JavaScript中依赖注入详细解析
- 格式:pdf
- 大小:319.96 KB
- 文档页数:8

什么是依赖注⼊1 定义依赖注⼊(Dependency Injection),简称DI,类之间的依赖关系由容器来负责。
简单来讲a依赖b,但a不创建(或销毁)b,仅使⽤b,b的创建(或销毁)交给容器。
2 例⼦为了把DI讲清楚,我们需要举⼀个简单例⼦。
例⼦⾜够⼩,希望让你能直观的了解DI⽽不会陷⼊真实⽰例的泥潭。
例⼦:⼩明要杀怪,那⼩明拿什么武器杀怪呢?可以⽤⼑、也可以⽤拳头、斧⼦等。
⾸先,我们创建⼀个演员类,名字叫“⼩明”,具有杀怪功能。
namespace NoInjection.ConsoleApp{public class Actor{private string name = "⼩明";public void Kill(){var knife = new Knife();knife.Kill(name);}}}然后,我们再创建⼀个武器-⼑类,具有杀怪功能。
using System;namespace NoInjection.ConsoleApp{public class Knife{public void Kill(string name){Console.WriteLine($"{name}⽤⼑杀怪");}}}最后,我们客户端调⽤演员类,执⾏杀怪功能。
using System;namespace NoInjection.ConsoleApp{class Program{static void Main(string[] args){var actor = new Actor();actor.Kill();Console.ReadKey();}}}让我们来看看输出结果:⼩明⽤⼑杀怪通过这个例⼦我们可以看到,Actor类依赖Knife类,在Actor中创建Knife,执⾏Knife.Kill⽅法。
我们可以回顾⼀下DI的定义,a依赖b,但a不创建(或销毁)b,仅使⽤b,显然这个不符合DI做法。

详解AngularJS中的依赖注⼊⼀般来说,⼀个对象只能通过三种⽅法来得到它的依赖项⽬:1. 我们可以在对象内部创建依赖项⽬2. 我们可以将依赖作为⼀个全局变量来进⾏查找或引⽤3. 我们可以将依赖传递到需要它的地⽅在使⽤依赖注⼊时,我们采⽤的是第三种⽅式(另外两种⽅式都会引起其他困难的挑战,例如污染全局作⽤域以及使隔离变得⼏乎不可能)。
依赖注⼊是⼀种设计模式,它移除了硬编码依赖,因此使得我们可以在运⾏中随时移除并改变依赖项⽬。
在运⾏过程中能够修改依赖项⽬的能⼒允许我们创建隔离环境,这对于测试来说是⾮常理想的。
我们可以⽤测试环境中的⼀个冒牌对象来替换⽣产环境中的⼀个真实对象。
从功能上来说,这种模式通过⾃动提前查找依赖以及为依赖提供⽬标,以此将依赖资源注⼊到需要它们的地⽅。
在我们编写⼀个依赖于其他对象或库的组件时,我们会描述它的依赖项⽬。
再运⾏过程中,⼀个注⼊器将会创建依赖的实例并将它们传递给⼀个依赖消费者。
// ⼀个来⾃于AngularJS的好例⼦function SomeClass(greeter) {this.greeter = greeter;}SomeClass.prototype.greetName = function(name) {this.greeter.greet(name)}注意:像上⾯的实例代码⼀样,在全局作⽤域中创建⼀个控制器永远不是⼀个好主意。
上⾯的代码只是为了简化说明依赖注⼊的原理。
在运⾏中,SomeClass并不关⼼它是如何获得greeter依赖的,只要得到它就⾏。
为了将greeter实例传递到SomeClass中,SomeClass的创造者还需要负责在创建函数时为它传递依赖。
基于以上原因,Angular使⽤$injector来管理依赖查询以及实例化依赖项⽬。
事实上,$injector负责处理我们的Angular组件中所有的实例,包括我们应⽤的模块,指令,控制器等等。

依赖注入的概念依赖注入(Dependency Injection,简称DI)是一种设计模式,它主要用于解耦和组织代码,使得代码易于测试、复用和维护。
依赖注入的核心思想是将依赖关系的创建和管理从被依赖的对象中抽离出来,由外部统一管理,通过将依赖对象注入到被依赖对象中,实现对象之间的解耦。
在传统的面向对象编程中,对象的创建和管理通常由对象自身负责。
当一个对象需要依赖其他对象进行操作时,它必须直接依赖于具体的对象实例,这就造成了对象之间的紧耦合关系。
这样的紧耦合会导致代码难以维护、扩展和测试。
而依赖注入通过将依赖的创建和管理责任交给外部来实现,从而实现了对象之间的解耦。
依赖注入的核心思想是:依赖应该由被依赖的对象的外部组件提供,被依赖的对象不应该关心依赖是如何创建的。
依赖注入的实现方式有多种,常见的有构造函数注入、Setter方法注入和接口注入。
具体的实现方式取决于编程语言和框架的特性。
构造函数注入是最常见的实现方式之一。
通过在对象的构造函数中接收依赖对象作为参数,将依赖对象注入到被依赖对象中。
这样,在创建被依赖对象时,外部组件可以通过构造函数来提供依赖对象,从而实现了依赖注入。
Setter方法注入与构造函数注入类似,通过在对象中定义Setter方法,将依赖对象通过Setter 方法注入到被依赖对象中。
接口注入是一种更加灵活的注入方式,通过定义一个接口来表示依赖,被依赖对象通过实现这个接口来表明自己需要依赖某个对象,外部组件则通过接口来提供依赖。
依赖注入的一个重要的好处是提高了代码的可测试性。
由于依赖对象的创建和管理被外部统一管理,我们可以通过使用Mock对象来代替真实的依赖对象,从而在测试环境下进行单元测试。
这种方式可以使测试更加专注和可控,提高了测试的效率和质量。
另一个重要的好处是提高了代码的复用性。
当一个对象的依赖发生变化时,只需要调整依赖注入的配置即可,而不需要修改被依赖对象的代码。
这样可以减少代码的复杂性和维护成本。

Javascript技术栈中的四种依赖注⼊详解作为⾯向对象编程中实现控制反转(Inversion of Control,下⽂称IoC)最常见的技术⼿段之⼀,依赖注⼊(Dependency Injection,下⽂称DI)可谓在OOP编程中⼤⾏其道经久不衰。
⽐如在J2EE中,就有⼤名⿍⿍的执⽜⽿者Spring。
Javascript社区中⾃然也不乏⼀些积极的尝试,⼴为⼈知的AngularJS很⼤程度上就是基于DI实现的。
遗憾的是,作为⼀款缺少反射机制、不⽀持Annotation语法的动态语⾔,Javascript长期以来都没有属于⾃⼰的Spring框架。
当然,伴随着ECMAScript草案进⼊快速迭代期的春风,Javascript社区中的各种⽅⾔、框架可谓群雄并起,⽅兴未艾。
可以预见到,优秀的JavascriptDI框架的出现只是早晚的事。
本⽂总结了Javascript中常见的依赖注⼊⽅式,并以inversify.js为例,⽂章分为四节:⼀. 基于Injector、Cache和函数参数名的依赖注⼊⼆. AngularJS中基于双Injector的依赖注⼊三. TypeScript中基于装饰器和反射的依赖注⼊四. inversify.js——Javascript技术栈中的IoC容器⼀. 基于Injector、Cache和函数参数名的依赖注⼊尽管Javascript中不原⽣⽀持反射(Reflection)语法,但是Function.prototype上的toString⽅法却为我们另辟蹊径,使得在运⾏时窥探某个函数的内部构造成为可能:toString⽅法会以字符串的形式返回包含function关键字在内的整个函数定义。
从这个完整的函数定义出发,我们可以利⽤正则表达式提取出该函数所需要的参数,从⽽在某种程度上得知该函数的运⾏依赖。
⽐如Student类上write⽅法的函数签名write(notebook, pencil)就说明它的执⾏依赖于notebook和pencil对象。

依赖注入实现原理
依赖注入(DependencyInjection)是一种面向对象编程的设计模式,通过将依赖对象注入到类中,实现类与类之间的解耦和可测试性的提升。
依赖注入的实现原理主要分为三种方式:构造函数注入、属性注入和接口注入。
构造函数注入是最常见的一种依赖注入方式,它通过在类的构造函数中接受依赖对象作为参数来实现依赖注入。
构造函数注入的优势在于可以保证依赖对象在类被创建时已经被注入,避免了在类中使用未实例化的依赖对象的问题。
属性注入是另一种常见的依赖注入方式,它通过在类中定义依赖对象的属性,并在类创建后将依赖对象注入到属性中来实现依赖注入。
属性注入的优势在于可以在类被创建后注入依赖对象,避免了构造函数注入中可能会存在的循环依赖问题。
接口注入是一种比较少见的依赖注入方式,它通过在类中定义一个接口,并在类创建后通过接口方法来实现依赖注入。
接口注入的优势在于可以提高代码的可读性和可维护性,同时也避免了构造函数注入和属性注入中可能存在的命名冲突问题。
无论是哪种依赖注入方式,它们都需要一个依赖注入容器来进行依赖对象的管理和注入。
依赖注入容器通常是一个单例对象,它负责在系统启动时创建依赖对象,并在需要注入依赖对象的类中进行注入。
总之,依赖注入作为一种设计模式,可以帮助我们实现类与类之间的解耦和便于测试,同时也可以提高代码的可读性和可维护性。
了
解依赖注入的实现原理对于我们在实际开发中的应用非常有帮助。

vue依赖注入原理Vue.js 是现代 JavaScript 框架之一,具有丰富的生态系统和良好的文档资料。
Vue 的设计理念追求简洁、灵活、易维护等特质,其中依赖注入就是一个很好的例子。
在 Vue 的组件开发中,组件之间的通信传递是一个重要的问题。
在 Vue 2.x 版本中,父组件可以通过 props 属性向子组件传递数据,子组件再通过事件向父组件通知数据的变化。
然而,有时候我们需要跨越多个组件级别传递数据,这时候就需要使用依赖注入。
依赖注入是一种将组件所需的依赖项自动传递给组件的机制。
在Vue 的实现中,通过在父组件中注册一个 provide 属性来提供数据,子组件可以通过 inject 属性来获取数据。
下面是具体的实现步骤:1. 在父组件中定义 provide 属性,并指定要提供给子组件的数据。
```export default {provide: {userData: {name: 'Tom',age: 20,},},};```2. 在子组件中定义 inject 属性,并指定要注入的数据键名。
```export default {inject: ['userData'],mounted() {console.log(erData);},};```3. 在子组件中使用注入的数据。
```<template><div>{{ }}{{userData.age}}</div></template>```在这个例子中,我们将 userData 对象提供给了子组件,子组件通过 inject 属性接收了 userData 属性,并在 mounted 生命周期中打印了 userData 对象。
需要注意的是,使用这种方式注入的数据是不响应式的,也就是说,如果提供的数据在父组件中被修改,子组件中的数据并不会自动更新,需要手动触发更新。

什么是Java的依赖注入有什么作用在Java 编程的世界里,依赖注入(Dependency Injection,简称DI)是一个重要的概念。
对于初学者来说,可能一开始会觉得有些抽象和难以理解,但其实它就像是给程序中的各个部分“送物资”,让它们能够顺利地完成自己的工作。
想象一下,我们正在构建一个复杂的系统,就像是建造一座大厦。
在这座大厦中,有各种各样的房间和设施,每个房间和设施都有自己特定的功能。
比如,有一个房间是负责处理数据的,另一个房间是负责显示界面的。
如果我们不使用依赖注入,那么每个房间都需要自己去获取它所需要的资源和工具。
这就好比每个房间都要自己去外面的市场购买所需的材料,不仅麻烦,而且容易出错。
而且,如果某个材料的获取方式发生了变化,那么每个房间都需要去修改自己获取材料的代码,这会导致大量的重复工作和代码的混乱。
那么,依赖注入是如何解决这个问题的呢?简单来说,依赖注入就是把对象所需要的外部资源,通过某种方式注入到对象内部,而不是让对象自己去获取。
举个例子,假设我们有一个`UserService` 类,它需要一个`UserRepository` 对象来访问数据库获取用户数据。
如果没有依赖注入,`UserService` 可能会这样创建`UserRepository` 对象:```javapublic class UserService {private UserRepository userRepository = new UserRepository();public void doSomething(){//使用 userRepository 进行操作}}```在上述代码中,`UserService` 自己创建了`UserRepository` 对象。
这样做的问题是,如果`UserRepository` 的创建方式发生了变化,或者我们想要使用不同的`UserRepository` 实现,那么就需要修改`UserService` 的代码。

依赖注入的原理
依赖注入是一种设计模式,它的核心思想是将对象的依赖关系从代码内部转移到外部容器中进行管理。
简而言之,依赖注入就是将一个对象所依赖的其他对象注入到它的构造函数、属性或方法中。
依赖注入的原理在于解耦和灵活性。
通过将对象的依赖关系与代码逻辑分离,我们可以更容易地修改、替换或扩展这些依赖对象,而无需修改原有代码。
依赖注入的过程通常分为三步:
1. 定义接口或抽象类:我们首先需要定义一个接口或抽象类,用于描述依赖对象的功能和行为。
这样做的目的是为了实现松耦合,便于后续的替换和扩展。
2. 创建依赖对象:接下来,我们需要创建具体的依赖对象,实现接口或抽象类中定义的方法和属性。
3. 注入依赖对象:最后,我们通过构造函数、属性或方法将依赖对象注入到被依赖对象中。
这可以通过手动实例化并传递依赖对象,或者通过容器(如Spring框架)自动完成。
依赖注入有助于提高代码的可维护性、可测试性和可扩展性。
它将应用程序的各个模块解耦,使得代码更易于理解、修改和扩展。
同时,依赖注入还促进了单元测试的实施,因为我们可以方便地替换或模拟依赖对象来进行测试。
总而言之,依赖注入是一种通过将对象的依赖关系从代码内部转移到外部容器中进行管理的设计模式。
它的原理在于解耦和灵活性,通过注入依赖对象可以提高代码的可维护性、可测试性和可扩展性。
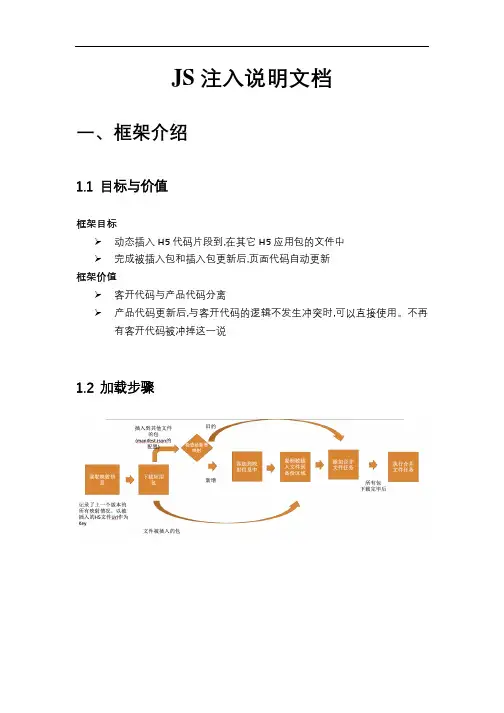
JS注入说明文档一、框架介绍1.1目标与价值框架目标➢动态插入H5代码片段到,在其它H5应用包的文件中➢完成被插入包和插入包更新后,页面代码自动更新框架价值➢客开代码与产品代码分离➢产品代码更新后,与客开代码的逻辑不发生冲突时,可以直接使用。
不再有客开代码被冲掉这一说1.2加载步骤二、编写配置文件编写需要注入的客开代码第一步要编写配置文件,配置文件编写参考其它标准应用包,注入重点关注manifest中的automerge字段。
编写示例:"automerge": [{// 被注入的文件(只能有一个)"src": "",// 注入的文件(可以注入多个文件)"insert": ["html/a.html","html/b.html"]}]automerge字段定义了注入配置信息,automerge的值是一个数组,可以定义多个src-insert对。
每个注入对中,src只能有一个,insert可以有多个注入文件。
➢Src详解在src中写被注入的文件,书写规则:“http://urlSchemes/版本/注入文件路径“urlSchemes的书写规则为:.cmp(budleName与team可以在标准应用包中的文件中找到)版本写v即可,自动取最新版本例如:下面的示例代码,声明了要注入到application应用中的文件。
如下图所示。
"src": ""图被注入的HTML➢insert详解insert中定义了注入的文件列表,也就是客开代码,注意必须写相对路径,注意目录结构。
例如:下面的示例代码,声明了注入的文件为a.html、b.html。
如下图所示。
"insert": ["html/a.html", // 注入的文件(客开代码)"html/b.html" // 注入的文件(客开代码)]图注入的HTML三、编写注入代码3.1 代码注入规则用正则表达式"(</body>){0,1}\\s*</html>(\\w|\\s|[\\*\\-]|(!>)|(<!))*$"从src文件中找到插入位置,然后在匹配位置之前插入客开代码。

函数传递依赖的名词解释依赖注入(Dependency Injection)是一种编程范式,它实现了软件设计和架构中非常重要的依赖性管理策略。
它旨在提供一种让对象从容易的位置获取外部资源的方法,而不尝试自己构建和处理需要的细节。
它也用于去除复杂应用程序中的耦合问题,以便有效地重构和测试代码。
一、什么是依赖注入:依赖注入(Dependency Injection)是一种编程范式,它实现了软件设计和架构中非常重要的依赖性管理策略。
它旨在提供一种让对象从容易的位置获取外部资源的方法,而不尝试自己构建和处理需要的细节。
它允许程序的一部分以简单的方式获取另一部分的依赖项,而无需让程序知晓他们之间的实现。
二、依赖注入的机制:依赖注入(DI)主要通过工厂对象,组件服务,端点服务,容器和其他各种技术结合来实现。
工厂对象是最常见的DI机制,它创建另一个对象的引用,以便依赖性可以接受和传输,而不是依赖性自己被实例化。
组件服务创建一个框架,允许大量的对象实例被注入,而不是每一个都要做手工的编码。
端点服务主要用于替换依赖性,以便在运行时可以更改与它们相关的对象。
容器提供依赖性注入的一个可视化界面,使您可以更自由地定义和提供服务注入模型。
三、依赖注入的优点:(1)降低耦合性:可以将不同部分的耦合性减少到最低,依赖注入可以在运行时动态地解决对象之间的依赖关系;(2)可测试性:通过依赖注入,编写实际的测试能够简单而专注,而不碰到耦合的问题,从而使代码更易于测试;(3)可维护性:注入不同的依赖项,可以很容易地在系统中重新组合不同的类或模块,更改或添加新的依赖项;(4)可扩展性:容纳新的功能的能力更强,用新的依赖项替换旧的依赖项,可以更方便地解决问题。
四、总结:总之,依赖注入(Dependency Injection)是一种编程模式,它实现了软件设计和架构中非常重要的依赖性管理策略。
它的机制主要通过工厂对象,组件服务,端点服务,容器和其他各种技术结合来实现。

依赖注入怎样实现有几种方式依赖注入(Dependency Injection,简称DI)是指通过外部将依赖对象传递给一个类,而不是在类内部创建依赖对象的方式。
它是面向对象编程中的一种设计模式,旨在降低类与类之间的耦合度,提高代码的可测试性和可维护性。
依赖注入有多种实现方式,下面将详细介绍其中的几种方式。
1. 构造函数注入(Constructor Injection):构造函数注入是最常见和推荐的依赖注入方式之一、通过在类的构造函数参数中声明需要依赖的对象,然后在类的实例化过程中将依赖对象传递给构造函数。
这种方式可确保依赖对象在类的创建时就被注入,并且在类的生命周期中都存在。
2. Setter方法注入(Setter Injection):Setter方法注入是另一种常见的依赖注入方式。
通过在类中定义与依赖对象对应的setter方法,在使用类的时候通过调用setter方法将依赖对象注入。
这种方式相较于构造函数注入更加灵活,可以在任何时候替换依赖对象,并且不需要修改类的构造函数。
3. 接口注入(Interface Injection):接口注入是一种相对较少使用的依赖注入方式。
它要求类实现一个特定的接口,在调用类的方法时,通过接口的方法将依赖对象注入。
这种方式相较于构造函数注入和setter方法注入更为灵活,但也增加了代码的复杂度和维护成本。
4. 注解注入(Annotation Injection):注解注入是一种基于注解的依赖注入方式。
通过在类或者类的成员上添加特定的注解来标识依赖对象,然后在运行时使用注解处理器来解析注解,并将依赖对象注入到相应的位置。
注解注入方式相较于前面几种方式更加灵活,对类的改动要求较小,但需要依赖于特定的注解框架。
除了上述几种依赖注入方式,还有一些其他的实现方式,如上下文注入、工厂方法注入等。
不同的依赖注入方式适用于不同的场景,选择合适的方式需要结合具体的业务需求和技术架构来决定。
依赖注入和装配的通俗理解依赖注入和装配是软件开发中常用的两个概念。
它们可以帮助我们更好地管理代码的依赖关系和组件的装配过程,提高代码的可维护性和可测试性。
让我们来看看依赖注入。
依赖注入是一种设计模式,它主要解决的问题是组件之间的依赖关系管理。
在传统的开发方式中,组件通常需要自己创建和管理它们所依赖的其他组件。
这样做的问题是,组件的创建和依赖关系很容易变得复杂,代码可读性差和可测试性差。
而依赖注入则是通过将组件所依赖的其他组件的创建和管理责任交给外部容器来实现的。
简单来说,就是组件不再自己创建和管理它们所依赖的其他组件,而是由外部容器来完成。
组件只需要声明它所依赖的其他组件,容器会自动将这些依赖注入到组件中。
这样做的好处是,组件的代码变得简洁清晰,可读性和可测试性都得到了提高。
接下来,我们来看看装配。
装配是指将组件之间的依赖关系连接起来的过程。
在依赖注入的基础上,我们需要将组件和它所依赖的其他组件连接起来,使它们能够正常工作。
这个过程可以通过两种方式来实现:构造函数注入和属性注入。
构造函数注入是指通过组件的构造函数来传递依赖的方式。
当一个组件被创建时,它的构造函数会被调用,并将它所依赖的其他组件作为参数传入。
这样做的好处是,组件的依赖关系在创建时就被明确地传递了,使代码更加清晰。
另一种方式是属性注入,也就是在组件中声明一个属性来接收所依赖的其他组件。
容器会通过反射等机制将依赖注入到这些属性中。
这种方式相对灵活,但可读性不如构造函数注入。
依赖注入和装配的好处是显而易见的。
首先,它们能够有效地解耦组件之间的依赖关系,提高代码的可维护性。
当一个组件的依赖关系发生变化时,我们只需要修改容器的配置,而不需要修改组件本身的代码。
其次,它们能够提高代码的可测试性。
通过将组件的依赖关系解耦,我们可以更容易地对组件进行单元测试,以确保其功能的正确性。
除了依赖注入和装配,还有一些相关的概念也值得我们了解。
比如,控制反转(Inversion of Control)和依赖查找(Dependency Lookup)。
provide和inject用法提供和注入是Vue.js中最常用的两个方法,用于在组件之间传递数据和共享状态。
在本文中,我们将深入探讨这两种方法的用法和实现方式,并提供一些实用技巧和最佳实践。
1. 什么是Provide和InjectProvide和Inject是Vue.js中的两个API,用于在父组件和子组件之间传递数据和共享状态。
它们的作用类似于React中的Context API,但提供了更灵活的实现方式和更高的性能。
Provide和Inject的具体实现方式是,父组件通过Provide方法提供一个数据对象,子组件通过Inject方法注入这个数据对象,并在组件中使用。
这个数据对象可以是任何类型的数据,例如字符串、数字、对象、函数等。
2. Provide和Inject的用法2.1 父组件中使用Provide在父组件中使用Provide方法,可以向子组件提供数据对象。
Provide方法接受一个对象作为参数,这个对象中包含了需要共享的数据。
例如,以下代码中,父组件提供了一个名为“userInfo”的数据对象,包含了用户的姓名和年龄。
```javascript<template><div><child-component></child-component></div></template><script>import ChildComponent from './ChildComponent.vue' export default {na 'ParentComponent',provide () {return {userInfo: {na '张三',age: 18}}},components: {ChildComponent}}</script>```2.2 子组件中使用Inject在子组件中使用Inject方法,可以注入父组件提供的数据对象。
MVC模式是软件工程中一种软件架构模式,一般把软件模式分为三部分,模型(Model)+视图(View)+控制器(Controller)。
MVC模式有助于将应用程序的逻辑和显示分离,以提高代码的可读性和可维护性。
在MVC中,依赖注入是一种设计模式,用于降低模块间的耦合度,提高代码的可重用性和可维护性。
通过依赖注入,一个模块不需要知道它的依赖项是如何实现的,只需要知道它提供了所需的服务即可。
在JavaScript中,依赖注入通常通过构造函数或服务定位器模式来实现。
构造函数模式使用构造函数来注入依赖项,而服务定位器模式使用一个单独的服务定位器对象来管理依赖项。
在依赖注入中,有一个提供者(Provider)负责创建和提供依赖项,一个消费者(Consumer)需要依赖项来执行其功能,而一个注入器(Injector)负责将依赖项注入到消费者中。
注入器可以是构造函数、服务定位器或任何其他对象,它负责解析和注入依赖项。
在JavaScript中,常见的依赖注入框架包括AngularJS、Vue.js和React等。
这些框架提供了内置的依赖注入机制,使得开发者可以更容易地实现模块化和组件化开发。
依赖注⼊的三种⽅式以及优缺点。
依赖注⼊是指在创建⼀个对象时,⾃动地创建它依赖的对象,并注⼊。
⼤家都知道有三种途径来实现依赖注⼊,我这⾥总结⼀下这三种⽅式的优缺点:1.构造⽅法注⼊:优点:在构造⽅法中体现出对其他类的依赖,⼀眼就能看出这个类需要其他那些类才能⼯作。
脱离了IOC框架,这个类仍然可以⼯作,POJO的概念。
⼀旦对象初始化成功了,这个对象的状态肯定是正确的。
缺点:构造函数会有很多参数(Bad smell)。
有些类是需要默认构造函数的,⽐如MVC框架的Controller类,⼀旦使⽤构造函数注⼊,就⽆法使⽤默认构造函数。
这个类⾥⾯的有些⽅法并不需要⽤到这些依赖(Bad smell)。
2. Set⽅法注⼊:优点:在对象的整个⽣命周期内,可以随时动态的改变依赖。
⾮常灵活。
缺点:对象在创建后,被设置依赖对象之前这段时间状态是不对的。
不直观,⽆法清晰地表⽰哪些属性是必须的。
3. ⽅法参数注⼊:⽅法参数注⼊的意思是在创建对象后,通过⾃动调⽤某个⽅法来注⼊依赖。
类似如下代码。
public class MovieRecommender {private MovieCatalog movieCatalog;private CustomerPreferenceDao customerPreferenceDao;@Autowiredpublic void prepare(MovieCatalog movieCatalog,CustomerPreferenceDao customerPreferenceDao) {this.movieCatalog = movieCatalog;this.customerPreferenceDao = customerPreferenceDao;}// ...}这种⽅式介于Set⽅法注⼊和构造⽅法注⼊之间。
⽐如说我们通常会⽤⼀个Init⽅法来接受依赖的参数。
这种⽅法可能不太常⽤,⼀般是只有⼀个⽅法依赖到注⼊的对象时⽤到,如果有多个⽅法依赖到注⼊的对象,还是⽐较倾向于使⽤构造⽅法注⼊。
依赖注入和控制反转概念一. 依赖注入1、依赖注入(Dependency Injection,简称DI)是什么?依赖注入是一种软件架构模式,它允许我们把一些模块或技术的实现和使用分离开来,从而使代码更易于维护和重用。
这种模式将系统所依赖的关键组件以及他们之间的依赖关系注入其中,而不是让类自己创建或查找所需组件,从而使得系统更加灵活,容易重构,可以使用不同的实现,避免了紧耦合。
2、依赖注入的作用是什么?依赖注入的主要作用有以下几点:(1)解耦:将实例的创建和它的使用分离,使得类之间的依赖关系更加松散,并且更容易实现复用。
(2)灵活:因为创建和使用实例分离,所以不同的实现可以被注入,使得系统更加灵活,不同的实现可以替换掉而不需要修改代码。
(3)测试:可以通过依赖注入来替换真实的组件,从而使得测试更加容易,实现在不依赖真实的组件和资源的情况下进行测试。
3、依赖注入的实现依赖注入一般可以有以下几种实现:(1)构造函数注入:给构造函数传入所需的对象,由构造函数来完成组装,这种方式比较简单,但是也会出现一些问题,比如要注入很多对象会导致构造函数参数过多,使得代码不易读和维护。
(2)Setter方式注入:通过提供Setter函数来完成注入,比如JavaBean中的Setter函数,这种方式的好处是,注入的灵活,可以逐个对象进行注入,也可以把所有的对象一次性注入,但是这种方式依赖于Setter函数,有些情况下不灵活,比如某些对象不适合用Setter函数进行注入。
(3)接口注入:这种方式是对于Setter注入的一种扩展,它将Setter函数定义在接口中,这样就不依赖于Setter函数,而是更为精细的控制,类只需要实现接口即可。
4、依赖注入的优势(1)配置灵活:可以在不同的配置文件中使用不同的实现,比如不同的数据库、不同的缓存服务器,而无需修改代码;(2)代码重用:可以实现代码的复用,比如对多个类使用一个服务,而不需要重复实现相同的代码;(3)易于测试:可以避免使用真实组件,使用Mock对象来模拟环境,更容易完成测试;(4)可读性:可以更好的控制类之间的依赖关系,从而使得代码更加清晰易读,更容易理解和维护。
依赖注入实现原理依赖注入(Dependency Injection)是一种软件设计模式,它通过将依赖对象的创建和管理交给外部容器来实现,从而解耦组件之间的依赖关系。
依赖注入的实现原理可以分为三个步骤:配置、创建和注入。
首先,配置阶段是指在应用程序的启动过程中,通过配置文件、注解或编程方式向容器注册服务的依赖关系。
这些依赖关系包括依赖的接口、实现类以及它们之间的关联关系。
其次,创建阶段是指容器根据配置信息创建所需的依赖对象。
在这个阶段,容器会根据依赖关系的类型,使用适当的方法(例如反射)实例化对象。
如果依赖对象有自身的依赖,容器会递归地创建它们。
最后,注入阶段是指容器将创建好的依赖对象注入到需要它们的组件中。
这一过程可以通过构造函数注入、属性注入或方法注入来实现。
容器会根据依赖关系的配置信息,将合适的依赖对象传递给需要它们的组件。
依赖注入的实现原理主要基于反射和动态代理技术。
反射技术允许程序在运行时动态地获取和操作对象的信息,而动态代理技术则允许程序在运行时动态地生成代理对象,从而实现对被代理对象的控制和管理。
在依赖注入的实现中,容器会使用反射技术来扫描应用程序的配置信息,获取需要创建的对象和它们的依赖关系。
容器会通过调用相应的构造方法或调用对象的无参构造方法来创建对象。
如果对象有自身的依赖,容器会递归地创建它们。
容器还会使用动态代理技术来生成代理对象,当需要注入依赖对象时,容器会将代理对象注入到需要它们的组件中。
通过代理对象,容器可以在运行时对依赖对象进行管理和控制,例如实现懒加载、AOP切面等功能。
总之,依赖注入的实现原理是通过配置、创建和注入三个步骤来实现的。
在配置阶段,容器会根据应用程序的配置信息注册依赖关系。
在创建阶段,容器会根据配置信息创建所需的对象,并递归地创建依赖对象。
在注入阶段,容器会将依赖对象注入到需要它们的组件中。
依赖注入的实现主要基于反射和动态代理技术,通过反射可以动态地获取和操作对象的信息,通过动态代理可以动态地生成代理对象,并实现对依赖对象的管理和控制。
JavaScript中依赖注入详细解析
计算机编程的世界其实就是一个将简单的部分不断抽象,并将这些抽象组织起来的过程。
JavaScript也不例外,在我们使用JavaScript编写应用时,我们是不是都会使用到别人编写的代码,例如一些著名的开源库或者框架。
随着我们项目的增长,我们需要依赖的模块变得越来越多,这个时候,如何有效的组织这些模块就成了一个非常重要的问题。
依赖注入解决的正是如何有效组织代码依赖模块的问题。
你可能在一些框架或者库种听说过“依赖注入”这个词,比如说著名的前端框架AngularJS,依赖注入就是其中一个非常重要的特性。
但是,依赖注入根本就不是什么新鲜玩意,它在其他的编程语言例如PHP中已经存在已久。
同时,依赖注入也没有想象种那样复杂。
在本文中,我们将一起来学习JavaScript中的依赖注入的概念,深入浅出的讲解如何编写“依赖注入风格”的代码。
目标设定
假设我们现在拥有两个模块。
第一个模块的作用是发送Ajax请求,而第二个模块的作用则是用作路由。
这时,我们编写了一个函数,它需要使用上面提到的两个模块:
在这里,为了让我们的代码变得有趣一些,这个参数需要多接收几个参数。
当然,我们完全可以使用上面的代码,但是无论从哪个方面来看上面的代码都略显得不那么灵活。
要是我们需要使用的模块名称变为ServiceXML或者ServiceJSON该怎么办?或者说如果我们基于测试的目的想要去使用一些假的模块改怎么办。
大讲台,混合式自适应IT职业教育开创者。
这时,我们不能仅仅去编辑函数本身。
因此我们需要做的第一件事情就是将依赖的模块作为参数传递给函数,代码如下所示:
在上面的代码中,我们完全传递了我们所需要的模块。
但是这又带来了一个新的问题。
假设我们在代码的哥哥部分都调用了doSomething方法。
这时,如果我们需要第三个依赖项该怎么办。
这个时候,去编辑所有的函数调用代码并不是一个明智的方法。
因此,我们需要一段代码来帮助我们做这件事情。
这就是依赖注入器试图去解决的问题。
现在我们可以来定下我们的目标了:
∙我们应该能够去注册依赖项
∙依赖注入器应该接收一个函数,然后返回一个能够获取所需资源的函数
∙代码不应该复杂,而应该简单友好
∙依赖注入器应该保持传递的函数作用域
∙传递的函数应该能够接收自定义的参数,而不仅仅是被描述的依赖项
requirejs/AMD方法
或许你已经听说过了大名鼎鼎的requirejs,它是一个能够很好的解决依赖注入问题的库:
requirejs的思想是首先我们应该去描述所需要的模块,然后编写你自己的函数。
其中,参数的顺序很重要。
假设我们需要编写一个叫做injector的模块,它能够实现类似的语法。
在继续往下之前,需要说明的一点是在doSomething的函数体中我们使用了expect.js这个断言库来确保代码的正确性。
这里有一点类似TDD(测试驱动开发)的思想。
现在我们正式开始编写我们的injector模块。
大讲台,混合式自适应IT职业教育开创者。
首先它应该是一个单体,以便它能够在我们应用的各个部分都拥有同样的功能。
这个对象非常的简单,其中只包含两个函数以及一个用于存储目的的变量。
我们需要做的事情是检查deps数组,然后在dependencies变量种寻找答案。
剩余的部分,则是使用.apply方法去调用我们传递的func变量:
如果你需要指定一个作用域,上面的代码也能够正常的运行。
在上面的代码中,Array.prototype.slice.call(arguments, 0)的作用是将arguments变量转换为一个真正的数组。
到目前为止,我们的代码可以完美的通过测试。
但是这里的问题是我们必须要将需要的模块写两次,而且不能够随意排列顺序。
额外的参数总是排在所有的依赖项之后。
反射(reflection)方法
根据维基百科中的解释,反射(reflection)指的是程序可以在运行过程中,一个对象可以修改自己的结构和行为。
在JavaScript中,简单来说就是阅读一个对象的源码并且分析源码的能力。
还是回到我们的doSomething方法,如果你调用doSomething.toString()方法,你可以获得下面的字符串:
这样一来,只要使用这个方法,我们就可以轻松的获取到我们想要的参数,以及更重要的一点就是他们的名字。
这也是AngularJS实现依赖注入所使用的方法。
大讲台,混合式自适应IT职业教育开创者。
在AngularJS的代码中,我们可以看到下面的正则表达式:
我们可以将resolve方法修改成如下所示的代码:
我们使用上面的正则表达式去匹配我们定义的函数,我们可以获取到下面的结果:
此时,我们只需要第二项。
但是一旦我们去除了多余的空格并以,来切分字符串以后,我们就得到了deps数组。
下面的代码就是我们进行修改的部分:
在上面的代码中,我们遍历了依赖项目,如果其中有缺失的项目,如果依赖项目中有缺失的部分,我们就从arguments对象中获取。
如果一个数组是空数组,那么使用shift方法将只会返回undefined,而不会抛出一个错误。
到目前为止,新版本的injector看起来如下所示:
在上面的代码中,我们可以随意混淆依赖项的顺序。
但是,没有什么是完美的。
反射方法的依赖注入存在一个非常严重的问题。
当代码简化时,会发生错误。
这是因为在代码简化的过程中,参数的名称发生了变化,这将导致依赖项无法解析。
例如:
因此我们需要下面的解决方案,就像AngularJS中那样:
这和最一开始看到的AMD的解决方案很类似,于是我们可以将上面两种方法整合起来,最终代码如下所示:
这一个版本的resolve方法可以接受两个或者三个参数。
下面是一段测试代码:
你可能注意到了两个逗号之间什么都没有,这并不是错误。
大讲台,混合式自适应IT职业教育开创者。
这个空缺是留给Other这个参数的。
这就是我们控制参数顺序的方法。
结语
在上面的内容中,我们介绍了几种JavaScript中依赖注入的方法,希望本文能够帮助你开始使用依赖注入这个技巧,并且写出依赖注入风格的代码。