则:ε???<--) (?)1(?)(?max k k k i i i i 本例中由于递推次数只有三十次,故不需要停机准则。 7. 分离参数:将a 1….a na b 1….b nb 从辨识参数θ中分离出来。 8. 画出被辨识参数θ的各次递推估计值图形。 为了说明噪声对递推最小二乘法结果的影响,程序5-7-2在计算模拟观测值时不加噪 声, 辨识结果为a1 =1.6417,a2 = 0.7148,b1 = 0.3900,b2 =0.3499,与真实值a1 =1.642, a2 = 0.715, b1 = 0.3900,b2 =0.35相差无几。 程序5-7-2-1在计算模拟观测值时加入了均值为0,方差为0.1的白噪声序列,由于噪 声的影响,此时的结果为变值,但变化范围较小,现任取一组结果作为辨识结果。辨识结果为a1 =1.5371, a2 = 0.6874, b1 = 0.3756,b2 =0.3378。 程序5-7-2-2在计算模拟观测值时加入了有色噪声,有色噪声为 E(k)+1.642E(k-1)+0.715E(k-2),E(k)是均值为0,方差为0.1的白噪声序列,由于有色噪声的影响,此时的辨识结果变动范围远比白噪声时大,任取一组结果作为辨识结果。辨识结果为a1 =1.6676, a2 = 0.7479, b1 = 0.4254,b2 =0.3965。 可以看出,基本的最小二乘法不适用于有色噪声的场合。
递推最小二乘法推导(RLS)——全网最简单易懂的推导过程 作者:阿Q在江湖 先从一般最小二乘法开始说起 已知x和y的一系列数据,求解参数theta的估计。用矩阵的形式来表达更方便一些: 其中k代表有k组观测到的数据, 表示第i组数据的输入观测量,yi表示第i组数据的输出观测量。令: ,则最小二乘的解很简单, 等价于即参数解为:如果数据是在线的不断的过来,不停的采用最小二乘的解法来解是相当消耗资源与内存的,所
以要有一种递推的形式来保证对的在线更新。 进一步推导出递推最小二乘法(RLS) 我们的目的是从一般最小二乘法的解 推导出 的递推形式。一定要理解这里的下标k代表的意思,是说在有k组数据情况下的预测,所以k比k-1多了一组数据,所以可以用这多来的一组数据来对原本的估计进行修正,这是一个很直观的理解。下面是推导过程: 先看一般最小二乘法的解 下面分别对 和 这两部分进行推导变换,令
得到下面公式(1) 下面来变换得到公式(2) 下面再来,根据一般最小二乘法的解,我们知道下式成立,得到公式(3)(注:后续公式推导用到) 好了,有了上面最主要的三步推导,下面就简单了,将上面推导的结果依次代入公式即可:
至此,终于变成 的形式了。 通过以上推导,我们来总结一下上面RLS方程: 注:以上公式7中,左边其实是根据公式1,右边I为单位矩阵
公式(5)和(7)中,有些文献资料是用右边的方程描述,实际上是等效的,只需稍微变换即可。例如(5)式右边表达式是将公式(1)代入计算的。为简化描述,我们下面还是只讨论左边表达式为例。 上面第7个公式要计算矩阵的逆,求逆过程还是比较复杂,需要用矩阵引逆定理进一步简化。 矩阵引逆定理: 最终RLS的方程解为:
加权最小二乘法(WLS) 如果模型被检验证明存在异方差性,则需要发展新的方法估计模型,最常用的方法是加权最小二乘法。 加权最小二乘法是对原模型加权,使之变成一个新的不存在异方差性的模型,然后采用普通最小二乘法估计其参数。下面先看一个例子。 原模型:, 如果在检验过程中已经知道: , 即随机误差项的方差与解释变量之间存在相关性,模型存在异方差。那么可以用去除原模型,使之变成如下形式的新模型: 在该模型中,存在 (4.2.1) 即同方差性。于是可以用普通最小二乘法估计其参数,得到关于参数的无偏的、有效的估计量。这就是加权最小二乘法,在这里权就是。 一般情况下,对于模型 (4.2.2)若存在: (4.2.3) 则原模型存在异方差性。设 , 用左乘(4.2.2)两边,得到一个新的模型: (4.2.4) 即 该模型具有同方差性。因为 于是,可以用普通最小二乘法估计模型(4.2.4),得到参数估计量为: (4.2.5) 这就是原模型(2.6.2)的加权最小二乘估计量,是无偏的、有效的估计
量。 如何得到权矩阵W?仍然是对原模型首先采用普通最小二乘法,得到随机误差项的近似估计量,以此构成权矩阵的估计量,即 (4.2.6) 当我们应用计量经济学软件包时,只要选择加权最小二乘法,将上述权矩阵输入,估计过程即告完成。这样,就引出了人们通常采用的经验方法,即并不对原模型进行异方差性检验,而是直接选择加权最小二乘法,尤其是采用截面数据作样本时。如果确实存在异方差性,则被有效地消除了;如果不存在异方差性,则加权最小二乘法等价于普通最小二乘法。 在利用Eviews计量经济学软件时,加权最小二乘法具体步骤是: 1 选择普通最小二乘法估计原模型,得到随机误差项的近似估计 量; ⑵ 建立的数据序列; ⑶ 选择加权最小二乘法,以 序列作为权,进行估计得到参数估计量。实际上是以乘原模型的两边,得到一个新模型,采用普通最小二乘法估计新模型。 (步骤见PPT文件)
偏最小二乘法 ( PLS)是光谱多元定量校正最常用的一种方法 , 已被广泛应用 于近红外 、 红外 、拉曼 、核磁和质谱等波谱定量模型的建立 , 几乎成为光谱分析中建立线性定量校正模型的通用方法 〔1, 2〕 。近年来 , 随着 PLS 方法在光谱分析尤其是分子光谱如近红外 、 红外和拉曼中应用 的深入开展 , PLS 方法还被用来解决模式识别 、定量校正模型适用性判断以及异常样本检测等定性分析问题 。 由于 PLS 方法同时从光谱阵和浓度阵中提取载荷和得分 , 克服主成分分析 ( PCA)方法没有利用浓度阵的缺点 , 可有效降维 , 并消除光谱间可能存在的复共线关系 , 因此取得令人非常满意的定性分析结果 〔3 ~ 5〕 。 本文主要介绍PLS 方法在光谱定性分析方面的原理及应用 实例 。 偏最小二乘方法(PLS-Partial Least Squares))是近年来发展起来的一种新的多元统计分析法, 现已成功地应用于分析化学, 如紫外光谱、气相色谱和电分析化学等等。该种方法,在化合物结构-活性/性质相关性研究中是一种非常有用的手段。如美国Tripos 公司用于化合物三维构效关系研究的CoMFA (Comparative Molecular Field Analysis)方法, 其中,数据统计处理部分主要是PLS 。在PLS 方法中用的是替潜变量,其数学基础是主成分分析。替潜变量的个数一般少于原自变量的个数,所以PLS 特别适用于自变量的个数多于试样个数的情况。在此种情况下,亦可运用主成分回归方法,但不能够运用一般的多元回归分析,因为一般多元回归分析要求试样的个数必须多于自变量的个数。 §§ 6.3.1 基本原理 6.3 偏最小二乘(PLS ) 为了叙述上的方便,我们首先引进“因子”的概念。一个因子为原来变量的线性组合,所以矩阵的某一主成分即为一因子,而某矩阵的诸主成分是彼此相互正交的,但因子不一定,因为一因子可由某一成分经坐标旋转而得。 在主成分回归中,第一步,在矩阵X 的本征矢量或因子数测试中,所处理的仅为X 矩阵,而对于矩阵Y 中信息并未考虑。事实上,Y 中亦可能包含非有用的信息。所以很自然的一种想法是,在矩阵X 因子的测试中应同时考虑矩阵Y 的作用。偏最小二乘正是基于这种思想的一种回归方法。 偏最小二乘和主成分分析很相似,其差别在于用于描述变量Y 中因子的同时也用于描述变量X 。为了实现这一点,在数学上是以矩阵Y 的列去计算矩阵X 的因子,与此同时,矩阵Y 的因子则由矩阵X 的列去预测。其数学模型为: E P T X +'=F Q U Y +'=
○1优点:结构清晰,可读性强,而且容易用数学归纳法来证明算法的正确性,因此它为设计算法、调试程序带来很大方便。 ○2缺点:递归算法的运行效率较低,无论是耗费的计算时间还是占用的存储空间都比非递归算法要多。 边界条件与递归方程是递归函数的二个要素 应用分治法的两个前提是问题的可分性和解的可归并性 以比较为基础的排序算法的最坏倩况时间复杂性下界为0(n·log2n)。 回溯法以深度优先的方式搜索解空间树T,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树T。 舍伍德算法设计的基本思想: 设A是一个确定性算法,当它的输入实例为x时所需的计算时间记为tA(x)。设Xn是算法A的输入规模为n的实例的全体,则当问题的输入规模为n时,算法A所需的平均时间为 这显然不能排除存在x∈Xn使得的可能性。希望获得一个随机化算法B,使得对问题的输入规模为n的每一个实例均有 拉斯维加斯( Las Vegas )算法的基本思想: 设p(x)是对输入x调用拉斯维加斯算法获得问题的一个解的概率。一个正确的拉斯维加斯算法应该对所有输入x均有p(x)>0。 设t(x)是算法obstinate找到具体实例x的一个解所需的平均时间 ,s(x)和e(x)分别是算法对于具体实例x求解成功或求解失败所需的平均时间,则有: 解此方程可得:
蒙特卡罗(Monte Carlo)算法的基本思想: 设p是一个实数,且1/2 题目: (递推最小二乘法) 考虑如下系统: )()4(5.0)3()2(7.0)1(5.1)(k k u k u k y k y k y ξ+-+-=-+-- 式中,)(k ξ为方差为0.1的白噪声。 取初值I P 610)0(=、00=∧ )(θ。选择方差为1的白噪声作为输入信号)(k u ,采用PLS 法进行参数估计。 Matlab 代码如下: clear all close all L=400; %仿真长度 uk=zeros(4,1); %输入初值:uk(i)表示u(k-i) yk=zeros(2,1); %输出初值 u=randn(L,1); %输入采用白噪声序列 xi=sqrt(0.1)*randn(L,1); %方差为0.1的白噪声序列 theta=[-1.5;0.7;1.0;0.5]; %对象参数真值 thetae_1=zeros(4,1); %()θ初值 P=10^6*eye(4); %题目要求的初值 for k=1:L phi=[-yk;uk(3:4)]; %400×4矩阵phi 第k 行对应的y(k-1),y(k-2),u(k-3), u(k-4) y(k)=phi'*theta+xi(k); %采集输出数据 %递推最小二乘法的递推公式 K=P*phi/(1+phi'*P*phi); thetae(:,k)=thetae_1+K*(y(k)-phi'*thetae_1); P=(eye(4)-K*phi')*P; %更新数据 thetae_1=thetae(:,k); for i=4:-1:2 uk(i)=uk(i-1); end uk(1)=u(k); for i=2:-1:2 yk(i)=yk(i-1); 浅谈加权最小二乘法及其残差图 关键词:异方差;加权最小二乘法;残差图;SPSS 一、引言 好几年没有翻《统计研究》了。最近,有一同行朋友打电话告诉我《统计研究》2005年第11期上刊登了一篇有关我与刘文卿合作编著的《应用回归分析》(2001.6.中国人民大学出版社)教材的文章。赶紧找到这期的《统计研究》,看到其中孙小素副教授的文章《加权最小二乘法残差图问题探讨——与何晓群教授商榷》一文,以下简称《孙文》。认真拜读后感触良多。首先衷心感谢孙小素副教授阅读了我们《应用回归分析》拙作的部分章节,同时感谢《统计研究》给我们提供这样一个好的机会,使我们能够借助贵刊对加权最小二乘法的有关问题谈谈更多的认识。 《孙文》谈到《应用回归分析》教材中有关加权最小二乘法残差图的问题。摆出了与加权最小二乘法相关的三类残差图,指出第三类残差图的局限性。直接的问题是三类残差图的作用,而更深层的原因应该是对加权最小二乘法统计思想的理解和认识上的差异。 二、对加权最小二乘法的认识 1. 加权最小二乘估计方法 拙作《应用回归分析》中对加权最小二乘法有详尽的讲述,这里仅做简要介绍。多元线性回归方程普通最小二乘法的离差平方和为: ∑=----=n i ip p i i p x x y Q 1211010)(),,,(ββββββ (1) 普通最小二乘估计就是寻找参数p βββ,,,10 的估计值p βββ?,,?,?10 使式(1)的离差平方和Q 达极小。式(1)中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项i ε等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。 然而在异方差的条件下,平方和中的每一项的地位是不相同的,误差项i ε的方差2i σ大的项,在式(1)平方和中的取值就偏大,在平方和中的作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。 由式(1)求出的p βββ?,,?,?10 仍然是p βββ,,,10 的无偏估计,但不再是最小方差线性无偏估计。 加权最小二乘估计的方法是在平方和中加入一个适当的权数i w ,以调整各项在平方和中的作用,加权最小二乘的离差平方和为: ∑=----=n i ip p i i i p w x x y w Q 1211010)( ),,,(ββββββ (2) 加权最小二乘估计就是寻找参数p βββ,,,10 的估计值pw w w βββ?,,?,?10 使式(2)的离差 递归算法的优缺点: ○ 1优点:结构清晰,可读性强,而且容易用数学归纳法来证明算法的正确性,因此它为设计算法、调试程序带来很大方便。 ○2缺点:递归算法的运行效率较低,无论是耗费的计算时间还是占用的存储空间都比非递归算法要多。 边界条件与递归方程是递归函数的二个要素 应用分治法的两个前提是问题的可分性和解的可归并性 以比较为基础的排序算法的最坏倩况时间复杂性下界为0(n·log2n)。 回溯法以深度优先的方式搜索解空间树T ,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树T 。 舍伍德算法设计的基本思想: 设A 是一个确定性算法,当它的输入实例为x 时所需的计算时间记为tA(x)。设Xn 是算法A 的输入规模为n 的实例的全体,则当问题的输入规模为n 时,算法A 所需的平均时间为 这显然不能排除存在x ∈Xn B ,使得对问题的输入规模为n 拉斯维加斯( Las Vegas )算法的基本思想: 设p(x) 是对输入x 调用拉斯维加斯算法获得问题的一个解的概率。一个正确的拉斯维加斯算法应该对所有输入x 均有p(x)>0。 设t(x)是算法obstinate 找到具体实例x 的一个解所需的平均时间 ,s(x)和e(x)分别是算法对于具体实例x 蒙特卡罗(Monte Carlo)算法的基本思想: 设p 是一个实数,且1/2 浅谈加权最小二乘法及其残差图 ——兼答孙小素副教授 何晓群 刘文卿 ABSTRACT The paper introduces some problems in relation to weighted least square regression ,and answers a question about weighted residual plots. 关键词:异方差;加权最小二乘法;残差图;SPSS 一、引言 好几年没有翻《统计研究》了。最近,有一同行朋友打电话告诉我《统计研究》2005年第11期上刊登了一篇有关我与刘文卿合作编著的《应用回归分析》(2001.6.中国人民大学出版社)教材的文章。赶紧找到这期的《统计研究》,看到其中孙小素副教授的文章《加权最小二乘法残差图问题探讨——与何晓群教授商榷》一文,以下简称《孙文》。认真拜读后感触良多。首先衷心感谢孙小素副教授阅读了我们《应用回归分析》拙作的部分章节,同时感谢《统计研究》给我们提供这样一个好的机会,使我们能够借助贵刊对加权最小二乘法的有关问题谈谈更多的认识。 《孙文》谈到《应用回归分析》教材中有关加权最小二乘法残差图的问题。摆出了与加权最小二乘法相关的三类残差图,指出第三类残差图的局限性。直接的问题是三类残差图的作用,而更深层的原因应该是对加权最小二乘法统计思想的理解和认识上的差异。 二、对加权最小二乘法的认识 1. 加权最小二乘估计方法 拙作《应用回归分析》中对加权最小二乘法有详尽的讲述,这里仅做简要介绍。多元线性回归方程普通最小二乘法的离差平方和为: ∑=----=n i ip p i i p x x y Q 1 211010)(),,,(ββββββ (1) 普通最小二乘估计就是寻找参数p βββ,,,10 的估计值p βββ?,,?,?10 使式(1)的离差平方和Q 达极小。式(1)中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项i ε等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。 然而在异方差的条件下,平方和中的每一项的地位是不相同的,误差项i ε的方差2i σ大的项,在式(1)平方和中的取值就偏大,在平方和中的作用就大,因而普通最小二乘估计 的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。 由式(1)求出的p βββ?,,?,?10 仍然是p βββ,,,10 的无偏估计,但不再是最小方差线性无偏估计。 加权最小二乘估计的方法是在平方和中加入一个适当的权数i w ,以调整各项在平方和 偏最小二乘法 1.1 基本原理 偏最小二乘法(PLS )是基于因子分析的多变量校正方法,其数学基础为主成分分析。但它相对于主成分回归(PCR )更进了一步,两者的区别在于PLS 法将浓度矩阵Y 和相应的量测响应矩阵X 同时进行主成分分解: X=TP+E Y=UQ+F 式中T 和U 分别为X 和Y 的得分矩阵,而P 和Q 分别为X 和Y 的载荷矩阵,E 和F 分别为运用偏最小二乘法去拟合矩阵X 和Y 时所引进的误差。 偏最小二乘法和主成分回归很相似,其差别在于用于描述变量Y 中因子的同时也用于描述变量X 。为了实现这一点,数学中是以矩阵Y 的列去计算矩阵X 的因子。同时,矩阵Y 的因子则由矩阵X 的列去预测。分解得到的T 和U 矩阵分别是除去了大部分测量误差的响应和浓度的信息。偏最小二乘法就是利用各列向量相互正交的特征响应矩阵T 和特征浓度矩阵U 进行回归: U=TB 得到回归系数矩阵,又称关联矩阵B : B=(T T T -1)T T U 因此,偏最小二乘法的校正步骤包括对矩阵Y 和矩阵X 的主成分分解以及对关联矩阵B 的计算。 1.2主成分分析 主成分分析的中心目的是将数据降维,以排除众多化学信息共存中相互重叠的信息。他是将原变量进行转换,即把原变量的线性组合成几个新变量。同时这些新变量要尽可能多的表征原变量的数据结构特征而不丢失信息。新变量是一组正交的,即互不相关的变量。这种新变量又称为主成分。 如何寻找主成分,在数学上讲,求数据矩阵的主成分就是求解该矩阵的特征值和特征矢量问题。下面以多组分混合物的量测光谱来加以说明。假设有n 个样本包含p 个组分,在m 个波长下测定其光谱数据,根据比尔定律和加和定理有: A n×m =C n×p B p×m 如果混合物只有一种组分,则该光谱矢量与纯光谱矢量应该是方向一致,而大小不同。换句话说,光谱A 表示在由p 个波长构成的p 维变量空间的一组点(n 个),而这一组点一定在一条通过坐标原点的直线上。这条直线其实就是纯光谱b 。因此由m 个波长描述的原始数据可以用一条直线,即一个新坐标或新变量来表示。如果一个混合物由2个组分组成,各组分的纯光谱用b1,b2表示,则有: 1122 T T T i i i a c b c b =+ 有上式看出,不管混合物如何变化,其光谱总可以用两个新坐标轴b1,b2来表示。因此可以 推出,如果混合物由p 个组分组成,那么混合物的光谱就可由p 个主成分轴的线性组合表示。 偏最小二乘法(PLS)简介 偏最小二乘法(PLS )简介 偏最小二乘法(PLS )简介 简介 偏最小二乘法是一种新型的多元统计数据分析方法,它于1983年由伍德(S.Wold)和阿巴诺(C.Albano)等人首次提出。近几十年来,它在理论、方法和应用方面都得到了迅速的发展。 偏最小二乘法 长期以来,模型式的方法和认识性的方法之间的界限分得十分清楚。而偏最小二乘法则把它们有机的结合起来了,在一个算法下,可以同时实现回归建模(多元线性回归)、数据结构简化(主成分分析)以及两组变量之间的相关性分析(典型相关分析)。这是多元统计数据分析中 的一个飞跃。 偏最小二乘法在统计应用中的重要性体现在以下几个方面: 偏最小二乘法是一种多因变量对多自变量的回归建模方法。偏最小二乘法可以较好的解决许多以往用 普通多元回归无法解决的问题。 偏最小二乘法之所以被称为第二代回归方法,还由于它可以实现多种数据分析方法的综合应用。 主成分回归的主要目的是要提取隐藏在矩阵X 中的相关信息,然后用于预测变量Y 的值。 这种做法可以保证让我们只使用那些独立变量,噪音将被消除,从而达到改善预测模型质量的目的。但是,主成分回归仍然有一定的缺陷,当一些有用变量的相关性很小时,我们在选取主成分时就很容易把它们漏掉,使得最终的预测模型可靠性下降,如果我们对每一个成分 进行挑选,那样又太困难了。 偏最小二乘回归可以解决这个问题。它采用对变量X 和Y 都进行分解的方法,从变量X 和Y 中同时提取成分(通常称为因子),再将因子按照它们之间的相关性从大到小排列。现在,我们要建立一个模型,我们只要决定选择几个因子参与建模就可以了 基本概念 偏最小二乘回归是对多元线性回归模型的一种扩展,在其最简单的形式中,只用一个线性模 型来描述独立变量Y 与预测变量组X 之间的关系: 偏最小二乘法(PLS) 简介 通常,一个函数在调用另一个函数之前,要作如下的事情:a)将实在参数,返回地址等信息传递给被调用函数保存; b)为被调用函数的局部变量分配存储区;c)将控制转移到被调函数的入口. 从被调用函数返回调用函数之前,也要做三件事情:a)保存被调函数的计算结果;b)释放被调函数的数据区;c)依照被调函数保存的返回地址将控制转移到调用函数.所有的这些,不论是变量还是地址,本质上来说都是"数据",都是保存在系统所分配的栈中的. ok,到这里已经解决了第一个问题:递归调用时数据都是保存在栈中的,有多少个数据需要保存就要设置多少个栈,而且最重要的一点是:控制所有这些栈的栈顶指针都是相同的,否则无法实现同步. 下面来解决第二个问题:在非递归中,程序如何知道到底要转移到哪个部分继续执行?回到上面说的树的三种遍历方式,抽象出来只有三种操作:访问当前结点,访问左子树,访问右子树.这三种操作的顺序不同,遍历方式也不同.如果我们再抽象一点,对这三种操作再进行一个概括,可以得到:a)访问当前结点:对目前的数据进行一些处理;b)访问左子树:变换当前的数据以进行下一次处理;c)访问右子树:再次变换当前的数据以进行下一次处理(与访问左子树所不同的方式). 下面以先序遍历来说明: void preorder_recursive(Bitree T) /* 先序遍历二叉树的递归算法*/ { if (T) { visit(T); /* 访问当前结点*/ preorder_recursive(T->lchild); /* 访问左子树*/ preorder_recursive(T->rchild); /* 访问右子树*/ } } visit(T)这个操作就是对当前数据进行的处理, preorder_recursive(T->lchild)就是把当前数据变换为它的左子树,访问右子树的操作可以同样理解了. 现在回到我们提出的第二个问题:如何确定转移到哪里继续执行?关键在于一下三个地方:a)确定对当前数据的访问顺序,简单一点说就是确定这个递归程序可以转换为哪种方式遍历的树结构;b)确定这个递归函数转换为递归调用树时的分支是如何划分的,即确定什么是这个递归调用树的"左子树"和"右子树"c)确定这个递归调用树何时返回,即确定什么结点是这个递归调用树的"叶子结点". 控制理论与控制工程 学位课程《系统辨识》考试报告 递推阻尼最小二乘法公式详细 推导 专业:控制理论与控制工程 班级:2011双控(研) 学生姓名:江南 学号:20110201016 任课教师:蔡启仲老师 2012年06月29 日 摘要 在参数辨识中,递推最小二乘法是用得最多的一种算法。但是,最小二乘法存在一些缺点,如随着协方差矩阵的减小,易产生参数爆发现象;参数向量和协方差矩阵的处置选择不当会使得辨识过程在参数收敛之前结束;在存在随机噪声的情况下,参数易产生漂移,出现不稳定等。为了防止参数爆发现象,Levenberg 提出在参数优化算法中增加一个阻尼项,以增加算法的稳定性。本文在一般的最小二乘法中增加了阻尼因子,构成了阻尼最小二乘法。又根据实时控制的要求,详细推到了递推阻尼最小二乘公式,实现在线辨识。 关键字:系统辨识,最小二乘法,递推算法 正文 1.题目的基本要求 已知单入单出系统的差分方程以及噪声,在应用最小二乘法进行辨识的时候,在性能指标中加入阻尼因子,详细推导阻尼最小二乘法的递推公式。 2.输入辨识信号和系统噪声的产生方法和理论依据 2.1系统辩识信号输入选择准则 (1)输入信号的功率或副度不宜过大,以免使系统工作在非线性区,但也不应过小,以致信噪比太小,直接影响辩识精度; (2)输入信号对系统的“净扰动”要小,即应使正负向扰动机会几乎均等; (3)工程上要便于实现,成本低。 2.2白噪声及其产生方法 (1) 白噪声过程 (2)白噪声是一种均值为0、谱密度为非0常数的平稳随机过程。 (3)白噪声过程定义:如果随机过程 () t ω的均值为0,自相关函数为 ()()2 R t t ωσδ= (2.2.1) 式中()t δ 为狄拉克(Dirac) 分布函数,即 (){ (),00,0 1t t t dt δδ∞ ∞=≠∞ ==? -且t (2.2.2) 则称该随机过程为白燥声过程。 2.3白噪声序列 (1) 定义 如果随机序列{() }w t 均值为0,并且是两两不相关的,对应的自相关函数为 ()2 ,0,1,2w l R l l σδ==±± 式中{1,0 0,0 l l l δ=≠=则称这种随机序列{()}w t 为白噪声序列。 2.4白噪声序列的产生方法 (1) (0,1)均匀分布随机数的产生 在计算机上产生(0,1)均匀分布随机数的方法很多,其中最简单、最方便的是数学方法。产生伪随机数的数学方法很多,其中最常用的是乘同余法和混合同余法。 ①乘同余法。 WLS:加权最小二乘 一般最小二乘估计精度不高的原因之一是不分优劣地使用了量测值,如果对不同量测值的质量有所了解,则可用加权的方法分别对待各量测量,精度质量高的权重取大些,精度质量低的权重取小些;权W 是适当取值的正定阵。 最小二乘估计是Gauss 在1795年为测定行星轨道而提出的参数估计算法。特点是方法简单,不必知道与被估计量任何统计信息。 假定量测信息z 可以表示为参数x 的线性函数,即 v Hx z +=, 其中()N m n ×∈ H , N m ∈ v 是一个零均值的随机向量;设()()N m N m ×∈ W 为对称正定阵(0≥W ),则如下估计 WLS T ????arg min()()=??x x z Hx W z Hx , 称为加权最小二乘(weighted least squares ,WLS )估计;如果=W I ,则称为最小二乘(Least Squares ,LS )估计。 注意:最小二乘法的最优指标只保证了估计量测的均方误差最小。 定理 设T H WH 可逆,则基于量测信息z 和加权矩阵W 对参数x 的WLS 估计为 WLS T 1T ?()?=x H WH H Wz , 证明:因为T T T T T min()()min(2)??=?+x x z Hx W z Hx z Wz z WHx x H WHx , 而 ()T T T T T T T T T 1 T T (2)(2)20 ?WLS x ???+??=?+?=?=∴=T T z Wz z WHx x H WHx x z Wz x H Wz x H WHx x H Wz +2H WHx H WH H Wz (注意:,T Ax x Ax A x x ?<>=+?,,x y y x ?<>=?) 关于估计方差: 如果量测误差v 的均值为0方差为R ,则加权最小二乘估计也是无偏估计。估计的协方差阵为 11111[]()()?(()()()) T T T T T T T T T T E xx H WH H WRWH H WH x x x H WH H WHx H WH H Wz H WH H Wv ?????==?=?=? ∵ (注意11()()T T A A ??=) 第一部分:程序设计思路、辨识结果分析和算法特点总结 (2) 一:RLS遗忘因子法 (2) RLS遗忘因子法仿真思路和辨识结果 (2) 遗忘因子法的特点: (3) 二:RFF遗忘因子递推算法 (4) 仿真思路和辨识结果 (4) 遗忘因子递推算法的特点: (5) 三:RFM限定记忆法 (5) 仿真思路和辨识结果 (5) RFM限定记忆法的特点: (7) 四:RCLS偏差补偿最小二乘法 (7) 仿真思路和辨识结果 (7) RCLS偏差补偿最小二乘递推算法的特点: (9) 五:增广最小二乘法 (9) 仿真思路和辨识结果 (9) RELS增广最小二乘递推算法的特点: (11) 六:RGLS广义最小二乘法 (12) 仿真思路和辨识结果 (12) RGLS广义最小二乘法的特点: (14) 七:RIV辅助变量法 (14) 仿真思路和辨识结果 (14) RIV辅助变量法的特点: (16) 八:Cor-ls相关最小二乘法(二步法) (17) 仿真思路和辨识结果 (17) Cor-ls相关最小二乘法(二步法)特点: (18) 九:MLS多级最小二乘法 (19) 仿真思路和辨识结果 (19) MLS多级最小二乘法的特点: (22) 十:yule_walker辨识算法 (23) 仿真思路和辨识结果 (23) yule_walker辨识算法的特点: (24) 第二部分:matlab程序 (24) 一:RLS遗忘因子算法程序 (24) 二:RFF遗忘因子递推算法 (26) 三:RFM限定记忆法 (28) 四:RCLS偏差补偿最小二乘递推算法 (31) 五:RELS增广最小二乘的递推算法 (33) 六;RGLS 广义最小二乘的递推算法 (36) 七:Tally辅助变量最小二乘的递推算法 (39) 八:Cor-ls相关最小二乘法(二步法) (42) 九:MLS多级最小二乘法 (45) 十yule_walker辨识算法 (49)递推最小二乘法算法
浅谈加权最小二乘法及其残差图
递归算法的优缺点
加权OLS权数确定
偏最小二乘法算法
偏最小二乘法(PLS)简介
递归算法工作栈的变化详解
递推阻尼最小二乘法辨识算法公式的详细推导与说明
加权最小二乘法—ls
(完整word版)多种最小二乘算法分析+算法特点总结
相关主题
文本预览