计量经济学——异方差性
5.3解:
(1)构建以家庭消费支出(Y)为被解释变量,家庭人均纯收入(X)为解释变量的线性回归模型:
Y i=β1+β2X i+u i
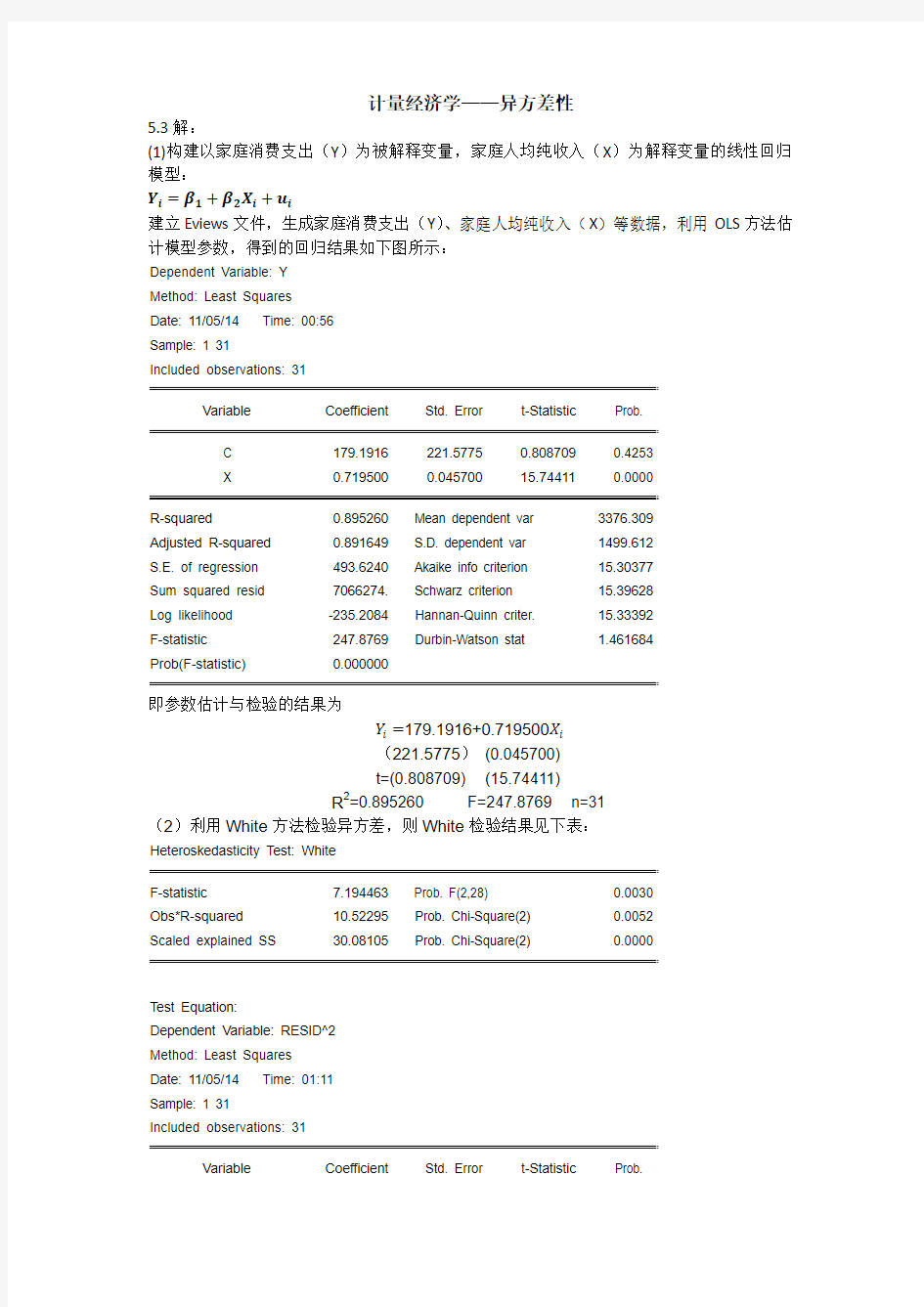
建立Eviews文件,生成家庭消费支出(Y)、家庭人均纯收入(X)等数据,利用OLS方法估计模型参数,得到的回归结果如下图所示:
Dependent Variable: Y
Method: Least Squares
Date: 11/05/14 Time: 00:56
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C 179.1916 221.5775 0.808709 0.4253
X 0.719500 0.045700 15.74411 0.0000
R-squared 0.895260 Mean dependent var 3376.309
Adjusted R-squared 0.891649 S.D. dependent var 1499.612
S.E. of regression 493.6240 Akaike info criterion 15.30377
Sum squared resid 7066274. Schwarz criterion 15.39628
Log likelihood -235.2084 Hannan-Quinn criter. 15.33392
F-statistic 247.8769 Durbin-Watson stat 1.461684
Prob(F-statistic) 0.000000
即参数估计与检验的结果为
Y i=179.1916+0.719500X i
(221.5775)(0.045700)
t=(0.808709) (15.74411)
R2=0.895260 F=247.8769 n=31
(2)利用White方法检验异方差,则White检验结果见下表:
Heteroskedasticity Test: White
F-statistic 7.194463 Prob. F(2,28) 0.0030
Obs*R-squared 10.52295 Prob. Chi-Square(2) 0.0052
Scaled explained SS 30.08105 Prob. Chi-Square(2) 0.0000
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 11/05/14 Time: 01:11
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
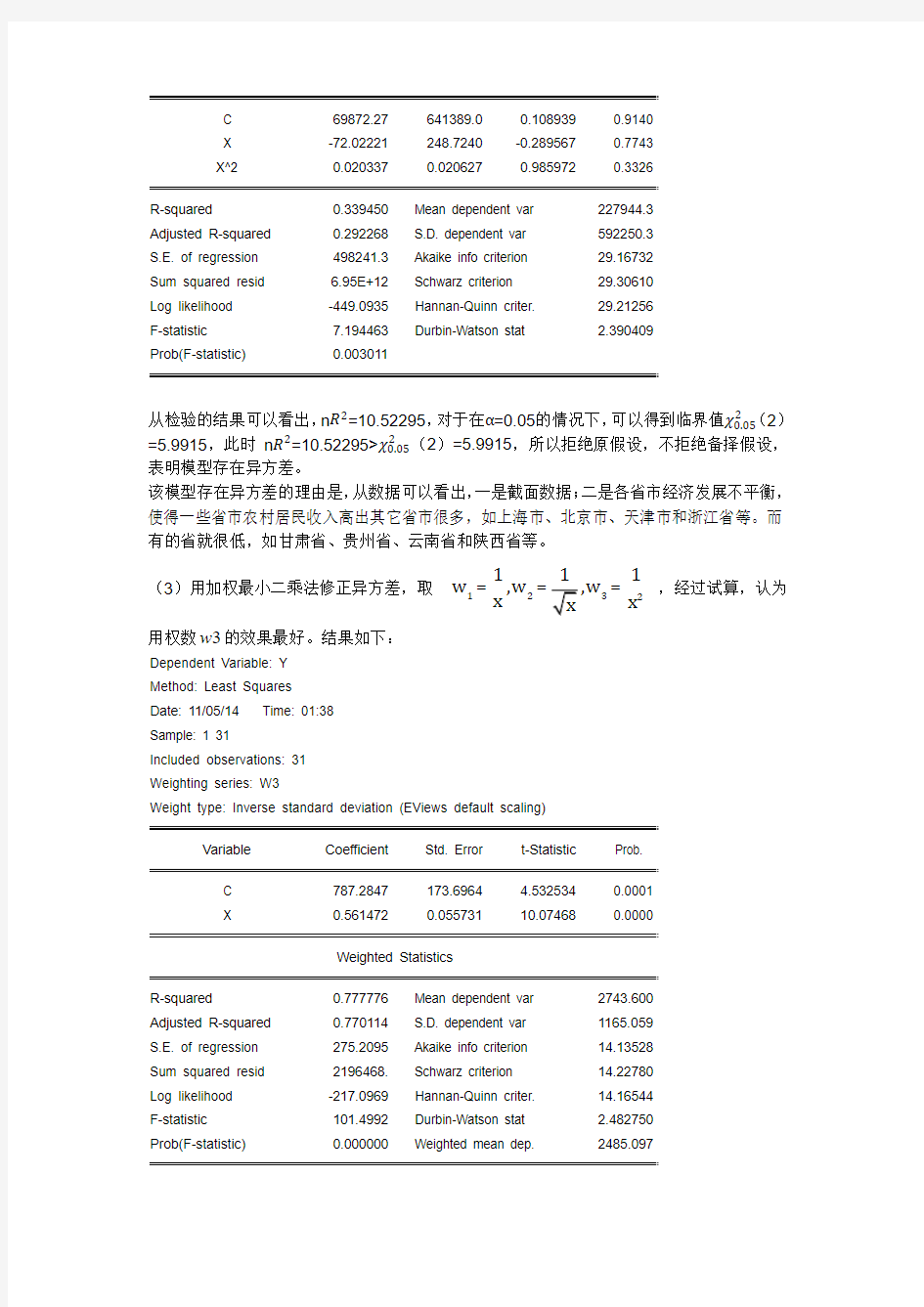
C 69872.27 641389.0 0.108939 0.9140 X -72.02221 248.7240 -0.289567 0.7743 X^2
0.020337
0.020627
0.985972
0.3326
R-squared 0.339450 Mean dependent var 227944.3 Adjusted R-squared 0.292268 S.D. dependent var 592250.3 S.E. of regression 498241.3 Akaike info criterion 29.16732 Sum squared resid 6.95E+12 Schwarz criterion 29.30610 Log likelihood -449.0935 Hannan-Quinn criter. 29.21256 F-statistic 7.194463 Durbin-Watson stat 2.390409 Prob(F-statistic)
0.003011
从检验的结果可以看出,n R 2=10.52295,对于在α=0.05的情况下,可以得到临界值χ0.052
(2)
=5.9915,此时 n R 2=10.52295>χ0.052
(2)=5.9915,所以拒绝原假设,不拒绝备择假设,表明模型存在异方差。
该模型存在异方差的理由是,从数据可以看出,一是截面数据;二是各省市经济发展不平衡,使得一些省市农村居民收入高出其它省市很多,如上海市、北京市、天津市和浙江省等。而有的省就很低,如甘肃省、贵州省、云南省和陕西省等。 (3)用加权最小二乘法修正异方差,取=
==
123211w ,w x x ,经过试算,认为用权数3w 的效果最好。结果如下:
Dependent Variable: Y Method: Least Squares Date: 11/05/14 Time: 01:38 Sample: 1 31
Included observations: 31 Weighting series: W3
Weight type: Inverse standard deviation (EViews default scaling)
Variable Coefficient Std. Error t-Statistic Prob. C 787.2847 173.6964 4.532534 0.0001 X 0.561472
0.055731 10.07468 0.0000
Weighted Statistics
R-squared 0.777776 Mean dependent var 2743.600 Adjusted R-squared 0.770114 S.D. dependent var 1165.059 S.E. of regression 275.2095 Akaike info criterion 14.13528 Sum squared resid 2196468. Schwarz criterion 14.22780 Log likelihood -217.0969 Hannan-Quinn criter. 14.16544 F-statistic 101.4992 Durbin-Watson stat 2.482750 Prob(F-statistic)
0.000000 Weighted mean dep. 2485.097
Unweighted Statistics
R-squared 0.848003 Mean dependent var 3376.309
Adjusted R-squared 0.842762 S.D. dependent var 1499.612
S.E. of regression 594.6448 Sum squared resid 10254472
Durbin-Watson stat 1.741955
修正后的结果为
Y i=787.2847+0.561472X i
(173.6964)(0.055731)
t=(4.532534) (10.07468)
R2=0.777776 F=101.4992 n=31
5.5解:
(1)构建以人均年交通通信消费支出(Y)为被解释变量,人均年可支配收入(X)为解释变量的线性回归模型:
Y i=β1+β2X i+u i
建立Eviews文件,生成人均年交通通信消费支出(Y)、人均年可支配收入(X)等数据,利用OLS方法估计模型参数,得到的回归结果如下图所示:
Dependent Variable: Y
Method: Least Squares
Date: 11/05/14 Time: 01:56
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C -562.9210 134.8840 -4.173372 0.0002
X 0.148116 0.012730 11.63514 0.0000
R-squared 0.823576 Mean dependent var 947.2394
Adjusted R-squared 0.817492 S.D. dependent var 478.4074
S.E. of regression 204.3801 Akaike info criterion 13.54018
Sum squared resid 1211365. Schwarz criterion 13.63270
Log likelihood -207.8728 Hannan-Quinn criter. 13.57034
F-statistic 135.3766 Durbin-Watson stat 1.890311
Prob(F-statistic) 0.000000
即参数估计与检验的结果为
Y i=-562.9210+0.148116X i
(134.8840)(0.012730)
t=(-4.173372) (11.63514)
R2=0.823576 F=135.3766 n=31
从估计结果看,各项检验指标均显著,但从经济意义看,各省市经济发展不平衡,使得一些省市人均年可支配收入高出其它省市很多,如上海市、北京市、江苏省和浙江省等。而有的省就很低,如甘肃省、青海省等,可能存在异方差。
(2)①利用White方法检验异方差,则White检验结果见下表:
Heteroskedasticity Test: White
F-statistic 4.599379 Prob. F(2,28) 0.0187
Obs*R-squared 7.665887 Prob. Chi-Square(2) 0.0216
Scaled explained SS 19.77379 Prob. Chi-Square(2) 0.0001
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 11/05/14 Time: 02:07
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C -667480.3 297213.6 -2.245793 0.0328
X 113.1286 50.90667 2.222274 0.0345
X^2 -0.003980 0.001999 -1.991032 0.0563
R-squared 0.247287 Mean dependent var 39076.30
Adjusted R-squared 0.193521 S.D. dependent var 96444.21
S.E. of regression 86610.90 Akaike info criterion 25.66800
Sum squared resid 2.10E+11 Schwarz criterion 25.80678
Log likelihood -394.8541 Hannan-Quinn criter. 25.71324
F-statistic 4.599379 Durbin-Watson stat 2.187659
Prob(F-statistic) 0.018742
2(2)从检验的结果可以看出,n R2=7.665887,对于在α=0.05的情况下,可以得到临界值χ0.05
2(2)=5.9915,所以拒绝原假设,不拒绝备择假设,=5.9915,此时n R2=7.665887>χ0.05
表明模型存在异方差。
②利用Goldfeld-Quanadt检验,将样本数据X递增排序: “Procs/Sort Series/输
入”X”/Ascending/ok,去掉中间7个数据, 分为”1-12”和”20-31”两个样本分别回归Dependent Variable: Y
Method: Least Squares
Date: 11/05/14 Time: 02:18
Sample: 1 12
Included observations: 12
Variable Coefficient Std. Error t-Statistic Prob.
C 1595.834 798.7367 1.997947 0.0736
X -0.111580 0.096596 -1.155120 0.2749
R-squared 0.117722 Mean dependent var 673.5108
Adjusted R-squared 0.029495 S.D. dependent var 73.22043 S.E. of regression 72.13254 Akaike info criterion 11.54590 Sum squared resid 52031.04 Schwarz criterion 11.62672 Log likelihood -67.27540 Hannan-Quinn criter. 11.51598 F-statistic 1.334302 Durbin-Watson stat 2.226348 Prob(F-statistic)
0.274896
此时, e 1i 2
=52031.04
Dependent Variable: Y Method: Least Squares Date: 11/05/14 Time: 02:20
Sample: 20 31
Included observations: 12
Variable Coefficient Std. Error t-Statistic Prob. C -556.5375 395.2875 -1.407931 0.1895 X
0.147985
0.029935
4.943622
0.0006
R-squared 0.709635 Mean dependent var 1341.009 Adjusted R-squared 0.680598 S.D. dependent var 578.9364 S.E. of regression 327.1896 Akaike info criterion 14.56997 Sum squared resid 1070530. Schwarz criterion 14.65079 Log likelihood -85.41981 Hannan-Quinn criter. 14.54005 F-statistic 24.43940 Durbin-Watson stat 1.919724
Prob(F-statistic)
0.000584
此时, e 2i 2
=1070530
F= e 2i
2
e 1i
2=
1070530
52031.04=20.57
在对于在α=0.05的情况下,可以得到临界值F 0.05(,10,10)=2.98,此时F=20.57>F 0.05(,10,
10)=2.98,所以拒绝原假设,不拒绝备择假设,表明模型存在异方差。 两种检验方式均证明该模型存在异方差。 5.6解:
(1)构建以农村人均生活消费支出(Y )为被解释变量,农村人均纯收入(X )为解释变量的线性回归模型: Y t =β1+β2X t +u t
建立Eviews 文件,生成农村人均生活消费支出(Y )、农村人均纯收入(X )等数据,利用OLS 方法估计模型参数,得到的回归结果如下图所示:
Dependent Variable: Y Method: Least Squares Date: 11/05/14 Time: 10:40 Sample: 1978 2011 Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C 92.55422 42.80529 2.162215 0.0382
X 0.746241 0.019120 39.03027 0.0000
R-squared 0.979426 Mean dependent var 1295.802
Adjusted R-squared 0.978783 S.D. dependent var 1188.791
S.E. of regression 173.1597 Akaike info criterion 13.20333
Sum squared resid 959497.2 Schwarz criterion 13.29311
Log likelihood -222.4566 Hannan-Quinn criter. 13.23395
F-statistic 1523.362 Durbin-Watson stat 1.534491
Prob(F-statistic) 0.000000
即参数估计与检验的结果为
Y t=92.55422+0.746241X t
(42.80529)(0.019120)
t=(2.162215) (39.03027)
R2=0.979426 F=1523.362 n=34
从估计结果看,各项检验指标均显著,但从经济意义看,改革开放以来,四川省农村经济发生了巨大变化,农村家庭纯收入的差距也有所拉大,使得农村居民的消费水平的差距也有所加大,在这种情况下,尽管是时间序列数据,也有可能存在异方差问题。
利用ARCH方法检验异方差,得ARCH检验结果:
Heteroskedasticity Test: ARCH
F-statistic 4.633028 Prob. F(2,29) 0.0179
Obs*R-squared 7.748742 Prob. Chi-Square(2) 0.0208
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 11/05/14 Time: 10:47
Sample (adjusted): 1980 2011
Included observations: 32 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 19189.52 17522.78 1.095118 0.2825
RESID^2(-1) -0.040983 0.186527 -0.219719 0.8276
RESID^2(-2) 0.564264 0.186572 3.024380 0.0052
R-squared 0.242148 Mean dependent var 29704.16
Adjusted R-squared 0.189883 S.D. dependent var 104785.3
S.E. of regression 94313.62 Akaike info criterion 25.83570
Sum squared resid 2.58E+11 Schwarz criterion 25.97311
Log likelihood -410.3712 Hannan-Quinn criter. 25.88125
F-statistic 4.633028 Durbin-Watson stat 1.998444 Prob(F-statistic)
0.017946
从检验的结果可以看出,(n-p )R 2=7.748742,对于在α=0.05的情况下,可以得到临界值
χ0.052(2)=5.9915,此时 (n ?p )R 2=7.748742>χ0.052(2)=5.9915,所以拒绝原假设,不拒绝备择假设,表明模型存在异方差。
采用用加权最小二乘法修正异方差,取=
==
123211
w ,w x x ,经过试算,认为用权数w 3的效果最好。结果如下:
Dependent Variable: Y Method: Least Squares Date: 11/05/14 Time: 10:55 Sample: 1978 2011 Included observations: 34 Weighting series: W3
Weight type: Inverse standard deviation (EViews default scaling)
Variable Coefficient Std. Error t-Statistic Prob. C 8.890886 3.604301 2.466744 0.0192 X 0.852193
0.020150
42.29335 0.0000
Weighted Statistics
R-squared 0.982425 Mean dependent var 230.2433 Adjusted R-squared 0.981875 S.D. dependent var 247.1718 S.E. of regression 16.20273 Akaike info criterion 8.465259 Sum squared resid 8400.912 Schwarz criterion 8.555045 Log likelihood -141.9094 Hannan-Quinn criter. 8.495879 F-statistic 1788.728 Durbin-Watson stat 0.604647 Prob(F-statistic)
0.000000 Weighted mean dep. 150.5004
Unweighted Statistics
R-squared 0.954142 Mean dependent var 1295.802 Adjusted R-squared 0.952709 S.D. dependent var 1188.791 S.E. of regression 258.5207 Sum squared resid 2138654.
Durbin-Watson stat
0.781788
修正后的结果为
Y t =8.890886+0.852193X t (3.604301) (0.020150) t=(2.466744) (42.29335)
R 2=0.982425 F=1788.728 n=34
(2)剔除物价上涨因素后,构建以农村人均生活消费支出(Y)为被解释变量,农村人均纯收入(X)为解释变量的线性回归模型:
Y t=β1+β2X t+u t
建立Eviews文件,生成农村人均生活消费支出(Y)、农村人均纯收入(X)等数据,利用OLS方法估计模型参数,得到的回归结果如下图所示:
Dependent Variable: Y
Method: Least Squares
Date: 11/05/14 Time: 11:01
Sample: 1978 2011
Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C 0.379068 0.324037 1.169827 0.2507
X 0.753732 0.020430 36.89255 0.0000
R-squared 0.977029 Mean dependent var 6.598743
Adjusted R-squared 0.976311 S.D. dependent var 10.48381
S.E. of regression 1.613583 Akaike info criterion 3.851814
Sum squared resid 83.31681 Schwarz criterion 3.941600
Log likelihood -63.48084 Hannan-Quinn criter. 3.882434
F-statistic 1361.060 Durbin-Watson stat 1.710873
Prob(F-statistic) 0.000000
即参数估计与检验的结果为
Y t=0.379068+0.753732X t
(0.324037)(0.020430)
t=(1.169827) (36.89255)
R2=0.977029 F=1361.060 n=34
利用ARCH方法检验异方差,得ARCH检验结果:
Heteroskedasticity Test: ARCH
F-statistic 3.362955 Prob. F(2,29) 0.0486
Obs*R-squared 6.024455 Prob. Chi-Square(2) 0.0492
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 11/05/14 Time: 11:03
Sample (adjusted): 1980 2011
Included observations: 32 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 1.829789 1.812738 1.009407 0.3211
RESID^2(-1) -0.032900 0.185590 -0.177273 0.8605 RESID^2(-2) 0.478930
0.185589
2.580590
0.0152
R-squared 0.188264 Mean dependent var 2.602494 Adjusted R-squared 0.132282 S.D. dependent var 10.64520 S.E. of regression 9.916144 Akaike info criterion 7.515265 Sum squared resid 2851.567 Schwarz criterion 7.652678 Log likelihood -117.2442 Hannan-Quinn criter. 7.560814 F-statistic 3.362955 Durbin-Watson stat 2.000572 Prob(F-statistic)
0.048586
从检验的结果可以看出,(n-p )R 2=6.024455,对于在α=0.05的情况下,可以得到临界值
χ0.052(2)=5.9915,此时 (n ?p )R 2=6.024455>χ0.052(2)=5.9915,所以拒绝原假设,不拒绝备择假设,表明模型存在异方差。
采用用加权最小二乘法修正异方差,取=
==
123211
w ,w x x ,经过试算,认为用权数w 3的效果最好。结果如下:
Dependent Variable: Y Method: Least Squares Date: 11/05/14 Time: 11:06 Sample: 1978 2011 Included observations: 34 Weighting series: W3
Weight type: Inverse standard deviation (EViews default scaling)
Variable Coefficient Std. Error t-Statistic Prob. C 0.206016 0.040275 5.115253 0.0000 X 0.773930
0.025284
30.61002 0.0000
Weighted Statistics
R-squared 0.966975 Mean dependent var 1.726892 Adjusted R-squared 0.965943 S.D. dependent var 2.475671 S.E. of regression 0.114820 Akaike info criterion -1.433877 Sum squared resid 0.421878 Schwarz criterion -1.344091 Log likelihood 26.37590 Hannan-Quinn criter. -1.403257 F-statistic 936.9734 Durbin-Watson stat 0.709007 Prob(F-statistic)
0.000000 Weighted mean dep. 1.404376
Unweighted Statistics
R-squared 0.976327 Mean dependent var 6.598743 Adjusted R-squared 0.975587 S.D. dependent var 10.48381 S.E. of regression
1.638053 Sum squared resid
85.86293
Durbin-Watson stat 1.582129
修正后的结果为
Y t=0.206016+0.773930X t
(0.040275)(0.025284)
t=(5.115253) (30.61002)
R2=0.966975 F=936.9734 n=34
(3)由(1)、(2)问可知,虽然在显著性为0.05的情况下,均拒绝原假设。但是,剔除物价上涨因素后的回归模型经ARCH检验得,在显著性水平为α=0.025的条件下,
2(2)=7.3776,故接收原假设,模型不存在异方差。而未剔(n?p)R2=6.024455<χ0.025
2
除物价上涨因素的回归模型在显著性水平为α=0.025的条件下,n?p)R2=7.748742>χ0.025(2)=7.3776,仍拒绝原假设,模型存在异方差。表明剔除物价上涨因素之后,异方差的问题有所改善。
《计量经济学》 习题 河北经贸大学应用经济学教研室 2004年7月
第一章绪论 ⒈为什么说计量经济学是经济理论、数学和经济统计学的结合? ⒉为什么说计量经济学是一门经济学科?它在经济学科体系中的地位是什么?它在经济研究中的作用是什么? ⒊建立与应用计量经济学模型的主要步骤有哪些? ⒋计量经济学模型有哪些主要应用领域?各自的原理是什么? ⒌下列假想模型是否属于揭示因果关系的计量经济学模型?为什么? ⑴St=112.0+0.12Rt 其中,St为第t年农村居民储蓄增加额(亿元),Rt为第t年城镇居民可支配收入总额(亿元)。 ⑵S t-1=4432.0+0.30R t 其中,S t-1为第(t-1)年底农村居民储蓄余额(亿元),Rt为第t年农村居民纯收入总额(亿元)。 ⒍指出下列假想模型中两个最明显的错误,并说明理由: RS t=8300.0-0.24RI t+1.12IV t 其中,RS t为第t年社会消费品零售总额(亿元),RI t为第t年居民收入总额(亿元)(城镇居民可支配收入总额与农村居民纯收入总额之和),IV t为第t年全社会固定资产投资总额(亿元)。 第二章一元线性回归模型
⒈ 对于设定的回归模型作回归分析,需对模型作哪些假定,这些假定为什么是必要的? ⒉ 试说明利用样本决定系数R 2为什么能够判定回归直线与样本观测值的拟和优度。 ⒊ 说明利用) (0∧ βS 、)(1∧βS 衡量 ∧ β、∧ 1β对 β、1β估计稳定性的道理。 ⒋ 为什么对 ∧ β、∧ 1β进行显著性检验?试述检验方法及步骤。 ⒌ 对于求得的回归方程为什么进行显著性检验?试述检验方法及步骤。 ⒍ 阐述回归分析的步骤。 ⒎ 试述计量经济模型与一般的经济模型有什么不同? ⒏ 一元线性回归模型有时采用如下形式: i i i X Y μβ+=1 模型中的截距为零,叫做通过原点的回归模型。试证明该模型中: (1) ∑∑=∧ 21i i i X Y X β (2) ∑ = ∧ 2 2 1)var(i X μ σ β ⒐ 下述结果是从一个样本中获得的,该样本包含某企业的销售额(Y )及相应价格(X )的11个观测值。 18 .519_ =X ; 82 .217_ =Y ; ∑=3134543 2 i X ; ∑=1296836 i i Y X ; ∑=539512 2i Y (1)估计销售额对价格的样本回归直线,并解释其结果。 (2)回归直线的判定系数是多少? ⒑ 已知某地区26年的工农业总产值与货运周转量的数据见下表。试作一元线性回归分析,若下一年计划该地区工农业总产值为8亿元,预测货运周转量。
计量经济学简答题及答案 1、比较普通最小二乘法、加权最小二乘法和广义最小二乘法的异同。 答:普通最小二乘法的思想是使样本回归函数尽可能好的拟合样本数据,反映在 图上就是是样本点偏离样本回归线的距离总体上最小,即残差平方和最小 ∑=n i i e 12min 。 只有在满足了线性回归模型的古典假设时候,采用OLS 才能保证参数估计结果的可靠性。 在不满足基本假设时,如出现异方差,就不能采用OLS 。加权最小二乘法是对原 模型加权,对较小残差平方和2i e 赋予较大的权重,对较大2i e 赋予较小的权重,消除异方差,然后在采用OLS 估计其参数。 在出现序列相关时,可以采用广义最小二乘法,这是最具有普遍意义的最小二乘 法。 最小二乘法是加权最小二乘法的特例,普通最小二乘法和加权最小二乘法是广义 最小二乘法的特列。 6、虚拟变量有哪几种基本的引入方式? 它们各适用于什么情况? 答: 在模型中引入虚拟变量的主要方式有加法方式与乘法方式,前者主要适用于 定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。 7、联立方程计量经济学模型中结构式方程的结构参数为什么不能直接应用OLS 估计? 答:主要的原因有三:第一,结构方程解释变量中的内生解释变量是随机解释变 量,不能直接用OLS 来估计;第二,在估计联立方程系统中某一个随机方程参数时,需要考虑没有包含在该方程中的变量的数据信息,而单方程的OLS 估计做不到这一点;第三,联立方程计量经济学模型系统中每个随机方程之间往往存在某种相关性,表现于不同方程随机干扰项之间,如果采用单方程方法估计某一个方程,是不可能考虑这种相关性的,造成信息的损失。 2、计量经济模型有哪些应用。 答:①结构分析,即是利用模型对经济变量之间的相互关系做出研究,分析当其 他条件不变时,模型中的解释变量发生一定的变动对被解释变量的影响程度。②经济预测,即是利用建立起来的计量经济模型对被解释变量的未来值做出预测估计或推算。③政策评价,对不同的政策方案可能产生的后果进行评价对比,从中做出选择的过程。④检验和发展经济理论,计量经济模型可用来检验经济理论的正确性,并揭示经济活动所遵循的经济规律。 6、简述建立与应用计量经济模型的主要步骤。 答:一般分为5个步骤:①根据经济理论建立计量经济模型;②样本数据的收集; ③估计参数;④模型的检验;⑤计量经济模型的应用。 7、对计量经济模型的检验应从几个方面入手。 答:①经济意义检验;②统计准则检验;③计量经济学准则检验;④模型预测检 验。
计算分析题(共3小题,每题15分,共计45分) 1、下表给出了一含有3个实解释变量的模型的回归结果: 方差来源 平方和(SS ) 自由度(d.f.) 来自回归65965 — 来自残差— — 总离差(TSS) 66056 43 (1)求样本容量n 、RSS 、ESS 的自由度、RSS 的自由度 (2)求可决系数)37.0(-和调整的可决系数2 R (3)在5%的显著性水平下检验1X 、2X 和3X 总体上对Y 的影响的显著性 (已知0.05(3,40) 2.84F =) (4)根据以上信息能否确定1X 、2X 和3X 各自对Y 的贡献?为什么? 1、 (1)样本容量n=43+1=44 (1分) RSS=TSS-ESS=66056-65965=91 (1分) ESS 的自由度为: 3 (1分) RSS 的自由度为: d.f.=44-3-1=40 (1分) (2)R 2=ESS/TSS=65965/66056=0.9986 (1分) 2R =1-(1- R 2)(n-1)/(n-k-1)=1-0.0014?43/40=0.9985 (2分) (3)H 0:1230βββ=== (1分) F=/65965/39665.2/(1)91/40 ESS k RSS n k ==-- (2分) F >0.05(3,40) 2.84F = 拒绝原假设 (2分) 所以,1X 、2X 和3X 总体上对Y 的影响显著 (1分) (4)不能。 (1分) 因为仅通过上述信息,可初步判断X 1,X 2,X 3联合起来 对Y 有线性影响,三者的变化解释了Y 变化的约99.9%。但由于 无法知道回归X 1,X 2,X 3前参数的具体估计值,因此还无法 判断它们各自对Y 的影响有多大。 2、以某地区22年的年度数据估计了如下工业就业模型 i i i i i X X X Y μββββ++++=3322110ln ln ln 回归方程如下: i i i i X X X Y 321ln 62.0ln 25.0ln 51.089.3?+-+-= (-0.56)(2.3) (-1.7) (5.8) 2 0.996R = 147.3=DW 式中,Y 为总就业量;X 1为总收入;X 2为平均月工资率;X 3为地方政府的
第一章绪论 1、什么是计量经济学?由哪三组组成? 答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科。 统计学、经济理论和数学三者结合起来便构成了计量经济学。 2、计量经济学的内容体系,重点是理论计量和应用计量和经典计量经济学理论方法方面的特 征 答:1)广义计量经济学和狭义计量经济学 2)初、中、高级计量经济学3)理论计量经济学和应用计量经济 理论计量经济学是以介绍、研究计量经济学的理论与方法为主要内容,侧重于理论与方法的数学证明与推导,与数理统计联系极为密切。除了介绍计量经济模型的数学理论基础、普遍应用的计量经济模型的参数估计方法与检验方法外,还研究特殊模型的估计方法与检验方法,应用了广泛的数学知识。 应用计量经济学则以建立与应用计量经济学模型为主要内容,强调应用模型的经济学和经济统计学基础,侧重于建立与应用模型过程中实际问题的处理。本课程是二者的结合。 4)、经典计量经济学和非经典计量经济学 经典计量经济学(Classical Econometrics)一般指20世纪70年代以前发展并广泛应用的计量经济学。 经典计量经济学在理论方法方面特征是: ⑴模型类型—随机模型; ⑵模型导向—理论导向; ⑶模型结构—线性或者可以化为线性,因果分析,解释变量具有同等地位,模型具有明
确的形式和参数; ⑷数据类型—以时间序列数据或者截面数据为样本,被解释变量为服从正态分布的连续随机变量; ⑸估计方法—仅利用样本信息,采用最小二乘方法或者最大似然方法估计模型。 经典计量经济学在应用方面的特征是: ⑴应用模型方法论基础—实证分析、经验分析、归纳; ⑵应用模型的功能—结构分析、政策评价、经济预测、理论检验与发展; ⑶应用模型的领域—传统的应用领域,例如生产、需求、消费、投资、货币需求,以及宏观经济等。 5)、微观计量经济学和宏观计量经济学 3、为什么说计量经济学是经济学的一个分支?(4点和综述) 答:(1)、从计量经济学的定义看 (2)、从计量经济学在西方国家经济学科中的地位看 (3)、从计量经济学与数理统计学的区别看 (4)、从建立与应用计量经济学模型的全过程看 综上所述,计量经济学是一门经济学科,而不是应用数学或其他。 4、理论模型的设计主要包含三部分工作,即选择变量,确定变量之间的数学关系,拟定模型 中待估计参数的数值范围。 5、常用的样本数据:时间序列,截面,面板(虚变量数据是错的,改为面板数据。主要要求时间数据序列数据和截面数据) 答:1、时间序列是一批按照时间先后排列的统计数据。 要注意问题:
计量经济学重点(简答题) 一、什么就是计量经济学?计量经济学,又称经济计量学,它就是以一定的经济理论与 实际统计资料为依据,运用数学、统计学与计算机技术,通过建立计量经济学模型,定量分析经济变量之间的随机因果关系、。 二、计量经济学的研究的步骤就是什么? 1)理论模型的设计 A.理论或假说的陈述; B.理论的数学模型的设定; C.理论的计量经济模型的设定。 i.把模型中不重要的变量放进随机误差项中; ii.拟定待估参数的理论期望值。 2)获取数据 数据来源:网络、统计年鉴、报纸、杂志 数据类别:时间序列数据、截面数据、混合数据、虚变量数据。 数据要求:完整性、准确性、可比性、一致性 i.完整性:模型中包含的所有变量都必须得到相同容量的样本观察值。 ii.准确性:统计数据或调查数据本身就是准确的。 iii.可比性:数据口径问题。 iv.一致性:指母体与样本的一致性。 3)模型的参数估计:普通最小二乘法。 4)模型的检验:经济学检验;统计学检验;计量经济学检验;模型的预测检验。 5)模型的应用:结构分析;经济预测;政策评价;经济理论的检验与发展。 三、简述统计数据的类别? 时间序列数据、截面数据、混合数据、虚变量数据。 1)时间序列数据:按时间先后排列收集的数据。
采纳时间序列数据的注意事项: A.所选择的样本区间的经济行为一致性问题。 B.样本数据在不同样本点之间的可比性问题。 C.样本数据过于集中的问题。不能反映经济变量间的结构关系,应增大观察区间。 D.模型的随机误差项序列相关问题。 2)截面数据:又称横向数据,就是一批发生在同一时间截面上的调查数据。研究某时 点上的变化情况。 采纳截面数据的注意事项: A.样本与母体的一致性问题。 B.随机误差项的异方差问题。 3)混合数据:也称面板数据,既有时间序列数据,又有截面数据。 4)虚变量数据:又称二进制数据,只能取0与1两个值,表示的就是某个对象的质量特 征。 四、模型的检验包括哪几个方面?具体含义就是什么? 1)经济学检验:参数的符合与大致取值。 2)统计学检验:拟合优度检验;模型的显著性检验;参数的显著性检验。 3)计量经济学检验:序列相关性;异方差检验;多重共线性检验。 4)模型的预测检验:a,扩大样本容量或变换样本重新估价模型;b,利用模型对样本期以 外的某一期进行预测。
名词解释 1、 因果效应:在理想化随机对照实验中得到的,某一给定的行为或处理对结果的影响 2、 实验数据:来源于为评价某种处理(某项政策)抑或某种因果效应而设计的实验 3、 观测数据:通过观察实验之外的实际行为而获得的数据 4、 截面数据:对不同个体如工人、消费者、公司或政府机关等在某一特定时间段内收集到的数据 5、 时间序列数据:对同一个体(个人、公司、国家等)在多个时期内收集到的数据 6、 面板数据:即纵向数据,是多个个体分别在两个或多个时期内观测到的数据 7、 离散型随机变量:一些随机变量是离散的 连续型随机变量:一些随机变量是连续的 8、 期望值:随机变量经过多次重复实验出现的长期平均值,记作E (Y ) 9、 期望:Y 的长期平均值,记作μY 10、方差:是Y 距离其均值的偏差平方的期望值,记作var (Y ) 11、标准差:方差的平方根来表示偏差程度,记作σY 12、独立性:两个随机变量X 和Y 中的一个变量无法提供另一个变量的相关信息 13、标准正态分布:指那些均值102==σμ、方差的正态分布,记作N (0,1) 14、简单随机抽样:n 个对象从总体中抽取,且总体中的每一个个体都有相等的可能性被选入样本 15、独立分布:两个随机变量X 和Y 中的一个变量无法提供另一个变量的相关信息,那么这两个变量X 和Y 独立分布 16、偏差:设Y Y E Y Y μμμμ-??)(为的一个估计量,则偏差是; 一致性:当样本容量增大时,Y μ ?落入真实值Y μ的微小领域区间内的概率接近于1,即Y Y μμ与?是一致的 有效性:如果Y μ ?的方差比Y μ~更小,那么可以说Y Y μμ~?比更有效 17、最小二乘估计量:21)(m i n i -Y ∑ =最小化误差m -i Y 平方和的估计量m 18、P 值:即显著性概率,指原假设为真的情况下,抽取到的统计量与原假设之间的差异程度至少等于样本计算值与 原假设之间差异程度的概率 19、第一类错误:拒绝了实际上为真的原假设 20、一元线性回归模型:i i 10i μββ+X +=Y ;1β代表1X 变化一个单位所导致Y 的变化量 21、普通最小二乘(OLS )估:选择使得估计的回归线与观测数据尽可能接近的回归系数,其中近似程度用给定X 时预 测Y 的误差的平方和来度量 22、回归2R :可以由i X 解释(或预测)的i Y 样本方差的比例,即TSS SSR TSS ESS R -==12 23、最小二乘假设:①给定i X 时误差项i μ的条件均值为零:0)(i i =X μE ; ②从联合总体中抽取的, ,,,),,(n ...21i i i =Y X 满足独立同分布; ③大异常值不存在:即i i Y X 和具有非零有限的四阶距 24、1β置信区间:以95%的概率包含1β真值的区间,即在所有可能随机抽取的样本中有95%包含了1β的真值 25、同方差:若对于任意i=1,2,...,n ,给定) (条件分布的方差时χμμ=X X i i i i var 为常数且不依赖于χ,则 称误差项i μ是同方差
大学生月消费支出调查报告 一、引言 在当前尚且低迷,尚未完全复苏的经济环境下,消费问题被大家广泛关注。物价的连续上涨,直接反映了社会的消费和需求问题。当前的消费市场中,大学生作为一个特殊的消费群体正受到越来越大的关注。由于大学生年龄较轻,群体较特别,他们有着不同于社会其他消费群体的消费心理和行为。一方面,他们有着旺盛的消费需求,另一方面,他们尚未获得经济上的独立,消费受到很大的制约。消费观念的超前和消费实力的滞后,都对他们的消费有很大影响。特殊群体自然有自己特殊的特点,同时难免存在一些非理性的消费甚至一些消费的问题。为了调查清楚大学生的消费情况,我决定在身边的同学中进行一次消费的调研,对大家的消费进行归宗和分析。 二、理论综述 我们主要对大学生每人每月消费支出进行多因素分析,并从周围同学搜集相关数据,建立模型,对此进行数量分析。 影响大学生每人每月消费支出的主要因素如下: 1、学习支出 2、消费收入 3、生活支出 三、模型设定 Y:每人每月消费支出 X1:学习支出X2:消费收入 X3:生活支出 四、数据搜集 1、数据说明 我们特对周围大学生的消费水平做了简单调查,再用计量经济学的知识分析其影响因素。 2、数据的搜集情况 人数每人每月消 费 支出Y 学习支出 (X1) 消费收入(X2)生活支出(X3) 1760310800450 2630230600400 311002301350880 4420170450250 59601601000800 6580280500300 78702201000650 8300110400190 910501501300900 10126016015001100 11130030015001000 12500190550310 13600180750420 149001401000760
一、单项选择题 4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据 B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据 D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型 B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型 D.确定模型导向→确定变量及方程式→估计模型→应用模型 13.同一统计指标按时间顺序记录的数据列称为( B )。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据14.计量经济模型的基本应用领域有( A )。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析
18.表示x 和y 之间真实线性关系的是( C )。 A .01???t t Y X ββ=+ B .01()t t E Y X ββ=+ C .01t t t Y X u ββ=++ D .01t t Y X ββ=+ 19.参数β的估计量?β具备有效性是指( B )。 A .?var ()=0β B .?var ()β为最小 C .?()0ββ-= D .?()ββ-为最小 25.对回归模型i 01i i Y X u ββ+=+进行检验时,通常假定i u 服从( C )。 A .2i N 0) σ(, B . t(n-2) C .2N 0)σ(, D .t(n) 26.以Y 表示实际观测值,?Y 表示回归估计值,则普通最小二乘法估计参数的准则是使( D )。 A .i i ?Y Y 0∑(-)= B .2i i ?Y Y 0∑(-)= C .i i ?Y Y ∑(-)=最小 D .2i i ?Y Y ∑(-)=最小 27.设Y 表示实际观测值,?Y 表示OLS 估计回归值,则下列哪项成立( D )。 A .?Y Y = B .?Y Y = C .?Y Y = D .?Y Y = 28.用OLS 估计经典线性模型i 01i i Y X u ββ+=+,则样本回归直线通过点___D______。 A .X Y (,) B . ?X Y (,) C .?X Y (,) D .X Y (,) 29.以Y 表示实际观测值,?Y 表示OLS 估计回归值,则用OLS 得到的样本回归直线i 01i ???Y X ββ+=满足( A )。 A .i i ?Y Y 0∑(-)= B .2i i Y Y 0∑(-)= C . 2i i ?Y Y 0∑(-)= D .2i i ?Y Y 0∑(-)= 30.用一组有30个观测值的样本估计模型i 01i i Y X u ββ+=+,在0.05的显著性水平下对1β的显著性作t 检验,则1β显著地不等于零的条件是其统计量t 大于( D )。 A .t 0.05(30) B .t 0.025(30) C .t 0.05(28) D .t 0.025(28) 31.已知某一直线回归方程的决定系数为0.64,则解释变量与被解释变量间的线性相关系数为( B )。 A .0.64 B .0.8 C .0.4 D .0.32
简答: 1、时间序列数据和横截面数据有何不同? 时间序列数据是一批按照时间先后排列的统计数据。截面数据是一批发生在同一时间截面上的调查数据。这两类数据都是反映经济规律的经济现象的数量信息,不同点:时间序列数据是含义、口径相同的同一指标按时间先后排列的统计数据列;而横截面数据是一批发生在同一时间截面上不同统计单元的相同统计指标组成的数据列。 2、建立计量经济模型赖以成功的三要素。P16(课本) 成功的要素有三:理论、方法和数据。理论:即经济理论,所研究的经济现象的行为理论,是计量经济学研究的基础;方法:主要包括模型方法和计算方法,是计量经济学研究的工具与手段,是计量经济学不同于其他经济学分支科学的主要特征;数据:反映研究对象的活动水平、相互间以及外部环境的数据,更广义讲是信息,是计量经济学研究的原料。三者缺一不可。 3、什么是相关关系、因果关系;相关关系与因果关系的区别与联系。 相关关系是指两个以上的变量的样本观测值序列之间表现出来的随机数学关系,用相关系数来衡量。 因果关系是指两个或两个以上变量在行为机制上的依赖性,作为结果的变量是由作为原因的变量所决定的,原因变量的变化引起结果变量的变化。因果关系有单向因果关系和互为因果关系之分。 具有因果关系的变量之间一定具有数学上的相关关系。而具有相关关系的变量之间并不一定具有因果关系。 4、回归分析与相关分析的区别与关系。P23-P24(课本) 相关分析与回归分析既有联系又有区别。首先,两者都是研究非确定性变量间的统计依赖关系,并能测度线性依赖程度的大小。其次,两者间又有明显的区别。相关分析仅仅是从统计数据上测度变量间的相关程度,而无需考察两者间是否有因果关系,因此,变量的地位在相关分析中饰对称的,而且都是随机变量;回归分析则更关注具有统计相关关系的变量间的因果关系分析,变量的地位是不对称的,有解释变量与被解释变量之分,而且解释变量也往往被假设为非随机变量。再次,相关分析只关注变量间的具体依赖关系,因此可以进一步通过解释变量的变化来估计或预测被解释变量的变化,达到深入分析变量间依存关系,掌握其运动规律的目的。 5、数理经济模型和计量经济模型的区别。 答:数理经济模型揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。计量经济模型揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述。 6、从哪几方面看,计量经济学是一门经济学科?P6(课本)
计量经济学分析计算题(每小题10分) 1.下表为日本的汇率与汽车出口数量数据, X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3= ,Y 554.2=,2 X X 4432.1∑ (-)=,2 Y Y 68113.6∑(-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 1.2427 7.2797 R 2=0.8688 F=52.99 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义 是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。
问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2 Y Y 68113.6∑ (-)=, 求判定系数和相关系数。 5.有如下表数据 日本物价上涨率与失业率的关系 (1)设横轴是U ,纵轴是P ,画出散点图。根据图形判断,物价上涨率与失业率之间是什么样的关系?拟合什么样的模型比较合适? (2)根据以上数据,分别拟合了以下两个模型: 模型一:1 6.3219.14 P U =-+ 模型二:8.64 2.87P U =- 分别求两个模型的样本决定系数。 7.根据容量n=30的样本观测值数据计算得到下列数据:XY 146.5= ,X 12.6=,Y 11.3=,2X 164.2=,2Y =134.6,试估计Y 对X 的回归直线。 8.下表中的数据是从某个行业5个不同的工厂收集的,请回答以下问题:
∑ x = 1264471.423 ∑ y = 516634.011 ∑ X = 52432495.137 ∑ ? ? ? ? 案例分析 1— 一元回归模型实例分析 依据 1996-2005 年《中国统计年鉴》提供的资料,经过整理,获得以下农村居民人均 消费支出和人均纯收入的数据如表 2-5: 表 2-5 农村居民 1995-2004 人均消费支出和人均纯收入数据资料 单位:元 年度 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 人均纯 收入 1577.7 1926.1 2090.1 2161.1 2210.3 2253.4 2366.4 2475.6 2622.2 2936.4 人均消 费支出 1310.4 1572.1 1617.2 1590.3 1577.4 1670.1 1741.1 1834.3 1943.3 2184.7 一、建立模型 以农村居民人均纯收入为解释变量 X ,农村居民人均消费支出为被解释变量 Y ,分析 Y 随 X 的变化而变化的因果关系。考察样本数据的分布并结合有关经济理论,建立一元线 性回归模型如下: Y i =β0+β1X i +μi 根据表 2-5 编制计算各参数的基础数据计算表。 求得: X = 2262.035 Y = 1704.082 2 i 2 i ∑ x i y i = 788859.986 2 i 根据以上基础数据求得: β1 = ∑ x i y 2 i i = 788859.986 126447.423 = 0.623865 β 0 = Y - β1 X = 1704.082 - 0.623865 ? 2262.035 = 292.8775 样本回归函数为: Y i = 292.8775 + 0.623865X i 上式表明,中国农村居民家庭人均可支配收入若是增加 100 元,居民们将会拿出其中 的 62.39 元用于消费。
课本中相关章节的证明过程 第2章有关的证明过程 2.1 一元线性回归模型 有一元线性回归模型为:y t = β0 + β1 x t + u t 上式表示变量y t 和x t之间的真实关系。其中y t 称被解释变量(因变量),x t称解释变量(自变量),u t称随机误差项,β0称常数项,β1称回归系数(通常未知)。上模型可以分为两部分。(1)回归函数部分,E(y t) = β0 + β1 x t, (2)随机部分,u t。 图2.8 真实的回归直线 这种模型可以赋予各种实际意义,收入与支出的关系;如脉搏与血压的关系;商品价格与供给量的关系;文件容量与保存时间的关系;林区木材采伐量与木材剩余物的关系;身高与体重的关系等。 以收入与支出的关系为例。 假设固定对一个家庭进行观察,随着收入水平的不同,与支出呈线性函数关系。但实际上数据来自各个家庭,来自各个不同收入水平,使其他条件不变成为不可能,所以由数据得到的散点图不在一条直线上(不呈函数关系),而是散在直线周围,服从统计关系。随机误差项u t中可能包括家庭人口数不同,消费习惯不同,不同地域的消费指数不同,不同家庭的外来收入不同等因素。所以,在经济问题上“控制其他因素不变”实际是不可能的。 回归模型的随机误差项中一般包括如下几项内容,(1)非重要解释变量的省略,(2)人的随机行为,(3)数学模型形式欠妥,(4)归并误差(粮食的归并)(5)测量误差等。 回归模型存在两个特点。(1)建立在某些假定条件不变前提下抽象出来的回归函数不能百分之百地再现所研究的经济过程。(2)也正是由于这些假定与抽象,才使我们能够透过复杂的经济现象,深刻认识到该经济过程的本质。
1. 请问自回归模型的估计存在什么困难?如何来解决这些苦难? 答:主要存在两个问题: (1) 出现了随机解释变量Y ,而可能与随机扰动项相关; (2) 随机扰动项可能存在自相关,库伊克模型和自适应预期模型的随机扰动项都会导致自相关,只有局部调整模型的随机扰动项无自相关。 对于第一个问题的解决可以使用工具变量法;对于第二个问题的检验可以用德宾h 检验法,目前还没有很好的解决办法,唯一能做的就是模型尽可能的设定正确。 2. 为什么要进行广义差分变换?写出其过程。 答:进行广义差分变换是为了处理自相关,写出其过程如下: 以一元模型为例:Y t = b 0 + b 1 X t +u t 假设误差项服从AR(1)过程:u t =ρu t-1 +v t -1 ≤ρ≤1 其中,v 满足OLS 假定,并且是已知的。 为了弄清楚如何使变换后模型的误差项不具有自相关性,我们将回归方程中的变量滞后一期,写为: Y t-1 = b 0 + b 1 X t-1 +u t-1 方程的两边同时乘以ρ,得到:ρY t-1 = ρb 0 + ρb 1 X t-1 +ρu t-1 现在将两方程相减,得到:(Y t -ρY t-1 ) = b 0 ( 1 -ρ) + b 1 (X t -ρX t-1 ) + v t 由于方程中的误差项v t 满足标准OLS 假定,方程就是一种变换形式,使得变换后的模型无序列相关。如果我们将方程写成:Y t * = b 0* + b 1 X t * +v t ,其中,Y t * = (Y t -ρY t-1 ) ,X t * = (X t -ρX t-1 ) ,b 0* = b 0 ( 1 -ρ)。 3. 什么是递归模型? 答:递归模型是指在该模型中,第一个方程的内生变量Y 1仅由前定变量表示,而无其它内生变量;第二个方程内生变量Y 2表示成前定变量和一个内生变量Y 1的函数;第三个方程内生变量Y 3表示成前定变量和两个内生变量Y 1与Y 2的函数;按此规律下去,最后一个方程内生变量Y m 可表示成前定变量和m -1个Y 1,Y 2、,Y 3,…、Y m-1的函数。 4. 为什么要进行同方差变换?写出其过程,并证实之。 答:进行同方差变换是为了处理异方差,写出其过程如下: 我们考虑一元总体回归函数Y i = b 0 + b 1 X i + u i 假设误差σi 2 是已知的,也就是说,每个观察值的误差是已知的。对模型作如下“变换”: Y i /σi = b 0 /σi + b 1 X i /σi + u i /σi 这里将回归等式的两边都除以“已知”的σi 。σi 是方差σi 2 的平方根。 令 v i = u i /σi 我们将v i 称作是“变换”后的误差项。v i 满足同方差吗?如果是,则变换后的回归方程就不存在异方差问题了。假设古典线性回归模型中的其他假设均能满足,则方程中各参数的OLS 估计量将是最优线性无偏估计量,我们就可以按常规的方法进行统计分析了。 证明误差项v i 同方差性并不困难。根据方程有:E (v i 2 ) = E (u i 2 /σi 2 ) = E (u i 2 ) /σi 2 =σi 2 /σi 2 = 1 显然它是一个常量。简言之,变换后的误差项v i 是同方差的。因此,变换后的模型不存在异方差问题,我们可以用常规的OLS 方法加以估计。 5. 简述逐步回归法的基本步骤。 答:先用被解释变量对每一个解释变量做简单回归,然后以对被解释变量贡献最大的解释变量所对应的回归方程为基础,再逐个引入其余的解释变量。这个过程会出现3种情形:①若新变量的引入改进了R 2 和F 检验,且其它回归系数的t 检验在统计上仍是显著的,则可考
计量经济学实验报告 我国居民储蓄余额的影响因素的计量分析 XX学院 XX专业 小组成员:(姓名及学号)
我国居民储蓄余额的影响因素的计量分析 一.研究的目的要求 1.研究的背景 居民储蓄额作为一个国家经济增长中来源最稳定、数额最大的影响因素,它的高低对一国的经济发展、投资和居民生活等方面都有不同程度的影响。目前我国国内居民储蓄意愿强劲、储蓄额居高不下,形成了储蓄的超常增长,主要呈现以下特点:(1)储蓄率世界之冠;(2)储蓄增长速度高于经济和居民收入增长速度;(3)城乡之间差别大;(4)不同收入阶层分布不均匀;(5)不同地区分布极不平均。我国储蓄的超常增长一方面能为银行提供了充足的信贷资金,保证金融机构的稳健运行,还能为国家提供了物质基础;此外,面对世界的日益发展,高储蓄额还能帮助我国进一步改革。但是,在另一方面我还国存在金融机构对资本的运用效益不高、居民投资渠不多、投资效益不稳定等问题。这些问题导致我国现在储蓄存款过剩、消费不足和资本形成不足同时并存的局面。 2013年6月余额宝正式上线,在此后的一年中该产品的客户数量和管理资产出现爆炸式的增长。截止2014年3月余额宝资金规模已经达到5413亿元,截止2014年4月,居民人民币存款减少1.23万亿元。余额宝作为一条“鲶鱼”和随后出现的众多“宝宝”们一起加速了中国利率市场化的进程,对未来我国储蓄额有着重大影响。 为了分析我国居民储蓄存款如今的发展状况、更好地把握我国储蓄余额未来的走向,所以对我国储蓄余额的及其影响因素的研究是十分必要的。 2.影响因素的分析 为了研究影响中国储蓄余额高低的主要原因,分析居民储蓄余额增长规律,预测中国储蓄余额的增长趋势,需要建立计量经济模型。通过参考相关文献并结合我国经济发展的实际情况提出了以下几个变量。(1)收入水平。根据经济理论可以认为,收入水平是影响储蓄的最主要因素。(2)利率水平。利率作为消费的机会成本也会对储蓄产生影响。理论上认为,利率越高,居民消费的机会成本越高,所以会减少消费增加储蓄;反之,利率越低消费成本越低,居民会增加消费减少储蓄。(3)物价水平。物价水平会影响消费和储蓄。物价水平越高相同消费水平需要支付的货币更多。而且物价水
计量经济学重点简答题 1.简述计量经济学与经济学、统计学、数理统计学学科间得关系。 答:计量经济学就是经济理论、统计学与数学得综合.经济学着重经济现象得定性研究,计量经济学着重于定量方面得研究。统计学就是关于如何收集、整理与分析数据得科学,而计量经济学则利用经济统计所提供得数据来估计经济变量之间得数量关系并加以验证。数理统计学作为一门数学学科,可以应用于经济领域,也可以应用于其她领域;计量经济学则仅限于经济领域。计量经济模型建立得过程,就是综合应用理论、统计与数学方法得过程,计量经济学就是经济理论、统计学与数学三者得统一。 2、计量经济模型有哪些应用? 答:①结构分析②经济预测③政策评价④检验与发展经济理论 3、简述建立与应用计量经济模型得主要步骤。 答:模型设定估计参数模型检验模型应用 或1)经济理论或假说得陈述2) 收集数据3)建立数理经济学模型4)建立经济计量模型5)模型系数估计与假设检验6)模型得选择7)理论假说得选择8)经济学应用 4、对计量经济模型得检验应从几个方面入手? 答:①经济意义检验②统计推断检验③计量经济学检验④模型预测检验 5、计量经济学应用得数据就是怎样进行分类得? 答:时间序列数据截面数据面板数据虚拟变量数据 6、解释变量与被解释变量,内生变量与外生变量 被解释变量就是模型要研究得对象,被称为“因变量”,就是变动得结果。 解释变量就是说明被解释变量变动得原因,被称为“自变量”,就是变动得原因. 内生变量就是其数值由模型所决定得变量,就是模型求解得结果。 外生变量就是其数值由模型以外决定得变量。 7、计量经济学得含义 计量经济学就是以经济理论与经济数据得事实为依据,运用数学、统计学得方法,通过建立数学模型来研究经济数量关系与规律得一门经济学科。 8、在计量经济模型中,为什么会存在随机误差项? 答:随机误差项就是计量经济模型中不可缺少得一部分. 产生随机误差项得原因有以下几个方面:①模型中被忽略掉得影响因素造成得误差;②模型关系认定不准确造成得误差;③变量得测量误差;④随机因素. 9.对于多元线性回归模型,为什么在进行了总体显著性F检验之后,还要对每个回归系数进行就是否为0得t检验? 答:多元线性回归模型得总体显著性F检验就是检验模型中全部解释变量对被解释变量得共同影响就是否显著。通过了此F检验,就可以说模型中得全部解释变量对被解释变量得共同影响就是显著得,但却不能就此判定模型中得每一个解释变量对被解释变量得影响都就是显著得。因此还需要就每个解释变量对被解释变量得影响就是否显著进行检验,即进行t 检验. 10、古典线性回归模型具有哪些基本假定。 答:1 随机误差项与解释变量不相关。2随机误差项得期望或均值为零。3随机误差项具有同方差,即每个随机误差项得方差为一个相等得常数。4 两个随机误差项之间不相关,即随机误差项无自相关。 11、在多元线性回归分析中,为什么用修正得决定系数衡量估计模型对样本观测值得拟合优度? 答:因为人们发现随着模型中解释变量得增多,多重决定系数得值往往会变大,从而增加了模
计量经济学:部分计算题解法汇总 1、求判别系数——R^2 已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2Y Y 68113.6∑(-)=, 2、置信区间 有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y Adjusted R-squared F-statistic Durbin-Watson (1(2)在95%的置信度下检验参数的显著性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在90%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其中29.3x =,2()992.1x x - =∑) 答:(1)回归模型的R 2 =,表明在消费Y 的总变差中,由回归直线解释的部分占到90%以上,回归直线的代表性及解释能力较好。(2分) 家庭收入对消费有显著影响。(2分)对于截距项,
检验。(2分) (3)Y f =+×45=(2分) 90%置信区间为(,+),即(,)。(2分) 注意:a 水平下的t 统计量的的重要性水平,由于是双边检验,应当减半 3、求SSE 、SST 、R^2等 已知相关系数r =,估计标准误差?8σ=,样本容量n=62。 求:(1)剩余变差;(2)决定系数;(3)总变差。 (2)2220.60.36R r ===(2分) 4、联系相关系数与方差(标准差),注意是n-1 在相关和回归分析中,已知下列资料: 222X Y i 1610n=20r=0.9(Y -Y)=2000σσ∑=,=,,,。 (1)计算Y 对X 的回归直线的斜率系数。(2)计算回归变差和剩余变差。(3) (2)R 2=r 2==, 总变差:TSS =RSS/(1-R 2)=2000/=(2分)
1.计量经济学与经济理论、统计学、数学的联系是什么?计量经济学与经济理论、统计学、数学的联系主要体现在计量经济学对经济理论、统计学、数学的应用方面,分别如下: 1)计量经济学对经济理论的利用主要体现在以下几个方面 (1)计量经济模型的选择和确定 (2)对经济模型的修改和调整 (3)对计量经济分析结果的解读和应用 2)计量经济学对统计学的应用 (1)数据的收集、处理、 (2)参数估计 (3)参数估计值、模型和预测结果的可靠性的判断3)计量经济学对数学的应用 (1)关于函数性质、特征等方面的知识 (2)对函数进行对数变换、求导以及级数展开 (3)参数估计 (4)计量经济理论和方法的研究 2.模型的检验包括哪几个方面?具体含义是什么? 模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。 ①在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号、大小、参数之间的关系是否与根据人们的经验和经济理论所拟订的期望值相符合; ②在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质,有拟合优度检验、变量显著检验、方程显著性检验等; ③在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等; ④模型的预测检验,主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 1.为什么计量经济学模型的理论方程中必须包含随机干扰项? 计量经济学模型考察的是具有因果关系的随机变量间的具体联系方式。由于是随机变量,意味着影响被解释变量的因素是复杂的,除了解释变量的影响外,还有其他无法在模型中独立列出的各种因素的影响。这样,理论模型中就必须使用一个称为随机干扰项的变量来代表所有这些无法在模型中独立表示出来的影响因素,以保证模型在理论上的科学性。3.为什么用可决系数R2评价拟合优度,而不是用残差平方和作为评价标准? 可决系数R2=ESS/TSS=1-RSS/TSS,含义为由解释变量引起的被解释变量的变化占被解释变量总变化的比重,用来判定回归直线拟合的优劣,该值越大说明拟合的越好;而残差平方和与样本容量关系密切,当样本容量比较小时,残差平方和的值也比较小,尤其是不同样本得到的残差平方和是不能做比较的。此外,作为检验统计量的一般应是相对量而不能用绝对量,因而不能使用残差平方和判断模型的拟合优度。 4.根据最小二乘原理,所估计的模型已经使得拟合优度差达到最小,为什么还要讨论模型的拟合优度问题? 普通最小二乘法所保证的最好拟合是同一个问题内部的比较,即使用给出的样本数据满足残差的平方和最小;拟合优度检验结果所表示的优劣可以对不同的问题进行比较,即可以辨别不同的样本回归结果谁好谁坏。 1.多元线性回归模型与一元线性回归模型有哪些区别? 多元线性回归模型与一元线性回归模型的区别表现在如下几个方面:一是解释变量的个数不同;二是模型的经典假设不同,多元线性回归模型比一元线性回归模型多了个“解释变量之间不存在线性相关关系”的假定;三是多元线性回归模型的参数估计式的表达更为复杂。 2.为什么说最小二乘估计量是最优线性无偏估计量?对于多元线性回归最小二乘估计的正规方程组,能解出唯一的参数估计量的条件是什么? 在满足经典假设的条件下,参数的最小二乘估计量具有线性性、无偏性以及最小性方差,所以被称为最优线性无偏估计量(BLUE) 对于多元线性回归最小二乘估计的正规方程组,能解出唯一的参数估计量的条件是(X X )-1存在,或者说各解释变量间不完全线性相关。