
javascript读取服务器端XML文件
最近需要用javascript解析一个XML文件,为了前期本地测试,在读取的时候用的是绝对地址,可后来发现不能读取服务器上的文件,不能用相对路径,一堆问题,无从解决.。找了相关资料,最后用XMLHTTP 来处理,注意这里可能会出现中文乱码问题......
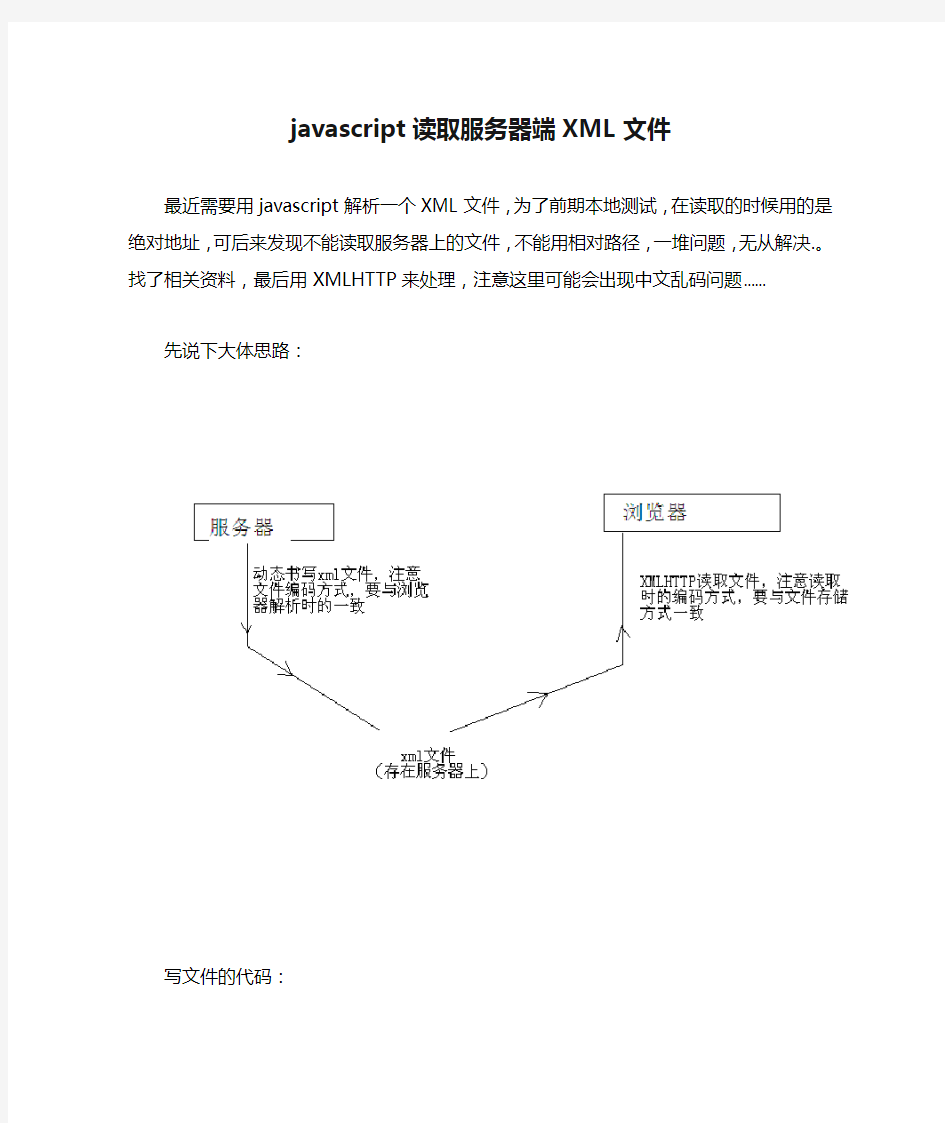
先说下大体思路:
写文件的代码:
FileOutputStream writerStream = new java.io.FileOutputStream(fileName2);
BufferedWriter writer = new java.io.BufferedWriter(new java.io.OutputStreamWriter(writerStream, "UTF-8"));//设置文件编码方//式
writer.write(strbuf.toString());//strbuf为文件内容
writer.close();
读文件的代码:
var xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
var url = "xxxxxxxxxx";//根据需要,这里以XX代替
xmlHttp.open("GET", url, false);
xmlHttp.setRequestHeader("Content-Type","utf-8"); //设置读取文件的编码方式
xmlHttp.send();
var content = "";
if(xmlHttp.status==200){
content = xmlHttp.responseText; //content就是读取到到的文本内容,当然,根绝不同需要,调用不同方法....
}
1、GET和POST的区别,何时使用POST? GET:一般用于信息获取,使用URL传递参数,对所发送信息的数量也有限制,一般在2000个字符 POST:一般用于修改服务器上的资源,对所发送的信息没有限制。 GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值, 也就是说Get是通过地址栏来传值,而Post是通过提交表单来传值。 然而,在以下情况中,请使用POST 请求: 无法使用缓存文件(更新服务器上的文件或数据库) 向服务器发送大量数据(POST 没有数据量限制) 发送包含未知字符的用户输入时,POST 比GET 更稳定也更可靠JavaScript是客户端和服务器端脚本语言,可以插入到HTML页面中,并且是目前较热门的Web开发语言。同时,JavaScript也是面向对象编程语言。 类似的基本题目还包括:JavaScript都有哪些类型?JavaScript是谁发明的?……2、列举Java和JavaScript之间的区别? Java是一门十分完整、成熟的编程语言。相比之下,JavaScript是一个可以被引入HTML页面的编程语言。这两种语言并不完全相互依赖,而是针对不同的意图而设计的。Java是一种面向对象编程(OOPS)或结构化编程语言,类似的如C ++或C,而JavaScript是客户端脚本语言,它被称为非结构化编程。
3. JavaScript和ASP脚本相比,哪个更快? JavaScript更快。JavaScript是一种客户端语言,因此它不需要Web服务器的协助来执行。另一方面,ASP是服务器端语言,因此总是比JavaScript慢。值得注意的是,Javascript现在也可用于服务器端语言(nodejs)。 4、什么是负无穷大? 负无穷大是JavaScript中的一个数字,可以通过将负数除以零来得到。 5、如何将JavaScript代码分解成几行吗? 在字符串语句中可以通过在第一行末尾使用反斜杠“\”来完成 例:document.write(“This is \a program”); 如果不是在字符串语句中更改为新行,那么javaScript会忽略行中的断点。
如何用vc创建和读取xml文件 当前Web上流行的剧本语言是以HTML为主的语言结构,HTML是一种标记语言,而不是一种编程语言,主要的标记是针对显示,而不是针对文档内容本身结构的描述的。也就是说,机器本身是不能够解析它的内容的,所以就出现了XML语言。XML (eXtensible Markup Language)语言是SGML语言的子集,它保留了SGML主要的使用功能,同时大大缩减了SGML的复杂性。XML语言系统建立的目的就是使它不仅能够表示文档的内容,而且可以表示文档的结构,这样在同时能够被人类理解的同时,也能够被机器所理解。XML要求遵循一定的严格的标准。XML分析程序比HTML浏览器更加要挑剔语法和结构,XML要求正在创建的网页正确的使用语法和结构,而不是象HTML一样,通过浏览器推测文档中应该是什么东西来实现HTML的显示,XML使得分析程序不论在性能还是稳定性方面都更容易实现。XML文档每次的分析结果都是一致的,不象HTML,不同的浏览器可能对同一个HTML作出不同的分析和显示。 同时因为分析程序不需要花时间重建不完整的文档,所以它们能比同类HTML能更有效地执行其任务。它们能全力以赴地根据已经包含在文档中的那个树结构建造出相应的树来,而不用在信息流中的混合结构的基础上进行显示。XML标准是对数据的处理应用,而不是只针对Web网页的。任何类型的应用都可以在分析程序的上面进行建造,浏览器只是XML的一个小的组成部分。当然,浏览仍旧极其重要,因为它为XML工作人员提供用于阅读信息的友好工具。但对更大的项目来说它就不过是一个显示窗口。因为XML具有严格的语法结构,所以我们甚至可以用XML来定义一个应用层的通讯协议,比如互联网开放贸易协议(Internet Open Trading Protocol)就是用XML来定义的。从某种意义上说,以前我们用BNF范式定义的一些协议和格式从原则上说都可以用XML来定义。实际上,如果我们有足够的耐心,我们完全可以用XML来定义一个C++语言的规范。 当然,XML允许大量HTML样式的形式自由的开发,但是它对规则的要求更加严格。XML主要有三个要素:DTD(Document Type Declaration——文档类型声明)或XML Schema(XML大纲)、XSL(eXtensible Stylesheet Language——可扩展样式语言)和XLink(eXtensible Link Language——可扩展链接语言)。DTD和XML大纲规定了XML文件的逻辑结构,定义了XML文件中的元素、元素的属性以及元素和元素的属性之间的关系;Namespace(名域)实现统一的XML文档数据表示以及数据的相互集成;XSL是用于规定XML文档呈现样式的语言,它使得数据与其表现形式相互独立,比如XSL能使Web浏览器改变文档的表示法,例如数据的显示顺序的变化,不需要再与服务器进行通讯。通过改变样式表,同一个文档可以显示得更大,或者经过折叠只显示外面得一层,或者可以变为打印得格式。而XLink将进一步扩展目前Web上已有的简单链接。 二、实现XML解析的说明 当然,从理论上说,根据XML的格式定义,我们可以自己编写一个XML的语法分析器,但是实际上微软已经给我们提供了一个XML语法解析器,如果你安装了IE5.0以上版本的话,实际上你就已经安装了XML语法解析器。可以从微软站点(https://www.doczj.com/doc/373926195.html,)下载最新的MSXML的SDK和Parser文件。它是一个叫做MSXML.DLL的动态链接库,最新版本为msxml3,实际上它是一个COM对象库,里面封装了所有进行XML解析所需要的所有必要的对象。因为COM是一种以二进制格式出现的和语言无关的可重用对象。所以你可以用任何语言(比如VB,VC,DELPHI,C++ Builder甚至是剧本语言等等)对它进行调用,
asp读取xml文件的方法 大家知道asp读取xml文件吗?下面我们就给大家详细介绍一下吧!我们积累了一些经验,在此拿出来与大家分享下,请大家互相指正。 ? strSourceFile=Server.MapPath(dataxml&”/Advertisement/”&id&”/a dv.xml”) ?SetobjXML=Server.CreateObject(“Microsoft.XMLDOM”)'创建一个XML对像 ?objXML.load(strSourceFile)'把XML文件读入内存 ?Setxml=objXML.documentElement.selectSingleNode(“Advertisement”)'选取节点Advertisement ?ADid=xml.childNodes.item(0).text ?ADname=xml.childNodes.item(1).text ?ADintro=xml.childNodes.item(2).text ?ADact=xml.childNodes.item(3).text ?ADclass=xml.childNodes.item(4).text ?Pids=xml.childNodes.item(5).text ?Picid=xml.childNodes.item(6).text ?ADurl=xml.childNodes.item(7).text ?ADwindow=xml.childNodes.item(8).text ?ADshow=xml.childNodes.item(9).text ?ADshows=xml.childNodes.item(10).text ?ADclick=xml.childNodes.item(11).text
J a v a s c r i p t笔试题及 答案 Company Document number:WTUT-WT88Y-W8BBGB-BWYTT-19998
Javascript面试笔试题 考试时间90分钟 一、不定项选择题(每题3分,共30分) 1.声明一个对象,给它加上name属性和show方法显示其name值,以下 代码中正确的是( D ) A.var obj = [name:"zhangsan",show:function(){alert(name);}]; B.var obj = {name:"zhangsan",show:”alert”}; C.var obj = {name:"zhangsan",show:function(){alert(name);}}; D.v ar obj = {name:"zhangsan",show:function(){alert;}}; 2.以下关于Array数组对象的说法不正确的是( CD) A.对数组里数据的排序可以用sort函数,如果排序效果非预期,可以给 sort函数加一个排序函数的参数 B.reverse用于对数组数据的倒序排列 C.向数组的最后位置加一个新元素,可以用pop方法 D.unshift方法用于向数组删除第一个元素 3.要将页面的状态栏中显示“已经选中该文本框”,下列JavaScript语句正确的 是( A ) A.="已经选中该文本框" B.="已经选中该文本框" C.="已经选中该文本框" D.="已经选中该文本框" 4.点击页面的按钮,使之打开一个新窗口,加载一个网页,以下JavaScript 代码中可行的是( AD)
在java环境下读取xml文件的方法主要有4种:DOM、SAX、JDOM、JAXB 1. DOM(Document Object Model) 此方法主要由W3C提供,它将xml文件全部读入内存中,然后将各个元素组成一棵数据树,以便快速的访问各个节点。因此非常消耗系统性能,对比较大的文档不适宜采用DOM方法来解析。 DOM API 直接沿袭了 XML 规范。每个结点都可以扩展的基于 Node 的接口,就多态性的观点来讲,它是优秀的,但是在Java 语言中的应用不方便,并且可读性不强。 实例: Java代码 1.import javax.xml.parsers.*; 2.//XML解析器接口 3.import org.w3c.dom.*; 4.//XML的DOM实现 5.import org.apache.crimson.tree.XmlDocument; 6.//写XML文件要用到 7.DocumentBuilderFactory factory = DocumentBuilderFactory.newInst ance(); 8. //允许名字空间 9. factory.setNamespaceAware(true); 10. //允许验证 11. factory.setValidating(true); 12. //获得DocumentBuilder的一个实例 13.try { 14. DocumentBuilder builder = factory.newDocumentBuilder(); 15.} catch (ParserConfigurationException pce) { 16.System.err.println(pce); 17.// 出异常时输出异常信息,然后退出,下同 18.System.exit(1); 19.} 20.//解析文档,并获得一个Document实例。 21.try { 22.Document doc = builder.parse(fileURI); 23.} catch (DOMException dom) { 24.System.err.println(dom.getMessage()); 25.System.exit(1); 26.} catch (IOException ioe) { 27.System.err.println(ioe); 28.System.exit(1); 29.}
XML:Extensible Markup Language(可扩展标记语言)的缩写,是用来定义其它语言的一种元语言,其前身是SGML(Standard Generalized Markup Language,标准通用标记语言)。它没有标签集(tag set),也没有语法规则(grammatical rule),但是它有句法规则(syntax rule)。 任何XML文档对任何类型的应用以及正确的解析都必须是良构的(well-formed),即每一个打开的标签都必须有匹配的结束标签,不得 含有次序颠倒的标签,并且在语句构成上应符合技术规范的要求。XML文档可以是有效的(valid),但并非一定要求有效。所谓有效文档是指其符合其文档 类型定义(DTD)的文档。如果一个文档符合一个模式(schema)的规定,那么这个文档是"模式有效的(schema valid)"。 XML文件在存储、交换和传输数据信息上有着很方便处理,那么今天这篇文章主要讲一下用C#如何实现对XML文件的基本操作, 如:创建xml文件,增、删、改、查xml的节点信息。所使用的方法很基础,方便易懂(用于自己的学习和记忆只需,同时也希望能够给你带来一些帮助, 如有不合适的地方欢迎大家批评指正)。 本文的主要模块为: ①:生成xml文件 ②:遍历xml文件的节点信息 ③:修改xml文件的节点信息 ④:向xml文件添加节点信息 ⑤:删除指定xml文件的节点信息假设我们需要设计出这样的一个xml文件来存储相应的信息,如下所示:
1.详解 1)DOM(JAXP Crimson解析器) DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准。DOM是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。DOM以及广义的基于树的处理具有几个优点。首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。它还可以在任何时候在树中上下导航,而不是像SAX那样是一次性的处理。DOM使用起来也要简单得多。 2)SAX SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。 而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。一般来说,SAX还比它的替代者DOM快许多。 选择DOM还是选择SAX?对于需要自己编写代码来处理XML文档的开发人员来说,选择DOM 还是SAX解析模型是一个非常重要的设计决策。 DOM采用建立树形结构的方式访问XML文档,而SAX采用的事件模型。 DOM解析器把XML文档转化为一个包含其内容的树,并可以对树进行遍历。用DOM解析模型的优点是编程容易,开发人员只需要调用建树的指令,然后利用navigation APIs访问所需的树节点来完成任务。可以很容易的添加和修改树中的元素。然而由于使用DOM解析器的时候需要处理整个XML文档,所以对性能和内存的要求比较高,尤其是遇到很大的XML文件的时候。由于它的遍历能力,DOM解析器常用于XML文档需要频繁的改变的服务中。 SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。SAX对内存的要求通常会比较低,因为它让开发人员自己来决定所要处理的tag.特别是当开发人员只需要处理文档中所包含的部分数据时,SAX这种扩展能力得到了更好的体现。但用SAX解析器的时候编码工作会比较困难,而且很难同时访问同一个文档中的多处不同数据。 3)JDOM https://www.doczj.com/doc/373926195.html, JDOM的目的是成为Java特定文档模型,它简化与XML的交互并且比使用DOM实现更快。由于是第一个Java特定模型,JDOM一直得到大力推广和促进。正在考虑通过“Java规范请求JSR-102” 将它最终用作“Java标准扩展”。从2000年初就已经开始了JDOM开发。 JDOM与DOM主要有两方面不同。首先,JDOM仅使用具体类而不使用接口。这在某些方面简化了API,但是也限制了灵活性。第二,API大量使用了Collections类,简化了那些已经熟悉这些类的Java开发者的使用。 JDOM文档声明其目的是“使用20%(或更少)的精力解决80%(或更多)Java/XML问题”(根据学习曲线假定为20%)。JDOM对于大多数Java/XML应用程序来说当然是有用的,并且大多数开
读取XML到ListBox/ComboBox 1,知识需求: (1)访问XML文件的两个基本模型: 一,DOM模型;使用DOM的好处在于它允许编辑和更新XML文档,可以随机访问文档中的数据,可以使用XPath查询,但是,DOM的缺点在于它需要一次性的加载整个文档到内存中,对于大型的文档,这会造成资源问题。 二,流模型;流模型很好的解决了这个问题,因为它对XML文件的访问采用的是流的概念,也就是说,任何时候在内存中只有当前节点,但它也有它的不足,它是只读的,仅向前的,不能在文档中执行向后导航操作。虽然是各有千秋,但我们也可以在程序中两者并用实现优劣互补。C#采用流模型。 流模型每次迭代XML文档中的一个节点,适合于处理较大的文档,所耗内存空间小。流模型中有两种变体——“推”push模型和pull“拉”模型。 推模型也就是常说的SAX,SAX是一种靠事件驱动的模型,也就是说:它每发现一个节点就用推模型引发一个事件,而我们必须编写这些事件的处理程序,这样的做法非常的不灵活,也很麻烦。 .NET中使用的是基于“拉”模型的实现方案,“拉”模型在遍历文档时会把感兴趣的文档部分从读取器中拉出,不需要引发事件,允许我们以编程的方式访问文档,这大大的提高了灵活性,在性能上“拉”模型可以选择性的处理节点,而SAX每发现一个节点都会通知客户机,从而,使用“拉”模型可以提高Application的整体效率。在.NET中“拉”模型是作为XmlReader类(抽象类)实现的 (2)XmlReader类 Represents a reader that provides fast, non-cached, forward-only access to XML data. 该类中有三个重要的衍生类:XmlT extReader;XmlT extValidatingReader;XmlNodeReader (3)XmlNodeType枚举 该枚举里面有很多实用的数。 2,案例(VS2008+XML)
Javascript面试笔试题 考试时间90分钟 一、不定项选择题(每题3分,共30分) 1.声明一个对象,给它加上name属性和show方法显示其name值,以下代码中正确 的是( D ) A.var obj = [name:"zhangsan",show:function(){alert(name);}]; B.var obj = {name:"zhangsan",show:”alert(https://www.doczj.com/doc/373926195.html,)”}; C.var obj = {name:"zhangsan",show:function(){alert(name);}}; D.var obj = {name:"zhangsan",show:function(){alert(https://www.doczj.com/doc/373926195.html,);}}; 2.以下关于Array数组对象的说法不正确的是(CD) A.对数组里数据的排序可以用sort函数,如果排序效果非预期,可以给sort函数加 一个排序函数的参数 B.reverse用于对数组数据的倒序排列 C.向数组的最后位置加一个新元素,可以用pop方法 D.unshift方法用于向数组删除第一个元素 3.要将页面的状态栏中显示“已经选中该文本框”,下列JavaScript语句正确的是( A ) A.window.status="已经选中该文本框" B.document.status="已经选中该文本框" C.window.screen="已经选中该文本框" D.document.screen="已经选中该文本框" 4.点击页面的按钮,使之打开一个新窗口,加载一个网页,以下JavaScript代码中可行 的是(AD) A. B. C. D.
5.使用JavaScript向网页中输出C#中常用的几种读取XML文件的方法 https://www.doczj.com/doc/373926195.html,/tiemufeng1122/article/details/6723764 XML文件是一种常用的文件格式,例如WinForm里面的app.config以及Web程序中的web.config文件,还有许多重要的场所都有它的身影。Xml是Internet环境中跨平台的,依赖于内容的技术,是当前处理结构化文档信息的有力工具。XML是一种简单的数据存储语言,使用一系列简单的标记描述数据,而这些标记可以用方便的方式建立,虽然XML占用的空间比二进制数据要占用更多的空间,但XML极其简单易于掌握和使用。微软也提供了一系列类库来倒帮助我们在应用程序中存储XML文件。 “在程序中访问进而操作XML文件一般有两种模型,分别是使用DOM(文档对象模型)和流模型,使用DOM的好处在于它允许编辑和更新XML文档,可以随机访问文档中的数据,可以使用XPath查询,但是,DOM的缺点在于它需要一次性的加载整个文档到内存中,对于大型的文档,这会造成资源问题。流模型很好的解决了这个问题,因为它对XML文件的访问采用的是流的概念,也就是说,任何时候在内存中只有当前节点,但它也有它的不足,它是只读的,仅向前的,不能在文档中执行向后导航操作。”具体参见在Visual C#中使用XML指南之读取XML 下面我将介绍三种常用的读取XML文件的方法。分别是 1:使用 XmlDocument 2:使用 XmlTextReader 3:使用 Linq to Xml 这里我先创建一个XML文件,名为Book.xml下面所有的方法都是基于这个XML文件的,文件内容如下: 1: 2:
python读取xml文件 还可以参见网址https://www.doczj.com/doc/373926195.html,/uid-22183602-id-3036442.html https://www.doczj.com/doc/373926195.html,/uid-22183602-id-3036442.html 2014-03-04 23:43 by 虫师, 13913 阅读, 1 评论, 收藏, 编辑 关于python读取xml文章很多,但大多文章都是贴一个xml文件,然后再贴个处理文件的代码。这样并不利于初学者的学习,希望这篇文章可以更通俗易懂的教如何使用python 来读取xml 文件。 什么是xml? xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 abc.xml
首先,它是有标签对组成,
1)DOM(JAXP Crimson解析器) DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准。DOM 是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。DOM以及广义的基于树的处理具有几个优点。首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。它还可以在任何时候在树中上下导航,而不是像SAX那样是一次性的处理。DOM使用起来也要简单得多。 2)SAX SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。一般来说,SAX还比它的替代者DOM快许多。 选择DOM还是选择SAX?对于需要自己编写代码来处理XML文档的开发人员来说,选择DOM还是SAX解析模型是一个非常重要的设计决策。DOM 采用建立树形结构的方式访问XML文档,而SAX采用的事件模型。 DOM解析器把XML文档转化为一个包含其内容的树,并可以对树进行遍历。用DOM解析模型的优点是编程容易,开发人员只需要调用建树的指令,然
后利用navigation APIs访问所需的树节点来完成任务。可以很容易的添加和修改树中的元素。然而由于使用DOM解析器的时候需要处理整个XML文档,所以对性能和内存的要求比较高,尤其是遇到很大的XML文件的时候。由于它的遍历能力,DOM解析器常用于XML文档需要频繁的改变的服务中。 SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。SAX对内存的要求通常会比较低,因为它让开发人员自己来决定所要处理的tag。特别是当开发人员只需要处理文档中所包含的部分数据时,SAX这种扩展能力得到了更好的体现。但用SAX解析器的时候编码工作会比较困难,而且很难同时访问同一个文档中的多处不同数据。 3)JDOM https://www.doczj.com/doc/373926195.html,/ JDOM的目的是成为Java特定文档模型,它简化与XML的交互并且比使用DOM实现更快。由于是第一个Java特定模型,JDOM一直得到大力推广和促进。正在考虑通过“Java规范请求JSR-102”将它最终用作“Java标准扩展”。从2000年初就已经开始了JDOM开发。 JDOM与DOM主要有两方面不同。首先,JDOM仅使用具体类而不使用接口。这在某些方面简化了API,但是也限制了灵活性。第二,API大量使用了Collections类,简化了那些已经熟悉这些类的Java开发者的使用。
Android读写XML(上)——package说明收藏 注明:本文转自https://www.doczj.com/doc/373926195.html,. XML 经常用作Internet 上的一种数据格式,其文件格式想必大家都比较清楚,在这里我结合Android平台,来说明Android SDK提供的读写XML的package。 首先介绍下Android SDK与Java SDK在读写XML文件方面,数据包之间的关系。Android 平台最大的一个优势在于它利用了Java 编程语言。Android SDK 并未向标准Java Runtime Environment (JRE) 提供一切可用功能,但它支持其中很大一部分功能。Java 平台支持通过许多不同的方式来使用XML,并且大多数与XML 相关的Java API 在Android 上得到了完全支持。举例来说,Java 的Simple API for XML (SAX) 和Document Object Model (DOM) 在Android 上都是可用的,这些API 多年以来一直都是Java 技术的一部分,较新的Streaming API for XML (StAX) 在Android 中并不可用。但是,Android 提供了一个功能相当的库。最后,Java XML Binding API 在Android 中也不可用,这个API 已确定可以在Android 中实现。Android SDK提供了如下package来支持XML的读写: 额外补充说明下,在android.util数据包中也提供了一个类Xml,不过这个类就是把以上package简单封装了下。 读取XML主要有2种方法:DOM与SAX(Simple API for XML),在这里对这2种方法分别加以说明。 DOM(文档对象模型),为XML文档的解析定义了一组接口,解析器读入整个文档,然后构造一个驻留内存的树结构,然后代码就可以使用DOM接口来操组整个树结构,其他点如下: ?优点:整个文档树都在内存当中,便于操作;支持删除、修改、重新排列等多功能。?缺点:将整个文档调入内存(经常包含大量无用的节点),浪费时间和空间。 ?使用场合:一旦解析了文档还需要多次访问这些数据,而且资源比较充足(如内存、CPU等)。 为了解决DOM解析XML引起的这些问题,出现了SAX。SAX解析XML文档为事件驱动,详细说明请阅读Android读写XML(中)–SAX。当解析器发现元素开始、元素结束,文本、文档的开始或者结束时,发送事件,在程序中编写响应这些事件的代码,其特点如下: ?优点:不用事先调入整个文档,占用资源少。尤其在嵌入式环境中,极力推荐采用SAX进行解析XML文档。
javascript读取服务器端XML文件 最近需要用javascript解析一个XML文件,为了前期本地测试,在读取的时候用的是绝对地址,可后来发现不能读取服务器上的文件,不能用相对路径,一堆问题,无从解决.。找了相关资料,最后用XMLHTTP 来处理,注意这里可能会出现中文乱码问题...... 先说下大体思路: 写文件的代码: FileOutputStream writerStream = new java.io.FileOutputStream(fileName2); BufferedWriter writer = new java.io.BufferedWriter(new java.io.OutputStreamWriter(writerStream, "UTF-8"));//设置文件编码方//式 writer.write(strbuf.toString());//strbuf为文件内容 writer.close(); 读文件的代码: var xmlHttp = new ActiveXObject("Microsoft.XMLHTTP"); var url = "xxxxxxxxxx";//根据需要,这里以XX代替 xmlHttp.open("GET", url, false); xmlHttp.setRequestHeader("Content-Type","utf-8"); //设置读取文件的编码方式 xmlHttp.send();
var content = ""; if(xmlHttp.status==200){ content = xmlHttp.responseText; //content就是读取到到的文本内容,当然,根绝不同需要,调用不同方法.... }
查找结点,读取结点属性------------------------------------------------------ 获取结点的属性------------------------------------- 设置结点的属性------------------------------------------------ 给结点添加新属性------------------------------------------- 设置一个结点的内容---------------------------------------------------- 添加新节点---------------------------------------------------- 编码问题------------------------------------------------------------------ XML树:
Java解析XML文件 ========================================== xml文件 <?xml version="1.0" encoding="GB2312"?> <RESULT> <VALUE> <NO>A1234</NO> <ADDR>四川省XX县XX镇XX路X段XX号</ADDR> </VALUE> <VALUE> <NO>B1234</NO> <ADDR>四川省XX市XX乡XX村XX组</ADDR> </VALUE> </RESULT> ========================================== 1)DOM(JAXP Crimson解析器) DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准。DOM是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。DOM以及广义的基于树的处理具有几个优点。首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。它还可以在任何时候在树中上下导航,而不是像SAX那样是一次性的处理。DOM使用起来也要简单得多。 import java.io.*; import java.util.*; import org.w3c.dom.*; import javax.xml.parsers.*; public class MyXMLReader{ public static void main(String arge[]){ long lasting =System.currentTimeMillis(); try{ File f=new File("data_10k.xml"); DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); DocumentBuilder builder=factory.newDocumentBuilder(); Document doc = builder.parse(f); NodeList nl = doc.getElementsByT agName("VALUE"); for (int i=0;i<nl.getLength();i++){ System.out.print("车牌号码:" +
jdom学习读取XML文件 用JDOM读取XML文件需先用org.jdom.input.SAXBuilder对象的build()方法创建Document对象,然后用Document类、Element类等的方法读取所需的内容。 例如:
相关主题
文本预览