
《数值分析与算法》喻文健,清华大学出版社,例题matlab源程序
%P33 example 2-2
a=1.0;
b=1.5;
while b-a>eps
x=a+(b-a)/2
if f_ex22(a)*f_ex22(x)>0 a=x;
else
b=x;
end
end
%P36 example 2-4
x=1.5
for i=1:10
x=(x+2)^(1/4)
end
%P42 example 2-7
x=1.5
for i=1:10
x=(3*x^4+2)/(4*x^3-1) end
%P54 example2-9
x01=1;
x02=2;
x0=[x01;x02];
for i=1:8
x01=x0(1,1);
x02=x0(2,1);
f01=x01+2*x02-2;
f02=x01^2+4*x02^2-4;
J01=[1,2];
J02=[2*x01,8*x02];
s0=inv([J01;J02])*[f01;f02]x1=x0-s0
x0=x1;
end
P94 example 3-14
A=[5 -1 -1;-1 3 -1;-1 -1 5];
A(:,1)=A(:,1)./sqrt(A(1,1));
A(2,2)=sqrt(A(2,2)-A(2,1)^2);
A(3,2)=(A(3,2)-A(3,1)^2)/A(2,2); A(3,3)=sqrt(A(3,3)-A(3,1)^2-A(3, 2)^2);
%%% P111, 6
n=12;
a=hilb(n);
x=ones(n,1);
b=a*x;
b=b+10^(-7)*ones(n,1);
L=chol(a,'lower'); %Cholesky
y=ones(n,1);
y(1)=b(1)/L(1,1);
for i=2:n
y(i)=(b(i)-sum(L(i,1:i-1)*y(1:i-1,1)))/L(i,i);%% L lower
end
M=L';
x(n)=y(n)/M(n,n);
for i=n-1:-1:1
x(i)=(y(i)-sum(M(i,i+1:n)*y(i+1: n,1)))/M(i,i);%% L' upper
end
r=b-a*x;
delt_x=x-ones(n,1);
norm_r=norm(r,inf) % norm of r norm_delt_x=norm(delt_x,inf) % norm of delt_x
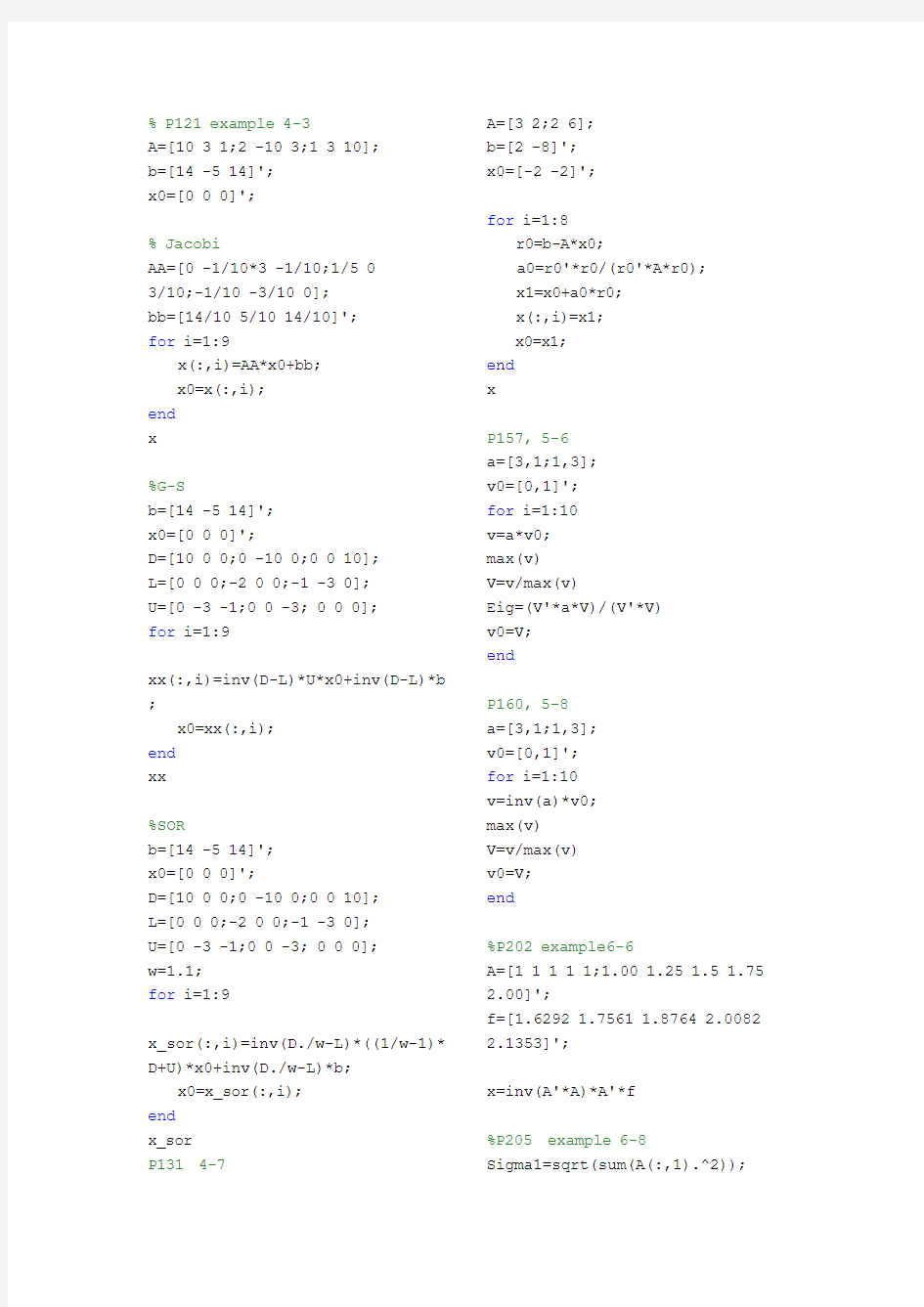
% P121 example 4-3
A=[10 3 1;2 -10 3;1 3 10];
b=[14 -5 14]';
x0=[0 0 0]';
% Jacobi
AA=[0 -1/10*3 -1/10;1/5 0
3/10;-1/10 -3/10 0];
bb=[14/10 5/10 14/10]';
for i=1:9
x(:,i)=AA*x0+bb;
x0=x(:,i);
end
x
%G-S
b=[14 -5 14]';
x0=[0 0 0]';
D=[10 0 0;0 -10 0;0 0 10];
L=[0 0 0;-2 0 0;-1 -3 0];
U=[0 -3 -1;0 0 -3; 0 0 0];
for i=1:9
xx(:,i)=inv(D-L)*U*x0+inv(D-L)*b ;
x0=xx(:,i);
end
xx
%SOR
b=[14 -5 14]';
x0=[0 0 0]';
D=[10 0 0;0 -10 0;0 0 10];
L=[0 0 0;-2 0 0;-1 -3 0];
U=[0 -3 -1;0 0 -3; 0 0 0];
w=1.1;
for i=1:9
x_sor(:,i)=inv(D./w-L)*((1/w-1)* D+U)*x0+inv(D./w-L)*b;
x0=x_sor(:,i);
end
x_sor
P131 4-7 A=[3 2;2 6];
b=[2 -8]';
x0=[-2 -2]';
for i=1:8
r0=b-A*x0;
a0=r0'*r0/(r0'*A*r0);
x1=x0+a0*r0;
x(:,i)=x1;
x0=x1;
end
x
P157, 5-6
a=[3,1;1,3];
v0=[0,1]';
for i=1:10
v=a*v0;
max(v)
V=v/max(v)
Eig=(V'*a*V)/(V'*V)
v0=V;
end
P160, 5-8
a=[3,1;1,3];
v0=[0,1]';
for i=1:10
v=inv(a)*v0;
max(v)
V=v/max(v)
v0=V;
end
%P202 example6-6
A=[1 1 1 1 1;1.00 1.25 1.5 1.75 2.00]';
f=[1.6292 1.7561 1.8764 2.0082 2.1353]';
x=inv(A'*A)*A'*f
%P205 example 6-8
Sigma1=sqrt(sum(A(:,1).^2));
v1=A(:,1)+Sigma1*[1 0 0 0 0]';
A1=A(:,1)-2*(v1'*A(:,1))./(v1'*v 1)*v1
A2=A(:,2)-2*(v1'*A(:,2))./(v1'*v 1)*v1
f2=f-2*(v1'*f)./(v1'*v1)*v1
AA=[A1,A2]
A2(1)=0;
Sigma2=-sqrt(sum(A2.^2))
v2=A2+Sigma2*[0 1 0 0 0]';
f3=f2-2*(v2'*f2)./(v2'*v2)*v2
A3=A2-2*(v2'*A2)./(v2'*v2)*v2
A3(1)=AA(1,2)
AAA=[A1,A3]
x=inv(AAA(1:2,1:2))*f3(1:2,1)
P218, 6-11
x=[0.4 0.55 0.65 0.8 0.9 1.05];
f=[0.41075 0.57815 0.69675 0.88811 1.02652 1.25382];
diff_1=(f(2:6)-f(1:5))./(x(2:6)-
x(1:5))
diff_2=(diff_1(2:5)-diff_1(1:4)) ./(x(3:6)-x(1:4))
diff_3=(diff_2(2:4)-diff_2(1:3)) ./(x(4:6)-x(1:3))
diff_4=(diff_3(2:3)-diff_3(1:2)) ./(x(5:6)-x(1:2))
diff_5=(diff_4(2)-diff_4(1))./(x (6)-x(1))
P230, 6-13
x=1:6;
y=[16 18 21 17 15 12];xi=0.75:0.05:6.25;
p=polyfit(x,y,5);
v1=polyval(p,xi);
v2=interp1(x,y,xi,'linear');
v3=interp1(x,y,xi,'pchip');
v4=interp1(x,y,xi,'spline'); subplot(2,2,1);plot(x,y,'o',xi,v 1,'-');
subplot(2,2,2);plot(x,y,'o',xi,v 2,'-');
subplot(2,2,3);plot(x,y,'o',xi,v 3,'-');
subplot(2,2,4);plot(x,y,'o',xi,v 4,'-');
%P249 example 7-4
x=0:1/8:1;
f=sin(x)./x;
f(1)=1;
% T
n=8;
h=(1-0)/n;
T=1/2*h*(f(1)+f(9)+2*sum(f(2:8)) )
%S
n=4;
h=(1-0)/n;
S=h/6*(f(1)+f(9)+4*sum(f(2:2:8)) +2*sum(f(3:2:7)))
%P255 example 7-5
%第二列
T01=1/2*(f(1)+f(9))
T02=T01/2+1/2*(f(5))
T03=T02/2+1/4*(f(3)+f(7))
%第三列
T11=1/3*(4*T02-T01)
T12=1/3*(4*T03-T02)
%第四列
T21=1/15*(16*T12-T11)
%P255 example 7-6
format long
T0=0.5;
h=1;
for i=1:5
a=1:2:2^i-1;
x=a/(2^i);
sum1=sum(x.^(3/2));
T=1/2*T0+h/2*sum1
T0=T;
TT(i)=T;
h=h/2;
end
TT=[0.5,TT]
TT1=1/3*(4*TT(2:6)-TT(1:5))
TT2=1/15*(16*TT1(2:5)-TT1(1:4)) TT3=1/(4^3-1)*(4^3*TT2(2:4)-TT2( 1:3))
TT4=1/(4^4-1)*(4^4*TT3(2:3)-TT3( 1:2))
TT5=1/(4^5-1)*(4^5*TT4(2)-TT4(1) )
P267, 7-10
for i=1:12
h=10^(-i);
x=2;
Dc=(sqrt(x+h)-sqrt(x-h))/(2*h) end
P270, 7-11
h=0.1;
x=0.5;
x1=x+h;
x2=x-h;
Dc1=(x1^2*exp(-x1)-x2^2*exp(-x2) )/(2*h);
h=0.05;
x=0.5;
x1=x+h;
x2=x-h;Dc2=(x1^2*exp(-x1)-x2^2*exp(-x2) )/(2*h);
h=0.025;
x=0.5;
x1=x+h;
x2=x-h;
Dc3=(x1^2*exp(-x1)-x2^2*exp(-x2) )/(2*h);
D1c1=1/3*(4*Dc2-Dc1)
D1c2=1/3*(4*Dc3-Dc2)
D2c1=1/15*(16*D1c2-D1c1)
P288, 8-7
format long
y1=0.4;
h=0.1;
t0=1;
for i =1:10
t=t0;
y=y1;
k1=t^3-y/t;
t=t0+h/2;
y=y1+h/2*k1;
k2=t^3-y/t;
t=t0+h/2;
y=y1+h/2*k2;
k3=t^3-y/t;
t=t0+h;
y=y1+h*k3;
k4=t^3-y/t;
y=y1+h/6*(k1+2*k2+2*k3+k4)
yy=1/5*t^4+1/(5*t)
y1=y;
t0=t; end
模糊聚类 function c=fuz_hc(a,b) %模糊矩阵的合成运算程序 %输入模糊矩阵a,b,输出合成运算结果c m=size(a,1);n=size(b,2);p=size(a,2); %错误排除 if size(a,2)~=size(b,1) disp('输入数据错误!');return; end %合成运算 for i=1:m for j=1:n for k=1:p temp(k)=min(a(i,k),b(k,j)); end c(i,j)=max(temp); end end disp('模糊矩阵a与b作合成运算后结果矩阵c为:'); c % 求模糊等价矩阵 function r_d=mhdj(r) [m,n]=size(r); for i=1:n for j=1:n for k=1:n r1(i,j,k)=min(r(i,k),r(k,j)); end r1max(i,j)=r1(i,j,1); end end for i=1:n for j=1:n for k=1:n
if r1(i,j,k)>r1max(i,j) r1max(i,j)=r1(i,j,k); end end r_d(i,j)=r1max(i,j); end end %模糊聚类程序 function f=mujl(x,lamda) %输入原始数据以及lamda的值 if lamda>1 disp('error!') %错误处理 end [n,m]=size(x); y=pdist(x); disp('欧式距离矩阵:'); dist=squareform(y) %欧氏距离矩阵 dmax=dist(1,1); for i=1:n for j=1:n if dist(i,j)>dmax dmax=dist(i,j); end end end disp('处理后的欧氏距离矩阵,其特点为每项元素均不超过1:'); sdist=dist/dmax %使距离值不超过1 disp('模糊关系矩阵:'); r=ones(n,n)-sdist %计算对应的模糊关系矩阵 t=mhdj(r); le=t-r; while all(all(le==0)==0)==1 %如果t与r相等,则继续求r乘以r r=t; t=mhdj(r); le=t-r;
2. Matlab程序 2.1 一次聚类法 X=[11978 12.5 93.5 31908;…;57500 67.6 238.0 15900]; T=clusterdata(X,0.9) 2.2 分步聚类 Step1 寻找变量之间的相似性 用pdist函数计算相似矩阵,有多种方法可以计算距离,进行计算之前最好先将数据用zscore 函数进行标准化。 X2=zscore(X); %标准化数据 Y2=pdist(X2); %计算距离 Step2 定义变量之间的连接 Z2=linkage(Y2); Step3 评价聚类信息 C2=cophenet(Z2,Y2); //0.94698 Step4 创建聚类,并作出谱系图 T=cluster(Z2,6); H=dendrogram(Z2); Matlab提供了两种方法进行聚类分析。 一种是利用 clusterdata函数对样本数据进行一次聚类,其缺点为可供用户选择的面较窄,不能更改距离的计算方法; 另一种是分步聚类:(1)找到数据集合中变量两两之间的相似性和非相似性,用pdist函数计算变量之间的距离;(2)用 linkage函数定义变量之间的连接;(3)用 cophenetic函数评价聚类信息;(4)用cluster函数创建聚类。 1.Matlab中相关函数介绍 1.1 pdist函数 调用格式:Y=pdist(X,’metric’) 说明:用‘metric’指定的方法计算 X 数据矩阵中对象之间的距离。’ X:一个m×n的矩阵,它是由m个对象组成的数据集,每个对象的大小为n。 metric’取值如下: ‘euclidean’:欧氏距离(默认);‘seuclidean’:标准化欧氏距离; ‘mahalanobis’:马氏距离;‘cityblock’:布洛克距离; ‘minkowski’:明可夫斯基距离;‘cosine’: ‘correlation’:‘hamming’: ‘jaccard’:‘chebychev’:Chebychev距离。 1.2 squareform函数 调用格式:Z=squareform(Y,..) 说明:强制将距离矩阵从上三角形式转化为方阵形式,或从方阵形式转化为上三角形式。 1.3 linkage函数 调用格式:Z=linkage(Y,’method’) 说明:用‘method’参数指定的算法计算系统聚类树。 Y:pdist函数返回的距离向量;
MATLAB数值计算 MATLAB数值计算 (1) 1创建矩阵 (3) 1.1直接输入 (3) 1.2向量 (3) 1.2.1linspace:线性分布 (3) 1.2.2冒号法 (3) 1.3函数创建 (4) 1.3.1eye:单位矩阵 (4) 1.3.2rand:随机矩阵 (4)
1.3.3zeros:全0矩阵 (4) 1.3.4ones:全1矩阵 (5) 2矩阵运算 (5) 2.1加减 (5) 2.1.1[M×N]±[M×N] (5) 2.2乘 (6) 2.2.1[M×N]*a (6) 2.2.2[M×N]*[N×M] (6) 2.3乘方 (7) 2.3.1[M×M]^a (7) 2.3.2a^[M×M] (7) 2.4特殊运算 (8) 2.4.1求逆inv (8) 2.4.2行列式det (8) 2.4.3特征值eig (8) 2.4.4转置'和.' (9) 2.4.5变形reshape (10) 2.4.6翻转rot90,fliplr,flipud (11) 2.4.7抽取diag,tril,triu (12) 2.5数组运算 (12) 2.5.1乘 (12) [M×N].*[M×N] (12) 2.5.2除 (13) [M×N]./[M×N] (14) [M×N].\[M×N] (14) 2.5.3乘方 (14) [M×N].^[M×N] (15) a.^[M×N] (15) 2.6除法 (15) 2.6.1求解线性方程组 (15) 3多项式 (16) 3.1系数表示法poly (16) 3.2求根roots (16) 3.3乘法conv (16) 3.4除法deconv (17) 3.5求值polyval (17) 3.6微分polyder (18)
本文在阐述聚类分析方法的基础上重点研究FCM 聚类算法。FCM 算法是一种基于划分的聚类算法,它的思想是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。最后基于MATLAB实现了对图像信息的聚类。 第 1 章概述 聚类分析是数据挖掘的一项重要功能,而聚类算法是目前研究的核心,聚类分析就是使用聚类算法来发现有意义的聚类,即“物以类聚” 。虽然聚类也可起到分类的作用,但和大多数分类或预测不同。大多数分类方法都是演绎的,即人们事先确定某种事物分类的准则或各类别的标准,分类的过程就是比较分类的要素与各类别标准,然后将各要素划归于各类别中。确定事物的分类准则或各类别的标准或多或少带有主观色彩。 为获得基于划分聚类分析的全局最优结果,则需要穷举所有可能的对象划分,为此大多数应用采用的常用启发方法包括:k-均值算法,算法中的每一个聚类均用相应聚类中对象的均值来表示;k-medoid 算法,算法中的每一个聚类均用相应聚类中离聚类中心最近的对象来表示。这些启发聚类方法在分析中小规模数据集以发现圆形或球状聚类时工作得很好,但当分析处理大规模数据集或复杂数据类型时效果较差,需要对其进行扩展。 而模糊C均值(Fuzzy C-means, FCM)聚类方法,属于基于目标函数的模糊聚类算法的范畴。模糊C均值聚类方法是基于目标函数的模糊聚类算法理论中最为完善、应用最为广泛的一种算法。模糊c均值算法最早从硬聚类目标函数的优化中导出的。为了借助目标函数法求解聚类问题,人们利用均方逼近理论构造了带约束的非线性规划函数,以此来求解聚类问题,从此类内平方误差和WGSS(Within-Groups Sum of Squared Error)成为聚类目标函数的普遍形式。随着模糊划分概念的提出,Dunn [10] 首先将其推广到加权WGSS 函数,后来由Bezdek 扩展到加权WGSS 的无限族,形成了FCM 聚类算法的通用聚类准则。从此这类模糊聚类蓬勃发展起来,目前已经形成庞大的体系。 第 2 章聚类分析方法 2-1 聚类分析 聚类分析就是根据对象的相似性将其分群,聚类是一种无监督学习方法,它不需要先验的分类知识就能发现数据下的隐藏结构。它的目标是要对一个给定的数据集进行划分,这种划分应满足以下两个特性:①类内相似性:属于同一类的数据应尽可能相似。②类间相异性:属于不同类的数据应尽可能相异。图2.1是一个简单聚类分析的例子。
第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
Matlab作业3(数值分析) 机电工程学院(院、系)专业班组 学号姓名实验日期教师评定 1.计算多项式乘法(x2+2x+2)(x2+5x+4)。 答: 2. (1)将(x-6)(x-3)(x-8)展开为系数多项式的形式。(2)求解在x=8时多项 式(x-1)(x-2) (x-3)(x-4)的值。 答:(1) (2)
3. y=sin(x),x从0到2π,?x=0.02π,求y的最大值、最小值、均值和标准差。 4.设x=[0.00.30.8 1.1 1.6 2.3]',y=[0.500.82 1.14 1.25 1.35 1.40]',试求二次多项式拟合系数,并据此计算x1=[0.9 1.2]时对应的y1。解:x=[0.0 0.3 0.8 1.1 1.6 2.3]'; %输入变量数据x y=[0.50 0.82 1.14 1.25 1.35 1.40]'; %输入变量数据y p=polyfit(x,y,2) %对x,y用二次多项式拟合,得到系数p x1=[0.9 1.2]; %输入点x1 y1=polyval(p,x1) %估计x1处对应的y1 p = -0.2387 0.9191 0.5318 y1 = a) 1.2909
5.实验数据处理:已知某压力传感器的测试数据如下表 p为压力值,u为电压值,试用多项式 d cp bp ap p u+ + + =2 3 ) ( 来拟 合其特性函数,求出a,b,c,d,并把拟合曲线和各个测试数据点画在同一幅图上。解: >> p=[0.0,1.1,2.1,2.8,4.2,5.0,6.1,6.9,8.1,9.0,9.9]; u=[10,11,13,14,17,18,22,24,29,34,39]; x=polyfit(p,u,3) %得多项式系数 t=linspace(0,10,100); y=polyval(x,t); %求多项式得值 plot(p,u,'*',t,y,'r') %画拟和曲线 x = 0.0195 -0.0412 1.4469 9.8267
3.数据标准化 (1) 数据矩阵 设论域12345678910,1112U={,,,,,,,,,,}x x x x x x x x x x x x 为被分类的对象,每个 对象又由指标123456789Y={,,,,,,,,}y y y y y y y y y 表示其性状即12345678910,1112x ={,,,,,,,,,,}i i i i i i i i i i i i i x x x x x x x x x x x x (i=1,2,…,12)于是得到原是数据矩阵 7 5 2 5 0 1 3 4 2 12 17 8 21 9 2 38 4 37 83 29 59 65 37 20 54 13 26 53 13 31 36 21 A= 23 12 18 14 178 69 112 78 104 36 94 31 47 23 25 36 11 12 11 24 6 16 101 32 53 52 86 52 41 38 94 28 6 7 8 8 2 0 3 29 169 51 58 72 49 30 48 37 146 327 91 126 92 89 69 79 29 49 93 27 54 64 24 17 23 11 49 18 7 9 5 1 2 18 3 8 ?? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??? (2) 数据标准化 将模糊矩阵的每一个数据压缩到[0,1]上,采用平移.极差变换进行数据标准化 1i n 1i n 1i n A(i,k)-{A(i,k)}B(i,k)={A(i,k)}-{A(i,k)} min max min ≤≤≤≤≤≤ (k=1,2,…,m) 运用matlab 编程由函数F_jisjbzh.m 【见附录3.4】的标准化矩阵是 附录3.4 function [X]=F_JISjBzh(cs,X) %模糊聚类分析数据标准化变换 %X 原始数据矩阵;cs=0,不变换;cs=1,标准差变换 %cs=2,极差变换 if(cs==0) return ;end [n,m]=size(X);% 获得矩阵的行列数 if(cs==1) % 平移极差变换 for(k=1:m) xk=0; for(i=1:n) xk=xk+X(i,k);end xk=xk/n;sk=0; for(i=1:n) sk=sk+(X(i,k)-xk)^2;end sk=sqrt(sk/n);
第6章 MATLAB 数值计算 例6.1 求矩阵A 的每行及每列的最大和最小元素,并求整个矩阵的最大和最小元素。 1356 78256323578255631 01-???? -? ?=???? -??A A=[13,-56,78;25,63,-235;78,25,563;1,0,-1]; max(A,[],2) %求每行最大元素 min(A,[],2) %求每行最小元素 max(A) %求每列最大元素 min(A) %求每列最小元素 max(max(A)) %求整个矩阵的最大元素。也可使用命令:max(A(:)) min(min(A)) %求整个矩阵的最小元素。也可使用命令:min(A(:)) 例6.2 求矩阵A 的每行元素的乘积和全部元素的乘积。 A=[1,2,3,4;5,6,7,8;9,10,11,12]; S=prod(A,2) prod(S) %求A 的全部元素的乘积。也可以使用命令prod(A(:)) 例6.3 求向量X =(1!,2!,3!,…,10!)。 X=cumprod(1:10) 例6.4 对二维矩阵x ,从不同维方向求出其标准方差。 x=[4,5,6;1,4,8] %产生一个二维矩阵x y1=std(x,0,1) y2=std(x,1,1) y3=std(x,0,2) y4=std(x,1,2) 例6.5 生成满足正态分布的10000×5随机矩阵,然后求各列元素的均值和标准方差,再求这5列随机数据的相关系数矩阵。 X=randn(10000,5); M=mean(X) D=std(X) R=corrcoef(X)
例6.6 对下列矩阵做各种排序。 185412613713-?? ??=?? ??-?? A A=[1,-8,5;4,12,6;13,7,-13]; sort(A) %对A 的每列按升序排序 -sort(-A,2) %对A 的每行按降序排序 [X,I]=sort(A) %对A 按列排序,并将每个元素所在行号送矩阵I 例6.7 给出概率积分 2 (d x x f x x -? e 的数据表如表6.1所示,用不同的插值方法计算f (0.472)。 x=0.46:0.01:0.49; %给出x ,f(x) f=[0.4846555,0.4937542,0.5027498,0.5116683]; format long interp1(x,f,0.472) %用默认方法,即线性插值方法计算f(x) interp1(x,f,0.472,'nearest') %用最近点插值方法计算f(x) interp1(x,f,0.472,'spline') %用3次样条插值方法计算f(x) interp1(x,f,0.472,'cubic') %用3次多项式插值方法计算f(x) format short 例6.8 某检测参数f 随时间t 的采样结果如表6.2,用数据插值法计算t =2,7,12,17,22,17,32,37,42,47,52,57时的f 值。 T=0:5:65; X=2:5:57;
用matlab做聚类分析 Matlab提供了两种方法进行聚类分析。 一种是利用clusterdata函数对样本数据进行一次聚类,其缺点为可供用户选择的面较窄,不能更改距离的计算方法; 另一种是分步聚类:(1)找到数据集合中变量两两之间的相似性和非相似性,用pdist函数计算变量之间的距离;(2)用linkage函数定义变量之间的连接;(3)用cophenetic函数评价聚类信息;(4)用cluster函数创建聚类。1.Matlab中相关函数介绍 1.1pdist函数 调用格式:Y=pdist(X,’metric’) 说明:用‘metric’指定的方法计算X数据矩阵中对象之间的距离。’X:一个m×n的矩阵,它是由m个对象组成的数据集,每个对象的大小为n。 metric’取值如下: ‘euclidean’:欧氏距离(默认);‘seuclidean’:标准化欧氏距离; ‘mahalanobis’:马氏距离;‘cityblock’:布洛克距离; ‘minkowski’:明可夫斯基距离;‘cosine’: ‘correlation’:‘hamming’: ‘jaccard’:‘chebychev’:Chebychev距离。 1.2squareform函数 调用格式:Z=squareform(Y,..)
说明:强制将距离矩阵从上三角形式转化为方阵形式,或从方阵形式转化为上三角形式。 1.3linkage函数 调用格式:Z=linkage(Y,’method’) 说明:用‘method’参数指定的算法计算系统聚类树。 Y:pdist函数返回的距离向量; method:可取值如下: ‘single’:最短距离法(默认);‘complete’:最长距离法; ‘average’:未加权平均距离法;‘weighted’:加权平均法; ‘centroid’:质心距离法;‘median’:加权质心距离法; ‘ward’:内平方距离法(最小方差算法) 返回:Z为一个包含聚类树信息的(m-1)×3的矩阵。 1.4dendrogram函数 调用格式:[H,T,…]=dendrogram(Z,p,…) 说明:生成只有顶部p个节点的冰柱图(谱系图)。 1.5cophenet函数 调用格式:c=cophenetic(Z,Y) 说明:利用pdist函数生成的Y和linkage函数生成的Z计算cophenet相关系数。 1.6cluster函数 调用格式:T=cluster(Z,…) 说明:根据linkage函数的输出Z创建分类。
MATLAB 编程题库 1.下面的数据表近似地满足函数2 1cx b ax y ++=,请适当变换成为线性最小二乘问题,编程求最好的系数c b a ,,,并在同一个图上画出所有数据和函数图像. 625 .0718.0801.0823.0802.0687.0606.0356.0995 .0628.0544.0008.0213.0362.0586.0931.0i i y x ---- 解: x=[-0.931 -0.586 -0.362 -0.213 0.008 0.544 0.628 0.995]'; y=[0.356 0.606 0.687 0.802 0.823 0.801 0.718 0.625]'; A=[x ones(8,1) -x.^2.*y]; z=A\y; a=z(1); b=z(2); c=z(3); xh=-1:0.1:1; yh=(a.*xh+b)./(1+c.*xh.^2); plot(x,y,'r+',xh,yh,'b*')
2.若在Matlab工作目录下已经有如下两个函数文件,写一个割线法程序,求出这两个函数 10 的近似根,并写出调用方式: 精度为10 解: >> edit gexianfa.m function [x iter]=gexianfa(f,x0,x1,tol) iter=0; while(norm(x1-x0)>tol) iter=iter+1; x=x1-feval(f,x1).*(x1-x0)./(feval(f,x1)-feval(f,x0)); x0=x1;x1=x; end >> edit f.m function v=f(x) v=x.*log(x)-1; >> edit g.m function z=g(y) z=y.^5+y-1; >> [x1 iter1]=gexianfa('f',1,3,1e-10) x1 = 1.7632 iter1 = 6 >> [x2 iter2]=gexianfa('g',0,1,1e-10) x2 = 0.7549 iter2 = 8
《应用多元统计分析》 ——报告 班级: 学号: 姓名:
聚类分析的案例分析 摘要 本文主要用SPSS软件对实验数据运用系统聚类法和K均值聚类法进行聚类分析,从而实现聚类分析及其运用。利用聚类分析研究某化工厂周围的几个地区的 气体浓度的情况,从而判断出这几个地区的污染程度。 经过聚类分析可以得到,样本6这一地区的气体浓度值最高,污染程度是最严重的,样本3和样本4气体浓度较高,污染程度也比较严重,因此要给予及时的控制和改善。 关键词:SPSS软件聚类分析学生成绩
一、数学模型 聚类分析的基本思想是认为各个样本与所选择的指标之间存在着不同程度的相 似性。可以根据这些相似性把相似程度较高的归为一类,从而对其总体进行分析和总结,判断其之间的差距。 系统聚类法的基本思想是在这几个样本之间定义其之间的距离,在多个变量之间定义其相似系数,距离或者相似系数代表着样本或者变量之间的相似程度。根据相似程度的不同大小,将样本进行归类,将关系较为密切的归为一类,关系较为疏远的后归为一类,用不同的方法将所有的样本都聚到合适的类中,这里我们用的是最近距离法,形成一个聚类树形图,可据此清楚的看出样本的分类情况。 K 均值法是将每个样品分配给最近中心的类中,只产生指定类数的聚类结果。 二、数据来源 《应用多元统计分析》第一版164 页第6 题 我国山区有一某大型化工厂,在该厂区的邻近地区中挑选其中最具有代表性的 8 个大气取样点,在固定的时间点每日 4 次抽取6 种大气样本,测定其中包含的8 个取样点中每种气体的平均浓度,数据如下表。试用聚类分析方法对取样点及 大气污染气体进行分类。 三、建立数学模型 一、运行过程
1、 在MATLAB 中用Jacobi 迭代法讨论线性方程组, 1231231234748212515 x x x x x x x x x -+=?? -+=-??-++=? (1)给出Jacobi 迭代法的迭代方程,并判定Jacobi 迭代法求解此方程组是否收敛。 (2)若收敛,编程求解该线性方程组。 解(1):A=[4 -1 1;4 -8 1;-2 1 5] %线性方程组系数矩阵 A = 4 -1 1 4 -8 1 -2 1 5 >> D=diag(diag(A)) D = 4 0 0 0 -8 0 0 0 5 >> L=-tril(A,-1) % A 的下三角矩阵 L = 0 0 0 -4 0 0 2 -1 0 >> U=-triu(A,1) % A 的上三角矩阵 U = 0 1 -1 0 0 -1 0 0 0 B=inv(D)*(L+U) % B 为雅可比迭代矩阵 B = 0 0.2500 -0.2500 0.5000 0 0.1250 0.4000 -0.2000 0 >> r=eigs(B,1) %B 的谱半径
r = 0.3347 < 1 Jacobi迭代法收敛。 (2)在matlab上编写程序如下: A=[4 -1 1;4 -8 1;-2 1 5]; >> b=[7 -21 15]'; >> x0=[0 0 0]'; >> [x,k]=jacobi(A,b,x0,1e-7) x = 2.0000 4.0000 3.0000 k = 17 附jacobi迭代法的matlab程序如下: function [x,k]=jacobi(A,b,x0,eps) % 采用Jacobi迭代法求Ax=b的解 % A为系数矩阵 % b为常数向量 % x0为迭代初始向量 % eps为解的精度控制 max1= 300; %默认最多迭代300,超过300次给出警告D=diag(diag(A)); %求A的对角矩阵 L=-tril(A,-1); %求A的下三角阵 U=-triu(A,1); %求A的上三角阵 B=D\(L+U); f=D\b; x=B*x0+f; k=1; %迭代次数 while norm(x-x0)>=eps x0=x; x=B*x0+f; k=k+1; if(k>=max1) disp('迭代超过300次,方程组可能不收敛'); return; end end
k-means聚类”——数据分析、数据挖掘 一、概要 分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应。但是很多时候上述条件得不到满足,尤其是在处理海量数据的时候,如果通过预处理使得数据满足分类算法的要求,则代价非常大,这时候可以考虑使用聚类算法。聚类属于无监督学习,相比于分类,聚类不依赖预定义的类和类标号的训练实例。本文介绍一种常见的聚类算法——k 均值和k 中心点聚类,最后会举一个实例:应用聚类方法试图解决一个在体育界大家颇具争议的问题——中国男足近几年在亚洲到底处于几流水平。 二、聚类问题 所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n 个可观察属性,使用某种算法将D 划分成k 个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。 与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域,相应的算法也非常的多。本文仅介绍一种最简单的聚类算法——k 均值(k-means)算法。 三、概念介绍 区分两个概念: hard clustering:一个文档要么属于类w,要么不属于类w,即文档对确定的类w是二值的1或0。
soft clustering:一个文档可以属于类w1,同时也可以属于w2,而且文档属于一个类的值不是0或1,可以是这样的小数。 K-Means就是一种hard clustering,所谓K-means里的K就是我们要事先指定分类的个数,即K个。 k-means算法的流程如下: 1)从N个文档随机选取K个文档作为初始质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类 3)重新计算已经得到的各个类的质心 4)迭代2~3步直至满足既定的条件,算法结束 在K-means算法里所有的文档都必须向量化,n个文档的质心可以认为是这n 个向量的中心,计算方法如下: 这里加入一个方差RSS的概念: RSSk的值是类k中每个文档到质心的距离,RSS是所有k个类的RSS值的和。 算法结束条件: 1)给定一个迭代次数,达到这个次数就停止,这好像不是一个好建议。
roots([1 -1 -1]) x=linspace(0,2*pi,10); y=sin(x); xi=linspace(0,2*pi,100); y1=interp1(x,y,xi); y2=interp1(x,y,xi,'spline'); y3=interp1(x,y,xi,'cublic'); plot(x,y,'o',xi,y1,xi,y2,xi,y3) x=[0 300 600 1000 1500 2000]; y=[0.9689 0.9322 0.8969 0.8519 0.7989 0.7491]; xi=linspace(0,2000,20); yi=1.0332*exp(-(xi+500)/7756); y1=interp1(x,y,xi,'spline'); subplot(2,1,1);plot(x,y,'o',xi,yi,xi,y1,'*') p=polyfit(x,y,2); y2=polyval(p,xi); subplot(2,1,2);plot(x,y,'o',xi,yi,xi,y2,'*') x=[0 300 600 1000 1500 2000]; y=[0.9689 0.9322 0.8969 0.8519 0.7989 0.7491]; xi=linspace(0,2000,20); y1=interp1(x,y,xi,'spline'); subplot(2,1,1);plot(x,y,'-o', xi,y1,'-*') p=polyfit(x,y,2); y2=polyval(p,xi); subplot(2,1,2);plot(x,y,'-o',xi,y2,'-*')
第二讲MATLAB的数值分析 2-1矩阵运算与数组运算 矩阵运算和数组运算是MATLAB数值运算的两大类型,矩阵运算是按矩阵的运算规则进行的,而数组运算则是按数组元素逐一进行的。因此,在进行某些运算(如乘、除)时,矩阵运算和数组运算有着较大的差别。在MATLAB中,可以对矩阵进行数组运算,这时是把矩阵视为数组,运算按数组的运算规则。也可以对数组进行矩阵运算,这时是把数组视为矩阵,运算按矩阵的运算规则进行。 1、矩阵加减与数组加减 矩阵加减与数组加减运算效果一致,运算符也相同,可分为两种情况: (1)若参与运算的两矩阵(数组)的维数相同,则加减运算的结果是将两矩阵的对应元素进行加减,如 A=[1 1 1;2 2 2;3 3 3]; B=A; A+B ans= 2 2 2 4 4 4 6 6 6 (2)若参与运算的两矩阵之一为标量(1*1的矩阵),则加减运算的结果是将矩阵(数组)的每一元素与该标量逐一相加减,如 A=[1 1 1;2 2 2;3 3 3]; A+2 ans= 3 3 3 4 4 4 5 5 5 2、矩阵乘与数组乘 (1)矩阵乘 矩阵乘与数组乘有着较大差别,运算结果也完全不同。矩阵乘的运算符为“*”,运算是按矩阵的乘法规则进行,即参与乘运算的两矩阵的内维必须相同。设A、B为参与乘运算的 =A m×k B k×n。因此,参与运两矩阵,C为A和B的矩阵乘的结果,则它们必须满足关系C m ×n 算的两矩阵的顺序不能任意调换,因为A*B和B*A计算结果很可能是完全不一样的。如:A=[1 1 1;2 2 2;3 3 3]; B=A;
A*B ans= 6 6 6 12 12 12 18 18 18 F=ones(1,3); G=ones(3,1); F*G ans 3 G*F ans= 1 1 1 1 1 1 1 1 1 (2)数组乘 数组乘的运算符为“.*”,运算符中的点号不能遗漏,也不能随意加空格符。参加数组乘运算的两数组的大小必须相等(即同维数组)。数组乘的结果是将两同维数组(矩阵)的对应元素逐一相乘,因此,A.*B和B.*A的计算结果是完全相同的,如: A=[1 1 1 1 1;2 2 2 2 2;3 3 3 3 3]; B=A; A.*B ans= 1 1 1 1 1 4 4 4 4 4 9 9 9 9 9 B.*A ans= 1 1 1 1 1 4 4 4 4 4 9 9 9 9 9 由于矩阵运算和数组运算的差异,能进行数组乘运算的两矩阵,不一定能进行矩阵乘运算。如 A=ones(1,3); B=A; A.*B ans= 1 1 1 A*A ???Error using= =>
function varargout = lljuleifenxi(varargin) % LLJULEIFENXI MATLAB code for lljuleifenxi.fig % LLJULEIFENXI, by itself, creates a new LLJULEIFENXI or raises the existing % singleton*. % % H = LLJULEIFENXI returns the handle to a new LLJULEIFENXI or the handle to % the existing singleton*. % % LLJULEIFENXI('CALLBACK',hObject,eventData,handles,...) calls the local % function named CALLBACK in LLJULEIFENXI.M with the given input arguments. % % LLJULEIFENXI('Property','Value',...) creates a new LLJULEIFENXI or raises the % existing singleton*. Starting from the left, property value pairs are % applied to the GUI before lljuleifenxi_OpeningFcn gets called. An % unrecognized property name or invalid value makes property application % stop. All inputs are passed to lljuleifenxi_OpeningFcn via varargin. % % *See GUI Options on GUIDE's Tools menu. Choose "GUI allows only one % instance to run (singleton)". % % See also: GUIDE, GUIDATA, GUIHANDLES % Edit the above text to modify the response to help lljuleifenxi % Last Modified by GUIDE v2.5 07-Jan-2015 18:18:25 % Begin initialization code - DO NOT EDIT gui_Singleton = 1; gui_State = struct('gui_Name', mfilename, ... 'gui_Singleton', gui_Singleton, ... 'gui_OpeningFcn', @lljuleifenxi_OpeningFcn, ... 'gui_OutputFcn', @lljuleifenxi_OutputFcn, ... 'gui_LayoutFcn', [] , ... 'gui_Callback', []); if nargin && ischar(varargin{1}) gui_State.gui_Callback = str2func(varargin{1}); end if nargout [varargout{1:nargout}] = gui_mainfcn(gui_State, varargin{:}); else gui_mainfcn(gui_State, varargin{:}); end % End initialization code - DO NOT EDIT % --- Executes just before lljuleifenxi is made visible. function lljuleifenxi_OpeningFcn(hObject, eventdata, handles, varargin) % This function has no output args, see OutputFcn. % hObject handle to figure % eventdata reserved - to be defined in a future version of MATLAB
5.2酿酒葡萄的等级划分 5.2.1葡萄酒的质量分类 由问题1中我们得知,第二组评酒员的的评价结果更为可信,所以我们通过第二组评酒员对于酒的评分做出处理。我们通过excel计算出每位评酒员对每支酒的总分,然后计算出每支酒的10个分数的平均值,作为总的对于这支酒的等级评价。 通过国际酿酒工会对于葡萄酒的分级,以百分制标准评级,总共评出了六个级别(见表5)。 在问题2的计算中,我们求出了各支酒的分数,考虑到所有分数在区间[61.6,81.5]波动,以原等级表分级,结果将会很模糊,不能分得比较清晰。为此我们需要进一步细化等级。为此我们重新细化出5个等级,为了方便计算,我们还对等级进行降序数字等级(见表6)。 通过对数据的预处理,我们得到了一个新的关于葡萄酒的分级表格(见表7):
考虑到葡萄酒的质量与酿酒葡萄间有比较之间的关系,我们将保留葡萄酒质量对于酿酒葡萄的影响,先单纯从酿酒葡萄的理化指标对酿酒葡萄进行分类,然后在通过葡萄酒质量对酿酒葡萄质量的优劣进一步进行划分。 5.2.2建立模型 在通过酿酒葡萄的理化指标对酿酒葡萄分类的过程,我们用到了聚类分析方法中的ward 最小方差法,又叫做离差平方和法。 聚类分析是研究分类问题的一种多元统计方法。所谓类,通俗地说,就是指相似元素的集合。为了将样品进行分类,就需要研究样品之间关系。这里的最小方差法的基本思想就是将一个样品看作P 维空间的一个点,并在空间的定义距离,距离较近的点归为一类;距离较远的点归为不同的类。面对现在的问题,我们不知道元素的分类,连要分成几类都不知道。现在我们将用SAS 系统里面的stepdisc 和cluster 过程完成判别分析和聚类分析,最终确定元素对象的分类问题。 建立数据阵,具体数学表示为: 1111...............m n nm X X X X X ????=?????? (5.2.1) 式中,行向量1(,...,)i i im X x x =表示第i 个样品; 列向量1(,...,)'j j nj X x x =’,表示第j 项指标。(i=1,2,…,n;j=1,2,…m) 接下来我们将要对数据进行变化,以便于我们比较和消除纲量。在此我们用了使用最广范的方法,ward 最小方差法。其中用到了类间距离来进行比较,定义为: 2||||/(1/1/)kl k l k l D X X n n =-+ (5.2.2) Ward 方法并类时总是使得并类导致的类内离差平方和增量最小。 系统聚类数的确定。在聚类分析中,系统聚类最终得到的一个聚类树,如何确定类的个数,这是一个十分困难但又必须解决的问题;因为分类本身就没有一定标准,人们可以从不同的角度给出不同的分类。在实际应用中常使用下面几种方法确定类的个数。由适当的阀值确定,此处阀值为kl D 。
2015.1.9 上机作业题报告 JONMMX 2000
1.Chapter 1 1.1题目 设S N =∑1j 2?1 N j=2 ,其精确值为 )1 1 123(21+--N N 。 (1)编制按从大到小的顺序1 1 131121222-+ ??+-+-=N S N ,计算S N 的通用程序。 (2)编制按从小到大的顺序1 21 1)1(111222-+ ??+--+-= N N S N ,计算S N 的通用程序。 (3)按两种顺序分别计算64210,10,10S S S ,并指出有效位数。(编制程序时用单精度) (4)通过本次上机题,你明白了什么? 1.2程序 1.3运行结果
1.4结果分析 按从大到小的顺序,有效位数分别为:6,4,3。 按从小到大的顺序,有效位数分别为:5,6,6。 可以看出,不同的算法造成的误差限是不同的,好的算法可以让结果更加精确。当采用从大到小的顺序累加的算法时,误差限随着N 的增大而增大,可见在累加的过程中,误差在放大,造成结果的误差较大。因此,采取从小到大的顺序累加得到的结果更加精确。 2.Chapter 2 2.1题目 (1)给定初值0x 及容许误差ε,编制牛顿法解方程f(x)=0的通用程序。 (2)给定方程03 )(3 =-=x x x f ,易知其有三个根3,0,3321= *=*-=*x x x ○1由牛顿方法的局部收敛性可知存在,0>δ当),(0δδ+-∈x 时,Newton 迭代序列收敛于根x2*。试确定尽可能大的δ。 ○2试取若干初始值,观察当),1(),1,(),,(),,1(),1,(0+∞+-----∞∈δδδδx 时Newton 序列的收敛性以及收敛于哪一个根。 (3)通过本上机题,你明白了什么? 2.2程序