XPath 数值函数
XPath 数值函数
数值函数用来对数值型数据进行数学计算,XPath支持的数值函数如表9-9所示。
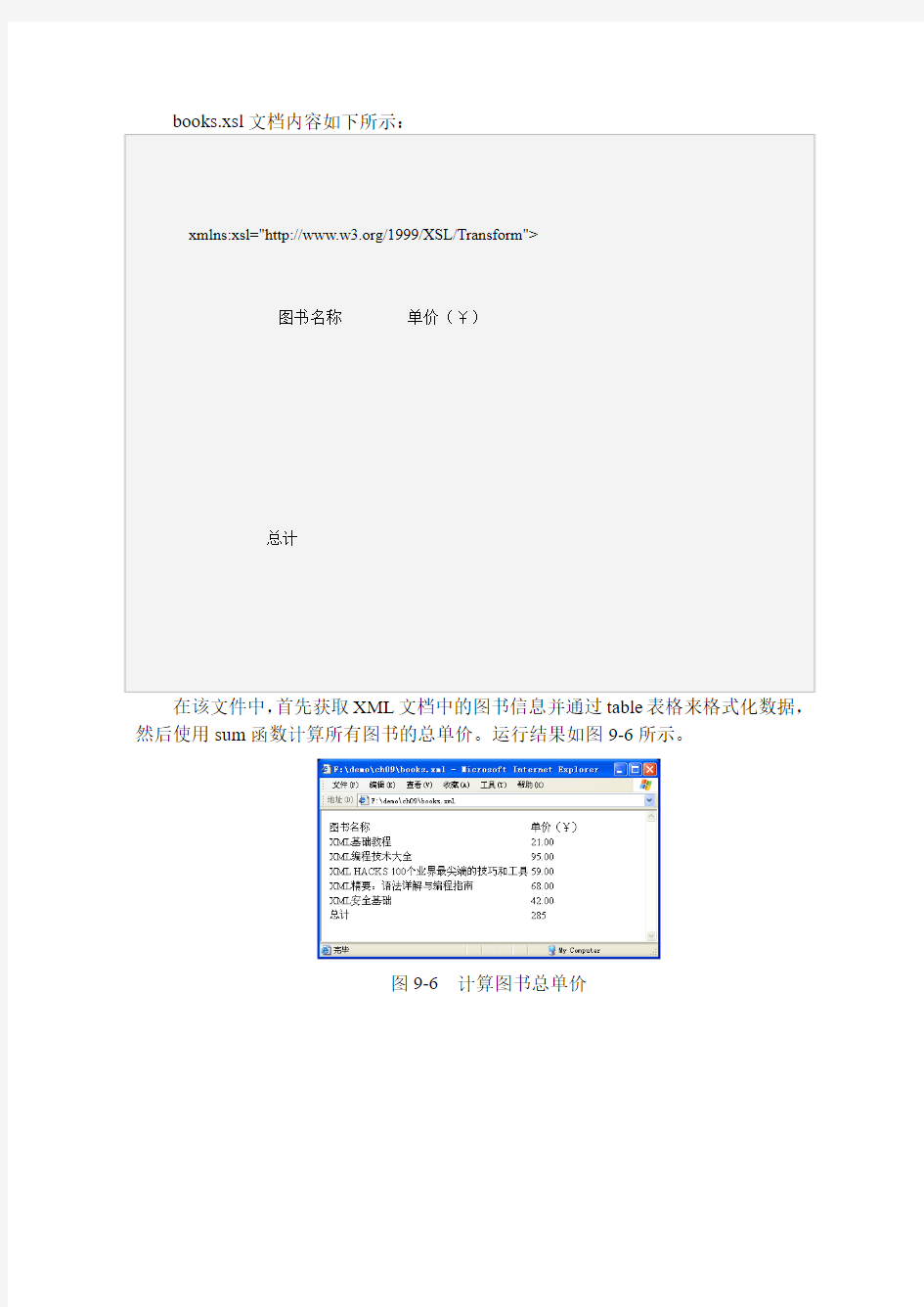
number()函数接受的参数是一个字符串值;sum方法接受的参数是一个路径定位表达式;其他函数一般是数值型数据。通过下面实例来具体介绍如何使用sum()函数,XML文档如下所示:
Xpath工具使用教程
https://www.doczj.com/doc/766077111.html, Xpath工具使用教程 本教程告诉大家如何使用八爪鱼内置的Xpath工具。 一、常见使用场景 在日常使用八爪鱼采集数据时,偶尔会出现一些特殊情况,比如说某个采集步骤因为网页或八爪鱼识别的问题,定位发生了偏差,导致自动生成的Xpath有一点问题,采集出错。这个时候需要我们手写Xpath来定位想要设置的步骤,而八爪鱼有个内置的Xpath工具,可以帮助大家写一些简单的Xpath位置(除了打开网页步骤没有Xpath工具以外,其他步骤都有)。 二、Xpath工具位置 Xpath工具可以在两个地方打开。 一个入口是:登陆进去后的软件首页-工具箱里可以直接打开。
https://www.doczj.com/doc/766077111.html, 另一个入口是:流程中步骤的“自定义”按钮,点击进入
https://www.doczj.com/doc/766077111.html, 点击“自定义”按钮后,点击“不懂xpath,试试xpath工具” 三、Xpath工具界面介绍 打开xpath工具,该工具界面主要分为五个部分:
https://www.doczj.com/doc/766077111.html, 左上是填写网址 左中是浏览器 左下是页面HTML 源码(由于 xpath 工具的网页源码层次不分明,查看源码的话建议使用火狐浏览器的插件firebug 和firepath ,这是xpath 的入门教程,新用户有兴趣的也可以去学习一下: https://www.doczj.com/doc/766077111.html,/tutorial?type=1&category=XPath&version=v7.00) 右上是定位参数(工具将根据你填写的参数生成Xpath ) 右下是按要求点击生成后匹配到的xpath 1、我们来看一下定位参数
acm常用字符串处理函数
sstrstr与strchar用法 原型:extern char *strstr(char *haystack, char *needle); 用法:#include 功能:从字符串haystack中寻找needle第一次出现的位置(不比较结束符NULL)。 说明:返回指向第一次出现needle位置的指针,如果没找到则返回NULL。 举例: #include #include main() { char *s="Golden Global View"; char *l="lob"; char *p; clrscr(); p=strstr(s,l); if(p) printf("%s",p); else printf("Not Found!"); getchar(); return 0; } 语法:int strstr(str1,str2) str1: 被查找目标string expression to search. str2:要查找对象The string expression to find. 该函数返回str2第一次在str1中的位置,如果没有找到,返回NULL The strstr() function returns the ordinal position within str1 of the first occurrence of str2. If str2 is not found in str1, strstr() returns 0. 例子: 功能:从字串” string1 onexxx string2 oneyyy”中寻找”yyy” (假设xxx和yyy都是一个未知的字串) char *s=” string1 onexxx string2 oneyyy”; char *p; p=strstr(s,”string2”); if(!p) printf(“Not Found!”); p=strstr(p,”one”); if(!p) printf(“Not Found!”); p+=strlen(“one”) printf(“%s”,p); 说明:如果直接写语句p=strstr(p,”one”),则找到的是xxx,不符合要求 所以需采用二次查找法找到目标
XPath注入攻击原理及防御
XPath注入攻击原理及防御 作者美创科技安全实验室 01什么是XPath XPath即为XML路径语言,是W3C XSLT标准的主要元素,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。 XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力,可用来在XML文档中对元素和属性进行遍历。 02XPath基础语法 1、查询基本语句 //users/user[name/text()=’abc’and password/text()=’test123’]。 这是一个XPath查询语句,获取name为abc的所有user数据,用户需要提交正确的name和password才能返回结果。如果黑客在name字段中输入:'or1=1并在password中输入:'or1=1就能绕过校验,成功获取所有user数据 //users/user[name/text()=''or1=1and password/text()=''or1=1] 2、节点类型 在XPath中,XML文档被作为节点树对待,XPath中有七种结点类型:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或成为根节点)。文档的根节点即是文档结点;对应属性有属性结点,元素有元素结点。 element(元素) attribute(属性) text(文本) namespace(命名空间) processing-instruction(处理指令) comment(注释) root(根节点) 3、表达式 XPath通过路径表达式(Path Expression)来选取节点,基本规则:
八爪鱼如何通过xpath实现自定义定位元素
https://www.doczj.com/doc/766077111.html, 八爪鱼如何通过xpath实现自定义定位元素 定位元素:八爪鱼通过Xpath来实现元素的定位。 适用情况:八爪鱼自动定位方式不能满足需求的情况。 下面演示如何通过自定义定位元素方式来修改元素匹配的Xpath,借此修改提取元素步骤采集到的数据。 示例网址: https://www.doczj.com/doc/766077111.html,/guide/demo/genremoviespage1.html 步骤一:点击自定义采集下的立即使用→输入网址并保存 自定义定位元素方式-图1
https://www.doczj.com/doc/766077111.html, 自定义定位元素方式-图2 步骤二:点击采集位置→循环采集元素→补充并修改提取元素步骤 自定义定位元素方式-图3
https://www.doczj.com/doc/766077111.html, 自定义定位元素方式-图4 说明:循环采集元素会采集所有信息,我们在补充并修改提取元素步骤进行了删除第一个字段操作,同时添加了我们需要的正确字段。 步骤三:修改自定义定位元素方式 选中要修改的字段→点击高级选项中自定义数据字段(如下图) →点击自定义定位元素方式 进入自定义定位元素方式后,我们在下图红框处修改Xpath
https://www.doczj.com/doc/766077111.html, 自定义定位元素方式-图6 其中元素匹配的Xpath是指可以通过这个Xpath路径在网页中直接找到所需数据的路径;相对Xpath指相对于循环Xpath的路径,将循环中的Xpath接上相对Xpath路径就可以生成一条直接匹配元素的路径。下面进行演示。 演示中使用了火狐浏览器的Firebug插件,详细使用情况请到Xpath使用教程中查看。 自定义定位元素方式-图7
VB常用字符串操作函数解读
VB常用字符串操作函数2009/11/25 18:321. ASC(X,Chr(X:转换字符字符码[格式]: P=Asc(X 返回字符串X的第一个字符的字符码 P=Chr(X 返回字符码等于X的字符 [范例]:(1P=Chr(65 ‘ 输出字符A,因为A的ASCII码等于65 (2P=Asc(“A” ‘ 输出65 2. Len(X:计算字符串X的长度 [格式]: P=Len(X [说明]:空字符串长度为0,空格符也算一个字符,一个中文字虽然占用2 Bytes,但也算 一个字符。 [范例]: (1 令X=”” (空字符串 Len(X 输出结果为0 (2 令X=”abcd” Len(X 输出结果为4 (3 令X=”VB教程” Len(X 输出结果为4 3. Mid(X函数:读取字符串X中间的字符 [格式]: P=Mid(X,n 由X的第n个字符读起,读取后面的所有字符。 P=Mid(X,n,m 由X的第n个字符读起,读取后面的m个字符。 [范例]: (1 X=”abcdefg” P=Mid(X,5 结果为:P=”efg” (2 X=”abcdefg” P=Mid(X,2,4 结果为 P=”bcde” 4. R eplace: 将字符串中的某些特定字符串替换为其他字符串 [格式]: P=Replace(X,S,R [说明]:将字符串X中的字符串S替换为字符串R,然后返回。[范例]:X=”VB is very good” P=Replace(X,good,nice 输出结果为:P=”VB is very nice” 5. StrReverse:反转字符串 [格式]: P=StrReverse(X [说明]:返回X参数反转后的字符串 [范例]:(1)X=”abc” P=StrReverse(X 输出结果:P=”cba” 6. Ucase(X,Lcase(X:转换英文字母的大小写 [格式]:P=Lcase(X ‘ 将X字符串中的大写字母转换成小写P=Ucase(X ‘ 将X字符串中的小写字母转换成大写 [说明]:除了英文字母外,其他字符或中文字都不会受到影响。 [范例]:(1)令X=”VB and VC” 则Lcase(X的结果为”vb and vc”,Ucase(X的结果为”VB AND VC” 7. InStr函数:寻找字符串 [格式]: P=InStr(X,Y 从X第一个字符起找出Y出现的位置 P=InStr(n,X,Y 从X第n个字符起找出Y出现的位置 [说明]:(1)若在X中找到Y,则返回值是Y第一个字符出现在X中的位置。(2) InStr(X,Y相当于 InStr(1,X,Y。(3)若字符串长度,或X为空字符串,或在X中找不到Y,则都 返回0。(4)若Y为空字符串,则返回0。 ---------------------------------------------------------------------------------------------- mid(字符串,从第几个开始,长度 ByRef 在[字符串]中[从第几个开始]取出[长度个字符串] 例如 mid("小欣无敌",1,3 则返回 "小欣无" instr(从第几个开始,字符串1,字符串2 ByVal 从规定的位置开始查找,返回字符
java 字符串常用函数及其用法
java中的字符串也是一连串的字符。但是与许多其他的计算机语言将字符串作为字符数组处理不同,Java将字符串作为String类型对象来处理。将字符串作为内置的对象处理允许Java提供十分丰富的功能特性以方便处理字符串。下面是一些使用频率比较高的函数及其相关说明。 String相关函数 1)substring() 它有两种形式,第一种是:String substring(int startIndex) 第二种是:String substring(int startIndex,int endIndex) 2)concat() 连接两个字符串 例:String s="Welcome to "; String t=s.concat("AnHui"); 3)replace() 替换 它有两种形式,第一种形式用一个字符在调用字符串中所有出现某个字符的地方进行替换,形式如下: String replace(char original,char replacement) 例如:String s=”Hello”.replace(’l',’w'); 第二种形式是用一个字符序列替换另一个字符序列,形式如下: String replace(CharSequence original,CharSequence replacement) 4)trim() 去掉起始和结尾的空格 5)valueOf() 转换为字符串 6)toLowerCase() 转换为小写 7)toUpperCase() 转换为大写 8)length() 取得字符串的长度 例:char chars[]={’a',’b’.’c'}; String s=new String(chars); int len=s.length(); 9)charAt() 截取一个字符 例:char ch; ch=”abc”.charAt(1); 返回值为’b’ 10)getChars() 截取多个字符 void getChars(int sourceStart,int sourceEnd,char target[],int targetStart) sourceStart 指定了子串开始字符的下标 sourceEnd 指定了子串结束后的下一个字符的下标。因此,子串包含从sourceStart到sourceEnd-1的字符。
Pascal常用字符串函数
一、数学函数: Inc(i) 使I:=I+1; Inc(I,b) 使I:=I+b; Abs(x) 求x的绝对值例:abs(-3)=3 Chr(x) 求编号x对应的字符。例:Chr(65)=’A’ chr(97)=’a’ chr(48)=’0’ Ord(x) 求字符x对应的编号。例:ord(‘A’)=65 ord(‘a’)=97 另外:ord(false)=0 o rd(true)=1 Sqr(x) 求x的平方。例:sqr(4)=16 Sqrt(x)求x的开方. 例:sqrt(16)=4 round(x) 求x的四舍五入例:round(4.5)=5 trunc(x) 求x的整数部分例:trunc(5.6)=5 结果是integer型 int(x) 求x的整数部分例int(5.6)=5.0 结果是real型 frac (x)求x的小数部分例frac(5.6)=0.6 pred(x) 求x的前导pred(‘b’)=’a’ pred(5)=4 pred(true)=false succ(x) 求x的后继succ(‘b’)=’c’ succ(5)=6 succ(false)=true odd(x) 判断x是否为奇数。如果是值为true,反之值为false. Odd(2)=false od d(5)=true power(a,n) 求a的n次方power(2,3)=8 exp(b*ln(a)) a的b次方 random 取0~1之间的随机数(不能取到1) randomize 随机数的种子函数,在每次设置随机数时都要把这个函数放在最前面. Fillchar(a,size(a),0) 数组初始化,即把数组a的值全部置为0 SHR: x SHR n 把x换成二进制后向右移n位,相当于把x 除以2n a shr n 等价于a div (2^n) SHL: x SHL n把x换成二进制后向左移n位,相当于把x 乘以2n 二、字符串函数 1. 连接运算concat(s1,s2,s3…sn) 相当于s1+s2+s3+…+sn. 例:concat(‘11’,’aa’)=’11aa’; 2. 求子串。Copy(s,i,L) 从字符串s中截取第i个字符开始后的长度为L的子串。 例:copy(‘abdag’,2,3)=’bda’ 3. 删除子串。过程Delete(s,i,L) 从字符串s中删除第i个字符开始后的长度为L的子串。
最简单的黑客入门教程大全
最简单的黑客入门教程大全 目录 1 黑客简介 (3) 2 保护自己电脑绝对不做黑客肉鸡 (4) 3 抓肉鸡的几种方法 (8) 4 防止黑客通过Explorer侵入系统 (17) 5 SQL注入详解 (19) 5.1 注入工具 (20) 5.2 php+Mysql注入的误区 (21) 5.3 简单的例子 (23) 5.4 语句构造 (26) 5.5 高级应用 (42) 5.6 实例 (50) 5.7 注入的防范 (55) 5.8 我看暴库漏洞原理及规律1 (56) 5.9 我看暴库漏洞原理及规律2 (61) 6 跨站脚本攻击 (65) 6.1 跨站脚本工具 (65) 6.2 什么是XSS攻击 (66)
6.3 如何寻找XSS漏洞 (66) 6.4 寻找跨站漏洞 (67) 6.5 如何利用 (67) 6.6 XSS与其它技术的结合 (71) 7 XPath注入 (71) 7.1 XPath注入介绍 (71) 7.2 XPath注入工具 (76) 声明:文章来源大多是网上收集而来,版权归其原作者所有。
1黑客简介 "黑客"(hacker)这个词通常被用来指那些恶意的安全破坏者。关于"黑客"一词的经典定义,最初来源于麻省理工学院关于信息技术的一份文档,之后便被新闻工作者们长期使用。但是这个在麻省理工被当做中性词汇的术语,却逐渐被新闻工作者们用在了贬义的环境,而很多人也受其影响,最终导致了"黑客"一词总是用于贬义环境。有些人认为,我们应该接受"黑客"一词已经被用滥并且有了新的意义。他们认为,如果不认可这种被滥用的词汇,那么将无法与那些不懂技术的人进行有效的交流。而我仍然认为,将黑客和恶意的骇客(cracker)分开表述,对交流会更有效,比如使用"恶意的安全骇客"会更容易让对方理解我所指的对象,从而能够达到更好的沟通交流效果,也避免了对"黑客"一词的滥用。之所以要区分黑客和恶意骇客,是因为在某些情况下,我们讨论的对象是那些毫无恶意并且不会对安全防御或者用户隐私造成损害的对象,这些人只有用"黑客"这个词来描述才最贴切。如果你只是简单的将"黑客"和"恶意的安全骇客"划等号,将无法在与人交流安全技术问题时,轻松的分辨别人所指的到底是哪种类型的人。黑客和骇客的区别是,黑客仅仅对技术感兴趣,而后者则是通过技术获取职业发展或者谋生。很多黑客和骇客都具有技术天赋,有些骇客据此进行职业发展。当然,并不是每个有技术天赋的人都必须沿着黑客或者骇客的方向发展。黑客这个术语的经典意义是指那些对于事物如何工作非常感兴趣的人,他们修理,制作或者修改事物,并以此为乐。对于某些人来说,这个词并不准确,而对于另一些人来说,黑客意味着最终能完全掌握某些事情。根据RFC1392的记载,互联网用户词汇将"黑客"定义为:迷恋于获取某些系统尤其是计算机和计算机网络系统内部运作机制的人。而这个词经常被错误的用于贬义环境。在贬义环境中,正确的用词应该是"骇客"。TheJargonWiki对于"黑客"的首次定义为:迷恋于探知可编程系统细节以及如何扩展其功能的人,与大多数只需了解系统基本知识的人
SQL无序字符比较函数
go --创建函数(第一版) create function get_orderstr(@str varchar(8000)) returns varchar(8000) as begin set @str=rtrim(@str) declare @tb table(s varchar(1),a int) while len(@str)>0 begin insert into @tb select left(@str,1),ascii(left(@str,1)) set @str=right(@str,len(@str)-1) end declare @sql varchar(8000) select @sql=isnull(@sql+'','')+s from @tb order by a return isnull(@sql,'') end --测试示例 if(dbo.get_orderstr('abc')=dbo.get_orderstr('acb')) print'相同' else print'不同' --运行结果 /* 相同 */ --第二版 /* * 功能:不按先后顺序比较字符串序列是否相同 * * 适用:SQL Server 2000 / SQL Server 2005 * * 返回:相同不相同 * * 作者:Flystone * * 描述:学习Limpire(昨夜小楼)的方法后做一个动态SQL的* */ go --创建存储过程(这个不是函数) CREATE proc sp_CompareString @Str1 varchar(100), @Str2 varchar(100), @Split varchar(10),
字符串处理函数大全
字符串处理函数大全 bcmp(比较内存内容)相关函数 bcmp,strcasecmp,strcmp,strcoll,strncmp,strncasecmp 表头文件;include 定义函数;int bcmp ( const void *s1,const void * s2,int n); 函数说明;bcmp()用来比较s1和s2所指的内存区间前n个字节,若参数n为0,则返回0。返回值;若参数s1 和s2 所指的内存内容都完全相同则返回0 值,否则返回非零值。 附加说明;建议使用memcmp()取代。 范例:参考memcmp()。 //================================================================ bcopy(拷贝内存内容)相关函数 memccpy,memcpy,memmove,strcpy,ctrncpy 表头文件;#include 定义函数;void bcopy ( const void *src,void *dest ,int n); 函数说明;bcopy()与memcpy()一样都是用来拷贝src所指的内存内容前n个字节到dest所指的地址,不过参数src与dest在传给函数时是相反的位置。 返回值 ;附加说明建议使用memcpy()取代 范例 #include main() { char dest[30]=”string(a)”; char src[30]=”string\0string”; int i; bcopy(src,dest,30);/* src指针放在前*/ printf(bcopy(): “) for(i=0;i<30;i++) printf(“%c”,dest[i]); memcpy(dest src,30); /*dest指针放在钱*/ printf(…\nmemcpy() : “); for(i=0;i<30;i++) printf(“%c”,dest[i]); 执行 bcopy() : string string memcpy() :string sring //================================================================ bzero(将一段内存内容全清为零)相关函数 memset,swab 表头文件;#include 定义函数;void bzero(void *s,int n); 函数说明:bzero()会将参数s所指的内存区域前n个字节,全部设为零值。相当于调用memset((void*)s,0,size_tn); 返回值:附加说明建议使用memset取代
Selenium XPath定位详解
Selenium XPath定位详解 By:授客 QQ:1033553122 什么是 XPath:https://www.doczj.com/doc/766077111.html,/TR/xpath/ XPath 基础教程:https://www.doczj.com/doc/766077111.html,/xpath/xpath_syntax.asp selenium 中被误解的 XPath :https://www.doczj.com/doc/766077111.html,/blog/category/webdriver/ XPath 是一种在 XML 文档中定位元素的语言。因为HTML可以看做 XML 的一种实现,selenium 用户可使用这种强大语言在web应用中定位元素。 注意:xpath_test.html页面内容如上,并把其放置于src目录下 语法:nodename 语义:选择名为"nodename"的所有节点 说明:必须结合使用 语法:/rootname
语义:选择根元素rootname driver.find_element_by_xpath('/html') 示例: # coding= utf-8 from selenium import webdriver import os import time if __name__ == "__main__": driver = webdriver.Firefox() driver.maximize_window() file_path = os.path.abspath('xpath_test.html') driver.get(file_path) #定位根元素(/root 定位) driver.find_element_by_xpath('/html') time.sleep(5) driver.quit() 语法:parent/child_element 语义:选择父元素parent节点下所有名为child_element的子元素: 示例: # coding= utf-8 from selenium import webdriver import os import time if __name__ == "__main__": driver = webdriver.Firefox() driver.maximize_window() file_path = os.path.abspath('xpath_test.html') driver.get(file_path) time.sleep(2) #定位复选框(parent/child_element 定位) 注意:匹配到第一个就不再往下点击了 driver.find_element_by_xpath('/html/body/form/input').click() time.sleep(5) driver.quit() 语法://element 语义:选择所有的element元素,不管它们在文档中的位置(个人理解:类似全文查找)
八爪鱼xpath入门学习(以提取网页中公司名和地址为例)
https://www.doczj.com/doc/766077111.html, xpath入门学习(以提取网页中公司名和地址为例) 本文用来讲解xpath的入门基础,适合对八爪鱼已经有一些基础的用户来学习。 文中示例地址为:https://www.doczj.com/doc/766077111.html,/qiye2309554/ https://www.doczj.com/doc/766077111.html,/qiye2275810/ 提取两个网页中的公司名称和地址字段。 Xml和Html之间既有相似之处,又有很大区别。Xml包含数据和对数据的描述,主要用来交换数据。Html也包含了数据和对数据的描述,但只是针对描述网页这种用途,Html结构看起来和Xml类似,但并不严格遵循Xml标准,可以看做不标准的Xml。 Xpath是专门针对Xml设计的,在复杂结构化数据中查找信息的语言,而我们的网页实质上是Html的文档,那如何对网页执行Xpath查询呢?八爪鱼采集器内部有一套针对Html 的Xpath引擎,使得直接用Xpath就能精准的查找定位网页里面的数据。 给大家介绍一个类似的工具,就是火狐浏览器里面firebug和firepath插件。 首先在电脑上先安装火狐浏览器,然后打开火狐浏览器右上角的打开菜单按钮,选择添加组件。
https://www.doczj.com/doc/766077111.html, Xpath入门1-图1:附件组件 在弹出的对话框中搜索firebug组件,搜索出来之后选择安装。
https://www.doczj.com/doc/766077111.html, Xpath入门1-图2:安装firebug 安装成功之后同样的方式搜索firepath进行安装。 小贴士:安装成功之后,浏览器需要重启一下才能完全安装成功。重新打开浏览器中,可以看到多了一个昆虫按钮,代表安装成功。 在浏览器中打开一个网页,再点击浏览器中的firebug按钮,就弹出了可以用xpath的firepath工具。 Xpath入门1-图3:firepath工具 按照下面的操作可以找到数据的精确位置。 点击firepath工具中“查看页面中的元素”按钮→选择网页中要提取的字段→可以看到firepath工具中显示出了xpath路径
通过Xpath定位元素
使用XPath进行元素定位 在Selenium中,定位HTML元素经常用到XPath表达式,下面将进行详细的介绍。XPath是在XML文档中查找信息的一种语言,可用来在XML文档中对元素和属性进行导航。XPath是W3C XSLT标准的主要元素,并且XQuery和Xpointer都构建于XPath表达之上。因此,对XPath的理解是很多高级XML应用的基础。 XPath使用路径表达式来选取XML文档中的节点或者节点集。这些路径表达式和常规的计算机文件系统中看到的表达式非常相似。 虽然XPath用于查找XML的节点,但由于HTML和XML结构类似,所以XPath也经常用于查找HTML文档中的节点。 为了使读者更好地了解XPath表达式是什么,这里直接用实例进行说明,列举一些最常用的XPath语法。 实例1-1 基本的XPath语法类似于在一个文件系统中定位文件,如果路径以斜线“/”开始,那么该路径就表示到一个元素的绝对路径,如表1-1至表1-3所示。 表1-1 以斜线开始的路径实例(一) 表1-2 以斜线开始的路径实例(二) 表1-3 以斜线开始的路径实例(三)
实例1-2 如果路径以双斜线//开始,则表示选择文档中所有满足双斜线“//”之后规则的元素(无论层级关系),如表1-4和表1-5所示。 表1-4 以双斜线开始的路径实例(一) 表1-5 以双斜线开始的路径实例(一)
星号* 表示选择所有由星号之前的路径所定位的元素,如表1-6至表1-8所示。表1-6 以星号开始的路径实例(一) 表1-7 以星号开始的路径实例(二) 表1-8 以星号开始的路径实例(三)
八爪鱼xpath入门教程以及定位元素实例
https://www.doczj.com/doc/766077111.html, xpath入门教程以及定位元素实例 本文用来讲解xpath的入门基础,本教材是xpath入门2,建议大家从入门1教程开始学习 Xpath的教程适合对八爪鱼已经有一些基础的用户来学习。 示例地址 /tutorial?type=0&page=0&tag=%E8%BF%9B%E9%98%B6&version=other Xpath:是一种路径查询语言,简单的说就是利用一个路径表达式找到我们需要的数据位置。Html:超文本标记语言,是用来描述网页的一种语言。主要用于控制数据的显示和外观。HTML文档也被称为网页。 Xpath专用于xml中沿着路径查找数据用的,但是八爪鱼采集器内部有一套针对Html的 就能精准的查找定位网页里面的数据。 Xpath引擎,使得直接用Xpath
https://www.doczj.com/doc/766077111.html, 例如下图通过火狐的firebug 、firepath 查看网页源码。查看方法参考“xpath 入门1”教程 xpath 入门2-图2 完整的HTML 文件至少包括标签、
标签、
标签和<BODY>标签,并且这些标签都是成对出现的,开头标签为<> ,结束标签为</>,在这两个标签之间添加内容。通过这些标签中的相关属性可以设置页面的背景色、背景图像等。 Html 标签</p><p>https://www.doczj.com/doc/766077111.html, 作为开始和结束的标记由尖括号包围的关键词,比如<html>标签对中,第一个标签是开始标签,第二个标签是结束标签 元素 HTML的网页内容是由元素组成的,从开始标签到结束标签的所有代码。 元素的开始和结束都使用标签作为开始和结束的标记 节点 所有事物都是节点 整个文档是一个文档节点 每个HTML 元素是元素节点 HTML元素内的文本是文本节点 每个HTML 属性是属性节点 注释是注释节点 Html常见标签</p><h2>从零开始学习黑客技术入门教程(基础)</h2><p>最简单的黑客入门教程 目录 1 黑客简介 (3) 2 保护自己电脑绝对不做黑客肉鸡 (5) 3 抓肉鸡的几种方法 (10) 4 防止黑客通过Explorer侵入系统 (19) 5 SQL注入详解 (22) 5.1 注入工具 (23) 5.2 php+Mysql注入的误区 (24) 5.3 简单的例子 (27) 5.4 语句构造 (30) 5.5 高级应用 (48) 5.6 实例 (57) 5.7 注入的防范 (62) 5.8 我看暴库漏洞原理及规律1 (64) 5.9 我看暴库漏洞原理及规律2 (70) 6 跨站脚本攻击 (75) 6.1 跨站脚本工具 (75) 6.2 什么是XSS攻击 (76) 6.3 如何寻找XSS漏洞 (77) 6.4 寻找跨站漏洞 (78) 6.5 如何利用 (78)</p><p>6.6 XSS与其它技术的结合 (81) 7 XPath注入 (82) 7.1 XPath注入介绍 (82) 7.2 XPath注入工具 (87) 声明:文章来源大多是网上收集而来,版权归其原作者所有。</p><p>1黑客简介 "黑客"(hacker)这个词通常被用来指那些恶意的安全破坏者。关于"黑客"一词的经典定义,最初来源于麻省理工学院关于信息技术的一份文档,之后便被新闻工作者们长期使用。但是这个在麻省理工被当做中性词汇的术语,却逐渐被新闻工作者们用在了贬义的环境,而很多人也受其影响,最终导致了"黑客"一词总是用于贬义环境。有些人认为,我们应该接受"黑客"一词已经被用滥并且有了新的意义。他们认为,如果不认可这种被滥用的词汇,那么将无法与那些不懂技术的人进行有效的交流。而我仍然认为,将黑客和恶意的骇客(cracker)分开表述,对交流会更有效,比如使用"恶意的安全骇客"会更容易让对方理解我所指的对象,从而能够达到更好的沟通交流效果,也避免了对"黑客"一词的滥用。之所以要区分黑客和恶意骇客,是因为在某些情况下,我们讨论的对象是那些毫无恶意并且不会对安全防御或者用户隐私造成损害的对象,这些人只有用"黑客"这个词来描述才最贴切。如果你只是简单的将"黑客"和"恶意的安全骇客"划等号,将无法在与人交流安全技术问题时,轻松的分辨别人所指的到底是哪种类型的人。黑客和骇客的区别是,黑客仅仅对技术感兴趣,而后者则是通过技术获取职业发展或者谋生。很多黑客和骇客都具有技术天赋,有些骇客据此进行职业发展。当然,并不是每个有技术天赋的人都必须沿着黑客或者骇客的方向发展。黑客这个术语的经典意义是指那些对于事物如何工作非常感兴趣的人,他们修理,制作或者修改事物,并</p><h2>C 中的string常用函数用法总结.</h2><p>C++中的string常用函数用法总结首先,为了在我们的程序中使用string类型,我们必须包含头文件<string>。 如下: #include <string> //注意这里不是string.h string.h是C字符串头文件 #include <string> using namespace std; 1.声明一个C++字符串 声明一个字符串变量很简单: string Str; 这样我们就声明了一个字符串变量,但既然是一个类,就有构造函数和析构函数。上面的声明没有传入参数,所以就直接使用了string的默认的构造函数,这个函数所作的就是把Str 初始化为一个空字符串。String类的构造函数和析构函数如下: a) string s; //生成一个空字符串s b) string s(str) //拷贝构造函数生成str的复制品 c) string s(str,stridx) //将字符串str内“始于位置stridx”的部分当作字符串的初值 d) string s(str,stridx,strlen) //将字符串str内“始于stridx且长度顶多st rlen”的部分作为字符串的初值 e) string s(cstr) //将C字符串作为s的初值 f) string s(chars,chars_len) //将C字符串前chars_len个字符作为字符串s的初值。 g) string s(num,c) //生成一个字符串,包含num个c字符 h) string s(beg,end) //以区间beg;end(不包含end)内的字符作为字符串s的初值 i) s.~string() //销毁所有字符,释放内存 都很简单,我就不解释了。</p><h2>(完整版)vb_字符串处理函数大全</h2><p>mid(字符串,从第几个开始,长度)ByRef 在[字符串]中[从第几个开始]取出[长度个字符串] 例如mid("坦然面对",1,3) 则返回"坦然面" instr(从第几个开始,字符串1,字符串2)ByVal 从规定的位置开始查找,返回字符串2在字符串1中的位置 例如instr(1,"坦然面对","坦") 则返回1,instr(2,"坦然面对","坦"),则返回0 。0 表示未找到 InStrRev(字符串1,字符串2,从第几个开始) ByVal 从规定的位置开始,从后住前查找,返回字符串2在字符串1中的位置,此处注意,虽是从后住前查找,但是返回的值还是从前往后算的。 例如instrRev("坦然面对","坦",2) 则返回2 ; instrRev("坦然面对","然",1) 则返回0 ,因为它从"坦然面对"的第1个字开始往前查找,所以找不到。0 表示未找到 left(字符串,长度) ByVal 从[字符串]的左边开始返回[长度]个字符 例如Left("坦然面对",3) 则返回"坦然面" right(字符串,长度) ByVal 从[字符串]的右边开始返回[长度]个字符 例如Right("坦然面对",3) 则返回"然面对" ucase(字符串) ByVal 返回[字符串]的大写形式,只对英文字符有效 例如ucase("tanRANmiAnDui") 则返回"TANRANMIANDUI" lcase(字符串) ByVal 返回[字符串]的小写形式,只对英文字符有效 例如lcase("tanRANmiAnDui") 则返回"tanranmiandui" asc(字符) Byval返回[字符]的ascii编码,若有多个字符,则只返回首字符的ascii编码,和Chr()函数是一个可逆的过程 例如asc("坦") 则返回-13127; asc("坦然面对") 也返回-13127 chr(ASCii编码) Byval 返回[Ascii]编码所代表的字符,和Chr()函数是一个可逆的过程 例如chr(-13127) 则返回"坦" ;chr(asc("坦")) 则返回"坦"(这里是为了说明asc和chr的可逆性,例用此特性可以加密文本) trim(字符串) Byval 返回去掉了前、后之后的[字符串] 例如trim("坦然面对") 则返回"坦然面对" ,中间的空格不受任何影响 string(个数,字符) Byval 返回[个数]个[字符] 例如string(3,"坦") 则返回"坦坦坦" , 而string(3,"坦然面对") 也返回"坦坦坦",只有首字符才有效 space(个数) Byval 返回[个数]个空格 例如space(5) 则返回""</p><h2>八爪鱼采集器提取数据-找不到时如何处理</h2><p>https://www.doczj.com/doc/766077111.html, 八爪鱼采集器提取数据-找不到时如何处理 八爪鱼提取字段时,有找不到时如何处理的选项。如下图: 八爪鱼提取数据 找不到时如何处理-图1 下面介绍如何设置找不到字段时的操作: 步骤一、点击需要设置的字段名称→自定义数据字段→自定义定位元素方式</p><p>https://www.doczj.com/doc/766077111.html, 八爪鱼提取数据找不到时如何处理-图2 八爪鱼提取数据找不到时如何处理-图3 进入自定义定位元素方式后,我们可以看到下图中红框内,有找不到时如何处理的三个选项,分为:使用默认值、该字段留空以及该步骤所有字段留空。 八爪鱼提取数据找不到时如何处理-图4</p><p>https://www.doczj.com/doc/766077111.html, 这里为了方便演示,我们修改一下元素匹配的Xpath,这样八爪鱼就抓取不到原来的字段了。 八爪鱼提取数据找不到时如何处理-图5 八爪鱼提取数据找不到时如何处理-图6 由于我们在标题处选择的是找不到时该字段留空,所以修改Xpath后,标题处提取到的数据为空。 八爪鱼提取数据找不到时如何处理-图7</p><p>https://www.doczj.com/doc/766077111.html, 我们同样修改类型和评分处的Xpath 看一下其余两项效果。评分处的使用默认值设置提取不到内容容时出现默认值,默认值设置如下: 八爪鱼提取数据 找不到时如何处理-图8 步骤二:保存并启动</p><p>https://www.doczj.com/doc/766077111.html, 八爪鱼提取数据找不到时如何处理-图9 可以看到弹出了采集错误报告,当前网页三条数据均未采集到信息 八爪鱼提取数据找不到时如何处理-图10 此处是因为类型中,找不到字段时该步骤所有字段留空,导致标题、类型、评分、上映年份以及时间均为空值,当八爪鱼一条信息采集不到任何一个字段时便会弹出错误提醒,我们可</p><h2>VB常用字符串函数解读</h2><p>VB 常用字符串函数 (1 作者:来源:发布时间:07-11-03 浏览:12899 次 PART 1 1. ASC (X, Chr(X:转换字符字符码 [格式 ]: P=Asc(X 返回字符串 X 的第一个字符的字符码 P=Chr(X 返回字符码等于 X 的字符 [范例 ]: (1P=Chr(65 … 输出字符 A, 因为 A 的 ASCII 码等于 65 (2P=Asc(“A” … 输出 65 2. Len (X:计算字符串 X 的长度 [格式 ]: P=Len(X [说明 ]: 空字符串长度为 0, 空格符也算一个字符, 一个中文字虽然占用 2 Bytes, 但也算一个字符。 [范例 ]:</p><p>(1 令X=”” (空字符串 Len(X 输出结果为 0 (2 令X=”abcd” Len(X 输出结果为 4 (3 令X=”VB 教程” Len(X 输出结果为 4 3. Mid (X函数:读取字符串 X 中间的字符 [格式 ]: P=Mid(X,n 由 X 的第 n 个字符读起,读取后面的所有字符。P=Mid(X,n,m 由 X 的第 n 个字符读起,读取后面的 m 个字符。[范例 ]: (1 X=”abcdefg” P=Mid(X,5 结果为:P=”efg” (2 X=”abcdefg” P=Mid(X,2,4 结果为P=”bcde”</p><p>4. Replace : 将字符串中的某些特定字符串替换为其他字符串 [格式 ]: P=Replace(X,S,R [说明 ]:将字符串 X 中的字符串 S 替换为字符串 R ,然后返回。 [范例 ]: X=”VB is very good” P=Replace(X,good,nice 输出结果为:P=”VB is very nice” 5. StrReverse :反转字符串 [格式 ]: P=StrReverse(X [说明 ]: 返回 X 参数反转后的字符串 [范例 ]: (1 X=”abc” P=StrReverse(X 输出结果:P=”cba” 6. Ucase (X, Lcase(X:转换英文字母的大小写 [格式 ]: P=Lcase(X</p>
<div>
<div>相关主题</div>
<div class="relatedtopic">
<div id="tabs-section" class="tabs">
<ul class="tab-head">
<li id="14296548"><a href="/topic/14296548/" target="_blank">xpath语法与函数</a></li>
<li id="13615362"><a href="/topic/13615362/" target="_blank">常用字符串函数</a></li>
<li id="6347365"><a href="/topic/6347365/" target="_blank">字符串比较函数</a></li>
<li id="3244135"><a href="/topic/3244135/" target="_blank">xpath入门</a></li>
<li id="15714613"><a href="/topic/15714613/" target="_blank">字符串函数的使用</a></li>
<li id="18891564"><a href="/topic/18891564/" target="_blank">xpath详解</a></li>
</ul>
</div>
</div>
</div>
<div class="container">
<div>文本预览</div>
<div class="textcontent">
</div>
</div>
</div>
<div class="category">
<span class="navname">相关文档</span>
<ul class="lista">
<li><a href="/doc/9c8987853.html" target="_blank">给xpath添加正则表达式匹配函数</a></li>
<li><a href="/doc/c714998528.html" target="_blank">Xpath使用实例简单粗暴</a></li>
<li><a href="/doc/177801269.html" target="_blank">python+xpath笔记</a></li>
<li><a href="/doc/f8157944.html" target="_blank">xpath详解总结,很全面</a></li>
<li><a href="/doc/3e9919718.html" target="_blank">Xpath语法格式</a></li>
<li><a href="/doc/766077111.html" target="_blank">XPath 数值函数</a></li>
<li><a href="/doc/ac148635.html" target="_blank">XPath学习总结</a></li>
<li><a href="/doc/e74294728.html" target="_blank">第7章 XPATH</a></li>
<li><a href="/doc/224620446.html" target="_blank">Selenium XPath定位详解</a></li>
<li><a href="/doc/4c10278749.html" target="_blank">XPath函数大全</a></li>
<li><a href="/doc/933729026.html" target="_blank">XPath注解(1)</a></li>
<li><a href="/doc/ca12638136.html" target="_blank">第六章 XML高级语法(2)</a></li>
<li><a href="/doc/1a3678505.html" target="_blank">基于关系数据库有效地处理XPath函数</a></li>
<li><a href="/doc/e210667274.html" target="_blank">【IT专家】使用JavaScript和XPath从DOM中选择元素</a></li>
<li><a href="/doc/367693149.html" target="_blank">XPath</a></li>
<li><a href="/doc/6014907916.html" target="_blank">python-selenium -- xpath定位方法详解</a></li>
<li><a href="/doc/9519033840.html" target="_blank">XPath官方手册中文版</a></li>
<li><a href="/doc/e01396432.html" target="_blank">xpath语法</a></li>
<li><a href="/doc/1e18621124.html" target="_blank">XPATH练习题</a></li>
<li><a href="/doc/fa5683613.html" target="_blank">XPath 节点集函数</a></li>
</ul>
<span class="navname">最新文档</span>
<ul class="lista">
<li><a href="/doc/0619509601.html" target="_blank">幼儿园小班科学《小动物过冬》PPT课件教案</a></li>
<li><a href="/doc/0a19509602.html" target="_blank">2021年春新青岛版(五四制)科学四年级下册 20.《露和霜》教学课件</a></li>
<li><a href="/doc/9619184372.html" target="_blank">自然教育课件</a></li>
<li><a href="/doc/3319258759.html" target="_blank">小学语文优质课火烧云教材分析及课件</a></li>
<li><a href="/doc/d719211938.html" target="_blank">(超详)高中语文知识点归纳汇总</a></li>
<li><a href="/doc/a519240639.html" target="_blank">高中语文基础知识点总结(5篇)</a></li>
<li><a href="/doc/9019184371.html" target="_blank">高中语文基础知识点总结(最新)</a></li>
<li><a href="/doc/8819195909.html" target="_blank">高中语文知识点整理总结</a></li>
<li><a href="/doc/8319195910.html" target="_blank">高中语文知识点归纳</a></li>
<li><a href="/doc/7b19336998.html" target="_blank">高中语文基础知识点总结大全</a></li>
<li><a href="/doc/7019336999.html" target="_blank">超详细的高中语文知识点归纳</a></li>
<li><a href="/doc/6819035160.html" target="_blank">高考语文知识点总结高中</a></li>
<li><a href="/doc/6819035161.html" target="_blank">高中语文知识点总结归纳</a></li>
<li><a href="/doc/4219232289.html" target="_blank">高中语文知识点整理总结</a></li>
<li><a href="/doc/3b19258758.html" target="_blank">高中语文知识点归纳</a></li>
<li><a href="/doc/2a19396978.html" target="_blank">高中语文知识点归纳(大全)</a></li>
<li><a href="/doc/2c19396979.html" target="_blank">高中语文知识点总结归纳(汇总8篇)</a></li>
<li><a href="/doc/1619338136.html" target="_blank">高中语文基础知识点整理</a></li>
<li><a href="/doc/e619066069.html" target="_blank">化工厂应急预案</a></li>
<li><a href="/doc/b019159069.html" target="_blank">化工消防应急预案(精选8篇)</a></li>
</ul>
</div>
</div>
<script>
var sdocid = "7508b67f580216fc700afdca";
</script>
<script type="text/javascript">bdtj();</script>
<footer class="footer">
<p><a href="/tousu.html" target="_blank">侵权投诉</a> © 2022 www.doczj.com <a href="/sitemap.html">网站地图</a></p>
<p>
<a href="https://beian.miit.gov.cn" target="_blank">闽ICP备18022250号-1</a> 本站资源均为网友上传分享,本站仅负责分类整理,如有任何问题可通过上方投诉通道反馈
<script type="text/javascript">foot();</script>
</p>
</footer>
</body>
</html>