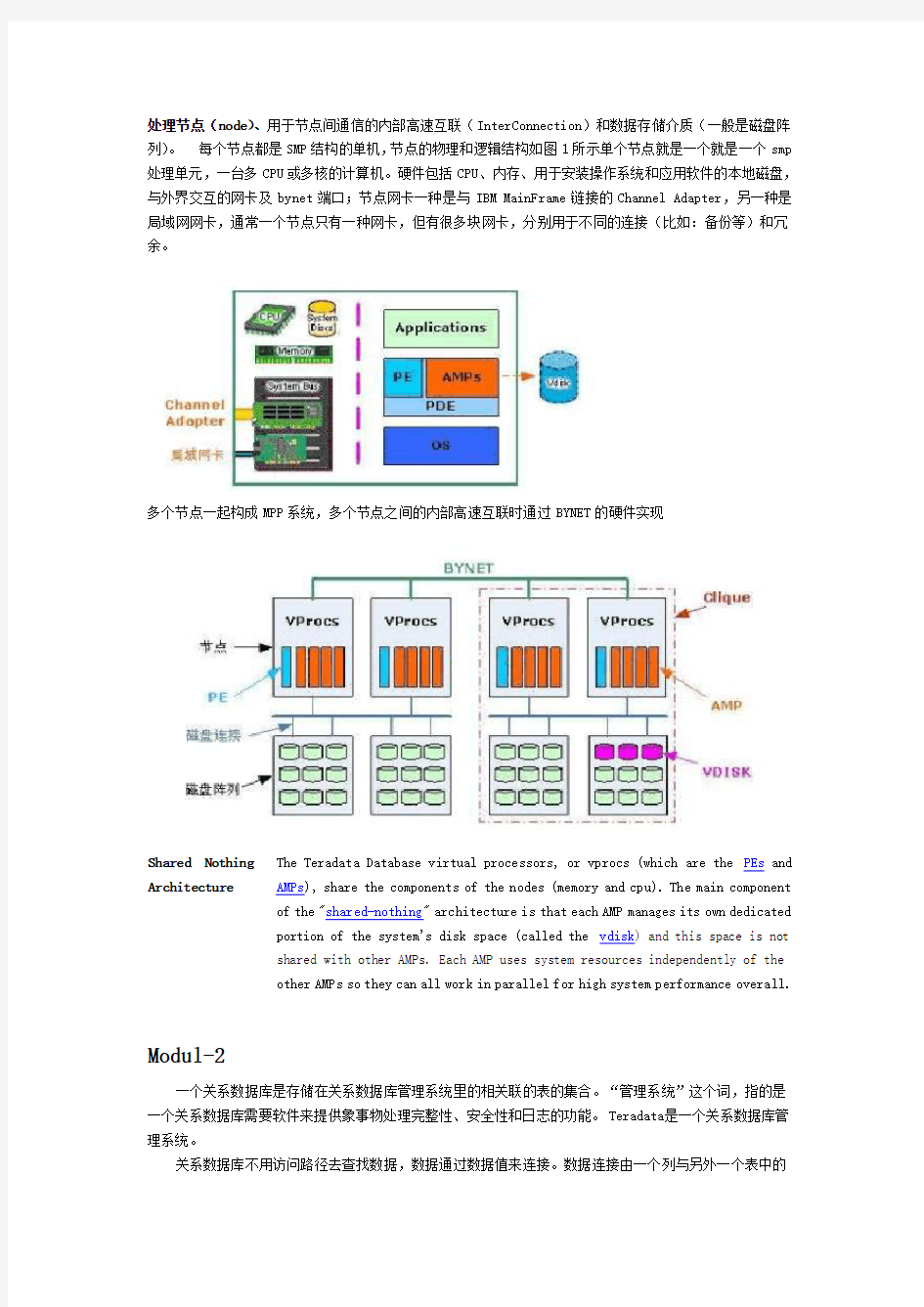

处理节点(node)、用于节点间通信的内部高速互联(InterConnection)和数据存储介质(一般是磁盘阵列)。每个节点都是SMP结构的单机,节点的物理和逻辑结构如图1所示单个节点就是一个就是一个smp 处理单元,一台多CPU或多核的计算机。硬件包括CPU、内存、用于安装操作系统和应用软件的本地磁盘,与外界交互的网卡及bynet端口;节点网卡一种是与IBM MainFrame链接的Channel Adapter,另一种是局域网网卡,通常一个节点只有一种网卡,但有很多块网卡,分别用于不同的连接(比如:备份等)和冗余。
多个节点一起构成MPP系统,多个节点之间的内部高速互联时通过BYNET的硬件实现
Shared Nothing Architecture The Teradata Database virtual processors, or vprocs (which are the PEs and AMPs), share the components of the nodes (memory and cpu). The main component of the "shared-nothing" architecture is that each AMP manages its own dedicated portion of the system's disk space (called the vdisk) and this space is not shared with other AMPs. Each AMP uses system resources independently of the other AMPs so they can all work in parallel for high system performance overall.
Modul-2
一个关系数据库是存储在关系数据库管理系统里的相关联的表的集合。“管理系统”这个词,指的是一个关系数据库需要软件来提供象事物处理完整性、安全性和日志的功能。Teradata是一个关系数据库管理系统。
关系数据库不用访问路径去查找数据,数据通过数据值来连接。数据连接由一个列与另外一个表中的
相关列的匹配值来实现。在相关联的术语中,连接就是指JOIN。
Module-3:Teradata的系统主要组成结构
分析引擎Parsing Engine
分析引擎(PE)是一个解释SQL 请求,接受输入记录,过虑数据的虚拟处理器。完成后的信息通过BYNET 传递给AMP。
包括:session control(会话控制),parser(解析,包括优化器optimizer),dispatcher(调度) 分析引擎主要负责:
管理单独的会话层(可以到120个)
分析和优化SQL 请求
将优化的计划发送给AMP
ASCII/EBCDIC 之间的转化(如果需要的话)
发送响应的结果给请求客户
BYNET
BYNET可以看作是精密复杂的通讯总线。它依靠使用的平台,既可以是软件也可以是硬件。它决定哪个存取模块处理器(AMP)将接收信息。
BYNET是负责:
AMP与PE之间的信息传送
广播,点对点和多点通讯
合并结果集返回给PE
让Teradata 的并行处理成为可能
BYNET被应用在多节点和单节点系统。
存取模块处理器Access Module Processor (AMP)
AMP 是一个专门设计用来管理整个数据库的一部分的虚拟处理器。它执行数据库所有的管理功能,例如排序,合计和格式化数据等。AMP从PE接收数据,格式化输出行,然后将数据分配到它所控制的存储磁盘单元。AMP也通过分析引擎接收行请求。一个AMP 最多可以控制64个物理磁盘
AMP 通过BYNET 的传送响应分析器和优化器的执行步骤,从它关联的磁盘中选择数据或存储数据。对于一些请求,AMP 还需要重新分配一个数据的副本到其他的AMP。
数据库管理的子系统依赖每一个AMP。数据库的管理:* 接收从发报机送来的执行步骤,处理这些执行步骤。它可以做:
—锁数据库和表
—建立,修改和删除表的定义
—插入,删除和修改表中的行
—从表和数据定义中获取信息
—收集统计数据,记录会话的访问过程,用户可以被准确地列出表来。
—响应返回给发报机
数据库管理为磁盘上数据的逻辑组织和物理组织提供了一座桥梁作用。数据库管理执行了空间管理的功能,控制了空间的分配和使用。AMP 也能进行数据转化,检查会话层和把Teradata 内部使用的8 位ASCII 转成请求的数据格式。(这与PE 将输入数据转成内部的ASCII 是一个相反的处理过程。)
磁盘
与AMP 相关联的磁盘和磁盘驱动器用来存储数据行。在当前的系统中,它们一般使用磁盘阵列。
磁盘阵列(Disk Array)
磁盘矩阵是一个利用专门的控制器来管理和分配数据和奇偶校验的磁盘驱动器结构,以此提供快速存取和数据完整性。每一个AMP 虚拟处理器都必须访问矩阵控制器,这个控制器依次访问物理磁盘。AMP 虚拟处理器和一个或多个rank 的数据相关联。一个AMP 虚拟处理器和相关联的总的磁盘空间被称为VDisk(虚拟存储器)。一个VDisk 最多可以有三个rank。
所有磁盘RAID 技术进行管理,其中有如下的几个方式:
_RAID LEVEL 5――多个磁盘的数据和奇偶保护
_RAID LEVEL 1――每个磁盘有一个数据复制的物理镜像
_RAID LEVEL S――类似RAID5 用于EMC 磁盘矩阵的数据和奇偶保护
磁盘矩阵控制器是一个双重可用的矩阵控制器,也就是说除了在相互备份时,两个控制器都可用。
每个AMP 能支持的最大磁盘空间
V2R2――46GB
V2R3/V2R4――119GB
_每个AMP虚拟处理器额可以指派给一个虚拟存储器
_每个虚拟存储器可以拥有119的磁盘空间
Teradata 存储过程
_分析引擎解释SQL 命令,将从主机那里得到的数据记录转化成一个AMP 信息。
_BYNET 把这一行分配给相应的AMP。
_AMP 格式化行并它们写到相关联的磁盘中去。
_磁盘保存行的并发访问路径。
主机或客户端系统提供数据记录。这些数据记录是未被加工的原始数据,数据库将从这些原始数据中构造。由于Teradata没有预先分配表空间的概念,所以表中的行不仅被随机分配到所有的AMP 中去,而且它们被随机存储在AMP 相关联的磁盘空间中。
Teradat 读取过程
从Teradata RDBMS读取数据与存储过程是相反的。一个数据请求传送到分析引擎(PE),PE 将优化这个处理请求使之更加有效,并为相应的AMP 产生执行的任务,使之处理请求的意图。这些任务然后通过BYNET 被发送到AMP 上。通常所有的AMP 都必须协作以建立结果集,就如将一个数据表中所有的行返回给客户端应用程序。其它时间只有一个或部分的AMP 参与。PE 将确保只有必要的AMP 才被指派任务。
一旦AMP 被指派任务,它们就读取各自任务所要求的数据行。如果需要的话,AMP 将进行数据排序、聚合或格式化等操作。然后这些数据行通过BYNET返回给请求的PE。之后PE 又将收到的返回结果传送到客户端应用程序。
_分析引擎发送一个请求读取一行或多行
_BYNET 确保相应的AMP 的可用性
_AMP 以并行访问方式查找并读取所需要的数据行
_BYNET 将读取的数据行返回给分析引擎
_分析引擎将结果数据返回到请求的客户端应用程序
多个AMP 上的多个表
你也许会认为RDBMS 将分配每个表到一个特定的AMP,因此AMP 就会把一个表存储在一个磁盘中。然而正相反,当你看到下面的图表,会知道其实并不是那样的。系统会把表中的所有的行分开存储到每一个可用的AMP 中。
_表被分配到所有的AMP 中,要经过所有的AMP 的行的分配应当均匀,以确保每个AMP 的工作量能够被均匀分配
_每个表都有一些行被分配到每个AMP
_每个AMP 控制一个由几个的物理磁盘组成逻辑存储单元
_大型的结构可以有数百个AMP
_全表扫描操作,要求并行地存取所有的AMP,查看表中所有的行。并行处理才能使存取海量的数据成为可能。
让我们看看这三个表:EMPLOYEE,DEPARTMENT 和JOB。
Teradata RDBMS 把每个表中的所有行分开存储到所有的AMP 中。AMP 把行分开存储到它们的磁盘。每个AMP 得到每个表的一部分。表拆分意味着所有的AMP 和它们相关联的磁盘在全表扫描中将被使用,这样就加快了对这些表的请求。
在我们的例子里,如果你有四个AMP,理论上每个AMP 将得到每个表的25%。如果1#AMP 得到EMPLOYEE 表90%的行,这被称作粗笨的数据分配。这种粗笨的数据分配将降低系统的响应速度,因为任意一个要求扫描EMPLOYEE 表所有行的请求在1#AMP 完成工作的时候都将会有三个AMP 处于空闲。因此把所有的表均匀分配到所有可用的AMP 中会比较好。在后面的章节中你将学会如何控制分配。
_表中的某些行可以在每个AMP 中找到
_每个AMP 可以有所有表中的行
_在理想情况下,每个AMP 将保存大致相同数量的数据
线性增长和扩展Linear Growth and Expandability
完成一个任务需要的时间总和直接与系统的大小成正比例的特点对于Teradata RDBMS来说是独一无
二的。Teradata 是一个线性扩展的RDBMS。系统构成在需求增长时可以线性扩展
Tera的并行处理Teradata Parallelism
并行处理在Teradata RDBMS中是最关键的。事实上系统的每一个部分都存在并行处理。如果没有并行处理,管理海量的数据不只是不可能,而且将是花费昂贵、效率低下的。
每个PE 能支持120 个用户的并行会话。可以是120 个不同的用户或单一用户在一个应用程序利用120个会话的处理能力。
每个会话可以并行处理多个请求。要是在某一时刻只有一个可用的请求代表一个会话,这个会话本身可以管理16 个请求的行为和它们相关的答案集。
BYNET 的是专门为设计的,以使它不会成为系统的瓶颈。因为BYNET 在不同的平台被不一样地实现,它总是在每个特定平台的最大吞吐量所需的带宽之内。
每个AMP 能并行地执行80 个任务。AMP 在某个时刻从不只对一条请求服务,而是并行地执行多条请求。因为AMP 设计用来管理数据库的一部分,它们必须在并行操作中完成即定结果。另外,如果步骤间不存在其它的耗费的话,优化器可以指示AMP 并行地处理某些步骤。这表明一个AMP 可以代表同一个请求并发地执行一个以上的步骤。
并行CLI 能让客户端应用程序实现并行处理,这对于多会话应用特别有用并且它是通过设定一些环境变量来完成的。它不需要改变应用程序的代码
Teradata 功能综述
Teradata数据库需要三个不同的软件模块:TPA,PDE 和OS。
可信任的并行应用(Trusted Parallel Application (TPA))执行虚拟处理器并在PDE 和操作系统之上运行。Teradata RDBMS被分类看成一个TPA。Teradata RDBMS的组成部件包括:
_通道驱动程序
_Teradata网关
_AMP
_PE
Teradata数据库并行扩展(PDE,parallel database extensions):管理和运行虚处理器:PE和AMPs 并行数据库扩展(PDE)软件是位于操作系统上面的接口层。PDE 支持并行的软件环境。客户端应用程序包括:
_一个大型主机系统,象IBM 或UNISYS 利用通道连接Teradata RDBMS
_PC 或UNIX 系统是通过网络连接的客户端应用程序向RDBMS 提交一个SQL 请求,接收响应并提交给用
通道连接的客户端软件综述
在通道连接的系统中,有三个主要的软件部件,在请求或者从Teradata RDBMS获得响应起了重要的作用。
一个是客户端应用程序,有可能是客户端的应用程序或者就是Teradata本身提供的程序。许多客户端应用程序被用于前台的SQL 递交,但也有被用来维护文件档案和产生报表的。任何客户端支持的语言只要能适合调用层接口(CLI)就可以被使用。
调用层接口(The Call Level Interface (CLI)),是针对Teradata RDBMS的底层接口。包括会话建立的系统调用,分配请求,返回缓冲,打包查询以及解包返回到目标库表
Teradata 主管程序(TDP)是一个Teradata 提供的程序,必须运行在任何使用通道连接到Teradata RDBMS的客户端系统。TDP管理在调用层接口与RDBMS之间的会话层的通信量。它的功能包括会话的开始,终
止,登录,确认,恢复,重新启动,从PE 的输入和输出(包括会话平衡)和队列的维护等等。TDP 也控制系统的安全。
网络连接客户端软件综述
在网络连接的系统中,有四个主要的软件部件在从Teradata RDBMS 取得请求中起了重要的作用。它们包括:
_程序员用客户端支持的语言编写的客户端应用程序。这个应用程序的用途是提交SQL 语句给RDBMS 并在结果集上执行处理。
_调用接口层(CLI)是用于客户端的程序库。客户端程序使用这些程序执行象登录,注销,提交SQL 查询这样的操作,并接收包含结果集的响应。这些程序在网络连接和通道连接的环境中基本相同。
_微型Teradata 主管程序(MTDP)是Teradata 提供的,必须连接到网络连接的Teradata RDBMS的应用程序。MTDP执行许多通道型的TDP相同的功能,包括会话管理。MTDP 没有对PE 间的会话平衡进行控制。连接和分配运行在Teradata系统中的服务器处理会话平衡。
_微型操作系统接口(MOSI)是一个程序库,给访问RDBMS 的客户端提供操作系统独立性。通过使用MOSI,只需要一个版本的MTDP 运行在所有的网络连接平台。
Teradata Objects
Tables
A table is the logical structure of data in an RDBMS. It is a two dimensional structure made up of columns and rows. A user defines a table by giving it
a table name that refers to the type of data that will be stored in the table.
A column represents attributes of the table. Column names are given to each column of the table. All information in a column is the same type. For example,
a column named date of birth would only hold date of birth information.
Each occurrence of an entity is stored in the table as a row. Entities are the people, things, or events that the table is describing.
Teradata 对象
Teradata数据库系统中的数据库是表、视图和宏这些对象的集合。数据库提供了逻辑的分组信息。它们也是空间分配和访问控制的基础。
_在Teradata 数据库中有三个基本对象:
表――行和列的数据
视图――预先定义的表的子集
宏――预先定义,存储SQL 命令
_这些对象用结构化查询语言(SQL)来进行创建、维护和删除
_对象定义存储在数据字典里
表
表在RDBMS 中是逻辑结构的数据。它是一个由行和列组成的二维结构。一个用户通过给定表名定义了一个表,提交的数据类型将被存储在表中。列表现出表的属性。表的每个列都有列名。列里所有的信息都是相同类型的。
举例来说,一个叫做出生日期的列就只包含出生日期的信息。
每个实体的出现就是存储在表中的行,实体可以是人、物体或表描述的事件。
视图
视图是预先定义的一个或多个表或其他视图的子集。它不是真正的表,而只是作为已存在的表或视图的参考。一种对视图的看法就是看作一个虚拟的表。视图在数据字典中被定义但没有包含任何物理行。视图可以被数据库的管理者用来控制对优先表的存取。视图可以用来隐藏用户的列,隔离数据库改变的应用程序,简单化和标准化存取的技术。
宏
宏是预先定义的用来存储一条或多条SQL 命令、可选择的格式化命令的集合。宏用来简单化经常使用的SQL 命令的执行
数据字典( DD)
数据字典是一个系统表的完整集合:
_存储有关于用户,数据库,资源使用,数据统计和安全规则这些数据库对象的定义和堆积信息。
_记录有关表、视图和宏的说明
_包含数据库对象的所有者、空间分配、统计和访问权限的信息数据字典的信息在处理Teradata 数据定义语言语言的过程中自动更新。提供给分析器必要的信息来处理所有的Teradata SQL 语句。
如果系统管理员授权,用户可以通过Teradata 提供的视图访问数据字典。
_是系统表的完整集合
_包含系统中所有对象的定义信息
_完全由RDBMS 来维持
_被分布到所有的AMP 中
_可以被管理者或维护人员查询
_通过Teradata提供的视图进行访问
视图的例子:
_DBC.Tables――所有表的信息
_https://www.doczj.com/doc/6d12982119.html,ers――所有用户的信息
_DBC.AllRights――存取权限的信息
_DBC.DiskSpace――空间使用的信息
EXPLAIN 工具
解释工具允许你事先查看Teradata 怎样执行一条查询请求。它返回TeradataRDBMS 要执行完成请求的步骤的概要。解释将说明所使用的存取方法和策略,包括多少的行和它所要花费的时间。使用解释来估计一条查询的性能并把它发展成一条可选择的处理策略,提高效率。解释可以对任何SQL 请求起作用。请求被充分地分析和优化,但不运行。解释的完整的计划将以可读的英语句子返回给用户。
EXPLAIN 提供了包括锁,排序,行选择标准,连接策略和条件,存取方法以及并行步骤处理的信息。
EXPLAIN 有利于调整性能,调试,预先确认请求和技术练习。
解释工具放在SQL语句之前,对该语句只是分析和优化,而不会执行解释返回:
_一条语句怎样被处理的文本
_估计将包括多少的行
_查询相关的花费(在时间单元上)
解释的信息用来:
_预测行的数量
_预测执行性能
_产生查询前的测试
_多方面的路径分析问题
1.传统数据库的优劣势 数据库技术产生于20世纪60年代末期,是计算机领域中最重要的技术之一,是一种比较理想的管理技术。数据库(Data Base)可以看作是与现实世界有一定相似的模型,是认识世界的基础,是集中、统一存储和管理某个领域信息的系统,它根据数据间的自然联系而构成,数据较少冗余,且具有较高的数据独立性,能为多种应用服务。而传统的数据库是指关系型数据库,如MySQL、Oracle、SqlServer等。 1.传统数据库的优势 ●灵活性和建库的简单性:从软件开发的前景来看,用户与关系数据库编 程之间的接口是灵活与友好的。目前在多数RDDMS产品中使用标准查询 语言SQL,允许用户几乎毫无差别地从一个产品到另一个产品存取信息。 与关系数据库接口的应用软件具有相似的程序访问机制,提供大量标准 的数据存取方法。 ●结构简单:从数据建模的前景看,关系数据库具有相当简单的结构(元 组),可为用户或程序提供多个复杂的视图。数据库设计和规范化过程也 简单易行和易于理解。由于关系数据库的强有力的、多方面的功能,已 经有效地支持许多数据库纳应用。 ●易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性) 大大减低了数据冗余和数据不一致的概率。 2.传统数据库的劣势 ●数据类型表达能力差:从下一代应用软件的发展角度来看,关系数据 库的根本缺陷在于缺乏直接构造与这些应用有关的信息的类型表达能 力,缺乏这种能力将产生以下有害的影响,例如:大多数RDBMS产品 所采用的简单类型在重构复杂数据的过程中将会出现性能问题;数据 库设计过程中的额外复杂性;RDBMS产品和编程语言在数据类型方面 的不协调。 大多数现代的RDBMS产品已成熟地用于商务和财政方面,而这些领域不要求很高和很复杂的数据模型。虽然这些产品多多少少克服了 一些以上所述的缺点,但从理论上看关系数据模型不直接支持复杂的
1.Teradata Client安装说明 1、安装程序地址:ftp://10.3.7.141/ 2、点击Setup.exe,开始运行安装程序 3、出现如下安装启动画面: 4、选择Custom安装方式(请不要选择Typical)
5、选择安装组件 请依次选择以下程序: 6、点击Next直至完成
2.Teradata数据库配置说明 1)测试数据库说明 2)配置ODBC 1、打开odbc数据源管理器、选择系统dsn页点击【添加】按钮
2、选择T eradata驱动程序,点击【Finish】按钮 3、填DB Source、T eradata Info、Uername、Password等选项点击【ok】按钮完成。
说明: ●Data Source:odbc的名称 ●Teradata Server Info Name(s):Teradata数据库的IP地址 ●Username:用户名 ●Password:密码 ●Default Database:默认数据库 3)配置HOST文件 1、打开系统目录-system32-Drivers-etc(如XP系统: C:\Windows\system32\drivers\etc)下的hosts文件 2、填写T eradata数据库的CLI接口地址:如 127.0.0.1 localhost 10.3.7.9 cpcimtcop1 说明: 第一部分为Teradata的ip地址,后面为任意名字和cop1、cop2的组合
3.Teradata客户端配置 1) Teradata Administrator配置 选择菜单T ools/Options 修改General选项,选中用SQL Assistant代替查询窗口选项。
1、 T eradata 优势 ,能否打数据并发 1)优势 以下是部分Teradata 客户数据仓库管理的内容,可说明Teradata 系统的强大处理能力: ? 多达千亿行数据的数据库表格 ? 每天数据加载超过30亿条记录 ? 每天捕获3000万笔客户交易 ? 每天为消费者在线提供150万种个性化产品和服务 ? 每小时处理100万次数据库查询 ? 每天响应1万个并发数据仓库用户 ? 业务查询响应时间仅为40-50毫秒 2)并发问题: 机制 :Teradata 巨表数据存放机制好像是每个节点均匀分布表中一部分数据,当查询的时候每个节点并行查询,结果汇总到某个节点反馈给查询者。这个复杂查询的实例形象地说明了Teradata 的多维并行处理机制。 M ulti-S tep 并 行 并 行 作1. 搜 索 LineItem 2. 搜 索 O rders 3. 联 接 Lineitem & O rders 并 行P R O C 同 时 与 各 自 相 关 据 图8-16 T eradata 内部并行处理机制说明 这里假设系统配置有4个虚拟处理器(VPROC),某个复杂查询被优化器分解成了7个步骤,
图中SUPPLIERS、PARTS、PARTSUPP等为数据库中表的名字。在每个步骤执行时,4个VPROC 同时处理与各自相关的数据块,例如搜索SUPPLIERS表,该表的记录是通过HASH算法均匀分布在四个VPROC各自负责的磁盘中的,搜索时4个VPROC将同时进行,把相关的记录搜索出来,这就是所谓的查询并行。 例子: 例如:使用NCR 5300服务器,2个节点,存储为2TB,RAID1,在业务高峰期,系统并发查询用户在300个以上,最高到1000个,此时系统响应速度有些缓慢大概业务查询响应时间30秒,峰值过后速度就加快了。主要进行的操作就是表之间的关联查询,4张表,每张6-7千万条记录,ETL加载的数据量不算太大。 2、T eradata内外部集建立原则 针对实际的应用,采用内外部集市可以有效的发挥起各自的优势: 1)松耦合原则 介于要将整个系统划分为数据和应用层,相互存在很多密切关联,在设计库表时要充分考虑数据和应用的相互影响,做到应用不影响到数据的处理,数据处理不直接针对应用的松耦合技术架构 2)任务明确原则 数据处理层和应用层在处理具体业务时,必然存在既可以在数据层处理有可以在应用层处理的问题,需要在设计时充分讨论业务需求,做到责任明确,任务单一,各负其责。 3、teradata比较oracle的优缺点 Teradata是专为数据仓库OLAP设计的,主要用来进行数据的综合分析和处理, Oracle更多的适合联机事务处理的OLTP应用,针对DW 数据仓库从以下几个角度对teradata进行分析: 1、数据管理能力(Data Management) 数据自动分配 Teradata中只有一种基于HASH算法的数据分配机制,当要插入一条记录时,根据主索引计算出相应的AMP,该条记录即通过此AMP存到其对应的磁盘上。由于主索引值的不同,一个表的各条记录将通过各AMP均匀地分布到各个磁盘上。分配过程完全自动进行,不需要DBA干预,这一点和其它OLTP DBMS有很大的区别。Teradata的HASHING算法经过长期的发展,已经十分完善。它采用了一个类似矩阵的HASH MAP,将计算出来的HASH值通过此矩阵
一、数据仓库厂商简介 1、IBM IBM,即国际商业机器公司,1911 年创立于美国,是全球最大的信息技术和业务解决方案公司,目前拥有全球雇员31 万多人,业务遍及160 多个国家和地区。2004 年,IBM 公司的全球营业收入达到九百六十五亿美元. 在过去的九十多年里,世界经济不断发展,现代科学日新月异,IBM 始终以超前的技术、出色的管理和独树一帜的产品领导着全球信息工业的发展,保证了世界范围内几乎所有行业用户对信息处理的全方位需求。众所周知,早在1969 年,阿波罗宇宙飞船载着三名宇航员,肩负着人类的使命,首次登上了月球;1981 年哥伦比亚号航天飞机又成功地飞上了太空。这两次历史性的太空飞行都凝聚着IBM 无与伦比的智慧。 IBM 与中国的业务关系源远流长。早在1934 年,IBM 公司就为北京协和医院安装了第一台商用处理机。1979 年,在中断联系近30 年之后,IBM 伴随着中国的改革开放再次来到中国。同年在沈阳鼓风机厂安装了中华人民共和国成立后的第一台IBM 中型计算机。 随着中国改革开放的不断深入,IBM 在华业务日益扩大。80 年代中后期,IBM 先后在北京、上海设立了办事处。1992 年IBM 在北京正式宣布成立国际商业机器中国有限公司,这是IBM 在中国的独资企业。此举使IBM 在实施其在华战略中迈出了实质性的一步,掀开了在华业务的新篇章。随后的1993 年,IBM 中国有限公司又在广州和上海建立了分公司。到目前为止,IBM 在中国的办事机构进一步扩展至哈尔滨、沈阳、深圳、南京、杭州、成都、西安、武汉、福州、重庆、长沙、昆明和乌鲁木齐等16 个城市,从而进一步扩大了在华业务覆盖面。伴随着IBM 在中国的发展,IBM 中国员工队伍不断壮大,目前已超过5000 人。除此之外,IBM 还成立了8 家合资和独资公司,分别负责制造、软件开发、服务和租赁的业务。 IBM 非常注重对技术研发的投入。1995 年,IBM 在中国成立了中国研究中心,是IBM 全球八大研究中心之一,现有150 多位中国的计算机专家。随后在1999 年又率先在中国成立了软件开发中心,现有近2000 位中国软件工程师专攻整合中间件,数据库,Linux 等领域的产品开发。 二十多年来,IBM 的各类信息系统已成为中国金融、电信、冶金、石化、交通、商品流通、政府和教育等许多重要业务领域中最可靠的信息技术手段。IBM 的客户遍及中国经济的各条战线。 与此同时,IBM 在多个重要领域占据着领先的市场份额,包括:服务器、存储、服务、软件和笔记本电脑等。 取诸社会,回馈社会,造福人类,是IBM 一贯奉行的原则。IBM 积极支持中国的教育事业并在社区活动中有出色的表现。 IBM 与中国高校合作关系的开始可追溯到1984 年,当年IBM 为中国高校作了一系列计算机设备硬件和软件的捐赠。1995 年 3 月,以IBM 与中国国家教委(现教育部)签署合作谅解备忘录为标志,“IBM 中国高校合作项目”正式启动,这一长期全面合作关系的基本宗旨是致力于加强中国高校在信息科学技术领域的学科建设和人才培养。10 年来,IBM 中国高校合作项目不断向着更高的水平、更深的层次和更广的领域发展,对中国高校信息技术相关专业的学科建设和人才培养起到了积极的推动作用。 自1995 年以来,IBM 已向中国高校捐赠了价值人民币10.1 亿元的计算机设备、软件及服务。此外,通过与教育部在基础教育领域的合作,IBM 向中国教育机构捐赠的设备总价值达人民币3177 万元。迄今为止,IBM 对中国教育机构的捐赠已高达人民币10.4 亿元。 在高校合作项目方面,目前IBM 已与50 多所中国知名高校建立了合作关系。30 万人次学生参加了IBM 技术相关课程的学习和培训,3.7 万人次学生获得IBM 全球专业技术认证证书,3000 人次教师参加了IBM 组织的不同形式的师资培训。 除了在高等教育领域与中国教育界进行合作之外,IBM 还将合作范围积极拓展到基础教育领域。继2001 年IBM KidSmart“小小探索者”儿童早期智力开发工程引入中国以来,IBM 已经连续4 年在中国开展了这一项目。目前IBM 已与遍及全国各省、市、自治区共38 个城市的近400 所幼教机构进行合作,
九大数据仓库方案特点比较 九大数据仓库方案特点 IBM、Oracle、Sybase、CA、NCR、Informix、Microsoft、和SAS等有实力的公司相继(通过收购或研发的途径)推出了自己的数据仓库解决方案,BO和Brio等专业软件公司也在前端在线分析处理工具市场上占有一席之地。 下面针对这些数据仓库解决方案的性能和特点做分析和比较。IBM IBM公司提供了一套基于可视数据仓库的商业智能(BI)解决方案,包括:Visual Warehouse(VW)、Essbase/DB2 OLAP Server 5.0、IBM DB2 UDB,以及来自第三方的前端数据展现工具(如BO)和数据挖掘工具(如SAS)。其中,VW是一个功能很强的集成环境,既可用于数据仓库建模和元数据管理,又可用于数据抽取、转换、装载和调度。Essbase/DB2 OLAP Server支持“维”的定义和数据装载。 Essbase/DB2 OLAP Server不是ROLAP(Relational OLAP)服务器,而是一个(ROLAP和MOLAP)混合的HOLAP服务器,在Essbase完成数据装载后,数据存放在系统指定的DB2 UDB数据库中。严格说来,IBM自己并没有提供完整的数据仓库解决方案,该公司采取的是合作伙伴战略。例如,它的前端数据展现工具可以是Business Objects的BO、Lotus的Approach、Cognos的Impromptu或IBM的Query Management Facility;多维分析工具支持Arbor Software的Essbase和IBM(与Arbor 联合开发)的DB2 OLAP服务器;统计分析工具采用SAS系统。Oracle Oracle数据仓库解决方案主要包括Oracle Express和Oracle Discoverer两个部分。 Oracle Express由四个工具组成:Oracle Express Server是一个MOLAP (多维OLAP)服务器,它利用多维模型,存储和管理多维数据库或多维高速缓存,同时也能够访问多种关系数据库;Oracle Express Web Agent通过CGI或Web插件支持基于Web的动态多维数据展现;Oracle Express Objects前端数据分析工具(目前仅支持Windows平台)提供了图形化建模和假设分析功能,支持可视化开发和事件驱动编程技术,提供了兼容Visual Basic语法的语言,支持OCX和OLE;Oracle Express Analyzer是通用的、面向最终用户的报告和分析工具(目前仅支持Windows平台)。Oracle Discoverer即席查询工具是专门为最终用户设计的,分为最终用户版和管理员版。在Oracle数据仓库解决方案实施过程中,通常把汇总数据存储在Express多维数据库中,而将详细数据存储在Oracle 关系数据库中,当需要详细数据时,Express Server通过构造SQL语句访问关系数据库。但目前的Express还不够灵活,数据仓库设计的一个变化往往导致数据库的重构。另外,目前的Oracle 8i和Express 之间集成度还不够高,Oracle 8i和Express之间需要复制元数据,如果Oracle Discoverer (或BO)需要访问汇总数据,则需要将汇总数据同时存放在Oracle和Express中,系统维护比较困难。值得注意的是,刚刚问世的Oracle 9i把OLAP和数据挖掘作为重要特点。 Sybase Sybase提供的数据仓库解决方案称为Warehouse Studio,包括数据仓库的建模、数据抽取与转换、数据存储与管理、元数据管理以及可视化数据分析等工具。其中,Warehouse Architect 是PowerDesigner中的一个设计模块,它支持星形模型、雪花模型和ER模型;数据抽取与转换工具包括PowerStage、Replication Server、Carleton PASSPORT,PowerStage是Sybase提供的可视化数据迁移工具。Adaptive Server Enterprise是Sybase企业级关系数据库,Adaptive Server IQ是Sybase公司专为数据仓库设计的关系数据库,它为高性能决策支持系统和数据仓库的建立作了优化处理,Sybase IQ支持各种流行的前端展现工具(如Cognos Impromptu、Business Objects、Brio Query 等);数据分析与展现工具包括PowerDimensions、EnglishWizard、InfoMaker、PowerDynamo等,PowerDimensions是图形化的OLAP分析工具,它支持SMP和多维缓存技术,能够集成异构的关系型数据仓库和分布式数据集市,从而形成单一的、新型的多维模式;数据仓库的维护与管理工具包括Warehouse Control Center、Sybase Central、Distribution Director,其中Warehouse Control Center 是为数据仓库开发人员提供的元数据管理工具。Sybase提供了完整的数据仓库解决方案
处理节点(node)、用于节点间通信的内部高速互联(InterConnection)和数据存储介质(一般是磁盘阵列)。每个节点都是SMP结构的单机,节点的物理和逻辑结构如图1所示单个节点就是一个就是一个smp 处理单元,一台多CPU或多核的计算机。硬件包括CPU、内存、用于安装操作系统和应用软件的本地磁盘,与外界交互的网卡及bynet端口;节点网卡一种是与IBM MainFrame链接的Channel Adapter,另一种是局域网网卡,通常一个节点只有一种网卡,但有很多块网卡,分别用于不同的连接(比如:备份等)和冗余。 多个节点一起构成MPP系统,多个节点之间的内部高速互联时通过BYNET的硬件实现 Shared Nothing Architecture The Teradata Database virtual processors, or vprocs (which are the PEs and AMPs), share the components of the nodes (memory and cpu). The main component of the "shared-nothing" architecture is that each AMP manages its own dedicated portion of the system's disk space (called the vdisk) and this space is not shared with other AMPs. Each AMP uses system resources independently of the other AMPs so they can all work in parallel for high system performance overall. Modul-2 一个关系数据库是存储在关系数据库管理系统里的相关联的表的集合。“管理系统”这个词,指的是一个关系数据库需要软件来提供象事物处理完整性、安全性和日志的功能。Teradata是一个关系数据库管理系统。 关系数据库不用访问路径去查找数据,数据通过数据值来连接。数据连接由一个列与另外一个表中的
TERADATA数据库 1.表属性: Set / Multiset ●Set Table 不允许记录重复 ●MultiSet Table 允许记录重复 ●默认值:Set Table > Create Table... AS ... 生成的目标表属性默 ●对SET Table 进行INSERT 操作,需要检查是否存在重复记录 > 相当的耗资源 > 若真要限定唯一性,可以通过UPI 或USI 实现 ●建议:Teradata中都用MultiSet 2.主索引(PI) 设置 ●PI 影响数据的存储与访问,其选择标准: > 不同值尽量多的字段(More Unique Values) > 使用频繁的字段:包括值访问和连接访问 > 少更新 > PI 字段不宜太多 > 最好是手动指定PI 3.分区索引(PPI) 设置 ●PPI (Partition Primary Index ,分区索引),把具有相同分区值的数据聚簇 存放在一起;类似于SQL Server 的聚簇索引(Cluster Index ),Oracle 的聚簇表(Cluster Table )。 ●利用PPI ,可以快速插入/ 访问同一个Partition (分区)的数据。 ●Partition 上不要使用表达式,否则Partition 不能被正确使用。 > Substring(T1. tx_date from 1 for 6) ='200709' > cast( '200710' || '01' as date) 写法错误,PPI 不起作用 4.临时表 1)可变临时表 ●在spool缓冲区中物化。 ●不使用数据字典和交易锁。 ●在cache中保留表的定义。 ●在一个会话中,能够被多个查询使用。
数据仓库Teradata的装载工具Fastload 秦大林,庞涛 1.简介: Teradata作为数据仓库行业的老大,其对数据并行处理能力令人钦佩,而Fastload工具填充数据的速度绝对可以让任何人惊讶。本文就Fastload工具的使用作一介绍,希 望能帮助读者快速掌握这个工具的使用。 Fastload支持批处理的脚本编写方式,也支持交互式的方式。其功能就是从数据文件中把大批数据快速插入Teradata数据库。在数据仓库建设阶段对ETL 是非常重要的手段,平均比其他第三方ETL工具快3倍以上。另外Fastload 也提供了错误-恢复执行功能,能够继续先前由于各种原因停下来没有完成的工 作。 Fastload能够从主机、专线、或者一般的TCP/IP连接的计算机节点上运行。 使用限制:必须是空表,并且该表上没有外健,也没有除了UPI或者NUPI以外的索引。还有要注意的一点,就是即使要上载的表是MULITISET(允许重复纪 录)的,FASTLOAD也不会将重复的纪录装入。 2.Fastload运行过程介绍 共有2个步骤,数据装载和数据排序过程 装载过程:接收从数据源文件传来的大量数据,并且按照HASH算法把数据进行分布,分布到对应的AMP里面去。数据记录被写入没有排序的数据块中。 数据排序:把装载步骤生成的大量数据块进行排序操作,并且把数据块写入磁盘。 3.支持的文件格式 在使用FASTLOAD时候,数据源文件有很严格的规则。 FASTLOAD支持5种文件格式 1.D ATA文件:使用FASTEXPORT或者BTEQ生成的数据文件。(用.export data file=… 命令生成)。 2.I NDICDATA文件:和第一种的区别在于文件包含了NULL的信息 (用.export indicdata file=…命令生成)。 3.V ARTEXT文件:变长的纪录字段,每个字段之间用某个特定的字符分隔。 4.无格式文件:需要指定某个字段的起始位置和长度,还要指定换行符的长度(需要注意的是UNIX里面用一个字节长度表示换行,WINDOWS里面是2个)例如文件格式为: 2003+ 01 +470000000542+0010+470000000659+Jan 2003+ 11 +470000000543+0011+470000000660+Jan 2003+ 23 +470000000544+0012+470000000661+Jan 就必须这样定义字段(WINDOWS环境) define SERV_ID (char(12)), deliml(char(1)), CUST_ID (char(4)), delim2(char(1)), CONTRACT (char(12)), delim3(char(1)), C_DATE (char(11)), delim4(char(1)), newlinechar(char(2))
数据仓库详细分析和说明 发表于2016/4/5 15:12:22 609人阅读 分类:大数据神经网络 数据仓库是企业统一的数据管理的方式,将不同的应用中的数据汇聚,然后对这些数据加工和多维度分析,并最终展现给用户。它帮助企业将纷繁浩杂的数据整合加工,并最终转换为关键流程上的KPI,从而为决策/管理等提供最准确的支持,并帮助预测发展趋势。因此,数据仓库是企业IT系统中非常核心的系统。 根据企业构建数据仓库的主要应用场景不同,我们可以将数据仓库分为以下四种类型,每一种类型的数据仓库系统都有不同的技术指标与要求。 传统数据仓库
图1:传统数据仓库的架构 企业会把数据分成内部数据和外部数据,内部数据通常分为两类,OLTP交易系统以及OLAP分析系统数据,他们会把这些数据全部集中起来,经过转换放到数据库当中,这些数据库通常是Teradata、Oracle、DB2数据库等。然后在这上面对数据进行加工,建立各种主题模型,再提供报表分析业务。一般来说,数据的处理和加工是通过离线的批处理来完成的,通过各种应用模型实现具体的报表加工。 实时处理数据仓库
随着业务的发展,一些企业客户需要对一些实时的数据做一些商业分析,譬如零售行业需要根据实时的销售数据来调整库存和生产计划,风电企业需要处理实时的传感器数据来排查故障以保障电力的生产等。这类行业用户对数据的实时性要求很高,传统的离线批处理的方式不能满足需求,因此他们需要构建实时处理的数据仓库。数据可以通过各种方式完成采集,然后数据仓库可以在指定的时间窗口内对数据进行处理,事件触发和统计分析等工作,再将数据存入数据仓库以满足其他一些其他业务的需求。因此,实时数据仓库增强了对实时性数据的处理能力要求,也要求系统的架构在技术层面上需要革命性的调整。 关联发现数据仓库 在一些场景下,企业可能不知道数据的内联规则,而是需要通过数据挖掘的方式找出数据之间的关联关系,隐藏的联系和模式等,从而挖掘出数据的价值。很多行业的新业务都有这方面的需求,如金融行业的风险控制,反欺诈等业务。上下文无关联的数据仓库一般需要在架构设计上支持数据挖掘能力,并提供通用的算法接口来操作数据。 数据集市 数据集市一般是用于某一类功能需求的数据仓库的简单模式,往往是由一些业务部门构建,也可以构建在企业数据仓库上。一般来说数据源比较少,但往往对数据分析的延时有很高的要求,并需要和各种报表工具有很好的对接。 数据仓库架构的挑战 到了移动互联时代,传统架构的数据仓库遇到了非常多的挑战,因此也需要对它的架构做更多的一些演变。 首先最大的问题是数据增长速度非常迅速,导致原有的数据仓库在处理这些数据存在架构上的问题,无法通过业务层面的优化来解决。譬如,一个省级农信社的数据审计类的数据通常在十几TB,现有基于关系数据库或者MPP的数据仓库方案已经无法处理这么大数据,亟需一种新的更强计算能力的架构设计来解决问题。 其次,随着业务的发展,数据源的类型也越来越多。很多行业的非结构化数据的