
数据仓库详细分析和说明
发表于2016/4/5 15:12:22 609人阅读
分类:大数据神经网络
数据仓库是企业统一的数据管理的方式,将不同的应用中的数据汇聚,然后对这些数据加工和多维度分析,并最终展现给用户。它帮助企业将纷繁浩杂的数据整合加工,并最终转换为关键流程上的KPI,从而为决策/管理等提供最准确的支持,并帮助预测发展趋势。因此,数据仓库是企业IT系统中非常核心的系统。
根据企业构建数据仓库的主要应用场景不同,我们可以将数据仓库分为以下四种类型,每一种类型的数据仓库系统都有不同的技术指标与要求。
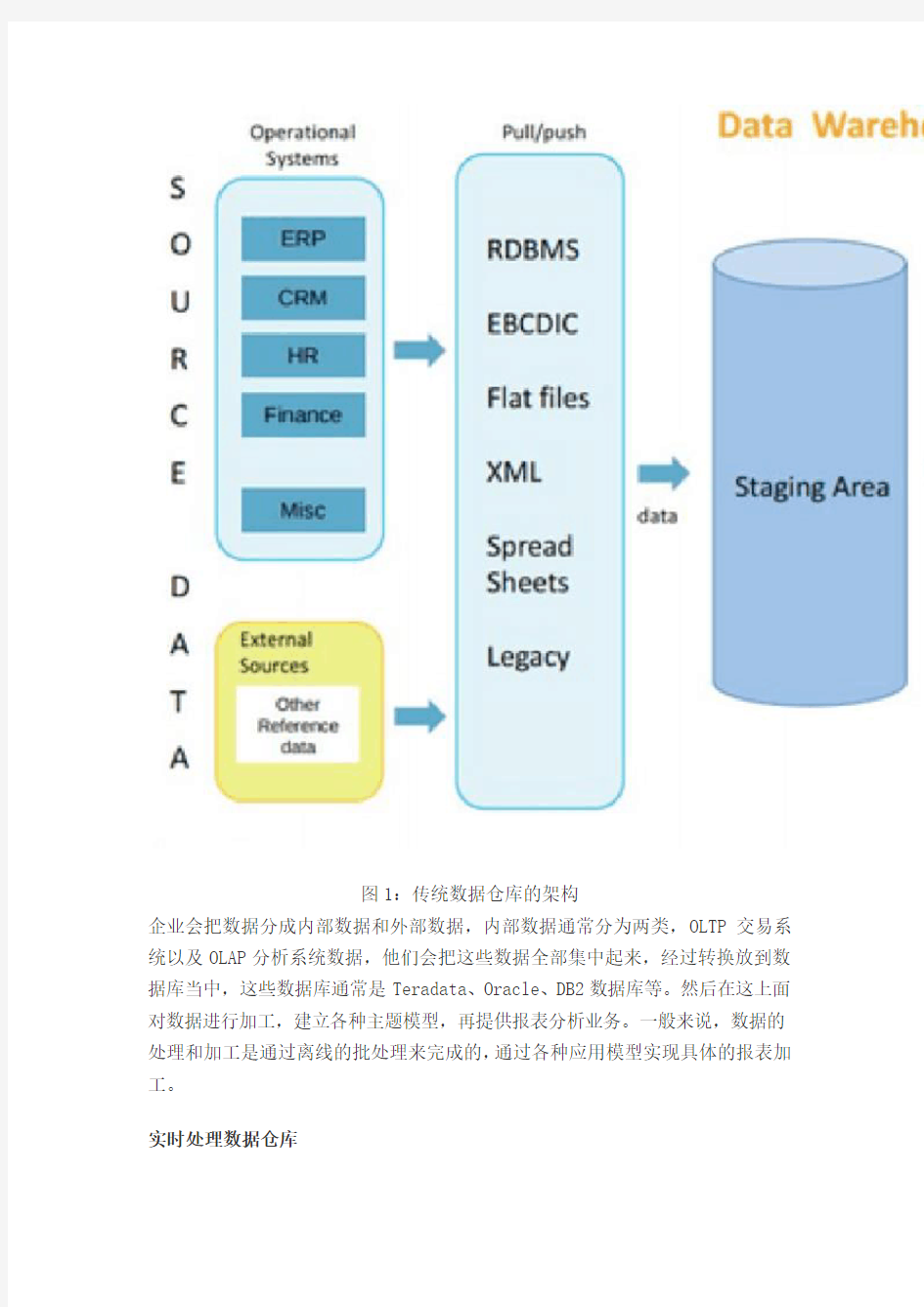
传统数据仓库
图1:传统数据仓库的架构
企业会把数据分成内部数据和外部数据,内部数据通常分为两类,OLTP交易系统以及OLAP分析系统数据,他们会把这些数据全部集中起来,经过转换放到数据库当中,这些数据库通常是Teradata、Oracle、DB2数据库等。然后在这上面对数据进行加工,建立各种主题模型,再提供报表分析业务。一般来说,数据的处理和加工是通过离线的批处理来完成的,通过各种应用模型实现具体的报表加工。
实时处理数据仓库
随着业务的发展,一些企业客户需要对一些实时的数据做一些商业分析,譬如零售行业需要根据实时的销售数据来调整库存和生产计划,风电企业需要处理实时的传感器数据来排查故障以保障电力的生产等。这类行业用户对数据的实时性要求很高,传统的离线批处理的方式不能满足需求,因此他们需要构建实时处理的数据仓库。数据可以通过各种方式完成采集,然后数据仓库可以在指定的时间窗口内对数据进行处理,事件触发和统计分析等工作,再将数据存入数据仓库以满足其他一些其他业务的需求。因此,实时数据仓库增强了对实时性数据的处理能力要求,也要求系统的架构在技术层面上需要革命性的调整。
关联发现数据仓库
在一些场景下,企业可能不知道数据的内联规则,而是需要通过数据挖掘的方式找出数据之间的关联关系,隐藏的联系和模式等,从而挖掘出数据的价值。很多行业的新业务都有这方面的需求,如金融行业的风险控制,反欺诈等业务。上下文无关联的数据仓库一般需要在架构设计上支持数据挖掘能力,并提供通用的算法接口来操作数据。
数据集市
数据集市一般是用于某一类功能需求的数据仓库的简单模式,往往是由一些业务部门构建,也可以构建在企业数据仓库上。一般来说数据源比较少,但往往对数据分析的延时有很高的要求,并需要和各种报表工具有很好的对接。
数据仓库架构的挑战
到了移动互联时代,传统架构的数据仓库遇到了非常多的挑战,因此也需要对它的架构做更多的一些演变。
首先最大的问题是数据增长速度非常迅速,导致原有的数据仓库在处理这些数据存在架构上的问题,无法通过业务层面的优化来解决。譬如,一个省级农信社的数据审计类的数据通常在十几TB,现有基于关系数据库或者MPP的数据仓库方案已经无法处理这么大数据,亟需一种新的更强计算能力的架构设计来解决问题。
其次,随着业务的发展,数据源的类型也越来越多。很多行业的非结构化数据的
产生速度非常快,使用传统Oracle/DB2的数据仓库并不能很好的处理这些非结构化数据,往往需要额外构建一些系统作为补充。
再次,在一家比较大的企业内部,因为业务不同企业内部可能会有几百个数据库,各自建设方案也不同,没有一个简单的办法将数据统一到一个数据平台上。因此需要一个数据库虚拟化技术,能够通过有效的方式将各个数据库统一化,有效的进行数据分析和批处理。而在过去,这个技术并不存在。
最后,过去的数据库没有提供搜索和数据挖掘的能力,而这些需求已经是企业的刚需。譬如金融行业需要使用复杂的数据挖掘方法代替传统的规则引擎来做风险控制,而这无法在基于关系数据库的方案中得到解决。随着Hadoop以及Spark 技术的快速成熟,基于Hadoop/Spark的数据仓库解决方案能有效的解决这些问题和挑战。
基于大数据的数据仓库关键技术
图2:基于Hadoop的数据仓库架构设计上图是一个典型的基于Hadoop的数据仓库的架构设计。
首先有一个传统数据仓库层,它包含一个集中的数据存储平台,以及元数据管理,数据稽查和数据处理的工作调度层。数据存储平台包含多种数据源,有结构化数据和非结构化数据。结构化数据的处理分为三层,按照数据模型分成贴源层、基础明细层和公共主题模型层,数据加工业务按照模型进行切分成不同的批处理业务,通过分布式计算引擎来执行离线的批处理计算。同时为了满足多个模型层的业务需求,有一个统一的资源调度层和工作流调度系统,保证每个业务能够得到给定配额的资源,确保资源分配的合理性和有效性。
其次就是几个不同的应用的场景,通过资源管理层动态分配出来的逻辑集群。各个业务集群获取模型层加工的数据,并结合自身的业务使用相关的数据,同时各个业务之间也可以通过数据库联邦等技术在计算中共享数据。这类业务包含各种查询与检索业务,数据集市以及关联发现数据仓库。
此外,上述方案还包括一个实时处理数据仓库。实时的数据源通过消息队列传入系统,按照数据的时间戳进行基于时间窗口的数据处理,如进行一些实时窗口上的数据统计,基于规则引擎的数据处理,甚至是数据挖掘模型的预测等。经过处理后的数据统一输入企业数据总线,其他逻辑数据仓库通过订阅服务获取相关数据。如数据集市可以从总线下订阅窗口数据直接插入内存后者SSD中,从而可以对这部分数据做实时的统计分析。此外,其他的应用也可以在企业数据总线上订阅相关的数据,从而实时的获取业务需要的数据。
因此,基于Hadoop的解决方案能够用一套系统实现企业对传统数据仓库,实时处理数据仓库,关联发现数据仓库以及数据集市的需求,并通过逻辑划分的方法使用一套资源来实现,无需多个项目重复建设。
从技术层面上,现有的一些SQL on Hadoop引擎(如SparkSQL,CDH等)能够部分实现数据仓库的需求,但是离完整覆盖还有一些距离。一些关键的技术特点必须实现突破,才能符合企业的数据仓库建设的业务指标。主要有以下技术指标:
分布式计算引擎
基于关系数据库的数据仓库一个最大的痛点在于计算和处理能力不足,当数据量到达TB量级后完全无法工作。因此,分布式的计算引擎是保证新数据仓库建设的首要关键因素。这个分布式引擎必须具备以下特点:
1.健壮稳定,必须能够7*24小时运行高负载业务
2.高可扩展性,能够随着硬件资源的增加带来处理能力的线性增长
3.处理能力强,能够处理从GB到几百TB量级的复杂SQL业务
目前开源的Map Reduce计算引擎满足健壮稳定和高可扩展性特点,但是处理能力很弱,无法有效的满足企业的性能需求;Spark在最近几年迅速发展,处理能力和扩展性都不错,但是在稳定性和健壮性方面还存在问题;其他一些SQL on Hadoop方案如Flink还处在发展的早期,还不适合商用。MPP的方案都存在一些可扩展性的问题,当数据量很大的情况下(如100TB级别)无法通过硬件资源的增加来解决,只能处理特定数据量级别的需求。
因此从技术选择的角度,Spark引擎如果能够有效的解决稳定性和健壮性问题,是分布式计算引擎的最佳选择。
标准化的编程模型
目前大部分在生产的数据仓库是基于关系数据库或者MPP数据库来实现的,一般系统规模都比较大,代码量级是数万到数十万行SQL或者存储过程。SQL 99是数据仓库领域的事实标准编程模型,因此支持SQL 99标准是大数据平台构建数据仓库的必备技术,而如果能够支持一些常见的SQL模块化扩展(如Oracle PL/SQL, DB2 SQL PL)等,将非常有利于企业将数据仓库系统从原有架构上平滑迁移到基于Hadoop的方案上来。使用非标准化的编程模型,会导致数据仓库实际建设的成本和风险无法控制。
数据操作方式的多样性
不同模型的数据加工过程要求平台具备多种数据操作的方式,可能是从某一文件或者数据库插入数据,也可能是用某些增量数据来修改或者更新某一报表等等。
因此数据平台需要提供多种方式的数据操作,譬如能通过SQL的INSERT/UPDATE/DELETE/MERGE等DML来操作数据,或者能够从文件或者消息队列等数据源来加载源数据等。同时,这些操作必须支持高并发和高吞吐量的场景,否则无法满足多个业务同时服务的需求。
数据一致性保证
在各个模型层的数据加工过程中,数据表可能会有多种数据源同时来加工。以某银行的贴源层为例,一个银行的某个总数据表可能同时被各个分行的数据,以及外部数据源(如央行数据)来加工。做并发的对统一数据源加工的过程中,数据
的一致性必须得到保障。因此,基于大数据平台的数据仓库也必须提供事务的保证,确保数据的修改操作满足一致性,持久性,完整性和原子性等特点。
OLAP交互式统计分析能力
对于数据集市类的应用,用户对于报表的生成速度和延时比较敏感,一般要求延时在10秒以内。传统的数据仓库需要配合一些BI工具,将一些报表提前通过计算生成,因此需要额外的计算和存储空间,并且受限于内存大小,能够处理的报表存在容量限制,因此不能完全适用于大数据的应用场景。
一些开源项目尝试通过额外的存储构建Cube来加速HBase中数据的统计分析能力,不过存在构建成本高,易出错,不能支持Ad-Hoc查询等问题,此外需要提高稳定性满足商业上的需求。
另外一些商业公司开始提供基于内存或者SSD的交互式统计分析的解决方案,通过将数据直接建立在SSD或者内存里,并通过内置索引,Cube等方式加速大数据量上统计分析速度,能够在10秒内完成十亿行级别的数据统计分析工作。这种方案通用性更强,且支持Ad-Hoc查询,是更合理的解决方案。
多类型数据的处理能力
在大数据系统中,结构化数据和非结构化数据的比例在2:8左右,文档,影像资料,协议文件,以及一些专用的数据格式等在内的非结构化数据在企业业务中非常重要,大数据平台需要提供存储和快速检索的能力。
开源HBase提供MOB技术来存储和检索非结构化数据,基本可以满足及本地的图像、文档类数据的检索,但是也存在一些问题,如Split操作IO成本很高,不支持Store File的过滤等;此外不能很好支持JSON/XML等常用数据文件的操作也是一个缺点。另外一些数据库如MongoDB对JSON等的支持非常好,但是对视频影像类非结构化数据支持不够好。
一个可行的技术方案是在HBase等类似方案中增加对JSON/XML的原生编码和解码支持,通过SQL层进行计算;同时改变大对象在HBase中的存储方式,将split 级别从region级别降低到column family级别来减少IO成本等优化方式,来提供更有效的大对象的处理能力。
实时计算与企业数据总线
实时计算是构建实时处理数据仓库的基本要求,也是企业各种新业务的关键。以银行业信贷为例,以前的信贷流程是业务人员在客户申请后去工商、司法等部门去申请征信数据后评分,周期长效率低。而如果采用实时数据仓库的方案,每个客户请求进入企业数据总线后,总线上的相关的微服务就可以实时的去接入征信、司法、工商等数据,通过总线上的一些挖掘算法对客户进行评分,再进入信贷系统后就已经完成了必要的评分和信贷额度的计算等工作,业务人员只需要根据这些数据来做最终的审批,整体的流程几乎可以做到实时,极大的简化流程和提高效率。
Spark Streaming和Storm都是不错的实时计算框架,相比较而言,Spark Streaming可扩展性更佳,此外如果分布式引擎使用Spark的话,还可以实现引擎和资源共享。因此我们更加推荐使用Spark Streaming来构建实时计算框架。目前开源的Spark Streaming存在一些稳定性问题,需要有一些产品化的改造和打磨,或者可以选择一些商业化的Spark Streaming版本。
实时计算的编程模型是另外一个重要问题,目前Spark Streaming或者Storm 还主要是通过API来编程,而不是企业常用的SQL,因此很多的线下业务无法迁移到流式计算平台上。从应用开发角度,提供SQL开发实时计算应用也是构建实时数据仓库的一个重要因素。目前一些商业化的平台已经具备通过SQL开发实时计算应用的能力。
Database Federation
由于企业内部存在很多套系统,加上一些数据敏感等原因,不可能所有的数据都可以汇总到数据仓库里面,因此Database Federation技术在很多场景下就是必须的功能。Database Federation技术让平台可以穿透到各个数据源,在计算过程中把数据从其他数据源中拉到集群当中来进行分布式计算,同时也把常见的数据源所具备的特性推到数据源中,减少数据的传输量。一推一拉,使得其性能表现的十分显著,对多重数据源进行交叉分析。
在这一领域有两个流派,传统的数据厂商希望用自己的SQL引擎来覆盖Hadoop,把Hadoop隐藏在他们的引擎下面,这种方式没有把计算完全分布出来。另外一种策略是利用Hadoop的SQL引擎来覆盖原来的关联数据,使原来的关联数据库
能够与Hadoop作为同一种数据源来进行完全分布式的计算。这种方式会更符合未来的技术趋势,分布式计算,扩展性增强。
数据探索与挖掘能力
企业经营经常需要做出预测性分析,但预测的准确率却都保持在低水平。这由两大方面原因造成,一方面是因为过去分析的数据都是采样数据,没有大规模的软件系统来存放数据,也无法对大的数据进行分析。另一方面是计算的模型过于简单,计算能力远远不够,无法进行复杂大规模的计算分析,这使得过去的预测都相当不准确。
除此以外,做预测性分析还应具备三方面特征,要具有完成的工具。第一个工具就是要有完整的特征抽取的方式,从大量的数据当中找出特征。即使在今天拥有工具的条件下,也仍然需要人来识别这些特征,做特征抽取。第二个是要有分布式机器学习的算法。目前,这种算法的数量仍然不够全面,我们需要有更完整的机器学习算法的列表。第三点是我们要有应用的工具来帮我们建造一个完整的机器学习算法的pipeline,从而更方便的做出分析。
目前市场上有多种数据挖掘的解决方案和开发商,主要分成两类:以提供模型和可视化编程为主的方案,如SAS;以及以提供算法和标准化开发接口为主的方案,如Spark MlLib等。图形化的方案在开发商更容易,但是这些系统多数和Hadoop 的兼容比较差,需要有专用系统。而类似Spark Mllib的方案能更好的和大数据结合,以及比较多的被工业界接受。
安全性和权限管理
数据的安全重要性无须赘述,安全问题在最近几年已经上升到国家层面。对于大数据平台,基于LDAP协议的访问控制和基于Kerberos的安全认证技术是比较通用的解决方案。
此外,数据的权限管理目前在Hadoop业界还处于完善阶段,应该提供一套基于SQL的数据库/表的权限控制,管理员可以设置用户对表的查询,修改,删除等权限,并包含一整套的角色设定,可以通过角色组的设置来便捷的实现用户权限控制。此外,一些应用场合需要提供对表的精确行级别控制。
混合负载管理
统一的数据仓库平台需要能够支持混合工作负载的管理方式,能够对多个租户进行资源的配额,同时也能实现资源共享,闲置资源分给其他客户,并且也能支持抢占。其次,它还需要能够支持资源和数据的隔离性,使多个租户之间互不干扰。再者,它需要具备能力把批处理任务和实时任务分开处理,对一些实时任务进行优化,从而可以支持多用户多部门多种混合复杂的应用场景。
利用容器技术可以有效的实现资源和数据的隔离性,再加上一个资源调度框架,可以实现工作负载和租户资源的配置。目前这个领域是创新的热点,涌现了很多解决方案,大概也有几个流派,一种是基于Mesosphere的技术路线,让Hadoop 的应用可以在Mesosphere资源框架上运行。这个方案的弱点首先是不具备通用性,所有的大数据和数据库的框架都需要定制和改造,无法标准化。第二个弱点在于隔离性太弱。另外一种是使用Kubernetes + Docker的方式,所有应用容器化,由Kubernetes提供资源调度和多租户管理,因此更加标准化,方便统一化部署和运维,目前我们认为是更好的解决方案。
微服务架构
随着平台技术的进步,应用系统的设计也将发生重大变化。以前一套系统包括前端、中间件、数据库都多个模块,系统耦合性高,构建复杂。未来的数据仓库上的应用系统可以微服务化,所有的功能由小的服务模块组建的,依靠依赖性让系统自动把应用打包集装,极大地促进了应用迁移的便捷性。有了这样一个系统之后,我们可以轻易的建造有几万个容器组成的应用系统,在上面可以运行几千个应用,它的扩展性可以在几分钟之内扩展到上千容器的规模。同时,它的资源隔离性也很好,满足对多租户的要求,进行资源的隔离、共享、抢占。
对未来的展望
这篇文章介绍了数据仓库的一些特性,以及构建基于Hadoop的数据仓库的关键技术。随着近年来大数据技术的高速演变,我们预计未来三年当中数据库以及数据仓库技术会发生的巨大变化。正如Gartner所预计的,我们的大部分企业客户会把数据仓库从以前的传统数据仓库转移到逻辑数据仓库中,Hadoop在其中会扮演非常重要的角色,很多企业应用也已经开始把Hadoop作为数据仓库的重要组成部分。2016年2月Gartner即将发布数据仓库的魔力象限,届时可以看到Hadoop技术作为数据仓库的技术方案被市场的接受程度。
数据平台市场每年创造的价值巨大,但大部分被Oracle、IBM、Teradata等国外巨头瓜分。因此我们希望更多的国内同行能够投入到基于Hadoop的数据仓库平台的研发之中,打造出大数据时代的杰出数据仓库产品,摆脱国外巨头对这个行业的垄断,帮助中国科技在企业服务领域实现质的突破。
2.5数据仓库模型的设计 数据仓库模型的设计大体上可以分为以下三个层面的设计151: .概念模型设计; .逻辑模型设计; .物理模型设计; 下面就从这三个层面分别介绍数据仓库模型的设计。 2.5.1概念模型设计 进行概念模型设计所要完成的工作是: <1>界定系统边界 <2>确定主要的主题域及其内容 概念模型设计的成果是,在原有的数据库的基础上建立了一个较为稳固的概念模型。因为数据仓库是对原有数据库系统中的数据进行集成和重组而形成的数据集合,所以数据仓库的概念模型设计,首先要对原有数据库系统加以分析理解,看在原有的数据库系统中“有什么”、“怎样组织的”和“如何分布的”等,然后再来考虑应当如何建立数据仓库系统的概念模型。一方面,通过原有的数据库的设计文档以及在数据字典中的数据库关系模式,可以对企业现有的数据库中的内容有一个完整而清晰的认识;另一方面,数据仓库的概念模型是面向企业全局建立的,它为集成来自各个面向应用的数据库的数据提供了统一的概念视图。 概念模型的设计是在较高的抽象层次上的设计,因此建立概念模型时不用考虑具体技术条件的限制。 1.界定系统的边界 数据仓库是面向决策分析的数据库,我们无法在数据仓库设计的最初就得到详细而明确的需求,但是一些基本的方向性的需求还是摆在了设计人员的面前: . 要做的决策类型有哪些? . 决策者感兴趣的是什么问题? . 这些问题需要什么样的信息? . 要得到这些信息需要包含原有数据库系统的哪些部分的数据? 这样,我们可以划定一个当前的大致的系统边界,集中精力进行最需要的部分的开发。因而,从某种意义上讲,界定系统边界的工作也可以看作是数据仓库系统设计的需求分析,因为它将决策者的数据分析的需求用系统边界的定义形式反映出来。 2,确定主要的主题域 在这一步中,要确定系统所包含的主题域,然后对每个主题域的内
计算机
王莹
本例采用的是SQl Server2005所提供的商业智能服务和工 具,主要包括Analysis Services(分析服务), Integration Services(集成服务),Reporting Services(集成服务)和Bussiness Intelligence Developer Studio(BIDS)。
分析服务(Analysis Services) SQL Server 分析服务(SSAS)是一个用于分析数据仓库中数据的工 具,它包括了OLAP和数据挖掘工具。在SQL Server 2005数据库系统 中,Analysis Services工具以服务器的方式为用户提供管理多维数 据立方体的服务。Analysis Services可以把数据仓库中的数据组织 起来,经过预先的聚集运算,加入到多维立方体中(即建立立方 体),然后对复杂的分析型访问做出迅速的回答。
集成服务(Integration Services) SQL Server 集成服务(SSIS)被定位成一个能生成高性能数据集成解决 方案(包括数据仓库中数据的提取、转换和加载(ETL))的平台。其集 成的含义主要就是指把ETL集成在一起。SSIS通过一个统一的环境向用户 提供了数据转换服务(DTS)所能提供的所有功能,并且大大减少了用户 花在编写程序和脚本上的精力和时间。 SSIS的基本功能包括:
? ? ? ? ? ? 合并来自异类数据源中的数据 填充数据仓库和数据集市 整理数据和将数据标准化 精确和模糊的查找功能 将商业智能置入数据转换过程 使管理功能和数据加载自动化
数据库表结构设计参考
表名外部单位表(DeptOut) 列名数据类型(精度范围)空/非空约束条件 外部单位ID 变长字符串(50) N 主键 类型变长字符串(50) N 单位名称变长字符串(255) N 单位简称变长字符串(50) 单位全称变长字符串(255) 交换类型变长字符串(50) N 交换、市机、直送、邮局单位邮编变长字符串(6) 单位标识(英文) 变长字符串(50) 排序号整型(4) 交换号变长字符串(50) 单位领导变长字符串(50) 单位电话变长字符串(50) 所属城市变长字符串(50) 单位地址变长字符串(255) 备注变长字符串(255) 补充说明该表记录数约3000条左右,一般不做修改。初始化记录。 表名外部单位子表(DeptOutSub) 列名数据类型(精度范围)空/非空约束条件 外部子单位ID 变长字符串(50) N 父ID 变长字符串(50) N 外键 单位名称变长字符串(255) N 单位编码变长字符串(50) 补充说明该表记录数一般很少 表名内部单位表(DeptIn) 列名数据类型(精度范围)空/非空约束条件 内部单位ID 变长字符串(50) N 主键 类型变长字符串(50) N 单位名称变长字符串(255) N 单位简称变长字符串(50) 单位全称变长字符串(255) 工作职责 排序号整型(4) 单位领导变长字符串(50) 单位电话(分机)变长字符串(50) 备注变长字符串(255)
补充说明该表记录数较小(100条以内),一般不做修改。维护一次后很少修改 表名内部单位子表(DeptInSub) 列名数据类型(精度范围)空/非空约束条件内部子单位ID 变长字符串(50) N 父ID 变长字符串(50) N 外键 单位名称变长字符串(255) N 单位编码变长字符串(50) 单位类型变长字符串(50) 领导、部门 排序号Int 补充说明该表记录数一般很少 表名省、直辖市表(Province) 列名数据类型(精度范围)空/非空约束条件ID 变长字符串(50) N 名称变长字符串(50) N 外键 投递号变长字符串(255) N 补充说明该表记录数固定 表名急件电话语音记录表(TelCall) 列名数据类型(精度范围)空/非空约束条件ID 变长字符串(50) N 发送部门变长字符串(50) N 接收部门变长字符串(50) N 拨打电话号码变长字符串(50) 拨打内容变长字符串(50) 呼叫次数Int 呼叫时间Datetime 补充说明该表对应功能不完善,最后考虑此表 表名摄像头图像记录表(ScreenShot) 列名数据类型(精度范围)空/非空约束条件ID 变长字符串(50) N 拍照时间Datetime N 取件人所属部门变长字符串(50) N 取件人用户名变长字符串(50) 取件人卡号变长字符串(50) 图片文件BLOB/Image
高效实现数据仓库的七个步骤 数据仓库和我们常见的RDBMS系统有些亲缘关系,但它又有所不同。如果你没有实施过数据仓库,那么从设定目标到给出设计,从创建数据结构到编写数据分析程序,再到面对挑剔的用户的评估,整个过程都会带给你一种与以往的项目完全不同的体验。一句话,如果你试图以旧有的方式创建数据仓库,那你所面对的不是预算超支就是所建立的数据仓库无法良好运作。 在处理一个数据仓库项目时需要注意的问题很多,但同时也有很多有建设性的参考可以帮助你更顺利的完成任务。开放思维,不断尝试新的途径,对于找到一种可行的数据仓库实现方法来说也是必需的。 1. 配备一个全职的项目经理或你自己全面负责项目管理 在通常情况下,项目经理都会同时负责多个项目的实施。这么做完全是出于资金和IT资源方面的考虑。但是对于数据仓库项目的管理,绝对不能出现一人身兼数个项目的情况。由于你所处的领域是你和你的团队之前没有进入过的领域,有关数据仓库的一切-数据分析、设计、编程、测试、修改、维护-全都是崭新的,因此你或者你指派的项目经理如果能全心投入,对于项目的成功会有很大帮助。 2. 将项目管理职责推给别的项目经理 由于数据仓库实现过程实在是太困难了,为了避免自虐,你可以在当前阶段的项目完成后就将项目管理职责推给别的项目经理。当然,这个新的项目经理一定要复合第一条所说的具有全职性。为什么要这么做呢?首先,从项目经理的角度看,数据仓库实施过程的任何一个阶段都足以让人身心疲惫。从物理存储设备的开发到Extract-Transform-Load的实现,从设计开发模型到OLAP,所有阶段都明显的比以前接触的项目更加困难。每个阶段不但需要新的处理方法、新的管理方法,还需要创新性的观点。所以将管理职责推给别的项目经理不但不会对项目有损害,还可以起到帮助作用。 3.与用户进行沟通 这里所讲的内容远比一篇文章本身要重要的多。你必须明白,在数据仓库的设计阶段,那些潜在用户自己也不清楚他们到底需要数据仓库为他们做什么。他们在不断的探索和发现自己的需求,而你的开发团队也在和客户的接触中做着同样的事情。更加频繁的与客户接触,多做记录,
数据库与信息管理 电脑知识与技术 1引言 传统的数据库技术是以单一的数据资源,即数据库为中心,进行事务处理、批处理、决策分析等各种数据处理工作,数据处理可划分为两大类:操作型处理(OLTP)和分析型处理(统计分析)。操作型处理也叫事务处理,是指对数据库联机的日常操作,通常是对一个或一组纪录的查询和修改,主要为企业的特定应用服务的,注重响应时间,数据的安全性和完整性;分析型处理则用于管理人员的决策分析,经常要访问大量的历史数据。而传统数据库系统利于应用的日常事务处理工作,而难于实现对数据分析处理要求,更无法满足数据处理多样化的要求。因此,专门为业务的统计分析建立一个数据中心,它是一个联机的系统,专门为分析统计和决策支持应用服务的,通过它可以满足决策支持和联机分析应用所要求的一切。这个数据中心就叫做数据仓库。 2数据仓库概念及发展 2.1什么是数据仓库 数据仓库就是面向主题的、集成的、不可更新的(稳定性)、随时间不断变化(不同时间)的数据集合,用以支持经营管理中的决策制定过程。数据仓库最根本的特点是物理地存放数据,而且这些数据并不是最新的、专有的,而是来源于其它数据库的。数据仓库的建立并不是要取代数据库,它要建立在一个较全面和完善的信息应用的基础上,用于支持高层决策分析,而事务处理数据库在企业的信息环境中承担的是日常操作性的任务。 2.2相关基本概念 2.2.1元数据 元数据(metadata):是“关于数据的数据”,相当于数据库系统 中的数据字典,指明了数据仓库中信息的内容和位置,刻画了数据的抽取和转换规则,存储了与数据仓库主题有关的各种信息,而且整个数据仓库的运行都是基于元数据的,如修改跟踪数据、抽取调度数据、同步捕获历史数据等。 2.2.2OLAP(联机分析处理On-lineAnalyticalProcessing)数据仓库用于存储和管理面向决策主题的数据,OLAP对数据仓库中的数据分析,并将其转换成辅助决策信息。OLAP的一个 重要特点是多维数据分析,这与数据仓库的多维数据组织正好形 成相互结合、相互补充的关系。OLAP技术中比较典型的应用是对多维数据的切片和切块、钻取、旋转等,它便于使用者从不同角度提取有关数据,其基本思想是:企业的决策者应能灵活地操纵企业的数据,以多维的形式从多方面和多角度来观察企业的状态、了解企业的变化。对OLAP进行分类,按照存储方式的不同,可将 OLAP分成ROLAP、MOLAP和HOLAP;ROLAP没有大小限制;现 有的关系数据库的技术可以沿用;可以通过SQL实现详细数据与概要数据的储存;现有关系型数据库已经对OLAP做了很多优 化,包括并行存储、并行查询、并行数据管理、基于成本的查询优化、位图索引、SQl的OLAP扩展等大大提高了ROALP的速度;可以针对SMP或MPP的结构进行查询优化。 一般比MDD响应 速度慢;只读、不支持有关预算的读写操作;SQL无法完成部分计算,主要是无法完成多行的计算,无法完成维之间的计算。 MOLAP性能好、 响应速度快;专为OLAP所设计;支持高性能的决策支持计算;复杂的跨维计算;多用户的读写操作;行级的计算。增加系统复杂度,增加系统培训与维护费用;受操作系统平台中文件大小的限制,难以达到TB级;需要进行预计算,可能导致数据爆炸;无法支持维的动态变化;缺乏数据模型和数据访问的标准。 HOLAP综合了ROLAP和MOLAP的优点。它将常用的数据存储为MOLAP,不常用或临时的数据存储为ROLAP,这样就兼顾 了ROLAP的伸缩性和MOLAP的灵活、纯粹的特点。 收稿日期:2006-03-24 作者简介:赵方(1979-),女,浙江杭州人,浙江树人大学助教,硕士在读,主要从事教学、科研工作,以数据库应用、信息管理为主要研究方向。 数据仓库技术及实施 赵 方 (浙江树人大学,浙江杭州310015) 摘要:介绍了数据仓库的基本概念,针对数据仓库建立对创建数据仓库的过程进行了分析,对实现数据抽取、数据仓库的存储和管理等进行分析和比较。 关键词:数据仓库;联机分析处理;数据抽取;数据存储中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2006)17-0032-02 ResearchofDataWarehouseTechnology ZHAOFang (ZhejiangShurenUniversity,Hangzhou310015,China) Abstract:Inthispaper,theinternalcharacteristicsofDataWarehouseareintroduced.AnalyzedtheprocedureofintegratedDataWarehouseandbuildingthedatawarehouse,DataExtract,DataWarehouseStorageandhowtomanagetheDataWarehouse. Keywords:DataWarehouse;OLAP(On-lineAnalyticalProcessing);DataExtractTransformLoad;DataStorage 32
互联网大数据与传统数据仓库技术比较研究 韩路 1.Hadoop技术简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,是目前全世界最主流的大数据应用平台。以分布式文件系统(HDFS)和MapReduce为核心的Hadoop,目前已整合了其他重要组件如Hive、HBase、Spark,以及统一资源调度管理组件Yarn,形成了一个完成的Hadoop产品生态圈。 1.1.HDFS HDFS是一个分布式文件系统,可设计部署在低成本硬件上。它可以通过提供高吞吐率支持大量数据的批量处理,同时支持应用程序流式访问系统数据。 1.2.MapReduce MapReduce是一种编程模型,用于大规模数据机的并行运算。MapReduce可以将一个任务分发到Hadoop平台各个节点上并以一种可靠容错的方式并行处理大量数据集,实现Hadoop的并行任务处理功能。 1.3.Hive Hive是用于对Hadoop中文件进行数据整理、特殊查询和分析储存的工具。Hive提供了一种结构化数据的机制,支持类似传统结构化数据库中SQL元的查询语言,帮助熟悉SQL的用户查询HDFS中数据。 1.4.HBase HBase是一个分布式的、列式储存的开源数据库。HBase不同于传统关系型数据库,适合非结构化数据储存,同时可以为一个数据行定义不同的列。HBase 主要用于需要随机访问、实时读写的大数据。 1.5.Spark Spark是基于内存计算的分布式计算框架。Spark提出了RDD概念,弥补了MapReduce在并行计算各个阶段无法进行有效数据共享的缺陷。同时,Spark形成了自己的生态系统:SparkSQL、SparkStreaming、MLlib,并完全兼容Hadoop 生态系统。
用友软件T3 用友通数据库表结构、表名 fa_Control 30_ 记录互斥fa_Departments 07_ 部门fa_Depreciations 11_ 折旧方法 fa_DeprList 34_ 折旧日志fa_DeprTransactions 19_ 折旧fa_DeprVoucherMain 23_ 折旧分配凭证主表fa_DeprVouchers 24_ 折旧分配凭证 fa_DeprVouchers_pre 24_ 折旧分配凭证_准备fa_Dictionary 12_ 常用参照字典 fa_EvaluateMain 21_ 评估单主表 fa_EvaluateVouchers 22_ 评估单fa_Items 12_ 项目fa_ItemsManual 32_ 自定义项目 fa_ItemsOfModel 14_ 对应各样式的项目 fa_ItemsOfQuery 35_ 查询项目fa_Log 33_ 日志fa_Models 13_ 样式fa_Msg 29_ 信息 fa_Objects 03_ 对象表fa_Operators 02_ 操作员fa_Origins 09_ 增减方式fa_QueryFilters 05_ 查询条件fa_Querys 04_ 查询 fa_ReportTemp fa_Status 10_ 使用状况 fa_Total 31_ 汇总表Accessaries 成套件表AccInformation 账套参数表Ap_AlarmSet 单位报警分类设置表Ap_BillAge 账龄区间表 Ap_Cancel 核销情况表Ap_CancelNo 生成自动序号Ap_CloseBill 收付款结算表Ap_CtrlCode 控制科目设置表Ap_Detail 应收/ 付明细账 AP_DispSet 查询显示列设置表Ap_InputCode 入账科目表Ap_InvCode 存货科目设置表 Ap_Lock 操作互斥表 Ap_MyTableSet 查询条件存储表 Ap_Note 票据登记簿 Ap_Note_Sub 票据登记簿结算表 Ap_SStyleCode 结算方式科目表 Ap_Sum应收/ 付总账表 Ap_Vouch 应付/ 收单主表 Ap_Vouchs 应付/ 收单主表的关联表 Ap_VouchType 单据类型表 Ar_BadAge 坏账计提账龄期间表 Ar_BadPara 坏账计提参数表 ArrivalVouch 到货单、质检单主表ArrivalVouchs 到货单、质检单子表AssemVouch 组装、拆卸、形态转换单主表
数据挖掘与数据仓库课程简介 英文名:Data Mining and Data Warehouse 开课单位:计算机学院 课程编码:203086 学分学时:学分,学时32(含实验10) 授课对象:计算机科学与技术专业方向选修课 先修课程:数据库 课程目的和主要内容: 通过本课程的学习,学生应能理解数据库技术的发展为何导致需要数据挖掘,以及数据挖掘潜在应用的重要性;掌握数据仓库和多维数据结构,OLAP(联机分析处理)的实现以及数据仓库与数据挖掘的关系;熟悉数据挖掘之前的数据预处理技术;了解定义数据挖掘任务说明的数据挖掘原语;掌握数据挖掘技术的基本算法,为将来从事数据仓库的规划和实施以及数据挖掘技术的研究工作打下一定的基础。 主要内容包括数据仓库和数据挖掘的基本知识;数据清理、数据集成和变换、数据归约以及离散化和概念分层等数据预处理技术;DMQL数据挖掘查询语言;用于挖掘特征化和比较知识的面向属性的概化技术、用于挖掘关联规则知识的基本Apriori算法和它的变形、用于挖掘分类和预测知识的判定树分类算法和贝叶斯分类算法以及基于划分的聚类分析算法等;了解先进的数据库系统中的数据挖掘方法,以及对数据挖掘和数据仓库的实际应用问题展开讨论。 参考教材: 《数据挖掘概念与技术》,机械工业出版社,JiaWei Han,Micheline Kamber著,范明等译 参考和阅读书目: 《Data Mining: Concepts and Techniques》Jiawei Han and Micheline Kamber, Morgan Kaufmann, 2000 《机器学习》,Tom Mitchell著,曾华军等译 《SQLServer2000数据挖掘技术指南》,机械工业出版社,Claude Seidman著,刘艺等译 数据挖掘与数据仓库教学大纲 一、课程概况 英文名:Data Mining and Data Warehouse 开课单位:计算机学院 课程编码:203086 学分学时:学分,学时32(含实验10) 授课对象: 先修课程:数据库 课程目的和主要内容: 通过本课程的学习,学生应能理解数据库技术的发展为何导致需要数据挖掘,以及数据
数据仓库之路 FAQ FAQ目录 一、与数据仓库有关的几个概念 (3) 1.1 目录 (3) 二、数据仓库产生的原因 (8) 三、数据仓库体系结构图 (11) 四、数据仓库设计 (12) 4.1 数据仓库的建模 (12) 4.2 数据仓库建模的十条戒律: (13) 五、数据仓库开发过程 (14) 5.1 数据模型的内容 (14) 5.2 数据模型转变到数据仓库 (14)
5.3 数据仓库开发成功的关键 (15) 六、数据仓库的数据采集 (16) 6.1 后台处理 (17) 6.2 中间处理 (17) 6.3 前台处理 (18) 6.4 数据仓库的技术体系结构 (18) 6.5 数据的有效性检查 (20) 6.6 清除和转换数据 (20) 6.7 简单变换 (22) 6.8 清洁和刷洗 (24) 6.9 集成 (25) 6.10 聚集和概括 (27) 6.11 移动数据 (27) 七、如何建立数据仓库 (30) 7.1 数据仓库设计 (31) 7.2 数据抽取模块 (32) 7.3 数据维护模块 (33)
一、与数据仓库有关的几个概念 1.1 目录 ?Datawarehouse ?Datamart ?OLAP ?ROLAP ?MOLAP ?ClientOLAP ?DSS ?ETL ?Adhocquery ?EIS ?BPR ?BI ?Datamining ?CRM ?MetaData Data warehouse 本世纪80年代中期,“数据仓库之父”William H.Inmon先生在其《建立数据仓库》一书中定义了数据仓库的概念,随后又给出了更为精确的定义:数据仓
数据库表结构: Admin(管理员表) 字段名描述类型约束备注ID唯一标示int Primary Key自增AdminType管理员类型int NOT NULL AdminName管理员姓名Char(12)NOT NULL LoginName管理员登录名CHAR(12)NOT NULL LoginPwd管理员登录密 码 CHAR(12)NOT NULL cart(购物车基本信息表) 字段名描述类型约束备注 ID唯一标示int Primary Key 自增 Member会员号int NOT NULL Money消费金额decimal(9,2)NOT NULL CartStatus购物车状态int NOT NULL 0代表商品放入购物车还未下单,1代表商品放入购物车且已下单 cartselectedmer 字段名描述类型约束备注ID唯一标示int Primary自增
Key Cart购物车int NOT NULL Merchandise商品int NOT NULL Number数量int NOT NULL Price商品市场价decimal(8,2)NOT NULL Money消费总额demical(9,2)NOT NULL category(商品类别表) 字段名描述类型约束备注 自增ID唯一标示int Primary Key CateName商品类别Char(40)NOT NULL CateDesc商品描述tex NOT NULL Leaveword(顾客留言表) 字段名描述类型约束备注 自增ID唯一标示int Primary Key Member会员号int NOT NULL Admin管理员int NOT NULL Number数量int NOT NULL Price商品单价decimal(8,2)NOT NULL Money消费总额demical(9,2)NOT NULL
1.数据仓库 1.1.概念 数据仓库项目是以关系数据库为依托,以数据仓库理论为指导、以OLAP为多层次多视角分析,以ETL工具进行数据集成、整合、清洗、加载转换,以前端工具进行前端报表展现浏览,以反复叠代验证为生命周期的综合处理过程。最终目标是为了达到整合企业信息信息,把数据转换成信息、知识,提供决策支持。 1.2.数据源 数据库、磁带、文件、网页等等。同一主题的数据可能存储在不同的数据库、磁带、甚至文件、网页里都有。 1.3.数据粒度 粒度问题第一反应了数据细化程度;第二在决策分析层面粒度越大,细化程度越低。一般情况,数据仓库需求存储不同粒度的数据来满足不同层面的要求。 例子如顾客的移动话费信息。 1.4.数据分割 分割结构相同的数据,保证灵活的访问数据。 1.5.设计数据仓库 ●与OLTP系统的接口设计:ETL设计 ●数据仓库本身存储模型的设计:数据存储模型设计 1.6.ETL设计难点 数据仓库有多个应用数据源,导致同一对象描述方式不同: ●表达方式不同:字段类型不同 ●度量方式不同:单位不同 ●对象命名方式不同:字段名称不同 ●数据源的数据是逐步加载到数据仓库,怎么确定数据已经加载过 ●如何避免对已经加载的数据的读取,提高性能 ●数据实时发生变化后怎么加载
2.数据存储模型 过程模型:适用于操作性环境。 数据模型:适用于数据仓库和操作性环境。 数据模型从设计的角度分:高层次模型(实体关系型),中间层建模(数据项集),物理模型。 2.1.数据仓库的存储方式 数据仓库的数据由两种存储方式:一种是存储在关系数据库中,另一种是按多维的方式存储,也就是多维数组。 2.2.数据仓库的数据分类 数据仓库的数据分元数据和用户数据。 用户数据按照数据粒度分别存放,一般分四个粒度:早期细节级数据,当前细节级数据,轻度综合级,高度综合级。 元数据是定义了数据的数据。传统数据库中的数据字典或者系统目录都是元数据,在数据仓库中元数据表现为两种形式:一种是为了从操作型环境向数据仓库环境转换而建立的元数据,它包含了数据源的各种属性以及转换时的各种属性;另一种元数据是用来与多维模型和前端工具建立映射用的。 2.3.数据存储模型分类 多维数据建模以直观的方式组织数据,并支持高性能的数据访问。每一个多维数据模型由多个多维数据模式表示,每一个多维数据模式都是由一个事实表和一组维表组成的。 多维模型最常见的是星形模式。在星形模式中,事实表居中,多个维表呈辐射状分布于其四周,并与事实表连接。 在星型的基础上,发展出雪花模式。通常来说,数据仓库使用星型模型。 2.3.1.星型模型 位于星形中心的实体是指标实体,是用户最关心的基本实体和查询活动的中心,为数据仓库的查询活动提供定量数据。每个指标实体代表一系列相关事实,完成一项指定的功能。 位于星形图星角上的实体是维度实体,其作用是限制用户的查询结果,将数据过滤使得从指标实体查询返回较少的行,从而缩小访问范围。每个维表有自己的属性,维表和事实表通过关键字相关联。 星形模式虽然是一个关系模型,但是它不是一个规范化的模型。在星形模式中,维度表被故意地非规范化了,这是星形模式与OLTP系统中的关系模式的基本区别。 使用星形模式主要有两方面的原因:提高查询的效率。采用星形模式设计的数据仓库的优点是由于数据的组织已经过预处理,主要数据都在庞大的事实表中,所以只要扫描事实表
数据仓库的设计与实现
第1章数据仓库的设计与实现 1.1数据仓库设计过程 数据仓库的设计一般从操作型数据开始,通常需要经过以下几个处理过程;数据仓库设计——数据抽取——数据管理。 一、数据仓库设计 根据决策主题设计数据仓库结构,一般采用星型和雪花模型设计其数据模型,在设计过程中应保证数据仓库的规范化和体系各元素的必要联系。 二、数据抽取 根据元数据库中的主题表定义、数据源定义、数据抽取规则定义对异地异构数据源进行清理、转换、对数据进行重新组织和加工,装载到数据仓库的目标库中。 三、数据管理 数据管理分为目标数据维护和元数据维护两方面。目标数据维护是根据元数据为所定义的更新频率、更新数据项等更新计划任务来刷新数据仓库,以反映数据源的变化,且对时间相关性进行处理。元数据是数据仓库的组成部分,元数据的质量决定整个数据仓库的质量。当数据源的运行环境、结构及目标数据的维护计划发生变化时,需要修改元数据。 1.2需求分析与决策主题的选取 通过对管理者和各级别的用户的数据分析需求进行调研,我们收集并整理出了用户的决策分析需求如下: 1.2.1 博士学位授予信息年度数据统计分析 一、按主管部门统计 从主管部门的角度,分析在一个时间段(年)内,各主管部门所授予的博士学位信息统计。可回答如“2008,由某部门主管的,博士学位授予一共有多少,其平均学习年限是多少,脱产学习的有多少人?”等问题。具有表格和图形两种方式来展示分析结果。典型报表格式如表1所示。
表1 200__年度授予博士学位情况统计表(按主管部门统计) 表1续200__年度授予博士学位情况统计表(按主管部门统计) 二、按性质类别统计
5.3.1新闻发布统计分析1.分析逻辑设计 2.数据组织设计 1)分析来源表
2)数据组织设计 表:YongRi_NewsArticles_Category 表:yongri_newsarticles_article
存储过程JZ_GetReport_XWFB USE[Zjsme] GO /****** Object: StoredProcedure [dbo].[JZ_GetReport_XWFB] Script Date: 05/28/2013 17:00:10 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO -- ============================================= -- Author:
SELECT CASE WHEN ISNULL(parentname,'')=''THEN'其他'ELSE parentname END,SUM(TM) FROM(select parentname,parentname as name,sum(isnull(sl,0))tm from ( select a.categoryid,name,parentid, parentname= case when parentid= 0 then name when parentid<> 0 then (select name from YongRi_NewsArticles_Category b where parentid= 0 and a.parentid=b.categoryid) end, d.sl from YongRi_NewsArticles_Category a left join( select categoryid,isnull(count(1),0)sl from yongri_newsarticles_article WHERE UpdatedDate BETWEEN@dtmBeginDate AND@dtmEndDate group by categoryid) d on a.categoryid=d.categoryid )c group by parentname union all select parentname,name,sl from ( select a.categoryid,name,parentid, parentname= case when parentid= 0 then name when parentid<> 0 then (select name from YongRi_NewsArticles_Category b where parentid= 0 and a.parentid=b.categoryid) end, d.sl from YongRi_NewsArticles_Category a left join( select categoryid,count(1)sl from yongri_newsarticles_article group by categoryid)d on a.categoryid=d.categoryid
数据仓库成功案例3 兴业证券数据仓库系统 编者按:兴业证券选择了Sybase的数据仓库解决方案,以帮助其成功地实现交易数据的集中处理和分析。该系统的应用采用三层式数据仓库结构,使系统具有优越的处理性能、高度可扩展性、开放性、灵活性和可管理性。 用户背景 兴业证券作为一家综合类专业证券公司、中国证券业协会理事单位,在福建省乃至全国的证券界都具有一定的影响力。公司总部设在福州,在上海也设立了区域管理总部,已经初步构建了辐射全国的业务经营机构网络。在中国加入WTO之后,兴业证券也面临着新的挑战和机遇。如何将现有的优势充分发挥并创造新的竞争优势,从而加强其在证券行业的领先地位,是兴业证券面临的重要课题。 从2001年7月开始,Sybase公司与兴业证券合作,共同开发兴业证券数据仓库和决策支持系统,帮助兴业证券总部实现对营业部集中管理和数据集中基础上的决策支持。 系统目标 兴业证券对现有信息系统的要求: * 对各个营业部交易数据汇总整合信息来源,从而提高决策信息的及时性、准确性、全局性、一致性; * 建立全面、统一、科学的日常决策分析报表/查询系统; * 深层次的信息加工,分析客户、市场、风险等主题项目,充分利用兴业证券的丰富数据; * 系统必须保证系统中每一条信息的安全性,对信息的访问进行安全性控制,这样才能充分保证信息不会泄漏,以维护证券市场的秩序; * 建立具有高处理能力和高扩展能力的数据仓库平台,以适应管理和处理日益庞大的市场数据的要求。 数据仓库系统将帮助兴业证券充分利用信息资源,为兴业证券提供坚实的信息基础以迎接上述的业务挑战和机遇。 建立数据仓库系统的目标: * 为各业务部门、兴业证券的领导层提供有效的决策管理信息支持,提高业务效率、
用友软件T3用友通数据库表结构、表名fa_Control 30_记录互斥 fa_Departments 07_部门 fa_Depreciations 11_折旧方法 fa_DeprList 34_折旧日志 fa_DeprTransactions 19_折旧 fa_DeprV oucherMain 23_折旧分配凭证主表 fa_DeprV ouchers 24_折旧分配凭证 fa_DeprV ouchers_pre 24_折旧分配凭证_准备 fa_Dictionary 12_常用参照字典 fa_EvaluateMain 21_评估单主表 fa_EvaluateV ouchers 22_评估单 fa_Items 12_项目 fa_ItemsManual 32_自定义项目 fa_ItemsOfModel 14_对应各样式的项目 fa_ItemsOfQuery 35_查询项目 fa_Log 33_日志 fa_Models 13_样式 fa_Msg 29_信息 fa_Objects 03_对象表 fa_Operators 02_操作员 fa_Origins 09_增减方式
fa_QueryFilters 05_查询条件 fa_Querys 04_查询 fa_ReportTemp fa_Status 10_使用状况 fa_Total 31_汇总表 Accessaries 成套件表AccInformation 账套参数表 Ap_AlarmSet 单位报警分类设置表Ap_BillAge 账龄区间表 Ap_Cancel 核销情况表 Ap_CancelNo 生成自动序号 Ap_CloseBill 收付款结算表 Ap_CtrlCode 控制科目设置表 Ap_Detail 应收/付明细账 AP_DispSet 查询显示列设置表 Ap_InputCode 入账科目表 Ap_InvCode 存货科目设置表 Ap_Lock 操作互斥表 Ap_MyTableSet 查询条件存储表Ap_Note 票据登记簿 Ap_Note_Sub 票据登记簿结算表Ap_SStyleCode 结算方式科目表
一、数据维护(发言人:刘海河) 1、数据维护所用的表。 (1)、基本数据表 UFSYSTEM表 建立帐套UA_ACCOUNT表 操作员UA_USER 表 操作员权限UA HOLDAUTH表 会计日历UA_PERIOD表 UFDA TA.MDB 编码方案GRADEDEF表 ACCINFORMA TION表 数据据精度ACCINFORMA TION表(包括各模块的选项)部门档案DEPARTMENT 职员档案PERSON 客户分类CUSTOMERCLASS 客户档案CUSTOMER 供应商分类VEMDORCLASS 供应商档案VENDOR 地区分类DISTRICTCLASS 存货分类INVENTORYCLASS 存货档案INVENTORY 科目表CODE 凭证类别DSIGN(S) 项目大类FITEM*** 外币设置汇率表EXCH 币种表FOREIGNCURRENCY 结处方式SETTLSSTYLE 付款条件PAYCONDITION 开户银行BANK 仓库档案W AREHOUSE 收发记录PR_STYLE 采购类型PURCHASETYPE 销售类型SULETYPE 产品结构PRODNCTSTRUCTURE(S) 成套件ACCESSARIES 费用项目EXPENSITEM 成本对象COSTOBJ 发运方式SHIPPINGCHOICE 常用摘要GL_BDIGEST 常用凭证GL_LFREA 自定义项自定义项定义表USERDEF 自定义项编码表USERDEFINE
采购计划 采购计划所用的数据表:采购周期(PP_Penod) 存货档案(Inventory) 产品结构Productstructure(s) 生产计划(PP_MPSmain、PP_MPSdetail) 相关需求(PP_RMRPmain、PP_RMRPdetail) 独立需求(PP_IMRPmain、PP_IMRPdetail)。 计划周期(PP_Period) 采购计划(PP_PPCmain、PP_PPCdetail) 业务处理: 采购周期(PP_Penod)、存货档案(Inventory)、产品结构(Productstructure(s))录入数据进行相对应的表中。 材料成本:不生成表,只根据存货档案(Inevntory)中的计划价、参考成本、最新成本。 生产计划:从采购周期(Pp_penod)、产品结构(Productstructure(s))审核后,写入生产计划表(PP_MPSmain、PP_MPSdetail)。 相关需求:从生产计划(PP_MPSmain、PP_MPSdetail)与采购周期(PP_Penod)中写入相关需求(PP_RMRPmain、PP_RMRPdetail)的两个表中。 独立需求:从存货档案(Inventory)中读出数据,写入独立需求(PP_IMRPmain、PP_IMRPdetail)。 汇总审核物料需求:从采购周期(PP_Penod)、相关需求(PP_RMRPmain、PP_RMRPdetail)、独立需求(PP_IMRPmain、PP_IMRPdetail)中只读出数据,写入计划周期表(PP_Period)。 生成审核采购计划:从采购周期(PP_Penod)、相关需求(PP_RMRPmain、PP_RMRPdetail)、独立需求(PP_IMRPmain、PP_IMRPdetail)、存货(Inventory)中读出,写入采购计划主、子表(PP_PPCmain、PP_PPCdetail)。 与入库单建立关联:从采购计划(PP_PPCmain、PP_PPCdetail),采购入库单(Rdrecord、Rdrecords)读出,写入关联关系(PP_pu)表。(此作用是用来查询采购完成情况)。 采购管理 采购管理所用的表:Rd Record 收发记录主表 RdRecords 收发记录子表 PurBillV ouch 采购发票主表 PurBillV ouchs 采购发票子表 PurSettleV ouch 采购结算单主表 PurSettleV ouchs 采购结算单子表 PU_LeftSum 采购余额一览表 GL_accV ouch 凭证及明细帐 AP_CloseBill 收付款结算表 PO_Pomain 采购订单主表
数据库表结构说明文档目录 接口 3 RIS/PACS接口中间表 RIS.BROKER 3 业务 4 病人信息表 RIS.TPATIENT 4 检查状态表 RIS.TEXAMINATION 5 诊断报告 RIS.TREPORT 8 病历追踪表 RIS.TMEDICALTRACK 9 基础数据 9 系统参数表 RIS.TPARAM 9 病人来源表 RIS.TPATIENTSOURCE 9 检查部位表 RIS.TCHECKPART 10 检查仪器资料表 RIS.TCHECKSET 10 临床诊断表RIS.TCLINICDIAG 11 请检医生表 RIS.TCLINICDOCTOR 11 请检科室表RIS.TDEPARTMENT 11
影像设备表RIS.TDEVICE 11 设备类型表 RIS.TDEVICETYPE 12 诊室信息表 RIS.TWORKROOM 12 报告元素表 RIS.TREGFIELDS 12 模板表 RIS.TTEMPLATE 13 诊断报告模板表 RIS.T_REPORT_TEMPLATE 13 权限/日记 14 操作日记表RIS.TLOG 14 报告日志表 RIS.TREPORTLOG 14 菜单项表 RIS.T_MENU 15 操作员表 RIS.T_OPER 15 角色列表 RIS.T_ROLE 16 角色-菜单配置表 RIS.T_ROLE_CFG 16 其他 16 图像表 RIS.TPICTURE 16 图片路径表 RIS.TPICTUREUSIS 17 排队队列表 RIS.TQUEUELIST 17
预约表 RIS.TRESERVATION 17 收费项目对应默认设备、检查部位设置 RIS.TSFXMDYSB 18 诊断报告 RIS.T_DIAG_REPORT 19 未分类 20 RIS.DEPT 20 RIS.EMP 20 RIS.EMP1 20 RIS.EMP2 21 RIS.PACS_PATIENT 21 RIS.PACS_USER 21 RIS.TCHECKPARTTYPE 22 RIS.TDOCNAMEPIC 22 RIS.TFAVORITE 22 RIS.TFP 22 RIS.THINTINFO 22 RIS.THISSOURCE 23 RIS.TLOGIN 23