
给xpath添加正则表达式匹配函数
做网页解析时,将html转成xml格式之后,再利用xpath则可以轻易地截取任何所需要的数据。在使用xpath时,常常会用到其中的一些函数,特别是字符串函数,完整的函数列表可在w3school找
到:https://www.doczj.com/doc/9c8987853.html,/xpath/xpath_functions.asp#string)。然而这仅仅是标准xpath里所提供的,dotnet里这只实现了一部分,特别是本标题所提到的正则匹配函数fn:matches(string,pattern),dotnet里竟然不支持。虽然dotnnet里还是能用诸如contains等判断函数,但比起强大的正则表达式,其实现的功能远远不能满足要求。
为了能够更加灵活、方便的匹配字符串,需要给xpath添加自定义的正则匹配函数,幸好dotnet提供了接口,先看看这些基类及接口。
XsltContext
封装可扩展样式表转换语言(XSLT) 处理器的当前执行上下文,使XML 路径语言(XPath) 在XPath 表达式中解析函数、参数和命名空间。需要定义一个继承XsltContext的子类,实现对自定义函数的调用。
IXsltContextFunction
为在运行库执行期间在可扩展样式表转换语言(XSLT) 样式表中定义的给定函数提供一个接口。实现该接口的子类定义以及提供自定义函数的功能。
IXsltContextVariable
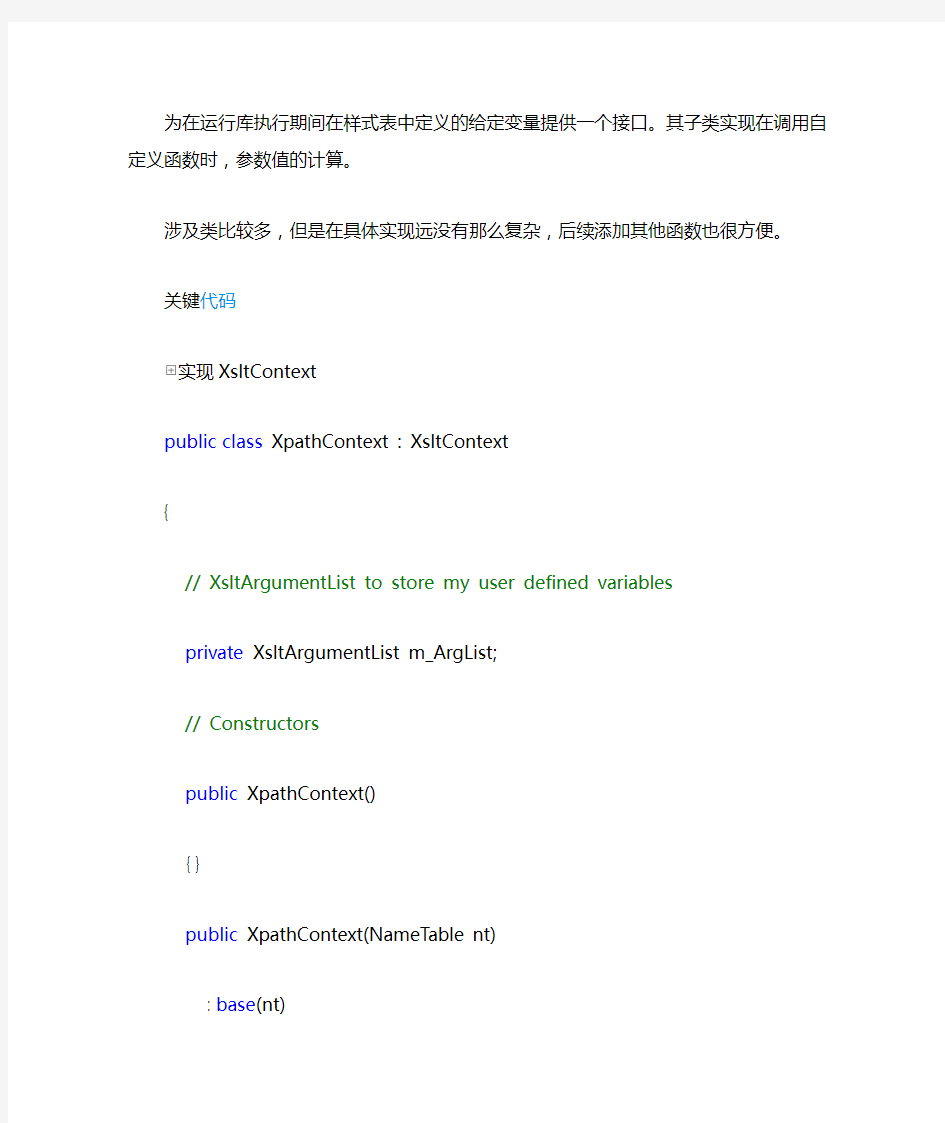
为在运行库执行期间在样式表中定义的给定变量提供一个接口。其子类实现在调用自定义函数时,参数值的计算。
涉及类比较多,但是在具体实现远没有那么复杂,后续添加其他函数也很方便。
关键代码
实现XsltContext
public class XpathContext : XsltContext
{
// XsltArgumentList to store my user defined variables
private XsltArgumentList m_ArgList;
// Constructors
public XpathContext()
{ }
public XpathContext(NameTable nt)
: base(nt)
{
}
public XpathContext(NameTable nt, XsltArgumentList argList)
: base(nt)
{
m_ArgList = argList;
}
// Returns the XsltArgumentList that contains custom variable definitions.
public XsltArgumentList ArgList
{
get
return m_ArgList;
}
}
// Function to resolve references to my custom functions.
public override IXsltContextFunction ResolveFunction(string prefix,
string name, XPathResultType[] ArgTypes)
{
XPathExtensionFunction func = null;
// Create an instance of appropriate extension function class.
switch (name)
{
// 匹配正则表达式, XPath1.0没有该方法
case"Match":
func = new XPathExtensionFunction("Match", 1, 2, new
XPathResultType[] { XPathResultType.NodeSet, XPathResultType.String }, XPathResultType.Boolean);
break;
// 去除空格
case"Trim":
func = new XPathExtensionFunction("Trim", 1, 1,
new XPathResultType[] { XPathResultType.String }, XPathResultType.String);
break;
default:
throw new ArgumentException("没有定义" + name + "函数");
}
return func;
}
// Function to resolve references to my custom variables.
public override IXsltContextVariable ResolveVariable(string prefix, string name)
{
// Create an instance of an XPathExtensionVariable.
XPathExtensionVariable Var;
Var = new XPathExtensionVariable(name);
return Var;
}
public override int CompareDocument(string baseUri, string nextbaseUri)
{
return0;
}
public override bool PreserveWhitespace(XPathNavigator node)
{
return true;
}
public override bool Whitespace
get
{
return true;
}
}
}
实现IXsltContextFunction
///
///自定义正则表达式函数
///
public class XPathExtensionFunction : IXsltContextFunction
{
private XPathResultType[] m_ArgTypes;
private XPathResultType m_ReturnType;
private string m_FunctionName;
private int m_MinArgs;
private int m_MaxArgs;
///
///获取函数的参数的最小数目。这使用户能够区分重载函数
///
public int Minargs
{
get
{
return m_MinArgs;
}
}
///
///获取函数的参数的最大数目。这使用户能够区分重载函数
///
public int Maxargs
{
get
{
return m_MaxArgs;
}
}
///
///获取为函数的参数列表提供的 XML 路径语言 (XPath) 类型。该信息可用于发现函数的签名,该签名使您能够区分重载函数
///
public XPathResultType[] ArgTypes
{
get
{
return m_ArgTypes;
}
}
///
///获取 XPathResultType,它表示函数返回的 XPath 类型
///
public XPathResultType ReturnType
{
get
{
return m_ReturnType;
}
}
///
///创建自定义函数的实例
///
///方法名称
///最小参数个数
///最大参数个数
///参数类型数组
///返回类型
public XPathExtensionFunction(string name, int minArgs, int maxArgs, XPathResultType[] argTypes, XPa thResultType returnType)
{
m_FunctionName = name;
m_MinArgs = minArgs;
m_MaxArgs = maxArgs;
m_ArgTypes = argTypes;
m_ReturnType = returnType;
}
// 在运行时调用
public object Invoke(XsltContext xsltContext, object[] args, XPathNavigator docContext)
{
// The two custom XPath extension functions
switch (m_FunctionName)
{
case"Match":
// 调用正则匹配参数一为正则表达式
return Regex.IsMatch(docContext.InnerXml, args[0].ToString());
case"Trim":
return docContext.Value.Trim();
default:
throw new ArgumentException("没有定义" + m_FunctionName + "函数");
}
}
}
具体调用(代码中连接来源于国家旅游局)
static void Main(string[] args)
{
string xml = @"
";
XmlDocument doc = new XmlDocument();
doc.LoadXml(xml);
XpathContext xpathContext = new XpathContext();
XmlNode node = doc.SelectSingleNode(@"//a[Match('\d{4}年\d{1,2}-\d{1,2}月主要城市接待情况\(二\)')]", xpathContext);
Console.WriteLine(node.Attributes["href"].Value);
}
完整代码
1.验证用户名和密码:("^[a-zA-Z]\w{5,15}$")正确格式:"[A-Z][a-z]_[0-9]"组成,并且第一个字必须为字母6~16位; 2.验证电话号码:("^(\d{3,4}-)\d{7,8}$")正确格式:xxx/xxxx-xxxxxxx/xxxxxxxx; 3.验证手机号码:"^1[3|4|5|7|8][0-9]\\d{8}$"; 4.验证身份证号(15位或18位数字):"\d{14}[[0-9],0-9xX]"; 5.验证Email地址:("^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$"); 6.只能输入由数字和26个英文字母组成的字符串:("^[A-Za-z0-9]+$"); 7.整数或者小数:^[0-9]+([.][0-9]+){0,1}$ 8.只能输入数字:"^[0-9]*$"。 9.只能输入n位的数字:"^\d{n}$"。 10.只能输入至少n位的数字:"^\d{n,}$"。 11.只能输入m~n位的数字:"^\d{m,n}$"。 12.只能输入零和非零开头的数字:"^(0|[1-9][0-9]*)$"。 13.只能输入有两位小数的正实数:"^[0-9]+(\.[0-9]{2})?$"。 14.只能输入有1~3位小数的正实数:"^[0-9]+(\.[0-9]{1,3})?$"。 15.只能输入非零的正整数:"^\+?[1-9][0-9]*$"。 16.只能输入非零的负整数:"^\-[1-9][0-9]*$"。 17.只能输入长度为3的字符:"^.{3}$"。 18.只能输入由26个英文字母组成的字符串:"^[A-Za-z]+$"。 19.只能输入由26个大写英文字母组成的字符串:"^[A-Z]+$"。 20.只能输入由26个小写英文字母组成的字符串:"^[a-z]+$"。 21.验证是否含有^%&',;=?$\"等字符:"[%&',;=?$\\^]+"。 22.只能输入汉字:"^[\u4e00-\u9fa5]{0,}$"。 23.验证URL:"^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$"。 24.验证一年的12个月:"^(0?[1-9]|1[0-2])$"正确格式为:"01"~"09"和"10"~"12"。 25.验证一个月的31天:"^((0?[1-9])|((1|2)[0-9])|30|31)$"正确格式为;"01"~"09"、"10"~"29"和“30”~“31”。 26.获取日期正则表达式:\\d{4}[年|\-|\.]\d{\1-\12}[月|\-|\.]\d{\1-\31}日? 评注:可用来匹配大多数年月日信息。 27.匹配双字节字符(包括汉字在内):[^\x00-\xff] 评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1) 28.匹配空白行的正则表达式:\n\s*\r 评注:可以用来删除空白行 29.匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> 评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力 30.匹配首尾空白字符的正则表达式:^\s*|\s*$
本文分十四个类别对正则表达式的意义进行了解释,这十四各类别是:字符/字符类/预定义字符类/POSIX字符类/https://www.doczj.com/doc/9c8987853.html,ng.Character类/Unicode块和类别的类/边界匹配器/Greedy数量词/Reluctant数量词/Possessive数量词/Logical运算符/Back引用/引用/特殊构造。 1.1.字符 x 字符 x。例如a表示字符a \\ 反斜线字符。在书写时要写为\\\\。(注意:因为java在第一次解析时把\\\\解析成正则表达式\\,在第二次解析时再解析为\,所以凡是不是1.1列举到的转义字符,包括1.1的\\,而又带有\的都要写两次) \0n 带有八进制值 0的字符 n (0 <= n <= 7) \0nn 带有八进制值 0的字符 nn (0 <= n <= 7) \0mnn 带有八进制值 0的字符 mnn(0 <= m <= 3、0 <= n <= 7) \xhh 带有十六进制值 0x的字符 hh \uhhhh 带有十六进制值 0x的字符 hhhh \t 制表符 ('\u0009') \n 新行(换行)符 ('\u000A') \r 回车符 ('\u000D') \f 换页符 ('\u000C') \a 报警 (bell) 符 ('\u0007') \e 转义符 ('\u001B') \cx 对应于 x 的控制符 1.2.字符类 [abc] a、b或 c(简单类)。例如[egd]表示包含有字符e、g或d。 [^abc] 任何字符,除了 a、b或 c(否定)。例如[^egd]表示不包含字符e、g或d。 [a-zA-Z] a到 z或 A到 Z,两头的字母包括在内(范围) [a-d[m-p]] a到 d或 m到 p:[a-dm-p](并集) [a-z&&[def]] d、e或 f(交集) [a-z&&[^bc]] a到 z,除了 b和 c:[ad-z](减去) [a-z&&[^m-p]] a到 z,而非 m到 p:[a-lq-z](减去) 1.3.预定义字符类(注意反斜杠要写两次,例如\d写为\\d) . 任何字符(与行结束符可能匹配也可能不匹配) \d 数字:[0-9] \D 非数字: [^0-9] \s 空白字符:[ \t\n\x0B\f\r] \S 非空白字符:[^\s] \w 单词字符:[a-zA-Z_0-9] \W 非单词字符:[^\w] 1.4.POSIX 字符类(仅 US-ASCII)(注意反斜杠要写两次,例如\p{Lower}写为\\p{Lower})
PHP 常用正则表达式正则 平时做网站经常要用正则表达式,下面是一些讲解和例子,仅供大家参考和修改使用:"^\d+$"//非负整数(正整数+ 0) "^[0-9]*[1-9][0-9]*$"//正整数 "^((-\d+)|(0+))$"//非正整数(负整数+ 0) "^-[0-9]*[1-9][0-9]*$"//负整数 "^-?\d+$"//整数 "^\d+(\.\d+)?$"//非负浮点数(正浮点数+ 0) "^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$"//正浮点数"^((-\d+(\.\d+)?)|(0+(\.0+)?))$"//非正浮点数(负浮点数+ 0) "^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"//负浮点数 "^(-?\d+)(\.\d+)?$"//浮点数 "^[A-Za-z]+$"//由26个英文字母组成的字符串 "^[A-Z]+$"//由26个英文字母的大写组成的字符串 "^[a-z]+$"//由26个英文字母的小写组成的字符串 "^[A-Za-z0-9]+$"//由数字和26个英文字母组成的字符串 "^\w+$"//由数字、26个英文字母或者下划线组成的字符串 "^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$"//email地址 "^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$"//url /^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日 /^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年 "^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$" //Emil /^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ //电话号码 "^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}| 1dd|2[0-4]d|25[0-5])$" //IP地址 匹配中文字符的正则表达式:[\u4e00-\u9fa5] 匹配双字节字符(包括汉字在内):[^\x00-\xff] 匹配空行的正则表达式:\n[\s| ]*\r 匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/ 匹配首尾空格的正则表达式:(^\s*)|(\s*$) 匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$ 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})? 匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$ 元字符及其在正则表达式上下文中的行为: \ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个后向引用、或一个八进制转
多少年来,许多的编程语言和工具都包含对正则表达式的支持,.NET基础类库中包含有一个名字空间和一系列可以充分发挥规则表达式威力的类,而且它们也都与未来的Perl 5中的规则表达式兼容。 此外,regexp类还能够完成一些其他的功能,例如从右至左的结合模式和表达式的编辑等。 在这篇文章中,我将简要地介绍System.Text.RegularExpression中的类和方法、一些字符串匹配和替换的例子以及组结构的详细情况,最后,还会介绍一些你可能会用到的常见的表达式。 应该掌握的基础知识 规则表达式的知识可能是不少编程人员“常学常忘”的知识之一。在这篇文章中,我们将假定你已经掌握了规则表达式的用法,尤其是Perl 5中表达式的用法。.NET的regexp类是Perl 5中表达式的一个超集,因此,从理论上说它将作为一个很好的起点。我们还假设你具有了C#的语法和.NET架构的基本知识。 如果你没有规则表达式方面的知识,我建议你从Perl 5的语法着手开始学习。在规则表达式方面的权威书籍是由杰弗里?弗雷德尔编写的《掌握表达式》一书,对于希望深刻理解表达式的读者,我们强烈建议阅读这本书。 RegularExpression组合体 regexp规则类包含在System.Text.RegularExpressions.dll文件中,在对应用软件进行编译时你必须引用这个文件,例如: csc r:System.Text.RegularExpressions.dll foo.cs 命令将创建foo.exe文件,它就引用了System.Text.RegularExpressions文件。 名字空间简介 在名字空间中仅仅包含着6个类和一个定义,它们是: Capture: 包含一次匹配的结果; CaptureCollection: Capture的序列; Group: 一次组记录的结果,由Capture继承而来; Match: 一次表达式的匹配结果,由Group继承而来; MatchCollection: Match的一个序列; MatchEvaluator: 执行替换操作时使用的代理; Regex: 编译后的表达式的实例。 Regex类中还包含一些静态的方法: Escape: 对字符串中的regex中的转义符进行转义; IsMatch: 如果表达式在字符串中匹配,该方法返回一个布尔值; Match: 返回Match的实例; Matches: 返回一系列的Match的方法; Replace: 用替换字符串替换匹配的表达式; Split: 返回一系列由表达式决定的字符串; Unescape:不对字符串中的转义字符转义。
Java正则表达式详解 仙人掌工作室 如果你曾经用过Perl或任何其他内建正则表达式支持的语言,你一定知道用正则表达式处理文本和匹配模式是多么简单。如果你不熟悉这个术语,那么“正则表达式”(Regular Expression)就是一个字符构成的串,它定义了一个用来搜索匹配字符串的模式。 许多语言,包括Perl、PHP、Python、JavaScript和JScript,都支持用正则表达式处理文本,一些文本编辑器用正则表达式实现高级“搜索-替换”功能。那么Java又怎样呢?本文写作时,一个包含了用正则表达式进行文本处理的Java规范需求(Specification Request)已经得到认可,你可以期待在JDK的下一版本中看到它。 然而,如果现在就需要使用正则表达式,又该怎么办呢?你可以从https://www.doczj.com/doc/9c8987853.html,下载源代码开放的Jakarta-ORO库。本文接下来的内容先简要地介绍正则表达式的入门知识,然后以Jakarta-ORO API为例介绍如何使用正则表达式。 一、正则表达式基础知识 我们先从简单的开始。假设你要搜索一个包含字符“cat”的字符串,搜索用的正则表达式就是“cat”。如果搜索对大小写不敏感,单词“catalog”、“Catherine”、“sophisticated”都可以匹配。也就是说: 1.1句点符号 假设你在玩英文拼字游戏,想要找出三个字母的单词,而且这些单词必须以“t”字母开头,以“n”字母结束。另外,假设有一本英文字典,你可以用正则表达式搜索它的全部内容。要构造出这个正则表达式,你可以使用一个通配符——句点符号“.”。这样,完整的表达式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,还匹配“t#n”、“tpn”甚至“t n”,还有其他许多无意义的组合。这是因为句点符号匹配所有字符,包括空格、Tab字符甚至换行符: 1.2方括号符号 为了解决句点符号匹配范围过于广泛这一问题,你可以在方括号(“[]”)里面指定看来有意义的字符。此时,只有方括号里面指定的字符才参与匹配。也就是说,正则表达式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因为在方括号之内你只能匹配单个字符 1.3“或”符号
正则表达式介绍(一) 正则表达式(Regular expressions 也称为 REs,或 regexes 或 regex patterns)本质上是一个微小的且高度专业化的编程语言。它被嵌入到 Python 中,并通过 re 模块提供给程序猿使用。使用正则表达式,你需要指定一些规则来描述那些你希望匹配的字符串集合。 这些字符串集合可能包含英语句子、 e-mail 地址、TeX 命令,或任何你想要的东东。 正则表达式模式被编译成一系列的字节码,然后由一个 C 语言写的匹配引擎所执行。对于高级的使用,你可能需要更关注匹配引擎是如何执行给定的 RE,并通过一定的方式来编写RE,以便产生一个可以运行得更快的字节码。本文暂不讲解优化的细节,因为这需要你对匹配引擎的内部机制有一个很好的理解。但本文的例子均是符合标准的正则表达式语法。 小甲鱼注释:Python 的正则表达式引擎是用 C 语言写的,所以效率是极高的。另,所谓 的正则表达式,这里说的 RE,就是上文我们提到的“一些规则”。 正则表达式语言相对较小,并且受到限制,所以不是所有可能的字符串处理任务都可以使 用正则表达式来完成。还有一些特殊的任务,可以使用正则表达式来完成,但是表达式会 因此而变得非常复杂。在这种情况下,你可能通过自己编写Python 代码来处理会更好些;尽管 Python 代码比一个精巧的正则表达式执行起来会慢一些,但可能会更容易理解。 小甲鱼注释:这可能是大家常说的“丑话说在前”吧,大家别管他,正则表达式非常优秀,她可以处理你 98.3% 的文本任务,一定要好好学哦~~~~~ 简单的模式 我们将从最简单的正则表达式学习开始。由于正则表达式常用于操作字符串的,因此我们 从最常见的任务下手:字符匹配。
[23:39:35] 王尧说:"^\d+$"//非负整数(正整数+ 0) "^[0-9]*[1-9][0-9]*$"//正整数 "^((-\d+)|(0+))$"//非正整数(负整数+ 0) "^-[0-9]*[1-9][0-9]*$"//负整数 "^-?\d+$"//整数 "^\d+(\.\d+)?$"//非负浮点数(正浮点数+ 0) "^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$"//正浮点数 "^((-\d+(\.\d+)?)|(0+(\.0+)?))$"//非正浮点数(负浮点数+ 0) "^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"//负浮点数 "^(-?\d+)(\.\d+)?$"//浮点数 "^[A-Za-z]+$"//由26个英文字母组成的字符串 "^[A-Z]+$"//由26个英文字母的大写组成的字符串 "^[a-z]+$"//由26个英文字母的小写组成的字符串 "^[A-Za-z0-9]+$"//由数字和26个英文字母组成的字符串 "^\w+$"//由数字、26个英文字母或者下划线组成的字符串 "^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$"//email地址 "^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$"//url /^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ //年-月-日 /^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ //月/日/年 ^(\w+((-\w+)|(\.\w+))*)\+\w+((-\w+)|(\.\w+))*\@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$ //Emil "(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)?" //电话号码 "^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1, 2}|1dd|2[0-4]d|25[0-5])$" //IP地址 匹配中文字符的正则表达式:[\u4e00-\u9fa5] 匹配双字节字符(包括汉字在内):[^\x00-\xff] 匹配空行的正则表达式:\n[\s| ]*\r 匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/ 匹配首尾空格的正则表达式:(^\s*)|(\s*$) 匹配Email地址的正则表达式:^(\w+((-\w+)|(\.\w+))*)\+\w+((-\w+)|(\.\w+))*\@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$ 匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$ 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})? 匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$ 漢字 Private Ps_KanjiRegex As String = "\u00A0-\u303F\u3200-\u33CF\u4E00-\uFF60\uFFA0-\uFFE5" ''入力可能漢字のコード(正規表現チェック用)
1、正则表达式-完结篇---工具类开发--- ? 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 '/.+/', 'email'=> '/^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$/', 'url'=> '/^http(s?):\/\/(?:[A-za-z0-9-]+\.)+[A-za-z]{2,4}(?:[\/ \?#][\/=\?%\-&~`@[\]\':+!\.#\w]*)?$/', 'currency'=> '/^\d+(\.\d+)?$/', 'number'=> '/^\d+$/', 'zip'=> '/^\d{6}$/', 'integer'=> '/^[-\+]?\d+$/', 'double'=> '/^[-\+]?\d+(\.\d+)?$/',
5 1 6 1 7 1 8 1 9 2 0 2 1 2 2 2 3 2 4 2 5 2 6 2'english'=> '/^[A-Za-z]+$/', 'qq'=> '/^\d{5,11}$/', 'mobile'=> '/^1(3|4|5|7|8)\d{9}$/', ); //定义其他属性 private$returnMatchResult=false; //返回类型判断 private$fixMode=null; //修正模式 private$matches=array(); //存放匹配结果 private$isMatch=false; //构造函数,实例化后传入默认的两个参数 public function __construct($returnMatchResult=false,$fixMode=null){ $this->returnMatchResult=$returnMatchResult; $this->fixMode=$fixMode; } //判断返回结果类型,为匹配结果matches还是匹配成功与否isMatch,并调用返回方法 private function regex($pattern,$subject){ if(array_key_exists(strtolower($pattern), $this->validate)) $pattern=$this->validate[$pattern].$this->fixMode; //判断后再连接上修正模式作为匹配的正则表达式 $this->returnMatchResult ?
正则表达式教程 半年前我对正则表达式产生了兴趣,在网上查找过不少资料,看过不少的教程,最后在使用 RegexBuddy 时发现他的教程写的非 常好,可以说是我目前见过最好的 ,结果 ,使 用“深入浅出”似乎已经太俗。但是通读原文以后,觉 得只有用“深入浅出”才能准确的表达出该教程给我的感受,所以也就不能免俗了。 本文是 Jan Goyvaerts 为 RegexBuddy 写的教程的译文,版权归原作者所有,欢迎转载。 但是为了尊重原作者和译者的劳动,请注明出处!谢谢! 1.什么是正则表达式 基本说来,正则表达式是一种用来描述一定数量文本的模式。Regex 代表 Regular Express。 本文将用<
要想学会正则表达式,理解元字符是一个必须攻克的难关。 不用刻意记 .:匹配任何单个字符。 例如正则表达式“b.g”能匹配如下字符串:“big”、“bug”、“bg”,但是不匹配“buug”,“b..g”可以匹配“buug”。 [ ] :匹配括号中的任何一个字符。 例如正则表达式“b[aui]g”匹配bug、big和bag,但是不匹配beg、baug。可以在括号中使用连字符“-”来指定字符的区间来简化表示,例如正则表达式[0-9]可以匹配任何数字字符,这样正则表达式“a[0-9]c”等价于“a[0123456789]c”就可以匹配“a0c”、“a1c”、“a2c”等字符串;还可以制定多个区间,例如“[A-Za-z]”可以匹配任何大小写字母,“[A-Za-z0-9]”可以匹配任何的大小写字母或者数字。 ( ) :将()之间括起来的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域,这个元字符在字符串提取的时候非常有用。把一些字符表示为一个整体。改变优先级、定义提取组两个作用。 | :将两个匹配条件进行逻辑“或”运算。 'z|food'能匹配"z"或"food"。'(z|f)ood'则匹配"zood"或"food"。 *:匹配0至多个在它之前的子表达式,和通配符*没关系。 例如正则表达式“zo*”能匹配“z”、“zo”以及“zoo”;因此“.*”意味着能够匹配任意字符串。"z(b|c)*"→zb、zbc、zcb、zccc、zbbbccc。"z(ab)*"能匹配z、zab、zabab(用括号改变优先级)。 + :匹配前面的子表达式一次或多次,和*对比(0到多次)。 例如正则表达式9+匹配9、99、999等。“zo+”能匹配“zo”以及“zoo”,不能匹配"z"。 ? :匹配前面的子表达式零次或一次。 例如,"do(es)?"可以匹配"do"或"does"。一般用来匹配“可选部分”。 {n} :匹配确定的n次。 "zo{2}"→zoo。例如,“e{2}”不能匹配“bed”中的“e”,但是能匹配“seed”中的两个“e”。 {n,} :至少匹配n次。 例如,“e{2,}”不能匹配“bed”中的“e”,但能匹配“seeeeeeeed”中的所有“e”。 {n,m}:最少匹配n次且最多匹配m次。 “e{1,3}”将匹配“seeeeeeeed”中的前三个“e” ^(shift+6):匹配一行的开始。 例如正则表达式“^regex”能够匹配字符串“regex我会用”的开始,但是不能匹配“我会用regex”。 ^另外一种意思:非!(暂时不用理解) $ :匹配行结束符。 例如正则表达式“浮云$”能够匹配字符串“一切都是浮云”的末尾,但是不能匹配字符串“浮云呀”
正则表达式是常见常忘,所以还是记下来比较保险,于是就有了这篇笔记。 希望对大家会有所帮助。J 1.什么是正则表达式 简单的说,正则表达式是一种可以用于文字模式匹配和替换的强有力的工具。是由一系列普通字符和特殊字符组成的能明确描述文本字符串的文字匹配模式。 正则表达式并非一门专用语言,但也可以看作是一种语言,它可以让用户通过使用一系列普通字符和特殊字符构建能明确描述文本字符串的匹配模式。除了简单描述这些模式之外,正则表达式解释引擎通常可用于遍历匹配,并使用模式作为分隔符来将字符串解析为子字符串,或以智能方式替换文本或重新设置文本格式。正则表达式为解决与文本处理有关的许多常见任务提供了有效而简捷的方式。 正则表达式具有两种标准: ·基本的正则表达式(BRE – Basic Regular Expressions) ·扩展的正则表达式(ERE – Extended Regular Expressions)。 ERE包括BRE功能和另外其它的概念。 正则表达式目前有两种解释引擎: ·基于字符驱动(text-directed engine) ·基于正则表达式驱动(regex-directed engine) Jeffery Friedl把它们称作DFA和NFA解释引擎。 约定: 为了描述起来方便,在本文中做一些约定: 1. 本文所举例的所有表达时都是基于NFA解释引擎的。 2. 正则表达式,也就是匹配模式,会简写为Regex。 3. Regex的匹配目标,也就是目标字符串,会简写为String。 4. 匹配结果用会用黄色底色标识。 5. 用1\+1=2 括起来的表示这是一个regex。 6. 举例会用以下格式: Regex Target String Description test This is a test 会匹配test,testcase等 2.正则表达式的起源正则表达式的?祖先?可以一直上溯至对人类神经系统如何工作的早期研究。Warren McCulloch 和 Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络。 1956 年, 一位叫 Stephen Kleene 的美国数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了一篇标题为?神经网事件的表示法?的论文,引入了正则表达式的概念。正则表达式就是用来描述他称为?正则集的代数?的表达式,因此采用?正则表达式?这个术语。
第一章正则表达式概述 正则表达式(Regular Expression)起源于人类神经系统的研究。正则表达式的定义有以下几种: ●用某种模式去匹配一类字符串的公式,它主要是用来描述字符串匹配的工具。 ●描述了一种字符串匹配的模式。可以用来检查字符串是否含有某种子串、将匹配的子 串做替换或者从中取出符合某个条件的子串等。 ●由普通字符(a-z)以及特殊字符(元字符)组成的文字模式,正则表达式作为一个模版, 将某个字符模式与所搜索的字符串进行匹配。 ●用于描述某些规则的的工具。这些规则经常用于处理字符串中的查找或替换字符串。 也就是说正则表达式就是记录文本规则的代码。 ●用一个字符串来描述一个特征,然后去验证另一个字符串是否符合这个特征。 以上这些定义其实也就是正则表达式的作用。 第二章正则表达式基础理论 这些理论将为编写正则表达式提供法则和规范,正则表达式主要包括以下基础理论: ●元字符 ●字符串 ●字符转义 ●反义 ●限定符 ●替换 ●分组 ●反向引用 ●零宽度断言 ●匹配选项 ●注释 ●优先级顺序 ●递归匹配 2.1 元字符 在正则表达式中,元字符(Metacharacter)是一类非常特殊的字符,它能够匹配一个位置或字符集合中的一个字符,如:、 \w等。根据功能,元字符可以分为两种类型:匹配位置的元字符和匹配字符的元字符。 2.1.1 匹配位置的元字符
包括:^、$、和\b。其中^(脱字符号)和$(美元符号)都匹配一个位置,分别匹配行的开始和结尾。比如,^string匹配以string开头的行,string$匹配以string结尾的行。^string$匹配以string开始和结尾的行。单个$匹配一个空行。单个^匹配任意行。\b匹配单词的开始和结尾,如:\bstr匹配以str开始的单词,但\b不匹配空格、标点符号或换行符号,所以,\bstr可以匹配string、string fomat等单词。\bstr正则表达式匹配的字符串必须以str开头,并且str以前是单词的分界处,但此正则表达式不能限定str之后的字符串形式。以下正则表达式匹配以ing结尾的字符串,如string、This is a string等 Ing\b 正则表达式ing\b匹配的字符串必须以ing结尾,并且ing后是分界符,以下正则表达式匹 配一个完整的单词:\bstring\b。 2.1.2匹配字符的元字符 匹配字符的元字符有7个:.(点号)、\w、\W、、s\、\S、\d和\D。其中点号匹配除换行之外的任意字符;\w匹配单词字符(包括字母、汉字、下划线和数字);\W匹配任意非单词字符、\s匹配任意的空白字符,如空格、制表符、换行等;\S匹配任意的非空白字符;\d匹配任意数字字符;\D匹配任意的非数字字符。如: ^.$匹配一个非空行,在该行中可以包含除了换行符以外的任意字符。 ^\w$匹配一个非空行,并且该行中只能包含字母、数字、下划线和汉字中的任意字符。 \ba\w\w\w\w\w\w\\b匹配以字母a开头长度等于7的任意单词 \ba\w\w\w\d\d\d\D\b匹配以字母a开头后面有3个字符三个数字和1个非数字字符长度等于8的单词 2.2字符类 字符类是一个字符集合,如果该字符集合中的任何一个字符被匹配,则它会找到该匹配项。字符类可以在[](方括号)中定义。如:
作者简介:张斌(1977-),硕士,讲师,研究方向:电子商务专业方向。 收稿日期:2010-05-06 正则表达式在垂直搜索引擎中的应用 张斌 (浙江越秀外国语学院,绍兴312000) 摘要:采用聚焦爬虫可以提高搜索引擎的检索效率,聚焦爬虫经常使用正则表达式来进行有效的信息检索,着重分析了网页检索中常用的正则表达式,为搜索引擎的构建提供帮助。关键词:正则表达式;聚焦爬虫;信息检索中图分类号:TP3 文献标识码:B 文章编码:1672-6251(2010)08-0162-02 Application of Regular Expressions in Vertical Search Engine ZHANG Bin (Zhejiang Yuexiu Foreign Language College,Shaoxing 312000) Abstract:Because focused crawler system can promote the efficiency of search engine and regular expression could used to get quick and efficient search.In this paper,regular expression used in web page index was analyzed for providing useful help for researcher in vertical search engine. Key words:regular expressions;focuses crawler;information retrieval 页面内容提取、分词、自然语言处理是聚焦爬虫的主要工作。在内容提取中采用正则表达可以明显提高效能,已在许多搜索程序中广泛应用。以下列举几个常用的正则表达,并分析其在聚焦爬虫中的应用方法,以供同行参考。 1正则表达式与文档内容提取 正则表达式是一种编程语言中使用的特殊代码模 式,可用其验证、查找、替换与划分文本内容。聚焦爬虫往往通过对主题网页的学习提取主题特征的正则表达式,以指导爬虫过滤与主题不相符的网页文本[4]。正则表达式基本技巧如下: (1)匹配多个字符之一。如匹配拼写错误的fac - tory ,可用:f [ae]ct [ou]ry ; (2)匹配文本行开始与结束。如以c 开始,a 结束,可用:^a.*b$; (3)匹配单词。如找dog ,可用:\bdog\b ; (4)Unicode 字母。如匹配中文,可用:[\u3400- \u4DB5\u4E00-\u9fa5]; (5)分组和捕获。如匹配年月日相同的日期,可用:\b\d\d (\d\d)-\1-\1\b ,其中1表示捕获分组1,即 (\d\d)中的内容,捕获分组可以表示临时存取的区域, 用于引用和替换; (6)重复匹配。完整HTML 文件可用: .*?
.*?正则基础之——贪婪与非贪婪模式 1 概述 贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。 属于贪婪模式的量词,也叫做匹配优先量词,包括: “{m,n}”、“{m,}”、“?”、“*”和“+”。 在一些使用NFA引擎的语言中,在匹配优先量词后加上“?”,即变成属于非贪婪模式的量词,也叫做忽略优先量词,包括: “{m,n}?”、“{m,}?”、“??”、“*?”和“+?”。 从正则语法的角度来讲,被匹配优先量词修饰的子表达式使用的就是贪婪模式,如“(Expression)+”;被忽略优先量词修饰的子表达式使用的就是非贪婪模式,如“(Expression)+?”。 对于贪婪模式,各种文档的叫法基本一致,但是对于非贪婪模式,有的叫懒惰模式或惰性模式,有的叫勉强模式,其实叫什么无所谓,只要掌握原理和用法,能够运用自如也就是了。个人习惯使用贪婪与非贪婪的叫法,所以文中都会使用这种叫法进行介绍。 2 贪婪与非贪婪模式匹配原理 对于贪婪与非贪婪模式,可以从应用和原理两个角度进行理解,但如果想真正掌握,还是要从匹配原理来理解的。 先从应用的角度,回答一下“什么是贪婪与非贪婪模式?” 2.1 从应用角度分析贪婪与非贪婪模式 2.1.1 什么是贪婪与非贪婪模式 先看一个例子 举例: 源字符串:aa
1. [……] : 匹配括号中的任何一个字符. [^……] : 匹配不在括号中的任何一个字符. \w : 匹配任何一个字符(a~z , A~Z , 0~9). \W : 匹配任何一个空白字符. \s : 匹配任何一个非空白字符. \S : 与任何非单词字符匹配. \d : 匹配任何一个数字. \D : 匹配任何一个非数字. [\b] : 匹配一个退格键字母. {n,m} : 最少匹配前面表达式n次,最大为m次. {n,} : 最少匹配前面表达式n次. {n} : 恰好匹配前面表达式为n次. ? : 匹配前面表达式0或1 次{0,1} + : 至少匹配前面表达式1 次{1,} * : 至少匹配前面表达式0次{0,} | : 匹配前面表达式或后面表达式. (…) : 在单元中组合项目. ^ : 匹配字符串的开头. $ : 匹配字符串的结尾. \b : 匹配字符边界. \B : 匹配非字符边界的某个位置.
2.举几个常用的正则表达式: (1)验证电子邮件. \w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 或 \S+@\S+\ .\S+ (2) 验证网址: HTTP://\S+\ .\S+ : 验证网址为大写字母 . http://\S+\ . \S + : 验证网址为小写字母. (3) 验证邮政编码: \d{6} (4) 其他 [0-9] : 表示0~9 十个数字. \d* : 表示任意个数字. \d{3,4}-\d{7,8} : 表示中国大陆的固定电话号码. \d{2}-\d{5} : 验证由两位数字. 一个连字符再加5位数字组成的ID号. <\s*(\S+)(\s[^>]*)?>[\s\S]*<\s*\/\1\s*> : 匹配HTML标记.