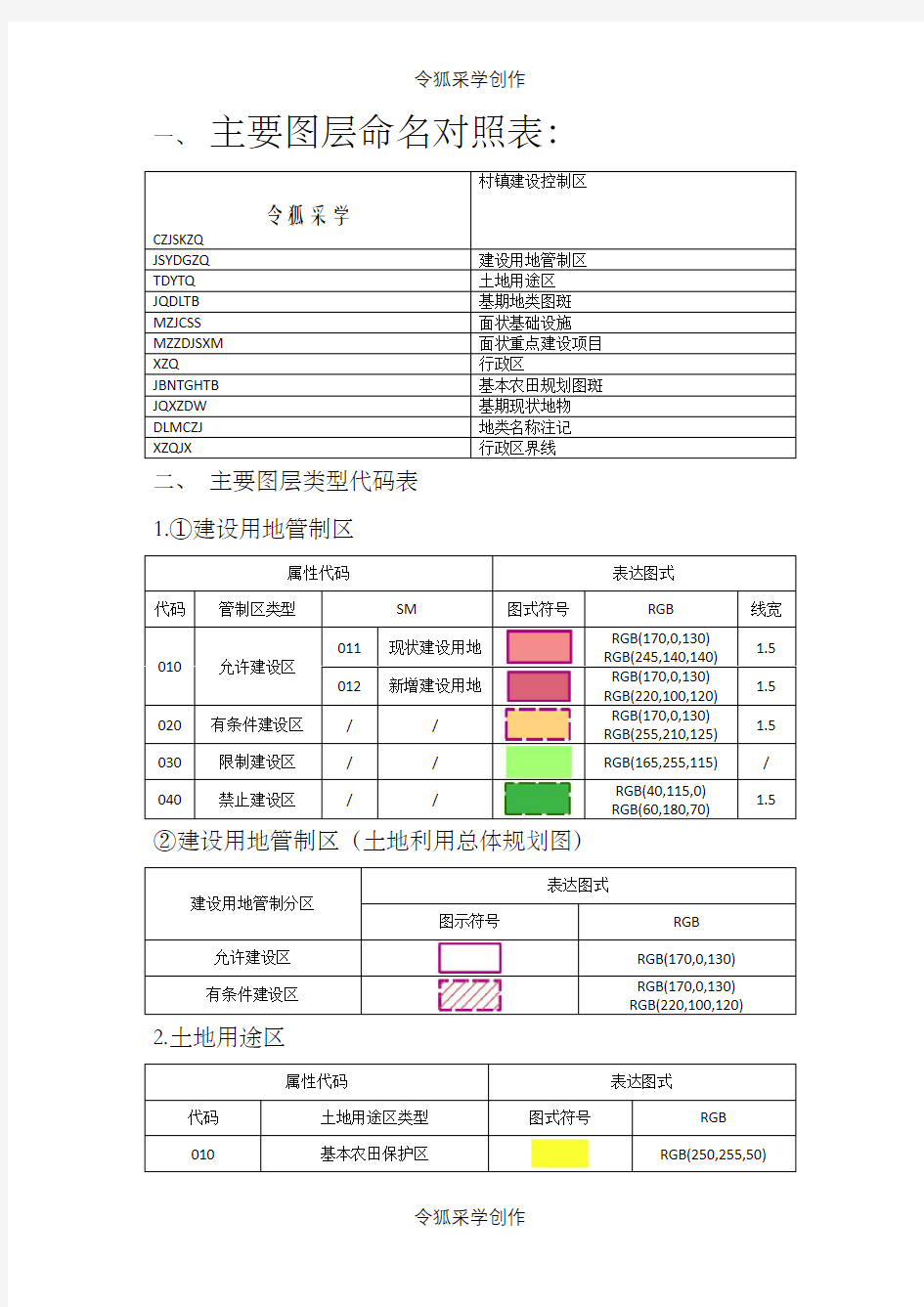
一、主要图层命名对照表:
令狐采学
CZJSKZQ
村镇建设控制区
JSYDGZQ建设用地管制区
TDYTQ土地用途区
JQDLTB基期地类图斑
MZJCSS面状基础设施
MZZDJSXM面状重点建设项目
XZQ行政区
JBNTGHTB基本农田规划图斑
JQXZDW基期现状地物
DLMCZJ地类名称注记
XZQJX行政区界线
二、主要图层类型代码表
1.①建设用地管制区
属性代码表达图式
代码管制区类型SM图式符号RGB线宽
010允许建设区011现状建设用地
RGB(170,0,130)
RGB(245,140,140)
1.5 012新增建设用地
RGB(170,0,130)
RGB(220,100,120)
1.5
020有条件建设区//
RGB(170,0,130)
RGB(255,210,125)
1.5
030限制建设区//RGB(165,255,115)/
040禁止建设区//RGB(40,115,0)
RGB(60,180,70)
1.5
②建设用地管制区(土地利用总体规划图)
建设用地管制分区
表达图式
图示符号RGB 允许建设区RGB(170,0,130)
有条件建设区
RGB(170,0,130) RGB(220,100,120)
2.土地用途区
属性代码表达图式代码土地用途区类型图式符号RGB
010基本农田保护区RGB(250,255,50)
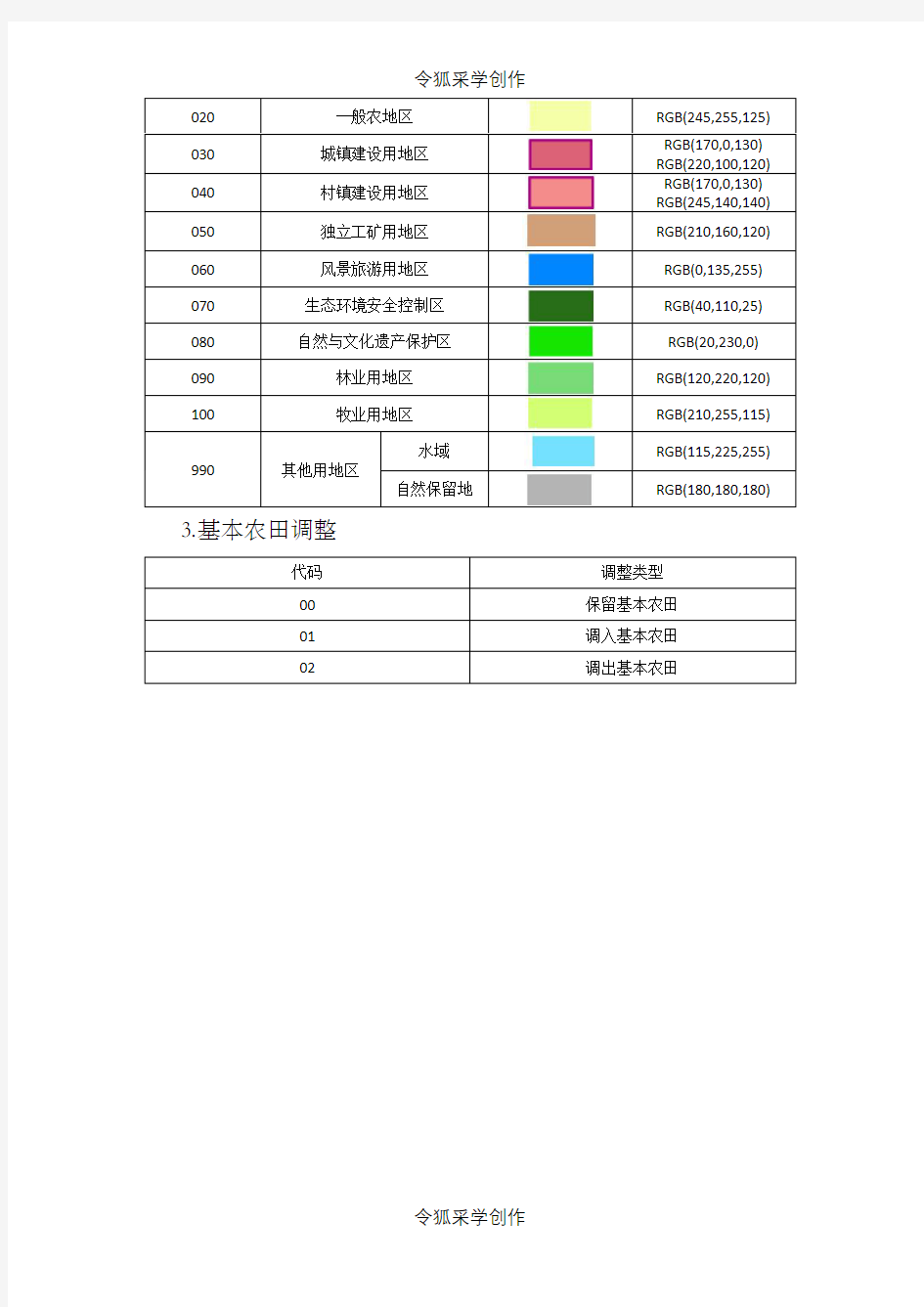
020一般农地区RGB(245,255,125)
030城镇建设用地区
RGB(170,0,130) RGB(220,100,120)
040村镇建设用地区
RGB(170,0,130) RGB(245,140,140)
050独立工矿用地区RGB(210,160,120) 060风景旅游用地区RGB(0,135,255) 070生态环境安全控制区RGB(40,110,25) 080自然与文化遗产保护区RGB(20,230,0) 090林业用地区RGB(120,220,120) 100牧业用地区RGB(210,255,115) 990其他用地区
水域RGB(115,225,255)
自然保留地RGB(180,180,180) 3.基本农田调整
代码调整类型
00保留基本农田
01调入基本农田
02调出基本农田
大型ORACLE数据库优化设计方案 本文主要从大型数据库ORACLE环境四个不同级别的调整分析入手,分析ORACLE的系统结构和工作机理,从九个不同方面较全面地总结了ORACLE数据库的优化调整方案。 对于ORACLE数据库的数据存取,主要有四个不同的调整级别,第一级调整是操作系统级 包括硬件平台,第二级调整是ORACLE RDBMS级的调整,第三级是数据库设计级的调整,最后一个调整级是SQL级。通常依此四级调整级别对数据库进行调整、优化,数据库的整体性能会得到很大的改善。下面从九个不 同方面介绍ORACLE数据库优化设计方案。 一.数据库优化自由结构OFA(Optimal flexible Architecture) 数据库的逻辑配置对数据库性能有很大的影响,为此,ORACLE公司对表空间设计提出了一种优化结构OFA。使用这种结构进行设计会大大简化物理设计中的数据管理。优化自由结构OFA,简单地讲就是在数据库中可以高效自由地分布逻辑数据对象,因此首先要对数据库中的逻辑对象根据他们的使用方式和物理结构对数据库的影响来进行分类,这种分类包括将系统数据和用户数据分开、一般数据和索引数据分开、低活动表和高活动表分开等等。数据库逻辑设计的结果应当符合下面的准则:(1)把以同样方式使用的段类型存储在一起; (2)按照标准使用来设计系统;(3)存在用于例外的分离区域;(4)最小化表空间冲突;(5)将数 据字典分离。 二、充分利用系统全局区域SGA(SYSTEM GLOBAL AREA) SGA是oracle数据库的心脏。用户的进程对这个内存区发送事务,并且以这里作为高速缓存读取命中的数据,以实现加速的目的。正确的SGA大小对数据库的性能至关重要。SGA 包括以下几个部分: 1、数据块缓冲区(data block buffer cache)是SGA中的一块高速缓存,占整个数据库大小 的1%-2%,用来存储从数据库重读取的数据块(表、索引、簇等),因此采用least recently used (LRU,最近最少使用)的方法进行空间管理。 2、字典缓冲区。该缓冲区内的信息包括用户账号数据、数据文件名、段名、盘区位置、表 说明和权限,它也采用LRU方式管理。 3、重做日志缓冲区。该缓冲区保存为数据库恢复过程中用于前滚操作。 4、SQL共享池。保存执行计划和运行数据库的SQL语句的语法分析树。也采用LRU算法 管理。如果设置过小,语句将被连续不断地再装入到库缓存,影响系统性能。 另外,SGA还包括大池、JAVA池、多缓冲池。但是主要是由上面4种缓冲区构成。对这
目录 一.需求描述和系统边界 (2) 二.需求分析 (2) 1.业务需求 (2) 2.功能需求及数据需求分析 (2) 3.业务规则分析 (3) 三.实体集及属性 (4) 四.联系集及E-R图 (5) 五.逻辑数据库设计 (6) 六.数据库编程 (7) 1.创建表 (7) 2.创建触发器 (10) 3.管理员操作 (10) 4.读者操作 (11) 5. 管理员对借阅关系的操作 (12) 七.代码实现 (13) 1.输入数据设计 (13) 2.完成借阅、续借、归还的操作设计 (15) 八.模式求精 (17) 九.小结 (17)
一.需求描述和系统边界 数据库技术和Internet的飞速发展,使它们已经成为现代信息技术的重要组成部分,是现在计算机信息系统和计算机应用系统的基础和核心。对于任何一个企业来说,数据是企业重要的资产,如何有效利用这些数据,对于企业发展起着极其重要的作用。随着我国市场经济的迅速发展和人们生活水平的不断提高,图书馆藏书的数目逐渐增大,这也挑战了图书管理方面的技术,以前的人工管理方式已经不再适应现在的环境,取而代之的是先进的图书管理系统,创建图书管理系统可以让管理人员方便而快捷的进行管理、查询、借阅、录入等工作。 该图书管理系统支持2类用户:管理员和读者。读者可以进行借阅、续借、归还和查询书籍等操作,管理员可以完成书籍和读者的增加,删除和修改以及对读者,借阅、续借、归还的确认。 二.需求分析 1.业务需求 图书管理系统的主要业务包括:包括图书馆内书籍的信息,读者信息,以及借阅信息。此系统功能分为面向读者和面向管理员两部分,其中读者可以进行借阅、续借、归还和查询书籍等操作,管理员可以完成书籍和读者的增加,删除和修改以及对读者,借阅、续借、归还的确认。 2.功能需求及数据需求分析 (1)注册管理 管理员注册。管理员注册时要求填写基本信息,包括管理员编号、姓名、性别、联系电话、家庭住址。系统检查所有信息填写正确后管理员注册成功。 读者注册。读者注册时要求填写基本信息,包括读者编号、姓名、性别、联系电话、学院等。系统检查所有信息填写正确后读者注册成功。 (2)图书管理 增加图书信息。当有新的图书入库时,管理员负责添加图书信息,包括书名、分类、图书编号、作者、出版社、出版时间、简介等。 图书信息查询。管理系统需提供方便快捷的方式进行图书检索。如可以输入
土地开发整理规划数据库标准 目次 前言 1范围1 2规范性引用文件1 3术语和定义1 4数据库内容和要素分类编码2 5数据库结构定义4 6数据文件命名规则14 7数据交换格式16 8元数据17 附录A(规范性附录)土地分类代码18 附录B(资料性附录)土地开发整理规划空间矢量数据交换格式样本23附录C(资料性附录)土地开发整理规划信息元数据示例27 表1土地开发整理规划数据库要素代码表2 表2土地开发整理规划空间信息要素分层、定义与属性关联表4 表3表格信息要素属性关联表5 表4行政区属性结构表(属性表代码:XZQ)5 表5行政界线属性结构表(属性表代码:XZJX)6 表6等高线属性结构描述表(属性表代码:DGX)6 表7高程注记点属性结构描述表(属性表代码:GCZJD)6 表8地类图斑属性结构描述表(属性表代码:DLTB)6
表9线状地物属性结构描述表(属性表代码:XZDW)7 表10零星地类属性结构描述表(属性表代码:LXDL)7 表11开发整理潜力属性结构表(属性表代码KFZLQL)8 表12开发整理规划区域属性结构表(属性表代码KFZLGHQY)9 表13面状工程、线状工程、点状工程属性结构表(属性表代码KFZLGC)9表14面状项目、线状项目、点状项目属性结构表(属性表代码KFZLXM)10表15注记属性结构描述表(属性表代码:ZJ)11 表16土地开发整理补充耕地区域平衡表(属性表代码BG_BCGDPHB)11 表17土地开发整理规划结构调整表(属性表代码BG_GHJGTZ)11 表18土地开发整理规划指标分解表(属性表代码BG_GHZBFJ)12 表19土地开发整理规划文本信息表(属性表代码WB_WBXX)12 表20界线类型代码表12 表21界线性质代码表13 表22等高线类型代码表13 表23权属性质代码表13 表24土地开发整理类型代码表13 表25比例尺代码表14 表26规划图类型代码表15 表27土地开发整理规划文本信息编码16 表《全国土地分类(试行)》代码表18 表《全国土地分类(过渡期适用)》代码表20 前言 附录A为规范性附录,附录B和附录C为资料性附录。
酒店管理系统数据库代码 use Hotel_Management1 select*from Customer select*from Employee select*from RoomType select*from Room select*from OrderInfo select*from Checkout drop database Hotel_Management1 ------------------------创建数据库Hotel_Management----------------------------------------------------------------------create database Hotel_MDB on primary (name=Hotel_Management1, filename='F:\Hotel_Management\Hotel_Management.MDF', size=10MB, filegrowth=20% ) log on (name=Hotel_Management1, filename='F:\Hotel_Management\Hotel_Management1.LDF', size=10MB, filegrowth=2MB) --使用数据库 USE Hotel_Management1 --------------------------------------------创建表--------------------------------------------------------------- --1顾客表 create table Customer (CustomerID int primary key, CustomerName nvarchar(40)not null, CustomerInfo nvarchar(18)not null, Csex nvarchar(1), CPhone nvarchar(11)not null, Notes ntext ) --drop table Customer --2员工表 create table Employee (EmployeeID int primary key, UserName nvarchar(40)not null, Password nvarchar(40)not null, EmployeeName nvarchar(40)not null, Esex nvarchar(1),
一、需求分析 1、问题的提出:这是一个企业销售管理系统,设计者的目标是满足公司运营和日常管理的需要,具有对产品,员工,客户管理的功能。销售员可以对销售的产品进行登记,并将销售情况反馈给数据库。管理员可以查看员工信息以及销售情况,管理员登陆后可以添加删除员工,以及销售员以外的特殊操作。为管理的方便性和信息传递的快速性提供了一个很好的平台。系统开发的总体任务是实现售后服务及销售登记自动化。总之,企业销售管理系统要实现登陆验证、商品销售管理、员工信息管理、客户信息管理几大部分。 2、系统的业务功能分析: 销售管理系统是一个典型的数据库开发应用程序,有基础信息模块,销售管理模块查询统计模块,系统设置模块4部分组成,规划系统功能模块如下: 基础信息模块 该模块主要用于管理添加、删除、修改商品信息、客户信息、用户信息。 销售管理模块 该模块主要用于管理添加销售信息和添加销售退货信息。 查询统计模块 该模块主要用于产品信息查询,销售退货信息查询,和产品销售排行。 系统设置模块 该模块主要用于管理修改密码,关于和退出登录。 3、E-R图: 根据以上各节对系统所做的需求分析和系统分析,规划处了本系统的数据库实体。下面介绍几个关键实体的E-R图:
总体 2-1E-R图 客户编号销售单据编号成交日期产品编号销售单据销售人员数量售价 产品编号入库时间产品名称产品成本库存供应商产地生产日期
用户编号加入时间用户信息用户姓名用户密码用户类型 图2.2 销售信息管理系统详细E-R图 4、数据流图: 销售单据信息购买信息订购处理销售信息客户货品信息销售员退货信息退货要求退货信息退货处理退货信息表 数据流图 三、系统设计 1、数据表:表的物理设计: 建立T_Customer表(客户信息表),T_Product表(产品信息表),T_User表(用
生产数据库性能优化方案(初稿) 1.背景 生产数据库上线一段时间后由于数据量远大于预期,导致数据库性能低下而影响正常业务,故需要对数据库进行性能优化。 2.现状 当前数据库结构如下图所示: 图2-1 系统结构示意图 上游三个数据源通过DI工具以定时任务的方式将上游数据抽取到基础数据库中(红色部分),从基础库到下游目标库则是通过用户操作应用程序将基础数
据库中的数据调度到目标数据库中。根据目前对数据量的统计基础库约为400GB+的数据总量。 目前基础数据库的性能低下,主要表现于定时抽取任务执行时间过长,任务间的时间间隔变短;应用执行数据调度时间过长,导致应用长时间处于无响应状态。 3.分析 基础数据库获取上游数据时,数据传输量较大,数据库写操作频繁,操作系统层表现于数据文件所在磁盘写IO高,并持续时间长。 由于基础库放数据到下游数据库是人为操作,数据库读操作频繁,操作系统层表现于数据文件所在磁盘读IO高,且经常会与DI定时任务同时执行,通过系统监控发现磁盘出现大量IO等待状态。 图3-1 磁盘IO状态
图3-2 磁盘等待状态 由于基础库保存原始数据并不对数据进行处理,所以CPU消耗很低,从监控看CPU不视为性能瓶颈点。 图3-3 CPU使用率 从以上分析可以判断数据库操作性能低下主要在高磁盘IO时造成IO挣用较
大导致拖慢整体性能。故本次优化将重点放在解决磁盘IO挣用问题和提高磁盘IOPS上。 4.优化方案 本着应用层变动最小的原则,为解决基础库磁盘IO性能低下问题,我们将从三个方面着手进行,即:优化数据库物理架构、优化DI任务执行时间和优化数据库数据文件所在Path的磁盘VG结构。 4.1.优化数据库物理架构 根据基础库的业务特点,这里将对基础库的读写操作进行分离(即:读、写分离)。这样做的好处在于可以最大限度规避数据库读、写同时操作所带来的磁盘IO挣用问题。调整后的架构如下图: 数据库采用主/从模式,使用binlog复制方式实现数据同步。由于考虑到大数据量复制可能带来的同步延迟问题,实现时需要注意优化复制线程参数。4.2.优化DI任务执行时间 为了避免多任务同时写一个数据库产生磁盘写IO过高的问题,需要对每一
第2章数据库高级编程 ADO、NET就是为、NET框架而创建的,就是对ADO(ActiveX Data Objects)对象模型的扩充。ADO、NET提供了一组数据访问服务的类,可用于对Microsoft SQL Server、Oracle等数据源的一致访问。ADO、NET模型分为、NET Data Provider(数据提供程序)与DataSet数据集(数据处理的核心)两大主要部分。 、NET数据提供程序提供了四个核心对象,分别就是Connection、Command、DataReader 与DataAdapter对象。功能如表2-1所示。 表2-1 ADO、NET核心对象 2、1 SQL Server相关配置 在使用C#访问数据库之前,首先创建一个名为“chap2”的数据库,此数据库作为2、1节及2、2节中例题操作的默认数据库。然后创建数据表Products,表结构如表2-2所示。创建完毕后可录入初始化数据若干条。 表2-2 Products表表结构 上机课的操作中出现问题较多的地方。 1.身份验证方式 SQL Server 2012在安装时默认就是使用Windows验证方式的,但就是安装过后用户可随时修改身份验证方式。 启动SQL Server 2012 Management Studio,在“连接到服务器”对话框中选择“Windows
身份验证”连接服务器,连接成功后,在窗体左侧的“对象资源管理器”中右键单击服务器实例节点,并在弹出的快捷菜单中选择“属性”菜单项,系统将弹出“服务器属性”窗体,切换至“安全性”选项卡,如图2-1所示。 图2-1 “服务器属性”对话框-“安全性”选项卡 在“服务器身份验证”部分选择“SQL Server与Windows身份验证模式”选项,并单击【确定】按钮。系统将提示需要重新启动SQL Server以使配置生效,如图2-2所示。 图2-2 系统提示框 右键单击“对象资源管理器”的服务器实例节点,在弹出的快捷菜单中选择“重新启动”菜单项,SQL Server将重新启动服务,重启成功后即可使用混合验证方式登录SQL Server服务器。 2.添加登录账户 大部分初学者都习惯于使用SQL Server的系统管理员账号“sa”来登录数据库服务器,而在实际工作环境中使用sa账号登录服务器就是不合理的。因为很多情况下系统的数据库就是部署在租用的数据库服务器上的,此时数据库设计人员或编程人员都不可能具有sa账号的使用权限,因此在将身份验证方式修改为SQL Server与Windows混合验证后,需要为某应用程序创建一个专用的登录账户。其操作步骤描述如下。 (1)使用Windows身份验证登录SQL Server,在对象资源管理器中点击“安全性”节点前面的加号“+”,在展开后的“登录名”子节点上单击右键,如图2-3所示,并在弹出的快捷菜单中选择“新建登录名”选项。
前面将数据及其来源进行了梳理,让我们对B2C网站可能出现的数据有了大概了解。但如何对这些数据进行组织、描述、分类,以便于日常使用呢? 一、从查询说起 常用查询方式主要有条件查询、模糊查询。 1.条件查询相对比较简单,通过选择一定条件,实现查询/筛选功能。例如下图中的红色框部分。 2.模糊查询又称作关键字/自定义查询,主要通过关键字匹配,实现查询功能。如下图中的蓝色框部分。 图1 查询的常用方式 无论何种查询方式,都是通过程序语句对后台数据库进行查询操作,所以我们需要对数据在入库前进行命名描述、分类汇总,才能通过各种查询方式得到想要的结果,这一步骤就称为标签处理。 二、那什么是标签呢? 在梳理数据时,我们了解这些数据分别代表的意义,但只了解意义远远不够,更需要站在业务应用角度,去判断、理解数据所代表的意义。 例:如果单纯从用户背景资料(性别、生日等)分析,不同性别用户对产品需求会有差异。但运营需要更进一步分析,希望数据能更多更有用信息,所以在数据准备上,可以将性别、年龄与用户行为进行交叉分析,以便得出更为精确的结果。
图2 基于用户背景资料与用户行为的交叉分析 “性别、年龄”对我们是可见的,即可以通过这两项找到相应的用户。但对数据库而言“性别、年龄”仅仅是文字表现,是通过该文字表现关联到用户,所以它们就像每个人的名字,可以关联到相应的人一样,而这就是标签。 因此,标签只是一种内容组织方式,是一种关联性很强的关键字,能很方便的帮助我们找到合适的内容及内容分类。 三、标签和标签体系 标签解决的是描述(或命名)的问题,但在实际应用中,还需要解决数据之间的关联。所以,我们通常将标签作为一个体系来设计,从而解决数据之间的关联问题。 一般来说,将能关联到具体用户数据的标签,称为叶子标签。对叶子标签进行分类汇总的标签,称为父标签。父标签和叶子标签共同构成标签体系,但两者是相对概念。例如:下表中,地市、型号在标签体系中相对于省份、品牌,是叶子标签。 表1:某网站标签体系示例 一级标签二级标签三级标签四级标签 移动属性用户所在地省份地市手机品牌品牌型号 业务属性用户等级普通 音乐普通会员音乐高级会员音乐VIP会员 四、用户标签体系与商品标签体系
农村集体建设用地使用权、宅基地使用权确权项 目数据库建设技术方案
一、地籍数据库建设 (一)、成果数据库建设的内容 农村地籍调查成果数据库建设是在农村集体建设用地和宅基地使用权地籍调查的基础上,按照相关数据库标准的要求,建立集空间信息和属性信息为一体的土地调查成果数据库。 农村集体建设用地和宅基地使用权数据库内容: 1、农村地籍数据库包括地籍区、地籍子区、土地权属、土地利用、基础地理等数据。 2、土地权属数据包括宗地的权属、位置、界址、面积等空间和属性信息; 3、土地利用数据包括行政区(含行政村)图斑的权属、地类、面积、界线等; 4、基础地理信息数据包括数学基础、境界、测量控制点、居民地、交通、水系、地理名称等。 (二)成果数据库建设要求 1、严格遵循数据库标准 农村集体建设用地和宅基地使用地籍调查数据库建设以《城镇地籍数据库标准》为基础,结合《宗地代码编制规则(试行)》等新的技术规范和要求,对相关要素属性结构表进行扩展,以满足农村地籍调查成果管理要求。 2、坐标系统
数据库建设采用的坐标系统为山西省全省及区域地籍测量控制及服务体系定制的独立坐标系统。 3、面积计算 农村集体建设用地和宅基地使用权宗地面积按高斯-克吕格投影面面积计算。 4、数据库逻辑结构 农村集体建设用地和宅基地使用权调查数据库由空间数据库和非空间数据库组成。空间数据由矢量数据和栅格数据组成,主要包括:基础地理数据、居民地数据、土地权属数据等。非空间数据由权属信息调查数据组成。农村集体建设用地和宅基地使用权调查数据库逻辑结构见图1。 空间数据库 农村集 体建设 用地和 宅基地 使用权 非空间数据库 扫描文件 调查表格 权属资料 其他数据 土地权属数据 居民地数据 基础地理数据 图1 农村集体建设用地和宅基地使用权调查数据库逻辑结构图
建立数据库: create database 数据库 建表: create table部门信息表 (部门编号char(2) primary key , 部门名称nchar(14), 部门职能n char(14), 部门人数char (4) ) go create table管理员信息表 (用户名n char(4) primary key , 密码char(10), ) go create table用户信息表 (用户名char(10) primary key , 用户类型char(10), 密码char(10) ) go create table员工工作岗位表 (姓名nchar(4) primary key , 员工编号char(4) 工作岗位n char(3), 部门名称n char(10), 参加工作时间char (4) ) go create table员工学历信息表 (姓名nchar(4) primary key , 员工编号char(4) 学历nchar(2), 毕业时间char(10), 毕业院校nchar (10), 外语情况n char(10), 专业n char(10) ) go create table员工婚姻情况表 (姓名nchar(4) primary key , 员工编号char(4) 婚姻情况n char(2), 配偶姓名n char(4), 配偶年龄char (3), 工作单位n char(10), ) go create table员工基本信息表
(员工编号char(4) primary key , 姓名nchar(4), 性别nchar(1), 民族nchar (3), 出生年月char(14), 学历nchar(10), 政治面貌n char(3), 婚姻状况nchar(2), 部门名称n char(10), 工作岗位n char(10), ) 建立视图: CREATE VIEW按员工工作岗位查询 as SELECT员工工作岗位表?工作岗位,员工基本信息表?员工编号, 员工基本信息表?姓名,员工基本信息表?性别,员工基本信息表?出生年月 员工基本信息表.学历,员工基本信息表.婚姻状况, 员工基本信息表部门名称 FROM员工工作岗位表INNER JOIN 员工基本信息表ON员工工作岗位表.姓名=员工基本信息表.姓名 go CREATE VIEW按员工详细信息查询 as SELECT员工基本信息表?* FROM员工基本信息表go CREATE VIEW按参加工作时间查询 as SELECT员工工作岗位表.参加工作时间,员工工作岗位表.工作岗位, 员工基本信息表.员工编号,员工基本信息表.姓名,员工基本信息表.性别,
数据库图书管理系统含代 码 The following text is amended on 12 November 2020.
目录
一.需求描述和系统边界 数据库技术和Internet的飞速发展,使它们已经成为现代信息技术的重要组成部分,是现在计算机信息系统和计算机应用系统的基础和核心。对于任何一个企业来说,数据是企业重要的资产,如何有效利用这些数据,对于企业发展起着极其重要的作用。随着我国市场经济的迅速发展和人们生活水平的不断提高,图书馆藏书的数目逐渐增大,这也挑战了图书管理方面的技术,以前的人工管理方式已经不再适应现在的环境,取而代之的是先进的图书管理系统,创建图书管理系统可以让管理人员方便而快捷的进行管理、查询、借阅、录入等工作。 该图书管理系统支持2类用户:管理员和读者。读者可以进行借阅、续借、归还和查询书籍等操作,管理员可以完成书籍和读者的增加,删除和修改以及对读者,借阅、续借、归还的确认。 二.需求分析 1.业务需求 图书管理系统的主要业务包括:包括图书馆内书籍的信息,读者信息,以及借阅信息。此系统功能分为面向读者和面向管理员两部分,其中读者可以进行借阅、续借、归还和查询书籍等操作,管理员可以完成书籍和读者的增加,删除和修改以及对读者,借阅、续借、归还的确认。 2.功能需求及数据需求分析 (1)注册管理 管理员注册。管理员注册时要求填写基本信息,包括管理员编号、姓名、性别、联系电话、家庭住址。系统检查所有信息填写正确后管理员注册成功。 读者注册。读者注册时要求填写基本信息,包括读者编号、姓名、性别、联系电话、学院等。系统检查所有信息填写正确后读者注册成功。 (2)图书管理 增加图书信息。当有新的图书入库时,管理员负责添加图书信息,包括书名、分类、图书编号、作者、出版社、出版时间、简介等。
仓库管理系统数据库设计 1概述(设计题目与可行性分析) 1.1设计题目 设计一个仓库数据库管理系统,要求实现入库、出库、库存和采购等功能。 随着经济的飞速发展,,仓库管理变成了各大公司日益重要的内容。仓库管理过程的准确性和高效性至关重要。影响着公司的经济发展和管理。利用人工管理强大而数据烦琐的数据库显的效率过于低。利用计算机高效、准确的特点能够很好的满足公司的管理需要。提高公司各个员工的工作效率和公司的运做效率。利用计算机对仓库数据信息进行管理具有着手工管理所无法比拟的优点。目前一个现代化的仓库管理系统已经成为仓库管理不可缺少的管理手段。 1.2 可行性研究 可行性研究的目的就是用最小的代价在尽可能短的时间内确定问题是否能够解决。可行性研究的目的不是解决问题而是分析问题能不能解决;至少从下面三个方面分析可行性研究。 1.2.1技术可行性 该仓库数据库管理系统不不是很复杂,设计实现该数据库技术难度不是很大,利用目前现有的技术和工具能在规定的时间内做出该系统。该系统利用SQL2000和 visual studio 工具就能很好的实现该系统。 1.2.2经济可行性 当今世界是经济时代,一个公司的员工工作效率的高低直接影响着这个公司的发展。因此利用计算机进行信息管理有着无可比拟的好处,该系统相对较小,代码行较少,数据库设计不是很麻烦,开发周期较短。而且便于维护。但其带来的经济效益远远高于其开发成本。在经济上是可行的。 1.2.3操作可行性 在当今社会,随着义务教育的普及。和计算机的普及,公司的员工基本上都会进行电脑的基本操作,由于本软件系统采用相对友好的界面,用户 在使用过程中不需要懂太多的电脑专业知识,只需要基本的电脑操作就可
数据库技术及应用项目设 计报告 学生成绩管理系统 姓名:Celia Yan 2015-01-07
一.设计目的及意义 在如今的高校日常管理中,学生成绩管理系统是其中非常重要的一环,特别是当前学校规模不断扩大,学生人数日益增加,课程门类多,校区分散等实际情况,学生成绩统计功能越来越繁重,稍有疏忽就会出现差错。因此,学生成绩管理系统更具有非常大的实际应用意义。在互联网快速崛起的今天,改革传统的手工录入方式,公正,准确,及时反映学生的信息和成绩的情况,以适应信息时代的要求,是学生成绩管理系统的一个新的理念。通过成绩管理可以大大提高学校的工作效率。学生成绩管理系统应该完成以下两个方面的内容:学生档案资料的管理、学生成绩的管理。通过学生成绩管理系统可以做到信息的规范管理,科学统计和快速查询、修改、增加、删除等,减少管理方面的工作量。 二.主要功能 该系统主要用于学校学生信息管理,总体任务是实现学生信息关系的系统化、规范化和自动化,其主要任务是用计算机对学生信息进行日常管理,如查询、修改、增加、删除,另外还考虑到用户登录的权限,针对学生信息和权限登录的学生成绩管理系统。 本系统主要包括注册管理、教师管理、学生信息查询、添加、修改、删除等部分。其主要功能有: (1)学生信息的添加,包括输入学生基本信息和成绩。 (2)学生信息的查询,包括查询学生的基本信息和成绩。 (3)学生信息的修改,包括修改学生基本信息和成绩。 (4)学生信息的删除,包括删除学生基本信息和成绩。 (5)登录用户密码修改,用户登录到系统可进行相应的用户密码修改。 (6)管理员用户对用户名的管理,包括添加新用户、删除用户。 学生成绩管理系统是典型的信息管理系统,其开发主要包括后台数据库的建立和维护以及前端应用程序开发两个方面。对于前者要求建立起数据一致性和完整性强、数据安全性
微服务系统和数据库设计方案 1.微服务本质 微服务架构从本质上说其实就是分布式架构,与其说是一种新架构,不如说是一种微服务架构风格。 简单来说,微服务架构风格是要开发一种由多个小服务组成的应用。每个服务运行于独立的进程,并且采用轻量级交互。多数情况下是一个HTTP的资源API。这些服务具备独立业务能力并可以通过自动化部署方式独立部署。这种风格使最小化集中管理,从而可以使用多种不同的编程语言和数据存储技术。 对于微服务架构系统,由于其服务粒度小,模块化清晰,因此首先要做的是对系统整体进行功能、服务规划,优先考虑如何在交付过程中,从工程实践出发,组织好代码结构、配置、测试、部署、运维、监控的整个过程,从而有效体现微服务的独立性与可部署性。 本文将从微服务系统的设计阶段、开发阶段、测试阶段、部署阶段进行综合阐述。 理解微服务架构和理念是核心。 2.系统环境
3.微服务架构的挑战 可靠性: 由于采用远程调用的方式,任何一个节点、网络出现问题,都将使得服务调用失败,随着微服务数量的增多,潜在故障点也将增多。 也就是没有充分的保障机制,则单点故障会大量增加。 运维要求高: 系统监控、高可用性、自动化技术 分布式复杂性: 网络延迟、系统容错、分布式事务 部署依赖性强: 服务依赖、多版本问题 性能(服务间通讯成本高): 无状态性、进程间调用、跨网络调用 数据一致性: 分布式事务管理需要跨越多个节点来保证数据的瞬时一致性,因此比起传统的单体架构的事务,成本要高得多。另外,在分布式系统中,通常会考虑通过数据的最终一致性来解决数据瞬时一致带来的系统不可用。 重复开发: 微服务理念崇尚每个微服务作为一个产品看待,有自己的团队开发,甚至可以有自己完全不同的技术、框架,那么与其他微服务团队的技术共享就产生了矛盾,重复开发的工作即产生了。 4.架构设计 4.1.思维设计 微服务架构设计的根本目的是实现价值交付,微服务架构只有遵循DevOps理念方可进行的更顺畅,思维方式的转变是最重要的。
广西交通职业技术学院信息工程系作品设计报告书题目:《图书管理系统》 班级网络2012-1班 学号 20120404026 姓名唐张森 课程名称数据库应用技术 指导教师乐文行 二O一三年六月
目录
数据库课程设计报告书 一、设计目标 1.掌握计算机管理信息系统设计的一般方法,主要包括系统分析、系统设计的组织 和实施。 2.关系型数据库管理系统的编程技术,并能独立完成一般小系统的程序设计、调试 运行等工作。 3.培养把所学知识运用到具体对象,并能求出解决方案的能力。 二、数据库存储设计指导思想 在数据库存储设计的无数选择中,简单是系统架构师和DBA 的秘密武器。 简单,有时候就来自于对一个特定的表或表空间没有选择最优I/O 特性,总有这么一种可能,一个富有经验的DBA 拥有高超的存储技能并可以没有时间限制的去为一个非常重要的表或者索引配置一个存储。然而这样做的问题是,就算能达到设计的最佳性能,为了维护原始对象,这也经常造成对一个系统的管理变得更加复杂。好的数据库存储设计的要点是,在一个动态系统上,实现所有目标应该是最初的系统设计的一部分,并应该在数据库运行过程中长期进行。这篇文档简单的最佳实践描述达到了这些目标并且几乎没有性能损失。 三、任务 角色:读者、图书馆馆员、系统管理员;基础数据:读者信息、图书信息、操作员信息;业务数据:借还书记录登记、罚款登记;统计数据:书籍借阅情况统计或读者借阅情况统计。基本要求:利用数据库技术,完成基础数据和业务数据的储存和操作,数据库设计合理1.设计报告:含E-R图、数据字典、关系模式、关系实例、查询描述、关系代数、SQL 实现的查询语言及查询结果。 2.上机实现。
一、主要图层命名对照表: CZJSKZQ 村镇建设控制区 JSYDGZQ 建设用地管制区 TDYTQ 土地用途区 JQDLTB 基期地类图斑 MZJCSS 面状基础设施 MZZDJSXM 面状重点建设项目 XZQ 行政区 JBNTGHTB 基本农田规划图斑 JQXZDW 基期现状地物 DLMCZJ 地类名称注记 XZQJX 行政区界线 二、主要图层类型代码表 1.①建设用地管制区 属性代码表达图式 代码管制区类型SM 图式符号RGB 线宽 010 允许建设区011 现状建设用地 RGB(170,0,130) RGB(245,140,140) 1.5 012 新增建设用地 RGB(170,0,130) RGB(220,100,120) 1.5 020 有条件建设区/ / RGB(170,0,130) RGB(255,210,125) 1.5 030 限制建设区/ / RGB(165,255,115) / 040 禁止建设区/ / RGB(40,115,0) RGB(60,180,70) 1.5
②建设用地管制区(土地利用总体规划图) 建设用地管制分区 表达图式 图示符号RGB 允许建设区RGB(170,0,130) 有条件建设区 RGB(170,0,130) RGB(220,100,120) 2.土地用途区 属性代码表达图式代码土地用途区类型图式符号RGB 010 基本农田保护区RGB(250,255,50) 020 一般农地区RGB(245,255,125) 030 城镇建设用地区 RGB(170,0,130) RGB(220,100,120) 040 村镇建设用地区 RGB(170,0,130) RGB(245,140,140) 050 独立工矿用地区RGB(210,160,120) 060 风景旅游用地区RGB(0,135,255) 070 生态环境安全控制区RGB(40,110,25) 080 自然与文化遗产保护区RGB(20,230,0) 090 林业用地区RGB(120,220,120) 100 牧业用地区RGB(210,255,115) 990 其他用地区 水域RGB(115,225,255) 自然保留地RGB(180,180,180)
高可用数据库架构设计标准化管理处编码[BBX968T-XBB8968-NNJ668-MM9N]
MySQL数据库高可用架构设计 目标: MySQL 数据库服务器不受单点宕机的影响,即时 A 服务器挂掉或者磁盘损坏物理故障导致数据库不可用也不会导致整个系统处于不可用状态,因为还有另外一台备用的数据库服务器可以提供服务。派宝箱采取方案双机主从热备 (Mater Slave 模式) 背景: 双机热备的概念简单说一下,就是要保持两个数据库的状态自动同步。对任何一个数据库的操作都自动应用到另外一个数据库,始终保持两个数据库数据一致。这样做的好处: 1. 可以做灾备,其中一个坏了可以切换到另一个。 2. 可以做负载均衡,可以将请求分摊到其中任何一台上,提高网站吞吐量。对于异地热备,尤其适合灾备。 原理: MySQL Replication双机热备 + 每天自动sqldump出物理文件备份 双机主从自动热备实现数据库服务的高可用加sqldump导出数据文件的方式备份。双重保险! 可能遇到的问题与挑战:
主从数据库数据一致性问题 宕机后主从切换的问题 1 复制概述 Mysql内建的复制功能(MySQL REPLICATION)是构建大型,高性能应用程序的基础。将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的数据复制到其它主机(slaves)上,并重新执行一遍来实现的。复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服务器将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从服务器的更新。当一个从服务器连接主服务器时,它通知主服务器从服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。 请注意当你进行复制时,所有对复制中的表的更新必须在主服务器上进行。否则,你必须要小心,以避免用户对主服务器上的表进行的更新与对从服务器上的表所进行的更新之间的冲突。 mysql支持的复制类型: (1):基于语句的复制:在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。 一旦发现没法精确复制时,会自动选着基于行的复制。 (2):基于行的复制:把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从开始支持(3):混合类型的复制: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。 . 复制解决的问题
数据库图书管理系统含 代码 Document number【SA80SAB-SAA9SYT-SAATC-SA6UT-SA18】
目录
一.需求描述和系统边界 数据库技术和Internet的飞速发展,使它们已经成为现代信息技术的重要组成部分,是现在计算机信息系统和计算机应用系统的基础和核心。对于任何一个企业来说,数据是企业重要的资产,如何有效利用这些数据,对于企业发展起着极其重要的作用。随着我国市场经济的迅速发展和人们生活水平的不断提高,图书馆藏书的数目逐渐增大,这也挑战了图书管理方面的技术,以前的人工管理方式已经不再适应现在的环境,取而代之的是先进的图书管理系统,创建图书管理系统可以让管理人员方便而快捷的进行管理、查询、借阅、录入等工作。 该图书管理系统支持2类用户:管理员和读者。读者可以进行借阅、续借、归还和查询书籍等操作,管理员可以完成书籍和读者的增加,删除和修改以及对读者,借阅、续借、归还的确认。 二.需求分析 1.业务需求 图书管理系统的主要业务包括:包括图书馆内书籍的信息,读者信息,以及借阅信息。此系统功能分为面向读者和面向管理员两部分,其中读者可以进行借阅、续借、归还和查询书籍等操作,管理员可以完成书籍和读者的增加,删除和修改以及对读者,借阅、续借、归还的确认。 2.功能需求及数据需求分析 (1)注册管理 管理员注册。管理员注册时要求填写基本信息,包括管理员编号、姓名、性别、联系电话、家庭住址。系统检查所有信息填写正确后管理员注册成功。 读者注册。读者注册时要求填写基本信息,包括读者编号、姓名、性别、联系电话、学院等。系统检查所有信息填写正确后读者注册成功。 (2)图书管理 增加图书信息。当有新的图书入库时,管理员负责添加图书信息,包括书名、分类、图书编号、作者、出版社、出版时间、简介等。
数据架构规划 一.当前架构 结合研发二部数据量最大的校讯通产品来描述,其他的产品在性能上出现瓶颈,可以向校讯通靠拢。 数据库整体架构:目前校讯通产品根据用户量的多少以及数据库服务资源的繁忙程度,横向采用了历史库+当前库的分库架构或者单一的当前库架构,其中历史库只作为web平台读数据库,纵向结合了applications的 memcache+Sybase ASE12.5传统永久磁盘化数据库架构。 数据模型架构:原则上采用了一事一地的数据模型(3NF范式),为了性能考虑,一些大数据量表适当的引用了数据冗余,根据业务再结合采用了当前表+历史表的数据模型。 以下就用图表来进行当前数据架构的说明: 横向分库数据库架构图:
纵向app layer+memcache layler+disk db layer图:
其中web层指的是客户端浏览器层,逻辑上:app层指的是应用服务层,mc 层指的是memcache的客户端层,ms层指的是memcache的服务层,db层指的是目前永久磁盘化的数据库层,当然在物理机器上可能app层跟mc层,ms层是重叠的部署在相同服务器上。 数据模型架构图:
其中以上数据模型中除了少数几张表外其他的都有历史表存在,当然有很多表是没在这个模型图中的,这部分是核心数据模型。这部分模型对象中也包括了一些冗余性的设计,比如用户中有真实姓名,特别是不在这个模型内,由模型核心表产生的一些统计报表,为了查询的性能冗余了合理一些学校名称,地区名称等方面的设计。 二.劣势现象 1.流水表性能瓶颈
当前架构的性能瓶颈集中在流水表的访问上,最大流水表的记录量达到了超5亿级别,这是由于目前外网在用的sybase数据库系统版本,没有采取很好的关于分区的技术。曾经有过把流水表进行物理水平分割,把不同月份的数据分割放在不同的物理表上的模型改造设想,碍于产生的应用程序修改工作量大,老旧数据迁移的麻烦,再加上进行了从单库架构改造到分库架构后,数据库性能瓶颈就不是特别突出。所以模型改造这部分工作没展开。 无论是单库或是分库的模式,出现平台访问数据库的性能瓶颈依然集中在大流水表上,在访问高峰高并发量情况下,短信的流水表进程堵塞,数据库服务 I/O ,CPU的资源耗费达到顶点,在服务器硬件环境不是特别理想情况下,出现了一定概率造成用户访问缓慢甚至觉得页面无法响应现象,造成了用户体念不良影响。 2. 运营维护难点 1)历史数据清理运维工作 为了存储充分利用,为了性能的提升,需要定期进行不再使用的历史数据清理, 由于清理的数据量庞大,传统的数据清理方法根本不可能保证一个晚上有效清理完毕,确保平台第二天正常的运行。虽然目前已经实行了比较高效且可行的数据清理方法,但是每次实行都需要晚上到通宵进行处理,使得数据清理的运维
书店信息管理系统的设计与实现 学生姓名:蒋斌指导老师:罗永红 摘要本课程设计主要是设计一个书店信息管理的系统,实现用户的注册、登录,书店书籍的添加、删除、修改、查询及图书的购买等功能。程序设计平台为Windows 7,程序设计语言采用JA V A,所连接的数据库是oracle 11g。在程序设计中,采用了结构化与面向对象两种解决问题的方法。程序通过调试运行,初步实现了目标。 关键词数据库;oracle 11g;JAVA;书店信息管理系统
The Design and Implementation of Book Store Information Management System Student Name:JiangBin Advisor:LuoYong-hong Abstract This course design is mainly to make a information management system of a online bookstore, The function of the system include book’adding ,deleting and querying and purchase books. Program design platform is Windows XP, programming language is JA V A, are the connected database is Oracle 10g. In the program process, I adopted two solution of the structured and object-oriented. Program run through the debugger, achieving the initial goal. Keywords Database; oracle 10g; JA V A; Online Bookstore Information Management System