
重庆市生产总值与城市人均可支配收入
的关系分析及讨论
摘要:一般来说,人均可支配收入越高,人民生活水平则越高。而该地区的生产总值又反应了当下该地区总的经济发展状况,即人均可支配收入的多少。所以通过研究地区生产总值来分析了解该地区的人民生活水平就存在很大的实际意义。本论文通过对重庆市从1985年到2010年的生产总值与城市人均可支配收入的实际调查统计数据(见表1)进行分析并找出其间可能存在的关系,并由此通过当下生产总值来评价人民的生活水平。我们得出结论:重庆市的生产总值与城市人均可支配收入确实存在一定的关系,并且我们知道是线性关系,同时得到简单一元统计回归模型
x
y247404866
.0
268173098
.1+
=
其中y
指城市人均可支配收入,
x
指重庆市生产总值。通过这个关系式我们就可以很容
易地由当年重庆市的生产总值推算出城市人均可支配收入,即可估计出当下人民的生活水平。
由于数据的有限性及统计数据过程中存在的误差影响,对本问题的研究会造成一定的影响。另外,城市人均可支配收入的影响因素有很多,也很复杂,仅仅只从分析该地区的生产总值来评价人民的生活水平是远远不够的。但是我们可以通过以上简单的统计回归模型定性的对人民的生活水平进行分析,很方便地即可了解到当下人民的生活状况并采取相应措施。
关键字:重庆市生产总值城市人均可支配收入一元统计回归模型数据分析
一、引言
随着目前科技和经济的快速发展,寻找一个衡量和预测人民生活水平的标准就非常有必要了。我们知道,一个地区的生产总值是指本地区所有常住单位在一定时期内生产活动的最终成果,地区生产总值等于各产业增加值之和。可见一个地区的生产总值能很好的反应当地经济的发展现状,而个人可支配收入的多少又刚好与本地的经济发展状况和人口有关。另外,人均可支配收入是指个人收入扣除向政府缴纳的个人所得税、遗产税和赠与税、不动产税、
人头税、汽车使用税以及交给政府的非商业性费用等以后的余额,个人可支配收入被认为是消费开支的最重要的决定性因素。所以,人均可支配收入常被用来衡量一国生活水平的变化情况。
综上所述,为了方便地知道一个地区人民的生活水平的高低,我们可以通过研究当地的人均可支配收入,继而可以通过研究本地的生产总值与人均可支配收入的关系来了解推测该地区人民的生活状况,为该地区在将来采取何种措施给出合理的理论依据。
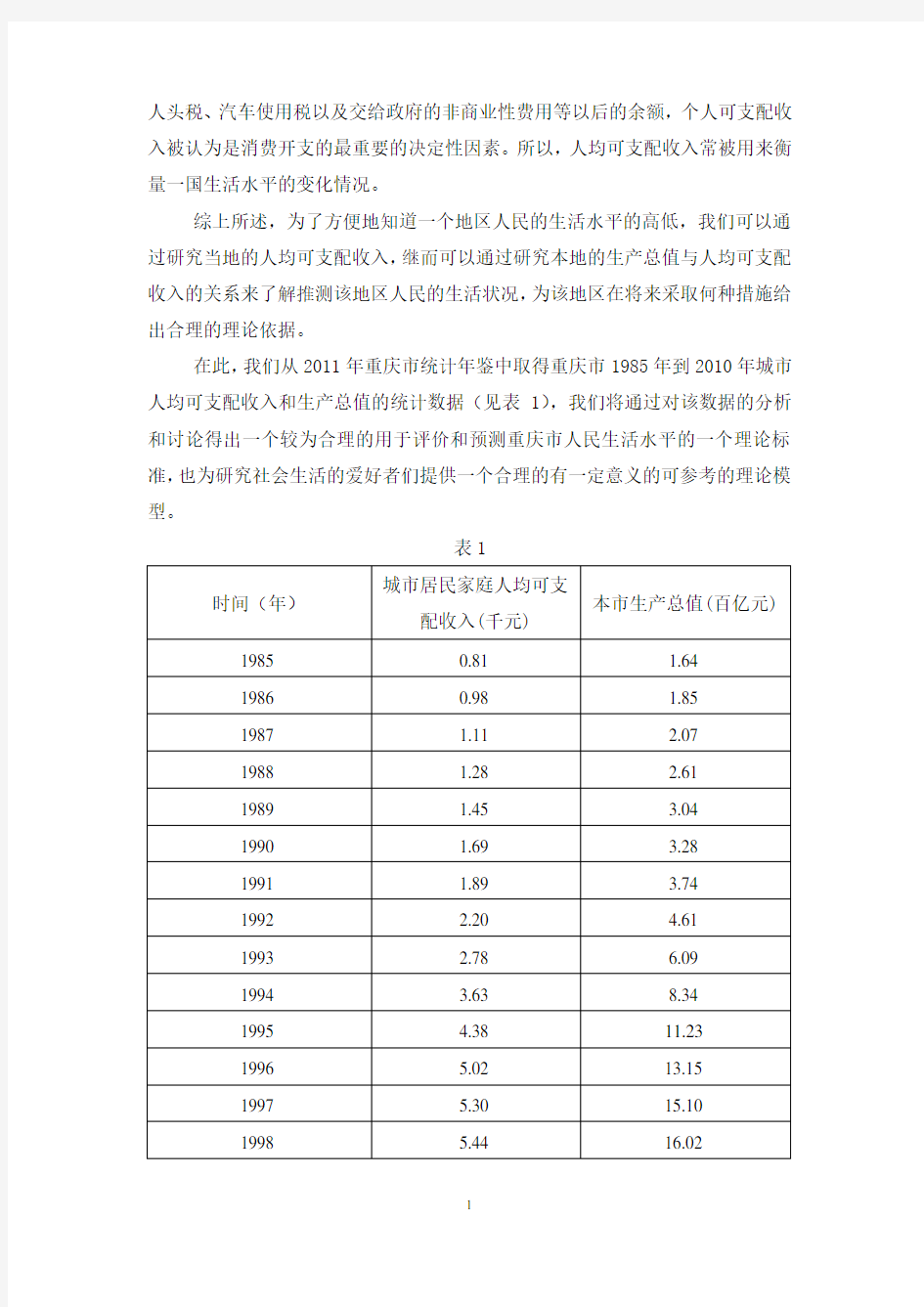
在此,我们从2011年重庆市统计年鉴中取得重庆市1985年到2010年城市人均可支配收入和生产总值的统计数据(见表1),我们将通过对该数据的分析和讨论得出一个较为合理的用于评价和预测重庆市人民生活水平的一个理论标准,也为研究社会生活的爱好者们提供一个合理的有一定意义的可参考的理论模型。
表1
时间(年)城市居民家庭人均可支
配收入(千元)
本市生产总值(百亿元)
1985 0.81 1.64 1986 0.98 1.85 1987 1.11 2.07 1988 1.28 2.61 1989 1.45 3.04 1990 1.69 3.28 1991 1.89 3.74 1992 2.20 4.61 1993 2.78 6.09 1994 3.63 8.34 1995 4.38 11.23 1996 5.02 13.15 1997 5.30 15.10 1998 5.44 16.02
1999 5.83 16.63 2000 6.18 17.91 2001 6.57 19.77 2002 7.24 22.33 2003 8.09 25.56 2004 9.22 30.35 2005 10.24 34.68 2006 11.57 39.07 2007 13.72 46.76 2008 15.71 57.94 2009 17.19 65.30 2010
19.10
79.26
数据来源:重庆市2011年统计年鉴。
二、数据分析及理论模型的建立
首先为了对数据的整体把握,我们在Excel 工作表中对数据分别作出时间对生产总值和城市人均可支配收入的散点图,得如下图一、图二:
生产总值散点图
0.00
10.0020.0030.0040.0050.0060.0070.0080.0090.001980
1985
1990
19952000
2005
2010
2015
时间/年
生产总值/百亿元
图一 生产总值散点图
图二 城市人均可支配收入散点图
由图一和图二我们可以清楚地看到,随着时间的推移城市人均可支配收入和城市生产总值有大致相同的增长趋势。那么它们之间是否存在一种特殊的关系呢?这将是我们要研究的主要问题。
在Excel 工作表中对城市人均可支配收入和城市生产总值的统计数据作出关系散点图(如图三):
生产总值与人均可支配输入散点图
0.00
5.0010.0015.0020.0025.000.00
10.0020.0030.0040.0050.0060.0070.0080.0090.00
生产总值/百亿元
人均可支配输入/千元
图三 生产总值与人均可支配输入散点图
由图三易知重庆市的生产总值与城市人均可支配输入之间存在明显的线性
相关性。考虑到生产总值的复杂性和问题的研究目的,在此我们选择城市人均可
城市人均可支配收入散点图
0.005.0010.0015.0020.0025.001980
1985
1990
199520002005
2010
2015
时间/年
城市人均可支配收入/千元
支配输入
y 作为因变量,生产总值x 作为自变量,可建立如下简单一元统计回
归模型(1)
εββ++=x y 10 (1)
其中
ε为随机误差,如果模型选择合适,ε应大致服从均值为0的正态分布。
在Excel 工作表中对统计数据用最小二乘法作线性拟合,得到如下结果(其中显著水平为α=0.01)(见表2):
表2
Coefficients 标准误差 t Stat P-value Intercept 1.268173098 0.172290259 7.360677862 1.3342E-07 X Variable 1 0.247404866 0.005812789 42.56216183
4.0488E-24
Lower 95% Upper 95% 下限 99.0% 上限 99.0% 0.912583482 1.623762714 0.786287667 1.75005853 0.235407859 0.259401873 0.231146847
0.263662885
从表2知,用最小二乘法求得0β,1β的估计值为:
268173098.10=β,247404866.01=β
即得到一元线性回归模型(2)
x y 247404866.0268173098.1+= (2)
同时,由表2还可知在显著性水平α=0.01下估计值0β,1β均是显著的。且在其显著性水平α下0β,1β的估计置信区间分别为[0.231146847, 0.263662885],[0.786287667, 1.75005853]。
对模型(2)进行线性回归方差分析,得(见表3):
表3
生产总值与城市人均可支配输入回归模型的方差分析表
df SS MS F Significance
F 回归 1 690.3395477 690.3395477 1811.53762 4.04878E-24 残差 24 9.145903989 0.381079333 总计 25 699.4854517
由方差分析表知道模型的P 值等于-24104.04878?,这个值远远小于给定的显
著性水平α=0.01。因此,我们认为在显著性水平0.01下模型是显著的,即线性
回归模型(2)是有意义的。并且,我们查表知显著水平为0.01的F(1,24)<8.1,从表3中知道F=1811.53762。可见,F远远大于F(1,24),这同样说明在显著性水平0.01下模型(2)是显著的。
同时对模型进行进一步的直观地检验,有模型得到预测数据
y'及残差z 如表4(为了方便比较我们将真实值也加入表格中):
表4
时间(年)城市居民家庭人
均可支配收入y
(千元)
预测
y'残差z
1985 0.81 1.674709 -0.86231
1986 0.98 1.724882 -0.74089
1987 1.11 1.779633 -0.67092
1988 1.28 1.914568 -0.63668
1989 1.45 2.019665 -0.57069
1990 1.69 2.079043 -0.38791
1991 1.89 2.193913 -0.30201
1992 2.20 2.409501 -0.21417
1993 2.78 2.773706 0.006914
1994 3.63 3.33054 0.30379
1995 4.38 4.046678 0.328752
1996 5.02 4.521844 0.501116
1997 5.30 5.003368 0.298682
1998 5.44 5.232539 0.210301
1999 5.83 5.383011 0.445419
2000 6.18 5.699194 0.477106
2001 6.57 6.159021 0.413279
2002 7.24 6.792377 0.445693
2003 8.09 7.591149 0.502521
2004 9.22 8.775872 0.445088
2005 10.24 9.847481 0.396509
2006 11.57 10.93485 0.63489
2007 13.72 12.83715 0.878104
2008 15.71 15.60197 0.10677
2009 17.19 17.42374 -0.23264
2010 19.10 20.87644 -1.77671
作出残差散点图(见图四)及城市居民家庭人均可支配收入真实值与预测值散点图(见图五):
残差散点图
-2
-1012
0.0020.00
40.00
60.00
80.00
100.00
生产总值X
残差
图四
居民家庭人均可支配收入真实值
与预测值散点图
0.00
5.0010.0015.0020.0025.000.0020.0040.0060.0080.00100.0
生产总值X
城市居民家庭人均可支配收入
Y
预测 Y
图五
从表4和图四、图五可以清楚地看到由模型(2)得到的结果非常里想,残差均落在-2与2之间,通过对真实值与预测值的比较所得模型结果均在允许范围内。
综上所诉,模型(2)通过了检验,由此说明该模型满足要求,可以用来对原研究问题进行讨论分析。
三、问题的实际讨论与应用
由以上模型(2),我们已经得到了一个具有一定理论依据的重庆市的生产总值与城市人均可支配收入的关系表达式。因为国民经济各行业的增加值之和就
等于地区生产总值,所以我们从地区生产总值数值的大小可以清楚地看到当地时下的一个总的经济状况。人均可支配收入不仅与生产总值有关,还与当地人口及其它因素有关,现在我们得到了一个生产总值与城市人均可支配收入的关系表达式,就可通过地区生产总值方便的了解到本地的人均可支配收入的多少,即可知道当下人民生活水平的高低。
我们所得到的研究模型非常简单,忽略了许多复杂的因素,使得人们能很容易地通过地区生产总值定性的了解到当地的一个居民生活状况。但是由于模型建立过程中数据的有限性及其它不可预测误差的影响,使得该模型有一定的缺陷,有待进一步的改进和完善。本模型可以作为对重庆市总的经济状况与人民生活水平高低研究的一个参考,可在该模型的基础上考虑更多的因素,使得模型得到完善,得出一个完整的人民生活水平影响研究体系。
参考文献:
[1]姜启源等.数学模型,高等教育出版社.北京,2011年1月:325-356.
[2]百度文库,https://www.doczj.com/doc/8f7330237.html,/tjnj/2011/yearbook/.
[3]茆诗松,程依明,濮晓龙.概率论与数理统计,高等教育出版社.北京,2011.2:448-466.
[4]孙荣恒.应用数理统计(第二版),科学出版社.北京,2002.
[5]克拉梅.统计的数学方法,魏宗舒等译,上海科学技术出版社.上海,1966.
谈数理统计的社会应用 姓名:胡强达专业班级:理科0916班学号:3090103757 数理统计是研究随机现象的统计规律性的一门数学学科。它以概率论为基础,研究如何合理有效地收集受到随机性影响的数据,如何对所获得的数据进行整理和分析,从而为随机现象选择合适的数学模型并提供检验的方法,在此基础上对随机现象的性质、特点和统计规律做出推断和预测,直至为决策提供依据和建议。 19世纪时,比利时的凯特勒(L.A.Quetelet)将概率论等数学原理引入社会经济现象的统计研究,将概率论原理应用到了人口、人体测量和犯罪等问题的研究,并对观测的数据进行误差分析,创立了数理统计学。而数理统计作为一个进一步完善的数学学科的奠基者是英国人费舍尔(R.A.Fisher)。费舍尔最终的理论研究成果颇丰,它包括:数据信息的测量、压缩数据而不减少信息、对一个模型参数估计等。而后20世纪的瑞典数学家拉默(H. Cramer)运用测度论方法总结数理统计的成果,美籍罗马尼亚数学家瓦尔德(A. Wald)提出“序贯抽样”方法,还用博弈的观点看待数理统计的问题,他们极大地推动了数理统计向应用于社会生活的方向发展。 由于随机现象是客观世界中普遍存在的一种现象,因而数理统计的应用十分广泛,在自然科学、社会科学、工程技术、军事科学、医药卫生以及工农业生产中都能用到数理统计的理论与方法。随着计算机的普及和软件技术的发展,多种使用便捷的统计软件的面世,使得各行各业中只要粗通统计知识的人,都可以方便地运用统计分析的各
种工具来为自己的研究课题服务。数理统计正在发挥着越来越大的作用,它的应用更加广泛深入。数理统计在我们的生活中的各个方面影响几乎无处不在。可以说,数理统计学的理论和方法,与人类活动的各个领域在不同程度上都有关联。因为各个领域内的活动,都得在不同的程度上与数据打交道。都有如何收集和分析数据的问题,因此也就有数理统计学用武之地。 首先,专门的统计部门会做社会统计工作,定期公布社会生活各方面数量规律的情报,例如研究CPI,GDP,基尼系数这些社会经济指数时,都必须用到数理统计进行各种分析,得出结论,供决策部门和研究部门使用,社会学工作者利用这些公布的资料,可以进行广泛的社会研究。 然后,数理统计在工业中也要非常重要的应用,例如假设我们已经生产了一种产品,在生产过程中,由于原材料,设备调整及工艺参数等条件可能的变化,而造成生产条件不正常并导致出现废品,这可以通过在生产过程中随时收集数据并用统计方法进行处理,可以监测出不正常情况的出现以便随时加以纠正,避免出大的问题;然后,大批量的产品生产出来后,还有一个通过抽样检验以检验其质量是否达到要求,是否可以出厂或为买方所接受的问题,处理这个问题也要使用数理统计方法,在我国现行的国家标准中有一些就与这个问题有关。 还有,在农业上,数理统计被极大程度地被应用于预测预报上,正确预测预报作物(动物)的生长发育进度(苗情)、产量和病虫害的发
数理统计中回归分析的探究与应用
回归分析问题探究 摘要 本文主要针对数理统计中的回归分析问题,通过对一元线性回归、多元线性回归以及非线性回归原理的探究,分别运用了SPSS和MATLAB软件进行实例分析以及进一步的学习。 首先,通过变量之间关系的概念诠释引出回归函数;其次,针 对回归函数,分别对一元线性回归原理上的学习,了解并会运用这三种线性回归模型、参数估计和回归系数的显著性检验来处理和解决实际的一元线性回归问题;接着,对多元线性回归和非线性回归进行学习,掌握它们与一元线性回归在理论和实践的联系与区别;然后,通过实际问题运用SPSS进行简单的分析,熟悉SPSS软件的使用步骤和分析方法,能够运用SPSS进行简单的数理分析;最后,用MATLAB编程来处理线性回归问题,通过多种方法进行比较,进行线性回归拟合计算并输出Logistic模型拟合曲线。 关键词:回归分析;一元线性回归;多元线性回归;非线性回归;SPSS;MATLAB
一、回归概念 一般来说,变量之间的关系大致可以分为两类:一类是确定性的,即变量之间的关系可以用函数的关系来表达;另一类是非确定性的,这种不确定的关系成为相关关系。相关关系是多种多样的,回归分析就是研究相关关系的数理统计方法。它从统计数据出发,提供建立变量之间相关关系的近似数学表达式——经验公式的方法,给出相关行的检验规则,并运用经验公式达到预测与控制的目的。 如随机变量Y与变量x(可能是多维变量)之间的关系,当自变量x确定后,因变量Y 的值并不跟着确定,而是按照一定的停机规律(随机变量Y的分布)取值。这是我们将它们之间的关系表示为 其中是一个确定的函数,称之为回归函数,为随机项,且。回归分析 的任务之一就是确定回归函数。当是一元线性函数形时,称之为一元线性回归;当 是多元线性函数形时,称之为多元线性回归;当是非线性函数形时,称之为非线性回归。 二、回归分析 2.1 一元线性回归分析 2.1.1 一元线性回归模型 设随机变量Y与x之间存在着某种相关关系,这里x是可以控制或可以精确测量的普通变量。对于取定的一组不完全相同的值做独立实验得到n对观察值 一般地,假定x与Y之间存在的相关关系可以表示为 , 其中为随机误差且,未知,a和b都是未知参数。这个数学模型成为医院 线性回归模型,称为回归方程,它所代表的直线称为回归直线,称b为回归系数。 对于一元线性回归模型,显然有。
概率论与数理统计课程设计
概率论的起源、发展和应用 作者: 摘要:论文简要介绍了概率论与数理统计学科的起源和发展,以及概率论与理统计在生活中的应用。 关键词:概率论与数理统计,起源,发展,应用 1、引言 《概率论与数理统计》是研究随机现象统计规律的一门数学学科,也是一门应用性很强又颇具特色的数学学科。它在包括控制、通信、生物、物理、力学、金融、社会科学等工程技术领域以及科学研究、经济管理、企业管理、经济预测等众多领域都有广泛的应用;它与其他数学分支有着紧密的联系(如微积分、高等代数、测度论等),是近代数学的重要组成部分;它的方法和理论向各个基础学科、工程学科的渗透,是近代科学技术发展的特征之一;它与基础学科相结合产生出了许多边缘学科,如生物统计、统计物理、数学地质等;它又是许多新兴的重要学科的基础,如信息论、控制论、可靠性理论、人工智能、信息编码理论和数据挖掘等。 《概率论与数理统计》是工科大学的一门应用性很强的必修基础课。学习和掌握概率论与数理统计的基本理论和基本方法并将其灵活应用于科学研究和工程实际中,是社会发展对高素质人才培养提出的必然要求。 2、概率论与数理统计的起源 概率论的萌芽源于十七世纪保险业的发展,但是真正引发数学家们思考的源泉,却是赌博者的请求。 十七世纪中叶,法国贵族德·美黑在骰子赌博中,有事急于抽身,须中途停止赌博,需要根据对胜负的预测把赌资进行合理的分配,但不知用什么样的比例分配才算合理,于是就写信向当时法国的最高数学家帕斯卡请教。正是这封信使概率论在历史的舞台迈出了第一步。
帕斯卡和当时第一流的数学家费尔玛一起,研究了德·美黑提出的关于骰子赌博的问题。于是,一个新的数学分支--概率论登上了历史舞台。三年后,也就是1657年,荷兰著名的天文、物理兼数学家惠更斯企图自己解决这一问题,结果写成了《论机会游戏的计算》一书,这就是最早的概率论著作。 为概率论确定严密的理论基础的是数学家柯尔莫哥洛夫。1933年,他发表了著名的《概率论的基本概念》,用公理化结构,这个结构明确定义了概率论发展史上的一个里程碑,为以后的概率论的迅速发展奠定了基础。 3、概率论与数理统计的发展 数理统计的发展大致可分为古典时期、近代时期和现代时期三个阶段。 古典时期(19世纪以前)——这是描述性的统计学形成和发展阶段,是数理统计的萌芽时期。在这一时期里,瑞土数学家贝努里(1654-1795年)较早地系统论证了大数定律。1763年,英国数学家贝叶斯提出了一种归纳推理的理论,后被发展为一种统计推断方法――贝叶斯方法,开创了数理统计的先河。法国数学家棣莫佛(1667-1754)于1733年首次发现了正态分布的密度函数,并计算出该曲线在各种不同区间内的概率,为整个大样本理论奠定了基础。1809年,德国数学家高斯(1777-1855)和法国数学家勒让德(1752-1833)各自独立地发现了最小二乘法,并应用于观测数据的误差分析。在数理统计的理论与应用方面都作出了重要贡献,他不仅将数理统计应用到生物学,而且还应用到教育学和心理学的研究。并且详细地论证了数理统计应用的广泛性,他曾预言:“统计方法,可应用于各种学科的各个部门。” 近代时期(19世纪末至1845年)——数理统计的主要分支建立,是数理统计的形成时期。上一世纪初,由于概率论的发展从理论上接近完备,加之工农业生产迫切需要,推动着这门学科的蓬勃发展。1889年,英国数学家皮尔逊(1857-1936)提出了矩估计法,次年又提出了频率曲线的理论,并于1900年在德国数学家赫尔梅特在发现c2分布的基础上提出了c2检验,这是数理统计发展史上出现的第一个小样本分布。1908年,英国的统计学家戈塞特(1876-1937)创立了小样本检验代替了大样本检验的理论和方法(即t分布和t检验法),这为数理统计的另一分支――多元分析奠定理论基础。1912年,英国统计学家费
数理统计在环境监测方面的应用 班级:14研3班姓名:漆麟学号:201420001101 直线回归在分光光度法分析中起着非常重要的作用,它反应出被测物质浓度与吸光度之间的变量关系。例如在测定亚硝酸盐氮标准曲线时,由于亚硝酸盐氮不稳定在空气中可被氧化成硝酸盐氮也易被还原成氨,因此,要求测定过程快速准确。而正确绘制标准曲线是获得准确结果的必要手段。如何做到正确绘制标准,可采用数理统计中最小二乘法对每组实验数据进行线性回归,根据回归方程式 y=a+bx,求解a、b后代入回归方程即可绘出最接近真实的标准曲线。因为在理论上每组实验数据经过最小二乘法处理后都能得到一条最佳直线,这样就可避免主观选择估计的因素,使测定结果接近真值。 采用《环境监测分析方法》中N-1萘-乙二胺比色法。在pH2.0~2.5时,水中亚硝酸盐与对氨基苯磺酰胺生成重氮盐,再与N-1萘-乙二胺偶联生成红色染料,在543nm波长处有最大吸收。其色度深浅与亚硝酸盐含量成正比,可比色测定。 向标准比色管分别加入每毫升含0.5μg的亚硝酸钠标准使用液1mL、3mL、 5mL、7mL、10mL,用水稀释至50mL。然后再分别加入1.0mL对氨基苯磺酰胺盐酸盐溶液摇匀,放置2-8min,加入1.0mLN-1A萘-乙二胺盐酸盐溶液,10min后比色测定。测定结果见表1。 表1 亚硝酸盐氮标准曲线测定结果 亚硝酸(μg)x钠使用液0.5 1.5 2.5 3.5 5.0 吸光度y 0.036 0.111 0.185 0.259 0.367 线性回归设标准物浓度为x1,x2,……,x n,相应的吸光度为y1,y2,……,y n,根据回归方程y=a+bx求解方程的b和a。经计算的测定结果列于表2。 表2 用最小二乘法绘制亚硝酸盐氮标准曲线 n x x2 y y2 xy 1 0.5 0.25 0.036 0.001296 0.018 2 1.5 2.25 0.111 0.01231 0.1665 3 2.5 6.25 0.185 0.034225 0.4625
概率论与数理统计课堂设计——概率论与数理统计在博彩中的应用 院系:班级: 姓名: 学号:
概率论与数理统计在博彩中的应用 作者: 摘要:赌博自古以来就一直是我们生活中的一个重要部分,各种形式的赌博存在于我们的生活中,但是我们也听过十赌九骗、十赌九输,那么赌博究竟有没有什么机制与规律呢?本文通过概率论的一些知识来揭示赌博中的规律,通过揭示其运行机制,让我们感受数学的美。关键字:赌博;概率论 1.发展历程 概率论是一门研究随机现象的规律的数学分支。其起源于16世纪,意大利学者吉诺拉莫·卡尔达诺(1501-1576)开始研究骰子等赌博中的一些问题,但真正刺激概率论发展的是来自17世纪的赌博者问题。数学家费马向法国数学家帕斯卡提出下列问题:现有两个赌徒相约赌若干局,谁先赢s局就算赢了,当赌徒A先赢a局(a 《概率论与数理统计》小论文概率与理性的发展 哈尔滨工业大学 2014年12月 《概率论与数理统计》课程小论文 概率与理性的发展 摘要概率论是一门研究事件发生的数学规律的学科。他起源于生活中的实际问题的思考,较传统的几何学等起步较晚,在伯努利、泊松等数学家的努力下,形成了现如今较为完备的理论体系。他与数理统计一起,在工程设计、自然科学、社会科学、军事等领域起着重要作用。而概率论提出后有很多人感感兴趣对其进行研究的原因之一是很多事件的主观上对概率的判 断与实际的理论概率有着很大的差异,于是有关概率的悖论有很多,也有很多与直觉相悖的概率问题,这也是概率的魅力之一。本文将从概率的发展、概率与感性的差异等方面出发对概率与感性和理性进行探讨。 关键词概率悖论直觉理性 一、概率的发展 概率论的初步发展起源于十七世纪中叶的法国。在那里出现了对赌博问题的研究,也正是对赌博问题的研究,推动了概率论的发展。最初的问题是从分赌金开始的。[1] 最初的问题大致是这样的:甲乙双方是竞技力量相当的对手,每人各拿出32枚金币,以争胜负。在竞争中,取胜一次,得一分。最先获得3分的人取得全部赎金64枚金币。可是,因某种缘故,竞争3次,赌博被迫终止。而此时,甲得2分,乙得1分,问赌金如何分配?很多问题的开端都是利益的纠纷,这也是一个例子,双方都会为自己的利益考虑而提出对这笔赌金的分法,而从直觉上看,很多理由似乎也是很有道理的。但是真相只有一个,到底理论上最公平的分法是怎样的?这个问题的当事人爱好赌博的德梅雷 向其好友著名的数学家帕斯卡请教,这个问题也受到了帕斯卡的关注。帕斯卡与其好友费尔马进行了三个月的书信往来讨论这个问题,最终得到了满意的答案:假设两赌徒中甲赢了两局,乙一局未赢,那么接下来可能出现的情况是:若甲再赢一局,得3分,将获全部赌金;若乙赢一局,出现2:1的局 统计源于生活,生活演绎统计 ——《女士品茶》读书随笔在老师推荐的几本统计学著作中,我毫不犹豫地选择了这本《女士品茶——20世纪统计怎样改变了科学》,我不知道女士品茶与统计学有何关联,其中的微妙之处让我产生了好奇。同时它的名字会让我们立刻脱离冷冰冰、一大串复杂的统计学公式,而转到一个更加贴近生活和应用的角度去欣赏统计学的魅力。书中作者试图用20世纪统计学革命中的权威大师们的生平故事来向大众阐述什么是统计模型?它们是怎么来的?在现实生活中它们意味着什么?初略本书的目录,着实给人一种和某些平乏生硬的教科书不一样的感觉,一个个故事生动地演绎着统计学一个又一个突破与飞跃! 本书一开头便解开读者心头的疑惑——女士品茶与统计学有何关联? 故事是在20世纪20年代后期发生的,在英国剑桥一个夏日的午后,一群大学的绅士和他们的夫人们,还有来访者,正围坐在户外的桌旁,享用着下午茶。在品茶过程中,一位女士坚称:把茶加进奶里,或把奶加进茶里,不同的做法,会使茶的味道品起来不同。在场的一帮科学精英们,对这位女士的“胡言乱语”嗤之以鼻。这怎么可能呢?他们不能想象,仅仅因为加茶加奶的先后顺序不同,茶就会发生不同的化学反应。 这时唯独一个身材矮小、戴着厚眼镜、下巴上蓄着的短尖髯开始变灰的先生,却不这么看,他对这个问题很感兴趣,认为这种现象可以作为一个假设并做实验验证,于是设计一个实验来测试这位女士是否能喝出两种冲泡法的区别,让她在不知情的情况下尝奶茶,猜这杯是先加奶还是先加茶。为了避免蒙中,茶的杯数要足够多,但也不能无限制的喝下去,那么为了确定那个女士能猜到多准,最少该喝多少杯呢? 这个实验很著名,是个似然估计问题。故事中那位蓄短胡须的先生便是在统计发展史上地位显赫、大名鼎鼎的罗纳德·艾尔默·费歇尔(Ronald Aylmer Fisher)。他是英国统计学家,近代数理统计的开创者。后来费歇尔在自己的著作中讨论了这个实验的各种可能结果,其中有关实验设计的著述是科学革命的要素之一。费歇尔在自己孜孜不倦地求索过程中得出一个结论:科学家需要从潜在实验结果的数据模型开始工作,这是一系列数据公式,其中一些符号代表实验中 研究生课程考核试卷 科目:数理统计教师:黄光辉 姓名:张振学号:20142002036 专业:环境科学与工程类别:学术 上课时间:2014 年9 月至2014 年11 月 考生成绩: 卷面成绩平时成绩课程综合成绩 阅卷评语: 阅卷教师(签名) 某商业银行不良贷款形成原因分析 摘要 根据某商业银行多家分行业务数据,建立线性回归模型,运用SPSS数理统计软件对此商业银行不良贷款情况进行运算与分析,以不良贷款为因变量(y),运用逐步回归法对变量数据进行筛选,最后以各项贷款余额(χ1)与本年固定资产投资额(χ4)为自变量,分别建立y与χ1的一元线性回归方程和y与χ1、χ4的二元线性回归方程,并对回归线性模型进行F检验、t检验和回归系数检验。最后结合实践经验,对模型进行检验,并运用Pearson相关系数测量因变量(y)与自变量(χ1、χ4)的线性相关关系,以及两个变量之间的相关性。 一、问题提出与分析 重庆一家某商业银行其业务主要是进行基础设施建设、重点项目建设、固定资产投资等项目的贷款。最近一段时间,在贷款额平稳增长的基础上,该银行的不良贷款记录也有大比例提高。为了弄清楚不良贷款形成的原因,该银行希望利用一些数据做些定量分析。 二、数据描述 表1是项目参考的变量名称;表2给出了该银行所属20家分行在2012年的相关业务数据。 表1 项目参考变量名 y:不良贷款(亿元)χ3:贷款项目个数(个) χ1:各项贷款余额(亿元)χ4:本年固定资产投资额(亿元) χ2:本年累计应收贷款(亿元) 表2 相关业务数据 分行编号不良贷款 各项贷款余 额 本年累计应 收贷款 贷款项目个数 本年固定资产投 资额 1 0.9 2 67.5 6.78 5 51.9 2 1.1 112.5 19.8 16 91.1 3 4.81 174.2 7.9 17 74.2 4 3.18 82.1 7.3 10 14.5 5 7.8 199.7 16.4 19 63.21 6 2. 7 16.3 2.2 1 2.2 7 1.6 106.2 10.7 17 20.2 研究生课程考核试卷 (适用于课程论文、提交报告) 科目:概率论与数理统计上课时间:2017.2-2017.5 姓名:刘振学号: 20160702031专业:机械工程教师:刘朝林 工作单位或所在行业:重庆大学 考生成绩: 卷面成绩平时成绩课程综合成绩阅卷评语: 阅卷教师 (签名) 回归分析在数理统计中的应用 摘要:回归分析是数理统计中重要的一种数据统计分析的思想, 是处理变量间的相关关系的一种有效工具。其目的在于根据已知自变量的变化来估计或预测因变量的变化情况,或者根据因变量来对自变量做一定的控制. 它可以提供变量间相关关系的数学表达式, 且利用概率统计知识,对经验公式及有关问题进行分析、判断以确定经验公式的有效性,从众多的解释变量中,判断哪些变量对因变量的影响是显著的,哪些是不显著的. 还可以利用所得经验公式,由一个或几个变量的值去预测或控制个变量的值时的值,去预测或控制另一个变量的取值,同时还可知道这种预测和控制可以达到什么样的精度。 本文就是针对实际问题运用回归分析中一元线性回归分析的统计方法,来确定自变量与 另一个变量的相关关系,并确立出较为合理的回归方程,再对其的可信度进行统计检验. 关键词:回归分析;回归方程;F检验法 1.问题的提出 调查一下重庆大学学生的生活费与家庭收入的关系,看看是否家庭收入越高,学生的每月支出也越多,从而根据学生每月消费支出,进而估计学生的家庭收入情况,对学生的生活补助等问题有重要的参考意义 2.数据描述 根据调研的重庆大学学生家庭月收入与每月生活费的数据,确定两者关系。数据来源100多份问卷调查的抽样,取其中10份,绘制表1如下图所示序号家庭月收入每月生活费14800 500 25200 600 35420 650 45600 700 56000 750 66400 800 76800 900 87000 1000 97200 1200 108000 1500 表1-1 重庆大学学生家庭月收入与每月生活费的数据利用matlab软件画出家庭月收入与每月生活费的散点图,如图一所示 二氧化碳吸附量与活性炭孔隙结构的线性回归分析 摘要:本文搜集了不同孔径下不同孔容的活性炭与CO2吸附量的实验数据。分别以同一孔径下的不同孔容作为自变量,CO2吸附量作为因变量,作出散点图。选取分布大致呈直线的一组数据为拟合的样本数据.对样本数据利用最小二乘法进行回归分析,参数确定,并对分析结果进行显著性检验。同时利用ma tl ab 的r egress 函数进行直线拟合。结果表明:孔径在3。 0~ 3. 5 nm 之间的孔容和CO2吸附量之间存在较好的线性关系。 关键字:活性炭 孔容 CO2吸附量 m atla b 一、问题分析 1。1.数据的收集和处理 本文主要研究同一孔径的孔容的活性炭和co2吸附量之间的线性关系,有关实验数据是借鉴张双全,罗雪岭等人的研究成果[1]。以太西无烟煤为原料、硝酸钾为添加剂,将煤粉、添加剂和煤焦油经过充分混合后挤压成条状,在600℃下炭化15 min,然后用水蒸气分别在920℃和860℃下活化一定时间得到2组活性炭,测定了CO2吸附等温线,探讨了2组不同工艺制备的活性炭的C O2吸附量和孔容的关系.数据如下表所示: 表1:孔分布与CO2吸附值 编号1~12是在不同添加剂量,温度,活化时间处理下的对照组。因为处理方式不同得到不同结果是互不影响的,可以看出C O2的吸附量的值是互相独立 编号 孔容/(11 10L g μ--?) CO 2吸附 量 1/()mL g -? 0。5~0。8nm 0.8~1.2nm 1。2~1。8nm 1.8~2。2nm 2.2~2。2n m 2。5~3。0nm 3.0~3。5 nm 1 7.18 16.2 24.4 75.2 70 96 115 64 2 6.59 14.4 18.4 53.7 50 85。6 91 55.1 3 4.5 4 11 18.9 71 6 5 78.3 91 53.7 4 5.13 13.4 29。9 10。3 90 7 6 122 53。 7 5 4.16 10.5 18。9 83.8 78 80。5 113 61。7 6 4。92 12。1 23.4 81.6 72 56 99 53.6 7 5.0 8 12.6 23.8 93.5 86 77.8 122 65。5 8 5.29 13 25。1 88.4 69 66.4 107 57。7 9 7.47 16.9 26.9 46。4 78 93.2 107 58.2 10 5.44 13 21.4 44.1 91 98.6 137 76。6 11 1。81 64。6 18.3 53.1 114 110 142 75 12 1.24 27.7 39。5 126 114 98。6 183 98.7 1 聚类分析 我们利用Matlab6.5中的cluster 命令实现,具体程序如下 x={ {n,m}=size(x); Stdr=std(x); xx=x./stdr(ones(n,1),;); % 标准化变换 y=pdist(xx); %计算各样本间距离(这里为欧氏距离) z=linkage(y); %进行聚类(这里为最短距离法) h=dendrogram(z); %画聚类谱系图 t=cluster(z,3) % 将全部样本分为3类 find(t==2); %找出属于第2类的样品编号 执行后得到所要结果 聚类谱系图见图1 t={3,1,3,1,1,2,2} 即全部样本分为3类。结果见表1 从图 1可以看出:七条河流中, 二干河、横套河、四干河属于一类, 污染 较重, 主要是CODmn 、BOD5超标多; 华妙河、盐铁塘属于一类, 污染一般, 主要是氨氮、石油类超标; 张家港河、东横河属于一类,污染较轻, 总的来说,各河流都存在不同程度的污染,因此全市应对各河流严格监督管理, 着力实施水污染防治工作, 太湖流域水污染源应限期治理达标排放, 巩固水污染防治工作成果,加大投入,新建或改、 扩建废水治理工程, 确保达标排放。 3.14 5.47 3.1 5.67 6.81 6.21 4.87 8.41 9.57 4.31 9.54 9.05 7.08 8.97 23.78 26.48 21.2 10.23 16.18 21.05 26.54 25.79 23.79 22.48 20.87 24.56 31.56 34.56 4.17 6.42 5.34 4.2 5.2 6.15 5.58 6.47 5.58 6.54 6.8 5.45 8.21 8.07 } 研究生“数理统计”课程课外作业 姓名:罗冲学号:20131002006 学院:动力工程学院专业:动力工程 类别:学术型上课时间:2013.9—2013.12 成绩: 城市供水管道长度与用水人口回归分析 摘要 为了分析城市居民供水问题,通过在国家统计局搜集数据,找到城市供水管道的长度和城市用水人口的相关数据,进行回归分析,运用参数估计、假设检验、回归分析的方法对其进行分析。讨论供水管道Y和用水人口X之间的线性关系,并讨论其在显著水平为α=0.05下,检验x和y是否具有显著线性关系。所以通过上述分析可以得到,供水管道的长度和用水人口成线性相关性。运用统计学知识,可以解决生活的问题。说明了随着人口的增长会,增加城市的供水管道的长度。 正文 一、问题提出,问题分析。 统计了有关供水的数据,通过对数据的分析,讨论供水管道Y和用水人口X 之间的线性关系,并讨论其在显著水平为α=0.05下,检验x和y是否具有显著线性关系;应用参数估计、假设检验、回归分析来解决问题。 二、数据描述(用表格表达数据信息,指出数据来源或提供原始数据) 问题中所给出的数据来源于国家统计局网站上面的相关信息,城市供水的信息。其中包括了生活、生产用水和用水人口、供水重量、管道长度等信息,选取的数据是2011年到2006年(如下表),进行相关分析。 三、模型建立: (1)提出假设条件,明确概念,引进参数; 讨论供水管道Y 和用水人口X 之间的线性关系,采用一元线性回归模型。 Y=β0+β1x+ ε ε~ N(0,2σ) 回归函数:y=β0+β1x 采用最小二乘法,求出相应的估计值: X =6 116=∑i i x =36036.4 Y =6 1 16=∑i i Y =496943.59 通过计算可以得到: l xx =6 21 ()i i x x - =-∑=34337890.49 l yy =21 ()n i i y y - =-∑=1.510297x1010 l xy =6 1 ()i i i x x y - =-∑=701606286 ^ y = ^β0+ ^ β1x (2)模型构建; 一元线性回归模型,进行求解,并会对其进行相关的验证。根据教材的相关公式进行求解。 课设要求: 1. 用R语言编写程序. 2. 理论方法先写出来,并附上程序. 程序中用注释详细的写出每一步的产生思路. 其中题目5供4人选择、其余题目分别供3人选择。注意同一个题目的三到四个人之间可以讨论, 但是不允许抄袭. 不能完全一致, 按自己想法独立完成. 3. 利用第二周第三周搜集资料, 完成课设. 第四周课设答辩, 具体时间另行通知. 答辩时每组选出一名代表汇报即可. 4. 答辩之后需要上交学生的课设实验报告, 程序源代码, 还有答辩 2012级数理统计课程设计题目 1. 已知两样本 A:79.98 80.04 80.02 80.04 80.03 80.03 80.04 79.97 80.05 80.03 80.02 80.00 80.02 B:80.02 79.94 79.98 79.97 79.97 80.03 79.95 79.97 计算两样本的T 统计量。 2. 建立一个R 文件,在文件中输入变量)3,2,1('=x ,)6,5,4('=y ,并作以下运算 (1) 计算e y x z ++=2,其中)1,1,1('=e ; (2) 计算x 与y 的内积; (3) 计算x 与y 的外积. 3. 已知有5名学生的数据,如表1所示,用数据框的形式输入数据. 4. 编写一个R 程序(函数),输入一个整数n ,如果n<=0,则终止运算,并输出一句话:“要 求输入一个正整数”;否则,如果n 是偶数,则将n 除2,并赋给n ;否则,将3n+1赋给n 。不断循环,直到n=1,才停止计算,并输出一句话:“运算成功”。 5. 某单位对100名女生测定血清总蛋白含量(g/L ),数据如下: 74.3 78.8 68.8 78.0 70.4 80.5 80.5 69.7 71.2 73.5 79.5 75.6 75.0 78.8 72.0 72.0 72.0 74.3 71.2 72.0 75.0 73.5 78.8 74.3 75.8 65.0 74.3 71.2 69.7 68.0 73.5 75.0 72.0 64.3 75.8 80.3 69.7 74.3 73.5 73.5 75.8 75.8 68.8 76.5 70.4 71.2 81.2 75.0 70.4 68.0 70.4 72.0 76.5 74.3 76.5 77.6 67.3 72.0 75.0 74.3 73.5 79.5 73.5 74.7 65.0 76.5 81.6 75.4 72.7 72.7 67.2 76.5 72.7 70.4 77.2 68.8 67.3 67.3 67.3 72.7 75.8 73.5 75.0 73.5 73.5 73.5 72.7 81.6 70.3 74.3 73.5 79.5 70.4 76.5 72.7 77.2 84.3 75.0 76.5 70.4 计算均值、方差、标准差、极差、标准误差、变异系数、偏度、峰度。 6. 绘出5题数据的直方图、密度估计曲线图、经验分布图和QQ 图,并将密度估计曲线与 正态密度曲线相比较,将经验分布曲线于正态分布曲线相比较(其中正态曲线的均值和 概率论与数理统计课程总结报告——概率论与数理统计在日常生活中的应用 姓名: 学号: 专业:电子信息工程 摘要:数学作为一门工具性学科在我们的日常生活以及科学研究中扮演着极其重要的角色。概率论与 数理统计作为数学的一个重要组成部分,在生活中的应用也越来越广泛,近些年来,概率论与数理统计知识也越来越多的渗透到经济学,心理学,遗传学等学科中,另外在我们的日常生活之中,赌博,彩票,天气,体育赛事等都跟概率学有着十分密切的关系。本文着眼于概率论与数理统计在我们生活中的应用,通过前半部分对概率论与数理统计的一些基本知识的介绍,包括概率的基本性质,随机变量的数字特征及其分布,贝叶斯公式,中心极限定理等,结合后半部分的事例分析讨论了概率论与数理统计在我们生活中的指导作用,可以说,概率论与数理统计是如今数学中最活跃,应用最广泛的学科之一。 关键词:概率论 数理统计 经济生活 随机变量 贝叶斯公式 基本知识 §1.1 概率的重要性质 1.1.1定义 设E 是随机试验,S 是它的样本空间,对于E 的每一事件A 赋予一个实数,记为P (A ),称为事件的概率。 概率)(A P 满足下列条件: (1)非负性:对于每一个事件A 1)(0≤≤A P (2)规范性:对于必然事件S 1)S (=P (3)可列可加性:设n A A A ,,,21 是两两互不相容的事件,有∑===n k k n k k A P A P 1 1 )()( (n 可以取∞) 1.1.2 概率的一些重要性质 (i ) 0)(=φP (ii )若n A A A ,,,21 是两两互不相容的事件,则有∑===n k k n k k A P A P 1 1 )()( (n 可以取∞) (iii )设A ,B 是两个事件若B A ?,则)()()(A P B P A B P -=-,)A ()B (P P ≥ (iv )对于任意事件A ,1)(≤A P (v ))(1)(A P A P -= (逆事件的概率) (vi )对于任意事件A ,B 有)()()()(AB P B P A P B A P -+=? 成绩评定表 课程设计任务书 摘要 21世纪信息技术迅猛发展,给人类的生产生活带来了深远的影响,无疑我们已经身处在一个信息化时代,信息的发展快慢在一定程度上决定了我国的发展,因此我国需要大量的信息人才,信息人才的培养至关重要,对此我们调查了某学校信息学院的学生汇编成绩,利用概率论与数理统计的知识对其进行系统的分析,为学校培养高素质的信息人才提供依据,概率论与数理统计作为数学中一个重要部分,在生活中的应用越来越广,同样也在发挥着越来越广泛的作用,现实生活中国存在着许多偶然现象,但这些偶然并不是没有规律的,概率论与数理统计将这蕴含在其中的规律找出,方便了人们的生产生活。而假设检验和方差分析本在这门学科中有着不可小视的重要性。 本文就是利用了假设检验和方差分析来对学生成绩进行分析,首先对学生汇编成绩的分布进行假设,其次利用皮尔逊2 对所得的分步进行检验,结合Matlab 数据处理软件与Excel数据处理软件求出想要得到的结果,最后用单因素的方差分析判断学生汇编课设等级对学生汇编成绩的影响,从而得到学生实际操作能力跟理论结合的情况。 关键词:假设检验;单因素方差分析;Matlab;Excel; 目录 1 设计目的 (1) 2 设计问题 (1) 3 设计原理 (2) 4 设计程序 (5) 4.1 问题一的解决 (5) 4.1.1 做出直方图 (5) 4.1.2 做假设检验 (6) 4.1.3 检验原假设 (8) 4.2 问题二的解决 (10) 4.2.1 计算平方和 (10) 4.2.2 比较F值和临界值 (11) 5 结果分析 (12) 6 设计总结 (12) 致谢 (13) 参考文献 (14) 重庆市固定资产投资与房地产投资 线性关系分析 学号 20111602084 姓名陈磊 学院土木工程学院专业土木工程 成绩 重庆市固定资产投资与房地产投资 线性关系分析 摘要:我国房地产投资近年来迅猛发展,无论在规模还是在增速上都达到了前所未有的水平,房地产业作为新兴的产业,对我国的经济发展起着举足轻重的作用。房地产投资与固定资产的投资息息相关,研究两者之间的关系并作出预测显得非常有必要。借助于数理统计的知识,在实际的数据的基础上,对两者之间进行一个简单的一元线性回归分析。在建立起模型之后,通过显著性检验方法进行检验,以检查结果的正确性。并通过模型对重庆市的房地产投资作出一个大致的预测,同时对相关结论进行分析,以指导实际工作。 关键词:固定资产投资;房地产投资;线性回归 一、问题提出及分析 重庆市作为国家中心城市之一,西部惟一的直辖市,凭借特殊的政策优势、基础条件优势, 经过政府一系列积极政举,经济发展环境持续向好,直辖以来积蓄的发展势能不断释放。在大力推动“五个重庆”、统筹城乡、内陆开放、深化改革、振兴区县、改善民生等重点工作的情况下,重庆市继续加强落实了中央扩大内需的投资项目和政府主导的投资计划,不断鼓励并激活社会资本,使得固定资产投资需求不断扩大、投资力度不断增强、投资结构不断优化,基础产业、基础设施、房地产及其他第三产业的投资齐头并进,全市固定资产投资保持平稳较快增长。 固定资产是指企业使用期限超过1年的房屋、建筑物、机器、机械、运输工具以及其他与生产、经营有关的设备、器具、工具等。固定资产投资是建造和购置固定资产的经济活动。按照管理渠道分,全社会固定资产投资总额分为基本建设、更新改造、房地产开发投资和其他固定资产投资四个部分。 房地产业作为一个国计民生的大行业,其投资额牵动着整个社会的安居问题。重庆目前又在推出宜居重庆的政策,由此引发思考:房地产投资在固定资产中是否存在一定的关系,与固定资产投资的关系如何,是否可以用一定的方式进行预测? 借助统计学与软件的分析,采用散点图的描绘,可以看到固定资产投资额与房地产投资额可能存在一定的线性关系,由此借助数理统计知识,通过一元线性回归的相关知识对该问题进行分析。 概率论的发展与应用 摘要:概率论与数理统计是一门研究随机现象及其规律性的数学学科。通过实验来观察随机现象,揭示其规律性,或根据实际问题的具体情况找出随机现象的规律。它起源于17世纪中叶,法国数学家帕斯卡、费马及荷兰数学家惠更斯基于排列组合方法,研究利用古典概型解决赌博中提出的一些问题。由于社会的发展和工程技术问题的需要,促使概率论不断发展,许多科学家进行了研究。发展到今天,概率论与数理统计在自然科学,社会科学,工业生产,金融及日常生活实际等诸多领域中起着不可替代的作用。 关键词:概率论与数理统计;起源与发展;应用 1.概率论的起源与发展 1.1 概率论的起源 概率论的起源与赌博有关,在17世纪中叶,一位名叫德·梅尔的赌徒向帕斯卡提出了“分赌注问题”即两个人决定赌若干局,事先约定谁先赢得s局便算赢家。如果在一个人赢a(a 应用MATLAB进行非线性回归分析 摘要 早在十九世纪,英国生物学家兼统计学家高尔顿在研究父与子身高的遗传问题时,发现子代的平均高度又向中心回归大的意思,使得一段时间内人的身高相对稳定。之后回归分析的思想渗透到了数理统计的其他分支中。随着计算机的发展,各种统计软件包的出现,回归分析的应用就越来越广泛。回归分析处理的是变量与变量间的关系。有时,回归函数不是自变量的线性函数,但通过变换可以将之化为线性函数,从而利用一元线性回归对其进行分析,这样的问题是非线性回归问题。下面的第一题:炼钢厂出钢水时用的钢包,在使用过程中由于钢水及炉渣对耐火材料的侵蚀,使其容积不断增大。要找出钢包的容积用盛满钢水时的质量与相应的实验次数的定量关系表达式,就要用到一元非线性回归分析方法。首先我们要对数据进行分析,描出数据的散点图,判断两个变量之间可能的函数关系,对题中的非线性函数,参数估计是最常用的“线性化方法”,即通过某种变换,将方程化为一元线性方程的形式,接着我们就要对得到的一些曲线回归方程进行选择,找出到底哪一个才是更好一点的。此时我们通常可采用两个指标进行选择,第一个是决定系数2R,第二个是剩余标准差s。进而就得到了我们想要的定量关系表达式。第二题:给出了某地区1971—2000年的人口数据,对该地区的人口变化进行曲线拟合。也用到了一元非线性回归的方法。首先我们也要对数据进行分析,描出数据的散点图,然后用MATLAB编程进行回归分析拟合计算输出利用 Logistic模型拟合曲线。 关键词:参数估计, Logistic模型,MATLAB 正文 一、一元非线性回归分析的求解思路: 1、求解函数类型并检验。 2、求解未知参数。可化曲线回归为直线回归,用最小二乘法求解;可化曲线回 归为多项式回归。 二、回归曲线函数类型的选取和检验 1、直接判断法 2、作图观察法,与典型曲线比较,确定其属于何种类型,然后检验。 3、直接检验法(适应于待求参数不多的情况) 4、表差法(适应于多想式回归,含有常数项多于两个的情况) 三、化曲线回归为直线回归问题 用直线检验法或表差法检验的曲线回归方程都可以通过变量代换转化为直 线回归方程,利用线性回归分析方法可求得相应的参数估计值。 题目: 例8.5.1 炼钢厂出钢水时用的钢包,在使用过程中由于钢水及炉渣对耐火材料的浸蚀,其容积不断增大。现在钢包的容积用盛满钢水时的重量y (kg)表示,相应的试验次数用x表示。数据见表8.5.1,要找出y与x的定量关系表达式。 表8.5.1 钢包的重量y与试验次数x数据 1) 1/y=a+b/x 2)y=a+b ln x = y+ b x a概率论课程小论文
数理统计论文——统计源于生活
数理统计论文
数理统计论文
数理统计课程设计一元线性回归
应用数理统计课程小论文数据,结果,分析过程
数理统计小论文
2012级数理统计课程设计题目(最终)
概率论与数理统计结课论文
概率概率论与数理统计课程设计
数理统计参考论文
概率论与数理统计结课论文
数理统计论文
相关主题
文本预览