
Udf概述
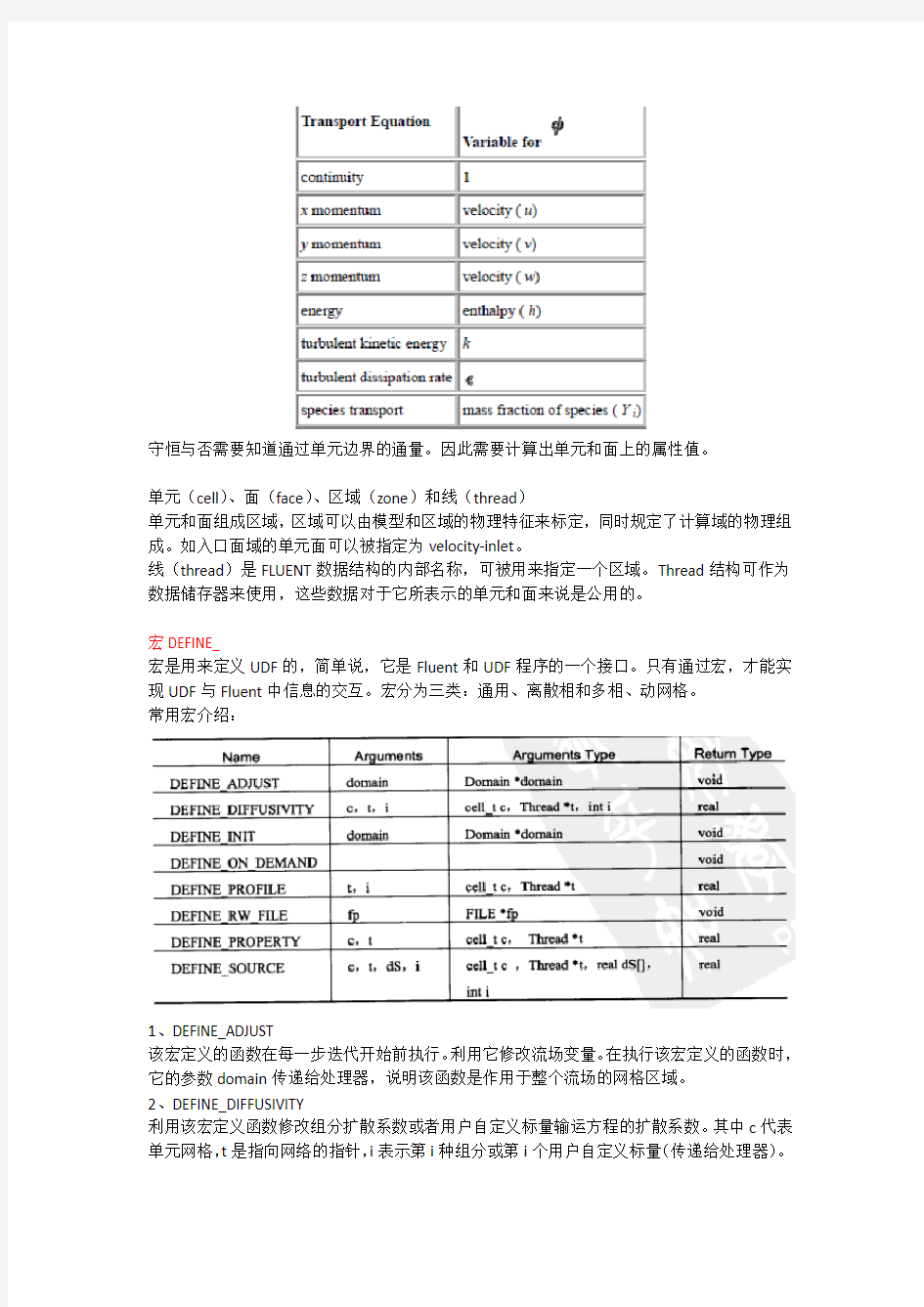
输运方程
FLUENT求解器建立在有限容积法的基础上,将计算域离散为有限数目的控制体或是单元。网格单元是FLUENT中基本的计算单元,这些单元的守恒特征必须保证。也就是说普通输运方程,例如质量、动量、能量方程的积分形式可以应用到每个单元:
??t
ρ?dV+ρ?V?dA=Γ???dA+S?dV
V
A
A
V
此处,?是描述普通输运数量的变量,根据所求解的输运方程可取不同的值。下面是输运方程中可求解?的子集
守恒与否需要知道通过单元边界的通量。因此需要计算出单元和面上的属性值。
单元(cell)、面(face)、区域(zone)和线(thread)
单元和面组成区域,区域可以由模型和区域的物理特征来标定,同时规定了计算域的物理组成。如入口面域的单元面可以被指定为velocity-inlet。
线(thread)是FLUENT数据结构的内部名称,可被用来指定一个区域。Thread结构可作为数据储存器来使用,这些数据对于它所表示的单元和面来说是公用的。
宏DEFINE_
宏是用来定义UDF的,简单说,它是Fluent和UDF程序的一个接口。只有通过宏,才能实现UDF与Fluent中信息的交互。宏分为三类:通用、离散相和多相、动网格。
常用宏介绍:
1、DEFINE_ADJUST
该宏定义的函数在每一步迭代开始前执行。利用它修改流场变量。在执行该宏定义的函数时,它的参数domain传递给处理器,说明该函数是作用于整个流场的网格区域。
2、DEFINE_DIFFUSIVITY
利用该宏定义函数修改组分扩散系数或者用户自定义标量输运方程的扩散系数。其中c代表单元网格,t是指向网络的指针,i表示第i种组分或第i个用户自定义标量(传递给处理器)。
函数返回real型数据。
3、DEFINE_INIT
用以初始化流场变量,他在fluent默认的初始化之后执行。作用区域为全场,无返回值。4、DEFINE_ON_DEMAND
定义函数不是在计算中有fluent自动调用,二是根据需要手工调用运行。
5、DEFINE_PROFILE
定义函数指定边界条件。T指向定义边界条件的网格线,i用来表示边界的位置。函数在执行时,需要循环扫遍所有的边界网格线,其值存储在F_PROFILE(f,t,i)中,无返回值。
6、DEFINE_PROPERTY
利用该宏定义的函数可以指定物质物性参数。C表示网格,t表示网格线,返回实型值。7、DEFINE_RW_FILE
该宏用于读写case和data文件。其中,fp是指向所读写文件的指针。
8、DEFINE_SOURCE
利用该宏定义除DO辐射模型之外其他所有输运方程的源项。在实际计算中,函数需要扫遍全场网格。其中c表示网格,t表示网格线,dS表示源项对所求输运方程的标量的偏导数,用于对源项的线性化,i标志已定义源项对应的输运方程。
UDF预定义函数
Fluent已经预先定义了一些函数,通过这些函数可以从求解器中读写数据,从而达到UDF 和Fluent标准求解器结合的目的。这些函数是定义在.h文件里的,例如mem.h。一般在UDF 源程序的开头包含udf.h文件,就可以使用这些预定义的函数。这里的函数是广义的,包括函数和宏,只有在源文件appropriate.h中定义的才是真正的函数。如果使用的是Interpreted 的UDF,则只能使用这些Fluent提供的函数。通过这些Fluent的预定义函数可以得到的变量有:
几何变量(坐标、面积、体积等)
网格和节点变量(节点的速度等)
溶液变量及其组合变量(速度、温度、湍流量等)
材料性质变量(密度、粘度、导电性等)
离散相模拟变量
Fluent自身有增加了几个数据类型:
Node:他表示相应的网格节点。
cell_t:单独一个控制体体积元,用来定义源项或物性。
face_t:它对应于网格面,用来定义入口边界条件等。
Thread:对应边界或网格区域的结构类型数据。
Domain:它是一种包含所有的threads、cells、faces、和nodes的结构。
上述结构区分大小写。
函数示例:
(6)循环宏
多数的UDF任务需要在一个线的所有单元和面上重复执行。比如,定义一个自定义轮廓函数会对一个面thread的所有单元和面进行循环。为了方便用户,Fluent向用户提供了一些循环宏工具(looping macro utilities)来执行对单元、面、节点和线的重复操作。
如果要实现扫描全场的网格就需要使用循环宏。Fluent的循环宏如下。
thread_loop_c:在一个domain中循环所有的cell线程。
thread_loop_f:在一个domain中循环所有的face线程。
beginend_c_loop:在一个cell线程中循环所有的cell。
beginend_f_loop:在一个face线程中循环所有的face。
c_face_loop:在一个cell中循环所有的face。
c_node_loop:在一个cell中循环所有的node。
循环宏大体可以分为两种类型:一种以begin开始,end结束,用来扫描线上的所有网格和面;一种用来扫描所有的线。大体结构如下:
cell_t c;
face_t f;
Thread*t;
Domain*d;
begin_c_loop(c,t)
{
}
end_c_loop(c,t) /*循环遍历线上的所有网格*/
begin_f_loop(f,t)
{
}
end_f_loop(f,t) /*循环遍历线上的所有面*/
thread_loop_c(t,d)
{
} /*遍历网格线*/
thread_loop_f(t,d)
{
} /*遍历面上的线*/
UDF的C语言基础
1、FLUENT的C数据类型
FLUENT的UDF解释程序支持下面的C数据类型:
Int整型Long长整型Real实型Float浮点型Double双精度型Char字符型
注意:UDF解释函数在单精度算法中定义real类型为float型,在双精度算法宏定义real为double型。因为解释函数自动作如此分配,所以使用在UDF中声明所有的float和double 数据变量时使用real数据类型是很好的编程习惯。
2、常数
常数是表达式中所使用的绝对值,在C程序中用语句#dedine来定义。最简单的常数是十进制整数。包含小数点或者字母e的十进制数被看成浮点常数。按惯例,常数的声明一般都使用大写字母。如:#define YMIN0.0 #define WALL_ID 5
3、变量
变量或者对象保存在可以存储数值的内存中。每一个变量都有类型、名字和值。变量在使用之前必须在C程序中声明。
变量声明结构如下:数据类型+变量名。变量声明可以给定初值。局部变量在函数内部声明。全局变量在单一函数的外部定义,一般在预处理程序之后的文件开始处声明。
如果全局变量在某一源代码中声明,但是另一个源代码的某一文件需要用到它,那么必须在另一个文件中声明它是外部变量,声明时只要在最前面加上extern即可。如果有几个文件涉及到该变量,最方便的处理方法就是在头文件中加上extern的定义,然后在所有的.c文件中引用该头文件即可。外部变量只用于complied UDF。
静态变量。static声明对于全局变量和局部变量的影响是不一样的。静态局部变量在函数调用返回之后,该变量不会被破坏。静态全局变量在定义该变量的.c源文件之外对任何函数保持不可见。静态声明也可以用于函数,使该函数只对定义它的.c文件保持可见。
4、自定义数据类型
C还允许用结构和typedef创建自定义数据类型。如下:typedef struct list
{
int a;
real b;
int c;
}
mylist; /*mylist为类型结构列表*/
mylist x,y,z; /*x,y,z为类型结构列表*/
5、强制转换
强制转换数据类型,如:
int x=1;
real y3.14159;
int z=x+((int)y); /*z=4*/
6、函数
UDF的编写
步骤
1、分析实际问题的模型,得到UDF对应的数学模型。
2、将数学模型使用C语言源代码表达出来
3、编译调试UDF源程序
4、在Fluent中执行UDF
UDF基本格式
编写Interpreted型和Compiled型用户自定义函数的过程和书写格式是一样的。其主要区别在于与C语言的结合程度:Compiled型能完全使用C语言的语法,而Interpreted型只能使用其中一小部分。基本格式归为三部分
1、定义恒定常数和包含库文件,分别由#DEFINE和#INCLUDE陈述
2、使用宏DEFINE定义UDF函数
3、函数体部分
包含的库有udf.h、sg.h、mem.h、prop.h、dpm.h等,其中udf.h是必不可少的,书写格式为#include udf.h;所有数值都应采用SI单位制;函数体部分字母采用小写,Interpreted型只能采用Fluent支持的C语言语法和函数。
Fluent提供的宏都以DEFINE_开始,对它们的解释包含在udf.h文件中,所以必须要包含库udf.h。
UDF编译和连接之后,函数名就会出现在Fluent相应的下拉列表内。例如DEFINE_PROFILE(inlet_x_velocity,thread,position),编译连接之后,就能相应的边界条件面板内找到一个名为inlet_x_velocity的函数,选定之后就可以使用。
UDF实例
在圆管中,入口水流速通过以下公式描述:
y2
u=0.5?0.5×
这个公式说明在壁面上速度为0,圆管中心线的速度为0.5m/s,而圆管入口面上的速度符合抛物线分布。
下面的UDF就是把上述的抛物线分布的入口速度与Fluent求解器结合起来,从而可以在Fluent求解器中把入口速度指定为抛物线形。
此例的C源代码如下:
//********************************************************//
//***********抛物线入口速度的定义*************************//
//********************************************************//
#include”udf.h”//这里一定要调用这个头文件
DEFINE_PROFILE(velocity_inlet,thread,position)
{
real x[ND_ND]; //定义质心的坐标所在的数组
real y; //定义质心y坐标变量
face_t f; //定义face_t类型的变量f
begin_f_loop(f,thread)
{
F_CENTROID(x,f,thread); //从Fluent函数得到各网格质心坐标,并且赋给矢量x
y=x[1]; //x[0]代表质心的横坐标,x[1]代表质心的纵坐标
F_PROFILE(f,thread,position)=0.5-y*y/(0.02*0.02)*0.5; //定义抛物线速度
}
end_f_loop(f,thread)
}
杂=待整理
宏定义
1.DEFINE_ON_DEMAND 异步执行,自动存储温度函数
2.DEFINE_ADJUST 在整个区域对湍流离散率进行积分
3.DEFINE_ADJUST 自定义一个标量是另外一个自定义标量的函数
4.DEFINE_INIT 初始化流场变量
5.DEFINE_RW_FILE 将自定义函数写入data文件中再读出
6.DEFINE_DELTAT 更改时间步长
7.DEFINE_DIFFUSIVITY 应用自定义标量计算空气的平均扩散率
8.DEFINE_HEAT_FLUX 在P-1辐射模型中的应用(10.5.2)
9.DEFINE_NOX_RA TE 计算NOx的产生率和reduction rates (4.3.4)
10.DEFINE_PROFILE 根据压力函数产生压力剖面(4.3.5
11.DEFINE_PROFILE 自定义x方向速度剖面,湍流动能,离散率(4.3.5)
12. DEFINE_PROFILE 叶轮计算中用来fix flow variables
13. DEFINE_PROPERTY 自定义粘度
14.DEFINE_SCAT_PHASE_FUNC 多个UDF连接在一个源程序中(4.3.7)
15.DEFINE_SOURCE 自定义源项(4.3.8)
16.DEFINE_SR_RA TE 自定义表面反应速率
17.DEFINE_TURB_PREMIX_SOURCE 在预混燃烧模型中自定义湍流火焰速度和源项
18.DEFINE_TURBULENT_VISCOSITY 标准k-e模型中自定义湍流粘度
19.DEFINE_UDS_FLUX 返回给定面上的质量流率
20.DEFINE_UDS_UNSTEADY 修改自定义的标量time derivatives
21.DEFINE_VR_RATE 定义体积反应率
22.DEFINE_VR_RATE 涉及到多个反应时的应用
23.DEFINE_CAVITATION_RATE 多相混合物中液相和气相之间的传质(4.4.1)
24.DEFINE_EXCHANGE_PROPERTY 自定义Syamlal drag law (4.4.2)
25.DEFINE_VECTOR_EXCHANGE_PROPERTY 两相混合时自定义滑移速度
26.DEFINE_DPM_BODY_FORCE 计算磁力magnetic force
27. DEFINE_DPM_DRAG 计算颗粒的曳力drag force
28.DEFINE_DPM_EROSION 壁面作用的后处理
29.DEFINE_DPM_INJECTION_INIT 初始化颗粒的粒径
30.DEFINE_DPM_LAW 自定义the evaporation swelling of particles的定律
31.DEFINE_DPM_OUTPUT 计算沿粒子轨迹的熔融指数melting index
32.DEFINE_DPM_PROPERTY 两种离散相物理特性连接在一个C程序中
33.DEFINE_DPM_SOURCE 应用评判标准在不同的DPM laws 中转化
34.sub_domain_loop 对某一特定相体积分数赋初值
35.Get_Domain 在单相中的应用
36.Lookup_Thread 找到指向给定区域thread的指针,此指针用于begin_f_loop and F_CENTROID
菜鸟学UDF的感觉,希望对UDFers有用。
光看书,感觉UDF不难。看例子,有些看个四五遍之后才能差不多看懂。原来,得靠UDF 帮助。我主要用的是fluent v6.3自带的html格式的帮助,里面东西很全,当然也包括UDF Manual。里面自带的search功能相当好,只是要注意用好+或-号(逻辑符号),另外,这个
功能似乎有些浏览器支持不太好,不过基本上用IE不太容易出问题。
对于从零开始学习UDF,建议还是先看一下UDF中文帮助,我估计大家知道的都是马世虎翻译的那本吧,感觉挺好。(没想到马世虎跟我是校友,去年给安世亚太投过一份简历,他给我打过电话,当时一阵兴奋,呵呵。)
对于只涉及到边界条件或物性等的UDF,一般用interpret就可以的,这些我觉得只需要根据例子改一下就是了。
$$ 对于要添加UDS方程的,相对难一点。我编程用的是三到五个UDS,几十个UDM。一开始编程时,没有头绪,后来看别人编的,才慢慢发现了一些基本思路。比如,可以用枚举定义UDS或UDM,这样用起来方便。
enum{
NP,
RHOH2O_Y_UP_X,
RHOH2O_Y_UP_Y,
RHOH2O_Y_UP_Z,
N_REQUIRED_UDS
};//枚举UDS变量名
对于UDM,则用N_REQUIRED_UDM代表个数。
然后在INIT与ADJUST函数中,检查变量个数时则比较方便,如:
DEFINE_INIT(init_parameter,domain)
{
if (n_uds < N_REQUIRED_UDS)
Error(”Not enough user defined scalars!(init)\n”);
if (n_udm Error(”Not enough user defined memories(init)!\n”); initialise(domain);//代表初始化 } DEFINE_ADJUST(adjust_compute,domain) { if (n_uds < N_REQUIRED_UDS) Error(”Not enoug h user defined scalars!(adjust)\n”); if (n_udm Error(”Not enough user defined memories(adjust)!\n”); update_parameter(domain);//代表主函数 } 初始化时,则可: cell_t c; Thread *t; int i; thread_loop_c(t,d) { if(NNULLP(THREAD_STORAGE(t,SV_UDS_I(NP)))&&NNULLP(THREAD_STORAGE(t,SV_UDS_I(NP_R )))) //为各UDS提供存储空间 { begin_c_loop(c, t) { for (i=0; i C_UDSI(c,t,i) = 0.0; } end_c_loop(c, t); } if(NNULLP(THREAD_STORAGE(t,SV_UDM_I))) { begin_c_loop(c, t) { for (i=0; i C_UDMI(c,t,i) = 0.0; } end_c_loop(c, t); } } 对于各UDM量,则可: real udm_v; udm_v=0;//用之前对变量进行初始化 …//UDM相关运行 C_UDMI(c,t,UDM_V)=udm_v;//把值输入给UDM,当然之前要对UDM_V进行定义 用UDM有个好处,一是可以在后处理中显示,二是传递变量相当方便,比如在ADJUST中计算的量用于源项或对流项等,用UDM可以直接调用。 对于invalid number错误,很多时候是因为分母为零,如果习惯UDM初始化为零,则要注意避免零作分母,可以令其初始化不为零或为零时不运算(第二种方法比较好)。 方程与计算 我编程计算的是两相流中一相凝结成核,需要用UDS方程来模拟其成核有关变量(不要来问我程序代码,呵呵)。我觉得对UDS变量控制方程搞清楚之后,这块一点儿也不难。一般变量的控制方程(Fluent能认识的),就是含有瞬态项(时间项),对流项,扩散项与源项。(方程如何处理fluent会自己弄的)对第一项,都有相应的宏来处理。 对于对流项,比如关于phi的方程中的:rho*U*phi的散度,其中U为速度矢量,则fluent 中需要知道的对流项则为rho*U.A,其中U.A代表U与A的点积,A代表单元格的面积向量。对流是对面而言(2D的话则对线而言),对于边界,只有一边有单元格,而对于内部surface,则两边都有单元格,这时单元格编号从0到1。比如,对于内部边界,代码可以与下面类似:real NV_VEC(psi),NV_VEC(A),flux1;//声明向量操作 c0=F_C0(f,t); t0=F_C0_THREAD(f,t); F_AREA(A,f,t);//A的获得 c1=F_C1(f,t); t1=F_C1_THREAD(f,t); NV_D(psi,=,C_UDMI(c0,t0,UPX),C_UDMI(c0,t0,UPY),C_UDMI(c0,t0,UPZ)); NV_D(psi,+=,C_UDMI(c1,t1,UPX),C_UDMI(c1,t1,UPY),C_UDMI(c1,t1,UPZ)); flux1=NV_DOT(psi,A)/2.0; 对于边界上,则可以只用单元格c0,t0处的值或用f,t处的值(代表直接在边界面上取值,前提是边界上有存储值)。 对于扩散项,一般比较简单,直接用宏DEFINE_DIFFUSIVITY定义扩散系数即可。注意它在fluent软件中的加入方式,一般是在material菜单中。species中加入的扩散项与UDS扩散项的加入不在同一处。 对于源项,如果不容易线性化,不如索性定义dS[eqn]=0,这样倒简单。 其它 一开始学fluent时,把松弛因子设为0.1就感觉挺小了。没想到刚用UDF计算时,得从1e-5开始,慢慢调到1e-1数量级上。想想挺可怕的。另外,很多CFD或多相流的东西都是理论与经验数据结合构成的公式,不一定完全准确,再加上数值解法的多样性,使算题时容易出各种各样的问题。而且UDF有个特点,不能单独运行的,调试也必须放到fluent中,这样当要加入的宏比较多时,就会变得很麻烦,常常一天要建十几个library,然后分别选择不同的宏加载到fluent,然后就是不停的调试。记得刚开始,我跟我师姐一块,她主要负责物理理论,我主要负责编程,经常因为一个小问题,要调试上大半天,因为编程中,任何一个小问题也必须解决掉。当然,也经常烦得很,还好,男女搭配干活不太累。 我觉得visual assistX这个软件相当不错,它是为了方便vc环境下的编程。而用udf编程时,大家感觉不爽的是,没有提示能力,因为它的宏VC环境下是不认识的,所以一片黑颜色不好看,主要的是不利于查错与写代码。而用visual assistX(网上有破解版的),将fluent udf 常用的几个头方便的目录加入visual assistX中后,就方便多了。 比如,输入C_时,可能就会提示C_UDMI,C_UDSI,C_U,C_R等,因为以C开头的宏太多了,所以只提示最近用过的几个。 又比如,各种枚举量,各种宏等,这时都会以不同的颜色表示,一般常见的拼写错误,一下子就能看出来,因为颜色不同,方便多了。visual assistX本身也带有spell check功能,不过最好关掉,因为我们定义变量时常常不是以完整的单词命名,而这时常常很多代码下面都有浅浅的红色的波浪线,很是不爽。 又如,visual assistX提供查询功能,比如,某个宏或某个系统自带的变量名等,会自动显示该名称的出处,点一下go即可查得源文件。这样可以很方便地查询自己不认识的宏或变量等。 一开始编程时常犯一个错误,就是这样写:powl(C_U(c,t),1/3),实际应该写为powl(C_U(c,t),1.0/3),因为1/3默认是int型的,所以值为0,显然不是我想要的。 一开始用fluent6.1编程,它对于某个UDF面板处一般只允许一个宏的存在,所以,当你改了一下代码,重新build一个library后,宏会默认地替换掉原来的,这样,对调试是有好处的。后来用fluent6.3,它允许一个地方加入多个宏,这样,build一个新的library后,需要自己改相关的宏(不变的宏可以不改),一开始觉得这样不如6.1,慢慢发现,它可以同时使用几个不同的library,比如某个量,可以用A方法求一会儿后再用B方法求,总之可以调的东西多了。 感觉,UDF编程除了需要专业知识与一定的C语言基础,更需要耐心。 时间项例子 #include "udf.h" //这里一定要调用这个头文件 DEFINE_PROFILE(velocity_inlet,thread,index) { real x[ND_ND]; //定义质心的坐标所在的数组 float t; face_t f; //定义face_t类型的变量 begin_f_loop(f,thread) { F_CENTROID(x,f,thread); //从Fluent函数得到各网格质心坐标,并且赋给矢量x t = RP_Get_Real("flow-time"); F_PROFILE(f,thread,index)=0.5+0.5*t; //定义抛物线速度 } end_f_loop(f,thread) } 第七章 UDF的编译与链接 编写好UDF件(详见第三章)后,接下来则准备编译(或链接)它。在7.2或7.3节中指导将用户编写好的UDF如何解释、编译成为共享目标库的UDF。 _ 第 7.1 节: 介绍 _ 第 7.2 节: 解释 UDF _ 第 7.3 节: 编译 UDF 7.1 介绍 解释的UDF和编译的UDF其源码产生途径及编译过程产生的结果代码是不同的。编译后的UDF由C语言系统的编译器编译成本地目标码。这一过程须在FLUENT运行前完成。在FLUENT运行时会执行存放于共享库里的目标码,这一过程称为“动态装载”。 另一方面,解释的UDF被编译成与体系结构无关的中间代码或伪码。这一代码调用时是在内部模拟器或解释器上运行。与体系结构无关的代码牺牲了程序性能,但其UDF可易于共享在不同的结构体系之间,即操作系统和FLUENT版本中。如果执行速度是所关心的,UDF文件可以不用修改直接在编译模式里运行。 为了区别这种不同,在FLUENT中解释UDF和编译UDF的控制面板其形式是不同的。解释UDF的控制面板里有个“Compile按钮”,当点击“Compile按钮”时会实时编译源码。编译UDF的控制面板里有个“Open按钮”,当点击“Open按钮” 时会“打开”或连接目标代码库运行FLUENT(此时在运行FLUENT之前需要编译好目标码)。 当FLUENT程序运行中链接一个已编译好的UDF库时,和该共享库相关的东西都被存放到case文件中。因此,只要读取case文件,这个库会自动地链接到FLUENT 处理过程。同样地,一个已经经过解释的UDF文件在运行时刻被编译,用户自定义的C函数的名称与内容将会被存放到用户的case文件中。只要读取这个case文件,这些函数会被自动编译。 注:已编译的UDF所用到的目标代码库必须适用于当前所使用的计算机体系结构、操作系统以及FLUENT软件的可执行版本。一旦用户的FLUENT升级、操作系统改变了或者运行在不同的类型的计算机,必须重新编译这些库。 对一个简单解释型udf程序的详细解释 #include "udf.h" /*udf.h是一个头文件,如果不写的话就不能使用fluent udf中的宏,函数等*/ DEFINE_PROFILE(pressure_profile, t, i) /*是一个宏,本例中用来说明进口压力与垂直坐标变量(还可以是其他的变量)的关系。pressure_profile 是函数名,可随意指定。t的数据类型是Thread *t ,t 表示指向结构体thread(这里的thread表示边界上所有的网格面的集合)的指针。i的数据类型是Int,表示边界的位置?或者说是什么每个循环内对位置变量(这里应该是质心的纵坐标)设置的数值标签*/ { real x[ND_ND]; /* 定义了质心的三维坐标,数据类型为real*/ real y; /*定义了一个变量y, 数据类型为real */ face_t f; /*定义了一个变量f, 数据类型为face_t,也就是网格面的意思,即f代表一个网格单元的网格面*/ begin_f_loop(f, t) /*表示遍寻网格面,它的意思是说在计算的时候,要扫描所定义边界的所有网格面,对每个网格面都要赋值,值存储在F_PROFILE(f, t, i)中*/ { F_CENTROID(x,f,t); /*一个函数,它的意思是读取每个网格面质心的二维坐标,并赋值给x。x 为名称,接收三维坐标值。f为网格面(因为这里只是取的面的二维坐标,所以为f,如果是网格单元的话,这里就为c)。t为指向结构体thread(这里的thread 表示边界上所有的网格面的集合)的指针*/ y = x[1]; /*把质心的三维坐标的纵坐标的数值赋给y*/ F_PROFILE(f, t, i) = 1.1e5 - y*y/(.0745*.0745)*0.1e5; /*赋给每个网格面的数值与网格质心纵坐标的关系。其实就是赋给质心的速度值(这里只有大小)与质心纵坐标的函数关系,因为fluent在计算的时候是把数据存储到网格质心上的,所以网格质心的速度值就代表网格的速度值。这里有了网格的质心纵坐标,然后有了质心速度值与纵坐标的函数关系,那么每个进口网格面的速度值也就知道了。f依然代表网格面。t表示指向结构体thread(这里的thread表示边界上所有的网格面的集合)的指针。i每个循环内对位置变量(这里应该是质心的纵坐标)设置的数值标签*/ } end_f_loop(f, t)/*结束循环*/ } 整体来看:包括两个宏:DEFINE_PROFILE(pressure_profile, t, i)和beginend_f_loop(f, t)。两个函数:F_CENTROID(x,f,t)和F_PROFILE(f, t, i)。其他都是变量。 F l u e n t蒸发相变模拟U D F 经过几天的不懈折腾,终于找到一个较为完成的用于fluent蒸发相变模拟的udf的一个程序。而且注释相对完整。 #include "udf.h" //包括常规宏 #include "sg_mphase.h" // 包括体积分数宏CVOF(C,T) #define T_SAT 373 //定义蒸发温度100℃ #define LAT_HT 1.e3 //定义蒸发潜热J/Kg DEFINE_SOURCE(liq_src, cell, pri_th, dS, eqn) //液相质量源项UDF { Thread *mix_th, *sec_th; //定义计算区线指针 real m_dot_l; //定义液相质量转移 kg/(m2.s) mix_th = THREAD_SUPER_THREAD(pri_th); //指向混合区的主相即液相的指针 sec_th = THREAD_SUB_THREAD(mix_th, 1); //指向单相控制区的气相的指针,气相为第二相 if(C_T(cell, mix_th)>=T_SAT) //如果液相单元的温度高于蒸发温度,液相向气相的质量质量转移{ m_dot_l = -0.1*C_VOF(cell, pri_th)*C_R(cell, pri_th)* fabs(C_T(cell, mix_th) - T_SAT)/T_SAT; dS[eqn] = -0.1*C_R(cell, pri_th)*fabs(C_T(cell, mix_th) - T_SAT)/T_SAT; //定义源项对质量转移偏导} else { m_dot_l = 0.1*C_VOF(cell, sec_th)*C_R(cell, sec_th)* fabs(T_SAT-C_T(cell,mix_th))/T_SAT; //如果指向混合区液相的单元温度小于蒸发温度,气相向液相的质量转移,液相得 dS[eqn] = 0.;//由于是气相向液相转移,所以液相的质量源项对质量转移的偏导为零} return m_dot_l; } 对一个简单解释型u d f程序的详细解释 精品资料 对一个简单解释型udf程序的详细解释 #include "udf.h" /*udf.h是一个头文件,如果不写的话就不能使用fluent udf中的宏,函数等*/ DEFINE_PROFILE(pressure_profile, t, i) /*是一个宏,本例中用来说明进口压力与垂直坐标变量(还可以是其他的变量)的关系。pressure_profile 是函数名,可随意指定。t的数据类型是Thread *t ,t表示指向结构体thread(这里的thread表示边界上所有的网格面的集合)的指针。i的数据类型是Int,表示边界的位置?或者说是什么每个循环内对位置变量(这里应该是质心的纵坐标)设置的数值标签*/ { real x[ND_ND]; /* 定义了质心的三维坐标,数据类型为real*/ real y; /*定义了一个变量y, 数据类型为real */ face_t f; /*定义了一个变量f, 数据类型为face_t,也就是网格面的意思,即f代表一个网格单元的网格面 */ begin_f_loop(f, t) /*表示遍寻网格面,它的意思是说在计算的时候,要扫描所定义边界的所有网格面,对每个网格面都要赋值,值存储在F_PROFILE(f, t, i)中*/ { F_CENTROID(x,f,t); /*一个函数,它的意思是读取每个网格面质心的二维坐标,并赋值给x。x 为名称,接收三维坐标值。f为网格面(因为这里只是取的面的二维坐标,所以为f,如果是网格单元的话,这里就为c)。t为指向结构体thread(这里的thread表示边界上所有的网格面的集合)的指针*/ 仅供学习与交流,如有侵权请联系网站删除谢谢2 转帖 udf编译的经验总结 关于:"nmake"不是内部命令或外部命令,也不是可运行程序 我在编译UDF时出现如下错误: Error: Floating point error: divide by zero Error Object: () > "nmake"不是内部命令或外部命令,也不是可运行程序 Error Object: () Error: open_udf_library:系统找不到指定目录 Error: Floating point error: divide by zero Error Object: () 我原来装的时turbo c/c++编译器,可能时环境变量没有设好的缘故。换用vc++6.0以后就没有这个问题了,另外,我用的是fluent6.2.16,希望遇到同样问题的同学借鉴一下,呵 呵。 udf编译的经验总结1)安装vc时候,只要选择了“环境变量”这一项,就不需要在“我 的电脑 > 属性 > 高级 > 环境变量”中 更改“include”“lib”“path”变量的值,保持默认状态即可; 2)如果是fluent6.1以上的版本,读入你的case文件,只要在 define->user-defined->functions->complied中, add你的udf源文件(*.c)和“udf.h”头文件,然后确定用户共享库(library name)的 名称,按“build”,就 相当于nmake用户共享库;在这一步中常出现的错误: (a)(system "move user_nt.udf libudf\ntx86\2d")0 (system "copy C:\Fluent.Inc\fluent6.1.22\src\makefile_nt.udf libudf\ntx86\2d\makefile")已复制 1 个文件。 (chdir "libudf")() (chdir "ntx86\2d")() 'nmake' 不是内部或外部命令,也不是可运行的程序 或批处理文件。 'nmake' 不是内部或外部命令,也不是可运行的程序 第七章UDF的编译与链接 编写好UDF件(详见第三章)后,接下来则准备编译(或链接)它。在7.2或7.3节中指导将用户编写好的UDF如何解释、编译成为共享目标库的UDF。 _ 第 7.1 节: 介绍 _ 第 7.2 节: 解释 UDF _ 第 7.3 节: 编译 UDF 7.1 介绍 解释的UDF和编译的UDF其源码产生途径及编译过程产生的结果代码是不同的。编译后的UDF由C语言系统的编译器编译成本地目标码。这一过程须在FLUENT运行前完成。在FLUENT运行时会执行存放于共享库里的目标码,这一过程称为“动态装载”。 另一方面,解释的UDF被编译成与体系结构无关的中间代码或伪码。这一代码调用时是在内部模拟器或解释器上运行。与体系结构无关的代码牺牲了程序性能,但其UDF可易于共享在不同的结构体系之间,即操作系统和FLUENT版本中。如果执行速度是所关心的,UDF文件可以不用修改直接在编译模式里运行。 为了区别这种不同,在FLUENT中解释UDF和编译UDF的控制面板其形式是不同的。解释UDF的控制面板里有个“Compile按钮”,当点击“Compile按钮”时会实时编译源码。编译UDF的控制面板里有个“Open 按钮”,当点击“Open按钮”时会“打开”或连接目标代码库运行 FLUENT(此时在运行FLUENT之前需要编译好目标码)。 当FLUENT程序运行中链接一个已编译好的UDF库时,和该共享库相关的东西都被存放到case文件中。因此,只要读取case文件,这个库会自动地链接到FLUENT处理过程。同样地,一个已经经过解释的UDF文件在运行时刻被编译,用户自定义的C函数的名称与内容将会被存放到用户的case文件中。只要读取这个case文件,这些函数会被自动编译。 注:已编译的UDF所用到的目标代码库必须适用于当前所使用的计算机体系结构、操作系统以及FLUENT软件的可执行版本。一旦用户的FLUENT升级、操作系统改变了或者运行在不同的类型的计算机,必须重新编译这些库。 UDF必须用DEFINE宏进行定义,DEFINE宏的定义是在udf.h文件中。因此,在用户编译UDF之前,udf.h文件必须被放到一个可被找到的路径,或者放到当前的工作目录中。 udf.h文件放置在: path/Fluent.Inc/fluent6.+x/src/udf.h 其中path是Fluent软件的安装目录,即Fluent.Inc目录。X代表了你所安装的版本号。 通常情况下,用户不应该从安装默认目录中复制udf.h文件。编译器先在当前目录中寻找该文件,如果没找到,编译器会自动到/src目录下寻找。如果你升级了软件的版本,但是没有从你的工作目录中删除旧版本的udf.h文件,你则不能访问到该文件的最新版本。在任何情 2.3. Model-Specific DEFINE Macros The DEFINE macros presented in this section are used to set parameters for a particular model in ANSYS Fluent. Table 2.2: Quick Reference Guide for Model-Specific DEFINE Functions – Table 2.6: Quick Reference Guide for Model-Specific DEFINE Functions MULTIPHASE ONLY provides a quick reference guide to the DEFINE macros, the functions they are used to define, and the dialog boxes where they are activated in ANSYS Fluent. Definitions of each DEFINE macro are listed in udf.h. For your convenience, they are listed in Appendix B. DEFINE_ANISOTROPIC_CONDUCTIVITY DEFINE_CHEM_STEP DEFINE_CPHI DEFINE_DIFFUSIVITY DEFINE_DOM_DIFFUSE_REFLECTIVITY DEFINE_DOM_SOURCE DEFINE_DOM_SPECULAR_REFLECTIVITY DEFINE_ECFM_SOURCE DEFINE_ECFM_SPARK_SOURCE DEFINE_EC_RATE DEFINE_EMISSIVITY_WEIGHTING_FACTOR DEFINE_FLAMELET_PARAMETERS DEFINE_ZONE_MOTION DEFINE_GRAY_BAND_ABS_COEFF DEFINE_HEAT_FLUX DEFINE_IGNITE_SOURCE DEFINE_NET_REACTION_RATE DEFINE_NOX_RATE DEFINE_PDF_TABLE DEFINE_PR_RATE DEFINE_PRANDTL UDFs DEFINE_PROFILE DEFINE_PROPERTY UDFs DEFINE_REACTING_CHANNEL_BC DEFINE_REACTING_CHANNEL_SOLVER DEFINE_SBES_BF DEFINE_SCAT_PHASE_FUNC DEFINE_SOLAR_INTENSITY DEFINE_SOLIDIFICATION_PARAMS DEFINE_SOOT_MASS_RATES DEFINE_SOOT_NUCLEATION_RATES DEFINE_SOOT_OXIDATION_RATE DEFINE_SOOT_PRECURSOR DEFINE_SOURCE DEFINE_SOX_RATE DEFINE_SPARK_GEOM (R14.5 spark model) DEFINE_SPECIFIC_HEAT DEFINE_SR_RATE DEFINE_THICKENED_FLAME_MODEL DEFINE_TRANS UDFs DEFINE_TRANSIENT_PROFILE DEFINE_TURB_PREMIX_SOURCE DEFINE_TURB_SCHMIDT UDF DEFINE_TURBULENT_VISCOSITY DEFINE_VR_RATE DEFINE_WALL_FUNCTIONS DEFINE_WSGGM_ABS_COEFF Table 2.2: Quick Reference Guide for Model-Specific DEFINE Functions Function DEFINE Macro Dialog Box Activated In anisotropic thermal conductivity DEFINE_ANISOTROPIC_CONDUCTIVITY Create/Edit Materials mixing constant DEFINE_CPHI User-Defined Function Hooks homogeneous net mass reaction rate for DEFINE_CHEM_STEP User-Defined Function Hooks all species, integrated over a time step 第二章.UDF的C语言基础 本章介绍了UDF的C语言基础 2.1引言 2.2注释你的C代码 2.3FLUENT中的C数据类型 2.4常数 2.5变量 2.6自定义数据类型 2.7强制转换 2.8函数 2.9数组 2.10指针 2.11声明 2.12常用C操作符 2.13C库函数 2.14用#define实现宏置换 2.15用#include实现文件包含 2.16与FORTRAN比较 2.1引言 本章介绍了C语言的一些基本信息,这些信息对处理FLUENT的UDF很有帮助。本章首先假定你有一些编程经验而不是C语言的初级介绍。本章不会介绍诸如while-do循环,联合,递归,结构以及读写文件的基础知识。如果你对C语言不熟悉可以参阅C语言的相关书籍。 2.2注释你的C代码 熟悉C语言的人都知道,注释在编写程序和调试程序等处理中是很重要的。注释的每一行以“/*”开始,后面的是注释的文本行,然后是“*/”结尾 如:/* This is how I put a comment in my C program */ 2.3FLUENT的C数据类型 FLUENT的UDF解释程序支持下面的C数据类型: Int:整型 Long:长整型 Real:实数 Float:浮点型 Double:双精度 Char:字符型 注意:UDF解释函数在单精度算法中定义real类型为float型,在双精度算法宏定义real为double型。因为解释函数自动作如此分配,所以使用在UDF中声明所有的float和double 数据变量时使用real数据类型是很好的编程习惯。 2.4常数 常数是表达式中所使用的绝对值,在C程序中用语句#define来定义。最简单的常数是十进制整数(如:0,1,2)包含小数点或者包含字母e的十进制数被看成浮点常数。按惯例,常数的声明一般都使用大写字母。例如,你可以设定区域的ID或者定义YMIN和YMAX 如下:#define WALL_ID 5 #define YMIN 0.0 #define YMAX 0.4064 2.5变量 变量或者对象保存在可以存储数值的内存中。每一个变量都有类型、名字和值。变量在使用之前必须在C程序中声明。这样,计算机才会提前知道应该如何分配给相应变量的存储类型。 2.5.1声明变量 变量声明的结构如下:首先是数据类型,然后是具有相应类型的一个或多个变量的名字。变量声明时可以给定初值,最后面用分号结尾。变量名的头字母必须是C所允许的合法字符,变量名字中可以有字母,数字和下划线。需要注意的是,在C程序中,字母是区分大小写的。下面是变量声明的例子: int n; /*声明变量n为整型*/ int i1, i2; /*声明变量i1和i2为整型*/ float tmax = 0.; /* tmax为浮点型实数,初值为0 */ real average_temp = 0.0; /* average_temp为实数,赋初值为0.1*/ 2.5.2局部变量 局部变量只用于单一的函数中。当函数调用时,就被创建了,函数返回之后,这个变量就不存在了,局部变量在函数内部(大括号内)声明。在下面的例子中,mu_lam和temp是局部变量。 DEFINE_PROPERTY(cell_viscosity, cell, thread) { real mu_lam; real temp = C_T(cell, thread); if (temp > 288.) mu_lam = 5.5e-3; else if (temp > 286.) mu_lam = 143.2135 - 0.49725 * temp; else mu_lam = 1.; UDF(用户自定义特征)的创建和使用 bysgjunfeng 1、什么是UDF? 2、UDF使用过程 2.1创建参照模型 2.2创建UDF 2.3放置UDF 3、替换UDF 4、UDF搭配族表的使用 1、什么是UDF? UDF即用户自定义特征。也就是说可以将数个特征组合起来形成一个新的自己定义的特征,并且会保存在UDF数据库中,随时调入。(类似于AutoCAD中的动态 块) 用户自定义特征用来复制相同或相近外形的特征组,此功能类似于“特征复制”,但又有所不同,功能上比较全面、灵活,但相应的步骤比较繁琐。因此,如果会用特征复制,特别是特征复制里的新参考,将会对此命令有所帮助。 UDF和特征复制的最大区别有以下两点: ●特征复制仅适用于当前的模型,而UDF可以适用与不同的模型。 ●特征复制的局部组无法用另一个局部组替换,而UDF可被另一个UDF替换 UDF的使用流程大体可分为三步:规划并创建参照模型——建立UDF——放置UDF,下面我们用一个简单的例子来说明如何使用UDF。 2、UDF使用过程 在使用UDF之前,首先要创建UDF,缺省时,Pro/ENGINEER将创建的UDF保存在当前工作目录中。为此,可创建UDF库目录,要访问Pro/ENGINEER 的UDF库目 录,可指定带置文件选项"pro_group_dir"的目录名。这样,每次插入UDF时将 自动打开该目录。 建立好参照模型后,单击单击"工具"(Tools)>"UDF 库"(UDF Library)。出现下 图所示UDF菜单 该对话框各选项含义如下: 创建 (Create):建立新的UDF并将其添加到UDF库。 修改 (Modify):修改现有的 UDF。如果有参照零件,系统将在单独的零件窗口 显示 UDF。 列表 (List):列出当前目录中的所有UDF文件,用于查看UDF信息。 数据库管理 (Dbms):管理当前UDF数据库。即对当前UDF数据库中的UDF进行保存、另存为、备份、重命名、拭除、清除、删除等操作。 集成 (Integrate):解决源 UDF 和目标 UDF 之间的差异。 以下以实例说明如何创建及使用UDF。 假定背景:在很多时候建立零件模型时,零件的粗坯都是一个长方体,并且要求该长方体关于基准平面左右前后对称(如下图所示),这就要求在草绘里绘制矩形时要多绘制两条中心线或多标两个尺寸。下面我们将演示如何将这样的长方体 作为UDF来使用。 本实例重在介绍UDF的使用过程,希望能起到抛砖引玉的作用,使大家在实际应 我接触UDF的时间不算长,2007年7月份开始看UDF的中文帮助,花了一周时间大体看完后,第一感觉:不难啊,至少不像以前别人给我讲的很高深的样子。然后就是UDF编程,直到10月底吧。然后用的时间就不多了。然后就是这两周,我马上就要研究生毕业了,可能这周结束后用UDF编程的可能性会很小了,所以想写点东西,给刚刚学UDF编程的人,希望对大家有用。对于UDF高手,估计是不用向下看了。 UDF框架 光看书,感觉UDF不难。看例子,有些看个四五遍之后才能差不多看懂。原来,得靠UDF帮助。我主要用的是fluent v6.3自带的html格式的帮助,里面东西很全,当然也包括UDF Manual。里面自带的search功能相当好,只是要注意用好+或-号(逻辑符号),另外,这个功能似乎有些浏览器支持不太好,不过基本上用IE不太容易出问题。 对于从零开始学习UDF,建议还是先看一下UDF中文帮助,我估计大家知道的都是马世虎翻译的那本吧,感觉挺好。(没想到马世虎跟我是校友,去年给安世亚太投过一份简历,他给我打过电话,当时一阵兴奋,呵呵。) 对于只涉及到边界条件或物性等的UDF,一般用interpret就可以的,这些我觉得只需要根据例子改一下就是了。 $$ 对于要添加UDS方程的,相对难一点。我编程用的是三到五个UDS,几十个UDM。一开始编程时,没有头绪,后来看别人编的,才慢慢发现了一些基本思路。比如,可以用枚举定义UDS 或UDM,这样用起来方便。 enum{ NP, RHOH2O_Y_UP_X, RHOH2O_Y_UP_Y, RHOH2O_Y_UP_Z, N_REQUIRED_UDS };//枚举UDS变量名 对于UDM,则用N_REQUIRED_UDM代表个数。 然后在INIT与ADJUST函数中,检查变量个数时则比较方便,如: DEFINE_INIT(init_parameter,domain) { if (n_uds < N_REQUIRED_UDS) Error(”Not enough user defined scalars!(init)\n”); if (n_udm /* reflect boundary condition for inert particles */ #include "udf.h" DEFINE_DPM_BC(bc_reflect,p,t,f,f_normal,dim) { real alpha; /* angle of particle path with face normal */ real vn=0.; real normal[3]; real vt[3]; real vn1[3]; real angle=0; int i, idim=dim; real NV_VEC(x); #if RP_2D /* dim is always 2 in 2D compilation. Need special treatment for 2d axisymmetric and swirl flows */ if (rp_axi_swirl) { real R=sqrt(P_POS(p)[1]*P_POS(p)[1]+P_POS(p)[2]*P_POS(p)[2]); if (R>1.e-20) { idim=3; normal[0]=f_normal[0]; normal[1]=(f_normal[1]*P_POS(p)[1])/R; normal[2]=(f_normal[1]*P_POS(p)[2])/R; } else { for (i=0; i 法一:边界造波法 程序一:inlet.c #include "udf.h" /* #include 7 自定义函数(UDF) 7.1,概述 用户自定义函数(User-Defined Functions,即UDFs)可以提高FLUENT程序的标准计算功能。它是用C语言书写的,有两种执行方式:interpreted型和compiled型。Interpreted型比较容易使用,但是可使用代码(C语言的函数等)和运行速度有限制。Compiled型运行速度快,而且也没有代码使用范围的限制,但使用略为繁琐。 我们可以用UDFs来定义: a)边界条件 b)源项 c)物性定义(除了比热外) d)表面和体积反应速率 e)用户自定义标量输运方程 f)离散相模型(例如体积力,拉力,源项等) g)代数滑流(algebraic slip)混合物模型(滑流速度和微粒尺寸) h)变量初始化 i)壁面热流量 j)使用用户自定义标量后处理 边界条件UDFs能够产生依赖于时间,位移和流场变量相关的边界条件。例如,我们可以定义依赖于流动时间的x方向的速度入口,或定义依赖于位置的温度边界。边界条件剖面UDFs用宏DEFINE_PROFILE定义。有关例子可以在5.1和6.1中找到。源项UDFs可以定义除了DO辐射模型之外的任意输运方程的源项。它用宏DEFINE_SOURCE 定义。有关例子在5.2和6.2中可以找到。物性UDFs可用来定义物质的物理性质,除了比热之外,其它物性参数都可以定义。例如,我们可以定义依赖于温度的粘性系数。它用宏DEFINE_PROPERTY定义,相关例子在6.3中。反应速率UDFs用来定义表面或体积反应的反应速率,分别用宏DEFINE_SR_RA TE和DEFINE_VR_RA TE定义,例子见6.4。离散相模型用宏DEFINE_DPM定义相关参数,见5.4。UDFs还可以对任意用户自定义标量的输运方程进行初始化,定义壁面热流量,或计算存贮变量值(用用户自定义标量或用户自定义内存量)使之用于后处理。相关的应用见于5.3,5.5,5.6和5.7。 UDFs有着广泛的应用,本文并不能一一叙述。如果在使用中遇到问题,可以联系FLUENT技术支部门要求帮助。在此推荐一个网站https://www.doczj.com/doc/a416730192.html,,上面有FLUENT论坛,可进行相关询问和讨论。 7.1.1 书写UDFs的基本步骤 在使用UDFs处理FLUENT模型的过程中,我们一般按照下面五步进行: 1.概念上函数设计 2.使用C语言书写 3.编译调试C程序 4.执行UDF 5.分析与比较结果 第一步分析我们所处理的模型,目的是得到我们要书写的UDF的数学表达式。第二步将数学表达式转化成C语言源代码。第三步编译调试C语言源代码。第四步在FLUENT中执行UDF。最后一步,将所得到的结果与我们要求的进行比较,如果不满足要求,则需要重复上面的步骤,直到与我们期望的吻合为止。 7.1.2 Interpreted型与Compiled型比较 Compiled UDFs执行的是机器语言,这和FLUENT本身运行的方式是一样 的。一个叫做Makefile的过程能够激活C编辑器,编译我们的C语言代码,从而建立一个目标代码库,目标代码库中包含有高级C语言的低级机器语言诠释。在运行的时候,一个叫做“dynamic loading”的过程将目标代码库与FLUENT 连接。一旦连接之后,连接关系就会在case文件中与目标代码库一起保存,所以读入case文件时,FLUENT就会自动加载与目标代码库的连接。这些库的建立是基于特定计算机和特定FLUENT版本的,所以升级FLUENT版本后,就必须重新建立相应的库。 相反,Interpreted UDFs是在运行的时候直接装载编译C语言代码的。在这种情况下,生成的机器代码不依赖于计算机和FLUENT版本。编译后,函数信息将会保存在case文件中,所以读入case文件时,FLUENT也会自动加载相应的函数。Interpreted UDFs具有较强的可移植性,而且编译比较简单。对于简单的UDFs,如果对运行速度要求不高,一般就采用Interpreted型的。 下面列出的是两种UDFs的一些特性: UDF中文教程 目录 第一章. 介绍 (4) 1.1什么是UDF? (4) 1.2为什么要使用UDF? (4) 1.3 UDF的局限 (5) 1.4Fluent5到Fluent6UDF的变化 (5) 1.5 UDF基础 (6) 1.6 解释和编译UDF的比较 (8) 1.7一个step-by-stepUDF例子 (9) 第二章.UDF的C语言基础 (16) 2.1引言 (16) 2.2注释你的C代码 (17) 2.3FLUENT的C数据类型 (17) 2.4常数 (17) 2.5变量 (17) 2.6自定义数据类型 (20) 2.7强制转换 (20) 2.8函数 (20) 2.9 数组 (20) 2.10指针 (21) 2.11 控制语句 (22) 2.12常用的C运算符 (24) 2.13 C库函数 (24) 2.14 用#define实现宏置换 (26) 2.15 用#include实现文件包含 (27) 2.16 与FORTRAN 的比较 (27) UDF 第3章写UDF (27) 3.1概述(Introduction) (28) 3.2写解释式UDF的限制 (28) 3.3 FLUENT求解过程中UDF的先后顺序 (29) 3.4 FLUENT 网格拓扑 (31) 3.5 FLUENT数据类型 (32) 3.6 使用DEFINE Macros定义你的UDF (33) 3.7在你的UDF源文件中包含udf.h文件 (34) 3.8在你的函数中定义变量 (34) 3.9函数体(Functin Body) (35) 3.10 UDF任务(UDF Tasks) (35) 3.11为多相流应用写UDF (41) 3.12在并行下使用你的UDF (50) 第四章DEFINE宏 (51) 4.1 概述 (51) 4.2 通用解算器DEFINE宏 (52) 4.3 模型指定DEFINE宏 (61) 对于只涉及到边界条件或物性等的UDF,一般用interpret就可以的,这些我觉得只需要根据例子改一下就是了。 $$ 对于要添加UDS方程的,相对难一点。我编程用的是三到五个UDS,几十个UDM。一开始编程时,没有头绪,后来看别人编的,才慢慢发现了一些基本思路。比如,可以用枚举定义UDS或UDM,这样用起来方便。 enum{ NP, RHOH2O_Y_UP_X, RHOH2O_Y_UP_Y, RHOH2O_Y_UP_Z, N_REQUIRED_UDS };//枚举UDS变量名 对于UDM,则用N_REQUIRED_UDM代表个数。 1. 然后在INIT与ADJUST函数中,检查变量个数时则比较方便,如: DEFINE_INIT(init_parameter,domain) { if (n_uds < N_REQUIRED_UDS) Error("Not enough user defined scalars!(init)\n"); if (n_udm 第八章 在FLUENT中激活你的UDF 一旦你已经编译(并连接)了你的UDF,如第7章所述,你已经为在你的FLUENT模型中使用它做好了准备。根据你所使用的UDF,遵照以下各节中的指导。 z8.1节激活通用求解器UDF z8.2节激活模型明确UDF z8.3节激活多相UDF z8.4节激活DPM UDF 8.1 激活通用求解器UDF 本节包括激活使用4.2节中宏的UDF的方法。 8.1.1 已计算值的调整 一旦你已经使用7.2节和7.3节中概括的方法之一编译(并连接)了调整已计算值UDF,这一UDF在FLUENT中将成为可见的和可选择的。你将需要在User-Defined Function Hooks面板的Adjust Function下拉菜单(图8.1.1)中选择它。 调整函数(以DEFINE_ADJUST宏定义)在速度、压力及其它数量求解开始之前的一次迭代开始的时候调用。例如,它可以用于在一个区域内积分一个标量值,并根据这一结果调整边界条件。有关DEFINE_ADJUST宏的更多内容将4.2.1节。调整函数在什么地方适合求解器求解过程方面的信息见3.3节。 8.1.2 求解初始化 一旦你已经使用7.2节和7.3节中概括的方法之一编译(并连接)了求解初始化UDF,这一UDF在FLUENT中将成为可见的和可选择的。你将需要在User-Defined Function Hooks面板的Initialization Function下拉菜单(图8.1.1)中选择它。 求解初始化UDF使用DEFINE_INIT宏定义。细节见4.2.2节。 8.1.3 用命令执行UDF 一旦你已经使用7.2节和7.3节中概括的方法之一编译(并连接)了你的UDF,你可以在Execute UDF On Demand面板中选择它(图8.1.2),以在某个特定的时间执行这个UDF,而不是让FLUENT在整个计算中执行它。 点击Execute按纽让FLUENT立即执行它。 以命令执行的UDF用DEFINE_ON_COMMAND宏定义,更多细节见4.2.3节 8.1.4 从case和data文件中读出及写入 一旦你已经使用7.2节和7.3节中概括的方法之一编译(并连接)了一个将定制片段从case 和data文件中读出或写入的UDF,这一UDF在FLUENT中将成为可见的和可选择的。你将需要在User-Defined Function Hooks面板(图8.1.1)中选择它。Fluent_UDF_第七章_UDF的编译与链接
对一个简单解释型udf程序的详细解释
蒸发过程UDF程序fluent
对一个简单解释型udf程序的详细解释教学文稿
udf编译的经验总结
Fluent UDF 中文教程UDF第7章 编译与链接
udf宏的功能
fluent UDF第二章
UDF(用户自定义特征)的创建和使用
udf使用心得
UDF程序
Fluent UDF造波源程序集
UDF的宏用法及相关算例
Fluent UDF教程
udf-使用心得
Fluent中的UDF详细中文教程(8)
相关主题
文本预览